
Abstract
Accurate temperature regulation in continuous stirred-tank heater (CSTH) systems is vital in chemical and thermal process industries, where deviations can cause energy inefficiencies, product quality degradation, or even safety hazards. However, CSTH systems pose a formidable control challenge due to inherent nonlinearities, parameter uncertainties, and susceptibility to external disturbances. Conventional proportional–integral–derivative (PID) tuning methods often struggle to handle these complexities, resulting in sluggish responses or instability. This study introduces a modified Newton-Raphson-based optimization (mNRBO), for optimal PID tuning tailored to nonlinear CSTH environments. The mNRBO framework integrates two key innovations: random opposition learning, to enhance population diversity and prevent premature convergence, and Lévy-flight-based guided learning, to improve global exploration and escape local optima. These mechanisms are systematically embedded into the Newton-Raphson-based optimizer (NRBO) to achieve a robust exploration–exploitation balance. A CSTH dynamic model is formulated using mass and energy conservation principles, and a multi-objective cost function evaluates rise time, settling time, overshoot, and steady-state error under realistic process constraints. Simulation studies compare mNRBO with NRBO, hippopotamus optimization, golden eagle optimizer, and slime mould algorithm. Results show that mNRBO achieves the lowest cost function value 53.29, smooth convergence with standard deviation 0.90, and superior closed-loop performance with rise time 62.05 s, settling time 206.88 s, overshoot 1.41%, and steady-state error 0.006%. These findings confirm that mNRBO delivers high-precision, disturbance-resilient control and is a promising solution for industrial thermal processes requiring reliability, efficiency, and precision.
Similar content being viewed by others
Introduction
Accurate temperature regulation in continuous stirred-tank heater (CSTH) systems is fundamental in chemical and thermal process industries, where even minor deviations can result in energy inefficiency, off-spec products, or safety risks1. The CSTH’s strong nonlinearities, parameter uncertainties, and susceptibility to external disturbances make it one of the most challenging benchmarks in process control. Among various strategies, the proportional–integral–derivative (PID) controller remains the most widely implemented due to its structural simplicity, reliability, and compatibility with industrial environments2,3. However, the controller’s performance depends critically on appropriate tuning of the proportional, integral, and derivative gains. Improper tuning often leads to oscillatory responses, overshoot, or instability, especially in nonlinear and time-varying systems4,5,6,7.
Traditional analytical approaches (such as Ziegler–Nichols, Cohen–Coon, and other model-based tuning rules) provide acceptable performance for linear systems but are often inadequate for highly nonlinear and parameter-sensitive plants like CSTH8,9. Consequently, research has shifted toward intelligent and metaheuristic optimization-based tuning methods, which can adaptively and efficiently search for optimal controller parameters without relying on analytical gradients10,11.
Over the last decade, a variety of bio-inspired and physics-based metaheuristic algorithms (including differential evolution (DE), particle swarm optimization (PSO), black hole optimization (BHO), Jaya optimization (JOA), and sunflower optimization (SFO)) have been applied for PID and fractional-order PID (FOPID) controller tuning12,13,14,15,16,17. For example, Basil and Marhoon16 demonstrated that FOPID tuning using BHO, JOA, and SFO improved robustness and trajectory tracking in NASA’s X-15 adaptive flight control system. Likewise, hybrid and multi-strategy algorithms such as PSO–ALO, HAOAROA, and FOPID–TID have achieved remarkable results in UAV and multi-rotor flight control, balancing disturbance rejection and dynamic stability better than single-algorithm approaches18,19,20. These advances illustrate the importance of combining diversity-preserving mechanisms with global exploration strategies to enhance convergence reliability in complex nonlinear problems.
Parallel developments in CSTH control have also expanded beyond traditional tuning. Mahmood and Nawaf21 reported that cascade control structures can suppress oscillations and accelerate settling, while Haghani et al.22 and Wang et al.23 proposed probabilistic and manifold-based optimization frameworks for robust fault isolation and performance monitoring. Predictive and adaptive control methods, such as broad learning-based predictive control24 and adaptive subspace predictive control (ASPC)25, have improved convergence and adaptability under varying process conditions. Neural network26 and reinforcement learning27 controllers further enhanced flexibility and disturbance tolerance. Meanwhile, the theoretical work of Do28 on systems driven by Lévy processes provided a strong mathematical foundation for employing Lévy-flight perturbations in control-oriented optimization.
Despite these advancements, achieving a simultaneous balance between global exploration and local exploitation remains a persistent challenge. Algorithms such as PSO, DE, SMA, GEO, HO, and NRBO have yielded performance gains but still encounter premature convergence, population collapse, or stagnation during optimization in complex nonlinear search landscapes. Moreover, deterministic opposition-based strategies and conventional trap-avoidance mechanisms do not always ensure sufficient diversity preservation or convergence reliability in real-world control problems.
To overcome these challenges, this study introduces a modified Newton–Raphson-based optimization (mNRBO) algorithm designed to enhance both optimization robustness and control performance. The original Newton-Raphson-based optimizer (NRBO)29 integrates Newton–Raphson search logic with a trap-avoidance mechanism to accelerate convergence and improve solution stability The proposed algorithm extends the standard NRBO29 by incorporating two synergistic strategies:
-
Random opposition learning (ROL)30 to periodically introduce stochastic diversity and prevent population stagnation, and.
-
Lévy-flight-based guided learning (LGL)28 to provide adaptive long-jump perturbations for improved global exploration and efficient escape from local optima.
