
Abstract
Pediatric wrist fracture detection is diagnostically challenging due to subtle fracture morphologies and growth plate obscuration. To address this, we propose FracDet-v11, a specialized real-time framework based on YOLOv11s. We introduce a series of architectural enhancements to optimize feature representation and detection robustness: (1) a reconstructed backbone integrating Haar Wavelet Downsampling (HWD) and PKI-CAA to effectively preserve high-frequency details, complemented by a Dual-branch Channel Attention Module (DCAM); (2) a lightweight Slim-Neck for efficient feature fusion; and (3) a detection head incorporating Deformable Convolution v4 (DCNv4) and Focaler-CIoU loss to adapt to geometric deformations and prioritize hard samples. Benchmarking on the GRAZPEDWRI-DX dataset demonstrates that FracDet-v11 achieves a precision of 73.9% and mAP50 of 64.8%, surpassing the baseline by 3.8% and 3.1%, respectively. Furthermore, the model exhibits robust generalization on the external FracAtlas dataset with an mAP50 of 47.9%, confirming its potential as a reliable assistive tool for clinical diagnosis. The code for this work is available on GitHub at https://github.com/boboji1233/FracDet-v11.
Similar content being viewed by others


Introduction
Wrist abnormalities constitute a prevalent clinical presentation among children, adolescents, and young adults. Specifically, fractures of the distal radius and ulna are highly frequent, with incidence rates peaking during adolescence1,2,3,4. The prompt and accurate assessment of these injuries is critical to preventing long-term functional impairment. While digital radiography remains the primary imaging modality for suspected wrist trauma, a definitive diagnosis often necessitates a holistic evaluation of the pathology, clinical presentation, and available medical resources. In cases where radiographic findings are equivocal, advanced imaging modalities, such as Magnetic Resonance Imaging (MRI), Computed Tomography (CT), or ultrasound, may be indicated.
In clinical practice, radiographic interpretation is frequently delegated to surgeons or junior physicians who may lack specialized radiological training. In settings devoid of immediate access to expert radiologists, these practitioners must rely on their own diagnostic judgment5. Consequently, diagnostic error rates for emergency X-ray interpretation have been reported to reach as high as 26%6,7,8. This diagnostic gap is further exacerbated by a shortage of radiologists in developed nations9,10 and limited specialist availability globally, posing substantial risks to patient safety11. This workforce deficit is projected to intensify, as the annual 5% increase in imaging demand continues to outpace the 2% growth in radiology residency positions12. Moreover, even with the utilization of advanced modalities, certain fractures may remain occult13,14.
Recent advancements in computer vision, particularly in the domain of object detection, have demonstrated significant potential for medical applications. Existing literature confirms the efficacy of these technologies in detecting pathologies within trauma radiographs15,16,17. Historically, object detection relied on sliding window approaches18, which partitioned images into grids for classification using cascade classifiers based on Local Binary Patterns (LBP) or Haar-like features. While effective for specific targets, these methods required systematic scanning of image patches, resulting in high computational costs. To mitigate this inefficiency, region-based methods were subsequently developed, operating on the principle of generating candidate object regions prior to classification.
Building upon these foundational techniques, single-stage detection methodologies have gained substantial traction in recent years due to their superior efficiency and robustness. Unlike two-stage detectors, which first generate region proposals and subsequently refine them to achieve high accuracy often at the cost of computational speed, single-stage detectors predict bounding box coordinates and class probabilities directly from the full image in a single forward pass. By eliminating the discrete region proposal stage, these architectures achieve inference speeds significantly exceeding those of region-based counterparts, striking a compelling balance between performance and latency.
Within the medical imaging domain, two-stage detection has historically been the predominant paradigm for identifying wrist abnormalities. However, there is a notable paucity of research investigating the efficacy of single-stage detectors in identifying a diverse spectrum of wrist pathologies beyond simple fractures. Therefore, this study is specifically dedicated to evaluating the performance of single-stage detectors for this critical diagnostic task. Furthermore, this work derives unique value from utilizing the GRAZPEDWRI-DX dataset, a large-scale, comprehensively annotated public repository19.
It is important to note that wrist fractures represent only one category of typical abnormalities; other common conditions include carpal tunnel syndrome (CTS), ganglion cysts, osteoarthritis, and tendonitis. The utilized dataset classifies detectable features into fracture, periosteal reaction, metallic implant, pronator quadratus sign, soft tissue, bone deformity, and bone lesion. We emphasize that the core objective of this study is the detection of these specific radiological signs rather than the diagnosis of a holistic clinical condition. In this context, the presence of any such feature is defined as an abnormality. Notably, the detection of non-fracture objects often implies associated pathologies; for instance, soft tissue anomalies may suggest CTS or cysts, while a bone lesion could indicate an avulsion fracture secondary to a severe sprain.
YOLO is recognized as a leading algorithm in medical image analysis, renowned for its real-time capabilities and high accuracy. The YOLOv1120 model builds upon the strengths of its predecessors by incorporating advanced features and optimizations. Nevertheless, the algorithm has significant room for improvement, particularly for detecting minute wrist fractures, where balancing accuracy and efficiency is paramount. This paper proposes FracDet-v11, an enhanced framework built upon YOLOv11s aimed at elevating performance in wrist abnormality detection. The specific contributions are summarized as follows:
-
1.
Backbone Upgrade: To mitigate the loss of fine-grained details in high-resolution X-rays, we reconstructed the backbone architecture by integrating Haar Wavelet Downsampling (HWD) and the PKI-CAA module. The HWD mechanism replaces traditional downsampling layers to effectively preserve high-frequency information and minimize spatial information loss during feature map reduction. Concurrently, the PKI-CAA module is employed to enhance the network’s capability in extracting discriminative feature representations. Complementing these backbone modifications, we introduced a novel Dual-branch Channel Attention Module (DCAM) driven by Spatial and Channel Collaborative Attention (SCSA) technology. This module dynamically recalibrates feature weights across different dimensions, thereby significantly improving the model’s sensitivity to fractures of varying scales and morphological complexities.
-
2.
Neck Architecture Optimization: We integrated a lightweight Slim-Neck based on Depthwise Convolution (DWConv) to improve feature fusion. This optimization enhances the definition of fracture boundaries and the differentiation between tissue types, thereby substantially reducing the false detection rate.
-
3.
Prediction Head Optimization: To further elevate the model’s localization accuracy, we redesigned the detection head by synergistically integrating Deformable Convolution v4 (DCNv4) with the Focaler-CIoU loss function. The DCNv4 module is introduced to enhance the network’s adaptability to geometric deformations, enabling precise feature extraction from fractures with irregular morphologies and varying scales. Complementing this structural improvement, we adopted the Focaler-CIoU loss for bounding box regression. This loss strategy incorporates a focusing mechanism that dynamically prioritizes hard-to-classify samples and optimizes localization precision, thereby significantly improving classification reliability, particularly in challenging diagnostic cases.
Related work
The identification of fractures constitutes a pivotal step in evaluating wrist injuries, with computer vision technologies playing a core role in advancing this field of study. This section provides a methodical overview of the current literature concerning fracture detection, emphasizing the consolidation of key scholarly contributions. Our review is bifurcated into two independent segments: the initial segment explores investigations based on two-stage detection methodologies, whereas the subsequent segment is dedicated to studies that rely solely on single-stage detection algorithms.
Two-stage detection
Two-stage object detection algorithms have become a dominant paradigm in computer-aided fracture diagnosis due to their robust localization capabilities. Early applications focused on adapting standard architectures to medical imaging. For instance, Yahalomi et al.21 demonstrated the feasibility of transfer learning by finetuning a VGG-16 based Faster R-CNN on a limited dataset of wrist X-rays. Despite the small sample size, data augmentation techniques enabled the model to achieve a mean Average Precision (mAP) of 0.87. Thian et al.22 advanced this approach by addressing the complexity of multi-view analysis. They developed separate Inception-ResNet Faster R-CNN models for frontal and lateral projections, achieving high sensitivity (0.96 and 0.97, respectively) by explicitly modeling the distinct visual features of each projection view.
Subsequent studies have focused on architectural enhancements to address specific challenges in X-ray analysis, such as feature ambiguity and scale variation. Guan et al.23 applied a standard R-CNN framework to the MURA dataset, establishing a baseline for arm fracture detection. To improve feature discriminability, Wang et al.24 introduced ParallelNet, a TripleNet-based architecture that enhances feature extraction, achieving an AP of 0.88 on thigh fracture radiographs. Similarly, addressing the issue of scale variance in femoral fractures, Qi et al.25 integrated a Feature Pyramid Network (FPN) with a ResNet50 backbone. This multi-scale approach effectively aggregated semantic information, improving detection performance across diverse fracture sizes.
