
Abstract
Trust in human-machine interaction is a critical factor for the performance of AI systems, but achieving it is still challenging because many AI models are considered black-box. Following the purpose of the study, we quantitatively analyze the role of XAI and ESNs on the trust calibration with two different benchmark datasets, CIFAR-10 for visual tasks and SQuAD for text-based tasks. Using a 2 × 2 between-subjects experimental design, we examine the influence of AI explainability (explainable AI vs. non-explainable AI) and interaction outcomes (successful vs. failed) on explicit and implicit measures of trust. To increase the transparency of the model, convolution neural networks are joined with Explainable Artificial Intelligence (XAI) techniques including Grad-CAM for visual explainability and attention mechanisms for text-based tasks. This study shows explainable AI as a significant moderator of trust levels, especially in failed interactions and when users are given rationales for AI decisions. Explanations based on CNNs (Convolutional Neural Networks) improve the understanding, hence building trust, by providing visual evidence that is often easier to comprehend. Though implicit and explicit trust measures show strong correlations between the two measures, implicit metrics reveal differences in trust dynamics that cannot be gea-verified using self-reports. In addition, demographic factors, such as gender, have no significant impact on trust, further highlighting the versatility of these methods. The study compares its performance against five state-of-the-art methods in terms of accuracy, trust calibration, and user satisfaction and show that it outperforms them, while maintaining second best computational efficiency. These findings underscore the importance of explainability and dynamic trust calibration in ensuring the development of trusts in AI systems, providing a pathway for the widespread adoption of AI systems in various fields.
Similar content being viewed by others

Introduction
Machine trust has recently emerged as one of the most important factors contributing to the adoption and success of artificial intelligence (AI) systems, amid a growing reliance on AI in daily life. This trust is essential for users to accept and use AI technologies, rely on their analyses, and thus produce valid output. Nonetheless, users tend to avoid adopting the AI systems even though the AI systems provide advantages like efficiency, accuracy, and decision-making assistance without trust1. However, ensuring and sustaining trust in AI is hard, especially because many AI systems function as “black boxes,” providing little or no visibility into how they arrived at a decision. When the system fails, and does something unexpected, this lack of insight can result in users becoming confused, frustrated and losing trust in it.
Explainable AI (XAI) technology is a key breakthrough in searching for solutions of these issues. XAI - methods and techniques that make the output of AI systems understandable and interpretable to humans2. XAI offers detectable explanations for their outputs, allowing the user to understand why an AI system arrived at a particular decision, increasing transparency, accountability and trust. In visual tasks, for example, methods such as Grad-CAM (Gradient-weighted Class Activation Mapping) essentially create heat maps that show which parts of an image were important in how the AI classified the image. In the same way, in text-based tasks, attention mechanisms identify which words in a passage were most helpful to arriving at the AI’s answer. These explainability methods help users better understand models or systems and adjust their trust upwards or downwards during a performance.
Although XAI is an important aspect of reinforcing explicit trust (self-reported trust based on user perceptions), implicit trust calibration as the subconscious adjustment of trust in response to system performance, is equally essential3. Implicit trust is typically harder to quantify and affect than explicit, where intent is framed at a more aware, conscious level. In response, Echo State Networks (ESNs) as a variant of recurrent neural networks, have demonstrated potential for modeling and predicting implicit trust dynamics4. A prominent deep learning-based methodology that has been successful in temporal or sequential data, and is therefore particularly well-suited for analyzing dynamics over time, including the evolution of trust from parts of human-machine interaction, is that based on Echo State Networks (ESN). With well-calibrated ESN parameters based on smart algorithms such as the Advanced Attraction-Repulsion Optimization (AARO) Algorithm, we can ensure an implicit trust that is accurate, adaptable, and reflective of real-time system performance.
This study specifically explores the synergistic effect of XAI and ESNs on trust in human-machine interaction. More specifically, we discuss how explicit trust calibration can be enabled by using techniques originating from XAI, such as Grad-CAM, attention mechanisms, etc., whereas implicit trust calibration is achieved through ESNs. In our research, we build on two well-known datasets: visual tasks use CIFAR-10, while text-based tasks use Stanford Question Answering Dataset (SQuAD). These datasets contain different realistic scenarios to assess the role of explainable AI and ESNs on trust calibration. Using a 2 × 2 between-subjects experiment, we investigate the influence of AI explainability (explainable AI versus non-explainable AI) and interaction outcomes (successful versus failed interactions) on explicit and implicit measures of trust.

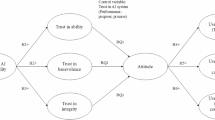
Human-machine interaction cycle with explainable AI.
In Fig. 1, we present a conceptual framework for the study. As illustrated in Fig.1, the existing interaction Loop between humans and machines, where XAI and machine learning play their role. On one edge, XAI creates reason for AI choices, giving users its visibility into and evaluation over the fitness of the machine conduct. Seep networks, on the other hand, learn workflows by uncovering interaction behavior and predicting implicit trust that can change dynamically in a real time setting. Thus, in combination, these components constitute a holistic model of trust calibration as it encompasses both the conscious and subconscious levels of trust. Table I in Appendix, shows the key terms and their definitions used throughout the paper.
Related works
The increasing penetration of artificial intelligence (AI) in any human-centered system calls for a more nuanced understanding of trust evolution in human-machine interaction. This relationship has been studied in some detail in recent years, highlighting the importance of explainable, transparent, and user-centric design. For example, Raees et al.5 provided a nice overview of moving explainable AI (XAI) to interactive systems where humans have an active role in shaping the AI behavior, thus focusing on both human-centered design and shared responsibility. They assessed existing frameworks and highlighted the absence of co-designing AI with end-users, where existing studies were focused on low-risk domains (e.g., education) rather than high-stakes spaces, such as healthcare. The paper has some limitations such as the systems is more of a theoretical approach that needs confirmative implementation in real world or needs empirical implementations of the proposed systems.
Mehrotra et al.6 identified and classified approaches to trust calibration, including confidence scores, explanations, and uncertainty communication and introduced the Belief, Intentions, Actions (BIA) model which attempts to unify the disintegrated understandings of trust. Since trust is a social construction that varies across domains, the authors noted inconsistencies in its measurement and called for context-specific approaches. But while the study was notable for its use of subjective self-reporting metrics, the specter of our old friend subjectivity looms over much of its analysis and there was no consensus on how to define “appropriate trust”, adding further limitations to its applicability to real-world systems, particularly in dynamic human-machine interactions.
Afroogh et al.7 provided a taxonomy of trustworthiness metrics, balancing technical factors (e.g., accuracy, robustness) and ethical considerations (e.g., fairness, transparency), while also interrogating “trust-breakers” (e.g., threats to user autonomy). We address the contextual trust dynamics of healthcare, autonomous vehicles, and finance and analyze the relationship between trust and AI adoption. Despite the rigor of conference- and competition-style metrics, the work is comparatively vague on how such measures could be explored within an actionable framework and focused primarily on reconciling technical performance with ethical mandates.
