
Abstract
The precise monitoring and timely alerting of river water levels represent critical measures aimed at safeguarding the well-being and assets of residents in river basins. Achieving this objective necessitates the development of highly accurate river water level forecasts. Hence, a novel hybrid model is provided, incorporating singular value decomposition (SVD) in conjunction with kernel-based ridge regression (SKRidge), multivariate variational mode decomposition (MVMD), and the light gradient boosting machine (LGBM) as a feature selection method, along with the Runge–Kutta optimization (RUN) algorithm for parameter optimization. The L-SKRidge model combines the advantages of both the SKRidge and ridge regression techniques, resulting in a more robust and accurate forecasting tool. By incorporating the linear relationship and regularization techniques of ridge regression with the flexibility and adaptability of the SKRidge algorithm, the L-SKRidge model is able to capture complex patterns in the data while also preventing overfitting. The L-SKRidge method is applied to forecast water levels in the Brook and Dunk Rivers in Canada for two distinct time horizons, specifically one- and three days ahead. Statistical criteria and data visualization tools indicates that the L-SKRidge model has superior efficiency in both the Brook (achieving R = 0.970 and RMSE = 0.051) and Dunk (with R = 0.958 and RMSE = 0.039) Rivers, surpassing the performance of other hybrid and standalone frameworks. The results show that the L-SKRidge method has an acceptable ability to provide accurate water level predictions. This capability can be of significant use to academics and policymakers as they develop innovative approaches for hydraulic control and advance sustainable water resource management.
Similar content being viewed by others

Introduction
Precise river water level predictions are imperative for flood alerts and efficient water resource management1,2,3. Researchers commonly use time series hydrological forecasting techniques to forecast future water level data. These forecasts provide significant insights into flood protection, catastrophe management, and resource management2,4,5. Forecasting river water levels (WL) is crucial for planning and addressing climate-related problems due to its dependence on hydro-meteorological aspects and inherent uncertainty. Precisely forecasting river flow patterns over high, medium, and low ranges is a challenging endeavor owing to their distinct nonlinear dynamics and hydrological processes. This complexity requires the creation of developed data-driven models6,7,8.
Diverse methodologies are employed to develop water level models that incorporate physical processes9,10. While physical models delve into the mechanism and dynamics of river flow, their adaptability is restricted by predictand variables, catchment conditions, and model parameters11,12. Nonlinearities arising from hydrological interactions and the mutual dependence of hydrological factors impede the predictive accuracy of physical models13. In contrast, data-driven methodologies aim to identify relationships among variables affecting water flow. They tackle the nonlinear attributes of predictor variables14. In conclusion, physical approaches use partial differential equations with constraints on boundaries, but data-driven models depend specifically on input-target parameter correlations, which simplifies model comprehending and reduces complexity.
The reliability of data-driven methods for water level prediction of rivers has been on the rise, as indicated by studies15,16,17. Employing artificial neural networks (ANN) as versatile tools, researchers have crafted single hidden layer of ANNs for forecasting both short-term18,19 and long-term11 variations in WL, treating the ANN as a black-box model. Wei created a forecasting methodology for river stages during typhoons in Taiwan’s Tanshui River Basin, comparing lazy (k-nearest neighbor (kNN) and locally weighted regression (LWR)) and eager (support vector regression (SVR), linear regression (REG), and artificial neural network (ANN)) learning approaches20. Using data from 50 typhoon events and hourly hydrological data from 1996 to 2007, results showed that ANN and SVR outperformed REG, while LWR was more effective than kNN, highlighting model-dependent performance. Deo and Şahin used the extreme learning machine (ELM) model to simulate average streamflow levels at three locations in eastern Queensland, showing its superiority compared to the ANN model16. The ELM model used nine predictors and ultimately resulted in acceptable precision measures (R2 = 0.964–0.997). Anh et al. developed a daily water level forecasting model based on the wavelet-ANN (WAANN) approach21. This method combined the benefits of wavelet method with ANN. Findings demonstrated that WAANN surpassed the conventional ANN model. Wang et al. devised a technique using a dilated causal convolutional neural network (DCCNN) which is capable of providing water-level predictions with lead durations ranging from 1 to 6 h18. The model was tested on a dataset of 16 typhoon events in Taiwan. The findings showed that the DCCNN outperformed existing support vector machine (SVM) and multilayer perceptron (MLP) methods.
Zhu et al. utilized the feed forward neural network (FFNN) and Deep learning (DL) to forecast monthly lake water levels in 69 temperate lakes in Poland for one month ahead5. The research indicated that the FFNN and DL models exhibited strong performance, with just negligible differences. The results showed that traditional methods might be enough to forecast lake water level. Phana and Nguyen introduced a hybrid method that included linear and nonlinear models1. Their methodology combines statistical MLMs with autoregressive integrated moving average (ARIMA) for predicting water levels.
To assess its efficacy, they applied this method to real datasets from the Vu Quang, Hanoi, and Hung Yen hydrological stations, revealing significant improvements in forecasting performance compared to other methods. Barzegar et al. improved long-term water level forecasts for Lake Michigan and Lake Ontario by combining the boundary corrected maximal overlap discrete wavelet transform (BC-MODWT) data preprocessing with a hybrid convolutional neural network (CNN) and long-short term memory (LSTM) (CNN-LSTM) model22. The suggested model’s performance was compared with the BC-MODWT-based MLMs, including random forest (RF) and SVR. From the results, the CNN-LSTM model performed better than the other models. An effective method to enhance the lake water level forecasting accuracy was shown using the BC-MODWT-CNN-LSTM model.
Masrur Ahmed et al. presented a novel hybrid DL model for the prediction of short-term river water levels (SWL)15. This model integrates the CNN, bi-directional long short-term memory (BiLSTM), and ant colony optimization (ACO) with a two-phase decomposition technique over several prediction time horizons. By combining variational mode decomposition (VMD), complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN), and efficient feature extraction approaches, the CVMD-CBiLSTM model attained a high level of accuracy. Jamei et al. developed research aimed at forecasting daily floodwater levels in Australia’s Clarence River at the Baryulgil and Lilydale stations from 2005 to 20212. Their novel methodology used a hybrid framework that integrated time-varying filter-based empirical mode decomposition (TVF-EMD) with feature selection using classification and regression trees (CART). Their results demonstrated that the CART-TVF-EMD-CFNN model surpassed other models at both stations.
Zakaria et al. utilized three machine learning algorithms (i.e., multi-layer perceptron neural network (MLP-NN), LSTM, and extreme gradient boosting (XGBoost)) to develop water level forecasting models for Malaysia’s Muda River23. The results showed that the MLP model had a higher accuracy of 0.871, which was superior to both the LSTM model (0.865) and the XGBoost model (0.831). Wang et al. evaluated five data preprocessing techniques VMD, wavelet packet decomposition (WPD), CEEMDAN, extreme-point symmetric mode decomposition (ESMD), and singular spectrum analysis (SSA)) in conjunction with a GRU model for forecasting monthly runoff24. The results showed that VMD and WPD increased accuracy. Xu and Wang25 presented an ensemble prediction model that employs least squares support vector machine (LSSVM) in conjunction with VMD, dung beetle optimization (DBO), and error correction (EC) to improve runoff forecast accuracy in the Ganjiang and Heihe River basins. The findings suggest that the proposed model could achieve high accuracy and enhance forecasts of extreme values.
Prior research has predominantly relied on the original version of MLMs and different types of optimization algorithms to derive optimal parameters22,26. The present study develops a novel version of Kernel Ridge regression (KRidge), called SKRidge, that combines the singular value decomposition (SVD) with Ridge regression. SKRidge enhances the precision and stability of the regression model by the integration of these two approaches. This makes it a potential method for predictive modeling. The proposed hybrid method integrates Ridge with SKRidge to create a linearly related model known as L-SKRidge. The Runge–Kutta (RUN) algorithm is used to improve control parameters for the L-SKRidge model in WL forecasting. Prior research has demonstrated the effectiveness and frequent usage of the RUN algorithm in various model tuning applications27,27,29. Therefore, the main goal of the present study is to evaluate the efficiency and capacity of MLMs in predicting water levels at various time frames in the future. The goal is to develop a thorough and dependable tool for academics and professionals that are interested in using MLMs for making water level projections in the future that extend beyond a single step. To the best of the authors’ awareness, the study introduces a pioneering attempt in crafting a novel structure for the kernel ridge regression model. It incorporates multivariate variational mode decomposition (MVMD) for real-world hydrological forecasting and employs the MARCOS methodology to identify the best machine learning model.
Models background
The work aims to improve the accuracy and efficiency of regression analysis by using singular value decomposition (SVD) and Ridge regression to compute the regression parameters (\(\psi\)) for the KRidge model. SVD decomposes incoming data into orthogonal components, therefore separating salient characteristics. The regression variable (\(\psi\)) is derived from the SVD output. This enables the model to effectively utilize input variables. It captures complex relationships while maintaining stability against multicollinearity using Ridge regression’s L2 regularization.
To create the proposed model, L-SKRidge, it is systematically applied SVD to highlight essential features, computed the regression parameters (\(\psi\)), and refined them using Ridge regression. Eventually, L-SKRidge uses both strategies into a hybrid model that equilibrates the predictions of both the SKRidge and conventional Ridge procedures based on a linear combination. The suggested model is also optimized using the Runge–Kutta (RUN) method. This novel methodology seeks to significantly improve the precision and efficacy of regression analysis and provide a reliable instrument for forecasting.
To implement the proposed framework, several techniques are developed, including the proposed ML model, the optimization method, the measurement of alternatives and ranking according to compromise solution (MARCOS), the decomposition method, the feature selection approach, and the criterion evaluation. These methods are described at the following sections.
linear regression
Multiple linear regression (MLR)30 outlines the association between the input variable u and a set of target variables {\(x_{1}\), \(x_{2}\), …, \(x_{M}\)}. A MLR with M independent variables can be represented as follows:
In Eq. (1), the training phase provides knowledge of the independent variables \(x\) and dependent variables y, and the primary task is to determine the regression coefficients (\(\phi\)).
Ridge regression
Multicollinearity issues can complicate MLR models, leading to challenges in accurate estimation. This complexity often leads to increased variance in the estimated regression coefficients and wider confidence intervals, resulting in significantly reduced estimation accuracy and poorer stability31. In simpler terms, in the MLR, when regression coefficients are substantial, even slight shifts in the data can have a substantial impact on prediction outcomes31.
Ridge regression is utilized to streamline the model by diminishing the significance of less important coefficients. It employs L2 regularization to the fitness function of linear regression, transforming the coefficient solution problem into a conditional optimization challenge32. This approach aims to simplify the coefficients and enhance the method’s capability. The fitness function of ridge regression is defined in Eq. (2).
where \(\eta\) has a positive amount. The \(\eta\) parameter is used to regulate the \(\left\| \phi \right\|_{2}^{2}\).
By derivative of Eq. (2), the parameter \(\phi\) can be calculated by Eq. (3).
where \(I\) indicates the identity matrix, and \(\mu_{0}\) expresses penalty coefficient. For computing the forecasted quantity, we establish the subsequent equation.
Saunders and Gammerman33 advocated employing kernel functions (Kr) for customizing Ridge Regression (RR). The kernel ridge regression (KRidge) technique33 is used to derive Eq. (5), which builds upon the fundamental research of Vapnik34.
The kernel function (\(Kr\left( {x,x_{k} } \right)\)) serves as a measure of relationship between variables, with the weights specified by \(\beta_{k}\). The procedure for establishing these weights includes optimizing the quantity of modifications applied to the fitness function.
Consequently, Eq. (7) resembles Ridge Eq. (3) with the sole difference being the substitution of all dot products with the Kr through the kernel method. To obtain an accurate value for the coefficients α, they can be defined by Eq. (7).
where \(U = \left( {U_{1} , \ldots ,U_{k} } \right)^{T}\).
The KRidge employs the Kr as an input parameter to calculate the Kr. In this study, the matrix computation is accomplished through the utilization of an efficient wavelet function (WF). The proposed Kr can be formally formulated in Eq. (8)35.
where \(\alpha\),\(\delta\), and \(\rho\) demonstrates three main unknown parameters of kernel function. In this work, the RUN optimization algorithm is employed to specify the main parameters of \(Kr\).
Singular value decomposition (SVD)
The SVD36 is a commonly used method for analyzing an input by separating it into different components, which allows for the discovery of several important and interesting qualities that are intrinsic to the original input. The SVD has the capability to decrease the number of dimensions by means of matrix decomposition. Given any i × n matrix X, the SVD decomposition can be represented as follows:
where \(D\) is a matrix where the only non-zero elements are on the diagonal. These diagonal elements represent singular values of the matrix X. According to Fig. 1, in order to mathematically express X, three matrices must be applied sequentially: scaling (D), rotation by (\(Z^{T}\)), and further rotation by Q. Also, the I represents identity matrix and the Q and Z matrices reflect unit orthogonal vectors, it follows that:

