
Abstract
Frogeye leaf spot (FLS), caused by Cercospora sojina, is a common soybean disease across the U.S. Fungicides are a key management tool, particularly when susceptible cultivars are planted; however, widespread QoI resistance has raised concern about overreliance on the remaining effective fungicide classes. Protecting these chemical classes is essential for long-term sustainability, particularly under narrow profit margins. To develop an FLS prediction model that supports more efficient fungicide use, environmental and epidemiological data from multiple site-years were analyzed in 2024 using correlation analysis, logistic regression (LR), and machine-learning approaches. The most effective model combined a 30-day moving average (ma) of daily hours of relative humidity (RH) ≥ 80% and maximum temperature (°C) in a LR model. FLS risk peaked when the 30-d ma of daily hours of RH ≥ 80% was 15–20 h and maximum temperature was 24–36 °C. When daily hours of RH ≥ 80% averaged < 5 h, risk remained low regardless of temperature. Random forest and support vector machine models achieved greater accuracy and sensitivity than LR but showed poorer specificity. This research provides a strong epidemiological foundation for improving decision-making and advancing integrated disease management. The resulting prediction model is deployed in a public decision support system (https://cropprotectionnetwork.org/crop-disease-forecasting), enabling real-time FLS risk assessments and promoting stewardship-minded fungicide use.
Similar content being viewed by others


Introduction
Frogeye leaf spot (FLS), caused by Cercospora sojina, is a yield-limiting disease of soybean (Glycine max) that occurs worldwide1,2. Researchers first reported FLS in Japan in 1915 and the U.S. in 19243,4,. In the U.S., FLS was historically more prevalent in southern states but has expanded northward, likely aided by warmer winters and widespread no-till practices that slow residue decomposition5,6,7,8. The pathogen can survive in infested plant residue for up to 24 months and possibly longer1,9,10, and primarily infects leaves but can also infect stems, pods, and seed11,12. Seed transmission can be a source of inoculum and may be particularlly important in fields with no prior history of soybean cultivation13.
Lesions of FLS develop 10 to 14 days after infection. They start as small water-soaked spots that later enlarge and develop gray centers with reddish-brown margins. Sporulation occurs on the abaxial leaf surface12. Younger leaves are the most susceptible, and symptoms typically develop in the mid- to upper canopy14,15. Under warm (23–30 °C) and humid (> 90% RH) conditions, conidia germinate rapidly, and periods of wind-driven rain favor short-distance dispersal12. Sporulating lesions provide secondary inoculum, driving additional cycles of infection16,12.
FLS epidemics can cause yield losses up to 60%, and reduce yield at a rate of 0.51% for each 1% increase in FLS severity15,16,17. Severe outbreaks have occurred in Argentina, Brazil, and North America, with losses exceeding $2 billion in Argentina in 2009/2010 alone18,19,20,21. In the U.S., yield losses for 2017 to 2024 totaled $125 million22. Resistance genes (Rcs1, Rcs2, and Rcs3) are a crucial management tool that provide variable levels of protection but are absent in many cultivars1,15. Premix fungicides with demethylation inhibitors (DMI; known as triazoles, FRAC group 3), methyl benzimidazole carbamates (MBC; thiophanates or benzimidazoles, FRAC group 1), and succinate dehydrogenase inhibitors (SDHI; carboxamides and benzamides, FRAC group 7) can provide effective control23,24. However, widespread resistance in C. sojina to quinone-outside inhibitor (QoI) fungicides (commonly known as strobilurins, FRAC group 11), documented between 2010 and 2025, has made this class of fungicides largely ineffective in the U.S.8,25,26,27,28,29,30,31,32,33,34,35,36,. Frequent fungicide use also exerts selection pressure for pathogen resistance, especially since many fungicides are applied in the absence of disease pressure, simply to benefit yield37,38. Overuse of fungicides can accelerate resistance development23,39. Although C. sojina has not been found to develop resistance to DMIs, MBCs, and SDHIs40,41. Barro et al.25 reported a trend of reduced field efficacy in controlling frogeye leaf spot with DMI and MBC fungicides. Using a premix fungicide with more than one mode of action (MoA), rotation of fungicides with different MoAs, and applying a fungicide only when it is needed can help reduce the risk of resistance development42.
Plant disease forecasting efforts have traditionally focused on using a few environmental variables and disease data to fit linear or logistic regression models43. However, the advent of machine learning algorithms such as random forest and support vector machine has facilitated new approaches44,45. For example, researchers have developed random forest algorithms for Fusarium head blight of wheat, both for predictor selection and disease modeling, resulting in enhanced accuracy46. Disease forecasting models can be incorporated into decision support systems (DSSs) that help farmers use fungicide sprays more efficiently and affordably47. For example, risk-based DSSs for tar spot (caused by Phyllachora maydis) of corn (Zea mays) and Sclerotinia stem rot (caused by Sclerotinia sclerotiorum) of soybean are currently available online (https://cropprotectionnetwork.org/crop-disease-forecasting). Although some FLS modeling research has been done previously16,48,49,50,, predictive modeling that can be readily incorporated into a risk prediction tool is still lacking. Given the economic importance of FLS and the widespread occurrence of fungicide-resistant FLS populations, predictive tools are needed to help farmers make more informed fungicide application decisions.
