
Abstract
The Lightv8nPnP lightweight visual positioning algorithm model has been introduced to make deep learning-based drone visual positioning algorithms more lightweight. The core objective of this research is to develop an efficient visual positioning algorithm model that can achieve accurate 3D positioning for drones. To enhance model performance, several optimizations are proposed. Firstly, to reduce the complexity of the detection head module, GhostConv is introduced into the detection head module, constructing the GDetect detection head module. Secondly, to address the issues of imbalanced sample difficulty and uneven pixel quality in our custom dataset that result in suboptimal detection performance, Wise-IoU is introduced as the model’s bounding box regression loss function. Lastly, based on the characteristics of the drone aerial dataset samples, modifications are made to the YOLOv8n network structure to reduce redundant feature maps, resulting in the creation of the TrimYOLO network structure. Experimental results demonstrate that the Lightv8nPnP algorithm reduces the number of parameters and computational load compared to benchmark algorithms, achieves a detection rate of 186 frames per second, and maintains a positioning error of less than 5.5 centimeters across the X, Y, and Z axes in three-dimensional space.
Similar content being viewed by others
Introduction
With the rapid development of the unmanned aerial vehicle (UAV) market, drones are increasingly being used in various fields. Initially, UAVs were primarily employed in military domains, such as border security1. Nowadays, UAVs are more commonly applied in civilian fields, including fire safety2, smart agriculture3, equipment inspection4, and urban management5. However, in many application scenarios, GPS signals are often unavailable or unreliable, especially in environments with obstructions or signal interference. Therefore, research on UAV positioning technology in the absence of GPS signals is of great importance. Vision-based positioning offers an effective solution for UAV localization under GPS-denied conditions. This method features low cost, rich information, strong autonomy and reliability, and high positioning accuracy6.
Currently, a large number of research achievements have emerged regarding vision-based positioning methods. These methods can be divided into Relative Visual Localization (RVL) and Absolute Visual Localization (AVL), with the difference being whether visual positioning is accomplished through matching between frames or between frames and a reference7. A core issue with RVL is the accumulation of errors, which leads to drift over time. For long-distance applications, RVL still requires correction using absolute positioning information8. AVL, on the other hand, offers unique advantages in addressing the problem of accumulated errors in UAV positioning. Couturier and Akhlouf conducted an investigation on UAVs, showing that UAV AVL, which uses precise geographic reference information, does not suffer from the issue of error accumulation over time9. AVL methods can be further divided into traditional AVL methods and deep learning-based AVL methods, depending on the approach used to extract image features. In recent years, with the advent of Convolutional Neural Networks (CNNs), researchers have begun to introduce deep learning-based computer vision into the field of visual positioning for feature extraction. For instance, Hoanh, Nguyen, and Tran Vu Pham10 proposed a multi-task framework for vehicle detection from high-resolution UAV imagery, which demonstrates how deep learning techniques can enhance object recognition in complex environments. This approach highlights the potential of CNNs in improving the accuracy of visual positioning systems, particularly in urban and highly structured environments. Similarly, Meng et al.11 integrated LiDAR data with pseudo 4D radar in a bird’s-eye view for traffic object detection, which shows the benefits of data fusion in enhancing detection capabilities, a strategy that could be adapted to improve visual localization systems for UAVs. Reference12 proposed a novel map construction method, but as the flight area increases, the mapping and weight files occupy more space, leading to increased computational costs. Therefore, the main challenges for deep learning-based visual positioning methods are the limitations of computational resources on board and the difficulty in achieving real-time positioning.
To make the deep learning-based UAV vision positioning algorithm more lightweight, the Lightv8nPnP lightweight vision positioning algorithm model has been proposed. To achieve this, we utilize the deep learning tool You Only Look Once (YOLO) as an integral part of the visual positioning algorithm model, where the detected objects provide key visual features that are then used to improve the accuracy of the UAV’s localization. By improving the YOLOv8n network, we have designed a more lightweight and higher-precision visual positioning algorithm, significantly reducing the computational resource requirements of the deep learning model. The positioning frame rate of the designed visual positioning algorithm reaches 62 frames per second, meeting the real-time requirements. The Lightv8nPnP vision positioning algorithm achieves a positioning error of less than 5.5 cm, which meets the positioning requirements for UAVs. In summary, this paper makes the following contributions:
(1) The Lightv8nPnP lightweight visual positioning algorithm model has been proposed to solve the problems of large parameter sizes and high computational demands in existing deep learning models, and to optimize the application of drone visual positioning on small mobile devices.
(2) By introducing GhostConv into the detection head module and modifying the original network structure, we constructed the GDetect detection head and TrimYOLO lightweight structure, reducing the complexity of the vision positioning algorithm and improving positioning efficiency.
(3) To address the issues of sample imbalance and uneven pixel quality in the custom dataset, Wise-IoU has been introduced as the bounding box regression loss function, which has improved the positioning results.