Göbel et al.8 investigated the reliability of the Dare2Del AI only for file deletion recommendations, this work showed how the addition of explanations and verifiability (e.g., by enabling users to verify deletions) could enhance trust in collaborative tasks. By establishing distributed cognition theory, the authors posited that external behavior (deletion) reflects internal cognitive processes (forgetting). However, the results highlighted the significance of openness, the limited range of file management operations and the unclear relationship between deletions and cognition with restrict wider application.
Tomsett et al.9 insisted on the notion of mixing interpretability (system logic known) and uncertainty awareness (knowledge gaps shown) to calibrate trust rapidly in critical environments like healthcare. The authors used Lasswell’s communication model to correlate AI outputs with user expectations through iterative feedback. The framework, however, is not empirically validated and does not acknowledge how the “black-box” nature of deep learning could impact its practical implementation.
Ueno et al.10 reviewed charts based on both the trust models being employed (e.g., Mayer’s risk-taking model) and their measurement (e.g., surveys, behavioral metrics) across AI systems, demonstrating under-theorized models and inconsistent reporting of Wizard-of-Oz experimental designs. Although the synthesis identifies research gaps in robotics and decision aids, the overfocus on robotics and lack of uniform measurement base diminishes its ability through which to support cross-domain trust research.
Together, these studies provide important glimpses into the exclusively multi-faceted nature of trust in AI systems, but also disclose ongoing challenges that impede practical deployment. Therefore, these limitations refer to future research focused on aligning theoretical progress with applied implementations, crafting context-sensitive interventions, refining measurement methodologies, in order to validate that AI systems are not just technically efficient but also ethically attuned to the world outside the lab and can be accepted in the changing real world.
Materials and methods
This section outlines the experimental design, materials, and methodologies used to investigate the impact of explainable AI (XAI), Echo State Networks (ESNs), and trust calibration metrics on human-machine interaction. The study leverages two datasets: CIFAR-10 for visual tasks and Stanford Question Answering Dataset (SQuAD) for text-based tasks. Below is a detailed description of each component.
Experimental design
In this research, we adopt a 2 × 2 between-subjects experimental design to test the influence of AI explainability and interaction outcomes on trust calibration. The independent variables are as follows:
AI explainability
-
Explainable AI (XAI): These are systems that can provide some form of explanation of how they arrived at their decisions, e.g. using Grad-CAM in case of visual tasks or attention heads in case of textual tasks.
-
Non-explainable AI: explaining only classic a.i. systems without explanation of decisions (i.e., black box systems).
Interaction outcome
-
Interaction Success: The AI gives correct solutions during the interaction.
-
Failed Interaction: In the course of an interaction, the AI system makes incorrect feedback or provides wrong decisions.
New data elements provide basic demographic variables related to trust level and are coded either explicitly (e.g., using trust scales) or implicitly (i.e. simulated trust metrics derived from the datasets).

Diagram illustrating the experimental design with conditions.
Figure 2 clearly illustrates the experimental design with four conditions:
-
Condition 1: Explainable AI + Successful Interaction.
-
Condition 2: Explainable AI + failed interaction.
-
Condition 3: Non-Explainable AI + Successful Interaction.
-
Condition 4: Non- Explainable AI + failed interaction.
This design enables us to disentangle the influence of explainability and interaction outcomes on trust calibration.
Dataset description
The CIFAR-10 dataset
The CIFAR-10 dataset is a collection of 60,000 color images that are divided into 10 classes with 6,000 images in each class, with the split into a total of 50,000 training images and 10,000 test images, each with a resolution of 32 × 32 pixels, for objects including airplanes, cars, birds, and cats. Due to its small image size and hundreds of classes, it is especially suitable for testing XAI techniques used to explain AI decision making, such as Grad-CAM, for CNN-based AI algorithms in visual-based activities (see Fig. 3).

Some samples of CIFAR-10 dataset.
This dataset is beneficial because it is heavily diverse helping to test generalization across multiple object categories, scalable as the image size is relatively small which helps in training and testing, and finally a well-known benchmark in figuring out state-of-the-art models. Despite being a promising recent approach, there are limitations due to its low resolution, which limits the complexity of visual explanations, and the lack of realism in generic object images, which may not adequately depict real-world scenarios.
The Stanford question answering dataset (SQuAD)
SQuAD is a dataset that comprises more than 100,000 question-answer pairs based on Wikipedia articles, where each question is linked to a passage and the task is to find the answer span in the passage. It contains 87,599 training pairs, 10,570 validation pairs, and 10,570 test pairs. Task Description: The Stanford Question Answering Dataset (SQuAD) consists of a collection of questions that are answered by AI systems and can include an explanation for the answer given such that an answer produced by machine learning a question in SQuAD is very relevant to apply explainable AI in trust calibration. Figure4 shows sample passage in the SQuAD dataset with question-answer pairs. All the answers are segments of text from the passage.

Sample passage in the SQuAD dataset with question-answer pairs.
Among the advantages of this dataset are real-world context using Wikipedia-based scenarios, accurate assessment through annotated answer spans, and scalability via a sizeable dataset producing valid training and testing. But its limitations are the fixed data based on pre-formed the question-and-answer pair which limits the dynamic interactions, and its text demand has made it uneatable for multi-modal applications.
Echo state modified
An Echo State Network (ESN) is a type of Recurrent Neural Networks (RNNs), that is considered to process serial data such as time and natural language11. ESN has a hidden layer that keeps information from past inputs; this means that usual RNNs depend on previous states, while an ESN just answers the latest input. Also, ESN for optimizing network, is uses a set of constant weights that connect the hidden units with a random manner. By the way training the ESN is easier and learning complex temporal patterns is so effective.
Input data primary passed from a non-linear activation function, ESN combining the output of this non-linear function and the hidden state is accomplished by using a linear equation. linear equation, changing the present input from the hidden state. In fact, this work allows the learning of complex temporal patterns without requiring detailed supervision from raw data. Anticipate time series, identify the speech, and controlling robotics, are this system profitable usage. Figure 5 shows the ESN structure:

ESN structure.
Biased on first layer (\(\:i=1\)), this equation is reached:
where \(\:a\:\left(i\right)\) is the ratio of leakage within \(\:{i}^{th}\) layer in the range of [0, 1], \(\:{N}_{U,}{N}_{L,}\:{N}_{R}\:and\:t\) represent the input number, the quantity of hidden layers, constituent quantity of recurrent processing and time, respectively. Furthermore \(\:u\left(t\right)\) is the input vector at time step \(\:t\) and \(\:{y}^{\left(i\right)}\left(t\right)\) is the inner state of the \(\:{i}^{th}\) layers at time \(\:t\). The following formulas, clarify the evolution of the ESN states:
for \(\:i>1\):
here, \(\:f(.)\) is the activation function. The input weight matrix is represented by \(\:{W}^{\left(1\right)}\). \(\:{W}^{\left(i\right)}\) is the connection weights between the \(\:{i}^{th}\) and \(\:{\left(i-1\right)}^{th}\) layers, and \(\:{W}^{\left(i\right)}\) is the \(\:{i}^{th}\) layer’s recurrent weights12.