The objective of this study was to apply logistic regression and machine learning to predict environment-based risk of FLS increase in soybean. To accomplish this, we used the results of field trials conducted from 2015 to 2023 in sequential modeling exercises.
Results
Development of the training and testing datasets
We used FLS severity observations from 279 site-years (2015 to 2023) to create a binary “delta” variable. For each site-year, the delta variable was coded as 0 when no increase in FLS severity occurred between consecutive evaluation dates and 1 when an increase occurred. Training and testing data subsets (in a ratio of 70:30) were created, and moving averages (ma) of weather variables over time intervals of 5, 7, 10, 14, 21, and 30 days before each evaluation date (windowpanes) were calculated. Pearson correlations were assessed, and logistic regression and machine learning models were fitted using environmental data and the FLS delta variable across the six windowpanes.
Correlation of environmental variables and FLS increase
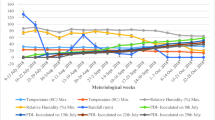
An average of total daily hours of RH ≥ 85% at the 30-d ma had the strongest correlation (P < 0.0001) with FLS increase (Suppl. Table 1). Wind speed (m/s), precipitation (mm/hour), and dew point depression (°C) were consistently negatively correlated with FLS increase across windowpanes (Fig. 1, Suppl. Table 1). Interestingly, mean precipitation intensity (mm/hour) correlated weakly with disease increase across several windowpanes, although it was highly correlated with other moisture-related variables (RH, leaf wetness duration, and average daily hours of high RH), which were strong predictors of FLS increase (Suppl. Table 1). Variables in the 30-, 21-, and 14-day windowpanes showed mostly stronger correlation values than those in shorter-duration windowpanes (Fig. 1).

Pearson correlation matrices of environmental variables and disease observations showing 30-, 21-, and 14-day moving averages. These windowpanes showed stronger correlations than shorter-duration windowpanes. Heat maps were created using the plotly package51 in RStudio software version 2025.09.1 + 40152. Environmental variables included air temperature (°C), relative humidity (%), wind speed (m/s), dew point (°C), precipitation (mm/hour), dew point depression (°C), and day and nighttime total wetness hours. The disease increase variable is shown as ‘DeltaPos’.
Performance of logistic regression models
We fit single- and multi-predictor logistic regression models using environmental variables and the FLS delta response and assessed their goodness-of-fit and predictive performance (Supp. Table 2, Table 1). Although environmental variables related to ambient temperature (AT) had some of the weakest Pearson correlation values, when combined with wetness-related variables they ranked among the strongest models (Table 1), (see Eq. 1 to 8). For example, mean daily maximum ambient temperature (°C) at the 30-day windowpane showed a weak Pearson correlation with disease progress (P > 0.05), but when combined with the 30-day mean daily hours of RH ≥ 80%, it provided the strongest predictive value for FLS increase (Eq. 7).
The linearized logistic regression models evaluated against the testing datasets were defined with the following equations:
Model LR7 consistently showed the highest accuracy and precision, with acceptable sensitivity, the greatest Kappa agreement, and significant McNemar’s value (P < 0.05) (Table 1). Moreover, LR7 demonstrated a good balance between specificity and sensitivity in comparison to the other models; along with models LR5 and E-1, it had the highest specificity value. In contrast, the model LR2 achieved the greatest sensitivity but showed low specificity (Table 1).
The variables (average daily hours of RH > 80% and daily maximum temperature in a 30-day windowpane) used in the best-performing model (LR7) were further explored to visualize their interaction with FLS risk (Figs. 2 and 3). LR7 showed a stronger impact effect of the temperature variable than the RH variable in driving FLS increase; risk increased to 36% when the AT reached 36 °C, even if average hours of RH > 80% was at its lowest point of ~ 3 h (Fig. 2). Risk percentage remained low (< 40%) when the 30-day ma of mean maximum AT was between 24 and 28 °C, as long as mean daily hours of RH ≥ 80% were below 12 h. When mean daily hours of RH ≥ 80% were between 15 and 20 h, FLS risk increased, especially if mean maximum temperature was ≥ 32 °C. The risk probability increased up to ~ 90% when mean RH hours ≥ 80% was at ~ 20 h and mean maximum AT was ~ 36 °C (Fig. 2).
Performance of machine learning models
The most accurate machine learning (ML) model, the SVM model, was 2.4% greater than the most accurate logistic regression (LR7). While the SVM model achieved the highest sensitivity, its specificity was ~ 25% lower than that of the best-performing logistic regression model (Table 1).

3D surface of risk probability of FLS increase or increase explained by 30-day mean of maximum temperature (°C) and 30-day mean of daily hours of maximum relative humidity ≥ 80%.

Univariate logistic regression models fitting risk probability (%) of FLS increase at the 30-day moving average of maximum ambient temperature (°C) (left) and the 30-day moving average of daily hours of relative humidity ≥ 80% (right).
