
Abstract
Modeling mineral and ore bodies from gravity anomalies remains challenging in geophysical exploration due to the ill-posed and non-unique nature of the inverse problem, particularly under conditions of noisy or sparse data. Established inversion methods, including local optimization and metaheuristic algorithms, often require extensive parameter tuning and may yield unstable or poorly constrained solutions. This study proposes a regularized ensemble Kalman inversion (EKI) framework enhanced by Tikhonov regularization to improve numerical stability and mitigate sensitivity to ensemble degeneracy, thereby enabling efficient uncertainty quantification through ensemble statistics. Controlled numerical experiments show that the ensemble size is larger than \(\:100\) with moderate regularization, we can achieve an optimal balance between convergence stability and model resolution. Benchmarking against established metaheuristic algorithms (PSO, VFSA, and BA) suggests superior computational efficiency and stable convergence. Synthetic and real gravity data inversion (chromite, Pb-Zn, sulphide, and Cu-Au deposits) suggests that the regularized EKI yields stable, geologically consistent results with prior interpretations and drilling data. These results highlight the regularized EKI framework as a robust and efficient tool for mitigating mining risks and supporting strategic decision-making in mineral exploration.
Similar content being viewed by others
Introduction
Historically, the gravity method has served as a fundamental tool in geophysical prospecting for mineral and ore exploration because of its ability to detect subsurface density variations associated with ore deposits1,2. By measuring the gravity field at multiple surface points, this method effectively identifies and maps gravity anomalies caused by mineralized bodies3,4,5. Moreover, gravity data can be directly used to calculate ore reserves2. Numerous studies have demonstrated its successful application in exploring various mineral resources, such as sulphides6, manganese7, zinc8, chromite9, tin10, uranium11, iron12, and copper-gold deposits4. Gravity data are considered economically significant for mineral exploration. Therefore, modeling mineral or ore bodies from gravity measurements is critical for reducing mining risks and supporting strategic investment planning5,11.
Modeling mineral or ore bodies using idealized geometric models (e.g., spheres, horizontal and vertical cylinders) remains widely adopted and continues to attract significant attention5,13,14,15. These models are especially suitable for geological settings with distinct anomalies that can be interpreted as isolated bodies, such as individual ore deposits. The modeling process involves inverting measured gravity data to estimate source parameters (e.g., depth, amplitude coefficient, body location, and shape factors) associated with the idealized models15,17,18. Hence, inversion plays a vital role in characterizing the source geometry of gravity anomalies.
Various inversion algorithms, including local and global search methods, have been proposed to estimate these parameters. Local methods, such as least-squares inversion and its variants, have been extensively studied13,19,20,21,22,23,24. These techniques typically estimate a limited set of parameters, such as depth, shape factor, and amplitude coefficient. However, accurate inversion requires simultaneous estimation of all model parameters, increasing ambiguity due to interdependencies16,25. Despite advancements in numerical techniques, the non-uniqueness and resolution of gravity data inversion remain significant challenges18,27. As a derivative-based method, least-squares inversion is sensitive to the initial guess. It often fails to thoroughly explore the parameter space, leading to poor solutions, particularly in ill-posed inverse problems3.
Global optimization methods, particularly metaheuristic algorithms, have been developed to address these issues. These algorithms can avoid local minima and explore the solution space more comprehensively than the existing algorithms27. Prominent examples include very fast simulated annealing (VFSA)16,17, differential evolution (DE)7, particle swarm optimization (PSO)28,29, the bat algorithm (BA)3, and the dual classification learning Rao (DL Rao) algorithm5. These methods have demonstrated promising results in addressing the non-uniqueness of gravity inversion by effectively balancing exploration and exploitation. However, many such systems require extensive parameter tuning, which increases the implementation complexity and computational cost. Improper parameter selection can result in premature convergence and inaccurate subsurface models.
Therefore, alternative inversion strategies that require minimal parameter tuning and efficient uncertainty handling are needed. Compared to metaheuristics, data assimilation techniques provide a systematic framework for integrating observational data with forward models, enabling more robust and efficient parameter estimation30,31. Among these methods, ensemble Kalman inversion (EKI) has emerged as a powerful and computationally attractive geophysical inversion method. The proposed method offers derivative-free estimation, straightforward implementation, and built-in uncertainty quantification, making it well-suited for complex, ill-posed inverse problems.
Ensemble Kalman inversion (EKI) is an advanced statistical approach in data assimilation32, which has been widely recognized as an effective method for solving Bayesian inverse problems33. Initially, EKI was developed for applications in weather forecasting34,35 and oceanography36. Since then, EKI has been successfully applied to various geophysical applications, including climate modeling37, reservoir characterization38,39, seismic tomography40, induced polarization and DC-resistivity41,42, and self-potential data analysis43. EKI is preferred for solving geophysical inverse problems due to its derivative-free nature and powerful computational capabilities44. EKI provides an efficient inversion approach, easy implementation, and uncertainty quantification without extensive parameter tuning41,42,43. EKI operates by leveraging an ensemble of parameter realizations to approximate the posterior distribution, combining the benefits of Monte Carlo sampling with the computational efficiency of Kalman filtering45,46,47. Despite its advantages, EKI is not without limitations. Numerical instability can hinder its performance, particularly when the covariance matrix of the model predictions becomes ill-conditioned or singular. This instability often leads to unreliable results or algorithm failure, particularly in noisy or incomplete data scenarios.
To address these limitations, this study introduces a regularized version of EKI that incorporates Tikhonov regularization into the Kalman gain computation. This enhancement stabilizes the inversion process by improving the covariance matrix conditioning, ensuring reliable updates even under noise or limited ensemble diversity48,49,50,51. This approach preserves EKI’s computational efficiency and uncertainty quantification while significantly enhancing its robustness and reliability. The proposed framework is capable of estimating model parameters, including depth \(\:\left({z}\right)\), location of the source origin \(\:\left({{x}}_{{0}}\right)\), amplitude coefficient \(\:\left({A}\right)\), and shape factors \(\left( {{{q}}\;{{and}}\;\mu } \right)\), along with their associated uncertainties derived from the posterior ensemble distribution. A key contribution of this study is the integration of Tikhonov regularization to address ill-posed problems and enhance the stability of EKI in gravity data inversion, reducing its sensitivity to noise and numerical precision errors.
The present work is organized as follows: section “Ensemble Kalman inversion” presents the development and principles of the EKI framework. Section “Methodology” describes the methodology, including forward gravity data modeling and EKI-based inversion. Section “Synthetic data inversion” discusses pre-inversion evaluation, followed by the results of synthetic-data inversion, including benchmarking. Section “Inversion of field data examples” presents field case studies from real gravity datasets. Finally, section “Conclusions” concludes with a summary of the findings and implications.
Ensemble Kalman inversion
The Kalman filter (KF) was initially introduced by Kalman52 for recursive state estimation in Gaussian systems and later extended to nonlinear systems. However, the extended KF faces limitations due to the computational burden of covariance estimation in high-dimensional systems. To address this limitation, the ensemble Kalman Filter (EnKF) was introduced36,53. EnKF is a Monte Carlo-based approach that uses an ensemble of particles to estimate statistical properties, such as the covariance and mean of the model parameters54. Due to its effectiveness, EnKF has gained significant interest across various disciplines, including inverse problems44.
The ensemble Kalman inversion (EKI) framework is an adaptation of the ensemble Kalman filter (EnKF) framework for inverse problems45. While EnKF estimates system states by sequentially assimilating new data, EKI adapts this approach to iteratively refine unknown parameters. Each iteration updates the parameter estimates, resembling a pseudo-time evolution. Compared to EnKF, which continuously updates state variables with each new observation, EKI uses the entire dataset in a static setting to iteratively minimize the misfit between calculated and observed data, refining the parameters33,45,47. This makes EKI particularly useful for inverse problems, offering efficient parameter estimation, uncertainty quantification, and robustness to noisy data without requiring explicit derivatives44,45,55.
The goal of EKI is to estimate the unknown parameters m from the given observational data \({{{d}}_{{{obs}}}}\) expressed as
where \(\mathcal{G}\left( m \right)\) denotes a forward modeling, and \(\eta\) represents the noise of the observed data. The probabilistic distribution \({{P}}\left( {{{m|}}{{{d}}_{{{obs}}}}} \right)\) represents the solution of the inverse problem. This distribution expresses the probability of the model parameter m given the observed data \({{{d}}_{{{obs}}}}\). The proposed approach follows Bayes’ theorem as follows:
\(P\left( m \right)\) represents the prior distribution of the model parameters, while \(P\left( {{d_{obs}}{{|}}m} \right)\) denotes the likelihood. The expression \(P\left( {m{{|}}{d_{obs}}} \right)\) defines the posterior distribution of the parameter. Direct sampling of the posterior distribution typically relies on Monte Carlo methods, which require millions of forward model evaluations43,56. To improve efficiency, global optimization methods with thresholding have been applied to estimate the model parameter m more effectively57.
The EKI process typically involves several steps : (1) ensemble initialization; (2) forward model evaluation; (3) ensemble statistical parameter calculation; (4) Kalman gain calculation; (5) parameter update; (6) convergence assessment53,58. Each of these steps is described in detail below.
-
(1)
Ensemble initialization: The process begins by generating an ensemble of \({N_e}\) parameter realizations, denoted as \({{M=\{ }}{{{m}}_{{i}}}{{\} }}_{{{{i=1}}}}^{{{{{N}}_{{e}}}}}\), sampled from an initial prior distribution. The ensemble members are drawn uniformly within parameter bounds:
$$m_{i}^{{\left( 0 \right)}}\sim \mathcal{U}\left( {{M_{min}},{M_{max}}} \right)$$(3)where \(m_{i}^{{\left( 0 \right)}}\) represents the initial parameter set of the i-th ensemble member, and \(\mathcal{U}\left( \cdot \right)\) denotes a uniform distribution within the parameter range.
-
(2)
Forward model evaluation: Each ensemble member is used as input to the forward model \(\mathcal{G}\), which predicts the corresponding calculated data \({d_{cal,i}}\) :
$$d_{{cal,i}} = {\mathcal{G}}\left( {m_{i} } \right)$$(4)where \(\mathcal{G}\) represent a geophysical model that relates the parameter \({m_i}\) to the observed data. The predicted values \({d_{cal,i}}\) are then compared with the observed data \({d_{obs}}\).
-
(3)
Calculation of ensemble statistical parameters: The statistical properties of the ensemble are computed in each iteration. The ensemble means of the parameters and predicted observations are calculated as
$$\bar{m} = \frac{1}{{N_{e} }}\mathop \sum \limits_{{i = 1}}^{{N_{e} }} m_{i}$$(5)$$\bar{d}_{{cal}} = \frac{1}{{N_{e} }}\mathop \sum \limits_{{i = 1}}^{{N_{e} }} d_{{cal,i}}$$(6)The sample covariance matrices for parameter-data relationships are then estimated as follows:
$$C_{{md}} = \frac{1}{{N_{e} - 1}}\mathop \sum \limits_{{i = 1}}^{{N_{e} }} \left( {m_{i} - \bar{m}} \right)\left( {d_{{cal,i}} - \bar{d}_{{cal}} } \right)^{T}$$(7)$$C_{{dd}} = \frac{1}{{N_{e} - 1}}\mathop \sum \limits_{{i = 1}}^{{N_{e} }} \left( {d_{{cal,i}} - \bar{d}_{{cal}} } \right)\left( {d_{{cal,i}} - \bar{d}_{{cal}} } \right)^{T}$$(8)where \({C_{md}}\) represents the cross-covariance between parameters M and observations, and \({C_{dd}}\) is the auto-covariance of the predictions.
-
(4)
Kalman gain calculation: To update parameters using the observed data, the Kalman gain K should be computed first. The Kalman gain K is a matrix that optimally weights the difference between observed data and model predictions to update parameter estimates in Kalman methods, minimizing posterior uncertainty45,52,54. It is generally calculated as follows45,53:
$${{K=~}}{{{C}}_{{{md}}}}\left( {{{{C}}_{{{dd}}}}{{+}}{{{C}}_{{d}}}} \right){~^{{{-1}}}}$$(9)where \({C_d}\) represents the covariance of the observational noise. This matrix is typically diagonal, with each diagonal element representing the observation noise variance at a given data point. The accuracy of the Kalman gain critically depends on the auto-covariance of the model parameters, which is approximated using a finite ensemble and may lead to unreliable updates59. Furthermore, if the parameter ensemble exhibits low variability and \({C_d}\) is undersized, the Kalman gain may become ill-conditioned or singular, leading to algorithm failure43. To handle this, Tikhonov regularization was implemented to stabilize Kalman gain computation. Regularization helps mitigate the effects of an ill-conditioned covariance matrix by adding a small positive term to the denominator in Eq. (9), thereby ensuring numerical stability and preventing singularities. The modified Kalman gain incorporating Tikhonov regularization is expressed as follows:
$$K = C_{{md}} \left( {C_{{dd}} + C_{d} + \lambda I} \right)^{{~ - 1}}$$(10)where \(\lambda\) is the regularization parameter, and I is the identity matrix. The inclusion of \(\lambda I\) serves to improve the conditioning of the inverse computation, enabling stable and reliable parameter updates while maintaining consistency with the observed data. The additional term improves the conditioning of matrix inversion, effectively damping unstable directions in the parameter space. Intuitively, the Tikhonov regularization acts as a smoothing mechanism, limiting the influence of ensemble noise and poorly constrained directions. This is particularly important for gravity inversion problems, which are often ill-posed and sensitive to shape-related parameters. By introducing a controlled level of bias, regularization enhances the stability and robustness of the inversion, ensuring reliable updates even in the presence of data noise or limited ensemble size.
-
(5)
Parameter update: Each ensemble member is updated using the computed Kalman gain and perturbed observations as follows:
$${{m}}_{{{i}}}^{{{{k+1}}}}{{=m}}_{{{i}}}^{{{k}}}{{+K}}\left( {{{{d}}_{{{obs}}}}{{+}}{{{\varvec{\upeta}}}_{{i}}}{{-d}}_{{{{cal,i}}}}^{{{k}}}} \right)$$(11)where \({\eta _i}\sim \mathcal{N}\left( {0,{C_d}} \right)\) represents synthetic noise added to the observations to account for uncertainty.
-
(6)
Convergence assessment: The iterative process continues until the misfit between predicted and observed data is minimized, which can be evaluated using an error metric, such as the root mean squared error (RMSE). Convergence is achieved when the error falls below a predefined threshold or when successive iterations exhibit minimal improvement. The final parameter estimates are obtained from the best-performing ensemble member.
In addition to using Tikhonov regularization to enhance the stability and performance of EKI, other strategies, such as greedy selection and boundary handling, have been implemented to maintain parameter feasibility and improve the inversion results43,59. Greedy selection ensures that only the best-performing ensemble members are retained, effectively refining the ensemble over successive iterations. Meanwhile, boundary handling techniques prevent parameters from assuming values beyond the physical limits defined by prior knowledge, thereby avoiding unrealistic solutions during the inversion process. These enhancements improve the robustness and reliability of the EKI framework for geophysical inverse problems, especially gravity data inversion.
Methodology
This section describes the formulation of the gravity forward modeling used to calculate the gravity response from the given parameters, as well as the gravity data inversion procedure, utilizing the ensemble Kalman inversion (EKI) algorithm.
Gravity data forward modeling
At a given location point \({x_i}\), the gravity anomaly along a profile is defined as
where \({x_0}\) represents the location of model’s origin, and z denotes the source depth. The shape factors q and \(\mu\) influence the amplitude coefficient A, ensuring that the gravity anomaly g is expressed in mGal units. The definitions of A, q, and \(\mu\) for different geometric models are provided in Table 1 and illustrated in Fig. 1.