Research has also explored guided mechanisms and multi-step pipelines to refine proposal quality. Ma and Luo27 proposed a cascaded workflow, utilizing CrackNet for initial fracture screening followed by Faster R-CNN for precise localization. This hierarchical strategy reduced false positives, yielding an accuracy of 0.88. To mitigate background interference, Wu et al.28 incorporated a Feature Ambiguity Mitigate Operator within a ResNeXt101-FPN framework. Furthermore, Xue et al.29 tackled the issue of fixed anchor shapes in hand X-rays by implementing a Guided Anchoring (GA) module. This adaptive mechanism allowed for the dynamic refinement of anchor shapes based on fracture morphology, resulting in an mAP of 0.71. Conversely, limitations in localization were highlighted by Raisuddin et al.26, whose DeepWrist model, despite high AP scores on simpler test sets, struggled with complex cases and lacked precise bounding box delineation.
Recent advancements have shifted towards ensemble learning and segmentation-assisted detection to maximize diagnostic precision. Hardalac et al.30 conducted a comprehensive comparative study of 26 models, proposing WFD-C, an ensemble architecture integrating five distinct base models. This method capitalized on the diversity of errors among individual models, achieving a superior average precision of 0.86 compared to standalone two-stage (e.g., Dynamic R-CNN) or single-stage detectors. Finally, Joshi et al.31 demonstrated the efficacy of auxiliary tasks by employing a Mask R-CNN for simultaneous detection and segmentation. By leveraging transfer learning from surface crack datasets, they achieved a detection precision of 92.3%, suggesting that pixel-level segmentation supervision can enhance feature learning for bounding box regression.
One-stage detection
The application of deep learning in fracture detection has evolved from two-stage architectures to more efficient single-stage detectors; however, the optimization of these models for pediatric wrist trauma remains an active area of investigation.
Sha et al.32 initially implemented a YOLOv2 architecture to locate fractures in 5134 spinal CT scans, attaining a mean Average Precision (mAP) of 0.75. In a subsequent experiment, Sha et al.33 evaluated a Faster R-CNN approach on the same dataset, which yielded a marginally lower mAP of 0.73. These comparative results imply that for this specific application, the single-stage YOLOv2 architecture may offer superior efficiency and feature extraction capabilities compared to the two-stage Faster R-CNN framework.
In the context of the “GRAZPEDWRI-DX” dataset, Hrzic et al.34 benchmarked the YOLOv4 framework against the U-Net segmentation approach developed by Lindsey et al.35. By implementing distinct configurations for fracture localization and quantification, the authors reported an AUC-ROC of 0.90 and an F1-score of 0.96 for the counting task. These findings indicate that object detection frameworks can provide diagnostic accuracy comparable to radiologist assessments while avoiding the computational overhead associated with pixel-level segmentation.
More recently, Nagy et al.19 established a performance baseline on the GRAZPEDWRI-DX dataset using the YOLOv5m architecture pre-trained on COCO. Validated on a cohort of 1000 test samples, the model exhibited a fracture detection mAP of 0.93 (at IoU=0.5).
Despite the prevalence of object detection models, recent studies have continued to refine segmentation and classification architectures to address specific clinical challenges such as weak supervision and data scarcity. For instance, Radillah et al.36 proposed an enhanced U-Net architecture integrating adaptive callback mechanisms and a dual-weighted loss strategy combining Dice and Binary Cross-Entropy loss. This approach dynamically adjusts training parameters to mitigate overfitting, achieving a recall of 86.70% on wrist fracture datasets. Similarly, Oh et al.37 addressed the lack of bounding box annotations in many medical datasets by employing a HyperColumn-Convolutional Block Attention Module (CBAM) within DenseNet169. By leveraging Gradient-weighted Class Activation Mapping (Grad-CAM), their method effectively localizes fracture regions without explicit box supervision, demonstrating that attention mechanisms can bridge the gap between classification and localization tasks.
The evolution of one-stage detectors has shifted towards integrating sophisticated attention mechanisms to enhance feature representation, particularly for subtle fracture lines that are easily obscured by soft tissue. Following the release of the GRAZPEDWRI-DX dataset, Ju et al.38 and Chien et al.39 explored the efficacy of the YOLOv8 architecture. Chien et al.38,39 introduced YOLOv8-AM, a variant incorporating multiple attention modules, including Residual CBAM (ResCBAM) and Efficient Channel Attention (ECA). Their ablation studies revealed that the ResCBAM variant achieved state-of-the-art performance with a mAP@50 of 65.8%, significantly outperforming the baseline by refining feature fusion in the network’s neck. These advancements underscore the necessity of forcing the network to focus on salient regions to distinguish between actual fractures and physiological growth plates in pediatric patients.
Concurrently, a significant body of research has focused on developing lightweight architectures suitable for deployment in resource-constrained clinical environments. To address the high computational cost of standard detectors, Ferdi40 proposed G-YOLOv11, which replaces standard convolutions with Ghost convolutions. This architectural modification reduced Floating Point Operations (FLOPs) by approximately 77% in the extra-large model variant while maintaining competitive accuracy, thereby establishing a new benchmark for efficiency. Similarly, Nguyen et al.41 devised a knowledge distillation pipeline where a compact student model (YOLOv8n-C2fP) learns from a high-performance teacher model. This approach reduced inference time by 85% and parameters by 90%, demonstrating that structural compression need not severely compromise diagnostic precision.
Most recently, researchers have sought to overcome the inherent class imbalance and multi-scale nature of pediatric fractures through novel feature extraction modules and loss functions. Liu et al.42 introduced Kid-YOLO, an architecture based on YOLOv11s that integrates a C3k2-WTConv module combining wavelet transforms with convolution to capture multi-scale frequency information. Furthermore, they implemented the Focaler-MPDIoU loss function, which dynamically adjusts sample weights to prioritize difficult-to-detect fractures, yielding a mAP@50-95 of 39.5%. Complementing supervised approaches, Thorat et al.43 explored self-supervised learning using the SimCLR framework with a ResNet-18 backbone. By leveraging contrastive learning on unlabeled data, they achieved a high specificity of 93.21%, illustrating that algorithmic improvements in loss formulation and pre-training strategies are as critical as architectural depth in modern fracture detection systems.
Notwithstanding these advancements, standard single-stage architectures often compromise the preservation of fine-grained textural details during downsampling, a critical drawback when delineating subtle fracture lines amidst physiological growth plates. To address these limitations, this study proposes FracDet-v11, a specialized framework constructed upon the YOLOv11s architecture. We introduce a reconstructed backbone integrating Haar Wavelet Downsampling (HWD) and Poly Kernel Inception with Context Anchor Attention (PKI-CAA) modules to effectively preserve high-frequency details and minimize spatial information loss. Complementing this, a novel Dual-branch Channel Attention Module (DCAM) is employed to extract multi-scale discriminative features, while a lightweight Slim-Neck architecture optimizes feature fusion efficiency. Furthermore, to accommodate the irregular morphology of pediatric fractures, the detection head is redesigned using Deformable Convolution v4 (DCNv4) and the Focaler-CIoU loss function, which dynamically prioritizes hard-to-classify samples to enhance localization accuracy.
Materials and methods
In this section, we provide a detailed description of the experimental framework and the proposed FracDet-v11 architecture for pediatric wrist fracture detection. We first introduce the datasets utilized, specifically GRAZPEDWRI-DX for primary training and FracAtlas for external validation, along with the patient-level data partitioning and augmentation strategies implemented to ensure diagnostic rigor. Subsequently, the overall architecture of FracDet-v11 is delineated, followed by a meticulous explanation of the targeted optimizations in the backbone (HWD, PKI-CAA and DCAM), neck (Slim-Neck), and prediction head (DCNv4 and Focaler-CIoU) designed to capture subtle radiographic features.
Dataset
This investigation utilizes the GRAZPEDWRI-DX dataset, a publicly available resource curated and disseminated by Nagy et al.19 with the explicit aim of advancing computer vision research. The dataset comprises a cohort of 6091 pediatric patients (mean age: 10.9 years; range: 0.2–19 years; 2,688 female, 3402 male, one of unknown gender), all of whom were managed at the Department of Pediatric Radiology, Medical University of Graz, Austria. The dataset encompasses a substantial corpus of 20,327 wrist radiographs, including both lateral and posteroanterior projections. These images were acquired between 2008 and 2018, with the annotation process being conducted from 2018 to 2020 by a team of professional radiologists and medical students. Critically, the fidelity of all annotations was subsequently corroborated by a panel of three senior radiologists. Notably, the dataset provides a high data density with an average of approximately 3.34 images per patient. This multiplicity arises from the standard clinical protocol of acquiring multiple projections (e.g., posteroanterior and lateral views) and serial follow-up examinations for individual patients. Such a structure allows the model to learn fracture features across varied projection angles and developmental stages. Exemplar images from the GRAZPEDWRI-DX dataset are presented in Fig. 1.
To evaluate the generalization capability of FracDet-v11 on unseen data from a different geographical and demographic domain, we employed the FracAtlas dataset. Collected from three medical centers in Bangladesh between 2021 and 2022, this dataset contains 4,083 musculoskeletal radiographs. Unlike the pediatric-focused training set, FracAtlas includes a broad age spectrum ranging from 8 months to 78 years, allowing for the assessment of model performance on adult and elderly bone structures. The demographic composition of FracAtlas shows a distinct gender divide, with approximately 62% male and 38% female subjects overall; specifically within the fracture-positive subset, males account for 85.4% of the cases. This dataset includes 717 images demonstrating fractures and 3,366 normal images. This significant class imbalance and anatomical diversity provide a challenging benchmark for testing the robustness of the proposed framework.

