
Abstract
Volumetric-modulated arc therapy (VMAT) planning for locally advanced non-small cell lung cancer (NSCLC) is an iterative and planner-dependent process that often requires multiple optimization cycles to balance target coverage and organ‑at‑risk (OAR) sparing. Deep‑learning dose prediction can accelerate planning by providing patient‑specific reference dose distributions, but the impact of prescription‑dose mixing during model training remains unclear. This study evaluated whether prescription‑stratified models improve VMAT dose prediction performance. Seventy-two NSCLC VMAT cases were recalculated to 50, 54, and 60 Gy and split into training, validation, and test sets (42/10/20 cases). Four models with identical 3D U-Net architecture were developed: three single-prescription models (50/54/60 Gy) and one mixed-prescription model (50 + 60 Gy). Performance was assessed using mean absolute error (MAE) for planning target volume (PTV) and OAR dose metrics. Single-prescription models reproduced PTV coverage (D95% and D99%) with MAEs < 4 Gy and hot-spot (D2cc and D5cc) errors < 1 Gy, while mean dose errors for lungs and heart were ≤ 2.3 Gy. The mixed-prescription model showed larger errors: PTV hot-spot MAE rose to 11.3 Gy, and spinal cord maximum-dose errors reached 5–6 Gy, although most other OAR metrics changed modestly. Voxel‑wise difference maps revealed local deviations of a few Gy in low-dose lung regions and near steep gradients. These findings indicate that prescription‑dose stratification improves clinically relevant prediction metrics and support deep‑learning dose prediction as a planning decision‑support and optimization‑guidance tool.
Similar content being viewed by others


Introduction
Lung cancer is the second most common cancer and the leading cause of cancer-related mortality worldwide1, placing a significant burden on health systems. Non-small cell lung cancer (NSCLC) accounts for the majority of lung cancers and is therefore a major focus of curative‑intent treatment strategies2,3,4. For locally advanced NSCLC, complete surgical resection is often not feasible, and concurrent or sequential chemoradiation becomes the standard of care5. Among radiation‑therapy techniques, external beam radiotherapy with advanced modalities such as volumetric‑modulated arc therapy (VMAT) enables highly conformal dose delivery that maximizes tumor coverage while sparing normal tissues6,7,8. However, VMAT planning for large thoracic targets adjacent to critical organs (lungs, heart, spinal cord) remains complex and typically requires multiple rounds of manual, trial‑and‑error optimization, which increases planner workload and prolongs the overall planning process9,10,11,12, leading to a time-consuming optimization loop. Furthermore, if lung dose constraints—such as V20Gy (the percentage of the total lung volume receiving ≥ 20 Gy)—are predicted to exceed tolerance limits, the radiation oncologist may consider reducing the prescribed total dose and/or adjusting the planning approach. If constraints remain unachievable despite these modifications, the treatment strategy may shift toward non-radiation management with chemotherapy alone. Therefore, early, anatomy-based dose prediction could provide a rapid estimate of achievable target coverage and organ-at-risk (OAR) dose volume histograms (DVHs) to screen plan feasibility (e.g., identify cases likely to violate lung constraints such as V20Gy) and reduce avoidable planning iterations.
Artificial intelligence (AI) is increasingly integrated into radiotherapy to improve treatment planning efficiency and consistency13,14, with dose prediction playing an important role as a clinical decision-support tool15,16. One of the earliest AI-driven approaches in this domain is knowledge-based planning (KBP)17,18—a technique that uses historical treatment plans to predict dose distributions and guide optimization. While early KBP was limited by scalar summaries that lost spatial information, modern KBP performs voxel-wise 3D dose prediction, as seen in the AAPM Open-KBP Grand Challenge19. However, these methods can still be constrained by hand-engineered geometric features that under-represent complex anatomy10. To overcome these limitations, deep learning (DL) has emerged as a recommended approach for radiation dose prediction20,21,22,23. DL models like Convolutional Neural Networks (CNNs) learn features directly from imaging data to produce voxel-level dose distributions without hand-engineered inputs10,17,22,23. This has driven rapid growth in DL-based automated treatment planning11, which has shown promising performance for dose prediction17,22,23 in several disease sites and can reduce manual effort and improve planning consistency and standardization, potentially freeing time for complex cases that require additional expert review.
While DL-based dose prediction for NSCLC is advancing, most prior work has often focused on fixed-field IMRT or has not systematically compared different modeling strategies for handling multiple prescription levels24,25,26. Important contributions include Shao et al.27, who proposed an asymmetric network for multi-prescription IMRT, Barragán-Montero et al.23’s beam-aware dense U-Net for 60 Gy IMRT, Zhang et al.24’s attention-augmented ResUNet for 60 Gy VMAT, and Cao et al.25’s multi-prescription 3D U-Net. Although mixed‑prescription models can perform well when prescription information is explicitly incorporated; however, the impact of training on combined prescriptions without prescription‑aware conditioning has not been systematically assessed for VMAT, where steep dose gradients and complex modulation may worsen domain shift. Consequently, a key implementation question therefore remains whether a single mixed‑prescription model can achieve VMAT dose‑prediction performance comparable to dedicated single‑prescription models for NSCLC, or whether prescription‑stratified models are required despite added complexity. In this study, four 3D U-Net models are developed and compared: three models stratified by prescription (50, 54, and 60 Gy) and one mixed-prescription model trained on 50 and 60 Gy cases. The aims are to determine whether prescription-dose stratification yields clinically meaningful improvements in VMAT dose prediction for locally advanced NSCLC and to define the role of such models as planning decision-support tools to enhance feasibility screening and optimization rather than to replace treatment-planning-system (TPS) dose calculation and verification.
