
Abstract
Targeted police stops are frequently carried out by police in response to real-world needs. The effectiveness of various purpose-driven police stop tactics on crime prevention and control varies. However, existing research has neither identified the associated factors of police stops nor explored their impact on crime with different factors. Therefore, this study focuses on the main urban areas of megacities along the southeast coast of China. The space is partitioned using hierarchical clustering after applying the XGBoost and SHAP algorithms to determine the factors related to police stops. Lastly, this study explores the causal effects of police stops with different associated factors on crime, using causal forests within double machine learning. There are three conclusions. First, there is a strong correlation between police stops and four variables: alarm, visiting population, criminal, and government agencies. Second, by clustering based on different associated factors of police stops, existing police stops can be classified into five categories according to their purposes: (i) composite stops positively associated with “Alarm, Visiting Population, Criminals” (AVC-CPS); (ii) composite stops positively associated with “Alarm, Visiting Population, Bus Station” (AVB-CPS); (iii) random stops with no significant positive association (NA-RPS); (iv) single police stops positively associated with “Alarm” (A-SPS); and (v) single stops positively associated with “Visiting Population” (V-SPS). AVC-CPS corresponds to the highest number of grids in the study area. Third, the influence of police stops on crime varies significantly depending on the factors that are associated with them. Among all categories, AVC-CPS has the best overall inhibitory effect on crime, while single police stops and random police stops have minimal or insignificant effects. In summary, the conclusions of this study can provide a basis for optimizing the spatial deployment of police forces, aiming to improve the effectiveness of stop operations and crime prevention and control capabilities.
Similar content being viewed by others

Introduction
Police stops are regarded as a common strategy that aims to prevent and control crimes since they are an essential tool for regulation and law enforcement in contemporary policing systems (Petersen et al., 2023). The existing literature predominantly examines police stops within Western contexts, focusing on aspects such as stop behaviors, racial discrimination, and their impact on crime (Braakmann, 2022; Gelman et al., 2007; Riksheim and Chermak, 1993; Sherman, 1980). In contrast, research in China has primarily concentrated on the legal frameworks governing police stop powers, legislation, and the standards for initiating such stops (Jiang and Li, 2006; Wan and Chen, 2009). Notably, there is a paucity of studies exploring the spatial correlates of police stops in China, their objectives, or the varying effects of different types of stops on crime. Although both China and Western countries conduct police stops within established legal frameworks—requiring officers to stop suspected lawbreakers—Western countries typically formulate procedural law standards. For example, in the United States, specific legal provisions require a clearly defined level of “reasonable suspicion” to justify a stop (Jones-Brown et al., 2010). Furthermore, the cultural and institutional environment in China—marked by lower ethnic heterogeneity and high public trust in law enforcement—results in greater public compliance with police stops. These unique characteristics not only shape the operational practices of police stops in China but also have implications for their effectiveness in crime prevention and control.
Police stop patterns and influencing factors
Police stop strategies are inherently multi-purpose (Famega, 2005), lacking clear, uniform criteria. Decisions often depend on factors such as the distribution of crime hotspots and population. For example, research indicates that police increase stops in high-crime areas (Ratcliffe, 2016). Avdija (2014) identified three key situational factors: whether the stop occurs during a period of high crime, whether the suspect appears to be fleeing, and whether the location has a high crime rate. Numerous studies have also revealed discriminatory practices in stops based on local population makeup (Borooah, 2011; Bowling and Phillips, 2007). Shapiro and Pearman (2017) demonstrated a self-developed interactive geoslicer to visualize and analyze police stops in New York City. They discovered that stops tend to decrease on major holidays, while officers target areas with higher Black and Hispanic populations.
Beyond targeting offenders, police stops also serve to increase police visibility, thereby enhancing public security. Therefore, high-traffic locations such as large business districts and subway stations—identified as both crime and stop hotspots (Weisburd et al., 2014)—often witness concentrated police activity. Public spaces with significant population turnover and diversity frequently become the focus of stop efforts (Suss and Oliveira, 2023). For instance, large business areas and subway stations provide more potential opportunities for offenders to commit crimes (Song et al., 2017). Ashby and Tompson (2017) discovered that taking population activities into account helps to explain some of the change in police stops across time.
Deterrent effect of police stops on crime
The impact of police stops on deterring crime remains a subject of debate. Some studies support a deterrent effect; for instance, Weisburd et al. (2016) discovered that police stops in New York City significantly reduce crime with Bartik’s instrumental variables approach. Wooditch and Weisburd (2016) constructed a bivariate spatio-temporal Ripley’s k-function for the spatio-temporal analysis of the relationship between police stops and crime, which shows that police stops reduce crime and that the effect is persistent. However, other research questions this effect. Petersen et al. (2023) noted uncertainty in the overall impact, and studies by Sherman and Weisburd (1995) and McGarrell et al. (2001) observed that, except for violent or gun-related offenses, stops generally do not have a noticeable effect on other crime types. Rosenfeld and Fornango (2014) further reported only a weak deterrent effect on robbery and burglary.
