
Abstract
Deep learning-based automated call detectors offer a solution to the labour- and time-intensive problem of isolating animal sounds within the enormous datasets generated by passive acoustic monitoring (PAM). Broad adoption of deep learning systems in PAM has been hampered by the need for large, labelled training datasets, which do not exist for species whose calls are seldom recorded. Additionally, significant computational resources are required to train many deep learning detectors, making them expensive both monetarily and in terms of energy use. We present an automated detection framework that mitigates these issues for animals that produce stereotyped sounds. First, we produce a semi-synthetic training dataset using a physically motivated data augmentation pipeline that introduces realistic variation into duplicates of a single exemplar recording of the target sound. Second, we fine-tune a pretrained neural network with transfer learning, allowing training on consumer-grade hardware in a matter of hours. Third, we demonstrate our detector on two baleen whale vocalisations and test the performance against ground truth annotations. Our best performing model achieved a recall of 99.4%, precision of 91.2% and an F1 score of 95.1%, matching or outperforming similar detectors, and having been trained on a dataset built from a single example of the target call. We propose that our framework advances the utility of deep learning detectors for baleen whales and likely other rare or elusive animals that produce tightly stereotyped vocalisations. The trained model and all associated code are made freely available, with the goal of reducing barriers to the use of deep learning detectors for the study of data-scarce, stereotyped animal sounds.
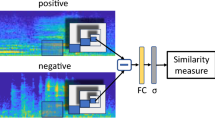
Similar content being viewed by others


Introduction
Passive acoustic monitoring
Whether studying animal behaviour, communication, social structure, population distributions, ecosystem biodiversity or conservation, research in ecology is predominantly observational in nature1. If the species of interest is scarce, nocturnal, timid, or resides in a habitat not easily accessed by humans, opportunities for observation may be exceedingly rare. This has driven the adoption of remote sensing technologies, which enable remote observation of wild animals in their natural habitats. Passive acoustic monitoring (PAM) is a field of remote sensing that involves the capture of animal sounds using audio recording equipment left to operate unattended in the field2. PAM methods first became popular in the early 90’s with the publication of several marine fauna studies enabled by the US Navy’s “Dual-Use” program, which allowed access to the ocean Sound Surveillance System (SOSUS) for civilian research3,4. PAM has since been used more broadly, for studies operating at ecosystem scales5, down to individual scales6, and for a range of biomes and taxa7,8,9,10. In recent years, the decreasing cost and physical size of audio electronics components has driven a proliferation of PAM hardware systems, from low cost, open source, DIY tools11, to multi-million dollar, planetary-scale systems like the Comprehensive Nuclear Test Ban Treaty Organisation’s International Monitoring System12. Historically, the task of isolating individual animal calls from these recordings has been performed by human analysists, largely by visual inspection of audio spectrograms, a process often termed “annotation”13. There are a growing number of PAM data archives, both open-access and proprietary, that were originally gathered for purposes outside the life sciences14,15,16,17,18,19,20,21,22,23, some of which cover global spatial scales and decadal time scales12. For biologists and ecologists these have huge data mining potential, and recent decades have seen a growing trend towards re-analysis of archived PAM data in the lab14,15,16,17,18,19,20,21,22,23,24,25,26. Since many of these data sets contain far more audio data than could ever feasibly be annotated by human analysts27, automated call detection has emerged as a key research challenge. Considering the value these data archives have to the bioacoustics community, and the substantial cost and logistical complexity involved in their acquisition12, reducing barriers to their re-use seems prudent.
Automated call detectors
A variety of automated call detectors have been developed, all with varying performance, implementation complexity and computational expense. They also vary widely in terms of how target sounds are represented to the detection algorithms (e.g., as waveforms, spectrograms, filter kernels, sparse dictionaries, etc.) and how many exemplars are needed. Many of the most performant detectors rely on deep-learning, and for these methods the requirement for massive training data sets is a significant barrier to broad adoption. Training often requires tens of thousands of unique examples of the target call, and for animals that are scarce, elusive or extant only in habitats inaccessible to humans, data scarcity may be an insurmountable obstacle in implementing those methods. Additionally, training deep learning-based solutions usually involves substantial computational resources, which aside from monetary expense can also entail non-trivial environmental impact28. Other existing methods suffer from limitations around reusability and adaptability to new target sounds and environments. Improving reusability and reducing the need for compute resources and training data are central goals of the present study. Below is a brief review of common automated detection approaches. For a more complete review of detector methodologies, see Gibb et al.,27.
Audio signal processing methods
Much of the early PAM work focussed on whale vocalisation, so baleen whale songs were a common target for early automated detectors like the time-domain matched filter method, used by Stafford et al.29 to detect northeast Pacific blue whale (Balaenoptera musculus musculus) songs. They measured the time-frequency characteristics of 303 recordings of their target call and used the average values to construct matching filter kernels. To detect songs in a recording, the computed the time-domain cross-correlation function of their kernel with the recording, with peaks indicating a detection. This method was also studied by Mellinger and Clark30, and they found it performed poorly when background noise levels were high, especially when the noise was temporally non-stationary and spectrally non-flat, which is often the case in bioacoustics recordings.
Mellinger and Clark30 proposed a similar method that instead operated in the time-frequency domain. This method is often termed spectrogram correlation and involves computing the two-dimensional cross correlation of an audio recording’s spectrogram and a spectrogram kernel designed to represent the target sound. They tested using bowhead whale songs, and found their method was superior to a Hidden Markov model detector and a matched filter detector. Subsequent work, also on whale song, has shown that spectrogram correlation suffers two major limitations: first, spectrogram kernels have extremely limited ability to generalize across even small variations in the target signal31. Such variations can be behavioural, like the inter- and intra- annual frequency declines that are observed in many baleen whale songs32,33,34,35,36, or can be related to acoustic propagation effects. Secondly, accuracy has been shown to drop significantly when background noise levels are high37,38.
Classical machine learning
Fagerlund (2007) proposed a method for detecting and classifying the songs of 14 bird species using a support vector machine (SVM). SVMs are class of machine learning algorithms that search for the boundary that best separates two or more classes of data. They used measured signal properties like spectral centroid to represent the target sound and reported 91% and 98% accuracy on two test datasets featuring different bird species. The authors noted that their tests featured a very small number of different individuals of the same species and suggested that their method may struggle with intra-species variations seen in real data or larger test sets.
Other methods have been developed that sacrifice general applicability for improved performance by mathematically modelling a specific target sound, as opposed to using real exemplars or empirically designed kernels. Socheleau et al.39 proposed a method for detecting the “Z-call” of the Antarctic blue whale, B. m. intermedia. When visualised on a spectrogram, this call has a “z” shape, and this simple structure makes the call ideally suited to modelling with a sigmoid function. The authors reported a 15% performance improvement over spectrogram correlation, even in the presence of interfering signals and noise. Unlike the Z-call however, many animal calls cannot be easily represented with a closed form, analytical function like a sigmoid, limiting the applicability of this method. This method was extended by Socheleau & Samaran40 to allow for more complex target sounds by modelling signals using sparse representations; sparse, linear combinations of rudimentary basis functions, or “atoms”41, learned from training data. They tested using Northeast Pacific blue whale D-calls and Southwest Indian Ocean (SWIO) pygmy blue whale songs and reported a true positive rate of 90% at 5 false alarms/h for the D-call, and 95% true positive rate @ 5 false alarms/h for the SWIO song. The authors point out that their method assumes targets can be accurately represented by a linear combination of atoms, which may not hold for highly non-linear vocalisations, sounds with “deterministic chaos” [see 42], or broadband, transient sounds like odontocete clicks, and they noted that like neural networks, insufficient training data can lead to overfitting.
Shallow neural networks
Potter et al.43 proposed one of the first animal call detectors to utilise an artificial neural network. Their system took cropped and down-sampled spectrograms as inputs and returned probabilities of target signal presence as output. They demonstrated an error rate of 1.5% when tested on bowhead whale (Balaena mysticetus) songs, though the authors noted that the test dataset included training data as well as unseen data. They also stated that many of their design choices were constrained by computational cost. This early work demonstrated the strength of machine learning methods, but like its deep learning successors, the need for large volumes of training data was a limitation.
Neural networks have also been used in terrestrial bioacoustics, with early work by Chesmore44 demonstrating a method to detect and classify sounds from 25 species of crickets and ten species of bird. They reported >99% accuracy for 24 out of 25 species of cricket tested, with a signal to noise ratio of 40 dB. When SNR was decreased to 10 dB, accuracy for some species fell to below 10%. PAM data often exhibits SNR much lower than 10 dB, so robustness to realistic noise conditions is for this method appears limited.
Deep neural networks
Early shallow neural network detectors had around 800 learnable parameters43, but in recent years, larger architectures like deep convolutional neural networks (dCNN) have become popular, some having as many as 1.9 x 107 parameters45. Parameter count has (at minimum) a quadratic relationship to the computational cost of training46, and this cost can present a barrier in the practical implementation of deep learning for research applications. Miller et al.47 used an efficient dCNN called DenseNet to develop a detector for the Antarctic blue whale D-call, trained on 5,137 spectrograms of the target call. They compared performance with a human analyst and reported a 90.1% probability of target detection, while the human scored only 74%. The size of their training dataset was modest by deep learning standards, however for rare, understudied or data-scarce animal sounds, sourcing even this volume of training data may prove challenging. Efficient models like DenseNet have helped to make deep learning detectors feasible in budget constrained research groups, but even the consumer-grade GPU like the one used in47 can represent a non-trivial expense.
Recursive, deep neural networks
dCNNs expect inputs (usually spectrograms) of a particular size, which can limit their applicability to sounds whose duration fits within a single input. For example, the network used by Miller et al.47 expected inputs as 24 x 67 matrices, while their spectrograms were generated with 33 frequency bins and 67 time bins, spanning 0-125 Hz, and a duration of 4.224 s. Thanks to the Antarctic blue whale D-call’s relatively simple time-frequency structure, which occurs between ~80 and ~30 Hz and has a duration of ~3 s48, Miller et al., were able to simply trim irrelevant frequency bins from their spectrograms to meet the input size, a valid and reasonable solution in their use case. Application of this network to a call with a longer or significantly shorter duration, however, would necessitate one of the following strategies:
-
1.
Increase or decrease the network’s input size
-
2.
Increase or decrease the duration of the spectrogram time steps
-
3.
Resize the spectrogram using resampling and interpolation
-
4.
Trim overflowing time bins or zero pad to fill empty ones
-
5.
Break the spectrogram into shorter frames to use as separate inputs
