
Abstract
While the segmentation of anatomical structures and pathological regions is indispensable for reliable disease assessment, contemporary algorithms often fail to achieve sharp demarcation. This deficiency stems from the high degree of morphological heterogeneity across different cases, which results in obscured contours and compromised segmentation accuracy. To address this gap, we propose a dual-branch attention network (D3T-Net) that combines deep split convolution and multi-dimensional Transformer. This network introduces parallel CNN branches and Transformer branches in the encoder and decoder, respectively, to capture local details and model global contextual information. In the CNN branch, a deep split module (DSM) is designed to enhance local representations through multiple sub-branches and fusion attention mechanisms. The Transformer stream employs multi-dimensional modules to capture extensive spatial and channel-wise dependencies, thereby mitigating the localized limitations inherent in standard self-attention. To facilitate robust feature exchange between the two pathways, we introduce a direction-aware interaction attention (LA) module within the encoder, designed to accentuate critical structural characteristics across various orientations. In the decoder, a cross-attention mechanism is introduced to achieve feature reorganization and integration. Additionally, to enhance feature expression capabilities, the model adopts a multi-scale fusion skip connection mechanism between the encoder and decoder to achieve efficient feature transfer, improve boundary retention ability, and enhance the segmentation effect of small objects. Extensive evaluations reveal that D3T-Net surpasses contemporary benchmarks in segmenting the liver and associated lesions. Such advancements in automated image analysis effectively augment diagnostic accuracy, thereby offering robust support for precision medicine in hepatology.
Similar content being viewed by others
Introduction
Within the realm of computer-aided diagnosis1, medical image segmentation serves as a fundamental prerequisite. This process necessitates the pixel-level categorization of anatomical structures or pathological abnormalities across various modalities, including magnetic resonance imaging (MRI) and computed tomography (CT). However, traditional medical image segmentation methods require radiologists to view the images one by one, which is easy to miss or misdiagnose due to fatigue or subjective factors. It is impractical to rely on manual segmentation of a large number of medical images2. Therefore, researchers are increasingly interested in automatic segmentation of medical images. The goal is to use computer vision to enable machines to automatically delineate organs, tissues, and lesions, thereby reducing the workload of doctors and increasing the automation level of medical systems.
With the development of GPU hardware and the open-source availability of a large number of medical datasets, deep learning has been advanced like never before3. Deep learning methods can realize automatic weight learning without manually designing features and parameter Settings, and the trained model has strong generalization ability4.
The field of image analysis has been significantly advanced by CNNs, primarily due to their exceptional capacity for non-linear feature extraction5. In terms of pixel-level classification, FCN represents the initial transition of CNNs toward semantic segmentation tasks6. Notably, the U-Net model has demonstrated remarkable efficacy in anatomical segmentation by integrating an encoder-decoder structure with strategic skip connections to preserve spatial details7.
Building on the foundational encoder-decoder paradigm, the U-shaped architecture has established itself as the dominant framework for medical image analysis8. Continuous research efforts have yielded numerous sophisticated variants, such as TransUNet9, CSCA U-Net10, and HmsU-Net11, each aiming to refine the original U-Net design. These advanced frameworks consistently surpass conventional methodologies by utilizing convolutional layers for hierarchical feature extraction and contextual encoding, thereby enabling precise object localization and pixel-level identification.
However, CNN models have natural limitations in modeling global context information. Due to the intrinsic inductive bias of local connectivity, the receptive field of standard convolutional kernels remains constrained. Consequently, CNN-based architectures encounter significant difficulties in capturing global contextual relationships and modeling long-range dependencies, which are vital for comprehensive feature representation. Specifically, CNN increases the receptive field by increasing the number of convolutional layers, but with the increase of the number of layers, the path of information transmission becomes longer, which leads to the greatly reduced efficiency of global information capture. In medical images, especially when dealing with images with complex structures or fuzzy boundaries, although local features can accurately identify edges or textures in images, it is easy to ignore the semantic information of the global background, which makes the segmentation effect of CNN poor when dealing with large-scale lesions or fuzzy boundaries, such as tumors and organs. Therefore, how to overcome the limitation of CNN receptive field and improve the modeling ability of global context information has become a big challenge in medical image segmentation.
To surmount these architectural constraints, Transformers utilize self-attention mechanisms to orchestrate the capture of expansive global dependencies, achieving remarkable breakthroughs in both Natural Language Processing (NLP) and Computer Vision (CV)12,13. A pivotal milestone in this evolution is the Vision Transformer (ViT), which effectively employs multi-head self-attention (MHSA) to distill high-level, long-range contextual representations directly from visual inputs14. Different from traditional CNNS, Transformers are able to directly model global features, and their self-attention mechanism captures long-distance dependencies by calculating the correlation between parts of an image, thereby enhancing the expression ability of global context information. Especially when dealing with long-distance relationships such as lesions and organ boundaries, Transformer can provide more accurate segmentation results through global information integration15. Transformers show great potential and advantages in image processing and medical image analysis tasks, especially in the complex global dependencies that need to capture the fuzzy boundaries between tumors and healthy tissues.
However, despite the powerful global modeling ability of transformers, its application still faces many challenges in medical image segmentation. First, transformers lack the local perception and inductive bias that convolutions have, which makes them perform poorly when dealing with fine-grained features and multi-scale information. In particular, when dealing with the boundary between tiny lesion regions and large-scale organs. Transformer lacks the ability of these local feature learning, it may ignore some key local details, resulting in decreased segmentation accuracy.
To this end, we present D3T-Net, a dual-branch hybrid framework that synergizes deep split convolutions with multi-dimensional Transformers for enhanced medical image segmentation. Built upon an encoder-decoder paradigm, the architecture deploys parallel streams to concurrently capture fine-grained local textures and expansive global contexts. Specifically, the Deep Splitting Module (DSM) within the CNN branch bolsters local feature representation via multi-path sub-branches and fusion-based attention. Simultaneously, the Transformer branch resolves long-range dependencies across spatial and channel axes, compensating for the inherent locality bias of self-attention. To foster inter-branch communication, a direction-aware interaction attention (LA) module is embedded in the encoder to accentuate multi-oriented structural cues. Furthermore, cross-attention mechanisms and multi-scale fusion skip connections are utilized in the decoder to optimize feature reintegration and the delineation of minute anatomical structures.
The main contributions of this paper can be summarized as follows:
-
1.
A novel encoder-decoder scheme is developed to unify CNNs and Transformers within a single framework. The proposed model achieves refined segmentation of complex structures by leveraging concurrent encoding of fine-grained details and long-range semantic information.
-
2.
The deep splitting module is designed, and the multi-branch convolution and fusion attention mechanism are introduced into the CNN branch to enhance the expression and direction perception ability of fine-grained features.
-
3.
A multi-dimensional Transformer module is constructed, which combines the attention mechanism of spatial and channel dimensions to improve the ability of Transformer branches to model structural boundaries and global context.
-
4.
The direction-aware interactive attention module (LA) and the cross-attention fusion strategy in the decoding stage are proposed to effectively enhance the information complementarity between the double branches, and the multi-scale skip connection is combined to achieve more refined medical image segmentation.
