
Abstract
Depth completion aims to predict dense depth from sparse sensor measurements with corresponding RGB guidance. Existing methods commonly suffer from texture copying and edge blurring due to the explicit fusion of RGB features. To address this, we propose a frequency-guided refinement approach that decouples structure from texture transfer in the frequency domain. Specifically, we decompose RGB features into wavelet sub-bands, and learn content-adaptive kernels that promote smooth propagation for low frequencies while preserving sharp boundaries for high frequencies. Importantly, RGB information serves only as conditioning signals to determine when and how filtering is applied, rather than being directly mixed with depth representations. To further improve robustness, a reliability-aware cross-stage modulation uses encoder features as priors to enhance trustworthy structures and suppress uncertain updates during multi-scale reconstruction. Extensive experiments on benchmark datasets demonstrate that our method generates high-fidelity depth maps with sharp edges and suppressed texture artifacts, achieving state-of-the-art performance.
Similar content being viewed by others


Introduction
Accurate and dense depth information serves as the foundation for numerous applications in computer vision and robotics. It is essential for tasks such as autonomous driving1, 3D reconstruction2, augmented reality3 and robotic navigation4. Although depth sensing technology has made significant progress in recent years, existing depth sensors often suffer from severe sparsity issues due to physical constraints and cost considerations. For instance, vehicle-mounted LiDAR systems commonly used in autonomous driving and mobile mapping typically produce extremely sparse point clouds. Even advanced 64-line LiDAR sensors achieve less than 6% pixel coverage when projected onto image planes. Such highly sparse depth data cannot directly meet the requirements of downstream tasks. Therefore, how to recover accurate dense depth maps from sparse depth measurements, known as depth completion, has become a critical concern for both academia and industry.
The core challenge in depth completion lies in inferring complete scene geometry from extremely limited observational information. Relying solely on sparse depth data is insufficient to achieve satisfactory completion results. Consequently, existing methods5,6,7,8,9,10 commonly incorporate simultaneously captured RGB images as auxiliary information. They leverage structural cues from RGB images to guide depth completion. Mainstream approaches typically adopt encoder-decoder architectures that achieve sparse-to-dense conversion through multi-scale feature extraction and fusion. These methods have continuously innovated in network design. They have evolved from early single-branch networks11,12,13 to dual-branch14,15,16 architectures. The approaches have progressed from simple feature concatenation17,18 to complex attention mechanisms19,20,21. They have expanded from standard convolutions to specialized operators designed specifically for sparse data22,23,24.
However, despite significant progress on benchmark datasets, existing methods still face a fundamental problem when using RGB information to guide depth completion. Specifically, explicit cross-modal feature fusion in the spatial domain often leads to two conflicting artifacts. The first is texture copying, where surface textures in RGB images are incorrectly interpreted as depth variations. The second is edge blurring, where excessive smoothing strategies are adopted to suppress textures, leading to the loss of sharp geometric boundaries. Although existing methods attempt to alleviate this contradiction through various fusion strategies, they struggle to solve this problem fundamentally. This is because they apply uniform processing to all frequency components in the spatial domain.
To address the limitations of spatial-domain operations, a growing body of research has explored frequency-domain analysis for depth completion and related tasks25,26,27. Using tools such as wavelet or Fourier transforms, these methods decouple global structures from local details, mitigating the noise sensitivity inherent in spatial convolutions. However, most frequency-based methods focus on directly reconstructing depth values in the frequency domain or performing explicit fusion of spectral features. While effective at separating general high and low-frequency components, these approaches often lack a mechanism to dynamically adapt the spatial propagation process based on frequency content. Consequently, distinguishing between useful geometric boundaries and misleading RGB textures remains a challenge, particularly when they share similar high-frequency characteristics.
Building on these insights, we argue that frequency components should serve as guidance for dynamic spatial filtering rather than merely being reconstruction targets. We propose an RGB-conditioned frequency-domain refinement approach that decouples structural guidance from texture transfer. In our formulation, RGB acts only as a conditioning signal to determine when and how filtering is applied, rather than being directly fused with depth representations. Specifically, we introduce the Guided Refinement Module (GRM). GRM employs a Frequency-Guided Dynamic Convolution (FGDC), which first applies a Stationary Wavelet Transform (SWT) to decompose RGB features into sub-bands. It then generates content-adaptive kernels whose sizes and shapes are dynamically selected per sub-band. This design enables the network to employ large receptive fields for smooth propagation in low-frequency regions and small receptive fields to preserve edges in high-frequency areas, thereby achieving frequency-domain depth refinement. To further improve robustness, we introduce a reliability-aware cross-stage modulation to model and utilize the reliability information of depth features. This strategy uses depth encoder features as priors and complements FGDC by constraining refinement with reliability cues closer to the sparse input. As a result, it reduces over-smoothing and mitigates texture leakage.
The main contributions of this paper are summarized as follows:
-
We propose an RGB-conditioned frequency-domain refinement approach, fundamentally alleviating texture copying and edge blurring by avoiding direct feature fusion across modalities.
-
We design a frequency-guided dynamic convolution that achieves adaptive adjustment of receptive field and filtering strength according to local spectral characteristics.
-
We introduce a cross-stage modulation that leverages encoder features as priors to selectively enhance reliable structures and suppress uncertain updates.
-
Extensive experiments on benchmark datasets validate the effectiveness of the proposed method, which better preserves edges and suppresses texture artifacts compared with state-of-the-art approaches.
