
Abstract
Underwater object detection presents both significant challenges and opportunities within ocean exploration and conservation. Although the current popular object detection algorithms generally achieve strong performance. Because underwater images are affected by insufficient illumination, wavelength-dependent scattering, and absorption, the detection performance for underwater objects is suboptimal. Therefore, a local channel information encoding method named Partial Semantic Encoding Module (PSEM) and an attention based detection head called Split Dimension Weighting Head (SDWH) are proposed by this paper to enhance the ability of models to extract and integrate semantic features of underwater targets, as well as the capability to locate foreground underwater targets. Specifically, PSEM enhances the fusion of features across multi-scales of the network. It successively completes semantically encoding feature information, followed by residual point-wise addition, and encoding local channel information. SDWH serially weights spatial and channel semantic information of fused features, enhancing the semantic perception of the detectors and the localization ability for foreground underwater objects. PSEM and SDWH are improvements to the neck and detection head of the YOLO series algorithms, respectively. Extensive experiments are conducted on UTDAC2020 and RUOD datasets. On the UTDAC2020 dataset, YOLOv8n improved with PSEM and SDWH achieves a 2.8% mAP increase compared to the original version, YOLOv5n shows a 1% mAP improvement, and YOLOv6n achieves a 3.0% mAP increase. Testing on the RUOD dataset, PSEM and SDWH enable YOLOv8n to achieve a 2.7% mAP improvement. YOLOv5n and YOLOv6n achieve improvements of 1.5% mAP and 3.7% mAP, respectively. Moreover, compared to other real-time underwater SOTA algorithms, YOLOv8n enhanced with PSEM and SDWH achieves the highest mAP of 82.9% on the UTDAC2020 dataset and 80.9% on the RUOD dataset. The proposed PSEM and SDWH are demonstrated to significantly improve the underwater object detection accuracy of YOLO series detectors with acceptable computational cost, and the real-time performance can fully satisfy practical requirements.
Similar content being viewed by others

Introduction
Underwater object detection1,2,3,4,5 plays a pivotal role in marine exploration, particularly in the realm of unmanned underwater exploration. Manual underwater detection is dangerous and time-consuming, which does not satisfy the growing demand for the ocean development6,7. Vision-based underwater detection provides a promising way to meet the demand due to its high efficiency and reliable performance8,9. Underwater detection methods based on traditional vision10,11 mainly rely on fixed descriptors by extracting limited features to identify and locate underwater targets. The descriptors are meticulously crafted to extract specific underwater object attributes such as contours12 and edges13, making it challenging to handle complex marine environments. The advent of Convolutional Neural Networks (CNNs) advances computer vision by automatically extracting features. Specifically, CNN-based object detection models, notably pioneered by two-stage and one-stage methods, such as Faster R-CNN14, YOLO15, and EfficientDet16. These techniques have attained state-of-the-art (SOTA) performance in various detection scenarios17,18,19,20. Thus, the object detectors based on deep learning are extensively utilized in underwater exploration realms21,22,23. The excellent real-time detection performance is required in underwater applications, and one-stage models can fulfill the aim very well, especially the YOLO series algorithms. However, traditional object detection methods are only partially effective for underwater tasks, primarily due to the numerous factors that degrade image quality in underwater environments. Examples are provided in Fig. 1a, the targets blurred targets caused by image quality degradation. Moreover, the natural camouflage of underwater organisms makes it challenging to distinguish the foreground from the background. As shown in Fig. 1b, the colors of echinus and starfish closely resemble those of the surrounding rocks, making them difficult to distinguish.

Challenges in underwater object detection: examples of difficult targets.
To address the challenges of complex underwater environments, such as Chen et al.24 first enhances the underwater image data and then applies the YOLOv5 method for underwater object detection. Although detection performance can be significantly improved, this method is time-consuming in the data processing stage, and its performance improvement is limited. Zhang et al.25 incorporates the Transformer architecture into the YOLOv5 method, the ability of detector to extract features of underwater targets is enhanced. Although the detection performance is significantly improved, the introduction of Transformer increases the parameters of YOLOv5, which negatively impacts detection efficiency. To improve the feature extraction ability of models and spatial semantic localization of underwater targets while maintaining detection efficiency. Therefore, this paper proposes a Partial Semantic Encoding Module (PSEM). This method applies partial channel convolutions26 to ensure model lightweighting while enhancing the ability of models to integrate semantic features of underwater targets, thereby improving model perception. Furthermore, an attention-based detection head named Split Dimension Weighting Head (SDWH) is proposed. The detection head is applied to weight the foreground semantic rather than background. The above methods can be applied in YOLO series detectors and bring significant performance improvements. The contributions of the paper are as follows.
-
A Partial Semantic Encoding Module (PSEM) is proposed. In this method, the local semantic information of underwater targets obtained through convolution is processed using residual connections and channel concatenation to ensure semantic accuracy. Partial channel convolutions are applied for refinement of the semantics, maintaining a lightweight model structure.
-
A Split Dimension Weighting Head (SDWH) is designed for weighting target semantics information of the feature maps at different scales. The ability of models to discriminate foreground objects is enhanced. SDWH employs attention mechanisms27 to sequentially weight the fused high-level semantic information across channel, spatial, and hierarchical dimensions in a cascaded manner, leading to the final detection output. Through attention weighting, the foreground information of underwater targets is effectively enhanced, while interfering background information is suppressed, thereby improving detection performance.