Geographic context and methodological differences further complicate the analysis. For example, Piza and Gilchrist (2018) found that the crime reduction effect of police stops can vary significantly by geography, with areas facing multiple risk factors (e.g., social disorder calls, gang territories, liquor stores) benefitting more. Likewise, Weisburd et al. (2014) observed a strong positive spatial correlation between stops and crime in New York City, underscoring the challenges of isolating the causal influence of stops.
Machine learning in evaluating police stop effectiveness
The challenge of isolating the causal effect of police stops on crime has prompted researchers to incorporate causal inference models into their analyses. Conventional approaches can suffer from model misspecification when relying on pre-established assumptions, and direct machine learning models may yield biased estimates. Recent advances—particularly double machine learning—offer a promising solution (Chernozhukov et al., 2018; Jung et al., 2021). The combination of machine learning models is able to better capture the nonlinear relationship between variables and flexibly handle multidimensional data, correct biases inherent in one-off estimates, and simultaneously capture the complex interplay among multiple variables.
In conclusion, current research still has the following drawbacks. There are two main shortcomings in the research on the relationship between “police stops-crime”, namely: (1) the strategy of police stops is driven by multiple factors, but fewer studies have taken police stops as the primary subject of analysis and identified the correlates of police stops in combination with crime and geographic environment factors; and (2) existing studies fail to categorize and explore the relationship between “police stops-crime” based on different purposes. In order to achieve this, this study classifies the various purpose-oriented police stops and finds correlations between them by taking into account characteristics related to the criminal scenario and the geographic environment. Simultaneously, a causal inference model is constructed to quantitatively assess the impacts and variations of various purpose-driven police stops on crime.
Data and methods
Data
The study area is the HT district of ZG city, a megacity on the southeast coast of China, which was initially divided into 619 cell grids measuring 500 × 500 m. However, since some parts of the area are mountainous and lack daily police stop activity, those grids were excluded, resulting in a final sample of 472 cells.
The study integrates multiple datasets, including police stops, alarm records, offender data, POI data, and population data. The police stops, alarm, and criminal data were provided by the ZG Public Security Bureau for the period from January 1, 2018 to December 31, 2018. The alarm data pertain to street crime, with each incident manually verified on-site by police, ensuring high data quality with no missing values. In contrast, the police stops data have a 28.74% missing rate, primarily due to reduced GPS accuracy indoors; however, since our analysis focuses on street crime, this limitation does not significantly affect our results.
The POI data were obtained from Daodotong Map and Navigation Company from 2018, and include government agencies, hotels, schools, malls, subway stations, and bus stations. Population data were sourced from Unicom’s big data analysis platform, and the data time is October 2019. Additionally, cell phone signaling data were used to estimate the number of visitors in each region. To meet the requirements of regression modeling and improve model reliability, all variables were logarithmized, resulting in a processed dataset that approximates a normal distribution.
Methods
In this study, we utilize the SHAP additive interpreter to visualize the “black box” XGBoost model, enabling us to effectively pinpoint the correlates of police stops. Subsequently, we integrate the SHAP values to cluster these correlates and differentiate the categories of police stops based on their various purposes. Ultimately, we employ double machine learning based on the causal forest method to calculate the causal effects of these purposeful police stops on crime impacts, thereby evaluating the efficacy of different existing police stop strategies.
Police stops correlate identification and spatial clustering methods
XGBoost is selected for its robustness in handling missing data, mitigating overfitting through regularization, and efficiently processing large, structured datasets, making it particularly well-suited for crime analysis. Unlike conventional feature importance metrics that merely rank variables, SHAP provides interpretable values for each prediction, enabling a more granular understanding of how individual variables influence police-stop decisions at both local and global levels (Slack et al., 2020).
XGBoost builds a regression model by combining multiple weak estimators, improving accuracy over a single model (Chen, 2015). In comparison with five alternative models (Table 1), XGBoost demonstrated superior predictive accuracy (R2 = 0.577 vs. 0.372–0.551), justifying its adoption as the primary modeling framework.
To enhance model interpretability, SHAP is integrated into the XGBoost model, a method widely applied in crime-related research (Kim and Lee, 2023; Movahedi and Derrible, 2020). SHAP values quantify the marginal contribution of each variable to predictions, with higher absolute values indicating a greater influence on police-stop decisions. Additionally, their spatial attributes make them particularly useful for analyzing the spatial heterogeneity of police stops.
To explore spatial patterns, we perform bottom-up hierarchical clustering using SHAP values of multiple variables across spatial grids. This approach yields a classification of the spatial distribution of police stops driven by various factors. Specifically, Euclidean distance is employed to calculate the distance between data points. The similarity between these points is determined by computing the distance between the SHAP value of one variable and the SHAP values of all other variables within each grid; a smaller distance signifies a higher similarity. Hierarchical clustering is chosen because it does not require predefining the number of clusters, making it more adaptable for detecting data-driven spatial patterns. Additionally, its dendrogram structure enhances interpretability, which is crucial for understanding the spatial heterogeneity of police stops.