Discussion
We developed the first area-wide predictive model to estimate the risk of FLS increase, using environmental and disease data from 279 site-years. This work provides a foundation for region-specific studies aimed at accelerating the development of decision-support systems for improved management of FLS across U.S. soybean regions. The models we developed here have been deployed on the Crop Protection Network (CPN) Website (https://cropprotectionnetwork.org/crop-disease-forecasting).
Our results verify that extended daily periods of RH ≥ 80% and other wetness-related variables are crucial for disease development. When this RH variable was combined with high AT (average daily max AT ≥ 32 °C), the risk of FLS increased significantly (Fig. 3). These environmental drivers play a crucial role in the occurrence of FLS epidemics, aligning with previous work showing high RH as a proxy to estimate leaf wetness, a key factor in pathogen infection and spread12,16,53,54,55,56. Combining a 30-day windowpane of mean maximum AT and RH ≥ 80% yielded the most accurate model to predict FLS increase, with the RH variable being the most important. Unlike studies that describe the optimal conditions for FLS development using daily averages, our longer-duration windowpane models revealed hours above a high RH threshold and the average of maximum AT as the strongest predictors.
A component of fungicide stewardship guidelines is to apply a fungicide in a timely manner and using premixes with different active ingredients57, which for FLS could be pinned down to apply only if the risk of disease development warrants a spray and using premixes including a SDHI, DMI, or MBC. QoI fungicides, such as azoxystrobin, pyraclostrobin, and trifloxystrobin, are commonly used as chemical tools to manage FLS in the U.S.1,23,. Nevertheless, QoI-resistant isolates of C. sojina are now ubiquitous in the soybean-growing regions of the U.S.35. Additionally, with foliar fungicide use increasing significantly since 200542,58,, optimizing the timing of fungicide applications is critical for resistance management and farmer profitability. Thus, predictive models are essential tools for decision-makers assessing when a fungicide application is truly needed.
We observed weak correlations between disease progress and environmental variables, a trend that can be inherent to fitting large epidemiological datasets encompassing broad geographic, environmental, and time ranges, originating from varied research groups and involving genetic differences among the cultivars used in the trials59,60.
Model LR7 outperformed the other models, demonstrating high accuracy and a balance of high sensitivity and specificity. Despite FLS’s 10- to 14-day latent period12, extended periods (30-day average) improved the prediction of FLS risk increasing. This outcome may be related to the polycyclic nature of FLS, where more than one cycle often needs to occur for the disease to be detected in field conditions61. Furthermore, conducive conditions are likely to occur intermittently in field conditions, influencing a stronger response of the models to environmental variables in the 30-d windowpane.
ML models have potential to outperform classic statistical models45,46. In our study, ML models achieved higher accuracy than the best logistic regression models. However, they also showed lower specificity, which may increase the risk of unnecessary fungicide applications. Notably, the SVM model achieved the highest sensitivity. This is a key component of a disease-warning system because it lowers the chance of missing crucial sprays or under spraying when disease risk is high; false negatives can lead to significant economic losses and reduce farmers’ confidence in a DSS. These results suggest that these ML models can be very good at predicting FLS risk and especially good at predicting true positives, but need to further improve the prediction of true negatives, as their specificity was only ~ 50%.
Potentially important variables for estimating FLS risk, such as inoculum presence or absence (e.g. spore traps), cultural practices, degree of cultivar susceptibility, and field history, were not included in our analysis but should be considered when interpreting the FLS risk model output, and could be explored in future works to further improve the predictive power of our models62,63,64.
A DSS must be readily deployable65. However, the user interface currently running the models does not support the more complex ML-based approach. Therefore, we adopted the most accurate logistic regression model for deployment and field validation. This decision favored interpretability and computational efficiency due to simpler calculations needed to run the logistic regression model, a characteristic that is particularly useful for generating disease risk forecasts rapidly.
Fungicide applications to suppress FLS can improve yield, especially in southern U.S. latitudes, late-planted fields, and high-yielding environments66. Current fungicide recommendations for FLS management in the U.S. emphasize a single spray, or two in some cases in southern regions, during the phenological stage R348,67,68,. Fungicide sprays are generally profitable when soybean market prices exceed $576.30 per metric ton; however, if disease pressure is low, spraying a fungicide is unlikely to provide a yield response benefit62,66. Yield response to fungicide applications depends on multiple factors, and fungicide efficacy and disease pressure play a major role in the economic outcome of making an application. For instance, applying a low-efficacy fungicide such as pyraclostrobin for FLS is unlikely to be profitable regardless of soybean market prices24; in contrast, spraying an effective fungicide for FLS (difenoconazole + pydiflumetofen) is likely to deliver economic returns under high disease pressure (> 14% severity) and soybean market prices are ≥ 0.30 US$ kg− 117.
