
Abstract
Image captioning is a key task in computer vision and natural language processing. It involves creating clear and accurate descriptions of what we see in images, helping to connect visuals with words in a meaningful way. This paper introduces MSSA (Memory-Driven and Simplified Scaled Attention), a novel framework for image captioning designed to enhance multimodal integration and caption generation. MSSA leverages Extended Multimodal Feature Extraction, incorporating a diverse range of features, including geometric features encoding spatial properties of bounding boxes, color features representing pixel intensity distributions in RGB space, texture features capturing local variations using Local Binary Patterns (LBP), edge features describing boundary structures via Canny edge detection, and frequency-domain features detecting orientation- and frequency-specific patterns through Gabor filters. This comprehensive feature set provides a richer understanding of complex visual scenes. The framework integrates two key mechanisms: Memory-Driven Attention (MDA) and Simplified Scaled Attention (SSA). MDA iteratively refines the alignment of visual and multimodal features using an LSTM-based memory mechanism, ensuring dynamic adaptation to contextually relevant image and textual elements. SSA generates context vectors by leveraging scaled dot-product attention, enabling efficient modeling of spatial, semantic, and contextual interactions while maintaining computational simplicity through the removal of complex gating mechanisms. Extensive experiments on the MSCOCO dataset demonstrate that MSSA outperforms state-of-the-art methods across several evaluation metrics. The proposed framework combines robust feature extraction with a simplified attention module, and we support the “streamlined” claim by reporting concrete efficiency evidence (Params/FP32 size, FLOPs, and inference latency) within our LSTM-based captioning pipeline, without implying a direct runtime advantage over Transformer-based captioning models. The codes and resources for MSSA are publicly available at: https://github.com/alamgirustc/MSSA.
Similar content being viewed by others

Introduction
Image captioning is a crucial task in computer vision, which involves generating natural language descriptions for visual content. This task requires bridging the gap between the visual and textual domains by extracting meaningful image features and mapping them to coherent textual representations. Early image captioning methods, which utilized Convolutional Neural Networks (CNNs) for visual feature extraction and Recurrent Neural Networks (RNNs) for sequence generation, formed the foundation of this field1,2. While these methods achieved promising results, they faced challenges in aligning detailed visual content with generated text, especially in images containing complex scenes with multiple objects, interactions, and contextual nuances.
A significant advancement in the field came with the introduction of attention mechanisms, which enabled models to focus on specific regions of an image while generating text. Traditional attention mechanisms, which use linear representations to assign weights to various regions of an image, helped improve the alignment between the visual and textual modalities3,4. However, these models still struggled with capturing complex, non-linear relationships between visual features and text, especially when dealing with images that involved intricate interactions between objects or dynamic visual cues. Traditional attention models rely on linear representations, which often struggle to fully capture the complex, non-linear relationships inherent in real-world images.
To address these limitations, the X-Linear Attention mechanism was proposed, which focuses on modeling second-order interactions between visual and textual features. By incorporating second-order feature interactions, X-Linear Attention improves the model’s ability to reason across modalities, resulting in more accurate captions. However, despite its improvements, X-Linear Attention still faces challenges in adapting to the dynamic nature of multimodal data. A key limitation of X-Linear Attention is its reliance on fixed representations, which limits the model’s ability to flexibly prioritize relevant visual features based on the specific context of the image. While X-Linear Attention effectively models second-order feature interactions, it remains constrained in terms of flexibility when processing a wide variety of visual content.
Building upon these advances, we introduce the Memory-Driven and Simplified Scaled Attention (MSSA) framework, which offers a new set of techniques aimed at improving the integration of multimodal features and enhancing image captioning. The MSSA framework addresses the limitations of both traditional attention mechanisms and X-Linear Attention by providing a more adaptive and flexible approach to multimodal data processing. Crucially, our design is motivated by the task properties of image captioning: captions are generated sequentially (word by word), so early attention mistakes can propagate and amplify; region features can be noisy/partial (occlusions, clutter, similar objects), so a single-pass alignment is often insufficient; and good captions require fine-grained region–word grounding (attributes, relations such as “on/under/next to”), not only global semantics. MSSA is built to directly mitigate these captioning-specific issues by (i) enriching region descriptors with complementary low-level cues and (ii) refining alignment iteratively while keeping the per-step attention computation lightweight for repeated decoding calls. Specifically, the MSSA framework introduces three key innovations.
Task-specific motivation and what is new beyond standard components. Although MDA and SSA draw on well-known building blocks (LSTM memory and scaled dot-product attention), our design is driven by the specific requirements of image captioning. Captioning is generated sequentially (word by word), so early attention mistakes can propagate and amplify; RoI region features can be noisy/partial under occlusion and clutter, so a single-pass alignment is often brittle; and high-quality captions require fine-grained region–word grounding of attributes and relations (e.g., “red”, “on”, “next to”), not only global semantics. MSSA addresses these captioning-specific issues by (i) enriching each region representation with complementary low-level cues (geometry/color/texture/edges/frequency) to reduce ambiguity among similar RoIs, (ii) iteratively refining region–word alignment using an internal LSTM-based memory (MDA) that revisits regions across T refinement steps, and (iii) simplifying the attention path (SSA) by removing channel-wise gating, which is typically invoked repeatedly during LSTM decoding but brings limited additional benefit once regions are already diversified by the extended descriptors. This clarifies that the contribution is not simply “using memory/attention”, but adapting them into a captioning-tailored refinement+streamlining strategy with measurable accuracy/efficiency evidence in “Computational Efficiency Analysis” section.
First, the MSSA framework incorporates extended multimodal feature extraction. Unlike earlier methods that primarily focus on standard visual features, our approach integrates a broader range of image features, including geometric, texture, edge, and frequency-domain features5,6,7. This expanded set of features enables the model to capture both global and local visual cues, which is especially useful for analyzing complex images with multiple objects and interactions. This diversity in feature extraction leads to a more comprehensive understanding of the image content.
Second, the MSSA framework introduces Memory-Driven Attention (MDA). This mechanism leverages Long Short-Term Memory (LSTM) networks to iteratively refine the alignment between visual and textual features. At each iteration, the model dynamically focuses on the most relevant parts of the image and the text, enhancing the coherence and accuracy of the generated captions. The captioning-specific role of MDA is to correct and stabilize region–word alignment under sequential decoding: unlike one-shot attention, MDA revisits the same RoI set across T refinement steps using an internal LSTM memory state, which reduces sensitivity to early mis-attention and improves robustness when multiple objects/relations compete for the next word. This iterative refinement ensures that the captions remain contextually precise and grounded in both the image and the textual information8,9.
Third, the MSSA framework introduces Simplified Scaled Attention (SSA), which utilizes scaled dot-product attention to effectively model interactions between spatial, semantic, and contextual features10,11. In our encoder–decoder setting, SSA is streamlined by removing channel-wise gating and keeping a simpler attention path. This simplification is also task-motivated: in LSTM captioning, attention is invoked repeatedly across decoding steps, so reducing redundant gating operations yields a better efficiency–accuracy trade-off while preserving the key requirement of captioning attention, namely precise spatial selection of RoIs for each generated word. Importantly, our “streamlined” claim is scoped to the attention design within our LSTM-based captioning framework; we provide concrete evidence via Params/FP32 size, FLOPs, and inference latency comparisons between SSA variants (with vs. without channel-wise attention) in “Computational Efficiency Analysis” section, rather than claiming a direct efficiency advantage over Transformer-based captioning models.
Together, these innovations represent a significant advancement over previous methods, enabling more flexible and contextually accurate extraction and alignment of multimodal features. The result is a model capable of generating more diverse, semantically rich, and accurate captions. By overcoming the limitations of traditional attention mechanisms and X-Linear Attention, the MSSA framework offers a more robust solution for handling the complexities of multimodal tasks, particularly in image captioning.
Contributions: This paper presents the following key contributions
-
We propose an extended image feature extraction method that integrates a broader set of visual features, including geometric, texture, edge, and frequency-domain features. This extension allows for richer and more diverse image representations, improving the model’s ability to capture complex scenes.
-
We introduce a novel Memory-Driven Attention (MDA) mechanism that iteratively refines the alignment between visual and textual modalities. The dynamic, memory-driven focus on the most relevant features at each iteration significantly improves the coherence and accuracy of generated captions.
-
We propose a Simplified Scaled Attention (SSA) mechanism that generates context-aware feature representations by modeling interactions across spatial, semantic, and contextual dimensions. This streamlined design replaces complex gating mechanisms, enabling efficient and accurate multimodal feature integration and improving overall captioning performance.