Materials and methods
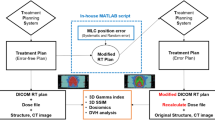
A summary of the workflow used in this study is provided in Fig. 1, which outlines the main methodological steps, including VMAT plan recalculation at three prescription levels, data preprocessing to generate standardized 9-channel input volumes, dataset division for training, validation, and testing, development of prescription-specific and mixed DL models, the 3D U-Net architecture used for dose prediction, and the overall model evaluation process.

Integrated methodological workflow and 3D U-Net architecture for deep-learning–based VMAT dose prediction. 3D U-Net model with 128 × 128 × 128 voxels and nine input channels—one for the planning target volume (PTV), seven for organs-at-risk (OARs), and one for CT images—to predict the three-dimensional dose distribution. Each blue box represents a multi‑channel feature map, gray boxes show copied feature maps, and arrows denote the different operations.
Plan selection and data collection
In this study, we retrospectively analyzed 72 cases of NSCLC treated between 2015 and 2024 at the Radiation Oncology Department of Chulabhorn Hospital. In the original 72‑patient cohort, 23 patients were planned at 50 Gy, 9 at 54 Gy, and 40 at 60 Gy, reflecting the prescription patterns used in our clinical practice. Patient selection adhered strictly to the National Comprehensive Cancer Network (NCCN) guideline2, which advocate for chemoradiation therapy (sequential or concurrent) for NSCLC patients with positive margins across stages IIB–IIIAB. Preoperative CCRT is advised for resectable cases, while definitive CCRT is recommended for unresectable cases. All patients were simulated and treated in the supine position using our institutional thoracic immobilization protocol, with both arms raised on a wing board to ensure a stable and reproducible setup. This standardized immobilization approach was applied uniformly across all patients, thereby minimizing inter-patient variability related to setup and positioning during model training and evaluation. This study was approved by the Institutional Review Board of Chulabhorn Royal Academy under approval number EC 125/2566. Informed consent was obtained from all subjects and/or their legal guardians. The study was performed in accordance with the Declaration of Helsinki. Given the limited sample size, a structured data split was adopted to ensure model robustness and sufficient testing. The 72 original patient cases were randomly divided into a training set (42 cases), a validation set (10 cases), and a test set (20 cases). To expand the training data and improve the robustness of the model, we performed left–right flipping augmentation on 28 out of the 42 training cases. These 28 cases were selected using simple random sampling without replacement, stratified to maintain the original tumor‑location distribution (60% right lung, 20% left lung, 20% central). This procedure yielded a total of 70 unique anatomical–dose paired training datasets, consisting of 42 original and 28 augmented cases, while the validation (10 cases) and independent test set (20 cases) remained unaugmented. This design was chosen to guarantee patient‑level independence between training, validation, and test sets, so that no patient appears in more than one split, at the cost of relying more heavily on augmentation within the training set. We acknowledge that this strategy may limit the diversity of non‑mirrored anatomies available for training and is further considered in the Discussion. For the mixed-prescription model, the 50 Gy and 60 Gy cohorts were fully combined prior to data splitting. This resulted in 140 training samples (70 at 50 Gy and 70 at 60 Gy). The validation set comprised 20 samples (10 cases × 2 prescriptions), and the independent test set comprised 40 samples (20 cases × 2 prescriptions), which were used exclusively for model selection and final evaluation.
Treatment planning was standardized throughout the study. Contouring followed NCCN-aligned institutional protocols, which were applied consistently across the study period. All patients were treated with VMAT. For model development, datasets were grouped according to three prescription doses—50 Gy, 54 Gy, and 60 Gy (all delivered at 2 Gy per fraction). Treatment plans employed asymmetric avoidance arcs (40°–120° and 300°–240°), tailored to patient anatomy and designed to reduce low-dose lung exposure in accordance with institutional protocol. This asymmetric avoidance-arc configuration reflects institution-specific clinical practice. While it was applied consistently across all cases to ensure internal consistency for model training and comparison, different VMAT arc strategies (e.g., full arcs with partial blocking or contralateral lung–avoidance arcs) may produce different dose patterns and modulation characteristics. As a result, the generalizability of the trained models to centers using alternative arc arrangements may be limited, and external validation or retraining using institution-specific planning protocols would be required prior to clinical deployment. Dose distributions were normalized to the PTV D95% (the dose covering 95% of the PTV). All treatments used 6 MV photon beams and followed NCCN dose constraints2. Calculations were performed using the Anisotropic Analytical Algorithm (AAA) algorithm in Eclipse TPS v16.1 (Varian Medical Systems, Palo Alto, CA, USA). All dose distributions were calculated with a 2.5 mm grid resolution. The uniform grid size across all cases ensures consistency in spatial resolution, which is critical for training DL models. Variations in grid size could introduce artifacts or inconsistencies in the learned dose patterns; therefore, maintaining a standardized grid resolution was essential for model reliability. CT images, contours, and dose distributions were exported as DICOM files for model development.
