
Abstract
Urban expansion and subsurface resource exploitation have intensified ground subsidence, posing significant geological risks. Conventional prediction models often overlook multi-scale spatiotemporal effects that critically influence accuracy. This study proposes an integrated MGTWR-CNN-BiLSTM-AM (MGCBA) model to address this gap. Utilizing SBAS-InSAR-derived deformation data from Shanghai’s primary subsidence zones, validated through GNSS and PS-InSAR observations, we developed a Multi-scale Geographically and Temporally Weighted Regression (MGTWR) framework. This model quantifies nonlinear spatiotemporal relationships between subsidence and driving factors, including monthly-scale variables (groundwater extraction, precipitation) and annual-scale parameters (land use, soil type), generating dynamic weight matrices. The integrated CNN-BiLSTM-AM (CBA) deep learning network extracts critical time-series features to optimize spatiotemporal weights adaptively. Experimental results demonstrate a prediction accuracy of 0.99347 (RMSE: 1.8643 mm), outperforming the standalone CBA model (0.98494) by 0.85%. SHAP value analysis identifies monthly groundwater levels, soil moisture, and annual-scale soil type/DEM as dominant contributors to Shanghai’s urban core subsidence. The proposed multi-scale spatiotemporal modeling framework advances surface deformation prediction by enhancing the interpretability of key drivers under spatiotemporally variable conditions.
Similar content being viewed by others
Introduction
During rapid urban development, frequent human activities and the inherent vulnerability of natural geography contribute to surface settlement. This is particularly evident in areas with extensive groundwater extraction or loose soil composition, where such changes represent irreversible geological phenomena1,2. This results in immeasurable damage to urban areas, including road infrastructure, surface cracking, and building tilts. Delta regions, such as the Yangtze River Delta and the Guangdong-Hong Kong-Macao Greater Bay Area, are at even higher risk of settlement, affecting larger areas and posing significant safety hazards3. Therefore, conducting high-precision, large-scale monitoring and forecasting of surface settlement in urban areas is crucial to mitigate the geological hazards associated with surface settlement4.
With the advancement of InSAR technology, multi-temporal In-SAR techniques have been widely adopted by researchers and are now extensively used for monitoring surface deformation5,6,7. Compared to traditional settlement measurement techniques, satellite remote sensing uses Synthetic Aperture Radar (SAR) image data to calculate surface deformation from the phase difference of microwaves captured in repeated surface observations8,9,10. In large-scale regional studies, mul-ti-temporal InSAR techniques, including PS-InSAR, SBAS-InSAR, and DS-InSAR, are now widely applied for surface monitoring. Wang et al.8 introduced a method for automatically detecting mining subsidence basins by integrating InSAR with a CNN-AFSA-SVM model. Utilizing Differential Interferometric Synthetic Aperture Radar (D-InSAR) to generate interferograms, they manually extracted training samples of mining subsidence basins. Ghaderpour et al.11 applied Persistent Scatterer Interferometric Synthetic Aperture Radar (PS-InSAR) technology to monitor settlement in the industrial area of Italy’s Sacco Valley. They employed the STPD method to detect trend turning points and used the LSCWA method to analyze river flow and precipitation time series. Ren et al.7 utilized InSAR technology, specifically Small Baseline Subset InSAR (SBAS-InSAR) and Independent Component Analysis (ICA), to monitor and analyze ground settlement characteristics in the Pearl River Delta from 2016 to 2021. Their findings provide valuable insights into the region’s spatial distribution of ground settlement. Monitoring urban surface deformation using SBAS-InSAR and PS-InSAR technologies is regarded as one of the most effective methods for detecting surface settlement12,13. Therefore, this paper employs SBAS-InSAR and PS-InSAR techniques to monitor surface settlement in Shanghai.
Predicting urban surface settlement can be studied using physics-based models, statistical models, and machine-learning algorithms6,14. For example, Dong et al.15 integrated multi-sensor C-band InSAR measurement data to construct a logical model that captures ground settlement measurements over the past thirty years (1992–2022). Their findings indicate that groundwater reserves in Beijing may significantly recover over the next decade; however, most severely subsided land and inelastic aquifers are unlikely to recover, resulting in a permanent loss of water storage capacity in the Beijing plain. He et al.6 integrated time series InSAR deformation data with time-distributed CNN segmentation and stacked PhLSTM into a unified network model. This approach provides scientific evidence for real-time monitoring and spatiotemporal surface deformation prediction in mining areas. Wang et al.16 studies employed an improved Water Balance-Constrained Recurrent Neural Network (WB-RNN) method to establish connections among precipitation data, evapotranspiration data, groundwater extraction, and groundwater levels. Additionally, they used the GRU-CNN approach to link groundwater levels with InSAR deformation, thereby establishing the relationship between the drivers of the binary water cycle and ground settlement.
This research enhances the understanding of the impacts of climate change and human activities on ground settlement, providing scientific support for related policy formulation. An increasing number of researchers are investigating the impact of these factors from various perspectives17,18. By improving settlement-driving models and proposing corresponding measures, they aim to mitigate or prevent the occurrence of settlement-related disasters. However, these models often exhibit poor fitting performance, difficulties obtaining the necessary input data, and a tendency to overlook the nonlinear variations in surface settlement. As a result, the predictions can vary significantly and may not be reliable for practical use. To address the nonlinear variations in surface settlement caused by factors such as soil geology, some researchers have turned to machine learning and deep learning algorithms. These methods include RF, BRT, CNN, and LSTM networks6,13,19, which offer promising solutions for this complex issue. While these models can provide insights into the impacts of settlement factors to some extent, they primarily focus on non-spatiotemporal changes and do not adequately account for spatial heterogeneity, including spatial bandwidth and the geographical characteristics of influencing factors20. The emergence of Geographic Weighted Regression (GWR) and Multiscale Geographic Weighted Regression (MGWR) methods has provided researchers with new approaches to address issues such as spatial heterogeneity21,22. Shang et al.23 utilized Geographic Weighted Regression (GWR) models to examine spatial heterogeneity based on groundwater level. Their findings underscore the importance of considering spatial heterogeneity in groundwater resource management and formulating surface settlement prevention strategies. L. Zhang et al.24 developed a method combining Multiscale Geographic Weighted Regression (MGWR) with satellite monitoring to estimate the factors influencing urban ground deformation quantitatively. The MGWR approach offers a deeper understanding of the factors affecting urban ground deformation, aiding in formulating proactive control plans to prevent ground settlement disasters25.
However, these methods often focus on the geographical spatial relationships between influencing factors and surface settlement, neglecting the spatiotemporal non-stationarity, particularly the nonlinear relationships across different spatiotemporal scales. Building on this, Yuan et al.25 proposed a deep learning model that combines Geographic and Temporal Weighted Regression (GTWR) with Long Short-Term Memory (LSTM) and Attention Mechanism (AM) to predict surface settlement. While this research successfully addresses spatiotemporal non-stationarity to enable accurate predictions of surface settlement, it primarily focuses on groundwater extraction, precipitation, and Normalized Difference Vegetation Index (NDVI) data as influencing factors17. There is a notable lack of exploration regarding other surface characteristics, such as soil type and elevation, concerning spatiotemporal non-stationarity26. In practical scenarios, many factors are primarily affected by issues of scale inconsistency, including imbalances in temporal scales and resolution challenges in spatial scales. The failure of data fusion in multi-scale contexts and the attempt to address these issues by continuously reducing the number of influencing factors to fit the scale of the study are unreliable approaches.