By embedding these mechanisms into the Newton–Raphson search logic, mNRBO achieves a well-balanced exploration–exploitation trade-off, enabling faster convergence and superior global search ability.
Before being applied to the CSTH control problem, the proposed mNRBO was first validated on a comprehensive set of classical benchmark functions, encompassing unimodal, multimodal, and composite test functions. These benchmarks were used to evaluate convergence speed, stability, precision, and global optimization capability against several state-of-the-art algorithms such as NRBO29, slime mould algorithm (SMA)31, golden eagle optimizer (GEO)32, and hippopotamus optimization algorithm (HO)33. The results confirmed that mNRBO consistently achieved the lowest mean error and standard deviation values, establishing its robustness and versatility as a high-performance optimizer suitable for complex nonlinear systems.
Subsequently, the algorithm was employed to optimize the PID controller parameters for a nonlinear CSTH process modeled through mass–energy balance equations. A multi-objective cost function integrating rise time, settling time, overshoot, and steady-state error was used for evaluation under realistic constraints. Comparative results with competing algorithms demonstrated that mNRBO achieved superior dynamic performance, with lower cost function values, faster transient response, and improved disturbance rejection. Quantitative metrics including recovery time, peak deviation, and integral absolute error further confirmed its robustness against parameter variations and external perturbations.
The major novelties and contributions of this study can be summarized as follows:
-
1.
Proposal of a novel modified Newton–Raphson-based optimization (mNRBO) algorithm integrating ROL and LGL to enhance exploration–exploitation balance.
-
2.
Comprehensive benchmarking of mNRBO against leading metaheuristic algorithms across standard test functions, demonstrating improved global search precision and convergence stability.
-
3.
Application of mNRBO for PID tuning in nonlinear CSTH temperature control, achieving significant performance improvements in rise time, settling time, overshoot, and steady-state error.
-
4.
Ablation and statistical significance analyses confirming the individual and synergistic effects of ROL and LGL via Wilcoxon’s non-parametric test.
-
5.
Quantitative disturbance evaluation using recovery time, peak deviation, and integral of absolute error metrics, evidencing superior disturbance rejection and steady-state accuracy under uncertainties.
-
6.
Industrial relevance and practicality, as the method maintains a standard PID structure compatible with existing control hardware, ensuring real-world implementability.
The remainder of this paper is organized as follows. Section “Overview of NRBO and proposed mNRBO algorithms” details the NRBO framework and the proposed modifications through ROL and LGL. Section “Dynamic modeling of the CSTH-based temperature control system” presents the dynamic modeling of the CSTH system. Section “Proposed control methodology” describes the application of mNRBO for PID tuning. Section “Results and discussion” discusses the comparative and statistical results, including benchmark analyses and disturbance rejection performance, and Section “Conclusion and future directions” concludes with key findings and directions for future work.
Overview of NRBO and proposed mNRBO algorithms
The basics of the NRBO
The NRBO represents a novel approach to solving complex optimization problems by harmonizing classical Newton-Raphson concepts with population-based stochastic search techniques29. Unlike conventional methods that rely purely on derivative-driven refinements, the NRBO introduces a hybrid strategy that enhances search efficiency, balances exploration and exploitation, and mitigates premature convergence. At the core of NRBO lies an iterative search mechanism that begins by estimating optimal solutions using Newton-Raphson’s gradient-based logic. This mechanism is enriched with probabilistic perturbations and diversity-preserving dynamics to effectively traverse the solution space. The algorithm operates on three key pillars: a Newton-inspired refinement strategy that leverages directional gradients, a stochastic variation mechanism that ensures widespread search diversity, and a trap avoidance strategy (TAS) designed to steer agents away from local optima.
The optimization challenge is framed as the minimization of a target objective function subject to bounded constraints. Each decision variable is confined within a defined interval [\({LB}^{j}\), \({UB}^{j}\)], ensuring feasibility across all dimensions \(j=\text{1,2},\ldots,Dim\). This constraint structure reflects real-world limitations, where variable ranges are typically dictated by practical or physical considerations.
A population of candidate solutions, denoted by \(Np\), is initialized randomly within the allowable bounds. Each agent in the population is described by a decision vector \({Y}_{j}^{n}\), where nnn indexes the individual and jjj the variable dimension. The initialization is given by:
During each iteration, the objective function is evaluated for all agents, yielding fitness values that are used to identify the best-performing solution \({Y}^{BEST}\) and the poorest one \({Y}^{WORST}\). These agents guide the adaptation process for the rest of the population.
The core update mechanism, termed the Newton-Raphson Search Rule (\(NRSR\)), revises each solution vector by computing a directionally informed shift based on differences among selected individuals. For two reference agents \({Y}_{1}\) and \({Y}_{2}\), the \(NRSR\) produces a step vector as:
where the differential component \(\varDelta{Y}_{12}\) is defined by:
The updated positions of agents are then computed through a combination of three dynamically generated vectors \({Y}_{1}\), \({Y}_{2}\), and \({Y}_{3}\), blended using a probabilistic coefficient \(R{d}_{1}\in\left[\text{0,1}\right]\):
Each component vector is constructed by incorporating gradient-derived shifts, elite guidance, and inter-agent differentials. The vectors are defined as:
Here, \({Y}_{R1}\) and \({Y}_{R2}\) are randomly selected individuals, while aaa and bbb are tuning parameters controlling exploration and exploitation. The intermediate reference points \({Z}_{w}\) and \({Z}_{v}\) are calculated as:
The third update component \({{Y}_{3}}_{n}\) introduces iteration-based scaling to support adaptive transition from exploration to exploitation:
To safeguard the search process against stagnation in local optima, NRBO introduces the Trap Avoidance Strategy (TAS). This mechanism generates alternative solutions depending on a selection condition involving a binary variable \(\beta\), determined by:
The adaptive coefficients \({\mu}_{a}\) and \({\mu}_{b}\) depend on \(\beta\) and a random variable \(R{d}_{3}\), providing additional variability:
Two offset components are then computed as:
The TAS-based update rule is:
The complete NRBO procedure can be outlined in the following sequence:
-
1.
