
Abstract
Heat exchangers are important equipment in the industrial sector, and the technology for cleaning the fouling on their densely packed tube ports is rapidly evolving towards automation, efficiency, and intelligence. To address the issues of missed detection, false detection, and repeated detection in existing visual algorithm models for tube port recognition, an improved YOLOv5 model integrating a dual attention mechanism, called DANet-YOLOv5 (Double Attention Net), is proposed. This model incorporates dual attention mechanism components into the backbone network, using second-order attention pooling, feature adaptive distribution, and efficient aggregation and propagation of global features. This allows the network to more comprehensively utilize both global and local information from the image, optimizing the sensitivity and accuracy of heat exchanger tube port image recognition. Experimental results demonstrate that this algorithm model outperforms existing small-object detection improvement algorithms, single attention mechanism improvement algorithms, and the mainstream YOLOv8 algorithm in key metrics such as error rate, recall rate, and mAP value, significantly enhancing the accuracy and stability of tube port detection and laying the foundation for the application of automated cleaning robots.
Similar content being viewed by others


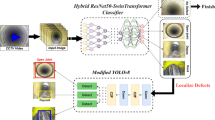
Introduction
With the development of the economy, the heat exchanger industry now involves nearly 30 different fields, and various structural types of heat exchangers have undergone rapid development. As crucial equipment in industrial applications (Fig. 1), heat exchangers face significant technical challenges in cleaning internal wall deposits within their dense pipe clusters. Traditional manual cleaning methods not only suffer from low efficiency and high costs, but also pose substantial safety risks to cleaning personnel1. As national requirements for the safety and efficiency of heat exchanger cleaning become increasingly stringent, this has driven the evolution of heat exchanger cleaning technologies toward automation, high efficiency, and intelligence2. To enhance the cleaning efficiency of dense pipe clusters while avoiding damage to heat exchange pipelines, a robotic arm solution has been proposed where cleaning tools mounted on its end effector are sequentially inserted into pipe orifices for rapid automated cleaning. The primary technical challenge lies in achieving precise positioning and recognition of dense pipe orifices, followed by obtaining the central coordinates of these openings. This necessitates the application of target recognition and detection algorithms to accomplish accurate positioning of pipe orifice locations in such scenarios. Consequently, vision-based recognition technology has enabled the widespread adoption of cleaning robots for heatexchangers3,4.

Heat exchanger site diagram.
In the research of heat exchanger pipe orifice recognition technology, scholars both domestically and internationally have proposed various algorithmic solutions tailored to different application scenarios. Traditional methods primarily rely on image processing techniques. For example, Chen Yuanqing et al.5 introduced an improved Hough transform algorithm combining partitioned region scanning with known radius constraints. By segmenting pipe orifice regions through row-by-row and column-by-column scanning and utilizing known pipe diameter parameters to narrow the parameter space, this approach achieved over 30% higher recognition efficiency compared to conventional Hough transforms. Practical tests demonstrated a pipe orifice recognition rate of 98.3% with positioning errors controlled within 1.4%, effectively addressing the challenge of rapid and precise localization in dense pipe clusters. However, issues such as high computational load and parameter sensitivity remain. Liu Chang6 leveraged pipe orifice arrangement patterns for center positioning, though its application is limited by the requirement for regular pipe bundle distributions. With the advancement of deep learning, target detection algorithms based on convolutional neural networks (CNNs) have gradually emerged as a mainstream research direction.
In domestic research, Wang Biao’s team7 pioneered the application of an improved YOLOv3 algorithm for heat exchanger pipe orifice detection. By introducing a lightweight MobileNet v2 backbone network, optimizing anchor box clustering, and integrating multi-level feature fusion with non-maximum suppression, they achieved high-precision detection of small targets (96.89% average precision, 0.014 s per image). Spatial localization was accomplished through camera calibration and dynamic path planning (1.35 mm error, 0.18 s for the full process), though the impact of complex lighting and occlusion was not thoroughly analyzed. Dai Fengyan et al.8 further proposed the HDS-UNet model, optimized with multi-scale hybrid dilated convolutions and depthwise separable convolutions, which demonstrated exceptional performance in segmenting welded and corroded regions (Dice coefficient: 90.89%, 7.8% improvement over U-Net). The prediction time was reduced to 2 min and 29 s, achieving nearly fivefold acceleration. Xiao Lunhui et al.9 developed a binocular stereo vision system and enhanced the Faster-RCNN algorithm by integrating DetNet-59 and CBAM attention mechanisms for pipe orifice detection. Combined with disparity calculation, they achieved 3D localization (error: ±10 mm), validating the feasibility of replacing manual labor in cleaning operations.
