
Abstract
Tourism has become a central pillar of Saudi Arabia’s Vision 2030, supporting national efforts to diversify the economy and reduce reliance on oil revenues. As the Kingdom expands its religious, recreational, heritage, and sports tourism sectors, accurate forecasting of tourist demand has become essential for sustainable planning, infrastructure development, and policy formulation. This study investigates the use of machine learning (ML) techniques to predict tourist arrivals in Saudi Arabia using a city-level dataset covering 2021–2023. A range of regression and ensemble models—including Random Forest, Gradient Boosting, HistGradientBoosting, and combinatorial stacking and voting ensembles—were evaluated across multiple experimental scenarios. The VotingR2 ensemble consistently achieved the strongest performance, with R² values of 0.9601 in mixed-year training (Scenario A), 0.8735 in temporal holdout evaluation (Scenario B), and 0.9578 under 10-fold time-series cross-validation (Scenario C). Long-horizon projections for 2024–2034 were generated using Prophet-driven feature extrapolation combined with ML-based forecasting. The results demonstrate the effectiveness of ensemble methods in capturing nonlinear tourism patterns and provide actionable insights to support strategic decision-making, infrastructure optimization, and tourism policy development within the framework of Vision 2030.
Similar content being viewed by others

Introduction
Tourism has increasingly become a vital engine of economic growth and development on a global scale. In developed and developing nations, tourism is pivotal in driving economic diversification, fostering investment opportunities, enhancing infrastructure, and promoting cultural exchange1. In the Kingdom of Saudi Arabia (KSA), tourism has emerged as a cornerstone of the nation’s Vision 2030 strategy, which aims to reduce dependence on oil revenues and stimulate growth in non-oil sectors. As a result, the tourism industry has seen a rapid transformation in recent years, positioning the kingdom as a competitive destination in the global tourism market2.
Recent statistics highlight the remarkable progress of the Saudi tourism sector. In 2023, the country recorded a 156% increase in international tourist arrivals compared to pre-pandemic levels, with the total number of visitors surpassing 100 million, a 65% increase over the previous year3. This growth is reflective of the kingdom’s commitment to developing a vibrant tourism ecosystem, supported by strategic reforms and large-scale investments. Religious tourism, one of the oldest and most significant tourism segments in Saudi Arabia, continues to generate substantial annual revenues through pilgrimages to holy sites such as Makkah and Madinah4. In parallel, the government has placed increased emphasis on expanding the scope of leisure and entertainment tourism, recognizing its potential to diversify the tourism base and attract new visitor demographics.
Sporting events have emerged as a key strategy for enhancing Saudi Arabia’s visibility on the global stage. Hosting high-profile international competitions, the kingdom seeks to project its organizational capacity, promote a modern national image, and generate tourism-related economic benefits. For instance, Saudi Arabia has successfully secured the hosting rights for major events such as the 2023 World Fighting Championship and the Seventh Asian Indoor Martial Arts Games in 20255. These events not only showcase Saudi Arabia’s potential as a global host but also contribute to an increase in tourist inflows, further solidifying the country’s position as a rising tourism destination. In addition to religious and sports tourism, leisure and heritage tourism are being actively developed through mega-projects such as Amala, AlUla, Qiddiya, and the Red Sea Project6,7,−8. These initiatives are designed to promote sustainable tourism, preserve cultural heritage, and transform the natural landscapes of Saudi Arabia into world-class attractions. Such investments are reshaping the tourism infrastructure and diversifying the country’s offerings to meet the needs of international and domestic tourists alike. Despite challenges posed by the COVID-19 pandemic and competition from established tourism markets, Saudi Arabia remains on a promising trajectory toward achieving its Vision 2030 goals9.
As the tourism sector expands, the ability to forecast tourist demand has become increasingly critical. Accurate forecasting enables policymakers and industry stakeholders to make informed decisions regarding resource allocation, infrastructure development, and service delivery. However, traditional statistical forecasting methods such as ARIMA, SARIMA, and exponential smoothing often fail to capture the nonlinear, seasonal, and multi-factor dynamics that characterize modern tourism data10,11. By contrast, machine learning (ML) techniques offer advanced capabilities for modeling nonlinear relationships, incorporating large multidimensional datasets, and integrating diverse influencing factors such as historical arrivals, economic indicators, spending behavior, and global events12,13,14.
Although ML methods have been increasingly applied in tourism demand forecasting across various regions, several critical gaps persist, particularly in the Saudi Arabian context:
-
1.
Lack of Saudi-specific forecasting models: Most prior studies adopt generic or regional models that overlook Saudi Arabia’s unique tourism structure, where religious, leisure, and event-driven tourism coexist and interact15.
-
2.
Limited integration of event-driven factors: Existing models rarely incorporate the effects of major sporting or cultural events, which have become central to the country’s tourism growth strategy16.
-
3.
Scarcity of ensemble ML comparisons: Few studies systematically evaluate and compare ensemble learning techniques for tourism forecasting within Saudi Arabia’s data-rich but complex environment, where tourism patterns are influenced by a combination of religious obligations (e.g., Hajj and Umrah), government-led mega-projects (e.g., NEOM, Qiddiya), and global sporting events.
Addressing these shortcomings is crucial for building accurate, context-aware forecasting systems that align with Vision 2030’s objectives of data-driven economic planning and sustainable tourism growth.
To bridge these gaps, this study proposes a novel ensemble-based machine learning framework for forecasting tourist inflows to Saudi Arabia. The model integrates multiple influencing factors—economic indicators, religious calendars, major events, and socio-cultural trends—to predict both seasonal and event-driven variations in tourism demand. Beyond empirical modeling, the study is theoretically grounded in tourism demand theory and the Tourism Area Life Cycle (TALC) framework, which together explain how destination development, economic forces, and external stimuli shape tourist behavior over time. This research is among the first to systematically examine the combined impact of religious, leisure, and event-driven tourism on Saudi tourist demand using machine learning methods. By uniting these theoretical perspectives with advanced ML forecasting techniques, the study establishes a conceptually informed, data-driven framework for modeling Saudi Arabia’s evolving tourism ecosystem.
In summary, the primary novelty of this research lies in (i) developing the first comprehensive ML-based forecasting framework tailored to the Saudi tourism context; (ii) integrating event-driven and religious tourism factors into a unified predictive model; and (iii) systematically comparing multiple ensemble regression techniques to identify the optimal model for Saudi tourism forecasting. The results aim to support policymakers, investors, and tourism authorities with evidence-based insights that inform long-term planning and decision-making in alignment with Vision 2030.
The remainder of this paper is structured as follows: Sect. 2 provides a review of relevant literature. Section 3 describes the methodology, including the proposed approach. Section 4 presents experimental results and performance evaluations. Finally, we discuss key findings and implications before concluding the study.
Related work
This section reviews prior research on machine learning applications in tourism forecasting and demand analysis. It examines how data-driven methods have been used to model tourist behavior, predict visitor flows, and support destination management. In addition, the review summarizes different types of tourism demand considered in the literature and identifies the key economic, seasonal, and destination-specific factors shown to influence forecasting accuracy. This synthesis establishes the methodological and conceptual foundations for the present study and highlights the gaps that the proposed models aim to address.
