
Abstract
The effects of various prompt engineering on Large Language Models (LLMs) performance in hypertension decision-making are not yet fully understood. We evaluate the impact of different prompt engineering on LLM performance in hypertension treatment decision-making. We conducted a two-stage validation study using 300 de-identified simulated hypertension cases based on real-world clinical scenarios. ChatGPT-4.1 with Guidance-Self-Consistency achieved optimal performance (91.3% accuracy), nearing expert-level competency, while zero-shot prompting yielded worst results (62.7% with DeepSeek-V3). Optimal LLM assistance consistently enhanced physicians’ average accuracy across all levels (community hospital: 73.4% to 82.5%; county hospital: 84.0% to 87.9%; teaching hospital: 91.5% to 92.0%) and reduced inappropriate regimen rates. The worst LLM configurations decreased physician performance below baseline, increasing inappropriate regimen rates from 26.6% to 35.2% across all levels. Effectively designed prompt strategies enable LLMs to provide reliable hypertension treatment recommendations, thereby supporting physicians’ clinical decisions. This study has been trial-registered (ChiCTR2500099307, March 21, 2025).
Similar content being viewed by others
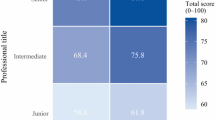
Data availability
The data underlying this article will be shared on reasonable request to the corresponding author.
Code availability
The code underlying this article will be shared on reasonable request to the corresponding author.
References
Zhou, T. et al. Primary care institutional characteristics associated with hypertension awareness, treatment, and control in the China Peace Million Persons Project and Primary Health-Care Survey: a cross-sectional study. Lancet Glob. Health 11, e83–e94 (2023).
Zhang, M. et al. Prevalence, awareness, treatment, and control of hypertension in China, 2004-18: findings from six rounds of a national survey. Bmj 380, e71952 (2023).
Li, X. et al. The primary health-care system in China. Lancet 390, 2584–2594 (2017).
Li, X. et al. Quality of primary health care in China: challenges and recommendations. Lancet 395, 1802–1812 (2020).
Lu, Y. et al. Barriers to optimal clinician guideline adherence in management of markedly elevated blood pressure: a qualitative study. JAMA Netw. Open 7, e2426135 (2024).
Wang, Y. et al. Efficacy of a wechat-based multimodal digital transformation management model in new-onset mild to moderate hypertension: randomized clinical trial. J. Med. Internet Res. 25, e52464 (2023).
Song, J. et al. Learning implementation of a guideline based decision support system to improve hypertension treatment in primary care in China: pragmatic cluster randomised controlled trial. BMJ 386, e79143 (2024).
Qiu, P. et al. Quantifying the reasoning abilities of LLMs on clinical cases. Nat. Commun. 16, 9799 (2025).
Singhal, K. et al. Toward expert-level medical question answering with large language models. Nat. Med. 31, 943–950 (2025).
Yang, X. et al. Application of large language models in disease diagnosis and treatment. Chin. Med. J. 138, 130–142 (2025).
Freyer, O., Wiest, I. C., Kather, J. N. & Gilbert, S. A future role for health applications of large language models depends on regulators enforcing safety standards. Lancet Digit Health 6, e662–e672 (2024).
Hager, P. et al. Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nat. Med. 30, 2613–2622 (2024).
Wang, L. et al. Prompt engineering in consistency and reliability with the evidence-based guideline for LLMs. Npj Digit. Med. 7, 41 (2024).
Anh-Hoang, D., Tran, V. & Nguyen, L. Survey and analysis of hallucinations in large language models: attribution to prompting strategies or model behavior. Front Artif. Intell. 8, 1622292 (2025).
Wang Y. et al. A multi-layer retrieval-augmented large language model framework for enhancing hypertension education. Hypertens Res. 49, 1428–1440 (2026).
Wang Y. et al. Large language model agent for managing patients with suspected hypertension. Hypertension. 83, https://doi.org/10.1161/HYPERTENSIONAHA.125.25305 (2025).
Wang, Y. et al. Hyper-dream, a multimodal digital transformation hypertension management platform integrating large language model and digital phenotyping: multicenter development and initial validation study. J. Med. Syst. 49, 42 (2025).
Zand J. et al. Performance of large language models in analyzing common hypertension scenarios. Hypertension. https://doi.org/10.1161/HYPERTENSIONAHA.125.25492 (2025).
Aguzzi, G. et al. Rag-enhanced open SLMs for hypertension management chatbots. J. Med. Syst. 49, 159 (2025).
Shool, S. et al. A systematic review of large language model (LLM) evaluations in clinical medicine. BMC Med. Inf. Decis. Mak. 25, 117 (2025).
Li, C. et al. Unveiling the potential of large language models in transforming chronic disease management: mixed methods systematic review. J. Med. Internet Res. 27, e70535 (2025).
Shimbo, D. et al. Transforming hypertension diagnosis and management in the era of artificial intelligence: a 2023 national heart, lung, and blood institute (NHLBI) workshop report. Hypertension 82, 36–45 (2025).
