
Abstract
Cognitive impairment is a frequent complication of Parkinson’s disease (PD), affecting up to half of newly diagnosed patients. To improve early detection and risk assessment, we developed machine learning models using clinical data from three independent PD cohorts, which are (LuxPARK, PPMI, ICEBERG). Models were trained to predict mild cognitive impairment (PD-MCI) and subjective cognitive decline (SCD) using Explainable Artificial Intelligence (XAI) for classification and time-to-event analysis. Multi-cohort models showed greater performance stability over single-cohort models, while retaining competitive average performance. Age at diagnosis and visuospatial ability were identified as key predictors. Significant sex differences observed highlight the importance of considering sex-specific factors in cognitive assessment. Men were more likely to report SCD. Our findings highlight the potential of multi-cohort machine learning for early identification and personalized management of cognitive decline in PD.
Similar content being viewed by others

Introduction
Parkinson’s disease (PD) includes motor and non-motor symptoms, the latter comprising a wide range of neuropsychiatric, autonomic, and sensory disturbances. Cognitive impairment (CI) affects 20–50% of newly diagnosed patients and significantly impacts quality of life1,2,3. It can manifest early in the disease course, with deficits in several domains, including memory, attention, executive function, visuospatial skills, and language4,5. CI in PD spans from mild cognitive impairment (PD-MCI) to PD dementia, with PD-MCI representing a key stage for potential early therapeutic intervention strategies.
Early identification of high-risk patients for development of CI is essential for preventive strategies, including pharmacological (e.g., cholinesterase inhibitors6, medication adjustments7) and non-pharmacological options (e.g., cognitive training8). While the impact of current interventions remains limited9,10, accurate risk prediction can facilitate the development of more targeted treatments and long-term care3,11.
CI in PD is influenced by multiple factors, including age at onset3,12, motor severity1,13, and non-motor symptoms (e.g., depression, apathy, autonomic dysfunction)14. The Montreal Cognitive Assessment (MoCA) is a widely used screening tool for assessing cognitive function3, with scores between 21 and 25 indicating PD-MCI according to Level I Movement Disorder Society (MDS) Task Force criteria15, and scores ≤20 suggesting more severe impairment. However, despite its widespread use, MoCA presents several important limitations as a cognitive assessment tool. It provides only a single-time-point measurement that cannot adequately capture the fluctuating nature of cognitive deficits in PD, and lacks sensitivity for detecting subtle or early-stage impairments16,17 (particularly in highly educated individuals). Additionally, subjective cognitive decline (SCD) provides insights into impairments that may even precede objectively measurable deficits18. Although the MoCA is a widely utilized tool for evaluating CI in PD, its correlation with SCD remains unclear18. Prior studies indicate objective cognitive assessments may not fully align with patient-perceived cognitive difficulties19, and SCD may be influenced by mood disturbances20, sleep disorders21, and fatigue22. Nevertheless, the concurrent assessment of objective and subjective CI has the potential to provide complementary insights into the patient experience and underlying pathology.
Previous studies on CI in PD focused on single cohorts with small sample sizes and several cohort-specific characteristics3,23,24,25. This cohort-specificity limits the generalizability of their findings and hinders the development of broadly applicable clinical tools. While machine learning (ML) can uncover complex relationships in clinical data, for CI assessment in PD it has only been used in single-cohort studies, limiting model generalizability and applicability across diverse patient groups26. To address this, this study integrates clinical data from three independent cohorts (the Luxembourgish Parkinson’s Study (LUXPARK)27, the Parkinson’s Progression Markers Initiative (PPMI)28, and the French cohort ICEBERG29) to identify more robust and generalizable predictors of CI in PD. We predict PD-MCI and SCD within four years and until the end of the follow-up period, and assess the robustness of models in heterogeneous populations that differ in demographics, disease severity, and follow-up duration by validating them across multiple independent cohorts. Using a cross-cohort modeling approach, we identified the most consistent and reliable predictors that are broadly applicable across different PD populations and might help to inform personalized intervention studies for PD patients at risk of CI in diverse clinical settings.
Results
Individual cohort analyses
The performance of ML models for predicting PD-MCI and SCD was first evaluated in each cohort separately (LuxPARK, PPMI, and ICEBERG). Here, we focus on presenting the results for the hold-out test set (for detailed cross-validation (CV) results, see Supplementary Tables 1–4).
For PD-MCI classification, the model trained and validated on the LuxPARK cohort reached the highest hold-out AUC (0.70), with a cross-validated AUC (CV-AUC) of 0.70 (Supplementary Table 1). In PPMI, the models showed comparable performance (hold-out AUC of 0.69, CV-AUC of 0.70). Performance was lower in ICEBERG due to its smaller sample size (Supplementary Fig. 1).
For time-to-PD-MCI analysis, the model derived from the LuxPARK cohort achieved a moderate hold-out C-index of 0.63 (Supplementary Table 2). The PPMI-specific models performed better (hold-out C-index of 0.72). The models’ performance using ICEBERG was again lower, likely due to sample size constraints (Supplementary Fig. 2).
Regarding SCD classification, the model using LuxPARK achieved a moderate hold-out AUC of 0.63. The PPMI model performed better (hold-out AUC of 0.70), and the ICEBERG model showed lower performance in line with smaller sample sizes (Supplementary Table 3 and Supplementary Fig. 3).
Furthermore, in the time-to-SCD analysis, the model trained on the PPMI cohort achieved the highest performance with a hold-out C-index of 0.76. The model obtained from LuxPARK had a lower hold-out C-index of 0.71, while performance was lowest for the model using ICEBERG (hold-out C-index of 0.60, Supplementary Table 4 and Supplementary Fig. 4).
Both PD-MCI and SCD analyses identified age at PD diagnosis and baseline MoCA30 as most informative among the top-15 predictors (Table 1). Key PD-MCI predictors included Benton Judgment of Line Orientation (JLO)31 and baseline CI (Movement Disorder Society-Unified Parkinson’s Disease Rating Scale (MDS-UPDRS) Part I18). For SCD, predictors included MDS-UPDRS Part I and II total scores, Scales for Outcomes in Parkinson’s Disease - Autonomic Dysfunction (SCOPA-AUT) symptoms (particularly gastrointestinal and urinary)32, and disease duration.
Multi-cohort analyses
Multi-cohort analyses were conducted to improve model robustness and overcome single-cohort limitations, assessing hold-out test set performance (for more detailed statistics, including cross-validation results, see Supplementary Figs. 1–4 and Supplementary Tables 5–8).
In PD-MCI classification, cross-cohort modeling achieved a largest hold-out AUC of 0.67, comparable to the best single-cohort results (Supplementary Table 5). In Leave-ICEBERG-out analyses, the models showed indications of overfitting, with low test set performance (best hold-out performance using GBoost: AUC 0.60). Leave-PPMI-out and Leave-LuxPARK-out analyses performed similarly to cross-cohort analysis (hold-out AUCs of 0.63 and 0.65, respectively).