Conceptualization of the SVD.
Compute the regression variables employing the SVD and Ridge approaches.
In the present section, the SVD and Ridge approaches are used to calculate the regression parameters (\(\psi\)) for the KRidge model, which improves model precision. Here X can be substituted in Eq. (3) by its SVD derivation. Additionally, it will be performed calculations for (\(X^{{\text{T}}} X\)) and (\(XX^{{\text{T}}}\)):
Applying Eqs. (11) and (12) in Eq. (3):
We can utilize the property that matrices H, J, and M adhere to the following relationship:
According to37, Eq. (3) can be resolved by employing SVD. Furthermore, matrix Q is identified as a lower-dimensional matrix.
Hybrid SVD, KRidge, and ridge methods
This part provides a description of the proposed hybrid ML model to forecast the WL. In this regard, the KRdige uses the SVD to calculate the regression parameter (\(\psi\)). The SVD is applied to the input variables and allows the framework to generate more efficient inputs by simultaneously utilizing the properties of the Ridge and SVD approaches. Equation (16) is defined to construct the SKRidge.
in which
Additionally, Eq. (19) is used to calculate the predicted variable (\(\hat{u}\)).
The objective of the present research was to improve the accuracy and efficiency of the framework. The proposed hybrid model (L-SKRidge) was developed by combining the SKRidge model with the Ridge approach through a linear connection. The hybrid model is shown as shown in Fig. 2. Pseudo code of the proposed model was presented in Algorithm 1.
where \(\theta\) has a positive amount within the range of [0, 1], and computed by the RUN algorithm.

Schematic of the SKRidge model.

Pseudo-code of L-SKRidge method.
RUN optimization method
Recently, researchers have developed numerous optimization algorithms to address various optimization problems. However, many of these methods draw inspiration from nature and lack a strong mathematical foundation38,39. Therefore, this study employs a mathematically grounded optimization technique known as Runge–Kutta optimization (RUN). The Runge–Kutta optimization algorithm was formulated with the foundation of the Runge–Kutta method40. The enhanced solution quality operator and the Runge–Kutta search mechanism (SM) make up the algorithm’s two operators. The RUN algorithm’s primary steps are described in the following subsections.
Updating solutions
The RUN algorithm is based on the RK method, and employs the SM to modify the current solution (\(x_{k}\)) at each iteration.
where \(v\) is used to represent an integer with the value of either 1 or − 1; \(r\) expresses a random coefficient in the range of [0, 2]; \(x_{c1}\) and \(x_{c2}\) express two positions, selected randomly within the range of [1, N]; N expresses the population size; \(A\) indicates an adaptive coefficient; and \(\gamma\) expresses a random coefficient. \(SM\) is formulated as:
where \(x_{{\text{w}}}\) and \(x_{{\text{b}}}\) indicate the worst and best positions; and \(a_{1}\) and \(a_{2}\) express two random numbers within the range of [0, 1]. \(\Delta x\) is formulated as:
where D indicates a random differential vector; \(U\) and \(L\) express the upper and lower bound; \(It\) indicates the iteration count; \(MIt\) indicates the upper limit for the number of iterations; and \(x_{avg}\) indicates the average of solutions at each iteration. In this research, \(x_{{\text{w}}}\) and \(x_{{\text{b}}}\) express as follows:
where \(x_{bst,k}\) represents the best solution that was achieved from three different solutions that were chosen randomly (\(x_{c1}\), \(x_{c2}\), and \(x_{c3}\)). \(A\) is formulated as:
\(x_{rdb}\) and \(x_{rd1}\) are given by:
where \(\omega\) represents a number that has been independently generated and falls within the range of 0 to 1; \(x_{best}\) indicates the best solution explored so far; and \(x_{lbest}\) expresses the best position attained during the ongoing iteration.
Enhanced solution quality (ESQ)
RUN utilizes a robust operator termed the enhance solution quality (ESQ), denoting enhanced solution quality, to elevate solution quality and prevent the occurrence of local solutions. The RUN algorithm creates solution \(V_{1}\) by employing the following method to carry out the ESQ operator.
where \({\Omega }\) represents a random number that generates between 0 and 1. Additionally, \(\tau\) signifies another random number, specifically 5 \(\times rand\) value, while \(\varphi\) represents an integer with possible values of 1, 0, or − 1.
As solution \(V_{1}\) might not yield a superior objective function result compared to solution \(x_{k}\) (i.e., where \(f\left( {V_{1} } \right)> f(x_{k} )\)), an additional attempt is made to generate a potential solution. This new solution, denoted as \(x_{new3}\), is constructed through the following formulation:
in which
In Eq. (23), \(\varrho\) represents a dynamic parameter, and its value decreases over the last iteration. The Flowchart of RUN algorithm was depicted in Fig. 3.