Related work
Relative visual localization
In recent years, significant progress has been made in RVL methods based on Visual SLAM, particularly in their application to dynamic scenes. Traditional SLAM algorithms often struggle with accumulating pose estimation errors or even losing track when dealing with moving objects in dynamic environments. To address this issue, researchers have proposed various improved methods that incorporate semantic information.
Many researchers have introduced deep learning networks, such as the YOLO series object detection models, to distinguish between dynamic and static feature points in a scene, thereby reducing the interference of dynamic objects on pose estimation. For example, in reference13, a semantic visual SLAM algorithm based on YOLOv7 can quickly extract semantic information from the scene and improve the accuracy of robot pose estimation by separating dynamic feature points. Anebarassane Y et al. integrated the YOLOv8 model with ORB-SLAM3, enabling the localization algorithm to not only achieve more accurate object detection and segmentation results but also significantly enhance the accuracy and real-time performance of the system in dynamic and complex environments14. In reference15, a lightweight object detection network was constructed by incorporating the MobileNetV3 backbone and depthwise separable convolution modules into the YOLOv5s model. This lightweight detection network, combined with geometric constraint methods, was used to eliminate dynamic feature points that affect the localization accuracy of SLAM algorithms. To further improve the performance of visual SLAM systems, reference16 proposed a dynamic visual SLAM (SEG-SLAM) system based on the ORB-SLAM3 framework and YOLOv5 deep learning methods. YOLO-SLAM17 introduced a novel geometric constraint method, Depth-RANSAC, which distinguishes static points within surrounding blocks. SG-SLAM18 proposed a fast dynamic feature removal method that combines epipolar constraints and bounding box semantic information. Tsintotas et al. explored the application of visual loop closure detection techniques within Simultaneous Localization and Mapping (SLAM) systems. The survey thoroughly covers a range of techniques from basic image matching methods to sophisticated deep learning models, significantly enhancing the robustness and accuracy of SLAM systems in dynamic environments19.
Absolute visual localization
Relative visual positioning methods are flexible and diverse, but relative positioning suffers from drift issues where errors accumulate over time. Absolute visual positioning effectively addresses the problem of error drift.
Extensive research has been conducted by scholars both domestically and internationally on UAV AVL algorithms. For example, references20,21 used deep learning frameworks to extract features of buildings and landscapes, and then matched this information with pre-existing geotagged images for localization. Liu et al. proposed the NIVnet network to process near-infrared and real-time visible light reference images, enabling a multimodal UAV visual localization system to operate in GPS-denied environments22. Many researchers have also been exploring the combination of landmark-based positioning with deep learning-based object detection for UAV AVL algorithms. Cui et al. used deep learning-based object detection algorithms to recognize QR codes and decode the UAV’s position through the corner points of the codes23. Xu et al. designed a high- and low-altitude visual localization algorithm using an improved YOLOX algorithm combined with location markers featuring QR codes24. Ma et al. utilized the YOLOv5 algorithm in conjunction with transmission towers of known dimensions to localize UAVs and complete power line inspections7. In the field of assistive visual localization technology, Cheng et al. provides an innovative hierarchical visual localization framework for visually impaired individuals, achieving precise localization through multimodal images. This study developed a novel dual descriptor network (Dual Desc) that effectively extracts both local and global image features, enhancing localization accuracy through geometric verification and sequence matching. Their system demonstrates robust performance in real-time environments, particularly in dynamic and variable urban settings25.
In this paper, the proposed method is different from the previous methods in the following aspects.
(1) While existing deep learning models perform exceptionally well in object detection, their high parameter count and computational requirements often limit their application on resource-constrained devices, such as UAVs. To address this issue, we designed the lightweight Lightv8n network, which significantly reduces computational load and improves the feasibility of deployment on small mobile devices.
(2) In many existing works, researchers introduce lightweight backbones like MobileNetV3 into YOLO models to achieve lightweight object detection. However, this paper further modifies the overall network structure of YOLOv8n and constructs the TrimYOLO network. By reducing redundant feature maps within the network, we optimized the computational efficiency of the model while maintaining high-precision localization capabilities.
Methods
The YOLO series of object detection algorithms stand out among many detection algorithms due to their balance between speed and accuracy, making them particularly well-suited for deployment on mobile devices. They have been widely used in fields such as object detection, tracking, and segmentation. In January 2023, the Ultralytics team introduced the latest version of the object detection network—YOLOv8. YOLOv8 comes in five versions: n, s, m, l, and x, and is especially suitable for object detection tasks in UAV aerial imagery26.
