
Abstract
Accurate identification of wheat varieties is essential for seed certification and precision agriculture, yet traditional visual inspection is subjective, labor-intensive, and often unreliable due to the morphological similarity among cultivars. This study presents a comprehensive comparative framework for automated wheat varietal classification using both handcrafted and deep-learning-based feature extraction methods. A controlled imaging system was used to capture seed images from six Iranian wheat cultivars. Handcrafted morphological, color, and texture descriptors were extracted and reduced using principal component analysis (PCA) prior to classification using a multi-layer perceptron (MLP). In parallel, convolutional neural networks (CNNs) were trained to learn deep features directly from raw images, and two classifier-head strategies—global average pooling (GAP) and fully connected layers (FCL)—were systematically compared. Hyperparameters were optimized through structured experimentation, and model stability was assessed using repeated training runs, one-way ANOVA, and 95% confidence intervals. Results show that the CNN-GAP model achieved the highest accuracy (92.19%) and demonstrated superior generalization stability compared with EfficientNet-B4 and Inception-ResNet-v2 models. PCA-based dimensionality reduction enhanced MLP performance, yielding 86.0% accuracy. Cross-domain testing on chickpea seeds highlighting sensitivity to domain shifts and emphasizing the need for species-specific training data. Practical considerations revealed that the lightweight CNN-GAP architecture, with an average inference time of 13.6 ms per image, is suitable for real-time deployment on low-cost agricultural hardware.
Similar content being viewed by others

Introduction
The use of certified and genetically pure seeds is essential for improving both the quality and quantity of wheat yields. Verifying varietal purity before cultivation ensures uniform germination, disease resistance, and optimal adaptation to specific agro-climatic and soil conditions1,2. However, the traditional identification of wheat varieties still relies heavily on expert visual inspection, which is time-consuming, subjective, and error-prone. The morphological similarity among different wheat cultivars makes reliable discrimination difficult3. Misidentification can lead to reduced yield, lower seed quality, and increased vulnerability to environmental stress. To overcome these challenges, automated and intelligent identification systems are increasingly required for seed certification and precision agriculture applications4,5,6.
Recent advances in machine learning (ML) and computer vision have enabled the development of automated systems capable of distinguishing crop varieties and detecting seed impurities with high accuracy. Classical ML models such as k-nearest neighbor (KNN), support vector machine (SVM), random forest (RF), and multilayer perceptron (MLP) have been applied to classify rice7,8, soybean9, and wheat10,11 seeds using handcrafted features (shape, color, and texture). Although these approaches have achieved accuracies above 90%, their reliance on manually extracted descriptors limits adaptability and scalability to new datasets.
The emergence of deep learning, particularly convolutional neural networks (CNNs), has revolutionized agricultural image analysis by enabling automatic feature extraction directly from raw images. CNNs have been successfully applied to classify beans12, sunflower13, and maize14, as well as to detect diseases in tomato and grape leaves15,16. In seed classification, CNNs have shown superior accuracy compared with traditional models, as demonstrated in the works of Lingwal et al.17 and Laabassi et al.18, who achieved accuracies of 97.53% and 85–90%, respectively. Despite their success, these models often suffer from overfitting and lack optimization transparency, particularly regarding the influence of architectural design and hyperparameter tuning on performance.
Hyperparameter optimization—including learning rate, filter size, dropout rate, number of layers, and batch size—plays a critical role in CNN performance19. Recent research has demonstrated that careful tuning and the use of global average pooling (GAP) instead of fully connected layers (FCL) can significantly reduce model complexity and enhance generalization20,21. However, few studies have systematically compared GAP and FCL structures under identical experimental conditions for single-seed classification tasks.
Several studies have explored cereal seed identification using either handcrafted or deep features2,6. Gao et al.22 applied transfer learning (ResNet-50, SE-ResNet, SE-ResNeXt) to classify wheat varieties at different growth stages, reporting up to 97.38% accuracy at flowering. Yet, such phenological stages are impractical for seed-level purity assessment. Lingwal et al.3 achieved high training accuracy but observed validation instability, suggesting potential overfitting. Consequently, there remains a need for a systematic comparative study that evaluates conventional MLP and CNN models using the same single-seed dataset, emphasizing optimized hyperparameter tuning, statistical validation, and architectural efficiency.