These three contributions collectively form a powerful and flexible framework that advances image captioning by producing more accurate, diverse, and semantically rich captions, even for complex images with varied objects and interactions.
Related work
Image captioning has progressed alongside the broader deep neural network (DNN) trend in visual understanding12,13,14, from early approaches based on Convolutional Neural Networks (CNNs) for visual feature extraction and Recurrent Neural Networks (RNNs) for text generation1,2, to more advanced multimodal frameworks that integrate attention and transformer-based mechanisms. Early CNN-RNN models established the foundation but struggled to align complex visual details with coherent textual descriptions.
The introduction of attention mechanisms marked a pivotal advance, enabling models to focus selectively on image regions when generating words2,8. However, early spatial attention often relied on linear relationships, limiting its ability to capture complex interactions. Subsequent transformer-based methods15,16,17 employed self-attention to dynamically represent both visual and textual sequences. Joint vision-language models such as UNITER10 further demonstrated state-of-the-art results by aligning multimodal features through unified attention layers.
To better capture higher-order interactions, second-order mechanisms like X-Linear Attention18 were proposed, improving visual–textual alignment but remaining constrained by fixed feature representations.
Recent works from the last few years further highlight how memory design, region construction, and multilingual alignment influence captioning quality. MeaCap19 introduces a memory-augmented zero-shot captioning pipeline that relies on external memory/retrieval to inject novel concepts and produce captions without paired training for the target domain. In contrast, MSSA targets the supervised COCO captioning setting and adopts an internal LSTM-based memory (MDA) to iteratively refine visual–text alignment given enriched multimodal features, rather than retrieving unseen concepts from external sources. From grids to pseudo-regions20 proposes dynamic memory augmented captioning with a dual relation transformer, transforming dense grid features into pseudo-regions and modeling relations among regions to reduce redundancy and improve relational reasoning. Differently, MSSA keeps detector-based RoI features (Faster R-CNN) and explicitly strengthens region representations via geometric/color/texture/edge/frequency descriptors, then applies SSA to compute efficient query–key interactions without additional channel-wise gating. For multilingual captioning, the Embedded Heterogeneous Attention Transformer (EHAT)21 focuses on cross-lingual alignment by embedding heterogeneous linguistic representations and aligning them with visual features through transformer-based attention. While our experiments focus on English COCO, the SSA+MDA design is compatible with multilingual decoders and can be extended to cross-lingual captioning by replacing the language module/embeddings and training on multilingual data.
Memory-augmented networks9 addressed long-range dependencies through iterative refinement, while multi-dimensional attention approaches10,11 extended modeling capacity across spatial, semantic, and contextual dimensions with improved efficiency.
Recent advancements in deep neural networks (DNNs) for fine-grained visual understanding emphasize stronger representation learning and attention/prompting strategies12,13,14; similarly, image captioning has increasingly focused on refining attention mechanisms to improve semantic alignment and descriptive accuracy. The model ARAFNet22 introduced an Attribute Refinement Attention Fusion Network to effectively integrate visual and semantic attributes, leading to more contextually grounded captions. Similarly, Semantic Embedding Guided Attention utilized explicit visual feature fusion to strengthen the relationship between visual regions and linguistic representations, demonstrating improved coherence in video captioning23. Moreover, Feature Refinement and Rethinking Attention addressed the challenge of redundant spatial information in remote sensing imagery by re-evaluating attention distribution for enhanced feature representation24. Building on these advances, the proposed MSSA is designed to capture dependencies efficiently within an LSTM-based captioning pipeline, and we quantify the efficiency impact of SSA design choices using Params/FP32 size, FLOPs, and inference latency in “Computational Efficiency Analysis” section.
Some other Recent innovations further expanded the field. Semantic-conditional diffusion networks25 enhanced semantic alignment through diffusion-based refinement. Distinctive captioning26 emphasized discriminative features to generate more unique descriptions. Multi-attention networks27 combined multiple attention pathways for complex scenes, while cross-modal retrieval frameworks such as CAST28 integrated external visual-textual alignment signals. Large-scale vision-linguistic models like InternVL29 scaled attention architectures to broader multimodal tasks.
Our Approach: Unlike traditional attention mechanisms that rely on linear or second-order modeling, the proposed MSSA framework introduces three key innovations: (i) Extended Multimodal Feature Extraction that incorporates geometric, color, texture, edge, and frequency-domain descriptors; (ii) a Memory-Driven Attention (MDA) mechanism that iteratively refines visual–textual alignment via LSTM-based memory updates; and (iii) a Simplified Scaled Attention (SSA) module that leverages scaled dot-product attention without complex gating. Together, these components enhance flexibility, improve feature integration, and enable the generation of accurate, diverse, and semantically rich captions.
As shown in Table 1, the MSSA framework addresses several limitations present in previous works, particularly in terms of handling complex visual interactions and improving multimodal feature integration.
Proposed model
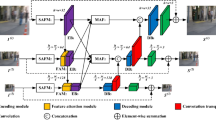
In this section, we introduce the proposed model architecture, which addresses the challenges of multimodal data processing by integrating advanced techniques for feature extraction, cross-modal alignment, and hierarchical representation. The architecture is designed to be robust, adaptable, and interpretable, making it suitable for diverse applications. Our architectural choices are driven by the requirements of image captioning: the decoder generates words sequentially and must repeatedly query visual regions; therefore, the attention module must be accurate for region–word grounding but also efficient under repeated calls. Moreover, images often contain multiple interacting objects, so alignment benefits from iterative refinement rather than a single attention pass. The overall architecture is depicted in Fig. 1.

Proposed model architecture. The architecture integrates multimodal feature extraction, alignment mechanisms, and advanced representation techniques to deliver interpretable outputs tailored for various applications.
The proposed architecture follows an encoder-decoder paradigm and incorporates specialized attention mechanisms and hierarchical strategies for effective multimodal processing. The primary components of the model are as follows:
Encoder–decoder architecture
The proposed framework adopts an encoder–decoder design that integrates multimodal feature extraction, attention, and sequential modeling for image captioning.
Encoder Visual features are extracted using a pre-trained Faster R-CNN model, while complementary descriptors—geometric, color, texture, edge, and frequency-domain (Gabor)—are computed through specialized extractors. This combination provides both global and local cues. Attention layers within the encoder align and refine these multimodal features, emphasizing the most informative regions.
Decoder The decoder employs a Long Short-Term Memory (LSTM) network with integrated attention. At each step, the LSTM models temporal dependencies in the caption sequence, while attention guides focus toward relevant encoded features. This ensures captions remain coherent and grounded in the visual context.
Why LSTM? We adopt an LSTM decoder for its strong sequential modeling with a transparent step-by-step prediction process and stable training on moderate-scale captioning setups. Since our decoder is LSTM-based (not a Transformer decoder), we do not claim a direct computational efficiency advantage over Transformer-based captioning models; instead, we evaluate the efficiency impact of our SSA design choices within this pipeline using Params/FP32 size, FLOPs, and inference latency (“Computational Efficiency Analysis” section).
Together, the encoder produces enriched multimodal embeddings, and the LSTM-based decoder transforms them into fluent and semantically accurate captions.
Multimodal feature extraction and representation
This section outlines a systematic methodology for extracting multi-dimensional features from the COCO dataset. The framework leverages geometric, color, texture, edge, and frequency-domain features to describe Regions of Interest (ROIs), enabling robust representations for tasks such as image captioning, object recognition, and scene understanding.
Multimodal feature extraction framework
The proposed feature extraction framework, illustrated in Fig. 2, operates in five stages. First, COCO annotation files are parsed to obtain image dimensions, filenames, and bounding box coordinates, ensuring accurate alignment of images with their regions of interest (ROIs). Next, bounding boxes are applied to isolate ROIs corresponding to objects. For each ROI, a diverse set of features is computed: geometric descriptors encode spatial properties, color histograms capture pixel intensity distributions in RGB space, texture features characterize local variations using Local Binary Patterns (LBP), edge features describe object boundaries through Canny edge detection, and frequency-domain features detect orientation and texture patterns via Gabor filters. All features are then normalized to maintain invariance to scale and resolution. Finally, the processed features are stored in .npz format for efficient retrieval during downstream tasks.

Overview of the multimodal feature extraction pipeline, including geometric, color, texture, edge, and frequency-domain feature computation for ROIs in the COCO dataset.