Overview of ML applications in tourism forecasting
Machine learning (ML) has emerged as a transformative approach for tourism demand forecasting, offering improved accuracy and adaptability compared to traditional statistical models. Studies have employed diverse algorithms—such as Support Vector Machines (SVM), Random Forests (RF), Artificial Neural Networks (ANN), and Long Short-Term Memory (LSTM)—to model nonlinear and dynamic relationships in tourism data. For instance, Mishra et al.17 compared SVR and RF for predicting global tourist arrivals between 2010 and 2020, reporting accuracies of 99.4% and 84.7%, respectively. Similarly, Afsahhosseini et al.18 compared SVM, Naïve Bayes, logistic regression, RF, and decision tree models using both annual and quarterly datasets, finding that SVM outperformed others on quarterly data. In addition, Núñez et al.19 presented a study to show that ML can participate in predicting tourism demand and transform tourism experiences by personalizing them. Data-driven insights of ML can significantly help decision-makers in the tourism industry attract more tourists and achieve competitiveness. Seker et al.10 emphasized the significant impact of ML on tourism development, as it enabled decision-making, customer experiences, and sustainable tourism.
Recent deep learning studies, such as20, demonstrated the superior performance of LSTM networks over traditional models by incorporating tourist motivation as an additional input. Optimization-based models like the Artificial Fish Swarm Optimized Dynamic Gated Recurrent Unit (AFSO-DGRU)21. This model achieved notable improvements (MAE of 42.01 and an MAPE of 1.34), indicating the potential of hybrid and metaheuristic-enhanced learning approaches.
Despite these advances, most studies focus on global or region-specific contexts outside the Country gulf, limiting their generalizability to Saudi Arabia’s distinct tourism structure. Many studies overlook region-specific variables (e.g., religious calendars, policy reforms, mega-events). Besides, few address how predictions can inform tourism management decisions, especially in data-scarce or rapidly evolving markets. Systematic comparisons among ensemble ML models remain rare, hindering understanding of model robustness across datasets.
ML-based tourism forecasting in the Saudi Arabian context
In Saudi Arabia, research on ML-driven tourism forecasting remains limited but growing. For example, Shah et al.22 applied ML to classify crowd density during Hajj, focusing on safety management rather than tourism demand forecasting, reaching 87% accuracy in crowd density classification, and 2.14% of the misclassification rate. Louati et al.23 used decision trees, Random Forests, and support vector classifiers to model tourist spending behaviors between 2015 and 2021, achieving strong predictive accuracy but without addressing time-series forecasting. These studies highlight early progress in applying AI to tourism data but stop short of constructing holistic forecasting frameworks.
More broadly, existing works on the Kingdom’s tourism sector tend to rely on traditional econometric or time-series models (e.g., ARIMA, gravity models)4,24, which inadequately capture the nonlinear dynamics of modern tourism patterns shaped by Vision 2030, mega-events, and religious travel cycles. Hence, there remains an empirical and methodological gap in integrating multiple data types (economic, cultural, religious, event-driven) into a unified ML-based forecasting system.
Factors influencing tourism demand
Tourism demand in Saudi Arabia is shaped by diverse and interdependent factors encompassing religious, leisure, and event-driven tourism. Religious tourism—particularly Hajj and Umrah—remains the cornerstone of the sector, driving millions of visits annually and contributing significantly to GDP4,24. Studies have highlighted correlations between prosperity indices, per capita income, and religious tourism flows25. Meanwhile, sports and cultural events have gained prominence under Vision 2030, with major events like WWE, Formula 1, the Riyadh Season, and international concerts attracting global visitors26,27.
Leisure and domestic tourism are also expanding rapidly due to infrastructure development and social reforms. Studies such as28,29 demonstrate how integrating online behavioral data (e.g., Google Trends) enhances forecasting accuracy for event- and season-sensitive tourism. However, these approaches remain underexplored in Saudi Arabia, where event-driven and religious tourism uniquely coexist.
Critical summary and research gaps
Table 1 summarizes representative studies on ML-based tourism forecasting, including their datasets, modeling approaches, and key findings.
Current state-of-the-art studies face significant limitations, primarily stemming from a scarcity of Saudi-specific forecasting frameworks that effectively incorporate the unique dynamics of religious and event-driven tourism. This is compounded by the limited comparative evaluation of ensemble Machine Learning (ML) techniques, which restricts the adoption of potentially more accurate predictive models. Furthermore, there is a consistent underutilization of integrated datasets that could combine essential socio-economic, seasonal, and event-based indicators, thus preventing models from fully capturing the complex, multifaceted factors that drive tourism demand in the region.
To address these deficiencies, this research proposes a novel ensemble ML forecasting framework for Saudi Arabia’s tourism demand, guided by tourism demand theory and the Tourism Area Life Cycle (TALC) framework. By integrating economic indicators, religious calendars, and event-driven factors, this study offers both methodological innovation and contextual relevance within the rapidly evolving Saudi tourism landscape.
Research methodology
Conceptual framework
The methodological design of this study is anchored in tourism demand theory and the Tourism Area Life Cycle (TALC) framework, both of which emphasize that tourism demand is influenced by economic, cultural, infrastructural, and event-driven factors. According to these theories, destinations evolve through distinct stages—exploration, development, consolidation, and transformation—each characterized by changing tourist flows and market dynamics. Within this theoretical lens, tourism demand forecasting is not merely a statistical exercise but a reflection of broader economic behavior and destination maturity.
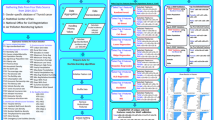
To operationalize these theoretical concepts in a modern, data-driven setting, this study employs machine learning regression and ensemble techniques capable of capturing complex, nonlinear relationships among diverse predictors. The integration of ML into tourism forecasting thus represents an application of data-driven economic modeling, where theory-guided feature selection (e.g., incorporating event-based and economic indicators) informs empirical model construction. Figure 1 illustrates the conceptual linkage between theoretical constructs, data inputs, ML models, and forecasting outputs.

The proposed methodology to predict and classify the total number of tourists in Saudi Arabia.
Building upon this conceptual foundation, the methodological workflow was designed to translate theoretical insights into an empirical ML forecasting pipeline. Specifically, factors derived from the tourism demand theory (economic, cultural, and event-driven) and TALC framework (destination development stage) were transformed into measurable predictors within the dataset. The subsequent preprocessing, augmentation, and modeling steps were therefore not arbitrary but theory-informed—each aimed at improving the model’s ability to capture the structural and behavioral dynamics of Saudi Arabia’s tourism demand.
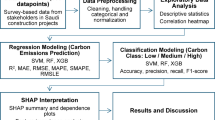
In this study, a variety of ML algorithms were evaluated to identify the most effective model for predicting tourist movement in Saudi Arabia. A comprehensive dataset on tourist movement was collected, and three key techniques were implemented to optimize model performance: preprocessing, data splitting, and data augmentation. For preprocessing, normalization was applied along with mean imputation for missing values and removal of duplicate records. To enhance model generalization, the Synthetic Minority Over-sampling Technique for Regression with Noisy Data (SMOTER) was used for data augmentation. Furthermore, a 10-fold cross-validation technique ensured robust and reliable performance evaluation. For forecasting, regression models such as AdaBoostRegressor (ABR), DecisionTreeRegressor (DT), RandomForestRegressor (RFR), BaggingRegressor (BR), ExtraTreesRegressor (ETR), GradientBoostingRegressor (GBR), HistGradientBoostingRegressor (HGBR), VotingRegressor, and StackingRegressor were tested. The same models were also extended to classification tasks (Scenario F), focusing on multi-label prediction.