Illustration of different geometric models of causative bodies: (a) vertical cylinder; (b) horizontal cylinder; (c) sphere.
Gravity data inversion using EKI
As described in the previous section, a gravity data inversion program using EKI was developed to estimate the model parameters of the source gravity anomalies. The EKI program was extended to improve its performance with additional features, including Tikhonov regularization for stability, greedy selection for optimal ensemble refinement, and boundary handling to maintain parameter feasibility.
The inversion program begins by initializing an ensemble of model parameters. First, the number of ensemble members (Ne), the total number of iterations (\({N_{iter}}\)), and the observation noise covariance \({C_d}\) are defined. The choice of Ne influences the statistical representation of the parameter space: a higher Ne provides better coverage but increases computational cost. Meanwhile, \({C_d}\) controls the perturbation of observations and the spread of ensemble members. Following previous work43, the exact value of \(\eta\) is adopted in this study.
Each ensemble \({m_i}\) consists of model parameters \(A,z,{x_0},q,~\)and \(\mu\), which defines the source of the gravity anomaly to be estimated. Prior bounds for each parameter, denoted as \({M_{min}}\) and \({M_{max}}\), constrain the search space for inversion. The initial ensemble members \(m_{i}^{{\left( 0 \right)}}\) are randomly generated within the following bounds:
where rand generates uniformly random values between 0 and 1. These prior bounds ensured that all solutions remained geologically plausible throughout the inversion process, consistent with the Bayesian framework (section “Ensemble Kalman inversion”). Next, forward modeling is performed to calculate the gravity response (\({{{g}}_{{{cal}}}}\)) for each ensemble member using Eq. (12). The misfit function quantifies the difference between observed (\({{{g}}_{{{obs}}}}\)) and calculated gravity (\({{{g}}_{{{cal}}}}\)) data as a function of the model parameters (M). This misfit was evaluated using the RMSE equation, which can be written as follows5 :
where N is the total number of gravity observations (\({{{g}}_{{{obs}}}}\)).
After the misfit evaluation, the ensemble of model parameters is updated iteratively using the EKI framework. The update step refines the model parameters by incorporating observational information while maintaining ensemble diversity. At each iteration, the statistical parameters in the EKI framework, e.g., the ensemble mean (\(\bar{m}\)), the mean of the predicted data (\(\bar{d}_{{cal}}\)), the cross-covariance (\({C_{md}}\)), and the data covariance (\({C_{dd}}\)) are computed sequentially using Eqs. (5), (6), (7), and (8). The Kalman gain (K) is then calculated using the Tikhonov-regularized formulation to stabilize the inversion process, as expressed in Eq. (10). The choice of the regularization parameter (\(\lambda\)) in Eq. (10) is critical. If \(\lambda\) is too small, regularization may be ineffective. Conversely, if \(\lambda\) is too large, the solution may be overly smooth or biased. To systematically assess the influence of \(\lambda\) on the inversion results, numerical experiments were performed with trial values of \({10^{ - 5}},{10^{ - 4}},{10^{ - 3}},{10^{ - 2}},{10^{ - 1}},\)1, and 10, covering a range from very small to relatively large regularization strengths. The next step is to generate perturbed observations to account for measurement noise (\({{g}}_{{{{obs}}}}^{{{j}}}\)), following:
where \({{N}}\left( {{{0,\varvec{\upsigma}}}_{{{\varvec{\upeta}}}}^{{{2}}}} \right)\) represents Gaussian noise with variance \({{\varvec{\upsigma}}}_{{{\varvec{\upeta}}}}^{{{2}}}\). The ensemble members are then updated using the following Kalman update equation:
After each update, boundary handling is applied to ensure that parameters remain within their prior bounds. Instead of simple truncation, a reflection scheme is used:
This reflection strategy prevents parameters from sticking at the boundaries and enhances exploration of the search space while preserving physical plausibility. To further promote convergence, a greedy selection strategy is applied after each iteration. The updated misfit of each ensemble member \(\left( {f_{i}^{{new}}} \right)\) is compared to its previous value \(\left( {f_{i}^{{old}}} \right)\). If an update produces improvement \(\left( {f_{i}^{{new}}<f_{i}^{{old}}} \right)\), the new parameter vector is accepted. Otherwise, the old solution is retained:
The combination of reflection-based boundary handling and greedy selection ensures that the inversion progresses consistently toward better solutions while maintaining stability of the ensemble.
In geophysical inversion, estimating model parameter uncertainties ensures a reliable interpretation. The ensemble in the EKI framework estimates these uncertainties using the limit of acceptability and objective function trade-off methods43,60,61. As a result, multiple parameter sets can produce acceptable fits, forming the posterior distribution model (PDM)62. Using its optimization capabilities, the EKI inversion program is expected to achieve optimal gravity inversion solutions with enhanced performance.