The present research addresses these gaps by: 1. Optimizing the hyperparameters of MLP and CNN models for wheat variety classification; 2. Comparing handcrafted (MLP-based) and automatically extracted (CNN-based) features; 3. Investigating the impact of dimensionality reduction on MLP performance; and 4. Evaluating the relative effects of GAP and FCL layers on CNN accuracy and generalization. By integrating these elements, this study provides a rigorous and interpretable framework for automated wheat variety identification. The findings contribute to the advancement of precision seed quality assessment and the future development of intelligent, low-cost sorting and certification systems for agricultural industries.
Materials and methods
Overview of the modeling process
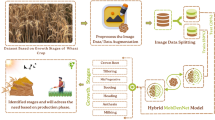
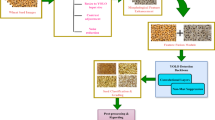
The overall workflow of this study is illustrated in Fig. 1. First, wheat seed images were captured under controlled conditions. Two modeling approaches were then applied. In the first, key handcrafted features—shape, color, and texture—were extracted and reduced in dimension using principal component analysis (PCA) before classification by a multi-layer perceptron (MLP). In the second, convolutional neural networks (CNNs) automatically extracted deep features from the same images. The hyperparameters of both the MLP and CNN models were systematically optimized, and two transition strategies—global average pooling (GAP) and fully connected layers (FCL)—were compared at the classification stage to assess their influence on model performance and susceptibility to overfitting.

Overall flowchart of the feature extraction and modeling process.
Sample preparation
Six Iranian wheat cultivars—Baran, Hashtrood, Heydari, Heyran, Pishgham, and Zarrineh—were obtained from the Research and Education Center for Agriculture and Natural Resources, Hamedan Province. A total of 400 RGB images (100 per cultivar) were captured at 4128 × 2322 pixels in JPG format using a Samsung A5 (2016) smartphone camera. Images were acquired inside a 50 × 50 × 50 cm light-controlled enclosure to eliminate ambient interference (Fig. 2). The camera was positioned 10 cm above the seeds, and a blue background facilitated segmentation by enhancing contrast between seeds and background. Uniform lighting was ensured using LED strips installed along the enclosure walls. Care was taken to avoid seed overlap during acquisition. Based on the objectives of this study, the developed models are intended for deployment in research laboratories and storage facilities such as grain silos, where imaging conditions can be carefully controlled. To ensure optimal classification performance, all images were therefore acquired under standardized and uniform conditions, minimizing variations in illumination, angle, and background that could negatively affect feature extraction. Given that these models were neither trained nor optimized for variable or unpredictable environments, their application in uncontrolled field conditions is not recommended. Further research would be required to adapt or retrain the models for robust performance under such circumstances.

The imaging chamber for controlling ambient light.
Image pre-processing and dataset preparation
Background removal was performed through adaptive thresholding to generate binary masks for individual grains. These masks were applied to isolate each seed, yielding segmented single-grain images (Fig. 3). In total, 9600 seed images (1600 per class) were obtained.

Image preprocessing steps for cropping single seeds.
For classification of seeds using MLP model, 58 handcrafted features were extracted. Feature matrices were standardized using z-score normalization, ensuring zero mean and unit variance for each feature. To enhance dataset diversity and reduce overfitting in CNN models, extensive data augmentation was applied, including rotations (± 90°), horizontal/vertical flips, and brightness adjustments. This produced a final dataset of 30 600 images. The dataset was divided into 70% training, 20% validation, and 10% testing subsets. Image pre-processing was conducted in MATLAB 2018, and model training was implemented in Python 3.9 (TensorFlow 2.10, Keras) on a system equipped with Intel Core i5-11300H (3.1 GHz), 16 GB RAM, and NVIDIA GTX 1650 GPU.
