
Abstract
Head pose estimation is a fundamental task in the field of computer vision, serving as an effective method to roughly determine a person’s gaze direction. However, accurate head pose estimation remains a huge challenge due to occlusion and low resolution. To address this challenge, this paper proposes a novel framework that combines classification and regression paradigms for head pose estimation. To begin with, we design a novel soft-label generation strategy for classification. This strategy first generates 3D facial models from different angles and then measures the similarity between poses by utilizing the displacements of 3D key points from different views. Additionally, we introduce the Stacked Dual Attention Module (SDAM), which includes the Multi-Receptive Attention Module (MRAM) and the Channel-wise Self-Attention Module (CSAM). MRAM uses convolution kernels of different sizes and explore multiple contextual semantics to perceive key features. CSAM employs a self-attention mechanism to adaptively model inter-channel dependencies, achieving effective channel attention. The design of SDAM takes into account the characteristics of the task itself, enabling it to extract more representative features and to be easily deployed in mainstream network architectures (e.g., ResNet). Extensive experiments on popular datasets demonstrate the competitiveness of our method. Furthermore, we apply the proposed head pose method to approximate and estimate students’ gaze points in large classroom scenarios.
Similar content being viewed by others
Introduction
Head pose estimation aims to predict the specific orientation of a person’s head in three-dimensional (3D) space by analyzing facial features in images or videos. It has a broad range of applications, including safe driving1,2, human-computer interaction3,4,5, medical systems6,7, virtual/augmented reality8, and other domains9,10,11.

Examples of facial images with occlusion, low resolution, or varying lighting conditions.
The factors such as occlusion and low resolution in the images (as shown in Fig. 1) make it difficult to capture key facial pose features during the learning process. Additionally, the head pose angle exhibits a continuous variation, and using bin classification methods to represent these continuous values may lead to information loss12, further restricting the model’s performance improvement. To tackle these challenges, soft label strategies are introduced as an alternative to head labels for representing the pose of facial images13,14,15. Compared to hard labels, soft labels are capable of better capturing the continuous characteristics of head poses as well as the similarity between adjacent angles. However, the current soft label generation approaches used in head pose estimation tasks typically construct Gaussian distributions with identical and fixed variances for the three Euler angles, namely yaw, pitch, and roll12,13,14. This type of method fails to adequately account for the differences in estimation difficulty across the three Euler angles. Therefore, we propose a novel soft-label construction strategy based on facial landmark information. In this strategy, we measure the similarity between head pose angles by calculating the displacements of 3D key points at these angles, which serves as an important step in soft label construction. At the three Euler angles, the same magnitude of angle change will lead to different degrees of changes in keypoint positions. In particular, changes in yaw and pitch angles cause large keypoint position shifts, whereas roll angle has a relatively small effect. These differences under the three Euler angles are encoded into soft labels.
Additionally, to enhance feature representation and improve the model’s discriminative capability, we propose the Stacked Dual Attention Module (SDAM) that includes the Multi-Receptive Attention Module (MRAM) and the Channel-wise Self-Attention Module (CSAM). Head pose estimation requires accurate modeling of the head’s global 3D orientation, which fundamentally depends on understanding the spatial arrangement of facial structures. This makes it essential to capture not only local features (e.g., contours and edges), but also the spatial relationships between local regions (e.g., the relative configuration of the eyes and nose), as well as the global structure of the head. To address these multi-level requirements, SDAM introduces a multi-scale spatial attention mechanism that leverages convolutional kernels with different receptive fields to generate attention maps sensitive to both fine-grained local cues and broader structural context. These attention maps guide the network to emphasize spatially informative and structure-related regions, facilitating the perception of key features through multiple contextual semantics. This design is highly compatible with head pose estimation task, as it typically requires a global perspective to accurately determine head pose. CSAM utilizes self-attention mechanism to construct attention weights to achieve channel attention. The self-attention mechanism explores the importance of different channels by calculating the global dependencies between them.
Furthermore, we apply our head pose estimation model to the estimation of students’ gaze points in classroom scenes. By accurately estimating students’ head poses, we can infer the position of their gaze points, providing support for analyzing their level of focus and points of interest. This application promotes the research and application of intelligent education by not only verifying the feasibility and effectiveness of the proposed method in practical scenarios but also by providing innovative technical support for human-computer interaction and intelligent analysis in the field of education. The main contributions of our work are as follows:
-
We propose a novel soft-label construction strategy (SLCS) that utilizes key point displacements to encode the differences in angle changes at the three Euler angles.
-
We propose the SDAM that utilizes two different attention modules to enhance feature representation. These two attention modules model features from the spatial dimension and channel dimension respectively to exploit more comprehensive information.
-
The practical application of the proposed method is successfully validated in a classroom setting, providing technical support for improving teaching strategies through the estimation of students’ gaze points.
-
We evaluate our head pose estimation model on two publicly available datasets: AFLW2000 and BIWI. The experiments show that our method achieves competitive performance.
Related work
In this section, we primarily present the existing methods for head pose estimation and the estimation of students’ gaze points in classroom scenarios. The existing methods for head pose estimation can primarily be divided into landmark-based methods and landmark-free methods.