Cross-cohort modeling for time-to-PD-MCI analysis yielded moderate performance, with a largest hold-out C-index of 0.65, similar to the LuxPARK and PPMI single-cohort analyses (Supplementary Table 6). The Leave-ICEBERG-out setting generally resulted in lower performance, except for the CW-GBoost model (hold-out C-index 0.63, CV-C 0.65). Leave-PPMI-out and Leave-LuxPARK-out analyses performed similarly to cross-cohort analysis, showing no trade-off in predictive power for increased robustness.
The cross-cohort analysis in SCD classification achieved a hold-out AUC of 0.72, slightly outperforming single-cohort analyses (Supplementary Table 7). Leave-ICEBERG-out showed lower performance (GOSDT-GUESSES hold-out AUC: 0.61, CV-AUC: 0.65), and Leave-LuxPARK-out analysis performed slightly lower (hold-out AUC 0.63, CV-AUC 0.68). Leave-PPMI-out achieved a similar hold-out AUC to the cross-cohort analysis (0.71).
For time-to-SCD analysis, the cross-cohort analysis yielded a hold-out C-index of 0.72, similar to the PPMI’s single-cohort results (Supplementary Table 8). Leave-ICEBERG-out achieved a lower hold-out C-index (0.64). Leave-PPMI-out and Leave-LuxPARK-out analyses showed comparable results.
Apart from achieving significant predictive accuracy, model stability is a further important aspect for developing reliable predictive tools that can be further developed towards clinical applications. Multi-cohort models provided more stable performance statistics than single-cohort models across CV cycles (see Supplementary Figs. 5–8). Incorporating diverse populations improved model robustness, reducing cohort-specific biases, and increasing clinical prediction reliability. The lower stability in ICEBERG, explained by its smaller sample size, highlights the importance of statistical power.
In summary, multi-cohort models achieved comparable performance to single-cohort models, with improved model stability and robustness, despite the more challenging nature of prediction tasks across multiple cohorts. This confirms that integrating data across cohorts improves model applicability and reliability while maintaining performance levels.
Comparative evaluation of cross-study normalization approaches
We assessed cross-study normalization methods by comparing the performance metrics on the hold-out test set data for the normalized and unnormalized models with the highest cross-validated AUC/C-index (CV-AUC/CV-C) in multi-cohort analyses. Normalization improved predictive performance for PD-MCI and SCD classification and time-to-SCD (Supplementary Tables 9, 10).
A notable gain in the Leave-PPMI-out analysis likely reflects distinctive value distributions in PPMI (Supplementary Table 11). However, benefits varied across studies, indicating that normalization can enhance model performance but should be tailored to cohort-specific biases.
Associations of clinical characteristics with cognitive impairment
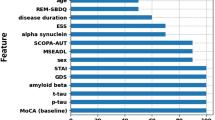
Cross-cohort analyses for PD-MCI classification and time-to-PD-MCI prediction revealed consistent key predictors of CI in PD through SHapley Additive exPlanations (SHAP) value plots (Fig. 1 and Supplementary Fig. 9).

Each row shows a predictor’s impact on mild cognitive impairment (PD-MCI) classification, with SHAP values indicating the direction and magnitude of effect. Points represent individual patients, with colors indicating the predictor’s value (red = high, blue = low). Positive SHAP values (right side) indicate increased likelihood of PD-MCI, while negative values (left side) suggest decreased likelihood. The Benton Judgment of Line Orientation score shows the strongest effect, with lower scores (blue) associated with increased PD-MCI risk. Age at PD diagnosis demonstrates the second strongest impact, with later onset (red) correlating with higher PD-MCI probability. Additional predictors include MDS-UPDRS subscores (Parts II, IV, and I) and weight, each showing varying degrees of influence on cognitive impairment classification.
Visuospatial ability (Benton JLO4) emerged as a top predictor for PD-MCI and time-to-PD-MCI, with better performance associated with a lower PD-MCI risk and delayed onset. Age at PD diagnosis and advanced motor impairment (MDS-UPDRS Part II and IV33) were also associated with increased PD-MCI risk.
For SCD, age at PD diagnosis and Benton JLO ranked highly (Fig. 2 and Supplementary Fig. 10), with age at PD diagnosis showing negative correlations with MoCA and Benton JLO (Supplementary Table 12).

Each row shows a predictor’s impact on subjective cognitive decline (SCD) classification, with SHAP values indicating the direction and magnitude of effect. Points represent individual patients, with colors indicating the predictor’s value (red = high, blue = low). Positive SHAP values (right side) indicate increased likelihood of SCD, while negative values (left side) suggest decreased likelihood. The MDS-UPDRS Part I score shows the strongest effect, with higher scores (red) associated with increased SCD risk. Age at PD diagnosis demonstrates the second strongest impact, with later onset (red) correlating with higher SCD probability.
In time-to-PD-MCI analysis, patients diagnosed at age 53 or older had a nearly 2.4-fold higher risk of CI compared to those at a younger age (Fig. 3). In the time-to-SCD analysis, patients diagnosed at age 62 or older had a 1.5-fold higher risk (Fig. 4). Factors such as MDS-UPDRS Part I, disease duration, tremors, and male sex were associated with increased SCD risk (Fig. 2). Meanwhile, lower Modified Schwab & England Activities of Daily Living (ADL) scores correlated with perceived CI.

Forest plot showing the relationship between two key predictors (Benton Judgment of Line Orientation score and age at PD diagnosis) and the development of mild cognitive impairment (PD-MCI). The left panel displays median conversion times with 95% confidence intervals (CIs), stratified by predictor thresholds (≥16 vs <16 for Benton score; ≥53 vs <53 years for age at PD diagnosis). Solid blue lines indicate statistically significant differences between groups (p-value < 0.05), while grey lines indicate non-significant differences. The right panel shows corresponding hazard ratios (HR) with 95% CIs, where HR greater than 1 indicate increased risk of PD-MCI for the higher category compared to the reference group (lower category). For age at PD diagnosis, patients diagnosed at ≥53 years show significantly higher risk of developing PD-MCI compared to those diagnosed earlier.

The plot illustrates how multiple clinical predictors affect subjective cognitive decline (SCD). The left panel shows median time to SCD onset with 95% confidence intervals (CIs), comparing subgroups for each predictor. Solid blue lines indicate statistically significant differences between groups (p-value < 0.05), while grey lines indicate non-significant differences. Key predictors include MDS-UPDRS Part I score (≥12 vs <12), postural abnormalities, tremor characteristics, and age at PD diagnosis (≥62 vs <62 years). The right panel displays corresponding hazard ratios (HR) with 95% CIs, where values > 1 indicate increased risk. Notable findings include a significantly higher SCD risk for patients diagnosed after age 62 and those with higher MDS-UPDRS Part I scores. Some features such as sleep problems and REM sleep behavior disorder show wider confidence intervals, suggesting more uncertainty in their predictive value.
