
Abstract
We introduce a deep learning framework comprising two models for automated segmentation (DCS) and large-scale deep temporal clustering (DTC) within a registry of single ventricle patients. The DCS model performs simultaneous classification and segmentation of velocity-encoded phase-contrast magnetic resonance (PCMR) data for five individual blood vessels, the left and right pulmonary arteries, aorta, superior vena cava, and inferior vena cava. Trained, validated and tested on 260 cardiac MRI exams (each containing 5 PCMR scans), it demonstrated a median Dice score of 0.91 on 50 unseen test exams. Integrated into a fully automated pipeline, the DCS model processed over 4500 registry exams without manual intervention, reaching 98% classification accuracy and 90% segmentation accuracy in cases with all five vessels present. Flow curves obtained from successful segmentations were used to train the DTC model, which performs deep temporal clustering to uncover unique flow patterns. Survival analysis showed that these groups were statistically correlated to increased risk of mortality or transplantation and to liver disease, highlighting the clinical relevance of the proposed framework.
Similar content being viewed by others

Introduction
Time-varying signals can provide important insights into cardiac pathophysiology, capturing dynamic processes that static measurements don’t fully characterize. For instance, it is well-recognized that certain blood flow patterns are associated with specific disease processes (e.g. abnormal early/atrial filling ratio in diastolic dysfunction)1. One of the most accurate methods of measuring time-varying blood flow is velocity-encoded phase-contrast magnetic resonance imaging (PCMR), a technique that is heavily used in the evaluation of congenital heart disease (CHD)2,3,4,5,6,7,8,9. However, usually only time-averaged PCMR metrics (e.g. net forward volume) are reported, neglecting much of the information encoded into the time-varying signal. More sophisticated methods of leveraging the time-varying nature of PCMR data have been developed, but access to large amounts of data is required to validate their clinical relevance.
A potential source of large amounts of PCMR data is the Fontan Outcomes Registry using CMR Examinations (FORCE, http://www.forceregistry.org)10, which contains > 4500 cardiovascular MR exams performed in patients with functionally single ventricles and the Fontan circulation. These patients are of particular interest in our study because they are characterized by highly abnormal flow patterns11,12,13,14. The registry does contain PCMR images, but they are unprocessed and only time-averaged metrics like net forward volume are stored. Thus, investigation of time-varying flow requires the PCMR images to be reprocessed (segmented). However, manual segmentation would be too time-consuming, as well as being prone to inter- and intra-observer variability15.
Deep learning (DL) offers the possibility of automatically processing PCMR images, but there are two significant challenges specific to our application: (i) Images in the FORCE registry are heterogeneous due to differing CMR protocols/hardware at the contributing sites (common to all registries) and highly variable and complex anatomy (specific to Fontan patients), and (ii) There are multiple distinct vessels that must be first identified and then segmented if processing is to be performed without human input. Our solution is a joint Deep Classification + Segmentation model (DCS) that uses a modified UNet3 + architecture (that we have shown works with other images in the FORCE registry16) to simultaneously classify and segment multiple vessels.
Once large amounts of PCMR images are processed, novel methods for analyzing time-varying flow data (e.g. temporal clustering) can be developed and validated. Clustering attempts to group patients based on similar characteristics in some N-dimensional space and has been used to discover new phenotypes in several cardiovascular diseases17,18,19. Although conventional temporal clustering (e.g. dynamic time warping) has been used to analyze time-varying signals20,21,22,23, Deep Temporal Clustering (DTC)24 has been shown to have superior performance.
The overall aim of our study is to combine DL-based classification/segmentation with DL-based temporal clustering to investigate the time-varying blood flow in the Fontan circulation. The specific aims were: (i) Develop and validate a DCS model for classification and segmentation of five different phase-contrast flow planes: aorta (Ao), superior vena cava (SVC), inferior vena cava (IVC), left pulmonary artery (LPA) and right pulmonary artery (RPA), (ii) Integrate the DCS model into an automated pipeline to process the whole of the FORCE registry data (> 4500 datasets) and evaluate segmentation quality, (iii) Perform Deep Temporal Clustering (DTC) on extracted time-varying flow curves from the FORCE registry to identify novel flow-based phenotypes, and iv) Perform time-to-event analysis to assess the association of these phenotypes with key clinical outcomes, including death/transplantation and liver disease.
Results
Study overview
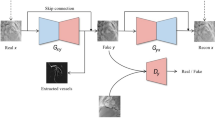
Figure 1 shows the pipeline consisting of two DL models (full details in methods section), one for deep classification/segmentation (DCS) and one for deep temporal clustering (DTC). The DCS model was a multi-class UNet3 + architecture with full-scale skip connections, deep supervision, and a novel tunable input based on the DICOM series description. The model was trained, validated and tested on 260 manually segmented exams from the FORCE registry (training/validation/testing split into 185/25/50 exams, each exam contains five 2D + time PCMR series, data demographics are in Supplementary Table 1). The DCS model was then integrated into a fully automated processing pipeline, with segmentation results rated by an expert. These generated flow curves were then inputted into the DTC model. The DTC model was based on temporal autoencoder backbone that generated a latent space representation that was further optimized for clustering by minimizing the Kullback–Leibler (KL) divergence. Finally, flow-curve based clusters were associated with clinical outcomes (death/transplantation and liver disease).

Overview of the deep learning framework for multi-vessel classification, segmentation, and phenomapping of phase-contrast MRI. The framework includes the Deep Classification + Segmentation (DCS) and Deep Temporal Clustering (DTC) models. DCS model: a 2D + time tunable UNet3 + with multi-class classification guidance. DTC model: a deep temporal clustering model architecture. MSE = Mean squared error, KL = Kullback–Leibler divergence, CGM = Classification-Guided Module adapted from UNet3 + 32.
Deep classification + segmentation model
Classification performance
The DCS model achieved an overall classification accuracy of 97% across all vessels in the 50 unseen test exams (250 PCMR series). Classification accuracy for the Ao, SVC and IVC was 100%, and for LPA and RPA was 94% (Supplementary Fig. 1A).
The added value of the tunable layer that leverages series description information (entered by the technologist at the time of scanning) was tested by training a vanilla model without the tunable layer. This model achieved 94% accuracy across all vessels (compared to 97% with the tunable layer). The robustness of the tunable layer was evaluated by modifying the tunable layer input at inference in 2 ways: (i) removing series descriptions, which resulted in 94% accuracy; and (ii) assigning incorrect series descriptions in all cases, resulting in 90% accuracy.
Full confusion matrix results are shown in Supplementary Fig. 1, suggesting that the tunable layer increases classification accuracy without making the DCS model overly sensitive to erroneous or missing data.
Segmentation performance
Median Dice score across all test vessels (N = 250, Supplementary Fig. 2) was 0.91 (IQR: 0.86–0.93). Vessel-specific Dice scores were: Ao - 0.93 (IQR: 0.91–0.95), IVC - 0.93 (IQR: 0.89–0.95), SVC - 0.89 (IQR: 0.85–0.91), LPA - 0.90 (IQR: 0.87–0.93), and RPA - 0.88 (IQR: 0.84–0.92). The Ao and IVC Dice scores were statistically higher than other vessels (p < 0.007).
Time-varying flow curves calculated from manual and DL segmentation are shown in Fig. 2 demonstrating good agreement over time for all vessels (further segmentation examples for each vessel in Supplementary Figs. 3–7). Comparison of net forward volumes calculated from these curves is shown in Fig. 3 with clinically acceptable limits of agreement and strong intraclass correlations (ICC > 0.95). However, DL segmentation did produce slightly higher net forward volumes than manual segmentations (2.2–6.7%), which were significant for the RPA, LPA, IVC, and SVC and trended for the Ao (p = 0.06).