Sample GRAZPEDWRI-DX dataset.
Data processing and augmentation
Since the GRAZPEDWRI-DX dataset does not provide standardized subsets, we implemented a patient-level partitioning strategy to ensure a robust evaluation and strictly prevent data leakage. Specifically, the dataset was divided into training, validation, and independent test sets with a ratio of 7:2:1. By grouping all images from the same patient into the same subset, we ensured that the model was tested on entirely unseen individuals, thereby maintaining the integrity of the performance assessment. This division yielded 14,292 images (70.31%) for training, 3,958 images (19.47%) for validation, and 2,077 images (10.22%) for testing. Crucially, data augmentation was applied exclusively to the training subset subsequent to this data splitting process.
To address the limited photometric variability in the GRAZPEDWRI-DX dataset, we utilized OpenCV weighted functions to modulate the contrast and brightness of the training images, this strategy expands the original training set from 14,292 images to 28,584 images. The validation and test sets remained comprised entirely of original, unaugmented images to ensure an unbiased evaluation.
Network structure
The YOLO framework is renowned in the computer vision community for real-time object detection, distinguished by its exceptional balance of processing speed and computational efficiency. Building upon its predecessors, YOLOv11 incorporates a suite of advanced features and optimizations that collectively yield superior detection accuracy and accelerated inference speeds. Key architectural enhancements that differentiate it from the YOLOv8 model include: (i) the substitution of C2f layers with C3K2 layers; (ii) the integration of a C2PSA layer subsequent to the SPPF module; (iii) a reconfiguration of the detection head via the replacement of two DWConv layers; and (iv) fine-tuned adjustments to the model’s depth and width parameters.
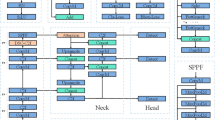
Notwithstanding these advancements, the standard YOLOv11 architecture necessitates further specialization for the nuanced task of wrist abnormality detection. The identification of subtle wrist fractures demands a delicate equilibrium between high precision and high recall, a requirement that poses a significant challenge to the baseline architecture. The default backbone, attention mechanisms, and loss functions may not be optimally configured to capture the fine-grained details and intricate patterns inherent in medical radiography. Consequently, we have implemented a series of targeted optimizations for these specific components, tailoring the model to the unique demands of this application. An illustration of the proposed FracDet-v11 model, purpose-built for wrist abnormality detection, is presented in Fig. 2.

FracDet-v11 algorithm structure diagram.
Backbone optimization
HWD
The original YOLOv11 object detection model typically employs Strided Convolution or Max Pooling to downsample feature maps. However, for the GRAZPEDWRI-DX dataset, this coarse-grained dimensionality reduction method presents significant drawbacks: it is highly prone to causing the loss of fine-grained trabecular textures and micro-fracture features. Particularly in pediatric wrist X-rays, where background soft tissue noise is complex and interference from growth plate textures exists, traditional downsampling further blurs the boundaries between fracture lines and the background, thereby weakening the model’s ability to recognize occult fractures. To address this, this paper introduces a Haar Wavelet Downsampling44 (HWD) module to replace the traditional downsampling convolution layers in the backbone network. The HWD module effectively reduces the spatial resolution of feature maps while maximizing the preservation of image edge gradients and texture information, thereby enhancing the model’s comprehensive perception capabilities for both global low-frequency structures (bone morphology) and local high-frequency details (fracture lines). Its structure is illustrated in Fig. 3.