Data preparation
Each patient’s data was co-registered using the Registration Graphical User Interface (OpenREGGUI), a MATLAB-based tool, to align CT images, contours, and dose distributions at 1 mm per pixel resolution. This alignment resulted in 512 × 512 × Z, where Z (the number of slices) varied per patient (mean: 110, range: 85–142). As the number of slices (z) varied across cases, we first applied zero padding (i.e., adding boundary voxels with value 0 outside the patient) to standardize the volume size (preserve the original aspect ratio) and then resized all channels to 128 × 128 × 128 voxels. Given that thoracic CTs may contain lung-related artifacts (e.g., respiratory motion and streaking), we applied HU clipping and intensity normalization; the CT images were then normalized using the rescaling method described in Eq. 1 to adjust pixel values within a range of 0 to 1, thereby ensuring balanced feature contribution in DL models; cases with substantial metal implants were excluded, and robustness to severe metal artifacts was not assessed.
where XOriginal represents the intensity of a given pixel in the original CT image, and XMin and XMax are the minimum and maximum pixel intensities found within that image, respectively. This transformation linearly maps all original CT values into the [0,1] range, preserving the relative contrast while standardizing the intensity scale.
To focus on relevant anatomical areas, non-essential regions were cropped, while masks for essential structures, including the PTV, esophagus, heart, lungs, spinal cord, and body, were extracted from the DICOM-RT structure sets. These masks were then converted into separate binary channels to serve as input data for model training and testing. The dose information extracted from the DICOM files was first converted to Gy units and normalized to the corresponding prescription dose. To create a consistent multi-prescription dataset, each patient’s plan was then recalculated at all three prescription levels (50 Gy, 54 Gy, and 60 Gy) using the same beam geometry and contours, with dose renormalization to PTV D95%, without re-optimization. This resulted in three standardized dose distributions per patient and ensured uniform representation across all prescription categories.
Model development
For model development, CT images and patient contours were used as input data, while the corresponding 3D dose distributions served as the ground truth. All input data—including CT images, structure masks, and dose distributions—were resampled to a uniform voxel spacing of 2.5 × 2.5 × 2.5 mm³ using trilinear interpolation to ensure consistency across patients. The resampled volumes were then standardized to a fixed size of 128 × 128 × 128 voxels, a dimension selected based on GPU memory limitations commonly encountered in 3D deep learning. This standardization ensures that spatial features are represented at consistent scales, which is essential for stable model training and performance. The models were developed using the 3D U-Net architecture, a common and effective choice for DL-based dose prediction due to its capacity to capture detailed spatial information through an encoder-decoder structure (Fig. 1). Our implementation utilized nine distinct input channels: one for the PTV, seven for organs-at-risk (OARs), and one for the CT imaging data. All nine input channels are three-dimensional, co-registered volumes (CT as a 3D image volume and each structure as a 3D binary mask volume) stacked to form a 9 × 128 × 128 × 128 input tensor. The input to the network was a 9-channel tensor, where each channel represented a binary mask for the PTV, an OAR (esophagus, heart, left lung, right lung, spinal cord, body), or the normalized CT image. All four models used the same 3D U-Net architecture, training pipeline, and nine anatomy-based input channels, optimized with an MAE loss. The prescription dose was deliberately excluded from both the inputs and the loss, to specifically assess the effect of training on combined prescriptions without explicit prescription conditioning. The 3D U-Net was implemented in MATLAB R2023b (MathWorks, Natick, MA, USA) using the Deep Learning Toolbox, with all components programmed in-house following the standard 3D U-Net architecture. The training was performed on a high-performance Lenovo ThinkVision workstation equipped with an Intel Xeon Gold 6258R processor and NVIDIA Quadro RTXP8000 GPU. A single data split was used for training and evaluation. The models were trained using the Adaptive Moment Estimation (Adam) optimizer and a Mean Absolute Error (MAE) loss function. The training configuration included a batch size of 4, an initial learning rate of 0.0001, and up to 500 training epochs. To prevent overfitting, early stopping was implemented based on the validation set performance; the model weights that yielded the lowest validation loss were selected for the final model. Importantly, all four models shared the same network architecture and training settings; they differed only in the prescription composition of the training data (single‑prescription: 50/54/60 Gy; mixed‑prescription: 50 + 60 Gy).
This study developed four separate models: three models correspond to individual dose prescriptions of 50 Gy, 54 Gy, and 60 Gy, respectively, while the fourth is a mixed-prescription model trained on both 50 Gy and 60 Gy cases. The purpose of the mixed-prescription model was to evaluate the model’s generalizability across different prescription levels. For this model, the 50 Gy and 60 Gy plan variations from the 42 training patients were used, creating a larger training set of unique anatomy-dose pairings. The mixed-prescription model was trained and evaluated exclusively on 50 Gy and 60 Gy cases. Intermediate prescription levels (e.g., 54 Gy) were not included in either training or testing and were therefore not used to assess interpolation across prescription doses.
Model evaluation
To assess model performance on unseen data, 20% of the dataset (20 cases) was reserved as an independent test set and was not used during training or validation. Model performance was evaluated using two complementary approaches: quantitative DVH metrics and dose distribution analysis. Quantitative evaluation used MAE for PTV and OAR DVH endpoints (Table 1), including homogeneity index (HI) as defined in Eqs. 2 and 3.
Quantitative DVH metrics
This evaluation involved comparing predicted dose distributions with ground truth values using mean absolute error (MAE) for DVH metrics, as specified in Table 1, and homogeneity index (HI), as outlined in Eqs. 2 and 3, respectively.
-
MAE: Computed for all DVH-derived metrics (e.g., D99%, Dmean, V95%, D2cc) by averaging the absolute errors across the N patients in the test set:
where pRef, i and pPre, i are the metric values from the ground truth and prediction for the ith patient, respectively.