The model we developed in this work was built from observations across multiple U.S. environments, cultivars, and production systems across large geographical and time scales, which captures the recent trend of FLS severity increase and its relationship to environmental variables. Local validation can advance understanding of how the model can be deployed most effectively. The foundation for the development of an actionable DSS for a smarter approach to managing FLS in soybeans in the U.S. has been laid in the current work. Ongoing field validation trials by our group in 2023, 2024 and 2025, encompassing > 40 site-years across 15 states, will help us understand how to use this tool in different geographical zones of the Midwest and Southern U.S. Thus, timely fungicide applications, based on epidemiological data can improve farmer’s return on investment and steward current chemical integrated pest management tools, while reducing unnecessary pesticide applications17,25,66.
Materials and methods
Development of the training and testing datasets
Data compilation
In 2024, we compiled a dataset with disease observations of average FLS percent severity from small-plot foliar fungicide field trials, and five official variety trials from OH and MS, between 2015 and 2023 across the U.S. Individual datasets were collected from several University- and industry-based research groups, totaling 279 site-years and comprising 543 total disease observations from 20 different states (Fig. 4). After reviewing individual datasets per site-year from collaborating research groups, we extracted FLS ratings from the non-treated control plots, averaged across replications for each site-year and rating date, and organized them into a master dataset, along with their corresponding rating dates and GPS coordinates. The research groups recorded the FLS ratings from the upper canopy leaves, with severity ratings ranging from 0 to 100% in the majority of the cases, and in some ratings, using a 0–9 scale69. Commercial, locally adapted cultivars were planted at each site-year, and common agronomic practices were followed.

Map of the sites (black dots) used for the development of the training and testing dataset (n = 279 site-years).
Environmental factors and FLS increase
We retrieved hourly environmental data from the IBM Environmental Intelligence weather service at a resolution of 4 km grids using the coordinates of each respective site-year. Thus, the dates and coordinates were used for acquiring the environmental data variables for each respective evaluation. The environmental variables retrieved included the hourly averages, and minimum and maximum hourly averages of AT (°C), RH (%), wind speed (WS, m/s), dew point (DP, °C), and precipitation (precip, mm/hour). Furthermore, we calculated additional environmental variables, including the dew point depression (DPD, °C), daily total wetness hours, and nighttime wetness hours between 8 pm and 6 am70. We defined wetness hours as a binary factor in which ‘1’ was recorded if the DPD was less than or equal to 2 °C, which is an estimation for free-water presence on leaf surfaces71,72. A factor of ‘0’ was recorded if the DPD was greater than 2 °C. Also, we compiled daily hours of RH (%) at or above 60, 65, 70, 75, 80, 85, 90, and 95%. Thus, we consider the uncertainty of estimated wetness and RH (%) acceptable due to the extensive work done in the estimation of these two variables56,70,72,73,74,75. However, we acknowledge that estimated weather data is sourced from ground weather stations; thus, in locations with few nearby stations accuracy of the data might be limited. Moving averages were used on each environmental variable, setting as a reference the evaluation date, and from there, averages at different windowpanes of time were calculated. For each FLS observation, we compiled hourly environmental data and moving averages (ma) for each of the environmental variables for 30, 21, 14, 10, 7, and 5 days prior to the disease observation. Then, we aligned a dataset with the moving averages of each variable at each windowpane of time to its respective disease observation according to their site-year coordinates and evaluation date. We transformed each disease observation into a binary variable within its evaluation site and date. A delta value of one was given when any disease increase occurred between consecutive evaluations, and a zero if the disease did not increase. In those cases where only one rating date was available, a value of 1 was given if any severity above 0% was recorded, and a 0 if no disease was present. The conversion of continuous severity data into binary response implies a loss of magnitude in the disease variable. To assess if adding a defined level of increase, we ran preliminary analyses setting a delta value of 1 if severity increased by more than 1% or 5%. However, these approaches resulted in a lower predictive accuracy and goodness of fit of the models (data not shown).
After creating the binary variable, we conducted analyses using R version 4.5.176 using RStudio version 2025.09.1 + 40152. The compiled dataset was randomly split into training (70%) and testing (30%) subsets. We used bootstrapping with replacement for internal validation of the predictive model performance. The training data set was unbalanced with 138 ‘0s’ and 239 ‘1s’. To address class imbalance during model training, we upsampled the data in the training dataset using the ‘upSample()’ function from the caret package77, while leaving out the testing dataset unchanged. We calculated Pearson correlations between disease observations and the 30-, 21-, 14-, 10-, 7-, and 5-day moving averages of each environmental variable. Correlations among all 28 variables were also assessed to examine interrelationships. Results were visualized in correlation matrices, with correlation coefficients and P values reported for each windowpane (Suppl. Table 1, Fig. 1). Then, we organized the strongest correlations in descending order according to their Pearson’s correlation coefficient and P value significance (Suppl. Table 1).
Logistic regression selection and testing
We ran several logistic regression models using the delta values as the dependent variable and the environmental values as predictors. The developed models assumed the presence of inoculum from infested residue in the soil, as propagules in or on soybean seed, or moving into the fields through wind and rain splash as the season progressed. We focused on studying environmental conditions as predictor variables driving the increase in FLS severity. Models were constructed using one or two potential significant environmental variables and the delta values across each windowpane of moving averages for a total of 609 models fitted (Suppl. Table 2). Environmental variables that were correlated with each other were not considered for this section. We compiled and organized the models by their Akaike information criterion (AIC), C-statistic, and Hosmer-Lemeshow goodness-of-fit test values (Suppl. Table 2). The 8 best-performing models were selected to be tested against the testing dataset (Table 1). The logit values for the logistic regression models were calculated with Eq. 9:
Furthermore, a logistic transformation was used to generate the probability of FLS increase as noted in Eq. 10.