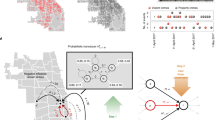
The utilization of SHAP values in cluster analysis offers significant advantages. First, the calculation of SHAP values serves as a preprocessing step, allowing raw data to be scaled to common units, thereby facilitating clustering under a consistent scale. Second, the algorithm assigns weights to variables based on their importance during the SHAP value calculation process, highlighting the most informative and crucial variables while minimizing the impact of irrelevant ones. In contrast, traditional clustering methods bias variables based on the size of their feature distribution without considering their actual information content. Therefore, the clustering results with strong differentiation and interpretation will be obtained by SHAP value calculation. The specific technical route is shown in Fig. 1.

Technological route.
Assessment of the utility of police stops for crime prevention and control methods
This study uses double machine learning based on causal forest methodology to delve into the impact of police stops on crime. When juxtaposed with traditional causal inference models, double machine learning based on causal forest offers distinct advantages in variable selection and model estimation.
Crime is intricately influenced by a multitude of factors, including the built environment, crowd dynamics, and regulatory mechanisms. Nevertheless, when dealing with high-dimensional control variables, traditional regression models often encounter challenges such as the curse of dimensionality and multicollinearity. These issues can lead to biased estimations, as the models may struggle to accurately capture the relationships among variables.
In contrast, double machine learning with a causal forest can automatically sift through the high-dimensional control variables. This not only circumvents the curse of dimensionality but also mitigates the estimation bias that may arise from relying on a limited number of primary control variables. Moreover, leveraging the capabilities of machine learning in handling nonlinear data, this approach effectively averts the problem of model misspecification. For instance, Zhang et al. (2022) successfully utilized double machine learning to quantify the influence of evening subway services on nighttime crime in London.
First, we construct a partially linear model of the following form:
where Y denotes the dependent variable, which is the number of street crimes occurring in the grid; T denotes the intervening variable, which is whether or not the grid performs a certain type of police stops, which is 1 for performing that type of police stops, and 0 otherwise; \(\theta\) the average treatment effect (ATE) of the police stop; X denotes the set of high-dimensional control variables, \(g\left(X\right)\) captures the non-linear influence of covariates; and U is the stochastic error term.
To eliminate the confounding effects of X, we take conditional expectations of both sides of Eq. (1) given Xi and subtract it from the original equation:
Using machine learning algorithms, we first estimate \({l}_{0}\left(X\right)=E\left({Y}_{i}|{X}_{i}\right)\) and \({m}_{0}\left(X\right)=E\left({T}_{i}|{X}_{i}\right)\). We then compute residuals:
To reduce bias, we apply Neyman orthogonalization, which constructs an orthogonal score function exploiting the independence between residuals of the treatment and the error term. The moment condition is defined as:
where \(W=\left(Y,T,X\right),{\rm{and\; \eta }}\equiv \left(l,m\right)\) denotes the nuisance parameters estimated in the first stage. The score function satisfies the moment condition \(E[\varphi \left({W;}\theta ,\eta \right)]=0\), allowing consistent estimation of \(\theta\).
Within the double machine learning framework, we incorporate causal forests to estimate the ATE, while using cross-fitting to prevent overfitting in nuisance parameter estimation:
Police stop correlates identification and spatial clustering results
Identification of correlation factors in police stops
In this study, the number of police stops was used as the dependent variable, while Alarm, Visiting Population, Criminal, Government Agencies, Hotel, School, Entertainment Venues, Mall, Subway Station, and Bus Station served as independent variables in the XGBoost model. Additionally, the prediction process was visualized using the SHAP additive interpreter. The strength of the association between each variable and police stops was assessed by calculating the mean of the absolute SHAP values. As shown in Fig. 2, the mean of the absolute values of the corresponding SHAP values of each variable is ranked from high to low, and this ranking shows how closely the variables are related to police stops; the top three variables are Alarm, Visiting Population, and Criminal. Thus, from a global perspective, alarm has the strongest correlation with police stops, followed by visiting population and criminal.

Sort by the mean of the absolute SHAP values of all features.
Spatial cluster analysis of police stops
Hierarchical clustering, utilizing SHAP values, can spatially categorize the various factors influencing police stops and delve deeper into the spatial attributes of each factor. The clustering results are presented in Table 2, with category labels defined according to the ranking of mean SHAP values for each contributing factor. Based on the clustering results, the study area is divided into five categories, which are (i) composite police stops positively associated with “Alarm, Visiting Population, Criminals” (AVC-CPS), (ii) composite police stops positively associated with “Alarm, Visiting Population, Bus Station” (AVB-CPS), (iii) random police stops with no significant positive association (NA-RPS), (iv) single police stops positively associated with “Alarm” (A-SPS), (v) single police stops positively associated with “Visiting Population” (V-SPS), in which (i) and (ii) can be considered together as a composite type of police stops, (iii) is a random type of police stops, and (iv) and (v) can be considered together as a single type of police stops.