Landmark-based methods
Landmark-based methods rely on the accurate detection of facial landmarks and their correspondence with the 3D reference model. The methods based on 2D landmarks16,17,18 are highly dependent on the accuracy and robustness of landmark detection, and the accurate localization of landmarks directly determines the performance of head pose estimation. In addition, to achieve accurate pose alignment, the detected head pose model needs to be as similar as possible to the corresponding 3D model19,20. However, when facing changes in lighting, facial expressions, and partial occlusion, the performance of landmark detection can degrade, which in turn affects the accuracy of head pose estimation. To address the limitations of 2D landmark-based methods, researchers have proposed head pose estimation methods based on 3D landmarks21,22,23. Unlike 2D landmark-based methods, which rely on the position of landmarks in 2D images, 3D landmark-based methods use feature points directly in 3D space to determine head pose, thereby more accurately capturing the rotation of the head in space.
Landmark-free methods
Landmark-free methods extracts global features directly from images using deep learning models and estimates head pose parameters in an end-to-end fashion. Since these methods do not rely on landmark detection, they are more robust against occlusion, large-angle rotations, and complex lighting conditions. HopeNet24 is a classic method for predicting Euler angles that combines classification and regression. It segments the range of head pose angles and optimizes them by combining cross-entropy loss and mean square error loss functions. Subsequently, QuatNet25 uses a quaternion representation to predict the head pose, thus avoiding the singularity problem of Euler angles. FSA-Net26 reveals aggregation features with fine-grained spatial structure and progressive stage fusion and proposes a network with stage regression and feature aggregation scheme to predict Euler angles. 6DRepNet27 proposes a six-dimensional rotation representation method that significantly improves the accuracy and stability of head pose estimation in complex environments, overcoming the limitations of traditional rotation representations.

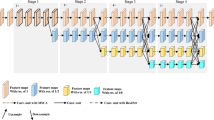
Overview of the proposed method.
Estimation of students’ gaze points
By estimating students’ gaze points, teachers can gain a clearer understanding of students’ focus and comprehension of the lesson content, which helps adjust teaching strategies in a timely manner and improves teaching quality. In a video instructional environment, Kok et al.28 use eye tracking to record students’ gaze data while watching videos. They employ visualization and statistical modeling to predict students’ understanding of the content. Soares Jr et al.29 use eye-tracking technology in elementary school classrooms to collect real-time gaze data from students and present this information to teachers, enabling them to better understand student concerns during the instructional process. Xu et al.30 use eye-tracking and object-detection techniques to automatically analyze students’ gaze distributions toward blackboards or slides in real classrooms, quantifying students’ attention characteristics and providing data references for instructional evaluation and design. In this paper, we propose a method for estimating students’ gaze points based on head pose, which is capable of estimating gaze points in low-resolution classroom scenes. This method is valuable for identifying students’ attention and evaluating their classroom participation.
Method
In this section, we provide a detailed introduction to our proposed method. The overall network architecture is shown in Fig. 2. We start with a head pose estimation strategy that combines classification and regression. Building upon this method, we propose a strategy for constructing soft labels based on facial landmarks and a Stacked Dual Attention Module. Finally, we outline methods for estimating students’ gaze points in the classroom.
Classification-regression head pose estimation
Among head pose estimation methods, HopeNet24 is a classic method to use a combination of classification and regression to estimate the Euler angles of head pose. This method sets the range of each Euler angle to \(\pm 99^\circ\) and divides them into categories with a \(3^\circ\) angle difference between adjacent ones. The angular category bins after division are: [0, 1, 2, ..., 65], resulting in a total of 66 categories. For one Euler angle, such as yaw, HopeNet uses the following loss for optimization:
where \(H(\cdot ,\cdot )\) and \(MSE(\cdot ,\cdot )\) represent cross entropy and mean square error loss functions, respectively. y is the one-hot encoded true class label, and \(\hat{y}\) is the predicted probability distribution over classes. \(\psi\) and \(\hat{\psi }\) are the true angle and the predicted angle. \(\alpha\) is a balancing factor that controls the relative importance of the two loss terms.
Although one-hot encoding (hard labels) has the advantage of being simple and intuitive, suitable for discrete classification tasks, and can clearly distinguish different categories. However, its limitation lies in the inability to express the similarities within categories and the gradual differences between categories, particularly in tasks such as head pose estimation. In contrast, soft labels can better model the above characteristics. Next, we will introduce the construction process of soft labels.
Soft label construction strategy
Before constructing soft labels, unlike HopeNet, we set the bin size to 1, resulting in a total of K = 199 classes for the yaw angle. In this case, we can simply assume that each category corresponds to a discrete angle within the range [\(-99^\circ\),\(99^\circ\)]. The same approach is applied to other Euler angles. Then, we utilize the Basel Face Model (BFM)31 to construct the 3D face models due to the its many advantages, such as precise controllability and continuous diversity. The number of 3D face models is equal to the class number. 68 commonly used 3D key points can be easily extracted from these models, which are distributed in key areas such as facial contours, eyes, and mouth.

This figure illustrates the calculation process of the similarity using the displacements of key points relative to the 3D reference face model \(M_0\) (yaw=\(0^\circ\)). The comparison is conducted across head pose models within an angle range of \(-99^\circ\) to \(99^\circ\).