Comparison of ground truth and deep learning segmentations for each vessel. Dice scores were computed across the test cohort, and the case with the median Dice score is shown. Only the first frame of the image is displayed, along with the corresponding flow curves over the full cardiac cycle. Total forward volume over the cycle is reported in mL. Vessel labels: LPA – Left Pulmonary Artery, RPA – Right Pulmonary Artery, AO – Aorta, SVC – Superior Vena Cava, IVC – Inferior Vena Cava.

Comparison of total volume derived from deep learning and ground truth segmentations. Bland–Altman and correlation plots comparing total volume calculated from deep learning segmentations to ground truth segmentations across 50 test cases for each vessel.
The correlation between Dice accuracy and percentage accuracy of flow compared to the ground truth is shown in Supplementary Fig. 8. It shows that the better the segmentation, the closer the derived flow is to the ground truth flow.
Pipeline performance
At the time of the study, the FORCE registry contained 4881 CMR exams (3369 patients) with at least one PCMR series. Registry demographics are reported in Supplementary Table 2, with a median age at time of scanning being 15.8 (IQR: 11.3–21.9) years, similar proportions of patients with extracardiac and lateral tunnels, and the most common underlying diagnosis being hypoplastic left heart syndrome (HLHS).
The DCS model was integrated into a cloud-based automated pipeline (8 vCPUs, 120 GB RAM) that processed the whole registry (excluding the 260 exams used for model development). The processing time was 127 ± 80 s per exam, which included: (i) Sorting through all series in an exam (~ 31 series per exam), (ii) Extracting the PCMR series (~ 11 series per exam, noting that FORCE registry exams can include additional flow planes beyond the five the model was trained on, such as pulmonary veins or repeat scans), (iii) Running the joint model on all PCMR series (2.9s per series on the cloud instance, compared 218ms when run locally on a NVIDIA RTX A6000 GPU), (iv) Storing flow curves and segmentation masks for the LPA, RPA, Ao, SVC and IVC, and (v) Creating a GIF showing segmentation results for quality assurance. The total time to process the whole registry was ~ 170 h, with no human interaction required during this time.
Out of the 4881 exams, 2902 exams had PCMR data for all five vessels. In these exams, acceptable classification/segmentation (as assessed by a human expert, see methods) was achieved in 90% of all vessels. Individual rates were: LPA – 91%, RPA – 82%, Ao – 83%, SVC – 96%, IVC – 97% (Supplementary Fig. 9). Segmentation success was significantly higher in the SVC and IVC than in the LPA, RPA, and Ao (p < 0.001), while the LPA showed better segmentation success than the RPA and Ao (p < 0.001).
Failures were mainly due to inaccurate segmentation, with vessel misclassification only occurring in the LPA (~ 50% of failures) and RPA (~ 21% of failures). Failures were associated with poor image quality (p < 0.03 for the RPA and SVC) and certain anatomical/morphological features (Table 1). These included: (i) Similarly sized neo- and native aortas (bilateral aortas), which resulted in 51% successful aortic segmentations compared to 87% in the rest of the population (Supplementary Fig. 10 for example), (ii) Bilateral SVCs with only 90% successful SVC segmentations compared to 97% in single SVCs (Supplementary Fig. 10 shows a bilateral SVC failure), and also significant effects on segmentation success for the LPA (87% vs 92%) and RPA (75% vs 83%), and (iii) Heterotaxy, which affected segmentation success across all vessels except the Ao, particularly in the LPA (71% vs 94% in non-heterotaxy) and RPA (59% vs 85% in non-heterotaxy).
Deep temporal clustering model
Separate deep temporal clustering models were trained for the combined LPA/RPA flow curves (DTCPA), and the combined SVC/IVC flow curves (DTCVC). For both models, exams were only included if vessel segmentations were rated acceptable. Furthermore, aortic segmentations had to be rated as acceptable as aortic flow was used to identify and remove exams that were pulse-gated. This resulted in 1943 LPA/RPA flow curves and 2286 SVC/IVC flow curves being included in the clustering models.
Clustering
The optimal number of clusters, k, was determined using a sensitivity analysis with values from 3–8 (Supplementary Table 3). The DTCPA and DTCVC models did not converge with more than six and four clusters respectively. For values of k that did produce stable clusters, the optimal k was based on maximizing the temporal silhouette score and demonstrating significant differences for death/transplantation and liver outcomes where priority was given to death/transplantation. Based on these criteria, the optimum number of clusters was k = 5 for DTCPA (silhouette score = 0.89, significant association with death/transplantation) and k = 4 for DTCVC (silhouette score = 0.90, significant association with death/transplantation and liver disease).
Supplementary Fig. 11 presents t-distributed stochastic neighbor embedding (t-SNE) plots of the clusters before and after joint optimization with the clustering layer that enforces more confident predictions, demonstrating that the DTC method generates more distinct clusters compared to simple k-means on the latent space, which is similar to Principal Component Analysis (PCA)-based methods25.
Pulmonary artery (PA) clusters
Fig. 4A shows the mean flow curves for patients in each of the five PA clusters and Table 2 shows the key differences in patient demographics between the clusters (Full demographic information in Supplementary Table 4 and 5). The PA cluster characteristics are summarized as follows:
-
1.
Normal Distribution, High Flow (PANorm-High): This group had normally distributed branch PA flow, with higher flow towards the right pulmonary artery (42% LPA / 58% RPA) and high total pulmonary blood flow (2.91 L/min/m2). This was the youngest group (median age 13.7 years, p < 0.001 vs. all except PARPA-Norm) and was 65% male. This group had EDVi of 101.5 mL/m2, ESVi of 47.5 mL/m2 and EF of 53%. The patients in this cluster also had the highest aortic flow (3.5 L/min/m2, p < 0.001) and lowest aorto-pulmonary collateral flow (18%, p < 0.04) compared to the other clusters. Fontan types were evenly split between lateral tunnel (46%) and extracardiac conduit (46%) and there was 6% heterotaxy.
-
2.
Normal Distribution, Low Flow (PANorm-Low): This group had normal distribution of branch PA flow (45% LPA / 55% RPA), but low overall total pulmonary blood flow (1.42 L/min/m2). This was the oldest group (median age 17.0 years, p < 0.002 vs. PANorm-High and PARPA-Norm) and was 53% male. This group also had the highest ventricular volumes (EDVi 105.6mL/m2, p < 0.001 vs. PABal-Norm; ESVi 54.0 mL/m2, p < 0.002 vs. PANorm-High and PABal-Norm) and the lowest EF (49%, p < 0.03). In addition, they had the lowest aortic flow (2.5 L/min/m2, p < 0.001) and highest aorto-pulmonary collateral flow (25%, p < 0.001 vs. PANorm-High and PABal-Norm). Furthermore, this group had greatest proportion of extracardiac conduits (48%) as well as the highest prevalence of heterotaxy (12%, p < 0.008 vs. PANorm-High and PARPA-Norm).
-
3.
Diastolic-Dominant, Normal Flow (PADia-Norm): In this group, a greater proportion of branch PA flow occurred in during diastole, even though the total amount was normal (1.96 L/min/m2). This group was generally older (median age 16.6 years, p < 0.02 vs. PANorm-High and PARPA-Norm) and 60% male. This group had EDVi of 102.8mL/m2 and ESVi of 51.3mL/m2, and EF of 51%. This group also had an aortic flow rate of 2.8L/min/m2 and a collateral flow of 23%. This group had 51% lateral tunnel, 43% extracardiac conduits and 7% heterotaxy.