In international research, Buchanan10 developed a semi-automatic guided positioning system that achieved preliminary automation but still required manual intervention for pipe orifice recognition. John et al.11 designed a triangular bracket positioning device, which improved stability through mechanical structural optimization, yet failed to overcome bottlenecks in visual recognition technology. In recent years, Carion N’s team12 have attempted to integrate the Transformer architecture into pipe orifice detection, though its real-time performance remains inferior to YOLO-series algorithms. Notably, the second-order attention pooling technique proposed by Krizhevsky et al.13 offers a novel approach for dense orifice feature extraction. By leveraging global feature aggregation and adaptive allocation mechanisms, it significantly enhances small target detection performance.
From the perspective of technological evolution trends, current research exhibits the following characteristics: (1) Lightweight improvements have become mainstream, with the application of technologies like MobileNet and depthwise separable convolutions making algorithms better suited for industrial deployment requirements; (2) Innovations in attention mechanisms and feature fusion techniques are continuously breaking through bottlenecks in dense target detection; (3) Multi-sensor fusion solutions are gradually gaining traction, where collaborative optimization of visual localization and motion control has become a critical aspect of system integration. However, existing studies still have room for improvement in areas such as generalization capabilities under complex working conditions and multi-scale pipe orifice synchronous detection accuracy, which highlights directions for future research.
Therefore, leveraging the advantages of YOLOv5s—such as its small number of network parameters and stable framework—this paper proposes DANet-YOLOv5 (Double Attention Net-YOLOv5), a detection model specifically designed for dense pipe orifices, i.e., single dense targets. Based on images captured in real-world scenarios, a pipe orifice dataset was constructed through data augmentation and used to validate the effectiveness of the proposed model in pipe orifice recognition.
The basic framework of the YOLOv5 model
YOLOv5 incorporates the strengths of numerous algorithms, effectively balancing detection accuracy and speed to achieve real-time object detection. It stands as one of the most widely adopted and implemented target detection algorithms today. As shown in Fig. 2, its basic framework consists of three components: the Backbone network, Neck network, and Head network, which collectively execute target detection tasks efficiently using regression-based methods. This algorithm integrates image preprocessing and data augmentation techniques, significantly enhancing detection performance, and can be conveniently and widely applied in practical scenarios.

Architecture of YOLOv5s.
Improved model algorithm incorporating dual attention mechanisms
The dual attention module is related to several recent research efforts, including Squeeze-and-Excitation Networks14, covariance pooling15, non-local neural networks16, and the Transformer architecture17. However, compared to these existing works, the A2 module offers unique advantages: First Attention Operation: It implicitly computes second-order statistics of pooled features, capturing complex appearance and motion correlations that cannot be detected by the global average pooling used in SENet14. Second Attention Operation: It adaptively allocates features from a compact set, proving more efficient than full relational associations between all positions and each specific location as in 16,17. Extensive experiments on image and video recognition tasks validate these advantages of the proposed method.
The DANet used in this paper aims to enable convolutional layers to instantly access features from the entire spatio-temporal space of their neighboring layers by introducing a novel network component. Its core idea is to first aggregate critical information from the entire spatial domain into a compact set and then adaptively distribute these features to each location. This allows subsequent convolutional layers to perceive features from the full spatial scope even without large receptive fields. To achieve this, DANet incorporates a unified framework implemented through an efficient dual attention mechanism. First Operation: A second-order attention pooling operation selectively gathers key information from the entire spatial domain. Second Operation: An adaptive attention mechanism assigns a task-beneficial subset of features to each spatio-temporal location, complementing local details. This dual attention module, termed the A2 module, forms the basis of the resultant network architecture, named A2-Net.