The above strategies are often effective, however their success depends on the characteristics of the target call, and if a detector is to be broadly re-usable, no single strategy will work in all cases. (1) is often reasonable, though compute cost scales with input size, so efficiency is a factor. (2) sacrifices time or frequency resolution, potentially reducing the network’s ability to distinguish between sounds49,50. (3) is effective in image classification51 because subjects in images are often scale-invariant (i.e., a zoomed-in photo of a dog is still recognizable as a dog). In spectrograms, scale has physical meaning (i.e., duration and bandwidth), and resizing breaks this mapping. (4) Trimming results in the loss of information, and zero padding contaminates training data with silence, which degrades erformance52. In image classification, (5) is effective because natural images exhibit spatial redundancy and local self-similarity – each “patch” is likely to contain sufficient discriminative structure to represent the whole53. This may not hold true for audio spectrograms of animal vocalisations54,55, and since dCNN’s do not retain information about previous inputs, each prediction must be made based on an incomplete subset of the information in the spectrogram.
A number of studies have discussed these issues and suggested the same solution; to use networks that consider sequences of inputs, and return sequences of predictions with temporal dependence56,57. Convolutional recurrent neural networks (CRNNs) extend the dCNN paradigm with temporal dependence. Whereas CNNs return a single prediction for a single spectrogram input of fixed size, an CRNN returns a vector of predictions, one for each ”chunk” of a longer spectrogram. The input size is therefore only fixed in the frequency dimension, allowing inputs of arbitrary and variable duration. In addition to ability to adapt to targets of varying durations, the extra temporal context captured by CRNNs can also aid in classification, since many animal vocalisations occur in calling bouts, where the structure and timing in a sequence of calls can provide disambiguating information. Previous studies have shown that architectures with temporal dependence may outperform CNNs in classification or detection tasks targeting bird calls58,59, fin whale songs57, and right whale songs60,61. It should be noted however, that CRNNs are not without their own limitations; compute complexity scales with input sequence length62, and for rudimentary CRNNs, the vanishing gradient problem leads to degraded performance as sequence length increases63. More modern recurrent architectures such as those that employ long short-term memory (LSTM64) or gated recurrent units (GRUs65) mitigate this problem somewhat, but care is still needed when using very long input sequences either at training or inference time.
Overcoming deep learning challenges
Transfer learning
Computational complexity can be a considerable limitation of deep learning methods. Battery powered field recording devices have been developed that incorporate deep-learning-based detectors66, and in that application, inference-time compute efficiency is the main constraint, since training is be completed prior to deployment. In lab analysis of archived datasets, training becomes the dominant constraint, and can consume substantial monetary, effort, and time costs. One way to mitigate training cost is by using transfer learning, the practice of fine-tuning a pretrained neural network to perform a new task in an adjacent, but related domain, rather than training from scratch. Tsalera et al. used transfer learning to fine-tune image classification dCNNs to classify spectrograms of various sounds and reported classification accuracy between 83.97% and 97.22%67. They also experimented with fine tuning networks that were originally trained to classify audio spectrograms, but with different target sounds than their own. In these cases, where the domain transfer was smaller, the audio spectrogram classifiers outperformed image classifiers, achieving accuracy between 91.25% and 100%. Re-training times for these networks were on the order of minutes, and though the hardware specifications were not provided, this implies a substantial reduction in training costs, compared to training from scratch. Additionally, transfer learning often requires far less data than training from scratch; their best performing model was trained on only ~1,080 samples from the “air compressor” dataset, which contained eight different classes of sounds. From this we can infer that this model achieved 100% classification accuracy from only ~135 training samples per class.
Data augmentation and synthetic data
While transfer learning reduces the necessary volume of training data, in PAM and bioacoustics applications, it may still be challenging to gather sufficient samples of the target call. For instance, Shephard’s beaked whales, Tasmacetus shepherdi, are rarely sighted, and to our knowledge, only two documented instances of their echolocation clicks have been recorded68,69. Similarly, the Australian night parrot, Pezoporus occidentalis, which is extremely rare, was first recorded in 201970, and a follow up project to build a detector noted data scarcity challenges71.
Many of the animals mentioned in this work thus far produce vocalisations that are tightly matched in time-frequency structure across individuals. This phenomenon, known as stereotyping, can be exploited in the design of automated detectors under data scarcity constraints. If the degree of variability in the sound is known or estimable, data augmentation techniques can be used to increase the number of training samples, by replicating existing recordings of the target sound, and introducing controlled, pseudo-random variations representative of real, natural variations. Augmentation methods have been well established in image classification, where common operations include random rotations, translations, scaling, masking and gaussian noise addition.
Spectrogram time-shift, noise addition, and masking have been used to increase the size of a detector training dataset for song of the North Atlantic humpback whale, Megaptera novaeangliae72, and were shown to improve detector performance. Data augmentation using semi-synthetic spectrograms has also been demonstrated for enlarging training datasets for classification of ultrasonic vocalisations of the brown rat (Rattus norvegicus)73. They duplicated real call spectrograms and performed smooth elastic deformations to the images. They found that this augmentation improved their classifier’s performance to human-level accuracy. In contrast however, Nanni et al.74 tested a model trained on a small base dataset, versus the same dataset enlarged using image-augmentation and audio-augmentation methods (applied to audio before transformation to spectrograms), and their results showed that for animal sound classification tasks, image augmentation methods may offer no improvement, or even degrade performance74. They suggest that audio-augmentation is the most robust method for increasing dataset size for animal call classification.
A synthetic data approach to augmentation was used by P. Li et al.75, who analysed the shape of common (Delphinus spp.) and bottlenose (Tursiops truncatus) dolphin whistles in spectrograms, and generated a library of synthetic curved lines with similar shapes. The curves were then superimposed on real spectrograms of recorded ocean background noise. They trained a CNN detector on this synthetic data alone, and achieved precision of 92.4%, recall of 69.3%, and an F1-score of 79.2%75. While this method did yield an excellent precision score, relatively low recall indicates that the curves were insufficiently varied, or the model did not generalise well to whistles with novel curve shapes. Additionally, this data synthesis method is limited to animal sounds with simple time-frequency structures. Complex vocalisations that feature strong non-linearity, harmonics, amplitude modulation sidebands, or noise-like components cannot be easily synthesised using these methods.
In recent years, machine-learning-based methods such as generative adversarial networks (GANs) have been proposed for generating synthetic training data. Kopets et al.76 used a GAN to generate synthetic sperm whale (Physeter macrocephalus) clicks specifically for the purpose of addressing data scarcity. They started with 81 click recordings, then augmented using conventional audio-domain and spectrogram-domain methods, yielding ~6,500 samples with which to train their GAN. They showed that their synthetic clicks bore a high degree of resemblance to real recordings, though they did not train and test a detector or classifier76. There are two limitations in this method; the first is the non-trivial data volume to required train the GAN itself – for truly data scarce species, 81 samples may not be available. The second relates to the significant financial and computational resource cost, and the increased complexity of the system in contrast to conventional augmentation methods. Utilising this method for PAM data analysis would mean training not one neural network but two, and GANs can often require substantial compute resources77,78. While efficient GAN architectures have been demonstrated, the use of a second deep neural network in the detection pipeline adds complexity and compute cost.
Blue whales
The International Union for the Conservation of Nature lists the blue whale (Balaenoptera musculus) as an endangered species, with an estimated 5,000-15,000 mature individuals currently in the wild79. Despite increased public interest following the IWC’s moratorium on commercial whaling in 1982, relatively little is known about blue whales, and this hampers conservation efforts80. Their scarcity and pelagic habitat make cetaceans a prime candidate for study via PAM methods, and in recent years, such studies have yielded new insights into population density and distribution, social structure, mating, migration, and vocal anatomy5,18,81,82,83,84.
Blue whale taxonomy is an open area of research and debate. Five subspecies are currently recognised by the Committee on Taxonomy of the Society for Marine Mammalogy; Northern blue whale (Balaenoptera musculus musculus), the Antarctic blue whale (B. m. intermedia), the Northern Indian ocean blue whale, (B. m. indica), pygmy blue whale (B. m. brevicauda) and the as-yet unnamed Chilean blue whale, though a recent study suggests that the Chilean may in fact be genetically indistinct from B. m. musculus80. Each of these subspecies can be divided into acoustic populations, and within each of these groups, all individuals sing the same song85, with inter-individual frequency variability of ≤3 % in a given year34, and for populations with amplitude modulated calls, average inter-individual variability in pulse rate is reported at ~1.8%18. As stated above, stereotyping is a useful property in the design of automated detectors, as a detector can be designed to recognise only the song of the population of interest. Alternatively, multi-call detectors can be designed to identify all populations that are present, and by analysing data from multiple sites, it is possible to map the temporo-spatial ranges of each group and their overlap.
Consistent, recurring themes in the literature indicate four main challenges that face current detector methodologies:
-
1.
Difficulty generalising to variations in target call
-
2.
Difficulty generalising to new recording locations and acoustic conditions
-
3.
Large computational expense
-
4.
The need for large training corpora
Here we present a data augmentation and detector training framework for stereotyped animal sounds that aims to address these challenges by using semi-synthetic training data to fine-tune a pretrained recurrent, deep convolutional neural network that can accept target calls of arbitrary duration. We then evaluate our detector on two annotated PAM datasets of blue whale vocalisations.
Results
Computational efficiency
The model was fine-tuned on a Dell Precision 3570 laptop computer with 64 GB of memory, and an NVIDIA T550 GPU with 4 GB of V-RAM. The training ran on the GPU and took approximately 5 hours to complete. The time to run inference on an audio file of 4 hours duration, with a sample rate of 250 Hz and a bit depth of 32 bits was approximately 90 s, including pre- and post-processing.
Pre-adjudication results
Below are initial performance values for each model, after comparing detections with reference annotation logs. Note that the reference logs were found to be unreliable, so these values do not represent the detector’s true performance, and are included here only to compare model configurations. The model configuration with the best recall for each call was selected for adjudication. The final post-adjudication results are given in section "Post-Adjudication Results". Activation threshold for these results was 0.5. Other post-processing parameters were as set as per Table 1,8.
Post-adjudication results
Following are post-adjudication results for the models that performed best for each call in the pre-adjudication results, ABWZ-C and CPBW-C-Small Table 2.
Decision logic refers to the three different criteria for classifying adjudicated detections as true positives, each one differing in how the presence of chorus is treated. Under “inclusive” logic, any detection confirmed by the adjudication analyst to contain chorus or a discrete call is treated as a true positive Fig. 1 and Fig. 2. Under “Discrete-Only” logic, any detection confirmed by the analyst to contain discrete calls – regardless of chorus presence – qualifies as a true positive. Under “strict-discrete” logic, only detections confirmed by the analyst to contain discrete calls with no chorus present, are treated as true positives. Table 3.