Algorithm 1: Pseudocode of the regularized ensemble Kalman inversion (EKI) program for gravity data inversion.
Synthetic data inversion
To assess the performance, stability, robustness, and efficiency of the proposed regularized ensemble Kalman inversion (EKI), we designed a series of controlled synthetic gravity data inversion experiments. First, a sensitivity analysis was performed to investigate the influence of model parameters on the gravity response. Second, a set of numerical experiments were conducted to systematically examine the effects of ensemble size and the regularization parameter \(\left( \lambda \right)\) on the inversion stability and convergence. Third, the EKI’s capacity to recover subsurface parameters was evaluated under both noise-free and noise-contaminated conditions using two scenarios: (1) a single-source anomaly representing a solitary orebody and (2) a multiple-source anomaly simulating the more complex case of overlapping bodies. Finally, the robustness and computational efficiency of the proposed method were benchmarked against well-established gravity inversion algorithms, providing a comparative basis to demonstrate the advantages of EKI.
Sensitivity analysis
Sensitivity analysis is commonly performed using the Jacobian matrix, typically computed via the finite difference method63. In this study, we employ a gradient-free approach64,65, which estimates the sensitivity of the gravity response by perturbing individual model parameters and observing the resulting changes in the forward-model outputs. This method circumvents computationally intensive derivative calculations while requiring no explicit gradient information. In this sensitivity test, we independently perturbed each parameter of the two-body gravity model by ± 50% of its true value, while keeping the other parameters fixed. The gravity responses were computed and visualized to qualitatively evaluate the influence of each parameter on the model response (anomaly shape and amplitude). This sensitivity analysis helps interpret inversion uncertainties by identifying the influence of parameters on the gravity response.

Sensitivity analysis of gravity response to ± 50% perturbation for each model parameter in multiple anomaly cases: A, z, \({x_0}\) (top row); q, µ (bottom row). The black dashed lines represent the gravity response from the unperturbed (true) model. The coloured spectrum indicates how changes in each parameter affect the gravity response.
In Fig. 2, the colour bar illustrates the relative sensitivity of each model parameter to perturbations. The depth parameter z showed the strongest effect, as the perturbation significantly altered both the amplitude and shape of the anomaly. The \({x_0}\) parameter also exhibited strong influence, with perturbation directly shifting the anomaly laterally. The shape factor q controlled the anomaly curvature, with perturbations resulting in sharper or broader anomaly peaks, reflecting medium-to-high sensitivity. In contrast, the amplitude coefficient A acted mainly as a linear scaling factor, modifying the overall magnitude without altering the curve geometry, thus showing lower sensitivity. Similarly, the shape factor \(\mu\) influenced the anomaly height but preserved the overall curve shape, making it less sensitive compared to z, \({x_0}\), and q. These findings demonstrate that gravity data provide strong constraints on location-related and shape parameters but weaker constraints on scaling parameters. The disparity in sensitivity underscores the need for systematic uncertainty analysis to ensure robust outcomes and mitigate interpretational bias.
Effect of ensemble size and regularization parameter \(\left( \varvec{\lambda} \right)\)
This section reports numerical experiments investigating the influence of ensemble size and the regularization parameter (\(\lambda\)) on the performance of the regularized EKI, as both are key determinants of inversion stability and accuracy.
Ensemble size
We investigated the effect of ensemble size (Ne) on inversion performance and statistical characteristics of the inverted parameters through controlled experiments with a single-anomaly model (Table 2). Seven ensemble sizes (Ne = 50–500) were tested across 30 independent realizations, enabling a robust evaluation of convergence behaviour, the best objective function values, and stochastic sampling variability.
The results reveal a clear dependence of convergence efficiency on ensemble size. For small ensembles ( Ne = 50–100), convergence typically required more than 300–400 iterations, with a wide interquartile range (IQR) indicating strong variability between realizations (Table 2). As Ne increased, the median number of iterations to convergence generally decreased, reaching approximately 128 ± 75 iterations at Ne = 500. This trend, with reduced spread across realizations, demonstrates that larger ensembles enhance stability and accelerate convergence, thereby enabling more efficient exploration of the parameter space (Fig. 3a).
The best objective function values across 30 realizations followed a similar trend, decreasing substantially as ensemble size increased. As shown in Table 2, for \(\:{N}_{e}\ge\:100\), the best objective function values were relatively close to each other, indicating consistency across realizations. The box-and-whisker plots (Fig. 3b) further illustrate this behaviour: small ensembles ( Ne = 50, 100) produced longer boxes and whiskers, reflecting higher variability in the achieved misfit values. In contrast, larger ensembles (Ne \(\:\ge\:\) 150) yielded narrower distributions, with the boxes and whiskers becoming very short and centred near zero, signifying reduced variability and more stable convergence. Nevertheless, the improvement between Ne = 100 and Ne = 150 was not strongly pronounced, suggesting that ensemble sizes of around 100–150 are already adequate to achieve optimal results for the single-anomaly case, while larger ensembles may be required for more complex scenarios.

Effect of ensemble size on the EKI results. Box-and-whisker plots summarizing the statistical outcomes from 30 realizations for each ensemble size. (a) The number of iterations to convergence illustrates that larger ensembles significantly accelerate the convergence. (b) Statistical distribution of the best objective function values, showing that larger ensembles yield more stable and consistent low misfit values.
In terms of parameter recovery (shown in Table 2; Fig. 4), geometric parameters ( e.g., z, \({x_0}\), and q) were consistently estimated with high accuracy across all ensemble sizes (Fig. 4b – d). Their median values remained very close to the actual values of model parameters, with negligible IQRs, confirming their strong resolvability. In contrast, amplitude A and the shape factor \(\mu\) (Fig. 4a, e) exhibited systematic deviations from the true values, with broader IQRs particularly at smaller ensembles, indicating higher variability and residual bias. Although increasing ensemble size (Ne \(\geqslant\) 100) improved the estimates and reduced posterior spread, but some bias persisted, especially for A and \(\mu\). This behaviour is consistent with the sensitivity analysis (section “Sensitivity analysis”), which demonstrated that gravity data strongly constrain z, \({x_0}\), and q, while A and \(\mu\) remain weakly constrained and therefore more susceptible to ensemble sampling effects and the ill-posedness of the inversion.

Median and interquartile range (IQR) of the recovered parameters across 30 realizations for different ensemble sizes. Geometric parameters (z, \({x_0}\), q) are accurately resolved with narrow IQRs (represented by error bar), while scaling-related parameters (A and \(\mu\)) show larger variability and bias, especially at Ne < 100. Larger ensembles reduce uncertainty, though residual bias persists for \(\mu\) due to its lower sensitivity.
From a Bayesian perspective, ensemble size directly governs the quality of posterior approximation in EKI. Small ensembles inadequately sample the parameter space, yielding biased estimates and inflated uncertainty. On the other hand, larger ensembles capture parameter correlations more faithfully, reducing posterior spread and accelerating convergence. Thus, ensemble size represents a trade-off between computational cost and inversion reliability, with larger ensembles offering more robust solutions at a higher expense. These findings provide practical guidance for selecting ensemble sizes in gravity data inversion to balance efficiency and accuracy.
Regularization parameter \(\varvec{\lambda}\)
In our implementation, the regularization parameter λ is introduced solely to stabilize the computation of the Kalman gain. Without this term, the auto-covariance matrix in Eq. (9) can become ill-conditioned or singular, preventing inversion. Adding λI (Eq. 10) improves the matrix conditioning and ensures that parameter updates remain numerically stable. To systematically assess the effect of the regularization parameter \(\lambda\) on the performance of EKI, we conducted numerical experiments covering both single-anomaly and multi-anomaly scenarios, under noise-free and noise-contaminated conditions. Seven \(\lambda\) values (1e-5–10) were tested, each with 30 independent realizations to account for stochastic variability in the ensemble initialization and to ensure robust statistical evaluation. Each realization used an ensemble size of Ne = 150 and a maximum of 200 iterations. Two primary metrics were analysed: the success rate (percentage of runs converging within the iteration limit) and the best objective function value (minimum data misfit achieved among all realizations) for a given \(\lambda\). Median and interquartile range (IQR) of the objective function were further calculated to provide a statistically robust characterization of stability and convergence behaviour.

