
Abstract
To overcome the limitations of single models in addressing complex, nonlinear problems in predicting rock shear strength parameters and the hyperparameter random selection problem, this study constructed a novel prediction framework for rock shear strength parameters. First, the light gradient boosting machine (LightGBM), extreme gradient boosting (XGBoost), categorical boosting (CatBoost), and random forest (RF) algorithms are employed as the base-learners for the ensemble model, with XGBoost serving as the meta-learner to build a stacking ensemble model. On the basis of the sparrow search algorithm (SSA), tent chaotic mapping is used to initialize the sparrow population, the Cauchy‒Gaussian hybrid mutation mechanism is used to dynamically select the probability control mutation type, the dynamic adaptive weight is used to adjust the balance between global exploration and local development, and Levy flight is used to help the sparrow population individuals jump out of the local optimum to construct the chaos-improved sparrow search algorithm (CISSA) to optimize the hyperparameters of the stacking model. Second, based on the 199 datasets of different rock types, the model was trained via fivefold cross-validation and evaluated based on the coefficient of determination (R²), root mean square error (RMSE) and mean absolute error (MAE). Concurrently, the Shapley additive explanations (SHAP) method was employed to analyse the degree of contribution of each predictive index. The results demonstrate that the CISSA-Stacking model achieves R² values of 0.9936 and 0.9744 for c and φ, respectively, with corresponding RMSE of 0.4303 and 0.7635 and MAE of 0.2161 and 0.5867, indicating significantly superior overall performance compared with benchmark models. SHAP interpretability analysis revealed that the importance rankings for c are Vp, UCS, BTS, and ρ, whereas those for φ are ρ, UCS, Vp, and BTS. Finally, intelligent prediction software based on the CISSA-Stacking model was developed. The software is simple in operation, intuitive in results and excellent in performance, enables rapid and accurate prediction of c and φ through manual input of the Vp, ρ, UCS, and BTS indices or by importing tabular data containing these four indices. The engineering application further confirmed the accuracy and practical utility of both the model and the software, providing a new efficient method for engineers to quickly and accurately estimate rock shear strength parameters.
Similar content being viewed by others

