
Abstract
Pancreatic cancer is a rare kind of cancer that is detected during the final stages. This is because the symptoms are very common and also do not show up in the starting phase. Hence an automated system for identification and classification of pancreatic cancer becomes essential. This becomes possible with the help of artificial intelligence and machine learning. The aim of this research is to develop a model that classifies pancreatic cancer using Pancreatic CT image dataset involving 1411 images from Kaggle website. The input images are augmented for increasing the dataset quality and preprocessed using Gabor filter. Segmentation is performed using UNet and features are extracted using YOLOv11 model. Pancreatic carcinoma classification is achieved using a modern deep learning-based classifier called the Vision Transformer. The classified results are optimized with the help of Parrot metaheuristic optimization algorithm. The proposed model produced an accuracy of 99%, precision of 98.5%, recall value of 97.7%, F1-Score of 96.4% and Matthew’s correlation coefficient value of 97.3% in addition to true positive and false positive rates of 96.1% and 0.07%. These results are considered phenomenal and superior when compared to existing models of Random Forest, Convolutional Neural Network, Deep belief networks, and Support Vector Machine.
Similar content being viewed by others
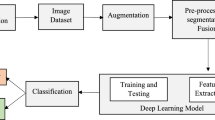

Introduction
Pancreatic cancer remains one of the most aggressive and life-threatening malignancies due to its asymptomatic progression and late-stage diagnosis, leading to extremely poor survival rates1,2,3,4. Despite continuous advancements in medical imaging and computational intelligence, early detection of pancreatic carcinoma continues to be a significant clinical challenge. Conventional diagnostic approaches rely heavily on radiological expertise, which introduces subjectivity and inter-observer variability. Although artificial intelligence-based techniques have been increasingly adopted for pancreatic cancer diagnosis, many existing models focus on isolated tasks such as segmentation or classification, thereby limiting their ability to capture the complex structural and contextual characteristics present in computed tomography (CT) images5,6.
Deep learning-based approaches, particularly Convolutional Neural Networks (CNNs), have demonstrated strong performance in extracting local spatial features. However, these models often struggle to capture long-range dependencies and global contextual relationships within medical images. Recently, transformer-based architectures have emerged as powerful alternatives due to their ability to model global interactions through self-attention mechanisms7,8. Nevertheless, transformer models require robust and informative feature representations for optimal performance and are sensitive to variations in input data. Furthermore, most existing studies lack a unified framework that integrates preprocessing, segmentation, feature extraction, and classification in a coherent manner.
Another critical limitation observed in current methodologies is the insufficient integration of detection-based feature extraction techniques with transformer-based classification models. While segmentation architectures such as UNet effectively localize regions of interest9, and detection-based models such as YOLO variants provide discriminative multi-scale feature representations10, their combined utilization for pancreatic cancer diagnosis remains limited. Additionally, optimization strategies in many studies are confined to conventional training procedures, without incorporating adaptive metaheuristic mechanisms to refine classification outcomes.
Moreover, several existing works report high classification accuracy; however, they often lack comprehensive evaluation using clinically relevant metrics such as Matthew’s correlation coefficient (MCC) and false positive rate (FPR), which are critical for ensuring reliability in medical diagnosis11,12. In addition, many approaches are constrained by limited exploration of hybrid architectures that can simultaneously exploit spatial localization, feature abstraction, and global contextual modeling.
Motivated by these challenges, there is a need for a comprehensive and integrated framework that can effectively combine multiple complementary techniques to enhance diagnostic performance. The proposed work addresses this requirement by developing a unified pipeline that incorporates preprocessing, UNet-based segmentation, YOLOv11-based feature extraction, Vision Transformer-based classification, and Parrot Optimization for performance refinement. This integrated approach enables improved representation learning, enhanced classification accuracy, and reduced misclassification, thereby contributing to a more reliable and efficient system for pancreatic cancer diagnosis.
Problem statement and motivation
The prognosis of pancreatic cancer remains extremely poor due to its late-stage detection and the absence of distinct early symptoms, leading to a significantly low survival rate3,4. Although treatment options are available, their effectiveness is highly dependent on early diagnosis, which is often not achieved in clinical practice. Conventional diagnostic procedures primarily rely on radiological interpretation, which may result in variability due to differences in expertise, fatigue, and subjective judgment. This variability can lead to delayed or inaccurate diagnosis, thereby increasing the risk to patient life.
In recent years, artificial intelligence-based approaches have been explored to improve diagnostic accuracy; however, many existing methods focus on single-stage learning and lack the ability to simultaneously capture fine-grained spatial details and global contextual information from CT images5,6. Moreover, several models do not incorporate robust feature extraction and optimization mechanisms, which are essential for handling the complexity and variability present in pancreatic imaging data. As a result, there remains a need for a more comprehensive and reliable framework that can address these limitations and support early-stage detection.
Motivated by these challenges, the objective of this research is to develop an integrated deep learning-based system that enhances the accuracy and consistency of pancreatic cancer classification. By combining advanced segmentation, feature extraction, transformer-based learning, and optimization techniques, the proposed approach aims to reduce diagnostic variability and improve decision support for clinicians. Such a system has the potential to assist medical practitioners in making more informed and consistent decisions, thereby contributing to improved patient outcomes and more effective management of pancreatic carcinoma.
Novelty of proposed work
The proposed work presents a novel and integrated framework for pancreatic cancer classification by combining multiple complementary deep learning components into a unified pipeline. Unlike existing approaches that predominantly rely on standalone convolutional or transformer-based models, the proposed system effectively bridges the gap between spatial localization and global contextual learning by integrating UNet-based segmentation9, YOLOv11-driven feature extraction10, and vision transformer-based classification13.
A key novelty of this work lies in the utilization of a detection-oriented feature extraction mechanism prior to transformer-based classification. While UNet accurately isolates the region of interest, the incorporation of YOLOv11 enables extraction of discriminative multi-scale features, which are then effectively modeled using the global attention mechanism of the Vision Transformer. This sequential integration ensures that both local structural details and long-range dependencies are captured efficiently, which is often not achieved in conventional single-stage models.
Another significant contribution is the introduction of the Parrot Optimization algorithm as a post-classification refinement strategy14. Unlike traditional optimization approaches that are limited to parameter tuning during training, the proposed method employs a metaheuristic optimization mechanism to enhance classification outcomes, thereby improving robustness and reducing misclassification. This adaptive optimization layer adds an additional level of performance enhancement that is not commonly explored in pancreatic cancer diagnosis frameworks.
Further, the proposed framework emphasizes a balanced and clinically relevant evaluation by incorporating performance metrics such as Matthew’s correlation coefficient (MCC) and false positive rate (FPR), which are crucial for assessing reliability in medical decision-making11,12. The structured integration of segmentation, detection-based feature extraction, transformer-based classification, and metaheuristic optimization distinguishes the proposed work from existing methods and contributes to improved diagnostic performance.
Contribution
This research develops a novel model for identifying and classifying pancreatic cancer using CT images by applying state of the art deep learning-based techniques. The major contributions of this work are stated below.
The major contributions of this research are outlined as follows:
-
A unified deep learning framework is developed for pancreatic cancer classification that integrates preprocessing, segmentation, feature extraction, classification, and optimization into a single pipeline.
-
UNet-based segmentation is employed to accurately isolate pancreatic regions from CT images, ensuring that relevant structural information is preserved for subsequent processing.
-
YOLOv11-based feature extraction is incorporated to obtain discriminative multi-scale features, enhancing the representation capability beyond conventional feature extraction methods.
-
A vision transformer-based classifier is utilized to model global contextual dependencies among image patches, improving classification performance compared to traditional convolution-based approaches.
-
A parrot optimization algorithm is introduced as a post-classification refinement mechanism to enhance classification accuracy and reduce misclassification rates.
-
Comprehensive evaluation is performed using multiple performance metrics including accuracy, precision, recall, F1-score, and Matthew’s correlation coefficient (MCC), along with comparative analysis against conventional classifiers.
Related works