Non-motor symptoms (MDS-UPDRS Part I, SCOPA-AUT) including sleep disturbances were associated with increased SCD risk, highlighting CI’s multifactorial nature. BMI was positively associated with PD-MCI (not SCD), and thermoregulatory and sexual dysfunction correlating with SCD alone (Supplementary Table 13).
Overall, cognitive decline in PD is associated with multiple clinical features, with distinct patterns for objective CI and subjective patient reports, highlighting the need for comprehensive, multifactorial approaches for prediction and clinical management.
Decision curve and calibration analysis
Decision curve analysis (DCA) and calibration analysis were performed to assess model reliability and clinical utility for PD-MCI and SCD outcomes. For PD-MCI classification, the AdaBoost-optimized model showed a high area under the net benefit curve (AUNBC) (0.23) and a calibration slope of 1.13 (Supplementary Fig. 11 and Supplementary Table 14), indicating high model reliability. In time-to-PD-MCI analysis, the penalized Cox-optimized model also achieved a high AUNBC (0.22; Supplementary Fig. 12), with a calibration slope of 1.30, showing slight overestimation for higher risks but overall reasonable agreement.
For SCD classification, the FIGS model provided the best calibration slope (0.74), though other models achieved higher AUNBC (0.08; Supplementary Fig. 13). Time-to-SCD analysis faced calibration challenges despite reasonable AUNBC (0.10; Supplementary Fig. 14) but lower calibration slopes, suggesting good risk distinction but less accuracy in estimating SCD risk.
These results highlight that model performance, net benefit and calibration need to be considered separately. While PD-MCI models show promise for clinical decision-making, SCD models, particularly for time-to-event prediction, need refinement for better calibration and clinical reliability.
Discussion
When assessing cognition in PD patients, both objective and subjective measures should be considered. Our study revealed a limited correlation between PD-MCI and SCD (0.41 for classification and 0.49 for time-to-event analysis in uncensored data), indicating that, while these outcomes share common predictors, they also capture distinct aspects of CI. Notably, the median time-to-PD-MCI and time-to-SCD (uncensored data) from the cross-cohort analysis were 1.84 and 3.01 years, respectively, highlighting differences in CI timing between objective and subjective measures.
This study used a multi-cohort approach to identify consistent predictors of PD-MCI and SCD in PD, ensuring broader model applicability by integrating diverse cohort data. Key strengths of this approach are that it mitigates cohort-specific biases26 of single-cohort studies and evaluates model performance more robustly and reliably across heterogeneous populations, thereby supporting the identification of predictors that are consistent and transferable across settings. While further model improvements will be needed for future clinical translation, this increases the utility of the findings for real-world applications across distinct patient populations, where patient characteristics, assessment protocols, and healthcare settings often vary.
Differences in predictive performance across cohorts highlight variations in clinical characteristics and data distributions. The LuxPARK cohort had an older average age at PD diagnosis and longer disease duration, ICEBERG participants had significantly lower average body weight and BMI, and the PPMI cohort exhibited milder disease severity with lower MDS-UPDRS and SCOPA-AUT scores. These baseline differences highlight the need to consider cohort-specific factors when interpreting model performance and the challenges of developing universally applicable predictive tools for CI in PD.
Cross-cohort models showed greater performance robustness than single-cohort models, maintaining predictive power without sacrificing accuracy in more heterogeneous datasets. Model stability is an important aspect of ML studies that is often underreported. Many previous studies have focused solely on average predictive performance, which is insufficient for comprehensive model evaluation. High variability can limit the reproducibility and generalizability of findings. Our empirical analyses confirm that integrating data from multiple cohorts improves model stability in terms of the variance of performance estimates across the CV cycles, while maintaining competitive average performance estimates compared to less reliable single-cohort models, an important step toward developing trustworthy tools for clinical use. Training on multiple cohorts also enabled the models to capture broader patient characteristics, increasing their generalizability. Conversely, single-cohort models were more affected by cohort-specific biases and smaller sample sizes, limiting their broader applicability.
Our study also identified stable predictors of CI that persist across different clinical settings and patient populations. While age at PD diagnosis was the top-ranked predictor in both single- and multi-cohort settings, other features, such as the Benton JLO, gained importance in the cross-cohort models, replacing less consistently selected features such as the MoCA that dominated the single-cohort results. This shift highlights the added value of multi-cohort integration in identifying robust features less influenced by cohort-specific characteristics and more likely to generalize across populations. These findings support the use of cross-cohort modeling to identify consistent predictors that could ultimately inform early intervention strategies.
Additionally, the cross-cohort validation framework ensures a rigorous performance assessment, by testing models across populations with different demographic and clinical characteristics. Comparable performance across cohorts with varying disease severity, age distributions, and assessment protocols suggests that the identified predictors are robust and clinically meaningful across different healthcare settings. These findings reflect a significant advancement toward the implementation of clinically useful, explainable artificial intelligence (XAI) tools that can function across healthcare systems.
The increased robustness of cross-cohort models and their stable significant performance demonstrated in our study builds upon previous research in CI prediction. Earlier studies relied on single-cohort data, limiting generalizability due to cohort-specific biases. Some of these studies reported higher AUCs, but they were not validated in distinct cohorts (e.g., 0.71 for a two-year longitudinal study2 and 0.80 with APOE status inclusion34). In cognitive assessment tools, MoCA demonstrated stronger predictive power for PD-MCI (AUC 0.83) than Mini-Mental State Examination (MMSE) (AUC 0.67)35, while studies incorporating biological factors and deep radiomic features reported AUCs ranging from 0.61 for PD-MCI36 to 0.89 and 0.81 for objective and subjective CI, respectively37. However, these performance estimates may be optimistic, as they do not account for cross-study variability and lack external validation. Our cross-cohort approach achieved hold-out AUC/C-index values of 0.67 for PD-MCI classification, 0.65 for time-to-PD-MCI, 0.72 for both SCD classification and for time-to-SCD. While these values are lower compared to the best single-cohort study results, they reflect a more thorough cross-cohort assessment and more robust models that account for real-world heterogeneity and reduce overfitting risks. This highlights an important limitation of the existing literature, strong average within-cohort performance does not guarantee model generalizability or robustness. By integrating data from three independent cohorts with varying characteristics and follow-up structures, our models reduce the sampling bias. Despite the added complexity and challenges of multi-cohort modeling, this approach yields more stable and reproducible predictors26, representing an essential step toward translating CI research findings into clinical decision support tools.
The DCA highlighted the potential utility of cross-cohort models to guide future intervention studies, showing higher net benefit across a broad range of threshold probabilities. We note that the interpretation of the net benefit depends on the assumed impact of possible early interventions. While the magnitude of the effect of a hypothetical treatment does not change the net benefit analysis, the practical utility of the model scales with the assumed impact of potential interventions. Calibration analysis further confirmed that the cross-cohort model for PD-MCI classification and time-to-SCD exhibited a high calibration slope, supporting its reliability for risk estimation in external applications.