Lucas, M. M., Yang, J., Pomeroy, J. K. & Yang, C. C. Reasoning with large language models for medical question answering. J. Am. Med. Inf. Assoc. 31, 1964–1975 (2024).
Kaiser, K. N. et al. Accuracy and consistency of publicly available large language models as clinical decision support tools for the management of colon cancer. J. Surg. Oncol. 130, 1104–1110 (2024).
Sandmann, S. et al. Benchmark evaluation of DeepSeek large language models in clinical decision-making. Nat. Med. 31, 2546–2549 (2025).
Bean, A. M. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat. Med. 32, 609–615 (2026).
Wang, G. et al. Human-large language model collaboration in clinical medicine: a systematic review and meta-analysis. Npj Digit. Med. 9, 195 (2026).
Shang, Y. et al. The effectiveness of large language models in medical AI research for physicians: a randomized controlled trial. Cell Rep. Med. 6, 102469 (2025).
Agweyu A. et al. Safety of a large language model-based clinical decision support system in African primary healthcare. Nature Health (2026).
Goh, E. et al. Large language model influence on diagnostic reasoning: a randomized clinical trial. JAMA Netw. Open 7, e2440969 (2024).
Pais, C. et al. Large language models for preventing medication direction errors in online pharmacies. Nat. Med. 30, 1574–1582 (2024).
Costa, F. et al. Artificial intelligence in cardiovascular pharmacotherapy: applications and perspectives. Eur. Heart J. 46, 3616–3627 (2025).
Shi, X. et al. The effectiveness of digital animation-based multistage education for patients with atrial fibrillation catheter ablation: randomized clinical trial. J. Med. Internet Res. 27, e65685 (2025).
Zhou, T. et al. The effectiveness of nurse-led multidimensional digital cardiac rehabilitation in patients with unstable angina undergoing percutaneous coronary intervention: emulated target trial. J. Med. Internet Res. 27, e75325 (2025).
Wang, J. et al. Multimodal data-driven, vertical visualization prediction model for early prediction of atherosclerotic cardiovascular disease in patients with new-onset hypertension. J. Hypertens. 42, 1757–1768 (2024).
Clinical practice guideline for the management of hypertension in China. Chin. Med. J. (Engl.) 137, 2907–2952 (2024).
Garin, D. et al. Improving large language models accuracy for aortic stenosis treatment via heart team simulation: a prompt design analysis. Eur. Heart J. Digit Health 6, 665–674 (2025).
Jeon, S. & Kim, H. A comparative evaluation of chain-of-thought-based prompt engineering techniques for medical question answering. Comput. Biol. Med. 196, 110614 (2025).
Chen, B., Zhang, Z., Langrene, N. & Zhu, S. Unleashing the potential of prompt engineering for large language models. Patterns 6, 101260 (2025).
Yu, Z. et al. Evaluating large language models for information extraction from gastroscopy and colonoscopy reports through multi-strategy prompting. J. Biomed. Inf. 168, 104844 (2025).
Liu, J., Liu, F., Wang, C. & Liu, S. Prompt engineering in clinical practice: tutorial for clinicians. J. Med. Internet Res. 27, e72644 (2025).
O’Sullivan, J. W. et al. A large language model for complex cardiology care. Nat. Med. 32, 616–623 (2026).
Ghersin, I. et al. Comparative evaluation of a language model and human specialists in the application of European guidelines for the management of inflammatory bowel diseases and malignancies. Endoscopy 56, 706–709 (2024).
Liu, X. et al. A generalist medical language model for disease diagnosis assistance. Nat. Med. 31, 932–942 (2025).
Wang, M. et al. Evaluation of large language models for diagnostic impression generation from brain MRI report findings: a multicenter benchmark and reader study. Npj Digit. Med. 9, 187 (2026).
Acknowledgements
Clinical and Translational Research Project of Anhui Province (202427b10020086, 202427b10020089, 202427b10020097); Research Funds of Joint Research Center for Regional Diseases of IHM (2024bydik001, 2024bydjk002, 2024bydjk005); Anhui Provincial Health and Health Commission Scientific Research Project (AHWJ2024Aa10053); Science Research Project of Bengbu Medical University (2024byfy008); National Engineering Research Center of Science and Technology Information (2025STI135); The First Affiliated Hospital of Bengbu Medical University for Excellent Young Scholars (2025byyfyyq09).
Author information
Authors and Affiliations
Contributions
Z.Y.L., H.Y.L., W.P.T., D.T., and S.P.D. conceived and performed the study. B.W.Z., L.T., X.Y.H., L.Y.H., P.Z. and W.Q.F. contributed to methodological optimisation, data processing, and model evaluation. Z.Y.L., H.Y.L., W.P.T., D.T. and S.P.D. performed data collection, analysis, and manuscript revision. B.W., J.J.L., Y.J.W., and J.W. supervised the clinical components of the study and drafted the article or critically revised it for important intellectual content. All authors approved the final manuscript and consented to its submission.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, Z., Liu, H., Tan, W. et al. The effects of multitype prompt engineering for large language models in hypertension treatment decisions. npj Digit. Med. (2026). https://doi.org/10.1038/s41746-026-02645-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41746-026-02645-y