-
PSEM and SDWH can be integrated into the neck and head structure of YOLO series. PSEM can replace the original convolution operations in the neck structure of the YOLO models, enhancing the fusion of high-level feature information. The fused features exhibit more accurate semantics. SDWH applies multi-dimensional semantic weighting to the fused features, further refining the spatial and channel information of foreground targets, thereby enhancing the detection capability for foreground objects of YOLO models.
The rest of this paper is structured as follows. “Related work” section introduces relevant deep learning algorithms for underwater object detection and relevant real-time detectors. In “Materials and methods” section, the relevant theories of PSEM and SDWH methods are introduced. The overall structure, which describes the modifications made to YOLO series models, is described. “Experimental results and discussion” section presents the experiments conducted with related methods on the datasets. Finally, “Conclusions” section concludes the paper.
Related work
In this section, “Underwater object detection” section introduces the relevant algorithms for underwater object detection, including one-stage, two-stage, and Transformer-based detection algorithms. It also analyzes the advantages and disadvantages of each algorithm. The real-time detection algorithms, along with YOLO-related algorithms and their application in underwater scenarios, are described in “Real-time object detectors” section.
Underwater object detection
The intricate underwater environment, insufficient lighting, and limitations of imaging equipment present substantial challenges for underwater object detection. In recent years, researchers and experts have proposed a variety of underwater object detection models. Early methods primarily relied on handcrafted features for detection. For example, Chuang et al.28 designed a fish recognition framework. Object parts are initialized using saliency and slack markers to ensure accurate matching. Non-rigid component models are subsequently learned based on separability, fitness, and discrimination criteria. Gupta et al.29 proposed a novel model for salient image detection in underwater scenes, identifying text or characters as salient regions. This approach aims to overcome the limitations of traditional feature extraction methods, which often depend on human supervision and lack automation. Sudhakar et al.30 identified that factors such as light disturbance, suspended particles, ocean snow, and color deviation interfere with underwater image acquisition. To address this, they developed an underwater image foreground extraction algorithm for the region of interest. The method involves color correction, contrast enhancement, and target area segmentation using the interactive GrabCut algorithm. Although the aforementioned methods utilize specific feature description operators, the underwater target area is identified and localized using bounding boxes. However, these feature descriptions typically depend on manual feature selection processes and set thresholds. The quality of features directly impacts subsequent applications, and efficiency remains a concern. As data scale increases, meeting the growing demands of applications becomes challenging.
The emergence of deep learning has propelled object detection advancements by automating feature extraction, significantly enhancing generalization across diverse application scenarios. Significant progress has been made by directly applying the vanilla detectors to underwater object detection31. such as YOLOv332 and Faster RCNN14. To overcome the limitations of manually set thresholds and feature selection in traditional methods. Many researchers have applied deep learning methods to underwater object detection. Chen et al.33 treated the noisy data as outliers and introduced an Invert Multi-Class Adboost (IMA) algorithm to disregard the learning of these potential outliers. These approaches yielded strong performance on noisy underwater datasets. Fan et al.34 introduced FERNet, a network designed to extract multi-scale semantic information from underwater images. These one-stage detection algorithms can avoid many limitations caused by manual involvement and efficiently complete detection tasks. However, one-stage detectors apply a single feature extractor, which is ineffective for extracting multi-scale underwater features. Therefore, these algorithms require significant improvements in detection accuracy.
A two-stage detection network and transformer-based methods are significant techniques commonly employed in underwater applications. For example, Zeng et al.35 integrated the Adversarial Occlusion Network (AON) with Faster R-CNN to enhance detection abilities for small targets. Song et al.36 applied weighted processing to the extracted features during the candidate box selection step, further refining the feature information and enhancing the detection performance. Dulhare et al.37 applied illumination transformation, angle transformation, and image degradation techniques to augment the dataset, which is then used to train Faster-RCNN, significantly improving detection performance. Gao et al.38 proposed an underwater object detection algorithm based on the Transformer architecture, named PE-Transformer. This method leverages the capability of Transformer to capture long-range semantic information to extract effective features. By employing a cross-fusion approach to integrate features, the model achieves strong feature perception capabilities for multi-scale targets. Although two-stage and Transformer-based underwater target detection methods achieve high accuracy, the methods are hindered by high model complexity and low detection efficiency. At the same time, numerous enhancements are applied to the original image to improve detection accuracy, which is time-consuming, and the improvement in accuracy is often limited. The YOLO algorithm improved with PSEM and SDWH achieves significant enhancement in detection performance while maintaining efficient detection speed. Additionally, it does not require additional data processing.