In our feature ranking analyses, age at PD diagnosis emerged as a key predictor of CI, with older patients at higher risk, aligning with previous findings on late-onset PD38, where patients diagnosed at age ≥53 years had a nearly 2.4-fold increased risk of developing CI. This association may reflect the increased vulnerability of age-related brain networks to neurodegenerative processes39. While both early- and late-onset PD exhibit altered functional connectivity of brain networks40, late-onset patients may experience faster cognitive decline. These findings highlight both challenges and opportunities for clinical application, emphasizing the need for timely intervention, particularly for high-risk patients.
Sex differences were observed in SCD, with men more likely to report CI. Women generally performed better on cognitive tests41,42, and had lower reported CI scores, suggesting sex-specific aspects of CI43. While the increased risk of PD-MCI in men with PD is well-documented41,42 and our cross-cohort analysis indicated sex as an informative predictor variable for SCD, a significant association was not detected in the single-cohort or PD-MCI analyses included in this study. This suggests that sex-related differences may influence self-perceived cognitive decline more prominently than objectively measured impairment.
Visuospatial deficits, as measured by the Benton JLO test, emerged as an important predictor, consistent with previous research4,24,31. These impairments may manifest as challenges in judging distances or mentally rotating objects, and are commonly evaluated using tasks such as the clock-drawing test44. Notably, women achieved higher global cognition scores, whereas men performed better on visuospatial tasks45,46, which may reflect biological and psychosocial factors. Hormonal differences may contribute to these variations, highlighting the importance of considering sex-specific factors in cognitive assessment and intervention47,48.
Non-motor symptoms, particularly autonomic dysfunction as measured by the SCOPA-AUT, were strongly associated with SCD, emphasizing the multifactorial nature of CI in PD49. In particular, gastrointestinal tract symptoms, such as constipation, have been linked to CI50,51, and autonomic dysfunction has been associated with PD progression52. Additionally, sleep disturbances may also influence CI, as poor sleep quality is known to exacerbate cognitive difficulties, including impaired memory processing53. Our analyses found that sleep problems at night, assessed via the MDS-UPDRS Part I, showed a significant hazard ratio (HR) in the time-to-SCD model. Patients with sleep disorders often experience challenges with attention, memory, and problem-solving54. These associations may reflect shared underlying mechanisms, such as neurotransmitter dysregulation55,56, that affect multiple functional domains simultaneously, rather than direct causal links. Therefore, it is important to interpret such predictors within a multivariate modeling framework to account for potential variable interactions.
ML models allowed us to explore the predictive features in greater depth than traditional statistical approaches, particularly in a multivariate context. Unlike univariate analyses, ML models can consider the interdependencies between variables, facilitating the distinction between direct and indirect causal variable relationships and non-causal associations. By applying ML techniques across multiple cohorts, we identified robust predictors that hold promise for precision medicine and general clinical practice. The identification of consistent predictors across cohorts provides clinicians with valuable tools for the early identification of high-risk patients, facilitating timely interventions and personalized management strategies. Given the reliance on commonly collected clinical variables, optimized versions of the developed models could be integrated into digital health platforms, including telemedicine systems or mobile health applications, for remote cognitive screening or ongoing monitoring. This integration into digital tools offers a scalable path toward precision medicine in PD and could also contribute to the broader translation of improved multi-modal ML models into practical clinical applications. However, important limitations remain to be addressed. Generalizability may be restricted by the populations covered in the cohorts, and the exclusion of variables unavailable across all cohorts. Differences in predictive performance may also arise from varying sample sizes and patient characteristics. Additionally, while our models showed significant predictive performance in a challenging cross-study setting, they are not yet directly applicable for clinical use, and further optimization and validation in prospective studies are needed before clinical translation. Despite these challenges, cross-cohort ML approaches provide a robust basis to further extend and optimize CI prediction models towards clinically relevant, digitally deployable tools for precision medicine applications in PD. Future research should further expand, optimize, and validate these predictors in diverse populations and explore their application to guide early intervention studies.
Methods
Inclusion criteria and sample characteristics
This study used data from three PD cohorts (Table 2): LuxPARK (number of subjects: 467 PD-MCI+, 64 PD-MCI−; 279 SCD+, 133 SCD–)27, a longitudinal monocentric observational study in Luxembourg and the surrounding Greater Region; PPMI (393 PD-MCI+, 232 PD-MCI−; 147 SCD+, 377 SCD−)28, a multicenter observational study; and ICEBERG (56 PD-MCI+, 61 PD-MCI−; 61 SCD+, 56 SCD−)29, a French early-stage PD cohort (see detailed cohort descriptions in the Supplementary Material). Participants met two criteria:
-
A PD diagnosis according to the UK Parkinson’s Disease Society Brain Bank (UKPDSBB) criteria57 for the LuxPARK and ICEBERG, or, for the PPMI, the presence of at least two of the following: resting tremor, bradykinesia, or rigidity (with resting tremor or bradykinesia required)58.
-
The clinically confirmed presence or absence of PD-MCI or SCD within four years of the baseline visit.
All participants enrolled in the Luxembourg Parkinson’s Study, the ICEBERG cohort, and the PPMI cohort provided written informed consent. The individual studies received approval from the National Research Ethics Committee (CNER Ref: 201407/13) for the Luxembourg Parkinson’s Study, IRB Paris VI (RCB: 2014-A00725-42) for the ICEBERG cohort, and from multiple institutional review boards/ethics committees at all participating sites for PPMI. All studies adhered to the principles outlined in the Declaration of Helsinki. Additionally, the Luxembourg Parkinson’s Study, ICEBERG, and PPMI are registered with ClinicalTrials.gov under the identifiers NCT05266872, NCT02305147, and NCT04477785, respectively.
The PD-MCI status was defined as positive (PD-MCI+) for a MoCA score <26, and as negative otherwise (PD-MCI-)3, while the SCD status was defined as positive (SCD+) if the score for the MDS-UPDRS Part I item 1.1 was above 1, and negative (SCD−) otherwise59. Level I MDS criteria were used for uniform cognitive profiling. Single-cohort and multi-cohort analyses followed a consistent workflow, detailed in the Supplementary Material.
Clinical characteristics were assessed for PD-MCI and SCD classification within four years of the baseline clinical visit, with time-to-event analysis tracking conversion from PD-MCI-/SCD- to PD-MCI+/SCD+ or the end of follow-up if censored.
Machine learning analysis of cognitive impairment
We developed a comprehensive ML framework to evaluate predictors of CI in PD, including data preprocessing, model training, and validation for classification and time-to-event analyses.
Prior to analysis, data preprocessing was performed to ensure the comparability of the relevant cohort variables. This included variable aggregation (Supplementary Table 15), missing value imputation for baseline features60,61, cross-study normalization (mean centering62, standardization, quantile normalization63,64, ComBat65,66, Ratio-A67, and M-ComBat68), undersampling69, and feature selection70. Feature selection included Recursive Feature Elimination (RFE) and Bidirectional Stepwise Feature Selection, both assessed via CV (for details on all data preprocessing and CV steps, see section “Data preprocessing” and “Cross-validation” in the Supplementary Material).