Data collection
The data used in this study were newly collected in collaboration with the Saudi Arabia Council’s Tourist Authority. This dataset captures essential metrics related to tourist movement within the Kingdom of Saudi Arabia over a three-year period (2021–2023). Data is recorded at a monthly frequency for each city and includes the following features:
-
City Name: Name of the city visited.
-
Number of Visitors (No Tourist): Total number of tourists (excluding non-tourist entries).
-
Month of Travel: Month corresponding to the observation.
-
Total Expenditure (Cost): Total spending associated with the visit.
-
Year of Data Entry.
These features were selected based on their relevance to modeling tourist demand30 and their consistent availability in the source dataset.
Data preparation and processing
The preprocessing stage aimed to enhance the quality and usability of the data for AI-based forecasting models. The steps included:
-
1.
Scaling: The “Number of Visitors” and “Cost” columns were normalized by dividing each value by the maximum value of its respective column (Eqs. 1 and 2). This reduced the impact of large absolute values on model error metrics (MAE and MSE)31.
-
2.
Handling Missing Values: Missing data were imputed using mean imputation based on each feature’s distribution, rather than filling with zeros, to reduce bias31.
-
3.
Duplicate Removal: Duplicate records were removed using drop_duplicates() in Pandas to maintain dataset uniqueness32.
-
4.
Feature Selection and Multicollinearity Check: A correlation heatmap (Fig. 2) was generated to identify potential multicollinearity33. Features with high correlation were carefully evaluated to ensure that only informative variables were retained, improving model stability and interpretability.
These preprocessing steps ensured data consistency, quality, and suitability for regression-based forecasting while maintaining reproducibility.

Feature correlation heatmap of the tourism dataset.
Data split and augmentation
To ensure rigorous model training and evaluation, four datasets were constructed using different splitting and augmentation techniques, each designed to simulate a specific forecasting condition. Data augmentation techniques were applied exclusively to the training set after the data was split.
Dataset 1 was created using an 80/20 random split of the full dataset (Table 2), providing a baseline evaluation without temporal constraints.
Dataset 2 used data from 2021 to 2022 for training and 2023 for testing, representing a realistic year-ahead forecasting scenario in which models predict future tourism levels based solely on past observations.
Dataset 3 incorporated regression-specific data augmentation using the Synthetic Minority Over-sampling Technique for Noisy Data (SMOGN)34. This method was selected because the tourism target variable contains locally sparse regions where models tend to underperform. SMOGN generates synthetic samples by interpolating within the nearest neighbors of underrepresented ranges while accounting for noise35. To examine stability, three variants of the dataset were generated using different k values (3, 5, and 7), following recommendations in the SMOGN literature and preliminary sensitivity checks36. The resulting augmented subsets were combined with the original dataset, producing a final dataset of 1,554 rows (1,243 training and 311 testing).
Dataset 4 was generated using k-means clustering to segment the data into eight well-separated clusters, enabling the evaluation of model performance in a multi-class segmentation context37,38. The choice of \(\:k\:=\:8\) was guided by elbow-curve and silhouette analyses, which indicated optimal cluster separation at this value. The resulting labeled dataset was then split into 80% training and 20% testing.
Together, these four datasets allow for comprehensive assessment of model behavior under baseline, temporal, augmented, and cluster-structured conditions.
The proposed AI models
-
Ensemble-Based Stacking Model.
Stacking is an ensemble learning technique designed to combine the predictive strengths of multiple base learners (level-0 models) by training a meta-learner (level-1 model) that learns the optimal way to integrate their outputs39, 40. This layered architecture helps capture complementary patterns across models, often resulting in improved generalization and robustness compared to any single model alone. Stacking can be effectively applied to both regression and classification tasks.
In this study, six individual AI models—Decision Tree (DT), Random Forest (RF), Gradient Boosting (GB), Histogram Gradient Boosting (HGB), Extra Trees Regressor (ETR), and AdaBoost Regressor (ABR)—were employed as candidate learners. These models were selected based on their consistent success in prior research4,17,22,23,33. To systematically explore their combined potential, a combinatorial ensemble design was adopted, allowing the creation of up to 216 possible ensemble configurations \(\:(6\times\:6\times\:6)\). In the stacking setup, two models were assigned as base learners and one as the meta-learner, whereas in the voting framework, three models were integrated with equal contribution. This structured approach provides an empirical, transparent, and reproducible method for identifying the most effective stacking and voting combinations, eliminating reliance on arbitrary or manually selected model pairings.
Among these alternatives, two optimized stacking configurations were ultimately implemented based on empirical performance:
-
Stacking1: LinearRegression and RandomForestRegressor were used as base estimators, with KNeighborsRegressor as the final meta-learner.
-
Stacking2: RandomForestRegressor and LinearRegression served as base estimators, while GradientBoostingRegressor acted as the final estimator.
For classification tasks, equivalent model configurations were adopted using the corresponding classification variants—RandomForestClassifier, LogisticRegression, KNeighborsClassifier, and GradientBoostingClassifier—to maintain architectural consistency across both problem domains.
This ensemble design not only integrates models with diverse learning biases (e.g., linear vs. non-linear) but also enhances stability against overfitting and data noise. The diversity of model architectures ensures that weaknesses of one learner are compensated by strengths of others, thereby yielding a more balanced and accurate predictive system.
-
Ensemble-Based Voting Model.
Voting is another widely used ensemble learning approach that aggregates predictions from multiple models through a voting or averaging mechanism to produce a final output39. For regression tasks, the ensemble output is computed as the average of predictions from all base learners, whereas for classification, a majority-vote rule determines the final predicted class. This technique leverages the principle that combining multiple, diverse learners reduces variance and improves overall prediction reliability.
In this study, two voting ensemble configurations were selected using the same combinatorial ensemble design employed for stacking. These configurations were chosen based on their superior predictive performance among all evaluated combinations.
-
VotingR1: LinearRegression and RandomForestRegressor as base estimators, with KNeighborsRegressor as the final estimator.
-
VotingR2: RandomForestRegressor and LinearRegression as base estimators, with GradientBoostingRegressor as the final estimator.
Similarly, for classification tasks, equivalent configurations were constructed using the corresponding classifier variants.
The motivation for employing both stacking and voting ensembles lies in their complementary nature and ability to integrate heterogeneous learning paradigms40,41. Linear models, such as LogisticRegression and LinearRegression, effectively capture global linear relationships between features and outputs. In contrast, tree-based and boosting models, such as RF, GB, and HGB, are adept at learning non-linear feature interactions and complex dependencies. By combining these paradigms, the ensemble benefits from both generalization and precision, leading to improved performance, robustness, and interpretability. This synergy empirically explains the superior outcomes achieved by the VotingR2 and Stacking configurations.
While a wide range of models could theoretically be incorporated into the ensemble, the selected configurations yielded the most stable and accurate results. Interestingly, even models with relatively lower standalone performance (e.g., LogisticRegression) contributed valuable decision boundaries that enhanced the ensemble’s overall learning capability. Conversely, including additional complex models—despite their individual strengths—sometimes led to reduced synergy, demonstrating that ensemble success depends on the diversity and complementarity of its components rather than sheer individual accuracy.