Real-time object detectors
The YOLO series has risen to prominence for its efficiency in real-time object detection after years of advancement. RT-DETR39 enhances the encoder–decoder architecture to address the inefficiency of DETR-like models, surpassing YOLO-L/X in both speed and precision. However, DETR-like structures still lag in the small model domain, where YOLO models remain state-of-the-art (SOTA) in balancing accuracy and speed. SSD40 demonstrates excellent real-time performance, it faces challenges such as redundant bounding boxes and lacks robustness in detecting small objects. For the field of underwater exploration, which has high real-time requirements, YOLO models remain the preferred choice. YOLOv1-v315,32,41 established the foundational single-stage detection architecture with backbone, neck, and head components, and utilized multi-scale branches to predict objects of various sizes, becoming a representative one-stage detector. However, due to the low accuracy of this classic model, they cannot adequately meet the requirements of underwater detection tasks. YOLOv442 optimizes the Darknet backbone and introduces enhancements such as the Mish activation function, PANet, and advanced data augmentation techniques. YOLOv543 builds on YOLOv442 with an enhanced data augmentation strategy and a wider range of model variants. Due to its improved data augmentation, YOLOv5 exhibits robust adaptability to complex environments, making it a popular choice for detection in underwater research. YOLOX44 integrates Decoupled Head, Anchor-free, and Multi Positives into its architecture, establishing a new paradigm for YOLO model design. Nevertheless, the real-time performance of YOLOX is not as good as YOLOv5. YOLOv645 introduces the reparameterization method to the YOLO series for the first time. Because it introduces the Rep-PAN Neck and EfficientRep Backbone, YOLOv6 has excellent real-time performance. YOLOv746 and YOLOv947 concentrate on evaluating the impact of gradient path on model efficacy. However, the detectors cannot achieve good lightweight performance. YOLOv848 merges the merits of its predecessors to achieve state-of-the-art (SOTA) performance within the YOLO series.
Because of the excellent real-time detection performance of YOLO methods, many researchers have improved and applied them to the field of underwater object detection. For example, Lei et al.49 utilized the Swin-Transformer architecture to replace the backbone of YOLOv5 and optimized Feature Pyramid Network (FPN) with residual connection mechanisms, which enhances the ability of extracting context from underwater datasets. Fu et al.50 introduced SE attention into the YOLOv5 backbone, modified the neck structure, and added the CBAM attention mechanism before the output, enhancing detection performance. Liu et al.51 proposed the TC-YOLO network, which improves the YOLOv5 backbone by introducing a coordinate attention mechanism and Transformer structure to enhance detection performance. Additionally, image augmentation methods are used to further improve detection metrics. Guo et al.52 improved YOLOv8 by incorporating the FasterNet structure, making the model more lightweight and further enhancing detection efficiency. These YOLO-based methods have achieved notable success in underwater object detection. However, attention mechanisms impact detection efficiency. On the other hand, lightweight models improve detection speed but reduce accuracy. The YOLO-n series of YOLO methods improved with PSEM and SDWH can enhance detection performance while maintaining efficient detection speed, achieving a better balance between accuracy and real-time. Moreover, PSEM and SDWH are universally applicable to the YOLO-n models.
Materials and methods
In this section, a network overview is provided in “Overview” section, following which the proposed partial semantic encoding module is described in “Partial semantic encoding module (PSEM)” section. The proposed split dimension weighting head is explained in “Split dimension weighting head (SDWH)” section. The methods described in this paper utilize publicly available datasets. The RUOD and UTDAC2020 datasets were used for testing and evaluation. All data and images used in this study are openly accessible, and the original authors of these datasets have granted permission for their inclusion in open-access publications. This research does not involve ethical issues or experiments related to biological samples. All methods were conducted in accordance with relevant guidelines and regulations. It has been confirmed that all experimental protocols have been approved by Shandong Zhongqing Intelligent Technology Co., Ltd and informed consent has been obtained from all participants and/or their legal guardians.

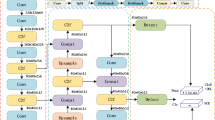
Demonstration of model architecture improvements in YOLO series.

Overview of improvements in YOLO series methods.
Overview
As shown in Fig. 2a, in the YOLO series algorithms, the Neck structure is responsible for multi-scale feature fusion, playing a crucial role in the ability of models to recognize underwater objects of varying sizes. Therefore, enhancing the effectiveness of multi-scale feature fusion plays a critical role in improving the performance of underwater object detection. As shown in Fig. 2b, the original Neck structure is improved by introducing the PSEM method, which enhances the feature extraction capability of model while improving the ability of YOLO to perceive features of multi-scale objects. To further enhance the model’s ability to recognize underwater foreground objects, SDWH is introduced before the final output of the model. By applying weighting to the fused effective information and reducing the impact of irrelevant information, the recognition capability of YOLO models is improved.
The overview of improvements in YOLO series methods is provided in Fig. 3. The YOLO series models comprise three essential components: a backbone for extracting features, a neck for integrating features, and a head for making predictions. CNNs are used in the three parts of YOLO networks. The models take input images of dimensions \(H\times W\times 3\). The backbone network is utilized to extract multi-scale features via multi-layer convolutions, encompassing low-level edge and texture features as well as high-level semantic features. This paper selects DarkNet as the backbone for extracting multi-scale features, comprising five blocks. The feature maps of the last three blocks, can be defined as \(C_i\in \textbf{R}^{h_i\times w_i\times c_i}(c_{i=\{1,2,3\}}=\{256, 512, 1024\})\) are then employed for further processing. And \(h_i\) and \(w_i\) can be formulated as \(H/2^i\) and \(W/2^i\). The neck structure plays a crucial role in integrating features from multi-layer feature maps. Using single-layer feature maps for prediction has been demonstrated to be insufficient, as it fails to accommodate the detection of objects with varying scales. To optimize the utilization of multi-layer feature maps, the pyramid structure has been introduced to facilitate feature fusion and reuse. To improve the effectiveness of semantic feature fusion for foreground targets of underwater in the network. PSEM is used in the neck structure of YOLO series detectors.