Related works
Depth completion methods can be categorized into two main classes based on whether additional modal information is introduced: non-guided methods and RGB-guided methods.
Non-guided methods
Non-guided depth completion methods rely solely on sparse depth map inputs for completion without utilizing guidance from other modal data (such as RGB images). Early non-guided methods were represented by sparsity-aware convolutional neural networks. Uhrig et al.28 proposed SI-CNN, which first applied deep learning to this task. They designed sparse convolution operations that use binary validity masks to distinguish between valid depth values and missing values. Convolution is performed only on valid data, avoiding the mosaic effects produced by standard convolutions on sparse inputs. This work laid the foundation for subsequent research. Huang et al.29 further proposed HMS-Net, which introduces sparsity-invariant operations to support the application of encoder-decoder architectures, significantly improving completion accuracy.
Normalized convolutional neural networks represent another important branch of non-guided methods. Their core improvement lies in replacing binary validity masks with continuous confidence maps to alleviate mask saturation problems in early network layers. Eldesokey et al.30 proposed NCNN, which generates continuous uncertainty maps through normalized convolution. They use the SoftPlus function31 to enforce non-negativity of kernel weights, stabilizing and accelerating training. The subsequent pNCNN32 further introduces self-supervised strategies to estimate input confidence maps. It suppresses interference from noisy measurements and improves performance with a lightweight network.

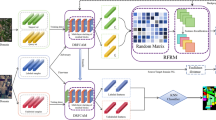
The architecture of the proposed network. The depth branch (blue) and RGB branch (orange) operate in parallel, with lighter shades indicating encoder stages and darker shades indicating decoder stages. The pre-filled sparse depth undergoes multi-scale encoding, while RGB features are extracted simultaneously. Guided Refinement Modules (GRMs) are placed at decoder scales to adaptively refine depth features using RGB information.
RGB-guided methods
RGB-guided depth completion methods fuse sparse depth maps with RGB images, leveraging semantic cues such as scene textures and edges provided by RGB to improve completion performance. These methods have gradually become the mainstream research direction in recent years. Early fusion models directly fuse multi-modal data at the input layer or first convolutional layer. Ma et al.11 concatenated RGB images with sparse depth maps and fed them into a ResNet-5033 based encoder-decoder network. They validated the accuracy advantages of RGB guidance under different sparsity levels. S2DNet34 further improved early fusion performance using a coarse-to-fine prediction strategy. It completes coarse prediction and refinement in stages through two pyramid networks.
Late fusion models use dual encoders to separately extract RGB and depth features, performing fusion at intermediate layers. This approach is more conducive to learning modality-specific features. Jaritz et al.14 adopted a dual-branch encoder that directly concatenates all intermediate layer features before feeding them to the decoder. GuideNet15 introduces guided convolution, learning spatially adaptive kernels from RGB features and applying them to depth features. It achieves more effective fusion through a dual encoder-decoder network structure.
Another class of methods is based on spatial propagation networks (SPN)35. The core idea is to model spatial correlations between depth points and their neighborhoods through affinity matrices. Cheng et al.36 proposed CSPN, which uses \(3\times 3\) local windows to replace directional propagation in SPN, achieving efficient spatial diffusion through convolution. CSPN++37 further adaptively learns the size and iteration count of propagation kernels to enhance propagation effects. DySPN38 introduces attention mechanisms to dynamically learn affinity matrices, optimizing the refinement process through recursive generation of attention maps. BP-Net10 proposes a 3-stage framework with an early bilateral propagation module. It dynamically generates propagation coefficients based on both radiometric difference and spatial distance to propagate dense initial depth from sparse measurements.
Inspired by the success of frequency domain analysis in image restoration39,40, researchers have recently introduced it into depth completion. These approaches aim to overcome the limitations of spatial operations, such as noise sensitivity and texture-structure entanglement. Ramamonjisoa et al.25 pioneered this paradigm by predicting sparse wavelet coefficients rather than direct depth values. They focus computation on high-frequency edges, significantly increasing efficiency while preserving fine details. Liu et al.26 further developed a dual-branch framework to explicitly decouple the estimation of high and low-frequency components. They use a low-pass filter to recover global structures and model high-frequency details through multi-modal fusion. More recently, Zhao et al.27 proposed a spatio-spectral framework based on Fourier analysis. This method effectively handles invalid regions and suppresses noise by enforcing phase consistency.
While these frequency-based works demonstrate the potential of frequency analysis, they primarily focus on reconstructing or directly fusing frequency features. Unlike these approaches, we propose leveraging frequency components to guide the learning of dynamic kernels. This strategy enables more effective separation of structural edges from textural noise during the propagation process, rather than merely reconstructing features in the frequency domain.
Methods
Overall framework
Given a sparse depth map \(D_0\in \mathbb {R}^{H\times W}\) from LiDAR point cloud projection and a color image \(I\in \mathbb {R}^{3 \times H \times W}\) as guidance reference, our goal is to predict accurate dense depth map \(\hat{D}\).
As shown in Fig. 1, to reduce the computational burden of the network, we first utilize non-learning methods41,42 to quickly pre-fill the sparse depth map. Then the RGB stream and depth stream perform feature extraction and reconstruction at multiple scales, respectively. Specifically, the encoder contains four downsampling levels, each composed of several residual blocks. It generates features at scales \(s \in \{1, 1/2, 1/4, 1/8, 1/16\}\). We deploy Guided Refinement Modules (GRM) at scales \(\{1, 1/2, 1/4, 1/8\}\) of the depth decoder. The GRM adaptively uses RGB features for frequency-guided refinement. This achieves specific guidance at different frequency bands, effectively suppressing edge blurring and texture copying. At the bottleneck scale \(s=1/16\), we only perform regular decoding without using GRM, since the highly compressed representation at this level primarily encodes global context and is unlikely to benefit from frequency-selective processing.

