
Abstract
While caesarean risk prediction models exist for nulliparous and high-risk pregnancies, there is a lack of models that predict the risk of caesarean delivery among multiparous women. This study aimed to develop and validate a risk prediction model for caesarean delivery and assess its clinical utility among multiparous women. Using data from 460 participants, a prediction model was developed to predict the risk of caesarean delivery. The model performance was evaluated using the area under the receiver operating characteristic curve (AUC) and calibration plot, and the model was internally validated using bootstrapping technique. A simplified risk score was calculated, and a nomogram was developed for the individual caesarean delivery risk guide. Additionally, a decision curve analysis was performed to assess the clinical utility of the model. The final model included four predictors: maternal age, previous caesarean delivery, pregnancy-induced hypertension, and antepartum hemorrhage. The model had an AUC of 78.0% (95% CI 71.1–84.8), indicating good discrimination capacity. The model also exhibited good calibration and a low overoptimism coefficient, indicating minimal risk of overfitting. The risk prediction model has good clinical utility for discriminating multiparous women at risk of caesarean delivery. The tool can guide clinicians in estimating the risk of caesarean delivery among multiparous women that could lead to improved maternal and neonatal outcomes, ultimately enhancing the quality of care delivered in low-resource settings.
Similar content being viewed by others

Introduction
Caesarean Delivery (CD) is a widely performed surgical procedure, with approximately 21% of women undergoing CD worldwide1. The rate of CD continues to rise due to an increase in primary CD and a decline in the number of vaginal births after prior CD2. Although CD can reduce maternal-perinatal morbidities and mortality3 when medically indicated, undergoing CD without proper indications can lead to adverse outcomes for both the mother and her baby1. Long-term complications of CD include miscarriage, antepartum hemorrhage and placenta accreta, stillbirth, subfertility, childhood asthma, and obesity in future pregnancies4. However, the likelihood of CD and associated complications varies among women.
Several factors, including advanced maternal age, parity > 1, fetal macrosomia, premature rupture of membranes5, and labor induction have been identified to increase the risk of CD in multiparous women6. Maternal demographic characteristics, antenatal factors, obstetric and medical complications, prior obstetric history, and current clinical characteristics have also been found to provide relevant information for predicting the risk of CD in multiparous women5,6,7. In Ethiopia, a recent study revealed that most women with a prior CD underwent a trial of labour after caesarean section (TOLAC)8. However, higher rates of morbidity and mortality in women undergoing TOLAC emphasize the importance of meticulous selection of women at higher risk of CD before attempting a trial of labor9. CD risk prediction tools have the potential to improve short- and long-term obstetric outcomes by identifying women who are likely to require CD10.
Over the years, predicting the risk of CD has gained attention from researchers7,10,11,12,13,14,15,16. With the increasing complexity and multidimensionality of healthcare data, advanced machine learning algorithms have become popular methods for predicting CD risk13,17,18. Nevertheless, existing CD prediction models primarily focus on nulliparous women, women with high-risk pregnancies, and women undergoing labor induction, often considering multiparous women to be at low risk. However, multiparous women with specific risk factors, such as prior caesarean scars and medical complications such as diabetes mellitus and other obstetric risks, i.e., polyhydramnios and premature rupture of membranes (PROM), can have a CD risk as high as that of nulliparous women19. Therefore, predicting the risk of CD in these women is an essential first step in providing appropriate obstetric interventions and addressing overlooked risks in this population.
Given the lack of prediction tools for assessing the risk of CD in multiparous women, having quantitative knowledge about the risk of CD can enhance provider-patient engagement, facilitate shared decision-making, and optimize resource allocation in clinical care7. Identifying women at risk of emergency CD using predictors collected at the onset of labor could reduce the incidence of complications associated with labor10. Additionally, CD prediction algorithms can help protect physicians against medicolegal issues17.
Therefore, in this study, we aimed to develop a prediction model for assessing the risk of CD in multiparous women using easily obtainable maternal and obstetric variables. We internally validated the prediction model, calculated a simplified risk score, and developed a nomogram for clinical use. Furthermore, we assessed the clinical utility of the model using decision curve analysis.