Geometric, color, texture, edge, and frequency-domain features
This section integrates various types of visual features that are extracted from Regions of Interest (ROIs) within an image. These features include geometric properties, color distribution, texture patterns, edge information, and frequency-domain representations, all of which provide complementary insights into the image content.
Rationale and complementarity of the chosen extended features. Although Faster R-CNN RoI features capture high-level semantics, they may miss low-level cues that help disambiguate captions (e.g., fine boundaries, material/texture, and repetitive patterns). We therefore select feature groups that cover complementary visual factors: (i) geometric features encode spatial layout (position, scale, aspect ratio), supporting relational words such as “on/under/beside”; (ii) color histograms capture appearance cues useful for attribute words (e.g., “red”, “blue”) and are robust to small spatial shifts; (iii) texture descriptors (LBP) represent local micro-patterns related to materials (e.g., grass, fur, brick), improving fine-grained noun/attribute selection; (iv) edge features (Canny) emphasize object boundaries and shape cues, which helps separate visually similar regions and improves attention localization; and (v) frequency-domain (Gabor) features encode oriented, scale-sensitive responses that complement LBP by highlighting directionality and repetitive structures. These descriptors are normalized and concatenated so the downstream attention modules can weight whichever cues are most informative at each decoding step, providing a more complete RoI representation than any single feature type alone.
Geometric Features: Geometric features capture spatial properties of bounding boxes that enclose objects. The key geometric properties include the bounding box dimensions \((x, y, w, h)\), aspect ratio \(\frac{w}{h}\), area \(w \cdot h\), centroid \(\left( x + \frac{w}{2}, \, y + \frac{h}{2} \right)\), compactness \(\frac{\text {Area}}{(2(w+h))^2}\), and circularity \(\frac{4\pi \cdot \text {Area}}{(2(w+h))^2}\). To ensure invariance to image resolution, all geometric features are normalized relative to the image width \(W\) and height \(H\), as:
These normalized geometric features provide scale-invariant representations critical for understanding object localization and spatial relationships.
Color Features: Color features are derived from the distribution of pixel intensities in the RGB color space. A 3D histogram is computed with 8 bins per channel, yielding \(8 \times 8 \times 8 = 512\) bins. The histogram is normalized to ensure invariance to the size of the ROI:
where \(H\) is the raw histogram and \(H'\) is the normalized version. This histogram captures the distribution of colors within the ROI, making it useful for distinguishing objects based on their visual appearance.
Texture Features: Texture features capture local intensity variations using the Local Binary Pattern (LBP) operator. The LBP value for a pixel at \((x, y)\) is calculated by comparing its intensity to the intensities of its neighboring pixels. The resulting LBP values are aggregated into a histogram with 256 bins and normalized:
This histogram provides a compact representation of the local texture pattern, which is invariant to image scale and useful for tasks such as texture classification and scene understanding.
Edge Features: Edge features capture the boundary structures of objects using the Canny edge detection algorithm. The process includes noise reduction, gradient computation, non-maximum suppression, and double thresholding. The resulting edge intensities are aggregated into a histogram and normalized to account for varying ROI sizes:
This histogram provides a scale-invariant representation of the object boundaries, essential for tasks such as object detection and scene segmentation.
Frequency-Domain Features: Frequency-domain features are derived from Gabor filters, which capture texture and orientation patterns. The Gabor filter is defined as:
where \(x'\) and \(y'\) are the coordinates in the rotated coordinate system, and \(\sigma\), \(\lambda\), \(\theta\), \(\psi\), and \(\gamma\) are parameters controlling the filter’s spatial extent, wavelength, orientation, phase offset, and aspect ratio. The filter responses are aggregated into a histogram with 256 bins and normalized:
This histogram provides a compact representation of frequency and orientation information, which is useful for texture classification and scene analysis.
By integrating geometric, color, texture, edge, and frequency-domain descriptors into a unified RoI representation, we ensure that each region contains complementary cues: geometry supports spatial relations, color supports visual attributes, texture/frequency support materials and repetitive patterns, and edges support boundary/shape information. This design reduces ambiguity when different objects share similar high-level RoI embeddings, and the normalization step ensures robustness across varying ROI sizes and image resolutions.
Feature extraction algorithm
Algorithm 1 provides a high-level overview of the feature extraction pipeline, encompassing metadata parsing, ROI extraction, feature computation, normalization, and storage.

Feature Extraction Pipeline
MDA-attention
Effectively fusing multimodal data is critical for tasks that require both spatial and contextual understanding, such as image captioning and object detection. To address this, we propose the Memory-Driven Attention (MDA) Mechanism with Iterative Memory Refinement, which alternates between attention-based feature integration and memory updates. This iterative process progressively refines feature representations, producing contextually enriched and spatially aligned embeddings. The mechanism comprises three core components: LSTM-based Memory Initialization (LMI), Multi-Head Attention Mechanism (MHAM), and LSTM Memory Update (LMU). The overall architecture is illustrated in Fig. 3.

Overview of the Memory-Driven Attention (MDA) Mechanism. The process alternates between MHAM and LMU over multiple iterations, starting with LMI.
Iterative refinement workflow
The mechanism operates in an iterative workflow, alternating between MHAM and LMU. Each iteration revisits and updates memory states based on attention-derived information, progressively improving their contextual depth and spatial alignment. This iterative approach ensures that intermediate states are dynamically refined, mitigating noise and producing robust multimodal representations. The workflow is shown in Fig. 4, which highlights the interaction between attention outputs and memory states across successive iterations.

Detailed workflow of the memory-driven attention (MDA) Mechanism. Each iteration alternates between MHAM and LMU, progressively refining multimodal feature representations.
Key components
The proposed mechanism consists of three core components:
LSTM Memory Initialization (LMI). The LMI module initializes memory states by pooling multimodal features. Given geometric features \(\textbf{X}_{\text {geo}} \in \mathbb {R}^{B \times S \times D}\), where \(B\) is the batch size, \(S\) is the sequence length, and \(D\) is the embedding dimension, memory initialization is defined as:
where \(\textbf{W}_{\text {init}} \in \mathbb {R}^{D \times M}\) projects pooled features into a memory space of size \(M\). This step provides the initial context for subsequent updates, as shown in Fig. 5.

LSTM Memory Initialization (LMI). Pooled features are projected into initial memory states.
Multi-Head Attention Mechanism (MHAM). MHAM models dependencies between visual and multimodal features using parallel attention heads. First, we compute the queries, keys, and values as:
where \(\textbf{W}_q, \textbf{W}_k, \textbf{W}_v \in \mathbb {R}^{D \times D}\) are learnable weight matrices. Next, we compute attention weights and outputs using scaled dot-product:
where \(d_h = D / H\) is the dimension per head. Finally, we combine outputs from all heads and project them back to the embedding space:
This process integrates spatial and contextual features, as depicted in Fig. 6.

Multi-head attention mechanism (MHAM). Attention integrates visual and multimodal features through scaled dot-product computations.
LSTM memory update (LMU)
LMU refines memory states by integrating attention outputs at each iteration. The hidden and cell states are updated as:
where \(\textbf{Z}_s^{(t)}\) represents attention outputs at iteration \(t\). This iterative refinement dynamically updates memory states, as illustrated in Fig. 7.

LSTM memory update (LMU). Memory states are refined iteratively using attention outputs.
Memory-Driven Attention (MDA) Algorithm. The complete process of iterative memory refinement is summarized in Algorithm 2, alternating between memory initialization, attention computation, and memory updates. In all experiments, we set the number of refinement iterations to \(T{=}4\) unless otherwise stated (see “Computational Efficiency Analysis” section for comparisons under identical decoding settings).

Memory-Driven Attention (MDA) with Iterative Memory Refinement
Simplified scaled attention (SSA)
We propose a novel attention mechanism, Simplified Scaled Attention (SSA), as depicted in Fig. 8, designed to address key limitations of existing attention modules in image captioning. Traditional attention mechanisms primarily capture first-order relationships between image regions and textual descriptions. However, such models often fail to capture the richer, higher-order interactions that are essential for effective multi-modal reasoning. SSA addresses this challenge by using a combination of scaled dot products and bilinear pooling, which capture second-order interactions between visual and textual features. This approach is inspired by recent advancements in multi-modal reasoning18, which emphasize the importance of higher-order interactions for improving image-text alignment.