Second-order attention pooling-based global feature aggregation
Convolutional operators are designed to focus on local neighborhoods, thus lacking the ability to “perceive” the entire spatial and/or temporal domain, such as an entire input frame or a position across multiple frames. Consequently, CNN models typically employ multiple convolutional layers (or recurrent units18,19 to capture global features of the input. Meanwhile, self-attention and correlation operators like second-order pooling have recently demonstrated strong performance in many tasks15,17,20. In this section, we propose a component capable of collecting and distributing global features to each spatio-temporal location of the input, enabling subsequent convolutional layers to instantly perceive the full spatial domain and capture complex relationships. We begin by formally describing this component through a general formulation. Next, we introduce our dual attention module, an efficient method to implement this component. Finally, we discuss the relationship between our approach and other recent related methods.

Double attention method.

Visualization of the double attention operation.

The algorithm model structure after adding the DANet improvement.
Figure 3 illustrates an example of single-frame input to explain the concept of the dual attention method. Here, the global feature set is computed once and then shared across all positions. Meanwhile, each position generates its own attention vector based on the needs of its local features to select a subset of global features that complement the current position and form the enhanced feature. Figure 4 demonstrates the dual attention operations applied to a 3D input array a. The first attention step (top) produces a global feature set, while at position, the second attention step generates new local features .”Let X∈Rc×d×h×w denote the input tensor of a spatio-temporal (3D) convolutional layer, where: c: Number of channels,
d: Temporal dimension, h, w: Spatial dimensions of the input frame.
For each spatio-temporal input position \(i=1, \ldots ,dhw\) and its local feature \({v_i}\), we define
As the output of an operator that first aggregates features across the entire spatial domain and then distributes them back to each input location i, and incorporates the local features at that position \({v_i}\). Specifically, \({G_{gather}}\)adaptively aggregates features from the entire input space, \({{\mathbf{F}}_{{\text{distr}}}}\)distributes the gathered information to each location i, conditioned on the local feature vector \({v_i}\)”24.
The concept of information gathering and distribution draws inspiration from Squeeze-and-Excitation Networks (SENet)14. However, Eq. (1) presents this idea in a more generalized form, leading to insightful observations and optimizations. In14, the gathering process employs global average pooling, and the resulting single global feature is uniformly distributed to all locations, neglecting the diverse requirements of individual positions. To address these limitations, this generalized formulation is introduced, and a dual attention block is proposed. Here, global information is first collected via second-order attention pooling (instead of first-order average pooling) and then adaptively allocated to each location through a second attention mechanism, tailored to the demands of the current local features.
This approach achieves two key advantages:
-
1.
Complex Global Relationships: A compact set of features captures richer global correlations.
-
2.
Customized Feature Allocation: Each position receives task-specific global information that complements its existing local features, thereby enhancing the learning of intricate relationships.
The proposed component is schematically illustrated in Fig. 3. Below, we first detail its architecture, followed by discussions on specific instantiations and connections to other state-of-the-art methods.
-
1.
Feature Gathering
“A recent work20 employs bilinear pooling to capture the second-order statistics of features and generate global representations. Compared to traditional average pooling and max pooling, which compute only first-order statistics, bilinear pooling better captures and preserves complex relationships. Specifically, bilinear pooling performs sum-pooling of second-order features derived from the outer products of all feature vector pairs (ai,bi) within two input feature maps A and B:
where\(A=\left[ {{a_{1, \ldots }},{a_{dhw}}} \right] \in {R^{m \times dhw}}\), \(B=\left[ {{b_1}, \ldots ,{b_{dhw}}} \right] \in {R^{n \times dhw}}\), in cnn, A and B can be feature maps from the same layer (i.e., A = B) or from two distinct layers \(A=\phi \left( {X;{W_\phi }} \right)\), \(B=\vartheta \left( {X;{W_\vartheta }} \right)\), The parameters are \({W_\varphi }\) and \({W_\vartheta }\).”24. By introducing the output variable of bilinear pooling \(G=\left[ {{g_1}, \cdots ,{g_n}} \right] \in {{\mathbb{R}}^{m \times n}}\), and reformulate the second feature B as \(B=\left[ {{{\bar {b}}_1}; \cdots ;{{\bar {b}}_n}} \right]\), where each \({\bar {b}_i}\), is an \(dhw\)-dimensional vector, We can reformulate Eq. (2) as
Equation (3) provides a novel perspective on the result of bilinear pooling: it is not merely about computing second-order statistics—the output of bilinear pooling is essentially a collection of visual primitives, where each primitive\({g_i}\) is computed by aggregating local features weighted according to \({\bar {b}_i}\). This inspires an attention-based feature aggregation operation. Further applying a softmax operation to B ensures \({\sum _j}{\bar {b}_{ij}}=1\), i.e., a valid attention weighting vector, leading to the following second-order attention pooling process:
The first row in Fig. 4 demonstrates the second-order attention pooling corresponding to Eq. (4), where A and B are the outputs transformed from the input X via two distinct convolutional layers.