Success rate of different regularization parameters (\(\lambda\)) over 30 realizations in each scenario. (a) single anomaly; (b) multi-anomaly. Blue and red bars correspond to noise-free and noise-contaminated scenarios, respectively.
The success rate serves as an initial indicator of the algorithm’s stability across varying lambda values. In the single-anomaly noise-free case, EKI achieved a high success rate (> 90%) for \(\lambda {{~}} \geqslant 1{{e}} - 4\), and reached 100% success when \(\lambda {{~}} \geqslant 0.1\) (Table 3). At \(\lambda\) = 1e-5, the stability is slightly reduced (83% success rate), with several realizations exhibiting complex objective function values, indicating ill-conditioned covariance matrices and oscillatory ensemble updates. Under noise-contaminated conditions, convergence became much more sensitive to \(\lambda\). The success rate was only 13–23% for \(\lambda {{~}} \leqslant 1{{e}} - 4\) but sharply increased to 80% at \(\lambda {{~}}={{~}}1{{e}} - 3\), and reached 100% success rate for \(\lambda {{~}} \geqslant 0.1\). When comparing the two conditions (Fig. 5), the noise-free case consistently achieved higher success rates than the noise-contaminated case. This trend demonstrates that adequate regularization suppresses noise amplification and maintains stable ensemble updates in the presence of measurement uncertainty. In contrast, all multi-anomaly scenarios maintained 100% success across all \(\lambda\) values (both noise-free and noise-contaminated conditions), suggesting that the stronger spatial structure of the model imposed an additional constraint that enhanced stability. This indicates that increasing model complexity and the presence of noise did not reduce stability, suggesting that EKI is relatively insensitive to \(\lambda\) variations in such settings. To further examine this behaviour, the distribution of best objective function values was analysed next.

Distribution of the best objective function values for different regularization parameters (\(\lambda )\) over 30 realizations per scenario. a) Single anomaly (noise-free); b) Single anomaly (noise-contaminated); c) Multi anomaly (noise-free); d) Multi anomaly (noise-contaminated).
The distribution of the best objective function values provides further insight (Table 3; Fig. 6). For the single-anomaly noise-free case, the median of the objective functions remained low and consistent for \(1e - 5~ \leqslant \lambda \leqslant 1e - 2\), with increased variability at \(\lambda \geqslant 0.1\). This pattern suggests that moderate regularization promotes convergence toward the global minimum, while excessive regularization leads to over-smoothing and reduces data-fitting capability. Under noise contamination, the median of the objective function is consistent at around 0.40 for all \(\lambda \geqslant 1e - 3\), with the narrow IQRs (Fig. 6), indicating that appropriate regularization effectively suppresses noise amplification and yields consistent results across different realizations. At \(\lambda \leqslant 1e - 4\), the objective function values distribution became erratic and exhibited occasional outliers, consistent with the reduced success rates and numerical instability discussed earlier. For the multi-anomaly case, the median objective function gradually increased with \(\lambda\), reflecting the influence of regularization strength on inversion smoothness. All realizations converge with compact IQRs, confirming stable and well-conditioned performance. Similar behaviour was observed under noise contamination, with slightly higher median objective function yet comparable variability.
Overall, these results demonstrate that the moderate regularization \(\left( {1e - 3 \leqslant \lambda \leqslant 1e - 1} \right)\), provides the best balance between stability and resolution. Excessively small \(\lambda\) value leads to under-regularization and unstable behaviour, whereas overly strong regularization (\(\lambda \geqslant 1)\) tends to over-dampen parameter updates, increasing residuals through over-smoothing. As a consequence, \(\lambda\) primarily functions as a numerical safeguard in the Kalman gain computation rather than a tuning parameter for data fitting. Selecting \(\lambda ~\)within a moderate range ensures robust, well-conditioned, and geologically plausible inversion results.
Single-anomaly scenario
The first scenario involves a vertical cylinder with predefined parameters (Table 4). Synthetic gravity data were generated along a linear profile and inverted using the regularized EKI framework (section “Methodology”). Two cases were tested to assess robustness: one with noise-free data and another where the synthetic data were perturbed with 10% Gaussian noise. The prior bounds described in section “Gravity data inversion using EKI” define the search space for inversion. Parameter estimates are reported as the median±interquartile range (IQR) across the ensemble members, providing robust measures of central tendency and dispersion while accounting for inversion uncertainty. In this case, an ensemble size of Ne = 100 and \({N_{iter}}\) = 200 iterations were used to balance convergence and computational efficiency.
Table 4 summarizes the true model parameters, search spaces, and inversion results. In the noise-free case, the recovered parameters were nearly identical to the true values with tight uncertainty bounds, confirming the accuracy of the EKI method. In the noise-contaminated case, the estimated parameters remain close to the true values, though with wider uncertainty bounds, particularly for the amplitude A and the shape factor µ, which are more sensitive to noise.

Marginal posterior distributions of parameters for a single anomaly case estimated using EKI: (a) noise-free data; (b) 10% noise-contaminated data.
Figure 7 illustrates the marginal posterior distributions of the model parameters. In the noise-free case (Fig. 7a), the narrow and symmetric distributions indicate a strong constraint. In the noisy case (Fig. 7b), the distributions broadened, especially for µ, reflecting increased uncertainty. These histograms highlight parameter identifiability: depth z and location \(\:{x}_{0}\) remain well-constrained, whereas shape factors are more sensitive to data quality.

Best-fit gravity curve compared to the observed synthetic data for a single anomaly: (a) noise-free data; (b) noisy data.
Figure 8 shows the gravity anomaly fit using the best-fit model. EKI accurately reproduces the observed data in both the noise-free (Fig. 8a) and noisy (Fig. 8b) cases. Figure 9 shows the inversion’s convergence behaviour. In the noise-free case, the median objective function rapidly decreased and stabilized within 100 iterations, accompanied by a narrowing IQR, indicating consistent ensemble contraction. In the noisy case, convergence was slower and less sharp, but the median and IQR remained stable, demonstrating robustness under data uncertainty.

Convergence performance of EKI for a single anomaly: (a) evolution of median RMSE; (b) evolution of the interquartile range (IQR).
Multiple anomaly scenario
A second experiment was performed to simulate more complex geological settings using two overlapping anomalies: a sphere and a horizontal cylinder (Table 5). This case involved estimating 10 parameters, increasing the nonlinearity and complexity of the inverse problem. The noise-free and 10% noise-contaminated data were considered. Given the increased dimensionality, a larger ensemble size (Ne = 200) and longer iterations (\({N_{iter}}\) = 4000) were used to ensure adequate exploration of the parameter space and convergence.
The inversion results are presented in Table 5. In the noise-free case, the estimated parameters closely match the true values with low uncertainty across most parameters. Under noise contamination, the inversion still performed reliably, though uncertainty increases, particularly for parameters related to the second anomaly, such as \({x_{02}},~{q_2}\), \({\mu _2}\). This reflects the challenges of resolving overlapping anomalies with noisy data, especially when their responses interfere nonlinearly.

Marginal posterior distribution of parameter distributions for multiple anomaly scenarios using EKI: (a) noise-free data; (b) 10% noise-contaminated data.
The posterior distributions presented in Fig. 10 provide further insights into the inversion process. In the noisy case, the distributions broaden and exhibit some skewness, especially for the shape parameters. However, the medians remain close to the ground truth. These results confirm that the EKI framework, enhanced by Tikhonov regularization and boundary constraints, can provide meaningful uncertainty quantification even in high-dimensional inverse problems.

Best-fit gravity curves compared to observed synthetic data for multiple anomalies: (a) noise-free data; (b) noisy data.
Figure 11 compares the observed and calculated gravity data using the best-fit model. EKI successfully recovered the composite anomaly in both noisy conditions, reproducing its shape and amplitude with high fidelity. The convergence performance shown in Fig. 12 further supports this. The median and IQR of the objective function steadily decreased, with the IQR showing a clear contraction, indicating ensemble stabilization. The choice of a larger ensemble and more iterations was validated by this behaviour, which enabled the EKI algorithm to resolve complex source geometries despite the non-uniqueness and noise.

Iterative convergence of EKI for multiple anomalies: (a) median RMSE; (b) IQR of the objective function.
The results of this comprehensive set of synthetic tests demonstrate that the regularized EKI method is a stable and efficient tool for gravity inversion. The capacity to handle uncertainty and resolve overlapping anomalies makes it a promising approach for real-world geophysical exploration problems.
Robustness and efficiency of EKI: benchmarking against established algorithms
To quantitatively assess the robustness and computational efficiency of the proposed ensemble Kalman inversion (EKI), we performed a benchmarking experiment against three established metaheuristic algorithms for gravity data inversion: particle swarm optimization (PSO), very fast simulated annealing (VFSA), and the bat algorithm (BA). Each algorithm was implemented using the parameter settings and procedural schemes reported in previous studies, such as– PSO66,67, VFSA14,16, and BA3, to ensure fairness and reproducibility. The inversion was considered successful when the objective function (Eq. 14) dropped below 0.01 mGal, with a maximum of 10,000 iterations (except VFSA, which used 100 × 10,000 iterations). Both PSO and BA employed a population size of 100, while EKI used an ensemble size Ne = 100. This benchmark was not intended to identify a universally superior algorithm, but rather to assess the relative robustness and efficiency of EKI compared to established inversion methods.
The benchmarking results are summarized in Table 6; Fig. 13. The proposed EKI consistently demonstrates superior robustness and computational efficiency across 30 independent realizations. It achieved a 100% success rate with a median CPU time of only 0.38 s and a median of 21 iterations to convergence, demonstrating rapid and stable convergence behaviour. In contrast, VFSA also achieved full convergence success but required significantly higher computational effort, with median CPU time exceeding 32 s and more than \(1.6 \times {10^5}\) iterations. PSO showed similarly reliable convergence (100% success rate) but was moderately slower than EKI, whereas BA failed to converge in all realizations under the same stopping criteria. Interestingly, although BA performed effectively in a previous study3, it failed to reach the convergence criteria in this benchmark. This discrepancy likely arises from differences in the objective function, consistent with the No Free Lunch (NFL) theorem, which states that no optimization algorithm can outperform others across all problem landscapes68. Despite these variations, all successful algorithms (EKI, VFSA, PSO) achieved comparable final objective function values (~ 0.0095–0.0098), suggesting that the main differences among them lie in robustness and computational efficiency rather than solution quality.