SSA simplifies the attention module in our captioning pipeline by removing the channel-wise attention component that is commonly used as an additional gating step in vision–language attention blocks. Importantly, SSA is not introduced as a brand-new attention primitive; rather, it is a captioning-tailored attention path that (i) preserves the key requirement of captioning attention—precise spatial selection of RoIs for each generated word—and (ii) streamlines per-step computation because attention is invoked repeatedly during sequential LSTM decoding. Our “streamlined” claim therefore refers to this internal design choice (with vs. without channel-wise gating) and is supported with Params/FP32 size, FLOPs, and inference-latency evidence in “Computational Efficiency Analysis” section, rather than a direct Transformer-vs.-SSA benchmark. We remove channel-wise attention for two reasons: (i) task-related redundancy and (ii) computational streamlining. First, in our encoder–decoder design, region features are already enriched by (a) Faster R-CNN RoI representations and (b) extended multimodal descriptors (geometric, color, texture, edge, and frequency-domain features). In this setting, an additional channel re-weighting gate tends to recalibrate channels that have already been explicitly diversified and aligned by SSA’s query–key interactions, bringing marginal benefit while increasing module complexity. Second, channel-wise attention typically introduces extra projections/nonlinear gating and additional memory access; removing it yields a simpler attention path with fewer operations and lower latency in practice. To empirically support this design, we report computational efficiency statistics (parameter count, storage footprint, and runtime) in “Computational Efficiency Analysis” section. In our implementation, the released MSSA checkpoint contains 85.92M parameters and requires 327.82MB storage in FP32, while maintaining strong captioning performance on COCO.
SSA is designed to integrate seamlessly into both the image encoder and text decoder in image captioning systems. In the encoder, SSA enhances region-level features by capturing higher-order intra-modal interactions. In the decoder, SSA facilitates inter-modal reasoning by aligning textual queries with relevant spatial regions of the image. This integration ensures that the model can generate more descriptive and contextually accurate captions.
Given an image and its corresponding textual input, the inputs to the SSA module are defined as follows. The query (Q) is a feature vector of size \(\mathbb {R}^{D_q}\) representing the current state of the textual decoder. The keys (K) are a set of \(N\) feature vectors \(\{k_i\}_{i=1}^N\), where each \(k_i \in \mathbb {R}^{D_k}\) corresponds to a spatial region of the image. The values (V) are a set of \(N\) feature vectors \(\{v_i\}_{i=1}^N\), where each \(v_i \in \mathbb {R}^{D_v}\) is the feature representation corresponding to the key \(k_i\).
SSA models the interaction between the query and each key using a scaled dot product operation, which captures richer, second-order relationships. The bilinear query-key interaction \(B_{k_i}\) is computed as follows:
where \(W_k \in \mathbb {R}^{D_B \times D_k}\) and \(W_q \in \mathbb {R}^{D_B \times D_q}\) are learnable weight matrices, and \(\sigma\) denotes the activation function (e.g., ReLU). The scaling factor \(\sqrt{D_q}\) ensures numerical stability.
After computing the bilinear query-key interactions \(B_{k_i}\), SSA applies a transformation to produce the spatial attention weights \(\varvec{s}_i\), which indicate the relevance of each image region to the textual query. This transformation is defined as:
where \(W_k^B \in \mathbb {R}^{D_c \times D_B}\) is a learned matrix that transforms the bilinear interactions. The unnormalized attention scores \(b_s\) are then computed as:
The spatial attention weights \(\varvec{s}_i\) are obtained by normalizing these scores using the softmax function:
These weights are then used to aggregate the visual features, generating the final attended visual feature \(\hat{v}\):
where \(B_{v_i}\) is computed as:
where \(W_v \in \mathbb {R}^{D_B \times D_v}\) is the embedding matrix for the values, and \(\odot\) denotes element-wise multiplication. The final attended feature \(\hat{v}\) is used to guide the captioning process in the decoder.
The SSA module provides several key advantages. It captures higher-order relationships between visual and textual features through bilinear pooling, enabling richer interactions than standard attention mechanisms. At the same time, it improves computational efficiency by removing the need for channel-wise attention, reducing overhead without compromising performance. Finally, SSA enhances spatial focus by ensuring precise alignment between image regions and textual queries, which directly improves the relevance and accuracy of generated captions.
SSA represents a powerful, computationally efficient method for improving image captioning by enabling richer interactions between visual and textual features. This results in captions that are both contextually accurate and grounded in the visual content.

Illustration of simplified scaled attention (SSA) for image captioning. The model performs second-order interactions between textual queries and image regions, followed by spatial attention and feature aggregation to generate contextually relevant captions.
In Fig. 8, we illustrate the SSA mechanism, showing how it captures second-order interactions between image regions and textual queries. This is followed by spatial attention and feature aggregation, which together generate contextually relevant and accurate captions.
Encoder with SSA
The encoder with Simplified Scaled Attention (SSA) models complex intra-modal relationships between image regions by stacking multiple SSA blocks. This hierarchical structure refines image representations, yielding rich contextual features essential for generating detailed and semantically coherent captions.
Initially, a Faster R-CNN model extracts region-specific features from the image, denoted as \(V = \{v_i\}_{i=1}^N\), where each \(v_i\) represents the feature vector of the \(i\)-th region. To obtain a global image representation, the region-level features are mean-pooled, resulting in a feature vector \(v^0\):
In each SSA block, \(v^0\) serves as the query, while the keys and values are derived from the region-specific features \(V\). The SSA mechanism computes attention scores between the global representation (\(v^0\)) and the region-level features (\(V\)) using Scaled Dot-Product Attention. These scores are used to compute a weighted sum of the value features, which is then combined with an additional embedding of the values. The updated global representation \(v^1\) is produced, refining the feature interactions. For the \(m\)-th layer of the encoder, this process is generalized as:
where \(Q^{(m-1)}, K^{(m-1)}, V^{(m-1)}\) are the query, key, and value inputs to the \(m\)-th SSA block. Specifically, \(Q^{(m-1)} = v^{(m-1)}\) represents the aggregated global representation from the previous layer, while \(K^{(m-1)}\) and \(V^{(m-1)}\) are derived from the region-specific features \(V\). This layered structure enables the encoder to capture both local and global relationships across image regions, progressively refining the representation.
The final output, \(V^{M+1}\), encodes comprehensive spatial and semantic relationships across image regions. This enriched representation is passed to the decoder to generate accurate and contextually rich descriptions.
Decoder with SSA
The decoder in our framework employs the Simplified Scaled Attention (SSA) mechanism to generate image captions by sequentially decoding the features processed by the encoder. Using a Long Short-Term Memory (LSTM) network, the decoder predicts one word at a time, leveraging both the refined visual context and the linguistic information from previously generated words.
At each decoding step \(t\), the LSTM takes as input the word embedding of the previously generated word \(w_t\), the previous hidden state \(h_{t-1}\), and a dynamically computed global context vector \(c_v\) derived from the visual features provided by the encoder.
The global context vector \(c_v\) is computed as either a mean-pooled or weighted average of the region-level visual features, depending on the attention mechanism. The LSTM updates its hidden state \(h_t\) as follows:
where \(c_v\) captures the refined global visual context provided by the encoder.
Attention-Based Refinement of Visual Context At each time step, the hidden state \(h_t\) serves as the query for the SSA mechanism, which refines the visual context by attending to the encoder’s region-level features. The features \(V^{M+1}\) from the encoder act as both the keys and values in the SSA mechanism. The attention scores are computed via a scaled dot-product operation, selecting the most relevant image regions for the current decoding step. The attended visual feature \(\hat{v}_d\) is computed as:
where \(h_t\) is the query, and \(V^{M+1}\) serves as both the keys and values. The SSA mechanism computes a weighted sum of the region features \(V^{M+1}\), modulated by attention scores derived from the scaled dot-product interaction. This ensures that the decoder focuses on the most relevant regions at each time step.
Combining Temporal and Visual Contexts. To generate the next word, the decoder combines the attended feature \(\hat{v}_d\) and the hidden state \(h_t\) into a context vector \(c_t\), which captures both the temporal and visual contexts. This combination is performed through concatenation and a linear transformation:
where \(W_c\) is a learnable weight matrix, and \([h_t; \hat{v}_d]\) denotes the concatenation of the hidden state and attended feature vector. The resulting context vector \(c_t\) provides a rich representation of both linguistic and visual cues, which are used to predict the next word.
Word Prediction. The context vector \(c_t\) is passed through a linear transformation followed by a softmax activation function to predict the probability distribution over the vocabulary for the next word:
where \(W_o\) is a learnable weight matrix. The word with the highest probability is selected as the next word in the caption. This process continues until the model generates an end-of-sequence token or reaches a predefined maximum length.