Among all categories, AVC-CPS occupies the largest spatial coverage. This indicates that the majority of police stops in the study region are focused on the alarm, visiting population, and criminal factors. This suggests that current police stops are purpose-driven, primarily aimed at maintaining public safety and preventing crime. The AVB-CPS, A-SPS, and V-SPS categories each contain a similar number of grids. Based on the calculated averages of police stops and alarms across all categories, those associated with alarm-related factors exhibit higher mean values for both indicators. In contrast, the NA-RPS category corresponds to the lowest average number of police stops and alarms.
The hierarchical analysis clustering results are visualized spatially, as shown in Fig. 3. Due to the confidentiality agreement with the public security department, the map is not allowed to have a compass rose. Through comparison, it is found that AVC-CPS occupies the most continuous space and is the main place of police stops distribution, and corresponds to a larger flow of people; the spatial distribution of AVB-CPS is similar to AVC-CPS, with most of it located adjacent to AVC-CPS areas; the spatial distribution of NA-RPS is dominated by green areas, such as forests or parks; the spatial distribution of A-SPS is relatively centralized, with the highest contribution of alarm, mostly crime hotspots, but other characteristics are not prominent; the distribution of V-SPS is more dispersed, corresponding to the highest contribution of the visiting population.

Spatial distribution of hierarchical clustering results of police stops.
From each of the five categories, grids were randomly chosen for an in-depth analysis of the local factors associated with police stops. The results are shown in Fig. 4, where the length of the bar indicates the contribution of each factor to police stops, with the right side indicating a positive influence and the left side indicating a negative influence. It is found that in the corresponding grid of AVC-CPS, alarm, visiting population, and criminals are the major factors positively associated with police stops. Additionally, there are other factors with lesser positive associations, such as school, mall, and hotel. The main negative correlate is entertainment venues, largely attributed to the fact that most of these venues have internal security measures in place, which contributes to relatively fewer police stops being conducted in and around these locations. In the grid corresponding to AVB-CPS, the primary factors positively correlated with police stops are alarms, visiting population, and bus stations. Notably, compared with the AVC-CPS, bus stations exhibit a higher flow of people and significant population heterogeneity, which presents opportunities for criminal activity. Criminals can easily conceal themselves within the dense crowd, prompting police to pay closer attention to these areas. The grid corresponding to NA-RPS is mostly distributed in the vicinity of green areas, characterized by a relatively low number of police stops and a small visiting population. Additionally, the sparsity of environmental facilities contributes to the absence of positive associations with police stops in this area. The grid corresponding to A-SPS has alarm as the main positive association with police stops, spatially corresponding to crime hotspots. Despite the fact that these places also have a large visiting population, the visiting population factor is significantly negatively associated with police stops. In this type of grid, which primarily encompasses residential zones and urban villages, police rarely conduct daily police stops due to the nature of the area. Instead, such police stops are predominantly performed in response to the actual occurrence of alarms. The grid corresponding to V-SPS has the strongest positive association between visiting population and police stops, followed by important facilities such as government agencies, hotels, and malls, all of which also correspond to a higher number of visitors. But the relationship between alarms and police stops is negative, and the mechanisms involved need to be explored further.

Local correlates of different categories of police stops.
Heterogeneous causal effects of police stops on crime across correlational factors
Descriptive statistics
To conduct a refined analysis of the causal effect of police stops, influenced by various factors, on crime, the variables were grouped and counted on a 7-day interval, encompassing a total of 52 such cycles in 2018. Consequently, the overall sample size amounted to the product of the number of grids and the time periods, totaling 24,544 entries. Using the clustering results from each grid, the study delves into the causal effect of changes in police stops on crime across different cycles. The descriptive statistics of each variable are shown in Table 3. The dependent variable Y signifies the standardized crime count per week; the control variable X encompasses the number of offenders, the size of the visiting population and the count of diverse facilities, including government agencies, hotels, schools, entertainment venues, malls, bus stations, and subway stations; and the treatment variable T, which takes a value of 0 or 1, indicates whether a region did not or did implement a particular type of police stop in the current cycle, respectively.
Results of double machine learning model based on causal forests
Table 4 illustrates the differential impacts of five distinct types of police stops on crime, with separately estimated models using double machine learning based on causal forests across the HT zone. The ATE is used to quantify the impact of the treatment variable on the dependent variable. A negative ATE indicates that police stops are associated with a reduction in crime, while a positive ATE suggests an increase in crime following police stops. The magnitude of the ATE reflects the strength of this causal relationship, with larger absolute values representing stronger effects.