Benchmarking of the proposed ensemble Kalman Inversion (EKI) against established stochastic optimization algorithms. Performance comparison of four algorithms (EKI, VFSA, PSO, and BA) based on 30 independent realizations: (a) success rate, (b) CPU time, (c) number of iterations (log scale), (d) Best objective function values.
In summary, the benchmarking experiment demonstrates that EKI achieves a remarkable balance between computational efficiency and convergence stability compared to established metaheuristic algorithms. These results highlight EKI’s potential as a robust and efficient inversion algorithm for gravity modelling. Nevertheless, since the benchmark was performed under controlled synthetic conditions, further validation using real field data is required to evaluate EKI’s practical applicability and performance under realistic geological and noise conditions. The following section presents the application of the proposed EKI to field gravity data.
Inversion of field data examples
To further validate the performance and applicability of the proposed regularized ensemble Kalman inversion (EKI) under real-world conditions, EKI was applied to four field gravity anomaly datasets associated with known mineralized regions: (1) the Camaguey chromite orebody in Cuba, (2) the Faro Pb-Zn deposit in Canada, (3) the Mobrun sulfide orebody in Canada, and (4) the Mundiyawas Cu-Au deposit in India. Each site represents a distinct geological setting and level of complexity, providing a diverse set of test cases to assess EKI’s robustness, accuracy, and capabilities for quantifying uncertainty. For all field datasets, the inversion results are presented alongside previous studies using metaheuristics and local inversion methods.
Camaguey chromite orebody, Cuba
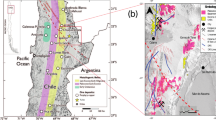
The Camaguey chromite deposit in Cuba was hosted within a serpentinized ultramafic complex comprising peridotite and dunite units known to concentrate chromite mineralization (Fig. 14). The USGS gravity surveys revealed a prominent anomaly over a ~ 89-meter-long profile (A2B2), which was interpreted to represent a dense chromite-bearing body, as shown in69.

Location and geological map of the Camaguey chromite deposit in Cuba (redrawn after Santana et al.,70 using Adobe Illustrator CC 2024 (https://www.its.ac.id/dptsi/en/licensed-software/) under institutional license from Institut Teknologi Sepuluh Nopember).
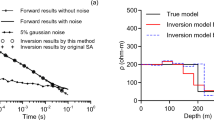
Table 7 presents the search space and the inversion results from EKI alongside the comparative estimates from previously published techniques, including the DL Rao algorithm, BA, VFSA, R-imaging, and least squares (LS). EKI successfully recovered the model parameters with relatively tight uncertainty bounds, especially for depth (15.10 ± 1.1 m), horizontal position (–1.4 ± 0.05 m), and amplitude coefficient (4.06 ± 0.61 mGal·m²). These estimates are consistent with those produced by DL Rao and VFSA methods, while offering more interpretable and geologically plausible values than R-imaging or LS. The shape parameters (q = 1.00 ± 0.08 and µ = 0.90 ± 0.22) fall within the expected ranges for chromite bodies identified as horizontal cylinders. Drilling data provided additional support for the EKI inversion, indicating that the top of the chromite orebody lies at approximately 9.15 m, as shown in3,6. The EKI-derived model placed the anomaly centroid at 15.10 ± 1.1 m, which is consistent with the expected depth of a symmetric body and in agreement with physical observations. This correspondence highlights the method’s ability to deliver accurate and interpretable subsurface models.

Inversion result of the Camaguey gravity anomaly using the regularized EKI: (a) the best-fit gravity response (blue line) shows strong agreement with the observed data (red points); (b) the marginal posterior distribution of the estimated model parameters, illustrating the uncertainty, concentration of ensemble solutions, and estimated value (blue ‘+’).
Figure 15a shows the gravity response computed from the best-fitting model, which closely matches the observed data with an RMSE of 0.0105 mGal. Compared with other methods (Table 7), EKI achieves one of the lowest RMSE values, indicating an excellent fit to the data. This value is comparable to that of the best-performing metaheuristic algorithms (DL Rao and VFSA) and significantly better than those of the remaining methods. Figure 15b shows the marginal posterior distributions of each parameter. The histograms are concentrated around the estimated values, particularly for depth and horizontal position. Such behaviour reflects high parameter identifiability and low inversion ambiguity. In contrast to traditional and metaheuristic methods, EKI provides point estimates and quantifies uncertainty across the ensemble, thereby enabling the probabilistic assessment of model reliability.
The Tikhonov regularization incorporated into EKI is pivotal for ensuring stable, and smooth updates, particularly for weakly sensitive shape factors (q, µ), which are otherwise prone to oscillation or overfitting. The regularized EKI algorithm successfully recovered geologically consistent subsurface structures from gravity data. The ability of EKI to produce reliable and uncertainty-informed estimates makes it a valuable tool for reducing exploration risk and guiding resource assessment.
Faro anomaly Pb-Zn deposit, Yukon Territory, Canada
The Faro deposit is a major lead-zinc (Pb-Zn) orebody located in the Faro Mining District of Yukon, Canada (Fig. 16). This region has a longstanding history of mineral exploration, with gravity surveys playing a central role in delineating high-density mineralized zones as depicted in Fig. 17. Significant density contrasts typically characterize the Pb-Zn deposits in this area relative to the surrounding host rocks. For this study, a residual gravity anomaly profile approximately 230 m in length was collected perpendicular to the strike of the mineral deposit, enabling high-resolution subsurface modeling.

Site layout and location map of the Faro Mining District of Yukon, Canada (redrawn and modified after Tang71, Yukon Government72 using Adobe Illustrator CC 2024 (https://www.its.ac.id/dptsi/en/licensed-software/) under institutional license from Institut Teknologi Sepuluh Nopember).

Geological map of the Anvil District, Canada, highlighting the location of the Faro sulphide ore deposit (redrawn and modified after Tang71 using Adobe Illustrator CC 2024 (https://www.its.ac.id/dptsi/en/licensed-software/) under institutional license from Institut Teknologi Sepuluh Nopember).
Table 8 presents the inversion results obtained using the regularized Ensemble Kalman Inversion (EKI) algorithm and the comparative solutions from previous studies, including the DL Rao algorithm, Bat Algorithm (BA), and R-imaging. The EKI method successfully estimated all model parameters with narrow uncertainty bounds, particularly for amplitude (546.17 ± 19.97 mGal·m2), depth (170.84 ± 4.47 m), and horizontal location (–33.17 ± 0.96 m). These values strongly agree with those reported by the DL Rao and BA methods, which demonstrated high gravity inversion performance. Notably, the estimated shape factor parameters (q = 1.00 ± 0.00, µ = 0.99 ± 0.01) are consistent with a horizontal cylinder-like body, a geometry commonly attributed to Pb-Zn deposits in sedimentary environments. These results also align with the borehole observations that placed the top of the ore body at a depth of approximately 76 m3,5, confirming the geologic plausibility of the EKI-derived model.
Figure 18a shows the best-fit gravity response generated by the EKI inversion. The model curve closely replicates the observed gravity data with an RMSE of 0.0858 mGal. This low residual error is comparable to that obtained with the DL Rao method and is substantially lower than that of the BA and R-imaging approaches (Table 8). Figure 18b shows the marginal posterior distributions of the inverted parameters. Most histograms were unimodal and sharply peaked around the median estimates, particularly for depth and lateral position. The narrow interquartile ranges across all parameters indicate strong ensemble agreement and low ambiguity in the recovered model, despite the challenge of imaging deep-seated ore bodies.