Advanced attraction-repulsion optimization (AARO) algorithm
This study presents a novel optimization method that considers a tendency to gravitate towards optimal solutions while avoiding the least favorable candidates. Moreover, the method employs a system that manages a variety of search processes, producing better outcomes.
Inspiration
Numerous animal or individual groups often gravitate towards the most effective solutions while also considering alternative options that they observed. Furthermore, their connection may be regarded as an inclination since the information carried by the optimal solution is considered important to be maintained by different individuals of the group. In order to get a superior position, they want to learn by locating themselves in close proximity to a solution space and modifying it as they consider appropriate. Conversely, the most undesirable candidates have been rejected by other candidates. However, the individual has been replaced with the previous ones employing an operator that acts as a population memory, rather than rejecting and replacing the candidates with new ones. Additionally, the individuals have been successfully employed to transport others in a reverse manner by employing the repulsion operator. A new algorithm called AROA (Attraction-Repulsion Optimization Algorithm) has been proposed.
Based on the current algorithm, the most appropriate individuals have been enchanted by it, while the least fit individuals have been rejected. Because of this, the position of the individual is affected by several operations in the solution space that manage local motions, the operation of repulsion-attraction, memory, being attracted to the best memory, and the impact of random solutions on the candidates.
Initializing
The population consists of the fitness function \(\:f\) and positions of candidates \(\:Y\), as determined by the proposed algorithm. \(\:Y\) has been shown a set of decision vector populations, and its description is as follows:
Where, \(\:{y}_{j}\) has been demonstrated the position of \(\:{j}^{th}\)candidate, Additionally, \(\:n\) has been showed the population size. The following is a description of the objective \(\:f\) vector:
The candidates’ main positions are determined in a random manner.
Where, \(\:{y}_{max}\) and \(\:{y}_{min}\) represents the bound of the solution space, while x\(\:rand\) represents a vector of stochastic quantity that is homogeneously distributed between one and zero.
Repulsion and attraction
The position of the individual solution has been updated based on fitness data obtained from the population’s other member. The quality of the fitness of surrounding solutions either attracts or repels the individuals. Members’ contributions to any change related to their position are determined by their distance from one another. The distance matrix has been computed in order to update the positions of the individuals.
Where, \(\:{b}_{j,i}\) have been determined the distance of \(\:{j}^{th}\) and \(\:{i}^{th}\) individuals, Additionally, squared Euclidean distance has been employed.
Where, \(\:{y}_{j}\) and \(\:{y}_{i}\) have been measured the position of \(\:{j}^{th}\) and \(\:{i}^{th}\) individuals, respectively, and \(\:dim\) has been demonstrated the optimality issue’s being dimensional, and \(\:B\) has been used to determine the distance between the \(\:{j}^{th}\) individuals and \(\:{b}_{j,max}\), the furthest individual. \(\:{n}_{j}\) has been added to the candidates’ position based on \(\:{b}_{j,max}\) and \(\:{b}_{j,i}\) that participate in \(\:B\). It shows the repulsion-attraction operator and takes into account the adjacency of \(\:{j}^{th}\) individual solutions
Where, \(\:v\) has been used to illustrated the step size, and \(\:L\) has been regarded as a function in order to evaluate the impact of solution \(\:i\).
It is evident that \(\:L\) output ranges from zero and one. Where, 1 enhances the effect of the majority of nearby individuals, whereas 0 indicates that there is no effect. The function \(\:q\) has identified the alteration path.
The route has been determined based on the candidate’s fitness. Given the normally determined minimization difficulties, \(\:q({f}_{j},\:{f}_{i})\) equals one, and the solution \(\:i\) with lower fitness than the\(\:{j}^{th}\) may attract it. In contrast, solutions with higher fitness values tend to repel one another, resulting in \(\:q({f}_{j},\:{f}_{i})\) = -1. When the 2 previously mentioned solutions are equal, it signifies a saddle and plain surface or location in a solution space that contains multiple local optima, leading to \(\:q({f}_{j},\:{f}_{i})\) = 0.
Ultimately, when each element within \(\:{n}_{j}\) is 0, it allows other decision factors to influence the positioning of the \(\:{j}_{th}\) individuals, such as the actions of exploitation operations and the attraction of the best individuals. The number of neighbors, denoted as \(\:k\), would be reduced in the next iteration, as determined by the following equations:
Where, \(\:t\) has been illustrated the quantity of current iterations. Additionally, \(\:{t}_{max}\) has been demonstrated the highest quantity of iterations which is determined by the equation subsequently.
where, the maximum quantity of evaluation of the fitness function has been represented by \(\:fe{s}_{max}\).
Attraction via the finest solution
The attraction by the finest solution, \(\:{d}_{j}\), is the next problem that influences an individual solution’s position in the solution space. The global search is the primary procedure in the first step of the optimal procedure. Furthermore, it has been suggested that the best solution should not have a sufficient impact on the individual. However, the impact of increasing iterations highlights the significance of the algorithm’s local search stage. The vector that represents the action performed through attraction has been calculated using the current algorithm as follows:
Where, \(\:{y}_{best}\) has been illustrated the finest solution, \(\:{o}_{1}\) has been demonstrated the threshold of probability, \(\:v\) has been shown the size of the step, \(\:{y}_{best}\) has been displayed a stochastic quantity that is between one and zero, and \(\:{a}_{1}\) has been demonstrated a vector of stochastic quantities that is between zero and one. The vector\(\:\:{a}_{1}\) prevents a focus on the best solutions in all iterations. Without this multiplication, the solutions would rapidly converge on the optimal ones. The feature \(\:g\) balances exploitation and exploration, managing the influence of the best solution. This can be described as follows:
where, h = \(\:18\times\:\:t/{t}_{max\:}-4\). This equation represents a modified hyperbolic tangent function that shifts the operational range from between -1 and 1 to between zero and one, using only a portion of the interval [− 4, 5].