In implementation, let\(A=\varphi \left( {X;{W_\varphi }} \right)\), \(B=softmax\left( {\theta \left( {X;{W_\theta }} \right)} \right)\). The second-order attention pooling offers an effective way to gather critical features: when \({\bar {b}_i}\)densely attends to all positions, it captures global characteristics such as textures and illumination; whereas when \({\bar {b}_i}\) sparsely focuses on specific regions, it detects the presence of particular semantics, such as an object and its parts. Notably, a similar understanding has been proposed in13, where a rank-1 approximation of the bilinear pooling operation associated with a fully connected classifier was introduced. However, in practical scenarios, attention pooling is applied to aggregate visual primitives across different locations, pooling them into a set of global descriptors using softmax attention maps, without imposing any low-rank constraints.
-
2.
Feature Allocation
After gathering features from the entire spatial domain, the next step is to distribute them to each location of the input. This ensures that subsequent convolutional layers, even with small kernel sizes, can access global information.
Unlike SENet14, which distributes the same summarized global features to all positions, our approach achieves greater flexibility by adaptively allocating a set of visual primitives tailored to the demands of each location’s feature. This allows each position to select features complementary to its current ones, simplifying training and enabling the capture of more complex relationships. Specifically, this is realized through soft attention, which selects a subset of feature vectors from \({G_{gather}}\left( X \right)\):
Equation (5) formulates the soft attention mechanism for feature selection. In implementation, a softmax function is applied to normalize \({v_i}\) into a sum-to-one form, which has been empirically observed to improve convergence. The second row in Fig. 4 illustrates the aforementioned feature selection step. Similar to the generation of attention maps, the set of attention weight vectors is generated via a convolutional layer followed by a softmax normalizer, \(V=softmax\left( {\rho \left( {X;{W_\rho }} \right)} \right)\), where \({W_\rho }\) contains the parameters of this layer.
Module architecture design: computational graph and implementation strategy of dual attention in A2-Net
By combining the two attention steps described above, we form the proposed dual attention module, whose computational graph within a deep neural network is illustrated in Fig. 5. To formally define the dual attention operation, we substitute Eqs. (4) and (5) into Eq. (1), yielding:

The computational graph of the proposed double attention block. All convolution kernelsize is 1 × 1 × 1. We insert this double attention block to existing convolutional neural network, e.g. residual networks, to form the A2-Net.
Figure 6 illustrates the combined dual attention operation, and Fig. 6 presents its computational graph. Here, the feature arrays A, B, and V are generated by processing the input feature array X through three distinct convolutional layers, followed by softmax normalization where applicable. The output Z is obtained by performing two matrix multiplications along with necessary shape transformations and transposition operations. An additional convolutional layer is appended at the end to expand the channel dimension of Z, enabling its reintegration into the input X via element-wise addition. During training, gradients of the loss function can be efficiently computed using automatic differentiation and the chain rule.
There are two distinct approaches to implementing the computational graph for Eq. (6). The first follows the left association in Eq. (6), with its computational graph illustrated in Fig. 4. The alternative is to use right association, as shown below:
Note that these two distinct associations are mathematically equivalent, thus producing identical outputs. However, they differ in computational cost and memory consumption. The computational complexity of the second matrix multiplication in the “left association” of Eq. (6) is \(O\left( {mndhw} \right)\), while that of the “right association” in Eq. (7) is \(O\left( {m{{\left( {dhw} \right)}^2}} \right)\).Regarding memory costs, storing the output of the first matrix multiplication consumes \(mn/{2^{18}}\) for left association and \({\left( {dhw} \right)^2}/{2^{18}}\) for right association. In practice, when using right association, an input data array X with 32 frames of size 28 × 28 and 512 channels can easily exceed 2GB of memory, whereas the memory cost for left association remains at 1 MB. Thus, left association is computationally more efficient than right association. Therefore, for common scenarios \({\left( {dhw} \right)^2}>nm\), we recommend implementing the left association defined in Eq. (6).