Inversion result of the Faro gravity anomaly using the regularized EKI: (a) the best-fit gravity response (blue line) shows strong agreement with the observed data (red points); (b) the marginal posterior distribution of the estimated model parameters, illustrating the uncertainty, concentration of ensemble solutions, and estimated value (blue ‘+’).
Generally, the regularized EKI demonstrates high accuracy, stability, and efficiency in modeling complex subsurface anomalies, such as the Faro Pb-Zn deposit. The integration of Tikhonov regularization enhances the numerical stability by improving the conditioning of the Kalman gain computation, particularly in the presence of noise or ensemble artifacts. Compared to previously published inversion techniques, EKI competes in accuracy and offers the added advantage of quantifying parameter uncertainties, making it a robust and interpretable tool for mineral exploration.
Mobrun sulphide orebody, Canada
The Mobrun sulphide orebody is situated in a volcanogenic massive sulphide (VMS) environment in Rouyn-Noranda, Canada, where mineralization is hosted within volcanic and intrusive rock formations74. This area contains a significant concentration of cherty pyrite-dominated sulphide mineralization, accompanied by minor quantities of chalcopyrite, copper, zinc, and silver73. Gravity surveys conducted over the site revealed a distinct residual anomaly associated with the high density of the sulphide body. The gravity profile AB7, spanning 230 m with a 2-meter spacing, was used as input for inversion to recover the source parameters and delineate the subsurface geometry.
Table 9 presents the search spaces and inversion results for the regularized EKI, along with comparative estimates from DL Rao, BA, VFSA, R-imaging, and LS methods. EKI achieved consistent recovery of all model parameters with relatively narrow uncertainty bounds, particularly for the amplitude coefficient (58.65 ± 3.67 mGal·m2), depth (36.21 ± 0.18 m), and location (–0.12 ± 0.02 m). These results closely align with the estimates obtained using DL Rao and VFSA methods, both of which are known for their robustness in handling complex inverse tasks. The shape factors (q = 0.76 ± 0.00, µ = 0.55 ± 0.02) suggest a source geometry consistent with a non-spherical, possibly horizontal cylinder, which aligns with the expectations for elongated sulphide lenses commonly observed in VMS-type deposits. In contrast, the LS and R-imaging methods produced broader or less physically plausible estimates, highlighting EKI’s ability to yield geologically realistic and statistically stable results. Notably, the estimated center of the orebody lies at 36.21 ± 0.18 m, while drilling reports place the top of the sulfide mineralization at approximately 23.34 m depth3,5, indicating that the inversion depth is consistent with the expected geometry of the deposit.

Inversion result of the Mobrun gravity anomaly using the regularized EKI: (a) the best-fit gravity response (blue line) shows strong agreement with the observed data (red points); (b) the marginal posterior distribution of the estimated model parameters, illustrating the uncertainty, concentration of ensemble solutions, and estimated value (blue ‘+’).
Figure 19a shows the gravity response computed from the EKI-derived best-fit model. The calculated gravity closely fits the observed data, yielding an RMSE of 0.0285 mGal, which is, identical to that obtained by DL Rao (Table 9). Compared with VFSA and BA, EKI demonstrates superior data-fitting performance. The marginal posterior distributions (Fig. 19b) are sharply peaked and centered near the estimated values for key parameters, particularly depth and location. These narrow distributions indicate a reduced ensemble spread and strong parameter identifiability. Moreover, the consistently small interquartile ranges across all parameters highlight high ensemble consistency and low model ambiguity, even when imaging deep-seated ore bodies.
Applying the regularized EKI to the Mobrun dataset demonstrates its robustness in recovering reliable parameters in a moderately complex geological setting. Tikhonov regularization enhances the numerical stability of the inversion, particularly when resolving shape parameters (q and µ), which are often poorly constrained in ill-posed gravity data inversion. Compared to metaheuristic methods, which often require extensive parameter tuning, EKI provides an efficient and interpretable inversion workflow. The ability to quantify uncertainty alongside parameter estimation makes it a valuable tool for early-stage exploration and resource targeting in sulfide-rich terrains.
Mundiyawas Cu-Au deposit, India
The Mundiyawas-Khera region, located within the Alwar Basin in the North Delhi Fold Belt (NDFB), India, is known for its copper (Cu) and gold (Au) mineralization, which is primarily hosted within Proterozoic felsic metavolcanic rocks (Figs. 20 and 21). The broader NDFB is a prominent metallogenic zone within the northwestern Indian plate, comprising three major volcano-sedimentary basins: Bayana, Alwar, and Khetri4,75. The Mundiyawas area is further characterized by tremolite-bearing dolomites, carbonaceous phyllites, and mica schists75, all of which are overlain by soil and scree layers of variable thickness (1.5–3 m). Airborne gravity surveys in this region have revealed complex, overlapping anomalies interpreted as multiple buried ore bodies at varying depths.

Location of the Alwar Basin within the North Delhi Fold Belt (NDFB), India, where the Mundiyawas area is situated (redrawn and modified after Sahoo et al.75 using Adobe Illustrator CC 2024 (https://www.its.ac.id/dptsi/en/licensed-software/) under institutional license from Institut Teknologi Sepuluh Nopember).

Geological map of the Alwar basin displaying our study area, the Mundiyawas-Khera region (redrawn and modified after Sahoo et al.75 using Adobe Illustrator CC 2024 (https://www.its.ac.id/dptsi/en/licensed-software/) under institutional license from Institut Teknologi Sepuluh Nopember).
The residual gravity profile AA’ analyzed in this study spans 1,280 m and was digitized at 10-meter intervals, as shown in4. The profile features of the two major gravity highs were suspected to represent deep and shallow mineralized sources. The inversion was performed using a dual-anomaly model within the regularized EKI framework. The results are summarized in Table 7, along with comparative estimates from the DL Rao and Bat Algorithm (BA) methods.
The regularized EKI algorithm effectively resolved both high-fidelity anomalies and well-constrained uncertainty bounds. The deeper body was estimated to have an amplitude of \({A_1}\)= 498.99 ± 4.05 mGal·m2 and a center depth of \({z_1}\)= 114.50 ± 0.78 m, consistent with prior interpretations and drilling evidence of buried sulfide-bearing felsic volcanics (Rao et al., 2019). The shallow body was delineated with a similar amplitude of \({A_2}\)= 499.08 ± 17.31 mGal·m2 and center depth of \({z_2}\)= 106.92 ± 0.76 m. Notably, the estimated horizontal locations of both bodies (\({x_{01}}\)= −212.26 ± 0.73 m and \({x_{02}}\)= 52.99 ± 0.25 m) correspond closely with the mapped anomaly peaks, supporting the structural interpretation of the profile.