Initialization: Define all algorithm parameters including population size, boundaries, dimensionality, and maximum iteration count. Set the weighting constants, and randomness coefficients.
-
2.
Population generation: Randomly initialize each search agent within the prescribed bounds.
-
3.
Fitness evaluation: Assess the fitness of all agents using the target objective function.
-
4.
Ranking: Identify the best and worst agents based on their fitness values.
-
5.
Search phase: Use a random number to switch between the NRSR-based update and TAS-enhanced update.
-
6.
Position update: Apply either the Newton-inspired update or the trap avoidance strategy to generate new candidate solutions.
-
7.
Iteration: Repeat the ranking, updating, and evaluation steps until the maximum number of iterations is completed.
-
8.
Termination: Output the best solution found as the final outcome of the optimization process.
This adaptive structure allows NRBO to effectively navigate complex search landscapes, striking a balance between convergence speed and global search robustness.
The proposed mNRBO algorithm
The original NRBO employs two search mechanisms: the Newton-Raphson Search Rule (NRSR) and the trap avoidance strategy (TAS). Both rely heavily on the best search agent; however, if this agent converges prematurely to a local optimum, the population quickly loses diversity and stagnates. To overcome these drawbacks, the modified NRBO (mNRBO) incorporates two additional strategies: random opposition learning (ROL) and Lévy-flight-based guided learning (LGL). ROL extends the concept of opposition-based learning30 by introducing a random factor when generating opposite solutions. For a candidate \({x}_{j}\) bounded within \([{L}_{j},{U}_{j}]\), its random opposite is defined as:
where \(r\in\left[\text{0,1}\right]\) is a random number. This ensures that the population explores new regions rather than deterministically revisiting mirrored solutions. In the mNRBO cycle, ROL is invoked periodically to reintroduce diversity and prevent premature convergence.
LGL combines guided exploitation with Lévy-flight exploration28. The new position of an agent is updated as:
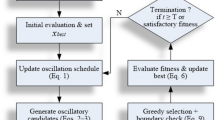
where \({x}_{best}\)is the current best solution, \(\alpha\)is a scaling parameter, and \(\text{Levy}\left(\beta\right)\)denotes a Lévy-distributed step length (\(1<\beta \le 3\)). This formulation allows frequent small adjustments around promising regions while occasionally performing long jumps, helping the optimizer escape local minima. Within the mNRBO framework (Fig. 1), ROL enhances the exploration stage by generating diverse candidate positions, while LGL strengthens the exploitation stage through adaptive jumps around the best solution. Together, these strategies maintain a robust balance between exploration and exploitation, enabling the optimizer to converge faster and with greater reliability compared to the standard NRBO.

Flowchart of the proposed mNRBO.
The effects of the improvement strategies
To better understand the individual and combined contributions of the proposed strategies, an ablation analysis was conducted. Figure 2 presents the convergence behavior of four variants: the baseline NRBO, NRBO enhanced with ROL (NRBO + ROL), NRBO combined with LGL (NRBO + LGL), and the complete mNRBO integrating both mechanisms. The curve corresponding to NRBO shows the expected convergence trend but with signs of stagnation, as the search agents tend to cluster around local optima. This behavior highlights the limited ability of the baseline algorithm to maintain diversity once an early promising region is identified.

Effects of different improvement strategies.
When ROL is incorporated, the resulting NRBO + ROL variant achieves noticeably broader exploration. The random generation of opposite solutions periodically disperses agents into new regions of the search space, reducing the risk of premature convergence.
However, while this diversity is maintained longer than in standard NRBO, the absence of a strong exploitation mechanism results in slower refinement near the optimal region. In contrast, NRBO + LGL emphasizes exploitation.
The Lévy-flight perturbations, guided toward the best solution, enable more intensive local search and facilitate occasional jumps that help avoid deceptive minima. Although this variant converges faster than NRBO, the lack of continuous diversity restoration sometimes causes the population to collapse prematurely, particularly in high-dimensional or irregular landscapes.
The full mNRBO, which integrates both ROL and LGL, demonstrates the most balanced performance. As shown in Fig. 2, the algorithm maintains a steady decrease in objective function values with fewer fluctuations, indicating an effective interplay between exploration and exploitation. ROL ensures that diversity is preserved throughout the process, while LGL accelerates convergence around promising areas without risking stagnation. This complementary interaction explains why the full mNRBO achieves lower final cost values and greater stability compared with all intermediate variants. In summary, the ablation results confirm that each enhancement contributes uniquely: ROL strengthens exploration, LGL reinforces exploitation, and their integration yields the robust search dynamics necessary for tackling complex nonlinear control problems. The findings underscore that the superior performance of mNRBO is not due to either mechanism in isolation but rather to their synergistic effect within the NRBO framework.