Introduction
In recent years, many geotechnically complex and geohazard-prone rock mass engineering projects have emerged worldwide in mining, water conservancy and hydropower, urban and rural construction, transportation, and other fields1,2. As the most direct foundation of all engineering construction, the mechanical properties of rock masses constitute the fundamental basis for engineering design, construction, and stability evaluation. Most catastrophic rock mass engineering disasters are attributed to issues in the test or value determination of the mechanical parameters of engineering rock masses. Among various rock engineering disasters, shear failure stands out as one of the main failure modes of rock instability3,4,5,6. As key parameters characterizing rock shear strength, cohesion c and the internal friction angle φ have been widely adopted in the stability evaluation of rock mass engineering7. Under normal circumstances, accurate acquisition of c and φ requires a shear test or triaxial compression test. However, these tests involve substantial manpower and material resources for sampling and specimen preparation, along with prolonged testing durations, high costs, and significant data scatter8,9,10, which often prevent engineers from obtaining relevant parameters in time, consequently compromising both project timelines and construction safety. Therefore, developing rapid, accurate, and cost-effective approaches to acquire the critical shear strength parameters c and φ has become an urgent priority in rock engineering practice.
In recent years, prediction methods based on machine learning models have been widely used in the field of rock mass engineering11,12,13,14,15,16,17,18,19,20. Researchers worldwide have developed numerous methods to indirectly estimate the shear strength parameters of rocks based on correlations between these parameters and other physical and mechanical indices, as shown in Table 1. Armaghani et al.21 established a predictive model for shale shear strength parameters by taking the dry density (DD), Schmidt hammer rebound number (SHn), Brazilian tensile strength (BTS), P-wave velocity (Vp), and point load index (Is(50)) as prediction indicators and using particle swarm optimization (PSO) to optimize an artificial neural network (ANN). Shen et al.22 proposed a shear strength parameter prediction model based on a genetic algorithm (GA) that incorporates the UCS, UTS, and confining stress (σ3) as input variables. M Zhang et al.23 employed Gaussian process theory to construct mapping relationships between rock shear strength parameters, UCS and UTS under different kernel functions. Shahani et al.24 selected Vp, density (ρ), UCS, and BTS as predictors and developed four machine learning-based prediction models for shear strength parameters, namely, LASSO regression (LR), ridge regression (RR), DT, and SVM. However, the above prediction methods generally use single-model approaches that can capture only limited data features. When dealing with the complex, nonlinear, and multidimensional characteristics inherent in rock shear strength parameter data, they demonstrate poor global search ability, a tendency to fall into local optima, an unstable prediction effect, low accuracy, and weak generalization ability.
In recent years, ensemble learning algorithms such as stacking have shown excellent performance in handling complex problems; for example, Chen et al.29 established a stacking model based on downhole vibration data from drilling parameters and Young’s modulus from rock mechanics parameters, aiming for accurate prediction of rock mechanics parameters. This model consistently achieved high accuracy in predicting the rock Young’s modulus across different datasets, providing a novel approach for the estimation and prediction of this parameter. Yang et al.30 proposed an improved FR-Stacking model based on clustering theory. By extracting both the attributive and clustering characteristics of landslide influencing factors in Yingshan County and inputting them into learning models, the model derived predictive values for landslide occurrence probability, enabling effective assessment of landslide disaster risk. Gao et al.31 integrated parameters traditionally used in ground motion prediction equations into a stacking ensemble model for predicting ground motion parameters. Compared with single models, this ensemble model exhibited superior performance in seismic hazard analysis and structural seismic performance assessment.
Although stacking models demonstrate excellent performance in handling complex nonlinear problems, they still suffer from the issue of random hyperparameter selection32. Existing research employs metaheuristic optimization algorithms, such as the sparrow search algorithm (SSA)33, particle swarm optimization (PSO)34,35, and harris hawks optimization (HHO)36,37, to optimize the hyperparameters of the base learner models within ensemble learning algorithms. These approaches can effectively mitigate the problem of unstable prediction performance caused by random hyperparameter selection. However, when applied to the prediction of rock shear strength parameters, these algorithms still encounter a series of issues. These include insufficient diversity during population initialization, unstable search efficiency, and a tendency to become trapped in local optima. Therefore, it is imperative to enhance the optimization algorithms by integrating existing improvement strategies.
To avoid the problem of a single model processing the complex nonlinear data of rock shear strength parameter prediction and effectively solve the problem of the unstable prediction effect caused by the random selection of hyperparameters, which is based on data-driven and interpretability analysis methods, Vp, ρ, UCS, and BTS are selected as input indices, and c and φ are used as output indices to construct a sample database. The data distribution was analysed via box line plots and frequency distribution histograms. LightGBM, extreme gradient boosting (XGBoost), categorical boosting (CatBoost), and random forest (RF) are used as the base-learners for the ensemble model, and XGBoost is used as the meta-learner to construct the stacking ensemble model to optimize the hyperparameters of the model through the chaos-improved sparrow search algorithm (CISSA), thereby constructing the CISSA-Stacking model for rock shear strength parameter prediction and interpreting the contribution of the prediction indicators by applying the Shapley additive exPlanations (SHAP) method, providing engineers with a novel, efficient method for rapid and precise estimation of rock shear strength parameters.
Establishment and analysis of the sample database
Prediction index selection
Based on the principles of geomechanics, analysis was conducted via the Mohr‒Coulomb criterion, revealing that the relationships between the rock shear strength and the parameters c and φ are as follows:
where τ is the rock shear strength and σn is the effective normal stress. The relationship of the principal stresses (σ1, σ3) can be represented via the linear envelope line:
where σ1 and σ3 are the uniaxial compressive strength and confining pressure, respectively, and where σci i is the unconfined compressive strength. In this case, the relationship between σci and c is linear, whereas the relationship between σci and φ is nonlinear. In recent years, researchers have proposed various failure criteria28, which can be expressed as follows:
where σt is the Brazilian tensile strength and R, m, s and a are empirical constants. σ1 and σt are closely related to σci and are related to c and φ.
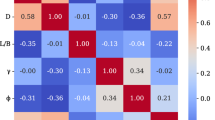
To explore the correlations between the UCS, BTS, and rock shear strength parameters c and φ, this study adopts 199 sets of UCS and BTS data from Kainthola et al.38 and conducts correlation analysis via Pearson correlation coefficients, as shown in Fig. 1.