The search space and the inversion result of the Mundiyawas Cu–Au gravity anomaly using regularized Ensemble Kalman Inversion (EKI): (a) Comparison between the observed residual gravity anomaly and the gravity response computed from the best-fit EKI model; (b) Marginal posterior distributions of the model parameters for both deep and shallow anomalies, illustrating the stability and ensemble consistency of the inversion.
Figure 22a presents the gravity response calculated from the EKI best-fit model, which closely fits the observed residual gravity profile. The resulting RMSE of 0.0704 is comparable to that of DL Rao and clearly outperforms BA (Table 10). Figure 22b shows the posterior distributions of each parameter. While the amplitude and depth parameters exhibit narrow, sharply peaked distributions indicative of strong identifiability, the shape factors (q and µ) show broader but still physically consistent spreads, reflecting the inherent difficulty in isolating geometry under overlapping conditions.
The EKI framework demonstrated superior performance in resolving the composite anomaly structure compared to published results. Its solutions are both geologically plausible and statistically reliable, with tighter uncertainty bounds than those produced by the BA and DL Rao methods. Tikhonov regularization is key in suppressing instability, particularly in the shape parameters. It allows the inversion to remain stable and interpretable even under challenging structural overlap. In summary, the Mundiyawas inversion underscores the capacity of the regularized EKI framework to address complex, high-dimensional gravity inversion problems in real mineralized terrains. Its ability to produce stable, interpretable, and uncertainty-aware solutions makes it a powerful tool for geophysical exploration in structurally intricate settings.
Conclusions
This study developed a regularized ensemble Kalman inversion (EKI) for robust and efficient gravity data modelling to identify mineral and ore deposits. By incorporating Tikhonov regularization \(\left( {\lambda I} \right)\) into the Kalman gain computation, the method effectively mitigates the numerical instabilities arising from the ill-conditioned covariance matrix of the Kalman gain, particularly under low ensemble variability or noisy data conditions. An ensemble size experiment demonstrated that using \({N_e} \geqslant 100\) improved the estimates and reduced posterior spread. Sensitivity analysis indicated that moderate regularization \(\left( {1e - 3 \leqslant \lambda \leqslant 1e - 1} \right)\) provides an optimal balance between stability and resolution, with \(\lambda\) functions as a numerical safeguard in the Kalman gain computation. Systematic benchmarking against established metaheuristic algorithms (PSO, VFSA, and BA) showed that the regularized EKI converges faster and exhibits superior stability while maintaining comparable accuracy, demonstrating its robustness and efficiency. Synthetic and real gravity data in mineral exploration (including chromite, Pb-Zn, sulphide, and Cu-Au deposits) demonstrated reliable, geologically consistent results that align with drilling information. Overall, the proposed framework advances ensemble-based inversion toward automated, uncertainty-aware exploration workflows. Future work will focus on adaptive regularization to enhance flexibility and data-driven implementation across diverse geophysical problems.
Data availability
The data set analyzed in this study is available upon request from the corresponding author Dharma Arung Laby (email: dharma.arunglaby@its.ac.id).
References
Hinze, W. J. Application of the gravity method to iron ore exploration. Econ. Geol. 55, 465–484. https://doi.org/10.2113/gsecongeo.55.3.465 (1960).
Nabighian, M. N. et al. Historical development of the gravity method in exploration. GEOPHYSICS 70, 63. https://doi.org/10.1190/1.2133785 (2005). ND-89ND.
Essa, K. S. & Diab, Z. E. Gravity data inversion applying a metaheuristic Bat algorithm for various ore and mineral models. J. Geodyn. 155, 101953. https://doi.org/10.1016/j.jog.2022.101953 (2023).
Rao, G. S., Arasada, R. C., Sahoo, P. R. & Khan, I. Integrated geophysical investigations in the Mudiyawas–Khera block of the Alwar basin of North Delhi fold belt (NDBF): implications on copper and associated mineralisation. J. Earth Syst. Sci. 128, 161. https://doi.org/10.1007/s12040-019-1193-7 (2019).
Warnana, D. D., Sungkono, S., Essa, S. & K Efficient and robust Estimation of various ore and mineral model parameters from residual gravity anomalies using the dual classification learning Rao algorithm. Arab. J. Sci. Eng. https://doi.org/10.1007/s13369-024-09774-0 (2024).
Roy, A. & Shaw, A. A new concept in Euler deconvolution of isolated gravity anomalies. Geophys. Prospect. 48, 559–575. https://doi.org/10.1046/j.1365-2478.2000.00203.x (2000).
Ekinci, Y. L., Balkaya, Ç., Göktürkler, G. & Turan, S. Model parameter estimations from residual gravity anomalies due to simple-shaped sources using differential evolution algorithm. J. Appl. Geophys. 129, 133–147. https://doi.org/10.1016/j.jappgeo.2016.03.040 (2016).
Essa, K. S., Mehanee, S. A., Soliman, K. S. & Diab, Z. E. Gravity profile interpretation using the R-parameter imaging technique with application to ore exploration. Ore Geol. Rev. 126, 103695. https://doi.org/10.1016/j.oregeorev.2020.103695 (2020).
Davis, W., Eugene, Jackson, W. H. & Richter, D. H. Gravity prospecting for chromite deposits in Camaguey Province. Cuba Geophys. 22, 848–869. https://doi.org/10.1190/1.1438427 (1957).
Chen, Y. Q., Zhang, L. N. & Zhao, B. B. Application of Bi-dimensional empirical mode decomposition (BEMD) modeling for extracting gravity anomaly indicating the ore-controlling geological architectures and granites in the Gejiu tin-copper polymetallic ore field, Southwestern China. Ore Geol. Rev. 88, 832–840. https://doi.org/10.1016/j.oregeorev.2016.06.031 (2017).
Zhang, P., Yu, C., Zeng, X., Tan, S. & Lu, C. Ore-controlling structures of sandstone-hosted uranium deposit in the Southwestern Ordos basin: revealed from seismic and gravity data. Ore Geol. Rev. 140, 104590. https://doi.org/10.1016/j.oregeorev.2021.104590 (2022).
Danaei, K. et al. 3D inversion of gravity data with unstructured mesh and least-squares QR-factorization (LSQR). J. Appl. Geophys. 206, 104781. https://doi.org/10.1016/j.jappgeo.2022.104781 (2022).
Mehanee, S. A. Accurate and efficient regularized inversion approach for the interpretation of isolated gravity anomalies. Pure Appl. Geophys. 171, 1897–1937. https://doi.org/10.1007/s00024-013-0761-z (2014).
Biswas, A., Parija, M. P. & Kumar, S. Global nonlinear optimization for the interpretation of source parameters from total gradient of gravity and magnetic anomalies caused by thin Dyke. Ann. Geophys. 60, G0218–G0218 (2017).
Trivedi, S., Kumar, P., Parija, M. P. & Biswas, A. Global optimization of model parameters from the 2-D analytic signal of gravity and magnetic anomalies. In Advances in Modeling and Interpretation in Near Surface Geophysics (eds. Biswas, A. & Sharma, S. P.) 189–221(Springer International Publishing, 2020). https://doi.org/10.1007/978-3-030-28909-6_8).
Biswas, A. Interpretation of residual gravity anomaly caused by simple shaped bodies using very fast simulated annealing global optimization. Geosci. Front. Special Issue: Geoinf. Techniques Nat. hazard. Model. 6, 875–893. https://doi.org/10.1016/j.gsf.2015.03.001 (2015).
Biswas, A. Interpretation of gravity anomaly over 2D vertical and horizontal thin sheet with finite length and width. Acta Geophys. 68, 1083–1096. https://doi.org/10.1007/s11600-020-00464-7 (2020).
Rao, K. & Biswas, A. Modeling and uncertainty Estimation of gravity anomaly over 2D fault using very fast simulated annealing global optimization. Acta Geophys. 69, 1735–1751. https://doi.org/10.1007/s11600-021-00649-8 (2021).
Abdelrahman, E. M., Bayoumi, A. I. & El-Araby, H. M. A least‐squares minimization approach to invert gravity data. Geophysics 56, 115–118. https://doi.org/10.1190/1.1442946 (1991).
Abdelrahman, E. M., El-Araby, H. M., El‐Araby, T. M. & Abo‐Ezz, E. R. Three least‐squares minimization approaches to depth, shape, and amplitude coefficient determination from gravity data. Geophysics 66, 1105–1109. https://doi.org/10.1190/1.1487058 (2001).
Abdelrahman, E. M. & El-Araby, T. M. Shape and depth solutions from moving average residual gravity anomalies. J. Appl. Geophys. 36, 89–95. https://doi.org/10.1016/S0926-9851(96)00038-9 (1996).
Abdelrahman, E. M. & Sharafeldin, S. M. A least-squares minimization approach to shape determination from gravity data. Geophysics 60, 589–590. https://doi.org/10.1190/1.1443797 (1995).
Essa, K. S. New fast least-squares algorithm for estimating the best-fitting parameters due to simple geometric-structures from gravity anomalies. J. Adv. Res. 5, 57–65. https://doi.org/10.1016/j.jare.2012.11.006 (2014).
Gupta, O. P. A least-squares approach to depth determination from gravity data. GEOPHYSICS 48, 357–360. https://doi.org/10.1190/1.1441473 (1983).
Biswas, A. Interpretation of gravity and magnetic anomaly over thin sheet-type structure using very fast simulated annealing global optimization technique. Modeling Earth Syst. Environ. 2 (1), 30 (2016).
Biswas, A. Interpretation and resolution of multiple structures from residual gravity anomaly data and application to mineral exploration In Basics of Computational Geophysics (eds. Samui, P., Dieu, B. T. & Dixon, B.) 293–318 (Elsevier, 2021).
Biswas, A. & Rao, K. Interpretation of magnetic anomaly over 2D fault and sheet-type mineralized structure using very fast simulated annealing global optimization–An Understanding of uncertainty and geological implications. Lithosphere. 2964057, 1–21. https://doi.org/10.2113/2021/2964057 (2021).
Essa, K. S., Abo-Ezz, E. R., Géraud, Y., Diraison, M. & Toushmalani, R. Gravity profiles interpretation applying a metaheuristic particle optimization algorithm of mineralized bodies resembled by finite elements. Heliyon 10, e31391. https://doi.org/10.1016/j.heliyon.2024.e31391 (2024).
Singh, A. & Biswas, A. Application of global particle swarm optimization for inversion of residual gravity anomalies over geological bodies with idealized geometries. Nat. Resour. Res. 25, 297–314. https://doi.org/10.1007/s11053-015-9285-9 (2016).
Ruiz, J. & Pulido, M. Parameter estimation using ensemble-based data assimilation in the presence of model error. Mon. Wea. Rev. 143, 1568–1582. https://doi.org/10.1175/MWR-D-14-00017.1 (2015).