Structure of the Haar wavelet downsampling module.
The HWD module primarily consists of two components: Lossless Feature Encoding and Feature Learning. The specific implementation is described as follows: utilizing the orthogonality of the Haar wavelet transform, the input features are decomposed. The basis function and scaling function of the first-order one-dimensional Haar wavelet are defined as follows:
In these equations, x represents the input feature; f(x) represents the basis function; and parameters j and k denote the scale (order) and translation (index) of the Haar basis function, respectively. In the HWD module (as shown in Fig. 3), low-pass decomposition filters \(H_0\) and high-pass decomposition filters \(H_1\) are utilized to process the input feature maps. The Haar wavelet transform decomposes the input feature map into four components with halved spatial resolution: the Low-frequency component (A), which contains the approximation information of the image, preserving the anatomical structural outlines of the radius and ulna; and the High-frequency components (H, V, D), which correspond to horizontal, vertical, and diagonal detail information, respectively, capturing multi-directional bone cortical edges and fracture fissure features.
The core advantage of this module lies in encoding information from spatial dimensions into channel dimensions. This transformation method effectively mitigates the loss of key defect feature information (such as subtle fissures) during the downsampling process and effectively reduces the overall spatial size of the feature maps. Through the subsequent feature learning component, the model is able to more efficiently aggregate multi-frequency features and optimize feature extraction capabilities, thereby further elevating the detection accuracy for complex fracture targets within the GRAZPEDWRI-DX dataset.
PKI-CAA
Distinct from conventional object detection tasks, fracture samples within the GRAZPEDWRI-DX dataset exhibit significant multi-scale heterogeneity. The same type of fracture (e.g., distal radius fracture) may manifest as extremely subtle linear fissures in some cases, while presenting as extensive cortical disruption or displacement in others. Traditional feature extraction methods often rely on large kernels to expand the receptive field; however, when processing X-ray images, this approach tends to introduce excessive soft tissue background noise, leading to the submergence of key local lesion features.
Drawing inspiration from PKINet45, this paper introduces a Poly Kernel Inception (PKI) module without expansion into the YOLOv11s backbone network. This module is designed to extract multi-scale bone texture features by employing parallel convolution kernels of varying sizes. It is combined with a Context Anchor Attention (CAA) mechanism to capture long-range anatomical structural dependencies. Consequently, this approach significantly enhances the model’s feature representation capabilities for multi-scale fracture targets while simultaneously suppressing background noise.
The overall structure of the PKI module is illustrated in Fig. 4. The input feature \(X_n \in \mathbb {R}^{C \times H \times W}\) (where C, H, and W represent the channel count, width, and height, respectively) is fed into two parallel branches for processing. The PKI branch is responsible for extracting local multi-scale texture features, yielding an output of \(P_n\). The CAA branch is tasked with capturing global and long-range contextual information, yielding an output of \(A_n\). The outputs of these two branches are fused via an element-wise product operation, allowing \(A_n\) to serve as an attention mask that activates key fracture feature regions within \(P_n\). Finally, the ultimate feature output is generated through a residual connection and a \(1 \times 1\) convolution.

The overall structure of the PKI module.
The PKI texture extraction block is shown in Fig. 5. The primary design objective of the PKI block is to simulate receptive fields of different sizes to adapt to fracture diversity. First, a small-kernel convolution (\(3 \times 3\)) is utilized to extract basic local features \(L_n\). Subsequently, the features enter a set of parallel Depth-wise Convolution layers with kernel sizes of \(5 \times 5\), \(7 \times 7\), \(9 \times 9\), and \(11 \times 11\), respectively. This multi-path parallel design enables the simultaneous capture of subtle bone fissures (via small kernels) and large-scale fracture displacements (via large kernels). Furthermore, it avoids the gridding artifacts potentially introduced by dilated convolutions, ensuring the continuity and integrity of the fracture texture information.

PKI module.
The Context Anchor Attention block is illustrated in Fig. 6. The CAA block aims to address the limitation of local convolutions in perceiving global anatomical structures. The module first aggregates global information through Average Pooling (AvgPool) and a \(1 \times 1\) convolution. Considering that fracture lines and long bones typically exhibit elongated geometric characteristics, which share similar morphological properties with “bridges” in remote sensing imagery, the CAA module employs Strip Convolution (specifically \(1 \times 11\) and \(11 \times 1\) convolution kernels). Compared to traditional square large-kernel convolutions, strip convolutions are not only more lightweight in terms of parameters but also more precisely match the directional features of linear fracture lines, effectively enhancing the model’s sensitivity to fracture boundaries. Finally, the attention weights \(A_n\) are generated via a Sigmoid activation function.

CAA module.
In summary, the introduction of the PKI-CAA module enables the network to both “clearly perceive” local micro-fracture textures and “comprehend” global skeletal orientation, thereby drastically improving the detection precision for complex fracture samples in the GRAZPEDWRI-DX dataset.
DCAM module
The primary feature extraction network processes feature maps using an SPPF module for efficient multi-scale pooling, after which the pooled features are transmitted to a C2PSA module for deep feature enhancement. Due to the subtle variations characteristic of fracture regions, the multi-head attention mechanism within the C2PSA module cannot effectively filter features based on global contextual relationships alone. To address this limitation, we introduce the Spatial and Channel Collaborative Attention46 (SCSA) mechanism. By comprehensively considering the relationships both between and within different feature maps, we have designed the DCAM module to replace the original C2PSA, thereby achieving more refined filtering of fissure-related features and an augmented feature representation of injury locations.
The architectural design of the SCSA module is depicted in Fig. 7. The module is constructed from two principal components: a Shared Multi-Semantic Spatial Attention block and a Progressive Channel Self-Attention block. The process commences with the partitioning of the incoming feature map along its spatial dimensions (height and width), which is then subjected to Global Average Pooling to yield two unidirectional, one-dimensional sequences. To enable the discernment of multi-semantic spatial information, these sequences are uniformly divided, contingent on the channel dimension, yielding four distinct sub-features. These sub-features are subsequently processed concurrently by depthwise one-dimensional convolutions with varying kernel sizes, a strategy designed to capture features with heterogeneous semantic spatial characteristics. The resulting feature sets are then aligned via a shared convolution before undergoing normalization and activation, culminating in the formation of a spatial attention map. The resultant output from this spatial attention process is subsequently channeled through pooling and linear transformations to yield the Query (Q), Key (K), and Value (V) tensors. These tensors are then leveraged to compute and form the final channel attention weights. This dual-pathway mechanism creates a synergistic fusion of spatial and channel-wise attention, thereby enhancing the model’s ability to synthesize information across both fine-grained and broad contextual scales.

SCSA module.
The configuration of our enhanced DCAM module is illustrated in Fig. 8. A key innovation within this module is the substitution of the conventional multi-head attention mechanism with our Spatial and Channel Collaborative Attention (PSABlock-SCSA) block. In a further refinement, group-wise spatial convolutional layers are employed in place of their traditional counterparts to optimize the feature selection process. This integration results in the final DCAM architecture, which embeds the PSABlock-SCSA. The module is designed to maintain the residual connection, and the count of the embedded PSABlock-SCSA blocks is fixed at one.

Dual-branch channel attention module.
Slim-neck fusion network
The native feature fusion mechanism within the network’s neck is predicated on the C3K2 module. This module substitutes the bottleneck blocks of the C2f layer with a C3K unit, which comprises two parallel bottleneck modules and a standard convolution. While the increased number of convolutions nominally enhances feature fusion, it paradoxically diminishes the saliency of features pertinent to wrist fractures, leading to a homogenization of the feature maps and a consequent loss of critical information. To mitigate this deficiency, we engineered a “Slim-Neck”47 feature fusion network by strategically incorporating Group-Shuffle Convolution (GSConv) and VoVNet-based Group-Shuffle Cross Stage Partial (VoV-GSCSP) modules. This novel neck architecture is designed to alleviate information attrition during the feature integration process.
The architecture of the GSConv module is delineated in Fig. 9. Within this design, the input feature map is initially processed by a standard convolution, yielding an intermediate feature map with half the channel dimension of the final output. Concurrently, a second feature map is generated via a depthwise separable convolution. These two distinct feature maps are then concatenated and subjected to a channel shuffle operation to produce the final output. This composite design philosophy circumvents computational redundancy while simultaneously mitigating the loss of inter-channel information exchange–a common artifact of standalone depthwise separable convolutions. Through the synergy of standard convolution, depthwise separable convolution, and channel shuffling, GSConv effectively emulates the expressive power of a standard convolution at a significantly reduced computational load, thereby bolstering the network’s capacity for non-linear representation.

Schematic diagram of the GSConv module structure.
The architecture of the VoV-GSCSP module, designed based on GSConv and DWConv, is depicted in Fig. 10. This module is created by first replacing the two standard convolutions within a bottleneck block with GSConv and substituting the standard convolution at the residual connection with a depthwise separable convolution, forming a new “GSbottleneck.” This approach balances the increased computational complexity from the MobileNetV4 backbone and prevents the partial loss of semantic information caused by spatial compression and channel expansion. The VoV-GSCSP module is then constructed by combining this GSbottleneck with a standard convolutional block, ensuring high accuracy while reducing complexity. Finally, the Slim-Neck network is formed by replacing two standard convolutions in the neck with GSConv and substituting the four C3K2 modules with VoV-GSCSP modules. This network more effectively integrates features extracted by the backbone.