-
4.
RPA-Dominant, Normal Flow (PARPA-Norm): In this group, flow was predominantly to the RPA (70%), with normal total flow (2.34 L/min/m2). This group was younger than average (median age 14.5 years, p < 0.002 vs. All expect PANorm-High) and 65% were male. This group has EDVi of 102.5mL/m2, ESVi of 49.8mL/m2 and EF of 52%. They also had an aortic flow rate of 3.2 L/min/m2 and collateral flow of 23%. This group had 53% lateral tunnel and 43% extracardiac conduits and the least heterotaxy (3%, p < 0.001 vs. PANorm-Low and PABal-Norm).
-
5.
Balanced Distribution, Normal Flow (PABal-Norm): This group had a balanced branch PA flow distribution where flow toward both pulmonary arteries were near-equal (52% LPA / 48% RPA) with normal total PA flow (2.18 L/min/m2). This group was older than the average (mean age 16.1) and 57% male. The ventricular volumes in this group were the lowest (EDVi 94.5 mL/m2, p < 0.002 and ESVi 44.4 mL/m2, p < 0.005), with an EF of 53%. This group had an aortic flow rate of 2.9 L/min/m2 and a collateral flow of 19%. This group also had the lowest proportion of lateral tunnels (38%) with a low proportion of extracardiac conduits (44%) and higher proportion of other Fontan types (18%). This group also had 11% heterotaxy.

Mean centroid flow curves for each cluster alongside the mean flow for each vessel for both DTC models. The Simon-Makuch survival plot shows risk probabilities for liver disease and death/transplantation. (Liver disease is excluded for DTCPA due to no significant group differences). The shaded regions indicate the confidence interval. LPA = Left Pulmonary Artery, RPA = Right Pulmonary Artery, SVC = Superior Vena Cava, IVC = Inferior Vena Cava. * Marks significant cluster differences according to time-varying Cox Regression.
Vena caval (VC) clusters
Fig. 4B shows the mean flow curves for patients in each of the four VC clusters and Table 3 shows key demographics differences between the clusters (Full demographic information in Supplementary Table 6 and 7). The characteristics of the VC clusters are summarized as follows:
-
1.
IVC-Dominant, Normal Flow (VCIVC-Norm): This group had a higher proportion of flow from the IVC (72%) with an average amount of total vena caval flow (2.32 L/min/m2). This was the oldest group (median age 20.6 years, 66% adult, p < 0.001), and 59% were male. This group had EDVi of 98.8mL/m2, ESVi of 47.5mL/m2, and EF of 51%. This group had an aortic flow of 2.8L/min/m2 and collateral flow of 20%. This group also had the highest prevalence of lateral tunnel procedures (56%), lowest extracardiac conduits (32%) and 10% heterotaxy.
-
2.
SVC-Dominant, High Flow (VCSVC-High): Greater proportion of flow from the SVC (56%) with high total vena caval flow of 2.83 L/min/m2. This was the youngest group (median age 8.2 years, 95% pediatric, p < 0.001), and 63% were male. This group had an EDVi of 98.6mL/m2 and ESVi of 46.7mL/m2, as well as the highest EF (53%, p = 0.001 vs. VCNorm-Norm). This group also had the highest aortic flow rate (3.7L/min/m2, p < 0.001) and one of the highest collateral flows (24%, p < 0.001 vs. VCIVC-Norm and VCNorm-High). This group also had the highest prevalence of extracardiac conduit procedures (65%), lowest lateral tunnel (27%) and generally higher prevalence of heterotaxy compared to the other clusters (12%, p = 0.02 vs. VCNorm-High).
-
3.
Normal Distribution, High Flow (VCNorm-High): Normal flow distribution (37% SVC / 63% IVC) with high total flow (2.86 L/min/m2). This group was predominantly younger (median age 13.5, p < 0.001) and 64% male. This group has EDVi of 101.4mL/m2, ESVi of 47.3mL/m2 and EF of 52%. This group had an average aortic flow rate of 3.3L/min/m2 and the lowest collateral flow (18%, p < 0.008). This group had 49% extracardiac conduits and lateral tunnel procedures of 43%, as well as the lowest prevalence of heterotaxy (7%, p < 0.02 vs. VCSVC-High and VCNorm-Norm).
-
4.
Normal Distribution, Normal Flow (VCNorm-Norm): Normal flow distribution (37% SVC / 63% IVC) with normal amount of flow (2.15 L/min/m2). This group was predominantly older (median age 17.2) and 57% male. This group had EDVi of 99.7mL/m2 and ESVi of 50.2mL/m2 and the lowest EF (51%, p < 0.02 vs. VCSVC-High and VCNorm-High). They also had the lowest aortic flow rate (2.7L/min/m2 vs. all except VCIVC-Norm) and one of the highest collateral flows (24%, p < 0.002 vs. VCIVC-Norm and VCNorm-High). This group had a similar amount of lateral tunnel and extracardiac conduits (44% and 43%) as well as the highest prevalence of heterotaxy (14%, p = 0.001 vs. VCNorm-High).
Cluster transition analysis
Supplementary Fig. 12 illustrates cluster transitions among patients with multiple scans, showing changes from the first to the last scan, as well as transitions between consecutive scans. In the PA model, 323 patients had multiple scans with 424 individual cluster transitions. Of these, 48% of patients remained in the same cluster between their first and last scan, while 52% remained in the same cluster between consecutive scans.
In the VC model, 390 patients had multiple scans, corresponding to 524 separate transitions. While 40% of patients remained in the same VC cluster from their first to last scan, 48% remained in the same cluster between consecutive scans.
These findings indicate that patients can develop distinct flow profiles over time. However, as patients with multiple scans represent a relatively small subset of the overall cohort, further analysis is required to draw conclusions regarding their outcome trajectories.
Cluster outcome analysis
Given that patients have multiple scans and their cluster membership can change over time, we performed time-varying time-to-event analysis (time-varying Cox regression26 adjusted for age, sex, indexed aortic flow rate, and ejection fraction EF, and Simon-Makuch plots, an extension of the Kaplan–Meier method for time-varying groups27,28). We investigated two outcomes (i) Death or transplantation as a composite outcome (death/transplantation), and (ii) The first diagnosis of Fontan-associated liver disease.
The Simon-Makuch plot for death/transplantation in the PA clusters is shown in Fig. 4A, with hazard ratios for pairwise cluster comparisons presented in Supplementary Fig. 13. The PABal-Norm group had a significantly lower risk of death/transplantation compared to the PANorm-Low group (HR = 0.33, p = 0.007). There was no significant difference in liver disease observed among these clusters.
Figure 4B shows Simon-Makuch plots for death/transplantation and liver disease for the vena caval clusters, with pairwise hazard ratios in Supplementary Fig. 14. The patients in the VCSVC-High cluster had a significantly lower risk of death/transplantation compared to the patients in the VCIVC-Norm (HR = 0.34, p = 0.023) and VCNorm-Norm clusters (HR = 0.31, p = 0.010). The VCSVC-High cluster also had a significantly lower risk of liver disease compared to the VCIVC-Norm (HR = 0.58, p = 0.027) and the VCNorm-Norm clusters (HR = 0.56, p = 0.018).