Model performance was evaluated using a two-level nested CV71. Firstly, the data were split into a training (67%) and a test set (33%), using stratification by cohort to maintain the distribution of cohorts. Within the training set, 5-fold stratified cross-validation was used to provide a first estimate of the average performance of the model and its variability. In addition, to assess generalizability across diverse populations, a leave-one-cohort-out validation strategy was applied. This involved training models on two cohorts and testing them on the third, enabling the evaluation of model robustness across cohorts with different demographics, disease characteristics, and follow-up durations. Hyperparameter tuning and feature selection were performed within the nested CV loops to minimize overfitting and ensure fair model evaluation (see Supplementary Figs. 15–17 and “Model optimization and evaluation” below).
For machine learning, nine algorithms were used for CI classification (PD-MCI+ or SCD+): AdaBoost72,73, CART74, CatBoost75, C4.5 trees76, FIGS77, GOSDT-GUESSES78, Gradient Boosting (GBoost)79, Hierarchical Shrinkage (HS)80, and XGBoost81. For time-to-event analysis, eight approaches were applied: Component-wise Gradient Boosting (CW-GBoost)82, Survival Trees83, Extra Survival Trees84, Survival GBoost70, Linear Support Vector Machine (LSVM), Naive Linear Support Vector Machine (NLSVM)85, Penalized Cox regression86,87, and Survival Random Forests (RF)88.
Hyperparameters were optimized using a nested CV to maximize the average area under the curve (AUC; classification) and concordance index (C-index; time-to-event). Single-cohort models were trained and validated within individual cohorts, while multi-cohort approaches included cross-cohort analyses (training on part of the samples from all cohorts, and testing on independent hold-out samples from all cohorts) and leave-one-cohort-out analyses (training on two cohorts and testing on the third cohort, see the supplementary material). As undersampling was applied to the training sets to address class imbalances, this nested CV structure inherently performs undersampling 15 times across different data partitions (5 outer folds × 3 inner folds), providing sufficient repeated sampling to mitigate potential sampling bias.
Interpretation of models and predictors
We applied SHAP value analysis89 to interpret prediction models and assess feature importance. The log-rank test compared Kaplan-Meier (KM) curves to assess time-to-PD-MCI/SCD differences across subgroups.
SHAP-derived HR were used to quantify the relative risk of PD-MCI/SCD, linking predictors to outcomes. Bootstrapped 95% confidence intervals (CIs) were computed to assess uncertainty around each HR estimate90.
Evaluation of model performance and stability
Model performance and stability were assessed using the CV-AUC and CV-C for PD-MCI/SCD prediction. 95% CIs were estimated via bootstrapping with 1000 resamples, using the 2.5th and 97.5th percentiles as CIs bounds. The effect of cross-study normalization on the hold-out test set performance was evaluated using DeLong’s test for classification91 and the one-shot non-parametric test for time-to-event analysis92. P-values were adjusted for multiple comparisons93 and Bayesian signed-rank tests used to assess model performance across cohorts94. Model stability was evaluated by computing the standard deviation of performance statistics across CV cycles.
Predictor selection statistics across cohorts
We used a common data model to identify informative baseline predictors across cohorts. Feature selection statistics were compared across single cohort analyses, calculating selection frequency over the CV cycles. Focusing on models with the highest CV-AUC/CV-C, features derived from the same categorical variable (via one-hot encoding) were grouped to avoid inflated importance. This approach ensured consistent and robust predictor identification across clinical settings.
Statistical analysis
We assessed group differences, distributions, and relationships between variables. To compare baseline characteristics between groups, the Mann–Whitney U test was used for non-normally distributed variables, the two-sample t-test for normally distributed variables, and Fisher’s exact test for categorical variables. The normality assumption was checked using the Shapiro–Wilk test to choose between parametric and non-parametric tests.
Cohort comparisons used ANOVA with Tukey’s HSD for normal distributions and Kruskal–Wallis with Dunn’s test for non-normal distributions. Variable associations were assessed using Spearman’s correlation for continuous/ordinal variables, the point-biserial correlation for binary and continuous/ordinal variables, Matthew’s Correlation Coefficient (MCC) for binary variables, and Kendall’s tau for ordinal variables. Significance was defined at p < 0.05 across all tests. As a final statistic, the median time to 50% PD-MCI/SCD conversion was examined to provide a clinically relevant measure of CI progression.
Assessment of clinical utility: decision curve and calibration analysis
Decision curve and calibration analysis were used to assess the models’ clinical utility and reliability:
DCA was applied to the hold-out test set to assess the net benefit over “treating all” or “none” scenarios95. The AUNBC was used to quantify clinical utility, with a larger AUNBC signifying a greater decision advantage. To evaluate the significance of AUNBC differences, bootstrapped hypothesis testing (1000 replicates) was used96.
For the Calibration analysis, the agreement between predicted probabilities and observed outcomes was assessed97. For time-to-PD-MCI/SCD, 4-year predicted probabilities were compared with KM estimates98, determining the calibration slope and mean square error (MSE).
Normalization and statistical analyses were performed using the R statistical programming language (v4.2.1). Python-3.8.6-GCCcore-10.2.0 was used for data processing and ML analyses. Figure 5 provides an overview of the workflow.

Machine learning analysis pipeline for predicting cognitive impairment in Parkinson’s Disease. Schematic representation of the data processing and analysis workflow. Input data from three independent cohorts (LuxPARK, PPMI, and ICEBERG) is pre-processed and then analyzed using both single-cohort and multi-cohort approaches. These analyses are applied to predict both mild cognitive impairment (PD-MCI) and subjective cognitive decline (SCD) outcomes in Parkinson’s disease. The models are evaluated using cross-validation, decision curve and calibration analyses.
Data availability
The LuxPARK clinical dataset used in this study was obtained from the National Centre of Excellence in Research on Parkinson’s Disease (NCER-PD). The dataset for this manuscript is not publicly available as it is linked to the Luxembourg Parkinson’s Study and its internal regulations. Any requests for accessing the dataset can be directed to request.ncer-pd@uni.lu. Further data used in the preparation of this article were obtained on May 9, 2024 from the Parkinson’s Progression Markers Initiative (PPMI) database (www.ppmi-info.org/data, RRID:SCR 006431). For up-to-date information on the study, please visit the PPMI website (www.ppmiinfo.org). Data from the ICEBERG cohort analyzed during this study is available from the corresponding study group (jean-christophe.corvol@aphp.fr, marie.vidailhet@aphp.fr).
Code availability
The open-source code is accessible in the following GitLab repository under the MIT license: https://gitlab.com/uniluxembourg/lcsb/bds/ml-cognitive-impairment.
References
Harvey, J. et al. Machine learning-based prediction of cognitive outcomes in de novo Parkinson’s disease. npj Parkinsons Dis. 8, 150 (2022).