For AVC-CPS implementation, this strategy yields a statistically significant ATE of −0.595, meaning that implementing AVC-CPS reduces crime by an average of 0.595 incidents per grid unit. AVC-CPS demonstrates the strongest inhibiting effect on crime, which is consistent with routine activity theory (Cohen and Felson, 1979). This theory posits that the spatial interactions among offenders, potential victims, and regulators are critical factors influencing crime distribution. Police stops under the AVC-CPS approach are typically conducted in areas characterized by high alarm frequencies, dense crowds, and proximity to offender residences. Consequently, these stops increase the likelihood of police interaction with potential offenders, thereby deterring criminal behavior and reducing crime.
For AVB-CPS implementation, this has a statistically significant ATE of −0.156 on crime, meaning it reduces crime by 0.156 incidents per grid unit. While this effect still reflects a reduction in crime, it is notably weaker than that of AVC-CPS. Bus stations are usually high-traffic places that provide potential offenders with opportunities to commit crimes and make offenders better hidden in the crowd (Levine et al., 1986; Yu, 2009). Police stops near bus stops can give offenders a stronger deterrent to achieve crime prevention.
For NA-RPS implementation, this has an ATE of 0.000 for crime, which is numerically close to 0 but statistically significant. This indicates that random police stops neither significantly increase nor decrease the number of crime incidents. The lack of spatial and temporal focus in these stops makes it impossible to effectively concentrate police resources in high-crime areas. As a result, random stops fail to provide sufficient deterrence and may even undermine police legitimacy, which reduces their overall effectiveness in preventing and combating crime.
For A-SPS implementation, the ATE of −0.153 indicates that, on average, approximately 0.153 fewer crimes occur per grid unit when A-SPS is applied. This finding is consistent with hotspot policing strategies, which demonstrate that focused interventions in high-crime areas can effectively suppress crime (Nagin et al., 2015; Taylor et al., 2011). However, the relatively modest impact of A-SPS—an approach based solely on alarm data—suggests that its effectiveness is limited by its narrow focus. While an alarm-driven strategy is useful for signaling immediate risks, it may not capture other critical dimensions of criminal activity, such as offender behavior, population dynamics, or environmental context.
For V-SPS implementation, this has a statistically significant ATE of −0.000 on crime. This finding indicates that visitor volume alone does not fully capture the complexity of crime risk. The relationship between population movement and crime is shaped not only by the number of visitors but also by factors such as population composition, socioeconomic conditions, and the built environment. High pedestrian traffic does not necessarily correspond to higher crime risk, especially if an area attracts transient but low-risk visitors. As a result, a strategy that focuses exclusively on visiting populations overlooks these critical dimensions, limiting its effectiveness in crime prevention.
In addition, the double machine learning model based on causal forests is constructed using decision trees, where features are randomly selected for node splitting and training samples are drawn via bootstrap for each tree. As a result, model outcomes can vary between runs. To ensure reproducibility, a fixed random seed is typically used. This study performed 1000 round robin trials for each of the five police stop models to assess the stability of their causal effects on crime. The final results are reported in Table 5.
For whether or not to implement AVC-CPS, the estimated effect remained negative across all 1000 simulations, with a mean value of −0.687. This suggests that this type of police stop has a highly stable and strong inhibitory effect on crime. For whether or not to implement AVB-CPS, the effect was negative in 87.6% of the simulations, with a mean value of −0.154. Although slightly weaker than that of AVC-CPS, this strategy still demonstrates a generally consistent crime-reducing effect. For whether or not to implement NA-RPS, the proportion of negative results is 0%, with a mean value of 0.000, which again verifies that this type of police stop may have a relatively limited impact on crime, and fails to show a significant inhibitory effect. For whether or not to implement A-SPS, the results show a certain negative correlation between it and crime, with a negative percentage of 82.4% and a mean value of −0.142, which indicates that in most cases, this kind of police stops based on alarm data has a more stable inhibitory effect on crime. Finally, for whether or not to implement V-SPS, although its results show a negative correlation of 100% with a mean of −0.000, the actual inhibitory effect on crime is minimal.
Discussion and conclusions
This study examines police stops by integrating multiple data sources, including police stop records, POI data, population data, alarm data, and crime data. Using XGBoost and SHAP, we analyze the key factors influencing police stops, while hierarchical clustering identifies five distinct types of police stop strategies. We further assess the differential impacts of these strategies on crime reduction. The main conclusions are as follows.
Firstly, the implementation of police stops is dominated by multiple factors. The four variables that are most strongly correlated with police stops in the region are alarm, visiting population, criminals, and government agencies. These variables also show a significant positive link with police stops.
Secondly, there is spatial heterogeneity in the correlates of police stops, which can be categorized into (i) composite police stops positively associated with “Alarm, Visiting Population, Criminals” (AVC-CPS), (ii) composite police stops positively associated with “Alarm, Visiting Population, Bus Station” (AVB-CPS), (iii) random police stops with no significant positive association (NA-RPS), (iv) single police stops positively associated with “Alarm” (A-SPS), (v) single police stops positively associated with “Visiting Population” (V-SPS). Among these, AVC-CPS has the largest proportion of grids, and the corresponding average number of police stops and average number of alarms in the region is also the largest. This suggests that current police stop practices are primarily crime-oriented, with supplementary preventive strategies.