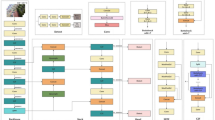
The Lightv8nPnP model for UAV visual positioning is introduced in this paper, where Lightv8n refers to the optimized network derived from the YOLOv8n network, designed for efficient object detection and feature extraction within our comprehensive visual positioning system. To ensure the network model remains lightweight while improving accuracy, a lightweight detection head, a lightweight network structure have been designed, and Wise-IoU has been adopted as the bounding box regression loss function. The GDetect detection head in the Lightv8n model incorporates a novel lightweight design primarily through the integration of the GhostConv module. This module deconstructs standard convolution operations and utilizes cost-effective linear transformations to expand feature maps without significantly increasing computational load. This design reduces both the parameter count and computational demand of the detection head, while still maintaining efficient detection performance. The network structure of Lightv8n has been optimized by removing redundant feature layers, particularly those that are less critical for UAV vision tasks involving large-sized targets. Through structural pruning, the model’s depth and width have been streamlined, which not only reduces the computational burden but also accelerates the data processing workflow. Wise-IoU is an innovative bounding box regression loss function that considers the difficulty of samples and the size of targets, dynamically adjusting the loss weights to better handle targets of varying difficulty. This loss function dynamically shifts the focus of learning, enhancing the model’s precision in predicting bounding box coordinates, especially in UAV images with occlusions or varying target sizes. The Lightv8n network model is shown in Fig. 1.

Lightv8n architecture diagram.
Principles of projection and the localization process
In unmanned aerial vehicle (UAV) vision systems, detecting key targets in acquired images to obtain UAV positional information is an important task. The system utilizes projection relationships and coordinate transformations to derive positional information through classical projection transformation equations between the pixel coordinate system \(\:(u,\nu\:)\), the image coordinate system \(\:\left(\begin{array}{c}x,y\end{array}\right)\), and the camera coordinate system \(\:\left(\begin{array}{c}{x}_{\text{c}},{y}_{\text{c}},{z}_{\text{c}}\end{array}\right)\).
The projection transformation equation is shown as Eq. (1)
where (\(\:{u}_{0}\),\(\:{\nu\:}_{0}\)) denotes the coordinates of the origin of the image coordinate system in the pixel coordinate system, \(\:f\) is the focal length, \(\:{f}_{\text{u}}=f/\text{d}x\), and \(\:{f}_{\text{v}}=f/\text{d}y\). The 3D orthogonal rotation matrix \(\:\varvec{R}\) and the translation vector \(\:\varvec{t}\) describe the transformation matrix from world coordinates to camera coordinates, enabling the conversion from the world coordinate system to the camera coordinate system through \(\:\text{R}\) and \(\:\varvec{t}\).
In practical applications, due to lens distortions, particularly in areas outside the image center, it is necessary to consider the impact of distortion on computational accuracy. The Zhengyou Zhang camera calibration method27 is employed to calibrate the UAV gimbal camera. The Levenberg-Marquardt method28 is used to solve multi-parameter nonlinear system optimization problems, thereby obtaining the UAV gimbal camera’s intrinsic matrix and distortion coefficients. This enables distortion correction, image correction, and the recovery of three-dimensional information, consequently enhancing the overall system’s measurement accuracy and reliability.
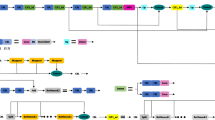
The UAV vision positioning algorithm replaces traditional image processing modules by integrating the Lightv8n object detection network into the visual projection process. Initially, the UAV captures ground images from high altitudes, then inputs these images into the Lightv8n network for object detection. Once targets are detected by the Lightv8n network, it retrieves the pixel coordinates of keypoints in the image. Subsequently, the actual positions of known keypoints, the obtained pixel coordinates of keypoints, the intrinsic matrix of the gimbal camera, and the distortion coefficients of the gimbal camera are used in the PnP algorithm to calculate the position of the UAV gimbal camera and thereby determine the UAV’s own position. The Lightv8nPnP algorithm process is shown in Fig. 2. Improvements to the detection algorithm can significantly enhance the rate of the image processing module and the number of keypoint pixel coordinates, thereby improving the performance of the positioning algorithm. This algorithm, combining object detection and the PnP algorithm, is expected to enhance the accuracy and robustness of UAV positional information during high-altitude flights.

Lightv8nPnP algorithm process.
Wise-IoU loss function
In this study, we employ Wise-IoU29 as the bounding box regression loss function for the Lightv8n model to enhance localization accuracy and address sample imbalance issues. Wise-IoU is particularly well-suited for handling the challenges of imbalanced samples and uneven pixel quality in our custom dataset, as it dynamically adjusts gradient gain and optimizes model response. This dynamic adaptability enables more precise localization performance in scenarios with varying data distributions and quality disparities.
Wise-IoU enhances performance through the following method:
(1) Dynamic Gradient Adjustment: Based on the correspondence between the target and the predicted bounding box, the gradient gain is dynamically adjusted to achieve more precise and stable learning during the training process.
(2) Outlier Handling: Effective identification of outliers between detection boxes and ground truth boxes, followed by adjustment of the loss function’s weights to ensure that losses are more focused on hard-to-predict samples.