Figure 3 illustrates the process of calculating the similarity using the displacements of key points. In this process, only the yaw angle is considered, so the pitch and roll angles are set to zero. We observed significant differences in facial shapes between the 3D face models \(M_0\) (yaw=\(0^\circ\)) and \(M_1\) (yaw=\(-99^\circ\)), as well as between \(M_0\) and \(M_2\) (yaw=\(99^\circ\)). To quantitatively describe this difference, we introduce the normalized Euclidean distance and exponential decay function to calculate the similarity. Given two 3D face models \(X_1\) and \(X_2\), the formula is defined as follows:

This figure presents the complete computation process of soft labels for yaw = 0. The obtained similarity vector is used to fit a Gaussian curve with a learnable variance.
where \({p}_i^{(1)}\) represents the 3D coordinates of the i-th landmark point in face model \({X}_1\), and \({p}_i^{(2)}\) represents the 3D coordinates of the i-th landmark point in face model \({X}_2\). dist is the normalization factor, represented here as the distance between the outer corners of the two eyes. Using the Eq. (2) to calculate the similarity between the 3D reference face model for angle \(\psi _j\) and the model sequence for the angle range \(\psi = [\psi _1,\psi _2,...\psi _K]=[-99^\circ ,...,99^\circ ]\), we can obtain a similarity vector, as follows:
where \(s_{j,i}\) is the similarity for angular categories j and i, and j is predetermined and determined by the specific angle being considered for generating the corresponding true soft label. For example, in Fig. 3, we generate the corresponding soft label for \(\psi _j=0\), so in this case, j is 100. Next, we normalize this vector to form a distribution in which the sum of all elements equals 1, as follows:
Then, as shown in Fig. 4, we model this distribution as a Gaussian distribution with mean \(\mu _j\) and standard deviation \(\sigma _j\). In other words, we fit a Gaussian curve that approximate the shape of the distribution. The standard deviation \(\sigma _j\) is a learnable parameter in curve fitting. The expression for the curve is as follows:
where \(\mu _j=\psi _j\), and \(\sigma _j\) can be obtained through the least squares method. The Gaussian distribution obtained above does not satisfy the condition that the sum of all elements is 1, therefore normalization is also required. After normalization, we obtain soft label, which is represented as follows:
For the Euler pitch and roll angles, we also employ the aforementioned strategy to obtain the soft label corresponding to each angle.

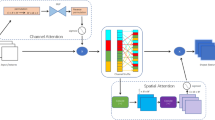
This figure illustrates our proposed stacked dual attention module (SDAM), which consists of two sub-modules: the multi-receptive attention module (MRAM) and the channel-wise self-attention module (CSAM). mm represents matrix multiplication.
Stacked dual attention module
In head pose estimation tasks, feature extraction is a critical step, and common methods for feature extraction include convolutional neural networks32, recurrent neural networks33, and autoencoders34. These methods can learn highly abstract feature representations by processing images in a layered manner. ResNet-5035 adopts a multi-layer residual structure, enabling it to effectively capture detailed features in images while maintaining high computational efficiency and robustness. Therefore, we chose ResNet-50 as our backbone network. ResNet-50 mainly consists of an initial convolutional layer (Conv1) and four residual blocks (Layer1, Layer2, Layer3, and Layer4). We design a Stacked Dual Attention Module (SDAM) that can be easily deployed at various levels of ResNet-50.
The SDAM is divided into two parts: the Multi-Receptive Attention Module (MRAM) and the Channel-wise Self-Attention Module (CSAM), as shown in Fig. 5. MRAM employs three different scales of convolutional kernels (3\(\times\)3, 5\(\times\)5, 7\(\times\)7) to capture contextual information with varying receptive fields through a hierarchical convolutional process. Before each convolution operation, appropriate padding is applied to maintain feature map dimensions. The extracted multi-scale features are then normalized using Group Normalization (GN) and aggregated to generate an attention map through a sigmoid function. This process can be represented by a formula as:
where \(M_F \in \mathbb {R}^{C \times H \times W}\) is the attention map, and \(\sigma\) is the sigmoid function. The output of MRAM is represented as:
where \(\otimes\) denotes element-wise multiplication. CSAM utilizes channel information based self-attention mechanism to explore inter-channel correlation of input features. Specifically, the input of CSAM passed through three \(1\times 1\) depthwise convolutions (DWConv) to generate the Query, Key, and Value. Before applying the attention mechanism, we should reshape Query, Key and Value from \(C\times H \times W\) to \(C\times (H\times W)\). After, the attention map is obtained through average pooling followed by a sigmoid function. The process is formalized as follows:
where \(M_C\) is the attention map and dim is \(H\times W\). Therefore, the output of CSAM (i.e., the output of SDAM) is:
SDAM expands the receptive fields by integrating convolution kernels with different receptive fields (such as \(3\times 3\), \(5\times 5\), and \(7\times 7\)), thereby producing multi-scale spatial attention maps that emphasize spatially informative and structure-related regions. Additionally, it further explores channel attention. In addition, similar to the typical CBAM36 module, our SDAM maintains the same output dimensions as its input features. This design ensures high compatibility and ease of deployment into existing mainstream network architectures. The effectiveness of SDAM is validated through subsequent ablation experiments.