We evaluated the prediction capabilities of the best-performing models against the testing dataset, adjusting the risk threshold of each model to their greatest prediction accuracy. On top of the logistic regression models developed, three ensemble models were also evaluated, named E-1, E-2, and E-3 (Table 1). Accuracy (%), Cohen’s Kappa value, McNemar’s P value, sensitivity (%), specificity (%), precision (%), false positive rate and false negative rate were calculated and considered for model evaluation. For each model we evaluated, the optimal thresholds were adjusted to maximize predictive accuracy and balance the false positive and false negative rates.
Machine learning algorithm testing
We examined two machine learning algorithms, including both random forest (RF) and support vector machine (SVM). These models were trained and evaluated using the same datasets as described above. All analyses were conducted in R76.
When examining the RF algorithm to predict FLS increase, the randomForest package78 was used alongside the caret package76 for model evaluation and tuning. The RF model was trained with 500 trees (ntree = 500) to ensure robustness of the analysis. To optimize the number of features randomly sampled at each split (mtry), we used the tuneRF function, testing values with a step factor of 1.5 and an improvement threshold of 0.01, starting with 100 trees (ntreeTry = 100). The optimal mtry was selected based on the lowest out-of-bag (OOB) error. To address class imbalance, the sample size parameter was set to balance the classes by sampling equal numbers of positive and negative cases. A minimum node size of 5 (nodesize = 5) was specified to control tree depth. Then, feature importance was assessed using the Mean Decrease in Accuracy metric (type = 1). We then retrained the RF model using the top 50% of features ranked by importance, with mtry adjusted to the square root of the number of selected features. Model performance was evaluated on both the training and testing datasets using confusion matrices generated by the caret package’s confusionMatrix function76, which provided metrics such as accuracy, sensitivity, and specificity.
When examining the SVM algorithm, we used the e1071 package79 for implementation and hyperparameter tuning. An SVM model with a radial basis function kernel was initially trained with a cost parameter of 10 and a gamma value of 0.03125. To optimize model performance, hyperparameter tuning was performed using the tune.svm function, which conducted a grid search over cost values ranging from 0.1 to 100 × 10− 1:2 and gamma values ranging from 0.03125 to 2 × 2− 5:1. Five-fold cross-validation was used to identify the best combination of hyperparameters based on classification accuracy. The tuned model was then used to make predictions on the testing dataset. We assessed model performance using confusion matrices from the caret package77, providing detailed classification metrics.
Data availability
The datasets generated and analyzed during the current study are not publicly available to preserve farm-level anonymity, but county-level data are available from the corresponding author upon reasonable request.Environmental variables were obtained through the IBM Environmental Intelligence Suite (EIS) weather data API, a proprietary dataset accessible via paid license from IBM. Information regarding access to the IBM Environmental Intelligence Suite and its weather data products is available at: [https://www.ibm.com/products/environmental-intelligence](https:/www.ibm.com/products/environmental-intelligence) . Researchers with appropriate access to IBM Environmental Intelligence Suite can independently obtain equivalent environmental data using the methods described in this study.
References
Barro, J. P., Neves, D. L., Ponte, D., Bradley, C. A. & E. M. & Frogeye leaf spot caused by Cercospora sojina: A review. Trop. Plant. Pathol. 48, 363–374 (2023a).
Grau, C. R., Dorrance, A. E., Bond, J. & Russin, J. S. Fungal diseases in soybeans: Improvement, production, and uses. Fungal Dis. 16, 679–763 (2004).
Lehman, S. G. Frogeye leaf spot of soybean caused by Cercospora diazu Miura. J. Agric. Res. 35, 811–833 (1928).
Melchers, L. E. Diseases of cereal and forage crops in the United States in 1924. Plant. Dis. 40, 186 (1925).
Bradley, C. A. et al. An overview of frogeye leaf spot. Crop Prot. Netw. https://doi.org/10.31274/cpn-20190620-013 (2016).
Buchanan, M. & King, L. D. Carbon and phosphorus losses from decomposing crop residues in no-till and conventional till agroecosystems. Agron. J. 85, 631–638 (1993).
Mengistu, A. et al. Tillage, fungicide, and cultivar effects on frogeye leaf spot severity and yield in soybean. Plant. Dis. 98, 1476–1484 (2014).
Zhang, G. Cercospora sojina: Over-winter survival and fungicide resistance. Ph.D. Thesis, University of Illinois at Urbana-Champaign (2012).
Cruz, C. D. & Dorrance, A. E. Characterization and survival of Cercospora sojina in Ohio. Plant. Health Prog. 10, 17 (2009).
Zhang, G. & Bradley, C. A. Survival of Cercospora sojina on soybean leaf debris in Illinois. Plant. Health Prog. 15, 92–96 (2014).