Correlation analysis plots.
Both the UCS and BTS are linearly related to c, with determination coefficients R2 of 0.936 and 0.929, respectively, indicating strong correlations. However, they are not linearly related to φ, as evidenced by their low R2 values of 0.087 and 0.073, respectively. Therefore, using only the UCS and BTS is inadequate for accurate prediction of the φ value, which is consistent with the above theoretical analysis. To address this issue, numerous scholars have introduced other physical and mechanical parameters to improve the prediction accuracy. Shahani et al.24 demonstrated that while the UCS and BTS are retained, the accuracy of the prediction results can be effectively improved by introducing the parameters Vp and ρ, which characterize the rock compactness obtained via P-wave velocity tests and density measurement tests. Among them, Vp reflects the density and elastic properties of the rock, whereas ρ is influenced by the composition and internal fabric of the rock mass. Compared with other parameters, such as σ3, which characterizes the stress range of shear failure obtained via triaxial compression tests, Vp and ρ have the advantages of lower acquisition costs and shorter testing cycles. Therefore, this study selects four indices—Vp, ρ, UCS, and BTS—to construct an index system for rock shear strength parameter prediction.
Establishment of the sample database
In the study of regression prediction via machine learning methods, the sample database is crucial to model prediction performance. This study employs Vp, ρ, UCS, and BTS as input indices, with the rock shear strength parameters c and φ as output indices for prediction. Vp was measured via a portable ultrasonic non-destructive digital indicating tester (PUNDIT), and the UCS was determined via uniaxial compression tests. BTS was obtained via Brazilian splitting tests. c and φ were derived from triaxial compression tests conducted on samples of four distinct rock types under confining pressures of 20, 40, and 60 MPa, and the failure load and confining pressure were then plotted in a graph from which c and φ were calculated for individual rock types from the tangent drawn to the arc. The dataset utilized in this study was sourced from reference38, and sample data were obtained from four rock types collected in the Luhri area, Himachal Pradesh, India: limestone, quartzite, slate, and quartz-mica schist.
For the limestone, the thin section shows a dominance of stained carbonate minerals, viz. calcite and dolomite, darkly colored, fine- to medium-grained rock.
Quartz comprises approximately 85% of the minerals present in the rock mass. The rounded to subrounded quartz grains have sutured boundaries, and the straight bound aries of the medium-sized quartz grains exhibit recrystallization. The detrital quartz grains also have sutured contacts.
Slate is a fine-grained rock consisting predominantly of clay minerals. The identification of individual minerals and textures is difficult because of the fineness of the groundmass. The rock mass shows the development of alternating dark and light bands. The light bands are distinguished by quartz grains, whereas the dark bands represent fine clay minerals. The dark bands are probably carbonaceous and are thicker than the lighter bands. Continuous fractures have developed across and along the bands.
For the the quartz–mica schist, muscovite, biotite, quartz and feldspar constitute most of the minerals in the rock. The rock mass is banded in nature, showing a typical schistose structure, and the schistosity is defined by a strongly preferred orientation of muscovite and biotite. The muscovite grains are smaller in size than the biotite grains. The biotite grains are present as both patchy and plump slabs.
After discrete values and repeated values are eliminated, the database comprises 49 sets of limestone, 50 sets of quartzite, 50 sets of slate and 50 sets of quartz–mica schist, totaling 199 sample groups. Partial data along with their statistical characteristics are presented in Table 2.
Data visualization analysis
Box line plots and frequency distribution histograms were employed for data visualization analysis. Figure 2 displays the frequency distribution histogram of each index in the sample data. Specifically, parameters ρ and c exhibit relatively standard normal distributions, with no significant left or right skewness. The other four parameters display bimodal distribution curves. Discrete values were observed in BTS, c, and φ. This phenomenon arises because the database compiled for this study comprises four distinct rock types. The data distribution of the established database is reasonable.

Frequency distribution histograms of each index in the database.
This study employed the Matplotlib library in Python to generate box line plots of each prediction indicator, as shown in Fig. 3. Owing to the differences in their physical and mechanical properties, the four types of rock have distinct data distribution ranges. However, the distribution states are relatively uniform, with no significant outliers, demonstrating that the sample database established in this study is scientifically reliable and can be used to predict rock shear strength parameters.

Box line plots for all indicators in the database.
CISSA-stacking prediction model and application software
Principle of the chaos-improved sparrow search algorithm
The sparrow search algorithm is a novel swarm intelligence optimization algorithm inspired by the foraging and antipredation behaviours of sparrows39. The foraging process of sparrows can be abstracted as a discoverer-follower mode, incorporating a scout and early warning mechanism. The discoverers, characterized by high self-fitness and a wide search range, guide the population in exploration and foraging. Followers, aiming to achieve better fitness, forage by following the discoverers. To improve their own predation rate, some followers monitor discoverers to compete for food with them or forage around them. When the whole population is threatened by predators or aware of danger, antipredation behaviour is triggered immediately. Compared with other metaheuristic optimization algorithms, such as the whale optimization algorithm, particle swarm optimization and Harris hawks optimization, the SSA has the advantages of high search accuracy, fast convergence speed and strong robustness. However, when the search is close to the global optimum, issues such as a reduction in population diversity, susceptibility to falling into a local optimum, and unstable search efficiency persist40,41,42.
To address the limitations of the SSA, considering that the Cauchy and Gaussian distribution functions exhibit superior search ability43, the dynamic adaptive weight can improve the stability of the search44, Levy flight helps the algorithm jump out of the local optimal solution45, and the tent chaotic sequence demonstrates uniform ergodicity and fast convergence46. This study adopts four improvement strategies to enhance the SSA as follows. First, the tent chaotic mapping is used to initialize the population so that the initial individuals are as evenly distributed as possible; then, leveraging the strong global exploration ability of Cauchy mutation and the property of Gaussian mutation suitable for local refinement, a Cauchy‒Gaussian hybrid mutation mechanism is adopted to dynamically select the probability control mutation type; next, Levy flight is introduced to adjust the individual when population aggregation or dispersion occurs to help the individual jump out of the local optimum; finally, dynamic adaptive weights are used to adjust the balance between global exploration and local exploitation. Higher weights are applied to enhance global exploration in the early stage of iteration, whereas lower weights strengthen local refinement in the later stage, as shown in Fig. 4.