Training loss
As shown in Fig. 2, we construct separate branches and loss functions for each Euler angle. Below, we take the yaw angle as an example and present its loss function. First, to measure the difference between soft labels and predicted distributions, we use the KL divergence loss function. For a sample x, assuming its true yaw angle is \(\psi\) and its discretized class label is j, the corresponding soft label is denoted as \(D=[d_1,d_2,...,d_{199}]\). Therefore, the KL divergence loss is given by:
where \(\hat{d}_{j,i}\) represents the probability of class j being predicted as class i. For a batch of samples, the above formula can be rewritten as:
where m is used to indicate the sample index, and M is the batch size. We follow the paradigm of combining classification and regression, defined as follows:
Finally, the total loss for yaw angle is obtained as:
where \(\alpha\) represent the regression coefficient.

Spatial position relationship of the world coordinate system, the camera coordinate system, the student’s head coordinate system, and the auxiliary coordinate system in the classroom.
students’ gaze points estimation in classroom
Since there is no publicly available dataset of students’ gaze points in the classroom, we conduct a data collection experiment in a real classroom setting. Specifically, two cameras are placed in the classroom to capture students’ head pose and facial features from multiple angles. The cameras are precisely configured to ensure high-quality image data. To collect diverse gaze points data, volunteers are positioned at different locations in the classroom and asked to sequentially focus on several pre-marked points on the blackboard. Whenever the volunteers shift to a new gaze point, the two cameras simultaneously capture images, recording their head poses. Ultimately, the collected data is used to validate gaze points estimation methods.

The calculation of the rotation matrix of the student’s head pose in the world coordinate system.
In the student’s gaze point estimation task, the central task is to compute two key parameters: The first one represents the rotation matrix of the student’s head pose in the world coordinate system. The second one represents the 3D coordinates of the position of the student in the classroom scenario in the world coordinate system. Combining the rotation matrix of the student’s head pose and 3D coordinates of the student’s position, the 3D coordinates of the student’s gaze point in the world coordinate system are computed by geometric reasoning. To do this, we construct four coordinate systems: the world coordinate system (WCS), the camera coordinate system (CCS), the coordinate system of the student’s head (SCS), and the auxiliary coordinate system (ACS), as shown in Fig. 6. From the observer’s point of view, the origin of WCS is located in the upper right corner of the blackboard (the \(Y_W\) axis points vertically downward toward the floor, and the \(Z_W\) axis points vertically toward the student). Two cameras are placed in the classroom, on either side of the blackboard, facing the students. When the student’s head is not rotated, the origin of SCS is the point of the tip of the student’s nose (the \(Y_S\) axis points vertically upward to the ceiling, and the \(Z_S\) axis points vertically toward the blackboard). Due to the complex rotational relationship between CCS and WCS, and the fact that the blackboard will not be in the camera’s field of view. Therefore, it is not possible to directly determine the transformation relationship between these two coordinate systems. To solve this problem, we introduce ACS to establish the relationship between CCS and WCS. The following is an example of estimating a single student’s gaze point in more detail.
Our proposed head pose model estimates a student’s head pose and converts the head pose Euler angles into a rotation matrix. We then convert the rotation matrix of the student’s head pose to WCS, as shown in Fig. 7. Subsequently, we need to compute the head pose rotation matrix \(R_{WS}\) for SCS with respect to WCS. This requires ACS to link the CCS and WCS relationships. First, place the chessboard directly in front of the blackboard. From the observer’s point of view, the origin of ACS is located in the upper right corner of the chessboard (the \(Y_A\) axis points vertically to the blackboard, and the \(Z_A\) axis points vertically upward to the ceiling), as shown in Fig. 6. By manually marking the chessboard and pose estimation method, the rotation matrix \(R_ {AC}\) and the translation vector \(t_ {AC}\) of CCS relative to ACS are obtained. By manually measuring the environmental data, the rotation matrix \(R_ {WA}\) and the translation vector \(t_ {WA}\) of the ACS relative to the WCS are obtained. Through the rotation relationship of each coordinate system, we can obtain the rotation matrix of the student’s head pose in WCS, as follows:
where \(R_{CS}\) is obtained by using our proposed head pose estimation model to obtain the Euler angles of the student in the photo and convert them into a rotation matrix relative to CCS.
As shown in Fig. 8, we need to determine the WCS 3D coordinates of the student’s position in the classroom. First, we use facial recognition and identity matching techniques to identify the same student in images captured by two cameras from different angles at the same time. After confirmation of identity consistency, we extract the image coordinates of the student’s nose tip from these two images. Subsequently, based on the student’s image coordinates, we use the triangulation method to calculate the 3D coordinates \(P_C\) of the student’s nose tip in CCS. Then, using the coordinate system conversion relationship between CCS and ACS, as well as the conversion relationship between ACS and WCS, we transform the 3D coordinates of the student’s position in the classroom from CCS to WCS, as follows:

The calculation of the 3D coordinates for the student’s nose tip in the world coordinate system.