-
5.
The proposed model shows good performance on various medical image data with different modalities, which indicates that it has the potential to be a reliable and general medical image segmentation model.
Related works
Convolutional neural networks for medical image segmentation
In the contemporary landscape of medical imaging, CNN-based methodologies have gained unparalleled prevalence, primarily attributed to their efficacy in capturing complex hierarchical features from clinical scans16. CNNs are highly effective at extracting local features from medical images, which aids in the identification of different tissue types and lesion areas, playing a critical role in the automatic analysis and diagnosis of medical images17. Despite their significant progress in this domain, CNN-based methods still face several challenges, primarily due to their limited receptive fields and inadequate ability to model global contextual information.
Remarkable segmentation fidelity is frequently attributed to the U-shaped encoder-decoder framework, an architectural staple that has gained immense traction in the medical imaging community for its robust feature integration capabilities18. This architecture progressively compresses image information through the encoder and restores image details through the decoder, ensuring high segmentation accuracy, particularly in pixel-level segmentation tasks. UNet’s simplicity and efficiency have made it a benchmark method in many medical image segmentation applications.
Architectural refinements have significantly evolved since the inception of U-Net. Enhanced feature propagation is achieved in UNet++ through the implementation of nested dense skip connections19. To address the need for spatial prioritization, Attention U-Net incorporates attention-gate modules to focus on task-relevant image areas20. Complexity in image structures is further resolved by R2U-Net, which synergizes recurrent neural networks with residual learning21. More recently, the concept of multi-scale integration was advanced by UNet3+, which utilizes comprehensive skip connections to harmonize internal decoder representations22.
Although these advancements contribute to improving segmentation model performance, they are still constrained by the limitations inherent in convolutional operations. CNNs typically operate with a fixed receptive field, meaning they are confined to extracting features from local regions and cannot fully capture distant contextual information. In medical image segmentation, many important details and structural relationships–such as the interaction between lesion areas and surrounding healthy tissues–extend across large spatial ranges, which poses a challenge for CNNs that rely primarily on local information. Consequently, while these methods perform well in specific tasks, their inability to effectively model global context and capture long-range dependencies limits their performance in more complex medical image segmentation scenarios.
Transformer for medical image segmentation
By leveraging Multi-Head Self-Attention (MHSA) to encode extensive contextual dependencies, Transformers have emerged as a powerful alternative for visual recognition23. Although originally conceptualized for linguistic translation, this architecture was adapted for image-level analysis through the Vision Transformer (ViT), which pioneered the use of a pure attention-based framework for visual data24. In ViT, an image is decomposed into discrete patches, which are subsequently processed by a Transformer encoder and a Multi-Layer Perceptron (MLP) for classification. Inspired by this success, the paradigm has been further extended to dense prediction tasks25,26. By facilitating the modeling of intricate pixel-wise correlations, Transformer architectures have significantly refined boundary delineation and semantic interpretation in complex segmentation scenarios.
Within the medical imaging landscape, Transformer-based frameworks have emerged as a formidable alternative to conventional techniques, primarily due to their proficiency in modeling long-range spatial dependencies27,28. A quintessential architecture is TransUNet29, which integrates a Transformer backbone to encode global context while employing a convolutional decoder for pixel-wise reconstruction. Despite these strengths, the inherent spatial resolution loss in standard Vision Transformers (ViT) often compromises the fine-grained localization required for organ segmentation. To mitigate this, more hierarchical designs like the Pyramid Vision Transformer (PVT)30 have been introduced. For instance, the DBCGN network31 utilizes a dual-branch cascading feature fusion (DCF) strategy to bridge CNNs and PVT, effectively synthesizing localized textures with global semantic cues to achieve superior segmentation fidelity.
Although Transformers have shown strong global modeling capabilities in medical image segmentation, they lack spatial local perception. Their fully connected attention structure often ignores key boundary details and local texture information, limiting the recognition of small objects or fuzzy structures. In addition, how to realize the explicit modeling of channel dimension and spatial structure while maintaining the ability of global information modeling is also important to improve the recognition ability of the model for complex structures.
Method
We begin by outlining the structural paradigm of D3T-Net, followed by a rigorous examination of its core components. Specifically, we unveil the technical specifications of the Deep Splitting Module, the Multi-dimensional Transformer Block, and the Interactive Attention Mechanism, illustrating how these modules synergize to facilitate precise medical image segmentation.
Overview of the proposed network
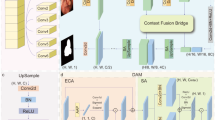
Challenges in precise anatomical delineation often stem from morphological inconsistencies, leading to blurred contours that complicate clinical intervention. This paper presents D3T-Net, a novel hybrid framework designed to unify the local representation power of CNNs with the global modeling capabilities of Transformers. Following the U-shaped hierarchical design depicted in Fig. 1, the model incorporates a bifurcated encoding-decoding scheme. This dual-branch configuration is specifically tailored to balance fine-grained feature extraction with long-range contextual integration, thereby overcoming the limitations of single-paradigm networks.
Within the encoder, each stage is partitioned into a symmetrical two-branch architecture consisting of a CNN stream and a Transformer stream. The CNN component is primarily tasked with aggregating localized representations and multi-scale visual cues, ensuring the robust extraction of intricate textures, fine details, and boundary-specific information from clinical imagery. Specifically, the Deep Splitting Module (DSM) is used in the CNN branch, which achieves efficient feature representation through channel division, multi-branch convolution and fusion attention mechanism. DSM divides the input features into multiple sub-groups, and performs parallel convolution respectively. The features of each branch are weighted and integrated through the fusion attention mechanism to enhance the expression ability of local structure and direction information. The Transformer branch uses the self-attention mechanism to model global features, which effectively captures long-distance dependencies and global semantic information in the image. Within the Transformer pathway, we deploy a multi-dimensional Transformer module to refine the representation of spatial and channel-wise information. This architecture facilitates multi-faceted modeling by synergizing Efficient Self-Attention (ESA) with dual-axis attention mechanisms–namely Spatial (SSA) and Channel (CSA) self-attention–thereby bolstering the model’s overall discriminative power. ESA reduces the computational burden, SSA enhances the capture ability of spatial location information, and CSA focuses on the complex relationship between channels, and multi-dimensional feature extraction highlights the target area of the medical image.
In addition, in order to solve the problem of information fragmentation between the double branches of the encoder, this paper introduces the interactive attention mechanism (LA) in the encoding stage, which is used to fuse the features of CNN and Transformer branches and highlight salient regions. The LA module extracts structural features of different scales and directions through a variety of pooling methods, and then uses convolution fusion to generate directional spatial attention maps, which effectively strengthens the expression ability of structural boundaries and local salient regions, and improves the perception ability of the model to key regions.
In the decoder, a dual-branch architecture is employed to facilitate the incremental integration of features from the encoder. This parallel design ensures a tight coupling between the CNN and Transformer components, securing both multi-scale resolution and holistic semantic flow. We introduce a Cross-Attention (CA) scheme specifically to resolve the bottleneck of inter-branch feature merging in the decoding stage32. By capturing the interdependent characteristics of each branch, the CA module enables effective information fusion and reorganization, significantly augmenting the final segmentation performance.