Methods
Study design and participants
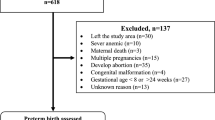
A prospective cross-sectional study was conducted among multiparous women presenting with labor complaints in two public hospitals in Hawassa city, Ethiopia, between February 1 and June 30, 2018. Multiparous women with singleton pregnancies at or beyond 28 weeks of gestation were included. We excluded women who presented with a second stage of labor or beyond.
Data collection
A total of 460 multiparous women presenting with labor pain at the study hospitals were recruited at admission to the labor ward. The total sample was allocated to the two study hospitals based on the proportion of the average number of childbirths that occurred three months prior to the study. Data were collected using a structured questionnaire from eligible participants and their medical records. A range of sociodemographic characteristics, antenatal factors, obstetric profiles, and pregnancy outcomes were collected. The tool used to collect the data were translated into local languages understandable by the participants (Amharic and Sidamic). The data were collected by six trained midwives. The process of data collection and completeness was followed by the principal investigator (NBY).
Variables
The outcome of interest was CD (yes/no) collected through observation and reviewing the medical charts. The initial predictors for model development were selected based on prior knowledge and clinical relevance20. Variables such as advanced maternal age (categorized as less than 35 (not advanced) and 35 or above (advanced)), parity (2–4 births (multiparous) and 5 and above (grand multiparous)), mode of delivery during last birth (coded as vaginal vs. caesarean delivery), history of medical illness (yes/no), history of abortion (yes/no), antenatal care (ANC) follow-up (yes/no), frequency of ANC (categorized as 1–3 and 4 or more), hypertensive disorders of pregnancy (HDP) (yes/no), antepartum hemorrhage (APH) (yes/no), premature rupture of membranes (PROM) (yes/no), preterm delivery (yes/no), and intrauterine fetal death (yes/no) were included as predictors. The variables were collected through interviewing women (history taking) and extraction from medical charts, which were again validated using physical examination and further clinical investigation results when necessary.
Statistical analysis
The collected data were entered into Epi-data version 4.4.3.1 and exported to R v 4.3.2 (https://www.r-project.org) for processing and analysis. The data were cleaned and explored for completeness, structure, and coding consistency before analysis. The distribution of data was checked for continuous variables using plots and Kolmogorov–Smirnov and the Shapiro–Wilk test. Continuous variables were categorized into relevant categories, and categorical coding was also used to determine meaningful factor levels.
The least absolute shrinkage and selection operator (LASSO) regression technique was used to select the predictor variables for our final model. The LASSO approach performs variable selection and shrinkage by adding a penalty term to the sum of residuals and is recommended for small events per predictor21. Given that the number of events per predictor in our model was reasonably low, we used LASSO regression for variable selection. The ‘glmnet’ function version 4.1-8 in R was used, and k-fold cross-validation was performed to identify the optimal lambda value, followed by extracting coefficients of the predictors that returned a value greater than the optimal threshold. The predictors identified via the LASSO technique were used to construct the final model.
The LASSO was formulated as:
.
Where yi represents the outcome variable, \(\hat {y}i\) is predicted probability based on logistic regression, \(\beta j\) represent coefficients of predictors, and \(\lambda\) is tunning parameter which controls the degree of shrinkage.
A logistic regression model was built with the selected predictors to calculate the risk of CD. We formulated the logistic regression model as follows:
\({\text{P}}({\text{Y}}\, = \,{\text{1}}{\mid }{\text{X}}_{{\text{1}}} ,{\text{ X}}_{{\text{2}}} , \ldots ,{\text{X}}_{{\text{p}}} ){\text{ }} = \frac{1}{{1 + e - \left( {\beta 0 + \beta 1X1 + \beta 2X2 + \ldots , + \beta pXp} \right)}}.\)
Where P(Y = 1∣X1, X2,…,Xp) is the predicted probability of CD, X1, X2,…,Xp are the predictors included in the model, β0 is intercept, β1,β2,…,βp are coefficients for each predictor.
The model performance was evaluated using the area under the receiver operating characteristic (AUROC) curve and calibration plot. An AUC value close to 1 was used to indicate good model discriminative power22. The calibration of the model was determined by plotting the predicted probabilities against the observed probabilities and assessing their proximity. Additionally, the p-value from the Hosmer‒Lemeshow goodness-of-fit test above 5% was used to indicate the goodness of fit of the model.