CISSA algorithm flowchart.
Performance test of the improved algorithm
To verify the performance of the proposed chaotic improved SSA, performance comparative experiments were conducted on the same test set as the original SSA and the widely used metaheuristic optimization algorithms, such as particle swarm optimization and whale optimization algorithms. To ensure fairness in the experiment, all algorithms were configured with identical parameters—a maximum of 500 iterations, a population size of 30, and 30 independent executions for each algorithm—to minimize the impact of stochastic variations on the results. Five functions with known optimal solutions of 0, including unimodal functions f1-f3 and multimodal functions f4-f5, were selected as the benchmark test functions, as shown in Table 3, and three-dimensional representations of the five chosen benchmark functions are shown in Fig. 5.

Three-dimensional benchmark function plots.
The mean value (Avg) and standard value (Std) are selected to evaluate the performance of each algorithm. The results of each benchmark test function are shown in Table 4, and the iteration curves of the test functions are shown in Fig. 6. Compared with other algorithms, the CISSA demonstrates superior performance and search optimization ability on both unimodal and multimodal functions. For the former f1-f3, the results of the improved CISSA are close to the optimal solution 0, showing orders-of-magnitude improvement in the optimization effect over those of the other algorithms. For the latter f4-f5, the CISSA exhibited outstanding performance in escaping the local optima, demonstrating advantages not only in terms of convergence speed but also in requiring fewer iterations to obtain the optimal result. This evidence indicates that the proposed CISSA possesses the characteristics of high search accuracy, fast convergence speed, and excellent stability and can avoid falling into local optima.

Comparison of iteration curves for benchmark functions.
Principle of the stacking ensemble model
As an ensemble learning algorithm, stacking has been widely applied across various industries in recent years. Its key characteristic lies in training multiple different base-learners and then feeding their output into the meta-learner for further training, thus effectively reducing the model’s overfitting risk while enhancing the overall accuracy and robustness47. The principle of the stacking ensemble algorithm is illustrated in Fig. 7. In this study, LightGBM, XGBoost, CatBoost, and RF are employed as base-learners, with XGBoost serving as the meta-learner to construct a stacking ensemble model. The selected models are all well-established and high-performance algorithms in the field of machine learning that are capable of extracting data features from multiple perspectives and fully leveraging their respective learning strengths.
Among them, LightGBM48, as a framework based on gradient boosting decision trees, improves computational efficiency when the database is processed through optimized algorithm design while maintaining excellent prediction performance.
XGBoost16, as an optimized distributed gradient boosting library, enhances the robustness of the ensemble model through its algorithmic stability and ability to handle missing values.
CatBoost49, as a gradient boosting algorithm library specifically designed for processing category features, prevents target leakage via orderly boosting while automatically processing high-cardinality category features, thereby increasing prediction diversity.
RF50 effectively reduces the variance and overfitting risk by constructing multiple decision trees through voting or averaging; as a nongradient boosting model, it complements the gradient boosting trees by covering different bias‒variance equilibrium points.

Principles of the stacking ensemble algorithm.
Model construction
The construction process of the CISSA-Stacking prediction model is shown in Fig. 8. First, Vp, ρ, UCS, and BTS are selected as input indices, and c and φ are used as output indices to construct a sample database. Fivefold cross-validation is used to divide the dataset, and the data distribution is analysed via box line plots and frequency distribution histograms. Second, the data in the database are input into the model, and the CISSA optimization algorithm is then employed to optimize the hyperparameters of each model. Based on the optimized hyperparameters for c and φ, the corresponding hyperparameters in the stacking ensemble model are adjusted to establish the CISSA-stacking prediction model. Third, fivefold cross-validation was used to train the model, and the performance of the model was tested by R2, the root mean square error (RMSE) and the mean absolute error (MAE). SHAP interpretability analysis is conducted to evaluate the contribution of each prediction indicator from three aspects: feature importance analysis, feature impact distribution analysis, and feature dependency analysis. Finally, based on the tkinter library in Python, intelligent prediction software for rock shear strength parameters is developed and used in engineering applications to test the practicability of the application software.

Architecture of the CISSA-stacking prediction model.
Model performance validation
To evaluate the performance of the CISSA-Stacking prediction model, individual base models and the stacking ensemble model without CISSA algorithm optimization were selected as comparative benchmarks. Under identical operating conditions, all the models received training via fivefold cross-validation and were subsequently utilized for predicting the rock shear strength parameters. The basic model hyperparameters of the stacking model optimized by the CISSA algorithm are shown in Table 5.
The performance evaluation results of each model are presented in Table 6. The proposed CISSA-Stacking model achieved superior performance, with R2 values of 0.9942 and 0.9724, RMSE values of 0.4203 and 0.7532, and MAE of 0.2261 and 0.5761 for c and φ, respectively, which significantly outperforms those of all basic models, confirming that the CISSA combined with the ensemble framework provides remarkable advantages for predicting rock shear strength parameters.
The comparison between the predicted and true values of c and φ for each model is shown in Figs. 9 and 10, where the black dotted lines represent the fitting line with a slope of 1, the area composed of the red lines demarcates a ± 10% margin around the fitting line, and each scatter spot corresponds to a data point. The closer the scatter point is to the fitting line, the closer the predicted value is to the true value. Compared with other models, the CISSA-Stacking model has high prediction accuracy, good stability, and strong generalization ability in predicting c and φ because the scatter points are densely distributed near the fitting line.