Flowchart of RUN algorithm.
Measurement of alternatives and ranking according to compromise solution (MARCOS)
Analysis of many options in a given context is the focus of multi-criteria decision making (MCDM), a field of study with applications across many disciplines41. The MCDM is quickly becoming one of the most widely used decision-making techniques across many different fields. In this investigation, the problem was solved with the assistance of MARCOS due to its consistency and convenience of use with utility-based features in terms of both negative and positive solutions. The following is a description of the steps involved in the MARCOS method:
Step 1: Consider \(P\) as the set of decision criteria (\(P = \left\{ {P_{1} ,P_{2} , \ldots ,P_{j} } \right\}\)) and B as the set of alternative routes (\(B = \left\{ {B_{1} ,B_{2} , \ldots ,B_{l} } \right\}\)). We begin by constructing an initial decision-making matrix. In this matrix, \(AIS = \left\{ {x_{ais1} } \right.\), \(\left. {x_{ais2} , \ldots ,x_{aisj} } \right\}\) represents the anti-ideal solution in the first row, while \(IS = \left\{ {x_{is1} ,x_{{\text{is2 }}} , \ldots ,x_{{\text{isl }}} } \right\}\) represents the ideal solution in the last row. Therefore, the initial enlarged decision-making matrix is structured as outlined below:
where \(AIS\) and \(IS\) represent the least favorable and most favorable attributes for each decision criterion. Here, \(x_{ij}\) corresponds to the performance of method i concerning decision criterion j. l denotes the number of methods, and j signifies the number of decision criteria, with i ranging from 1 to l and k ranging from 1 to j. The attribute values are computed using Eqs. (26) and (27)42.
where B and nB pertain to the advantageous and disadvantageous decision criteria.
Step 2: The initial normalized decision matrix, denoted as \(E =\) \(\left[ {e_{ij} } \right]_{k \times j}\), is formed using the properties of decision criteria as defined in Eqs. (28) and (29):
where \(e_{ij}\) denotes the normalized attribute of method \(i\) and decision criterion \(j\).
Step 3: The original weighted normalized decision matrix, denoted as \(S = \left[ {s_{ij} } \right]_{k \times j}\), is created by multiplying the normalized characteristic with its associated weight as described in Eq. (30):
where \(w_{j}\) indicates the weighted normalized amount of method \(i\) and decision criterion \(j\).
Step 4: The utility degrees of AIS and IS are calculated utilizing Eqs. (31) and (32):
where \(C_{i} \left( {i = 1,2, \ldots ,j} \right)\) indicates the sum of the elements of matrix \(s\), which is calculated by Eq. (33).
Step 5. Formulating the utility function (UF) for the evaluated option possibilities as specified in Eq. (34).
The UF related to the AIS is denoted as \(f\left( {g_{i}^{ - } } \right)\), and the UF associated with the IS is expressed as \(f\left( {g_{i}^{ + } } \right)\). These functions can be computed utilizing Eqs. (35) and (36) respectively.
where \(f\left( {g_{i}^{ - } } \right)\) and \(f\left( {g_{i}^{ + } } \right)\) represent the positive and negative UFs of method i.
Decomposition method
To decompose the input dataset in this study, the MVMD method introduced by43 was used. The MVMD technique takes the standard variational mode decomposition (VMD) and expands it to a space with more than one dimension. The technique guarantees mode alignment across different variables and adds a useful feature for managing multivariate data43. In contrast to EMD, which use recursive filtering, MVMD makes advantage of the common frequency components that are present in multivariate datasets in order to produce intrinsic mode functions (IMFs). Below are the comprehensive stages of MVMD applied to input data x(t), composed of N channels, depicted as \(\left[ {x_{1} \left( t \right),x_{2} \left( t \right), \cdots ,x_{N} \left( t \right)} \right]\):
-
(1)
Let’s consider the presence of M multivariate modulated fluctuations \(\zeta_{l} \left( t \right)\) that satisfy the following assumption:
$$x\left( t \right) = \mathop \sum \limits_{l = 1}^{M} \varrho_{l} \left( t \right)$$(37)where \(\varrho_{l} \left( t \right) = \left[ {\varrho_{l,1} \left( t \right),\varrho_{l,2} \left( t \right), \cdots ,\varrho_{l,N} \left( t \right)} \right]\), and \(\varrho_{l,N} \left( t \right),l = 1,2, \cdots ,N\) represents the data’s \(l\)-th element corresponding to channel n.
-
(2)
To acquire the analytical representation \(\varrho_{ + }^{l} \left( t \right)\) for each vector in \(\varrho_{l} \left( t \right)\), the Hilbert transform is applied to calculate the one-sided frequency spectrum (OSFS). Subsequently, a complex exponential \({\text{e}}^{{ - j\psi_{l} t}}\) with a central frequency \(\psi_{l} \left( t \right)\) is utilized to implement harmonic combination and shift the resultant OSFS to the baseband. The last step involves calculating the L2 norm of the gradient function of the harmonically conveyed \(\varrho_{ + }^{l} \left( t \right)\) to provide an estimate of the bandwidth of each mode \(\varrho_{l} \left( t \right)\).
Because a singular frequency element (FE) \(\psi_{l} \left( t \right)\) is used to execute harmonic combining of the full vector \(\varrho_{ + }^{l} \left( t \right)\), it is essential to locate a common FE for multivariate fluctuations \(\varrho_{l} \left( t \right)\) throughout multiple channels. This is because a single FE is used to carry out harmonic combining of the whole vector. Therefore, it is necessary for the collective influence of the IMFs to possess the capability to accurately decompose the original signal, while simultaneously minimizing the total bandwidth of the IMFs. Given the underlying assumption, the corresponding optimization problem with constraints could be expressed in the following manner43:
$$\begin{array}{*{20}c} {\mathop {{\text{minmize}}}\limits_{{\left\{ {\varrho_{l,m} \left( t \right)} \right\},\left\{ {\psi_{l} } \right\}}} \left\{ {\mathop \sum \limits_{l} \mathop \sum \limits_{n} \left\| {\partial_{t} \left[ {\varrho_{ + }^{l,n} \left( t \right){\text{e}}^{{ - j\psi_{l} t}} } \right]_{2}^{2} } \right\|} \right\}} \\ {{\text{ subject to }}\mathop \sum \limits_{l} \varrho_{l,n} \left( t \right) = x_{n} \left( t \right),n = 1,2, \ldots ,N} \\ \end{array}$$(38)where \(\varrho_{ + }^{l,n} \left( t \right)\) indicates the analytical modulated signal associated with l in channel n; {\(\varrho_{l,n} \left( t \right)\)} represents a set of multivariate modulated oscillations; \(\partial_{t} \left[ \cdot \right]\) denotes the partial derivative with respect to time; and {\(\psi_{ln}\)} indicates to a set of center frequencies of {\(\varrho_{l,n} \left( t \right)\)}.
-
(3)
To solve the variational problem that was described before, the additional Lagrange function is used as shown previously.
$$\begin{aligned} L\left( {\left\{ {\varrho_{l,n} \left( t \right)} \right\},\left\{ {\psi_{l} } \right\},\sigma_{n} \left( t \right)} \right) & = \varphi \mathop \sum \limits_{l} \mathop \sum \limits_{n} \left\| {\partial_{t} \left[ {\varrho_{ + }^{l,n} \left( t \right){\text{e}}^{{ - j\psi_{l} t}} } \right]} \right\|_{2}^{2} + \mathop \sum \limits_{n} \left\| {x_{n} \left( t \right) - \mathop \sum \limits_{l} \varrho_{l,n} \left( t \right)} \right\| \\ & \quad + \mathop \sum \limits_{n} \left\langle {\sigma_{n} \left( t \right),x_{n} \left( t \right) - \mathop \sum \limits_{l} \varrho_{l,n} \left( t \right)} \right\rangle \\ \end{aligned}$$(39)where \(\varphi\) represents the penalty factor; \(\sigma_{n} \left( t \right)\) indicates the Lagrange multiplier; \(\left\langle { \cdot , \cdot } \right\rangle\) stands for the vectors’ inner product.
-
(4)
To continually update the variables \(\varrho_{l,n} \left( t \right),\psi_{l}\) and \(\sigma_{n} \left( t \right)\) in the frequency domain for a certain difficult unrestricted variational problem described in Eq. (40)43, the alternative direction technique of multipliers is utilized.
$$\begin{gathered} \hat{\varrho }_{l,n}^{k + 1} \left( \psi \right) = \frac{{\hat{x}_{n} \left( \psi \right) - \mathop \sum \nolimits_{i \ne l} \hat{\varrho }_{l,n} \left( \psi \right) + \frac{{\hat{\sigma }_{c} \left( \psi \right)}}{2}}}{{1 + 2\theta \left( {\psi - \psi_{l} } \right)^{2} }} \hfill \\ \phi_{l}^{k + 1} \left( \psi \right) = \frac{{\mathop \sum \nolimits_{n} \mathop \smallint \nolimits_{0}^{\infty } \phi \left| {\hat{\varrho }_{l,n} \left( \psi \right)} \right|^{2} {\text{ d}}\psi }}{{\mathop \sum \nolimits_{n} \mathop \smallint \nolimits_{0}^{\infty } \left| {\hat{\varrho }_{l,n} \left( \psi \right)} \right|^{2} {\text{ d}}\psi }} \hfill \\ \hat{\sigma }_{n}^{k + 1} \left( \psi \right) = \hat{\sigma }_{n}^{k} \left( \psi \right) + \phi \left[ {\hat{x}_{n} \left( \psi \right) - \mathop \sum \limits_{l} \hat{u}_{l,n}^{k + 1} \left( \psi \right)} \right] \hfill \\ \end{gathered}$$(40)where the signals in the frequency domain reflect the Fourier transform of the signals in the related time frame and are indicated by the notation \(x_{n} \left( \psi \right)\) and \(\sigma_{n} \left( \psi \right)\), respectively. The number of iterations is represented by the parameter k, whereas the time step is represented by the variable. By using the aforementioned update algorithms, it is feasible to dynamically divide the signal’s bandwidth, leading to the formation of M narrow-band IMFs. In addition, the MVMD algorithm has the ability to simultaneously handle numerous data channels. This functionality not only guarantees precise mode alignment across numerous channels but also enhances the resilience of the signal decomposition process.
Feature selection
The existence of a large number of characteristics, which might make it difficult to recognize patterns, is a problem that often arises in the course of data analysis. As a result, one typical strategy is to make use of a feature selection technique with the end goal of reducing the total number of features44,45. In this regard, the light gradient boosting machine (LGBM) method is employed to specify the most important input variables. The LGBM is a highly efficient and scalable gradient boosting system that utilizes decision tree (DT) algorithms46. It is characterized by its quick execution, distributed computing capabilities, and superior efficiency. Many other machine learning applications use it for classification and feature selection. LGBM is an ensemble technique that combines the outputs of many decision trees (by a simple arithmetic addition) to generate a robust generalization46,47.
To develop an LGBM model with T trees, the iterative training process for a dataset of n data points can be described as follows46:
where \(\hat{y}_{i}^{{\left( {{\text{i}}t} \right)}}\) indicates the estimation amount of the \(j\)-th at \(it\)-th iteration. The \(h_{it}\) represents function for \(it\)-th DT.
The hs of each iteration can be determined by minimizing the following loss as much as feasible.
The initial term represents the loss function between the actual and predicted values, while the regularization component is composed of \({\upomega }\left( {h_{it} } \right)\). LGBM stands as an implementation of gradient boosting decision trees (GBDT). LGBM uses two distinct strategies across the training and partitioning of each individual DT (h): gradient-based one-side sampling (GOSS) and leaf-wise growth. Consequently, the LGBM model is used to identify the best features for the WL forecasting in this study.
Criterion evaluation
The ability of each MLM was assessed utilizing seven statistical metrics: R (correlation coefficient), Nash–Sutcliffe efficiency (NSE), RMSE (root-mean-square error), index of agreement (IA), U95% (uncertainty coefficient at a 95% confidence level), MAPE (mean absolute percentage error), and maximum absolute error (MaxAE)28,48,49. Statistical criteria were used to assess the accuracy and reliability of the models. The following equations outline the mathematical relationships for the criteria.
where the \(WL_{F,k}\) and \(WL_{M,k}\) indicate the forecasted and measured values of the WL, respectively. The averages of forecasted and measured values are determined by \(\overline{WL}_{F}\) and \(\overline{WL}_{M}\), respectively. N represents the size of the data collection, whereas SD represents the standard deviation. A suitable MLM would provide R and NSE values of 1, signifying perfect correlation and precision. Additionally, it would provide MAPE, RMSE, U95%, and MaxAE values of 0, indicating the best effectiveness.
Modelling development
This research has developed a new modern intelligent framework for multi-temporal forecasting of the river water level in two case studies of Atlantic Canada province, Prince Edward Island (PEI). The aim of this research is to several hydro-meteorological signals like F, H, P, T, DP, and HD have been dedicated in the in Dunk and Brook Rivers over the 01/01/2015 to 31/12/2019. The MVMD decomposition constitutes the modern hybrid model, LGBM feature selection, and MCDM-based SVD-Kernel ridge regression scheme optimized by the RUN mathematical foundations algorithm to forecast the river WL. Also, to validate the primary model (MVMD-L-SKRidge), four advanced models, namely LASSO (Least Absolute Shrinkage and Selection Operator), CFNN, KRidge (Kernel Ridge Regression), and dRVFL (Deep random vector functional Link), were adopted in complementary (MVMD-KRidge, MVMD-dRVFL, MVMD-LASSO, and MVMD-CFNN) and standalone counterpart frameworks.
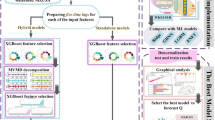
Here, the MVMD decomposition technique is performed in MATLAB programming tool. The rest of the model is developed in the Python platform using the MEALPY50, Scikit-learn51, and LGBM open-source libraries. All computational attempts have been performed on a laptop with the 3.10 GHz Intel Core i7 CPU and 8 GB RAM. All the modeling stages can be seen as a roadmap, as shown in Fig. 4. The main steps in the figure to forecast water level in Brook and Dunk Rivers are described as follows:
-
1.
Data collection: The first step is to gather time series datasets t forecast water level in the Dunk and Brook rivers in Canada. In this regard, seven parameters (F, WL, T, HD, P, DP, and H) are gathered.
-
2.
Feature selection: The LGBM method is used to select the most important features to predict water level fluctuations.
-
3.
Time lag selection: Auto-Correlation Function (ACF), partial Auto-correlation function (PACF), and cross-correlation (CrC) analysis are employed to identify appropriate time lags.
-
4.
Decomposition of input variables: Decomposition of input variables is carried out by the use of the MVMD technique. Various oscillatory patterns within the data can be discovered using the process of decomposing variables into IMFs.
-
5.
Feature importance in decomposed signals: The LGBM method is once again used to identify the most significant IMFs. This stage guarantees the selection of the most important elements of the decomposing signals to decrease the dimension and more precise forecasts.
-
6.
Modeling and forecasting: Five ML models (LASSO, CFNN, KRidge, dRVFL, and L-SKRidge) are implemented to forecast the water levels at both rivers.
-
7.
Model evaluation with MARCOS method: The MARCOS method is applied to determine the best model. This method uses seven metrics (R, RMSE, MAPE, NSE, IA, MaxAE, and U95%) to specify the best model.
-
8.
Graphical analysis for model assessment: Different graphical tools are used to evaluate and verify the ML models even further. These comprise scatter plots to compare model predictions against actual observations, violin plots to show relative error’s distribution and spread, Taylor plots to summarize model performance in pattern and amplitude terms, and empirical cumulative distribution function (ECDF) plots to evaluate the forecast error distribution among models.
-
9.
Specify and best model: Graphical analysis and statistical metrics is used to select the best model for predicting water levels in the Brook and Dunk rivers. These evaluations ensure that the selected model not only predicts the actual dataset well, but also provides reliable and precise forecasts.