The model was internally validated to assess the risk of overfitting using the bootstrapping technique. A total of 1000 bootstrapping samples were created with random resampling with replacement. The over-optimism coefficient was calculated by subtracting the average AUC value of the bootstrapping sample from the original AUC and dividing it by the original AUC. A coefficient of less than 0.1 was used to indicate a low risk of bias or over-fitting23.
The regression coefficients of the predictors in the final model were used to calculate the simplified risk scores. The scores were calculated by dividing each predictor’s coefficient by the smallest coefficient and rounding it to the nearest integer. The total risk score was then estimated as the product of the multiplicative value of predictors with their corresponding risk scores. Furthermore, a nomogram was developed as a visual tool that can be used to guide the individual risk of caesarean section based on the final predictors included in the prediction model. The nomogram was plotted using the ‘nomogram’ function from the ‘rms’ package in R. Linear predictors were transformed to a probability scale for intuitive interpretation of the predictions by the model.
Decision curve analysis was used to show the clinical utility of the developed predictive model. The net benefit of the model and other alternative strategies was plotted at different threshold probabilities with a 95% confidence interval (CI). Then, the standardized net benefit was compared for interventions guided by the predictive model, interventions for all patients, and interventions for none of the patients. Additionally, the plot included cost‒benefit ratios to show potential benefits and harms associated with different threshold probabilities of the curve. A total of 1000 bootstrap samples were used in the analysis to reduce bias and provide a more accurate estimate of the predictive model’s net benefit.
This paper followed the Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD) statement24.
Ethical approval
The study was approved by the institutional review board of Hawassa University College of Medicine and Health Sciences (IRB/164/10). Written consent was obtained from the study participants. The confidentiality of the participants was assured by anonymizing personal identifiers in the data. All methods and procedures in the study were performed in accordance with the Declaration of Helsinki.
Results
Characteristics of the sample
Of the total 460 participants, approximately 14% underwent CD. Among the women included in the study, approximately 1 in 10 had a prior caesarean scar. Furthermore, 6.7%, 3.5%, and 4.1% of the participants had hypertensive disorders, antepartum hemorrhage, and premature rupture of membranes during their current pregnancy, respectively (Table 1).
Predictors of caesarean delivery
Predictors of CD in multiparous women were identified through LASSO regression. Variables such as maternal age, abortion, parity, last mode of delivery (prior caesarean delivery), number of antenatal care visits, medical illnesses, hypertensive disorders of pregnancy, and antepartum hemorrhage were included in the LASSO regression. Four of these predictors returned with coefficients shrank to zero, while the remaining four predictors (Table 2) were selected to fit the final model. The optimum lambda value used to select the predictors was 0.0097.
In the logistic regression model, prior caesarean delivery and antepartum haemorrhage during the current pregnancy were found to be significantly associated with the risk of CD. To calculate a simplified risk score, we divided each variable’s regression coefficient by the smallest coefficient (0.3 for maternal age) and approximated the result to the nearest integer. The total risk score was then calculated as follows:
\(\begin{aligned} {\text{Pr}}\left( {{\text{CD}}} \right) & ={\text{ }}\left( {{\text{1}}*{\text{advanced maternal age}}} \right){\text{ }} \\ & \;\;\;+{\text{ }}\left( {{\text{11}}*{\text{caesarean delivery for last birth}}} \right){\text{ }} \\ & \;\;\;+{\text{ }}\left( {{\text{3}}*{\text{hypertensive disorders of pregnancy}}} \right){\text{ }} \\ & \;\;\;+{\text{ }}\left( {{\text{6}}*{\text{antepartum haemorrhage}}} \right). \\ \end{aligned}\)
Using the coefficients of the predictors in the logistic regression model, a nomogram was developed that provides a graphical aid to estimate the individual probability of caesarean delivery risk (Fig. 1).

Nomogram used to predict the risk of caesarean delivery (CD) for multiparous (MP) women at admission to labour. For individual women, points are assigned to each predictor using the point axis at the top of the figure, and a total score is obtained. The total points correspond to the predicted probability of CD for MP women. For example, for a woman aged > = 35 years (12 points) who had prior CD (100 points) with HDP (34 points) but without APH (0 points), the calculated total point was 146, which corresponded to 88% risk of CD at admission.