Therefore, this study aims to advance our understanding of the spatiotemporal heterogeneity of surface settlement by investigating the following key questions: (1) What methods can be used to quantitatively analyze the geographical and temporal relationships between various influencing factors and surface settlement? (2) Which methods should be employed to assess the models and articulate their predictive and analytical outcomes? (3) How do we interpret the characteristics of spatiotemporal non-stationarity and heterogeneity in surface settlement? This study proposes a deep learning model that combines Multiscale Geographic and Temporal Weighted Regression with Convolutional Neural Networks, utilizing Bidirectional Long Short-Term Memory (Bi-LSTM) and an Attention Mechanism (MGCBA). The model aims to investigate the multiscale spatiotemporal non-stationary relationships between various influencing factors and surface settlement across different scales.
The MGTWR model explores the spatiotemporal non-stationary relationships between ground settlement and its influencing factors within a multiscale geographic context. The CNN-BiLSTM (CNN-BL) framework is employed to make predictions based on the constructed data. By incorporating an Attention Mechanism (AM), the model captures vital information from the time series data, allowing for dynamic adjustments and weight allocations of the influencing factors. This process involves refining the weight values based on training outcomes, ultimately enhancing the accuracy of the predictions. This paper utilizes SHAP analysis about the relationship of influencing factors on predictor variables, which helps explain the internal mechanism of model prediction27. The SHAP analysis effectively improves the model’s accuracy and elucidates the advantages of multifactor prediction of sedimentation28.
Study area and data sets
Brief description of the study area
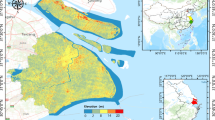
Figure 1 shows the geographical location of the study area. This study focuses on Shanghai, a coastal city in eastern mainland China, situated between longitudes 120°52′ to 122°12′ E and latitudes 30°40′ to 31°53′ N. Located at the mouth of the Yangtze River, Shanghai experiences a subtropical monsoon climate characterized by heavy rainfall, particularly during the plum rain season, which typically peaks from June to August.

(A) Illustrates the general location of the region; (B) The hydrogeological profile information of the confined aquifer in Shanghai; (C) The location of the study area along with the positions of confined water, unconfined water, and meteorological stations; and Panel D depicts the hydrogeological profile of the confined aquifer. This information is sourced from (https://data.sigs.cn/).
Shanghai’s unique geographic and geological features make it an ideal study area. Its complex hydrogeological structure, location at the Yangtze River mouth, and soft soils (e.g., silty clay) with high compressibility and low bearing capacity are prone to subsidence due to external loads or groundwater mining. Rapid urbanization and groundwater-resource conflicts exacerbate subsidence. Compared to other cities like the Pearl River Delta and Beijing–Tianjin–Hebei, Shanghai is more representative in terms of geological conditions, urbanization intensity, and data completeness. Its coastal location and the combined effect of sea-level rise and subsidence intensify flooding risks, making it a valuable case for studying composite disasters beyond just subsidence.
Sentinel-1A SAR data
Sentinel-1A data is derived from the Sentinel-1 radar satellite launched by the European Space Agency. This study utilizes 78 Sentinel-1A SAR images from the same track, covering January 2020 to September 2023. By selecting and processing these images in bulk, we generated interferometric pairs from 78 SAR images using HPY3. Subsequently, MintPY was employed to analyze the interferometric data29, resulting in monthly surface deformation data and annual average subsidence changes. To mitigate the impact of elevation errors on surface deformation, we employed the Shuttle Radar Topography Mission (SRTM) data for elevation correction. We utilized precise orbital data to address systematic errors30. This approach effectively eliminates the influences of topographic phase errors. A detailed discussion of the SBAS-InSAR processing method will be presented in Section “SBAS-InSAR processing”.
Main influencing factor data
A review of the literature indicates that the primary factors influencing urban surface subsidence include topography, climate, hydrology, and human activities4,31,32,33. Hydrological and climatic factors include precipitation and soil permeability. The hydrological and geological factors involve aquifer parameters such as aquifer thickness, transmissivity, and confining layer characteristics, along with variations in the thickness of different soil layers and the percentage content of silt and clay31. In the context of Shanghai, the main influencing factors include changes in groundwater extraction, variations in precipitation, and monthly soil moisture content33.
In Shanghai, monthly changes in bearing water (AW) and submerged water (PW) drive settlement by affecting soil stress. The city’s subtropical monsoon climate, with heavy summer rains, recharges groundwater via infiltration, and short-term precipitation shifts can trigger settlement through pore–water–pressure changes. Topography influences runoff and recharge, with low-lying areas prone to waterlogging and soil softening. Soft soils (e.g., silty clay) are highly susceptible to settlement, and urban expansion alters surface-load distribution. Our parameters cover climate, hydrology, topography, and human activities, addressing multi-scale spatio-temporal heterogeneity.
Monthly precipitation data
The study area is in a subtropical monsoon climate, with most rainfall between June and August. Literature reviews suggest that precipitation and surface water can significantly contribute to groundwater recharge, thereby influencing surface deformation16. This study utilizes daily average precipitation data published by the National Meteorological Administration and GSOD meteorological observation data as input variables34. We processed the monthly variations in precipitation for both datasets from January 2020 to September 2023 to obtain the monthly precipitation data. The primary method employed is ordinary kriging interpolation35. The interpolation relies mainly on data from the eight nearest stations to avoid excessive smoothing. Finally, the results from both datasets are compared with actual station data for validation. Construct Function represents the weight of the two datasets (\(\omega_{1} + \omega_{2} = 1\)) and \(n\) indicates the number of data points. The usability of the dataset is confirmed through comparative validation.
Monthly groundwater data
We obtained monthly groundwater level data for 249 Shanghai monitoring wells (219 confined, 30 unconfined) from the Chinese Environmental Monitoring Institute. Given Shanghai’s Yangtze River-mouth location, surface and groundwater are correlated. We used ordinary kriging interpolation for monthly time-series data, with 90% for interpolation and 10% for validation. The dataset’s 98.95% accuracy confirms its reliability.
Monthly NDVI (normalized difference vegetation index) data
NDVI data, used for vegetation monitoring, was incorporated as a long-term input into our model following literature and experimental needs. Monthly NDVI data was obtained from the National Earth System Science Data Sharing Platform for analysis.
Additional multiscale factor data
This study considers long-erm data (groundwater extraction, precipitation variations, NDVI) and multi-scale factors from the National Earth System Science Data Sharing Platform and ArcGIS Living Atlas of the World. Table 1 lists all data sources.
Methodology
SBAS-InSAR processing
This study uses the SBAS method to monitor Shanghai’s ground subsidence, enabling precise measurement of surface deformation in the city center, processed with ESA’s HPY3 program36. The temporal baseline was set to 60 days, and the spatial baseline was set to 200 m. This approach was implemented to gather more relevant data. The generated interferograms are primarily based on the following formula:
In this context, \(M\) represents the number of interferograms while \(N\) denotes the quantity of SAR images in the study area.
Based on prior experience and documented literature, we set the coherence threshold at 0.9 and incorporated a water body mask during processing to enhance the reliability of the results. To address the potential issue of limited area coverage in the output, we applied a 10 × 2 multilook ratio, ensuring both data accuracy and a broader spatial output. However, it is essential to note that various errors may arise during processing, as outlined in Eq. (2).