Comparison to PCA-based clustering
We used PCA-based k-means clustering to generate clusters (Supplementary Fig. 15) with the same number of clusters as the DTC method (Fig. 4) for direct comparison. The figures show that centroid flow patterns from both methods were similar, suggesting that the DTC method for generating a latent space representation is robust and the flow patterns observed are replicable. Furthermore, the DTC method generates more distinct clusters, as shown by higher silhouette scores (PA: 0.89, VC: 0.90) compared to the PCA method (PA: 0.12, VC: 0.20).
More importantly, the two methods differ in their ability to create clusters with prognostic association. The DTC method finds clusters that have significant differences in death/transplantation for both PA and VC vessels (p = 0.007, p < 0.023, respectively). Conversely, the PCA-based clusters only just reach significance for PAs (p = 0.049) and are non-significant for VCs. Nevertheless, for liver disease, both the DTC and PCA methods find similar significant differences between VC clusters.
Discussion
This is the first study, to our knowledge, to develop a deep learning model for the simultaneous classification and segmentation of multiple vessels (imaged using PCMR) and flow-based clustering of Fontan patients. The key findings were: (i) The joint deep classification and segmentation model (DCS) demonstrated high accuracy in classifying and segmenting major blood vessels, (ii) Incorporating the DCS model into an automated pipeline allowed rapid processing of the complete FORCE registry (> 4500 exams), providing robust flow measurement for about 90% of vessels, (iii) The deep temporal clustering (DTC) approach identified distinct flow dynamics between patient clusters, and (iv) These clusters showed significant associations with major clinical outcomes, including death or transplantation and liver disease. Our unified approach helps unlock the full potential of phase-contrast MR (PCMR) images stored in the FORCE registry by identifying novel physiologically distinct groups with prognostic significance. Importantly, our approach could be easily adapted to other CMR registries that contain PCMR images (e.g. The Indicator Cohort or PVDOMICS29,30).
Deep learning PCMR segmentation
Manual core-lab segmentation of the PCMR images in the FORCE registry (> 4500 exams) would take ~ 2000 person-hours (~ 50 working weeks of non-stop segmentation). This is not tractable, which is why we developed a DL-based processing pipeline that processed the entire registry without human interaction in ~ 170 h (even when run on a cloud CPU). Importantly, we demonstrated high Dice scores compared to manual segmentation, as well as strong agreement between flow curves derived from manual and DL segmentations. This is despite the challenging and complex anatomy of Fontan patients31. We believe this is primarily due to the underlying UNet3 + architecture32, which allows better multi-scale feature fusion and provides a richer understanding of both fine details and global context. Although we have previously used a UNet3 + to successfully segment short-axis images in the FORCE registry16, extensive modifications were made to optimize the architecture for flow segmentation. One of the most important modifications was the use of a single network to perform both classification and segmentation. Previous studies that have aimed to segment multiple vessels used separate classifiers and vessel-specific networks, which adds complexity to training and inference, while limiting information sharing between tasks33. In contrast, our simpler joint approach leverages the UNet3 + architecture and also introduces a novel tunable input based on series descriptions. This input provides contextual information added by technologists during CMR scans without hard-coding, thereby improving classification accuracy while remaining robust to missing (~ 7% of all exams) or incorrect descriptions. The network was also modified to accept 2D + time data by using 3D convolutions. This enabled feature learning between consecutive frames and enforced temporal consistency. Finally, the imaginary component of the complex signal was also included as an additional input to our model, which leveraged velocity information to improve accuracy without having to manage the high levels of noise present in phase images33.
Our models demonstrated 90% success across the FORCE registry, which includes data from various scanners, clinical sites and complex anatomies, providing very large amounts of data for flow-based clustering. Nevertheless, there were certain situations in which the joint classification + segmentation model performed less well. This included specific anatomies; for instance, heterotaxy seemed to confuse the model because the LPA can look like the normal RPA plane and vice versa.
Although the aorta had the highest Dice score in the test set (0.93), it had one of the lowest segmentation success rates in the full pipeline (83%). This discrepancy cannot only be explained by differences in the amount of bilateral aorta cases, as they were similar in the pipeline cohort (12%) compared to the test set (10%). This suggests that the pipeline cohort likely included greater variability or combinations of variability that are difficult to quantify or were not explicitly analyzed. For example, another main difference is that the test set was drawn from hospitals used for model training, whereas the pipeline involved inference on data from multiple previously unseen centers with potentially different underlying imaging characteristics.
If these cases were underrepresented in the training data, future performance could improve by including more examples of uncommon anatomies or unusual imaging protocols.
Temporal clustering analysis
Deriving clinically useful biomarkers from time-varying data requires temporal dimensionality reduction. This is often achieved using simple methods (such as reporting peak or mean values), and for PCMR data, usually only net forward volumes are reported34,35. However, these simplistic approaches do not extract all the potentially useful physiological information from flow data. Principal component analysis offers a more sophisticated approach by decomposing temporal flow curves into weighted principal components (PCs) that account for the majority of variance in the populations. This method has already been applied to flow in the Fontan circulation, where poorer outcomes were associated with certain flow patterns (e.g. diastolic dominant PA flow)36,37,38. Furthermore, it is possible to combine PCA with k-means clustering to perform temporal clustering39,40,41,42. In our study, we demonstrated that although PCA-based clustering produced similar clusters to DTC, the DTC method produced more distinct clusters (as shown by higher silhouette scores) with more significant associations with outcomes. The poorer performance of PCA-based clustering is potentially related to the PCA being constrained by the linear summation of orthogonal PCs, which may limit the expressivity of the method. Therefore, we opted to use DTC, a method that uses a temporal autoencoder to generate a latent space that can capture more complex temporal patterns compared to using PC decomposition. This method also employs a joint optimization step to maximize the certainty of cluster assignment. Importantly, as our DSC pipeline model provided >20× more data than previous studies on blood flow in Fontan patients36,37,38, providing a dataset large enough for deep learning to reliably learn complex, high-dimensional temporal patterns without overfitting.
Deep temporal clustering analysis of the FORCE dataset revealed distinct flow patterns that in some cases were associated with clinically relevant outcomes. Patients in the PANorm-Low group (normal distribution, low flow) had an increased risk of death. This might be unsurprising, but our analysis was corrected for indexed aortic flow rate and EF, suggesting that this was not simply the result of poor perfusion and cardiac function. Interestingly, this group did have the highest systemic to pulmonary collateral flow, and one possibility is that they have higher pulmonary vascular resistance, which would explain their higher mortality. It is also possible that low pulsatility and diastolic-dominance in these patients reflect an additional adverse physiology that contributes to higher mortality. A more surprising finding is that the PABal-Norm (balanced distribution, normal flow) group had the best outcome. This group had slightly greater flow to the left lung, which could not be fully explained by heterotaxy (although heterotaxy was slightly overrepresented). An intriguing explanation for these findings is that Fontan anatomy with equal or slightly greater left lung flow is associated with better hemodynamics and thus, improved outcome. This could be investigated by leveraging DL-based anatomical segmentation and flow field estimation43 to investigate power loss and TCPC resistance44.
We also found that patients in the VCNorm-Norm group (normal distribution and normal flow) have an increased risk of death/transplantation. Conversely, patients with dominant SVC flow were associated with a lower risk of death/transplantation and liver disease. These patients were younger, which is expected as SVC/IVC flow ratio reduces with age. Nevertheless, the association with outcome remained even after correction for age, suggesting that other mechanisms resulted in better prognosis in these patients. One possibility is that increased splanchnic circulation is associated with worse mortality. This idea is supported by the fact that the cluster with dominant IVC flow also had higher mortality, and a potential mechanism is increased liver disease in both these groups. Another possible explanation is that higher SVC flow leads to less flow collision between the vena caval flow streams, resulting in great hemodynamic efficiency. Further investigation of flow distribution is required to better understand the reason for these associations, which is achievable using the comprehensive data available in the FORCE registry.