Feature extraction
Once individual grains were separated, visual features such as area, major length, minor length, the ratio of major length to minor length, eccentricity, and perimeter over area were extracted from the binary images. Medians, Means, and other color features were extracted from the RGB, HSV, and LAB color spaces. Table 1a displays the color features exclusively for the RGB color space, while similar features were obtained for the HSV and LAB color spaces. Additionally, texture features extracted from the GLCM were computed according to Table 1b. In total, 58 features were extracted from each grain. After extracting all 58 features, the PCA algorithm was applied to reduce feature dimensionality, thereby decreasing model complexity and mitigating the risk of overfitting. Following PCA implementation, 27 principal components that accounted for more than 98% of the total variance were selected as inputs for the ANN model.
In total, 58 features were obtained. Dimensionality reduction using PCA retained 27 principal components explaining more than 98% of total variance, reducing complexity and mitigating multicollinearity before training the MLP.
ANN configuration and training
The ANN employed a multilayer perceptron (MLP) architecture trained using the back-propagation algorithm. Network weights and biases were optimized via the Adam optimizer with an initial learning rate of 0.001. Hidden layers: one or two; Neuron counts: first layer = 27–57 neurons; second = 14–28 neurons; Activation functions: ReLU (hidden layers) and Softmax (output); Dropout rates: 0–0.5; Loss function: categorical cross-entropy; Batch size: 32; Epochs: 100 and Early stopping: patience = 10 epochs to prevent overfitting.
The selection of neuron numbers followed the guidelines proposed by Heaton23 and Ma et al.24, combined with a trial-and-error approach to ensure adequate representational capacity while avoiding over-parameterization. Statistical robustness was verified by performing five independent runs and computing mean ± standard deviation for each performance metric.
Inception-ResNet-v2 and EfficientNet-B4 models
In this study, two state-of-the-art transfer learning architectures—Inception-ResNet-v2 and EfficientNet-B4—were employed for the classification of wheat varieties. Inception-ResNet-v2 combines the multi-scale feature extraction capability of the Inception modules with the training stability of residual connections, enabling effective learning in very deep neural networks25. EfficientNet-B4 utilizes a compound scaling strategy that uniformly increases network depth, width, and input resolution, producing a highly optimized architecture with superior accuracy-efficiency trade-offs compared with conventional CNN models26. Both networks were pre-trained on large-scale image datasets and fine-tuned on the wheat dataset, benefiting from rich feature representations that accelerate convergence and enhance generalization. Previous studies have shown that these architectures outperform earlier transfer learning models in fine-grained classification tasks, further supporting their suitability for agricultural image analysis. The use of these advanced models in the present study provides a robust foundation for achieving reliable differentiation of wheat varieties under varying imaging conditions.
CNN architecture and hyperparameter setting
In this study, architectures comprising two, three, and four convolutional blocks were evaluated to examine the influence of network depth on classification performance. Each block employed a ReLU activation function followed by a 2 × 2 max-pooling operation to ensure nonlinearity and progressive spatial downsampling. The numbers of filters were set to 32, 64, and 128 in successive blocks, providing a controlled increase in representational capacity while maintaining an appropriate balance between model complexity and generalization. A step-decay learning-rate schedule was applied (Eq. 1) to enhance training stability and convergence efficiency.
where \(\eta_{0}\) = 0.01, decay = 0.1, and step = 10.
To examine the influence of the classifier head on model performance, two network variants were trained. The CNN-FCL model employed a flattening operation followed by a fully connected layer prior to the Softmax classifier, whereas the CNN-GAP model replaced the flattening stage with a global average pooling (GAP) layer to reduce the number of trainable parameters and mitigate the risk of overfitting.
The training parameters were set as follows: epochs = 100, batch size = 32, dropout = 0.3–0.5, optimizer = Adam, and loss = categorical cross-entropy.
All experiments were repeated five times with random initialization. Model stability was assessed via one-way ANOVA (p < 0.05) across runs, and 95% confidence intervals were computed for accuracy and F1-score.