Receiver operating characteristics curve for the post-adjudicated results of the ABWZ-C model.

Receiver operating characteristics curve for the post-adjudicated results of the CPBW-C-Small model.
Figure 3 and Figure 4 illustrate the changes to the numbers of true positives, false positives, true negatives, and false negatives, for CPBW-C-Small and ABWZ-C models respectively.

Comparison of performance metrics pre- and post-adjudication for the ABWZ-C model.

Comparison of performance metrics pre- and post-adjudication for the CPBW-C-Small model.
Discussion
Detector performance
Post-adjudication results using the “inclusive” decision logic demonstrate that detectors can achieve high precision even when trained on semi-synthetic datasets built from very few recordings of the target call. The best performing Antarctic blue whale Z-call (ABWZ) detector (ABWZ-C) successfully detected 87% of target calls, with a precision of 0.65, while the best performing Chagos pygmy blue whale (CPBW) detector (CPBW-C-Small) correctly detected 99.4% of target calls, with only 9% of all detections being false positives (precision = 0.91). More impressive than the raw performance values, is the fact that the CPBW-C-Small detector achieved them under extreme source data scarcity; the training dataset for that model was built from a single exemplar of the target call.
These results stand in contrast to the pre-adjudication results, which first appeared to show relatively poor detector performance for both target calls. The pre-adjudication results for the best performing ABWZ detector (ABWZ-C) successfully detected only 66% of target calls, with a large number of false positives (precision= 0.2). Precision of 0.2 means that 80% of all detections were false positives, and for most applications, this false positive rate is too high for the detector to be considered fit for purpose. Prior to adjudication, the best performing CPBW detector (CPBW-C-Small) successfully detected 98% of target calls, but again, returned many false positives (precision = 0.28). During pilot experiments, manual inspection of audio spectrograms, detector outputs and ground truth logs revealed that many of these false positives were in fact true positives that were missing from the ground truth logs. Based on those investigations, and the findings of previous studies13,47,86, the reference logs were deemed to be unreliable, and an adjudication protocol was implemented to resolve disagreements between ground truth logs and the detector. This is further discussed in section "Unreliable Ground Truth".
The post-adjudication results for both calls indicate that the VADNet model, originally trained to detect of human speech in microphone recordings under typical indoor noise conditions, was, through transfer learning, able to learn the domain-adjacent task of whale call detection in hydrophone recordings captured in a high-noise mid-ocean, submarine environment. In addition to this task-domain transfer, the model appears to have successfully adapted to a new audio sampling rate and operating frequency range, new mel filter bank bandwidth and resolution, and new short-time Fourier transform window and hop sizes. In other words, the GAVDNet model was able to accurately interpret spectrograms with substantially different temporal and spectral ranges and resolutions than the ones VADNet was trained on.
The disparity between the results for the two target calls may be related to the complexity of their respective shapes when represented in spectrogram form; the CPBW has a complex time-frequency structure with a plurality of overlapping frequency components, featuring both amplitude and frequency modulation, while the ABWZ consists of a single sinusoid that steps down from one stable frequency to another. For a human analyst, this simple structure can make the ABWZ more difficult to distinguish amongst background noise in a spectrogram, compared to the CPBW song. We suggest that this may also apply to neural network-based detectors.
This effect may be exacerbated by the fact that ambient noise conditions at the two recording sites are quantitatively and qualitatively different. In the region around Diego Garcia Island, where the CPBW data was captured, the daily median noise level between 2002 and 2012 has been reported at 88.2 dB re 1 µPa2/Hz in the 5-30 Hz band, 86.0 dB in the 40-60 Hz band87. Some seasonal variation in noise levels was reported in data recorded before 2009, with lower levels during the austral winter, possibly attributed to monsoonal rainfall and the northern migration of Antarctic blue whales, however post-2009, these fluctuations diminished in magnitude and a consistent level of shipping noise became the dominant noise source in the region.
The ABWZ data was recorded off Casey station, Antarctica, and while we were not able to find published noise levels for this region, one study has reported median noise levels in the Scotia Sea off the Antarctic Peninsula at ~105 dB in the 11-30 Hz band, and ~100 in the 31-50 Hz band, with approximately ±5 dB of seasonal variation. Several studies have shown that sea ice is a dominant source of ocean noise in Antarctic waters, and that seasonal increases in noise levels are correlated with sea ice breakup88,89,90. The Casey 2014 data was recorded throughout 2014, a year of record high sea ice extent91. In September of that year, the sea ice extended to within ~170 km of the Casey 2014 hydrophone, while at the minimum in February, the nearest sea ice was ~960 km away92, and this likely caused considerable intra-annual variation in the character and amplitude of ambient noise in the dataset. It has also been shown that noise levels in Antarctic waters fluctuate on a diurnal basis due to the cracking of sea ice in response to sunlight93, a phenomenon unlikely to affect noise levels in the tropical waters around Diego Garcia. The Casey 2014 dataset is therefore not only noisier than the H08S1 data, but the noise conditions are also more variable, and these challenging conditions may be another factor in the performance discrepancy since the network may have a more varied set of non-target sounds to learn (see section "Detection is Open Set Classification").
Alongside the long-term downward frequency shift observed in the songs of all known blue whale populations34,35,94, Leroy et al.,94 have described a cyclical, intra-annual frequency shift of ~0.1Hz in the Antarctic blue whale Z-call, and shown that this periodic fluctuation is highly correlated with cryogenic noise levels. They observed a similar trend in vocalisations of fin whales and Southwest Indian Ocean pygmy blue whales. Such an intra-annual frequency shift has not been reported for the Chagos pygmy blue whale, and this difference may at first appear to be a contributor to the performance discrepancy. We suspect though, that the small magnitude of the observed intra-annual frequency shift makes this unlikely, since our data augmentation applies random frequency shift of up to +/-2 Hz when synthesising training data, which should be more than sufficient to capture the real degree of frequency variation. It is also reasonable to assume that the CPBW may exhibit an intra-annual shift that has not yet been described, as this phenomenon appears to be common amongst baleen whales, and cryogenic noise has not been conclusively established as the driver.
The labelling convention of the Z-call in the SORP-IWC dataset may also have affected performance for that call. As mentioned in section "Ground Truth Reference Datasets", annotations in that dataset differentiate between complete Z-calls and A and B units observed in isolation. Since the detector was not trained to reject isolated A or B units, these may have triggered positive detections since they are, in terms of time-frequency structure, identical to Z-calls that were only partially captured. During pre-adjudication evaluation, the test set annotations would have ruled these as false alarms, and this too may help to explain some of the disparity in pre-adjudication results.
Detection as a probabilistic problem
Automated call detection is conventionally framed as a binary process, but machine learning detectors output streams of signal presence probabilities, not binary results. This is due not only to the statistical underpinnings of machine learning systems, but to the probabilistic nature of the task itself. Due to varying acoustic propagation conditions, source-receiver distance, and background noise levels, a recording may capture the target animal sound with varying degrees of fidelity and completeness. For instance, the recording may fail to capture all the sound’s high-frequency harmonics, or the start or end of the sound may be absent. Those parts of the signal might be absent because they failed to propagate to the recording device at sufficient amplitude, or they may be masked by background noise95. The goal of an ideal detector is to answer the question “is the target sound present in this audio”, but a more practical question to ask is “how much of the target sound is present in this audio”. At first glance, it may seem that we can obtain a binary result by reformulating this question as “is the signal present within the pickup distance of the recording equipment?” This is difficult to answer though, since pickup distance depends on the target sound’s amplitude & frequency, hydrophone sensitivity, source-receiver geometry, and properties of the propagation environment, as well as the amplitudes and locations of background noise sources. Many of these are unknown, or only known approximately, and some are time-varying. The mismatch between the probabilistic nature of the task, and the binary nature of our desired result is problematic, because it forces us to coerce probabilities into a binary (presence/absence) result during post-processing using detection thresholds and heuristics that are often set through trial and error (see section "Probability Post-Processing"). It is therefore inevitable that all detectors will be subject to some degree of precision-recall trade-off, resulting from these post-processing decisions.
A recent paper proposed an improved method for probability post-processing termed a Boundary Proposal Network, which uses learned representations to gate the detector network’s output96. The authors showed that it offered a 16.8% improvement in precision when used with an existing blue whale vocalisation detector. The downside of this method is the requirement to train an additional neural network, and the associated training data requirements and computational costs. Additionally, reliability of ground truth labels may be problematic, as discussed in section "Unreliable Ground Truth".
Chambert et al.97 proposed a probabilistic method that does not require a neural network, and is therefore comparatively low-cost. They designed a hierarchical, false-positive occupancy model in which the total detection count is modelled as the sum of two Poisson processes; a false-positive process and a true-detection process. Their approach estimates the probability of a detection being a true positive by considering detection abundance and an estimate of the detector’s error rate, obtained through a human-adjudication process on a small test set. Additional covariates that affect the probability such as time of day, ambient noise metrics and detector post-processing thresholds are included in the model with parameters estimated in a Bayesian framework. While this model is not appropriate for direct implementation as a post-processor in our detector framework, its approach could be adapted, and this is an opportunity for future improvement.
Unreliable ground truth
Another difficulty in measuring detector performance is the matter of defining a ground truth. Since passive acoustic monitoring, by definition, involves unattended recording equipment, there is no human observer to confirm the sound source, and in marine contexts, no footprints, scat or other physical evidence as to the animal that made the recorded sound. Even the use of video recorders alongside audio systems is not a viable solution in marine environments – efficient ocean acoustic propagation all but guarantees that the audio system will record calls produced by animals that are far outside the camera’s visual range. There is, therefore, no real ground truth, and any automated method to generate one (e.g., by using an existing detector) is inherently uncertain and potentially unreliable. Standard practice is to use human-generated annotated reference logs as ground truth, since human annotation is viewed as being the most reliable method38,98. A study by Leroy et al.13 has shown however, that human analysts exhibit significant variation in annotation accuracy, both between analysts, and also within an individual analyst’s annotations over the duration a long task. Two trained analysts were tasked with annotating recordings for North Atlantic right whale and Antarctic blue whale songs, and analysis of their logs showed that less than 50% of their annotations agreed. Additionally, decreasing signal-to-noise-ratio (SNR) was correlated with decreasing agreement between analysts13. A similar study used synthetic data composed of gaussian noise representing background noise and polynomial phase signals representing simple tonal animal calls86. The use of synthetic signals allowed construction of a ground truth, which in turn allowed objective accuracy scoring of five human analysts who performed manual annotations on the synthetic data. The results showed probability of detection was 95-100% for data with 24 dB SNR, but this decreased rapidly with decreasing SNR, to 6-41% for data with 18 dB SNR. It’s worth noting that in the context of mid-ocean PAM recordings, 18 dB SNR is considered high.
A study by Miller et al.47 further demonstrated the pitfalls of using a human-annotated reference log as ground truth when testing automated detectors. Much like our study, their initial tests showed unremarkable detector performance, but when disagreements between the detector and the reference log were adjudicated by an experienced analyst, they found that many of the detections that were deemed false positives by comparison with ground truth, were in fact, true positives. Similarly, some detections that were listed in the ground truth log but missed by the detector (false negatives), were judged by the adjudicator to be true negatives. In other words, the detector was more accurate than the human analyst that produced the ground truth reference log. This outcome parallels the results of the present study.
The test set for the ABWZ was annotated by a single human analyst, with no validation, and in light of the literature, it is perhaps not surprising that annotations proved inaccurate. The test set for the CPBW models was annotated by an automated detector, and validated by an experienced human analyst18, and this two-stage process may have lent this test set some improved reliability, however, again, human validation does not guarantee accuracy. The pre-adjudication results are therefore strongly dependent on the recall and precision of unreliable human analysts and the detector used in99, and should be taken as preliminary results only, not indicative of true performance.
The adjudication procedure itself may be subject to the same human-analyst-reliability pitfalls, though this task differs from annotation in some important respects. Annotation typically involves the analyst scrolling through a long-duration spectrogram, picking out target calls. In contrast, in adjudication the analyst is shown a spectrogram of a short, fixed duration and must resolve the disagreement by deciding call present or call absent. Our intuition, while untested, is that annotation constitutes an open-ended task with greater room for interpretation (“find all the calls”), while adjudication is a set of bounded tasks with a binary response (“is this a call?”). We propose that adjudication may be less prone to error than annotation. To prevent operator bias during adjudication, the analyst was not told whether disagreements were false positives or false negatives, and was not permitted to freely scroll through the spectrogram to view detections in a wider context, which was suggested as a source of bias in47. Given these points, we consider the post-adjudication results reliable to within a reasonable degree of confidence, though the need for a reliable ground truth and best-practice measures of detector performance remain areas for further research.
The influence of chorus
A key design decision when building a detector is defining precisely what constitutes a positive detection in the specific context of the study at hand. It is not immediately obvious, but subtle differences in this definition can mean the difference between a detector that performs well for its given application, and one that is entirely unfit for purpose. An example is whether to consider “chorus” as a positive detection.
A single animal call, recorded under anechoic conditions, will appear in a spectrogram as a localised concentration of energy, with a distinct start and end along the time axis. If a recording of a single animal repeating such a sound at regular intervals is passed into a detector, the result will be a time series of probabilities with clear and discrete peaks or plateaus, each corresponding to an instance of the target sound. PAM recordings are far from anechoic though and often capture multiple individuals vocalising simultaneously. Chorus occurs when multiple individuals simultaneously produce sequences of repeated vocalisations. The superimposition of those calls with energy from multipath reflections and reverberations manifests in a spectrogram as a noise-like band of acoustic energy within the same bandwidth as the target call, but with little or no temporal structure (see Fig. 5 and Fig. 6). The influence of chorus on human analyst accuracy has been shown to be significant13, and depending on the application, it may be desirable for the detector to reject chorus, treating it as “non-target”.

An example of a discrete Antarctic blue whale Z-call (left) and Z-call chorus (right). Both recordings are from the Kerguelen Island recordings of the IWC-SORP dataset. The discrete call was recorded on March 1st, 2014, and the chorus, on July 12th, 2014.