Kandiah, N. et al. Montreal cognitive assessment for the screening and prediction of cognitive decline in early Parkinson’s disease. Parkinsonism Relat. Disord. 20, 1145–1148 (2014).
Wilson, H. et al. Predict cognitive decline with clinical markers in Parkinson’s disease (PRECODE-1). J. Neural Transm. 127, 51–59 (2020).
Garcia-Diaz, A. I. et al. Cortical thinning correlates of changes in visuospatial and visuoperceptual performance in Parkinson’s disease: a 4-year follow-up. Parkinsonism Relat. Disord. 46, 62–68 (2018).
Luca, A. et al. Cognitive impairment and levodopa induced dyskinesia in Parkinson’s disease: a longitudinal study from the PACOS cohort. Sci. Rep. 11, 867 (2021).
van Laar, T., De Deyn, P. P., Aarsland, D., Barone, P. & Galvin, J. E. Effects of cholinesterase inhibitors in Parkinson’s disease dementia: a review of clinical data. CNS Neurosci. Ther. 17, 428–441 (2011).
Sun, C. & Armstrong, M. J. Treatment of Parkinson’s disease with cognitive impairment: current approaches and future directions. Behav. Sci. 11, 54 (2021).
Bernini, S. et al. A double-blind randomized controlled trial of the efficacy of cognitive training delivered using two different methods in mild cognitive impairment in Parkinson’s disease: preliminary report of benefits associated with the use of a computerized tool. Aging Clin. Exp. Res. 33, 1567–1575 (2020).
Mantovani, E., Zucchella, C., Argyriou, A. A. & Tamburin, S. Treatment for cognitive and neuropsychiatric non-motor symptoms in Parkinson’s disease: current evidence and future perspectives. Expert Rev. Neurotherapeutics 23, 25–43 (2023).
Loetscher, T. Cognitive training interventions for dementia and mild cognitive impairment in Parkinson’s disease - a cochrane review summary with commentary. NeuroRehabilitation 48, 385–387 (2021).
Carlisle, T. C., Medina, L. D. & Holden, S. K. Original research: initial development of a pragmatic tool to estimate cognitive decline risk focusing on potentially modifiable factors in Parkinson’s disease. Front. Neurosci. 17, 1278817 (2023).
Pavelka, L. et al. Age at onset as stratifier in idiopathic Parkinson’s disease – effect of ageing and polygenic risk score on clinical phenotypes. npj Parkinsons Dis. 8, 102 (2022).
Chung, S. J. et al. Baseline cognitive profile is closely associated with long-term motor prognosis in newly diagnosed Parkinson’s disease. J. Neurol. 268, 4203–4212 (2021).
Yıldız, Z. et al. Relationship between apathy and cognitive functions in Parkinson’s disease. Psychological Appl. Trends https://doi.org/10.36315/2023inpact145 (2023).
Goldman, J. G. et al. Diagnosing PD-MCI by MDS Task Force criteria: how many and which neuropsychological tests?. Mov. Disord.30, 402–406 (2014).
Pan, F.-F., Huang, L., Chen, K.-L., Zhao, Q.-H. & Guo, Q.-H. A comparative study on the validations of three cognitive screening tests in identifying subtle cognitive decline. BMC Neurol. 20, 78 (2020).
Cersonsky, T. E. K. et al. Using the Montreal cognitive assessment to identify individuals with subtle cognitive decline. Neuropsychology 36, 373–383 (2022).
Mills, K. A. et al. Cognitive impairment in Parkinson’s disease: Association between patient-reported and clinically measured outcomes. Parkinsonism Relat. Disord. 33, 107–114 (2016).
Rosenblum, S. et al. The Montreal Cognitive Assessment: Is it suitable for identifying mild cognitive impairment in Parkinson’s disease?. Mov. Disord. Clin. Pract. 7, 648–655 (2020).
Marino, S. E. et al. Subjective perception of cognition is related to mood and not performance. Epilepsy Behav. 14, 459–464 (2009).
Goldman, J. G., Stebbins, G. T., Leung, V., Tilley, B. C. & Goetz, C. G. Relationships among cognitive impairment, sleep, and fatigue in Parkinson’s disease using the MDS-UPDRS. Parkinsonism Relat. Disord. 20, 1135–1139 (2014).
Huang, J. et al. Subjective cognitive decline in patients with Parkinson’s disease: an updated review. Front. Aging Neurosci. 15, 1117068 (2023).
Ren, J. et al. Comparing the effects of GBA variants and onset age on clinical features and progression in Parkinson’s disease. CNS Neurosci. Ther. 30, e14387 (2024).
Wang, Y.-X. et al. Associations between cognitive impairment and motor dysfunction in Parkinson’s disease. Brain Behav. 7, e00719 (2017).
Ikeda, M., Kataoka, H. & Ueno, S. Can levodopa prevent cognitive decline in patients with Parkinson’s disease?. Am. J. Neurodegener. Dis. 6, 9–14 (2017).
Loo, R. T. J. et al. Levodopa-induced dyskinesia in Parkinson’s disease: Insights from cross-cohort prognostic analysis using machine learning. Parkinsonism Relat. Disord. 126, 107054 (2024).
Pavelka, L. et al. Luxembourg Parkinson’s study -comprehensive baseline analysis of Parkinson’s disease and atypical parkinsonism. Front. Neurol. 14, 1330321 (2023).
Marek, K. et al. The Parkinson Progression Marker Initiative (PPMI). Prog. Neurobiol. 95, 629–635 (2011).
Dodet, P. et al. Sleep disorders in Parkinson’s disease, an early and multiple problem. npj Parkinson’s Dis. 10, 46 (2024).
Zhang, Z. et al. Effect of onset age on the levodopa threshold dosage for dyskinesia in Parkinson’s disease. Neurol. Sci. 43, 3165–3174 (2022).
Ciafone, J., Little, B., Thomas, A. J. & Gallagher, P. The neuropsychological profile of mild cognitive impairment in lewy body dementias. J. Int. Neuropsychol. Soc. 26, 210–225 (2020).
Devigili, G. et al. Unraveling autonomic dysfunction in GBA-related Parkinson’s disease. Mov. Disord. Clin. Pract. 10, 1620–1638 (2023).
Kelly, M. J. et al. Predictors of motor complications in early Parkinson’s disease: a prospective cohort study. Mov. Disord. 34, 1174–1183 (2019).
Chen, J. et al. Predictors of cognitive impairment in newly diagnosed Parkinson’s disease with normal cognition at baseline: A 5-year cohort study. Front. Aging Neurosci. 15, 1142558 (2023).
Biundo, R. et al. Cognitive profiling of Parkinson disease patients with mild cognitive impairment and dementia. Parkinsonism Relat. Disord. 20, 394–399 (2014).
Phongpreecha, T. et al. Multivariate prediction of dementia in Parkinson’s disease. npj Parkinson’s Dis. 6, 20 (2020).