Graphical steps of WL forecasting using the proposed framework.
The main steps to prepare the input for the machine learning models are outlined as follows:
Step 1: Optimal estimation of the significant features for standalone models.
Prior to applying any pre-processing procedures, the datasets are separated into 70% training and 30% testing subsets. This division is required to develop an artificial intelligence model capable of forecasting WL on a multi-temporal daily basis. In the first stage, all the meteorological factors were assessed to recognize the most important for every horizon and case study separately. Due to this, the LGBM feature (LGBM-FS) scheme has been implemented to evaluate all the features based on the importance values. Figure 5 and Appendix A depict the variation of the feature importance values of LGBM-FS for the Brook River. According to the results, it can be concluded that for all the underlying case studies, the F, H, and DP with the higher importance values have considered the influential feature to construct the forecasting models.

Significant feature extraction using the LGBM FS scheme for every horizon and case study.
Step 2: Specify the time-lags.
Given the highly non-stationary nature of the input signal, a robust technique is required to estimate the sub-sequence lags associated with optimal input features from the previous pre-processing stage. In this regard, in order to characterize the significant lags, sub-components of input signals for simple (standalone) models were extracted using ACF and the PACF associated with each selected input signal, including F, H, and DP in Brook and Dunk Rivers, for the -one and -three days ahead were computed for 20 lags to survey the best antecedent sub-components aimed at the hybrid model configuration. The results of ACF are displayed in Appendix B. In addition, the results of PACF are in Fig. 6. Based on the ACF, selecting the optimal time lags was challenging; therefore, the PACF was used. According to Fig. 6, the first three lags equivalent to the antecedent information associated with the previous three days were adopted as proper input features for reconstructing the simple (standalone models) in one and three days ahead horizons. In this research, to further confirm the selection of time lags, the cross-correlation (CrC) method was also applied (Fig. 7). Based on this figure and the PACF results, the first three lags were chosen to forecast the WL at the two stations.