-
HI: Applied exclusively to the PTV to evaluate dose uniformity:
where D5% and D95% denote the doses delivered to 5% and 95% of the PTV, respectively, a value closer to 1 indicates more homogeneous dose coverage.
All statistical tests were performed on paired per-patient DVH metrics comparing predicted and reference values within the independent test set. The Shapiro-Wilk test was used to assess data normality. A t-test was subsequently applied to normally distributed data, while the Wilcoxon signed-rank test was used for data that did not follow a normal distribution.
Dose distribution and DVH-based assessment
For the dose distribution and DVH-based assessment, axial dose distributions were overlaid (prediction vs. ground truth), and pixel-wise difference maps were generated to calculate spatial deviations between the prediction and ground truth, with a particular focus on both high- and low-dose regions. In parallel, DVH from the predicted and reference were plotted together for PTV and OARs. We specifically analyzed high- and low-dose regions, as well as steep gradients, to detect any systematic overestimation or underestimation.
Results
Prediction accuracy for PTV metrics
MAEs for the PTV are summarized in Table 2. Overall, the eight dosimetric parameters evaluated (D99%, D98%, D95%, Dmean, D2cc, D5cc, V95%, and HI), the single-prescription models (Models 1–3) consistently exhibited lower MAEs than the mixed-prescription model (Model 4). For the high-dose coverage indices (D99%, D98%, D95%), the prescription-stratified models consistently outperformed the mixed-prescription model. The 50 Gy model achieved the lowest errors across coverage metrics, while the 60 Gy model showed slightly higher variability, with statistically significant deviations for D99%. In contrast, the mixed-prescription model demonstrated significantly larger errors across all high-dose coverage indices. Errors in mean and hot-spot dose metrics (Dmean, D2cc, and D5cc) remained low for all prescription-specific models but increased significantly for the mixed-prescription model, with approximately twofold higher errors and statistically significant deviations from the reference plans. Volumetric coverage followed a similar trend, with prescription-specific models yielding lower V95% errors than the mixed-prescription model. Homogeneity index errors were comparable across all models and did not differ significantly from the reference plans. Altogether, seven of the eight metrics for Model 4 and three metrics for Model 3 deviated significantly from ground-truth distributions, whereas Model 1 showed no significant differences and Model 2 only two. These results indicate that prescription-dose stratification has its most pronounced effect on PTV coverage and hot-spot control, with mixed prescriptions leading to clearly larger PTV errors.
Prediction accuracy for OAR metrics
Figures 2 and 3 present the MAE values for all OAR dose-volume parameters across the four models, and detailed numerical values for each OAR metric are reported in Supplementary Table S1. For the esophagus, differences among the 50 Gy, 54 Gy, 60 Gy, and mixed-prescription models were small and never reached statistical significance. Mean-dose errors stayed between 2.46 ± 1.72 Gy and 3.39 ± 1.90 Gy, while the maximum dose of 2 cm³ (D2cc) varied from 1.27 ± 1.42 Gy to 2.06 ± 1.77 Gy. Volume-based errors at 40 Gy and 50 Gy did not exceed 8% for any model. Cardiac predictions showed a similarly narrow spread. Model 1 gave a heart mean-dose error of 1.35 ± 1.10 Gy; Models 2, 3, and 4 produced values up to 2.22 ± 2.13 Gy, but none differed significantly. D2cc errors ranged from 2.57 ± 4.21 Gy to 4.00 ± 7.60 Gy, again without statistically significant variation. For the heart, volume‑based mean absolute errors remained modest across all models: V30Gy MAEs were 1.95 ± 2.49%, 3.14 ± 2.85%, 3.45 ± 4.87%, and 2.37 ± 3.19% for Models 1–4, V35Gy MAEs were 2.56 ± 4.25%, 3.74 ± 3.86%, 3.45 ± 4.87%, and 2.56 ± 3.77%, and V40Gy MAEs were 3.92 ± 4.88%, 5.31 ± 5.18%, 4.75 ± 5.35%, and 3.46 ± 4.62%, respectively. Mean‑lung‑dose errors were modest—1.10 ± 0.65 Gy to 1.50 ± 1.00 Gy for the combined lungs and 1.40 ± 0.70 Gy to 1.92 ± 1.97 Gy for each lung—while low‑ and mid‑dose volume errors remained small (combined‑lung V5Gy MAEs 6.04–6.79%, V20Gy MAEs 3.30–5.38%; right‑lung V5Gy 5.79–6.49%, V20Gy 4.69–5.98%; left‑lung V5Gy 8.00–8.98%, V20Gy 3.32–5.31%). The spinal cord was the only structure for which model choice proved significant. Compared with Model 1, Models 2, 3, and 4 produced larger MAEs in D2cc—about 5 Gy (p = 0.013 for Model 2; p = 0.010 for Model 4)—and in Dmax, which reached 5.68–5.72 Gy (p ≤ 0.049). Model 1 showed lower values—3.88 ± 3.22 Gy for D2cc and 4.24 ± 3.19 Gy for Dmax—which were not statistically significant (p > 0.05). No other OAR metric displayed significant inter-model variation. Taken together, these findings suggest that most OAR metrics are relatively robust to prescription mixing, with the spinal cord being the main exception and the most prescription-sensitive OAR to prescription-dose stratification.

Mean absolute errors for the esophagus, heart, and lungs across four models, evaluated using dose-based metrics (mean dose, Dmax, and D2cc).