-
Hyperparameter Tuning.
To ensure fairness and reproducibility across models, all AI algorithms were fine-tuned using a consistent experimental setup. As shown in Table 3, hyperparameter tuning was conducted using GridSearchCV (for tree-based and boosting models) and manual empirical adjustments (for linear and ensemble-based models), with 10-fold cross-validation applied to prevent overfitting and assess generalization performance. The final parameters were selected based on optimal validation performance (minimum RMSE for regression tasks and maximum accuracy for classification tasks).
For baseline models such as Decision Tree (DT), default parameters were retained (unrestricted depth and no pruning) to serve as a reference for more complex ensemble learners. Random Forest (RF) and Extra Trees Regressor (ETR) both utilized 100 estimators, with RF employing bootstrapping and ETR disabling it for variance reduction. Gradient Boosting (GB) was configured with 100 estimators, a learning rate of 0.1, and shallow trees (depth = 3), optimized for bias–variance balance. The Histogram-Based Gradient Boosting (HGB) model was set to 100 iterations, using the default regularization and early stopping mechanisms for stability. AdaBoost Regressor (ABR) applied 50 boosting stages with linear loss, emphasizing simplicity and computational efficiency.
For ensemble techniques—Bagging, Stacking, and Voting—standard configurations were used with minimal hyperparameter alteration to preserve interpretability and assess the intrinsic contribution of model combination rather than hyperparameter complexity. Specifically, the stacking and voting ensembles were evaluated using empirically optimized combinations of base and meta learners, as discussed in the ensemble model section.
Evaluation metrics
Various commonly used assessment criteria, such as precision, accuracy, F1-score, and recall, are utilized to train and test the suggested models. The specific mathematical definitions for each metric are as follows:
\(\:\text{w}\text{h}\text{e}\text{r}\text{e}\:{\text{y}}_{\text{i}}\:\text{i}\text{s}\:\)prediction, \(\:{\text{x}}_{\text{i}}\)is the true value, and n is the total number of data points.
\(\:\text{w}\text{h}\text{e}\text{r}\text{e}\:{\text{y}}_{\text{i}}\:\text{i}\text{s}\:\)observed values, \(\:{\text{x}}_{\text{i}}\)is the predicted value, and n is the total number of data points.
RSS is the sum of squares of residuals, and S is the sum of squares.
The use of “TP” for True Positive, “TN” for True Negative, and “FP” for False Positive is important in evaluating the k-means clustering algorithm’s ability to distinguish between different classes. The Receiver Operating Characteristic (ROC) curve and its Area Under the Curve (AUC) value are used for this evaluation7.
The use of “TP” for True Positive, “TN” for True Negative, and “FP” for False Positive is important in evaluating the k-means clustering algorithm’s ability to distinguish between different classes. The Receiver Operating Characteristic (ROC) curve and its Area Under the Curve (AUC) value are used for this evaluation42,43.
Results and discussion
This section presents the evaluation of machine learning models applied to forecast and classify tourist movements in Saudi Arabia. Structured around seven distinct scenarios (A–G), the analysis systematically examines model performance under varied experimental conditions, including temporal data splits, cross-validation, data augmentation, and multi-label classification. Key metrics such as MAE, MSE, R² scores, precision, and F1-scores are employed to assess predictive accuracy and robustness.
Scenario A: baseline model evaluation using mixed-year data
This scenario establishes a baseline assessment of all models by training and testing on mixed-year data from Dataset 1. The purpose is to evaluate general model behavior without temporal constraints, reflecting short-term within-year forecasting, where historical and current-year data are jointly available. Such settings are common in operational tourism analytics where updates are performed monthly or quarterly.
By excluding explicit year identifiers, this scenario isolates the impact of core predictors and enables an early assessment of feature contribution—particularly the “Cost” indicator. Understanding the baseline predictive structure helps guide feature selection for more advanced forecasting scenarios.
Performance comparisons show that the VotingR2 ensemble achieved the strongest results (MAE of 0.0133, MSE of 0.0007, and an R2 of 0.9601) due to its ability to integrate diverse learning patterns, as shown in Table 4. This superior result underscores the fundamental advantage of ensemble learners, as VotingR2 effectively leveraged model diversity, combining the strength of tree-based learners (for nonlinear patterns) with linear components (for prediction stability)33,44. The resulting prediction curves (Figs. 3 and 4) were smoother than those of individual base models, indicating reliable long-term trend capture.
Conversely, the sequential nature of HistGradientBoosting (HGB) led to the lowest performance among ensembles (R2 = 0.9001). This is attributed to HGB’s reliance on monotonic gradient-based splits, which limits its ability to generalize effectively when the feature space involves complex, mixed distributional patterns45.
The performance gap was most evident when comparing ensemble methods to the traditional time series models, ARIMAX and Prophet. While these traditional models achieved a near-perfect fit on the training data (R2train consistently near 1.0), they subsequently showed substantially poorer metrics on the test set, indicating significant overfitting and a failure to generalize. This limitation is linked to their core methodology: ARIMAX and Prophet are ill-suited for modeling our disaggregated data structure, which includes Year, Month, City, and the exogenous Cost regressor. Their fixed, global assumptions about trend and seasonality struggle to capture the numerous independent local patterns across multiple cities, leading to an over-emphasis on noise in the training set46.

Predicted curves for the number of tourists generated by the VotingR2 model when applied to the test set of Dataset 1.

Predicted curves for the number of tourists generated by the AI models when applied to the test set of Dataset 1.
On the other hand, when the Cost column was removed (Table 5), most ensemble models—especially VotingR2, VotingR1, and Stacking2—experienced performance degradation, whereas individual models (RF, BR, GB) still have strong performance. This behavior suggests that Cost is an influential feature; its effect is captured more effectively by single models than by ensembles, likely because ensemble methods distribute feature importance across learners, or tree-based ensembles can dilute weak but informative signals when the dataset is small. This result aligns with previous forecasting studies, where the removal of important features often reduced ensemble performance more than individual tree models47,48.
Scenario B: year-ahead forecasting using historical data (2021–2022 → 2023)
Scenario B evaluates the model’s ability to perform forward-looking, year-ahead forecasting, a setting highly relevant to tourism authorities and planners. Here, models are trained exclusively on historical data (2021–2022) and tested on the unseen year 2023 using Dataset 2, as shown in Fig. 5. This design simulates real policy workflows where forecasts are generated for upcoming years, such as projections for 2026–2034 to support Vision 2030 tourism targets.
This scenario evaluates how models perform under different seasonal phases, distribution shifts, and varying training lengths, conditions that frequently occur in real tourism environments due to policy changes, holidays, or global events.
Despite this challenge, the VotingR2 ensemble maintained the best overall performance (MAE = 0.0339, R2 = 0.8736), as shown in Table 6. Its superior accuracy stems from the synergy between its diverse base learners, particularly the inclusion of the GB model. GB, with the highest individual R2 (0.8457) and a competitive MAE (0.0291), demonstrated strong short-term sensitivity to recent patterns in 2022, effectively modeling the residual errors right up to the cutoff point. By averaging this strong performance, VotingR2 mitigated the tendency of individual models to overfit noise, thereby ensuring robustness against the temporal shift to 2023, as shown in Fig. 6.