The research presented in15 discusses about the different applications of deep learning in the diagnosis and treatment of pancreatic cancer. The application of artificial intelligence and its related techniques in the healthcare industry have been increasing year by year for the betterment of patients and their treatment. Apart from this, it also helps in improving the diagnosis accuracy, treatment outcome, and management of medical administration to some extent. A recent survey has shown that the number of publications related to pancreatic diseases in combination with artificial intelligence and deep learning techniques has increased exponentially. Different types of articles such as retrospective, reviews and prospective articles which are based on the PDAC pathology have been discussed with various artificial intelligence algorithms such as convolutional neural network, ResNet50, VGG11, long short term memory, ResNet18, natural language processing, generative adversarial networks, 3D UNet, deep neural networks etc. along with corresponding accuracies.
The authors of11 have developed a computer aided diagnosis system for the identification of pancreatic cancer with the help of an automated deep learning model. It has been stated that due to poor prognosis of pancreatic cancer, an intervention is needed which is provided rightly by deep learning techniques. It can fasten the treatment process, reduce the overhead of the medical professional, and help them with more precise and individualized treatment. The biggest advantage of artificial intelligence tools is that they are affordable and easily accessible. It can also be customized according to the need and field in which they are being applied. The application of deep learning-based techniques for the interpretation of medical images has grown prominently because of the promising results that they have been producing over time. CT images which were used as input were classified into 5 stages such as normal, pancreatic tumor, benign, premalignant, and malignant. Augmentation and preprocessing techniques such as vertical and horizontal flipping, resizing and anisotropic diffusion filtering were used. Watershed segmentation and UNet based feature extraction were performed later. An 11 layer of AlexNet CNN model was used for the classification purpose. The images were morphologically refined for extracting features and Grey Level Co-Occurrence Matrix was performed along with texture analysis. The accuracy produced at the end was 99.64% with AUC of 0.9979. The processing time taken by the proposed model was around 1.51 s.
Article16 provides a comparative study of random forest and logistic regression in the classification of pancreatic cancer. A real time dataset was collected from Al-Islam hospital in Indonesia which contained 203 patient details including 6 disease attributes such as age, CA 19–9, hemoglobin, leukocyte, hematocrit, thrombosis etc. The data samples were classified using logistic regression and random forest with the help of threefold cross validation technique. The final results show that logistic regression produced an accuracy of 96.48% and random forest classifier produced 99.38% accuracy stating the superiority of random forest classifier.
The findings of17 elaborate about the performance of Convolutional Neural Networks (CNN)in the process of grading pancreatic cancer using pathological images.138 pathological images with three different resolutions were obtained. They were stained with May-Grunwald-Giemsa (MGG) and Haematoxylin and Eosin (H&E) stains. Preprocessing was done with squared slicing method. The images were augmented and normalized for obtaining better results. 14 CNN models such as VGG16, VGG19, Xception, ResNet50, InceptionV3, Mobile net, DenseNet121, NasNet and more were used employed for classification. The results were fine-tuned and in the end, it was DenseNet201 that achieved highest F1-scores of 0.8786, 0.9561 and 0.8915 respectively for MGG, H&E and mixed stains.
The authors of12 have presented a research article regarding the classification of gastrointestinal cancer with the help of CapsNet and Deep Belief Network (DBN). The Kvasir data set containing 5000 samples were used for execution of the proposed model and the images were preprocessed using bilateral filtering. Feature extraction was done using CapsNet and classification was performed by a deep belief network-based classifier. Snake optimization algorithm (SOA) was used for improving the classification results which led to a classification accuracy of 99.72%.
The research findings in18 elaborate s about the classification of pancreatic cancer into three different types such as chronic pancreatitis, intraductal papillary mucinous neo plasm and pancreatic carcinoma using two novel support vector machine-based classifiers. Stable nested SVM and margin moment based SVM are the two types of classifiers proposed in this article. For the nested SVM, the training accuracy was 81.82% and for the moment based SVM classifier the classification accuracy was 66.82%.
Article19 has proposed a novel Vision transformer based pancreatic cancer classification system using shuffle instance and Rapid On-Site Evaluation (ROSE) technique. For the execution of the proposed model real time ROSE images were acquired from Peking Union Medical College hospital with the approval of the Ethics Committee. The data was then labeled and preprocessed using bag of patches which were then split and labels were assigned. For the classification purpose, a vision transformer and two multilayer perceptron-based heads were used. A shuffle step is performed in order to create bags of shuffle instances for better understanding of the relationships among the input samples. Finally, a classification accuracy of 94% was achieved by the proposed classifier with a precision value of 91.98% and recall value of 90.68%.
A robust DACTransNet has been proposed in20 for the classification of histopathological images of pancreatic cancer. Spatial pyramids have been appended to the architecture for more accurate results and automation. Features have been extracted using Convolutional Neural networks which extract both abstract and spatial features. Migration learning was applied at the end for bettering the obtained classification accuracy of 96%. Table 1 lists the important details of related articles that have been discussed in this section.
From the critical analysis of existing studies21,22, it is observed that most pancreatic cancer diagnosis frameworks have primarily focused on either conventional machine learning classifiers, CNN-based models, or standalone transformer architectures. Although these methods have produced encouraging results, several limitations remain. First, many works emphasize final classification accuracy without sufficiently explaining how region localization, feature representation, and classification decisions are connected. Second, several CNN-based approaches are effective in extracting local features but have limited ability to model long-range contextual relationships within CT images. Third, transformer-based models can capture global dependencies, but their performance depends strongly on the quality of input feature representations. Fourth, optimization strategies in existing studies are mostly restricted to standard training procedures and do not provide an additional adaptive refinement mechanism for improving classification outcomes.
The reviewed works also indicate that the integration of segmentation, detection-oriented feature extraction, transformer-based classification, and metaheuristic optimization has not been adequately explored for pancreatic CT image classification. For instance, UNet-based approaches support region-level segmentation, while YOLO-based models provide strong multi-scale feature representation. However, their combined use with Vision Transformer classification remains limited. Similarly, although optimization algorithms have been applied in some medical image classification studies, their role in refining transformer-based pancreatic cancer classification has not been sufficiently examined. These gaps show the need for a unified framework that can combine local structural information, multi-scale discriminative features, global contextual learning, and adaptive optimization.
The proposed work addresses these limitations by developing an integrated ViT-PO framework. In this model, Gabor filtering enhances the CT images before segmentation, UNet isolates relevant pancreatic regions, YOLOv11 extracts discriminative multi-scale features, and Vision Transformer captures global dependencies for classification. The Parrot Optimization algorithm is then incorporated to refine the classification performance. Therefore, instead of merely applying a single classifier, the proposed framework establishes a sequential and complementary pipeline in which each stage supports the next stage. This structured integration directly addresses the gaps identified in previous works and improves the reliability of pancreatic carcinoma classification.
Proposed methodology
The proposed vision transformer based parrot optimization (ViT-PO) model has been developed with an aim to classify pancreatic cancer images with the help of computed tomography (CT) images utilizing the power of deep learning and artificial intelligence. The input images were obtained from Kaggle website named Pancreatic CT image dataset. It comprises 1411 CT images which were divided into a ratio of 70:30 for the purpose of training and testing. Data augmentation is performed on the input images using methods like rotation, horizontal flipping, vertical flipping, scaling, and translation. After augmenting the images, they are preprocessed using Gabor filter. UNet based segmentation is done for segmenting the preprocessed CT images, after which feature extraction is performed with the help of YOLOv11 model. From the extracted features, pancreatic carcinoma classification is accomplished into two classes such as normal and pancreatic tumour using Vision Transformer based classifier. Parrot optimization algorithm is then applied on the acquired results for further improving the classification accuracy. Performance of the proposed vision transformer based pancreatic cancer classification system is evaluated by calculating metrics of accuracy, precision, recall, F1-Score and Matthew’s correlation coefficient (MCC). Once the performance has been evaluated, they are compared with existing classifiers like Random Forest, Convolutional Neural Network, Deep Belief Networks and Support Vector Machine which will yield a comparative analysis for projecting the outstanding performance of the proposed model. Figure 1 shows the workflow of the proposed ViT-PO based pancreatic cancer classification.