Mean absolute errors for the esophagus, heart, and lungs across four models, evaluated using volume-based dose metrics (V5Gy, V20Gy, V30Gy, V35Gy, V45Gy, and V50Gy), where VxGy denotes the volume of the organ-at-risk receiving at least x Gy.
Dose distribution and DVH-based assessment
Overall, the models preserved clinically meaningful DVH trends, but voxel-wise discrepancies persisted, most notably in the low-dose lung bath and in steep-gradient regions near small serial organs (spinal cord and, to a lesser extent, esophagus). Visual inspection (Fig. 4) showed good agreement of high-dose PTV regions across models, yet signed difference maps (prediction − ground truth) revealed localized deviations in the low-dose lung bath and near steep gradients around the spinal cord and esophagus regions. DVH comparisons (Fig. 5) were consistent overall: for a typical 50 Gy case from the single‑prescription model (Model 1, Patient 5), PTV curves closely overlapped the ground truth and OAR DVHs showed only slight overestimation of low‑dose lung volume (< 30 Gy; 1–3%) and smoothing of high‑dose gradients for the spinal cord and esophagus (> 20 Gy, divergences up to 5 Gy), whereas the 50 Gy example from the mixed‑prescription model (Model 4, Patient 4) illustrates a more challenging case with visibly larger spinal cord deviations.

Example axial dose distributions for four models (Model 1: 50 Gy; Model 2: 54 Gy; Model 3: 60 Gy; Model 4: mixed 50 + 60 Gy): ground truth, prediction, and signed dose difference (prediction − ground truth).

Dose–volume histograms for PTV and OARs for two representative 50 Gy test cases: Model 1 (Patient 5, left) and the mixed‑prescription Model 4 (Patient 4, right). Solid lines indicate ground truth and dashed lines the predicted DVHs. The Model‑4 panel illustrates a case with larger spinal cord deviations compared with the single‑prescription model.
Collectively, the models demonstrated robust accuracy in predicting PTV dose distributions with minimal variability. OAR dose predictions were generally reliable, but limitations persist in low-dose lung regions and steep-gradient structures (spinal cord, esophagus).
Discussion
This study demonstrates that prescription-stratified 3D U-Net models can predict VMAT dose distributions for locally advanced NSCLC with promising agreement. Importantly, the primary contribution of this work is not architectural innovation but the systematic investigation of prescription-dose stratification as a modeling and training strategy for VMAT dose prediction. By holding the network architecture and training pipeline constant, we isolate the effect of prescription handling and demonstrate its clinical relevance for treatment-planning decision-support, including feasibility screening and optimization guidance. By using an identical network architecture across models, we specifically quantified the effect of prescription-dose stratification on performance and found that prescription handling is a major determinant of prediction accuracy in this VMAT setting. Our primary finding is that stratifying models by prescription dose yields superior accuracy for PTV coverage and hot-spot metrics compared to a single model trained on mixed prescriptions, while most OAR doses remain relatively similar across models except for the spinal cord, a small serial organ with steep dose gradients.
To place these findings in context, we interpret them relative to prior work on DL–based dose prediction. Knowledge-based planning has advanced markedly since machine-learning techniques were first applied to radiotherapy dose prediction, yet variability in tumor geometry, beam modulation, and prescription level continues to limit accuracy. DL models have begun to close this gap, but most investigations have focused on fixed-field IMRT—most notably by Jhanwar et al.17, Barragán-Montero et al.23, and Miao et al.26. Because VMAT delivers radiation through continuous arcs, it introduces steeper gradients and greater low-dose spread—characteristics that challenge dose prediction networks trained on more uniform beam arrangements. By developing and evaluating prescription-specific convolutional networks for VMAT in locally advanced NSCLC, this study extends the evidence base into a modality now preferred for thoracic planning.
Our findings both agree with and extend previous work on DL–based dose prediction. In fixed-field IMRT, Shao et al.27 demonstrated that multi-prescription learning can be successful when prescription information is explicitly encoded in the network architecture. In contrast, our mixed-prescription VMAT model performed poorly, indicating that the continuous arc modulation of VMAT introduces greater complexity and makes multi-prescription learning more challenging without explicit conditioning. At the same time, our results confirm the findings of Barragán-Montero et al.23 and Zhang et al.24, showing that prescription-specific models can achieve high accuracy, particularly for PTV coverage and high-dose regions. While Cao et al.25 extended VMAT dose prediction across a broad prescription range, their study did not systematically isolate the impact of mixed versus stratified prescriptions within a fixed architecture. By holding the network design constant, our study demonstrates that prescription-dose stratification itself is a key determinant of prediction performance in VMAT, especially for structures with steep dose gradients such as the spinal cord. It is important to emphasize that the inferior performance of the mixed-prescription model observed in this study does not imply that mixed-prescription deep-learning dose prediction is inherently limited. Prior work has shown that multi-prescription models can perform well when prescription information is explicitly encoded through network inputs, loss design, or physics-informed constraints. In contrast, our mixed-prescription VMAT model was trained without explicit prescription conditioning and relied solely on anatomical information to infer the intended dose level. As implemented, the mixed-prescription model learned from heterogeneous data at two discrete prescription levels and should not be interpreted as a continuous, prescription-interpolating predictor; evaluation of interpolation across unseen prescription levels was beyond the scope of this study. Taken together, these findings indicate that prescription-dose stratification and prescription-aware mixed-prescription modeling should be viewed as complementary strategies rather than competing paradigms.