In addition, both CNN and Transformer branches realize skip connections between their encoders and decoders by multi-scale fusion, which not only retains the shallow spatial details, but also ensures the effective transmission and integration of deep semantic information. This cross-layer and cross-scale feature fusion mechanism shows more robust segmentation in medical image regions with complex structures or fuzzy boundaries.
Overall, the D3T-Net achieves a synergistic representation of localized textures and holistic semantic contexts through its integrated dual-branch paradigm. In the encoding phase, the LA module is deployed to facilitate multi-directional feature fusion and saliency enhancement, while the Deep Splitting Module (DSM) bolsters the robustness of local feature representation. Simultaneously, the multi-dimensional Transformer modules refine the modeling of dependencies across both spatial and channel axes. During decoding, a cross-attention mechanism orchestrates the interactive integration of heterogeneous features, ultimately culminating in a highly accurate and resilient framework for medical image segmentation.

Architecture of D3T-Net for medical image segmentation.
Deep splitting module(DSM)
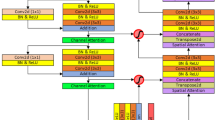
As illustrated in Fig. 2, the CNN encoder is composed of three hierarchical layers. Central to this design is the Deep Splitting Module, which incorporates a fusion attention mechanism to resolve cross-branch feature interactions. For an input tensor \(\textbf{X} \in \mathbb {R}^{H \times W \times C}\), where H, W, C denote height, width, and channel count, the module initiates a spatial decomposition into \(K=4\) distinct maps: \(\{\textbf{X}_i\}_{i=1}^4\). Each map undergoes further partitioning into sub-regions \(\textbf{X}_i \in \mathbb {R}^{H/k \times W/k \times C}\), with k representing the partition factor. These localized fragments are then processed via foundational encoder branches, each integrating self-attentive convolutional blocks. These blocks–comprising standard convolution followed by Batch Normalization (BN)–are stacked to generate a refined high-level feature map with a spatial resolution of \(H/4 \times W/4\).
To consolidate the split feature streams, a fusion attention mechanism is embedded within the branches, interlinking the K feature maps \(\{\textbf{U}_r\}_{r=1}^K\) as illustrated in Fig. 2(b). This module initiates the fusion process by executing an element-wise summation across the K maps, effectively merging the disparate branch outputs. Subsequently, a global average pooling operation is performed on the integrated map to extract the holistic context vector s, which encapsulates the global statistical information of the fused features.
Following the global pooling stage, the context vector is mapped through a bottleneck structure consisting of two fully connected (FC) layers. By employing a nonlinear activation function, such as Softmax, the module generates a set of discrete attention weights \(\{a_r\}_{r=1}^K\) corresponding to each split branch. These coefficients are subsequently used to recalibrate the initial feature maps \(\{U_r\}_{r=1}^K\) via a gating mechanism, resulting in the following reconstructed feature representation:
The process yields K primary feature maps \(\{\textbf{V}_i\}_{i=1}^K\), which serve as inputs to a channel-wise attention mechanism. This stage generates a corresponding series of feature saliency maps by emphasizing task-relevant channels within each branch. Subsequently, these refined outputs are dimensionally integrated via a concatenation operation along the channel axis, resulting in a high-dimensional feature volume that encapsulates the synergistic information from all split branches.
Here, \(V_{i,j}\) denotes the output of a \(1 \times 1\) convolution operation. Specifically, the index i signifies the channel-wise orientation, while j represents the j-th spatial slice within the k-th feature map. For the implementation presented in this study, the hyperparameters K and n are both assigned a value of 2.

The structure of the deep splitting module (a) and the fusion attention (b).
Multi-dimensional transformer modules
Drawing inspiration from recent advancements33,34, we introduce the MT module to rectify the spatial and channel modeling deficiencies of traditional self-attention in medical vision tasks. As depicted in Fig. 3, the module comprises Efficient Self-Attention (ESA), alongside dedicated Spatial (SSA) and Channel (CSA) attention components. To bridge the gap in locality modeling, the architecture couples these attention mechanisms with parallel convolutional branches. Through an adaptive interaction mechanism, the model dynamically reweights and merges global dependencies with local structural cues, thereby achieving a superior balance of information.
Efficient Self-Attention (ESA): Standard self-attention35 performs a linear mapping on the input sequence \(X \in \mathbb {R}^{N \times D}\) (where \(N = H \times W\)) to obtain:
and computes:
The computational complexity of this operation is \(O(N^2)\).
For Efficient Self-Attention, a modified equation reduces the computational burden:
The transformation of the key sequence K is achieved by a spatial decomposition and subsequent linear projection. Specifically, K is reshaped to \(\frac{N}{R} \times (C \cdot R)\), a process governed by the hyper-parameters N, C, and R. By applying a linear transformation layer that maps \(C_{\text {in}}\) to \(C_{\text {out}}\), the resultant key matrix adopts a final dimension of \(\frac{N}{R} \times C\). Consequently, the quadratic complexity of \(O(N^2)\) is curtailed to \(O(N^2/R)\). This strategy leverages the factor R to significantly lower the memory footprint and computational overhead during the attention calculation.
Given an input \(X_{\text {in}}\), the output of Efficient Self-Attention (ESA) can be written as:
Here, \(Y_E\) represents the output from the ESA operation, where the input sequence \(X_{\text {in}}\) undergoes the ESA transformation and is added to the original input sequence.
Spatial Self-Attention (SSA): Accurate delineation of boundaries and morphological structures in medical imaging relies heavily on robust spatial-level representations. To enhance the spatial discriminative power of the feature maps, we extend the self-attention paradigm to the spatial axis, as illustrated in Fig. 3. Specifically, given an input feature map \(f \in \mathbb {R}^{H \times W \times C}\), we execute a linear projection to map the original features into the following latent space:
Here, f represents the input feature map, while \(W_Q^s\), \(W_K^s\), and \(W_V^s \in \mathbb {R}^{C \times C}\) denote the learnable weight matrices responsible for generating queries, keys, and values within the spatial domain. These projection matrices are implemented without bias terms. Following the linear mapping, the resulting Q, K, and V are segmented into discrete, non-overlapping windows. Each window is subsequently flattened to form the localized representations \(Q_{sp}\), \(K_{sp}\), and \(V_{sp}\), which are then allocated across h parallel attention heads:
Each head’s output is then computed as follows:
where \(D\) signifies the relative position encoding. By reshaping and concatenating the outputs \(Y_{sp}^i\) from all heads, we acquire the feature map \(Y_{sp}\):
The variable \(W_{\text {merge}}\) signifies the linear transformation layer responsible for integrating the multi-head features. To augment the model’s spatial awareness and introduce necessary inductive biases, we supplement the attention mechanism with parallel depth-wise convolutional pathways. This architectural choice is designed to capture fine-grained local textures that attention layers might overlook. Specifically, for an input feature map f, the extraction of localized spatial information is formulated as follows:
Here, \(Y_{\text {local}}\) contains the local features that encode 2D spatial position information, which can be used to capture position-related information in the feature map. Given two features \(X_1\) and \(X_2 \in \mathbb {R}^{H \times W \times C}\), we apply two interaction mechanisms to better fuse and aggregate these features:
The mechanism of interaction between the features \(X_1\) and \(X_2\) is defined as:
To implement the gating and pooling mechanisms, we utilize the sigmoid function (\(\sigma\)) and global average pooling (\(\text {GAP}\)). For the adjustment of channel depth, point-wise convolutions with weight matrices W are applied to perform dimensional expansion or reduction. These operations are governed by the following ratio settings:
For a provided input tensor \(X_{\text {in}}\), the feature transformation within the Spatial Self-Attention (SSA) module yields the output defined by:
In this architecture, \(W_{\text {merge}}\) serves as the fusion projection matrix, yielding the final SSA output \(Y_S\).