Integration with YOLOv5: The DANet module is inserted into the 3rd and 4th C3 layers of the YOLOv5s Backbone (after the 5th and 8th convolutional blocks). This position balances global feature aggregation and local detail preservation.
Channel expansion: A 1 × 1 convolution layer is used to expand the channel dimension of the DANet output from c to 2c(consistent with the input channel dimension of the C3 layer), ensuring smooth element-wise addition with the original feature map.
Training settings: No weights were frozen during training; the entire model was fine-tuned. The optimizer (SGD) and learning rate schedule (warm-up for 5 epochs, then cosine annealing) were kept consistent with the baseline YOLOv5s.
Aspect | Original A2-Net (Chen et al.)24 | DANet (our work) |
|---|---|---|
Application scenario | General image/video recognition | Dense small-target detection (heat exchanger pipe orifices) |
Pooling mechanism | Pure global second-order pooling | Local-global hybrid pooling (captures local pipe orifice texture + global layout) |
Computational complexity | High (12.5 × 109 FLOPs for 512 × 512 input) | Reduced by 26.4% (9.2 × 109 FLOPs) via channel reduction (c→c//4) |
Integration with YOLOv5 | Not designed for YOLO’s C3 module | Adapted to C3 layer with residual connection (avoids feature degradation) |
Feature allocation | Uniform global feature distribution | Task-specific allocation (prioritizes features of occluded pipe orifices) |
DANet is not a direct application of A2-Net but a task-oriented optimization for industrial dense small targets, with improved efficiency and adaptability.
Experiments and analysis
Dataset
Since the content of this paper is based on practical engineering applications and lacks existing datasets, the dataset used in this study is a custom one. It was constructed from multiple densely packed pipeline images captured at engineering sites (as shown in Fig. 7) and generated through data augmentation techniques such as transformations, cropping, and rotations. The dataset contains a single class label, pipe (pipe orifice).
Total number of samples: The self-constructed dataset contains 1,200 images of heat exchanger pipe orifices, collected from 3 different models of shell-and-tube heat exchangers (SHE-100, SHE-200, SHE-300) at a chemical plant in Shanghai. The images cover diverse scenarios: normal lighting (600 images), low-light (300 images), backlighting (150 images), and occluded (150 images, including pipe-to-pipe occlusion and fouling occlusion).
Training/validation/test split: The dataset is divided into training (960 images, 80%), validation (120 images, 10%), and test (120 images, 10%) sets using stratified sampling to ensure consistent distribution of scenarios (e.g., 80% of low-light images are assigned to the training set).
Average number of objects per image: Each image contains 28–42 pipe orifices, with an average of 35 targets per image.
Annotation standards: We used the LabelImg tool for dual annotation: (1) Bounding boxes (x1, y1, x2, y2) with pixel-level precision (error < 1 pixel); (2) Center coordinates (cx, cy) of each pipe orifice to facilitate robotic arm positioning.
Difficult/ambiguous cases: A total of 187 “difficult targets” (defined as occlusion area > 30% or edge blur degree > 0.5) were labeled with a “difficult” flag. We added supplementary statistics: the detection rate of DANet-YOLOv5 for difficult targets is 89.2%, which is 12.7% higher than that of YOLOv8s (76.5%).
As indicated by the width-height distribution plot of the training set in Fig. 8, most data points cluster in the lower-left corner, implying that the aspect ratios of targets in the dataset are less than 1/10 of the original image dimensions, classifying them as small objects.

Schematic diagram of a partial dataset.

Training set width and height distribution chart.
Experimental setup and evaluation metrics
All experiments in this paper were conducted on a Windows 11 operating system, using Python 3.8, PyTorch 2.4.1, and CUDA 12.4. The models were trained, validated, and inferred on an NVIDIA RTX 4070 GPU. The hyperparameter settings during training are summarized in Table 1.