Developed ViT-PO Model.
The input CT image is first preprocessed using Gabor filtering and then passed to the UNet model to obtain a segmentation mask. This mask is applied to the original image to generate a region-focused (masked) image, which serves as the input to the YOLOv11 backbone. YOLOv11 then performs feature extraction, producing compact multi-scale feature representations. These extracted features are subsequently converted into patch embeddings and provided as input to the Vision Transformer, which performs the final classification. Thus, the pipeline follows a clear flow: Preprocessing→Segmentation (UNet)→Masked Image Generation→Feature Extraction (YOLOv11)→Patch Embedding→Classification (ViT) →Optimization (POA). No parallel or ambiguous feature paths are involved.
Data augmentation
Data augmentation is the process of creating new images that are similar to the input imagesfor inflating the dataset. This is performed primarily for enhancing the total number of images that are about to be used for execution of the proposed system. It is done by multiplying the existing images with methods like normalization, rotation, horizontal flipping, vertical flipping, scaling and translation23. Equations for the methods are given below in (1) to (6).
where D—input image, min(D) and max(D) represent the minimum and maximum values of pixel, \({D}_{nor}\) indicates the normalized image.
Here \({D}_{rot}\left(k\text{,}l\right)\) stands for rotation process, \({D}_{{\text{h}}or}\left(k\text{,}l\right)\) for horizontal flipping, \({D}_{ver}\left(k\text{,}l\right)\) for vertical flipping, \({D}_{sca}\left(k\text{,}l\right)\) for scaling and \({D}_{tra}\left(k\text{,}l\right)\) for translation tasks.
Preprocessing with Gabor filter
Medical images need to be dealt with extreme care because each and every pixel is absolutely essential. But noisy and unwanted information must be eliminated as well for easier and precise processing. In this case, a Gabor filter is employed for achieving preprocessed inputs. Basically, categorized as a linear, orientation sensitive filter, it is the combination of sinusoidal wave and gaussian functions24. They have been applied to a variety of computer vision related tasks such as preprocessing, edge detection, segmentation, object detection etc. It can obtain good resolutions in both spatial and frequency domains. It is two dimensional in form consisting of several rotations, convolution functions, and dilations. A simple product of gaussian kernel along with the sinusoidal signal gives the result of this filter. Its impulse response is defined by the Fourier transformation of both the products. It is also a bandpass filter which has the ability to permit certain signals and forbid unwanted noisy signals. The function of Gabor filter can be represented by factors such as wavelength, phase offset value, frequency, orientation, standard deviation of the gaussian kernel. The equation for the representation of Gabor filter is given below in Eq. (7).
\(p\left(a\text{,}b\right)\) represents the sinusoidal wave as defined in Eq. (8) and \({q}_{r}\text{(}a\text{,}b\text{)}\) indicates the gaussian function.
\({\text{(}m}_{0}\text{, }{n}_{0}\text{)}\) stands for the frequency and SP is the phase value. It has certain parts associated with it such as the real and imaginary parts which can be seen in (9) and (10).
The magnitude (\({M}_{0}\)) and direction (\({\omega}_{0}\)) are given by Eqs. (11) and (12) as shown below.
Gabor filtering is employed in this work due to its strong capability in capturing both spatial and frequency domain information, which is particularly important for medical CT images where subtle texture variations indicate pathological changes. Unlike conventional smoothing or denoising filters (e.g., Gaussian or median filters) that primarily suppress noise, Gabor filters are orientation- and frequency-selective, enabling them to enhance edge, boundary, and texture-specific features relevant to pancreatic tumour regions24.
Compared to its alternatives, Gabor filtering provides superior localization in both spatial and frequency domains, allowing better preservation of fine structural details while reducing noise. This makes it more effective for preprocessing in segmentation and feature extraction pipelines, as it improves the quality of input data for subsequent UNet segmentation and YOLOv11 feature extraction stages.
UNet based segmentation
Segmentation is done by UNet architecture of convolutional neural network. It is a very precise model that has been built and refined iteratively for performing image processing tasks such as segmentation and so on. It gains the name from its U-shaped symmetrical architecture which is made up of several encoders and decoders. It takes very little processing time even for segmenting large scale input images and can perform well with a tiny dataset. It is because of these two reasons that they are overwhelmingly used in medical image processing. The key components of a UNet model are the encoder set, decoder set and bottleneck layer in between both of them9.
The encoding block consists of a 2*2 max pooling layer and Rectified Linear Unit (ReLu) functions to impart no linearity for enhanced processing. Decoding block comprises layers of upsampling, 3*3 convolutions and skip connections. Upsampling is performed to regain the image size convolution is done in order to optimize the output. Skip connections meanwhile help to retrieve any lost information in the whole process. Bottleneck layer contains the fine-grained information that acts as the core part of the entire model. The architecture has been designed in such a manner that at each level of encoding, the size is reduced while retaining the key features and at the decoding end, the actual image is recreated by swift mapping employing skip connections. The energy function of the model is defined by the Eq. (13)
where \({C}_{f}\) shows the energy function of the channel, \(t\) represents the features, \(s\) indicates the weight, \({d}_{l}\) shows the final feature map which is further defined in (14).
L is the channel and \({act}_{l}\) is channel activation. Figure 2 below depicts the architecture of UNet.