In this manner, Wise-IoU achieves optimization of the conventional loss function within the Lightv8n model, enabling the model to maintain high detection accuracy and robustness even in complex application scenarios.
GDetect module
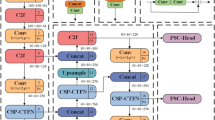
To accommodate the requirements of UAV platforms, our model is designed to minimize its size and computational burden while maintaining high inference speed and accuracy. Analysis and experimentation on the YOLOv8n network revealed that the computational load of its detection head module reaches up to 3.64 GFLOPs, accounting for approximately 41% of the total computational load of the network. To address this, we have integrated a lightweight detection head module named GDetect, featuring the GhostConv30 module, aimed at significantly reducing the use of computational resources.
The GhostConv module comprises three main components: the standard convolution module, the cheap linear operation module, and the fusion module. Initially, the module utilizes a small number of standard convolutions to extract basic features from the input image. This is followed by cost-effective linear operations that further enhance these features without substantially increasing the computational load. These cheap operations are designed to augment the dimensionality and complexity of the features. Ultimately, the fusion module integrates these processed features into the final feature map. The core design principle of the GhostConv module lies in achieving richer semantic information through lighter convolution operations, thereby enhancing the robustness of the network model.
As illustrated in Fig. 3, the lightweight GDetect detection head employs two parallel convolution layers. This parallel processing structure allows the model to handle multi-scale features more effectively, significantly improving its capability to detect objects of varying sizes. Additionally, this structure mitigates the interference of redundant gradient information and reduces the number of conventional convolutions, achieving a dual reduction in parameter count and computational load. Such optimizations not only enhance convolutional efficiency but also facilitate the flexible deployment of the model on UAV platforms.The speed comparison between Conv and GhostConv is detailed in Eq. (2)
where \(\:{W}^{{\prime\:}}\) and \(\:{H}^{{\prime\:}}\) represent the width and height of the output feature map, \(\:n\) refers to the number of output channels after the standard convolution operation, \(\:k\) is the kernel size of the standard convolution, \(\:C\) represents the number of input channels, \(\:m\) refers to the number of output channels in the standard convolution of GhostConv, \(\:\left(n-m\right)\) refers to the number of output channels from the linear operation, \(\:d\) represents the kernel size of the linear operation, and \(\:s\) denotes the stride.

GDetect structure.
Structure pruning
By running the network structure output code, it was found that the 7th, 8th, 19th, and 21st layers of the YOLOv8n network have the highest parameter counts. When an image of size 640*640*3 is input into the network, the three output feature maps are of sizes 80*80*256, 40*40*512, and 20*20*1024, corresponding effectively to small, medium, and large sized targets, respectively. Since UAV-captured images predominantly contain small to medium-sized targets, the contribution of the 7th and 8th layers to aerial imagery is minimal. Therefore, pruning these layers in the YOLOv8n network can significantly reduce the number of network parameters. Additionally, layers 19 and 21 were also pruned and optimized, simplifying the feature transmission path and reducing jump connections and upsampling operations within the network. This not only enhances the efficiency and speed of network computations but also minimizes potential errors caused by complex connections. Through these improvements, a new network structure, TrimYOLO, was obtained, as shown in Fig. 4.
TrimYOLO, by reducing the focus on detecting large objects, slightly affects the detection accuracy but has a very limited impact on overall performance for UAV-typical small to medium-sized object detection scenarios. In terms of speed, by trimming unnecessary layers and optimizing the network structure, the model’s operational speed has been significantly enhanced. This improvement is particularly important for applications running in compute-constrained environments, ensuring faster real-time detection performance and thus enhancing the algorithm’s positioning speed.

TrimYOLO network structure.
Experimental results and analysis
UAVLD dataset
A set of identification images has been designed for UAV visual positioning. Considering the varying sizes of captured images at different altitudes, a total of 13 identification images with different sizes have been designed. The identification symbols are depicted in Fig. 5.

Positioning identifier.
The UAV Vision Location Dataset (UAVLD) was developed utilizing drones and designated marker images for drone visual positioning. To construct the UAVLD dataset, we printed the specially designed marker patterns for drone visual positioning on KT boards, and manually operated drones to capture these patterns. During the shooting process, frames were extracted from video recordings; due to the high similarity between adjacent frames, we captured one image every 50 frames to build the dataset. Additionally, to make the data more representative of real-world application scenarios, videos were collected at different scenes, times, heights, and angles, after the final frame extraction and selection, a total of 460 real-captured images were obtained. Given the diverse work environments during drone inspections, relying solely on manual collection and labeling is labor-intensive, costly, and offers limited scene variety, which does not meet the complex and varied work environments required for drone inspection tasks. Utilizing data synthesis technology, the dataset was augmented with hard-to-collect scene data to enhance the model’s generalizability24. Initially, 120 images of wind farms and campus scenes were collected from the internet using web scraping technology, and the visual positioning marker patterns were synthesized onto these two types of backgrounds. As the background is only visible in aerial shots, 120 images from the real-captured 460 were randomly selected for high-altitude shots and synthesized with these backgrounds using random rotations and placements. To enhance model robustness, from the 700 labeled images, 310 were randomly chosen for data augmentation by adjusting brightness and adding noise. This completed the UAVLD dataset with a total of 1010 images. Examples of the dataset are shown in Fig. 6, and the dataset contents are detailed in Table 1.