Exploration-exploitation analysis
The effectiveness of any metaheuristic algorithm depends on how well it balances exploration of the search space with exploitation of promising regions. Figure 3 illustrates this trade-off for the proposed mNRBO in comparison with the original NRBO and other benchmark algorithms. As shown in the figure, the exploration stage of mNRBO is strengthened by the introduction of ROL. This mechanism periodically generates randomized opposite solutions, which broadens the search space and prevents the population from clustering too early around local optima. Consequently, mNRBO sustains higher population diversity during the early and mid-iterations, enabling the algorithm to sample from wider regions of the solution landscape. On the other hand, the LGL mechanism enhances exploitation in later iterations. By allowing small local refinements interspersed with occasional long jumps, LGL ensures that the algorithm not only intensifies the search around the best solution but also maintains the ability to escape deceptive minima. This dual behavior explains the smoother convergence trend observed in Fig. 3, where mNRBO consistently avoids stagnation and progresses toward the global optimum more reliably.

Exploration and exploitation analysis of mNRBO.
The combined impact of ROL and LGL is reflected in the convergence trajectories. While other algorithms exhibit fluctuations or premature plateaus, mNRBO demonstrates a steady decline in objective function values, indicating both effective exploration and efficient exploitation. This explains why, in later sections, the algorithm achieves faster convergence, lower cost values, and superior closed-loop control performance. Ultimately, Fig. 3 confirms that the strength of mNRBO lies not merely in achieving improved numerical results but in the mechanistic balance it maintains between global search and local refinement, a balance that is critical for solving complex nonlinear control problems.
Dynamic modeling of the CSTH-based temperature control system
The CSTH system is widely employed in industrial processes requiring precise thermal regulation. This system ensures consistent heating by utilizing a jacketed structure to manage the temperature of the fluid contained within the tank. The CSTH’s operation encompasses complex interactions among fluid flow, heat exchange, and control mechanisms. These interactions are often described by nonlinear dynamic models, making accurate system modeling and parameter tuning essential for maintaining energy efficiency and reliable performance. A general overview of the CSTH configuration is depicted in Fig. 434.

Simplified diagram of CSTH temperature control system.
Governing physical principles
The CSTH system operates based on fundamental conservation laws involving mass and energy, alongside heat transfer mechanisms.
Mass balance section
The conservation of mass across the system can be described through a mass balance equation:
In the mass balance equation, \(m\) denotes the mass of the fluid within the tank, while \({\rho}_{f}\) epresents the fluid density. The terms \({Q}_{in}\) and \({Q}_{out}\) correspond to the inlet and outlet flow rates, respectively.
Energy balance section
To describe thermal dynamics within the tank, an energy balance equation is employed. It accounts for heat exchange due to both conduction and fluid inflow/outflow:
where, \(T\), \({T}_{in}\), \({T}_{j}\), \({C}_{p}\), \(U\), \(A\) and \(V\) are tank fluid temperature, inlet fluid temperature, temperature of the jacket fluid, specific heat capacity, overall heat transfer coefficient, heat transfer area and volume of the tank respectively.
Heat transfer equation
The heat transfer rate from the jacket to the tank fluid is quantified using:
This equation highlights the direct relationship between heat transfer efficiency and the temperature difference across the heat exchange surface.
Transfer function derivation for CSTH system
To analyze the system’s dynamic response, the Laplace transform is applied to the energy balance equation. Rearranging the equation yields the transfer function between heater input and tank temperature:
where, \(\tau\) and \(K\) are system time constant and process gain respectivly. Additionally, the influence of inlet temperature on tank temperature can also be modeled:
These transfer functions serve as linear approximations to describe the CSTH’s temperature dynamics under small perturbations.
Parameter configuration of the CSTH system
Accurate modeling of the CSTH system requires a set of physical, thermal, and operating parameters that define its dynamic behavior. To maintain clarity and readability, only the key parameters relevant for mass and energy balance modeling and controller design are reported in the main text. Table 1 summarizes these essential parameters, including fluid properties, main geometrical attributes, heat transfer characteristics, and control setpoints that directly affect temperature regulation. These parameters capture the dominant thermal dynamics and provide the foundation for simulation and controller design. For reproducibility, a comprehensive list of all structural dimensions, transmitter gains, valve coefficients, hydraulic resistances, pump pressures, and auxiliary constants used for high-fidelity modeling is provided in Appendix A (Supplementary Material).
Proposed control methodology
Standard PID controller
The PID controller is one of the most established and widely applied control strategies in industrial automation and process control due to its straightforward structure and reliable performance35. The standard form of the PID controller in the Laplace domain is given as:
where,\(U\left(s\right)\), \(E\left(s\right)\), \({K}_{P}\), \({T}_{I}\) and \({T}_{D}\) are the controller output in the Laplace domain, the error signal (difference between the reference input and system output), the proportional gain, the integral time constant and the derivative time constant respectivly. In addition, \(\alpha\) is a small positive constant \((0<\alpha<1)\) used to implement a low-pass filter on the derivative term. This formulation enhances the classical PID controller by incorporating a first-order filter on the derivative action, which is crucial for attenuating high-frequency measurement noise and improving the robustness of the controller in practical applications. The proportional term \({K}_{P}\) provides an immediate response to the error, the integral term \(\frac{1}{{T}_{I}s}\) accumulates the past error to eliminate steady state offset, and the derivative term \(\frac{{T}_{D}s}{\alpha{T}_{D}s+1}\) predicts future error trends while filtering out high-frequency noise. The effectiveness of this controller lies in its ability to balance responsiveness, stability, and steady-state accuracy. The block diagram of the standard PID controller is depicted in Fig. 5, illustrating how each component contributes to the overall control loop.