Schematic diagram of the Guided Refinement Module (GRM). The module consists of two parts: (1) Frequency-Guided Dynamic Convolution (FGDC), which dynamically selects kernels based on RGB frequency sub-bands to refine depth features; (2) Cross-stage Modulation, where encoder features modulate the FGDC output through attention mechanisms based on reliability priors.
For each scale \(s\) where GRM is deployed, the module takes three inputs: the upsampled depth decoder feature from the previous scale \(\tilde{F}^{dec}_{d,s}\), the RGB decoder feature at the current scale \(F^{dec}_{rgb,s}\) and the depth encoder feature from skip connections \(F^{enc}_{d,s}\). The update process for the depth branch at each scale is expressed as:
Finally, the predicted depth is obtained through a reconstruction layer at scale \(s=1\).
Next, we focus on introducing GRM, which comprises two parts. First, frequency-guided dynamic convolution learns filter shapes and selects appropriate kernels at different frequencies. Second, cross-stage modulation controls enhancement strength based on depth reliability to avoid excessive modification.
Frequency-guided dynamic convolution (FGDC)
FGDC decouples kernel selection from application strength to maintain controllability in dynamic convolution. RGB features are used to determine filter shapes and sizes, while frequency-domain analysis, combined with depth features, decides where and with what intensity to apply these filters. This approach avoids erroneously injecting high-frequency textures into depth. It also stably propagates continuous information in low-frequency regions, balancing boundary fidelity with global consistency. FGDC consists of three steps: base kernel generation, SWT sub-band gating, and sub-band dynamic convolution. Its inputs are the upsampled depth decoder feature from the previous scale \(\tilde{F}^{dec}_{d,s}\) and the RGB decoder feature at the current scale \(F^{dec}_{rgb,s}\). For brevity, we omit the scale subscript \(s\) in the following.
Base kernel generation
As shown in Fig. 2, we first employ three \(1\times 1\) convolutions to predict base kernels of three kernel sizes pixel-wise from \(F^{dec}_{rgb}\):
where \(\mathcal {G}_i\) represents the kernel generator, producing \(k_i^2\) kernel weights for each spatial position. Here we set the base kernel sizes \(k_1\), \(k_2\) and \(k_3\) to 3, 5 and 7, respectively. To enable a unified combination of base kernels in subsequent steps, we embed the \(3\times 3\) and \(5\times 5\) base kernels into \(7\times 7\) space using center-aligned zero padding. Denoting the embedding operator as \(\mathcal {P}_{k_i\rightarrow 7}\), we obtain:
SWT sub-band gating
We use Stationary Wavelet Transform (SWT) to perform one-level decomposition of \(F^{dec}_{rgb}\) using Haar filters. This explicitly separates frequency components while maintaining spatial resolution and translation invariance:
Each sub-band captures different frequency information. Specifically, \(F_{rgb}^{LL}\) represents low-frequency content corresponding to smooth regions and global structure. \(F_{rgb}^{LH}\) and \(F_{rgb}^{HL}\) capture horizontal and vertical edges, respectively. \(F_{rgb}^{HH}\) contains high-frequency details such as corners and textures.
For each sub-band \(t \in \{LL, LH, HL, HH\}\), we concatenate it with the input depth features and compress through \(1\times 1\) convolution. We then map it to three scalar weights indicating the per-pixel preference over the three kernel sizes for that sub-band:
where the three channels of \(G^t\) correspond to weights for each kernel size. Softmax is applied along the channel dimension to ensure \(\sum _{i=1}^{3} G_i^t(x) = 1\) at each spatial position.
The design motivation for this frequency band-specific gating mechanism is that different spectral components should be processed by kernels with different receptive fields. Low-frequency regions (guided by \(G^{LL}\)) typically benefit from larger kernels (\(5\times 5\) or \(7\times 7\)) to smoothly propagate depth values in texture-free areas. Conversely, high-frequency regions (guided by \(G^{LH}\), \(G^{HL}\), and \(G^{HH}\)) prefer smaller kernels (\(3\times 3\)) to maintain sharp edges and suppress RGB-to-depth texture copying. By concatenating the RGB frequency sub-band with the depth feature, the gating mechanism’s decision is informed not only by the image’s local frequency content but also by the current geometric context of the scene. This allows the network to make more reliable choices for the appropriate kernel size.
Sub-band dynamic convolution
We then linearly recombine the \(7\times 7\) base kernels according to gating weights for each sub-band \(t \in \{LL, LH, HL, HH\}\):
where \(\odot\) denotes element-wise multiplication with broadcasting across the kernel dimension. These dynamic kernels are applied to depth features through depthwise convolution, producing frequency-specific filtered outputs:
where \(\circledast\) represents pixel-wise dynamic depthwise convolution. At the same spatial position, the 2D kernel is shared across all channels and applied channel-wise without cross-channel mixing. This avoids the expensive overhead of predicting separate kernels for each channel while retaining sufficient anisotropic modeling capability. We concatenate the outputs from the four frequency bands along the channel dimension to obtain the frequency-guided depth features:
The residual connection with \(\tilde{F}^{dec}_{d}\) preserves the original depth structure while incorporating frequency-specific refinements. This design facilitates stable training and prevents over-reliance on RGB-guided features.