Architecture of UNet.
Feature extraction using YOLOv11
You only look once (YOLO) is a very successful model for object detection, feature extraction, and localization. It has been elegantly designed in such a way to take up a wide range of image processing tasks. Its diverse nature makes it easily adaptable and compatible with many other existing models. The key advantages of this model are elevated accuracy, better tradeoff and applicability, enhanced object detection, optimized accuracy etc. The specific advancements to this latest version of YOLOv11 are the addition of new blocks for enhanced performance such as C3K2 block, Spatial Pyramid Pooling Fast (SPPF) block, Cross Stage Partial with Spatial Attention block (C2PSA).
In the proposed framework, YOLOv11 is utilized to extract high-level discriminative and multi-scale spatial features from CT images. These features include region-aware representations such as object boundaries, intensity variations, texture patterns, and spatial localization cues that are critical for distinguishing between normal and pancreatic tumour regions. The backbone of YOLO captures hierarchical convolutional features, while its neck (with SPPF and attention blocks) enhances multi-scale feature aggregation, resulting in rich and compact feature embeddings suitable for downstream classification10.
The use of YOLO is motivated by its ability to efficiently learn localized and context-aware feature representations, unlike traditional feature extractors that may only capture global or handcrafted descriptors. This makes it particularly effective in medical imaging tasks where subtle structural variations need to be identified.
In this work, feature extraction is performed on the segmented regions obtained from the UNet model, rather than on the entire image. This ensures that the extracted features are focused specifically on the relevant pancreatic region, reducing background noise and improving the quality and relevance of the feature representations. This targeted feature extraction directly contributes to improved classification performance when passed to the Vision Transformer.
Three basic components that make up the architecture of YOLO are the head, neck, and backbone10. The backbone is the most crucial block of the YOLO architecture as it acts as the chief feature extractor. It performs tasks such as convolutions, batch normalization, max pooling, and concatenation with the help of sub-blocks like C3K2 and bottle neck layer. Equation (15) gives the operation of standard convolution.
Here, c stands for output value at position \({pos}_{0}\), \(R\) represents the sample points, \({pos}_{n}\) shows the offset value at the selected position, w indicates the kernel weight and i is the input map value.
The small 3*3 kernels present in the C3K2 block allows extraction of minor features from the image. The neck region is yet another crucial block which collects the information from the backbone and passes it on to the head. It collects features with the help of the newly added SPPF block using repeated max pooling operations. Similarly, the C2PSA block brings attention mechanisms into this architecture for concentration on specific regions of interest. Upsampling happens here in multiple scales for concatenating and combining the features obtained so far.
The head block consists of multiple levels of detection boxes namely low, medium, and high referring to the different stages and resolutions of the image. CBS (Convolution Batch-norm SiLu layers) block is also present in the head region which refines the output produced by the neck and backbone regions. Figure 3 below represents the architecture of YOLOv11 highlighting the vital components.

Architectural model of YOLOv11.
In the proposed framework, the output of the UNet segmentation is not used as a separate parallel input but is directly integrated into the feature extraction stage through region-focused masking. Specifically, the segmentation mask produced by UNet is applied to the original CT image to isolate the pancreatic region, effectively suppressing background and irrelevant structures. This masked (segmented) image is then provided as the input to the YOLOv11 backbone for feature extraction. Thus, YOLOv11 operates on region-refined inputs, ensuring that the extracted features are concentrated on clinically relevant areas rather than the entire image. This sequential integration establishes a clear dependency where segmentation enhances feature quality by reducing noise and improving spatial focus.
Classification using vision transformer
Vision transformer (ViT) is a novel deep learning transformer model that has been adapted specially for computer vision tasks. Basically, used in natural language processing applications, ViTs are now available for use in several image-based classification tasks and have emerged as the opponent of convolutional neural network (CNN). It divides the image into patch sequences and then converts them into vectors and subsequent matrices. Its architectural innovations have led to such tremendous performance. Instead of convolutions, it uses self-attention methods for processing spatial relations among the images. ViTs have developed a strong space for themselves in the medical imaging sector where their ability can span from medical image segmentation, classification, object detection to image synthesis, generation, and restoration. The key advantages of this model over CNN are the large data handling capacity, ability to extract global dependencies, which is highly flexible due to the absence of convolutions and improved end accuracy in the classification tasks. They also suffer from certain limitations like more training time required and also computational expenses sometimes.
There are several computational steps involved in the architecture of a vision transformer such as dividing the images into patches, flattening and embedding them13. The next step is positional encoding, adding tokens and passing through layers of encoders. Finally, classification is performed using a MultiLayer Perceptron (MLP) head.
Step 1: Patch division
Instead of treating an image as a pixel grid, a vision transformer treats it as a patch sequence. Hence the first step is to divide the images into subsequent fixed sized patches which do not overlap with each other. The created patches are then flattened into single dimension vectors. Equation 16 describes this step.
Here p is a predefined value, n is the line vector, r is the result, E stands for the embedding tensor.
Step 2: Embedding patches
The flattened patches are then embedded using a linear projection which lets them learn more robust features from the image.
Step 3: Encoding of positions
The resulting patch embeddings are then augmented with positional information for better understanding of relative positions among the input image. This is done to keep track of the patch positions and retain the spatial order. A token is then appended to each patch embedding for collective information gathering.
Step 4: Transformer encoders
After patches are created and their positional information added to them, they are put through a set of transformer encoder layers which consist of Multi-head Self-attention (MSA). MSA refers to the process of self-attention carried out in multiple heads which enables to aggregate rich information across all directions. Once the self-attention process is complete, patches are again passed into a Feed Forward Network (FFN). The brain behind vision transformers is the self-attention mechanism which is nothing but an entity that is used to compute the interactions and dependencies present in the image patches and thereby learn the hierarchical relationships amongst them as given in Eqs. (19) to (26).
where l = 1……..L, L represents the transformer stack.
q stands for query, k for key and v for value. Similarly, b stands the number of heads, D is the dimension. Figure 4 shows the layer details of transformer encoder.

Layers of transformer encoder.
Step 5: Classification head
The output of the transformer encoders and FFN is used for the classification purpose and given as input to a MLP which typically contains fully connected layers and a softmax layer at the end. Figure 5 shows the depiction of ViT architecture.