As shown in Fig. 3. Firstly, from the top to bottom, the neck network adopts a \(3 \times 3\) convolution to process \(C_3\) and get \(F_3\), which can be formulated as
where \(Conv_{3*3}(.)\)53 is a \(3 \times 3\) convolution. Then feature maps \(C_i(i={1,2})\) and \(F_{i}(i=2,3)\) are used as inputs, upsampling to align the channel and size of feature maps in different layers. Then adjacent feature maps are fused by a simple concatenation operation. The process can be defined as
where \(F_i\in \textbf{R}^{h_i\times w_i\times c_i}(i=1,2,3)\), PSEM(.) is the method named partial semantic encoding module, Concat(, )53 is concatenation operation, Up(.)43 is the \(2\times\) upsampling operation by using bilinear interpolation. Secondly, from the bottom to top, the neck network adopts a \(3 \times 3\) convolution to process \(F_1\) and get \(p_1\), which can be computed as
From the bottom to top, feature maps \(F_i(i={2,3})\) and \(P_{i}(i=1,2)\) are used as inputs, upsampling to align the channel and size of feature maps in different layers. Then adjacent feature maps are fused by a simple concatenation operation. The process can be defined as follows:
where \(P_i\in \textbf{R}^{h_i\times w_i\times c_i}(i=1,2,3)\). Finally, SDWH is utilized to weight the objects semantic, which can be formulated as
where \(O_i\in \textbf{R}^{h_i\times w_i\times c_i}\) is the outputs of YOLO series methods, SDWH(.) is the detection head named split dimension weighting head. PSEM and SDWH can be applied to boost the performance of YOLO methods by enhancing feature fusion and weighting the foreground of underwater datasets.

The structure of partial semantic encoding module (PSEM).
Partial semantic encoding module (PSEM)
The PSEM (partial semantic encoding module) utilizes residual point-wise summation and concatenation to perform global semantic encoding on feature maps. Subsequently, it employs partial convolution26 to distill the most refined channel semantic information of underwater small targets while ensuring lightweight processing. As is shown in Fig. 4a, \(X\in \textbf{R}^{h_i\times w_i\times c_i}\) is the input of the module, which can be divided into two branches. \(C_{in1}\) is processed to get \(P_{in1}\) by three CBS blocks. \(P_{in1}\) can be used for pixel-wise summation, which can be derived as
where CBS(.)46, shown in Fig. 4b, is a block which combines a \(3\times 3\) convolution, a batch normalization and a SiLU function. \(C_{in1},P_{in1}C_{out1}\in \textbf{R}^{h_i\times w_i\times c_i}\). Another branch, \(C_{in2}\) is processed by a \(1\times 1\) convolution, which can be computed as
where \(C_{in2},P_{in2}\in \textbf{R}^{h_i\times w_i\times c_i}\), \(Conv_{1*1}(.)\)53 is a \(1\times 1\) convolution. \(P_{in2}\) and \(C_{out1}\) are processed by concatenation operation to get \(C_{out2}\). Finally, PConv which is shown in Fig. 4c, is used to process \(C_{out2}\) and get \(C_{out3}\). The operation can be formulated as follows:
where \(C_{out3}\in \textbf{R}^{h_i\times w_i\times c_i}\), PConv(.)26 is a partial channel convolution. Concat(.)53 is the concatenation operation.
The PSEM is utilized to enhance the channel semantic information between multi-scale feature maps, which can improve the fusion effect of network features for underwater small targets. Thereby, the module enhances the detection performance of the YOLO methods in underwater environments.
Split dimension weighting head (SDWH)
Attention mechanisms can emphasize more important semantic information while attenuating the semantic features of less significance27 by weighting. Attention weighting can enhance the ability of the models to distinguish foreground and recognize the positioning of small targets in underwater realms.

The structure of Split Dimension Weighting Head (SDWH).
SDWH utilizes three types of attention to weight the output features of the neck network, as shown in Fig. 5a. Firstly, a \(1\times 1\) convolution is used to integrate channel information, and then Level-wise is applied to weight the channel information to get \(O_{in1}\), which is shown in Fig. 5b. The specific formulas are as follows:
where \(C_{out3},O_{in1}\in \textbf{R}^{h_i\times w_i\times c_i}\), \(\odot\) is pixel-wise multiplication, AvgPool(.)54 is the operation of average pooling, Relu(.)55 is an activation function, HSigmoid(.)56 is Hard sigmoid activation function. \(Conv_{1*1}(.)\)53 is a \(1 \times 1\) convolution. Detection targets possess various scales, corresponding to different scale-sized feature maps. Level-wise can enhance the scale perception ability of YOLO methods, by altering the expressive capability of different levels within the neck. Secondly, spatial-wise enhances the localization ability of detectors for foreground targets by weighting the spatial semantic information of \(O_{in1}\), which is provided in Fig. 5c. The processing can be shown below:
where \(O_{in2}\in \textbf{R}^{h_i\times w_i\times c_i}\), Sigmoid(.)56 is an activation function. \(Conv_{3*3}(.)\)53 is a \(3\times 3\) convolution. Underwater targets may appear at arbitrary positions within the image, corresponding to different spatial feature maps. The spatial positional perception ability of YOLO methods can be enhanced, by modifying the expressive capability of different spatial levels.
Finally, task-wise processes the global semantic information of \(O_{in2}\), which can be seen in Fig. 5d. The process is defined as
where \(O_{i}\in \textbf{R}^{h_i\times w_i\times c_i}\), FC(.)57 is a fully connected layer. Relu(.)55 is an activation function. The different task information representations of detecting targets are concentrated in the channel dimension. By weighting them, the important semantics of detecting targets can be highlighted, leading to improve detection performance.