We have demonstrated the potential of deep temporal clustering for the analysis of time-varying signals at scale. This method could easily be applied to multiple time-varying signals in the cardiovascular imaging space, including flow in other pathologies, myocardial strain, and ventricular/atrial volumetric curves. However, use in large registries does require a joint segmentation-clustering approach.
Limitations
The main limitation of our study was that segmentation was not successful in all cases, meaning that human review for all outputs of the DCS model was necessary. However, this can be done in a matter of seconds per exam, which is feasible even when reviewing thousands of exams.
Another issue is that our tunable input relies on a curated data dictionary to extract tokens from series descriptions. This dictionary was developed using descriptions from the current FORCE registry, so it may not perform well with new datasets that may have different naming conventions. This could be remedied by using a large language model (LLM) to represent the series descriptions as an embedding that can be inputted into the MLP of the tunable layer in place of the current one-hot encoding, with end-to-end training of both the UNet3 + and LLM. However, we demonstrated that our model does have high classification accuracy, and an LLM may be an unnecessary complication.
Another limitation is that we cannot assess the bias of segmentation failures on the clustering results, as only successful segmentations were used during training and inference of the clustering model. Furthermore, although we measured the number of transitions that a patient has between different scans according to their cluster membership. These findings indicate that patients can develop distinct flow profiles over time. However, as patients with multiple scans represent a relatively small subset of the overall cohort, further analysis is required to draw conclusions regarding their outcome trajectories.
One known issue with PCMR is the background phase, particularly with older exams. We didn’t perform background phase correction because software methods that aim to fit parabolic planes to the image are highly sensitive to the amount/segmentation of static tissue. In clinical use, these methods are checked and discarded if they are clearly incorrect. However, our pipeline is designed not to require significant human input, and background phase correction would be difficult under these conditions. While the lack of background phase correction can result in the flow offsets, our DTC method has been trained to cluster based on the shape of the flow curve as well as absolute flow values. Thus, we believe that clustering is partially robust to phase offsets. Furthermore, it is recognized that background phase errors are more prevalent with older scanners. If clustering was heavily influenced by background phase, one might expect difference in scan date between clusters. However, Supplementary Tables 4–7 show there were no significant differences found in scan date for any PA clusters. It should be noted that VCSVC-High cluster scans were acquired significantly earlier than the other groups. However, patients in this cluster were also significantly younger, which may explain why the scans were older rather than due to bias from background phase effects.
Finally, we were unable to assess the effect of different types of acquisition (e.g. free breathing, breath-hold, and real-time) and known artefacts (e.g. due to stents) on both segmentation accuracy and cluster assignment. This is because this data wasn’t available in the FORCE registry, but the high success rate in segmentation does suggest good overall generalizability. Furthermore, although the models were validated on heterogeneous data from multiple scanners, protocols, and sites, they have not been tested on patients beyond the single-ventricle population and may perform less reliably on more typical cardiac anatomy. Nevertheless, the methods developed in this study could be applied to other datasets.
Conclusion
In this study, we introduce a unified framework for flow segmentation and clustering. Our deep classification segmentation (DCS) model processes multiple blood vessels using PCMR images from different sites, scanners, and types of single-ventricle physiology. We validated the DCS model on a large dataset (2902 exams, 14,510 phase-contrast series), achieving an average success rate of 90% across all five vessels. By leveraging the flow curve data, we used DTC to identify clusters and analyze curve characteristics, linking them to clinical outcomes. We believe our method can provide new insights into Fontan physiology and potentially provide new methods of treatment. In addition, our methodology could easily be modified for other large cardiovascular datasets that contain time-varying signals (e.g. PCMR, strain data, or even ECG data). In a clinical environment, we envisage an automated system, applied directly after scanning, which segments all five vessels, to provide a full flow profile, and classifies the patients into higher or lower risk, without human input.
Methods
This was a multicenter study approved by the Institutional Review Boards or research ethics committees at each participating institution or via a reliance Institutional Review Board agreement with Boston Children’s Hospital. The study proposal and this manuscript were approved by the FORCE Data Governance and Publications Committee. The study involved no direct participation of the patients. The complete list of FORCE Investigator co-authors and affiliations is enumerated in the Authors’ Contribution section.
Deep classification + segmentation model
Model architecture
The Deep Classification + Segmentation model (DCS), shown in Fig. 1, is based on a five-scale UNet3 + architecture with increasing filters at each scale (16, 32, 64, 128 and 255). An additional tunable layer (1 filter) is concatenated at the bottleneck, increasing the total number of filters at this scale to 256. The modifications implemented to enable simultaneous classification and segmentation of multiple vessels are described below.
Dual channel input
PCMR images consist of both magnitude (anatomical) and phase (velocity) data, although only magnitude images are conventionally used for DL segmentation. Phase images can also be included, but high noise in areas of very low signal (e.g. air) can have a detrimental effect on DL. Thus, we converted the magnitude and phase images to a complex representation and then extracted the imaginary component. In the imaginary image, flowing blood has a high signal, while both static tissue and air have near-zero signal (Supplementary Movie 1). By using the magnitude and imaginary data as inputs, we were able to leverage the blood flow signal to aid segmentation without having to contend with the high noise in the phase data.
Full-scale skip connections and deep supervision
Inspired by the UNet3 + , we incorporated full-scale skip connections and deep supervision into our UNet32. These modifications integrate coarse and fine-grained features at multiple scales, and we have previously shown that this architecture is well-suited to the segmentation of complex and heterogeneous anatomy16.
Incorporating time
The DCS architecture utilizes 3D convolutional kernels that can process the 2D + time PCMR cine images in one pass. These 3D convolutions enable information to be passed between frames, producing more consistent segmentation across time. It should be noted that no maxpooling is performed in the time dimension to prevent unwanted temporal compression.
Tunable series description input
The DICOM series description is entered by the technologist at the time of scanning and often includes information about the imaging plane. Inspired by the tunable UNet45, this information was injected into the DCS network to aid classification. The DICOM series description was first converted into a one-hot encoded six-element vector with one entry for each vessel (LPA, RPA, SVC, IVC, and Ao) and one for empty or other series descriptions. This was achieved using a data dictionary containing predefined terms commonly associated with the five vessels (Supplementary Table 8, Tunable Input Data Dictionary). The one-hot encoded series description was then processed through a multi-layered perceptron (MLP) that outputs a 64-element output vector that is reshaped to 8 × 8 and tiled to 8 × 8 × 32 to match the size of the UNet bottleneck feature map. This was then concatenated with the bottleneck features to yield an 8 × 8 × 32 × 256 tensor. By incorporating these features into the bottleneck, the model can leverage additional information about the imaging plane in the decoding arm to aid classification.
Multiclass classification
We incorporated a multichannel output in which each channel was dedicated to producing a specific vessel segmentation mask, enabling joint classification and segmentation. We augmented the multiclass classification by including a Classification-Guided Module (CGM), also inspired by the UNet3 + 32. The CGM was an additional branch from the bottleneck layer that attempted to constrain segmentations to a single output channel. The multiclass classification module in the DCS model generates a six-class classification output: one for each vessel and one for the background.