Advantages of SSA in the Decoder. The integration of Simplified Scaled Attention (SSA) allows the decoder to dynamically adjust its focus across image regions at each decoding step. By combining the temporal context of the LSTM hidden state with the visual features highlighted by SSA, the decoder effectively captures cross-modal interactions and produces coherent, contextually rich captions. Unlike heavier attention schemes, SSA eliminates redundant computations, offering improved efficiency while preserving attention quality. Moreover, it balances fine-grained region-level focus with global semantic understanding, enabling the generation of captions that are both detailed and holistic.
Optimization: cross-entropy and CIDEr
Training image captioning models involves a two-step optimization process: initial training with Cross-Entropy (CE) loss and subsequent fine-tuning using the CIDEr reward. These stages ensure both syntactic correctness and semantic richness in the generated captions.
Cross-entropy loss: syntactic training
In the first stage, the model is trained with Cross-Entropy loss to align its predictions with reference captions. Given an image \(I\) and a target caption \(y = (y_1, \dots , y_T)\), the CE loss is defined as:
where \(P(y_t | I, y_1, \dots , y_{t-1})\) represents the conditional probability of predicting word \(y_t\) given the image and previous words in the caption. This stage enforces syntactic correctness, ensuring that the model learns proper language structure. However, this method suffers from exposure bias, as the model, during inference, must rely on its own predictions rather than true prior words, which can lead to error accumulation.
CIDEr fine-tuning: semantic refinement
To overcome the limitations of exposure bias, the model is fine-tuned using the CIDEr metric, which measures the semantic quality of captions based on n-gram overlap with human references. The CIDEr score rewards frequent, relevant n-grams while penalizing infrequent or irrelevant ones. The objective is to maximize the expected CIDEr score \(r(\hat{y})\), with the corresponding loss defined as:
where \(P_\theta\) denotes the model’s probability distribution over captions. Optimization is performed using the REINFORCE algorithm30, which computes gradients as:
with \(b\) as a baseline to reduce variance. This stage fine-tunes the model to generate captions that better align with human preferences and improve semantic accuracy.
Combined optimization: balancing syntax and semantics
Together, the CE and CIDEr stages provide complementary benefits. The Cross-Entropy loss ensures that the generated captions are syntactically valid, while CIDEr fine-tuning refines the model to produce semantically rich captions. This two-phase optimization results in a model capable of generating captions that are both linguistically sound and contextually accurate, improving performance on standard evaluation metrics.
Experiments
Dataset and implementation details
We evaluate our model on the COCO dataset5, a benchmark for image captioning. Each image in the dataset is associated with five human-annotated captions, providing diverse and rich descriptions. We use the Karpathy split31 for consistent training and evaluation, which divides the dataset into 113,287 training images, 5000 validation images, and 5000 test images. Detailed dataset statistics and preprocessing procedures are provided in Table 2.
For caption preprocessing, we convert all text to lowercase and remove infrequent words (appearing fewer than six times across the dataset). This reduces the vocabulary size to 9487 words, optimizing training efficiency while preserving descriptive quality.
Our feature extraction pipeline leverages multiple modalities to enhance caption generation. Visual features are extracted using a Faster R-CNN model32 pretrained on ImageNet and fine-tuned on Visual Genome. These features capture key regions of interest (RoI) and are embedded in a high-dimensional vector space.
In addition to visual features, we incorporate geometric features such as bounding box coordinates, aspect ratios, and centroids, which are normalized to the image scale to provide important spatial context. Textual features are represented as one-hot vectors, projected into a continuous embedding space for integration with visual and geometric features.
The model is trained using the parameters and configurations listed in Table 4, and the detailed multimodal feature types and dimensions are provided in Table 5. For completeness, we also report computational footprint statistics: the released MSSA checkpoint contains 85.92M parameters and requires 327.82MB FP32 storage (see “Computational Efficiency Analysis” section).
Reproducibility details (training schedule, seeds, and MDA iterations). For reproducibility, all random seeds are fixed to 1546884941.160048 for Python, NumPy, and PyTorch (CPU/GPU), with CuDNN set to deterministic mode (deterministic=True, benchmark=False). Training is performed in two stages: (i) Cross-Entropy (CE) training for \(E_{\text {CE}}{=}100\) epochs with base learning rate \(\alpha _{\text {CE}}{=}5\times 10^{-4}\) using Adam (\(\beta _1{=}0.9\), \(\beta _2{=}0.98\), \(\epsilon {=}10^{-9}\)) and gradient clipping with max-norm 0.5, followed by (ii) CIDEr-optimized fine-tuning for \(E_{\text {CIDEr}}{=}70\) epochs with \(\alpha _{\text {CIDEr}}{=}1\times 10^{-5}\) using Adam (\(\beta _1{=}0.9\), \(\beta _2{=}0.999\), \(\epsilon {=}10^{-8}\)) and gradient clipping by clamping at 0.1. For CE training, we apply a learning-rate warmup of \(S_{\text {warmup}}{=}10{,}000\) steps and then use the Noam schedule (factor 1.0, model size 1024), i.e., \(\text {lr}\propto \min \left( s^{-1/2},\, s\cdot S_{\text {warmup}}^{-3/2}\right)\). For CIDEr fine-tuning, we use a Plateau schedule that decays the learning rate by a factor of 0.8 with patience 3 epochs. Unless otherwise stated, the Memory-Driven Attention (MDA) module runs for \(T{=}4\) iterative refinement steps in all experiments (Algorithm 2) (Table 3).
Computational efficiency analysis
This section provides a deeper empirical justification for removing channel-wise attention from SSA by quantifying its effect on both captioning quality and computational cost within the MSSA captioning pipeline. We compare two implementations under identical training and decoding conditions: (i) SSA + Channel-wise Attention and (ii) SSA (ours, without Channel-wise Attention). We report model size (parameter count and FP32 checkpoint storage), captioning performance (BLEU@4, CIDEr, SPICE), and runtime-related statistics (FLOPs and inference-time latency).
Rationale for removing channel-wise attention. In SSA, selective feature routing is primarily governed by query–key interactions that assign spatial relevance across RoI regions and produce a context vector for decoding. In MSSA, region representations are already substantially enriched by (i) Faster R-CNN RoI features and (ii) extended multimodal descriptors (geometric, color, texture, edge, and frequency-domain features). This enrichment diversifies channel content and injects complementary cues before attention is applied, so an additional channel-wise re-weighting gate often performs a secondary recalibration over channels that have already been implicitly emphasized through SSA’s spatial attention pathway. As a result, channel-wise attention tends to provide limited incremental representational benefit while introducing extra projection layers, nonlinear gating operations, and additional memory traffic. Removing it yields a simpler attention path with fewer operations and reduced memory access, improving efficiency without compromising alignment quality.
Complexity and expected overhead. Let N denote the number of RoI regions and D the feature dimension. SSA computes attention-driven feature aggregation using query–key interactions over regions. Channel-wise attention typically adds an extra set of linear projections and a gating function over the D channels (e.g., channel projection + sigmoid/softmax gating), which increases parameter count and introduces additional multiply-add operations and activation reads/writes. Although this overhead is modest relative to the full captioning model, it is systematic and can translate into measurable latency differences during sequential decoding, where the attention module is invoked repeatedly across time steps.
Measurement protocol. Model size. Parameter counts and FP32 checkpoint sizes are computed directly from saved PyTorch checkpoints. The SSA variant without channel-wise attention corresponds to the released MSSA checkpoint (85.92M parameters; 327.82MB in FP32). Compute. FLOPs are measured for the captioning network forward pass using identical input tensor shapes for both variants, and we exclude Faster R-CNN feature extraction by using pre-extracted RoI features. FLOPs are reported for generating a full caption under greedy decoding with maximum length \(L{=}20\) by summing the per-step forward passes. Latency. Inference-time latency is measured under the same decoding configuration (greedy decoding, \(L{=}20\), batch size 1) and the same software environment. All timing experiments are conducted on a single NVIDIA GeForce RTX 3080 Ti GPU. We report the mean per-image decoding time averaged over repeated runs after warm-up, using CUDA synchronization to ensure accurate GPU timing. Because caption generation is sequential, we focus on the relative latency difference between the two variants as the most informative comparison.
Captioning quality impact of channel-wise attention. To complement the efficiency analysis, we evaluate captioning performance with and without channel-wise attention under the same training and decoding setup on the COCO Karpathy test split (CIDEr-optimized training). Table 6 reports BLEU@4, CIDEr, and SPICE. The results show that channel-wise attention yields only marginal changes in captioning metrics (B@4: 39.9 vs. 40.0, CIDEr: 131.2 vs. 131.4, SPICE: 23.1 vs. 23.2), indicating that it provides negligible gains once SSA and the enriched multimodal features are in place.