In this context, \(\lambda\) represents the wavelength, \(W\) indicates the unwrapping operation, and \(\Delta d\) refers to the line-of-sight (LOS) displacement value between the two images. Additionally, \(\Delta h\) denotes the DEM error, \(\theta\) represents the angle of incidence, and \(r\) signifies the range measurement. Furthermore, \(\Delta \phi\) encompasses various errors, including phase delay errors, orbital errors, and noise phase. To address unwrapping errors, we used 30-m DEM data to enhance the unwrapping process. A linear method was employed to correct phase ramp-induced errors in the phase data, and the inversion weight type was changed to a covariance format for more effective processing. The data was processed using MintPy to obtain numerical representations of subsidence areas. However, radar imaging can influence practical results, as line-of-sight (LOS) measurements often fail to accurately reflect vertical ground deformation. Thus, based on literature and improved processing methods, this study used LOS measurements as the final results, denoted by Equation \(D_{(LOS)} *\cos \theta\). These results are compared with the PS-InSAR outcomes, and data from Shanghai’s IGS stations are analyzed to validate the findings. Here, \(D_{(LOS)}\) represents the distance along the line of sight, and \(\theta\) indicates the radar satellite’s angle of incidence. Finally, after removing the residual phase errors, the interferometric phase is simplified as represented in Eq. (3):
In this context, \(v_{i}\) represents the average deformation rate over the period from \(t1\) to \(t2\), corrected along the line of sight (LOS).
We validated the data via PS-InSAR-based comparative analysis and used Shanghai IGS She Shan station data to analyze subsidence changes over the period, comparing the results with actual measurements for verification.
The MGTWR-CNN-BILSTM-AM algorithm
This study’s algorithm includes four parts: MGTWR, CNN, BILSTM, and AM37,37. MGTWR analyzed spatial–temporal stability of ground subsidence and factors, obtaining weights of driving factors. Data were trained with CNN-BL, and AM adjusted parameter influence. Parameters were optimized to improve Shanghai subsidence predictions, compared with other models. For detailed model info, see the supplementary document.
In this study, after conducting correlation and collinearity tests on the selected factors, we included the following variables as time-varying data: ground subsidence (\(LS_{i,t}\)), groundwater levels (including confined aquifer (\(AW_{i,t}\)) and unconfined aquifer (\(PW_{i,t}\))), monthly precipitation (\(P_{i,t}\)), monthly NDVI (\(N_{i,t}\)), and monthly soil moisture (\(SMC_{i,t}\)). Additionally, land use (\(LU_{i,y}\)), soil type (\(ST_{i}\)), and DEM (\(DEM_{i}\)) were incorporated as spatial dimension data. See Supplementary file S1 for correlation and covariance tests among them. The input matrix format for constructing the predictive model is as follows:
In this context, \(TIF\) represents the matrix of time-varying influence factors that change over time \(t(0 - 31)\), \(SIF\) denotes the matrix of spatial dimension influence factors, and \(y\) indicates the variation across different years.
The ground subsidence matrix is represented by a one-dimensional matrix (\(DV\)), which captures the cumulative ground subsidence data \(i\) at various points over time \(t\), as illustrated below:
The MGTWR results, mainly a weight matrix, address ground subsidence’s spatial–temporal heterogeneity across scales via two approaches: First, all factors are input into the MGTWR model to analyze bandwidths and generate the weight matrix. Second, time and spatial data are processed separately to obtain different weighted matrices, with weights assigned proportionally based on each factor’s importance. A comparison is then made, as shown in the following equation:
In this context, the matrix \(W_{TIF} ,W_{SIF} ,W\) represents the weight matrices for the time and spatial dimension characteristic factors, as well as the weight factors corresponding to the MGTWR model for all aspects. Meanwhile, the matrix \(W\) indicates the spatiotemporal weight matrix \(\widehat{\beta }(u_{i} ,v_{i} ,t_{i} )\) at the \(i\) point, determined by the regression coefficient matrix at \(t\).
Ultimately, we multiply the weights of the spatial and temporal dimension matrices by their corresponding input factor matrices to obtain the output matrix \(X_{i,t}^{1}\) and the prediction matrix \(Y_{i,t}^{1}\). Additionally, we multiply the weight matrix obtained from directly processing all factors by the corresponding input factor matrix to yield the output matrix \(X_{i,t}^{2}\) and the prediction matrix \(Y_{i,t}^{2}\). We then validate the final results from both approaches, selecting the optimal processing outcome as the fundamental weight matrix for addressing spatial–temporal heterogeneity.
The output matrix \(X_{i,t}^{1}\) and the prediction matrix \(Y_{i,t}^{1}\) are represented as follows:
The output matrix \(X_{i,t}^{2}\) and the prediction matrix \(Y_{i,t}^{2}\) are represented as follows:
This study normalizes data at specified points and splits it into a training set (70%), validation set (20%), and test set (10%) for model processing. During experiments, we ran multiple trials with various random parameter combinations, informed by literature and experience, to determine the optimal parameters.Furthermore, to further assess the accuracy of the prediction results, we utilized evaluation metrics such as \(R^{2} ,RMSE,MAE,sMAPE\).
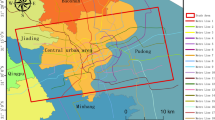
This study sampled Shanghai uniformly (Fig. 2A), using GIS to process data and extract average spatial distributions at different times, yielding ~ 800 points. After removing those with missing values, 657 points were used for the first analysis. For the second round (Fig. 2B), areas with annual average subsidence > 10 mm were processed via GIS, resulting in 653 points. Excluding those with missing data left 583 points. In the third round (Fig. 2C), unconfined and confined groundwater monitoring points were selected. Finally (Fig. 2D), data was reprocessed to select several areas for model validation, including high subsidence areas (3) and groundwater mining sites (3), totaling 112 points for model prediction and accuracy validation.

(A) The distribution of average sampling points in the study area, (B) The distribution of sampling points at subsidence sites, (C) The distribution of sampling points at water table sites, and (D) represents the points in the region of interest.
This study evaluates the predictions and accuracy of the MGCBA model against diverse approaches, including BILSTMm (BL), CNN-BILSTMm (CNN-BL), CNN-BILSTMm-AM (C-BL-A), GTWR-CNN-BILSTMm (GCBA), and MGTWR-CNN-BILSTMm (MGCB), across multi-scale temporal and spatial conditions. The comparison between MGTWR and GTWR models is discussed to determine whether the spatiotemporal weighting effect of MGTWR improves accuracy relative to other learning models. Additionally, the predictive performance of the AM algorithm across all models is analyzed. A flow chart of this study is shown in Fig. 3.

Flowchart presentation of this study.
Model interpretation using SHapley interpretation (SHAP)
The SHAP algorithm is derived from game-theoretic problems in economics that govern the fair distribution of “payouts” among players based on their contributions to the outcome of a task27,38. This algorithm effectively analyzes the importance of each input variable in the output. By examining these variable importances, the model’s predictive logic can be explained or verified using empirical evidence or physical knowledge, enhancing the interpretability of the model’s internal mechanisms38. The calculation formula for SHAP values is based on the definition of Shapley values and can be expressed as:
where: \(\phi_{i}\): SHAP value for feature \(i\); \(N\):The set of all features; \(S\): A subset of \(N\) that does not include \(i\); \(\upsilon (S)\): The value (e.g., prediction) of the subset \(S\); \(|S|\): The number of elements in subset \(S\); \(|N|\): The total number of features. This formula distributes the contribution of each feature to the overall prediction fairly, ensuring interpretability.