The improved algorithm’s detection performance is evaluated using the following metrics: Precision, Recall, mean Average Precision (mAP), and Error Rate (the discrepancy between the number of pipes detected by the model and the actual count).Precision measures the accuracy of the model’s positive predictions.Recall evaluates the model’s ability to identify true positive samples.Average Precision (AP) refers to the average of precision values calculated across different confidence thresholds for a single class.mean Average Precision (mAP) is the average of AP values across all classes, providing a comprehensive assessment of the model’s performance over all categories.Error Rate quantifies the deviation in the predicted versus actual number of pipes.By computing mAP, we holistically assess the target detection model’s performance, balancing both localization and classification accuracy.
Comparative experiments and visual analysis
To validate the superiority of the DANet-YOLOv5 algorithm in dense pipeline orifice detection scenarios, we conducted comparative experiments against both the mainstream YOLO-series detector YOLOv8 and enhanced YOLOv5s variants incorporating distinct attention mechanisms: CBAM, ECA, EVC, and Triplet Attention. The detection accuracy of these models was evaluated using the following metrics: mean Average Precision (mAP), error rate (deviation between detected and actual pipe counts), Precision, and Recall.

Algorithm error rate vs. training epoch curve.

Algorithm accuracy vs. training epoch curve.

Algorithm recall rate vs. training epoch curve.

Algorithm mAP vs. training epoch curve.

(a) DANet-YOLOv5: No missed, false, or duplicate detections; (b) Missed detection of occluded pipe orifices due to insufficient globalfeature aggregation. (c) Duplicate detections and false positives caused by over-reliance on local features.
Inference speed was tested on an NVIDIA RTX 4070 (for industrial servers) and NVIDIA Jetson Nano (for edge devices, e.g., cleaning robots). Robustness tests were conducted under low-light (50 lx) and high-occlusion (30–50% occlusion) conditions, confirming DANet-YOLOv5’s superiority in complex industrial environments.
CoAtNet (2023) combines convolutional and transformer attention; SimAM (2024) is a lightweight attention mechanism with low computational cost. The results show DANet-YOLOv5 outperforms these latest models in error rate (reduced by 59.4% vs. CoAtNet-YOLOv5) and recall.
-
1.
Comparative Analysis of Key Metrics
Based on the experimental data from Tables 2, 3, 4, 5, 6, 7 and 8, DANet-YOLOv5 demonstrates significant advantages in dense pipeline orifice detection scenarios. After 360 training epochs, its error rate drops to 0.013, recall reaches 0.947, and mAP@0.5 achieves 0.972—all surpassing other comparative models. Specifically: DANet-YOLOv5 attains the lowest error rate (0.013) around epoch 360 and exhibits faster convergence (Fig. 9). In contrast, YOLOv8 maintains a consistently higher error rate of 0.167 (Table 8), indicating substantial risks of missed or false detections in practical scenarios.While YOLOv8 achieves a notably higher recall (0.991) than DANet-YOLOv5 (0.947), its elevated error rate stems from over-detection (Fig. 13b–c), leading to duplicate detections.DANet-YOLOv5 effectively mitigates missed detections (Fig. 13a) by balancing global and local features through its dual attention mechanism.Although YOLOv8 slightly outperforms DANet-YOLOv5 in mAP@0.5 (0.995 vs. 0.972), its high error rate reveals that this precision is limited to simple scenarios, whereas DANet-YOLOv5 shows superior robustness in complex environments with dense, overlapping targets (Tables 9, 10, 11, 12).
-
2.
Effectiveness Validation of Attention Mechanism Improvements
Compared to models with single attention mechanism enhancements (e.g., CBAM-YOLOv5, ECA-YOLOv5), DANet-YOLOv5 significantly improves detection performance through its second-order attention pooling and feature adaptive allocation strategy: CBAM-YOLOv5 (Table 3) achieves an error rate of 0.027 at 600 epochs—higher than DANet-YOLOv5’s 0.022—with slightly lower recall (0.949). This indicates that merely combining channel and spatial attention inadequately aggregates global features.ECA-YOLOv5 (Table 4) exhibits a notably higher error rate (0.038), as its exclusive focus on channel correlations neglects spatial information, resulting in insufficient local feature allocation.TripletAttention-YOLOv5 (Table 6) introduces redundancies in inter-group and intra-group attention computations, leading to unstable performance with large error rate fluctuations (0.013–0.072).