VoV-GSCSP structure.
Prediction head optimization
DCNv4
The original detection head of YOLOv11 relies primarily on standard 2D convolution layers (Conv2d) to perform the decoupled processing of classification and regression features. However, traditional convolution operations possess significant inherent limitations due to their fixed geometric sampling grids and static weight distributions. When processing the GRAZPEDWRI-DX dataset, pediatric wrist fractures often exhibit a high degree of irregularity (such as oblique fractures and comminuted fractures) and variable geometric morphologies. It is difficult for standard convolutions to dynamically adjust their receptive fields according to the actual trajectory of fracture lines. Consequently, this leads to imprecise feature extraction when the model encounters morphologically complex fracture targets, rendering it susceptible to interference from background growth plate textures.
To endow the detection head with stronger geometric transformation modeling capabilities, this paper introduces the fourth-generation Deformable Convolution48 (DCNv4) to reconstruct the decoupled detection head of YOLOv11. Specifically, the standard convolution layers used for initial feature extraction within the detection head are replaced by DCNv4 operators (as illustrated in Fig. 11). Relative to its predecessor, DCNv3, DCNv4 implements two key optimizations specifically addressing the requirements of high-precision medical object detection.

Structure of the detection head reconstructed with DCNv4.
First, DCNv4 eliminates the Softmax normalization constraint used for spatial aggregation in DCNv3, adopting an unbounded dynamic weighting mechanism instead. This improvement removes constraints on feature intensity expression, enabling the model to assign higher aggregation weights to key fracture edge pixels without being limited by probability distributions, thereby significantly enhancing the model’s responsiveness to subtle fracture textures. Second, addressing the challenge of high computational loads associated with high-resolution X-ray image processing, DCNv4 substantially reduces redundant memory access costs through a redesigned operator implementation. This optimization not only accelerates the forward propagation speed of feature maps and shortens model convergence time but also ensures that high-efficiency inference performance is maintained while introducing complex deformation perception capabilities.
By integrating DCNv4 into the detection head, the model is able to adaptively adjust sampling locations to closely align with the non-rigid deformation characteristics of fracture lines. This improvement effectively addresses the issue of inaccurate localization of irregular lesions by traditional convolutions within complex anatomical backgrounds. It enables the improved YOLOv11 to more precisely capture the subtle features of fracture regions, thereby significantly elevating detection performance for multi-scale and polymorphic fracture targets within the GRAZPEDWRI-DX dataset.
Focaler-CIoU loss function
The morphological characteristics of traumatic wrist regions deviate substantially from those of archetypal fractures. This discrepancy poses a significant challenge for conventional bounding box loss functions in achieving optimal parameterization, particularly when relying on the subtle feature variations present within feature maps. To address this limitation, we re-formulated the bounding box loss by incorporating the concept of linear mapping into the foundational Complete Intersection over Union (CIoU) loss function49. This enhancement, termed \(L_{Focaler-CIoU}\), empowers the model to dynamically balance the contributions of complex versus simple samples during loss computation. Specifically, by reconstructing the IoU metric via a linear interval mapping, the loss function assigns higher weights to difficult instances with lower overlap rates, thereby compelling the model to concentrate its learning resources on the identification of these more challenging samples. The \(L_{Focaler-CIoU}\) is defined as follows:
where \(L_{CIoU}\) denotes the standard CIoU loss (Eq. 4), \(\text {IoU}\) signifies the standard intersection over union between the predicted bounding box B and the true bounding box \(B^{gt}\) (Eq. 7), and \(\text {IoU}_{Focaler}\) represents the focused IoU reconstruction (Eq. 8).
The standard CIoU loss addresses the limitations of standard IoU by incorporating penalty terms for center point distance and aspect ratio:
where b and \(b^{gt}\) denote the centroids of the predicted and ground truth bounding boxes, respectively; \(\rho (\cdot )\) represents the Euclidean distance; and c corresponds to the diagonal length of the smallest enclosing rectangle covering both boxes. The parameter \(\alpha\) is a positive trade-off weight, and v measures the consistency of the aspect ratio. These are calculated as:
Here, \(w^{gt}, h^{gt}\) and w, h represent the width and height of the ground truth and predicted boxes, respectively. The standard IoU is defined as:
Finally, the \(\text {IoU}_{Focaler}\) introduces the linear interval mapping to reshape the regression curve:
where \([d, u] \in [0, 1]\) represents the linear mapping interval. The hyperparameters d and u serve as critical modulators of the focusing mechanism. In this study, we set \(d=0\) and \(u=0.95\). This specific configuration was determined through a sensitivity analysis on the GRAZPEDWRI-DX dataset. While the original Focaler-IoU framework49 suggests a range of potential values, our empirical results indicated that the combination of \(d=0\) and \(u=0.95\) yields the optimal trade-off between training stability and the suppression of simple background samples. This setting effectively compels the model to focus on hard-to-detect fracture instances, which are crucial for improving recall in pediatric wrist trauma diagnosis. The overall implementation logic of the reconstructed detection head in FracDet-v11 is summarized in Algorithm 1.