The sustained high R2 by VotingR2 confirms its ability to robustly handle the high-dimensional feature space (which includes Cost and City). The ensemble successfully weighted the complex, non-linear interactions driven by the disaggregated spatial data and the external economic regressor, proving more stable than single-feature-focused models.
Models such as HGB and VotingR1 performed poorly, likely due to sensitivity to year-to-year shifts in tourism patterns or inability to generalize to structural changes between 2021 and 2023.
In contrast, models like HGB and VotingR1 performed poorly. This is likely due to their high sensitivity to structural breaks, sudden shifts in tourism patterns that occur between years (e.g., changes in policy of visiting or tourist conditions in 2023). HGB, which relies on a rigid sequential correction process49, struggled to generalize from the 2021–2022 distribution to the unseen 2023 period, indicating low stability when faced with a genuine distributional shift. Studies show that combining prediction outputs from diverse models is the most effective strategy for managing temporal non-stationarity and structural changes48,49,50.

Predicted curves for the number of tourists generated by the proposed AI model when applied to the test set of Dataset 2.

Predicted curves for the number of tourists generated by the VotingR2 model when applied to the test set of Dataset 2.
By applying controlled linear increments (0.05/year) to the features, the models successfully generated smooth upward-projected curves for the long horizon (2024–2034) (Figs. 7 and 8). The VotingR2 ensemble produced the most stable long-horizon forecasts, demonstrating superior generalization beyond the immediate test period. In contrast, models like HGB and RF exhibited larger variance in their projections, which is consistent with their established tendency to overfit short-term training patterns, making them less reliable for ten-year projections.
However, removing the Cost feature from Dataset 2 caused a noticeable reduction in ensemble performance, while individual models such as BR recorded the highest performance, as shown in Table 7. This confirms that Cost remains a key predictive feature for forecasting into the deep future, and its importance is amplified in a strict year-split evaluation.

Predicted curves for the number of tourists for the year 2024, generated by increasing the tourist numbers of 2023 by 0.05 for each corresponding value.

Predicted curves for the number of tourists for the year 2034, generated by increasing the tourist numbers of 2023 by 0.05 × 10 for each year and their corresponding value.
Long-horizon projections (2024–2034)
Instead of artificially scaling any feature, we constructed future inputs for 2024–2034 by modeling the temporal evolution of key predictors using the historical dataset (Year, Month, City, Cost) from 2021 to 2023.
First, the Cost variable—identified as the strongest continuous predictor in the training models—was forecasted forward to 2034 using a univariate time-series model (Prophet)46. Monthly predictions were generated for each city between January 2024 and December 2034, producing a fully data-driven and temporally coherent input feature. The categorical predictors (City and Month) were encoded exactly as in the training phase (data from 2021 to 2023) to ensure compatibility with the regressors. This procedure created a complete and realistic feature matrix of future scenarios without any manual scaling or imposed linear growth.
Next, all four supervised models (Random Forest, Gradient Boosting, HistGradientBoosting, and the VotingR2 ensemble) were applied to the 2024–2034 feature matrix after being trained exclusively on the 2021–2023 period. Therefore, the resulting long-horizon projections reflect each model’s inductive bias, learned patterns, and sensitivity to the time-series evolution of the Cost variable, rather than any user-defined numerical trend.
As shown in Fig. 9, the proposed VotingR² ensemble consistently yields the highest estimates, forecasting an increase from roughly 35 million tourists in 2024 to nearly 88 million by 2034. This model captures a stronger acceleration in long-term growth than the individual learners, which may reflect interactions or nonlinear patterns present in the underlying features. While the ensemble offers improved short-term stability relative to its components, the faster late-period growth also underscores the importance of treating long-horizon predictions with caution, particularly in the presence of structural uncertainty.

Long-horizon tourism forecasts for 2024–2034. The future input features were generated using a univariate time-series model (Prophet), and the projected tourist numbers were predicted using the VotingR2, Gradient Boosting (GB), Random Forest (RF), and HistGradientBoosting (HGB) models.
Scenario C: 10-fold time series cross-validation (temporal robustness evaluation)
Scenario C employs a 10-fold Time Series Split (TSS) to assess model consistency and robustness across multiple temporal partitions. Unlike random k-fold cross-validation, TSS preserves chronological order by iteratively expanding the training window and testing on the next block of unseen observations. This prevents data leakage and mimics real forecasting conditions where future values depend only on past information. This scenario evaluates how models perform under different seasonal phases, distribution shifts, and varying training lengths—conditions that frequently occur in real tourism environments due to policy changes, holidays, or global events.
For each of the ten folds, the dataset was divided chronologically using TimeSeriesSplit(n_splits = 10) and \(\:random\_state\:=\:1\) was set to all models. Each model was trained on the growing training window and evaluated on the subsequent test segment, and performance metrics—including MAE, MSE, and R²—were recorded for both training and testing sets. The final results were reported as the mean and standard deviation across all folds, providing a comprehensive evaluation of model stability and robustness.
Overall, the ensemble-based VotingR2 model achieved the strongest generalization performance (Mean MAE = 0.0046, Mean MSE = 0.0004, Mean R² = 0.9578), with very low variance across folds (Table 8). This consistency indicates that the ensemble approach effectively mitigates overfitting and adapts well to temporal fluctuations in the data.
In contrast, deep tree-based models such as HGB and DT demonstrated substantial overfitting. Although these models reached near-perfect accuracy on the training folds, their performance deteriorated considerably on unseen temporal segments, aligning with known limitations of high-variance learners when trained on relatively small or noisy time-series datasets45,51,52.
Across all cross-validation folds in Scenario C, the feature importance analyses derived from the RF and GB base learners consistently produced a stable ranking of the predictive variables. Cost emerged as the most influential feature, followed by Year, which captured temporal progression in tourist demand. City contributed meaningful geographic variation, while Month provided seasonal context. This consistent ordering across folds highlights the robustness of the underlying patterns in the dataset and reinforces the reliability of the models’ learned relationships.
Scenario D: data augmentation
In Scenario D, Dataset 3—expanded using controlled data augmentation—was used to evaluate whether enriching the feature space can improve model generalization. Among all models, HGB achieved the strongest performance (MAE = 0.0146%, MSE = 0.0010%, R² = 0.9577), as shown in Table 9. This is expected because HGB is highly effective at modeling smooth nonlinear relationships and performs well when the dataset contains many repeated or synthetic patterns, as produced by augmentation53,54.
The VotingR2 ensemble also delivered competitive performance (MAE = 0.0255%, R² = 0.9218), although it was slightly outperformed by HGB. Unlike Scenario A and B, where VotingR2 consistently led performance, the augmented dataset favored single, high-capacity learners rather than ensembles. This suggests that data augmentation reduced variance but did not introduce substantial structural diversity, allowing strong base models like HGB and GB to fit the underlying relationships more directly, while ensembles (e.g., VotingR2) benefit most when the input patterns are diverse and heterogeneous.