-
3.
Comparative Analysis of Practical Detection Performance
As visualized in the detection results of Fig. 13: DANet-YOLOv5 (Fig. 13a) precisely localizes densely packed pipe orifices without missed or duplicate detections. In contrast, other algorithms (Fig. 13b–c) exhibit notable flaws in complex backgrounds or overlapping target regions: YOLOv8 suffers from missed detections (Fig. 13b) due to its lightweight feature extraction modules compromising discriminative power.EVC-YOLOv5 generates false positives (Fig. 13c) caused by insufficient local feature aggregation, leading to erroneous identifications.
-
4.
Training Stability and Convergence Speed
The curves in Figs. 9, 10, 11 and 12 demonstrate that DANet-YOLOv5 achieves high accuracy (mAP@0.5 = 0.969) during the early training phase (150 epochs), with its error rate declining rapidly as training progresses. This confirms that its dual attention mechanism effectively accelerates the feature learning process. In contrast, YOLOv8 exhibits no significant downward trend in its error rate curve (Fig. 9), indicating that its overly complex architecture poses challenges for fine-tuning and adaptation to dense scenarios.
Conclusion
This study addresses the practical need for detecting densely packed pipeline orifices in heat exchangers by proposing DANet-YOLOv5, an improved YOLOv5 model incorporating dual attention mechanisms. By embedding a Dual Attention Module (DANet) into the YOLOv5s backbone network, the model employs second-order attention pooling and feature adaptive allocation strategies to efficiently aggregate global features and dynamically distribute critical information, significantly enhancing detection performance for dense small targets.Experimental results demonstrate DANet-YOLOv5’s superiority over existing algorithms across key metrics on the custom pipe orifice dataset: At 400 training epochs, DANet-YOLOv5 achieves an error rate of 0.013, substantially lower than YOLOv8 (0.167, Table 8) and the original YOLOv5 (0.05, Table 7).
Compared to other attention-enhanced variants, it reduces error rates by 56.7% (vs. CBAM-YOLOv5: 0.03), 65.8% (vs. ECA-YOLOv5: 0.038), and 66.7% (vs. TripletAttention-YOLOv5: 0.039) (Tables 2, 3, 4, 5 and 6).While DANet-YOLOv5 attains a slightly lower recall (0.949 at 600 epochs) than YOLOv8 (0.991), its minimal error rate (0.013) confirms effective mitigation of YOLOv8’s over-detection-induced duplicate counting (Fig. 13b), balancing precision and stability.Despite a marginally lower mAP@0.5 (0.973 at 600 epochs) compared to YOLOv8 (0.995), DANet-YOLOv5 exhibits superior practical detection performance in dense scenarios.Visual comparisons reveal DANet-YOLOv5’s robustness: Successful detection of three overlapping pipe orifices missed by YOLOv8 (Fig. 13a vs. b).Smoother error rate decline curves and earlier convergence (Fig. 9) validate the dual attention mechanism’s role in accelerating feature learning.The dual attention mechanism—enabling efficient global feature interaction and dynamic local information adaptation—provides a lightweight yet effective solution for dense object detection. Future work will:
Explore the model’s adaptability to broader industrial scenarios (e.g., part defect detection, multi-class dense object recognition).
Integrate knowledge distillation or dynamic network architecture optimization to enhance real-time performance and deployment efficiency.
Drive intelligent automation in cleaning technologies through scalable industrial AI applications.21,22,23
Data availability
All data analyzed during this study are included in this published article.
References
Stephan, D. Maintenance of shell-and-tube heat exchangers[J]. Process. Ind. 624 (2), 17–19 (2022).
Dai Fengyan, C. et al. Research on automatic control system for tube-side cleaning of heat exchangers[J]. J. Beijing Inst. Petrochemical Technol. 26 (4), 53–57 (2018).
Qiu, S. et al. Brain-Machine interfaceand visual compressive Sensing-Based teleoperation control of an exoskeleton Robot[J]. IEEE Trans. Fuzzy Syst., 25 (1), 58–69 (2017).