Model evaluation
Performance was evaluated using accuracy, precision, recall, and F1-score, with confusion matrices generated for all models. Statistical analyses ensured fair comparisons among architectures. Computational efficiency (inference time) was recorded to assess real-time feasibility on low-cost hardware platforms.
Results and discussion
Models performance
Tables 2 and 3 present the confusion matrices and evaluation metrics for the models examined in this study. As the results indicate, the proposed model demonstrates the most consistent and accurate classification performance among all evaluated architectures. Its confusion matrix exhibited strong diagonal dominance, indicating reliable separation of wheat varieties with minimal inter-class overlap. Quantitatively, it attained the highest accuracy (0.922) and F1-score (0.936), outperforming both EfficientNet-B4 (0.852) and Inception-ResNet-v2 (0.830). The model’s balanced precision (0.929) and recall (0.943) demonstrate effective generalization and robust feature extraction. Although the MLP-PCA model achieved lower complexity and competitive accuracy (0.860), its slightly reduced recall and F1-score reveal limited capability in complex cases. Nonetheless, MLP-PCA outperformed both Inception-ResNet-v2 and EfficientNet-B4, showing that combining PCA-based feature reduction with a tuned neural network can yield efficient and accurate classification. Furethermore, the Proposed CNN-GAP model achieved the narrowest confidence interval (0.922 ± 0.044), indicating highly stable performance across varieties. The MLP-PCA and EfficientNet-B4 models also demonstrated moderate stability, with intervals of 0.860 ± 0.059 and 0.860 ± 0.076, respectively. In contrast, Inception-ResNet-v2 exhibited the widest interval, reflecting greater variability and a higher tendency toward misclassification. These statistics confirm that the Proposed CNN-GAP model not only achieves the highest accuracy but also demonstrates superior consistency and generalization within the wheat dataset.
Although Inception-ResNet-v2 and EfficientNet-B4 are state-of-the-art deep architectures, their lower accuracy in this study can be attributed to several technical factors. Both models contain a very large number of parameters, which makes their performance highly dependent on the availability of large and diverse training datasets. When applied to a relatively small dataset, these deep networks are prone to overfitting. This tendency is evident in their confusion matrices, where a higher frequency of misclassifications appears, particularly among visually similar wheat variety classes. In contrast, the Proposed CNN-GAP model employs a lighter architecture that reduces overfitting and yields a confusion matrix with stronger diagonal dominance, indicating more reliable class separability.
Furthermore, the MLP-PCA model benefits from the dimensionality-reduction capability of PCA, which effectively removes noisy, redundant, and highly correlated features. This process results in a more compact and discriminative feature representation, contributing to the model’s higher precision and recall values. Overall, the Proposed Model and MLP-PCA demonstrated the best performance and were therefore selected for further optimization and comparative evaluation.
MLP performance with dimensionality reduction
As illustrated in Fig. 4, the principal component analysis (PCA) method significantly improved the accuracy of the MLP classifier. Using 27 PCA-selected features yielded an average validation accuracy of 90.55%, compared with 89.14% when all 58 extracted features were used. Thus, dimensionality reduction enhanced classification by mitigating noise and multicollinearity. Comparable findings were reported by Asif et al.27, who achieved 92.3% accuracy in rice grain classification using PCA-reduced morphological features. Similarly, Gayathri et al.28 demonstrated that feature selection improved MLP accuracy for rice disease classification from 86.6 to 90.2%. These results collectively confirm that PCA-based feature selection improves generalization and training efficiency for seed classification tasks.

Effect of dimensionality reduction on (a) accuracy and (b) loss of the MLP for both the training and validation datasets.
Optimization of MLP architecture
To achieve optimal MLP performance, the number of neurons and layers was systematically varied (Fig. 5). The first hidden layer ranged from 27 to 57 neurons, and the second from 14 to 28 neurons. The training was repeated 10 times for each configuration, and mean ± standard deviations were calculated for performance metrics. Results demonstrated that while neuron number had a fluctuating influence, two hidden layers with 37 and 21 neurons, respectively, combined with a dropout rate of 0.3, achieved the best performance.