Thirdly, there are differences in the impact of daily police stops on crime associated with different factors. In particular, composite-factor-oriented police stops had a significant positive impact on crime reduction. In contrast, single-factor-oriented police stops had a weaker positive impact on crime reduction, while random police stops with no significant positive association had almost no impact on crime reduction.
Our findings align with and extend existing knowledge. Consistent with Bradford (2017) and Piza and Gilchrist (2018), we confirm that police stops are shaped by multiple contextual factors, with alarms playing a central role in guiding patrol placements (Avdija, 2014; Ratcliffe, 2016). Furthermore, while (Weisburd et al., 2014; Weisburd et al., 2016) established the spatial clustering of stops and their causal link to crime reduction, our analysis reveals how strategic variations—such as composite versus single-factor approaches—lead to divergent outcomes. Methodologically, prior studies on police stop efficacy primarily rely on two approaches: hotspot policing experiments requiring quasi-experimental designs (Braga, 2006) and observational analyses using traditional methods like difference-in-differences (DID) (MacDonald et al., 2016) or instrumental variables (IV) with administrative data (Weisburd et al., 2016). However, DID assumes untestable parallel trends, while IV often lacks credible instruments. To address these limitations, by leveraging machine learning’s capacity to handle high-dimensional covariates and nonlinear relationships, we quantify heterogeneous treatment effects of police strategies while avoiding restrictive parametric assumptions. Furthermore, SHAP values reveal how interactive factors (e.g., alarms and population mobility) spatially shape stop distributions—mechanisms opaque to traditional regression-based analyses.
Multi-purpose composite police stops demonstrate greater effectiveness in crime reduction. For instance, AVC-CPS substantially lowers crime rates by integrating alarm data, population mobility patterns, and offender activity zones. Through multidimensional data fusion, this approach enables the identification of high-risk areas and potential offenders, leading to significant improvements in crime prevention. In addition, AVB-CPS also shows moderate crime deterrent effects. Strengthening the efforts of police stops in this area is of positive significance in the timely detection and prevention of potential criminal acts, given that bus stops, as transportation hubs with high pedestrian flow and prone to criminal activities, have unique geographic locations and pedestrian flow characteristics that provide convenient conditions for offenders to commit and escape crimes. Therefore, in order to protect public safety, police should enhance the intensity of police stops and pay particular attention to bus stops and the areas surrounding them, especially during peak hours and times when there is a lot of foot traffic. In contrast, NA-RPS, which lack clear associations with contextual factors, demonstrate no significant impact on crime reduction. Their implementation suggests some blindness and arbitrariness in the current police stop tactics in some locations. Multi-factor composite police stops are more effective because they integrate alarm data with the movement patterns of the visiting population. This combination helps to identify high-risk areas where criminal activity is more likely to occur. Alarm reports provide immediate indicators of potential threats, while the presence of a significant visiting population highlights areas where offenders can exploit crowded environments. By considering both aspects, police can more efficiently target areas where the likelihood of encountering offenders or preventing crimes is highest.
While single-factor police stops still exhibit some advantages in crime reduction compared to random stops, their effectiveness is significantly weaker than multi-factor composite strategies. This aligns with Situational Crime Prevention Theory, which emphasizes the need to address multiple opportunity structures simultaneously (Clarke and Cornish, 2003). For example, A-SPS primarily targets locations with high crime reporting but does not consider other environmental or situational factors. While alarms serve as important indicators of recent criminal activity, a solely alarm-driven strategy may result in reactive policing—responding to crime after it occurs rather than preventing it proactively. Similarly, V-SPS relies on high foot traffic as an indicator of potential crime risk. However, high pedestrian volume does not inherently correlate with criminal activity, and stops based on this factor alone may lead to inefficient allocation of police resources. Despite these limitations, single-factor police stops still outperform random stops (NA-RPS) in crime reduction. In particular, A-SPS aligns with hotspot policing strategies, reinforcing the importance of targeted interventions in high-crime areas (Braga, 2001; Braga et al., 2018; Durlauf and Nagin, 2011). A-SPS provides some deterrent effect by ensuring a law enforcement presence in areas where crime is likely to recur. While V-SPS does not always align with crime hotspots, it can still be useful in specific high-risk environments with significant transient populations, such as nightlife districts or transportation hubs. However, to maximize crime prevention outcomes, police stops should be guided by a multi-factor risk assessment, as single-factor strategies, while more effective than random stops, lack the situational adaptability of composite strategies.