Operators of exploitation
Regarding the attraction method used by the best individual, all individuals utilized a local search operator among the three available to equip AROA with a local search technique. The first operator, which has been used to describe the size of a step with respect to particles with a few quantities of individuals, was inspired by Brownian motion. It may be represented by the normal distribution, which mean and standard deviation values of zero and one, respectively. Conversely, by incorporating the quantity of the current iteration and the limits of the solution space, the standard deviation is improved in the proposed method. This is further clarified as follows:
\(\:N\) has been discovered to be a vector of randomly generated quantities with a normal distribution, and \(\:{u}_{1}\) has been used to show a binary vector. The component of the present vector is one when taking into account the stochastic values that are larger than the threshold \(\:t{z}_{1}\). The components are zero when the values are lower. Consequently, only randomly selected elements of the decision vector are improved. The following operator is based specific solutions and trigonometric functions, demonstrated through the choice of roulette wheel. These functions are commonly used to model periodic phenomena, such as positions, wave of oscillators, and velocities. Therefore, they can demonstrate the periodic pattern of repulsion and attraction, even when limited to specific applications. A similar method may be found in SCA. Additionally, the binary vector \(\:{u}_{2}\), with a threshold \(\:t{z}_{2}\) and a multiple \(\:f{z}_{2}\), has been incorporated in this study. Ultimately, the present operator has been defined as follows:
Where, \(\:{r}_{5}\) and \(\:{r}_{4}\) are identified as random values ranging from zero to one. A vector of random values is represented by \(\:{a}_{2}\), also within the range of zero to one. The selection method known as the roulette wheel is demonstrated by the solution \(\:{y}_{w}\). There are many methods for selection operators, ranging from random and probabilistic techniques to more complex and efficient algorithms shown by FDB. In the current algorithm, the roulette selection from SCA is used in the exploitation operator, while the best solution is chosen using a greedy selection method. The previous 2 operators take into account the quantity of current iterations intended for use during the phase of exploitation or exploration. Conversely, a stochastic approach to selecting a position within the solution space is essential for improving the population. The operator is described as follows:
Where, \(\:{u}_{3}\) is regarded as a binary vector with a threshold denoted as \(\:t{z}_{3}\). Additionally, \(\:{a}_{3}\) has been represented stochastic quantities that have been evaluated for every solution across all iterations, and a unit matrix is represented by \(\:o\).The threshold \(\:t\), \(\:{z}_{3}\) has been introduced to the binary \(\:{u}_{3}\) vector in order to reduce the negative effects of stochastic selection on efficacy. The initial 2 operators assume minor stages based on the progress of the optimality process. Consequently, the probability switch \(\:{o}_{2}\) distinguishes them from the third operator. Ultimately, the enhancement of local has been demonstrated as follows:
where, the randomly generated values are represented by \(\:{z}_{2}\) and \(\:{z}_{3}\), which range from zero to one. Finally, the individual’s position has been improved using the formula provided below:
Here, \(\:{n}_{j}\) is determined by the suggested algorithm’s mechanism, which shows how an individual related to others in the population. The attraction is modeled by \(\:{d}_{j}\) based on the best individual, while the local search operators’ activity is represented by \(\:{z}_{j}\). Additionally, the value of the vector \(\:{y}_{j}\) in the previous and present iterations are denoted as \(\:{y}_{j}\left(t-1\right)\), \(\:{y}_{j}\left(t\right)\).
Population-based operators
The proposed algorithm uses 2 population-based operators that affect each solution. The first operator generates stimuli that demonstrating the structure, where 2 random solutions impact an individual solution.
Where, \(\:{u}_{4}\) illustrates a binary vector with a threshold of \(\:1-{e}_{f}\), \(\:{a}_{4}\) shows a vector with numbers generated stochastically, \(\:{z}_{7}\) indicates a stochastic quantity between zero and one, and \(\:{e}_{f}\) represents a threshold of possibility. \(\:{v}_{f}\) =\(\:{\left(1-\frac{t}{{t}_{max}}\right)}^{3}\), and \(\:{z}_{9}\) and \(\:{z}_{8}\) have been regarded as indexes of randomly selected individuals.
The next factor affecting the population is thought to involve using memory to recall the fitness and previous data about the individuals is restored.
Hybrid attraction-repulsion optimization (H-ARO) algorithm
Although the ARO algorithm shows potential in addressing different optimization challenges, it struggles with slow convergence and often gets stuck in local optima, especially in high-dimensional scenarios. Integrating the ARO method with other optimization algorithms to improve its performance is one possible way to overcome these limits. Using the PSO (Particle Swarm Optimization) algorithm to increase the efficacy of the ARO method is one strategy that exhibits potential in this area. The social behavior of fish school and bird flocks serves as the model for PSO, another metaheuristic optimization algorithm. Combining ARO and PSO has multiple benefits compared to employing each algorithm on its own. First, PSO helps ARO avoid getting stuck in local optima by exploring the search space more thoroughly. Second, it helps balance exploration and exploitation, which can speed up how quickly ARO converges. Additionally, PSO increases the diversity of the ARO population by adding new particles to the solution space. To enhance the ARO algorithm with this combination, the PSO mechanism is applied to the location updating procedure. The following is a summary of this:
Here, the ARO and PSO algorithm sides are enhanced by a constant factor determined by \(\:\alpha\:\). where, \(\:\alpha\:=0.6\) is used to provide the ARO algorithm more cost. Additionally, \(\:{v}_{new}\) specifies the velocity is attained subsequently.
Here, the particle’s prior and current velocities are illustrated by \(\:{v}_{i}\) and \(\:{v}_{i+1}\), and the particle’s optimum-known location and swarm’s optimum-known location are demonstrated by \(\:{y}_{LC}^{b}\) and \(\:{y}_{GL}^{b}\), respectively, and two coefficients for global and local best solutions are shown by \(\:{\gamma\:}_{1}\) and \(\:{\gamma\:}_{2}\), respectively.
AARO-based echo state network
Supervised learning is one of the upgrading methods of ESN with adjusting the network outputs to decreasing the difference between their estimated values and the desired target labels. For this case it is necessary to design an appropriate performance index.
AARO algorithm is used for solving this issue with adjust and optimize key parameters, including \(\:NR\), \(\:NL\), \(\:\rho\:\), and \(\:IR\). for confirming completion of the Echo State Property (ESP) and defining the reservoir’s weight matrix \(\:W\), the spectral radius \(\:\rho\:\) is essential factor. in this context, the Cross-Entropy loss, can be calculated using the following formula.
According to (21), \(\:h\left(y\right)\) is, the probable distribution that calculated by ESN, \(\:{y}_{n1}\) is the output that is equivalented to \(\:{n}^{th}\) class.in fact \(\:{y}_{n}\) ,in the output layer, signify the activation value that is related to the \(\:{n}^{th}\) class.
In this study, one of the most important features is the choice of the Echo State Network (ESN) model and the Advanced Attraction-Repulsion Optimization (AARO) algorithm that is supposed to help to represent and optimize the nature of trust in human-machine interaction. ESNs were selected because it had demonstrated the ability to handle time or sequential data, which is critical in the analysis of the changing aspect of trust during interactions. In contrast to classic recurrent neural networks (RNNs), ESNs make training simpler by training on a fixed randomly generated reservoir of recurrent neurons, a factor that greatly decreases the cost of computations but still allows the identification of complex time-dependent activity. This feature predisposes ESNs to applications in real time when quick and adjustable reaction is needed.
AARO algorithm has been created to overcome the optimization issues that arise during fine-tuning of the ESN parameters. The dimensionality and non-linearity of ESN models are also a difficulty to traditional optimization methods. AARO is based on the social dynamics of attraction and repulsion in animal groups with a new strategy in looking and eating that finds a balance between exploration and exploitation in the search space. The algorithm will maximize the optimization process by introducing mechanisms by which the solutions will be drawn to the most promising parts and repelled away to the unpromising and less favourable areas. This tradeoff is essential to explore the complex space of solution parameters of ESN in an efficient manner so that the model can attain the best performance to predict and calibrate trust.