Block diagram of standard PID controller.
Objective function and application of proposed mNRBO
To evaluate the performance of the proposed mNRBO algorithm in controlling the highly nonlinear CSTH system, a step change in the setpoint (\({Y}_{T,sp}\left(t\right)\)) was introduced. Specifically, the reference value was increased from 76 to 81% at \(t=100\,\hbox{s}\), simulating a realistic operating scenario with abrupt variations in desired output.
A modified version of the cost function from14 was used to assess the transient and steady-state response of the system. The objective function is defined as:
where, \({N}_{rt}\),\({N}_{st}\), \({N}_{po}\) and \({N}_{pse}\) are normalized rise time (10–90%), normalized settling time (\(2\%\) tolerance region), normalized percent overshoot and normalized percent steady-state error at the final time \({t}_{f}=1000\) s. In addition, the scaling factor is \(\phi={e}^{-1}=0.3679\). This cost function ensures a trade-off between dynamic response (rise and settling time) and output accuracy (overshoot and steady-state error). The value of \(\phi\) can be adjusted to emphasize either time-domain dynamics or final value accuracy, depending on the specific application requirements. In this study, a value of \(\phi=0.3679\) was chosen to provide balanced performance. so that no single metric dominates the optimization, thereby achieving a balanced trade-off between fast response, low overshoot, and minimal steady-state error. To perform optimization using mNRBO, the search was bounded by the following constraints on the PID parameters and the filter coefficient:
These boundaries ensure that the optimized parameters remain within practical and physically meaningful limits, preventing instability or excessive actuator effort. The mNRBO algorithm was executed iteratively to minimize \({F}_{cost}\), yielding the optimal tuning values for the PID controller under the defined operational constraints. Figure 6 illustrates the proposed control methodology applied to the CSTH system, showcasing how the mNRBO algorithm integrates with the feedback control loop to enhance system performance.

The proposed control methodology for highly nonlinear CSTH system.
Results and discussion
Comparisons with recently reported metaheuristic algorithms
In order to evaluate the effectiveness and robustness of the proposed mNRBO algorithm, a comparative study was conducted against four state-of-the-art metaheuristic optimization techniques: NRBO29, HO33, GEO32, and SMA31. All algorithms were implemented using default parameter settings, with a population size of 20, over 30 independent runs, and each run comprising 50 iterations.
Table 2 presents the statistical metrics of the cost function obtained through the five algorithms. The proposed mNRBO algorithm outperformed the other methods in terms of achieving the minimum, average, and standard deviation values of the cost function. Specifically, mNRBO attained the lowest minimum cost value of 53.2881, compared to 55.7018 by NRBO, 56.1413 by HO, 58.4120 by GEO, and 57.4850 by SMA. Moreover, mNRBO exhibited the lowest standard deviation (0.9038), indicating superior stability and convergence consistency across multiple runs. The statistical significance of mNRBO’s improvement is confirmed by the p-values, all below 0.05 when compared to the other algorithms, highlighting a statistically significant enhancement in performance. It is worth noting that all p-values were obtained using the Wilcoxon signed-rank non-parametric test, which does not assume normality and is widely recommended for the statistical comparison of stochastic optimization algorithms36,37. This test ensures that the reported significance values reliably capture the performance differences among algorithms across multiple independent runs.
Figure 7 illustrates the evolution of PID parameters \(({K}_{P},{T}_{I},{T}_{D}\,and\,\alpha)\) across iterations for all algorithms. The results show that mNRBO maintains smoother and more stable parameter trajectories, converging earlier and with less fluctuation. This indicates the algorithm’s strong capability in effectively exploring and exploiting the search space. Correspondingly, Fig. 8 shows the variation of the cost function with respect to the number of iterations. Again, mNRBO demonstrates faster convergence to a lower cost value, reinforcing its robustness in achieving optimal solutions with fewer iterations.

Variation of standard PID controller parameters (\({K}_{P}\), \({T}_{I}\), \({T}_{D}\) and \(\alpha\)) with respect to iterations via mNRBO, NRBO, HO, GEO and SMA.

Variation of cost function (\({F}_{cost}\)) with respect to iterations via mNRBO, NRBO, HO, GEO and SMA.
Table 3 summarizes the final optimal PID parameters obtained through each algorithm along with their respective search ranges. The mNRBO algorithm delivered optimized gains of \({K}_{P}=6.6595\), \({T}_{I}=138.6948\), \({T}_{D}=27.7611\)while also resulting in the smallest cost value. These parameters lie well within the defined bounds and reflect a precise tuning capability of the mNRBO method. Furthermore, the cost function value achieved by mNRBO is notably lower than those derived from NRBO, HO, GEO, and SMA, emphasizing the enhanced control accuracy enabled by the proposed method.
The impact of these optimally tuned parameters is further validated through time-domain simulations of the system response. Figure 9 displays the temperature response of the tank under PID control for each algorithm, with mNRBO providing the fastest and most stable response. A magnified view in Fig. 10 confirms the improved settling and tracking behavior achieved by the proposed approach. Table 4 quantitatively supports these observations by reporting key stability metrics, including normalized rise time \(\left({N}_{rt}\right)\), normalized settling time \(\left({N}_{st}\right)\), normalized percent overshoot \(\left({N}_{po}\right)\), and normalized percent steady-state error \(\left({N}_{pse}\right)\). The mNRBO method yields the best performance across all metrics, with the shortest rise and settling times (62.0506 s and 206.8783 s respectively), and the lowest overshoot (1.4098%) and steady-state error (0.0060%).