Detection head optimization.
Having established the theoretical framework and architectural innovations of the FracDet-v11 model, we proceed to validat its performance empirically. The following section details the experimental setup and a comprehensive comparative analysis against state-of-the-art object detection benchmarks.
Results
Experimental environment
The operational deployment of the proposed framework is computationally demanding, thereby imposing specific hardware prerequisites for optimal performance. A comprehensive breakdown of the hardware and software configuration utilized for this study is delineated in Table 1.
To ensure experimental rigor and fairness, we standardized all hyperparameter settings, as detailed in Table 2.
Comparison experiment
Bounding box loss function comparison experiment
To substantiate the effectiveness of our proposed Focaler-CIoU, we conducted comparative experiments against several mainstream bounding box regression loss functions, including Complete IoU (CIoU), Efficient IoU (EIoU), SCYLLA-IoU (SIoU), and Wise-IoU (WIoU). To ensure a fair comparison, all loss functions were evaluated under identical experimental configurations and training protocols. The quantitative results are systematically tabulated in Table 3.
As detailed in Table 3, Focaler-CIoU demonstrates superior performance across both evaluation metrics. Specifically, it achieves an mAP50 of 64.80% and an mAP50-95 of 42.70%, surpassing the standard CIoU by 1.05% and 1.00%, respectively. Furthermore, it outperforms the second-best method (WIoU) by 0.67% in mAP50. These results indicate that the proposed focusing mechanism effectively optimizes the regression process, resulting in higher detection precision compared to contemporary state-of-the-art loss functions.
Model comparison experiment
To strictly evaluate the efficacy of our proposed framework, a rigorous benchmarking study was conducted using the GRAZPEDWRI-DX dataset. The proposed model, designated as FracDet-v11, was compared against a diverse cohort of architectures, including legacy frameworks (Faster R-CNN, SSD), lightweight models (GhostNetV2), Transformer-based detectors (RT-DETR), and the YOLO series (v5s through v11s). A unified training and testing protocol was enforced to ensure a fair comparison. The quantitative results, detailed in Table 4, demonstrate that our optimized framework achieves a superior trade-off between detection accuracy and computational efficiency.
Legacy architectures exhibited limitations in this specific task. Faster R-CNN and SSD yielded moderate precision scores of 64.85% and 64.05%, respectively. While Faster R-CNN offered reasonable accuracy, its inference speed (139.3 FPS) was suboptimal for time-sensitive clinical applications. Similarly, the Transformer-based RT-DETR achieved competitive precision (68.57%) but was hindered by high computational costs (110.00 GFLOPs) and a substantial parameter count (32.00 M), limiting its deployability on resource-constrained edge devices.
In the context of the YOLO series, a progressive improvement in performance was observed from v5s to v10s. However, our proposed FracDet-v11 significantly outperformed the YOLOv11s baseline across all accuracy metrics. Specifically, FracDet-v11 achieved a Precision of 73.9%, Recall of 63.1%, mAP50 of 64.8%, and mAP50-95 of 42.7%. Compared to the baseline, this represents a substantial improvement of 3.8% in precision and 3.1% in mAP50.
Crucially, these performance gains were realized alongside a reduction in model complexity. As shown in Table 4, FracDet-v11 reduced the parameter count to 7.90 M and computational cost to 18.10 GFLOPs, compared to 9.41 M and 21.30 GFLOPs for the baseline. Although the inference speed of 184.8 FPS is slightly lower than the baseline, it remains well above the real-time requirement and significantly faster than Faster R-CNN and RT-DETR. This confirms that FracDet-v11 effectively addresses the challenge of detecting minute and morphologically complex fractures while maintaining a lightweight architecture suitable for clinical deployment.
Ablation experiment
To systematically evaluate the contribution of each proposed improvement to the YOLOv11s architecture, an ablation study was conducted on the GRAZPEDWRI-DX dataset. The improvements were categorized into three incremental configurations: (A) the integration of HWD, PKI-CAA, and DCAM modules into the backbone; (B) the refinement of the neck architecture (Slim-Neck); and (C) the optimization of the prediction head and loss function using DCNv4 and Focaler-CIoU. The step-by-step quantitative results are detailed in Table 5.
The baseline YOLOv11s model yielded a precision of 70.1%, recall of 57.2%, and mAP50 of 61.7%. The introduction of Enhancement A (HWD, PKI-CAA, and DCAM) resulted in immediate performance gains, boosting precision by 1.7% and recall by 2.4%. This improvement is attributed to the HWD module’s ability to prevent information loss during downsampling, coupled with the enhanced feature extraction and channel attention provided by PKI-CAA and DCAM.
Building upon this strengthened backbone, the incorporation of the Slim-Neck architecture (Enhancement B) further elevated the model’s performance. As shown in Table 5, this configuration increased precision to 73.1% and mAP50 to 64.1%. The Slim-Neck design effectively balances computational efficiency with feature fusion capabilities, allowing for more precise boundary delineation of fracture lines.
Finally, the integration of Enhancement C, which comprises the DCNv4 module and the Focaler-CIoU loss function, culminated in the optimal configuration (YOLOv11s + A + B + C). This final addition improved recall by 1.5% and mAP50 by 0.7% compared to the previous stage, achieving a peak performance of 73.9% Precision, 63.1% Recall, 64.8% mAP50, and 42.7% mAP50-95. The DCNv4 module enhances the model’s adaptability to irregular fracture shapes, while Focaler-CIoU dynamically focuses the training process on hard examples, thereby maximizing detection accuracy. These results confirm that the synergistic integration of these modules significantly enhances the baseline capabilities without compromising stability.
To visually validate the effectiveness of the FracDet-v11 model, Fig. 12 presents a comparison of the detection results between the proposed model and the YOLOv11s baseline on the GRAZPEDWRI-DX dataset. The comparative analysis demonstrates that the improved model achieves significant enhancements in both detection accuracy and robustness.
Specifically, in the samples shown in the first two columns of Fig. 12, although the baseline model successfully localizes the fracture regions, it exhibits lower confidence scores (e.g., only 0.5 in the first column) and suboptimal bounding box regression compactness. In contrast, FracDet-v11 not only generates bounding boxes that align more closely with the ground truth but also significantly boosts detection confidence (e.g., increasing to 0.7 in the first column), thereby evidencing its enhanced feature extraction capability for subtle fractures.
In the dense object scenarios depicted in the third and fourth columns of Fig. 12, when detecting wrist fractures characterized by complex features and mutual occlusion, the baseline model exhibits marked localization deviations. Conversely, the improved model remains capable of clearly distinguishing dense targets, demonstrating superior performance in complex backgrounds.
Of particular note is the sample in the fifth column of Fig. 12, where soft tissue injury manifests as low-contrast diffuse swelling; these weak textural features result in a failure of identification by both the baseline and the improved models regarding the soft tissue. However, even within this challenging sample where the baseline model completely fails to detect any targets, FracDet-v11 successfully extracts and precisely localizes the fracture regions most critical for clinical diagnosis. This indicates that while the detection of weak-texture targets remains a challenge, the improved model has effectively surmounted the feature extraction bottleneck, ensuring the successful detection of core lesions.
In summary, by enhancing feature extraction and localization capabilities, FracDet-v11 effectively addresses detection difficulties associated with small objects, dense scenarios, and multi-scale variations, rendering it highly suitable for clinical computer-aided diagnosis.

Comparison of detection results on the GRAZPEDWRI-DX dataset.
To enhance model interpretability and visually validate its capability to capture key lesion features, this study employs the Gradient-weighted Class Activation Mapping (Grad-CAM) technique to conduct a visualization analysis of the feature maps generated by the YOLOv11s baseline and the proposed method. As illustrated in Fig. 13, the color intensity of the heatmaps reflects the model’s degree of attention toward specific regions: warm-toned areas (e.g., red) represent high activation responses, indicating critical feature regions used by the model for target discrimination; conversely, cool-toned areas (e.g., blue) correspond to the background or regions with lower weight importance.

Grad-CAM heatmap visualization of feature maps from YOLOv11s and FracDet-v11.
To precisely and visually assess the differences in detection efficacy between YOLOv11 (small/medium/large) and FracDet-v11, Fig. 14 presents the visualized detection results across different categories. This comparison intuitively highlights the performance enhancements achieved by the proposed model.

Visualized detection results of YOLOv11 (small/medium/large) and FracDet-v11.
FracAtlas dataset experiments
To rigorously evaluate the robustness and stability of our proposed model, we employed the FracAtlas dataset, a curated collection of 4,083 radiographic images designated for skeletal fracture detection. Diverging from conventional datasets, FracAtlas encompasses a wide spectrum of fracture types and complexities, ranging from common, conspicuous cases to rare and occult fractures. This inherent diversity provides a comprehensive benchmark for assessing the resilience of detection algorithms. All images underwent uniform preprocessing to ensure consistency, rendering the dataset an ideal testbed for our validation experiments (illustrated in Fig. 15).

Sample FracAtlas dataset.
To assess the generalizability and robustness of our proposed framework beyond the primary dataset, we conducted a rigorous benchmarking study on the FracAtlas dataset. The model was trained and evaluated against a comprehensive array of leading architectures, including RT-DETR and the YOLO series (v5s through v11s). Performance was systematically quantified using standard metrics: Precision, Recall, mAP50, and mAP50-95.
As delineated in Table 6, our proposed FracDet-v11 demonstrated superior performance across all evaluated metrics, surpassing both the transformer-based RT-DETR and the latest YOLOv11s baseline. Specifically, our model achieved a Precision of 60.5%, Recall of 48.2%, mAP50 of 47.9%, and mAP50-95 of 20.9%. Notably, compared to the YOLOv11s baseline, FracDet-v11 yielded a substantial improvement of 9.7% in Recall and 4.4% in mAP50. These findings indicate that our architectural enhancements significantly mitigate missed detections (false negatives), which is a critical advantage in clinical fracture diagnosis.
Further qualitative analysis is presented in Fig. 16, which contrasts the detection outcomes of the Ground Truth (GT) against different models. The visualizations corroborate the quantitative data, demonstrating our model’s enhanced capability in identifying minute and morphologically atypical fractures that were frequently missed by competing architectures. Collectively, these extensive evaluations on the FracAtlas dataset substantiate the robustness of our approach and its potential for deployment in diverse clinical environments.