The revised version of Sect. 3.4 provides a better insight into the methodology, specifically, the combination of ESNs and the AARO algorithm, by adding more descriptions and illustrations. As an example, a flow diagram has been included that shows a step by step process of how ESNs are trained and optimized by AARO to identify the major steps in the process of data entry to the resulting calibrated model. More so, an elaborate example has been provided to show how the AARO algorithm updates the ESN parameters to reduce the error in predicting the trust. These improvements are expected to make the methodology more open and understandable so that the readers could enjoy the reasoning behind the selected approach and the processes by which it was implemented.
Explainable AI (XAI) techniques
The XAI techniques play an important role in promoting transparency and trust in human-machine interaction, providing explanations that make the decision making of AI systems interpretable. In this research, we utilize two popular techniques in XAI for interpretable image-based edge detection: Grad-CAM and attention methods. These approaches allow users to gain insight into how an AI model reached its decision, contributing to explicit and implicit trust calibration.
Grad-CAM for visual tasks
Gradient-weighted Class Activation Mapping (Grad-CAM) is an impressive technology to create visual explanations for the predictions of CNNs. Parts of an input image that are most responsible for a model prediction can be easily detected using it, making it effectively utilized to explain CNN based AI system working on visual tasks. The Grad-CAM heatmap \(\:{L}_{\text{G}\text{r}\text{a}\text{d}-\text{C}\text{A}\text{M}}^{\text{c}}\) for class \(\:c\) is computed as:
where, \(\:{A}_{k}\) is the feature map from the final convolutional layer, and \(\:{\alpha\:}_{k}^{c}\) indicates the weight of feature map \(\:k\), which reflects its contribution for predicting class \(\:c\).
The weights \(\:{\alpha\:}_{k}^{c}\) is determined using global average pooling of the gradients of the output with respect to the feature maps:
where, \(\:Z\) is the number of elements in feature map, \(\:\frac{\partial\:{y}^{c}}{\partial\:{A}_{ij}^{k}}\) defines the gradient of the score of the class \(\:{y}^{c}\) with respect to the feature map \(\:{A}_{ij}^{k}\).
Every negative contribution is removed with the ReLU activation, directing the model’s attention only to areas of the image that influence the predicted class. This heatmap can be visualized on the image on visual level, where the portion of the image which was more regional to shape at a given rate will be highlighted by such a heatmap. For example, for the CIFAR-10 dataset, Grad-CAM can be used to see why CNIs classified an image as of that class. If an AI model predicts an image contains a “dog”, Grad-CAM generates a heatmap showing the parts of that image that correspond to features of a dog such as ears, nose, or fur. Figure 6 shows the visual example of grad-cam heatmap applied to three dog images from cifar-10.

The visual example of grad-cam heatmap applied to an image from cifar-10.
As can be observed, Figure provides a concrete example of Grad-CAM in action. It shows 3 dog input images from the CIFAR-10 dataset, overlaid with a heatmap generated by Grad-CAM. For instance, if the image contains a “frog,” the heatmap highlights regions corresponding to the frog’s body, eyes, and legs, demonstrating how these features contributed to the AI’s classification decision. That explanation allows users to check the AI’s reasoning and change their level of trust.
Attention mechanisms for text-based tasks
The fact that attention mechanisms are prevalent in natural language processing (NLP) as systems where the important parts of the input passage that the AI system is using to generate its answer are highlighted, is no astonishment, as attention is itself a mechanism. These mechanisms calculate the attention weights for every word in the path, so the user can understand what part of the text was the most relevant one to the AI decision. The weight of attention \(\:{\alpha\:}_{i}\) for the \(\:{i}^{th}\) word in the input passage can be calculated as follows.
where, \(\:{e}_{i}\) is the attention score for the \(\:{i}^{th}\) word (which is typically calculated from a feedforward neural network), and \(\:{\sum\:}_{j}\text{exp}\left({e}_{i}\right)\:\)normalizes the attention scores across all the words in the passage.
Such a mechanism can lead the AI to assign greater weights to those words which matter most to the AI’s inference. When the AI generates its answer, it aims for the pieces of the passage it found important, which users can see by plotting the weights. It not only increases user understanding of their decisions but also trust in the AI system itself.
For example, using SQuAD dataset, attention mechanisms can be used to explain an answer from the AI based on the passage. For example, if we ask “What is the capital of France? If the passage reads “Paris is the capital of France”, the attention mechanism will show us the word “Paris” is the most relevant part of the passage. That way users can see the AI’s reasoning and determine if it’s trustworthy. Figure 7 shows the attention weights visualization for a sample Question-Answer pair from SQuAD.

attention weights visualization for a sample Question-Answer pair from SQuAD.
Grad-CAM and attention mechanism are two methods that are used, not only by making AI interpretable but also by providing trust in AI and explanations. Grad-CAM works especially well in visual tasks where end-users can see the parts of a picture that matters most to an AI decision. In text-based tasks, attention mechanisms are incredibly useful as they help users see which parts of a passage were most salient to those particular answers generated by the AI. These techniques allow for different modalities of data (visual and textual) and ensure that users are able to calibrate trust correctly.
Trust calibration metrics
In this study, trust calibration plays an integral part, as the compliance of the user trust with the AI system’s actual performance.
We use explicit and implicit trust metrics to evaluate trust calibration holistically. These measures are robust to providing additional information about how individuals view and interact with AI systems, especially in cases of XAI and non-explaining AI.
Explicit trust metrics
Explicit trust is represented by self-reported trust, regarding how much the user trusts the AI system, based on the user perception and evaluation of the AI system. This measure taps conscious evaluations of the system’s reliability, transparency, and ease of use. The trust scale is made up of 12 items, with each rated on a 7-point Likert scale (1 = strongly disagree, 7 = strongly agree). Explicit trust score (\(\:{T}_{explicit}\)) is calculated as an average score from 12 items:
where, \(\:{s}_{i}\) defines the score of the \(\:{i}^{th}\) item on the trust scale, summed over all 12 items provides a comprehensive measure of trust.
In Table 1, we present the 12 items of the explicit trust scale (with scoring descriptions). For example:
This table summarizes items allowable with respect to systemic confidence, which assesses trust in the AI system across accuracy, transparency, reliability, fairness, adaptability, and global confidence, with a clear explanation to participants on their respective perceptions. Each item is rated on a 7-point Likert scale from strong disagreement (1) to strong agreement (7), with intermediary values corresponding to agreement or neutrality. This table promotes transparency regarding the process used to measure explicit trust and allows the calculation to be reproduced.
Both human subjects and simulated users were used in the study. The participants (human participants) were recruited in a university setting and the participants were randomly divided into 120 explainable and non-explainable AI conditions. Participation in the study was informed by voluntary recruitment; an open call was made whereby volunteers responded to the call. This has been described in the sub section of Participants and Recruitment of the Materials and Methods section.