mNRBO, NRBO, HO, GEO and SMA based time responses for tank temperature sensor.

Zoom view of Fig. 9.
These results demonstrate that the mNRBO algorithm not only improves convergence efficiency and solution accuracy in the PID tuning process but also enhances overall system performance. Compared to the other benchmark algorithms, mNRBO consistently provides superior results in both statistical metrics and control response, validating its potential as a reliable and powerful optimization strategy for complex control systems.
Performance evaluation of mNRBO-tuned PID controller in terms of setpoint tracking and disturbance rejection
To assess the effectiveness of the proposed mNRBO algorithm in tuning PID controller parameters, its performance was evaluated under scenarios involving both variable setpoints and disturbances. The tracking ability of the controller in response to a dynamically changing reference signal was first examined. As illustrated in Fig. 11, the mNRBO-tuned controller successfully maintained precise tracking across a range of setpoints, demonstrating minimal overshoot, fast rise time, and negligible steady-state error. This confirms the robustness and adaptability of the proposed method in maintaining optimal performance under time-varying reference conditions.

Performance of proposed mNRBO for variable setpoint.
The system’s disturbance rejection performance was evaluated through testing different disturbance types against the controller. As shown in Fig. 12, two categories of disturbances were considered. Figure 13 demonstrates how the mNRBO-based tuning method improves controller resilience through rapid recovery and stable operation free of oscillatory behavior when facing disturbances. The controller maintained system stability and kept the output near the desired trajectory despite the presence of parameter uncertainties. A detailed assessment confirms that the mNRBO-tuned PID controller demonstrates exceptional performance in handling setpoint adjustments and unexpected disruptions which makes it suitable for application in unpredictable settings.

Type of disturbances (a) change of \({Q}_{i}\), (b) change of \({T}_{ci}\).

Performance of the proposed mNRBO with respect to disturbance and parameter changes.
In addition to the qualitative assessment illustrated in Figs. 9, 10, 11, 12 and 13, quantitative stability metrics were computed to further evaluate the disturbance rejection characteristics of the controllers. The selected indicators include the normalized settling time (\({N}_{st}\)), defined as the time required for the output to return within ± 2% of the setpoint after a disturbance; the normalized percent overshoot (\({N}_{po}\)), representing the maximum transient deviation from the reference; and the integral absolute error (\(IAE\)), which quantifies the accumulated deviation over the entire simulation horizon. The IAE was evaluated using Eq. (26):
where \({t}_{final}=2000\) s. The results are summarized in Table 5. The proposed mNRBO-based controller achieves the lowest IAE (497.9906), the shortest settling time (1.7199E+03), and competitive overshoot (7.9070) compared with the other optimization algorithms. These findings confirm that mNRBO provides faster disturbance recovery, improved stability, and enhanced resilience against parameter perturbations, establishing its advantage over NRBO, HO, GEO, and SMA during dynamic operating conditions. The overall analysis verifies that the mNRBO-tuned PID controller combines rapid disturbance rejection with minimal error accumulation, ensuring both transient stability and steady-state accuracy under uncertain and time-varying conditions.
Conclusion and future directions
This study introduced a new modified algorithm called mNRBO for optimal PID tuning in nonlinear process control and demonstrated its effectiveness on a CSTH system. By incorporating ROL and LGL, the algorithm achieved a balanced exploration–exploitation trade-off, resulting in faster convergence, improved tracking performance, and enhanced disturbance rejection compared with NRBO, HO, GEO, and SMA. The use of a standard PID structure ensures compatibility with existing control infrastructures, making the approach practical for industrial deployment. Future work will focus on hardware-in-the-loop validation and real-time implementation to assess performance under measurement noise, actuator constraints, and latency. Extending mNRBO to multi-input–multi-output (MIMO) systems and exploring hardware-aware, computationally lightweight variants will address scalability challenges. Moreover, integration with adaptive or model predictive control frameworks could further enhance responsiveness to process variability, while hybridization with machine learning surrogates may enable scalable, data-driven optimization in resource-constrained settings. Overall, mNRBO provides a computationally efficient and industrially relevant solution for nonlinear PID tuning, with clear potential for application in large-scale thermal process industries where reliability, energy efficiency, and precision are critical.
Data availability
The datasets used and/or analyzed during the current study available from the corresponding author on reasonable request.
References
Blondin, M. J. Controller Tuning Optimization Methods for Multi-Constraints and Nonlinear Systems (Springer International Publishing, 2021). https://doi.org/10.1007/978-3-030-64541-0
Rojas, J. D., Arrieta, O. & Vilanova, R. Industrial PID Controller Tuning (Springer International Publishing, Cham, 2021). https://doi.org/10.1007/978-3-030-72311-8
Alfaro, V. M. & Vilanova, R. Model-Reference Robust Tuning of PID Controllers (Springer International Publishing, 2016). https://doi.org/10.1007/978-3-319-28213-8
Jabari, M., Izci, D., Ekinci, S., Bajaj, M. & Zaitsev, I. Performance analysis of DC-DC Buck converter with innovative multi-stage PIDn(1+PD) controller using GEO algorithm. Sci. Rep. 14, 25612. https://doi.org/10.1038/s41598-024-77395-6 (2024).