Thus, RGB only indirectly influences depth through kernel shape and scale selection. Where and with what intensity to apply is determined by sub-band gating, which depends on depth features. This fundamentally reduces the risk of erroneously injecting high-frequency textures into depth.
Mechanism analysis
We note that FGDC involves cross-modal interaction between RGB and depth. Here, we analyze why its specific interaction form is fundamentally less prone to texture leakage than conventional spatial fusion. The key reason is a structured information bottleneck that constrains what can be transferred from RGB to depth.
In conventional spatial fusion methods, such as concatenation, addition, or attention-weighted combination, RGB feature values are directly mixed into depth representations. These activations jointly encode both structural and textural information, so texture patterns inevitably leak into depth features. It is inherently difficult to suppress these artifacts because geometric edges and surface textures often share similar spatial characteristics.
In contrast, FGDC restricts RGB-to-depth information flow to two narrowly defined pathways. The first is operator transfer rather than value transfer. RGB features generate convolution kernel weights that define how neighboring depth values are locally combined. These kernels are applied exclusively to depth features. Therefore, the output at each position is a weighted sum of depth values only, and no RGB activations are injected into the depth stream. Even if kernel shapes are influenced by RGB texture, the filtering result remains grounded in the depth domain. The second is low-dimensional routing via scalar gating. The sub-band gating produces only three scalar weights per pixel per sub-band, serving as a kernel-size selection signal. This extremely low-dimensional bottleneck is insufficient to encode spatial texture patterns. This contrasts with full-dimensional feature fusion, in which channels can transfer arbitrary information.
Together, these two pathways ensure that RGB determines how depth features are locally filtered, but cannot dictate what values appear in the depth output. This structural separation between guidance and content is what distinguishes FGDC from conventional fusion.
Cross-stage modulation
To further utilize fidelity information from the original input, we introduce a cross-stage modulation strategy. It uses encoder features \(F^{enc}_{d}\) as reliability priors because they are closer to the original sparse input. It then modulates and optimizes the features \(F_{d}^{guide}\) refined by FGDC. We first concatenate and compress the two features.
To determine where and what to modulate, we generate modulation mask through parallel spatial and channel attention mechanisms. Spatial attention mask \(A_{s}\) identifies which spatial locations require enhancement or suppression based on local reliability. Channel attention mask \(A_{c}\) determines which feature channels are more important for preserving structural information. We combine the two attention masks multiplicatively to form the final modulation mask:
Finally, GRM outputs the refined decoder features through residual modulation:
This residual formulation preserves the base structure from FGDC while enabling selective enhancement or suppression based on cross-stage reliability. In regions where encoder features indicate high confidence, the modulation enhances the refined features. Conversely, in uncertain regions where FGDC might over-smooth or introduce artifacts, the modulation suppresses excessive modifications. This adaptive mechanism ensures that our network achieves robust depth completion by balancing frequency-guided refinement with reliability-aware adjustment.
Training objective
During training, we employ Mean Squared Error (MSE) loss to constrain depth value accuracy. MSE loss directly measures the difference between predicted and ground truth depth values. For each pixel position \((i,j)\) in the input image, the MSE loss is defined as:
where \(\hat{D}\) represents the model-predicted depth values, \(D\) represents the corresponding ground truth depth values, \(\Omega\) represents the valid pixel region, and \(N\) is the total number of valid pixels.
Experiments
Implementation details
We implement our model using the PyTorch framework and conduct experiments on GeForce RTX 3090 GPUs. The model is trained for 45 epochs with an initial learning rate of \(10^{-3}\), which is decayed by a factor of 0.5 every 10 epochs. We use the Adam optimizer43 to optimize the network with a batch size of 8. The hyperparameters are \(\beta _{1}=0.9\), \(\beta _{2}=0.999\) and a weight decay of \(10^{-6}\).
Datasets and metrics
We conduct experimental validation on two widely used benchmark datasets: the KITTI dataset and the NYUv2 dataset.
The KITTI dataset28 is a widely used real-world dataset for outdoor scene depth completion. It primarily covers urban driving scenarios and includes diverse objects such as roads, buildings, vehicles and pedestrians. The dataset contains sparse depth maps projected from raw LiDAR scan data along with corresponding RGB images. It consists of 86000 training images, 1000 selected validation images and 1000 test images without ground truth.
The NYUv2 dataset44 focuses on indoor scene depth completion, containing 464 indoor scenes captured with a Kinect sensor. Following the settings of existing research work15,24,45,46, we uniformly sample 50000 images from the training set for model training and evaluate performance on the official 654-frame test set. During both training and inference phases, we downsample the original \(640\times 480\) images to half resolution and perform center cropping to obtain \(304\times 228\) images.
For evaluation metrics, we follow existing depth completion methods. For outdoor scenes, we use the following 4 standard metrics for evaluation: Root Mean Square Error (RMSE), Mean Absolute Error (MAE), inverse RMSE (iRMSE), and inverse MAE (iMAE). RMSE and MAE measure the deviation between predicted and ground truth depth. iRMSE and iMAE focus more on prediction accuracy for near-range depths. For indoor scenes, we use RMSE, relative error (REL), and threshold accuracy \(\delta _i\) for evaluation. \(\delta _i\) measures the proportion of pixels where the relative error is smaller than a certain threshold. Specifically, i takes values of 1.25, \(1.25^2\), and \(1.25^3\) for evaluation. Larger i values correspond to more relaxed constraints, and larger \(\delta _i\) values indicate better prediction results.