An example of a discrete Chagos pygmy blue whale song (left) and Chagos song chorus (right). Both were recorded at Diego Garcia South by the H08S1 hydrophone of the CTBTO’s IMS. The discrete call was recorded on August 2st, 2015, and the chorus, on October 28th, 2017.
In post-adjudication results, the detector’s precision drops significantly when the adjudication decision logic is switched to exclude detections that feature chorus (ABWZ = 65.3% for “Inclusive” to 29.2% for “Discrete-only”; CPBW = 91.2% for “Inclusive” to 33.6% for “Discrete-only”, Fig. 3 and Fig. 4). This suggests that chorus was a dominant source of false positives in the pre-adjudication results, and this is not surprising, since no training samples in the negative class included chorus. Whenever the detector encountered chorus, it judged it to bear a stronger resemblance to the target signal than any non-target signal, likely because chorus has the same frequency bandwidth as the target. The comparison of pre- and post-adjudication results (Fig. 3 and Fig. 4) also shows that for both ABWZ and CPBW, the post-adjudication results using “Discrete-only” decision logic are in good agreement with pre-adjudication results. This suggests that the ground truth annotation logs not only treated chorus as negative class, but also discrete calls that were accompanied by chorus. This supports the existing evidence in the literature that chorus is a significant factor affecting human annotation accuracy. For applications where chorus should be excluded, our detector could easily be fine-tuned to reject it by including chorus in the noise-only regions (i.e., regions labelled “negative”) of the synthetic training sequences. Inclusion of a chorus generator in the audio augmentation framework is an area for further work.
Detection is open set classification
Automated call detection is essentially a binary classification task, with classes “target” and “non-target”. The common intuition is that these tasks are simpler than multi-label classification, since there are only two classes for the network to learn. In fact, detection of a single target is an open-set classification (OSC) problem, and is potentially harder than multi-label classification, because the space of all possible non-target sounds is large and unknown.
In the present study, the target animal sounds occupy a relatively small portion of the total frequency range and have very specific time-frequency structures. The space of all other possible sounds in the data is enormous, even if the possibilities are limited to sounds within the detector’s operating frequency range. A binary classifier makes no attempt to distinguish between all those other possible sounds. The problem is well illustrated by framing the task as a cluster analysis; the cluster of sounds representing the target occupies a small, isolated region of the network’s embedding space, whereas the space occupied by all other sounds is enormous, and surrounds the target cluster in all directions. In other words, the non-target class is an unbounded, heterogeneous, and infinitely variable set of unknowns. In a multi-label classification task, there are many isolated clusters of well-defined target sounds, so a larger proportion of the embedding space is known and recognizable. This increased segmentation of the embedding space into a greater number of disambiguated, known classes may help the model make accurate detections.
OSC problems are an open area of research in machine learning100,101,102,103. Morgan and Braasch101 evaluated techniques for improving performance of bird call detectors that fall into the OSC category, two that involved adding extra classes during training, and three were post-inference techniques. For all methods, the performance gains were mixed, and highly dependent on the similarity between known (labelled) and unknown (unlabelled) sounds in the training and test data. A recent study by Chen & Yang analysed target/non-target discrimination in OSC tasks not in terms of detector performance, but by analysing the networks’ learned internal representations of the sounds104. They reduced high-dimensional embeddings to 2 dimensions then performed a cluster analysis, comparing the strength of class-clustering between different types of classifier networks. They found that for multi-label classification tasks, networks that were fine-tuned with additional, new classes showed among the strongest clustering, but when the same models were fine-tuned for binary classification (i.e., detection), internal representations showed weaker clustering, and these models failed more often to discriminate between target and background sounds. Notably, some of their tests also showed that models originally pretrained for image classification outperformed those pretrained for audio classification. These findings suggest that in binary classification tasks using transfer learning, models pretrained for audio classification may be less suitable than ones pretrained for image classification.
The simplest and most obvious method to improve our detector may be to simply train it to classify additional sounds. Several open access audio datasets exist for sounds such as shipping noise and earthquakes, though the effect of using non-target training samples recorded in acoustic environments different from the target animal’s natural range is untested. There may also be benefits to adding non-target animal sounds with similar time-frequency structures to the target call. There are at least 7 acoustic populations of baleen whale active in the region around the Chagos Archipelago in besides the Chagos pygmy blue whale, and their songs all share similarities18. While labelled training data for these songs may not be readily available in volume, there is no reason that the semi-synthetic pipeline used to build our original target song dataset could not also be used for those calls, and only relatively minor changes would be necessary for the network architecture to accommodate additional classes. This too is an area for further study.
Computational efficiency
Once fully unfrozen, GAVDNet’s CRNN architecture had 109,700 learnable parameters. For reference, the dCNN used by Miller et al.,47 had 54,000 parameters, and YAMNet, a popular, general purpose sound classification dCNN has 3.7 million, while animal2Vec, a transformer-based animal call detector has 315 million105. Our chosen architecture is therefore relatively small in terms of parameters. Other aspects of network architecture can have implications for efficiency; CRNNs can suffer increased in inference latency when processing longer input sequences due to sequential dependence in the recurrent stage, which prevents parallelization; additionally, the accumulation of hidden state vectors can push up memory consumption.
Our primary intended use for GAVDNet was the analysis of existing PAM datasets in the lab, so while compute efficiency was a goal, we did not aim to achieve the extreme efficiency required for a detector deployed onboard a battery powered field recording device. Our compute efficiency goals were defined in practical terms. Specifically, that 1) training and inference could be run on consumer hardware, and 2) training could be completed in a day or two, and inference on a 4-hour-long recording in a few minutes. Given those goals, and our intended use case, we believe the results indicate a satisfactory trade-off between performance, data efficiency, costs and general applicability through adaptability to variable duration target calls.
Applicability to other taxa
Though this study validates our methodology using baleen whale songs, it may work well for other animal sounds, though with some strict caveats. The method’s applicability would be limited to calls with tight stereotyping in time-frequency structure. There is no suggestion that this method would work for non-stereotyped sounds such as dolphin signature whistles. The augmentation pipeline uses signal processing that emulates acoustic propagation effects (e.g., transmission loss, multipath propagation, Doppler shifts), and vocalisation behaviours (e.g., bulk frequency shifts, as observed in33,34,35, amplitude variation, and time stretching, approximating variation in call duration and pulse rate shift as observed in106). It is not, however, designed to modify the structure of the call itself. For example, it cannot add or remove silence in between call units, change the frequency spacing of overlapping tones, or modify frequency contours within call units. By definition, stereotyped calls do not exhibit significant variation in these respects, so the augmentation pipeline as currently built appears sufficient to model these sounds. Extending the pipeline to include additional signal modifications representative of non-stereotyped calls would improve GAVDNet’s utility for a broader range of sounds.
Our results indicate that the pretrained VADNet model, which was designed to operate on Mel-spectrograms with bin center-frequencies from ~44 to ~7500 Hz, was, through fine-tuning, able to generalise well to our Mel-spectrograms, which had center-frequencies from ~11 Hz to ~48 Hz. This generalisation, independent of frequency range and resolution, would suggest that the methodology’s re-use would not be limited to low-frequency sounds. Similarly, the disparity in spectrogram time resolutions between VADNet and GAVDNet indicates generalisation to sounds with differing degrees of temporal complexity. Further, in contrast to architectures with fixed input sizes, the CRNN architecture explicitly affords the model the flexibility to target sounds of arbitrary duration without loss of spectrogram information, or temporal context. Validation of applicability to other stereotyped sounds is an area for future study.
Methodological limitations
Wherever possible, augmentation parameter ranges were set according to estimated values from the literature, for instance swim speed and frequency shift ranges. Other parameters like time stretch range were set somewhat arbitrarily, though conservatively, and a visual inspection of augmented signals’ spectrograms was conducted as an informal check that the augmented signals were representative of real calls. It is not known whether all the augmentation operations we used are in fact necessary to obtain high performance. Previous work has shown that audio classification dCNNs can show performance gains using just a few augmentation methods107,108, though those studies used data augmentation only to increase training dataset size and diversity. Our intuition is that creating a large training dataset from a single sample likely requires a larger and more diverse set of physically motivated augmentations to allow generalisation beyond the exemplar. In the interest of streamlining the pipeline, a sensitivity analysis is a future area of exploration.
Six of the Z-call exemplars used to construct training data were taken from sites and years completely independent of the test set. The seventh was taken from the Casey 2014 dataset, and this accidental oversight created an overlap of a single call between training and test set (n=1091 calls). To minimise the risk of overfitting, the unmodified exemplars were never used for training, but rather, they served as seeds for the augmentation pipeline, which applied random combinations of audio effects as described in section "Data Augmentation".
To investigate the possibility of data leakage, we analysed similarity between the Casey 2014 exemplar and its derivatives in the training set (n = 26,600; post-augmentation, pre-noise-addition). We also measured similarity between all seven (7) of the ABWZ exemplars to gain an indication of similarity between real-world calls from different years, sites and individuals. Our metric for similarity was the structural similarity index (SSIM) between Mel spectrograms generated as per the procedure and parameters in section "Training Data Composition". Here, \(SSIM= 0\) indicates maximally dissimilar signals, while \(SSIM= 1\) indicates identical signals. The mean of SSIMs between the seven exemplar calls was \(SSI{M}_{all exemplars}=0.507\), while the mean of SSIMs between the Casey 2014 exemplar and the 26,600 training samples was \(SSI{M}_{Casey exemplar \& all training}=0.522\). The Cohen’s effect size between \(SSI{M}_{all exemplars}\) and \(SSI{M}_{Casey exemplar \& all training}\) was \(d=-0.304\). This indicates that the augmented training samples were only slightly more similar to the unmodified Casey 2014 exemplar than the seven real-world, independent exemplars were to each other.
Despite the small effect size, we cannot rule out that the model retains some small advantage in detecting that specific instance of the target call that was used as an exemplar. Any potential advantage is however, confined to a single call of the 1,091 in the test set; no advantage is conferred to the remaining 1,090 calls, which are truly unseen by the training procedure. The impact on ABWZ-A, B and C is therefore unlikely to be significant, and the single exemplar used for tra ining the ABWZ-C-Small model was sourced from the Elephant Island 2014 dataset, so training data was completely independent of the test set. The training data for all CPBW models was built from exemplars that were completely independent of the test set, and these were the best performing models. The use of a call that appears in the test set as an exemplar for training data synthesis therefore represents a methodological limitation, but we consider the influence on results to be negligible.
The similarity analysis described above also facilitated comparison of the diversity in the training data against that of real calls. The mean SSIM amongst the 26,600 training samples was \(SSI{M}_{all training}= 0.496\), while the SSIM between the 7 exemplars was \(SSI{M}_{all exemplars}=0.507\). The effect size between \(SSI{M}_{all exemplars}\) and \(SSI{M}_{all training}\) was \(d=0.189\), though the limited sample size for \(SSI{M}_{all exemplars}\) makes this a noisy estimate. While these results are lacking in statistical power, and a more rigorous analysis using independent, real calls is planned for a future study, we take them, and the detector’s performance as indications that the diversity in the training data was representative of real whale calls.
Conclusion
Passive acoustic monitoring data archives are a valuable resource for ecological and biological research, and while significant progress has been made in their analysis, their full exploitation is constrained by the need for automated call detection tools that are reliable, accurate, easy to use, require minimal labelled data to train, and can be trained without expensive high-performance computing resources. Here we presented a framework for training data synthesis, neural network fine-tuning, inference and post-processing that can be applied to baleen whale calls and likely other stereotyped animal sounds. Our system can be run on inexpensive consumer hardware, and performance evaluations showed that it can achieve >99% recall and >91% precision, even when trained on a dataset built from a single example of the target call, making it a promising method for the study of data-scarce animals. This result, however, does come with a caveat that emerged from the adjudication of ground truth-detector disagreements; extreme care must be taken when defining target and non-target sounds to achieve such high performance. Both positive and negative classes of the training data should reflect the full diversity of sounds that will be encountered in deployment, and if chorus, low SNR, or partially captured calls are to be considered as non-target, samples of these should be included in non-target segments of the training sequences. Additionally, this work supports indications in existing literature that the lack of reliable ground truth and best practice test methodologies are open problems in bioacoustics detector research, and that more work is needed in these areas.
Methods
Overview
The automated detector framework presented in this work consists of two main components; one that builds semi-synthetic training data and fine-tunes a pretrained neural-network, and another that performs inference and post-processes probability vectors. The data synthesis uses conventional audio signal processing methods and does not involve machine learning techniques. The process flow for the synthesis and training is shown in Fig. 7, and the process flow for inference, postprocessing and performance evaluation are shown in Fig. 8.