In this study, we used the SHAP algorithm to evaluate the importance of all features in predicting subsidence. By constructing SHAP functions to analyze the MGTWR-CNN-BILSTM-AM model, we assessed the model’s robustness and applicability.
Analysis of the importance of driving factors
Following established literature, we applied random seed perturbation to the driving factors of monthly and annual-scale data one by one, recording the resulting \(R^{2}\) after predictions. We then compared the outcomes to evaluate the differences in \(R_{DIF}^{2} = R_{PRE}^{2} - R_{FIRE}^{2}\) before and after the perturbation. We can assess each factor’s impact on subsidence by calculating this value. Additionally, comparing the perturbed prediction results with the original outcomes reveals the significance of the driving factors. This analysis helps to highlight which factors are most influential in contributing to ground subsidence. We hypothesize that if \(R^{2}\), the model prediction accuracy decreases, it indicates that the driving factor is significant for model predictions. Conversely, if it remains unchanged, it suggests that the factor is not essential.
To reveal and determine the impact of driving factors on subsidence, we perform random seed perturbation on each driving factor for both monthly-scale and annual-scale data. We calculate \(R_{DIF}^{2}\) for each factor before and after the perturbation and then accumulate the changes in \(R_{DIF}^{2}\) for each factor. This allows us to compute the importance of each driving factor concerning ground subsidence, as expressed in the following formula:
In this context, \(Weight_{DF}\) represents the importance level of different driving factors while \(R_{DF\_DIF}^{2}\) indicates the results of these factors before and after random seed perturbation. Additionally, \(\sum\nolimits_{1}^{n} {R_{DIF}^{2} }\) denotes the total sum from 1 to \(n\) for the changes in results of the driving factors before and after the perturbation, represented as \(R_{DIF}^{2}\).
Results
InSAR results and accuracy assessment
The subsidence map of Shanghai from January 2021 to August 2023, generated using Sentinel-1 satellite data, illustrates the cumulative subsidence changes and annual average rates, as shown in Fig. 4. The results indicate an average yearly subsidence rate ranging from − 18 mm/year to 2.7 mm/year, with cumulative subsidence values between − 54 mm and 16 mm.

(A and B) The cumulative subsidence values and annual average subsidence rates for Shanghai obtained through SBAS-InSAR processing. (C and D) Bland–Altman plots comparing SBAS-InSAR and PS-InSAR results.
Figure 4 reveals that most areas within the study region exhibit stable ground surfaces, while subsidence is observed in certain areas, primarily in the central southern part of Shanghai. To assess the reliability of these subsidence results, we conducted a comprehensive evaluation using concurrent PS-InSAR results and data from Shanghai GNSS observation points. The PS-InSAR data were generated using Sentinel-1 satellite images from January 2020 to September 2023 via ENVI software. GNSS data were collected and processed from the IGS station at Sheshan in Shanghai. Given the limited number of GNSS stations, we first compared the SBAS and PS results with the GNSS data at each station. Subsequently, we compared the SBAS and PS results with each other for further validation. Table 2 presents the comparison and validation results between SBAS, PS, and GNSS data. The absolute deviations between the actual subsidence values (derived from data near GNSS stations) and the results from SBAS and PS indicate a high level of agreement between SBAS, PS, and GNSS measurements.
We applied PS-InSAR processing to conduct a quantitative comparison and performed uniform sampling across the study area, selecting 18,000 points. We then extracted cumulative subsidence values and annual average subsidence rates from SBAS-InSAR and PS-InSAR data to calculate the measurement differences between the two methods. Figure 4C and 4D display the distribution of differences between measurements obtained from the two methods and their average values. While some outliers are present, most sampled points fall within the confidence interval. This supports the acceptability of errors in both methods and confirms the suitability of SBAS-InSAR for subsidence data analysis.
Model development and result analysis
As shown in Table 3, before the experiments, to ensure that all models were at their optimum, we used stochastic multiparameter combinations to determine the best parameter combinations after several runs, and the best parameter combinations were considered in the selected models for the experiments. At the same time, for subsequent optimization, we restrict the model as a whole to ensure that it runs with optimal results while acquiring the results in the shortest time, which effectively saves the testing cost and plays an important role in the promotion of the model.
According to the results in Table 3, the MGCBA model is best fitted with Lr, batch size, epoch, LSTM_layer1, LSTM_layer2, and dropout values of 0.026, 32, 160, 16, 32 and 0.08, respectively.
Uniform sampling for subsidence modeling across the entire region
This study generated InSAR results and a uniform sampling point map for surface settlement in Shanghai based on the previously outlined model and experimental design. The collected data on factors driving surface settlement were then input into the model to obtain experimental results, which were analyzed and compared. In Figure S1, panels A and D represent two correlation tests (Pearson and Spearman). Table S1 presents the results of the VIF test, confirming that there is no multicollinearity among the various factors. As shown in Table 4 and Fig. 5, the MGCBA model achieved the highest accuracy, with an \(R^{2}\) of 0.99347, indicating its optimal performance across the average sampling points. The MGCB model ranked second in accuracy, with an \(R^{2}\) of 0.98797, representing a 3% improvement over the GCB model’s \(R^{2}\) of 0.95777. These results indicate that MGTWR offers superior correction in handling multiscale spatial–temporal heterogeneity compared to GTWR. The comparison experiments involving the addition of the attention mechanism (AM) showed that AM consistently improved accuracy. For instance, the accuracy of C-B-A was approximately 1.9% higher than that of CNN-BL. Thus, incorporating the attention mechanism effectively enhances predictive accuracy.

The validation comparison of the selected models’ predicted and actual InSAR values after uniform sampling over the whole region, where the optimal model is 0.99347.
Figure 5 shows the correlation between the predicted results of models ranging from BILSTM to MGCBA and surface settlement data from SBAS-InSAR.
To avoid the impact of sampling precision on the experiment, GIS sampling was conducted at pixel ratios of 0.01, 0.005, 0.001, and 0.0005. After multiple trials, as shown in Table 5, the model’s accuracy remained nearly unchanged regardless of sampling point density. Among the models tested, MGCBA demonstrated the best performance with optimal balance. The analysis shows that while spatial–temporal heterogeneity shifts slightly with increased sampling point density, it remains stable and does not fluctuate significantly. At a sampling density of 0.005, the model’s final accuracy is nearly identical to higher densities, making the difference negligible. Therefore, a sampling density of 0.005 was selected for this study.
Subsequently, we used Shapley values to validate the model with a sampling density of 0.005 and the MGCBA model, aiming to explain its accuracy. Figure 6 presents a summary of SHAP values from the average sampling point experiment, along with a distribution chart of feature importance, which is used to assess the contribution of each feature to the variation in settlement values. In Fig. 6, each point represents the Shapley value of a feature for a given instance. Feature importance is ranked based on its average contribution to the prediction (i.e., the average absolute SHAP value). The most important feature is PW, followed by MP and AW, indicating a strong relationship between surface settlement and factors such as water resource utilization. The Shapley values are determined along the x-axis, where the direction (positive or negative) indicates the correlation between the feature’s instance and the prediction.

The SHAP value of all the influences in the homogeneous sampling area, which indicates the importance of the influences, where PW is ranked first.