where \(P_W\) is the 3D coordinate of the student’s position in the classroom in WCS. Finally, we derive the 3D coordinates of the student’s gaze point in WCS through spatial geometric relationships. Specifically, assuming there is a point \(P_ {SZ}\) in SCS with coordinates of (0, 0, 1). We can obtain the 3D coordinates of point \(P_ {SZ}\) in WCS, as follows:
where \(P_ {WZ}\) is the 3D coordinate of \(P_ {SZ}\) in WCS. Assume that the rotation matrix \(R_{WS}\) and \(P_W\) are represented as follows:
For this, we obtain the position of SCS origin \(O_S(t_1, t_2, t_3)\) in WCS, as well as the position of the point \(P_{WZ}(R_{13} + t_1, R_{23} + t_2, R_{33} + t_3)\) in WCS. Based on these definitions, we can calculate the 3D coordinates of the student’s gaze point \(P(x_W, y_W, z_W)\) in WCS, as follows:
Ethics approval and consent to participate
All methods were carried out in accordance with relevant guidelines and regulations. The study was approved by the Human Ethics Committee of Guangxi Normal University, and the ethical review number is 20250810008. Informed consent was obtained from all participants involved in the experiments.
Experiments
In this section, we describe the implementation of our method, followed by validation on a public dataset, comparison with existing methods, and presentation of ablation experiments. Finally, we introduce the practical application of our method for evaluating students’ gaze points in the classroom.
Implementation details
Our method is implemented using PyTorch. In Eq. (5), each value for yaw angle has an associated standard deviation. In our experiment, we observe that the variance differences between different angle values are relatively small. Therefore, for different yaw angle values, we set a fixed standard deviation. Similarly, the pitch and roll angles are processed in the same way. Specifically, the standard deviations for yaw, pitch, and roll angles are set to \(\sigma _y = 0.997\), \(\sigma _p = 0.939\), and \(\sigma _r = 1.25\). All input images are first detected and cropped using the MTCNN37 face detector. The cropped image is scaled to 224 \(\times\) 224. To enhance the training data diversity for better handling changes in various practical scenarios, we use various data augmentation techniques, including random horizontal flipping, random scaling, random cropping, random rotation (ranging from \(-45^\circ\) to \(45^\circ\)), and further image color processing, such as random blurring, random brightness, and contrast changes. During the optimization process, we initialize the learning rate of the Adam optimizer to 1e-4 and reduce it by half every 10 epochs, over a total of 80 epochs. Using this dynamic learning rate adjustment strategy, we aim to improve the model’s convergence in the later stages of training, thereby achieving better performance.

The images in the first, second, and third rows are from the 300W-LP, AFLW2000, and BIWI datasets, respectively.
Dataset
We use three popular datasets, namely 300W-LP38, AFLW200039 and BIWI40, to train and evaluate our model, ensuring a comprehensive and valuable evaluation of our network. Some samples from these datasets are shown in Fig. 9. 300W-LP and AFLW2000 are collected in an unrestricted field environment, while BIWI is collected in a restricted laboratory environment.
300W-LP dataset is a large pose dataset obtained by applying deformation flipping to the 300W dataset. It contains over 120,000 images and 3837 volunteers, with 68 key points and three head pose angles per image.
AFLW2000 dataset contains the first 2000 images from the AFLW dataset, annotated with ground truth 3D faces and corresponding 68 landmarks. It includes samples with large variations in lighting and occlusion conditions.
BIWI dataset consists of 15,678 images, recorded using Kinect equipment in a laboratory environment, covering 20 different subjects with varying head pose. In this dataset, the head occupies only a small area in the image.
Ablation study
We conduct ablation experiments on the regression coefficient \(\alpha\) in the loss function. Specifically, we conduct experiments with different \(\alpha\) values of 4, 2, 1, and 0.1, respectively. The models are retrained, showing the Mean Absolute Error (MAE) on the AFLW2000 and BIWI datasets. The experimental results are shown in Table 1. The model exhibits relatively stable performance for different \(\alpha\) values and performs best when \(\alpha\) is 2. Therefore, we use this value as the default configuration in all experiments.
To verify the effectiveness of SDAM and SLCS, we design several ablation experiments, and the results are shown in Table 2. In the experiment, we choose a method that combines classification and regression as the baseline. For ablation experiments, we add or replace our modules based on this. When SDAM and SLCS are not used as baselines, the MAE on the AFLW2000 and BIWI datasets are 4.07 and 4.03, respectively. When only the SDAM is added to the baseline, the experimental results show a decrease in MAE from 4.07 to 3.82 on the AFLW2000 dataset. The MAE decreases from 4.03 to 3.90 on the BIWI dataset. This indicates that the SDAM effectively enhances feature representation, resulting in improved accuracy of head pose estimation on AFLW2000 and BIWI datasets.
When only SLCS is used, the experimental results show a decrease in MAE from 4.07 to 3.41 on the AFLW2000 dataset. The MAE decreases from 4.03 to 3.46 on the BIWI dataset. This suggests that using soft labels is preferable to using hard labels for indicating the pose of a face image. As a result, on the AFLW2000 and BIWI datasets, the accuracy of the model’s head pose estimation is significantly improved. The combination of SDAM and SLCS achieves optimal performance on both AFLW2000 and BIWI datasets, significantly reducing MAE compared to baseline. Specifically, on the AFLW2000 dataset, the MAE decreases from 4.07 at baseline to 3.33, a reduction of approximately 18.2%, significantly reducing errors at all angles. Similarly, on the BIWI dataset, the MAE decreases from the baseline of 4.03 to 3.38, a reduction of approximately 16.1%. It is evident that the integration of all modules leads to higher accuracy and optimal results.
