
Abstract
Designing molecules with desirable properties is a critical endeavor in drug discovery. Because of recent advances in deep learning, molecular generative models have been developed. However, the existing compound exploration models often disregard the important issue of ensuring the feasibility of organic synthesis. To address this issue, we propose TRACER, which is a framework that integrates the optimization of molecular property optimization with synthetic pathway generation. The model can predict the product derived from a given reactant via a conditional transformer under the constraints of a reaction type. The molecular optimization results of an activity prediction model targeting DRD2, AKT1, and CXCR4 revealed that TRACER effectively generated compounds with high scores. The transformer model, which recognizes the entire structures, captures the complexity of the organic synthesis and enables its navigation in a vast chemical space while considering real-world reactivity constraints.
Similar content being viewed by others

Introduction
Small molecules constitute one of the essential modalities in drug discovery. However, new drug candidates have become increasingly difficult to discover, and some take more than 12 years to develop and cost an average of $2.6 billion to bring to the market1,2. In the early stages of research, hit compounds with high inhibitory activity against the target protein are often identified via high-throughput screening or virtual screening. These hit compounds are then structurally expanded by adding building blocks to explore compounds with the desired properties3. To find drug candidate compounds within a vast chemical space by starting from hit compounds,improving the efficiency of the DMTA cycle, which is a process used in drug discovery to design, make, test, and analyze compounds, is crucial.
Recent advances in deep learning models and their generalization capabilities have led to the development of generative models for de novo design and hit-to-lead optimization purposes4. However, most of these methods focus only on “what to make” and do not sufficiently consider “how to make”. Molecular generative models utilizing various architectures such as recurrent neural networks (RNNs)5,6,7,8, variational autoencoders (VAEs)9,10, and generative adversarial networks (GANs)11,12, as well as molecular design methods that explicitly consider interactions with target proteins13,14,15 have been developed. Since these methods do not consider how to synthesize the generated molecules, chemists must search for candidates for synthetic experiments from the numerous compounds suggested by the employed generative models; this aspect is a significant barrier preventing a shift to bench synthesis16.
The most commonly used scoring function for estimating synthetic ease, the SA score17, penalizes fragments, chiral centers, and certain substructures that are rarely seen in the PubChem database. Recently, Chen et al. developed a scoring method using building blocks and chemical reaction datasets to improve the SA score18. However, these topological methods are well suited for providing a rough estimate of the ease of synthesis in a high-throughput manner and cannot truly consider synthetic feasibility19. Although retrosynthesis models have been proposed to computationally predict synthetic pathways20, they are unable to consider the complexity of chemical reactions; thus, the knowledge and experience of human experts are indispensable during the synthesis planning process21. Despite the recent advances in machine learning-based scoring functions22,23,24,25,26,27, these functions predict only the results of retrosynthesis models. Therefore, the fundamental problems of these models remain unsolved21.
One approach for addressing the problem of generating synthesizable molecules is to construct virtual libraries through molecular design tasks with synthetic pathways by using predefined sets of reaction templates, which describe how reactants can be transformed into products28,29,30,31,32,33,34. Advances in machine learning have led to the development of deep learning-based analogous methods in combination with optimization algorithms (e.g., genetic algorithms or Bayesian optimization)35,36,37,38. These methods generate molecules that are similar to a given input compound in a descriptor space, such as extended connectivity fingerprints (ECFPs), and they also generate reaction pathways described by reaction templates. Reinforcement learning models, such as actor-critic and Monte Carlo tree search (MCTS), have been reported to be able to generate optimized compounds39,40,41,42 by training neural networks to predict reaction templates and building blocks that maximize the value of the reward function. Recently, a template-based method utilizing GFlowNet was reported for generating compounds with a probability that is proportional to a reward value43,44. However, the reaction templates used in these models are oversimplified, and chemoselectivity and regioselectivity, which are important aspects in real chemical reactions, are challenging to consider (Fig. 1a). Even though these selectivities may be considered by describing the patterns of the target reaction in detail, the scope of the substrates for all possible reactions is unrealistic to comprehensively define. Since new chemical reactions are reported daily, describing detailed chemical transformations is a time-consuming process.