Singh, T. & Sinclair, J. B. Histopathology of Cercospora sojina in soybean seeds. Phytopathology 75, 185–189 (1985).
Wise, K. A. & Newman, M. E. Frogeye leaf spot. In Compendium of Soybean Diseases and Pests (eds. Hartman, G. L. et al.). 43–45 (APS, 2015).
Sautua, F. J. et al. Detection and chemical control of Cercospora sojina infecting soybean seed in Argentina. Trop. Plant. Pathol. 43, 552–558 (2018).
Bohra, Y. Frog eye leaf spot in soybean: From symptoms to management. In Soybean Production Technology: Crop Pests and Diseases (ed. Singh, K. P., Singh, N. K. & Aravind, T.). 189–204 (Springer, 2025).
Mian, M. A. R., Missaoui, A. M., Walker, D. R., Phillips, D. V. & Boerma, H. R. Frogeye leaf spot of soybean: A review and proposed race designations for isolates of Cercospora sojina Hara. Crop Sci. 48, 14–24 (2008).
Sepulcri, M. G., Moschini, R. C. & Carmona, M. A. Soybean frogeye leaf spot [Cercospora sojina]: First weather-based prediction models developed from weather station and satellite data. Adv. Appl. Agric. Sci. 3, 1–13 (2015).
Barro, J. P. et al. Meta-analytic modeling of the severity–yield relationships in soybean frogeye leaf spot epidemics. Plant. Dis. 107, 3422–3429 (2023b).
Balardin, R. S. Doenças na soja. Univ. Fed. Santa Maria 107 (2002).
Bradley, C. A. et al. Soybean yield loss estimates due to diseases in the United States and Ontario, Canada, from 2015 to 2019. Plant. Health Prog. 22, 483–495 (2021).
Carmona, M. Damages caused by frogeye leaf spot and late season disease in soybean in Argentina and control criteria. Trop. Plant. Pathol. 3, 1356–1358 (2011).
Yorinori, J. T. A Mancha “olho-de-ra” (Cercospora sojina Hara) (EMBRAPA-CNPSo, 1988).
Crop Protection Network. Disease Loss Calculator. https://loss.cropprotectionnetwork.org (2025).
Crop Protection Network. Fungicide Efficacy for Control of Soybean Foliar Diseases. https://doi.org/10.31274/cpn-20190620-014 (2025).
Dangal, N. K. et al. Fungicide Efficacy Guides for Foliar Diseases in Corn and Soybean: Development and Validation. Plant. Health Prog. https://doi.org/10.1094/PHP-02-25-0073-RS (2025).
Barro, J. P. et al. Efficacy and profitability of fungicides for managing frogeye leaf spot on soybean in the United States: A 10-year quantitative summary. Plant. Dis. 107, 3487–3496 (2023c).
Harrelson, B. C. et al. Assessment of quinone outside inhibitor sensitivity and frogeye leaf spot race of Cercospora sojina in Georgia soybean. Plant. Dis. 105, 2946–2954 (2021).
Mathew, F. M., Byamukama, E., Neves, D. L. & Bradley, C. A. Resistance to quinone outside inhibitor fungicides conferred by the G143A mutation in Cercospora sojina (causal agent of frogeye leaf spot) isolates from South Dakota soybean fields. Plant. Health Prog. 20, 104–105 (2019).
Mengistu, A., Kurtzweil, N. C. & Grau, C. R. First report of frogeye leaf spot (Cercospora sojina) in Wisconsin. Plant. Dis. 86, 1272–1272 (2002).
Neves, D. L., Chilvers, M. I., Jackson-Ziems, T. A., Malvick, D. K. & Bradley, C. A. Resistance to quinone outside inhibitor fungicides conferred by the G143A mutation in Cercospora sojina (causal agent of frogeye leaf spot) isolates from Michigan, Minnesota, and Nebraska soybean fields. Plant Health Prog. 21, 230–231 (2020).
Neves, D. L., Webster, R. W., Smith, D. L. & Bradley, C. A. The G143A mutation in the cytochrome b gene is associated with quinone outside inhibitor fungicide resistance in Cercospora sojina from soybean fields in Wisconsin. Plant. Health Prog. 23, 241–242 (2021).
Neves, D. L. et al. First detection of frogeye leaf spot in soybean fields in North Dakota and the G143A mutation in the cytochrome b gene of Cercospora sojina. Plant. Health Prog. 23, 269–271 (2022).
Piñeros-Guerrero, N., Neves, D. L., Bradley, C. A. & Telenko, D. E. Determining the distribution of QoI fungicide-resistant Cercospora sojina on soybean from Indiana. Plant. Dis. 107, 1012–1021. https://doi.org/10.1094/PDIS-08-22-1744-SR (2023).
Onofre, R. B., Neves, D. L. & Bradley, C. A. Cercospora sojina isolates from Kansas soybean fields with the G143A mutation conferring resistance to quinone outside inhibitor fungicides. Plant. Health Prog. 25, 144–145 (2024).