Comparison with state-of-the-art methods
We follow the convention of using the synthetic 300W-LP dataset for training and the ALFW2000 and BIWI datasets for testing, with the evaluation metric being the MAE of the Euler angles. We compare our method with other state-of-the-art methods listed in Table3. 3DDFA38 uses deep neural networks to fit a 3D face model and estimate head pose angles. FAN41 obtains multiscale information for pose estimation by repeatedly fusing feature blocks between network layers. QuatNet25, using a quaternion representation to predict head pose, avoids the singularity problem of Euler angles. FSA-Net26 introduces a method called soft-stage regression, which combines feature aggregation and achieves excellent performance. FDN42, using a feature decoupling method, obtains distinct features from different angles to estimate head pose. Img2Pose43 estimates the six degrees of freedom pose of the face directly from the image using an end-to-end deep learning model, achieving efficient and accurate face alignment and recognition. 6DRepNet27 proposes a new six-dimensional rotation representation method that accurately estimates head pose in unconstrained environments, overcoming the limitations of traditional rotation representations. ASG Learning44 encodes the column vectors of the rotation matrix into an anisotropic spherical Gaussian distribution, using an adaptive training paradigm. TokenHPE45 implements head pose estimation based on Transformer by introducing novel token learning concepts and directional tokens. HeadDiff46 considers head pose estimation as a denoising diffusion process on the SO(3) manifold, improving pose accuracy and reducing ambiguity by exploiting facial semantic information and cyclic consistency learning. WQuatNet47 frames head pose estimation as landmark-free quaternion regression on a RepVGG-D2se backbone with quaternion-specific losses, enabling full 0–360° orientation prediction without Euler gimbal-lock. HRHPE48 focuses on facial regions of interest and heterogeneous relations between adjacent poses, combining region-attention feature generation, a rugby-style hierarchical structure, and Transformer-based relation mining to achieve robust head pose estimation.

Example images with converted Euler angle visualization.
On the AFLW2000 dataset, compared to ASG Learning, our model reduced the MAE from 3.64 to 3.33, achieving an 8.5% improvement. Meanwhile, compared to HeadDiff’s MAE, our method reduced it by 6.7%. On the BIWI dataset, our model reduced the MAE from 3.61 in ASG Learning and 3.46 in HeadDiff to 3.38, improving by 6.4% and 2.3%, respectively. In addition, our method exhibits small errors in the yaw, pitch, and roll angles, further demonstrating the accuracy of the model. Fig. 10 provides qualitative comparisons between HopeNet and our method. The visualizations show that our predictions align more closely with the ground truth.

The visualization of students’ gaze points estimation results.
Gaze point estimation for Students in classroom scenarios
The proposed head pose estimation model is applied to the students’ gaze points estimation task, and the results are shown in Fig. 11. The first and second rows exhibit smaller errors, whereas the third row exhibits larger errors. The errors in the first and second rows are relatively small mainly because the shorter distance renders the depth estimation of the binocular vision system more stable, and the disparity information is stronger, which improves the accuracy of depth estimation. In contrast, the error in the third row is relatively large, which is attributed to the increased binocular distance measurement error caused by a greater distance. As the disparity information becomes weaker, the accuracy of depth estimation decreases. During the coordinate system conversion process, the initial detection error is amplified, resulting in an increase in the deviation of gaze point prediction, which significantly affects the accuracy of the prediction results.
Conclusion
In this paper, we propose a new soft-label construction strategy for head pose estimation task. The strategy utilizes the displacements of 3D key points from different angles. The constructed soft labels adopt different variances for three Euler angles. A larger variance results in a smoother distribution, making it more suitable for the easily estimable roll angle, while a smaller variance produces a sharper distribution, which is better suited for the more challenging estimation of yaw and pitch angles. Additionally, we propose the SDAM that contains two sub-modules: MRAM and CSAM, which effectively enhances feature representation, as demonstrated through our ablation study. Moreover, we conduct experiments on the public datasets AFLW2000 and BIWI, and the experimental results demonstrate that our method achieves competitive performance compared to other approaches in the head pose estimation task. Furthermore, we extend our method to compute students’ gaze points in classroom scenarios, successfully inferring their gaze positions and providing technical support for attention analysis in intelligent education.
Data availability
The 300W-LP, AFLW2000, and BIWI datasets used in this study are publicly available at https://ibug.doc.ic.ac.uk/resources/300-W/, https://www.tugraz.at/institute/icg/research/team-bischof/learning-recognition-surveillance/downloads/aflw/, and https://vision.ee.ethz.ch/datsets.html respectively.
References
Jha, S. & Busso, C. Estimation of driver’s gaze region from head position and orientation using probabilistic confidence regions. IEEE Trans. Intell. Vehicles 8, 59–72. https://doi.org/10.1109/TIV.2022.3141071 (2022).
Lu, Y., Liu, C., Chang, F., Liu, H. & Huan, H. Jhpfa-net: Joint head pose and facial action network for driver yawning detection across arbitrary poses in videos. IEEE Trans. Intell. Transp. Syst. 24, 11850–11863. https://doi.org/10.1109/TITS.2023.3285923 (2023).