SDWH weights feature maps across three dimensions: level, spatial, and channel, sequentially. This enhances the ability of detectors to discern underwater foreground targets and improves the localization capabilities of the YOLO methods.
Experimental results and discussion
In this section, the datasets used for model training and testing and the evaluation metrics employed in the model testing are introduced in “Datasets and evaluation metrics” section. The hyperparameter settings and the choice of optimizer for the model are described in “Implementation details” section. The testing and comparative experiments of the algorithm on the UTDAC2020 dataset are presented in “Demonstration of the proposed methods on UTDAC2020” section. The experiments on the RUOD dataset are described in “Demonstration of the proposed methods on RUOD” section. The analysis of the real-time performance and the complexity are introduced in “Complexity and real-time performance analysis” section.
Datasets and evaluation metrics
For evaluating the performance of the proposed method, The UTDAC2020 and RUOD datasets are utilized. UTDAC2020 consists of 6461 images with 4 categories. RUOD consists of 14,000 images with 10 categories. We randomly select 1036 different images from RUOD dataset to test the proposed methods, and the rest of images are used to train the models. 518 images from UTDAC2020 dataset are selected to test the models, and the rest of the images are applied to train the detectors.
For a comprehensive evaluation of performance, average precision (AP) with a specific threshold is used as the metric to evaluate the performance of the proposed methods. AP@0.5 and AP@0.75 are the values that at the thresholds of 0.5 and 0.75. The mean Average Precision (mAP), calculated as the average of AP values at a threshold of 0.5, is used as the metric. Moreover, APs, APm, and APl are used in this paper to evaluate the mAP performances in the detection of small, medium, and large objects, respectively.
Implementation details
Our methods are implemented on a GPU named NVIDIA GeForce RTX 2080 SUPER. Network parameters are initialized with a normal distribution. Stochastic Gradient Descent (SGD) is used as the optimizer, with a weight decay of 0.0001 and a momentum of 0.9. With a batch size of 32, the initial learning rate is set to 0.01, and it will be decreased by multiplying by 0.1 at epochs 24 and 30 out of a total of 50 epochs. During the training and testing phases, input images are resized to 640 \(\times\) 640 pixels. The input images are augmented by horizontal and vertical flipping with a probability of 0.5.
Demonstration of the proposed methods on UTDAC2020
Ablation experiments on UTDAC2020
The proposed methods, PSEM and SDWH, aim to address the issues of feature fusion and resistance to background interference for underwater targets. In the ablation experiments, YOLO series models, which include v5n, v6n, and v8n are utilized as baselines. The way of improvement for baselines is shown in Fig. 3. The convolution operations in the neck networks, following the concatenation operations, are replaced with PSEM. SDWH is added to the detection head of the detectors.
Then, we evaluate the design choices of PSEM and SDWH, incrementally adding them to analyze their effects. The evaluation results are shown in Table 1. The application of PSEM and SDWH consistently improves performance of the models. PSEM improves the performance of YOLOv8n from 80.1% mAP to 81.0% mAP and SDWH bring a better improvement of 2.7% mAP. Meanwhile, the AP50 and AP75 performances are improved simultaneously. By using both of them, the proposed methods, PSEM and SDWH, bring a considerable improvement of 2.8% mAP (80.1% vs 82.9%). In addition, ablation experiments were conducted on YOLOv5n and YOLOv6n. PSEM improves the performance of YOLOv5n from 80.8% mAP to 80.9% mAP. SDWH brings an improvement from 80.8% to 81.2%. At the same time, AP50 and AP75 performances are improved simultaneously. By using both of them, the proposed methods, PSEM and SDWH, bring a considerable improvement of 1% mAP (80.8% vs 81.8%). YOLOv6 has an improvement from 77.2% mAP to 78.1% mAP by PSEM. SDWH brings a better improvement of 2.7% mAP. Meanwhile, the AP50 and AP75 performances are improved simultaneously. By using both of them, the proposed methods, PSEM and SDWH, bring a considerable improvement of 3% mAP (77.2% vs 80.2%). The experiments demonstrate the significance of PSEM in feature fusion, and the significance of SDWH in weighting the foreground targets.

Examples of detection results on UTDAC2020 dataset.

Typical underwater objecs of UTDAC2020 dataset and visualization of the feature maps are depicted. (a) Shows the ground truth of the objects. (b,c) Visualize the feature maps in which the color represents the degree of activation. The feature maps obtained by the YOLOv8 and the improved YOLOv8 with the proposed methods are shown in (b,c), respectively. The improved YOLOv8 can extract the feature information of ground truth exactly.
Performance demonstration on UTDAC2020
Examples of underwater object detection, are shown in Fig. 7. The corresponding feature maps obtained by using YOLOv8 and the improved YOLOv8 are visualized in Fig. 7b,c. Evidently, the activation of underwater targets features achieved by the improved YOLOv8 surpasses that obtained with YOLOv8, which means that the proposed methods can guide the attention of network towards the ground truth regions. These methods significantly enhance the identification of underwater target features, thereby improving the classification and regression of underwater objects.
To further demonstrate the improved performance of YOLO models with PSEM and SDWH, a performance comparison is conducted with underwater real-time detection algorithms. The results of the comparison experiments are provided in Table 2. Among the compared methods, MIPAM-YOLO achieves the highest mAP of 81.2% and AP75 of 48.2%. Compared with MIPAM-YOLO, YOLOv8Plus can achieve 82.9% mAP and 48.4%AP75. Meanwhile, YOLOv5Plus achieves the highest AP75 of 49.1%mAP. In the APs, APm, and APl metrics, YOLOv8Plus also achieved the highest performance. The improvements are obvious, which demonstrates the effectiveness of PSEM and SDWH.