When the Cost variable was excluded from the feature set (Table 10), model performance declined dramatically. The R² values, which previously ranged from 0.92 to 0.96, dropped to just 0.12–0.45 across all models. This sharp reduction indicates that Cost is the single most influential predictor in the dataset, capturing critical economic dynamics that strongly explain variations in tourism growth.
Models that had previously demonstrated high predictive accuracy—such as HGB, GB, and VotingR2—experienced substantial degradation in performance. This outcome highlights an important limitation: data augmentation cannot compensate for the omission of essential domain-specific variables54. In the absence of Cost, the models were forced to depend on comparatively weaker and more volatile features, resulting in unstable and significantly less accurate predictions.
Scenario E: additional validation and diagnostic analyses using an external dataset
Since no publicly available tourism dataset exists for Saudi Arabia at the city-level, we addressed this limitation by incorporating a real-world external dataset from a different country. This approach does not provide geographic external validity but offers methodological external validation—assessing whether the trained algorithms remain stable when applied to a larger and more heterogeneous tourism dataset.
To this end, we used the Thailand Domestic Tourism Statistics Dataset (January 2019 – February 2023), which includes 30,800 records describing monthly provincial tourist volumes, occupancy rates, and tourism-generated profits for both domestic and international visitors55.
To ensure a fair comparison with our earlier experiments, the same 10-fold time-series cross-validation protocol used in Scenario C (Sect. 4.4) was applied. All models were trained exclusively on the Thailand dataset and evaluated using identical splits, metrics, and hyperparameters.
As illustrated in Table 11, all models exhibited decreased performance when compared to their results on the Saudi dataset. This outcome was anticipated, as the Thailand dataset consists of significantly more samples and exhibits much higher variance, making it more challenging and less likely to lead to overfitting.
Despite this increased difficulty, the VotingR2 ensemble remained the most robust model, achieving an R² of 0.8443 on the held-out test sets. The relatively high MSE and MAE values, some exceeding 1, indicate that certain high-variance samples could not be modeled accurately, again reflecting genuine data complexity rather than overfitting.
Scenario F: multiple classification
In Scenario F, the problem was reframed from regression into multi-class classification, using Dataset 4 generated through k-means clustering (eight groups), as presented in Fig. 10. This transformation allowed the models to learn broader behavioral patterns of tourism activity rather than predicting raw numerical counts.
Several models — including DT, GB, Bagging, and StackingV2 — achieved perfect classification performance (100% accuracy, recall, precision, and F1-score) as shown in Table 12. Such exceptionally high metrics strongly suggest that the k-means clusters were very well separated, and that the underlying tourism data contains clear, distinct patterns that are easily classifiable.
Although the VotingR2 ensemble was originally developed for regression tasks, its classification variant remained highly effective, achieving 98.90% across all test-set metrics as shown in (Fig. 11) for confusion matrix classification. The slight reduction compared to the perfect performance of Gradient Boosting (100%) can be attributed to the contribution of weaker base learners within the ensemble, particularly Random Forest, which achieved a lower accuracy of 97.8%. Methodologically, this outcome highlights an important property of voting-based ensembles: while they often provide robustness in noisy or overlapping feature spaces, their aggregate performance is constrained by the variability of their constituent models. Consequently, even when class boundaries are sharply defined—as in this dataset—the presence of a less accurate base learner can moderate the ensemble’s final predictive performance56,57,58,59.

The k-means algorithm was applied to the original dataset to create 8 distinct clusters for classification by the proposed AI models.
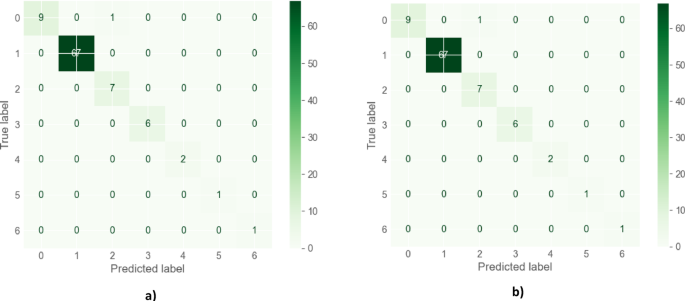
The confusion matrix for the proposed VotingR1 in (a) and VotingR2 in (b).
Scenario G: SHAP implementation and feature interpretability
This scenario introduces SHAP analysis to obtain feature-level interpretability for the best-performing ensemble model (VotingR2). Interpretability is essential for real-world decision-making, as policymakers require transparent explanations for why forecasts increase or decrease under certain conditions.
The SHAP summary plot (Fig. 12) illustrates both the magnitude and direction of feature effects. Cost is clearly the dominant predictor, exerting a strong positive influence on the predicted tourism numbers—consistent with the results observed in Sect. 4.1–4.5. Year ranks second, capturing long-term temporal trends, while City and Month contribute smaller but meaningful variations associated with local and seasonal patterns.
Overall, the SHAP analysis validates that the ensemble model’s predictions align with known economic and temporal dynamics in tourism. It also confirms that the model effectively captures both broad trends and localized fluctuations, strengthening confidence in its applicability for policy analysis and operational forecasting.

SHAP summary plot illustrating the relative importance and direction of feature contributions to the ensemble model’s predictions. Each dot represents an individual observation, where the horizontal axis denotes the SHAP value (impact on model output) and color intensity reflects the feature value (blue = low, red = high). Cost exhibited the highest positive contribution to tourism demand predictions, followed by Year, City, and Month, indicating that economic and temporal factors are dominant drivers in the model’s decision process.
Summary discussion
The results presented in Sect. 4.1–4.8 demonstrate that accurate tourism forecasting requires rigorous preprocessing, thoughtful model selection, and thorough evaluation across diverse forecasting conditions. While classical statistical approaches were effective in capturing broad temporal trends, machine-learning and ensemble methods, especially stacking and hybrid models, showed superior capability in modeling nonlinear relationships, seasonal effects, and complex interactions, resulting in the lowest forecasting errors. The observed seasonal fluctuations and distribution shifts also underscore the critical role of feature engineering and season-aware modeling in achieving robust and reliable predictions.
Beyond statistical accuracy, the results carry clear practical implications. Reliable forecasts can support infrastructure planning by helping authorities anticipate hotel, transport, and service capacity needs during peak and off-peak periods. They also enable targeted tourism marketing by identifying growth periods and regional demand trends, and contribute to economic diversification strategies by projecting tourism’s role in non-oil revenue expansion. Thus, the integrated hybrid modeling framework is not only technically effective but also well suited for real-world decision-making and long-term tourism policy development.
Conclusion
This study evaluated the performance of several machine learning models for forecasting tourist movement in Saudi Arabia across seven experimental scenarios. Among the tested approaches, the VotingR2 ensemble consistently showed strong predictive capability, achieving the lowest MAE and MSE and the highest R² in mixed-year, temporal, and cross-validation experiments. These results emphasize the importance of robust preprocessing procedures and the influence of key variables—particularly cost-related features and visitor counts—in improving model accuracy.
Beyond quantitative performance, the forecasting outcomes offer practical insights for tourism planning. The projected increase in tourist flows is aligned with Saudi Arabia’s Vision 2030 objectives, suggesting potential relevance for infrastructure development, marketing strategies, and resource allocation. Reliable demand forecasts can assist stakeholders in optimizing hotel capacity, transport services, seasonal staffing, and targeted promotional campaigns, thereby supporting broader economic diversification efforts.