Comparison between the predicted and actual cohesion values.

Comparison between the predicted and actual values of the internal friction angle.
The error analysis figures for c and φ of each model are shown in Figs. 11 and 12. Compared with the other models, the CISSA-Stacking model maintains prediction errors within 1.5% for cohesion c and within 2% for the internal friction angle φ, demonstrating superior prediction accuracy.

Cohesion error analysis figures.

Internal friction angle error analysis figures.
Application software development
To facilitate the engineering application of the proposed CISSA-Stacking prediction model, intelligent software for estimating rock shear strength parameters based on the Tkinter library in Python was developed, as illustrated in Fig. 13. The software adopts a modular design. With the four-rock physical‒mechanical parameters of Vp, ρ, UCS, and BTS input, it can quickly estimate the values of c and φ. Batch prediction of c and φ can also be realized by clicking the “importing data” button to import tabular data containing the four parameters. The software features a user-friendly operation, intuitive result visualization, and excellent performance, making it suitable for diverse engineering applications.

Graphical user interface of the prediction software.
SHAP interpretability analysis
Feature importance analysis
The importance of each feature variable is quantified by computing the absolute value of the average Shapley value of each feature in the prediction model through SHAP. The higher the Shapley value is, the more important the feature variable is to the prediction results. The SHAP method is employed to evaluate the contributions of the four features in the CISSA-Stacking model, as visualized in Fig. 14. The figure shows that for cohesion c, the variable with the highest absolute value of the Shapley value and the most significant feature importance is Vp, followed by UCS, BTS, and ρ; for the internal friction angle φ, the variable with the highest absolute value of the Shapley value and the most significant feature importance is ρ, followed by UCS, Vp, and BTS, which proves that the parameters Vp and ρ, which represent the density of rock, can effectively improve the prediction accuracy of the model.

Feature importance ranking plots.
Feature influence distribution analysis
Figure 15 shows the scatter plot of the feature influence distribution based on the SHAP calculation. The abscissa represents the Shapley value of the data points, with points greater than 0 indicating positive contributions to the prediction results, whereas those less than 0 indicate negative contributions. The ordinate represents the feature value of the data point, with interpretations that the redder the color of the data point is, the larger the feature value of the point is, the bluer the color is, the smaller the feature value of the point is, and the purple indicates that the feature value of the point is the intermediate value. Each feature variable is arranged in order of importance from top to bottom. Therefore, the influence of each feature variable on the prediction results can be judged by the distribution and color difference of the data points in the figure. The figure shows that for cohesion c, Vp has the most significant impact on the prediction results, and when its feature value is large, it contributes positively to the prediction; for the internal friction angle φ, ρ has the most significant impact, and when its feature value is large or close to the intermediate value, it makes a positive contribution to the prediction; moreover, for the four feature variables, as their values increase, the Shapley values for c and φ also show an upwards trend, which demonstrates that each feature variable exhibits a significant positive correlation with the prediction results of the rock shear strength parameters.

Scatter plots of feature influence distributions.
Feature dependency analysis
To evaluate the interaction between feature variables in the prediction process, the SHAP method is used to quantify the interaction among them, thereby analysing their influence on the prediction results. Figure 16 displays the feature interaction plots for the most significant variables in the prediction of the rock shear strength parameters. In the figure, the horizontal axis represents the feature value, the left vertical axis denotes the Shapley value, and the scatter points represent individual data points. A feature variable that interacts most significantly with the primary variable is selected as the color axis—redder hues correspond to higher values of the interacting feature at that data point. As shown in the plot, the feature variable Vp contributes the most to the prediction of cohesion c, and with increasing feature values, the Shapley value and UCS feature values show an increasing trend, which proves that the influence of the UCS on Vp is relatively obvious, whereas the characteristic variable ρ contributes the most to the prediction of the internal friction angle φ, and with increasing feature values and Shapley values, the feature value of the UCS does not show a similar increasing trend, suggesting that the UCS has no significant influence on ρ.

Partial feature dependence plots.
Engineering application
During the Kunyang phosphate mine No. 2 concession in Yunnan Province, China, roadway headings frequently suffer roof fall and cave-in due to complex geological conditions (such as concealed karst caves, faults, folds, fracture zones, and concentrated karst fissure water), combined with strong blasting disturbances, which seriously affect construction safety and progress. To address this, the basic physical‒mechanical parameters of the surrounding rock under engineering disturbance are determined via a series of rock mechanics tests, including uniaxial compression tests, Brazilian splitting tests and variable‒angle shear tests. The results provide critical references for roadway support, stope filling and stability evaluation. Table 7 presents the physical‒mechanical parameters of the five types of disturbed rock from the mine51.
The c and φ values were predicted via the CISSA-Stacking software developed in this study, and the results are summarized in Table 8. The comparative plots between the actual values and the predicted values are shown in Fig. 17. As shown, the model achieves an absolute error (AE) below 0.6 for both the c and φ values across all five types of disturbed rock strata, which demonstrates that the results predicted by the software are close to the real values and can be effectively applied to practical engineering.