Effect of the number of neurons and layers on the performance of the MLP for the train dataset. 27 PCA were used as the inputs of the MLP.
The dropout layer improved model generalization by preventing co-adaptation among neurons. Validation accuracy increased from 87.64% to 89.55% with dropout (Fig. 6), confirming its regularization effect29,30. However, a dropout ratio of 0.5 led to a decline in accuracy due to excessive weight deactivation. These outcomes align with prior studies emphasizing that moderate dropout (0.2–0.4) often yields the best regularization balance31,32.

Effect of dropout on the (a) accuracy and (b) loss of the MLP model for the train and validation dataset.
Effect of GAP and FCL on CNN performance
Figure 7 compares the convergence behavior of CNNs employing global average pooling (GAP) and fully connected layers (FCL). The CNN-GAP exhibited stable learning behavior, with training and validation curves converging smoothly, suggesting minimal overfitting. Conversely, the CNN-FCL achieved higher training accuracy but demonstrated divergence in loss curves—an indication of overfitting.

The trend in (a) accuracy and (b) loss of proposed-GAP and proposed-FCL for the train and validation dataset.
The superior performance of the GAP-based network can be attributed to its parameter efficiency, reducing the risk of overfitting and enhancing generalization. GAP eliminates dense weight matrices, decreases computational burden, and improves robustness—particularly valuable for small datasets. Similar trends were observed by Haseli Golzar et al.33 in the classification of cucumber and Azadnia et al.20 in medicinal plant identification, where GAP-based CNNs improved both efficiency and accuracy compared with dense-layer designs.
Statistical evaluation confirmed the robustness of CNN-GAP performance, with ANOVA tests (p < 0.05) showing significant improvement over FCL-based CNNs and MLP models. Across five independent training runs, the mean test accuracy for CNN-GAP was 92.2 ± 0.044%, highlighting strong repeatability.
Influence of structural parameters
The effect of architectural parameters on CNN performance is summarized in Table 4. Among the tested architectures, the best-performing configuration included three convolutional layers (32, 64, and 128 filters), one hidden layer with 128 neurons, and a dropout rate of 0.5. Adding a fourth convolutional layer slightly decreased validation accuracy due to overfitting and longer convergence time.
In investigating the effect of the number of dense layers in the classification part on the performance of the CNN, no significant differences were observed between using one or two hidden layers. Thus, only a single hidden layer was employed with the view of minimizing network complexity. When assessing the effect of the number of neurons in the hidden layer on estimation accuracy, the results indicated that increasing the neuron number did not significantly improve model performance. Therefore, 128 neurons were selected as the optimal number for the hidden layer to prevent overfitting.
In investigating the effect of the number of convolutional layers on the performance of the proposed CNN network, the results demonstrated that the network with three convolutional layers with 32, 64, and 128 filters achieved superior performance compared to two or four layers. Additionally, implementing a dropout layer with a dropout ratio of 0.5 had a notable impact on network accuracy. Specifically, the accuracy decreased as the dropout rate decreased. From Table 4, lower dropout rates are associated with decreased accuracy, proving that dropout is an important hyperparameter to be tuned to optimize the performance of the CNN. Among those variations, the best performance of the proposed CNN was obtained using a dropout rate of 0.5, three convolutional layers, and one hidden layer in the classifier block.
Batch normalization is widely recognized for its contribution to the stabilization of the training process in CNNs. On the contrary, this is not a universally beneficial approach because sometimes it can have an adverse effect on the performance of the model. Specifically, this technique may contribute to overfitting, especially in networks trained on smaller datasets or when batch sizes are very small34,35. The results presented in Table 4 demonstrate that, in both the fully connected layer (FCL) and global average pooling (GAP) methods, batch normalization negatively impacts CNN performance.
Visualization of discriminative features
Figure 8 displays the class saliency maps of the final CNN-GAP model, highlighting image regions most influential in classification. High activations concentrated around seed edges and surface textures suggest that the network primarily relied on morphological and textural cues to differentiate varieties. The strong consistency of activation patterns across samples within each class demonstrates that the model captured robust, variety-specific discriminative features. This finding aligns with the biological reality that wheat varieties exhibit subtle yet distinctive variations in shape and texture.