Jabari, M. & Rad, A. Optimization of speed control and reduction of torque ripple in switched reluctance motors using metaheuristic algorithms based PID and FOPID controllers at the edge. Tsinghua Sci. Technol. https://doi.org/10.26599/TST.2024.9010021 (2024).
Konings, T., Esch, J., Kandler, C., Ding, S. X. & Louen, C. Robust, optimal PI-controller tuning for integrator plus delay plants with varying parameters based on randomised algorithms, in: 2013 Conference on Control and Fault-Tolerant Systems (SysTol) 110–115 (IEEE, 2013). https://doi.org/10.1109/SysTol.2013.6693834
Li, L., Ding, S. X., Qiu, J., Yang, Y. & Xu, D. Fuzzy observer-based fault detection design approach for nonlinear processes. IEEE Trans. Syst. Man. Cybern Syst. 47, 1941–1952. https://doi.org/10.1109/TSMC.2016.2576453 (2017).
Wang, Y. & Ma, G. Fault-tolerant control of linear multivariable controllers using iterative feedback tuning. Int. J. Adapt. Control Signal. Process. 29, 457–472. https://doi.org/10.1002/acs.2484 (2015).
Jabari, M. et al. Parameter identification of PV solar cells and modules using bio dynamics grasshopper optimization algorithm. IET Gener. Transm. Distrib.. 18, 3314–3338. https://doi.org/10.1049/gtd2.13279 (2024).
Kong, W. et al. PID control algorithm based on multistrategy enhanced dung beetle optimizer and back propagation neural network for DC motor control. Sci. Rep. 14, 28276. https://doi.org/10.1038/s41598-024-79653-z (2024).
Basil, N. et al. Accelerated black hole optimization algorithm with enhanced FOPID controller for omni-wheel drive mobile robot system. Neural Comput. Appl. 37, 16983–17014. https://doi.org/10.1007/s00521-025-11310-6 (2025).
Mohd Tumari, M. Z., Ahmad, M. A., Suid, M. H. & Hao, M. R. An improved marine predators algorithm-tuned fractional-order PID controller for automatic voltage regulator system. Fractal Fract. 7, 561. https://doi.org/10.3390/fractalfract7070561 (2023).
Sahin, A. K., Cavdar, B. & Ayas, M. S. An adaptive fractional controller design for automatic voltage regulator system: sigmoid-based fractional-order PID controller. Neural Comput. Appl. 36, 14409–14431. https://doi.org/10.1007/s00521-024-09816-6 (2024).
Ekinci, S. et al. Efficient control strategy for electric furnace temperature regulation using quadratic interpolation optimization. Sci. Rep. 15, 154. https://doi.org/10.1038/s41598-024-84085-w (2025).
Jabari, M., Ekinci, S., Izci, D., Bajaj, M. & Zaitsev, I. Efficient DC motor speed control using a novel multi-stage FOPD(1+PI) controller optimized by the pelican optimization algorithm. Sci. Rep. 14, 22442. https://doi.org/10.1038/s41598-024-73409-5 (2024).
Basil, N. & Marhoon, H. M. Selection and evaluation of FOPID criteria for the X-15 adaptive flight control system (AFCS) via Lyapunov candidates: optimizing trade-offs and critical values using optimization algorithms. E-Prime Adv. Electr. Eng. Electron. Energy. 6, 100305. https://doi.org/10.1016/j.prime.2023.100305 (2023).
Rahnamayan, S., Jesuthasan, J., Bourennani, F., Naterer, G. F. & Salehinejad, H. Centroid opposition-based differential evolution. Int. J. Appl. Metaheuristic Comput. 5, 1–25. https://doi.org/10.4018/ijamc.2014100101 (2014).
Basil, N. et al. Multi-criteria decision model for multicircular flight control of unmanned aerial vehicles through a hybrid approach. Sci. Rep. 15, 18962. https://doi.org/10.1038/s41598-025-01508-y (2025).
Basil, N. et al. Performance analysis of hybrid optimization approach for UAV path planning control using FOPID-TID controller and HAOAROA algorithm. Sci. Rep. 15, 4840. https://doi.org/10.1038/s41598-025-86803-4 (2025).
Basil, N., Marhoon, H. M. & Mohammed, A. F. Evaluation of a 3-DOF helicopter dynamic control model using FOPID controller-based three optimization algorithms. Int. J. Inform. Technol. https://doi.org/10.1007/s41870-024-02373-0 (2024).
Mahmood, Q. A. & Nawaf, A. T. Performance analysis of continuous stirred tank heater by using PID-cascade controller. Mater. Today Proc. 42, 2545–2552. https://doi.org/10.1016/j.matpr.2020.12.577 (2021).
Haghani, A., Jeinsch, T., Ding, S. X., Koschorrek, P. & Kolewe, B. A probabilistic approach for data-driven fault isolation in multimode processes. IFAC Proc.. 47, 8909–8914. https://doi.org/10.3182/20140824-6-ZA-1003.02353 (2014).
Wang, K. et al. Manifold-constrained trace ratio optimization for nonstationary process performance monitoring. J. Process. Control. 129, 103058. https://doi.org/10.1016/j.jprocont.2023.103058 (2023).