In light of the practical implications of our findings, we emphasize the importance of a comprehensive approach when formulating police stop strategies. Specifically, police resources should be strategically allocated to areas with frequent alarms, high population mobility, and known criminal activity, as these locations are more likely to be crime hotspots. Our empirical analysis suggests that AVC-CPS and AVB-CPS zones exhibit the strongest effects in crime reduction and should therefore be prioritized in resource allocation. To further enhance the efficacy of police stops, we recommend that law enforcement agencies reduce reliance on random or single-factor-driven police stops, as these are less efficient and can lead to misallocation of resources. Instead, a dynamic, risk-based model should be implemented, where police presence is adjusted in real time according to crime patterns and alarm frequency. This approach ensures that high-risk areas receive more targeted, proactive policing, while minimizing interventions in lower-risk zones. By considering these factors and adopting a data-driven approach, police agencies can optimize their strategies, reduce inefficiencies, and enhance their ability to prevent and combat crime effectively.
In summary, this study advances policing research through three key contributions. First, it categorizes police stops into five distinct types and evaluates their heterogeneous effects on crime, offering new insights into their spatial applicability. Second, by integrating XGBoost with SHAP, it enhances the interpretability of police stop decision-making, providing a more nuanced understanding compared to traditional regression-based approaches. Third, it applies double machine learning (DML) to estimate the causal effects of different police stop strategies on crime, effectively addressing endogeneity concerns and strengthening causal inference in policing research.
However, this study has several limitations that warrant further attention in future research. First, due to the dynamic nature of certain factors, such as population flow, alarm frequency, and key locations, future studies should incorporate time-series models to capture temporal variations. For instance, differentiating the effectiveness of police stops between weekdays and weekends could provide more actionable insights and improve the precision of police resource allocation. Second, while weather conditions are known to affect crime patterns (Ashby and Tompson, 2018), this study does not integrate meteorological data. Future research could address this by incorporating weather variables, such as temperature or precipitation, to explore how these factors influence the frequency and effectiveness of police stops. Third, using clustering results as treatment variables has inherent limitations. While using silhouette score validation confirms reasonable internal cohesion, clustering does not provide absolute group assignments. Subsequent research could explore alternative approaches, such as fuzzy clustering, to better account for uncertainties in classification.
Data availability
Due to police department and telecommunications company requirements, the data that have been used are confidential.
References
Ashby, M, & Tompson L (2018). Does a good cop really never get wet? The impact of weather on stop and frisk
Ashby MP, Tompson L (2017) Routine activities and proactive police activity: a macro-scale analysis of police searches in London and New York City. Justice Q 34(1):109–135
Avdija AS (2014) Police stop-and-frisk practices: an examination of factors that affect officers’ decisions to initiate a stop-and-frisk police procedure. Int J Police Sci Manag 16(1):26–35
Borooah VK (2011) Racial disparity in police stop and searches in England and Wales. J Quant Criminol 27:453–473
Bowling B, Phillips C (2007) Disproportionate and discriminatory: reviewing the evidence on police stop and search. Mod law Rev 70(6):936–961
Braakmann N (2022) Does stop and search reduce crime? Evidence from street-level data and a surge in operations following a high-profile crime. J R Stat Soc Ser A Stat Soc 185(3):1370–1397
Bradford B (2017) Stop and search and police legitimacy. Taylor & Francis
Braga AA (2001) The effects of hot spots policing on crime. ANNALS Am Acad Political Soc Sci 578(1):104–125
Braga AA (2006) The crime prevention value of hot spots policing. Psicothema 18:630–637
Braga AA, Weisburd D, Turchan B (2018) Focused deterrence strategies and crime control: an updated systematic review and meta‐analysis of the empirical evidence. Criminol Public Policy 17(1):205–250
Chen T (2015) Xgboost: extreme gradient boosting. R package version 0.4-2, 1(4)
Chernozhukov V, Chetverikov D, Demirer M, Duflo E, Hansen C, Newey W, Robins J (2018) Double/debiased machine learning for treatment and structural parameters. Oxford University Press Oxford, UK
Clarke RV, Cornish D (2003) Opportunities, precipitators and criminal decisions: a reply to Wortley’s critique of situational crime prevention. Crime Prev Stud 16:41–96
Cohen LE, Felson M (1979) Social change and crime rate trends: a routine activity approach (1979). In Classics in environmental criminology CBC Press, p 203–232
Durlauf SN, Nagin DS (2011) Imprisonment and crime: can both be reduced? Criminol Public Policy 10(1):13–54
Famega CN (2005) Variation in officer downtime: a review of the research. Polic Int J Police Strateg Manag 28(3):388–414