Efficiency comparison. Table 7 reports computational footprint under the same decoding configuration. Adding channel-wise attention increases parameters from 85.92M to 86.05M and FP32 size from 327.82MB to 328.32MB. It also increases FLOPs from 8.04G to 8.05G and inference latency from 10.8ms/img to 11.0ms/img. While the absolute differences are modest, they are consistent and accumulate across decoding steps due to the sequential nature of caption generation. Combined with the negligible captioning-quality differences in Table 6, these results provide an empirical justification for removing channel-wise attention to achieve a better efficiency–performance trade-off.
Discussion. Overall, Tables 6 and 7 show that removing channel-wise attention preserves captioning accuracy while consistently reducing computational overhead. Channel-wise attention provides only marginal changes in BLEU@4/CIDEr/SPICE, yet introduces extra parameters, additional compute, and a measurable latency increase under the same decoding setup. These findings complement the accuracy results reported in Tables 8 and 9 and support the claim that SSA offers a favorable efficiency–performance trade-off within MSSA.
Performance comparison
The comparative analysis of state-of-the-art models with the proposed MSSA framework on the COCO Karpathy test split is presented in Tables 8 and 9. For a comprehensive evaluation, we analyze model performance under two widely used training regimes: Cross-Entropy (CE) Loss and CIDEr Optimization. This dual evaluation highlights the capabilities of the models in generating high-quality, semantically accurate, and socially relevant captions.
Performance comparison with cross-entropy loss
In training image captioning models, Cross-Entropy (CE) loss is a widely used objective that evaluates the negative log-likelihood of the target sequence given the predicted probability distribution. This loss ensures that the model generates captions that closely match human-annotated references by minimizing the discrepancy between predicted and actual word sequences33. Specifically, CE loss trains the model to learn the mappings between visual features and natural language, fostering accurate and descriptive captions.
We evaluate the performance of our model and compare it against several state-of-the-art approaches trained with CE loss on the COCO test Karpathy split31. Metrics used include: BLEU@N (B@1, B@2, B@3, B@4): Precision-based n-gram overlap metrics with length penalties. METEOR (M): Measures semantic adequacy by aligning phrases. ROUGE-L (R): Computes the longest common subsequence overlap. CIDEr (C): Assesses TF-IDF-weighted n-gram similarity to human captions. SPICE (S): Evaluates semantic content by analyzing scene graphs.
Table 8 presents the comparative results. Earlier sequence models, such as LSTM1, achieved limited success, with BLEU@4 of 29.6% and CIDEr of 94.0, highlighting challenges in capturing detailed visual semantics. SCST34 improved results moderately by employing reinforcement learning, reaching BLEU@4 of 30.0% and CIDEr of 99.4. The Up-Down model35 further enhanced performance by integrating object detection, achieving BLEU@4 of 36.2% and CIDEr of 113.5.
Subsequent works introduced more sophisticated attention mechanisms. For example, SGAE36 and AoANet37 achieved BLEU@4 of 36.9% and 37.2%, respectively, while Meshed-Memory38 leveraged memory-augmented networks to reach BLEU@4 of 38.1% and CIDEr of 120.4. SCD-Net25 applied semantic-driven refinement, producing competitive scores with BLEU@4 of 37.3% and CIDEr of 118.0. X-LAN18 modeled second-order feature interactions, achieving one of the strongest results with BLEU@4 of 38.2% and CIDEr of 122.0.
Our proposed MSSA surpasses these models by integrating Extended Multimodal Features, Memory-Driven Attention (MDA), and Simplified Scaled Attention (SSA). As shown in Table 8, MSSA achieves BLEU@1 of 78.8%, BLEU@2 of 63.3%, BLEU@3 of 49.5%, BLEU@4 of 38.4%, METEOR of 28.7, ROUGE-L of 58.3, CIDEr of 121.1, and SPICE of 21.9. These results confirm that MSSA produces captions with high precision, semantic richness, and contextual alignment, setting a new benchmark for models trained with CE loss.
Performance comparison with CIDEr optimization
We present a performance comparison of various image captioning models optimized for the CIDEr score, as shown in Table 9. The evaluation includes BLEU scores (B@1 to B@4), METEOR (M), ROUGE (R), CIDEr (C), and SPICE (S), which collectively provide a comprehensive assessment of caption quality across different dimensions.
The MSSA model achieves consistent improvements over most previous methods, particularly in BLEU@3 (51.9), BLEU@4 (40.0), and CIDEr (131.4). Its SPICE score of 23.2 further highlights its ability to generate captions that are both fluent and semantically rich. Among the baselines, LSTM1 and SCST34 provided early benchmarks but showed limited performance in CIDEr (106.3 and 114.0, respectively). The Up-Down model35 improved results by incorporating object detection, reaching CIDEr 120.1.
Later approaches introduced more sophisticated attention mechanisms. SGAE36 achieved CIDEr 127.8, while AoANet37 pushed the performance further to 129.8. Transformer-based methods also demonstrated strong capabilities: the \(M^2\) Transformer38 achieved CIDEr 131.2, while DLCT45 recorded the highest CIDEr score (133.8). X-Transformer18 and X-LAN18 also performed competitively, with CIDEr scores of 132.8 and 132.0, respectively, and strong BLEU scores, reflecting the advantages of advanced attention and higher-order interactions.
More recent innovations include MAN27, which obtained CIDEr 126.5, and SCD-Net25, which achieved CIDEr 131.6, showing the impact of semantic-driven refinement. ADF43 and ICEAP44 also delivered solid results, with CIDEr scores of 123.3 and 123.8, respectively. TCCTN42 produced a strong CIDEr score of 132.8, further underscoring the benefits of triple-context modeling.
In summary, MSSA achieves BLEU@1 of 81.1, BLEU@2 of 66.1, BLEU@3 of 51.9, BLEU@4 of 40.0, METEOR of 29.5, ROUGE-L of 59.3, CIDEr of 131.4, and SPICE of 23.2. These results demonstrate that MSSA not only generates fluent and precise captions but also captures rich semantic information. While models like DLCT and X-Transformer achieve slightly higher CIDEr scores, MSSA delivers stronger overall balance across BLEU, CIDEr, and SPICE, establishing it as a competitive state-of-the-art approach under CIDEr optimization.
Qualitative analysis
In this section, we provide a qualitative comparison of the image captions generated by our proposed model MSSA, the baseline X-LAN model, and the corresponding ground truth (GT) captions. Figure 9 illustrates the comparison for nine distinct images. The captions generated by MSSA are evaluated for their alignment with the ground truth and contrasted against the captions produced by X-LAN. The objective of this qualitative analysis is to demonstrate the improved contextual understanding and object relationship modeling capabilities of MSSA, as well as its effectiveness in providing more detailed and spatially aware captions.
The following examples showcase the distinct advantages of MSSA over X-LAN, highlighting cases where the integration of geometric and spatial features produces more accurate and human-like captions.
In the first example, depicting a group of men standing around a street, MSSA generates the caption “a group of men standing around a street looking at their cell phones.” This output accurately identifies the location, subjects, and their activity. In contrast, X-LAN produces the caption “a group of men standing around a cell phone,” which omits both the location and the activity, leading to a less informative description. The ground truth captions (e.g., “a group of men standing around a sidewalk together”) align more closely with MSSA’s output.
The second example features a woman at a table. MSSA produces “a woman sitting at a table with a plate of food and a bottle of water,” successfully identifying all relevant objects and their spatial arrangement. X-LAN’s output, “a woman sitting at a table with a plate of food,” fails to mention the water bottle, an important contextual detail. Ground truth captions confirm MSSA’s more complete description.
For an image containing a banana and a bowl of food, MSSA generates “a banana sitting on top of a table next to a bowl of food.” This captures both the objects and their relative placement. X-LAN, however, produces “a yellow banana sitting on top of a table,” which overlooks the bowl of food. Ground truth captions again support MSSA’s more contextually accurate output.
In the case of pizza and orange juice, MSSA outputs “a slice of pizza on a white plate next to a glass of orange juice,” correctly identifying all objects and their relationships. X-LAN generates “a slice of pizza sitting on top of a white plate,” omitting the detail of the juice. Ground truth captions reference both food and drink, further validating MSSA’s description.