PACF examination of all the input features to construct the feeding components of the complementary models.

The outcomes of cross correlation to estimate the significant lags of the selected input features related to the simple models based on the importance values of the ten lags.
The MVMD approach decomposed all the input features to minimize signal complexity before putting them into the ML models. This was done to create the complimentary models. Figure 8 demonstrates the decomposed sub-components of the discharge flow parameter using the MVMD technique as a sample of the signal decomposition process. Here, the mode decomposition number (k) is the most important tuning parameter of the MVMD method, and it is a crucial component in achieving satisfactory precision. It is used a trial-and-error approach to determine the optimal value of k at each station. Following the aforementioned method, the best value of (k) for the Dunk River was 12 and for the Brook River it was 10. The default settings for the other setup parameters were used as a starting point: 2000 for Alfa, 10–7 for tolerance, zero for DC, and zero for Inti. The next step is to apply the three-lag time sub-sequences to the decomposed signals related to the features that were chosen. In order to improve the forecasting procedure’s precision and decrease computing costs, the most important components have been filtered through the LGBM-FS method. This process is executed with 30% of the whole dataset. The most promising decomposed features calculated using MVMD were selected from the pool to use in the ML models. Figure 9 reveals the results of the LGBM-FS technique for filtering the significant sub-components related to all the constructive features in the Brook and Dunk Rivers of PEI. It should be noted that the results of Dunk River are depicted in Appendix A.

MVMD-based decomposition process of discharge signals as the sample in Boork (A) and Dunk (B) Rivers.

Outcomes of the LGBM-FS scheme on the most effective sub-components extraction among available pool of decomposed sub-sequences in every horizon for Brook river.
Step 3: Machine learning configuration and tuning hyperparameters.
One of the most important phases of developing forecasting models is tuning ML model parameters. Using non-optimal hyperparameters could decrease the models’ precision and lead to an unfair comparison between the comparative prediction methods. For this purpose, the RUN method was used to optimize the main parameters (θ) of the L-SKRidge method. Notably, the main parameters of the other ML models (KRidge, LASSO, CFNN, and dRVFL) are optimized using the RUN algorithm. Tables 1 and 2 report the optimal values of the hyperparameter related to the ML models for Brook and Dunk Rivers, respectively. For instance, the main hyperparameters of the dRVFL and CFNN are the number of layers, neuron number, activation function, and hidden layer neuron number, respectively, their adjustments are more complicated than the KRidge and LASSO models.
The datasets were normalized within the range of [0, 1] before they were utilized as inputs for the model’s goal and predictor variables. This normalization procedure guaranteed that each variable had a similar order of magnitude. A linear-based normalization technique was used to achieve this, which can be stated as follows52:
where \(X_{N}\) represents normalized input data, \(X_{Real}\) represents real-time values data, \(X_{MIN}\) represents the minimum real-time values, and \(X_{MAX}\) denotes the maximum real-time values.
Case study and data preparation
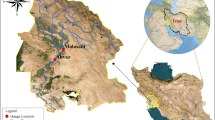
The main aim of the present research is to evaluate the efficiency and ability of MLMs to forecast water levels in multiple steps in the future for two rivers, Brook and Dunk, situated in the Prince Edward Island (PEI) province near the Gulf of Saint Lawrence in Canada. Figure 10 shows the geographical location of the Brook and Dunk Rivers in PEI. The Carruthers Brook Station near St. Anthony (Station No. 01CA003) is located on Brook River at 46° 44′ 38″ N latitude and 64° 11′ 13″ W longitude and has a gross drainage area of 46.8 km2. The Dunk River Station at Wall Road (Station No. 01CB002) is on the Dunk River at a latitude of 46° 20′ 45″ N and longitude of 63° 38′ 00″ W, a gross drainage area of 114 km2 (https://wateroffice.ec.gc.ca/).

Geographic location of the Brook and Dunk Rivers stations in PEI province of Canada, developed by ArcMap53.
The Brook and Dunk Rivers on PEI are significant for their ecological, agricultural, and recreational aspects. Both rivers provide essential habitats for wildlife, facilitate local agriculture via water supply and drainage, and enhance PEI’s natural ecology. The Brook and Dunk rivers are significant for flood control, water quality management, and provide recreational activities like fishing and canoeing, therefore improving the surrounding community’s quality of life. Studies on the Brook and Dunk Rivers have shown problems with agricultural runoff, sedimentation, and nutrient leaching. Attempts at water level monitoring by the PEI Department of Environment, Energy and Climate Action show that phosphorus and nitrogen levels often surge during spring runoff, hence possibly degrading water quality and causing algal blooms54,55. Additionally, seasonal variations in water levels are prevalent, with heightened runoff occurring during spring thaw and intense precipitation, potentially leading to localized floods and impacting agricultural output56,57 by eroding the topsoil. Effective monitoring of water levels using modern techniques may enhance watershed management plans to safeguard PEI’s freshwater resources58.
According to an analysis of historical hourly meteorological reports and model reconstructions from 1980 to 2016, the climate of PEI is characterized by moderate summers, cold winters with snow and wind, and partly cloudy throughout the year (https://weatherspark.com). July is the hottest month of the year in PEI (average maximum temperature of 24 °C), and January is the coldest month with an average minimum temperature of − 9 °C. Rainfall in PEI occurs continuously throughout the year. October is the wettest month (average rainfall of 60 mm), and February is the driest month (average rainfall of 15 mm). There is significant seasonal variation in monthly snowfall in PEI. February has the highest snowfall, with an average snowfall of 142 mm. (https://weatherspark.com).
To develop a multi-step-ahead water level forecast model for the Brook and Dunk rivers, hydrological and meteorological parameters obtained from the stations in the study area were utilized as input data (from 2015 to 2019 with daily time-step). The parameters are water level (m) (WL), flow (m3/s) (F), heat degree days (°C) (HD), total precipitation (mm) (P), mean temperature (°C) (T), relative humidity (%) (H), and dew point temperature (°C) (DP). Table 3 presents the statistical summaries of the parameters employed to develop the ML model.
For the Brook River, the data sets of T (°C), HD (°C), DP (°C), and H (%) collected from Carruthers Brook Station have distributions of approximately symmetric (-0.34 < Skewness < 0.28) and close to normal (2.01 < kurtosis < 2.63). Also, at the Brook River, the data sets of the Total Precipitation (mm), Flow (m3/s), and Level (m) are extremely skewed (Skewness values > 1) and with high positive values of Kurtosis (> 3) indicating Leptokurtic distribution (Table 3).
For the Dunk River at the Dunk River Station, the data sets of T (°C), HD (°C), DP (°C), and H (%) with skewness values between [− 0.5, 0.5] are nearly symmetrical and close to normal distributions (0 < Kurtosis < 3). The data sets of Total Precipitation (mm), Flow (m3/s) and Level (m) with Skewness values [6.57, 2.34] are highly skewed and have Leptokurtic distributions (Kurtosis > 3) at the Dunk River Station (Table 3). Figure 11 demonstrates the original signals related to the input features and the water level in two cases study.