The results show that PW, MP, AW, and SMC are the top-ranking variables, representing the most critical factors in evaluating changes in settlement values. These factors positively influence the model’s output, indicating that higher values of these features tend to lead to more significant settlement variation errors. Although NDVI has a relatively small impact, the model’s output shows a positive relationship with it, indicating that higher values of NDVI are associated with more significant errors. Like DEM and ASP, these factors are ranked lower in importance and do not cause substantial positive or negative errors. This can be attributed to the fact that the average sampling points in Shanghai show slight variation in factors such as DEM, leading to the absence of noticeable positive or negative feedback. It can also be observed that factors at the annual average scale tend to have a minor impact on settlement variation errors. In contrast, monthly scale data leads to more significant errors. Therefore, incorporating more monthly-scale information can enhance the accuracy of surface settlement predictions.
Subsidence modeling for major subsidence areas
To better clarify the significance of this study, the current experiment addresses the potential issue from the first round, where uniform sampling may not have reflected settlement patterns at specific points. We focused on settlement areas for the second round of experiments by extracting 653 points from regions with settlement values greater than 10mm. After filtering, 583 valid points were selected as the basis for this round of experimentation. Similarly, in Figure S1, panels B and E represent two different correlation tests (Pearson and Spearman), while Table S1 presents the results of the VIF test. As shown in Table 6 and Figure S3, the prediction accuracy results of different models are presented. It can be observed that the MGCBA model used in this study achieves an accuracy of 0.97515, indicating its strong applicability. The accuracy of the GCB and MGCB models are 0.96684 and 0.97209, respectively, further confirming that under multiscale spatial–temporal heterogeneity, the latter model provides more reliable accuracy than the former.
As shown in Fig. 7, the SHAP analysis of settlement point areas reveals that the top five factors are still based on monthly-scale data. However, compared to Fig. 6, MP has risen by one rank, indicating that precipitation significantly impacts settlement variation. It can also be observed that the variations in MP are nearly symmetrical, indicating that regardless of changes in rainfall, settlement variations consistently occur. From Fig. 7, it can be roughly inferred that higher precipitation values significantly impact settlement changes. Additionally, PW and AW rank second and third in terms of influence, highlighting the considerable impact of groundwater extraction on settlement. Moreover, a decrease in PW within the settlement areas exacerbates settlement. However, it is also observed that as PW increases, settlement intensifies even more, with the degree of intensification being much more significant than when PW decreases. Similarly, the changes in AW closely mirror those of PW. In the case of annual-scale data, it is observed that variations in DEM lead to changes in ASP and SLO, which in turn affect settlement changes. As DEM increases, the settlement variation becomes more pronounced. Overall, the predictive variables exhibit varying degrees of influence on settlement changes in the settlement areas. These influences can be attributed to changes in water resource utilization. As further indicated by Figs. 6 and Fig. 7, factors at the annual average scale tend to cause more minor errors in settlement variation. In contrast, monthly-scale data result in more significant errors, particularly concerning changes in water resource utilization.

Represents the SHAP values of all the influencing factors within the main settlement area, with MP in the first place.
Subsidence modeling for groundwater extraction sites
In the third round of experiments, groundwater monitoring points, precisely extraction points, were chosen as the focus. These points represent the most accurate locations for current groundwater extraction. Similarly, in Figure S1, panels C and F show the results of two different correlation tests (Pearson and Spearman), while Table S1 presents the results of the VIF test.
As shown in Table 7 and Figure S4, the results indicate that for settlement prediction at groundwater extraction points, the MGCBA model used in this study remains the most optimal, achieving an accuracy of 0.96559. Compared with the first two rounds of experiments, it can be observed that the prediction accuracy for settlement at groundwater extraction points has decreased. This decline can be attributed to the significant impact of water resource utilization near extraction points, which leads to a decrease in prediction accuracy at these locations. As shown in Fig. 8, PW and AW are ranked in the top two positions, and their positive influence on settlement is more pronounced. Additionally, it can be observed that SMC has risen in rank. Overall, the higher water content in the soil layers near groundwater extraction points is one of the main factors influencing surface settlement. The impact of DEM on this area is primarily reflected in the adverse effect, which intensifies as the DEM value decreases. Additionally, it is observed for the first time that MP has dropped to the fifth position, indicating that near groundwater extraction points, changes in water availability have a more substantial influence on surface settlement. This further underscores the necessity of this experiment.

The SHAP values for all the influencing factors within the groundwater extraction area, with PW in the first place.
Based on the above experiments, this study found that the predictive variables exert varying degrees of influence on settlement changes across the three experimental areas. Additionally, the effects of data changes at different scales vary across regions. AW and MP have a clear positive impact in the average sampling point area, ranking highly important. While PW also has a positive influence, its effect is smaller than that of AW and MP. Yet, its importance is higher, indicating a more substantial coupling effect among these three factors. Similarly, in the settlement point area, the importance of MP becomes more pronounced, with both its positive and negative impacts becoming more significant. PW and AW continue to have strong influence, maintaining their top positions. Compared to the average sampling point area, this further validates the findings. In the groundwater extraction area experiment, the factors related to groundwater, namely PW, AW, and SMC, occupy the top three positions, with DEM ranking fourth. Notably, MP has fallen out of the top three for the first time. This indicates that in the groundwater extraction area, the utilization of water resources in the land has a more pronounced effect on settlement changes. The coupling effect between PW, AW, and MP is more evident overall. To comprehensively assess the settlement areas and groundwater extraction center regions, this study uses settlement modeling for selected areas of interest to analyze the model (refer to Section “Subsidence modeling for points of interest”).
Subsidence modeling for points of interest
We processed the data to monitor and analyze the surface deformation trends in key settlement and groundwater extraction areas better and selected multiple regions for the final model validation. This includes three high-subsidence areas and three groundwater extraction points, totaling 112 points, to predict and validate the model’s accuracy in the final round. As shown in Table 8, the settlement point information for the main settlement areas and groundwater extraction regions is provided. These points include locations with the highest cumulative settlement and areas with significant groundwater fluctuations. F1 to F3 represent the groundwater extraction center regions, while F4 to F6 correspond to several places with the most critical surface settlement changes. The annual average groundwater level changes are calculated by averaging the interpolated results.
To evaluate model accuracy, multiple models were applied to predict surface settlement in the six regions (F1 to F6). As shown in Fig. 9, the MGCBA model consistently produces the best results in all six areas. The following best models are MGCB and GCB, indicating that models incorporating spatial–temporal geographical weighting effectively address the issue of accuracy loss that arises when spatial heterogeneity is not considered. It can also be further observed that the Attention Mechanism (AM) plays a crucial role in the model. Whether comparing MGCBA with MGCB or C-B-A with CNN-BL, the accuracy increases with the inclusion of AM. Additionally, based on the results from the first three experiments, it can be observed that in the most severely subsided area, F6, the model shows the most significant discrepancy with the proper values, with RMSE values consistently above 2.86. This indicates that the settlement area has the most considerable interference in predicting settlement changes. An analysis of the terrain and geological conditions reveals that areas with more significant settlement changes are located in coastal regions. These areas are influenced by additional factors that have not been fully explored in this study, and further data will be needed to support these findings.