Kytö, M., Ens, B., Piumsomboon, T., Lee, G. A. & Billinghurst, M. Pinpointing: Precise head-and eye-based target selection for augmented reality. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, 1–14. https://doi.org/10.1145/3173574.3173655 (2018).
Strazdas, D., Hintz, J. & Al-Hamadi, A. Robo-hud: Interaction concept for contactless operation of industrial cobotic systems. Appl. Sci. 11, 5366. https://doi.org/10.3390/app11125366 (2021).
Foster, M. E., Gaschler, A. & Giuliani, M. Automatically classifying user engagement for dynamic multi-party human-robot interaction. Int. J. Social Robotics 9, 659–674. https://doi.org/10.1007/s12369-017-0414-y (2017).
Amara, K., Guerroudji, M. A., Kerdjidj, O., Zenati, N. & Ramzan, N. Holotumor: 6 dof phantom head pose estimation-based deep learning and brain tumor segmentation for ar visualization and interaction. IEEE Sensors J. 23, 23367–23376. https://doi.org/10.1109/JSEN.2023.3305596 (2023).
Ritthipravat, P. et al. Deep-learning-based head pose estimation from a single rgb image and its application to medical crom measurement. Multimedia Tools Appl. 1–20. https://doi.org/10.1007/s11042-024-18612-2 (2024).
Bühler, M. C., Meka, A., Li, G., Beeler, T. & Hilliges, O. Varitex: Variational neural face textures. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 13890–13899 (2021).
Potluri, T., S, V. & K, V. K. K. An automated online proctoring system using attentive-net to assess student mischievous behavior. Multimedia Tools Appl. 82, 30375–30404. https://doi.org/10.1007/s11042-023-14604-w (2023).
Tomenotti, F. F., Noceti, N. & Odone, F. Head pose estimation with uncertainty and an application to dyadic interaction detection. Comput. Vision Image Understanding 243, 103999. https://doi.org/10.1016/j.cviu.2024.103999 (2024).
Wang, J., Yuan, S., Lu, T., Zhao, H. & Zhao, Y. Video-based real-time monitoring of engagement in e-learning using mediapipe through multi-feature analysis. Expert Syst. Appl. 128239. https://doi.org/10.1016/j.eswa.2025.128239 (2025).
Zhang, Y., Fu, K., Wang, J. & Cheng, P. Learning from discrete gaussian label distribution and spatial channel-aware residual attention for head pose estimation. Neurocomputing 407, 259–269. https://doi.org/10.1016/j.neucom.2020.05.010 (2020).
Liu, Z., Chen, Z., Bai, J., Li, S. & Lian, S. Facial pose estimation by deep learning from label distributions. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 1232–1240 (2019).
Geng, X., Qian, X., Huo, Z. & Zhang, Y. Head pose estimation based on multivariate label distribution. IEEE Trans. Pattern Anal. Mach. Intell. 44, 1974–1991. https://doi.org/10.1109/TPAMI.2020.3029585 (2020).
Xia, H., Liu, G., Xu, L. & Gan, Y. Collaborative learning network for head pose estimation. Image Vision Comput. 127, 104555. https://doi.org/10.1016/j.imavis.2022.104555 (2022).
Werner, P., Saxen, F. & Al-Hamadi, A. Landmark based head pose estimation benchmark and method. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), 3909–3913 (IEEE, 2017).
Kazemi, V. & Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1867–1874 (2014).
Gupta, A., Thakkar, K., Gandhi, V. & Narayanan, P. Nose, eyes and ears: Head pose estimation by locating facial keypoints. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1977–1981 (IEEE, 2019).
Guo, J. et al. Towards fast, accurate and stable 3d dense face alignment. In Proceedings of the European Conference on Computer Vision, 152–168 (Springer, 2020).
Li, S., Xu, C. & Xie, M. A robust o (n) solution to the perspective-n-point problem. IEEE Trans. Pattern Anal. Mach. Intell. 34, 1444–1450. https://doi.org/10.1109/TPAMI.2012.41 (2012).
Tulyakov, S., Jeni, L. A., Cohn, J. F. & Sebe, N. consistent 3d face alignment. IEEE Trans. Pattern Anal. Mach. Intell. 40, 2250–2264. https://doi.org/10.1109/TPAMI.2017.2750687 (2017).
Wu, C.-Y., Xu, Q. & Neumann, U. Synergy between 3dmm and 3d landmarks for accurate 3d facial geometry. In Proceedings of the 2021 International Conference on 3D Vision (3DV), 453–463 (IEEE, 2021).
Li, H., Wang, B., Cheng, Y., Kankanhalli, M. & Tan, R. T. Dsfnet: Dual space fusion network for occlusion-robust 3d dense face alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4531–4540 (2023).
Ruiz, N., Chong, E. & Rehg, J. M. Fine-grained head pose estimation without keypoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition workshops, 2074–2083 (2018).
Hsu, H.-W., Wu, T.-Y., Wan, S., Wong, W. H. & Lee, C.-Y. Quatnet: Quaternion-based head pose estimation with multiregression loss. IEEE Trans. Multimedia 21, 1035–1046. https://doi.org/10.1109/TMM.2018.2866770 (2018).