Despite these strengths, several limitations warrant caution in interpretation. The primary dataset, although informative, remains relatively small and may not fully capture long-term behavioral dynamics, external shocks, or policy-driven fluctuations. Some models also showed sensitivity to feature selection, raising concerns about generalizability when applied to different cities or future periods with evolving data distributions. Additionally, the study did not incorporate external variables,such as mobility patterns, climate conditions, or real-time macroeconomic indicators,that could improve long-range forecasting accuracy.
To address these challenges and strengthen methodological rigor, the study incorporated an additional validation step using the Thailand Domestic Tourism dataset. This external test offered a practical means of evaluating the robustness of the models under a different statistical distribution. However, its use also underscores an important limitation: the absence of a geographically matched, city-level tourism dataset for Saudi Arabia. Cross-country validation is informative but cannot fully reflect the cultural, seasonal, economic, and event-driven characteristics unique to Saudi tourism demand. Future work should therefore prioritize collaboration with national tourism authorities to access or develop comprehensive, long-term datasets tailored to the Saudi context. Such data would enable true external validation, support the development of transfer-learning or domain-adaptation approaches, and enhance the reliability of national-scale forecasting systems.
Looking forward, future research will focus on expanding the dataset, integrating additional external features, and exploring hybrid modeling frameworks that incorporate mobility data, climate indicators, and major-event calendars (e.g., Riyadh Season, Hajj periods). These enhancements will improve predictive realism and support the creation of a fully operational, AI-driven forecasting tool for the Saudi Arabian tourism sector.
Overall, this work demonstrates the potential of machine learning–based forecasting as a decision-support tool for tourism management while underscoring the need for broader datasets, external validation, and continuous model refinement to strengthen real-world applicability.
Data availability
The datasets used in this paper are publicly available at the Saudi Ministry of Tourism via these links: [https://mt.gov.sa/tic/dashboard/domestic-tourism],https://cdn.mt.gov.sa/mtportal/mt-fe-production/content/tic/dashboard/mt-master-sheet-data-25092022.xlsx.
References
Bhattarai, K. & Conway, D. Impacts of economic growth, transportation, and tourism on the contemporary environment. 563–662. https://doi.org/10.1007/978-3-030-50168-6_7 (2021).
Naseem, S. The role of tourism in economic growth: empirical evidence from Saudi Arabia. Economies 9, 117 (2021).
Tourism, M. Domestic Tourism Dashboard. https://mt.gov.sa/tic/dashboard/domestic-tourism (2024).
Alshammari, R. & Shaheen, R. The economics of religious tourism (Hajj) and it’s impact on the Saudi economy. PalArch’s J. Archaeol. Egypt/Egyptol. 18, (2021).
Ishac, W. Arab countries’ strategies to bid and to host major sport events. In The Routledge Handbook of Sport in Asia 437–446 (Routledge, 2020).
AMAALA. AMAALA, A Hidden Gem. https://www.visitredsea.com/en/destinations/amaala.
Chalastani, V. I. et al. Reconciling tourism development and conservation outcomes through marine Spatial planning for a Saudi Giga-Project in the red sea (The red sea Project, vision 2030). Front. Mar. Sci. 7, (2020).
Trew, B. Saudi Arabia to build ‘Riviera of the Middle East’ in bid to turn country into global tourist destination. The Independent https://www.independent.co.uk/news/world/middle-east/url-saudi-arabia-luxury-holiday-destination-riviera-of-the-middle-east-tourism-giga-projects-a8558411.html (2018).
Al-Mohmmad, S. & Butler, G. Tourism SME stakeholder perspectives on the inaugural ‘Saudi seasons’: an exploratory study of emerging opportunities and challenges. Tour Hosp. Manag. 27, 669–687 (2021).
Seker, F. Evolution of machine learning in tourism: A comprehensive review of seminal research. J. Artif. Intell. Data Sci. 3, 54–79 (2023).
Bangare, M. L. et al. Role of machine learning in improving tourism and education sector. Mater. Today Proc. 51, 2457–2461 (2022).
Al-Hejri, A. M. et al. ETECADx: ensemble Self-Attention transformer encoder for breast cancer diagnosis using Full-Field digital X-ray breast images. Diagnostics 13, 89 (2022).
Rehman, A. & Alnuzhah, A. Dentifying travel motivations of Saudi domestic tourists: case of hail Province in Saudi Arabia. Geoj. Tour Geosites. 43, 1118–1128 (2022).
Al-Tam, R. M. et al. A hybrid workflow of residual convolutional transformer encoder for breast cancer classification using digital X-ray mammograms. Biomedicines 10, 2971 (2022).
Alzahrani, A., Alshehri, A., Alamri, M. & Alqithami, S. AI-driven innovations in tourism: developing a hybrid framework for the Saudi tourism sector. AI 6, 7 (2025).
Alshammari, B., South, R. B. & Raleigh, K. Saudi Arabia outbound tourism: an analysis of trends and destinations. J. Policy Res. Tour Leis Events 1–23 https://doi.org/10.1080/19407963.2023.2243960 (2023).
Mishra, R. K. et al. and and and Machine learning based forecasting systems for worldwide international tourists arrival. Int. J. Adv. Comput. Sci. Appl. 12, (2021).
Afsahhosseini, F. & Al-Mulla, Y. Machine learning in tourism. In The 3rd International Conference on Machine Learning and Machine Intelligence 53–57. https://doi.org/10.1145/3426826.3426837 (ACM, 2020).
Núñez, J. C. S., Gómez-Pulido, J. A. & Ramírez, R. R. Machine learning applied to tourism: A systematic review. WIREs Data Min. Knowl. Discov. 14, (2024).
Kaewsompong, N., Thongkairat, S. & Maneejuk, P. Application of machine learning concept to tourism demand forecast. 401–412. https://doi.org/10.1007/978-3-030-77094-5_31 (2022).
Gulati, S., Rathod, M. J. & Agarwal, V. J., G. A novel approach for forecasting tourist arrivals using web search data and artificial intelligence. INTI J. 2022 (2024).
Shah, A. A. A machine learning model for crowd density classification in Hajj video frames. ArXiv Prepr arXiv2501 04911. https://doi.org/10.48550/arXiv.2501.04911 (2025).
Louati, A. et al. Machine learning and artificial intelligence for a sustainable tourism: A case study on Saudi Arabia. Information 15, 516 (2024).
Alanzi, E. M., Kulendran, N., Nguyen, T. H. & and Religious tourism demand and country prosperity: an empirical study of Saudi Arabia. Int. J. Relig. Tour Pilgr. 11, 40–60 (2023).
Rosak-Szyrocka & Santos, G. Joanna and {\.Z}ywio{\l}ek, Justyna and Wolniak, Rados{\l}aw and Main reasons for religious tourism-from a quantitative analysis to a model. Int. J. Qual. Res. 17, (2023).
Khan, S. & Khan, H. U. Role of big data analytics and FIFA world cup 2022 on the qatar’s tourism industry: systematic review. J. Theor. Appl. Inf. Technol. 100, 22 (2022).
Fourie, J. & Santana-Gallego, M. The impact of mega-sport events on tourist arrivals. Tour Manag. 32, 1364–1370 (2011).