In this study, we trained three single-prescription models (50 Gy, 54 Gy, and 60 Gy) and a fourth model that combined the 50 Gy and 60 Gy cases. We trained and evaluated the models using total physical dose because clinical plan evaluation and feasibility decisions—including prescription feasibility and OAR constraint compliance (e.g., lung V20Gy and spinal cord Dmax)—are made in total-dose terms. In practice, if a higher prescription is predicted to be unlikely to meet key OAR constraints, the prescription level or planning strategy (e.g., beam arrangement or optimization priorities) may be adjusted early in the planning process. An important future direction is to train the model to predict dose per fraction (or dose normalized to prescription) and then scale to total dose; this may reduce prescription-related domain shift, but it requires explicit validation of spatial agreement—particularly in steep-gradient regions and near serial OARs. In our evaluation, the single-prescription models reproduced high-dose coverage for the PTV with MAEs below 4 Gy; however, these DVH-metric MAEs are not directly comparable to clinical audit tolerances, which assess local dose agreement (e.g., point-dose differences analysis) and include additional sources of uncertainty. In contrast, the mixed-prescription model produced larger discrepancies across almost every PTV metric. The degradation mirrors the domain-shift effect described by Shao et al.27, who noted similar losses when heterogeneous beam-angle protocols were combined without explicit conditioning. These findings confirm that a network must learn two distinct dose-gradient regimes when prescriptions differ by ≥ 10 Gy; either stratification or a prescription-aware architecture is therefore essential.
For OARs, however, the choice of model was less critical. Mean-dose errors for the esophagus, heart, and lungs stayed below 3.5 Gy, and volume-based MAEs remained under 8% regardless of the model. Because the dose to these large, low-contrast structures is governed mainly by patient anatomy and global beam geometry, the model generalized across prescriptions without appreciable loss of fidelity. The spinal cord was the exception. Its small cross-section and steep surrounding gradients magnify spatial misalignments; once high-prescription cases were introduced, MAEs for both D2cc and Dmax rose to ≈ 5–6 Gy and became statistically significant—roughly 10% of the customary 45 Gy tolerance. Consistent with findings by Barragán-Montero et al.23 and by Shao et al.27, these results suggest that serial organs with sharp gradients benefit from prescription-specific models or loss functions that assign greater weight to high-dose voxels.
Our results compare favorably with earlier IMRT studies. Despite the added complexity of continuous-arc delivery, the 60 Gy model achieved PTV MAEs that differ from those reported by Barragán-Montero et al.23 by < 1 Gy for D99%, D98%, D95%, and D5cc. Likewise, the mixed network outperformed Shao et al.27 for all core PTV metrics at both 50 Gy and 60 Gy prescriptions, and lung mean-dose predictions differed from prior benchmarks by ≤ 0.3 Gy. Slight overestimation of esophageal V40Gy and V50Gy (≈ 1–2% volume) and higher variability in heart V40Gy mirror the challenges others have reported in modeling low-dose bath—an area influenced by tumor location and breathing-induced anatomic changes.
Visual inspection of axial dose distributions (Fig. 4) showed good alignment of the high-dose isodose contours between the predictions and ground truth across all models. The difference maps are displayed with a 20 Gy color scale to show the full dynamic range; however, within the PTV and OARs, most voxels differed by only a few Gy. The largest deviations were rare and occurred predominantly at the periphery of high-dose regions and in voxels outside the contoured structures used for training, where steep dose gradients make the prediction problem more challenging. These regions have minimal influence on the DVH-based metrics reported in Table 2 and S1. It is also important to clarify the rationale behind our choice of evaluation metrics. We focused on MAE and DVH-derived parameters because they provide direct, clinically interpretable measures of dose accuracy. Other similarity metrics, such as the Gamma index and Pearson correlation coefficient, were not used for methodological reasons. Gamma analysis is highly sensitive to spatial resolution and interpolation, and our model outputs were generated on resampled 128 × 128 × 128 grids, which might yield gamma results that do not reflect true clinical discrepancies. Similarly, correlation coefficients capture global agreement but may miss clinically relevant local deviations in steep dose-gradient regions. For these reasons, MAE and DVH metrics were considered more appropriate for evaluating clinically meaningful dose differences, while future studies may incorporate gamma analysis on native TPS grids and correlation-based measures as complementary tools. Although DVH-based errors were generally modest, signed difference maps revealed localized deviations—particularly in the low-dose lung bath and in high-gradient regions near small serial organs (e.g., spinal cord). These discrepancies are important because they can be clinically relevant even when summary DVH metrics appear acceptable, and they limit the current framework to planning guidance and benchmarking rather than dosimetric verification.
The proposed framework is intended as a treatment planning decision-support and benchmarking tool rather than a replacement for the TPS dose calculation. In practice, the predicted dose distribution and derived DVH metrics may be used for early feasibility screening (e.g., identifying cases likely to violate key OAR constraints before time-consuming optimization) and for optimization guidance by providing a patient-specific reference dose pattern that can inform inverse planning or automated planning pipelines. Given the observed voxel-wise deviations, particularly in low-dose lung regions and near steep gradients, the model output should be interpreted as a planning aid; final dose computation, clinical approval, and patient-specific QA remain within the standard TPS-based workflow.