The model prediction accuracies for 112 observations in the F1–F6 region. The histogram bars in the image indicate the MAE and RMSE of the model, whose accuracies are indicated using the left scale, while the circles and star connecting lines indicate the magnitude of sMAPE and \(R^{2}\), whose accuracies are indicated using the right scale.
Importance analysis of settlement influencing factos
The feature importance of settlement driving factors is analyzed using the method proposed in Section “Analysis of the importance of driving factors” of this study. The importance of factors for each region has already been determined through SHAP analysis. Therefore, the importance of the driving factors for each area will not be discussed again here. Figure 10 shows the results of the importance of multiple factors. Figure 10 shows that in the first three experiments, the importance identification results proposed in this study are broadly consistent with the SHAP results. When GWE (i.e., PW and AW) is removed, the importance share of MP and SMC rapidly increases and remains almost constant. This indicates that after removing the groundwater extraction data, which affects surface settlement in groundwater regions, MP and SMC become more prominent in influencing settlement. This further highlights the significant impact of water resource utilization on settlement. It can also be analyzed that the combined effect of PW, AW, MP, and SMC on settlement is likely to be significant.

Importance results of settlement driving factors. The first three of these areas indicate the major subsidence areas with uniform sampling across the region, subsidence values greater than 10 mm, and groundwater mining areas; the last indicates the comparative validation values for groundwater mining areas with groundwater effects removed.
As shown in Fig. 10, monthly-scale factors significantly impact surface settlement, while annual-scale data may not have as strong a comparative effect. This suggests the need for further analysis of the influence of additional monthly-scale data or even daily-scale data on settlement.
Discussion
Comprehensive evaluation of the relationship between variables and models
In all models, the bias caused by the influence of factors cannot be ignored. However, SHAP can effectively eliminate the impact of certain factors on settlement, helping to prevent overfitting and improving the model’s accuracy. This study selected ten variables as settlement-driving factors, ensuring that the model avoids overfitting while maintaining the accuracy of settlement change predictions based on multiple factors. In previous studies, many authors analyzed settlement phenomena using an excessive number of factors. Some of these studies did not consider the issue of multicollinearity between factors, while others did not assess the importance of each factor in the analysis (Han et al., 2023; Liu et al., 2023; Qin et al., 2024; Yuan et al., 2024). In contrast, we used the SHAP algorithm to analyze the ten factors proposed in this study, assessing the contribution of each feature to the output in each region. The study results show that, as illustrated in Figs. 6, Fig. 7, and Fig. 8, the importance ranking of the selected factors is valid across the entire study area, and different factors have varying degrees of influence on the results. Overall, in Experiment 1 (average sampling point area), the monthly-scale data has the most significant proportion, and PW, AW, and MP are ranked in the top three. In Experiment 2 (settlement point area), the monthly-scale data still has the most significant proportion, and PW, AW, and MP remain the top three, but MP’s ranking has risen. This suggests that settlement changes are related to variations in MP. In Experiment 3 (groundwater extraction area), the importance of NDVI in the monthly-scale data decreases, while GWE remains in the top three. Interestingly, the importance of DEM increases, indicating that terrain impacts surface settlement, with a more significant negative effect—i.e., a decrease in DEM values leads to more noticeable settlement.
The accuracy and precision of the models indicate that the MGCBA model achieves the best performance, particularly in the average sampling point modeling, with a score of 0.99346, while BL shows the lowest accuracy. Additionally, the model results suggest that the GCB model may not be suitable for handling spatial heterogeneity under multi-scale temporal and spatial conditions. It is better suited for analyzing spatial heterogeneity at uniform scales. The AM mechanism effectively demonstrates that the model’s accuracy improves to varying degrees after incorporating the attention mechanism. This further confirms that the AM mechanism positively impacts settlement prediction results, especially in areas with severe settlement.
Sampling space distribution and sample allocation ratio analysis with model results.
In Experiment 1, we tested different pixel ratios and found that the prediction results were most suitable at a ratio of 0.005. Therefore, this study selects the sampling interval at this scale. Although the results of this experiment show that the 0.005 ratio is the most suitable, it can be observed that the results at the 0.0005 ratio might be slightly better. The primary reasons for not selecting this scale ratio are as follows: (1) The model sampling becomes more challenging due to the large data volume, and using GIS table conversion functions can cause the system to crash; (2) Spatial–temporal geographic weighted models, such as MGTWR, are slower to process. At a 0.0005 pixel resolution, the model requires continuous operation for over 10 days on average, which can lead to system crashes; (3) Deep learning models, such as CNN, are even slower. Due to the specific nature of CNN and similar models, adding the AM mechanism further extends the running time, which reduces data processing speed like point (2). These issues slow down model operation and result in considerable fluctuations in the final accuracy. In multiple experiments, we found that when using samples at a 0.0005-pixel resolution for spatial–temporal geographic weighting, the resulting experimental weight matrix is often microscopic, typically around \(x \times 10^{ - 10}\), where \(x\) value represents the integer part. This leads to difficulty distinguishing the data during processing with models like CNN, which degrades the accuracy of the model’s results.
To assess the impact of the sample point distribution ratio on the robustness of the MGCBA model, we divided all sample points into different ratios. We conducted modeling experiments using the average sample points as an example. As shown in Table 9, when the training set ratio is 60% or 50%, the model’s prediction accuracy significantly decreases compared to when the training set ratio is 70% or 80%. Upon comprehensive analysis, we believe that the reduction in the number of sample points in the training set limits the model’s ability to fully learn the future trends of surface settlement, leading to a decrease in accuracy. When comparing the training set ratios of 70% and 80%, the model’s prediction accuracy improves, with the enhancement being more pronounced at the 80% ratio. Overall, the MGCBA model demonstrated consistent accuracy across various sample splits without sudden performance jumps. This indicates that the model exhibits robustness in surface settlement prediction.
Our proposed MGCBA model performs well in predicting surface subsidence in Shanghai, but its potential limitations need to be considered in practical applications. Surface subsidence is a dynamic process that is affected by multiple factors over time. Models need to be continuously updated and adjusted to accommodate these dynamic changes. However, model updating and maintenance may require additional resources and time, limiting their flexibility in practical applications. Therefore, we believe that we need to improve the accuracy and reliability of the model in future studies by improving the data quality, optimizing the model structure, and considering uncertainty propagation and dynamic changes, which can further improve the accuracy and reliability of the model.
Subsidence management and prevention
Based on the results of the Shanghai case study, we suggest that a multi-dimensional and comprehensive management strategy should be adopted for the prevention and control of ground subsidence, with the following specific recommendations: Optimize the dynamic groundwater extraction quota, and based on the dominant influence of groundwater (AW/PW) in the SHAP analysis, we suggest the establishment of a dynamic quota system for groundwater extraction based on seasonal and regional differences. For example, reduce extraction during the rainy season (June–August) and utilize precipitation to naturally recharge the aquifer. Layered monitoring and recharge: To address the high sensitivity of the pressurized aquifer (AW), implement artificial recharge projects in key subsidence zones (e.g., the southern central area), and adjust the recharge rate in conjunction with real-time monitoring data to balance groundwater pressure. Soft soil zone development restriction: In silty clay distribution zones (DEM low-value zones), restrict the density of high-loaded buildings (e.g. super high rise) and promote lightweight foundation technology (e.g. pile foundation optimization). Promotion of green infrastructure: through the correlation analysis of NDVI and subsidence, increase urban green space coverage to enhance soil water-holding capacity and reduce the impact of surface runoff on groundwater.