Gelman A, Fagan J, Kiss A (2007) An analysis of the New York City police department’s “stop-and-frisk” policy in the context of claims of racial bias. J Am Stat Assoc 102(479):813–823
Jiang L, Li X (2006) A brief discussion on the police power of interrogation and examination and the assurance of human rights. Hebei Law Science (04), 117-120. https://doi.org/10.16494/j.cnki.1002-3933.2006.04.025
Jones-Brown DD, Gill J, Trone J (2010) Stop, question & frisk policing practices in New York City: a primer. Center on Race, Crime and Justice, John Jay College of Criminal Justice
Jung Y, Tian J, Bareinboim E (2021) Estimating identifiable causal effects through double machine learning. In Proceedings of the AAAI Conference on Artificial Intelligence, 2–9 February 2021
Kim S, Lee S (2023) Nonlinear relationships and interaction effects of an urban environment on crime incidence: application of urban big data and an interpretable machine learning method. Sustain Cities Soc 91:104419
Levine N, Wachs M, Shirazi E (1986) Crime at bus stops: a study of environmental factors. J Archit Plan Res 3(4):339–361
MacDonald J, Fagan J, Geller A (2016) The effects of local police surges on crime and arrests in New York City. PLoS ONE 11(6):e0157223
McGarrell EF, Chermak S, Weiss A, Wilson J (2001) Reducing firearms violence through directed police patrol. Criminol Public Policy 1(1):119–148
Movahedi A, Derrible S (2020) Interrelated patterns of electricity, gas, and water consumption in large-scale buildings
Nagin DS, Solow RM, Lum C (2015) Deterrence, criminal opportunities, and police. Criminology 53(1):74–100
Petersen K, Weisburd D, Fay S, Eggins E, Mazerolle L (2023) Police stops to reduce crime: a systematic review and meta‐analysis. Campbell Syst Rev 19(1):e1302
Piza EL, Gilchrist AM (2018) Measuring the effect heterogeneity of police enforcement actions across spatial contexts. J Crim Justice 54:76–87
Ratcliffe JH (2016) Intelligence-led policing. Routledge
Riksheim EC, Chermak SM (1993) Causes of police behavior revisited. J Crim justice 21(4):353–382
Rosenfeld R, Fornango R (2014) The impact of police stops on precinct robbery and burglary rates in New York City, 2003-2010. Justice Q 31(1):96–122
Shapiro BR, Pearman FA (2017) Using the interaction geography slicer to visualize New York City Stop & Frisk. 2017 IEEE VIS Arts Program (VISAP)
Sherman LW (1980) Causes of police behavior: the current state of quantitative research. J Res Crime Delinq 17(1):69–100
Sherman LW, Weisburd D (1995) General deterrent effects of police patrol in crime “hot spots”: a randomized, controlled trial. Justice Q 12(4):625–648
Slack D, Hilgard S, Jia E, Singh S, Lakkaraju H (2020) Fooling lime and shap: adversarial attacks on post hoc explanation methods. In: Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society
Song G, Xiao L, Zhou S, Long D, Zhou S, Liu K (2017) Impact of residents’ routine activities on the spatial-temporal pattern theft from person. Acta Geogr Sin 72(02):356–367
Suss JH, Oliveira TR (2023) Economic inequality and the spatial distribution of stop and search: evidence from London. Br J Criminol 63(4):828–847
Taylor B, Koper CS, Woods DJ (2011) A randomized controlled trial of different policing strategies at hot spots of violent crime. J Exp Criminol 7:149–181
Wan Y, Chen D (2009) A research on some legal issues of the police interrogation and check. J Nanjing Norm Univ 5:33–44
Weisburd D, Telep CW, Lawton BA (2014) Could innovations in policing have contributed to the New York City crime drop even in a period of declining police strength? The case of stop, question and frisk as a hot spots policing strategy. Justice Q 31(1):129–153
Weisburd D, Wooditch A, Weisburd S, Yang SM (2016) Do stop, question, and frisk practices deter crime? Evidence at microunits of space and time. Criminol Public Policy 15(1):31–56
Wooditch A, Weisburd D (2016) Using space–time analysis to evaluate criminal justice programs: an application to stop-question-frisk practices. J Quant Criminol 32:191–213
Yu S-SV (2009) Bus stops and crime: Do bus stops increase crime opportunities in local neighborhoods? Rutgers The State University of New Jersey, Graduate School-Newark
Zhang Y, Li H, Ren G (2022) Quantifying the social impacts of the London Night Tube with a double/debiased machine learning based difference-in-differences approach. Transp Res Part A Policy Pract 163:288–303
Acknowledgements
This research was funded by National Natural Science Foundation of China (Grant No. 42471270, 42171218) and Natural Science Foundation of Guangdong Province (Grant No. 2023A1515011462).
Author information
Authors and Affiliations
Contributions
Zhuoying Fan drafted the original manuscript, conducted formal analysis, and curated the research data. Xuewei Zhang reviewed and edited the manuscript and contributed to software development. Guangwen Song drafted the original manuscript and conceptualized the study. Chunxia Zhang reviewed and edited the manuscript. All authors contributed to and reviewed the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
This article does not contain any studies with human participants performed by the authors.
Informed consent
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Fan, Z., Zhang, X., Song, G. et al. Factors influencing the spatial distribution of police stops and their efficacy in crime prevention and control. Humanit Soc Sci Commun 12, 1026 (2025). https://doi.org/10.1057/s41599-025-05355-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1057/s41599-025-05355-0