Qualitative comparison with state-of-the-art methods on the KITTI dataset. Our method better preserves thin structures (lamp post, left) and handles color ambiguity (black car roof, right) compared to other methods which show boundary blurring and foreground-background mixing. Zoom in for better visualization.
Comparison with state-of-the-art methods
KITTI dataset
We first compare with various representative methods on the KITTI validation set. As shown in Table 1, our method achieves highly competitive results across all metrics and surpasses all comparison methods on the key RMSE metric. It achieves 1.86 1/km and 0.79 1/km on iRMSE and iMAE metrics, respectively. The inverse-depth errors are comparable to the best methods, demonstrating robustness in near-field regions and sparse boundaries. In terms of model complexity, we achieve the above performance with 36.3M parameters. This is significantly more lightweight than CFormer (83.5 M) and OGNI-DC (83.4 M), achieving a superior accuracy–complexity trade-off.
Additionally, we further evaluate the model’s generalization capability across different sparsity levels. Results shown in Table 2 demonstrate that our method maintains stable advantages across various sparsity levels. Under the 32-line setting, RMSE is 1008.7 mm, which is on par with and slightly better than the best OGNI-DC (1017.2 mm). In more sparse 16-line and 8-line scenarios, we achieve RMSE of 1745.3 mm and 2514.7 mm, respectively. We noticeably outperform most methods while exhibiting more moderate MAE increases. This indicates that the proposed framework can more effectively utilize high-confidence sparse measurements and image priors. It alleviates error amplification under extreme sparsity, thereby improving robustness and practicality for real autonomous driving.
The qualitative results in Fig. 3 further intuitively demonstrate the superiority of our method. The figure shows that our method noticeably outperforms other comparison methods in handling complex scenes and maintaining structural consistency. In the left example, the distant lamp post contains only a few discrete points in the sparse depth map. Other methods show some degree of fusion between the completed lamp post and background in depth map. In contrast, our method maintains the complete shape and clear boundaries of lamp post. It proves that the model can perform robust structural recovery using image semantic information even under extremely sparse inputs. In the right example, the black car roof has similar colors to the background, causing other methods to suffer from foreground–background mixing. However, our method can more accurately utilize the roof structure in the image to complete the depth map, thereby obtaining complete vehicle contours.
NYUv2 dataset
On the indoor NYUv2 dataset, our method also achieves optimal or jointly optimal performance across comprehensive metrics (see Table 1). Under the standard 500 sampling point setting, we achieve current optimal levels with RMSE of 0.085 m and REL of 0.011. Furthermore, we evaluate the model’s generalization capability under different sparsity point sampling. As shown in Table 3, when reducing from 500 points to 200/100/50 points, our method maintains optimal or sub-optimal performance on both RMSE and REL. Especially under 200 and 100 point settings, compared to CFormer and NLSPN, our degradation under extremely low point counts is more moderate. Although OGNI-DC has slight advantages under extreme 50-point conditions, our RMSE and REL remain competitive overall.
Figure 4 provides qualitative comparisons on NYUv2 indoor scenes. Our method can generate depth maps with clearer boundaries and stronger geometric consistency in indoor environments with low light, occlusion and significant material variations. In terms of boundary preservation, our method is closer to RGB structure at object contours without obvious boundary leakage. Meanwhile, our method can more accurately distinguish foreground and background layers, maintaining clearer depth segmentation at object-background interfaces. The above quantitative and qualitative results jointly demonstrate that our method has stronger boundary fidelity and global geometric consistency under cross-scene and cross-sparsity conditions.

Qualitative comparison with state-of-the-art methods on the NYUv2 dataset. Our method maintains sharper object boundaries and better foreground-background separation in challenging indoor scenes, while other methods show boundary leakage and depth discontinuities. Zoom in for better visualization.
Ablation studies
To systematically verify the effectiveness of each core component in our proposed depth completion network, we conduct a series of comprehensive ablation experiments on the KITTI dataset. KITTI is selected because its outdoor scenes with larger depth ranges provide clearer visual and quantitative distinctions between different configurations. We mainly study the deployment strategy of the Guided Refinement Module (GRM), the internal mechanisms of Frequency-Guided Dynamic Convolution (FGDC), and the contribution of the cross-stage modulation.
GRM deployment strategy analysis
GRM is the core of our network. Its deployment position in the decoder directly affects the efficiency of multi-scale information fusion. To explore the role of GRM at different scales, we design multiple experiments that apply GRM at different stages of the decoder. As shown in Table 4, the baseline model (first row) does not contain any GRM and thus lacks RGB guidance, achieving RMSE and MAE of 808.7 and 222.4, respectively. We then progressively examine the role of RGB guidance from coarse to fine scales. Deploying GRM only at the bottleneck layer (1/16 scale, second row) provides a marginal improvement, with RMSE reduced by 7.4. When GRM is applied at intermediate low-resolution scales (1/4 and 1/8, third row), the improvement becomes more substantial, with RMSE reduced by 29.5, demonstrating that RGB guidance at global and contextual levels is effective. Further moving to shallow high-resolution scales (full-scale and 1/2, fourth row), performance improves noticeably with RMSE reduced by 52.1, which indicates that RGB guidance at levels close to output resolution is crucial for recovering fine structures. This pattern of progressive improvement reveals that RGB guidance becomes increasingly important as features approach the output resolution.