Comparison of model prediction results.
Discussion
In this investigation, we introduced FracDet-v11, a specialized object detection framework based on the YOLOv11s architecture, engineered specifically for the challenging task of pediatric wrist fracture detection. The proposed model demonstrates significant advancements in detection precision, inference speed, and generalization capability across diverse datasets. To address the scope of the diagnostic task, it is imperative to clarify that while the GRAZPEDWRI-DX dataset encompasses multiple diagnostic categories—including soft tissue damage and bone lesions—this study primarily prioritizes fracture detection. This focus is justified by the critical need for immediate orthopedic intervention in fracture cases. However, we acknowledge that fractures frequently present with concomitant pathologies; therefore, the model is designed to operate effectively within this multi-class environment, ensuring that co-occurring abnormalities do not compromise the detection of primary fractures.
Crucially, FracDet-v11 is intended to function as an assistive diagnostic tool rather than a standalone replacement for radiologists. Its primary clinical utility lies in effectively triaging cases and flagging suspicious regions to reduce diagnostic oversight, particularly in high-volume emergency settings. The empirical results confirm its proficiency in identifying subtle and morphologically complex fractures without compromising high-throughput processing speeds.
Despite the promising performance of FracDet-v11, several limitations inherent to both the imaging modality and the deep learning methodology warrant critical discussion.
First, the model’s reliance on 2D radiographic projections constitutes a fundamental physical constraint. Anatomical superimposition—where bones overlap in the projection plane—can obscure fracture lines, leading to inevitable false negatives. This is particularly problematic in complex anatomical regions like the wrist, where multiple carpal bones are densely packed. Future frameworks could mitigate this by incorporating multi-view fusion strategies (e.g., fusing PA and lateral views) to reconstruct spatial context.
Second, specific to the pediatric population, the physiological presence of epiphyseal growth plates poses a significant challenge. These structures morphologically resemble fracture lines, potentially inducing false positives. Although our model incorporates attention mechanisms to distinguish these features, distinguishing between a normal fusing epiphysis and a subtle fracture remains a difficult task that requires further architectural refinement tailored to developmental anatomy.
Third, the model’s performance upper bound is constrained by the quality of the ground truth labels. Medical image annotation is subject to inter-observer variability, where even expert radiologists may disagree on ambiguous cases. Consequently, the model may inadvertently learn the biases or inconsistencies present in the training data. Future research should explore uncertainty quantification methods to flag ambiguous predictions that require human review.
Finally, like most deep learning-based detectors, FracDet-v11 operates as a “black box”. While it provides accurate bounding boxes, it lacks the ability to provide explicit clinical reasoning (explainability) for its decisions. Bridging the gap between high detection accuracy and model interpretability will be crucial for fostering trust among clinicians and facilitating seamless integration into routine workflows.
Conclusion
The performance of the YOLOv11s framework in pediatric wrist fracture detection was substantially elevated through a series of bespoke architectural modifications. To mitigate the loss of high-frequency information in radiographic imagery, the backbone was reconstructed by integrating Haar Wavelet Downsampling (HWD) and the PKI-CAA module, complemented by a Dual-branch Channel Attention Module (DCAM) to extract discriminative features across diverse scales. A “Slim-Neck” architecture was employed to optimize feature fusion efficiency by refining boundary delineation. Furthermore, the detection head was redesigned by synergizing Deformable Convolution v4 (DCNv4) with the Focaler-CIoU loss function. This combination enhances the model’s adaptability to geometric deformations and strategically prioritizes hard-to-classify samples.
Benchmarked on the GRAZPEDWRI-DX dataset, our proposed model, FracDet-v11, established a new performance standard, achieving a precision of 73.9%, recall of 63.1%, mAP50 of 64.8%, and mAP50-95 of 42.7%. These metrics represent a significant improvement over the baseline and competing models. Notably, these gains were realized alongside a reduction in model complexity (7.90 M parameters) and computational cost (18.10 GFLOPs), while maintaining a real-time inference speed of 184.8 FPS. The independent contributions of each module were rigorously confirmed via a systematic ablation analysis. Subsequent evaluations on the external FracAtlas dataset affirmed the framework’s robust generalization capability, where it achieved a precision of 60.5% and recall of 48.2%, significantly outperforming the baseline.
Looking ahead, several avenues for future research are identified to bridge the gap between algorithmic performance and clinical ubiquity. First, regarding methodological refinement, future iterations will focus on enhancing detection acuity for occult micro-fractures, potentially by incorporating super-resolution techniques or few-shot learning paradigms to handle rare fracture patterns. Second, to improve data robustness, we aim to augment the training corpus with multi-center data encompassing a broader spectrum of radiological presentations and device manufacturers, ensuring the model’s resilience to domain shifts. Third, model interpretability remains a priority; we plan to integrate Explainable AI (XAI) modules, such as saliency maps, to visualize the decision-making process, thereby fostering trust among clinicians. Finally, we intend to initiate prospective clinical trials to rigorously assess the model’s impact on diagnostic workflow efficiency and patient outcomes in real-world settings.
Data availability
The datasets analyzed during the current study are publicly available. The GRAZPEDWRI-DX dataset can be found at https://www.nature.com/articles/s41597-022-01328-z, and the FracAtlas dataset is available at https://www.nature.com/articles/s41597-023-02432-4.
References
Daniels, A. M. et al. Bone microarchitecture and distal radius fracture pattern complexity. J. Orthop. Res. 37, 1690–1697 (2019).
Randsborg, P. H. et al. Fractures in children: Epidemiology and activity-specific fracture rates. J. Bone Jt. Surg. 95, e42 (2013).
Tsukutani, Y. et al. Epidemiology of fragility fractures in Sakaiminato, Japan: Incidence, secular trends, and prognosis. Osteoporos. Int. 26, 2249–2255 (2015).
Nellans, K. W., Kowalski, E. & Chung, K. C. The epidemiology of distal radius fractures. Hand Clin. 28, 113 (2012).
Kromrey, M. L. et al. Navigating the spectrum: Assessing the concordance of ml-based AI findings with radiology in chest X-rays in clinical settings. Healthcare 12, 2225 (2024).
Mounts, J. et al. Most frequently missed fractures in the emergency department. Clin. Pediatr. 50, 183–186 (2011).
Erhan, E. R. et al. Overlooked extremity fractures in the emergency department. Ulus Travma Acil Cerrahi Derg 19, 25–28 (2013).
Kim, D., Lim, S. H. & Seo, P. W. Iatrogenic perforation of the left ventricle during insertion of a chest drain. Korean J. Thorac. Cardiovasc. Surg. 46, 223 (2013).
Burki, T. K. Shortfall of consultant clinical radiologists in the UK. Lancet Oncol. 19, e518 (2018).
Rimmer A. Radiologist shortage leaves patient care at risk, warns royal college. BMJ 359 (2017).
Rosman, D., Nshizirungu, J., Rudakemwa, E. et al. Imaging in the land of 1000 hills: Rwanda radiology country report. J. Glob. Radiol. 1 (2015).