Standish, J. R., Tomaso-Peterson, M., Allen, T. W., Sabanadzovic, S. & Aboughanem-Sabanadzovic, N. Occurrence of QoI fungicide resistance in Cercospora sojina from Mississippi soybean. Plant. Dis. 99, 1347–1352. https://doi.org/10.1094/PDIS-02-15-0157-RE (2015).
Zhang, G. et al. Widespread occurrence of quinone outside inhibitor fungicide-resistant isolates of Cercospora sojina, causal agent of frogeye leaf spot of soybean, in the United States. Plant. Health Prog. 19, 295–302 (2018).
Zhou, T. & Mehl, H. L. Rapid quantification of the G143A mutation conferring fungicide resistance in Virginia populations of Cercospora sojina using pyrosequencing. Crop Prot. 127, 104942 (2020).
Bandara, A. Y. et al. Modeling the relationship between estimated fungicide use and disease-associated yield losses of soybean in the United States I: Foliar fungicides vs foliar diseases. PLoS ONE. 15, e0234390. https://doi.org/10.1371/journal.pone.0234390 (2020).
Russell, P. E. A century of fungicide evolution. J. Agric. Sci. 143, 11–25 (2005).
Hollomon, D. W. Fungicide resistance: facing the challenge – A review. Plant. Prot. Sci. 51, 170–176. https://doi.org/10.17221/42/2015-PPS (2015).
Neves, D. L. & Bradley, C. A. Baseline sensitivity of Cercospora sojina and Corynespora cassiicola to pydiflumetofen. Crop Prot. 147, 105461 (2021).
Zhang, G., Neves, D. L., Krausz, K. & Bradley, C. A. Sensitivity of Cercospora sojina to demethylation inhibitor and methyl benzimidazole carbamate fungicides. Crop Prot. 149, 105765 (2021).
Mueller, D. S., Wise, K. A., Dufault, N. S., Bradley, C. A. & Chilvers, M. A. (eds.) Fungicides for Field Crops (APS, 2013).
Madden, L. V., Hughes, G. & Bosch, F. V. D. The Study of Plant Disease Epidemics (APS, 2007).
Alves, K. S., Shah, D. A., Dillard, H. R., Ponte, D. & Pethybridge, S. J. E. M. Safer and smarter: Leveraging interpretation-guided modeling and data merging of disease and environmental data for plant disease risk prediction. Phytopathology 10, 1329–1343 https://doi.org/10.1094/PHYTO-01-25-0008-FI (2025).
Jensen, A., Brown, P., Groves, K. & Morshed, A. Next generation crop protection: A systematic review of trends in modelling approaches for disease prediction. Comput. Electron. Agric. 234, 110245 (2025).
Shah, D. A. et al. Into the trees: Random forests for predicting Fusarium head blight epidemics of wheat in the United States. Phytopathology 113, 1483–1493 (2023).
Magarey, R. D., Travis, J. W., Russo, J. M., Seem, R. C. & Magarey, P. A. Decision support systems: Quenching the thirst. Plant. Dis. 86, 4–14 (2002).
Bishop, B. Applying foliar fungicides on soybeans using predictive models. MSc Thesis. Iowa State University. https://doi.org/10.31274/cc-20240624-233 (2022).
Huang, C. Y. et al. Study on forecasting the epidemiology of frogeye leaf spot and yield loss in soyabean. Soybean Sci. 17, 48–52 (1998).
Yang, C. & Wang, J. A mathematical model for frogeye leaf spot epidemics in soybean. Math. Biosci. Eng. 21, 1144–1166 (2023).
Sievert, C. plotly: Create interactive web graphics via plotly.js. R package version 4.10.4. https://CRAN.R-project.org/package=plotly (2025).
Posit Team. RStudio: Integrated development environment for R. https://posit.co (Posit Software, 2025).
Camera, J. N., Ghissi, V. C., Reis, E. M. & Deuner, C. C. The combined effects of temperature and leaf wetness periods on soybean frogeye leaf spot intensity. Semin. Ciênc Agrár. 37, 77–84 (2016).
El Jarroudi, M. et al. Weather-based predictive modeling of Cercospora beticola infection events in sugar beet in Belgium. J. Fungi. 7, 777 (2021).
Lavilla, M., Martinez, M., Ivancovich, A. & Díaz-Paleo, A. Modelo predictivo de la severidad del tizón foliar por Cercospora kikuchii mediante variables meteorológicas. Agron. Mesoam. 34, 53248 (2023).
Sentelhas, P. C. et al. Suitability of relative humidity as an estimator of leaf wetness duration. Agr Meteorol. 148, 392–400 (2008).
Adaskaveg, J. E., Michailides, T. & Eskalen, A. Fungicides, bactericides, biocontrols, and natural products for deciduous tree fruit and nut, citrus, strawberry, and vine crops in California. Univ Calif. Agric. Nat. Resour. (2025).
Wieben, C. M. Estimated annual agricultural pesticide use by major crop or crop group for states of the conterminous United States, 1992–2017. https://www.sciencebase.gov/catalog/item/5d88c231e4b0c4f70d0ab2c6 (U.S. Geological Survey Data Release, 2019).