Finally, when we deploy GRM at all four key scales (full-scale, 1/2, 1/4 and 1/8), the model achieves near-optimal performance with RMSE reduced by 87.2. This supports our multi-scale guidance strategy: at coarse scales, GRM helps propagate global structural information; at fine scales, it focuses on depicting sharp edges. Notably, further applying GRM to the bottleneck layer (1/16) brings minimal performance gain with RMSE reduced by an additional 3.4. This validates our design consideration that features at this scale are too abstract to benefit from frequency-selective processing. Therefore, we adopt the configuration with GRM deployed at full-scale, 1/2, 1/4, and 1/8 for all our experiments.
Effectiveness verification of FGDC
FGDC aims to achieve more controllable cross-modal feature utilization by decoupling structural and textural information. Through experiments shown in Table 5, we systematically verify the effectiveness of two key designs in FGDC: (1) a combination of multi-size dynamic kernels; (2) a sub-band gating mechanism based on Stationary Wavelet Transform (SWT). First, we evaluate the necessity of multi-size dynamic kernels. Scheme (a) serves as the baseline without any dynamic convolution, achieving a high RMSE of 796.1. Schemes (b) to (d) progressively introduce \(3\times 3\), \(5\times 5\), and \(7\times 7\) dynamic kernels without SWT guidance. Results show that each additional kernel size brings noticeable improvements. This proves that dynamically generating convolution kernels of different sizes noticeably enhances depth completion performance. The key lies in enabling the network to adaptively adjust receptive fields based on local content characteristics. Next, we verify the core role of the SWT sub-band gating mechanism. By comparing schemes (d) and (i), we can see that with the same use of three dynamic kernels, introducing SWT guidance noticeably reduces RMSE from 735.4 to 721.5, and MAE from 192.0 to 184.5. This improvement strongly proves the superiority of our proposed frequency guidance mechanism. By explicitly separating features of different frequencies and matching the most appropriate convolution kernels, it successfully suppresses inappropriate leakage of RGB textures to depth while ensuring effective propagation of structural information. Furthermore, comparisons of schemes (e) to (h) also indicate that under SWT guidance, fusing multiple kernel sizes outperforms any single or dual-size combinations. It is worth noting that scheme (e) (SWT with a single \(3\times 3\) kernel) achieves an RMSE of 740.7, failing to surpass the RMSE of 735.4 obtained by scheme (d) (three kernels without SWT). This indicates that neither SWT nor the multi-kernel design alone can achieve optimal performance. Only when both components are combined in scheme (i) does the model achieve the best result. This confirms that SWT-based frequency guidance and the multi-kernel design work synergistically rather than contribute independently.
To intuitively evaluate the effectiveness of key designs in our proposed FGDC, we show visual comparison results of key ablation schemes in Fig. 5. As shown in the figure, the baseline model (Scheme a) without dynamic convolution and frequency guidance generates depth maps that exhibit certain degrees of edge blurring and structural distortion. This proves that simple encoder-decoder structures alone cannot accurately recover geometric information from sparse point clouds. After introducing multi-scale dynamic convolution (Scheme d), depth map quality improves noticeably. The model can capture basic contours of the guide post and truck, separating them from the background. This proves that dynamically generating convolution kernels of different sizes is crucial for adapting receptive fields in various regions and reconstructing the object’s main structures. However, this scheme still suffers from obvious texture copying problems. Due to a lack of effective filtering of RGB features, the model incorrectly interprets black and white stripes on guide posts as depth variations. This causes unwanted mottled artifacts on their depth surfaces. At the clear boundary between the truck roof and sky, the model fails to utilize strong edge information in the RGB image precisely and cannot form a sharp depth transition. Finally, our complete model (Scheme i) combined with SWT frequency guidance shows optimal visual effects. Compared to Scheme (d), Scheme (i) successfully suppresses texture copying phenomena on guide post surfaces, making depth estimation smooth and internally consistent. For truck scenes, contour edges also become clearer and cleaner, effectively avoiding background information infiltration. This visual comparison powerfully demonstrates the effectiveness of our design. Multi-scale dynamic convolution combined with frequency guidance selectively utilizes RGB information to sharpen edges while suppressing irrelevant textures via frequency-specific processing. As a result, it generates high-quality dense depth maps with both structural accuracy and surface consistency.

Qualitative comparison of key ablation schemes on frequency-guided dynamic convolution (FGDC).
Role of cross-stage modulation
The cross-stage modulation aims to adaptively adjust FGDC outputs based on feature reliability. It fuses early information from the encoder to suppress artifacts and enhance reliable structures. To verify the effectiveness of this strategy, we conduct ablation analysis on its internal spatial attention and channel attention mechanisms. The results are shown in Table 6. Without any cross-stage modulation (first row), the model achieves an RMSE of 730.8. When we introduce spatial attention alone, performance improves to 726.6, indicating that the model focuses on regions requiring correction or preservation in the spatial dimension. Similarly, introducing channel attention alone also brings performance improvement (RMSE 727.2), showing that the model can identify and enhance feature channels that are more important for depth completion. Finally, when we combine spatial attention and channel attention, the model achieves optimal performance (RMSE 721.5, MAE 184.5). This confirms the complementarity of the two attention mechanisms. Spatial attention focuses on where to modulate, while channel attention determines what to modulate. Their combination enables the network to utilize bypass information from the encoder in a more refined and comprehensive manner. It enhances effective features while suppressing potential noise and uncertainty, which results in more robust feature refinement.