Our findings have important lessons for cities facing similar challenges around the world, particularly in three types of regions: coastal floodplain cities (e.g., Jakarta, Bangkok, New Orleans), which share Shanghai’s characteristics of soft ground, high water tables, and intensive human activity. Rapidly urbanizing emerging cities (e.g., Mumbai, Lagos), where the dramatic increase in surface loading due to urban expansion can be captured dynamically by C-B-A models. Resource-dependent cities (e.g., Mexico City, Tehran) that experience subsidence due to mining or agricultural pumping require model parameters to be adjusted to incorporate mine deformation or irrigation water use data.
Scalability and adaptability of models
Adaptation to different geographic environments. We believe that in bedrock areas, ground subsidence is mainly driven by oil and gas extraction or fault activity. The model needs to extend the weight matrix of MGTWR to the geotectonic parameters (e.g., fault distance, rock permeability) and extract local fracture features by CNN. In permafrost regions, the subsidence due to seasonal freezing and thawing is strongly cyclic, and temperature time series data need to be introduced into BL and the AM mechanism needs to be adjusted to focus on the critical periods of freezing and thawing (e.g., spring thaw). For some areas, there may be limited data, so we propose that for areas lacking high-density monitoring wells (e.g., rural Africa), groundwater storage changes can be inverted using GRACE satellite gravity data or meteorological reanalysis data (e.g., ERA5) can be used as a substitute for surface precipitation observations.
Rural-specific applications include mainly agricultural area applications: agricultural pumping is the main cause of sedimentation in the Ganges Plain in India or the Central Valley in the United States. The model needs to add parameters such as irrigation water use, crop type, etc., and use Sentinel-2 data to extract farmland NDVI time series to reflect changes in cropping patterns. Secondly for river erosion or karst collapse (e.g., Guangxi), spatial factors such as river distance and karst development index can be introduced into the model, and the pulse-like effects of flood events can be captured by BiLSTM.
The MGCBA model proposed in this study not only provides a high-precision subsidence prediction tool for Shanghai, but its modular design (geographic weighting, time-series learning, and interpretable analysis) makes it widely adaptable. By adjusting the driving factors, data sources, and computational strategies, the framework can be extended to urban and rural areas in different geographic and socio-economic contexts around the world. In the future, by combining interdisciplinary data and policy simulation tools, the model is expected to become a core decision-making system to support the construction of “resilient cities” and provide a scientific paradigm to address the global land subsidence challenge.
Conclusion
This study predicts surface subsidence in the main urban areas of Shanghai using the MGCBA model combined with SHAP, based on surface subsidence data observed from January 2020 to August 2023. The results indicate that the model achieves high accuracy in predicting surface subsidence in Shanghai, with the optimal performance reaching 0.99347. The following conclusions can be drawn from this study:
-
(1)
Surface subsidence in Shanghai from January 2020 to August 2023 was monitored using SBAS-InSAR technology, with validation by PS-InSAR and GNSS. The findings indicate an average annual subsidence rate ranging from -18 mm/year to 2.7 mm/year, with cumulative subsidence between -54 mm and 16 mm. Most of the study area shows stable surface conditions, although some regions exhibit subsidence, primarily in the central southern part of Shanghai.
-
(2)
The MGCBA model was used to explore the spatial–temporal heterogeneity between surface subsidence and its influencing factors, demonstrating that deep learning can improve prediction accuracy. Compared to MGCB, including the AM mechanism enhanced the model’s accuracy. Compared to GCB, the model showed a clear advantage in capturing multi-scale spatial–temporal heterogeneity. Furthermore, compared to other deep learning models, incorporating spatial–temporal heterogeneity made the model more stable and improved its overall accuracy.
-
(3)
Using SHAP and the method proposed in Section “Analysis of the importance of driving factors” of this study, the influence of multiple factors on subsidence variation was analyzed, enhancing the model’s interpretability and further demonstrating its strengths. In this study, monthly-scale data from the main urban areas of Shanghai significantly impacted subsidence, particularly factors such as PW, AW, MP, and SMC. DEM also played a significant role in influencing subsidence on an annual scale.
Future research may yield more noticeable results by using L-band SAR data from the China Land Observation Satellite-1 (LT-1) to predict surface subsidence. Additionally, future research could consider developing a three-dimensional multi-scale spatial–temporal geographic weighted model for data analysis or using OMGD to analyze geographic spatial–temporal heterogeneity. Furthermore, employing other deep learning algorithms (such as RNN, Transformer, GAN, etc.) from a data-driven and three-dimensional perspective could help explore the regional spatial–temporal heterogeneity between various factors influencing surface subsidence, potentially further improving the accuracy of subsidence predictions.
Data availability
The radar data and the Precise Orbit Determination (POD) data were obtained from the European Space Agency’s (ESA) Sentinel-1A satellite (https://search.asf.alaska.edu/). The external Digital Elevation Model (DEM) utilized was derived from the Shuttle Radar Topography Mission (SRTM) (https://earthexplorer.usgs.gov/). Additional data are provided in the manuscript or in the Supplementary Information document.
References
Haaf, E. et al. A metamodel for estimating time-dependent groundwater-induced subsidence at large scales. Eng. Geol. 341, 107705 (2024).
Monir, Md. M., Sarker, S. C. & Islam, A. RMd. T. A critical review on groundwater level depletion monitoring based on GIS and data-driven models: Global perspectives and future challenges. HydroResearch 7, 285–300 (2024).
Lou, Q.-N., Han, H.-M., Xu, Q.-Y., Wei, G.-Q. & Shi, B. A new distributed water pressure monitoring method for ground subsidence caused by groundwater overexploitation. Measurement 242, 115801 (2025).
Cianflone, G. et al. Different ground subsidence contributions revealed by integrated discussion of Sentinel-1 datasets, well discharge, stratigraphical and geomorphological data: The case of the Gioia Tauro coastal plain (Southern Italy). Sustainability 14, 2926 (2022).
Alesheikh, A. A. et al. Land subsidence susceptibility mapping based on InSAR and a hybrid machine learning approach. Egypt. J. Remote Sens. Space Sci. 27, 255–267 (2024).
He, Y. et al. Time-series analysis and prediction of surface deformation in the Jinchuan Mining Area, Gansu Province, by using InSAR and CNN–PhLSTM Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 15, 6732–6751 (2022).
Ren, T., Gong, W., Gao, L. & Zhao, F. Understanding land subsidence in the pearl river delta region of china based on InSAR observations. Eng. Geol. 339, 107646 (2024).
Wang, L. et al. Automatic-detection method for mining subsidence basins based on InSAR and CNN-AFSA-SVM. Sustainability 14, 13898 (2022).
Zhang, L., Su, Y., Li, Y. & Lin, P. Estimating urban land subsidence with satellite data using a spatially multiscale geographically weighted regression approach. Measurement 228, 114387 (2024).
Zhong, W. et al. Integrated coastal subsidence analysis using InSAR, LiDAR, and land cover data. Remote Sens. Environ. 282, 113297 (2022).
Ghaderpour, E., Mazzanti, P., Bozzano, F. & Scarascia Mugnozza, G. Ground deformation monitoring via PS-InSAR time series: An industrial zone in Sacco River Valley, central Italy. Remote Sens. Appl. Soc. Environ. 34, 101191 (2024).