Shadkam, E. Parameter setting of meta-heuristic algorithms: a new hybrid method based on DEA and RSM. Environ. Sci. Pollut Res. 29, 22404–22426. https://doi.org/10.1007/s11356-021-17364-y (2022).
Asch, M., Bocquet, M. & Nodet, M. Data Assimilation: Methods, Algorithms, and Applications (SIAM, 2016).
Ding, Z. & Li, Q. Ensemble Kalman inversion: mean-field limit and convergence analysis. Stat. Comput. 31, 9. https://doi.org/10.1007/s11222-020-09976-0 (2021).
Ghil, M., Cohn, S., Tavantzis, J., Bube, K. & Isaacson, E. Applications of Estimation theory to numerical weather prediction. In Dynamic Meteorology: Data Assimilation Methods (eds. Bengtsson, L., Ghil, M. & Källén, E.) 139–224 (Springer, 1981). https://doi.org/10.1007/978-1-4612-5970-1_5.
Houtekamer, P. L. & Mitchell, H. L. A Sequential Ensemble Kalman Filter for Atmospheric Data Assimilation. Mon. Wea.Rev. 129, 123–137. https://doi.org/10.1175/1520-0493(2001)1290123:ASEKFF2.0.CO;2 (2001).
Evensen, G. & Van Leeuwen, P. J. Assimilation of Geosat altimeter data for the agulhas current using the ensemble Kalman filter with a quasigeostrophic model. Mon. Weather Rev. 124 (1), 85–96 (1996).
Schneider, T., Lan, S., Stuart, A. & Teixeira, J. Earth System Modeling 2.0: A Blueprint for Models That Learn From Observations and Targeted High-Resolution Simulations. Geophys. Res. Lett. 44, 12396–12417. https://doi.org/10.1002/2017GL076101 (2017).
Aanonsen, S. I., Nœvdal, G., Oliver, D. S., Reynolds, A. C. & Vallès, B. The ensemble Kalman filter in reservoir engineering—a review. SPE J. 14, 393–412. https://doi.org/10.2118/117274-PA (2009).
Krymskaya, M. V., Hanea, R. G. & Verlaan, M. An iterative ensemble Kalman filter for reservoir engineering applications. Comput. Geosci. 13, 235–244. https://doi.org/10.1007/s10596-008-9087-9 (2009).
Muir, J. B. & Tsai, V. C. Geometric and level set tomography using ensemble Kalman inversion. Geophys. J. Int. 220, 967–980. https://doi.org/10.1093/gji/ggz472 (2020).
Tso, C. H. M., Iglesias, M. & Binley, A. Ensemble Kalman inversion of induced polarization data. Geophys. J. Int. 236, 1877–1900. https://doi.org/10.1093/gji/ggae012 (2024).
Tso, C. H. M. et al. Efficient multiscale imaging of subsurface resistivity with uncertainty quantification using ensemble Kalman inversion. Geophys. J. Int. 225, 887–905. https://doi.org/10.1093/gji/ggab013 (2021).
Sungkono, Apriliani, E. & Saifuddin, Fajriani, Srigutomo, W. Ensemble Kalman inversion for determining model parameter of Self-potential data in the mineral exploration. In Self-Potential Method: Theoretical Modeling and Applications in Geosciences (ed. Biswas, A.) 179–202 (Springer International Publishing, 2021). https://doi.org/10.1007/978-3-030-79333-3_7.
Chada, N. K. A review of the EnKF for parameter estimation. In Inverse Problems - Recent Advances and Applications (IntechOpen, 2022). https://doi.org/10.5772/intechopen.108218.
Iglesias, M. A., Law, K. J. H. & Stuart, A. M. Ensemble Kalman methods for inverse problems. Inverse Probl. 29, 045001. https://doi.org/10.1088/0266-5611/29/4/045001 (2013).
Kovachki, N. B. & Stuart, A. M. Ensemble Kalman inversion: a derivative-free technique for machine learning tasks. Inverse Probl. 35, 095005. https://doi.org/10.1088/1361-6420/ab1c3a (2019).
Schillings, C. & Stuart, A. M. Convergence analysis of ensemble Kalman inversion: the linear, noisy case. Appl. Anal. 97, 107–123. https://doi.org/10.1080/00036811.2017.1386784 (2018).
Chada, N. K., Stuart, A. M. & Tong, X. T. Tikhonov regularization within ensemble Kalman inversion. SIAM J. Numer. Anal. 58, 1263–1294. https://doi.org/10.1137/19M1242331 (2020).
Tarantola, A. Inverse problem theory and methods for model parameter estimation, other titles in applied mathematics. Soc. Ind. Appl. Math. (2005). https://doi.org/10.1137/1.9780898717921.
Tikhonov, A. N., Goncharsky, A. V., Stepanov, V. V. & Yagola, A. G. Numerical Methods for the Solution of Ill-Posed Problems (Springer Netherlands, 1995). https://doi.org/10.1007/978-94-015-8480-7.
Zhdanov, M. S. (ed), Chapter 2 - Ill-posed problems and the methods of their solution. In Geophysical Inverse Theory and Regularization Problems, Methods in Geochemistry and Geophysics 29–57 (Elsevier, 2002). https://doi.org/10.1016/S0076-6895(02)80039-7.
Kalman, R. E. A new approach to linear filtering and prediction problems. J. Basic. Eng. 82, 35–45. https://doi.org/10.1115/1.3662552 (1960).
Chada, N. K., Iglesias, M. A., Roininen, L. & Stuart, A. M. Parameterizations for ensemble Kalman inversion. Inverse Probl. 34, 055009. https://doi.org/10.1088/1361-6420/aab6d9 (2018).
Evensen, G. Nonlinear variational inverse problems. In Data Assimilation: the Ensemble Kalman Filter (ed. Evensen, G.) 71–93 (Springer, 2009). https://doi.org/10.1007/978-3-642-03711-5_6.
Pensoneault, A. & Zhu, X. Uncertainty quantification for deeponets with ensemble Kalman inversion. J. Comput. Phys. 523, 113670. https://doi.org/10.1016/j.jcp.2024.113670 (2025).
Zhang, J. et al. Improving simulation efficiency of MCMC for inverse modeling of hydrologic systems with a Kalman-Inspired proposal distribution. Water Resour. Res. 56, e2019WR025474. https://doi.org/10.1029/2019WR025474 (2020).
Sungkono, Warnana, D. D. Black hole algorithm for determining model parameter in self-potential data. J. Appl. Geophys. 148, 189–200. https://doi.org/10.1016/j.jappgeo.2017.11.015 (2018).
Chada, N. K., Schillings, C. & Weissmann, S. On the incorporation of box-constraints for ensemble Kalman inversion. Found. Data Sci. 1, 433–456. https://doi.org/10.3934/fods.2019018 (2019).
Wang, Y., Li, G. & Reynolds, A. C. Estimation of depths of fluid contacts by history matching using iterative ensemble Kalman smoothers. In Presented at the SPE Reservoir Simulation Symposium, p. SPE-119056-MS (2009). https://doi.org/10.2118/119056-MS.
Fernández-Martínez, J. L., Fernández-Muñiz, Z., Pallero, J. L. G. & Pedruelo-González, L. M. From Bayes to tarantola: new insights to understand uncertainty in inverse problems. J. Appl. Geophys. 98, 62–72. https://doi.org/10.1016/j.jappgeo.2013.07.005 (2013).
Laby, D. A., Sungkono, Santosa, B. J. & Bahri, A. S. RR-PSO: fast and robust algorithm to invert Rayleigh waves dispersion. Contemp. Eng. Sci. 9, 735–741. https://doi.org/10.12988/ces.2016.6685 (2016).
Vrugt, J. A. & Beven, K. J. Embracing equifinality with efficiency: limits of acceptability sampling using the DREAM(LOA) algorithm. J. Hydrol. 559, 954–971. https://doi.org/10.1016/j.jhydrol.2018.02.026 (2018).
Pan, L., Chen, X., Wang, J., Yang, Z. & Zhang, D. Sensitivity analysis of dispersion curves of Rayleigh waves with fundamental and higher modes. Geophys. J. Int. 216, 1276–1303. https://doi.org/10.1093/gji/ggy479 (2019).
Ai, H. et al. Modified barnacles mating optimizing algorithm for the inversion of Self-potential anomalies due to ore deposits. Nat. Resour. Res. 33, 1073–1102. https://doi.org/10.1007/s11053-024-10331-7 (2024).
Mianshui, R., Li-Yun, F., José, F., Weijia, S. S. & S Joint inversion of earthquake-based horizontal-to-vertical spectral ratio and phase velocity dispersion: applications to garner Valley. Front. Earth Sci. 2022, 10. https://doi.org/10.3389/feart.2022.948697 (2022).
Carlisle, A. & Dozier, G. An off-the-shelf PSO. In Proceedings of the Workshop on Particle Swarm Optimization. Purdue Sch. Eng. Technol. Indianap. IN (2001).
Fernández Martínez, J. L., García Gonzalo, E., Fernández Álvarez, J. P., Kuzma, H. A. & Menéndez Pérez, C. O. PSO: a powerful algorithm to solve geophysical inverse problems: application to a 1D-DC resistivity case. J. Appl. Geophys. 71, 13–25. https://doi.org/10.1016/j.jappgeo.2010.02.001 (2010).
Wolpert, D. H. & Macready, W. G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1, 67–82. https://doi.org/10.1109/4235.585893 (1997).
Davis, W. E., Jackson, W. H. & Richter, D. H. Gravity prospecting for chromite deposits in Camaguey Province, Cuba. Geophysics 22, 848–869. https://doi.org/10.1190/1.1438427 (1957).
Santana, M. M. U. et al. The La Unión Au ± Cu prospect, Camagüey District, cuba: fluid inclusion and stable isotope evidence for ore-forming processes. Min. Deposita. 46, 91–104. https://doi.org/10.1007/s00126-010-0313-8 (2011).
Tang, M. S. M. Delineation of groundwater capture zone for the Faro Mine, Faro Mine Complex, Yukon Territory. https://doi.org/10.14288/1.0053598 (2011).
Crown-Indigenous Relations and Northern Affairs Canada. Adaptive Management Plan for the Faro Mine Remediation Project,Version July 15, 2021. Government of Canada (2021).
Grant, F. S. & West, G. F. Interpretation theory in applied geophysics. McGraw-Hill Book. Co. 103, 184–184. https://doi.org/10.1017/S0016756800050627 (1965).
Barrett, T. J., Cattalani, S., Hoy, L., Riopel, J. & Lafleur, P. J. Massive sulfide deposits of the Noranda area, Quebec. IV. The mobrun mine. Can. J. Earth Sci. 29, 1349–1374. https://doi.org/10.1139/e92-110 (1992).
Sahoo, J., Sahoo, P. R., Khan, I. & Venkatesh, A. S. Insights into the metallogenesis of the felsic volcanic hosted Mundiyawas-Khera Cu Deposit, Alwar Basin, Western India. Minerals 12, 370. https://doi.org/10.3390/min12030370 (2022).
Acknowledgements
We thank the Editor and anonymous reviewers for their kind suggestions, which have improved the study. The authors (DAL and SS) gratefully acknowledge the support of the Department of Geophysical Engineering at the Institut Teknologi Sepuluh Nopember (ITS), Indonesia, for providing computational facilities and academic guidance during this research. AB acknowledges GSU, ISI Kolkata for computational facilities and space. Appreciation is also given to the authors of the previously published datasets used in the field case comparisons.
Funding
No funding is received for this work.
Author information
Authors and Affiliations
Contributions
Dharma Arung Laby: Conceptualization, Data Curation, Methodology, Software, Investigation, Writing - Original Draft; S.Sungkono: Methodology, Software, Investigation, Formal Analysis, Supervision, Writing - Review & Editing; Arkoprovo Biswas: Investigation, Formal Analysis, Visualization, Writing - Review & Editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Laby, D.A., Sungkono, S. & Biswas, A. Regularized ensemble Kalman inversion for robust and efficient gravity data modeling to identify mineral and ore deposits. Sci Rep 15, 43401 (2025). https://doi.org/10.1038/s41598-025-30141-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-30141-y