Tao, M., Gao, T., Li, X. & Li, K. Broad learning aided model predictive control with application to continuous stirred tank heater. Front. Control Eng. 2, 788492. https://doi.org/10.3389/fcteg.2021.788492 (2021).
Wu, X., Yang, X. & Qiu, J. A novel adaptive subspace predictive control approach with application to continuous stirred tank heater. IEEE Trans. Ind. Inf. 20, 9026–9036. https://doi.org/10.1109/TII.2024.3379665 (2024).
Gaurav, K. & Mukherjee, S. Design of artificial neural network controller for continually stirred tank heater. In: IECON 2012–38th Annual Conference on IEEE Industrial Electronics Society 2228–2231 (IEEE, 2012). https://doi.org/10.1109/IECON.2012.6388677
Veerasamy, G., Balaji, S., Kadirvelu, T. & Ramasamy, V. Reinforcement learning based adaptive PID controller for a continuous stirred tank heater process, Iran. J. Chem. Chem. Eng. 44, 265–282. https://doi.org/10.30492/ijcce.2024.2029225.6615 (2025).
Do, K. D. Stability in probability and inverse optimal control of evolution systems driven by levy processes. IEEE/CAA J. Autom. Sinica. 7, 405–419. https://doi.org/10.1109/JAS.2020.1003036 (2020).
Sowmya, R., Premkumar, M. & Jangir, P. Newton-Raphson-based optimizer: a new population-based metaheuristic algorithm for continuous optimization problems. Eng. Appl. Artif. Intell. 128, 107532. https://doi.org/10.1016/j.engappai.2023.107532 (2024).
Tizhoosh, H. R. & Learning, O. B. A New Scheme for Machine intelligence. in: International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06) 695–701 (IEEE, 2005). https://doi.org/10.1109/CIMCA.2005.1631345
Li, S., Chen, H., Wang, M., Heidari, A. A. & Mirjalili, S. Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput. Syst. 111, 300–323. https://doi.org/10.1016/j.future.2020.03.055 (2020).
Mohammadi-Balani, A., Dehghan Nayeri, M., Azar, A. & Taghizadeh-Yazdi, M. Golden eagle optimizer: A nature-inspired metaheuristic algorithm. Comput. Ind. Eng. 152, 107050. https://doi.org/10.1016/j.cie.2020.107050 (2021).
Amiri, M. H., Mehrabi Hashjin, N., Montazeri, M., Mirjalili, S. & Khodadadi, N. Hippopotamus optimization algorithm: A novel nature-inspired optimization algorithm. Sci. Rep. 14, 5032. https://doi.org/10.1038/s41598-024-54910-3 (2024).
Izci, D. et al. A new intelligent control strategy for CSTH temperature regulation based on the starfish optimization algorithm. Sci. Rep. 15, 12327. https://doi.org/10.1038/s41598-025-96621-3 (2025).
Cominos, P. & Munro, N. PID controllers: Recent tuning methods and design to specification. IEE Proc. Control Theory Appl. 149, 46–53. https://doi.org/10.1049/ip-cta:20020103 (2002).
Suid, M. H., Ahmad, M. A., Nasir, A. N. K., Ghazali, M. R. & Jui, J. J. Continuous-time Hammerstein model identification utilizing hybridization of augmented sine cosine algorithm and game-theoretic approach. Results Eng. 23, 102506. https://doi.org/10.1016/j.rineng.2024.102506 (2024).
Suid, M. H. & Ahmad, M. A. A novel hybrid of nonlinear sine cosine algorithm and safe experimentation dynamics for model order reduction. Automatika 64, 34–50. https://doi.org/10.1080/00051144.2022.2098085 (2023).
Acknowledgements
This research is funded by European Union under the REFRESH—Research Excellence For Region Sustainability and High-Tech Industries Project via the Operational Programme Just Transition under Grant CZ.10.03.01/00/22_003/0000048; in part by the National Centre for Energy II and ExPEDite Project a Research and Innovation Action to Support the Implementation of the Climate Neutral and Smart Cities Mission Project TN02000025; and in part by ExPEDite through European Union’s Horizon Mission Programme under Grant 101139527. The authors would like to express their sincere gratitude to Lukas Prokop and Stanislav Misak for their exceptional supervision, project administration, and overall guidance throughout the course of this project. Their expertise and support were instrumental to its success.
Funding
This research is funded by European Union under the REFRESH—Research Excellence For Region Sustainability and High-Tech Industries Project via the Operational Programme JustTransition under Grant CZ.10.03.01/00/22_003/0000048; in part by the National Centre for Energy II and ExPEDite Project a Research and Innovation Action to Support the Implementation ofthe Climate Neutral and Smart Cities Mission Project TN02000025; and in part by ExPEDite through European Union’s Horizon Mission Programme under Grant 101139527.
Author information
Authors and Affiliations
Contributions
Rizk M. Rizk-Allah, Serdar Ekinci, Mostafa Jabari: Conceptualization, methodology, software, visualization, investigation, writing—original draft preparation. Davut Izci, Olena Rubanenko: Data curation, validation, supervision, resources, writing—review and editing. Mohit Bajaj, Vojtech Blazek: Project administration, supervision, resources, writing—review and editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Rizk-Allah, R.M., Ekinci, S., Jabari, M. et al. Enhanced PID controller tuning for nonlinear continuous stirred-tank heaters using a modified Newton-Raphson optimizer with random opposition and Lévy-flight learning. Sci Rep 15, 45220 (2025). https://doi.org/10.1038/s41598-025-28802-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-28802-z