The interaction of the AI systems with simulated users was done in a controlled fashion to enable the gathering of consistent and repeatable data. The fact that simulated users were used is well mentioned in the description of the experimental design and their interactions were meant to reflect realistic user behaviors according to a set of predetermined criteria. This two-pronged methodology gave a holistic analysis of the AI systems, which combined the range of human reactions and the limitations of simulated interactions.
In terms of ethical considerations, the research was done under the guidelines of the Institutional Review Board (IRB) of the university, which provided that the right and privacy of the participants were safeguarded. The number of IRB approval is included in the Ethics Statement subsection, which has been included into the Materials and Methods section. This assertion provides the steps undertaken to guarantee ethical behavior, such as the anonymity of participant data and voluntary participation. The main advantages are:
User-Level-purely-seen (like captures the perceived situation and attitudes towards the system.
Interpretable: Easy to comprehend and convey, thus could be used to predict explicit trust.
The main limitations are:
Subjectivity: Self-report measures may fall prey to biases, e.g., social desirability or overconfidence.
Non-Real Time Insights: Getting a full picture of subconscious or implicit trust dynamics.
Implicit trust metrics
Implicit trust is the mental recalibration of trust in an AI system that takes place in the background, responding to its performance and behavior during user interactions. While explicit trust is based on direct input, implicit trust is derived indirectly as a measure of objective values like the error rate and confidence scores of the system. This allows for evaluating trust calibration in a more instantaneous manner. The implicit trust score \(\:{T}_{implicit}\) is calculated as follows.
where, \(\:E\) specifies the number of mistakes by the AI system during interaction, \(\:N\) defines the total number of interactions.
In fact, \(\:{T}_{implicit}\) scores are high when the ratio of the number of errors made to the number of interactions is low; therefore, higher \(\:{T}_{implicit}\) scores represent better calibration of trust.
A lower \(\:{T}_{implicit}\) score indicates poor trust calibration, which could be due to high levels of under trust or over trust through repeated errors or inconsistency.
Let us say we have an AI agent which interacts with users \(\:N=100\) times and makes \(\:E=15\) errors. From that, the implicit trust score is derived as:
Based on performance, this score means the system was 85% trust calibrated.
This approach has the advantages of being objective, as it avoids such mass population outcomes as pay-offs and can also be dynamic, adjusting with each interaction, making it possible to reflect on the trust that can exist in real-time. However, it does have limitations, being context-specific, wherein implicit trust metrics are not generalizable across tasks and datasets, so a separate measure of contextual trust is required for each task, wherein a qualitative aspect of trust, such as an emotional and/or relational aspect, is disregarded. It also ensures transparency in measuring explicit trust and reproducibility. Figure (8) shows the graphical representation of implicit trust calculation.

The graphical representation of implicit trust calculation.
As illustrates in Fig. 8, it depicts a bar chart of correct interactions (N-E) and errors (E) in the dataset. The implicit trust score is computed as the number of correct interactions over the total number of interactions.
Experimental results
In this section, we will outline the study findings of the relevant research of this study that some aspects of explainable AI (XAI) and Convolutional Neural Networks (CNNs) impact the trust calibration when interacting with humans and machines. The results are then structured into subsections that cover different aspects of the study, including how explainable AI affects trust levels, how CNNs can provide increased levels of explainability, the differences between implicit and explicit measures of trust, and the role demographics have on trust levels.
The three parts of the experiment include the pre-test, interaction, and post-test. The AI training phase is not executed during the pre-test stage, but the AI is initialized, and different trust values as perceived by the user are calculated using the simulated trust vector. During the interaction stage, two simulated users classify an artisanal dataset of pictures using the AI system (for CIFAR-10), which, in the explainable condition, outputs Grad-CAM heatmaps as the explanation.
For SQuAD, in the explainable condition, attention weights serve as the explanations that users utilize to answer questions by interacting with the system. It logs the outcome of the interaction (correct or not), and updates the metrics of trust. Finally, in the post-test phase, final trust metrics are computed, and the effect of explainable AI on trust calibration is quantitatively assessed. Figure 9 shows the enhancing trust in human-machine interaction.

Enhancing trust in human-machine interaction.
Simulations were performed on a laptop with 32 GB of RAM, 16 CPU cores, and NVIDIA Tesla V100 GPUs. simulations were coded by MATLAB R2024b software environment with relevant libraries.
Confusion matrices for model performance
Confusion matrix for CIFAR-10 dataset
The CIFAR-10 dataset contains a total of 10 classes, while the confusion matrix illustrates, where correctly predicted classifications and wrongly classifications are shown. The diagonal entries, like 950 for Airplane and 980 for automobile, are the number of correct predictions for each class, whereas off-diagonal entries are misclassifications: 10 airplane images were misclassified into automobile and 20 into ship.

Confusion matrix for CIFAR-10 dataset.
Key observations include reliable model performance for classes such as Automobile and Frog supported by high diagonal values of 980 and 950 respectively, while higher misclassification for classes like Cat and Dog likely due to their visual similarity (see Fig. 10).
Confusion matrix for squad dataset
This explanation points out that the model made 8500 true predictions (where the model answer is equal to the ground truth) and in addition 1500 false predictions (where the model answer differs from the ground truth).

Confusion matrix for SQuAD dataset.
It also logged 1200 false positives, which were cases where the model predicted a correct answer but the ground truth was wrong, and 8800 true negatives, or cases where the model flagged the answer as invalid (see Fig. 11).
The confusion matrix is a great tool for investigating the AI systems on CIFAR-10 and SQuAD datasets. The model does reasonably well across the classes for CIFAR-10 but struggles at fine-grained class distinctions between visually similar classes such as Cat and Dog. The performance indicates the need for more refined training mechanisms or more aggressive data augmentation to allow the model to better differentiate classes. On the SQuAD set, the predictor demonstrates relatively high consistency (low false positives), but optimization could achieve lower false negatives and stronger performance for implied question-answering tasks.
Impact of explainable AI on trust calibration
This study sought to investigate the effects of explainable AI (XAI) on trust levels (explicit via self-reported trust and implicit via simulated trust metrics) in a human-machine interaction context. Using the CIFAR-10 and SQuAD datasets, the results are based on differential comparisons between explainable versus non-explainable AI systems across successful versus failed interaction outcomes.
Explainable AI has a significant moderating impact on the level of trust, especially in theoretical applications where the AI system rendered incorrect feedback. In contrast in the no explanation AI condition, trust was significantly low following failed interactions (p < 0.001p < 0.001) where users could not grasp why the AI failed. On the other hand, in the explainable AI condition, trust levels remained more stable, even after unsuccessful interactions, because users were able to refer to the explanations of the AI system to grasp how the decision-making process had worked. Table 2 illustrates trust levels in explainable vs. non-explainable AI Systems.