Comparisons between the actual values and the predicted values.
Conclusion
To overcome the limitations of single models in addressing complex, nonlinear problems in predicting rock shear strength parameters and the hyperparameter random selection problem, a novel prediction framework for rock shear strength parameters was constructed, providing a new approach for engineers to rapidly and accurately estimate these parameters. Specifically:
-
(1)
Integrated correlation analysis and reference review indicate that the parameters Vp and ρ, obtained via P-wave velocity tests and density measurement tests, significantly enhance the predictive accuracy when combined with the UCS and BTS. Furthermore, compared with other parameters, such as σ3 from triaxial compression tests, which characterize the stress range for shear failure initiation, Vp and ρ have the advantages of lower acquisition costs and shorter testing cycles.
-
(2)
To avoid the problems of population diversity reduction, susceptibility to local optima, and unstable search efficiency in existing rock shear strength parameter prediction models when searching near global optima, four improvement strategies—the tent chaotic mapping, Cauchy‒Gaussian hybrid mutation mechanism, Levy flight, and dynamic adaptive weight—are implemented to improve the sparrow search algorithm, and five benchmark test functions are used to test the performance of the sparrow search algorithm, particle swarm optimization algorithm and whale optimization algorithm before and after improvement. The results show that the chaos-improved sparrow search algorithm (CISSA) has superior search accuracy, faster convergence, better stability, and the ability to escape local optima.
-
(3)
Following the data-driven principle, LightGBM, XGBoost, CatBoost, and RF are used as base-learners, with XGBoost serving as the meta-learner, and the CISSA is applied to optimize the hyperparameters of each base-learner and meta-learner, thereby constructing the CISSA-Stacking prediction model. Predicting the cohesion c and internal friction angle φ via the model yields R2 values of 0.9942 and 0.9724, RMSE values of 0.4203 and 0.7532, and MAE of 0.2261 and 0.5761, respectively—all of which are superior to those of comparative models, confirming the excellent performance and strong generalizability ability of the model. Furthermore, to facilitate rapid and accurate estimation of rock shear strength parameters for engineering practitioners, a new intelligent prediction software for rock shear strength parameters is developed based on the model in this study. The software was successfully applied to predict the c and φ values for five types of disturbed rock strata in the Kunyang phosphate mine No. 2 concession, Yunnan, China, which verified its practical utility.
-
(4)
The SHAP interpretability analysis method was applied to evaluate the contributions of the prediction indices to the outputs of the CISSA-Stacking model. The analysis revealed the following importance rankings for c: Vp, UCS, BTS, and ρ and for φ: ρ, UCS, Vp, and BTS. These results demonstrate that the rock density parameters Vp and ρ can effectively enhance the prediction performance.
Further research
Considering that the database employed in this study encompasses only four rock types and contains a limited database of only 199 sample groups, predictions derived from a small sample size may constrain the model’s generalizability. Furthermore, the current research solely utilized data from the Kunming phosphate mine for engineering applications, which precludes assessment of the model’s robustness across diverse geological environments. Consequently, future research will focus on the following:
-
(1)
A larger-scale database incorporating various lithologies will be established to predict rock shear strength parameters.
-
(2)
Validation using data from sources beyond the Kunming phosphate mine will be undertaken to test the robustness of the proposed model in other geological settings, such as jointed rock masses.
-
(3)
Further refine the validation procedures and error reporting mechanisms of the developed application software to increase its credibility.
-
(4)
Additionally, the model’s practical utility will be further examined through laboratory physical tests, onsite monitoring data, and onsite software predictions.
Data availability
The authors declare that the rock shear strength parameter prediction data supporting the findings of this study are available within the paper (https://doi.org/10.1007/s10706-015-9899-z), or its supplementary information files.
References