The class saliency map visualization from the last convolutional layer of the proposed CNN-GAP model.
Table 5 compares the performance of the proposed method with several state-of-the-art approaches for seed classification. For adulteration recognition in bulk paddy samples, an accuracy of 93.31% was reported using an MLP model trained on PCA-reduced features36. Comparable findings have been reported in CNN-based studies on chickpea37 and corn38, where accuracies of 94% and 96.46% were achieved, reflecting the benefits of deep feature extraction and optimized hyperparameters.
Across the literature, two factors consistently influence performance: the number of varieties examined and the degree of similarity among their morphological patterns. The lower accuracy obtained in the present study, relative to results reported in39,40, can be attributed to the high similarity among the wheat varieties evaluated. Unlike rice or maize, which exhibit more pronounced visual distinctions, wheat varieties share subtle differences in shape, surface texture, and pigmentation, resulting in reduced inter-class separability. Additionally, the inherent intra-class variability in wheat further complicates fine-grained classification. These characteristics make wheat-variety identification inherently more challenging and explain the slightly lower accuracy of the proposed CNN-GAP model.
Model generalization and practical considerations
Testing the CNN-GAP model on unseen chickpea samples yielded an average accuracy of 68.12%, revealing limited cross-domain generalization. This outcome underscores the model’s sensitivity to domain shifts—particularly variations in seed morphology and color. The reduced performance observed in the chickpea evaluation highlights an important limitation of the current study. Because the proposed model was specifically optimized to capture intra-class variability among wheat varieties, its accuracy naturally decreases when applied to a morphologically distinct crop. Chickpea seeds differ substantially in shape, surface texture, size, and color distribution, and these domain shifts fall outside the feature space learned during training. Such a decline is therefore expected and underscores the necessity of species-specific training data for reliable cross-crop deployment. Importantly, this result does not reflect a deficiency in the model architecture itself; rather, it demonstrates the inherent sensitivity of deep-learning classifiers to domain mismatches when trained exclusively on a narrow, single-species dataset.
To mitigate these limitations and enhance generalization in real-world applications, several strategies should be explored in future work. These include: 1- constructing multi-species training datasets that incorporate diverse grain types; 2- applying domain-adaptive augmentation techniques, such as brightness variation, color jitter, random shadows, and heterogeneous illumination patterns; and 3- leveraging transfer learning from large-scale agricultural image datasets that encompass multiple seed categories. These strategies collectively provide a clear pathway for improving the robustness, transferability, and practical applicability of the proposed model in broader agricultural contexts. Additionally, computational evaluation revealed that the CNN-GAP architecture achieved an average inference time of 13.6 ms per seed on a mid-range GPU, indicating feasibility for real-time sorting applications. The lightweight structure (≈2.1 M parameters) makes it suitable for integration into low-cost embedded hardware for on-site agricultural deployment.
Conclusion
This study evaluated several machine learning models for classifying six Iranian wheat varieties based on both handcrafted and automatically extracted features. The results confirmed the superiority of the CNN-GAP model, which achieved an accuracy of 92.19%, outperforming all other architectures, including the MLP. Applying dimensionality reduction improved MLP performance, whereas increasing the number of layers in the CNN classification block did not yield further accuracy gains. Using individual seed images rather than bulk samples enhanced feature distinctiveness and classification precision, demonstrating the effectiveness of deep learning and optimized hyperparameters for accurate varietal identification using RGB images. The primary limitation of this work lies in its controlled imaging setup, which ensured uniform lighting but restricted real-world applicability. Model performance may decline under uncontrolled conditions involving variable illumination, shadows, or partial occlusion. To enhance robustness and facilitate deployment in practical agricultural environments, future research should: (1) Expand the dataset to include images captured under different conditions and additional wheat varieties; (2) Apply advanced data augmentation techniques, such as brightness, hue, and blur variation; and (3) Adopt transfer learning from large-scale agricultural datasets to strengthen model generalization. Overall, the CNN-GAP architecture demonstrates considerable potential for integration into automated seed identification and quality assessment systems, offering a foundation for developing efficient and reliable tools to support precision agriculture.