Gorji, A. & Jouzdani, A. F. Machine learning for predicting cognitive decline within five years in Parkinson’s disease: comparing cognitive assessment scales with DAT SPECT and clinical biomarkers. PLoS ONE 19, e0304355 (2024).
Palermo, G. et al. Dopamine transporter, age, and motor complications in Parkinson’s disease: a clinical and single-photon emission computed tomography study. Mov. Disord. 35, 1028–1036 (2020).
Xiao, Y. et al. Different associated factors of subjective cognitive complaints in patients with early- and late-onset Parkinson’s disease. Front. Neurol. 12, 749471 (2021).
Zhou, F. et al. Abnormal intra- and inter-network functional connectivity of brain networks in early-onset Parkinson’s disease and late-onset Parkinson’s disease. Front. Aging Neurosci. 15, 1132723 (2023).
Picillo, M. et al. Sex-related longitudinal change of motor, non-motor, and biological features in early Parkinson’s disease. J. Parkinsons Dis. 12, 421–436 (2021).
Beheshti, I., Booth, S. & Ko, J. H. Differences in brain aging between sexes in Parkinson’s disease. npj Parkinsons Dis. 10, 35 (2024).
Iwaki, H. et al. Differences in the presentation and progression of Parkinson’s disease by sex. Mov. Disord. 36, 106–117 (2021).
Chen, H. et al. Performance of the Benton Judgment of Line Orientation test across patients with different types of dementia. J. Alzheimers Dis. 102, 437–448 (2024).
Cholerton, B. et al. Sex differences in progression to mild cognitive impairment and dementia in Parkinson’s disease. Parkinsonism Relat. Disord. 50, 29–36 (2018).
Chiara, P. et al. Cognitive function in Parkinson’s disease: the influence of gender. Basal Ganglia 3, 131–135 (2013).
Bakeberg, M. C. et al. Differential effects of sex on longitudinal patterns of cognitive decline in Parkinson’s disease. J. Neurol. 268, 1903–1912 (2021).
Reekes, T. H. et al. Sex specific cognitive differences in Parkinson disease. npj Parkinsons Dis. 6, 7 (2020).
Almgren, H. et al. Machine learning-based prediction of longitudinal cognitive decline in early Parkinson’s disease using multimodal features. Sci. Rep. 13, 13193 (2023).
Kang, S. H., Lee, J. & Koh, S.-B. Constipation is associated with mild cognitive impairment in patients with de novo Parkinson’s disease. J. Mov. Disord. 15, 38–42 (2021).
Jones, J. D., Rahmani, E., Garcia, E. & Jacobs, J. P. Gastrointestinal symptoms are predictive of trajectories of cognitive functioning in de novo Parkinson’s disease. Parkinsonism Relat. Disord. 72, 7–12 (2020).
Tur, E. K. & Gözke, E. Autonomic symptoms in early-stage Parkinson’s patients and their relationship with cognition and disease parameters. Anatol. Curr. Med J.5, 498–502 (2023).
Nagy, A. V. et al. Cognitive impairment in REM-sleep behaviour disorder and individuals at risk of Parkinson’s disease. Parkinsonism Relat. Disord. 109, 105312 (2023).
Maggi, G., Trojano, L., Barone, P. & Santangelo, G. Sleep disorders and cognitive dysfunctions in Parkinson’s disease: a meta-analytic study. Neuropsychol. Rev. 31, 643–682 (2021).
Cosgrove, J., Alty, J. E. & Jamieson, S. Cognitive impairment in Parkinson’s disease. Postgrad. Med. J. 91, 212–220 (2015).
Ma, C.-H., Ren, N., Xu, J. & Chen, L. Clinical features, plasma neurotransmitter levels and plasma neurohormone levels among patients with early-stage Parkinson’s disease with sleep disorders. Cell Commun. Signal. 23, 144 (2025).
Gibb, W. R. & Lees, A. J. The relevance of the Lewy body to the pathogenesis of idiopathic Parkinson’s disease. J. Neurol. Neurosurg. Psychiatry 51, 745–752 (1988).
Marek, K. et al. The Parkinson’s progression markers initiative (PPMI) – establishing a PD biomarker cohort. Ann. Clin. Transl. Neurol. 5, 1460–1477 (2018).
Rosenblum, S., Meyer, S., Richardson, A. & Hassin-Baer, S. Capturing subjective mild cognitive decline in Parkinson’s disease. Brain Sci. 12, 741 (2022).
Azur, M. J., Stuart, E. A., Frangakis, C. & Leaf, P. J. Multiple imputation by chained equations: what is it and how does it work?. Int. J. Methods Psychiatr. Res. 20, 40–49 (2011).
van Buuren, S. & Groothuis-Oudshoorn, K. mice: Multivariate Imputation by Chained Equations in R. J. Stat. Soft. 45, 1–67 (2011).
Luo, J. et al. A comparison of batch effect removal methods for enhancement of prediction performance using MAQC-II microarray gene expression data. Pharmacogenomics J. 10, 278–291 (2010).
Bolstad, B. M., Irizarry, R. A., Åstrand, M. & Speed, T. P. A comparison of normalization methods for high density oligonucleotide array data based on variance and bias. Bioinformatics 19, 185–193 (2003).
Kostka, D. & Spang, R. Microarray based diagnosis profits from better documentation of gene expression signatures. PLoS Comput. Biol. 4, e22 (2008).
Johnson, W. E., Li, C. & Rabinovic, A. Adjusting batch effects in microarray expression data using empirical Bayes methods. Biostatistics 8, 118–127 (2007).
Chen, C. et al. Removing batch effects in analysis of expression microarray data: an evaluation of six batch adjustment methods. PLoS One 6, e17238 (2011).
Lazar, C. et al. Batch effect removal methods for microarray gene expression data integration: a survey. Brief. Bioinform. 14, 469–490 (2012).
Stein, C. K. et al. Removing batch effects from purified plasma cell gene expression microarrays with modified ComBat. BMC Bioinforma. 16, 63 (2015).
Bach, M., Werner, A. & Palt, M. The proposal of undersampling method for learning from imbalanced datasets. Proc. Comput. Sci. 159, 125–134 (2019).
Karami, G., Giuseppe Orlando, M., Delli Pizzi, A., Caulo, M. & Del Gratta, C. Predicting overall survival time in glioblastoma patients using gradient boosting machines algorithm and recursive feature elimination technique. Cancers 13, 4976 (2021).
Wood, I. A., Visscher, P. M. & Mengersen, K. L. Classification based upon gene expression data: bias and precision of error rates. Bioinformatics 23, 1363–1370 (2007).
Freund, Y. & Schapire, R. E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 55, 119–139 (1997).
Freund, Y. & Schapire, R. A short introduction to boosting. J. Jpn. Soc. Artif. 14, 1612 (1999).
Berk, R. A. Classification and Regression Trees (CART). In Statistical Learning from a Regression Perspective (ed. Berk, R. A.) 157–211 (Springer International Publishing, 2020). https://doi.org/10.1007/978-3-030-40189-4_3.
Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V. & Gulin, A. CatBoost: unbiased boosting with categorical features. In Advances in Neural Information Processing Systems ((NeurIPS, 2018).
Quinlan, J. R. Improved use of continuous attributes in C4.5. J. Artif. Intell. Res. 4, 77–90 (1996).
Tan, Y. S. et al. Fast interpretable greedy-tree sums. Proc. Natl. Acad. Sci. U.S.A. 122, e2310151122 (2025).
McTavish, H. et al. Fast Sparse Decision Tree Optimization via reference ensembles. AAAI 36, 9604–9613 (2022).
Friedman, J. H. Greedy function approximation: a gradient boosting machine. Ann. Stat. 29, 1189–1232 (2001).
Agarwal, A., Tan, Y. S., Ronen, O., Singh, C. & Yu, B. Hierarchical shrinkage: improving the accuracy and interpretability of tree-based models. In International Conference on Machine Learning 111–135 (PMLR, 2022).
Chen, T. & Guestrin, C. XGBoost: a scalable tree boosting system. In ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 785–794, https://doi.org/10.1145/2939672.2939785 (2016).
He, K. et al. Component-wise gradient boosting and false discovery control in survival analysis with high-dimensional covariates. Bioinformatics 32, 50–57 (2015).
Bertsimas, D., Dunn, J., Gibson, E. & Orfanoudaki, A. Optimal survival trees. Mach. Learn. 111, 2951–3023 (2022).
Geurts, P., Ernst, D. & Wehenkel, L. Extremely randomized trees. Mach. Learn. 63, 3–42 (2006).
Wang, M. et al. Dementia risk prediction in individuals with mild cognitive impairment: a comparison of Cox regression and machine learning models. BMC Med. Res. Methodol. 22, 284 (2022).
Park, M. Y. & Hastie, T. L1-regularization path algorithm for generalized linear models. J. R. Stat. Soc. Ser. B Stat. Methodol. 69, 659–677 (2007).
Simon, N., Friedman, J., Hastie, T. & Tibshirani, R. Regularization paths for Cox’s proportional hazards model via coordinate descent. J. Stat. Softw. 39, 1–13 (2011).
Ishwaran, H., Kogalur, U. B., Blackstone, E. H. & Lauer, M. S. Random survival forests. Ann. Appl. Stat. 2, 841–860 (2008).
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. In Neural Information Processing Systems (NIPS 2017) 4768–4777 (NIPS, 2017).
Sundrani, S. & Lu, J. Computing the hazard ratios associated with explanatory variables using machine learning models of survival data. JCO Clin. Cancer Inform. 5, 364–378 (2021).
Sun, X. & Xu, W. Fast implementation of DeLong’s algorithm for comparing the areas under correlated receiver operating characteristic curves. IEEE Signal Process. Lett. 21, 1389–1393 (2014).
Kang, L., Chen, W., Petrick, N. A. & Gallas, B. D. Comparing two correlated C indices with right-censored survival outcome: a one-shot nonparametric approach. Stat. Med. 34, 685–703 (2015).
Ferreira, J. A. & Zwinderman, A. H. On the Benjamini–Hochberg method. Ann. Stat. 34, 1827–1849 (2006).
Corani, G. & Benavoli, A. A Bayesian approach for comparing cross-validated algorithms on multiple data sets. Mach. Learn. 100, 285–304 (2015).
Piovani, D., Sokou, R., Tsantes, A. G., Vitello, A. S. & Bonovas, S. Optimizing clinical decision making with decision curve analysis: Insights for clinical investigators. Healthcare 11, 2244 (2023).
Zhang, Z. et al. Decision curve analysis: a technical note. Ann. Transl. Med. 6, 308 (2018).
Trucano, T. G., Swiler, L. P., Igusa, T., Oberkampf, W. L. & Pilch, M. Calibration, validation, and sensitivity analysis: What’s what. Reliab. Eng. Syst. Saf. 91, 1331–1357 (2006).
Bamber, D. Evaluation of the performance of survival analysis models: Discrimination and calibration measures. In Handbook of Statistics vol. 23 1–25 (Elsevier, 2003).
Acknowledgements
We acknowledge support by the Luxembourg National Research Fund (FNR) as part of the projects RECAST (INTER/22/17104370/RECAST), PreDYT (INTER/EJP RD22/17027921/PreDYT), AD-PLCG2 (INTER/JPND23/17999421/AD-PLCG2), and EPI_T-ALL (INTER/TRANSCAN23/18333087/EPI_T-ALL). For the purpose of open access, and in fulfillment of the obligations arising from the grant agreement, the authors have applied a Creative Commons Attribution 4.0 International (CC BY 4.0) license to any Author Accepted Manuscript version arising from this submission. The ICEBERG cohort received funding and support from the Agence Nationale de la Recherche (ANR) under grant agreements ANR-10-IAIHU-06 (IHU ICM), association France Parkinson, and the Fondation d’Entreprise EDF, and the Fondation Saint Michel, and Energipole. The machine learning predictions in this paper were partly performed using the HPC facilities of the University of Luxembourg (see http://hpc.uni.lu). We are grateful to Patrick May and Zied Landoulsi for providing the genetic data that was crucial for this work. We also acknowledge the valuable contributions of the pre-publication check (PPC) team for their pre-review process (see https://r3.lcsb.uni.lu/). We would like to thank all participants of the Luxembourg Parkinson’s Study for their important support of our research. Furthermore, we acknowledge the joint effort of the members of the National Centre of Excellence in Research on Parkinson’s Disease (NCER-PD) Consortium from the partner institutions Luxembourg Centre for Systems Biomedicine, Luxembourg Institute of Health, Centre Hospitalier de Luxembourg, and Laboratoire National de Santé generally contributing to the Luxembourg Parkinson’s Study. Furthermore, we extend our gratitude to the ICEBERG study group for their contribution. The DIGIPD (INTER/ERAPerMed20/14599012) research project used data collected during the C13-74 ICEBERG study sponsored by Inserm. The study was granted approval by the local Ethics Committee (“Comité de Protection des Personnes Ile-de-France VI”) on August 25, 2014, authorized by the French National Agency for Medicines and Health Products Safety (ANSM) on July 11, 2014, and by the Commission Nationale Informatique et Libertés (CNIL) on January 25, 2021. The study was registered in a public trials registry (NCT02305147). All study participants provided their informed written consent in accordance with French legal guidelines.
Author information
Authors and Affiliations
Consortia
Contributions
R.T.J.L.: Writing original draft, visualization, validation, methodology, formal analysis. E.G.: Writing original draft, review & editing of all parts of the manuscript, supervision, methodology, investigation, funding acquisition. L.P., G.M., F.K., M.V., J.C.C.: Review & editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Loo, R.T.J., Pavelka, L., Mangone, G. et al. Multi-cohort machine learning identifies predictors of cognitive impairment in Parkinson’s disease. npj Digit. Med. 8, 482 (2025). https://doi.org/10.1038/s41746-025-01862-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-025-01862-1