Wang, Y., Chen, Q., Dai, B. & Wang, D. Guidance and review: advancing mining technology for enhanced production and supply of strategic minerals in China. Green. Smart Min. Eng. 1 (1), 2–11 (2024).
Zhang, R. & Li, J. Buckling failure analysis and numerical manifold method simulation for high and steep slope: A case study. Geohaz Mech. 2 (2), 143–152 (2024).
Liu, J. et al. Effect of normal boundary conditions on the shear mechanics and acoustic emission characteristics of anchored rock joints. J. Min. Sci. Techno. 10 (02), 173–183 (2025).
Zuo, J., Yang, S., Shen, J., Du, J. & Sun, C. Failure behavior of blocky multiple-jointed rock mass and GSI prediction model. Nonferr Met. (Min Sect). 77 (02), 175–185 (2025).
Zhai, Q. et al. Simulation on shear failure of anchored jointed rock mass under impact dynamic load. Min. Res. Dev. 44 (03), 121–127 (2024).
Zhu, L. et al. Investigation on the damage accumulation mechanisms of landslides in earthquake-prone area: role of loading–unloading cycles. Geohaz Mech. 3 (1), 59–72 (2025).
Zhang, H. Research on Stability Analysis Method of Rock Slope Based on data-driven (Kunming University of Science and Technology, 2023).
Gong, F., Luo, S., Lin, G. & Li, X. Evaluation of shear strength parameters of rocks by preset angle shear, direct shear and triaxial compression tests. Rock. Mech. Rock. Eng. 53 (5), 2505–2519 (2020).
Xu, W. & Chen, W. The triaxial compressive mechanical properties and failure characteristics of backfill-rock combined bodies with different interface angles. J. Min. Sci. Techno. 8 (05), 633–641 (2023).
Cai, M. Practical estimates of tensile strength and Hoek–Brown parameter mi of brittle rocks. Rock. Mech. Rock. Eng. 43 (2), 167–184 (2020).
Pradeep, T., Samui, P., Kardani, N. & Asteris, P. Ensemble unit and AI techniques for prediction of rock strain. Front. Struct. Civ. Eng. 16, 858–870 (2022).
Thangavel, P. & Samui p. Determination of the size of rock fragments using RVM, GPR, and MPMR. Soils Rocks 45(4), e2022008122 (2022).
Pradeep, D., Kumar, T., Kumar, M., Samui, P. & Armaghani, D. A novel approach to estimate rock deformation under uniaxial compression using a machine learning technique. Bull. Eng. Geol. Environ. 83, 278 (2024).
Pradeep, T., Bardhan, A. & Samui, P. Prediction of rock strain using soft computing framework. Innov. Infrastruct. Solut. 7, 37 (2022).
Pradeep, T. & Samui, P. Prediction of rock strain using hybrid approach of ann and optimization algorithms. Geotech. Geol. Eng. 40, 4617–4643 (2022).
Danial, F. et al. Prediction of Mixed-mode I and II effective fracture toughness of several types of concrete using the extreme gradient boosting method and metaheuristic optimization algorithms. Eng. Fract. Mech. 276(PB) (2022).
Arsalan, M. et al. Estimating the effective fracture toughness of a variety of materials using several machine learning models. Eng. Fract. Mech. 286, 109321 (2023).
Danial, F., Hamid, R., Arsalan, M., Hamid, S. & Ehsan, T. Estimating the tensile strength of geopolymer concrete using various machine learning algorithms. Comput. Concr. 33 (2), 175–193 (2024).
Kumar, S., Kumar, D., Kumar, M., Wipulanusat, W. & Kaewmoracharoen, M. A novel approach to analyzing the 3D slope of Mount St. Helens via soft computing techniques. Earth Sci. Inf. 18, 252 (2025).
Kumar, M., Kumar, D., Khatti, J., Samui, P. & Grover, K. Prediction of bearing capacity of pile foundation using deep learning approaches. Front. Struct. Civ. Eng. 18, 870–886 (2024).
Armaghani, D., Hajihassani, M., Bejarbaneh, B., Marto, A. & Mohamad, E. Indirect measure of shale shear strength parameters by means of rock index tests through an optimized artificial neural network. Measurement 55, 487–498 (2014).
Shen, J. & Jimenez, R. Predicting the shear strength parameters of sandstone using genetic programming. Bull. Eng. Geol. Environ. 1647–1662 (2018).
Zhang, H., Wu, S., Li, B. & Zhao, Y. Uncertainty estimation of rock shear strength parameters based on Gaussian process regression. Rock. Soil. Mech. 45 (S1), 415–423 (2024).
Shahani, N. et al. Predicting angle of internal friction and cohesion of rocks based on machine learning algorithms. Mathematics 10 (20), 3875 (2022).
Mahmoodzadeh, A. et al. Machine learning techniques to predict rock strength parameters. Rock. Mech. Rock. Eng. 55 (3), 1721–1741 (2022).
Fathipour-Azar, H. Data-oriented prediction of rocks’ Mohr–Coulomb parameters. Arch. Appl. Mech. 92, 2483–2494 (2022).
Li, D., Yang, B., Liu, Z., Liu, Y. & Zhao, J. Prediction method of rock cohesion and internal friction angle based on ensemble tree algorithm. Gold. Sci. Technol. 32 (05), 847–859 (2024).
Han, D. & Xue, X. Machine learning-based prediction of shear strength parameters of rock materials. Rock. Mech. Rock. Eng. 57, 8795–8819 (2024).