High-level process flow chart of the data synthesis and model training systems.

High-level process flow chart of the inference system.
Neural network architecture
The base model used in this work was a pretrained neural network109, available in MATLAB’s Deep Learning Toolbox110. This model is a port of the “vad-crdnn-libriparty” network, released as part of the open source SpeechBrain toolkit111. The architecture was a C-RDNN with bidirectional gated recurrent unit (GRU) layers. The complete network architecture is shown in Fig. 9.

Neural network architecture.
The network input size was 40xT, (frequency bins x time bins), T being arbitrary and variable, based on preprocessing parameters. CNN and DNN dropout layers were set at 15%, leaky rectified linear units used a scale of 0.01, and the total number of learnable parameters in the network was 109,745.
Target sounds
The target sounds were the Z-call of the Antarctic blue whale (ABWZ), and the song of the Chagos Archipelago population of the pygmy blue whale (CPBW). Blue whales were selected as the target species since PAM and automated detectors are firmly established methods for their study. Additionally, acoustic conditions in the open ocean represent a particularly challenging case for automated detectors due to the large variety of interfering sounds and noise sources. These specific vocalisations were chosen due to their dramatically different time-frequency structures.
The ABWZ is a simple, frequency modulated tone, in the 15 – 30 Hz frequency range, with a duration of 18-26 s112 with a 3-unit structure (Fig. 10). It has no amplitude modulation, sidebands or non-linear features.

Scalogram of a recording of the Antarctic blue whale Z-call, units annotated. Scalogram calculated by multiplicative superlet transform with frequency interval = [10, 40]; number of frequency bins = 60; initial number of superlet cycles = 3; interval of super resolution orders = [10, 40].
The CPBW is far more complex, its 1st unit consisting of amplitude modulated sound with multiple sideband frequency components and noise-like, possibly non-linear features referred to as “deterministic chaos”42. Unit 1 continues with a frequency modulated tone, followed by units 2 and 3, which are simple tones. This song’s total duration is 34-35 s with unit structure shown in Fig. 11. Unit 1’s energy is primarily in the 25 – 45 Hz frequency range.

Scalogram of a recording of the Chagos pygmy blue whale song, units annotated. Scalogram calculated by multiplicative superlet transform with frequency interval = [10, 60]; number of frequency bins = 100; initial number of superlet cycles = 3; interval of super resolution orders = [10, 40].
Ground truth reference datasets
Two reference datasets were used to test the detector. Each one consisted of a collection of audio files, and an annotated reference log. The ABWZ detector was tested on the “Casey 2014” dataset, from the open access IWC-SORP Annotated Library113,114. Audio was recorded off the coast of Casey Station, Antarctica, at latitude -63.7955, longitude 111.7871 (Fig. 12), between 2013-12-25 and 2014-12-12. Audio data was sampled at 1,000 Hz, (down sampled in the present study to 250Hz) and the dataset contained 194 hours of audio. The annotations were performed by a human analyst, and the log contained 1,091 ABW Z-calls. The hydrophone depth was 2,770 meters, and while mooring type was not specified, depth and bathymetry suggest direct sea-floor mooring.

The location of the IWC-SORP Casey 2014 hydrophone, the source of the audio dataset used to test the Antarctic blue whale Z-call detector. Bathymetric contour lines are drawn at 500 m intervals.
The CPBW detector was tested using audio data sourced from the Comprehensive Nuclear Test Ban Treaty Organisation’s International Monitoring System, recorded on hydrophone H08S1, off the south coast of Diego Garcia Island in the Chagos Archipelago, central Indian Ocean at latitude −7.6453, longitude 72.4744 (Fig. 13), throughout 2007. The hydrophone is moored to the sea floor and suspended at a depth of 1,413 meters by subsurface float. Audio data was sampled at 250 Hz.

The location of the CTBTO IMS hydrophone H08S1, the source of the audio dataset used to test the Chagos pygmy blue whale song detector. Bathymetric contour lines are drawn at 1000 m intervals.
The reference annotations for the CPBW dataset were generated during a previous study using an automated detector and manually reviewed by a human analyst, who removed false positives18. This dataset of reference annotations has been previously used by other studies, and is considered to be of high quality23. The complete dataset consists of over 8,000 hours of audio, so to reduce it to a more manageable size for testing, a MATLAB program was written to subsample the data creating a balanced, representative subset. The detector used in18 (originally described in99) returns estimates of SNR and signal-to-interference-plus-noise ratio (SINR) for every detection, where SINR is a measure of similarity between audio under inspection, and the target call; effectively a measure of detection confidence. These parameters were used in the subsampling procedure. First, the annotation reference log was filtered to remove any detections associated with audio files that were missing, corrupt, contained no valid audio, or were shorter than 10 minutes. Based on the filtered reference log, audio files were sorted into those that did contain detections, and those that did not. Detections were then stratified into bins by SNR, SINR, hour of day, and month of year. The final test set was sampled proportionally from each bin to maintain the original distribution across these dimensions, until the target test set duration of 500 hours was reached. 1% of the audio files included in the final dataset contained no detections. The final test dataset consisted of 500 hours of test audio and a reference log of 6,843 CPBW songs.
Experimental conditions
For each target call, we trained and tested four models. Each one was trained on samples synthesised with a different range of SNRs, allowing us to investigate the influence of training data SNR on performance. The models and their data synthesis parameters are listed in Table 4. To evaluate precision-recall trade-off, we also tested each of the models across a range of post-processing activation threshold values (see section 5.13). The values tested are listed in Table 5. In summary, for each of the 2 target animal calls, we tested 4 models, and 8 activation thresholds, for a total of 64 experimental conditions.
Noise library compilation
Noise recordings were required to build realistic synthetic training data. It was assumed noise recordings should be site-specific, so a separate noise library was compiled for each target call. The noise recordings were sourced from the same recording datasets as the exemplars, but once again, audio used in the test sets was held out. Automated methods for excluding target calls from the noise libraries were compared informally using a sample set of 10 noise recordings. Time domain cross-correlation and spectrogram cross-correlation methods showed high false negative rates, allowing too many target calls to leak into the noise library. The best method was a wavelet correlation detector using a comparison wavelet generated from the mean of the exemplars for each call. The exemplar waveforms were time-aligned and averaged, to produce a representative template that retained the core spectral structure of the call while smoothing over inter-annual frequency shift, and other natural variation. Manual inspection of the detector output revealed some remaining target calls in the noise library, mainly chorus, not discrete calls. As a final measure the target call was absent, a custom MATLAB GUI program was built to facilitate manual inspection of every recording in the noise library via spectrogram. Any recording that contained target calls, discrete or chorus, at any SNR, were excluded from the noise library. It is possible that some very low SNR calls did make it into the noise library despite this validation procedure, however since the noise library source data were independent from the test sets, training data contamination was not possible. If anything, the appearance of target calls in the noise library would degrade performance, though there is no indication that was the case. Additionally, there is a circularity implied by the use of the same exemplars for training and target call exclusion when building the noise library. We do not view this as problematic since the exclusion detector served only as a coarse filter to reduce manual workload, not a component of the training or evaluation pipeline.
Target call exemplars
The synthetic training data for the Z-call models ABWZ-A, ABWZ-B and ABWZ-C were constructed from seven (7) high-SNR exemplars of the target sound, sourced from the IWC-SORP library. One of these exemplars was taken from the Casey 2014 dataset, the remaining six were from other recording sites and years. The ABWZ-C-Small model’s training dataset was built from a single exemplar, sourced from the IWC-SORP library, recorded on the Elephant Island hydrophone on 26 August 2014 (Fig. 14).

Scalograms of the Antarctic blue whale Z-call exemplar used to construct the semi-synthetic training data for the ABWZ-C-Small model configuration. Left: the original exemplar, prior to denoising. Right: The denoised exemplar. Scalograms calculated by multiplicative superlet transform with frequency interval = [10, 60]; number of frequencies = 100; initial number of superlet cycles = 3; interval of super resolution orders = [10, 40].
Twelve (12) exemplars were used to build the synthetic training data for the CPBW-A, CPBW-B and CPBW-C model configurations. These exemplars were isolated from the same IMS dataset as the test data, but from different years. The CPBW-C-Small model configuration’s training dataset was built using a single exemplar, recorded on 19 August 2005 (Fig. 15).