Park, S., Lee, J. & Song, W. Short-term forecasting of Japanese tourist inflow to South Korea using Google trends data. J. Travel Tour Mark. 34, 357–368 (2017).
Tovmasyan, G. Forecasting the number of incoming tourists using Arima model: case study from Armenia. Mark. Manag Innov. 5, 139–148 (2021).
Zhang, Y., Tan, W. H. & Zeng, Z. Tourism demand forecasting based on a hybrid Temporal neural network model for sustainable tourism. Sustainability 17, 2210 (2025).
Gupta, T., Bhatia, R. & Sharma, S. An ensemble-based enhanced short and medium term load forecasting using optimized missing value imputation. Sci. Rep. 15, 21857 (2025).
Al-Maamari, M. R., Ramteke, R., Al-Hejri, A. M. & Alshamrani, S. S. Integrating CNN and transformer architectures for superior Arabic printed and handwriting characters classification. Sci. Rep. 15, 29936 (2025).
Al-Tam, R. M., Hashim, F. A., Maqsood, S., Abualigah, L. & Alwhaibi, R. M. Enhancing parkinson’s disease diagnosis through stacking Ensemble-Based machine learning approach. IEEE Access. 12, 79549–79567 (2024).
Branco, P., Torgo, L. & Ribeiro, R. P. SMOGN: a pre-processing approach for imbalanced regression. In First International Workshop on Learning with Imbalanced Domains: Theory and Applications 36–50 (2017).
Alahyari, S. & Domaratzki, M. S. M. O. G. A. N. Synthetic minority oversampling with GAN refinement for imbalanced regression. https://arXiv.org/abs/2504.21152. (2025).
Avelino, J. G., Cavalcanti, G. D. C. & Cruz, R. M. O. Resampling strategies for imbalanced regression: a survey and empirical analysis. Artif. Intell. Rev. 57, 82 (2024).
Zhou, Q. & Sun, B. Adaptive K-means clustering based under-sampling methods to solve the class imbalance problem. Data Inf. Manag. 8, 100064 (2024).
Kovács, L. & Optimized K-Means clustering for enhanced regression performance. Interdiscip J. Res. Dev. 12, 1 (2025).
Dong, X., Yu, Z., Cao, W., Shi, Y. & Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 14, 241–258 (2020).
Al-Hejri, A. M. et al. A hybrid explainable federated-based vision transformer framework for breast cancer prediction via risk factors. Sci. Rep. 15, 18453 (2025).
Al-Tam, R. M. et al. A hybrid framework of transformer encoder and residential conventional for cardiovascular disease recognition using heart sounds. IEEE Access. 12, 123099–123113 (2024).
Pedregosa, F. et al. Scikit-learn: machine learning in python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Al-Tam, R. M., Al-Hejri, A. M., Alshamrani, S. S., Al-antari, M. A. & Narangale, S. M. Multimodal breast cancer hybrid explainable computer-aided diagnosis using medical mammograms and ultrasound images. Biocybern Biomed. Eng. 44, 731–758 (2024).
Tian, Y. & Tang, X. The use of artificial neural network algorithms to enhance tourism economic efficiency under information and communication technology. Sci. Rep. 15, 8988 (2025).
Qinghe, Z., Wen, X., Boyan, H., Jong, W. & Junlong, F. Optimised extreme gradient boosting model for short term electric load demand forecasting of regional grid system. Sci. Rep. 12, 19282 (2022).
Elneel, L., Zitouni, M. S., Mukhtar, H. & Al-Ahmad, H. Examining sea levels forecasting using autoregressive and prophet models. Sci. Rep. 14, 14337 (2024).
Vasenska, I. Comparative analysis of machine learning and deep learning models for tourism demand forecasting with economic indicators. FinTech 4, 46 (2025).
Heredia Cacha, I., Sáinz-Pardo D\’\iaz, J. & Castrillo, M. López Garc\’\ia, Á. Forecasting COVID-19 spreading through an ensemble of classical and machine learning models: spain’s case study. Sci. Rep. 13, 6750 (2023).
Alsalem, K. A hybrid time series forecasting approach integrating fuzzy clustering and machine learning for enhanced power consumption prediction. Sci. Rep. 15, 6447 (2025).
Luo, M., Chen, D., Hou, X., Luo, K. & Wang, T. Combined CNN-BiLSTM-Att tourism flow prediction based on VMD-MWPE decomposition reconstruction. Sci. Rep. 15, 18003 (2025).
Wang, S. & Ma, J. A novel GBDT-BiLSTM hybrid model on improving day-ahead photovoltaic prediction. Sci. Rep. 13, 15113 (2023).
Cui, X. Urban tourism management based on artificial neural networks analysis and data mining. Sci. Rep. 15, 19709 (2025).
Imani, M., Beikmohammadi, A. & Arabnia, H. R. Comprehensive analysis of random forest and XGBoost performance with SMOTE, ADASYN, and GNUS under varying imbalance levels. Technologies 13, 88 (2025).
Khan, A. A., Chaudhari, O. & Chandra, R. A review of ensemble learning and data augmentation models for class imbalanced problems: Combination, implementation and evaluation. Expert Syst. Appl. 244, 122778 (2024).
R, T. Thailand domestic tourism statistics. https://doi.org/10.34740/KAGGLE/DSV/5447799 (2023).
Al-antari, M. A. et al. A hybrid segmentation and classification CAD framework for automated myocardial infarction prediction from MRI images. Sci. Rep. 15, 14196 (2025).
Al-Hejri, A. M. et al. A hybrid vision transformer with ensemble CNN framework for cervical cancer diagnosis. BMC Med. Inf. Decis. Mak. 25, 411 (2025).
Houssein, E. H. et al. Using deep densenet with cyclical learning rate to classify leukocytes for leukemia identification. Front. Oncol. 13, (2023).
Ma, X., Yang, Z. & Zheng, J. Analysis of Spatial patterns and driving factors of provincial tourism demand in China. Sci. Rep. 12, 2260 (2022).
Acknowledgements
The project was supported by KAU Endowment (WAQF) at king Abdulaziz University, Jeddah, Saudi Arabia. The authors, therefore, acknowledge with thanks WAQF and the Deanship of Scientific Research (DSR) for technical and financial support.
Author information
Authors and Affiliations
Contributions
Amjad A. Alsulami: Conceptualization, data curation, formal analysis, investigation, methodology, resources, software, visualization, writing—original draft, and writing—review & editing. Amal Alharbi: Data curation, formal analysis, investigation, methodology, resources, software, visualization, and writing—review & editing. Usman Ali Khan: Data curation, formal analysis, investigation, methodology, resources, software, visualization, and writing—review & editing. Aymen M. Al-Hejri: Data curation, formal analysis, investigation, methodology, resources, software, visualization, and writing—review & editing. Sultan S. Alshamrani: Formal analysis, investigation, methodology, resources, software, visualization, and writing—review & editing. Jasem Almotiri: Formal analysis, investigation, methodology, resources, software, visualization, and writing—review & editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Alsulami, A.G., Alharbi, A., Khan, U.A. et al. Predicting tourism growth in Saudi Arabia with machine learning models for vision 2030 perspective. Sci Rep 16, 2556 (2026). https://doi.org/10.1038/s41598-025-32509-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32509-6