Vision transformer architecture.
Parrot optimization algorithm
The parrot optimization algorithm (POA) is employed in this work to enhance the classification performance by providing an additional adaptive optimization layer beyond conventional training-based optimization. While the Vision Transformer is trained using standard optimizers such as Adam, POA is applied as a refinement mechanism to further improve the classification outcomes by exploring the solution space more effectively14.
POA belongs to the class of population-based metaheuristic algorithms and its counterparts include widely used techniques such as genetic algorithm (GA), particle swarm optimization (PSO), Harris Hawk optimization (HHO), and red deer optimization (RDO). Compared to these methods, POA offers a balanced exploration–exploitation strategy through its unique behavioral modeling of foraging, staying, communication, and predator-avoidance mechanisms. This enables the algorithm to avoid premature convergence and improves its ability to identify near-optimal solutions in complex, non-linear search spaces.
The key advantage of POA in this work is its ability to adaptively refine classification decisions, thereby reducing misclassification and improving robustness. As demonstrated in the experimental results, the integration of POA leads to improved accuracy compared to other optimization algorithms, highlighting its effectiveness in fine-tuning the classification process. The impact of POA is reflected in the overall performance improvement, particularly in achieving higher accuracy and reduced error rates, making the proposed framework more reliable for medical diagnosis.
Optimization algorithms whose aim is to find fittest solution to the given problem in all aspects have become increasingly important because of the performance trade-offs they provide. They can produce better results, optimize time and valuable resources, and can be widely adapted and applied to both engineering and real-world challenges. Out of the many types of optimization algorithms such as deterministic, metaheuristic and biological algorithms, population inspired biological based evolutionary algorithms have been gaining popularity in recent times. Parrot optimization algorithm is one such metaheuristic algorithm which has been designed based upon the characteristics of parrots belonging to the class Pyrrhura Molinae. Commonly called green cheeked parrots, they are extensively domesticated and have certain unique behaviors such as foraging habits, staying, communicating and stranger fear14. The population is initialized with the help of Eq. (27).
Lower and upper stand for the lower and upper boundaries of the searching space with a population size of P and maximum iteration limit of \({M}_{j}\). \(rand\left(\text{0,1}\right)\) refers to any random number in the range 0 to 1. Figure 6 shows the flow process of parrot optimization.

Flow process of parrot optimization.
Step 1: Foraging
Foraging is nothing but identifying food source and attaining them in groups or in person considering the location, orientation, position of owner, abundance of food with the help of visual and odor clues. They fly to the food source based upon the below Eq. (28).
\({L}_{i}^{t}\) is the current location of parrots, \({L}_{i}^{t+ \text{1} }\) is the next location to be moved on and \({L}_{mean}^{t}\) is the average location which is further defined in Eq. (29).
\(Levy\left(own\right)\) indicates the position in accordance with the owner as described in (30).
\(\beta\) takes a constant of value 1.5. \(\sigma\) is calculated using (32).
Step 2: Staying
Green cheeked parrots are very friendly and hence often fly to their owner and stay with them for a while in a random manner. This mechanism can be figured out in the Eq. (33).
\(B\text{(1,}own\text{)}\) refers to the owner’s body.
Step 3: Communication
These animals are very sociable and communicate well among each other and also with the surroundings around them. This communication involves two flying movements namely flying before communication and returning back after communication. These two processes are defined in Eqs. (34) and (35).
R is a random number between 0 and 1.
Step 4: Stranger fear
Any animal is scared of strangers and so are these parrots and hence adopts a sudden movement of flying to seek a safe place and stay away from any potential source of danger. This process can be defined in (36).
Figure 7 pictorially represents the parrot optimization algorithm stages.

Parrot optimization algorithm.

Parrot optimization algorithm.
Experimental results and analysis
The pancreatic CT image dataset used in this study was carefully preprocessed to ensure consistency and reliability of the results. All images were standardized in terms of size and intensity distribution before further processing. Gabor filtering was applied to enhance texture and edge information while suppressing noise. The dataset obtained from Kaggle consists of labeled images categorized into normal and pancreatic tumour classes, and these labels were retained as provided, assuming standard annotation practices. To address class imbalance, augmentation techniques such as rotation, flipping, scaling, and translation were applied, particularly to the minority class, thereby improving class distribution and model generalization. Further, the use of UNet-based segmentation ensures that only the relevant pancreatic regions are considered for feature extraction and classification, which reduces the impact of background variations and enhances reproducibility. These preprocessing and data handling steps collectively contribute to the robustness and reliability of the proposed framework.
Experimental setup
The proposed ViT-PO classifier based pancreatic cancer classification model was executed using the latest version of MATLAB R2021b running on a Windows 10 system that had an Intel Core i7 processor with 16 GB RAM. For this process Deep Learning Toolbox, Image Processing Toolbox, and Statistics and Machine Learning Toolbox were utilized from the library. The base model of ViT has 12 layers with a hidden node size of 768, MLP size of 3072, 12 numbers of heads and 86 M parameters. Table 2 presents the hyper parameter details of ViT classifier.
The hyperparameters listed in Table 2 are selected based on a combination of standard Vision Transformer (ViT-Base) configurations and empirical tuning to suit the pancreatic CT image dataset. Specifically, parameters such as patch size (16), number of layers (12), hidden dimension (768), MLP dimension (3072), and number of attention heads (12) follow the widely adopted ViT-Base architecture reported in the literature13, ensuring a balanced trade-off between model complexity and performance. The training-related parameters, including learning rate (0.001), batch size (32), dropout rate (0.2), and number of epochs (100), are determined through iterative experimentation to achieve stable convergence and avoid overfitting on the given dataset. The Adam optimizer is selected due to its proven efficiency in handling transformer-based models and its ability to adapt learning rates dynamically.
Overall, the parameter configuration ensures compatibility with the ViT architecture, computational feasibility, and optimal performance for the given dataset, while maintaining consistency with established practices in transformer-based medical image analysis.
The hyper parameters of the chosen ViT-Base classifier were carefully picked with utmost care for achieving maximum performance. Patch size of 16 is chosen so that minute details in the image can be well captured, with 12 layers of transformer encoders which represent the depth of the classifier. This value has to be chosen in medium manner as cost and computational complexity increase linearly with the number of encoder blocks. The embedding size was selected as 768 as this is a base model. Higher models such as ViT-Huge and ViT-Large have higher dimensions. The embedding size is also called the hidden dimension of the classifier. It is in this size that the vector is represented for the whole block of transformer encoder.
The dimension of MLP is 3072 which represents the number of hidden neurons that are to be present in the MLP layers for appropriate data learning. 12 number of attention head are present in this classifier for concentrating on various parts of the input images. Batch size was set as 32 for maintaining good balance and to attain model stability. The learning rate was 0.001 as it is the speed at which weights are periodically updated. Since ViTs are critical to optimization, Adam optimizer has been selected for efficiency. The rate of dropout has been rightly set as 0.2. The model has been trained for 100 epochs which provides good speed, convergence, and average computation.
Execution and results
Implementation of the proposed work was carried out with the help of 1411 images acquired from Pancreatic CT image dataset. In this dataset, 646 normal images and 765 pancreatic tumour images were present. A total of 400 images were created in data augmentation process which were appended to the original dataset of 1411 images thus taking the total count of input images to 1811, respectively. Table 3 below displays the partitioning of input data for training and testing phases. The images were split into a ratio of 70:30 for training and testing phases. 1268 training images and 543 testing images were employed for the execution of the proposed ViT-PO model.
Figure 8 displays the sample images collected from the Pancreatic CT image dataset in addition to preprocessed images with the help of Gabor filter and UNet based segmented images.