Scalograms of the Chagos pygmy blue whale song exemplar used to construct the semi-synthetic training data for the CPBW-C-Small model configuration. Left: the original exemplar, prior to denoising. Right: The denoised and trimmed exemplar. Scalograms calculated by multiplicative superlet transform with frequency interval = [10, 60]; number of frequencies = 100; initial number of superlet cycles = 3; interval of super resolution orders =[10, 40].
All exemplars were manually denoised in the time-frequency domain using the spectral editor tool in Izotope RX115 and any silence was trimmed from the start. Fig. 14 and Fig. 15 show exemplars of each call pre- and post-denoising.
The Z-call’s first unit (unit-A) is often observed without the following B and C units, however given the lack of structural complexity of the A unit, we chose to train on the entire ABW Z-call, under the assumption that the added structure of the B and C units would improve selectivity of the detector. Additionally, the IWC-SORP library differentiates the Z-call from discrete A calls and A-B calls, so we chose to likewise treat them as distinct.
Unit 1 of the CPBW song contains the most energy, and previous studies have noted that units 2 and 3 are sometimes absent, possibly due to propagation effects, noise masking, or variations in vocal behaviour18. We therefore chose to train the CPBW detector only on unit 1, and the rest of the song was trimmed from the denoised exemplars. The resulting exemplars served as the “seed samples” from which the augmented copies were constructed.
The denoised and trimmed exemplars were further conditioned by applying 0.2 s half-hann windows to the starts and ends to avoid discontinuities. They were then DC-centred and normalized to a range of [-1, 1]. A dynamic range compression algorithm was applied that reduced dynamic range of the exemplars to a target range of 2 dB.
Data augmentation
A unique training set was built for each experimental condition, using different numbers of exemplars. Exemplars were used as seeds for producing large volumes of augmented call copies, from which training sequences were built. The raw, unmodified exemplars were not included in the training data. For the training sets that were built from more than one exemplar, equal numbers of augmented calls were built from each exemplar. For example, in condition CPBW-A, the dataset was built from 12 exemplars, and required a total of 63,600 augmented call copies, therefore each exemplar was used to generate 5300 augmented copies.
The audio augmentation processing was physically motivated, emulating acoustic propagation phenomena and variations in vocal behaviour and anatomy, though no propagation models were used. To avoid artifacts caused by time stretching and pitch shifting operations, the exemplars were up-sampled to 1000 Hz, augmented, then down-sampled back to 250Hz. The following audio augmentations were applied in independently and sequentially, in the following order:
-
1.
Random time stretching was applied with speed factors in the range of 0.94 to 1.06 times the original audio speed. Time scale modification was achieved using a phase vocoder, so frequency was not modified, and phase locking was used to maintain phase coherence within each frequency bin. Probability of this augmentation being applied to any given sample was 50%.
-
2.
Random pitch shift was applied to 100% of samples, each one shifted up or down by some constant frequency for its entire duration. The shift range was calculated based on the mean frequency in the year that the exemplar sample was recorded, the annual rate of change reported in previous studies (ABWZ = 0.135 Hz/year, CPBW = 0.33 Hz/year,) and the temporal span of the synthetic training data (ABWZ = 2013-2015, CPBW = 2006-2008). An additional random pitch shift in the range of ±2 Hz was added to capture additional natural variation, accounting for any possible outliers in the population. Again, a phase vocoder was used, so pitch shifting did not affect playback speed.
-
3.
Subtle non-linear distortion was applied using a Volterra Kernel with probability of 50%, with a random distortion amount between 0.1 and 0.5. This unitless parameter controls the amplitude of generated distortion products. This was intended to emulate behavioural or anatomical variation in non-linear effects in vocal production, as well as non-linear propagation effects that sometimes occur for very high amplitude sources in the nearfield.
-
4.
Doppler pitch shift (a time-varying frequency modulation) was applied with probability of 50% using random source velocities from 1 to 8.3 m/s, along a linear trajectory, with the receiver stationary. The maximum velocity limit was set slightly higher than the typical 5 m/s baleen whale swim speed to add robustness and account for outlier behaviours. The “passing time” – the point at which the source transitions from approaching to receding - was randomly set between 35% and 75% of the call duration.
-
5.
High and low pass filters were not used for the ABWZ, since this call consists of a single sinusoid. For the CPBW, low pass and high pass filters were applied with probability of 50%, with random cutoff frequencies in the ranges 37 to 50 Hz and 10 to 33 Hz respectively. This was intended to emulate a diverse set of frequency-dependant attenuation conditions.
-
6.
Reverb was applied with a 50% probability and a wet/dry mix of 50%. Reverb decay time was randomly set between 0.1 and 10s, emulating multipath reflection and reverberation.
-
7.
An aperiodic, random oscillator drove amplitude attenuations with 50% probability, an attenuation factor of 0.1 to 0.75 and a loss density of 0.1 to 0.5. The density parameter set the duty cycle of the random waveform driving the amplitude attenuation, with 0.5 resulting in 50% of the signal’s duration being randomly attenuated. This emulated time varying transmission loss.
-
8.
Random end trimming was applied, with probability of 50% and a random duration, between 0.1 and 1 seconds.
Training data composition
The training datasets each consisted of 1200 audio sequences of 1800 s duration, and 1200 corresponding binary masks, with an element indicating target presence or absence for every audio sample. These masks were used as the labels aka. targets in training, effectively providing ground truth for the location of augmented calls in each sequence. Each sequence was constructed by placing multiple augmented calls at random, non-overlapping time indices within a continuous background noise segment drawn from the library. A minimum time separation between consecutive calls was enforced (ABWZ = 1 s; CPBW = 0.5s). Each call was independently scaled to a randomly set signal-to-noise ratio (SNR) within the configured range (Table 4), where SNR was measured as the ratio of signal power to noise power, measured in the 10 - 50 Hz band, at the call’s intended time placement in the noise recording. The number of calls to place in each sequence was determined automatically from the mean duration of augmented calls, such that calls occupied approximately 45% of the sequence. Dataset size and composition is described comprehensively in Table 6.
Audio pre-processing
The preprocessing procedure and settings used to prepare audio sequences and binary masks were identical for both training and inference. Audio sequences were transformed into mel-scaled spectrograms, which were then broken into frames along the time axis. The binary masks were broken into corresponding frames. The preprocessing function applied the following operations:
-
1.
Resample audio to the target sampling frequency
-
2.
Compute short time Fourier transform spectrograms and square the magnitude
-
3.
Apply Mel filter bank to spectrogram
-
4.
Convert the mel spectrogram from linear to logarithmic power
-
5.
Saturate the mel spectrogram to the specified dynamic range
-
6.
Break mel spectrogram into overlapping frames
-
7.
Standardize each frame’s frequency bins by subtracting the mean and dividing by the standard deviation
The recordings in the noise libraries contain infrequent, short duration but extremely high-power events like undersea earthquakes and iceberg calvings. In terms of signal power, these events are statistical outliers and can drown out the comparatively low-power target animal call, pushing it into the noise floor. Breaking the full-sequence spectrograms into shorter frames and standardizing each frame by its local statistics ensures that every frame (i.e., every training input) has the same mean and standard deviation. Additionally, framing reduces the probability of any given training sample containing a high-power outlier event, reducing the number of animal calls potentially lost below the noise floor. Frame buffering occurs at both training and inference time. The labels (i.e., signal presence/absence masks) were also broken into frames of the same frame size and overlap. Parameters used in the preprocessing procedure described above are given in Table 7, with identical settings used for the ABWZ and the CPBW.
The final spectrograms produced by the preprocessor had a time resolution of 0.05 s. The Mel -spaced frequency bins had bandwidths from 1.98 Hz at the lowest bin (fc = 10.94 Hz) to 2.00 Hz at the highest (fs = 48.99 Hz).
Transfer learning
The base model was pretrained and fine-tuned by transfer learning. By default, VADNet’s convolutional and fully connected layers are learnable, while the GRU layers are frozen, and not updated in fine tuning. Since VADNet’s original task (human voice activity detection) involved different temporal scales than our application, we unfroze the GRU layers to ensure that they also adapted to the new task domain. The differences in temporal scale arise from, differing sample rates, spectrogram window and hop durations, and different temporal scales of the target and interfering signals.
Training was performed using the ADAM optimiser116. The minibatch size was set to 12, with an initial learn rate of 0.005, a learning rate drop factor of 0.5, a drop period of 2 epochs, and an L2 regularization factor of 1e-4. Training was allowed to run for a maximum of 9 epochs, with validation running 10 times per epoch, with a validation patience of 8 for early stopping. The training data set was shuffled every epoch. The training loss function was binary cross-entropy, defined as:
Here, \(N\) is the number of samples in the training dataset, \({y}_{i}\) is the true label (i.e., the target) for the \(i\)-th sample, (\(y=1\) if the target signal is present, else \(y=0\) if it is absent), and \({\widehat{y}}_{i}\) is the network’s predicted probability that the \(i\)-th sample contains the target signal. Recall, precision and F-score were also tracked during training and validation, with F-score serving as the validation criterion for early stopping. Upon finishing, the training program returned the model with the best validation score. For all models tested, the training routine met the validation criterion and stopped before reaching the max epochs limit.
Inference time operation
The network input was a matrix representing a Mel-scaled spectrogram, \(\mathbf{\rm X} \in {\mathbb{R}}^{FxT}\) where \(F=40\) frequency bins and \(T\) is the arbitrary number of time bins. The model internally broke \(\mathbf{\rm X}\) into subframes, \({\mathbf{\rm X}}_{\text{t}} \in {\mathbb{R}}^{Fx4} t=\text{1,2},\dots ,T\). Each spectrogram subframe was passed through a series of convolutional layers followed by a flattening operation to produce a sequence of feature vectors, \({\mathbf{f}}_{t}\):
where \(d\) is the feature dimension. After feature extraction and embedding, feature vectors were processed by a bidirectional gated recurrent unit117, which captured forward and backward temporal context to produce a hidden state representation at each time frame. Bidirectional hidden states were concatenated to form the final hidden state representation.
Per-frame posterior probabilities of target signal presence were computed by passing the concatenated hidden states through a fully connected layer with a sigmoid activation function. Note that the network did not retain hidden state between inputs, ensuring independence of predictions across unrelated audio sequences.
At the end of an inference run on an audio vector of length \(n\), the network’s final output was a probability vector of length \(m\), where \(m = \left[ {\frac{n - L}{H}} \right] + 1\) , \(L\) being the spectrogram window length (212 samples) and \(H\) being the spectrogram hop size (12 samples), with each element corresponding to a spectrogram time bin.
Probability post-processing
A post-processing function was written to convert the continuous vectors of probabilities returned by the network, which have continuous values between 0 and 1, into binary decisions and region-of-interest timestamps. The start and end points of discrete positive detections were determined from user-defined probability thresholds and detection-duration heuristics intended to filter out probability spikes that were likely to be false positives. Closely spaced, consecutive runs of high probability values that were likely part of the same detected call were merged. The complete set of post processing parameters are given in Table 8. The AT parameter was swept, and performance was evaluated for each value (see section "Experimental Conditions").
Performance evaluation
After running the detector on test sets in each experimental condition, the results were compared to the ground truth annotations. Timestamps for detections were matched to ground truth annotation timestamps using the Hungarian algorithm for optimal assignment, whereby optimal one-to-one matching of a detection to a ground truth annotation minimized temporal mismatch. Matches were only considered valid if temporal mismatch was less than 30 s.
The numbers of true positives (TP), false positives (FP) and false negatives (FN) were counted, then performance metrics were calculated following standard definitions: \(precision = \frac{TP}{{TP + FP}}\), \(recall (aka. sensitivity)=\frac{TP}{TP+FN}\), and \(\begin{gathered} F1\,score = 2\;\left( {precision \cdot recall} \right) \hfill \\ /\left( {precision + recall} \right) \hfill \\ \end{gathered}\). The disagreements (FP’s and FN’s) were saved for further analysis.
Disagreement adjudication
The reference annotation logs used as ground truth were found to be unreliable (see section "Unreliable Ground Truth"). To resolve disagreements between the detector and the ground truth, an adjudication procedure was undertaken by an experienced analyst. Due to the substantial time involved in manual adjudication, this procedure was undertaken for only two of the eight experimental conditions – one for each call. Informal inspection of the disagreements prior to adjudication indicated that most of the disagreements were cases where the ground truth incorrectly ruled a true positive to be false. On this basis, we reasoned that the pre-adjudication recall scores might be relatively accurate, but that the precision scores might be artificially low, so the models with the highest recall scores were selected for adjudication. The analyst was familiar with both target whale songs and was provided with a simple GUI application to display spectrograms and record decisions. The spectrograms displayed to the analyst began 5 s before the detection timestamp and ended either 40 s from the detection start time, or at the detection end time, whichever was longer. To avoid bias, analyst was not permitted to know whether the displayed detections were false positives, false negatives, or true detections, and was not permitted to scroll forward or backward to gain additional temporal context. To evaluate the influence of chorus on the detector’s performance, the analyst was asked to respond to each disagreement with one of four options: “Discrete Call(s) Present”, “Chorus Present”, “Discrete Call(s) and Chorus Present” or “No Call(s) or Chorus Present”. Every single disagreement was adjudicated. The ABWZ disagreements consisted of 2821 false positives, and 376 false negatives for a total of 3,197 adjudication decisions. The CPBW consisted of 17,232 false positives and 141 false negatives, for a total of 17,373 adjudication decisions. Adjudication was performed in short sessions over a period of two months to minimise analyst fatigue. Fig. 16.