Festa, D. et al. Nation-wide mapping and classification of ground deformation phenomena through the spatial clustering of P-SBAS InSAR measurements: Italy case study. ISPRS J. Photogramm. Remote Sens. 189, 1–22 (2022).
Wang, R. et al. Large-scale surface deformation monitoring using SBAS-InSAR and intelligent prediction in typical cities of Yangtze River Delta. Remote Sens. 15, 4942 (2023).
Leng, J. et al. Spatio-temporal prediction of regional land subsidence via ConvLSTM. J. Geogr. Sci. 33, 2131–2156 (2023).
Dong, J. et al. Tri-decadal evolution of land subsidence in the Beijing Plain revealed by multi-epoch satellite InSAR observations. Remote Sens. Environ. 286, 113446 (2023).
Wang, H. et al. Research on land subsidence-rebound affected by dualistic water cycle driven by climate change and human activities in Dezhou City. China. J. Hydrol. 636, 131327 (2024).
Li, F., Liu, G., Tao, Q. & Zhai, M. Land subsidence prediction model based on its influencing factors and machine learning methods. Nat. HAZARDS 116, 3015–3041 (2023).
Nasiri, A., Shafiee, N. & Zandi, R. Spatial analysis of factors influencing land subsidence using the OLS model (case study: Fahlian aquifer). EARTH Sci. Inform. 14, 2133–2144 (2021).
Cai, J. et al. Automatic identification of active landslides over wide areas from time-series InSAR measurements using faster RCNN. Int. J. Appl. Earth Obs. Geoinf. 124, 103516 (2023).
Xiao, F., Wang, J., Xiong, M. & Mo, H. Does spatiotemporal heterogeneity matter? Air transport and the rise of high-tech industry in China. Appl. Geogr. 162, 103148 (2024).
Dou, M. et al. Public responses to heatwaves in Chinese cities: A social media-based geospatial modelling approach. Int. J. Appl. Earth Obs. Geoinf. 134, 104205 (2024).
Liu, L. An ensemble framework for explainable geospatial machine learning models. Int. J. Appl. Earth Obs. Geoinf. 132, 104036 (2024).
Shang, R.-K., Shiu, Y.-S. & Ma, K.-C. Using geographically weighted regression to explore the spatially varying relationship between land subsidence and groundwater level variations: A case study in the Choshuichi alluvial fan, Taiwan. In Proceedings 2011 IEEE International Conference on Spatial Data Mining and Geographical Knowledge Services 21–25 (2011). https://doi.org/10.1109/ICSDM.2011.5968998.
Zhang, L., Li, Y. & Li, R. Driving forces analysis of urban ground deformation using satellite monitoring and multiscale geographically weighted regression. Measurement 214, 112778 (2023).
Yuan, Y. et al. Land subsidence prediction in Zhengzhou’s main urban area using the GTWR and LSTM models combined with the attention mechanism. Sci. Total Environ. 907, 167482 (2024).
Bombrun, L., Gay, M., Trouve, E., Vasile, G. & DEM Mars, J. Error retrieval by analyzing time series of differential interferograms. IEEE Geosci. REMOTE Sens. Lett. 6, 830–834 (2009).
Chen, C., Liu, Y., Li, Y. & Chen, D. Explainable artificial intelligence framework for urban global digital elevation model correction based on the SHapley additive explanation-random forest algorithm considering spatial heterogeneity and factor optimization. Int. J. Appl. Earth Obs. Geoinf. 129, 103843 (2024).
Chu, W. et al. SHAP-powered insights into spatiotemporal effects: Unlocking explainable Bayesian-neural-network urban flood forecasting. Int. J. Appl. Earth Obs. Geoinf. 131, 103972 (2024).
Yunjun, Z., Fattahi, H. & Amelung, F. Small baseline InSAR time series analysis: Unwrapping error correction and noise reduction. Comput. Geosci. 133, 104331 (2019).
Liu, K. et al. Mapping inundated bathymetry for estimating lake water storage changes from SRTM DEM: A global investigation. Remote Sens. Environ. 301, 113960 (2024).
Han, J. et al. Mechanism the land subsidence from multiple spatial scales and hydrogeological conditions—A case study in Beijing-Tianjin-Hebei, China. J. Hydrol. Reg. Stud. 50, 101531 (2023).
Sahadevan, D. K. & Pandey, A. K. Groundwater over-exploitation driven ground subsidence in the himalayan piedmont zone: Implication for aquifer health due to urbanization. J. Hydrol. 617, 129085 (2023).
Zhang, Z. et al. Hazard assessment model of ground subsidence coupling AHP, RS and GIS—A case study of Shanghai. Gondwana Res. 117, 344–362 (2023).
Pervez, M. S. & Henebry, G. M. Projections of the Ganges-Brahmaputra precipitation—Downscaled from GCM predictors. J. Hydrol. 517, 120–134 (2014).
Workneh, H. T., Chen, X., Ma, Y., Bayable, E. & Dash, A. Comparison of IDW, Kriging and orographic based linear interpolations of rainfall in six rainfall regimes of Ethiopia. J. Hydrol. Reg. Stud. 52, 101696 (2024).
Agapiou, A. & Lysandrou, V. Detecting displacements within archaeological sites in Cyprus after a 5.6 magnitude scale earthquake event through the hybrid pluggable processing pipeline (HyP3) cloud-based system and Sentinel-1 interferometric synthetic aperture radar (InSAR) analysis. Sel. Top. Appl. Earth Obs. Remote Sens. 13, 6115–6123 (2020).
Li, J. et al. Spatiotemporal differentiation of the ecosystem service value and its coupling relationship with urbanization: A case study of the Lanzhou-Xining urban agglomeration. Ecol. Indic. 160, 111932 (2024).
Lundberg, S. M. & Lee, S.-I. A Unified Approach to Interpreting Model Predictions.
Acknowledgements
This work was supported by the Anhui Province Key Research and Development Program of 2021: Construction of a public service platform for coordinated monitor-ing, analysis, and decision-making on mining subsidence disasters from space, air, and ground perspectives [grant number 202104a07020014] and the 2021 Anhui Province Major Scientific and Technological Special Project: “Beidou+” Collaborative Monitoring and Rapid Warning Cloud Platform for Typical Geological Disasters 500 Re-search and Development and Demonstration Application (Xuexiang Yu), [Grant Number 202103a05020026]. Thanks to the land use data from ArcGIS Living Atlas of the World (https://livingatlas.arcgis.com/en/home/) and the European Space Agency’s Sentinel-1 data and processing platform, the groundwater data from GeoCloud-CGS, etc. (cgs.gov.cn), and various types of data are provided by the National Platform for Earth System Science Data Sharing (geodata. cn).
Author information
Authors and Affiliations
Contributions
Wen Jiang Long: Data curation, Investigation, Methodology, Software, Writing—original draft, Validation. Xue Xiang Yu: Conceptualization, Writing—review & ed-iting. Ming Fei Zhu: Formal analysis, Validation, Writing—review & editing. Li Xue: Formal analysis, Writing—review & editing. Guang Hui Zhang: Data curation, In-SAR Software. Lin Lin Wang: MGTWR and GTWR Software.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wen-Jiang, L., Xue-Xiang, Y., Ming-Fei, Z. et al. SHAP-enhanced interpretive MGTWR-CNN-BILSTM-AM framework for predicting surface subsidence: a case study of Shanghai municipality. Sci Rep 15, 19771 (2025). https://doi.org/10.1038/s41598-025-95694-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-95694-4