Several limitations and future research directions should be considered. First, GPU‑memory‑restricted input size and the required down‑sampling may blunt spatial fidelity, particularly in low-dose volumes such as lung V5Gy and V20Gy, and could impact normal tissue complication probability assessments. These deviations suggest the need for improved model calibration, as minor overestimations in esophagus V40Gy and V50Gy could influence toxicity predictions and dose constraints. Similarly, higher variability in heart V40Gy predictions could necessitate additional safety margins to mitigate cardiac toxicity risks. Second, although 72 cases provide more heterogeneity than many single-center series, the dataset remains modest and increases the risk of over-fitting. Third, the spinal cord sample contained relatively few voxels near the tolerance threshold, which likely contributed to its larger prediction variance. Lastly, the impact of the dose calculation grid size on model performance warrants further investigation. While we maintained a uniform 2.5 mm grid resolution, clinical practice may involve different grid sizes, and model robustness to such variations should be evaluated. Taken together, these findings underscore that prescription-dose stratification is not a minor implementation detail but a key modeling decision that directly affects clinically relevant prediction accuracy, especially for PTV coverage and spinal cord sparing. Future work will therefore focus on prescription‑aware mixed‑prescription modeling, including explicit prescription or fraction‑number inputs, prescription‑normalized outputs, and gradient‑ or organ‑at‑risk–weighted loss functions to mitigate the domain shift observed in the current anatomy‑only implementation. An additional limitation is the modest size and single‑institution origin of the cohort, combined with a data‑splitting strategy that relies heavily on left–right flipping within the training set while reserving 10 and 20 completely independent patients for validation and testing, respectively. Although this approach avoids patient‑level data leakage between splits, it reduces the diversity of non‑mirrored anatomies available for training and may lead to somewhat optimistic validation performance, particularly for left–right asymmetries that are not fully captured by flipping. In future work, larger multi‑institutional datasets, alternative splitting schemes such as cross‑validation, and more diverse augmentation (e.g., elastic deformations, intensity perturbations) will be important to improve robustness and generalizability.
In addition, this study includes explicit binary masks of the PTV and multiple OARs as input channels to enable anatomy‑aware learning of clinically relevant trade‑offs between target coverage and OAR sparing, which are critical to prescription‑feasibility assessment and optimization guidance. A potential trade‑off of using multiple OAR masks is increased input dimensionality and data requirements; however, this is offset by clearer encoding of serial versus parallel organ geometry, which is essential for constraint‑focused feasibility assessment in thoracic VMAT. This design follows common practice in DL‑based dose prediction, where CT images and multiple structure masks (PTV and OARs) are provided as multi‑channel inputs to encode anatomical context for voxel‑level dose estimation17,20,22,23,24,25. This design contrasts with recent work by Loebner et al. (DeepSMCP)28, who proposed a deep‑learning–based denoising framework that uses a fast, high‑statistical‑uncertainty Monte Carlo dose distribution together with CT as inputs—without explicit OAR masks—to recover a low‑noise Monte Carlo dose distribution at substantially reduced computational time. While DeepSMCP focuses on accelerating high‑fidelity dose calculation for a given treatment plan and beam configuration, our framework targets an earlier stage of the workflow by predicting anatomy‑conditioned dose patterns for prescription feasibility screening and VMAT optimization guidance20,24,25. These approaches are therefore complementary rather than competing: DeepSMCP refines a physics‑based approximate dose, whereas our model provides an anatomy‑based prior that can inform planning decisions before final dose computation, and a promising future extension would be to combine anatomical masks with fast, approximate dose inputs (e.g. coarse or noisy Monte Carlo) to further reduce local discrepancies, particularly in steep‑gradient regions and near serial organs24,25.
In conclusion, these findings highlight key directions for improving clinical applicability. These limitations identify specific areas for improvement to enhance clinical applicability: (1) increasing cohort size and diversity (ideally multi-institutional) to improve generalizability; (2) incorporating explicit prescription and/or fractionation conditioning to reduce domain shift; (3) using higher-resolution or multi-scale modeling and gradient-aware loss functions to better capture steep dose fall-off near serial organs; and (4) adding uncertainty estimation to flag cases or regions where predictions are less reliable and warrant closer review.
Conclusion
This study evaluated the impact of prescription-dose stratification on DL–based VMAT dose prediction for NSCLC. Prescription-stratified 3D U-Net models trained on individual prescription levels (50, 54, and 60 Gy) were able to closely reproduce the corresponding clinical dose distributions, with the most pronounced benefit observed for PTV coverage, where mean absolute errors remained below 4 Gy and OAR dose errors were low for most organs. In contrast, a mixed-prescription model trained on 50 and 60 Gy plans degraded performance, increasing PTV coverage and hot-spot errors, while doses to the lungs, heart, and esophagus changed only modestly across models. These findings indicate that prescription-dose stratification is a key design choice for reliable VMAT dose prediction, especially for ensuring adequate PTV coverage, and suggest that such models can serve as robust clinical decision-support tools to improve treatment planning quality and efficiency. They should be validated further in larger, multi-institutional cohorts before routine clinical implementation.
Data availability
The datasets generated and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Sung, H. et al. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 71, 209–249 (2021).
Ettinger, D. S. et al. NCCN Guidelines® insights: Non–small cell lung cancer, version 2.2023. J. Natl. Compr. Cancer Netw. 21, 340–350 (2023).
Molina, J. R., Yang, P., Cassivi, S. D., Schild, S. E. & Adjei, A. A. Non-small cell lung cancer: Epidemiology, risk factors, treatment, and survivorship. Mayo Clin. Proc. 83, 584–594 (2008).