Time series graph of all date sets for (A) Brook and (B) Dunk.
Result and discussion
The standalone version of the models L-SKRidge, dRVFL, LASSO, KRidge, CFNN, and their MVMD-based hybrid version to forecast WL at (t + 1) and (t + 3) employing a set of metrics to measure and examine the performance accuracy in Brook and Dunk River Canada. The outcomes are presented mainly in tabular form as well as different ranges of diagnostic plots to evaluate these models for forecasting purposes.
Tables 4 and 5 demonstrate water level (WL) forecasting for Brook River to evaluate the performance of the standalone L-SKRidge, dRVFL, LASSO, KRidge, and CFNN models (Table 4) and their MVMD-based hybrid version (Table 5) at (t + 1) and (t + 3). The MVMD coupled with L-SKRidge model outperforms hybrid and standalone models and appears to be the most precise forecasting method based on (R = 0.971, RMSE = 0.054, NSE = 0.940, MaxAE = 0.484, U95% = 0.148)-train and (R = 0.970, RMSE = 0.051, NSE = 0.937, MaxAE = 0.411, U95% = 0.142)-test at (t + 1), followed by MVMD-based KRidge, CFNN, dRVFL, and LASSO models. The MVMD-based L-SKRidge model was better at predicting WL at (t + 3) than other MVMD-based and stand-alone methods used to predict WL at Brook River (Tables 4 and 5). Furthermore, the MVMD-based L-SKRidge model performed better for Brook River for both forecasting horizons (t + 1) and (t + 3) than other standalone and MVMD based methods (Table 4 and 5). It is also noteworthy that the hybrid models were better than their standalone counterpart models revealing better forecasting ability. The forecasting improvement in MVMD based L-SKRidge model based on NSE can be seen up to 12% at (t + 1) and 33% at (t + 3). Moreover, a significant increase in accuracy can be seen in other MVMD-based dRVFL, LASSO, KRidge, and CFNN methods compared with the standalone version.
Tables 6 and 7 illustrate the efficacy of the MVMD-based hybrid and solo models in predicting WL for Dunk River at (t + 1) and (t + 3). Analysis of Tables 6 and 7 demonstrates that the MVMD-based L-SKRidge model consistently achieved the best precision in forecasting WL at both (t + 1) and (t + 3), as shown in the tables previously mentioned, in comparison to other models. The MVMD-based L-SKRidge model achieved superior performance metrics, with training scores of R = 0.975, RMSE = 0.030, MAPE = 2.690, NSE = 0.951, and MaxAE = 0.238, and testing scores of R = 0.958, RMSE = 0.039, MAPE = 3.371, NSE = 0.914, and MaxAE = 0.275, for forecasting WL at (t + 1).
The other MVMD-based hybrid versions of the models were also reasonably good in accuracy but could not surpass the MVMD-based L-SKRidge model, while the performance of standalone models was very lower. Similarly, the MVMD-based L-SKRidge model had the best level of accuracy in predicting WL for Dunk River at (t + 3) compared to other models (Tables 6 and 7). The MVMD-based hybrid models demonstrate superior performance relative to the solo models in predicting the WL at both forecast horizons. Overall, the MVMD-based L-SKRidge model demonstrated superior accuracy in forecasting WL compared to other models. A significant increase in accuracy has been seen by integrating the MVMD with the L-SKRidge model.
The present study uses the MARCOS approach as an MCDM method to choose the best appropriate model using a set of criteria. The MARCOS used seven statistical metrics (R, RMSE, MAPE, NSE, IA, MaxAE, and U95%) to select the best model. The MARCOS technique guarantees a comprehensive and equitable evaluation of model performance. It facilitates the discovery of the model that most effectively satisfies the specified requirements for accuracy and dependability.
Figure 12 indicates the MARCOS Score attained by the hybrid MVMD-based and standalone L-SKRidge, dRVFL, LASSO, KRidge, and CFNN models during training and testing periods to predict WL at two time horizons ((t + 1) and (t + 3)) for Brooke and Dunk Rivers. The MVMD-based L-SKRidge method achieved an outstanding MARCOS score for Brooke River at both (t + 1) and (t + 3) in comparison to other ML methods.

MARCOS scores achieved by five ML models over two-time horizons for simple and hybrid modes and in (A) Brooke and (B) Dunk River.
Similarly, the top values of TOPSIS score were seen in Dunk River, which is evidence that the MVMD-based L-SKRidge model demonstrates a superior level of precision especially to forecasting WL at (t + 1) and (t + 3) compared with the other models. As a result, the MARCOS score suggests that the MVMD-based L-SKRidge model is superior to accurately estimate WL for Brooke and Dunk River.
Figure 13 is based on a scatter diagram to inspect the comparison between the measured and forecasted WL generated by the standalone ML-based L-SKRidge, dRVFL, LASSO, KRidge, and CFNN models in the testing period for Brook and Dunk River at (t + 1) and (t + 3). Moreover, the values of R metrics and fitted lines with equations is also incorporated along with lower and upper bounds. This research established upper and lower boundaries around the regression line to illustrate possible diversity in predictions. A best-fit line was produced by linear regression, illustrating the primary trend in the correlation between the measured and predicted values. The methodology determined the boundaries by examining the distance of individual data points from the line, which represents the unexplained variability not accounted for by the trend. The minimum and maximum deviations from the line were used to determine the limits, forming a lower and upper boundary around the best-fit line over the whole data range. These boundaries effectively provide a “buffer zone” around the projected values, signifying the range in which the actual data points are expected to reside. The interval width, shown as dashed lines on the graph, graphically represents the possible mistake in the predictions. Incorporating these limitations enhances the model’s prediction reliability and aids users in comprehending the variability margin in the projected values.

Scatter plots of all standalone ML models over two time horizons for Brook river.
The standalone version of the models was relatively poor based on scatter plots in Fig. 13 compared to the MVMD-based methods (Fig. 14). From Fig. 13, the proposed L-SKRidge yields the best results with the smallest values of U–L (i.e., the difference between their lower and upper limits (U–L)) for two-time horizons (U–L(t + 1) ) = 0.91 and U–L(t + 3) = 0.86) compared with the other standalone models. Figure 14 presents a scatter map that examines the contrast between the observed and predicted water levels (WL) provided by several models, including the hybrid MVMD-based L-SKRidge, dRVFL, LASSO, KRidge, and CFNN models. This analysis is conducted throughout the testing period for the Brook and Dunk River at time points (t + 1) and (t + 3). The comparative analysis of prediction outcomes for two-time horizons reveals that the L-SKRidge model has superior performance compared to the dRVFL, LASSO, KRidge, and CFNN approaches in relation to the U–L. In the scenario involving WL for t + 1, it is seen that L-SKRidge demonstrates the narrowest discrepancy between the upper and lower bounds (U–L), with a value of 0.47. This value is comparatively less than those obtained for dRVFL (0.83), LASSO (0.79), KRidge (0.81), and CFNN (0.9), indicating L-SKRidge’s superior performance in minimizing the U–L gap. The model that has been suggested also exhibits the smallest difference between U and L for WL at t + 3, as seen in Fig. 13, with a numerical value of 0.64. The hybrid MVMD based L-SKRidge model at (t + 1) and (t + 3) outperformed to forecast WL in terms of R = 0.97, and 0.932 followed by MVMD based KRidge, LASSO, dRVFL, and CFNN models for Brook River. For Dunk River, the MVMD-based L-SKRidge model once again obtained better precision against other MVMD-based hybrid and standalone counterparts to forecast WL at both forecasting horizons (refer to Appendix C). Consequently, the scatter plots demonstrated that MVMD-based methods outperform solo variants in forecasting WL for both stations. The L-SKRidge model, based on MVMD, outperforms all other models in terms of accuracy. This performance is highly promising.

Scatter plots of all hybrid ML models over two time horizons for Brook river.
The violin plots in Fig. 15 provide a diagnostic assessment calculating the relative error of the forecasted WL for the MVMD-based models as well as standalone L-SKRidge, dRVFL, LASSO, KRidge, and CFNN models at (t + 1) and (t + 3). From the figure, the hybrid MVMD-based L-SKRidge clearly showed a smaller relative error and more accurate and consistent violin distribution (i.e., ranging between − 0.4 and + 0.4) at (t + 1) and (− 0.5 and + 0.5 at (t + 3) to forecast WL in Brook River compared with all other MVMD-based models. Similarly, the hybrid MVMD based L-SKRidge method appeared to be accurate for Dunk River using violin plot distributions based on relative error against other comparing models at both forecast horizons (see Fig. 16). Thus, MVMD based L-SKRidge model achieves better WL forecasting accuracy for both rivers at (t + 1) and (t + 3).

Violin plot of relative error for all ML models at two-time horizons in Brook River.

Violin plot of relative error for all ML models at two-time horizons in Brook River.
The forecasted WL of Brooke and Dunk Rivers are given in Figs. 17 and 18 using the empirical cumulative distribution function (ECDF) within the lower and upper confidence intervals to evaluate the precision of the MVMD-based L-SKRidge model to other models for a clearer representation of the results. The ECDF plot provides a cumulative view of relative errors, showing the proportion of data points below each error value. It helps assess overall model performance, reliability, and robustness by illustrating error accumulation. This visualization makes it easier to compare models and communicate performance effectively. By using the ECDF plot, you emphasize cumulative accuracy and provide a comprehensive analysis.

ECDF calculated using five ML methods at two-time horizons in Brook River.

ECDF calculated using five ML methods at two-time horizons in Dunk River.
The ECDF of the MVMD-based L-SKRidge model for both Brooke and Dunk Rivers had a remarkably similar pattern at both (t + 1) and (t + 3) forecasting horizons compared to other MVMD-based dRVFL, LASSO, KRidge, and CFNN models. The analysis also depicts that the forecasts based on MVMD based L-SKRidge model are within the lower and upper confidence bounds to confirm the validity against other comparing models. Hence, these figures further authenticate the suitability of the MVMD-based L-SKRidge method to predict WL at the time horizons.
The Taylor plots in Fig. 19 referred to the referenced and forecasted WL using MVMD-based L-SKRidge (red), dRVFL (green), LASSO (purple), KRidge (Cyan), and CFNN (pink) models at (t + 1) and (t + 3) to evaluate the precision for both Rivers. A comprehensive evaluation of the models’ comparability with respect to standard deviation and correlation coefficient is facilitated by these graphic design. For Brooke River, clearly the MVMD-based L-SKRidge positioned very closely to the reference WL with a correlation coefficient between 0.95 and 0.99 (t + 1) and 0.90–0.95 (t + 3) with a standard deviation (0.20– 0.25). The hybrid MVMD-based dRVFL, LASSO, KRidge, and CFNN comparing models are reasonably satisfactory but could not go ahead than the MVMD-based WKRidge model. Additionally, the MVMD-based L-SKRidge model achieved a superior rank in terms of accuracy for Dunk River in comparison to other models that were used to estimate WL at (t + 1) and (t + 3). The Taylor diagram thus supports the suitability for better WL forecasting of the MVMD-based L-SKRidge model.