Chen, W. Research on rock Young’s modulus prediction based on stacking integrated learning. Wuhan Polytech. Univ. (2024).
Yang, W. Landslide Susceptibility Evaluation Based on Stacking Fusion Model (Chongqing Three Gorges University, 2024).
Gao, Z. Research on Ground Motion Parameter Prediction Method Based on Improved Stacking Model (Kunming University of Science and Technology, 2024).
Cui, Z., Xu, Y. & Su, H. Research on influencing factors of coal spontaneous combustion tendency based on stacking-SHAP. Coal Technol. 44 (01), 150–155 (2025).
Shui, K. Research on Slope Stability Prediction Method Based on TAS-SSA-Stacking (Kunming University of Science and Technology, 2024).
Pradeep, T., Bardhan, A., Burman, A. & Samui, P. Rock strain prediction using deep neural network and hybrid models of Anfis and meta-heuristic optimization algorithms. Infrastructures 6, 129 (2021).
Kumar, M., Kumar, D. & Wipulanusat, W. Reliability-based design for strip-footing subjected to inclined loading using hybrid LSSVM ML models. Geotech. Geol. Eng. 42, 7677–7697 (2024).
Kumar, D. et al. Machine learning approaches for prediction of the bearing capacity of ring foundations on rock masses. Earth Sci. Inf. 16, 4153–4168 (2023).
Nadgouda, P., Kumar, D., Sharma, A. & Wipulanusat, W. Optimizing compressive strength prediction of sustainable concrete using ternary-blended agro-waste ash, sugarcane bagasse ash, and rice husk ash with soft computing techniques. Struct Concr. 10 (2025).
Kainthola, A. et al. Prediction of strength parameters of Himalayan rocks: A statistical and ANFIS approach. Geotech. Geol. Eng. 33 (5), 1255–1278 (2015).
Xue, J. & Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 8 (1), 22–34 (2020).
Tang, C., Wang, C., Huan, Z. & Chen, L. Feasibility detection for time-sensitive network configurations based on MIC-SSA-SVM. J. Kunming Univ. Sci. Technol. (Nat Sci). 49 (01), 73–82 (2024).
Wang, W., Zhang, Q., Guo, S., Liang, B. & Liu, C. Prediction of rock burst intensity based on SSA-BP neural network. Nonferr. Met. (Min. Sect.). 76 (01), 77–83 (2024).
Lin, H. et al. Research on the height prediction method of fracture zone in mining overburden rock based on SSA-LSTM. Min. Saf. Environ. Prot. 51 (03), 8–15 (2024).
Guo, J., Qin, R. & He, T. Sine-cosine hybrid algorithm combining cauchy distribution and Gaussian disturbance. J. Chengdu Technol. Univ. 27 (06), 25–31 (2024).
Zhao, Q., Li, J., Yu, J. & Ji, H. Bat optimization algorithm based on dynamically adaptive weight and Cauchy mutation. Comput. Sci. 46 (S1), 89–92 (2019).
Li, A. et al. Estimation parameters of using water a quality ensemble learning model optimized with Levy flight and sparrow search algorithms. J. Tongji Univ. (Nat Sci). 53 (03), 450–461 (2025).
Xu, H., Xu, W. & Kong, Z. Mayfly algorithm based on tent chaotic sequence and its application. Control Eng. Chin. 29 (03), 435–440 (2022).
Zhang, H. Landslide Susceptibility Assessment Considering Time-Variance of Dynamic Factors (Shandong University of Technology, 2023).
Kumar, R. et al. Bearing capacity of eccentrically loaded footings on rock masses using soft computing techniques. Eng Sci 24 (2024).
Wu, X., Liu, J., Wang, J. & Qin, Y. Mult objective prediction and optimization of large-diameter slurry shield posture based on CatBoost-MOEAD. Chin. Saf. Sci. J. 34 (10), 50–57 (2024).
Taiwo, O. et al. Machine learning based prediction of flyrock distance in rock blasting: A safe and sustainable mining approach. Green. Smart Min. Eng. 1 (3), 346–361 (2024).
Zhao, J. et al. Experimental study on determination of physical and mechanical parameters of disturbed rock in 2 mine of Kunyang phosphate mine. Min. Technol. 25 (01), 42–47 (2025).
Funding
This research was supported by the National Natural Science Foundation of China (42367024), Yunnan Fundamental Research Projects (202301AT070462), Yunnan Province Professional Degree Graduate Teaching Case Library Construction Project (202327, 202416), and Interdisciplinary Research Program of Kunming University of Science and Technology (KUST-xk202025003).
Author information
Authors and Affiliations
Contributions
Zi-Jun Jin: Methodology, Visualization, Writing-original draft, Software. Chao Wang: Funding acquisition, Methodology, Software, Supervision. Shuai Qi: Data curation, Supervision, Software. Yv Liu: Data curation, Software. Hao Yu: Software. Zi-Wang He: Investigation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jin, ZJ., Wang, C., Qi, S. et al. Prediction method for rock shear strength parameters based on data-driven and interpretability analysis. Sci Rep 16, 3080 (2026). https://doi.org/10.1038/s41598-025-32687-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32687-3