Yang, T.-Y., Chen, Y.-T., Lin, Y.-Y. & Chuang, Y.-Y. Fsa-net: Learning fine-grained structure aggregation for head pose estimation from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1087–1096 (2019).
Hempel, T., Abdelrahman, A. A. & Al-Hamadi, A. 6d rotation representation for unconstrained head pose estimation. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), 2496–2500 (IEEE, 2022).
Kok, E. M., Jarodzka, H., Sibbald, M. & van Gog, T. Did you get that? predicting learners’ comprehension of a video lecture from visualizations of their gaze data. Cognitive Sci. 47, e13247. https://doi.org/10.1111/cogs.13247 (2023).
Soares Jr, R. d. S. et al. Integrating students’ real-time gaze in teacher–student interactions: Case studies on the benefits and challenges of eye tracking in primary education. Appl. Sci. 14, 11007. https://doi.org/10.3390/app142311007 (2024).
Xu, H., Zhang, J., Sun, H., Qi, M. & Kong, J. Analyzing students’ attention by gaze tracking and object detection in classroom teaching. Data Technol. Appl. 57, 643–667. https://doi.org/10.1108/DTA-09-2021-0236 (2023).
Paysan, P., Knothe, R., Amberg, B., Romdhani, S. & Vetter, T. A 3d face model for pose and illumination invariant face recognition. In Proceedings of the 2009 sixth IEEE International Conference on Advanced Video and Signal-Based Surveillance, 296–301 (IEEE, 2009).
Li, Z., Liu, F., Yang, W., Peng, S. & Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 33, 6999–7019. https://doi.org/10.1109/TNNLS.2021.3084827 (2021).
Zaremba, W. Recurrent neural network regularization. arXiv:1409.2329https://doi.org/10.48550/arXiv.1409.2329 (2014).
Ma, W.-D.K., Lewis, J. & Kleijn, W. B. The hsic bottleneck: Deep learning without back-propagation. In Proceedings of the AAAI Conference on Artificial Intelligence 34, 5085–5092 (2020).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision, 3–19 (2018).
Zhang, K., Zhang, Z., Li, Z. & Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Proc. Lett. 23, 1499–1503. https://doi.org/10.1109/LSP.2016.2603342 (2016).
Zhu, X., Lei, Z., Liu, X., Shi, H. & Li, S. Z. Face alignment across large poses: A 3d solution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 146–155 (2016).
Zhu, X., Lei, Z., Yan, J., Yi, D. & Li, S. Z. High-fidelity pose and expression normalization for face recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 787–796 (2015).
Fanelli, G., Dantone, M., Gall, J., Fossati, A. & Van Gool, L. Random forests for real time 3d face analysis. Int. J. Comput. Vis. 101, 437–458. https://doi.org/10.1007/s11263-012-0549-0 (2013).
Bulat, A. & Tzimiropoulos, G. How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). In Proceedings of the IEEE International Conference on Computer Vision, 1021–1030 (2017).
Zhang, H., Wang, M., Liu, Y. & Yuan, Y. Fdn: Feature decoupling network for head pose estimation. In Proceedings of the AAAI Conference on Artificial Intelligence 34, 12789–12796 (2020).
Albiero, V., Chen, X., Yin, X., Pang, G. & Hassner, T. img2pose: Face alignment and detection via 6dof, face pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7617–7627 (2021).
Cao, Z., Liu, D., Wang, Q. & Chen, Y. Towards unbiased label distribution learning for facial pose estimation using anisotropic spherical gaussian. In Proceedings of the European Conference on Computer Vision, 737–753 (Springer, 2022).
Zhang, C., Liu, H., Deng, Y., Xie, B. & Li, Y. Tokenhpe: Learning orientation tokens for efficient head pose estimation via transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8897–8906 (2023).
Wang, Y. et al. Headdiff: Exploring rotation uncertainty with diffusion models for head pose estimation. IEEE Trans. Image Proc. https://doi.org/10.1109/TIP.2024.3372457 (2024).
Algabri, R., Shin, H., Abdu, A., Bae, J.-H. & Lee, S. Wquatnet: Wide range quaternion-based head pose estimation. J. King Saud Univ. Comput. Inf. Sci. 37, 24. https://doi.org/10.1007/s44443-025-00034-1 (2025).
Liu, H. et al. Hrhpe: Froi guides heterogeneous relationship representation learning for precise head pose estimation. Neurocomputing 130623, https://doi.org/10.1016/j.neucom.2025.130623 (2025).
Funding
This work was supported by the National Natural Science Foundation of China (Grant nos. 62167001, 62307009) and the Guangxi Natural Science Foundation (Grant no. 2025GXNSFBA069290).
Author information
Authors and Affiliations
Contributions
L. X.: Conceptualization, Methodology, Writing-original draft, Funding acquisition. Z. L.: Investigation, Data curation, Software, Validation, Writing-original draft. Y. G.: Supervision, Funding acquisition, Writing-review & editing. H. X.: Resources, Visualization.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xu, L., Li, Z., Gan, Y. et al. Soft-label guided stacked dual attention network for head pose estimation and its application to classroom gaze analysis. Sci Rep 16, 405 (2026). https://doi.org/10.1038/s41598-025-29814-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-29814-5