Complementing the spatial analysis,Channel Self-Attention (CSA) is introduced to resolve intricate inter-channel dependencies, which is vital for segmenting medical targets with diverse scales and morphologies. By extending the self-attention paradigm to the channel axis, CSA effectively synergizes with the Transformer’s token-based attention. Specifically, the input f is projected into channel-wise queries, keys, and values (\(Q_{\text {ch}}, K_{\text {ch}}, V_{\text {ch}}\)), which are subsequently reshaped into \(R \times HW \times C\). These representations are then partitioned into h independent heads, where the attention mechanism for the i-th head is executed as follows:
The channel-specific feature enhancement within the i-th head is represented by the output \(Y_{\textrm{ch}}^i\). The response of this attention operation is governed by a learnable factor \(\alpha\), which acts as a scaling coefficient. By adaptively tuning the attention sensitivity through \(\alpha\), the module ensures a more robust feature representation across different medical imaging scales and shapes.
The global channel-wise feature map, \(Y_{\textrm{Ch}}\), is synthesized by aggregating the individual outputs \(Y_{\textrm{ch}}^i\) from all heads. This process involves a concatenation operation followed by a spatial-channel reshaping, after which the integrated features are refined through a linear projection matrix \(W_{\textrm{merge}}\) to produce the final representation:
Given an input \(X_{\text {in}}\), the output from Channel Self-Attention (CSA) is computed as:
Finally, the output of the multi-dimensional Transformer block can be formulated as:
A comprehensive feature space for medical segmentation is established by aggregating the initial self-attention with its spatial and channel-wise counterparts. This fusion is governed by the weights \(\lambda _1 = 0.6\) and \(\lambda _2 = 0.4\), which balance the contribution of the SSA and CSA branches, respectively. After the weighted summation, a multilayer perceptron (MLP) is applied to the combined result to produce the final block output Y, ensuring that the network effectively distills both geometric and semantic correlations.

Architecture of multi-dimensional transformer modules.
Interactive attention mechanism(LA)
To further enhance the model’s perception of image structure and positional information, this study introduces an interactive attention mechanism (LA) that integrates multi-scale and multi-directional contextual information. The design philosophy of this module is to capture rich spatial structural statistical features through multi-directional pooling operations and utilize a direction-sensitive attention mechanism to assign adaptive weights to different positions in the feature map, thereby enhancing the expression of significant regions. This process effectively alleviates the performance degradation in segmentation tasks under scenarios with blurry boundaries, rich target details, or complex structures.
Given the input feature map \(x \in \mathbb {R}^{B \times C \times H \times W}\), we first obtain multi-source structural information through four different directional pooling operations. Specifically, horizontal average pooling:
captures global statistical features at the row level in the horizontal direction. Vertical maximum pooling:
extracts significant responses along the column direction and retains texture and edge information. Furthermore, to enhance direction invariance and rotation robustness, we perform \(90^\circ\) and \(270^\circ\) rotations on the input feature map and apply average pooling:
These operations capture spatial structural statistical information from different directions, providing multi-view contextual information for the subsequent feature fusion.
To integrate these multi-source features, we concatenate \(x_{\textrm{avg}}, x_{\textrm{max}}, x_{\textrm{rot1}}, x_{\textrm{rot2}}\) along the channel dimension and perform 1\(\times\)1 convolution for feature integration. Then, batch normalization (BN) and nonlinear activation function \(\delta (\cdot )\) (e.g., ReLU or H-swish) are applied to enhance the feature representation ability:
After obtaining the fused feature \(f\), two parallel convolution branches are used to generate the attention weights in the horizontal and vertical directions:
where \(\sigma (\cdot )\) represents the Sigmoid function, and \(\textrm{Conv}_H\) and \(\textrm{Conv}_W\) are the convolution operations performed along the height and width directions, respectively. The two attention maps are multiplied using broadcasting to obtain the 2D spatial attention map:
This attention map characterizes the importance distribution at each position in the spatial domain.
Finally, the input feature map is multiplied pixel-wise with the attention map to recalibrate the features based on spatial saliency:
Thus, we obtain the enhanced feature map:
The model’s proficiency in boundary localization and fine-grained recognition is augmented by a strategic weighting process. While maintaining a comprehensive grasp of global information, this approach prioritizes structural components through higher response intensities. Consequently, the network achieves a more refined balance between holistic context awareness and localized detail extraction.
To optimize model efficiency, the LA mechanism implements a targeted weighting strategy on salient regions of the input feature map. This process is underpinned by a dual-stream analysis that considers both spatial coordinates and directional context. Beyond spatial focus, the LA framework deciphers complex relationships between distinct channels, thereby enhancing the model’s capacity to resolve the intricate internal architecture of feature representations(Fig. 4).

Architecture of LA.
Experiments
Dataset
The Synapse multi-organ segmentation dataset originates from the MICCAI 2015 Multi-Graph Abdominal Tagging Challenge. Unlike single-organ tasks, this dataset requires the simultaneous delineation of eight abdominal structures: the aorta, gallbladder, spleen, liver, pancreas, stomach, and both kidneys. Comprising 30 clinical abdominal CT scans, the collection yields 3,778 2D slices, with each volume containing between 85 and 192 sections. For our experiments, all images were standardized to a \(512 \times 512\) resolution. The voxel spatial resolution varies within the ranges of \(([0.54 \sim 0.54] \times [0.98 \sim 0.98] \times [2.5 \sim 5.0]) \text { mm}^3\). We utilized 18 cases for model training and reserved the remaining 12 for performance evaluation.
The Skin Lesion Segmentation dataset, curated for the ISIC 2018 challenge, serves as a benchmark for skin lesion analysis, including segmentation and diagnostic classification. This collection comprises 2,594 images with a fixed resolution of \(512 \times 512\) pixels. The diagnostic distribution of the dataset includes melanoma (20.0%), melanocytic nevi (72.0%), and seborrheic keratosis (8.0%). Our study focuses on the segmentation masks provided to enhance lesion boundary detection.