Smith-Bindman, R. et al. Trends in use of medical imaging in US health care systems and in Ontario. JAMA 322, 843–856 (2019).
Fotiadou, A. et al. Wrist injuries in young adults: The diagnostic impact of CT and MRI. Eur. J. Radiol. 77, 235–239 (2011).
Neubauer, J. et al. Comparison of diagnostic accuracy of radiation dose-equivalent radiography, multidetector computed tomography and cone beam computed tomography for fractures of adult cadaveric wrists. PLoS One 11, e0164859 (2016).
Adams, S. J. et al. Artificial intelligence solutions for analysis of X-ray images. Can. Assoc. Radiol. J. 72, 60–72 (2021).
Tanzi, L. et al. Hierarchical fracture classification of proximal femur X-ray images using a multistage deep learning approach. Eur. J. Radiol. 133, 109373 (2020).
Choi, J. W. et al. Using a dual-input convolutional neural network for automated detection of pediatric supracondylar fracture on conventional radiography. Invest. Radiol. 55, 101–110 (2020).
Lampert, C. H., Blaschko, M. B. & Hofmann, T. Beyond sliding windows: Object localization by efficient subwindow search. In CVPR. 1–8 (2008).
Nagy, E., Janisch, M., Hržić, F. et al. A pediatric wrist trauma x-ray dataset (grazpedwri-dx) for machine learning. Sci. Data 9, 222. https://www.nature.com/articles/s41597-022-01328-z (2022).
Khanam, R. & Hussain, M. YOLOv11: An overview of the key architectural enhancements. arXiv preprint arXiv:2410.17725. https://www.arxiv.org/abs/2410.17725 (2024).
Yahalomi, E., Chernofsky, M. & Werman, M. Detection of distal radius fractures trained by a small set of X-ray images and Faster R-CNN. In Intell. Comput. 971–981 (2019).
Thian, Y. L. et al. Convolutional neural networks for automated fracture detection and localization on wrist radiographs. Radiol. Artif. Intell. 1, e180001 (2019).
Guan, B. et al. Arm fracture detection in X-rays based on improved deep convolutional neural network. Comput. Electr. Eng. 81, 106530 (2020).
Wang, M., Yao, J., Zhang, G. et al. ParallelNet: Multiple backbone network for detection tasks on thigh bone fracture. Multimed. Syst. 1–10 (2021).
Qi, Y. et al. Ground truth annotated femoral X-ray image dataset and object detection based method for fracture types classification. IEEE Access 8, 189436–189444 (2020).
Raisuddin, A. M. et al. Critical evaluation of deep neural networks for wrist fracture detection. Sci. Rep. 11, 6006 (2021).
Ma, Y. & Luo, Y. Bone fracture detection through the two-stage system of crack-sensitive convolutional neural network. Inform. Med. Unlocked 22, 100452 (2021).
Wu, H. Z. et al. The feature ambiguity mitigate operator model helps improve bone fracture detection on X-ray radiograph. Sci. Rep. 11, 1589 (2021).
Xue, L. et al. Detection and localization of hand fractures based on GA_Faster R-CNN. Alex. Eng. J. 60, 4555–4562 (2021).
Hardalaç, F. et al. Fracture detection in wrist X-ray images using deep learning-based object detection models. Sensors 22, 1285 (2022).
Joshi, D., Singh, T. P. & Joshi, A. K. Deep learning-based localization and segmentation of wrist fractures on X-ray radiographs. Neural Comput. Appl. 34, 19061–19077 (2022).
Sha, G., Wu, J. & Yu, B. Detection of spinal fracture lesions based on improved Yolov2. In AICA. 235–238 (2020).
Sha, G., Wu, J. & Yu, B. Detection of spinal fracture lesions based on improved faster-rcnn. In AIIS. 29–32 (2020).
Hržić, F. et al. Fracture recognition in paediatric wrist radiographs: An object detection approach. Mathematics 10, 2939 (2022).
Lindsey, R. et al. Deep neural network improves fracture detection by clinicians. Proc. Natl. Acad. Sci. U.S.A. 115, 11591–11596 (2018).
Radillah, T., Defit, S. & Nurcahyo, G. W. Enhancing U-Net for wrist fracture segmentation in X-ray images using adaptive callbacks and weighted loss functions. J. Appl. Data Sci. 6, 2623–2635 (2025).
Oh, J., Hwang, S. & Lee, J. Enhancing X-ray-based wrist fracture diagnosis using HyperColumn-convolutional block attention module. Diagnostics 13, 2927 (2023).
Ju, R. Y., Chien, C. T. & Chiang, J. S. Yolov8-rescbam: Yolov8 based on an effective attention module for pediatric wrist fracture detection. In ICONIP. 403–416 (2024).
Chien, C. T. et al. YOLOv8-AM: YOLOv8 based on effective attention mechanisms for pediatric wrist fracture detection. IEEE Access 13, 52461–52477 (2025).
Ferdi, A. Lightweight g-yolov11: Advancing efficient fracture detection in pediatric wrist X-rays. Biomed. Signal Process. Control 113, 108861 (2026).
Nguyen, T. T., Tran, H. L. & Vu, D. L. An Efficient Model for Fracture Detection in Wrist Trauma Images. In FDSE. 419–426 (2025).
Liu, D. et al. Artificial intelligence-based method for detecting wrist fractures in children. Sci. Rep. 15, 38555 (2025).
Thorat, S. R. et al. Wrist fracture detection using self-supervised learning methodology. J. Musculoskelet. Surg. Res. 8, 133–141 (2024).
Gao, Y. et al. A lightweight anti-unmanned aerial vehicle detection method based on improved YOLOv11. Drones 9, 11 (2024).
Cai, X., Lai, Q., Wang, Y. et al. Poly kernel inception network for remote sensing detection. In CVPR. 27706–27716 (2024).
Si, Y. et al. SCSA: Exploring the synergistic effects between spatial and channel attention. Neurocomputing 634, 129866 (2025).
Li, H. et al. Slim-neck by GSConv: A lightweight-design for real-time detector architectures. J. Real-Time Image Proc. 21, 62 (2024).
Guo, L., Liu, X., Ye, D. et al. Underwater object detection algorithm integrating image enhancement and deformable convolution. Ecol. Inform. 103185 (2025).
Zhang, H. & Zhang, S. Focaler-iou: More focused intersection over union loss. arXiv preprint arXiv:2401.10525. https://arxiv.org/abs/2401.10525 (2024).
Acknowledgements
This work was supported by Chongqing Social Science Planning Project(2023NDYB89), Chongqing Municipal Science and Health Joint Research Project(2020FYYX092), Chongqing Technology Innovation and Application Development Projects (CSTC2021jscx-gksb-N0007) and Graduate Innovation Program Project of Chongqing University of Science and Technology(YKJCX2521202).
Author information
Authors and Affiliations
Contributions
Haifeng Qiu: Writing – original draft, Visualization,Validation, Methodology, Formal analysis, Data curation,Conceptualization. Yong He: Supervision, Project administration,Funding acquisition. Lin He: Writing—review &editing, Supervision, Conceptualization. Yadong Luo: Supervision,Project administration, Funding acquisition. Li Liu: Supervision, Project administration, Funding acquisition. Jiale Hong: Writing—-Visualization, Validation, Methodology, Formal analysis, Data curation, Polishing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics statement
This study constitutes a retrospective analysis using exclusively publicly available, anonymized data; therefore, approval from an Institutional Review Board (IRB) was waived. The research utilized the GRAZPEDWRI-DX and FracAtlas datasets, both of which are distributed under the Creative Commons Attribution 4.0 International (CC BY 4.0) license. This license grants permission for the use, redistribution, and adaptation of the data for research purposes. All patient-identifiable information within these datasets was fully de-identified by the original data curators prior to public release, ensuring strict adherence to patient confidentiality and data privacy standards. The authors further declare that the deep learning model developed in this study is intended solely for scientific research and assistive diagnostic exploration. It has not been cleared for clinical use and must not be interpreted as a substitute for professional medical diagnosis, clinical judgment, or pathological confirmation.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Qiu, H., Liu, L., Hong, J. et al. FracDet-v11: a multi-scale attention and wavelet-enhanced network for real-time pediatric wrist fracture detection. Sci Rep 16, 5888 (2026). https://doi.org/10.1038/s41598-026-35827-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-35827-5