Data availability
The data for this manuscript are not publicly available but may be accessed upon request to the corresponding author.
References
Pourreza, A., Pourreza, H., Abbaspour-Fard, M.-H. & Sadrnia, H. Identification of nine Iranian wheat seed varieties by textural analysis with image processing. Comput. Electron. Agric. 83, 102–108 (2012).
Zapotoczny, P. Discrimination of wheat grain varieties using image analysis and neural networks. Part I. Single kernel texture. J. Cereal Sci. 54, 60–68 (2011).
Lingwal, S., Bhatia, K. K. & Tomer, M. S. Image-based wheat grain classification using convolutional neural network. Multimed. Tools Appl. 80, 35441–35465 (2021).
ElMasry, G., Mandour, N., Al-Rejaie, S., Belin, E. & Rousseau, D. Recent applications of multispectral imaging in seed phenotyping and quality monitoring—An overview. Sensors 19, 1090 (2019).
Gawdiya, S. et al. Field scale wheat yield prediction using ensemble machine learning techniques. Smart Agric. Technol. 9, 100543 (2024).
Khojastehnazhand, M., Mohammadi, V. & Minaei, S. Maturity detection and volume estimation of apricot using image processing technique. Sci. Hortic. 251, 247–251 (2019).
Robert Singh, K. & Chaudhury, S. A cascade network for the classification of rice grain based on single rice kernel. Complex Intell. Syst. 6, 321–334 (2020).
Ozan, A., Güllü, A. & Uçar, E. Classification of rice grains using image processing and machine learning techniques. In International Scientific Conference 20–21 (2015).
Çetin, N. Machine learning for varietal binary classification of soybean (Glycine max (L.) Merrill) seeds based on shape and size attributes. Food Anal. Methods 15, 2260–2273 (2022).
Xu, X. et al. Segmentation and counting of wheat spike grains based on deep learning and textural feature. Plant Methods 19, 77 (2023).
Yasar, A. & Golcuk, A. Deep learning and evolutionary intelligence with fusion-based feature extraction for classification of wheat varieties. Eur. Food Res. Technol. 251, 1603–1616 (2025).
Kılıç, K., Boyacı, İH., Köksel, H. & Küsmenoğlu, İ. A classification system for beans using computer vision system and artificial neural networks. J. Food Eng. 78, 897–904 (2007).
Kurtulmuş, F. Identification of sunflower seeds with deep convolutional neural networks. Food Meas. 15, 1024–1033 (2021).
Ma, Z. et al. Maize leaf disease identification using deep transfer convolutional neural networks. Int. J. Agric. Biol. Eng. 15, 187–195 (2022).
Agarwal, M., Gupta, S. K. & Biswas, K. K. Development of efficient CNN model for tomato crop disease identification. Sustain. Comput. Inform. Syst. 28, 100407 (2020).
Liu, B. et al. Grape leaf disease identification using improved deep convolutional neural networks. Front. Plant Sci. 11, 1082 (2020).
Lingwal, S., Bhatia, K. K. & Tomer, M. S. Image-based wheat grain classification using convolutional neural network. Multimed. Tools Appl. 80, 35441–35465 (2021).
Laabassi, K., Belarbi, M. A., Mahmoudi, S., Mahmoudi, S. A. & Ferhat, K. Wheat varieties identification based on a deep learning approach. J. Saudi Soc. Agric. Sci. 20, 281–289 (2021).
Wang, R., Nabney, I. & Golbabaee, M. Efficient hyperparameter importance assessment for CNNs. In Neural Information Processing Vol. 2282 (eds Mahmud, M. et al.) 16–31 (Springer, Singapore, 2025).
Azadnia, R. et al. An AI based approach for medicinal plant identification using deep CNN based on global average pooling. Agronomy 12, 2723 (2022).
Dogan, Y. A new global pooling method for deep neural networks: Global average of top-K max-pooling. TS 40, 577–587 (2023).