The Chest X-Ray dataset utilized in this study for lung segmentation is sourced from a collaborative effort between the U.S. National Library of Medicine (NIH) and Shenzhen No.3 People’s Hospital in China. The dataset provides 710 chest radiographs along with their corresponding ground-truth annotations. Prior to training, all X-ray films were rescaled to a uniform size of \(512 \times 512\) to maintain consistency across the experimental pipeline.
Evaluation metrics
The efficacy of the proposed method is validated using five standard statistical indicators to ensure a comprehensive analysis of the segmentation maps. Specifically, the degree of overlap and boundary fidelity are quantified through Dice, IoU, RVD, ASSD, and MSD. Within this evaluative framework, we represent the reference ground truth as \(R_{gt}\) and the automated segmentation result as \(R_{seg}\). These metrics are computed according to the following equations:
-
1.
Dice coefficient (Dice): This metric measures the normalized overlap between two sets, specifically the ratio of their intersection to their total volume. The coefficient spans the interval [0, 1], where a maximal value of 1 denotes an absolute correspondence between the target and the predicted structures.
$$\begin{aligned} \text {DIC}&= \frac{2 \left( R_{\text {gt}} \cap R_{\text {seg}} \right) }{R_{\text {gt}} + R_{\text {seg}}} \end{aligned}$$(29) -
2.
Intersection over Union (IoU): This metric defines the overlap ratio between the inferred segmentation and the reference gold standard. By calculating the intersection-to-union area, it provides a normalized assessment of the model’s accuracy in capturing the target structure’s extent.
$$\begin{aligned} \text {IOU}&= \frac{\left| R_{\text {seg}} \cap R_{\text {gt}} \right| }{\left| R_{\text {seg}} \cup R_{\text {gt}} \right| } \end{aligned}$$(30) -
3.
Relative Volume Difference (RVD): This parameter assesses the volumetric mismatch between the predicted and actual segmentation results. The proximity of the RVD value to zero is a direct indicator of high segmentation accuracy, reflecting the model’s capability to correctly estimate the overall scale of the target organs.
$$\begin{aligned} \text {RAVD}&= \frac{R_{\text {seg}}}{R_{\text {gt}}} - 1 \end{aligned}$$(31) -
4.
Average Symmetric Surface Distance (ASSD): ASSD characterizes the mean separation between the surfaces of the automated segmentation \(R_{seg}\) and the ground truth \(R_{gt}\). Let d(a, b) represent the distance between points on the opposing boundaries. By averaging these symmetric surface deviations, the metric provides a comprehensive measure of how closely the predicted shape conforms to the actual anatomical structure.
$$\begin{aligned} \text {ASSD}&= \frac{1}{\left| R_{\text {seg}} \right| + \left| R_{\text {gt}} \right| } \left( \sum _{a \in R_{\text {seg}}} \mathop {\min }\limits _{b \in R_{\text {gt}}} d(a, b) + \sum _{b \in R_{\text {gt}}} \mathop {\min }\limits _{a \in R_{\text {seg}}} d(a, b) \right) \end{aligned}$$(32) -
5.
Maximum Symmetric Surface Distance (MSD): MSD quantifies the maximal spatial gap between the segmented surface \(R_{seg}\) and the gold standard \(R_{gt}\). Lower MSD values correspond to a superior alignment of the entire contour, ensuring that the model’s prediction does not suffer from significant localized deviations. This metric serves as a rigorous benchmark for the consistency of morphological boundaries.
$$\begin{aligned} \text {MSD}&= \left( \mathop {\max }\limits _{i \in R_{\text {seg}}} \left( \mathop {\min }\limits _{j \in R_{\text {gt}}} d(i, j) \right) , \mathop {\max }\limits _{i \in R_{\text {gt}}} \left( \mathop {\min }\limits _{j \in R_{\text {seg}}} d(i, j) \right) \right) \end{aligned}$$(33)
Experimental details
The proposed models were developed in Python 3.8 and executed within a PyTorch environment. Our computational infrastructure consisted of an Intel Xeon E5-2680 v4 processor and 128 GB of DDR4 memory, while parallel processing was facilitated by eight NVIDIA RTX 2080Ti GPUs. Training Protocol: We adopted a consistent set of hyperparameters for all benchmarking experiments. Specifically, models were optimized via the Adam algorithm over 200 training epochs. The training pipeline employed a batch size of 16, an initial learning rate of 0.0003, and a weight growth rate of 0.0001.
To rigorously validate the efficacy of the proposed D3T-Net, we conducted a comprehensive benchmarking analysis against five state-of-the-art (SOTA) segmentation architectures: U-Net36, UNet++19, SWinU-Net37, TransU-Net9, HiFormer38 DCSAU-Net39, TM-UNet40,HRMedSeg41, MambaVesselNet++39, Co-Seg++42 and HCMFDS-Net43. For a fair assessment, all baseline models were initialized with their default parameter configurations and underwent a complete retraining process on our training set for 200 epochs. To mitigate experimental stochasticity and ensure statistical significance, each model was evaluated five times on the test set, with the final results reported as the mean value across all metrics.
Comparison with state-of-the-art methods
The efficacy of D3T-Net is validated through extensive experiments across three representative medical imaging tasks, involving multi-organ, skin lesion, and pulmonary segmentation. By leveraging the Synapse, ISIC2018, and Chest X-ray datasets, we provide a multifaceted assessment of the model’s performance. The experimental results are meticulously compared with top-tier segmentation baselines, including U-Net, UNet++, swin-Unet, TransUNet, HiFormer, kDCSAU-Net, TM-UNet,HRMedSeg,MambaVesselNe++t,Co-Seg++,HCMFDS-Net, utilizing both statistical metrics and visual heatmaps for a thorough performance analysis.
Experiments on the Synapse multi-organ segmentation dataset
In the Synapse multi-organ segmentation dataset, we conducted a systematic comparison of D3T-Net with multi-class representative methods, and the quantitative results are shown in Table 1. D3T-Net achieved the best score of 81.49 in the Dice index, outperforming all the comparison methods. Compared with U-Net, D3T-Net improved by 5.62 percentage points, indicating that the proposed model has a significant advantage in the overall regional consistency of multi-organs. Compared with the Transformer or hybrid structure baseline, D3T-Net still leads, improving by 1.78 compared to TransUNet and 1.54 compared to HiFormer, demonstrating that the dual-branch collaborative modeling can further enhance the local structure characterization ability while maintaining global semantic consistency. In the recent method comparison, D3T-Net also surpassed HRMedSeg, Co-Seg++, and HCMFDS-Net, demonstrating the stable advantage and good generalization ability of this structure in the Synapse task.
It is noteworthy that the IoU value of D3T-Net appears relatively lower despite its superior Dice and boundary-related performance. This discrepancy is mainly related to differences in aggregation strategies and the sensitivity of IoU to class imbalance in multi-organ segmentation. Dice is computed as a macro-average across foreground organs, whereas IoU is aggregated using dataset-level accumulation with different handling of empty slices and union terms, which weakens the strict correspondence between the two metrics. Furthermore, IoU penalizes small false-positive expansions more strongly, particularly in small organs and weak-boundary regions. Since D3T-Net emphasizes boundary continuity and structural completeness, slight peripheral expansions that improve contour stability may increase the union term and lead to a relatively lower IoU without indicating degraded segmentation quality. The superior ASSD and MSSD results further support that the model effectively reduces extreme boundary deviations, explaining the observed metric divergence.