Van Schil, P. E. et al. Surgical treatment of early-stage non-small-cell lung cancer. Eur. J. Cancer Suppl. 11, 110–122 (2013).
Zappa, C. & Mousa, S. A. Non-small cell lung cancer: Current treatment and future advances. Transl. Lung Cancer Res. 5, 288–300 (2016).
Afrin, K. T. & Ahmad, S. Is IMRT or VMAT superior or inferior to 3D conformal therapy in the treatment of lung cancer? A brief literature review. J. Radiother. Pract. 21, 416–420 (2022).
Teoh, M., Clark, C. H., Wood, K., Whitaker, S. & Nisbet, A. Volumetric modulated arc therapy: A review of current literature and clinical use in practice. Br. J. Radiol. 84, 967–996 (2011).
Rana, S. Intensity modulated radiation therapy versus volumetric intensity modulated arc therapy. J. Med. Radiat. Sci. 60, 81–83 (2013).
Nguyen, D. et al. A feasibility study for predicting optimal radiation therapy dose distributions of prostate cancer patients from patient anatomy using deep learning. Sci. Rep. 9, 1076 (2019).
Kajikawa, T. et al. A convolutional neural network approach for IMRT dose distribution prediction in prostate cancer patients. J. Radiat. Res. 60, 685–693 (2019).
Wang, M., Zhang, Q., Lam, S., Cai, J. & Yang, R. A review on application of deep learning algorithms in external beam radiotherapy automated treatment planning. Front. Oncol. 10, 580919 (2020).
Chen, X. et al. DVHnet: A deep learning-based prediction of patient‐specific dose volume histograms for radiotherapy planning. Med. Phys. 48, 2705–2713 (2021).
Putz, F. & Fietkau, R. The increasing role of artificial intelligence in radiation oncology: How should we navigate it? Strahlenther. Onkol. 201, 207–209 (2025).
Giraud, P. & Bibault, J. E. Artificial intelligence in radiotherapy: Current applications and future trends. Diagn. Interv. Imaging 105, 475–480 (2024).
Elhaddad, M. & Hamam, S. AI-driven clinical decision support systems: An ongoing pursuit of potential. Cureus 16, e57728 (2024).
Alowais, S. A. et al. Revolutionizing healthcare: The role of artificial intelligence in clinical practice. BMC Med. Educ. 23, 689 (2023).
Jhanwar, G., Dahiya, N., Ghahremani, P., Zarepisheh, M. & Nadeem, S. Domain knowledge driven 3D dose prediction using moment-based loss function. Phys. Med. Biol. 67, 185017 (2022).
Momin, S. et al. Knowledge-based radiation treatment planning: A data‐driven method survey. J. Appl. Clin. Med. Phys. 22, 16–44 (2021).
Babier, A. et al. OpenKBP: The open-access knowledge-based planning grand challenge and dataset. Med. Phys. 48, 5549–5561 (2021).
Liu, J., Zhang, X., Cheng, X. & Sun, L. A deep learning-based dose prediction method for evaluation of radiotherapy treatment planning. J. Radiat. Res. Appl. Sci. 17, 100757 (2024).
Lagedamon, V., Leni, P. E. & Gschwind, R. Deep learning applied to dose prediction in external radiation therapy: A narrative review. Cancer/Radiothérapie 28, 402–414 (2024).
Nguyen, D. et al. 3D radiotherapy dose prediction on head and neck cancer patients with a hierarchically densely connected U-net deep learning architecture. Phys. Med. Biol. 64, 065020 (2019).
Barragán-Montero, A. M. et al. Three‐dimensional dose prediction for lung IMRT patients with deep neural networks: Robust learning from heterogeneous beam configurations. Med. Phys. 46, 3679–3691 (2019).
Zhang, H., Yu, Y. & Zhang, F. Prediction of dose distributions for non-small cell lung cancer patients using MHA‐ResUNet. Med. Phys. 51, 7345–7355 (2024).
Cao, W. et al. Dose prediction via deep learning to enhance treatment planning of lung radiotherapy including simultaneous integrated boost techniques. Med. Phys. 52, 3336–3347 (2025).
Miao, Y. et al. Dose prediction of CyberKnife Monte Carlo plan for lung cancer patients based on deep learning: Robust learning of variable beam configurations. Radiat. Oncol. 19, 170 (2024).
Shao, Y. et al. Prediction of three-dimensional radiotherapy optimal dose distributions for lung cancer patients with asymmetric network. IEEE J. Biomed. Health Inf. 25, 1120–1127 (2021).
Loebner, H. A. et al. DeepSMCP—Deep-learning powered denoising of Monte Carlo dose distributions within the Swiss Monte Carlo Plan. Z. Med. Phys. https://doi.org/10.1016/J.ZEMEDI.2025.02.004 (2025).
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
C.K. and T.C. conceptualized and designed the study. C.K., S.C., and D.O. provided consultation. T.C. and P.I. conducted data collection. T.C. performed model generation and data analysis. K.N. and P.K. assisted with coding. T.C. and C.K. wrote the main manuscript text. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
The Institutional Review Board of Chulabhorn Royal Academy approved this study under approval number EC 125/2566.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chaipanya, T., Nimjaroen, K., Chamchod, S. et al. Prescription‑dose stratification improves deep learning‑based VMAT dose prediction in locally advanced NSCLC. Sci Rep 16, 8707 (2026). https://doi.org/10.1038/s41598-026-43192-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-43192-6