Failure cases of our method in challenging scenarios. (a) Glass facade: reflections on glass surfaces cause inconsistent depth predictions. (b) Overexposed condition: unreliable RGB information leads to degraded depth quality.
Limitations
While our method achieves state-of-the-art performance overall, we identify several challenging scenarios where improvements are still needed:
Transparent and reflective surfaces: Glass windows and mirrors remain challenging as they violate the assumption of consistent depth-RGB correspondence. The frequency decomposition may interpret reflections as high-frequency texture, leading to incorrect depth estimates. Figure 6 shows an example where a glass facade causes our method to produce inconsistent depth values.
Extreme lighting conditions: Under very low light or overexposed conditions, RGB features become unreliable for guidance. While our cross-stage modulation helps mitigate this issue by relying more on encoder features, performance still degrades somewhat in such scenarios.
These failure cases suggest directions for future improvements, including incorporating semantic understanding to handle special materials and developing adaptive strategies for challenging lighting conditions.
Conclusion
This paper addresses the texture copying and edge blurring problems in guided depth completion by proposing an RGB-conditioned frequency-domain refinement network. The network achieves controlled cross-modal interactions through Guided Refinement Modules (GRM) deployed at multiple scales. The core of GRM lies in two major innovations: it decouples structure and texture in the frequency domain through frequency-guided dynamic convolution and utilizes feature reliability for adaptive optimization through a cross-stage modulation. Comprehensive experiments validate the effectiveness and complementarity of each component in our proposed method. In future work, we will explore more efficient and learnable frequency-domain transformations, and lighter dynamic kernel parameterizations to further improve robustness and efficiency toward real-time applications.
Data availability
The datasets analyzed during the current study are available in the KITTI repository, https://www.cvlibs.net/datasets/kitti/index.php and NYU repository, https://cs.nyu.edu/~fergus/datasets/nyu_depth_v2.html
References
Song, Z., Lu, J., Yao, Y. & Zhang, J. Self-supervised depth completion from direct visual-lidar odometry in autonomous driving. IEEE Trans. Intell. Transp. Syst. 23, 11654–11665 (2021).
Choe, J., Im, S., Rameau, F., Kang, M. & Kweon, I. S. Volumefusion: Deep depth fusion for 3d scene reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 16086–16095 (2021).
Du, R. et al. Depthlab: Real-time 3d interaction with depth maps for mobile augmented reality. In Proceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology, 829–843 (2020).
Ma, F., Carlone, L., Ayaz, U. & Karaman, S. Sparse depth sensing for resource-constrained robots. Int. J. Robot. Res. 38, 935–980 (2019).
Zhang, Y. & Funkhouser, T. Deep depth completion of a single RGB-D image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 175–185 (2018).
Lu, K., Barnes, N., Anwar, S. & Zheng, L. From depth what can you see? Depth completion via auxiliary image reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11306–11315 (2020).
Hu, M. et al. Penet: Towards precise and efficient image guided depth completion. In 2021 IEEE international Conference on Robotics and Automation (ICRA), 13656–13662 (IEEE, 2021).
Lu, H., Xu, S. & Cao, S. Sgtbn: Generating dense depth maps from single-line lidar. IEEE Sens. J. 21, 19091–19100 (2021).
Chen, D., Huang, T., Song, Z., Deng, S. & Jia, T. Agg-net: Attention guided gated-convolutional network for depth image completion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 8853–8862 (2023).
Tang, J., Tian, F.-P., An, B., Li, J. & Tan, P. Bilateral propagation network for depth completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and pattern recognition, 9763–9772 (2024).
Ma, F. & Karaman, S. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. In 2018 IEEE International Conference on Robotics and Automation (ICRA), 4796–4803 (IEEE, 2018).
Imran, S., Long, Y., Liu, X. & Morris, D. Depth coefficients for depth completion. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 12438–12447 (IEEE, 2019).
Qu, C., Nguyen, T. & Taylor, C. Depth completion via deep basis fitting. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 71–80 (2020).
Jaritz, M., De Charette, R., Wirbel, E., Perrotton, X. & Nashashibi, F. Sparse and dense data with CNNS: Depth completion and semantic segmentation. In 2018 International Conference on 3D VIsion (3DV), 52–60 (IEEE, 2018).
Tang, J., Tian, F.-P., Feng, W., Li, J. & Tan, P. Learning guided convolutional network for depth completion. IEEE Trans. Image Process. 30, 1116–1129 (2020).
Yan, Z. et al. Rignet: Repetitive image guided network for depth completion. In European Conference on Computer Vision 214–230 (Springer, Cham, 2022).
Long, Y., Yu, H. & Liu, B. Depth completion towards different sensor configurations via relative depth map estimation and scale recovery. J. Vis. Commun. Image Represent. 80, 103272 (2021).
Xu, Y. et al. Depth completion from sparse lidar data with depth-normal constraints. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2811–2820 (2019).
Van Gansbeke, W., Neven, D., De Brabandere, B. & Van Gool, L. Sparse and noisy lidar completion with RGB guidance and uncertainty. In 2019 16th International Conference on Machine Vision Applications (MVA), 1–6 (IEEE, 2019).
Qiu, J. et al. Deeplidar: Deep surface normal guided depth prediction for outdoor scene from sparse lidar data and single color image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3313–3322 (2019).