From the visualization results in Fig 5, it can be further observed that the segmentation masks of D3T-Net are more stable in terms of the conformity of organ contours, the separation at organ junctions, and the preservation of small structures compared to the true labels. Compared with some comparison methods that exhibit boundary adhesion or contour rupture in the contact areas between the liver and adjacent organs, the boundaries of D3T-Net are more continuous and closer to the true contours, and can better maintain the integrity of the anatomical structure. In the regions of small organs such as the gallbladder and pancreas, D3T-Net covers more completely and has fewer local gaps, reflecting the model’s stronger ability to recognize low-contrast small targets. Some methods show obvious expansion or contraction of local boundaries, resulting in an increase in boundary deviation in the worst-case scenario. However, D3T-Net’s predictions at these difficult locations are more stable and restrained, which is consistent with the conclusion in Table 1 that it achieves the lowest MSSD, indicating that the model has stronger robustness for complex structures and fuzzy boundary areas.

Visualization of the segmentation results of D3T-Net on the Synapse multi-organ segmentation dataset.
Experiments on the ISIC 2018 skin lesion dataset
On the ISIC 2018 skin lesion segmentation dataset, we evaluated D3T-Net against a wide range of competing methods. The quantitative results in Table 2 demonstrate that D3T-Net achieves the best overall overlap accuracy, reaching a Dice score of 90.79 and an IoU of 82.18, both of which are the highest among all compared methods. Relative to U-Net with a Dice of 85.27 and U-Net++ with a Dice of 87.93, D3T-Net improves the Dice score by 5.52 and 2.86 percentage points, respectively, indicating a clear advantage in lesion region delineation. Compared with strong Transformer-based baselines, D3T-Net also shows consistent gains, exceeding TransUNet with a Dice of 88.65 by 2.14 points and surpassing HiFormer with a Dice of 88.31 by 2.48 points, suggesting that the proposed dual-branch design effectively combines local boundary cues with global contextual reasoning for more accurate lesion segmentation. In addition, D3T-Net delivers the lowest RAVD value of 5.48, which is markedly smaller than SwinUNet, TransUNet, HiFormer, Co-Seg++, and HCMFDS-Net, indicating reduced volume bias and better consistency in lesion size estimation. For boundary robustness, D3T-Net achieves an MSSD of 28.96, which is lower than many competing methods such as U-Net, U-Net++, SwimUNet, HiFormer, Co-Seg++, and HCMFDS-Net, implying fewer extreme surface deviations and improved stability against challenging boundary outliers. Although the ASSD value of D3T-Net is 18.93 and is not the lowest among all methods, the combination of the best Dice and IoU together with the lowest RAVD and a comparatively low MSSD indicates that D3T-Net achieves a strong balance between region overlap, volumetric fidelity, and worst-case boundary error control.
The qualitative comparisons in Fig. 6 further corroborate these observations, where D3T-Net produces smoother and more continuous lesion contours with more complete target coverage, while several competing methods exhibit jagged edges, local holes, or mild over-expansion and under-segmentation around ambiguous borders, which can undermine reliability in clinical scenarios with low-contrast and irregular lesion boundaries.

Visualization of the segmentation results of D3T-Net on the ISIC 2018 skin lesion dataset.
Experiments on the chest X-ray dataset
On the Chest X-Ray dataset, we further evaluated D3T-Net against a broad spectrum of competing approaches. The quantitative results in Table 3 indicate that D3T-Net achieves the best overall performance across the main overlap and boundary-related metrics, obtaining a Dice score of 97.78 and an IoU of 94.84, both of which are the highest among all compared methods. Relative to U-Net with a Dice of 96.12 and U-Net++ with a Dice of 96.63, D3T-Net improves Dice by 1.66 and 1.15 percentage points, respectively, confirming its advantage even on a relatively easier high-contrast anatomical segmentation task. Compared with Transformer-based baselines, D3T-Net also shows clear gains, surpassing TransUNet with a Dice of 96.83 by 0.95 points and exceeding HiFormer with a Dice of 96.42 by 1.36 points, indicating that the proposed dual-branch modeling can provide complementary local and global cues that benefit lung field delineation.
In addition to region overlap, D3T-Net demonstrates strong boundary fidelity. It achieves an MSSD of 6.28, which is the lowest among all methods, indicating the smallest worst-case surface deviation and improved robustness against extreme boundary errors. This advantage is particularly meaningful for chest radiographs, where the lung contour includes challenging regions around the cardiac silhouette and the costophrenic angles. D3T-Net also maintains a competitive ASSD of 2.19, comparable to TransUNet at 2.16 and HRMedSeg at 2.26, while providing markedly better worst-case boundary control than these methods. For volumetric consistency, D3T-Net yields an RAVD of −3.57. Although this value is not the closest to zero among all methods, the consistently superior Dice and boundary metrics suggest that D3T-Net prioritizes contour integrity and full coverage of the lung field, which can be beneficial for downstream clinical measurements that require complete anatomical delineation.
The qualitative comparisons in Fig. 7 further corroborate these quantitative results. D3T-Net produces smooth and anatomically consistent lung masks with clear boundaries, especially in difficult regions where other methods tend to over-expand near the heart shadow or exhibit local boundary shifts at the lung apices and diaphragmatic contours. Several competing approaches show minor contour irregularities or under-coverage in low-contrast areas, whereas D3T-Net yields more complete and coherent segmentation, aligning closely with the ground truth. Overall, these results demonstrate that D3T-Net achieves robust and accurate lung field segmentation on chest X-ray images, combining high overlap accuracy with improved worst-case boundary reliability.

Visualization of the segmentation results of D3T-Net on the Chest X-Ray dataset.
Ablation studies
In order to further verify the independent effects and synergistic effects of each key module of D3T-Net, we designed a stepwise ablation experiment on the Synapse dataset. The combination forms include basic U-Net (U), adding DSM module (D), adding multi-dimensional Transformer module (M), introducing multi-scale skip connection (MS), fusing LA module (L), and finally forming the complete D3T-Net architecture. Table 4 shows that the introduction of each module resulted in a significant performance improvement: In order to evaluate the role of DSM module, compared with U, Dice of U+D is improved from 75.87 to 76.34, and RVD is improved from −8.19 to −7.22, indicating that DSM has a clear contribution in direction perception and local structure modeling.
In order to evaluate the role of MT module, compared with U+D, Dice of U+D+M is further increased to 76.53, and MSD is reduced from 28.64 to 27.16, which reflects the importance of MT in global modeling. In order to evaluate the effect of MS, compared with U+D+, Dice of U+D+M+MS increases to 78.68, RVD changes from −6.29 to 4.58, and ASSD decreases to 4.85, indicating that the multi-scale connection mechanism can effectively improve semantic consistency and structural continuity.