Dataset example.
The dataset was annotated using the open-source data annotation software, labelImg, following the annotation principles of the VOC2012 dataset format. If an image of a certain category is obscured by 1/3 or more, it is discarded without annotation. Due to the uncertainty of the angles at which the UAV captures the identification patterns in the air, images were captured and annotated from multiple angles and rotation directions. Subsequently, the dataset was divided into training, validation, and testing sets in a ratio of 7:1:2. The dataset partitioning is presented in Table 2.
Experimental environment and parameter configuration
The experiment was conducted under the operating system Ubuntu 20.04.3, with a Tesla V100 GPU and 16GB of RAM. The environment included Python 3.8.13, CUDA 11.3, and torch 1.10.1 for model training. The training parameters are shown in Table 3.
The SGD optimizer is used for weight updates to minimize the error function; 300 training epochs indicate that the entire dataset will be reused 300 times; a batch size of 8 means that 8 samples are processed at a time; 8 workers are used to accelerate data loading and preprocessing speeds; a random seed of 100 ensures the reproducibility of the experiment; a weight decay of 0.0005 helps reduce model overfitting; warmup momentum of 0.8 and momentum of 0.937 are used to accelerate model convergence; an initial learning rate of 0.01 and a learning rate decay factor of 0.01 control the changes in learning rate; a warmup period of 3 and a warmup bias learning rate of 0.1 gradually increase the learning rate during the initial phase of training; and Wise-IoU parameters α at 1.9 and δ at 3 optimize the bounding box regression loss function used in object detection, enhancing the performance of the loss function through these parameter adjustments.
Experimental evaluation indicators
In this paper, we utilize a multi-dimensional set of evaluation metrics to comprehensively assess the Lightv8n network. These metrics include Precision (P), Recall (R), Mean Average Precision (mAP), model parameters (Params), total floating-point operations (FLOPs), and frames per second (FPS), along with model size. These provide a multi-faceted evaluation of model performance. Smaller network models with lower complexity are generally easier to deploy on drones, significantly reducing the demands on the processor.
\(\:Precision\) is used to evaluate the accuracy of predictions made by the Lightv8n model. It is defined as:
\(\:Recall\) is used to measure the ability of the Lightv8n model to identify correct samples. It is defined as:
where \(\:TP\) represents the number of true boxes correctly detected, \(\:FN\) stands for the number of true boxes not detected, and \(\:FP\) denotes the number of incorrect bounding boxes.
\(\:A{P}_{i}\)(Average Precision) represents the average precision for the ith category. It is defined as:
where \(\:P\left(r\right)\) is the \(\:Precision\) at a \(\:Recall\) rate of \(\:r\).
\(\:mAP\) is a comprehensive evaluation metric that considers the \(\:Precision\) across different categories, providing a more global understanding of the model’s overall performance. It is defined as:
where \(\:N\) represents the total number of categories.
\(\:Params\) and \(\:Flops\) are shown as Eqs. (7)-(8)
where \(\:O\) denotes constant order, \(\:K\) denote convolution kernel size, \(\:C\) denotes the number of channels, \(\:M\) denote input image size, and \(\:i\) denotes the number of iterations.
The inference speed is also an integral aspect of the algorithm performance quantification. This experiment used the FPS to characterize the inference speed of the model. The formula for calculating \(\:FPS\) is as shown in Eq. (9)
where pre is the preprocessing time of the model, including the time consumed by image scaling, padding, and channel transformation. Inference is the inference time of the model, which refers to the time from the preprocessed image input to the model output result. Post is the post-processing time of the model, which refers to the time spent on the line conversion of the model output results. \(\:FPS\) is the inference speed of the model.
The Lightv8nPnP visual localization algorithm measures the accuracy of the localization method using the average positioning error along the X, Y, and Z axes. The error formulas are as follows:
where \(\:{x}_{i}\) represents the predicted coordinate on the X-axis for the \(\:i\)th iteration, \(\:{x}_{{i}_{-}tru}\) is the true coordinate on the X-axis. \(\:{y}_{i}\) represents the predicted coordinate on the Y-axis for the \(\:i\)th iteration, \(\:{y}_{{i}_{-}tru}\) is the true coordinate on the Y-axis. \(\:{z}_{i}\) represents the predicted coordinate on the Z-axis for the \(\:i\)th iteration,\(\:{z}_{{i}_{-}tru}\) is the true coordinate on the Z-axis, and \(\:N\) denotes the total number of predictions.