Gao, J. et al. Identification method of wheat cultivars by using a convolutional neural network combined with images of multiple growth periods of wheat. Symmetry 13, 2012 (2021).
Heaton, J. Introduction to Neural Networks with Java (Heaton Research, St. Louis, 2008).
Ma, C. & Wu, L. The Barron space and the flow-induced function spaces for neural network models. Constr. Approx. 55, 369–406 (2022).
Szegedy, C., Ioffe, S., Vanhoucke, V. & Alemi, A. Inception-v4, Inception-ResNet and the impact of residual connections on learning. AAAI 31, (2017).
Tan, M. & Le, V. Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning 6105–6114 (2019).
Asif, M. J., Shahbaz, T., Tahir Hussain Rizvi, S. & Iqbal, S. Rice grain identification and quality analysis using image processing based on principal component analysis. In 2018 International Symposium on Recent Advances in Electrical Engineering (RAEE) 1–6 (IEEE, Islamabad, Pakistan, 2018). https://doi.org/10.1109/RAEE.2018.8706891.
Gayathri Devi, T. & Neelamegam, P. Image processing based rice plant leaves diseases in Thanjavur, Tamilnadu. Clust. Comput. 22, 13415–13428 (2019).
Wan, L., Zeiler, M., Zhang, S., Le Cun, Y. & Fergus, R. Regularization of neural networks using DropConnect. In Proceedings of the 30th International Conference on Machine Learning, vol. 28, 1058–1066 (2013).
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I. & Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958 (2014).
Shojaeian, A. et al. The potential application of innovative methods in neural networks for surface crack recognition of unshelled hazelnut. J. Food Process. Preserv. 2023, 1–9 (2023).
Baldi, P. & Sadowski, P. The dropout learning algorithm. Artif. Intell. 210, 78–122 (2014).
Haseli Golzar, S., Bagherpour, H. & Amiri Parian, J. A new method to optimize deep CNN model for classification of regular cucumber based on global average pooling. J. Food Process. Preserv. 2024, 5818803 (2024).
Chai, E., Pilanci, M. & Murmann, B. Separating the effects of batch normalization on CNN training speed and stability using classical adaptive filter theory. In 2020 54th Asilomar Conference on Signals, Systems, and Computers 1214–1221 (IEEE, Pacific Grove, 2020). https://doi.org/10.1109/IEEECONF51394.2020.9443275.
Lim, B., Son, S., Kim, H., Nah, S. & Lee, K. M. Enhanced deep residual networks for single image super-resolution. Preprint at https://doi.org/10.48550/arXiv.1707.02921 (2017).
Chini, S., Yakkundimath, R., Malvade, N. N. & Gadagin, N. Automated classification of wheat varieties using soft computing techniques. In Cognition and Recognition Vol. 1697 (eds Guru, D. S. et al.) 89–98 (Springer, Cham, 2022).
Taheri-Garavand, A. et al. Automated in situ seed variety identification via deep learning: A case study in chickpea. Plants 10, 1406 (2021).
Xu, P. et al. Varietal classification of maize seeds using computer vision and machine learning techniques. J. Food Process Eng. 44, e13846 (2021).
Rajalakshmi, R., Faizal, S., Sivasankaran, S. & Geetha, R. RiceSeedNet: Rice seed variety identification using deep neural network. J. Agric. Food Res. 16, 101062 (2024).
Kozłowski, M., Górecki, P. & Szczypiński, P. M. Varietal classification of barley by convolutional neural networks. Biosyst. Eng. 184, 155–165 (2019).
Author information
Authors and Affiliations
Contributions
H. Bagherpour: Conceptualization, methodology, software, validation, formal analysis, writing—reviewing and editing. Siavash Shamohammadi: Data curation, software, formal analysis, writing—original draft preparation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Bagherpour, H., Shamohammadi, S. Machine learning approach for wheat variety identification using single-seed imaging. Sci Rep 16, 6472 (2026). https://doi.org/10.1038/s41598-026-35252-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-35252-8