The user interface for the adjudicator app. The spectrogram displayed shows ABWZ call chorus.
Data availability
The audio datasets used in this work are not the property of the authors and cannot be redistributed. The raw detector results, ground truth disagreements and adjudication results are publicly available at the UNSWorks repository: http://hdl.handle.net/1959.4/106411. All code generated in this project is open-source, and freely available for reuse under the MIT licence. The model training, inference and evaluation framework, and the adjudication app are available at https://github.com/b-jancovich/GAVDNet. The training data augmentation toolkit is a dependency for the model training system and is available from https://github.com/b-jancovich/customAudioAugmenter.
References
Sagarin, R. & Pauchard, A. Observation and Ecology (Island Press/Center for Resource Economics, 2012). https://doi.org/10.5822/978-1-61091-230-3.
Farina, A. & Gage, S. H. Ecoacoustics: The Ecological Role of Sounds (John Wiley and Sons, 2017). https://doi.org/10.1002/9781119230724.
Abileah, R. & Lewis, D. Monitoring high-seas fisheries with long-range passive acoustic sensors. In OCEANS 96 MTS/IEEE Conference Proceedings. The Coastal Ocean - Prospects for the 21st Century vol. 1 378–382 (IEEE, Fort Lauderdale, FL, USA, 1996).
Clark, C. W. & Mellinger, D. K. Application of Navy IUSS for whale research. J. Acoust. Soc. Am. 96, 3315–3315 (1994).
Rostami, B. & Nansen, C. Application of active acoustic transducers in monitoring and assessment of terrestrial ecosystem health—A review. Methods Ecol. Evol. 13, 2682–2691 (2022).
Knight, E. et al. Individual identification in acoustic recordings. Trends Ecol. Evol. 39, 947–960 (2024).
Kirschel, A. N. G. et al. Using songs to identify individual Mexican antthrush Formicarius moniliger: Comparison of four classification methods. Bioacoustics 19, 1–20 (2009).
Mellinger, D. K. & Clark, C. W. Methods for automatic detection of mysticete sounds. Mar. Freshw. Behav. Physiol. 29, 163–181 (1997).
Sugai, L. S. M., Silva, T. S. F., Ribeiro, J. W. & Llusia, D. Terrestrial passive acoustic monitoring: review and perspectives. Bioscience 69, 15–25 (2019).
Thompson, M. E., Schwager, S. J., Payne, K. B. & Turkalo, A. K. Acoustic estimation of wildlife abundance: methodology for vocal mammals in forested habitats. Afr. J. Ecol. 48, 654–661 (2010).
Hill, A. P., Prince, P., Snaddon, J. L., Doncaster, C. P. & Rogers, A. AudioMoth: A low-cost acoustic device for monitoring biodiversity and the environment. HardwareX 6, e00073 (2019).
Gibbons, S. J. The hydroacoustic network of the CTBT international monitoring system: access and exploitation. J. Peace Nucl. Disarm. 5, 452–468 (2022).
Leroy, E. C., Thomisch, K., Royer, J.-Y., Boebel, O. & Van Opzeeland, I. On the reliability of acoustic annotations and automatic detections of Antarctic blue whale calls under different acoustic conditions. J. Acoust. Soc. Am. 144, 740–754 (2018).
Cerchio, S. et al. A new blue whale song-type described for the Arabian Sea and Western Indian Ocean. Endanger. Species Res. 43, 495–515 (2020).
Gavrilov, A. N., McCauley, R. D., Salgado-Kent, C., Tripovich, J. & Burton, C. Vocal characteristics of pygmy blue whales and their change over time. J. Acoust. Soc. Am. 130, 3651–3660 (2011).
Harris, D. V., Miksis-Olds, J. L., Vernon, J. A. & Thomas, L. Fin whale density and distribution estimation using acoustic bearings derived from sparse arrays. J. Acoust. Soc. Am. 143, 2980–2993 (2018).
Le Bras, R. J., Kuzma, H., Sucic, V. & Bokelmann, G. Observations and Bayesian location methodology of transient acoustic signals (likely blue whales) in the Indian Ocean, using a hydrophone triplet. J. Acoust. Soc. Am. 139, 2656–2667 (2016).
Leroy, E. C., Royer, J.-Y., Alling, A., Maslen, B. & Rogers, T. L. Multiple pygmy blue whale acoustic populations in the Indian Ocean: Whale song identifies a possible new population. Sci. Rep. 11, 8762 (2021).
Marques, T. A. et al. Estimating animal population density using passive acoustics. Biol. Rev. 88, 287–309 (2013).
Samaran, F., Adam, O. & Guinet, C. Detection range modeling of blue whale calls in Southwestern Indian Ocean. Appl. Acoust. 71, 1099–1106 (2010).
Sousa, A. G. & Harris, D. Description and seasonal detection of two potential whale calls recorded in the Indian Ocean. J. Acoust. Soc. Am. 138, 1379–1388 (2015).
Stafford, K. M., Chapp, E., Bohnenstiel, D. R. & Tolstoy, M. Seasonal detection of three types of “pygmy” blue whale calls in the Indian Ocean. Mar. Mamm. Sci. 27, 828–840 (2011).
Huang, J. L., Leroy, E. C., Truong, G. & Rogers, T. L. Changes of oceanic conditions drive chagos whale migration patterns in the Central Indian Ocean. Frontiers in Marine Science 9, (2022).
Stowell, D., Wood, M. D., Pamuła, H., Stylianou, Y. & Glotin, H. Automatic acoustic detection of birds through deep learning: the first Bird Audio Detection challenge. Methods Ecol. Evol. 10, 368–380 (2019).
Sagar, H. S. S. C. et al. Global analysis of acoustic frequency characteristics in birds. Proc. Biol. Sci. 291, 20241908 (2024).
Morrison, C. A. et al. Bird population declines and species turnover are changing the acoustic properties of spring soundscapes. Nat. Commun. 12, 6217 (2021).
Gibb, R., Browning, E., Glover-Kapfer, P. & Jones, K. E. Emerging opportunities and challenges for passive acoustics in ecological assessment and monitoring. Methods Ecol. Evol. 10, 169–185 (2019).
Tuia, D. et al. Perspectives in machine learning for wildlife conservation. Nat. Commun. 13, 792 (2022).
Stafford, K. M., Fox, C. G. & Mate, B. R. Acoustic detection and location of blue whales (Balaenoptera musculus) from SOSUS data by matched filtering. J. Acoust. Soc. Am. 96, 3250–3251 (1994).
Mellinger, D. K. & Clark, C. W. Bioacoustic transient detection by image convolution. J. Acoust. Soc. Am. 93, 2358–2358 (1993).
Mellinger, D. K. & Clark, C. W. Recognizing transient low-frequency whale sounds by spectrogram correlation. J. Acoust. Soc. Am. 107, 3518–3529 (2000).
Mäder, P. et al. The Flora Incognita app – Interactive plant species identification. Methods Ecol. Evol. 12, 1335–1342 (2021).
Malige, F., Patris, J., Hauray, M., Giraudet, P. & Glotin, H. Mathematical models of long term evolution of blue whale song types’ frequencies. J. Theor. Biol. 548, 111184 (2022).
McDonald, M. A., Hildebrand, J. & Mesnick, S. Worldwide decline in tonal frequencies of blue whale songs. Endanger. Species Res. 9, 13–21 (2009).
Rice, A. et al. Update on frequency decline of Northeast Pacific blue whale (Balaenoptera musculus) calls. PLoS ONE 17, e0266469 (2022).
Thode, A. M., Blackwell, S. B., Conrad, A. S., Kim, K. H. & Michael Macrander, A. Decadal-scale frequency shift of migrating bowhead whale calls in the shallow Beaufort Sea. J. Acoust. Soc. Am. 142, 1482–1502 (2017).
Munger, L. M., Mellinger, D. K., Wiggins, S. M., Moore, S. E. & Hildebrand, J. A. Performance of spectrogram cross-correlation in detecting right whale calls in long-term recordings from the bering sea. Can. Acoust. 33, 25–34 (2005).
Širović, A. Variability in the performance of the spectrogram correlation detector for North-east Pacific blue whale calls. Bioacoustics 25, 145–160 (2016).
Socheleau, F.-X. et al. Automated detection of Antarctic blue whale calls. J. Acoust. Soc. Am. 138, 3105–3117 (2015).
Socheleau, F.-X. & Samaran, F. Detection of Mysticete Calls: a Sparse Representation-Based Approach. (Dépt. Signal et Communications (Institut Mines-Télécom-IMT Atlantique-UBL) ; Laboratoire en sciences et technologies de l’information, de la communication et de la connaissance (UMR 6285 - CNRS - IMT Atlantique - Université de Bretagne Occidentale - Université de Bretagne Sud - ENSTA Bretagne - Ecole Nationale d’ingénieurs de Brest) ; École nationale supérieure de techniques avancées Bretagne. (Ministère de la Défense), 2017).
Elad, M. Sparse and Redundant Representations (Springer New York, 2010). https://doi.org/10.1007/978-1-4419-7011-4.
Wilden, I., Herzel, H., Peters, G. & Tembrock, G. Subharmonics, biphonation, and deterministic chaos in mammal vocalization. Bioacoustics 9, 171–196 (1998).
Potter, J. R., Mellinger, D. K. & Clark, C. W. Marine mammal call discrimination using artificial neural networks. J. Acoust. Soc. Am. 96, 1255–1262 (1994).
Chesmore, E. D. Application of time domain signal coding and artificial neural networks to passive acoustical identification of animals. Appl. Acoust. 62, 1359–1374 (2001).
He, K., Zhang, X., Ren, S. & Sun, J. Deep Residual Learning for Image Recognition. Preprint at https://doi.org/10.48550/arXiv.1512.03385 (2015).
Pleiss, G. et al. Memory-Efficient Implementation of DenseNets. Preprint at https://doi.org/10.48550/arXiv.1707.06990 (2017).
Miller, B. S., Madhusudhana, S., Aulich, M. G. & Kelly, N. Deep learning algorithm outperforms experienced human observer at detection of blue whale D-calls: a double-observer analysis. Remote Sensing in Ecology and Conservation n/a, (2022).
Rankin, S., Ljungblad, D., Clark, C. & Kato, H. Vocalisations of Antarctic blue whales, Balaenoptera musculus intermedia, recorded during the 2001/2002 and 2002/2003 IWC/SOWER circumpolar cruises, Area V Antarctica. JCRM 7, 13–20 (2023).
Dörfler, M., Bammer, R. & Grill, T. Inside the spectrogram: convolutional neural networks in audio processing. In 2017 International Conference on Sampling Theory and Applications (SampTA) 152–155 (2017). https://doi.org/10.1109/SAMPTA.2017.8024472.
Liu, H., Liu, X., Kong, Q., Wang, W. & Plumbley, M. D. Learning temporal resolution in spectrogram for audio classification. Preprint at https://doi.org/10.48550/arXiv.2210.01719 (2024).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet classification with deep convolutional neural networks. Commun. ACM 60, 84–90 (2017).
Feng, J., Erol, M. H., Chung, J. S. & Senocak, A. ElasticAST: An audio spectrogram transformer for all length and resolutions. Preprint at https://doi.org/10.48550/arXiv.2407.08691 (2024).
Simoncelli, E. P. & Olshausen, B. A. Natural image statistics and neural representation. Annu. Rev. Neurosci. 24, 1193–1216 (2001).
Schlüter, J. & Grill, Th. Exploring Data Augmentation for Improved Singing Voice Detection with Neural Networks. In Proceedings of the 16th International Society for Music Information Retrieval Conference (ISMIR) 121–126 (2015).
McLoughlin, I. et al. Spectrogram features for audio and speech analysis. Appl. Sci. https://doi.org/10.3390/app16020572 (2026).
Palanisamy, K., Singhania, D. & Yao, A. Rethinking CNN Models for Audio Classification. Preprint at https://doi.org/10.48550/arXiv.2007.11154 (2020).
Madhusudhana, S. et al. Improve automatic detection of animal call sequences with temporal context. J. R. Soc. Interface. 18, 20210297 (2021).
Cakir, E., Adavanne, S., Parascandolo, G., Drossos, K. & Virtanen, T. Convolutional recurrent neural networks for bird audio detection. In 2017 25th European Signal Processing Conference (EUSIPCO) 1744–1748. https://doi.org/10.23919/EUSIPCO.2017.8081508. (201)
Gupta, G., Kshirsagar, M., Zhong, M., Gholami, S. & Ferres, J. L. Comparing recurrent convolutional neural networks for large scale bird species classification. Sci. Rep. 11, 17085 (2021).
Shiu, Y. et al. Deep neural networks for automated detection of marine mammal species. Sci. Rep. 10, 607 (2020).
Olatinwo, D. D. & Seto, M. L. Low-SNR Northern Right Whale upcall detection and classification using passive acoustic monitoring to reduce adverse human–whale interactions. Mach. Learn. Knowl. Extr. https://doi.org/10.3390/make7040154 (2025).
Vaswani, A. et al. Attention Is All You Need. Preprint at https://doi.org/10.48550/arXiv.1706.03762 (2023).