Taylor diagram of five ML models for two-time horizons in Brook and Dunk River.
Conclusion
A new hybrid model called SKRidge has been created by combining the effective characteristics of SVD and KRidge. Additionally, the model incorporates MVMD and employs LGBM as an astute feature selection method, supplemented by the application of the RUN algorithm for parameter tuning. Furthermore, the SKRidge, combined with ridge regression and incorporating a linear relationship, has made a significant contribution to the formulation of the proposed model, known as L-SKRidge, with the specific objective of enhancing forecasting accuracy. The main objective of this research is to forecast water levels in Canada’s Brook and Dunk Rivers for two timeframes.
The proposed framework exhibits the following critical features:
-
Hybridization of SKRidge and Ridge regression: L-SKRidge uses the capabilities of SKRidge and ridge regression. This combination considerably increases the overall model performance. It is especially focused on improving predicting accuracy.
-
MVMD method: The model leverages MVMD for the decomposition of input variables into IMFs, and utilizes PACF to identify influential lags at both (t + 1) and (t + 3).
-
Feature selection with importance value factor: The proposed framework employs an efficient feature selection (LGBM) to identify the most influential input datasets. The selected features are incorporated into the L-SKRidge model to improve its predictive abilities.
-
Comparative analysis with other models: To assess the forecasting accuracy and identify MVMD-L-SKRidge’s ability, the MVMD is combined with other models (dRVFL, LASSO, KRidge, and CFNN).
Summary of research results:
The study findings provide a comprehensive evaluation of several forecasting models for predicting water levels in the Canadian rivers Dunk and Brook. Here are the key findings and numerical outcomes:
-
i.
Brook river forecasting results at (t + 1):
-
L-SKRidge exhibited superior precision with an R value of 0.97, RMSE of 0.054, MAPE of 7.371, NSE of 0.940, IA of 0.984, MaxAE of 0.484, and U95% of 0.148 in training.
-
For testing, L-SKRidge achieved an R value of 0.970, RMSE of 0.051, MAPE of 6.309, NSE of 0.937, IA of 0.982, MaxAE of 0.411, and U95% of 0.142.
-
-
ii.
Brook river forecasting results at (t + 3):
-
L-SKRidge continued to outperform other models with high accuracy, surpassing both standalone and hybrid versions.
-
-
iii.
Dunk river forecasting results:
-
L-SKRidge maintained its superiority, exhibiting higher accuracy for forecasting at (t + 1) and (t + 3) compared to other models, including the standalone versions.
-
-
iv.
Forecasting improvement:
-
The integration of MVMD with WKRidge resulted in a notable increase in forecasting accuracy, with NSE improvements of up to 12% at (t + 1) and 33% at (t + 3).
-
-
v.
Comparative performance:
-
The hybrid models consistently outperformed their standalone counterparts, underlining their improved forecasting abilities.
-
-
vi.
Taylor plots and ECDF analysis:
-
Taylor plots revealed the high precision of L-SKRidge, with correlation coefficients ranging from 0.90 to 0.99 and standard deviations of 0.20 to 0.25 for Brook River.
-
ECDF analysis confirmed the consistency of MVMD-based L-SKRidge forecasts within the lower and upper confidence bounds.
-
In summary, the research showcases the exceptional forecasting capacity of the proposed MVMD-based L-SKRidge model, which consistently outperforms other models across various evaluation metrics, and offers a substantial advancement in water level prediction accuracy for the Brook and Dunk Rivers.
The proposed MVMD-based L-SKRidge model exhibits enhanced forecasting precision, particularly for water level predictions in the Brook and Dunk Rivers. The main advantages of this method are the development of an efficient model, the decomposition of inputs into effective signals provided by MVMD, and the selection of specific features through LGBM, all of which increase the prediction accuracy. The suggested approach exhibits great forecasting accuracy for water level predictions; nonetheless, practical obstacles persist. The main concerns are the computational complexity of the model, which requires significant resources, and the over-sensitivity of the fit resulting from fine-tuning of the parameters. Scalability is an important issue, as the model may require a more powerful optimization for use on larger datasets or diverse contexts.
Further studies should focus on broadening the model’s application to forecast in other domains, such as climate change impacts, renewable energy trends, and agricultural forecasts, which might significantly enhance its relevance and utility. Validation in these new areas may improve the model and uncover any specific requirements or modifications needed. Moreover, integrating the L-SKRidge model into a comprehensive decision-support framework might enhance its practical use. Real-time forecasts and integration with geographic information systems (GIS) might improve decision-making tools for policymakers and stakeholders in water resource management and other domains.
Data availability
Data availability The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Nguyen, X. H. Combining statistical machine learning models with ARIMA for water level forecasting: The case of the Red river. Adv. Water Resour. 142, 103656 (2020).
Jamei, M. et al. Forecasting daily flood water level using hybrid advanced machine learning based time-varying filtered empirical mode decomposition approach. Water Resour. Manag. 36, 4637–4676 (2022).
Kim, D. et al. Application of AI-based models for flood water level forecasting and flood risk classification. KSCE J. Civ. Eng. 27(7), 3163–3174 (2023).
Ahmed, A. A. M. et al. New double decomposition deep learning methods for river water level forecasting. Sci. Total Environ. 831, 154722 (2022).
Zhu, S., Lu, H., Ptak, M., Dai, J. & Ji, Q. Lake water-level fluctuation forecasting using machine learning models: A systematic review. Environ. Sci. Pollut. Res. 27, 44807–44819 (2020).
Li, Y., Shi, H. & Liu, H. A hybrid model for river water level forecasting: Cases of Xiangjiang river and Yuanjiang river, China. J. Hydrol. 587, 124934 (2020).
Ruma, J. F., Adnan, M. S. G., Dewan, A. & Rahman, R. M. Particle swarm optimization based LSTM networks for water level forecasting: A case study on Bangladesh river network. Results Eng. 17, 100951 (2023).
Hajian, R., Jalali, M. R. & Mastouri, R. Multi-step Lake Urmia water level forecasting using ensemble of bagging based tree models. Earth Sci. Inform. 15, 2515–2543 (2022).
Gebremariam, S. Y. et al. A comprehensive approach to evaluating watershed models for predicting river flow regimes critical to downstream ecosystem services. Environ. Model. Softw. 61, 121–134 (2014).
Romagnoli, M. et al. Assessment of the SWAT model to simulate a watershed with limited available data in the Pampas region, Argentina. Sci. Total Environ. 596, 437–450 (2017).
Li, F., Wang, Z. & Qiu, J. Long-term streamflow forecasting using artificial neural network based on preprocessing technique. J. Forecast. 38, 192–206 (2019).
Yaseen, Z. M. A new benchmark on machine learning methodologies for hydrological processes modelling: A comprehensive review for limitations and future research directions. Knowl.-Based Eng. Sci. 4, 65–103 (2023).
Wen, X. et al. Two-phase extreme learning machines integrated with the complete ensemble empirical mode decomposition with adaptive noise algorithm for multi-scale runoff prediction problems. J. Hydrol. 570, 167–184 (2019).
Naganna, S. R., Beyaztas, B. H., Bokde, N. & Armanuos, A. M. On the evaluation of the gradient tree boosting model for groundwater level forecasting. Knowl.-Based Eng. Sci. 1, 48–57 (2020).
Ahmed, A. A. M. et al. Deep learning hybrid model with Boruta-Random forest optimiser algorithm for streamflow forecasting with climate mode indices, rainfall, and periodicity. J. Hydrol. 599, 126350 (2021).
Deo, R. C. & Şahin, M. An extreme learning machine model for the simulation of monthly mean streamflow water level in eastern Queensland. Environ. Monit. Assess. 188, 1–24 (2016).
Fijani, E. & Khosravi, K. Hybrid iterative and tree-based machine learning algorithms for lake water level forecasting. Water Resour. Manag. 37(14), 5431–5457 (2023).
Wang, J.-H., Lin, G.-F., Chang, M.-J., Huang, I.-H. & Chen, Y.-R. Real-time water-level forecasting using dilated causal convolutional neural networks. Water Resour. Manag. 33, 3759–3780 (2019).