For the tennis example, MSSA generates “a man in a black and white uniform playing a game of tennis.” This is accurate in terms of activity, attire, and context. X-LAN incorrectly describes the scene as “a man in a baseball uniform with a ball,” misidentifying both the sport and context. Ground truth captions confirm that MSSA captures the scene more faithfully.
In another case involving a dessert, MSSA produces “a piece of cake on a plate with a glass of orange juice.” X-LAN outputs a similar but less specific caption, “a piece of cake on a plate with a glass of juice,” omitting the detail that the juice is orange. Ground truth captions reference cake and juice, aligning with MSSA’s richer description.
An example with a group of women shows MSSA generating “a group of young women sitting on top of a grass-covered field.” This captures both the subjects and setting, whereas X-LAN provides “a group of young women sitting next to each other,” omitting the environmental context. Ground truth captions support the accuracy of MSSA’s output.
For an image of a man, woman, and dog, MSSA produces “a man and a woman sitting on a green bench with a white dog.” This identifies all subjects and contextual details. X-LAN generates the less specific caption “a man and a woman sitting on a bench with a dog,” omitting both bench color and dog description. Ground truth references confirm MSSA’s superior detail.
Finally, in the red plane example, MSSA outputs “a red plane flying in the sky with smoke coming out of it.” X-LAN provides a similar caption, “a red plane flying in the sky with smoke,” but omits the causal detail that the smoke originates from the plane. Ground truth captions, such as “an airplane flying in the sky with smoke coming out of it,” confirm that MSSA offers the most accurate account.
Overall, these examples demonstrate MSSA’s consistent ability to generate captions that capture objects, activities, and spatial relationships with greater detail and semantic accuracy than X-LAN, producing outputs that align more closely with human-annotated ground truth.
This qualitative analysis demonstrates the clear advantages of the MSSA model in terms of accuracy and contextual understanding. By incorporating geometric features, MSSA produces more detailed and spatially aware captions compared to the baseline X-LAN model. The captions generated by MSSA not only provide a better alignment with ground truth descriptions but also exhibit a higher level of consistency in capturing the relationships between objects and their environments.

Examples of image captioning results by X-LAN and our proposed model MSSA, with corresponding ground truth captions.
Experimental analysis
Ablation study
To validate the contribution of each module in the MSSA framework, we conducted an ablation study on the COCO Karpathy test split under the CIDEr optimization phase. Specifically, we analyze the progressive impact of Extended Multimodal Features, the Memory-Driven Attention (MDA) mechanism, and the Simplified Scaled Attention (SSA) module. Each variant is added sequentially to the baseline to evaluate its effect on captioning performance.
Table 10 summarizes the results. The baseline employs only visual features extracted from Faster R-CNN with an LSTM decoder. Introducing Extended Multimodal Features improves performance across all metrics by providing richer visual descriptors. Incorporating the MDA mechanism further refines feature alignment, yielding notable improvements, particularly in CIDEr and SPICE. Finally, adding SSA achieves the best results, confirming the effectiveness of the full MSSA framework.
Analysis. The ablation results highlight the importance of each component in the MSSA framework. The inclusion of Extended Multimodal Features enhances the descriptive quality of captions by capturing geometric, texture, edge, and frequency-domain cues. Adding MDA significantly boosts CIDEr (+3.3) and SPICE (+0.8), demonstrating the benefits of iterative memory refinement for aligning visual and textual features. Finally, the SSA module provides the largest overall gains, raising BLEU@4 from 39.0 to 40.0 and CIDEr from 129.7 to 131.4, confirming that simplified scaled attention is critical for maximizing both fluency and semantic richness. Together, these results validate the design choices of MSSA and its superiority over reduced variants.
Attention visualization
To evaluate the attention mechanisms of the proposed MSSA model, we compared its attention maps with those generated by the X-LAN model. Attention maps highlight the regions within an image that are prioritized during caption generation. The MSSA model incorporates geometric features, such as bounding box coordinates, object dimensions, and spatial relationships, enabling a more refined understanding of object placement and contextual relationships within the image. This enhanced spatial reasoning allows MSSA to generate captions with improved accuracy and semantic richness compared to X-LAN.


Figures 10 and 11 illustrate the differences in attention patterns between X-LAN and MSSA.
-
1.
Analysis of Fig. 10a and b: X-LAN’s attention map (10a ) focuses primarily on visually prominent objects, such as the boy and scissors, leading to the caption “a young boy cutting a piece of paper scissors.” This caption is incomplete, omitting important spatial and contextual details, such as the presence of the table and the proper description of the scissors. - In contrast, MSSA’s attention map (10b ) captures the spatial relationships between the boy, the table, and the scissors. This results in the caption “a young boy sitting at a table cutting a piece of paper with a pair of scissors,” which is semantically accurate and contextually descriptive. MSSA’s ability to focus on both the primary object and its surroundings demonstrates the advantages of integrating geometric features.
-
2.
Analysis of Fig. 11a and b: X-LAN generates the caption “a group of people standing outside of a building,” as shown in Fig. 11a . While this provides a general overview of the scene, it lacks specificity regarding individual objects and spatial relationships. X-LAN’s attention is limited to the most visually prominent areas, which results in less detailed descriptions. - MSSA, on the other hand, produces the caption “a man wearing a white shirt and tie standing in front of a building,” as demonstrated in Fig. 11b . This caption is more specific and detailed, highlighting individual features, such as the man’s attire and position relative to the building. The attention map (11b ) confirms that MSSA effectively prioritizes relevant regions, leading to a semantically rich and spatially accurate caption.
These findings underscore the advantages of MSSA’s integration of geometric features. By leveraging spatial attributes such as bounding box coordinates, relative positions, and object dimensions, MSSA enhances its ability to model complex scenes. This results in captions that not only accurately describe the primary objects but also capture the relationships and context within the scene.
The ability to model spatial relationships effectively is particularly critical in image captioning, where understanding object interactions is essential for generating natural and descriptive captions. MSSA bridges the gap between object detection and comprehensive scene understanding, setting a new benchmark for models requiring detailed spatial comprehension. By incorporating geometric reasoning into its attention mechanisms, MSSA generates captions that are both precise and aligned with human-like descriptions, offering a significant advancement in the field of image captioning.
Conclusion
This paper introduced Memory-Driven and Simplified Scaled Attention (MSSA), a novel framework for image captioning that enhances multimodal integration through two key mechanisms: Memory-Driven Attention (MDA) for iterative refinement of visual–textual alignments, and Simplified Scaled Attention (SSA) for efficient modeling of spatial, semantic, and contextual interactions. Complemented by Extended Multimodal Feature Extraction, which incorporates geometric, texture, edge, and frequency-domain features, MSSA captures richer representations of visual scenes and object relationships.
Extensive experiments on the COCO dataset demonstrated that MSSA achieves state-of-the-art performance across BLEU, METEOR, ROUGE-L, CIDEr, and SPICE, surpassing strong baselines such as X-LAN and Meshed-Memory. Ablation studies confirmed the contributions of each module, while qualitative analysis showed MSSA’s ability to generate detailed and contextually accurate captions, particularly in complex spatial scenarios.
Future work may explore integrating large pre-trained vision–language models, extending MSSA to multilingual captioning, and developing lightweight variants for real-time applications on edge devices.
Overall, MSSA provides a robust and efficient architecture for multimodal feature integration and caption generation, establishing a strong foundation for future research in image captioning and related tasks.
Data availability
No datasets were generated or analysed during the current study.
References
Vinyals, O., Toshev, A., Bengio, S. & Erhan, D. Show and tell: A neural image caption generator. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) 3156–3164 (2015).
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhutdinov, R., Zemel, R. & Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In: Proceedings of the 32nd international conference on machine learning (ICML) 2048–2057 (2015).
Hossen, M. B., Ye, Z., Abdussalam, A. & Hossain, M. I. Gva: Guided visual attention approach for automatic image caption generation. Multimed. Syst. 30, 50. https://doi.org/10.1007/s00530-023-01249-w (2024).
Hossen, M. B., Ye, Z., Abdussalam, A. & Wahab, F. E. Attribute guided fusion network for obtaining fine-grained image captions. Multimed. Tools Appl. 84, 1–35 (2024).
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P. & Zitnick, C.L. Microsoft coco: Common objects in context. In: Lecture Notes in Computer Science, Volume 8693, European Conference on Computer Vision (ECCV) 740–755 (Springer, 2014).
He, K., Gkioxari, G., Dollár, P. & Girshick, R. Mask r-cnn. In: Proceedings of the IEEE international conference on computer vision (ICCV) 2961–2969 (2017).