Performance of the model
The observed probabilities of the model were plotted against the predicted probabilities and showed a perfect calibration, as evidenced by all dots on the diagonal line (Fig. 2). The p-value from the Hosmer–Lemeshow test also indicated that the model fit the data well.

Calibration plot comparing observed and predicted probabilities of caesarean delivery among multiparous women. The plot demonstrates the predictive accuracy of the model with dots on the diagonal line representing perfect calibration.
Additionally, the model exhibited good performance in discriminating true and false positives, with an AUC of 78% (95% CI 71.1–84.8) (Fig. 3). The model built with the simplified risk score as a predictor also exhibited nearly similar performance, indicating a non-significant loss of discriminative power due to simplifying the model.

ROC curve illustrating the performance of the prediction model for caesarean delivery risk in multiparous women. The curve plots the true positive rate (sensitivity) against the false positive rate (1-specificity) across different threshold values. The AUC shows the models ability to discriminate between women at risk of caesarean delivery and those not at risk.
Internal validation
The mean AUC value of the bootstrapping sample was 74.47%. The over-optimism coefficient was 0.04.
Decision curve analysis
The decision curve plot compares the net benefit of using the model to treat women versus treating all or none of the women (Fig. 3). The net benefits of the model were greater than those of the treating all, and none at the different threshold probabilities (Fig. 4).

Decision curve analysis illustrating the prediction model’s clinical utility by plotting the net benefit across threshold probabilities. The standardized net benefit includes the trade-offs between true positives and false positives to determine whether the model has greater value compared to ‘treat all’ or ‘treat none’. The light blue and green lines above and below the dark line are confidence intervals for the model’s net benefit.
Discussion
In this study, we developed a prediction model and calculated a simplified risk score for CD among multiparous women using maternal characteristics and obstetric factors at admission to labor. The final model included four predictors: advanced maternal age, prior CD, hypertensive disorders of pregnancy, and antepartum hemorrhage. The model demonstrated good discrimination and calibration ability, indicating its potential usefulness in clinical practice.
The model in the development sample also performed well in the bootstrapping samples, resulting in a very low overoptimism coefficient. This finding is indicative of a lower risk of bias and overfitting, which enhances the potential application of the model in a real-world setting without compromising its performance. The robustness of our model in the bootstrapping analysis further supports its reliability and generalizability, strengthening its value as a predictive tool for CD in multiparous women.
The results of the decision curve analysis also demonstrated a greater net benefit of using our model across a range of threshold probabilities at which considering an alternative intervention is beneficial. Specifically, our model exhibited comparable net benefit to the “treating all” strategy when the threshold probability was between 0 and 0.1. However, the net benefit of our model outperformed that of the default strategies for a threshold probability of 0.1 and above. However, it is important to note that the default strategies of treating all or none of the women may not be the most realistic comparisons. Nevertheless, our model demonstrated promising clinical value in facilitating decision-making.
The simplified risk score and nomogram were also derived from the prediction model, offering a practical tool for assessing the risk of CD. The risk score assigns weights to each predictor based on their regression coefficients, enabling a numerical representation of an individual’s likelihood of undergoing CD. This scoring system enhances the interpretability of the model’s predictions and provides clinicians with a straightforward risk assessment tool. The risk score ranges from 0 to 21, with higher scores indicating an increased risk of CD. The nomogram serves as a visual and easily interpretable guide for calculating an individual’s total points and determining the corresponding risk of CD. This user-friendly tool aids clinicians in risk stratification and facilitates informed decision-making.
Comparing the performance of our model with previous studies, our model outperformed a model developed in Canada (AUC: 74%)12. Moreover, our model demonstrated comparable performance to similar models developed in Spain (AUC: 74–81%)13 and the Netherlands (AUC: 73–81%)16. However, it is worth noting that our model was constructed using only four easily obtainable predictors, making it a practical and feasible tool for implementation. Although our model performed slightly worse than recent studies conducted in Ethiopia (AUC: 82%)14 and Indonesia (AUC: 81.3%)15, it is important to consider that these previous models included numerous antenatal and intrapartum predictors, which may delay diagnosis and risk stratification. Additionally, the inclusion of nulliparous women who underwent labor induction in previous studies introduces different risk factors for CD than the multiparous women included in our study.