Zhang, Y., Wei, P., Li, H. & Zheng, N. Multiscale adaptation fusion networks for depth completion. In 2020 International Joint Conference on Neural Networks (IJCNN), 1–7 (IEEE, 2020).
Chen, Y., Yang, B., Liang, M. & Urtasun, R. Learning joint 2d-3d representations for depth completion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 10023–10032 (2019).
Xiong, X. et al. Sparse-to-dense depth completion revisited: Sampling strategy and graph construction. In European Conference on Computer Vision 682–699 (Springer, Cham, 2020).
Zhao, S., Gong, M., Fu, H. & Tao, D. Adaptive context-aware multi-modal network for depth completion. IEEE Trans. Image Process. 30, 5264–5276 (2021).
Ramamonjisoa, M., Firman, M., Watson, J., Lepetit, V. & Turmukhambetov, D. Single image depth prediction with wavelet decomposition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11089–11098 (2021).
Liu, Q. et al. Sehlnet: separate estimation of high-and low-frequency components for depth completion. In 2022 International Conference on Robotics and Automation (ICRA), 668–674 (IEEE, 2022).
Zhao, Z. et al. S2ml: Spatio-spectral mutual learning for depth completion. IEEE Trans. Multimedi. 28, 1431–1444 (2025).
Uhrig, J. et al. Sparsity invariant CNNS. In 2017 International Conference on 3D Vision (3DV), 11–20 (IEEE, 2017).
Huang, Z. et al. Hms-net: Hierarchical multi-scale sparsity-invariant network for sparse depth completion. IEEE Trans. Image Process. 29, 3429–3441 (2019).
Eldesokey, A., Felsberg, M. & Khan, F. S. Propagating confidences through CNNS for sparse data regression. In 29th Critish Machine Vision Conference, BMVC 2018 (2019).
Glorot, X., Bordes, A. & Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 315–323 (JMLR Workshop and Conference Proceedings, 2011).
Eldesokey, A., Felsberg, M., Holmquist, K. & Persson, M. Uncertainty-aware cnns for depth completion: Uncertainty from beginning to end. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12014–12023 (2020).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
Hambarde, P. & Murala, S. S2dnet: Depth estimation from single image and sparse samples. IEEE Trans. Comput. Imag. 6, 806–817 (2020).
Liu, S. et al. Learning affinity via spatial propagation networks. Adv. Neural Inf. Process. Syst. 30 (2017).
Cheng, X., Wang, P. & Yang, R. Learning depth with convolutional spatial propagation network. IEEE Trans. Pattern Anal. Mach. Intell. 42, 2361–2379 (2019).
Cheng, X., Wang, P., Guan, C. & Yang, R. CSPN++: Learning context and resource aware convolutional spatial propagation networks for depth completion. Proc. AAAI Conf. Artifi. Intell. 34, 10615–10622 (2020).
Lin, Y., Cheng, T., Zhong, Q., Zhou, W. & Yang, H. Dynamic spatial propagation network for depth completion. Proc. AAAI Conf. Artif. Intell. 36, 1638–1646 (2022).
Sheng, Z., Liu, X., Cao, S.-Y., Shen, H.-L. & Zhang, H. Frequency-domain deep guided image denoising. IEEE Trans. Multimed. 25, 6767–6781 (2022).
Cui, Y., Ren, W., Cao, X. & Knoll, A. Image restoration via frequency selection. IEEE Trans. Pattern Anal. Mach. Intell. 46, 1093–1108 (2023).
Ku, J., Harakeh, A. & Waslander, S. L. In defense of classical image processing: Fast depth completion on the CPU. In 2018 15th Conference on Computer and Robot Vision (CRV), 16–22 (IEEE, 2018).
Levin, A., Lischinski, D. & Weiss, Y. Colorization using optimization. In ACM SIGGRAPH 2004 Papers, 689–694 (2004).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Silberman, N., Hoiem, D., Kohli, P. & Fergus, R. Indoor segmentation and support inference from RGBD images. In European Conference on Computer Vision 746–760 (Springer, Cham, 2012).
Wang, Y. et al. Lrru: Long-short range recurrent updating networks for depth completion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 9422–9432 (2023).
Wang, Y. et al. Improving depth completion via depth feature upsampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 21104–21113 (2024).
Conti, A., Poggi, M. & Mattoccia, S. Sparsity agnostic depth completion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 5871–5880 (2023).
Park, J., Joo, K., Hu, Z., Liu, C.-K. & So Kweon, I. Non-local spatial propagation network for depth completion. In European Conference on Computer Vision 120–136 (Springer, Cham, 2020).
Zhang, Y. et al. Completionformer: Depth completion with convolutions and vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18527–18536 (2023).
Zuo, Y. & Deng, J. OGNI-DC: Robust depth completion with optimization-guided neural iterations. In European Conference on Computer Vision 78–95 (Springer, Cham, 2024).
Funding
This research project was financially supported by Mahasarakham University.
Author information
Authors and Affiliations
Contributions
H.W. implemented the method and conducted the experiments. H.W. and Z.P.T. analyzed the experimental results. P.P. assisted with data collection and validation. R.C. supervised the research and provided critical feedback. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, H., Tang, Z., Pawara, P. et al. RGB-conditioned frequency domain refinement for sparse-to-dense depth completion. Sci Rep 16, 10757 (2026). https://doi.org/10.1038/s41598-026-45432-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-45432-1