Kagoda, P. A., Ndiritu, J., Ntuli, C. & Mwaka, B. Application of radial basis function neural networks to short-term streamflow forecasting. Phys. Chem. Earth Parts A/B/C 35, 571–581 (2010).
Wei, C.-C. Comparing lazy and eager learning models for water level forecasting in river-reservoir basins of inundation regions. Environ. Model. Softw. 63, 137–155 (2015).
Anh, N. T. N., Dat, N. Q., Van, N. T., Doanh, N. N. & Le An, N. Wavelet-artificial neural network model for water level forecasting. in 2018 International Conference on Research in Intelligent and Computing in Engineering (RICE) 1–6 (IEEE, 2018).
Barzegar, R., Aalami, M. T. & Adamowski, J. Coupling a hybrid CNN-LSTM deep learning model with a boundary corrected maximal overlap discrete wavelet transform for multiscale lake water level forecasting. J. Hydrol. 598, 126196 (2021).
Zakaria, M. N. A. et al. Exploring machine learning algorithms for accurate water level forecasting in Muda river, Malaysia. Heliyon 9, e17689 (2023).
Wang, W. et al. Evaluating the performance of several data preprocessing methods based on GRU in forecasting monthly runoff time series. Water Resour. Manag. https://doi.org/10.1007/s11269-024-03806-y (2024).
Xu, D., Li, Z. & Wang, W. An ensemble model for monthly runoff prediction using least squares support vector machine based on variational modal decomposition with dung beetle optimization algorithm and error correction strategy. J. Hydrol. 629, 130558 (2024).
Najafzadeh, M. Neuro-fuzzy GMDH systems based evolutionary algorithms to predict scour pile groups in clear water conditions. Ocean Eng. 99, 85–94 (2015).
Ahmadianfar, I. et al. Gradient-based optimization with ranking mechanisms for parameter identification of photovoltaic systems. Energy Reports 7, 3979–3997 (2021).
Ahmadianfar, I., Shirvani-Hosseini, S., Samadi-Koucheksaraee, A. & Yaseen, Z. M. Surface water sodium (Na+) concentration prediction using hybrid weighted exponential regression model with gradient-based optimization. Environ. Sci. Pollut. Res. 29(35), 53456–53481 (2022).
Fang, Y. et al. An accelerated gradient-based optimization development for multi-reservoir hydropower systems optimization. Energy Reports 7, 7854–7877 (2021).
Hocking, R. R. Methods and Applications of Linear Models: Regression and the Analysis of Variance (Wiley, 2013).
Wang, X. et al. High-performance reversible data hiding based on ridge regression prediction algorithm. Sign. Process. 204, 108818 (2023).
Hoerl, A. E. & Kennard, R. W. Ridge regression: Applications to nonorthogonal problems. Technometrics 12, 69–82 (1970).
Saunders, C. & Gammerman, A. Ridge regression learning algorithm in dual variables. in 15th International Conference on Machine Learning (ICML ’98) (01/01/98) (1998).
Vapnik, V. N. The Nature of Statistical Learning Theory (Springer, 2000). https://doi.org/10.1007/978-1-4757-3264-1.
Chen, H., Ahmadianfar, I., Liang, G. & Heidari, A. A. Robust kernel extreme learning machines with weighted mean of vectors and variational mode decomposition for forecasting total dissolved solids. Eng. Appl. Artif. Intell. 133, 108587 (2024).
Novitasari, I. D., Murfi, H. & Wibowo, A. Finding anchor words of separable-nonnegative matrix factorization based on singular value decomposition. in 2017 1st International Conference on Informatics and Computational Sciences (ICICoS) 225–230 (IEEE, 2017).
Hasan, M. M., Bala, B. & Yoshitaka, A. SVD aided eigenvector decomposition to compute PCA and it’s application in image denoising. in 2015 International Conference on Informatics, Electronics & Vision (ICIEV) 1–6 (IEEE, 2015).
Ahmadianfar, I., Heidari, A. A., Noshadian, S., Chen, H. & Gandomi, A. H. INFO: An efficient optimization algorithm based on weighted mean of vectors. Expert Syst. Appl. 195, 116516 (2022).
Ahmadianfar, I., Bozorg-Haddad, O. & Chu, X. Gradient-based optimizer: A new metaheuristic optimization algorithm. Inf. Sci. (Ny) 540, 131–159 (2020).
Ahmadianfar, I., Heidari, A. A., Gandomi, A. H., Chu, X. & Chen, H. RUN beyond the metaphor: An efficient optimization algorithm based on Runge Kutta method. Expert Syst. Appl. 181, 115079 (2021).
Stević, Ž, Pamučar, D., Puška, A. & Chatterjee, P. Sustainable supplier selection in healthcare industries using a new MCDM method: Measurement of alternatives and ranking according to COmpromise solution (MARCOS). Comput. Ind. Eng. 140, 106231 (2020).
Deveci, M., Özcan, E., John, R., Pamucar, D. & Karaman, H. Offshore wind farm site selection using interval rough numbers based Best-Worst Method and MARCOS. Appl. Soft Comput. 109, 107532 (2021).
ur Rehman, N. & Aftab, H. Multivariate variational mode decomposition. IEEE Trans. Sign. Process. 67, 6039–6052 (2019).
Jamei, M. et al. Designing a multi-stage expert system for daily ocean wave energy forecasting: A multivariate data decomposition-based approach. Appl. Energy 326, 119925 (2022).
Jamei, M. et al. Development of wavelet-based kalman online sequential extreme learning machine optimized with boruta-random forest for drought index forecasting. Eng. Appl. Artif. Intell. 117, 105545 (2023).
Ke, G. et al. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 30, (2017).
Chen, T. et al. Prediction of extubation failure for intensive care unit patients using light gradient boosting machine. IEEE Access 7, 150960–150968 (2019).
Ahmadianfar, I., Shirvani-Hosseini, S., He, J., Samadi-Koucheksaraee, A. & Yaseen, Z. M. An improved adaptive neuro fuzzy inference system model using conjoined metaheuristic algorithms for electrical conductivity prediction. Sci. Rep. 12, 1–34 (2022).
Jamei, M. et al. The assessment of emerging data-intelligence technologies for modeling Mg+ 2 and SO4− 2 surface water quality. J. Environ. Manage. 300, 113774 (2021).
Van Thieu, N. & Mirjalili, S. MEALPY: An open-source library for latest meta-heuristic algorithms in Python. J. Syst. Archit. 139, 102871 (2023).
Pedregosa, F. et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Jamei, M., Ali, M., Karbasi, M., Sharma, E. & Jamei, M. Engineering applications of artificial intelligence A high dimensional features-based cascaded forward neural network coupled with MVMD and Boruta-GBDT for multi-step ahead forecasting of surface soil moisture. Eng. Appl. Artif. Intell. 120, 105895 (2023).
Johnston, K., Ver Hoef, J. M., Krivoruchko, K. & Lucas, N. Using ArcGIS Geostatistical Analyst Vol. 380 (Esri Redlands, 2001).
PEI Department of Environment and Climate Change. Water Quality Monitoring Reports. Retrieved from the official website (2019).
PEI Agricultural Awareness and Environmental Studies Program. Nutrient Management and Water Quality on PEI. PEI Government Reports (2021).
Canada’s Atlantic Ecosystem Initiative. Water Quality in the Atlantic Region. Fisheries and Oceans Canada, Government of Canada (2022).
PEI Watershed Management Fund. Monitoring Water Quality in PEI Rivers and Streams. PEI Department of Environment and Climate Change (2020).
Nagamuthu, P. Climate change impacts on surface water resources of the northern region of Sri Lanka. Knowl.-Based Eng. Sci. 4, 25–50 (2023).
Acknowledgments
The authors would like to thank the reviewers and editors for their comprehensive and constructive comments for improving the manuscript. In addition, Zaher Mundher Yaseen would like to thank the Civil and Environmental Engineering Department, King Fahd University of Petroleum & Minerals, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
Iman Ahmadianfar: Conceptualization, Methodology, Formal analysis, Writing—original draft, Writing—review and editing, Software, Visualization, Investigation. Aitazaz Ahsan Farooque: Methodology, Formal analysis, Writing—original draft, Writing—review and editing, Software, Visualization, Investigation, Supervision. Mumtaz Ali: Methodology, Formal analysis, Writing—original draft, Writing—review and editing, Software, Visualization, Investigation. Mehdi Jamei: Formal analysis, Writing—original draft, Writing—review and editing, Visualization, Investigation. Mozhdeh Jamei: Formal analysis, Writing—original draft, Writing—review & editing, Visualization, Investigation. Zaher Mundher Yaseen: Formal analysis, Writing—original draft, Writing—review and editing, Visualization, Investigation.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ahmadianfar, I., Farooque, A.A., Ali, M. et al. A hybrid framework: singular value decomposition and kernel ridge regression optimized using mathematical-based fine-tuning for enhancing river water level forecasting. Sci Rep 15, 7596 (2025). https://doi.org/10.1038/s41598-025-90628-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-90628-6