The strength of our study lies in its good discrimination and calibration ability, as well as its robust performance in bootstrapping samples with easily obtainable variables. This suggests that our model is not only reliable but also practical for implementation in diverse clinical settings. The simplified risk score and nomogram provide user-friendly tools for risk assessment, facilitating effective risk stratification and enabling healthcare providers to make informed decisions tailored to individual patients.
Moreover, the implications of our model extend beyond individual patient care; it provides a framework for optimizing intervention thresholds. By aiding clinicians in evaluating when to recommend caesarean deliveries, our model implies a more strategic allocation of healthcare resources. This could lead to improved maternal and neonatal outcomes, ultimately enhancing the quality of care delivered in low-resource settings. Thus, the clinical utility of our model is profound, offering both immediate benefits for patient management and broader implications for healthcare policy and practice. The variables to develop the current model influences the risk of caesarean delivery in several ways. It has been hypothesised that contractility of myometrium and effect of oxytocin decrease with advancing maternal age25. Risk of caesarean delivery tends to be higher in women with prior caesarean scar due to risk of uterine rupture when vaginal delivery is attempted and increased adverse obstetric conditions such as invasive placentation and antepartum haemorrhage which ultimately necessitate repeat caesarean delivery9. Similarly, hypertensive disorders during pregnancy, including preeclampsia increases the risk of maternal and neonatal outcomes that necessitates caesarean delivery to prevent sever morbidities and mortality26. The four variables used to build our model can be easily collected from mothers through history and physical examination or non-invasive tests upon presentation to the obstetric ward. Hence, selection of mothers who need caesarean delivery can be aided by this model that in turn helps to prevent adverse outcomes.
However, we acknowledge limitations in our study. Due to limited statistical power, we were unable to include some important clinical variables. Additionally, the specific cause of antepartum hemorrhage (i.e., placental abruption, placenta previa or vasa previa) used for model development was not specified, which may introduce some uncertainty. The wide 95% CI for predictors such as prior CD and antepartum haemorrhage in our model may suggest the degree of uncertainty and its potential to compromise the accuracy of our prediction. Further large-scale studies are imperative to validate the advantages of our predictors and to explore additional clinical variables that could improve the prediction of CD risk. External validation of the model is also important for evaluating its performance in independent datasets and facilitating its implementation in different clinical settings.
Conclusions
The risk prediction model developed to predict CD in multiparous women demonstrated good discrimination and calibration ability, as well as promising clinical utility. The risk score and nomogram provide practical tools for clinicians to estimate individual risk and guide decision-making. While our model performed well compared to previous studies, it should also be noted that it was constructed using easily obtainable predictors, making it practical for implementation. However, the highlighted limitations of this model should be considered when using and interpreting the results of this model.
Data availability
The datasets used to generate the findings of this study are available as supplementary file.
References
Angolile, C. M., Max, B. L., Mushemba, J. & Mashauri, H. L. Global increased cesarean section rates and public health implications: a call to action. Health Sci. Rep. 6(5), e1274 (2023).
Nagy, S. & Papp, Z. Global approach of the cesarean section rates. J. Perinat. Med. 49(1), 1–4 (2021).
Betran, A. P., Torloni, M. R., Zhang, J. J. & Gülmezoglu, A. M. WHO statement on caesarean section rates. Bjog 123(5), 667–670 (2016).
Keag, O. E., Norman, J. E. & Stock, S. J. Long-term risks and benefits associated with cesarean delivery for mother, baby, and subsequent pregnancies: systematic review and meta-analysis. PLoS Med. 15(1), e1002494 (2018).
Buyuk, G. N. et al. Risk factors for intrapartum cesarean section delivery in low-risk multiparous women following at least a prior vaginal birth (robson classification 3 and 4). Rev. Bras. Ginecol. Obstet. 43(6), 436–441 (2021).
Derbent, A. U., Karabulut, A., Yıldırım, M., Simavlı, S. A. & Turhan, N. Evaluation of risk factors in cesarean delivery among multiparous women with a history of vaginal delivery. J. Turk. Ger. Gynecol. Assoc. 13(1), 15–20 (2012).
Ramos, S. Z. et al. Predicting primary cesarean delivery in pregnancies complicated by gestational diabetes mellitus. Am. J. Obstet. Gynecol. 229(5), 549 (2023).