Training data
The training dataset included 260 CMR exams from single ventricle patients in the FORCE registry, comprising 1300 individual PCMR series (each exam contains one for each vessel: LPA, RPA, SVC, IVC, and Ao). Of these, 185 exams were used for training, 25 for validation, and 50 for testing. The training set maintained a similar site distribution to the FORCE registry database, while the validation and test datasets had approximately equal numbers from each site. Supplementary Table 1 illustrates the demographic information of the ground truth data. No significant differences in BSA, age, sex, situs type, heterotaxy, diagnosis, type of Fontan surgery, or dominant ventricle were found between the training, validation, and test datasets.
A clinical researcher (N.S.C.) with five years of cardiac imaging experience identified phase-contrast exams for each of the five vessels, segmenting only the vessel of interest for each view, even if other vessels were visible (e.g., the aorta in an SVC-specific plane). We specifically selected patient exams with all five vessels scanned to enable direct comparison across patients and vessels and because flow measurements from all vessels are required for the deep temporal clustering method. The vessels were contoured over the entire cardiac cycle using a semi-automatic algorithm with manual correction (Circle cvi42 version 6.1.2; Circle Cardiovascular Imaging).
Preprocessing, model training, and post-processing
Data preprocessing included the pixel size being reduced to 2 × 2mm spatial resolution using spline interpolation, and the resultant images being center-cropped or padded to a size of 128 × 128 pixels. Reducing the image size helped to keep memory requirements down during training and had no discernible effect on final accuracy. The number of time frames was interpolated to 32 (median for all ground truth exams) using spline interpolation. Contrast-limited adaptive histogram equalization (CLAHE) was applied to the magnitude images to improve contrast and generalizability46.
The DCS model was trained using a weighted combination of focal Tversky loss for segmentation and categorical cross-entropy for the classification-guided module, with respective weights of 1.00 and 0.25. The combined loss was calculated at each deep supervision layer, with the first four layers equally weighted at 0.25 and the final layer at 1.00. The model was trained for 400 epochs with a batch size of 8 using the Adam optimizer. Image augmentation included random on-the-fly variations in rotation, translation, brightness, contrast, cropping, padding, and resizing to improve the model’s segmentation robustness. The series description (represented as a one-hot encoded vector) was also randomly assigned in 5% of cases to help the model tolerate missing or incorrect labels. To ensure the model was invariant to the direction of flow encoding, the sign of the imaginary pixel values was alternatingly inverted during training.
During post-processing, only the largest connected components of the LPA, RPA, and IVC masks were retained. For the aortic and SVC masks, the two largest components were kept to account for neo and native aortas or bilateral SVCs. The predicted segmentation masks were then resized and projected onto the original PCMR images. Flow curves were generated from both DL and manual segmentation as previously described47, and net forward volumes were calculated by integrating the flow curve over time.
Deep classification + segmentation model evaluation
The Deep Classification + Segmentation (DCS) model was validated on five vessel planes from the 50 ground truth test datasets (250 PCMR series). The classification accuracy of our model was evaluated per vessel.
To evaluate the importance of the tunable layer, we also trained a vanilla DCS model without the series description input layer. Furthermore, we assessed the robustness of the tunable layer by additionally testing the model at inference with 2 different tunable layer inputs: (i) using missing series descriptions (one-hot encoding the ‘missing’ entry); and (ii) using incorrect series descriptions (randomly selecting the wrong vessel entry in one-hot encoding).
Segmentation accuracy of the DCS model was assessed using the Dice score between the predicted outputs and ground truth. For cases with Dice scores above zero, flow curves and net forward volumes derived from predicted and ground truth data were compared.
Pipeline overview
We developed an automated pipeline to apply the DCS model to phase-contrast images in the FORCE registry without human input. The pipeline uses DICOM headers to identify phase-contrast series from CMR exams, runs the DCS model to classify and segment the image planes, and applies rule-based methods to select the most appropriate vessel plane when multiple series are classified as the same vessel by the model. Full details are reported in Supplementary Sect. “Pipeline Overview”.
The clinical researcher (N.S.C.), who manually segmented the ground truth data, reviewed all segmentations produced by the automated pipeline. For every exam, each vessel’s segmentation was individually rated as acceptable (clinically usable), unacceptable, or misclassified. The clinical usability of the segmentations was determined based on whether additional mask edits would be required and whether the resulting flow curves were physiologically consistent across vessels within a patient, as assessed by the expert, thus reflecting standard clinical practice.
Deep temporal clustering model
Model architecture
Unsupervised clustering of flow curves was performed using Deep Temporal Clustering 24. The model consisted of a temporal autoencoder and a temporal clustering layer (Fig. 1).
Temporal autoencoder
The autoencoder reduced the dimensionality of the input flow curve data to a latent space representation (zi) that preserved key temporal features48. The encoder consisted of a 1D convolutional layer (50 filters, kernel size = 10), a 1D max pool (pool size = 3), and two bidirectional long short-term memory layers (50 and 1 units) . The decoder reconstructed sequences using a time-distributed fully connected layer (50 filters), followed by upsampling and a deconvolutional layer (kernel size = 10).
Temporal clustering layer
This layer clusters the latent vectors, zi, from the autoencoder, into groups with similar temporal patterns49. It first initialized k centroids via k-means on zi, then computed soft cluster probability assignments (qij) based on the Euclidean distance between each zi and cluster centroid μj, using Student’s t-distribution, defined as 25:
The clustering layer then self-trains by iteratively minimizing the Kullback–Leibler (KL) divergence between the soft assignments (qij) and a target distribution (pij), resulting in higher-confidence and more distinct clusters. The target distribution was defined as 49:
Training data
The DTC model was trained using flow curve data derived from DCS-based segmentations. Only data from CMR exams with acceptable aortic segmentations were included. Exams were also excluded if: (i) The aortic flow curve peaked in the second half of the cardiac cycle (N = 21) as they were likely pulse-gated, since pulse-gated data cannot be aligned in the diastolic frame with the rest of the data which is ECG-gated, (ii) The aortic flow was non-physiological (< 10 mL; N = 7), or (iii) The nominal interval (N = 16) or BSA (N = 196) data were missing.
After exclusions, 2416 exams had acceptable aortic segmentations and complete demographic data; of these, 1943 had acceptable LPA/RPA and 2286 had acceptable SVC/IVC segmentations.
To have consistent data for clustering, all flow curves were BSA-indexed and cubic-spline interpolated to 30 frames (median frames across all PCMR series in the pipeline). Each flow curve was z-score normalized by subtracting the mean and dividing by the standard deviation of the whole dataset. Processed flow curves from the LPA/RPA or SVC/IVC were then concatenated and treated as separate channels.
Model training
Our DTC model was trained following the original methodology described by Madiraju et al. 24. To establish meaningful latent representations before clustering, the autoencoder was pretrained for 100 epochs with a learning rate of 0.001, minimizing the mean square error between the input and the reconstruction. The initial latent space of the autoencoder was used to initialize cluster centroids in the temporal clustering layer to create soft cluster labels. The autoencoder and clustering layer were then optimized jointly using the Adam optimizer (learning rate = 0.001), minimizing both mean squared error for accurate latent space representation and the KL divergence to increase cluster clarity50, with both losses equally weighted. Cluster assignments were updated every 100 epochs until convergence was reached, defined as fewer than 0.1% of samples changing cluster assignments.
We trained two DTC models for the branch pulmonary arteries (DTCPA) and for the vena cavae (DTCVC). Both models shared the same architecture and training parameters. As DTC is fully unsupervised, the entire dataset was used for both training and inference.