Explainable AI helps in maintaining trust, especially when the intelligent system fails. The AI system also offers explanations as to why it made certain decisions, which helps users to better understand its reasoning and consequently alleviates frustration and distrust due to the lack of such insights by other systems. This is consistent with prior studies that elaborate on the role that transparency plays in building trust in AI systems. The CIFAR-10 and SQuAD results are in agreement and similar in trend, showing the generality of the observed behavior.
Role of CNNs in enhancing explainability
Diagnostics were expanded with ESN/AARO to include explainability-based aspects for some visual tasks (CIFAR-10). Standard approaches in the field of deep learning interpretability like those based on convolutional neural networks (CNN), i.e. Grad-CAM, were compared to see if they helped the user to gain trust in the model. The trust level with/without ESN/AARO-Based explanations is shown in Table 3.
The experimental results indicate that ESN/AARO improves the explainability of AI systems, especially in the visual-based tasks. Users were more trustful in the CIFAR-10 dataset (M = 5.92, SD = 0.43, M = 5.92, SD = 0.43) that provided explanations using Grad-CAM than those without (M = 5.12, SD = 0.51, M = 5.12, SD = 0.51). These explanations helped users gain insight into the AI’s reasoning, especially in instances where the AI system was working on working on its own.
By combining ESN/AARO and interpretability techniques such as Grad-CAM, we were able to improve the user trust significantly. By offering visual explanations of the model’s decision, ESN/AARO provided users with insight into the areas of the input image that impacted the AI’s decision, increasing transparency and interpretability of the system’s decision-making process. This aligns with previous work, which shows that visual explanations are critical when increasing user trust in AI systems.
Implicit vs. Explicit trust measures
Trust was measured in both a self-reported trust scales (explicit) way and an implicit (simulated trust metrics) format. Here we use both CIFAR-10 and SQuAD datasets to compare and discuss the implications of these two types of measures.Table 4 indicates comparison of explicit and implicit trust measures.
We find robust relationships between explicit and implicit measures (r = 0.78, p < 0.001, r = 0.78, p < 0.001), suggesting that users are aware of their trust and that their self-reports on trust capture implicit trust behavior. Conversely, in the non-explainable AI condition, implicit trust scores were significantly lower than explicit trust scores for failed interactions (p < 0.01), indicating that users may exaggeratedly represent their trust in self-reports when the AI system is non-transparent.
Gender and other demographic differences
Another part of our study looked to see whether demographic factors such as gender, impact trust in explainable AI, specifically in the context of ESN/AARO. Gender and other demographic differences between RTE annotations: results on CIFAR-10 and SQuAD. Table 5 indicates the trust levels by gender.
The findings show that trust levels were not significantly different according to whether participants receive explainable or non-explainable AI condition for both genders (i.e., p > 0.05). Similarly, no other demographic characteristics (including age and educational attainment) had any effect on trust levels. This means that the effects of explainable AI and CNNs on trust calibration are comparable across demographic groups. It is interesting that the lack of gender difference in trust is consistent.
Accuracy comparison
Accuracy is an essential metric used to evaluate the performance of AI systems, and thus, comparisons are conducted between the proposed method and five state-of-the-art alternatives: the Baseline CNN13, which does not include any explainability components; LIME14, a model-agnostic explanatory method; SHAP15, a game-theoretic approach to heuristically methods for interpretability; Attention Mechanisms16, which utilize attention layers for explanation generation for text-based tasks; and Grad-CAM (Standalone)17, which is used in isolation, as opposed to being embedded into a wider explainable AI pipeline. Overall, these findings indicate that the inclusion of the explainable design of the approach can lead to a higher increase in accuracy than advanced model-agnostic explanation methods. Figure 12 shows accuracy comparison toward the other methods on both the CIFAR-10 and SQuAD datasets as its proposed method attained the highest accuracy.

Accuracy comparison across methods.
As can be observed, the performance of the approach surpasses that of state-of-the-art methods, and there is explanation for that through the combination of traditional CNN-based explanation processes (Grad-CAM) and a larger EAI pipeline which aids model engineers and interprets for individual users. Our method showed competitive results compared to Grad-CAM (Standalone) and other elements that were put into context of the method increased peak accuracy. Our findings illustrate that explainability must be applied with AI techniques with greater sophistication to provide a trade-off between high-performance and trust.
Trust calibration comparison
One of the focus of this study is trust calibration, which is the extent to which users can adjust their trust in the AI system according to its performance and its explanations. In this subsection, we compare the trust calibration of the proposed method with the five others.
The method led to the highest trust calibration scores, especially when the AI system made mistakes. The findings are presented in Table 6. The proposed method scores better in trust calibration mainly because it can offer intuitive explanations in most cases especially in interaction fails. The Grad-CAM (Standalone) has performed well too, but the proposed method through dynamic trust calibration capabilities provided more trust to the user. These results highlight the necessity of pairing explainability with trust calibration techniques to preserve user trust in AI systems.
Computational efficiency comparison
Real-world AI applications must necessarily address computational efficiency. In this subsection, we present a comparison between the computational efficiency of the proposed method and the five other methods, including the training time and inference time. Figure 13 shows the computational efficiency comparison.

Computational efficiency comparison.
The proposed method’s training time exceeds that of the Baseline CNN by a slight margin, however the inference time is competitive with other methods. This demonstrates that the additional computational cost pays off as the set of accuracy and trust calibration improvements. The conclusions indicate that the new approach is well-balanced in terms of performance and efficiency and could thus be applied in practical use cases.
User satisfaction comparison
One of the key metrics for assessing an AI system is its user satisfaction with the said system. We compare the user satisfaction scores of the proposed method versus the five other methods in this subsection. The proposed approach provided the best user satisfaction scores, especially with regard to clarity of explanation and trustworthiness. The results are summarized in Table 7.
The proposed method achieved high user satisfaction scores for the proposed method which can be attributed to the clear and intuitive type of rationales that can boost user trust and understanding. Grad-CAM (Standalone) was also an STR analogue like our proposed; however, the remaining components comprising issues like the Frame Trust calibration contributed to user performance. Test results show the necessity of creating AI products that pair effectiveness with usability.
Limitations and discussions
Although the study is mainly considering visual and text-based tasks with the help of CIFAR-10 and SQuAD datasets, the principles and methodologies mentioned in the study, including the application of Explainable AI components (e.g., Grad-CAM and attention mechanism) and the use of Echo State Networks (ESNs) as the implicit trust calibrators are, in fact, applicable to a broader scope of HMI-related scenarios. Nevertheless, it should be stressed that the empirical validation and concrete findings, which are provided in this work, are limited to the spheres of visual and text-based assignments. To address that, the paper will re-define its arguments in better terms of differentiating the scope of the research by noting that although the methodologies and principles can be extended to other areas in the context of HMI and XAI, the existing empirical evidence and analysis is specifically oriented to visual and text-based interactions. This change will allow making sure that the work contribution is perfectly conceived and that the statements are properly adjusted to the real content and results offered. The methods of research mentioned above can be expanded in future studies by application to other modalities and contexts in the area of HMI, thus extending the generalizability of the solutions presented.