Wagaw, A. C., Sendekie, A. K., Nigatu, S. G. & Mihretie, G. S. Preferred mode of delivery and its associated factors in pregnant women with a previous cesarean scar at a tertiary care hospital in Ethiopia: institutional-based cross-sectional study. BMC Pregn. Childbirth 23(1), 585 (2023).
Young, C. B. et al. Mode of delivery after a previous cesarean birth, and associated maternal and neonatal morbidity. Cmaj 190(18), E556–e64 (2018).
Burke, N. et al. Prediction of cesarean delivery in the term nulliparous woman: results from the prospective, multicenter Genesis study. Am. J. Obstet. Gynecol. 216(6), 598 (2017).
Danilack, V. A. et al. Development and validation of a risk prediction model for cesarean delivery after labor induction. J. Womens Health (Larchmt). 29(5), 656–669 (2020).
Tun, M. H. et al. Prediction of odds for emergency cesarean section: a secondary analysis of the CHILD term birth cohort study. PLOS ONE. 17(10), e0268229 (2022).
Campillo-Artero, C., Serra-Burriel, M. & Calvo-Pérez, A. Predictive modeling of emergency cesarean delivery. PLoS One. 13(1), e0191248 (2018).
Fente, B. M., Asaye, M. M., Gudayu, T. W., Mihret, M. S. & Tesema, G. A. Prediction of unplanned cesarean section using measurable maternal and fetal characteristics, Ethiopia, a retrospective cohort study. BMC Pregn. Childbirth. 24(1), 161 (2024).
Irwinda, R., Hiksas, R., Lokeswara, A. W. & Wibowo, N. Maternal and fetal characteristics to predict c-section delivery: a scoring system for pregnant women. Womens Health (Lond.) 17, 17455065211061969 (2021).
Schuit, E. et al. A clinical prediction model to assess the risk of operative delivery. Bjog 119(8), 915–923 (2012).
Beksac, M. S., Tanacan, A., Bacak, H. O. & Leblebicioglu, K. Computerized prediction system for the route of delivery (vaginal birth versus cesarean section). J. Perinat. Med. 46(8), 881–884 (2018).
Rahman, S., Khan, M. I., Satu, M. S. & Abedin, M. Z. Risk prediction with machine learning in cesarean section: optimizing healthcare operational decisions. In Signal Processing Techniques for Computational Health Informatics (eds. Ahad, M. A. R. & Ahmed, M. U.) 293–314 (Springer International Publishing, 2021).
Luo, J. et al. Pregnancy complications among nulliparous and multiparous women with advanced maternal age: a community-based prospective cohort study in China. BMC Pregnancy Childbirth. 20(1), 581 (2020).
Harrell, F. E. Regression Modeling Strategies: With Applications to Linear Models, Logistic Regression, and Survival Analysis (Springer, 2001).
Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B: Stat. Methodol. 58(1), 267–288 (1996).
Steyerberg, E. W. & Vergouwe, Y. Towards better clinical prediction models: seven steps for development and an ABCD for validation. Eur. Heart J. 35(29), 1925–1931 (2014).
Pavlou, M. et al. How to develop a more accurate risk prediction model when there are few events. Bmj 351, h3868 (2015).
Collins, G. S., Reitsma, J. B., Altman, D. G. & Moons, K. G. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. Ann. Intern. Med. 162(1), 55–63 (2015).
Arrowsmith, S., Robinson, H., Noble, K. & Wray, S. What do we know about what happens to myometrial function as women age? J. Muscle Res. Cell. Motil. 33(3–4), 209–217 (2012).
Caughey, A. B., Cahill, A. G., Guise, J-M. & Rouse, D. J. Safe prevention of the primary cesarean delivery. Am. J. Obstet. Gynecol. 210(3), 179–193 (2014).
Acknowledgements
The authors are thankful to the data collectors and study participants.
Funding
The authors did not receive any funds for this work.
Author information
Authors and Affiliations
Contributions
NBY conceived the study. NBY and EGM designed the study, cleaned the data, and performed the analysis. NBY wrote the original draft of the manuscript. NBY and EGM wrote, reviewed, and edited the final version of the manuscript. Both authors read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yimer, N.B., Mekonnen, E.G. Development and validation of a risk prediction model for caesarean delivery among multiparous women. Sci Rep 15, 5326 (2025). https://doi.org/10.1038/s41598-025-86015-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-86015-w