Sample, preprocessed and segmented images.
Performance measures
In this segment, some of the standard performance measures like accuracy, precision, recall, F1-Score and Matthew’s correlation coefficient (MCC) are calculated for assessing the classification performance of the proposed ViT-PO model. The classification outcome will be correct or wrong, which can be signified as one among the four popular classes of true positive (TP), true negative (TN), false positive (FP) and false negative (FN).
TP: Precise classification of positive class.
TN: Precise classification of negative class.
FP: Imprecise classification of positive class.
FN: Imprecise classification of negative class.
Equations for the calculation of accuracy, precision, recall, F1-Score and MCC have been given in (37) to (41).
Figure 9 displays the confusion matrix produced by the proposed ViT-PO based pancreatic cancer classification system.

Confusion matrix of the proposed ViT classifier.
The proposed ViT model has achieved a good classification performance with 1142 true positives and 611 true negatives. There were only 23 false negatives and 35 false positives, thus signaling near-perfect balance. These results firmly establish the ViT-PO model’s exceptional precision and trust worthiness in the field of computer-aided diagnosis. Table 4 presents the values achieved by the proposed ViT-PO system in the process of training and testing the pancreatic CT images. The proposed model attained an accuracy of 99%, precision value of 98.5%, recall value of 97.7%, F1-score of 96.4% and MCC score of 97.3%.
Accuracy analysis
In this section, a relative comparison of accuracy values is made among the proposed model and conventional methods which have been employed in the pancreatic carcinoma classification process. Table 5 exhibits the variance in accuracy values attained by the proposed ViT-PO classifier and existing classification systems like Random Forest (RF), Support Vector Machine (SVM), Convolutional Neural Network (CNN), and Deep Belief Network (DBN) at specified epochs of 25, 50, 75 and 100. After the completion of the 25th cycle, the accuracy score of the proposed model reaches 97.9% and after 50th, 75th and 100th epochs, they are 98.2%, 98.5% and 99%. It is noteworthy that the accuracy scores have been consistently high throughout the entire training and testing phases, which reflects the stand-alone performance of the proposed model.
Figure 10 shows the accuracy of the proposed system in contrast to the accuracy details of other models like RF, CNN, DBN and SVM for highlighting the proposed model’s superiority in the classification of pancreatic carcinoma. The figure is an exact reflection of the excellent performance of the proposed ViT-PO model.

Relative analysis of accuracy.
Precision analysis
This section shows the difference in precision scores among the various classifiers. Table 6 demonstrates the precision values recorded by the proposed ViT-PO model and other existing systems. After reaching 25th and 50th epoch cycles, the precision values attained by the proposed model are 96.2% and 97% correspondingly. Likewise, after 75th and 100th epochs, they reach 97.4% and 98.5% which are fairly high than all of the other models under study thus signifying the exclusiveness of the proposed work.
From Fig. 11, which illustrates graphically the above-mentioned precision scores, it is evident that the ViT-PO model works in a better and advanced in terms of precision thus validating the smarter performance of the proposed system.

Precision results.
Recall analysis
It can be clearly noticed from this section that the proposed model significantly outshines the other models as far as recall scores are concerned. Table 7 contains the different recall scores recorded by the proposed ViT-PO model at four specific epoch cycles of 25, 50, 75 and 100. At the specified epochs, the recall scores are 95.8%, 96.5%, 97.1% and 97.7% respectively, all of which are higher than the existing models explicitly stating the improved performance of the proposed classifier.
The recall values registered at different epoch cycles by existing and proposed classifiers are illustrated in Fig. 12.

Analysis of recall scores.
F1-Score analysis
The analysis of F1-Score done in this section clearly shows that the proposed work of ViT-PO attains much better F1-Score than all the preceding models in the classification of pancreatic carcinoma. Table 8 consists of the F1 scores achieved by the proposed model and existing models at 25th, 50th, 75th and 100th epochs. The F1-Scores achieved by the proposed method were 95.3%, 95.8%, 96.1% and 96.4% at the mentioned epochs.
Figure 13 depicts the F1-Score comparison in a graphical manner which was developed from the above table. Consistent good performance by the proposed model in terms of F1-Score increases the reliability of the model hugely.

F1-score comparison.
MCC analysis
A comparison is made between the current classifiers and the proposed one regarding the MCC scores. Table 9 describes the MCC values produced by the proposed ViT-PO classifier after completing certain epochs of 25, 50, 75 and 100. The MCC score at 25th epoch is 95.9%, 50th epoch is 96.2%, 75th epoch is 96.8% and after 100th epoch, it reaches 97.3% finally. The MCC scores of the proposed model surpass that of the other conventional models in all the specified epoch cycles portraying the robustness of the proposed ViT-PO model.
Figure 14 presents a mathematical graphical model of MCC scores achieved by different classifiers at selected epochs.

MCC analysis.
TPR analysis
This part carries the true positive rate (TPR) analysis for pancreatic cancer classification using ViT-PO model. The results are given in Table 10 and Fig. 15. The proposed method attains the highest TPR in all the epoch iterations, insisting the advanced sensitivity it has in detecting true positives cases which is very essential for medical diagnosis. The proposed model attain 94.9% and 95.1% in the initial epochs and finally reach 95.5% and 96.1% at the end of 100 epochs which are comparatively higher than all the existing conventional methods.

TPR graphical analysis.
FPR analysis
The False Positive Rate (FPR) Analysis has been presented here between the current approaches and the proposed model as stated in Table 11 and Fig. 16. It is apparent from the given table that the proposed ViT-PO method possesses the lowest rate of FPR, exhibiting a better proficiency to mitigate false cases thus aiding oncologists in their work. The proposed work is superior to all the other compared models of RF, SVM, CNN and DBN.

FPR analysis.
Table 12 provides the consolidated scores of all the classifiers under study in the final epoch cycle of 100. In all the areas of evaluation, the proposed ViT-PO model surpasses all the classifiers at least by a small margin, indicating the phenomenal performance.
The same has been visually shown in Fig. 17 to provide a wholesome view.