Experimental results
To further validate the performance of the Lightv8n model, the Lightv8n algorithm was compared with YOLOv3-tiny31, YOLOv5n, YOLOv6n32, YOLOv7-tiny33, and YOLOv8n on a custom dataset. The experimental results are shown in Table 4.
Table 4 demonstrates the performance comparison between the Lightv8n model and the comparison models on several key metrics. On the self-built UAVLD dataset, the Lightv8n model is at the optimum in all the metrics, especially in the inference speed, the number of parameters and the model size to achieve significant results.
(1) Inference speed: By comparing with other models, the Lightv8n model is more outstanding in inference speed, reaching 186 frames/second. Compared with the optimal model for this metric, the Lightv8n model improves 66 frames/sec. It shows that the Lightv8n model can not only perform better in terms of accuracy, but also have higher real-time performance in practical applications.
(2) Number of model parameters: the Lightv8n model also shows better results in the indicator of the number of parameters. Compared with the model with the lowest number of parameters compared, the Lightv8n model has a 53% decrease in the number of parameters. This enables the Lightv8n model to significantly reduce the demand for device computational resources.
(3) Model size: the size of the Lightv8n model is 1.9 M, which is 2 M lower than the model with the smallest size, which makes the Lightv8n model more effective for deployment on hardware platforms with limited storage resources.
Analysis of lightweight structures
To ensure the model’s deployment on drones, it is necessary for the network to be compact, fast, and accurate. Therefore, we implemented lightweight modifications to the model structure. Given that the targets captured by drone cameras are predominantly medium or small-sized in the images, we pruned network layers that were more impactful for larger targets. After pruning, it was observed that the feature information from layers 12 and 15 had a greater impact on the detection heads. As a result, the number of detection heads was reduced from three to two, further lightening the model structure. The comparative experiments are shown in Table 5.
In Table 5, v1: YOLOv8n network structure after pruning, using 3 Detect heads; v2: YOLOv8n network structure after pruning, using 2 Detect heads.
The experimental results indicate that although the changes to the network structure resulted in a 0.3 decrease in average precision, the model’s parameter count decreased by 63%, computational demand was reduced by 19%, and model size was lowered by 62%. Additionally, inference speed improved. These outcomes validate the effectiveness of the improved structure in this experiment.
Ablation experiments
To verify the effectiveness of the improvements proposed in this paper, ablation studies were conducted based on the custom UAVLD dataset. Using YOLOv8n as the baseline algorithm, modifications were made to the network to achieve lightweight objectives. The results of the ablation studies are presented in Table 6.
From the ablation study results presented in Table 6, we can conclude the following:
(1) WIoU-v8n Model: This model replaces CIoU with Wise-IoU. The results show a decrease of 0.1 points in Precision and mAP@0.5 compared to the YOLOv8n network, but an increase of 0.9 points in mAP@0.5:0.95, with other metrics remaining almost unchanged.
(2) GDetect Model: This model involves replacing the YOLOv8n detection head module with the improved GDetect detection head module. The experiments indicate a slight decrease in precision, but significant reductions in model parameter count, computational demand, and model size, along with an increase in inference speed.
(3) TrimYOLOv8n Model: This model involves structural changes to the YOLOv8n network. The results demonstrate a decrease in precision by 0.3, reduced model complexity, and improved inference speed.
(4) Lightv8n Network Model: This model integrates all the improvements on the YOLOv8n model. Compared to the baseline algorithm, the Lightv8n model shows improvements in Precision, Recall, mAP@0.5, mAP@0.5:0.95, and FPS. It also shows a 72% reduction in parameter count, a 41% reduction in computational demand, and a 70% reduction in model size, indicating that this approach successfully achieves a balance between lightweight design, real-time performance, and accuracy.
Drone flight experiment
Data collection was conducted at the flight experiment site using a drone, configured as shown in the Table 7 low:
To evaluate the effectiveness of the Lightv8nPnP algorithm in UAV visual positioning, images were collected at specific altitudes with camera shooting angles of 45°, 60°, and 90°. The UAV’s true position within a self-established coordinate system was recorded. A point on the ground was randomly selected as the origin of the coordinate system, with the southward direction as the X-axis, the eastward direction as the Y-axis, and the upward direction as the Z-axis, thus establishing the OXYZ coordinate system. The positions of each identifier’s center point within this coordinate system were measured. By combining the UAV gimbal camera’s intrinsic matrix and distortion coefficients, the PnP algorithm was used to determine the relative positions between the targets and the UAV. This further enabled the calculation of the UAV gimbal camera’s position, thereby determining the UAV’s location. Images collected were input into the Lightv8nPnP positioning algorithm, and the position data derived from the Lightv8nPnP algorithm were compared with the UAV’s recorded actual position data, as presented in Table 8.