Couëdel, A. et al. Assessing environment types for maize, soybean and wheat in the United States as determined by spatio-temporal variation in drought and heat stress. Agric. Meteorol. 307, 108513 (2021).
Mikel, M. A., Diers, B. W., Nelson, R. L. & Smith, H. H. Genetic diversity and agronomic improvement of North American soybean germplasm. Crop Sci. 50, 1219–1229 (2010).
Ray, R. V. Effects of pathogens and disease on plant physiology. In Agrios’ Plant Pathology (ed. Oliver, R. P.). 63–92 (Academic, (2024).
Kandel, Y. R. et al. Analysis of yield and economic response from foliar fungicide and insecticide applications to soybean in the North Central United States. Plant. Health Prog. 17, 232–238 (2016).
Cunniffe, N. J. et al. Thirteen challenges in modelling plant diseases. Epidemics 10, 6–10. https://doi.org/10.1016/j.epidem.2014.06.002 (2015).
Reich, J. & Chatterton, S. Predicting field diseases caused by Sclerotinia sclerotiorum: A review. Plant. Pathol. 72, 3–18 (2023).
Gent, D. H. & Del Ponte, E. M. Plant disease warning systems. In Agrios’ Plant Pathology. 247–257 (Academic, 2024).
Shah, D. A. et al. A machine learning interpretation of the contribution of foliar fungicides to soybean yield in the north-central United States. Sci. Rep. 11, 18769 (2021).
Fehr, W. R., Caviness, C. E., Burmood, D. T. & Pennington, J. S. Stage of development descriptions for soybeans, Glycine max (L.) Merrill. Crop Sci. 11, 929–931 (1971).
Kyveryga, P. M., Blackmer, T. M. & Mueller, D. S. When do foliar pyraclostrobin fungicide applications produce profitable soybean yield responses? Plant. Health Prog. 14, 6 (2013).
Price, T., Purvis, M. & Pruitt, H. A quantifiable disease severity rating scale for frogeye leaf spot of soybean. Plant. Health Prog. 17, 27–29 (2016).
Webster, R. W. et al. Uncovering the environmental conditions required for Phyllachora maydis infection and tar spot development on corn in the United States for use as predictive models for future epidemics. Sci. Rep. 13, 17064. https://doi.org/10.1038/s41598-023-44338-6 (2023).
Payne, A. F. & Smith, D. L. Development and evaluation of two pecan scab prediction models. Plant. Dis. 96, 1358–1364 (2012).
Sentelhas, P. C., Monteiro, J. E. B. A. & Gillespie, T. J. Electronic leaf wetness duration sensor: Why it should be painted. Int. J. Biometeorol. 48, 202–205 (2004).
Sentelhas, P. C. et al. Spatial variability of leaf wetness duration in different crop canopies. Int. J. Biometeorol. 49, 363–370 (2005).
Gleason, M. L. et al. Obtaining weather data for input to crop disease-warning systems: Leaf wetness duration as a case study. Sci. Agric. 65, 76–87 (2008).
Willbur, J. F. et al. Weather-based models for assessing the risk of Sclerotinia sclerotiorum apothecial presence in soybean (Glycine max) fields. Plant. Dis. 102, 73–84 (2018).
R Core Team. R: A Language and Environment for Statistical Computing. https://www.R-project.org/ (R Foundation for Statistical Computing, 2025).
Kuhn, M. Classification and Regression Training. R package version 6.0-94. https://CRAN.R-project.org/package=caret (2025).
Liaw, A., Wiener, M. & randomForest Breiman and Cutler’s random forests for classification and regression. R package version 4.7–1.1. https://CRAN.R-project.org/package=randomForest (2025).
Meyer, D., Dimitriadou, E., Hornik, K., Weingessel, A. & Leisch, F. e1071: Misc functions of the Department of Statistics, TU Wien. R package version 1.7–16. https://CRAN.R-project.org/package=e1071 (2025).
Acknowledgements
We acknowledge the numerous research staff and students from several research groups whose efforts made this work possible. Their contributions in establishing, maintaining and monitoring experiments, as well as data collection, were vital to the development of this study. We sincerely thank them for their time, expertise, and care in generating the dataset that underpinned this research.
Funding
This research was partially supported by Iowa State University USDA Hatch Project IOW04108 and the soybean checkoff through the United Soybean Board, North Central Soybean Research Program, Atlantic Soybean Council, Mid-South Soybean Board, Southern Soybean Research Program, Indiana Soybean Alliance, and Louisiana Soybean and Feed Grains Research and Promotion Board.
Author information
Authors and Affiliations
Contributions
J.F.G. and R.W.W. ran the statistical analysis and co-wrote the manuscript draft. R.W.W. is the corresponding author. All authors contributed to the collection of data and reviewed and edited the iterative manuscript drafts.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
González-Acuña, J.F., Allen, T.W., Bish, M.D. et al. Modeling the environment-related risk of frogeye leaf spot (Cercospora sojina) in soybean across the United States. Sci Rep 16, 16236 (2026). https://doi.org/10.1038/s41598-026-46975-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-46975-z