Examples of underwater object detection in UTDAC2020 are shown in Fig. 6. The results demonstrate that PSEM and SDWH are efficient at detecting underwater targets in low contrast environments.
Demonstration of the proposed methods on RUOD
Ablation experiments on RUOD
The ablation experiments are conducted on RUOD dataset to comprehensively validate the effectiveness of PSEM and SDWH. The results are provided in Table 3. As shown in Table 3, a single PSEM or SDWH could stably boost performance. The improvement by using PSEM for v8n, v5n and v6n are 0.9% mAP, 0.5% mAP, 1.1% mAP respectively. While that of SDWH are 1.9% mAP, 0.9% mAP, 3.1% mAP. The improvement from using PSEM and SDWH for v8n, v5n and v6n is 2.7% mAP, 1.5% mAP, 3.7% mAP respectively. Concurrently, there is simultaneous improvement in the performances of AP50 and AP75. The experiments highlight the importance of PSEM in feature fusion and the role of SDWH in weighting foreground targets.

Examples of detection results on RUOD dataset.

Typical underwater targets of RUOD dataset are depicted alongside the visualization of feature maps. (a) Presents the ground truth of these targets, while (b,c) display the feature maps, with colors indicating activation levels. Feature maps from YOLOv8 and the enhanced version by our proposed methods are shown in (b,c), respectively. The enhanced YOLOv8 accurately extracts feature information corresponding to ground truth.
Performance demonstration on RUOD
Examples of underwater object detection from the RUOD dataset are illustrated in Fig. 9. The feature maps generated by YOLOv8 and its enhanced version are depicted in Fig. 9b,c, respectively. Clearly, the improved YOLOv8 outperforms YOLOv8 in activating features related to underwater targets, indicating that the proposed methods effectively direct the attention of network towards ground truth regions. These approaches notably enhance the detection of underwater target features, thus improving the classification and regression of underwater objects. To illustrate the effectiveness, PSEM and SDWH are applied to YOLO series detectors. The results of the comparison experiments are presented in Table 4. Among the comparison methods, MIPAM-YOLO achieves the highest mAP of 79.8% and KCF-Faster R-cnn achieves the highest AP75 of 47.1%. Compared with MIPAM-YOLO and KCF-Faster R-cnn, YOLOv8Plus achieves 80.9% mAP and YOLOv5Plus achieves 47.3%AP75. Meanwhile, YOLOv5Plus achieves the highest APs of 19.0%. In the APm, and APl metrics, YOLOv8Plus also achieves the highest performance. The improvements are evident, which demonstrate the effectiveness of PSEM and SDWH.
Figure 8 showcases examples of detection results from the RUOD dataset. The results demonstrate the effectiveness of PSEM and SDWH in detecting weak and small targets. The conducted experiments and visualizations collectively substantiate the efficacy of the proposed methods. The presented results highlight the substantial enhancement of underwater targets detection achievable through our approach. Notably, PSEM and SDWH seamlessly integrate with YOLO series detectors, resulting in a discernible performance improvement in underwater applications.
Complexity and real-time performance analysis
Due to the high real-time requirements of underwater environment detection, network complexity and real-time performance are significant concerns for evaluating the practicality of detectors.
Taking YOLOv8n, YOLOv5n and YOLOv6n as the baselines, we analyze the floating point operations (FLOPs), parameters (Params), and frames per second (FPS) to compare the complexities and real-time performances of the methods. As shown in Table 5, for YOLOv8n, with the utilization of PSEM and SDWH, the FLOPs increase by about 10%. while the Params increase by about 5%. The inference speed is reduced by 7 FPS. About YOLOv5n, after enhancement, the FLOPs increase by about 18%. while Params by about 16%. The inference speeds are reduced by 9 FPS. For YOLOv6n, the FLOPs increase by about 9%. while the Params increase by about 10%. The inference speed is reduced by 14 FPS.
As a result, The enhancement of PSEM and SDWH for YOLO series detectors can meet real-time requirements in underwater applications. The additional time cost brought by the proposed methods falls within the acceptable range.
Conclusions
This paper proposes a method to enhance feature fusion by locally encoding channel information in the neck network features, called the Partial Semantic Encoding Module (PSEM). An attention mechanism is integrated into the detection head in this paper, called the Split Dimension Weighting Head (SDWH). PSEM utilizes residual pixel-wise addition block to encode the spatial semantics of the feature maps in the neck networks. Moreover, the partial channel convolution is used by PSEM to enrich the contextual information with low cost. SDWH operates on feature maps that have been fused by concatenation, where the hierarchical semantics, spatial semantics, and channel semantics of the feature maps are weighted separately. Finally, the detection outputs of the model are completed. PSEM and SDWH improve the ability of detectors to locate and identify underwater foreground targets. The proposed methods can be seamlessly integrated into different YOLO series models for efficient detection in the underwater realm. Experiments are conducted on the UTDAC2020 and RUOD datasets. PSEM and SDWH can effectively improve the performance of the models with an acceptable computational cost. The effectiveness of PSEM and SDWH indicates further potential for real-world underwater applications.
Data availability
Data is provided within the manuscript.
References
Xu, S. et al. A systematic review and analysis of deep learning-based underwater object detection. Neurocomputing 527, 204–232 (2023).