To determine the optimal number of clusters, we performed a sensitivity analysis varying from 3–8 clusters. The optimal number of clusters was based on maximizing the temporal silhouette score (which quantifies intra-cluster cohesion and inter-cluster separation51) and demonstrating significant differences for death/transplantation and liver outcomes using time-varying cox regression.
To assess temporal changes in the patients’ flow profiles, we also measured the changes in the cluster assignments identified by the DTC models across multiple scans over time for patients with multiple scans.
Comparison to PCA-based clustering
As DTC is a more complex deep learning methodology, we also compared our method with conventional temporal PCA followed by k-means clustering to see if the observed flow patterns in the centroid clusters generated were consistent across methods.
To ensure consistency, the training data used to train the DTC models was kept the same for the PCA models (PA model: N = 1943 and VC model: N = 2286). As with the DTC model, all flow curves were interpolated to a consistent 30 timepoints. For each model, the vessel flow curves were concatenated end-to-end to create a 60-dimensional feature vector (LPA/RPA for the PA model and SVC/IVC for the VC model). The data was then centered at the mean by subtracting the mean of the whole dataset from each flow curve, separately for the PA and VC models. PCA was performed to obtain PC weights for each data sample. These weights were then used as input into the k-means clustering model, using the same number of clusters as the DTC model.
Statistical analysis
Continuous variables are expressed as medians with IQRs, as most variables were not normally distributed. Statistical analyses were performed using the SciPy (version 1.9.0), scikit-posthocs (version 0.11.2), pengouin (version 0.5.5), and lifelines (version 0.27.8) libraries in Python, and p < 0.05 was considered statistically significant.
To compare patient demographics across train, validation, and test ground truth datasets, as well as between patient clusters identified by DTC models, we used the Kruskal–Wallis test with post-hoc Dunn testing (Benjamini/Hochberg correction) for continuous variables. For categorical variables, we applied the χ2 test followed by post-hoc pairwise χ2 comparisons.
Segmentation performance analysis
For evaluation of the DCS model on the test set (N = 50 exams), Kruskal–Wallis and post-hoc Dunn (Benjamini/Hochberg correction) tests were applied to identify statistical differences in Dice score across vessels. Intraclass correlation and Bland–Altman analysis assessed agreement between net forward volumes from DL and manual segmentations. Wilcoxon signed-rank tests were used to assess the significance of differences between the DL and manually derived net forward volumes.
For evaluation on the FORCE registry (N = 2902 exams), we used χ2 tests to compare the categorical variables that influenced the segmentation success (Table 1).
Cluster outcome analysis
To evaluate the prognostic significance of flow phenotype clusters derived from our DTC models, we assessed their association with two clinical outcomes: (i) Death or transplantation and (ii) First diagnosis of Fontan-associated liver disease, the number of patients with these outcomes are shown in Supplementary Table 9. We applied the same methodology to the clusters found using PCA-based clustering for comparison.
Since many patients underwent multiple exams, clusters were assigned independently for each exam. Time-dependent Cox proportional hazards models were used to estimate risk, adjusting for age, sex, body surface area (BSA), indexed aortic flow rate, and ejection fraction to control for potential confounders. Each cluster was used once as the reference group when calculating hazard ratios.
Risk was visualized using Simon-Makuch plots, which extend Kaplan–Meier curves to incorporate time-varying covariates. Plots were truncated when fewer than ten individuals remained at risk in any cluster to preserve interpretability.
To explore potential explanations for differences in survival, we compared patient characteristics and clinical metrics across the identified flow phenotypes. Patient characteristics included age, sex, body surface area, type of Fontan procedure, type of systemic ventricular circulation, presence of heterotaxy, situs type, and diagnosis. Clinical metrics obtained from the same session as the PCMR included end-diastolic volume, end-systolic volume, and ejection fraction, all derived from short-axis cine imaging. PCMR-specific measures included collateral flow, the distribution of flow across vessels, and the flow rate in each of five key vessels. The data used in this study was from the Fontan Outcomes Registry using CMR Examinations (FORCE registry), http://www.forceregistry.org, which is available to members of the registry.
Data availability
The data used in this study is only available for access for institutes with an agreement with the FORCE registry. For inquiries, contact the FORCE registry’s principal investigator, Rahul H. Rathod, at rahul.rathod@childrens.harvard.edu.
Code availability
The code for the implementation of the DCS and DTC models has been made publicly available: https://github.com/Ti-Yao/MultiFlow.
References
Richter, Y. & Edelman, E. R. Cardiology is flow. Circulation 113, 2679–2682 (2006).
Rebergen, S. A., van der Wall, E. E., Doornbos, J. & de Roos, A. Magnetic resonance measurement of velocity and flow: technique, validation, and cardiovascular applications. Am. Heart J. 126, 1439–1456 (1993).
Boesiger, P., Maier, S. E., Kecheng, L., Scheidegger, M. B. & Meier, D. Visualization and quantification of the human blood flow by magnetic resonance imaging. J. Biomech. 25, 55–67 (1992).
Nayak, K. S. et al. Cardiovascular magnetic resonance phase contrast imaging. J. Cardiovasc. Magn. Reson. 17, 1–26 (2015).
Goldberg, A. & Jha, S. Phase-contrast MRI and applications in congenital heart disease. Clin. Radiol. 67, 399–410 (2012).
Vasanawala, S. S., Hanneman, K., Alley, M. T. & Hsiao, A. Congenital heart disease assessment with 4D flow MRI. J. Magn. Reson. Imaging 42, 870–886 (2015).
Srichai, M. B., Lim, R. P., Wong, S. & Lee, V. S. Cardiovascular applications of phase-contrast MRI. Am. J. Roentgenol. 192, 662–675 (2009).
Chai, P. & Mohiaddin, R. How we perform cardiovascular magnetic resonance flow assessment using phase-contrast velocity mapping. J. Cardiovasc. Magn. Reson. 7, 705–716 (2005).
Midgett, M., Thornburg, K. & Rugonyi, S. Blood flow patterns underlie developmental heart defects. Am. J. Physiol. Heart Circ. Physiol. 312, H632–H642 (2017).
Fontan. force study fontan outcomes registry using cmr examinations. Preprint at https://www.forceregistry.org (2023).
Jarvis, K. et al. Evaluation of blood flow distribution asymmetry and vascular geometry in patients with Fontan circulation using 4-D flow MRI. Pediatr. Radiol. 46, 1507–1519 (2016).
Rijnberg, F. M. et al. Energetics of blood flow in cardiovascular disease: concept and clinical implications of adverse energetics in patients with a fontan circulation. Circulation 137, 2393–2407 (2018).
Dasi, L. P. et al. Fontan hemodynamics: importance of pulmonary artery diameter. J. Thorac. Cardiovasc. Surg. 137, 560–564 (2009).
Haggerty, C. M., Whitehead, K. K., Bethel, J., Fogel, M. A. & Yoganathan, A. P. Relationship of single ventricle filling and preload to total cavopulmonary connection hemodynamics. Ann. Thorac. Surg. 99, 911–917 (2015).
Margossian, R. et al. Comparison of echocardiographic and cardiac magnetic resonance imaging measurements of functional single ventricular volumes, mass, and ejection fraction (from the pediatric heart network fontan cross-sectional study). Am J Cardiol. 104, 419–428 (2009).
Yao, T. et al. A deep learning pipeline for assessing ventricular volumes from a cardiac MRI registry of patients with single ventricle physiology. Radiol. Artif. Intell. 6, e230132 (2024).
Shah, S. J. et al. Phenomapping for novel classification of heart failure with preserved ejection fraction. Circulation 131, 269 (2014).