The results in the Table 8 demonstrate that by incorporating the Lightv8n network in place of traditional image processing modules for drone visual positioning, the Lightv8nPnP visual positioning algorithm can achieve drone positioning errors within 5.5 cm, which meets the requirements for drone visual positioning. The Lightv8nPnP visual positioning algorithm can achieve a frame rate of 62 frames per second and a total computational demand of 4.65 GFlops. This allows for real-time drone positioning and deployment of the algorithm on mobile devices.
Random samples of data collected at different times were selected to validate the Lightv8nPnP algorithm and the baseline algorithm YOLOv8nPnP. The results of the positioning errors are shown in Table 9.
The results in the table indicate that by incorporating the improved object detection network to handle visual information in drone visual positioning, the drone’s positioning error can be maintained within 5.5 cm on the X, Y, and Z axes, meeting the requirements for drone visual positioning.
The actual position information and the position information obtained from the algorithm were plotted as shown in Fig. 7.

Fitting results on X, Y, and Z axes.
The black line represents the actual positioning data, the red line represents the positioning data from the original algorithm, and the blue line represents the positioning data from the improved algorithm.
We validated the collected experimental data using both the Lightv8nPnP algorithm and the YOLOv8nPnP algorithm. Analysis of the experimental results indicates that the Lightv8nPnP visual positioning algorithm exhibits superior performance on the X, Y, and Z axes compared to the YOLOv8nPnP algorithm.
Conclusion
In this paper, the Lightv8nPnP drone lightweight visual positioning algorithm is introduced. This algorithm combines the Lightv8n algorithm with the Perspective-n-Point (PnP) algorithm to achieve visual positioning of drones, which can significantly reduce the impact of external environmental factors on drone localization and effectively improve the accuracy of positioning results. Additionally, we have implemented lightweight improvements to the object detection network, reducing the parameter count and computational demand by 72% and 41% respectively compared to the original network model. The detection rate reaches 186 frames per second, meeting the real-time requirements for drone localization. The substantial reduction in model size, parameter count, and computational load makes this model easier to deploy on drones. Through flight experiments, the drone visual positioning algorithm presented in this paper achieves an error within 5.5 cm on the X, Y, and Z axes and a correct detection rate of over 97%, fulfilling the requirements for drone visual positioning.
Data availability
The codes and original datasets used in this study are available from the corresponding authors.
References
Lei, X. et al. A multi-UAV deployment method for border patrolling based on Stackelberg game[J]. J. Syst. Eng. Electron. 34 (1), 99–116 (2023).
Lattimer, B. Y. et al. Use of unmanned aerial systems in outdoor firefighting[J]. Fire Technol. 59 (6), 2961–2988 (2023).
Amarasingam, N. et al. A review of UAV platforms, sensors, and applications for monitoring of sugarcane crops[J]. Remote Sens. Applications: Soc. Environ. 26, 100712 (2022).
Luo, Y. et al. A survey of intelligent transmission line inspection based on unmanned aerial vehicle[J]. Artif. Intell. Rev. 56 (1), 173–201 (2023).
Bakirci, M. Smart city air quality management through leveraging drones for precision monitoring[J]. Sustainable Cities Soc. 106, 105390 (2024).
Gao, W. et al. Recent advances in curved image sensor arrays for bioinspired vision system[J]. Nano Today. 42, 101366 (2022).
Ma, L. et al. Visual localization with a monocular camera for unmanned aerial vehicle based on landmark detection and tracking using YOLOv5 and DeepSORT[J]. Int. J. Adv. Rob. Syst. 20 (3), 17298806231164831 (2023).
Tang, P., Li, J. & Sun, H. A review of Electric UAV Visual Detection and Navigation Technologies for Emergency Rescue Missions[J]. Sustainability 16 (5), 2105 (2024).
Couturier, A. & Akhloufi, M. A. A review on absolute visual localization for UAV[J]. Robot. Auton. Syst. 135, 103666 (2021).
Hoanh, N. & Pham, T. V. A multi-task Framework for car Detection from high-resolution uav Imagery Focusing on road regions[J] (IEEE Transactions on Intelligent Transportation Systems, 2024).
Meng, Z. Y. et al. Traffic Object Detection for Autonomous Driving Fusing LiDAR and Pseudo 4D-Radar under Bird’s-Eye-View[J] (IEEE Transactions on Intelligent Transportation Systems, 2024).
Zhao, C. et al. A visual positioning method of UAV in a large-scale Outdoor Environment[J]. Sensors 23 (15), 6941 (2023).
Liu, H., Luo, J. & YES-SLAM YOLOv7-enhanced-semantic visual SLAM for mobile robots in dynamic scenes[J]. Meas. Sci. Technol. 35 (3), 035117 (2023).
Anebarassane, Y. et al. Enhancing ORB-SLAM3 with YOLO-based Semantic Segmentation in Robotic Navigation[C]//2023 and (AIC). IEEE, 874–879. (2023).