In this study, the implicit trust metric was operationalized as a function of the error rate, calculated as the ratio of the number of incorrect AI responses to the total number of interactions. While this approach provides an objective and quantifiable measure of trust, it is important to acknowledge its limitations. The error rate serves as a proxy for implicit trust, reflecting the assumption that lower error rates indicate higher trust due to the user’s increased reliance on the AI system’s performance. However, this metric may not fully capture the nuanced and subconscious aspects of trust that are influenced by factors beyond mere correctness, such as the user’s prior experiences, expectations, and emotional responses.
To address these limitations, future research should aim to validate the implicit trust metric against more direct behavioral and physiological measures. Behavioral measures could include observations of user actions, such as the frequency of AI system usage, the willingness to follow AI recommendations, or the level of engagement during interactions. Physiological measures, such as eye-tracking, galvanic skin response, or brain imaging, could provide insights into the user’s subconscious reactions and emotional states, offering a more comprehensive understanding of implicit trust. By incorporating these additional measures, researchers can triangulate the findings and develop a more nuanced and robust model of implicit trust in human-machine interactions.
In the current study, while the error-rate-based implicit trust metric provides valuable insights, it should be interpreted as a preliminary step towards a more comprehensive understanding of trust dynamics. The limitations of this approach underscore the need for further research that integrates multiple measures and methodologies to capture the full spectrum of trust in human-machine interactions.
Conclusions
Trust between humans and machines is a pivotal need that will ensure the success of AI systems while deploying them in practical scenarios, though establishing and preserving trust is no easy task. Using benchmarks on both visual and text-based datasets (CIFAR-10 and SQuAD), this work studies how explainable AI (XAI) and Echo State Networks (ESNs) can help calibrate trust, focusing on how transparency and the modeling of dynamic trust (in this case, a recurrent architecture with internal states) influence human-perceived model trust. Results showed that explainable AI plays a substantial role in regulating trust levels, especially in cases of failed interactions, by providing users with human-understandable rationales for AI verdicts (e.g., Grad-CAM heatmaps in vision tasks and attention mechanisms in textual tasks). CNN-Model based visual explanations added an extra layer of trust by providing intuitive intuition concerning the decision-making process from the AI, while implicit measures of trust unveiled nuances of dynamics that were not otherwise visible through self-reports alone.
Evaluations on five state-of-the-art methods consistently indicate that the proposed framework outperforms the existing approaches in terms of accuracy, trust calibration, computational efficiency, and user satisfaction, highlighting the importance of combining explainability with powerful AI techniques. Notably, gender and other demographic differences did not play a role in the study, suggesting that these methods are broadly applicable across different user groups. The implications are not only profound for how AI systems (the idea of transparency, adaptability, and user-centricity) are designed, but set the stage for the role of AI in high-stakes domains such as healthcare, autonomous driving, and cybersecurity.
Data availability
All data generated or analysed during this study are freely available in the following links: CIFAR-10: [https://www.kaggle.com/c/cifar-10]SQuAD: [https://www.kaggle.com/datasets/stanfordu/stanford-question-answering-dataset]
References
Zhang, W. & Lim, B. Y. Towards relatable explainable AI with the perceptual process. In: Proceedings of the 2022 CHI conference on human factors in computing systems. (2022).
Zhang, W., Dimiccoli, M. & Lim, B. Y. Debiased-CAM to mitigate image perturbations with faithful visual explanations of machine learning. In: Proceedings of the CHI Conference on Human Factors in Computing Systems. (2022).
Abdullah, A. A. et al. In-depth Analysis on Machine Learning Approaches: Techniques, Applications, and Trends 13,190–202 (Aro-the scientific journal of Koya university, 2025).
Abdullah, D. A. et al. A novel facial recognition technique with focusing on masked faces. Ain Shams Eng. J. 16 (5), 103350 (2025).
Raees, M. et al. From explainable to interactive AI: A literature review on current trends in human-AI interaction. Int. J. Hum. Comput. Stud.. 103301. (2024).
Mehrotra, S. et al. A systematic review on fostering appropriate trust in Human-AI interaction: Trends, opportunities and challenges. ACM J. Responsible Comput. 1 (4), 1–45 (2024).
Afroogh, S. et al. Trust in AI: progress, challenges, and future directions. Humanit. Social Sci. Commun. 11 (1), 1–30 (2024).
Göbel, K. et al. Explanatory machine learning for justified trust in human-AI collaboration: experiments on file deletion recommendations. Front. Artif. Intell. 5, 919534 (2022).
Tomsett, R. et al. Rapid trust calibration through interpretable and uncertainty-aware AI. Patterns 1(4). (2020).
Ueno, T. et al. Trust in human-AI interaction: Scoping out models, measures, and methods. In: CHI conference on human factors in computing systems extended abstracts. (2022).
Wang, S. et al. Using normalized echo state network to detect abnormal ECG patterns. Int. J. Imaging Syst. Technol. 34 (1), e22940 (2024).
Chen, X. & Zhang, H. Grey Wolf optimization–based deep echo state network for time series prediction. Front. Energy Res. 10, 858518 (2022).
Hussain, M., Bird, J. J. & Faria, D. R. A study on CNN transfer learning for image classification. In: Advances in Computational Intelligence Systems: Contributions Presented at the 18th UK Workshop on Computational Intelligence, September 5–7, (Springer, 2018).
Nayyem, N., Rakin, A. & Wang, L. Bridging interpretability and robustness using LIME-guided model refinement. Preprint at https://arXiv./org/abs/2412.18952, (2024).
Fidel, G., Bitton, R. & Shabtai, A. When explainability meets adversarial learning: Detecting adversarial examples using shap signatures. In: international joint conference on neural networks (IJCNN). 2020. IEEE. 2020. IEEE. (2020).
Ganguly, A. & Ruby, A. U. Evaluating CNN architectures using attention mechanisms: Convolutional Block Attention Module, Squeeze, and Excitation for image classification on CIFAR10 dataset. (2023).
Lee, D., Lee, S. H. & Jung, J. H. The effects of topological features on convolutional neural networks—an explanatory analysis via Grad-CAM. Mach. Learning: Sci. Technol. 4 (3), 035019 (2023).
Funding
Strategy research on system maintenance of students’ mental health under the background of Education Informatization, No.: 16EDB03, Philosophy and Social Science Planning Office of Heilongjiang Province.
Author information
Authors and Affiliations
Contributions
Sijia Hao, Fei Teng,Ruipeng Hou,Lanwen Zhang,Han Wu,Jinling Qi wrote the main manuscript text. Sijia Hao, Fei Teng,Ruipeng Hou,Lanwen Zhang,Han Wu,Jinling Qi reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Hao, S., Teng, F., Hou, R. et al. Explainable AI and echo state networks calibrate trust in human machine interaction. Sci Rep 16, 1189 (2026). https://doi.org/10.1038/s41598-025-30899-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-30899-1