Qiao, W., Khishe, M. & Ravakhah, S. Underwater targets classification using local wavelet acoustic pattern and multi-layer perceptron neural network optimized by modified whale optimization algorithm. Ocean Eng. 1, 108415 (2021).
Fayaz, S., Parah, S. A. & Qureshi, G. Underwater object detection: Architectures and algorithms—A comprehensive review. Multimedia Tools Appl. 81, 20871–20916 (2022).
Moniruzzaman, M., Islam, S. M. S., Bennamoun, M. & Lavery, P. Deep learning on underwater marine object detection: A survey. In Advanced Concepts for Intelligent Vision Systems: 18th International Conference, ACIVS 2017, Antwerp, Belgium, September 18–21, 2017, Proceedings 18 150–160 (Springer, 2017).
Yeh, C.-H. et al. Lightweight deep neural network for joint learning of underwater object detection and color conversion. IEEE Trans. Neural Netw. Learn. Syst. 33, 6129–6143 (2021).
Zhang, L., Li, C. & Sun, H. Object detection/tracking toward underwater photographs by remotely operated vehicles (rovs). Futur. Gener. Comput. Syst. 126, 163–168 (2022).
Er, M. J., Chen, J., Zhang, Y. & Gao, W. Research challenges, recent advances, and popular datasets in deep learning-based underwater marine object detection: A review. Sensors 23, 1990 (2023).
Wang, C. et al. Gold-yolo: Efficient object detector via gather-and-distribute mechanism. Preprint at http://arxiv.org/abs/2309.11331 (2023).
Mathias, A., Dhanalakshmi, S., Kumar, R. & Narayanamoorthi, R. Deep neural network driven automated underwater object detection. Comput. Mater. Continua 70, 1 (2022).
Li, X., Shang, M., Qin, H. & Chen, L. Fast accurate fish detection and recognition of underwater images with fast r-cnn. In OCEANS 2015-MTS/IEEE Washington 1–5 (2015).
Villon, S. et al. Coral reef fish detection and recognition in underwater videos by supervised machine learning: Comparison between deep learning and hog+ svm methods. In International Conference on Advanced Concepts for Intelligent Vision Systems 160–171 (2016).
Gong, X.-Y. et al. Contour extraction and quality inspection for inner structure of deep hole components. IEEE Trans. Components Packag. Manuf. Technol. 9, 575–585 (2018).
Ni, X., Liu, H., Ma, Z., Wang, C. & Liu, J. Detection for rail surface defects via partitioned edge feature. IEEE Trans. Intell. Transp. Syst. 23, 5806–5822 (2021).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 28, 1 (2015).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 779–788 (2016).
Lin, T.-Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision 2980–2988 (2017).
Yang, X., Qian, Y., Zhu, H., Wang, C. & Yang, M. Baanet: Learning bi-directional adaptive attention gates for multispectral pedestrian detection. In 2022 International Conference on Robotics and Automation (ICRA) 2920–2926 (IEEE, 2022).
Bozcan, I. & Kayacan, E. Context-dependent anomaly detection for low altitude traffic surveillance. In 2021 IEEE International Conference on Robotics and Automation (ICRA) 224–230 (IEEE, 2021).
Liao, M., Shi, B. & Bai, X. Textboxes++: A single-shot oriented scene text detector. IEEE Trans. Image Process. 27, 3676–3690 (2018).
Bae, S.-H. Deformable part region learning and feature aggregation tree representation for object detection. IEEE Trans. Pattern Anal. Mach. Intell. (2023).
Jiang, G. et al. Underwater moving object localisation based on weak electric fish bionic sensing principle and lstm. In 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO) 744–749 (2021).
Jiang, Z. & Wang, R. Underwater object detection based on improved single shot multibox detector. In Proceedings of the 2020 3rd International Conference on Algorithms, Computing and Artificial Intelligence 1–7 (2020).
Huang, H. et al. Faster r-cnn for marine organisms detection and recognition using data augmentation. Neurocomputing 1, 372–384 (2019).
Chen, H., Lin, J., Zhuge, L. & Xia, X. Underwater image restoration and target detection based on monocular depth estimation. In 2021 China Automation Congress (CAC) 5597–5601 (IEEE, 2021).
Zhang, L. et al. Underwater fish detection and counting using image segmentation. Aquaculture International 1–19 (2024).
Chen, J. et al. Run, don’t walk: Chasing higher flops for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 12021–12031 (2023).
Dai, X. et al. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 7373–7382 (2021).
Chuang, M.-C., Hwang, J.-N. & Williams, K. A feature learning and object recognition framework for underwater fish images. IEEE Trans. Image Process. 25, 1862–1872 (2016).
Gupta, N. & Jalal, A. S. A robust model for salient text detection in natural scene images using mser feature detector and grabcut. Multimedia Tools Appl. 78, 10821–10835 (2019).
Sudhakar, M. & Meena, M. J. An efficient interactive segmentation algorithm using color correction for underwater images. Wireless Netw. 27, 5435–5446 (2021).
De Langis, K., Fulton, M. & Sattar, J. Towards robust visual diver detection onboard autonomous underwater robots: Assessing the effects of models and data. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 5372–5378 (2021).
Redmon, J. & Farhadi, A. Yolov3: An incremental improvement. Preprint at http://arxiv.org/abs/1804.02767 (2018).
Chen, L. et al. Fluorescence biosensor for dna methyltransferase activity and related inhibitor detection based on methylation-sensitive cleavage primer triggered hyperbranched rolling circle amplification. Anal. Chim. Acta 1122, 1–8 (2020).