In order to evaluate the effect of LA, compared with U+D+M+MS+L, DIC is further increased to 79.27, IOU is increased to 67.92, and MSD is reduced to 24.13, which highlights the key role of directional spatial attention mechanism in saliency enhancement.
The final D3T-Net model achieves the best performance in five indicators, Dice is 81.49, IOU is 61.42, ASSD is 4.23, which verifies that the collaborative design of each module has a significant superposition advantage in performance.
In the ablation experiment visualization of Fig 8, we can observe that the segmentation of small organs or boundary complex structures by the basic U-Net model appears obvious deviation, and there is missing or wrong segmentation. After adding DSM, the edges of the structure are clearer, but the overall shape is still incomplete. After introducing the MT module, the overall shape of the model is closer to the real structure, especially in the long strip or asymmetric organ area, the performance is more stable. After adding MS connection, the complete prediction of large organs such as liver and pancreas was significantly improved. The final model D3T-Net shows the advantages of boundary close to the real label, no fracture, and coherent morphology in all visualization graphs, especially at the junction of multiple organs, it shows excellent discrimination ability.
To evaluate the effectiveness of the proposed interactive attention module, we conducted quantitative ablation experiments under different directional interaction settings, as summarized in Table 5. When only the basic pooling-based interaction is applied, the model achieves a Dice of 80.32 and an MSSD of 23.12, indicating that limited feature interaction provides moderate performance gains. Introducing single-direction interaction improves Dice to 80.58 while reducing ASSD and MSSD, suggesting that directional feature exchange enhances structural consistency and boundary stability. When full multi-directional interaction is enabled, the model reaches the best performance with a Dice of 81.49, IoU of 61.43, and the lowest boundary deviation, reflected by ASSD of 4.23 and MSSD of 22.31. These results demonstrate that multi-directional interactive attention effectively strengthens cross-branch information alignment, allowing the model to better capture complementary local and global features and suppress extreme boundary errors. The consistent improvement across overlap and boundary metrics confirms the necessity of the proposed interaction design.
In summary, through numerical and image comparison, the positive contribution and collaborative gain of each module to the segmentation performance are fully verified, and the scientific and effective design of the proposed D3T-Net architecture is also verified.

Visualization of ablation experiment segmentation results on the Synapse multi-organ segmentation dataset.
Complexity calculation
To further assess whether the performance gains of D3T-Net justify its architectural complexity, we compared its computational cost with a diverse set of streamlined hybrid and transformer-based segmentation models, as summarized in Table 6. Although D3T-Net adopts a dual-branch design, its computational requirement remains moderate, requiring 40.14 GFLOPs, which is comparable to classical CNN baselines such as U-Net and U-Net++ and substantially lower than transformer-dominant frameworks such as TransUNet and Co-Seg++. This suggests that the proposed multi-dimensional Transformer branch introduces global modeling capability without incurring excessive computational overhead.
From an inference perspective, D3T-Net achieves a latency of 22.98 ms, remaining competitive with widely used segmentation networks and noticeably faster than several hybrid and transformer-based approaches including TransUNet, HiFormer, and MambaVesselNet++. While D3T-Net contains 51.58M parameters, exceeding compact memory-efficient designs such as DCSAU-Net, TM-UNet, and HRMedSeg, the parameter increase is accompanied by consistent improvements in Dice and boundary-related metrics, indicating that the additional capacity contributes directly to segmentation quality rather than redundant complexity.
Importantly, compared with streamlined single-stream hybrid models that integrate attention within a single backbone, the dual-branch structure of D3T-Net enables parallel modeling of local texture and global context, leading to improved boundary reliability and structural consistency while maintaining feasible runtime cost. Overall, these results demonstrate that D3T-Net achieves a favorable accuracy–efficiency trade-off, where the moderate increase in parameters is justified by measurable gains in overlap accuracy and boundary robustness, supporting its practical applicability in clinical scenarios.
These findings indicate that D3T-Net improves segmentation fidelity, particularly boundary robustness and structural consistency, with only a moderate increase in computational cost, demonstrating a practical and well-balanced accuracy–efficiency trade-off.
Conclusion
This paper introduces D3T-Net, a hybrid framework engineered to simultaneously capture fine-grained local textures and long-range dependencies, thereby facilitating high-precision segmentation of clinical organs and lesions. By unifying the strengths of CNNs and Transformers, the architecture comprises a localized extraction stream and a remote dependency pathway. Specifically, we developed a Deep Splitting Module (DSM) within the CNN branch to refine local representations via multi-pathway sub-branches. Concurrently, the Multi-dimensional Transformer (MT) modules resolve spatial and channel-wise correlations, mitigating the inherent locality limitations of standard self-attention. To synchronize these dual streams, a Direction-aware Interaction Attention (LA) module is deployed in the encoder to distill orientation-specific structural cues. Furthermore, a cross-attention mechanism in the decoder facilitates feature reorganization, while multi-scale fusion skip connections ensure efficient feature propagation and robust boundary retention. Extensive benchmarking against state-of-the-art methods validates the superior performance and generalization of D3T-Net across diverse public datasets.
Data availability
All datasets analyzed in this study are in the public domain. This includes the Synapse multi-organ set (https://gitcode.com/UniversalTool/058d2), the ISIC Skin Lesion set (https://challenge.isic-archive.com/landing/2018/), and the Chest X-Ray set (https://lhncbc.nlm.nih.gov/publication/pub9931). For inquiries regarding specific experimental data, the corresponding author should be contacted.
References
Huang, Z., Ling, Z., Gou, F. & Wu, J. Medical assisted-segmentation system based on global feature and stepwise feature integration for feature loss problem. Biomed. Signal Process. Control 89, 105814 (2024).
Wang, Z. et al. Dual-branch dynamic hierarchical u-net with multi-layer space fusion attention for medical image segmentation. Sci. Rep. 15, 8194 (2025).
Nazir, A., Hussain, A., Singh, M. & Assad, A. Deep learning in medicine: Advancing healthcare with intelligent solutions and the future of holography imaging in early diagnosis. Multimed. Tools Appl. 84, 17677–17740 (2025).
Ahmed, S. F. et al. Deep learning modelling techniques: Current progress, applications, advantages, and challenges. Artif. Intell. Rev. 56, 13521–13617 (2023).
Zhao, X. et al. A review of convolutional neural networks in computer vision. Artif. Intell. Rev. 57, 99 (2024).
Kassaymeh, S., Alweshah, M., Al-Betar, M. A., Hammouri, A. I. & Al-Ma’aitah, M. A. Software effort estimation modeling and fully connected artificial neural network optimization using soft computing techniques. Cluster Comput. 27, 737–760 (2024).
Azad, R. et al. Medical image segmentation review: The success of u-net. IEEE Trans. Pattern Anal. Mach. Intell. https://doi.org/10.1109/TPAMI.2024.3435571 (2024).
Peng, Y., Chen, D. Z. & Sonka, M. U-net v2: Rethinking the skip connections of u-net for medical image segmentation. In 2025 IEEE 22nd International Symposium on Biomedical Imaging (ISBI), 1–5 (IEEE, 2025).