Consolidated performance graph.
Optimization analysis
This section shows the analysis of different optimization algorithms in the process of pancreatic cancer classification. The comparative evaluation is done with the proposed Parrot optimization algorithm against standard optimization algorithms like genetic algorithm, Harris Hawk optimization and Red Deer optimization in terms of accuracy values as listed in Table 13. Notably, the proposed optimization algorithm attains a higher accuracy value in the process of same pancreatic cancer using different datasets. This endorses the effectiveness of the proposed ViT-PO model in fine-tuning parameters for achieving exceeded performance.
Misclassification analysis
This segment consists of an investigation about the misclassifications and errors that happened in the process of pancreatic cancer classification. Although the proposed model performed well, there were certain misclassifications. The reason for this can be attributed to the fact that some of the images were ambiguous and not enough details could be gathered from it. Another setback was due to improper lighting during the process of capturing the image. Normal images were misclassified as pancreatic tumour due to the presence of minor artifacts. This study could offer an understanding of the mistakes that happened, where they happened and what went wrong in the whole process. These details will help in identifying and avoiding those particular mistakes in future. It can also contribute well to augmenting the classification accuracy and upgrade the overall performance of the proposed work.
Convergence and stability analysis of POA
To evaluate the convergence behavior and stability of the Parrot Optimization Algorithm (POA), experiments were conducted across multiple independent runs. The fitness value (classification accuracy) was monitored over iterations, and statistical consistency was analyzed (Table 14).
The convergence analysis shows that the POA rapidly improves classification performance within the first few iterations and stabilizes after approximately 40–50 iterations, indicating efficient convergence without oscillatory behavior.
The stability analysis across multiple runs demonstrates minimal variation in performance metrics, confirming that the optimization process is consistent and does not suffer from instability. The negligible difference in accuracy (within ± 0.2%) across runs validates the robustness of POA in refining classification outcomes (Table 15).
These results confirm that POA achieves a balanced exploration–exploitation trade-off, ensuring both fast convergence and stable performance in the proposed framework.
Computational analysis
Integrating segmentation, transformer-based classification, and optimization introduces additional computational overhead. However, the framework is designed in a sequential and modular manner, where each component operates on progressively refined data, thereby reducing unnecessary computation. Specifically, UNet-based segmentation restricts processing to relevant regions, which reduces input complexity for subsequent stages, and YOLOv11 extracts compact feature representations instead of operating on full-resolution images. Furthermore, the Vision Transformer used corresponds to a base configuration, and training parameters are carefully controlled to maintain computational feasibility. The optimization stage (POA) is applied only as a lightweight refinement step rather than during full network training, limiting its computational impact.
Apart from the theoretical point of view, real-world implementation of the proposed work in medical arena needs a certain degree of computational findings. In order to review the practical implications of the proposed ViT-PO model, its computational efficiency was evaluated and. The proposed ViT-PO required 108 s for execution, with almost 500 MB memory space.
Cross-validation analysis
To further strengthen the reliability of the proposed model, a fivefold cross-validation experiment was conducted on the same dataset. The dataset was randomly partitioned into five equal subsets, where in each iteration, four subsets were used for training and one subset was used for testing. The average performance across all folds is reported in Table 16.
The cross-validation results demonstrate consistent performance of the proposed ViT-PO model across different data splits, with minimal variation in evaluation metrics. The average accuracy of 98.94% closely aligns with the previously reported results, indicating that the model does not overfit to a specific train-test split. The low standard deviation across folds confirms the stability and generalization capability of the proposed framework.
Although external dataset validation is not included due to dataset availability constraints, the cross-validation analysis provides strong evidence of the robustness and reliability of the proposed model. Future work will focus on validating the model on larger and multi-institutional datasets to further enhance its clinical applicability.
Ablation analysis
To evaluate the contribution of each component in the proposed framework, an ablation study is conducted by progressively enabling different modules of the system. The performance is measured using standard evaluation metrics on the same dataset and experimental setup.
The ablation results in Table 17 clearly demonstrate the contribution of each component in the proposed framework. The baseline CNN model shows comparatively lower performance due to limited feature representation capability. The use of Vision Transformer improves performance by capturing global contextual dependencies. Incorporating UNet-based segmentation further enhances the results by focusing on relevant pancreatic regions. The addition of YOLOv11-based feature extraction improves multi-scale feature representation, leading to better classification outcomes. Finally, the inclusion of Parrot Optimization results in the highest performance, indicating its effectiveness in refining classification decisions. Overall, the progressive improvement across configurations validates that each module contributes significantly to the final performance of the proposed ViT-PO framework.
Discussion
The proposed ViT-PO framework demonstrates strong and consistent performance across all key evaluation metrics, indicating its effectiveness for pancreatic cancer classification. The model achieves an overall accuracy of 99%, with precision of 98.5%, recall of 97.7%, F1-score of 96.4%, and MCC of 97.3%, reflecting a well-balanced classification capability. The high MCC value, in particular, confirms the robustness of the model in handling both positive and negative classes without bias, which is critical in medical diagnosis.
From a diagnostic perspective, the model attains a true positive rate of 96.1% and a low false positive rate of 0.07%, indicating high sensitivity in detecting tumour cases while minimizing false alarms. This is clinically significant, as reducing false negatives is essential to avoid missed diagnoses, and controlling false positives prevents unnecessary follow-up procedures.
The ablation analysis further validates the contribution of each component in the proposed framework. The performance improves progressively from 96.8% (baseline) to 99% (full model), confirming that segmentation (UNet), feature extraction (YOLOv11), transformer-based classification (ViT), and optimization (POA) each play a meaningful role in enhancing the overall system. Additionally, the cross-validation results show an average accuracy of 98.94%, demonstrating the model’s stability and generalization capability across different data splits.
The optimization analysis reveals that the proposed POA achieves higher accuracy compared to other algorithms such as Genetic Algorithm (93.9%), Harris Hawk Optimization (96%), and Red Deer Optimization (98.51%), confirming its effectiveness in refining classification outcomes. Convergence analysis indicates stable performance within 40–50 iterations, and multi-run experiments show negligible variation (± 0.2%), validating its reliability.
From a clinical standpoint, the integration of segmentation-based region focusing and attention-based global learning enables the model to capture both anatomical structures and contextual dependencies. This makes the system suitable as a decision-support tool for radiologists, assisting in early-stage detection and improving diagnostic consistency. However, the absence of external dataset validation and reliance on binary classification limit immediate clinical deployment.
Overall, the results indicate that the proposed framework provides a highly accurate, stable, and clinically relevant solution, while highlighting the need for further validation on diverse datasets and real-world clinical settings.
Conclusion