Fan, B., Chen, W., Cong, Y. & Tian, J. Dual refinement underwater object detection network. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XX 16 275–291 (2020).
Zeng, L., Sun, B. & Zhu, D. Underwater target detection based on faster r-cnn and adversarial occlusion network. Eng. Appl. Artif. Intell. 100, 104190 (2021).
Song, P., Li, P., Dai, L., Wang, T. & Chen, Z. Boosting r-cnn: Reweighting r-cnn samples by rpn–s error for underwater object detection. Neurocomputing 530, 150–164 (2023).
Dulhare, U. N. & Ali, M. H. Underwater human detection using faster r-cnn with data augmentation. Mater. Today Proc. 80, 1940–1945 (2023).
Gao, J., Zhang, Y., Geng, X., Tang, H. & Bhatti, U. A. Pe-transformer: Path enhanced transformer for improving underwater object detection. Expert Syst. Appl. 246, 123253 (2024).
Zhao, Y. et al. Detrs beat yolos on real-time object detection. Preprint at http://arxiv.org/abs/2304.08069 (2023).
Liu, W. et al. Ssd: Single shot multibox detector. In Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14 21–37 (2016).
Redmon, J. & Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 7263–7271 (2017).
Bochkovskiy, A., Wang, C.-Y. & Liao, H.-Y. M. Yolov4: Optimal speed and accuracy of object detection. Preprint at http://arxiv.org/abs/2004.10934 (2020).
Wu, W. et al. Application of local fully convolutional neural network combined with yolo v5 algorithm in small target detection of remote sensing image. PLoS ONE 16, e0259283 (2021).
Ge, Z., Liu, S., Wang, F., Li, Z. & Sun, J. Yolox: Exceeding yolo series in 2021. Preprint at http://arxiv.org/abs/2107.08430 (2021).
Li, C. et al. Yolov6: A single-stage object detection framework for industrial applications. Preprint at http://arxiv.org/abs/2209.02976 (2022).
Wang, C.-Y., Bochkovskiy, A. & Liao, H.-Y. M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 7464–7475 (2023).
Wang, C.-Y., Yeh, I.-H. & Liao, H.-Y. M. Yolov9: Learning what you want to learn using programmable gradient information. Preprint at http://arxiv.org/abs/2402.13616 (2024).
Talaat, F. M. & ZainEldin, H. An improved fire detection approach based on yolo-v8 for smart cities. Neural Comput. Appl. 35, 20939–20954 (2023).
Lei, F., Tang, F. & Li, S. Underwater target detection algorithm based on improved yolov5. J. Mar. Sci. Eng. 1, 310 (2022).
Fu, S., Xu, F., Liu, J., Pang, Y. & Yang, J. Underwater small object detection in side-scan sonar images based on improved yolov5. In 2022 3rd International Conference on Geology, Mapping and Remote Sensing (ICGMRS) 446–453 (IEEE, 2022).
Liu, K., Peng, L. & Tang, S. Underwater object detection using tc-yolo with attention mechanisms. Sensors 23, 2567 (2023).
Guo, A., Sun, K. & Zhang, Z. A lightweight yolov8 integrating fasternet for real-time underwater object detection. J. Real-Time Image Proc. 21, 49 (2024).
Gu, J. et al. Recent advances in convolutional neural networks. Pattern Recogn. 77, 354–377 (2018).
Zhao, J. & Snoek, C. G. Liftpool: Bidirectional convnet pooling. Preprint at http://arxiv.org/abs/2104.00996 (2021).
Xu, B. Empirical evaluation of rectified activations in convolutional network. Preprint at http://arxiv.org/abs/1505.00853 (2015).
Noel, M. M. & Oswal, Y. A significantly better class of activation functions than relu like activation functions. Preprint at http://arxiv.org/abs/2405.04459 (2024).
Long, J., Shelhamer, E. & Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 3431–3440 (2015).
Zhang, J., Zhu, L., Xu, L. & Xie, Q. Mffssd: An enhanced ssd for underwater object detection. In 2020 Chinese Automation Congress (CAC) 5938–5943 (IEEE, 2020).
Shen, X., Wang, H., Cui, T., Guo, Z. & Fu, X. Multiple information perception-based attention in yolo for underwater object detection. Vis. Comput. 40, 1415–1438 (2024).
Tian, T., Cheng, J., Wu, D. & Li, Z. Lightweight underwater object detection based on image enhancement and multi-attention. Multimedia Tools and Applications 1–19 (2024).
Xu, F. et al. Real-time detecting method of marine small object with underwater robot vision. In 2018 OCEANS-MTS/IEEE Kobe Techno-Oceans (OTO) 1–4 (IEEE, 2018).
Acknowledgements
This work was supported in part by the Key Research and Development Program of Shandong Province in 2023 (Major Science and Technology Innovation Engineering)—Research and Development Project on Wide-Width Line Scanning Machine Technology (2023CXGC010203).
Author information
Authors and Affiliations
Contributions
X.L. as a key participant of this project, was mainly responsible for writing the article, data collection, and part of the experimental and design of the algorithm and the experimental part; Y.Z. and H.S. analysed the results; Y.W. and G.C. provided technical and writing guidance.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, X., Zhao, Y., Su, H. et al. Efficient underwater object detection based on feature enhancement and attention detection head. Sci Rep 15, 5973 (2025). https://doi.org/10.1038/s41598-025-89421-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-89421-2