Satish, T. et al. Phenomapping the response of patients with ischemic cardiomyopathy with reduced ejection fraction to surgical revascularization. Clin. Cardiol. 48, e70094 (2025).
Segar, M. W. et al. Development and validation of optimal phenomapping methods to estimate long-term atherosclerotic cardiovascular disease risk in patients with type 2 diabetes. Diabetologia 64, 1583–1594 (2021).
Giannoula, A., Gutierrez-Sacristán, A., Bravo, Á., Sanz, F. & Furlong, L. I. Identifying temporal patterns in patient disease trajectories using dynamic time warping: a population-based study. Sci. Rep. 8(1), 1–14 (2018).
Giannoula, A., De Paepe, A. E., Sanz, F., Furlong, L. I. & Camara, E. Identifying time patterns in Huntington’s disease trajectories using dynamic time warping-based clustering on multi-modal data. Sci. Rep. 15(1), 1–16 (2025).
Qin, Y., Van Der Schaar, M. & Lee, C. T-Phenotype: discovering phenotypes of predictive temporal patterns in disease progression. 206, (2023).
Mariam, A. et al. Unsupervised clustering of longitudinal clinical measurements in electronic health records. PLOS Digit. Health 3, e0000628 (2024).
Madiraju, N. S., Sadat, S. M., Fisher, D. & Karimabadi, H. Deep temporal clustering : fully unsupervised learning of time-domain Features. Preprint at https://doi.org/10.48550/arXiv.1802.01059 (2018).
Van Der Maaten, L. & Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605 (2008).
Zhang, Z., Reinikainen, J., Adeleke, K. A., Pieterse, M. E. & Groothuis-Oudshoorn, C. G. M. Time-varying covariates and coefficients in Cox regression models. Ann. Transl. Med. 6, 121 (2018).
Simon, R. & Makuch, R. W. A non-parametric graphical representation of the relationship between survival and the occurrence of an event: application to responder versus non-responder bias. Stat. Med. 3, 35–44 (1984).
Schultz, L. R., Peterson, E. L. & Breslau, N. Graphing survival curve estimates for time-dependent covariates. Int. J. Methods Psychiatr. Res. 11, 68–74 (2002).
Valente, A. M. et al. Rationale and design of an International Multicenter Registry of patients with repaired tetralogy of Fallot to define risk factors for late adverse outcomes: the INDICATOR cohort. Pediatr. Cardiol. 34, 95–104 (2013).
Hemnes, A. R. et al. PVDOMICS: a multi-center study to improve understanding of pulmonary vascular disease through phenomics. Circ. Res. 121, 1136 (2017).
Saraf, A. et al. Biomarker profile in stable Fontan patients. Int. J. Cardiol. 305, 56 (2020).
Huang, H. et al. UNet 3+: A full-scale connected UNet for medical image segmentation . arXiv; 2020 [cited 2023 Feb 14]. Preprint at http://arxiv.org/abs/2004.08790 (2020).
Pradella, M. et al. Fully-automated deep learning-based flow quantification of 2D CINE phase contrast MRI. Eur. Radiol. 33, 1707–1718 (2023).
Craven, T. P. et al. Exercise cardiovascular magnetic resonance: feasibility and development of biventricular function and great vessel flow assessment, during continuous exercise accelerated by Compressed SENSE: preliminary results in healthy volunteers. Int. J. Cardiovasc. Imaging 37, 685–698 (2021).
Elstad, M. & WallØe, L. Heart rate variability and stroke volume variability to detect central hypovolemia during spontaneous breathing and supported ventilation in young, healthy volunteers. Physiol. Meas. 36, 671 (2015).
Schäfer, M. et al. Flow profile characteristics in Fontan circulation are associated with the single ventricle dilation and function: principal component analysis study. Am. J. Physiol. Heart Circ. Physiol. 318, H1032–H1040 (2020).
Ferrari, M. R., Schäfer, M., Hunter, K. S. & Di Maria, M. V. Coupled waveform patterns in the arterial and venous Fontan circulation are related to parameters of pulmonary, lymphatic and cardiac function. Int. J. Cardiol. Congenit. Heart Dis. 11, 100429 (2023).
Ferrari, M. R., Schäfer, M., Hunter, K. S. & Di Maria, M. V. Central venous waveform patterns in the Fontan circulation independently contribute to the prediction of composite survival. Pediatr. Cardiol. 45, 1617 (2023).
Ding, C. & Xiaofeng, H. K-means clustering via principal component analysis.
Huang, X. et al. Time series k-means: a new k-means type smooth subspace clustering for time series data. Inf. Sci. (N Y) 367–368, 1–13 (2016).
Steinbach, M., Ertöz, L. & Kumar, V. The challenges of clustering high dimensional data. In New Directions in Statistical Physics 273–309 (Springer, 2004). https://doi.org/10.1007/978-3-662-08968-2_16.
Aghabozorgi, S., Seyed Shirkhorshidi, A. & Ying Wah, T. Time-series clustering – a decade review. Inf. Syst. 53, 16–38 (2015).
Yao, T. et al. Image2Flow: a proof-of-concept hybrid image and graph convolutional neural network for rapid patient-specific pulmonary artery segmentation and CFD flow field calculation from 3D cardiac MRI data. PLoS Comput. Biol. 20, e1012231 (2024).
Whitehead, K. K. et al. Nonlinear power loss during exercise in single-ventricle patients after the Fontan. Circulation 116, I–165 (2007).
Kang, S., Uchida, S. & Iwana, B. K. Tunable U-Net: controlling image-to-image outputs using a tunable scalar value. IEEE Access 9, 103279–103290 (2021).
Pizer, S. M., Johnston, R. E., Ericksen, J. P., Yankaskas, B. C. & Muller, K. E. Contrast-limited adaptive histogram equalization: Speed and effectiveness. Proceedings of the First Conference on Visualization in Biomedical Computing 337–345 (1990) https://doi.org/10.1109/VBC.1990.109340.
Watanabe, T. et al. Accuracy of the flow velocity and three-directional velocity profile measured with three-dimensional cine phase-contrast MR imaging: verification on scanners from different manufacturers. Magn. Reson. Med. Sci. 18, 265 (2019).
Forest, F. FlorentF9/deeptemporalclustering: keras implementation of the deep temporal clustering (DTC) model. https://github.com/FlorentF9/DeepTemporalClustering (2019).
Xie, J., Girshick, R. & Farhadi, A. Unsupervised Deep embedding for clustering analysis. https://github.com/piiswrong/dec (2016).
Guo, X., Gao, L., Liu, X. & Yin, J. Improved deep embedded clustering with local structure preservation (2017).
Rousseeuw, P. J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65 (1987).
Acknowledgements
The FORCE registry is funded through grants from Additional Ventures and the Evan’s Heart Fund.
Funding
N.S.C., M.G., G.F.M., and R.H.R. received funding from Additional Ventures through the FORCE registry.
Author information
Authors and Affiliations
Consortia
Contributions
T.Y. and V.M. designed and conducted the study and performed model development and analysis. N.S.C., G.M., and M.G. curated and organized the data. M.Q., S.M., A.L.D., M.A.F., R.K., C.Z.L., J.D.R., T.C.S., J.W., J.A.S., and R.H.R. contributed to study conceptualization and analysis. All authors contributed to manuscript writing and revision and approved the final version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yao, T., Clair, N.S., Gong, M. et al. Deep learning for vessel segmentation and flow analysis to identify clusters associated with adverse outcomes in a fontan patient registry. Sci Rep 16, 11956 (2026). https://doi.org/10.1038/s41598-026-40738-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-40738-6