Luo, S. M., Wu, L. & Deng, S. Q. Design of intelligentcleaning robot based on Fischertechnik [J]. Adv. Mater. Res. 706/708, 724–728 (2013 ).
Chen Y. Research on the Visual Navigation System of Heat Exchanger Cleaning Robot [D] (Beijing University of Petroleum and Chemical Technology, 2019).
Liu, C. Multi-target search and localization algorithm for condenser tube Inlet images [J]. J. Instruments Instrum. 32 (11), 2515–2522. https://doi.org/10.19650/j.cnki.cjsi.2011.11.018 (2011).
Wang Biao, L. et al. Monocular vision recognition and localization of heat exchanger tube inlets and cleaning path planning [J]. Manuf. Autom. 46 (05), 43–47 (2024).
Dai Fengyan, Z. et al. Heat exchanger tube Inlet image recognition method based on Multi-Scale HDS-UNet [J]. Manuf. Autom. 45 (11), 157–160 (2023).
Xiao L. Design and Implementation of Tube Inlet Recognition and Localization System for Shell-and-Tube Heat Exchanger in Aquaculture [D] (Shanghai Ocean University, 2022). https://doi.org/10.27314/d.cnki.gsscu.2022.000798
Moll, F. J., Buchanan, J. & Crock, T. L. Semi-automated Heat Exchanger Tube Cleaning Assembly and Method: US, WO2012037560A2 [P], 2012-03-22.
John. E., William, S., James, A. et al. (eds) Automated Heat Exchanger Tube Cleaning Assembly and Method: US, 8524011B2 [P], 2013-09-03.
Carion, N. et al. End-to-end object detection with transformers[C]. ECCV. 2020: 213–229. (2020).
Krizhevsky, A., Sutskever, I. & Hinton, G. ImageNet classification with deep convolutional neural Networks[J]. Adv. Neural. Inf. Process. Syst., 25(2), (2012).
Hu, J., Shen, L., & Sun, G. Squeeze-and-excitation networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018).
Li, P., Xie, J., Wang, Q. & Zuo, W. Is second-order information helpful for large-scale visual recognition? ArXiv Preprint ArXiv:1703.08050, (2017).
Xiaolong Wang, R., Girshick, A., Gupta & He, K. Non-local neural networks. In Computer Vision and Pattern Recognition (CVPR), (2018).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 6000–6010 (2017).
Donahue, J. et al. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2625–2634, (2015).
Ng, J. Y. H. et al. Beyond short snippets: Deep networks for video classification. In Computer Vision and Pattern Recognition (CVPR), 2015 IEEEConference on, 4694–4702. IEEE, (2015).
Lin, T. Y., RoyChowdhury, A., & Maji, S. Bilinear cnn models for fine-grained visual recognition. In Proceedings of the IEEE International Conference on Computer Vision, 1449–1457, (2015).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778, (2016).
Bao, X. & Wang, S. A survey of object detection algorithms based on deep Learning[J]. Transducer Microsyst. Technol. 41 (04), 5–9. https://doi.org/10.13873/J.1000-9787(2022)04-0005-05 (2022).
Guihua Yang, Z., Wu, Z. & Yang Research on QFN chip surface defect detection technology based on YOLOX[J]. Transducer Microsyst. Technol. 44 (03), 46–49. https://doi.org/10.13873/J.1000-9787(2025)03-0046-04 (2025).
Chen, Y., Kalantidis, Y., Li, J. & Yan, S. Jiashi Feng.A2-Nets: Double Attention Networks,arXiv:1810.11579.
Funding
The author (s) received no financial support for the research, authorship, and/or publication of this article.
Author information
Authors and Affiliations
Contributions
Y.R. (Yang Ruijun) and Z.Y. (Zhu Yining) designed the core framework of the DANet-YOLOv5 model, including the integration of the dual attention mechanism into the YOLOv5 backbone network, and wrote the main manuscript text.All authors reviewed the manuscript, and Y.R. and J.S. finalized the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yang, R., Zhu, Y., Xu, B. et al. Heat exchanger pipe orifice recognition using an improved YOLOv5 model integrated with dual attention mechanisms. Sci Rep 16, 4508 (2026). https://doi.org/10.1038/s41598-025-34704-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-34704-x