Hu, H., Gu, J., Zhang, Z., Dai, J. & Wei, Y. Relation networks for object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR) 3588–3597 (2018).
Bahdanau, D., Cho, K. & Bengio, Y. Neural machine translation by jointly learning to align and translate. Preprint at arXiv:1409.0473 (2014).
Anderson, P., Fernando, B., Johnson, M. & Gould, S. Spice: Semantic propositional image caption evaluation. In: European Conference on Computer Vision 382–398 (Springer, 2016).
Chen, Y.C., Li, L., Yu, L., Kholy, A.E., Ahmed, F., Gan, Z., Cheng, Y. & Liu, J. Uniter: Universal image-text representation learning. In: Proceedings of the European conference on computer vision (ECCV) 104–120 (2020).
Zhao, F., Yu, Z., Zhao, H., Wang, T. & Bai, T. Integrating grid features and geometric coordinates for enhanced image captioning. Appl. Intell. 54, 231–245. https://doi.org/10.1007/s10489-023-05198-9 (2024).
Zhou, H., Huang, S., Zhang, F. & Xu, C. Ceprompt: Cross-modal emotion-aware prompting for facial expression recognition. IEEE Trans. Circuits Syst. Video Technol. 34, 11886–11899. https://doi.org/10.1109/TCSVT.2024.3424777 (2024).
Zhou, H., Huang, S. & Xu, Y. Uncertainty-aware representation learning framework for facial expression recognition. Neurocomputing 621, 129261. https://doi.org/10.1016/j.neucom.2024.129261 (2025).
Zhou, H., Huang, S. & Xu, Y. Inceptr: Micro-expression recognition integrating inception-cbam and vision transformer. Multimed. Syst. 29, 3863–3876. https://doi.org/10.1007/s00530-023-01164-0 (2023).
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. & Polosukhin, I. Attention is all you need. In: Proceedings of the advances in neural information processing systems (NeurIPS) 5998–6008 (2017).
Devlin, J., Chang, M.W., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of NAACL-X-Linear attention networks for image CaptioningHLT 4171–4186. https://www.aclweb.org/anthology/N18-1202https://doi.org/10.18653/v1/N18-1202 (2018).
Dosovitskiy, A., et al. An image is worth 16x16 words: Transformers for image recognition at scale. Preprint at arXiv:2010.11929 (2020).
Pan, Y., Yao, T., Li, Y. & Mei, T. X-linear attention networks for image captioning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR) 10971–10980 (2020).
Zeng, Z., Xie, Y., Zhang, H., Chen, C., Wang, Z. & Chen, B. Meacap: Memory-augmented zero-shot image captioning. Preprint at arXiv:2403.03715. submitted on 6 Mar 2024 (2024).
Zhou, W. et al. From grids to pseudo-regions: Dynamic memory augmented image captioning with dual relation transformer. Expert. Syst. Appl. 273, 126850. https://doi.org/10.1016/j.eswa.2025.126850 (2025).
Song, Z., Hu, Z., Liu, H., Jiang, J. & Hong, R. Embedded heterogeneous attention transformer for cross-lingual image captioning. IEEE Trans. Multimed. 26, 9008–9020. https://doi.org/10.1109/TMM.2024.3384678 (2024).
Hossen, M. B., Ye, Z., Hossain, M. S. & Hossain, M. I. Arafnet: An attribute refinement attention fusion network for advanced visual captioning. Digit. Signal Process. 162, 105155 (2025).
Dong, S., Niu, T., Luo, X., Liu, W. & Xu, X. Semantic embedding guided attention with explicit visual feature fusion for video captioning. ACM Trans. Multimed. Comput. Commun. Appl. 19, 1–18 (2023).
Li, Y. et al. Feature refinement and rethinking attention for remote sensing image captioning. Sci. Rep. 15, 8742 (2025).
Luo, R., Xie, R., Ma, L., Bai, L. & Zhang, W. Semantic-conditional diffusion networks for image captioning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR) 1984–1993 (2023).
Wang, J., Xu, W., Wang, Q. & Chan, A. On distinctive image captioning via comparing and reweighting. IEEE Trans. Pattern Anal. Mach. Intell. 45, 2088–2103 (2023).
Lu, Y., Qiu, S., Zheng, W. & Li, B. Man: Multi-attention network for enhanced image captioning. IEEE Trans. Pattern Anal. Mach. Intell. 45, 1154–1167 (2023).
Cao, S., An, G., Cen, Y., Yang, Z. & Lin, W. Cast: Cross-modal retrieval and visual conditioning for image captioning. Pattern Recognit. 153, 110555 (2024).
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X. & Lu, L. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 24185–24198 (2024).
Williams, R. J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 8, 229–256 (1992).
Karpathy, A. & Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3128–3137 (2015).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In: Advances in Neural Information Processing Systems 28 (NIPS 2015), pp. 91–99 (2015).
Goodfellow, I., Bengio, Y. & Courville, A. Deep Learning (MIT Press, 2016).
Rennie, S.J., Marcheret, E., Mroueh, Y., Ross, J. & Goel, V. Self-critical sequence training for image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) 7008–7024 (2017).
Anderson, P., He, X., Buehler, C., Teney, D., Johnson, M., Gould, S. & Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) 6077–6086 (2018).
Yang, X., Tang, K., Zhang, H. & Cai, J. Auto-encoding scene graphs for image captioning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR) 10685–10694 (2019).
Huang, L., Wang, W., Chen, J. & Wei, X.Y. Attention on attention for image captioning. In: Proceedings of the IEEE international conference on computer vision (ICCV), pp. 4634–4643 (2019).
Cornia, M., Stefanini, M., Baraldi, L. & Cucchiara, R. Meshed-memory transformer for image captioning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR) 10578–10587 (2020).
Dubey, S., Olimov, F., Rafique, M. A., Kim, J. & Jeon, M. Label-attention transformer with geometrically coherent objects for image captioning. Inf. Sci. 623, 812–831 (2023).
Abdussalam, A., Ye, Z., Hawbani, A., Al-Qatf, M. & Khan, R. Numcap: A number-controlled multi-caption image captioning network. ACM Trans. Multimed. Comput. Commun. Appl. 19, 1–24 (2023).
Zhao, J., He, K., Li, X. & Zhang, Y. Csa: Comprehensive semantic attention for improved image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition 13041–13049 (2023).
Li, J., Zhou, W., Wang, K. & Hu, H. Triple-stream commonsense circulation transformer network for image captioning. Comput. Vis. Image Underst. 249, 104165 (2024).
Hossen, M. B., Ye, Z., Abdussalam, A. & Hassan, S. U. Attribute-driven filtering: A new attributes predicting approach for fine-grained image captioning. Eng. Appl. Artif. Intell. 137, 109134 (2024).
Hossen, M. B., Ye, Z., Abdussalam, A. & Hossain, M. A. Iceap: An advanced fine-grained image captioning network with enhanced attribute predictor. Displays 84, 102798. https://doi.org/10.1016/j.displa.2024.102798 (2024).
Luo, Y., Ji, J., Sun, X., Cao, L., Wu, Y., Huang, F., Lin, C.W. & Ji, R. Dual-level collaborative transformer for image captioning. In: Proceedings of the AAAI conference on artificial intelligence 2286–2293. https://doi.org/10.1609/aaai.v35i3.16328 (2021)
Yan, C. et al. Taaic: Task-adaptive attention for image captioning. IEEE Trans. Circuits Syst. Video Technol. 32, 43–51 (2022).
Acknowledgements
This research was supported by the ANSO Scholarship for Young Talents, funded by the Alliance of International Science Organizations (ANSO) in partnership with the University of Science and Technology of China (USTC). The authors extend their gratitude to the Islamic University, Bangladesh, for its valuable support and contributions to Mohammad Alamgir Hossain’s Ph.D. program.
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
Mohammad Alamgir Hossain: Conceptualization, Methodology, Investigation, Software, Validation, Visualization, Writing-original draft. Md Bipul Hossen: Investigation, Writing -review and editing.Md. Atiqur Rahman Writing -review and editing.Md Shohidul Islam: Writing -review and editing. Md. Ibrahim Abdullah: Writing -review and editing. Zhongfu Ye: Supervision, Writing-review and editing,
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Hossain, M.A., Ye, Z., Hossen, M.B. et al. MSSA: memory-driven and simplified scaled attention for enhanced image captioning. Sci Rep 16, 11203 (2026). https://doi.org/10.1038/s41598-026-40164-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-40164-8