Bengio, Y., Simard, P. & Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 5, 157–166 (1994).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–1780 (1997).
Cho, K. et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. Preprint at https://doi.org/10.48550/arXiv.1406.1078 (2014).
Vuilliomenet, A., Martínez Balvanera, S., Mac Aodha, O., Jones, K. E. & Wilson, D. Acoupi: an open-source python framework for deploying bioacoustic AI models on edge devices. Methods Ecol. Evol. 17, 67–76 (2026).
Tsalera, E., Papadakis, A. & Samarakou, M. Comparison of pre-trained CNNs for audio classification using transfer learning. JSAN 10, 72 (2021).
Dawson, S. M. et al. Shepherd’s beaked whale (Tasmacetus shepherdi) produces a diverse variety of ultrasonic pulses. Mar. Mamm. Sci. 41, e13199 (2025).
Leunissen, E. M., Webster, T. & Rayment, W. Characteristics of vocalisations recorded from free-ranging Shepherd’s beaked whales, Tasmacetus shepherdi. J. Acoust. Soc. Am. 144, 2701–2708 (2018).
Leseberg, N. et al. Descriptions of known vocalisations of the Night Parrot Pezoporus occidentalis. Australian Field Ornithol. 36, 79–88 (2019).
Leseberg, N., Venables, W. N., Murphy, S. A., Jackett, N. A. & Watson, J. E. M. Accounting for both automated recording unit detection space and signal recognition performance in acoustic surveys: a protocol applied to the cryptic and critically endangered Night Parrot (Pezoporus occidentalis). Austral Ecol. 47, 440–455 (2022).
Kather, V. et al. Development of a machine learning detector for North Atlantic humpback whale song. J. Acoust. Soc. Am. 155, 2050–2064 (2024).
Scott, K. J., Speers, L. J. & Bilkey, D. K. Utilizing synthetic training data for the supervised classification of rat ultrasonic vocalizations. J. Acoust. Soc. Am. 155, 306–314 (2024).
Nanni, L., Maguolo, G. & Paci, M. Data augmentation approaches for improving animal audio classification. Ecol. Inform. 57, 101084 (2020).
Li, P. et al. Learning Deep Models from Synthetic Data for Extracting Dolphin Whistle Contours. In 2020 International Joint Conference on Neural Networks (IJCNN) 1–10 (IEEE, Glasgow, United Kingdom, 2020). https://doi.org/10.1109/IJCNN48605.2020.9206992.
Kopets, E., Shpilevaya, T., Vasilchenko, O., Karimov, A. & Butusov, D. Generating synthetic sperm whale voice data using StyleGAN2-ADA. Big Data Cogn. Comput. 8, 40 (2024).
Iglesias, G., Talavera, E. & Díaz-Álvarez, A. A survey on GANs for computer vision: recent research, analysis and taxonomy. Comput. Sci. Rev. 48, 100553 (2023).
Li, M. et al. GAN compression: Efficient architectures for interactive conditional GANs. IEEE Trans. Pattern Anal. Mach. Intell. 44, 9331–9346 (2022).
Braulik, G. T. et al. Red-list status and extinction risk of the world’s whales, dolphins, and porpoises. Conserv. Biol. 37, e14090 (2023).
Attard, C. R. M. et al. Global conservation genomics of blue whales calls into question subspecies taxonomy and refines knowledge of population structure. Anim. Conserv. 27, 626–638 (2024).
Branch, T. A. et al. Separating historical catches among pygmy blue whale populations using recent song detections. Mar. Mamm. Sci. 41, e70003 (2025).
Cantor, M. et al. Multilevel animal societies can emerge from cultural transmission. Nat. Commun. 6, 8091 (2015).
Cazau, D., Adam, O., Aubin, T., Laitman, J. T. & Reidenberg, J. S. A study of vocal nonlinearities in humpback whale songs: From production mechanisms to acoustic analysis. Sci. Rep. 6, 31660 (2016).
Herman, L. M. The multiple functions of male song within the humpback whale (Megaptera novaeangliae) mating system: Review, evaluation, and synthesis. Biol. Rev. 92, 1795–1818 (2017).
McDonald, M. A., Mesnick, S. L. & Hildebrand, J. A. Biogeographic characterization of blue whale song worldwide: Using song to identify populations. J. Cetacean Res. Manag. 8, 55–65 (2006).
Urazghildiiev, I. R. & Clark, C. W. Detection performances of experienced human operators compared to a likelihood ratio based detector. J. Acoust. Soc. Am. 122, 200–204 (2007).
Miksis-Olds, J. L., Bradley, D. L. & Maggie Niu, X. Decadal trends in Indian Ocean ambient sound. J. Acoust. Soc. Am. 134, 3464–3475 (2013).
Dziak, R. P. et al. Sources and Levels of Ambient Ocean Sound near the Antarctic Peninsula. PLoS ONE 10, e0123425 (2015).
Menze, S., Zitterbart, D. P., Van Opzeeland, I. & Boebel, O. The influence of sea ice, wind speed and marine mammals on Southern Ocean ambient sound. R. Soc. Open Sci. 4, 160370 (2017).
Yun, S. et al. Quantifying Soundscapes in the Ross Sea (Antarctica Using Long-Term Autonomous Hydroacoustic Monitoring Systems, Front Mar Sci, 2021).
Massonnet, F., Guemas, V., Fučkar, N. S. & Doblas-Reyes, F. J. The 2014 high record of Antarctic sea ice extent. Bull. Am. Meteorol. Soc. 96, S163–S167 (2015).
European Union-Copernicus Marine Service. Global Ocean Sea Ice Concentration Time Series REPROCESSED (EUMETSAT OSI-SAF). Mercator Ocean International https://doi.org/10.48670/MOI-00136 (2015).
Kibblewhite, A. C. & Jones, D. A. Ambient noise under Antarctic sea ice. J. Acoust. Soc. Am. 59, 790–798 (1976).
Leroy, E. C., Royer, J.-Y., Bonnel, J. & Samaran, F. Long-term and seasonal changes of large whale call frequency in the Southern Indian Ocean. J. Geophys. Res. Oceans 123, 8568–8580 (2018).
Erbe, C., Reichmuth, C., Cunningham, K., Lucke, K. & Dooling, R. Communication masking in marine mammals: A review and research strategy. Mar. Pollut. Bull. 103, 15–38 (2016).
Geldenhuys, C. M., Tonitz, G. & Niesler, T. R. WhaleVAD-BPN: Improving baleen whale call detection with boundary proposal networks and post-processing optimisation. Preprint at https://doi.org/10.48550/arXiv.2510.21280 (2025).
Chambert, T., Waddle, J. H., Miller, D. A. W., Walls, S. C. & Nichols, J. D. A new framework for analysing automated acoustic species detection data: occupancy estimation and optimization of recordings post-processing. Methods Ecol. Evol. 9, 560–570 (2018).
Yack, T. M. et al. Comparison of beaked whale detection algorithms. Appl. Acoust. 71, 1043–1049 (2010).
Socheleau, F.-X. & Samaran, F. Detection of mysticete calls: a sparse representation-based approach. https://hal.archives-ouvertes.fr/hal-01736178 (2017).
Mendes Júnior, P. R. et al. Nearest neighbors distance ratio open-set classifier. Mach Learn. 106(359), 386 (2017).
Morgan, M. M. & Braasch, J. Open set classification strategies for long-term environmental field recordings for bird species recognition. J. Acoust. Soc. Am. 151, 4028–4038 (2022).
Naranjo-Alcazar, J., Perez-Castanos, S., Zuccarello, P., Antonacci, F. & Cobos, M. Open set audio classification using autoencoders trained on few data. Sensors 20, 3741 (2020).
You, J., Wu, W. & Lee, J. Open set classification of sound event. Sci Rep 14, 1282 (2024).
Chen, C. & Yang, Z. No Free Lunch from Audio Pretraining in Bioacoustics: A Benchmark Study of Embeddings. Preprint at https://doi.org/10.48550/arXiv.2508.10230 (2025).
Schäfer-Zimmermann, J. C. et al. animal2vec and MeerKAT: A self-supervised transformer for rare-event raw audio input and a large-scale reference dataset for bioacoustics. Preprint at http://arxiv.org/abs/2406.01253 (2024).
Malige, F. et al. Inter-annual decrease in pulse rate and peak frequency of Southeast Pacific blue whale song types. Sci Rep 10, 8121 (2020).
Salamon, J. & Bello, J. P. Deep convolutional neural networks and data augmentation for environmental sound classification. Preprint at https://doi.org/10.1109/LSP.2017.2657381 (2016).
Park, D. S. et al. SpecAugment: a simple data augmentation method for automatic speech recognition. Interspeech 2019, 2613–2617. https://doi.org/10.21437/Interspeech.2019-2680 (2019).
vadnet. The Mathworks Inc. (2022).
Deep learning toolbox version: 24.2 (R2024b). The Mathworks Inc. (2024).
Ravanelli, M. et al. SpeechBrain: A general-purpose speech toolkit. Preprint at https://doi.org/10.48550/arXiv.2106.04624 (2021).
Rankin, S., Ljungblad, D., Clark, C. & Kato, H. Vocalisations of Antarctic blue whales, Balaenoptera musculus intermedia, recorded during the 2001/2002 and 2002/2003 IWC/SOWER circumpolar cruises, Area V Antarctica. JCRM 7, 13–20 (2005).
Miller, B. S. et al. An annotated library of underwater acoustic recordings for testing and training automated algorithms for detecting Antarctic blue and fin whale sounds. Australian Antarctic Data Centre https://doi.org/10.26179/5E6056035C01B (2020).
Miller, B. S. et al. An open access dataset for developing automated detectors of Antarctic baleen whale sounds and performance evaluation of two commonly used detectors. Sci. Rep. 11, 806 (2021).
iZotope RX. Native instruments (2023).
Kingma, D. P. & Ba, J. Adam: a method for stochastic optimization. Preprint at https://doi.org/10.48550/arXiv.1412.6980 (2017).
Cho, K., Merrienboer, B. van, Bahdanau, D. & Bengio, Y. On the properties of neural machine translation: encoder-decoder approaches. Preprint at https://doi.org/10.48550/arXiv.1409.1259 (2014).
Acknowledgements
The CTBTO-IMS H08S1 dataset used to train and test the Chagos Pygmy blue whale song detector was obtained by T.L.R. and B.A.J. under a vDEC contract between the Preparatory Commission for the Comprehensive Nuclear-Test-Ban Treaty Organization and UNSW Sydney. The Provisional Technical Secretariat (PTS) of the Preparatory Commission gave access to the IMS data and is not responsible for the views of the authors. The IWC-SORP dataset used to train and test the Antarctic blue whale Z-call detector was released by the Australian Antarctic Division and Southern Ocean Research Project under a Creative Commons CCBY Attribution License (http://creativecommons.org/licenses/by/4.0/). The authors thank the CTBTO, AAD and SORP for making their data available.The pre- and post-processing functions written for this project were based on the ‘vadnetPreprocess’ and ‘vadnetPostprocess’ functions from the MATLAB Machine Learning Toolbox110.
Funding
This research was supported by an Australian Government Research Training Program (RTP) Scholarship awarded to Benjamin Jancovich during his PhD candidature at the University of New South Wales. The sponsor had no role in the study design, or in the collection, analysis or interpretation of data, the writing of the report; or the decision to submit the article for publication.
Author information
Authors and Affiliations
Contributions
**Benjamin Jancovich** : Conceptualization (lead); data curation (lead); formal analysis (lead); investigation (lead); methodology (lead); project administration (lead); resources (lead); software (lead); validation (equal); visualization (lead); writing – original draft (lead); writing – review and editing (equal). **Tracey L. Rogers** : Conceptualization (supporting); data curation (supporting); formal analysis (supporting); investigation (supporting); supervision (lead); validation (supporting); writing – review and editing (equal). **Gary Truong** : Formal analysis (equal); validation (equal); writing – review and editing (supporting). **Victor Sanchez** : Conceptualization (supporting); supervision (supporting); investigation (supporting); writing – review and editing (supporting).
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no conflicts of interest and no relevant commercial relationships. The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jancovich, B.A., Sanchez, V., Truong, G. et al. Automated detection of stereotyped animal sounds using data augmentation and transfer learning. Sci Rep 16, 13137 (2026). https://doi.org/10.1038/s41598-026-48308-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-48308-6