The incidence of pancreatic carcinoma has shown a consistent rise over recent years, coupled with persistently low survival rates due to late-stage diagnosis. This highlights the critical need for reliable and automated diagnostic systems capable of supporting early detection. In this context, the proposed work presents a structured and integrated framework for pancreatic cancer classification using CT images, combining Gabor-based preprocessing, UNet-driven segmentation, YOLOv11-based feature extraction, and Vision Transformer classification enhanced through Parrot Optimization. This multi-stage design enables effective capture of both local structural characteristics and global contextual dependencies, thereby strengthening the overall diagnostic capability of the system. The experimental findings demonstrate that the proposed ViT-PO model achieves high performance across multiple evaluation metrics, including accuracy (99%), precision (98.5%), recall (97.7%), F1-score (96.4%), and MCC (97.3%), along with a high true positive rate and minimal false positive rate. These results indicate not only strong classification capability but also consistency and reliability, which are essential in medical diagnosis. Further, comparative analysis confirms that the proposed model outperforms conventional classifiers such as Random Forest, CNN, DBN, and SVM, thereby validating the effectiveness of the integrated approach. The strength of the proposed framework lies in its ability to combine segmentation-based region focusing, detection-driven feature extraction, transformer-based global learning, and metaheuristic optimization within a single pipeline. This coordinated design directly addresses key limitations observed in existing methods and contributes to improved diagnostic performance. However, the current model is limited to binary classification and involves moderate computational complexity, which may impact large-scale deployment. Future work can focus on extending the model for multi-class classification of pancreatic disease stages, optimizing computational efficiency, and validating the framework on larger and multi-institutional datasets. Integration with additional imaging modalities and clinical parameters can further enhance its applicability. Overall, the proposed framework offers a promising and reliable approach for computer-aided pancreatic cancer diagnosis, with potential to support early detection and improve clinical decision-making. The proposed framework, while demonstrating strong performance, is currently limited by the use of a moderately sized dataset and binary classification, which may affect its generalizability across diverse clinical scenarios. Additionally, the computational complexity associated with transformer-based models may pose challenges for real-time deployment in resource-constrained settings. From a clinical perspective, the model can serve as a supportive diagnostic tool to assist radiologists in early detection; however, extensive validation on multi-institutional datasets and integration with clinical workflows are essential before practical adoption.
Data availability
The dataset utilized for the execution of the proposed pancreatic carcinoma classification system is available in the following link. https://www.kaggle.com/datasets/jayaprakashpondy/pancreatic-ct-images.
References
Chen, P. T. et al. Pancreatic cancer detection on CT scans with deep learning: A nationwide population-based study. Radiology 306(1), 172–182 (2023).
Hema, A., Hussaian Basha, C.H., Senthilkumar, S., Gopika, B.S., Muthaiyan, R. & Ramanan, R. Automated COPD diagnosis from CT scans: A hybrid deep learning and machine learning approach with explainable AI. In International Conference on Research and Development in Information, Communication, and Computing Technologies (ICRDICCT`25), April 4th and 5th, (2025). https://doi.org/10.5220/0013910500004919.
Jan, Z., El Assadi, F., Abd-Alrazaq, A. & Jithesh, P. V. Artificial intelligence for the prediction and early diagnosis of pancreatic cancer: Scoping review. J. Med. Internet Res. 25, e44248 (2023).
Viriyasaranon, T. et al. Annotation-efficient deep learning model for pancreatic cancer diagnosis and classification using CT images: A retrospective diagnostic study. Cancers 15(13), 3392 (2023).
Cao, K. et al. Large-scale pancreatic cancer detection via non-contrast CT and deep learning. Nat. Med. 29(12), 3033–3043 (2023).
Gandikota, H. P., S, A. & M, S. K. CT scan pancreatic cancer segmentation and classification using deep learning and the tunicate swarm algorithm. PLoS ONE 18(11), e0292785 (2023).
Dinesh, M. G., Bacanin, N., Askar, S. S. & Abouhawwash, M. Diagnostic ability of deep learning in detection of pancreatic tumour. Sci. Rep. 13(1), 9725 (2023).
Halbrook, C. J., Lyssiotis, C. A., di Magliano, M. P. & Maitra, A. Pancreatic cancer: Advances and challenges. Cell 186(8), 1729–1754 (2023).
Chaithanyadas, K. V. & King, D. G. G. Automated detection of pancreatic cancer with segmentation and classification using fusion of UNET and CNN through spider monkey optimization. Biomed. Signal Process. Control. 102, 107413 (2025).
Chen, X. HD-YOLO: Real-time detection of benign and malignant endometrial lesions using YOLO11. Signal Image Video Process. 19(7), 535 (2025).
Nadeem, A., Ashraf, R., Mahmood, T. & Parveen, S. Automated CAD system for early detection and classification of pancreatic cancer using deep learning model. PLoS ONE 20(1), e0307900 (2025).
Almarshad, F. A. et al. An efficient optimal CapsNet model-based computer-aided diagnosis for gastrointestinal cancer classification. IEEE Access. 99, 1–1 (2024).
Peng, Z. et al. Vision transformer network discovers the prognostic value of pancreatic cancer pathology sections via interpretable risk scores. Discov. Oncol. 16(1), 1–11 (2025).
Houssein, E. H. et al. An efficient improved parrot optimizer for bladder cancer classification. Comput. Biol. Med. 181, 109080 (2024).
Patel, H., Zanos, T. & Hewitt, D. B. Deep learning applications in pancreatic cancer. Cancers 16(2), 436 (2024).
Rustam, Z., Zhafarina, F., Saragih, G. S. & Hartini, S. Pancreatic cancer classification using logistic regression and random forest. IAES Int. J. Artif. Intell. 10(2), 476 (2021).
Sehmi, M. N. M., Fauzi, M. F. A., Ahmad, W. S. H. M. W. & Chan, E. W. L. Pancreatic cancer grading in pathological images using deep learning convolutional neural networks. F1000Research 10, 1057 (2022).
Washburn, A., Fan, N. & Zhang, H. H. Novel SVM-based classification approaches for evaluating pancreatic carcinoma. Ann. Math. Artif. Intell. 93(1), 93–108 (2025).
Zhang, T., Feng, Y., Feng, Y. & Zhang, G. (2022). Pancreatic cancer ROSE image classification based on multiple instance learning with shuffle instances. arXiv preprint arXiv:2206.03080.
Kou, Y., Xia, C., Jiao, Y., Zhang, D. & Ge, R. DACTransNet: A hybrid CNN-transformer network for histopathological image classification of pancreatic cancer. In Artificial Intelligence. CICAI 2023. Lecture Notes in Computer Science (eds. Fang, L., Pei, J., Zhai, G. & Wang, R.), vol 14474 (Springer, Singapore, 2024).
Imran, S. M. A., Arif, M., Jaffar, A. & Kushi, H. M. T. Deep-learning based multi-modalities fusion for the detection of brain-related diseases: A review. In Computing and Emerging technologies, 149–170 (2025)
Khushi, H. M. T., Masood, T., Jaffar, A. & Rashid, M. Improved multiclass brain tumor detection via customized pretrained EfficeintNetB7 model. IEEE Access 99, 1–21 (2023).
Wei, K., Li, T., Huang, F., Chen, J. & He, Z. Cancer classification with data augmentation based on generative adversarial networks. Front. Comput. Sci. 16(2), 162601 (2022).
Dodda, K. & Muneeswari, G. IANFIS: A machine learning–based optimized technique for the classification and segmentation of pancreatic cancer. Res. Biomed. Eng. 40(2), 373–385 (2024).
Kamatchi, S., Preethi, S., Kumar, K. S., Reddy, N. N, D. N. & Karthick, S. Multi-objective genetic algorithm optimised convolutional neural networks for improved pancreatic cancer detection. In 2025 3rd International Conference on Data Science and Information System (ICDSIS), Hassan, India 1–7(2025)
Chegireddy, R. P. R. & Srinagesh, A. A novel method for human MRI based pancreatic cancer prediction using integration of Harris Hawks varients and VGG16: A deep learning approach. Informatica 47(1), 4433 (2023).
Lakkshmanan, A. & Ananth, C. A. An automated deep learning based pancreatic tumor diagnosis and classification model using computed tomography images. Int. J. Intell. Comput. Cybern. 15(3), 454–470 (2022).
Acknowledgements
The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for supporting this work through Large Research Project under grant number RGP2/219/46. Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2026R303), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Funding
Funding is not available for this research work.
Author information
Authors and Affiliations
Contributions
C. Mallika and E. Dinesh—concept creation, conduct of the research work, and manuscript preparation. Hadeel Alsolai and Munya A. Arasi—data collection, literature review, and final drafting of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mallika, C., Dinesh, E., Alsolai, H. et al. Maximizing pancreatic carcinoma classification performance using parrot optimized vision transformer. Sci Rep 16, 16277 (2026). https://doi.org/10.1038/s41598-026-53240-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-53240-w