Ji, Y. et al. Robust and Accurate Multi-UAV Cooperative Semantic SLAM Leveraging Lightweight YOLO[C]. In 2023 7th International Symposium on Computer Science and Intelligent Control (ISCSIC). pp. 155–159 (IEEE, 2023).
Cong, P. et al. SEG-SLAM: dynamic indoor RGB-D visual SLAM integrating geometric and YOLOv5-Based semantic Information[J]. Sensors 24 (7), 2102 (2024).
Wu, W. et al. YOLO-SLAM: a semantic SLAM system towards dynamic environment with geometric constraint[J]. Neural Comput. Appl., : 1–16. (2022).
Cheng, S. et al. SG-SLAM: a real-time RGB-D visual SLAM toward dynamic scenes with semantic and geometric information[J]. IEEE Trans. Instrum. Meas. 72, 1–12 (2022).
Tsintotas, K. A., Bampis, L. & Gasteratos, A. The revisiting problem in simultaneous localization and mapping: a survey on visual loop closure detection[J]. IEEE Trans. Intell. Transp. Syst. 23 (11), 19929–19953 (2022).
Amer, K. et al. Convolutional neural network-based deep urban signatures with application to drone localization. In Proceedings—2017 IEEE international conference on computer vision workshops, ICCVW. Venice,Italy, 22–29 October 2017, pp. 2138–2145 (IEEE, 2017).
Mughal, M. H., Khokhar, M. J. & Shahzad, M. Assisting UAV localization via deep contextual image matching. IEEE J. Sel. Top. Appl. Earth Obs Remote Sens. 14, 2445–2457 (2021).
Liu, Z. et al. Multimodal Absolute Visual Localization for Unmanned Aerial Vehicles[J] (IEEE Transactions on Vehicular Technology, 2024).
Cui, Q., Liu, M., Huang, X. & Gao, M. Coarse-to-fine visual autonomous unmanned aerial vehicle landing on a moving platform. Biomim. Intell. Rob. 3 (1), 100088 (2023).
Xu, Y. et al. A novel uav visual positioning algorithm based on a-yolox.Drones,6(11), 362. (2022).
Cheng, R. et al. Hierarchical visual localization for visually impaired people using multimodal images[J]. Expert Syst. Appl. 165, 113743 (2021).
Wang, G. et al. UAV-YOLOV8: a small-object-detection model based on improved YOLOV8 for UAV aerial photography scenarios. Sensors 23 (16), 7190 (2023).
Zhang, Z. A flexible new technique for camera calibration[J]. IEEE Trans. Pattern Anal. Mach. Intell. 22 (11), 1330–1334 (2000).
Moré, J. J. The Levenberg-Marquardt algorithm: implementation and theory[C]. In Numerical analysis: proceedings of the biennial Conference held at Dundee, June 28–July 1, 1977. Berlin, Heidelberg, pp. 105–116 (Springer, Berlin Heidelberg, 2006).
Tong, Z., Chen, Y., Xu, Z. & Yu, R. Wise-IoU: bounding box regression loss with dynamic focusing mechanism.arXiv preprint arXiv:2301.10051. (2023).
HAN, K. et al. Ghostnet: more features from cheap operations[C]. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1580–1589 (2020).
Redmon, J. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767 (2018).
Li, C. et al. YOLOv6: a single-stage object detection framework for industrial applications[J]. arXiv preprint arXiv:2209.02976 (2022).
Wang, C. Y., Bochkovskiy, A. & Liao, H. Y. M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 7464–7475 (2023).
Acknowledgements
This work was supported by Tianshan Talent Training Project - Xinjiang Science and Technology Innovation Team Program (2023TSYCTD) and Xinjiang Uygur Au-tonomous Region Metrology and Testing Institute Project(Grant No. XJRIMT2022-5).
Author information
Authors and Affiliations
Contributions
Yuhang Wang (First Author): Conceptualization, Data Curation, Formal Analysis, Investigation, Methodology, Software, Writing-Original Draft, Writing-Review & Editing; Xuefeng Feng: Methodology, Supervision; Feng Li: Methodology, Supervision; Qinglong Xian: Methodology, Supervision; Zhenhong Jia (Corresponding Author): Conceptualization, Funding Acquisition, Resources, Supervision, Validation, Writing-Original Draft, Writing-Review & Editing; Zongdong Du: Data Curation, Investigation; Chang Liu: Data Curation, Investigation;
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, Y., Feng, X., Li, F. et al. Lightweight visual localization algorithm for UAVs. Sci Rep 15, 6069 (2025). https://doi.org/10.1038/s41598-025-88089-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-88089-y
Keywords
This article is cited by
-
A review of localization and sensing technologies for UAV swarms in SAR missions
EURASIP Journal on Advances in Signal Processing (2025)
-
CD-YOLOv8s: an optimized high-altitude real-time UAV recognition method based on image detection
The Journal of Supercomputing (2025)