Chen, J. et al. Transunet: Rethinking the u-net architecture design for medical image segmentation through the lens of transformers. Med. Image Anal. 97, 103280 (2024).
Shu, X., Wang, J., Zhang, A., Shi, J. & Wu, X.-J. Csca u-net: A channel and space compound attention CNN for medical image segmentation. Artif. Intell. Med. 150, 102800 (2024).
Fu, B. et al. Hmsu-net: A hybrid multi-scale u-net based on a CNN and transformer for medical image segmentation. Comput. Biol. Med. 170, 108013 (2024).
Zhang, H. & Shafiq, M. O. Survey of transformers and towards ensemble learning using transformers for Natural Language Processing. J. Big Data 11, 25 (2024).
Haruna, Y. et al. Exploring the synergies of hybrid convolutional neural network and vision transformer architectures for computer vision: A survey. Eng. Appl. Artif. Intell. 144, 110057 (2025).
Han, K. et al. A survey on vision transformer. IEEE transactions on pattern analysis and machine intelligence 45, 87–110 (2022).
Tragakis, A., Kaul, C., Murray-Smith, R. & Husmeier, D. The fully convolutional transformer for medical image segmentation. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, 3660–3669 (2023).
Mienye, I. D., Swart, T. G., Obaido, G., Jordan, M. & Ilono, P. Deep convolutional neural networks in medical image analysis: A review. Information 16, 195 (2025).
Kattenborn, T., Leitloff, J., Schiefer, F. & Hinz, S. Review on convolutional neural networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 173, 24–49 (2021).
Pan, P., Zhang, C., Sun, J. & Guo, L. Multi-scale conv-attention U-Net for medical image segmentation. Sci. Rep. 15, 12041 (2025).
Zhou, Z., Rahman Siddiquee, M. M., Tajbakhsh, N. & Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In International workshop on deep learning in medical image analysis, 3–11 (Springer, 2018).
Das, N. & Das, S. Attention-Unet architectures with pretrained backbones for multi-class cardiac MR image segmentation. Curr. Probl. Cardiol. 49, 102129 (2024).
Alom, M. Z., Yakopcic, C., Taha, T. M. & Asari, V. K. Nuclei segmentation with recurrent residual convolutional neural networks based u-net (r2u-net). In NAECON 2018-IEEE National Aerospace and Electronics Conference, 228–233 (IEEE, 2018).
Chen, C., Shi, J., Xu, Z. & Wang, Z. Attention Unet3+: A full-scale connected attention-aware Unet for CT image segmentation of liver. J. Electron. Imaging 32, 063012–063012 (2023).
Wolf, T. et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, 38–45 (2020).
Arnab, A. et al. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF international conference on computer vision, 6836–6846 (2021).
Chen, C.-F. R., Fan, Q. & Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF international conference on computer vision, 357–366 (2021).
Okolo, G. I., Katsigiannis, S. & Ramzan, N. Ievit: An enhanced vision transformer architecture for chest x-ray image classification. Comput. Methods Programs Biomed. 226, 107141 (2022).
Manzari, O. N., Ahmadabadi, H., Kashiani, H., Shokouhi, S. B. & Ayatollahi, A. Medvit: A robust vision transformer for generalized medical image classification. Comput. Biol. Med. 157, 106791 (2023).
Hussain, T. et al. Effresnet-vit: A fusion-based convolutional and vision transformer model for explainable medical image classification. IEEE Access https://doi.org/10.1109/ACCESS.2025.3554184 (2025).
Chen, J. et al. 3d transunet: Advancing medical image segmentation through vision transformers. arXiv:2310.07781 (2023).
Wang, W. et al. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF international conference on computer vision, 568–578 (2021).
Song, P., Li, J., Fan, H. & Fan, L. Dbcgn: Dual branch cascade graph network for skin lesion segmentation. Int. J. Mach. Learn. Cybern. 14, 2847–2865 (2023).
Hou, R., Chang, H., Ma, B., Shan, S. & Chen, X. Cross attention network for few-shot classification. Advances in neural information processing systems 32 (2019).
Li, X., Dong, J., Tang, J. & Pan, J. Dlgsanet: lightweight dynamic local and global self-attention networks for image super-resolution. In Proceedings of the IEEE/CVF international conference on computer vision, 12792–12801 (2023).
Chen, S. et al. Sparse sampling transformer with uncertainty-driven ranking for unified removal of raindrops and rain streaks. In Proceedings of the IEEE/CVF international conference on computer vision, 13106–13117 (2023).
Zhao, H., Jia, J. & Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10076–10085 (2020).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, 234–241 (Springer, 2015).
Cao, H. et al. Swin-unet: Unet-like pure transformer for medical image segmentation. In European conference on computer vision, 205–218 (Springer, 2022).
Heidari, M. et al. Hiformer: Hierarchical multi-scale representations using transformers for medical image segmentation. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, 6202–6212 (2023).
Xu, Q. et al. Dcsau-net: A deeper and more compact split-attention u-net for medical image segmentation. Comput. Biol. Med. 154, 106626 (2023).
Jiao, Y. et al. Tm-unet: Token-memory enhanced sequential modeling for efficient medical image segmentation. arXiv:2511.12270 (2025).
Xu, Q. et al. Hrmedseg: Unlocking high-resolution medical image segmentation via memory-efficient attention modeling. arXiv:2504.06205(2025).
Xu, Q., Luo, Y., Duan, W. & Chen, Z. Co-seg++: Mutual prompt-guided collaborative learning for versatile medical segmentation. IEEE Trans. Med. Imaging https://doi.org/10.1109/TMI.2025.3643631 (2025).
Zhao, Y. et al. Spatio-temporal memory-driven CT organ segmentation with hybrid CNN-mamba encoding and frequency-domain decoding. Neurocomputing https://doi.org/10.1016/j.neucom.2025.131137 (2025).
Acknowledgements
The author would like to express sincere gratitude to the Education Department of Heilongjiang Province and the Science and Technology Bureau of Qiqihar City for their financial support of this project.
Funding
This work was supported by the Qiqihar Science and Technology Plan Joint Guidance Project (LHYD-2021042), the 2024 Basic Scientific Research Business Expenses Project of Heilongjiang Provincial Undergraduate Universities (2024KYYWF-0345), and the science and technology planning project of Qiqihar (LSFGG-2025131).
Author information
Authors and Affiliations
Contributions
D.L and C.Y made significant contributions to the conceptualization and design of this study, as well as to the analysis of the data. Y.Y, Y.Q and H.Y made significant contributions to the acquisition of the data. All authors have approved the submitted version and any substantially modified version involving their contributions to the study. All authors have consented to assume responsibility for their contributions and to ensure that issues related to the accuracy or completeness of any part of the work, even if not directly related to the authors themselves, are properly investigated, resolved, and documented in the literature.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, D., Yuan, C., Yao, Y. et al. Dual-branch attention network with deep split convolution and multi-dimensional transformers for medical image segmentation. Sci Rep 16, 14238 (2026). https://doi.org/10.1038/s41598-026-44413-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-44413-8