a Scheme of a rule-based methods. In this example, the ortho-para orientation and steric hindrance are disregarded. b Outline of the previous works. This type of model, which learns a latent space representation, enables smooth compound exploration within the learned distribution. c Our work. A direct tree search occurs from the starting material on the basis of the virtual reactions performed by a conditional transformer model trained on real chemical reactions.
As a data-driven approach, the development of structural optimization methods that can explicitly learn chemical reactions has the potential to address the above challenges. Bradshaw et al. proposed models that embed molecules or reaction trees into a latent space, which is a low-dimensional representation learned from the input data; here, similar data points (i.e., chemical structures or reaction trees) are embedded to make them close together45,46. The Molecule Chef45 learns the latent space from a “bag of reactants” (summation of reactant embeddings) and connects these reactants to the property of the product predicted by Molecular Transformer47. Despite the fact that this process enables compound generation while considering real chemical reactions, it can only handle single-step reactions. DoG-Gen46 has succeeded in mapping a latent vector of reaction trees via a hierarchical gated graph neural network (GGNN), achieving multistep synthetic pathway generation. However, in structural optimization cases, DoG-Gen cannot follow the drug discovery process; it is incapable of generating compounds by starting from specific hit compounds.
In this study, we propose TRACER, which is a molecular generation model that combines a conditional transformer and an MCTS. The transformer model is constructed on the basis of attention mechanism, which allows it to selectively and directly focus on the important components contained in the input sequence data48. Therefore, the transformer model trained on chemical reactions such as the structural transformation contained in the simplified molecular input line entry system (SMILES)49 is expected to recognize the substructures that affect reactions from the whole reactants, achieving high accuracy in forward synthesis prediction tasks47. Previously developed data-driven methods45,46 generate optimized structures in the latent space, so they can search for compounds with the desired properties in a structure that smoothly fills a continuous space (Fig. 1b). In contrast with previous works that used end-to-end architectures, our proposed framework decouples the transformer as a product prediction model from the MCTS, which is used as a structural optimization algorithm. Therefore, TRACER enables direct optimization on the basis of virtual chemical reactions; thus, it is expected to propose structures and synthetic pathways that are far from the training dataset (Fig. 1c). Our model learns 1000 reaction types that are associated with a real chemical conversions, enabling the model to learn more fine-grained information than that of the rule-based methods, which use approximately 100 reaction templates35,36,38,39,40,41,42. With the continuous growth of chemical reaction databases, the model needs to be applied to an increasingly diverse range of reactions. However, transformer models have been verified to follow scaling laws50 in natural language processing tasks, indicating that increasing the number of model parameters can effectively address this challenge.
Results and discussion
Effect of the conditional token on chemical reactions
In this study, the transformer model was trained on molecular pairs created from chemical reactions via the SMILES sequences of reactants and products as source and target molecules, respectively. Following the evaluation method proposed by Yoshikai et al.51, partial accuracy (the accuracy per SMILES token) and perfect accuracy (the accuracy per molecule) were calculated for the validation data to assess the ability of the model to recognize partial and whole product structures. The impact of including or excluding reaction template information on the accuracy of the model was investigated (Fig. 2). The partial accuracy quickly reached approximately 0.9, regardless of the presence or absence of the reaction template information; this result indicated the ability of the model to learn partial product structures from the reactants, which aligned with the chemical knowledge that the scaffolds of reactants often remain in the products. However, the perfect accuracy increased more slowly than the partial accuracy did in both the unconditional and conditional models; thus, learning the entire product structure required more time. The perfect accuracy plateaued at approximately 0.6 for the conditional model and 0.2 for the unconditional model. These results indicated that the model had difficulty reproducing the chemical reactions from the training data without the reaction templates, and the accuracy improved when this information was provided. These results indicate the fact that a single substrate can undergo numerous chemical reactions and yield various products in the absence of additional constraints.

a Partial accuracy (calculated per SMILES token). b Perfect accuracy (calculated per molecule).
The top-n accuracies attained by the models for the test data were calculated (Table 1). The top-1, top-5, and top-10 accuracies were improved by adding information to the reaction templates. These results indicate that knowledge regarding the chemical reactions narrows the chemical space for predicting molecules and improves the ability of the model to generate appropriate products from the learned chemical reactions.
In some cases, bias was observed in the products generated by the unconditional transformer from the reactants. Figure 3a shows an example where the top-10 products were generated by a beam search with a beam width of 100 in the trained unconditional transformer, where the SMILES sequence of the depicted reactant was used as the input. The generated products were biased toward compounds transformed by reactions involving Csp(3) bonds to an indole-type nitrogen atom; these results were attributed to the bias in the chemical reactions involving similar transformations in the USPTO dataset. In contrast, by using the conditional transformer and the reaction templates predicted by the GCN, compounds could be generated through diverse chemical reactions (Fig. 3b). The GCN selected not only combinations of the reactants and reaction templates included in the training data, such as epoxide ring opening reactions and Buchwald-Hartwig cross-coupling with vinyl halides but also combinations of compounds and reaction templates that were not present in the training data, such as amidation and sulfonamidation, and successfully generated reasonable product candidates. These results indicated that the conditional transformer can extract chemical reaction knowledge from conditional tokens and propose rational products even for unknown combinations of reactants and chemical reactions. An example of the product generation results produced under the condition of unmatched reaction templates, where no partial structure matches were found, is presented in Supplementary Fig. 1.

a Examples generated by the unconditional transformer. The top 10 compounds for which the beam width was set to 100 are shown. b Compounds generated by the conditional transformer. The numbers indicate the indices of the reaction templates predicted by the GCN. The bolded indices represent novel compound-reaction template combinations that did not exist in the training data. The generated molecules were the top-1 results when the beam width was set to 10.
Optimization of compounds involving the generation of synthetic routes targeting specific proteins via a QSAR model
Five starting materials were selected for DRD2, AKT1, and CXCR4 from the USPTO 1k TPL dataset. The detailed procedure is described in Section 4.5, and the selected molecules are shown in Fig. 4. Utilizing these reactants as the root nodes, the MCTS calculations from selection to backpropagation were executed for 200 steps. The number of reaction templates predicted in the expansion step was set to 10. These hyperparameters could be adjusted on the basis of the available computational resources.

For each target protein, QSAR values were calculated for preprocessed compounds. Starting compounds were then determined by randomly sampling one compound from each QSAR value bin: 0-0.1, 0.1-0.2, 0.2-0.3, 0.3-0.4, and 0.4-0.5.
The compounds generated by the MCTS were evaluated in terms of the beam width in the transformer inference process, the total number of generated molecules (Total), the ratio of the number of unique molecules to those contained in the USPTO dataset, the number of molecules (Num) and the proportion of molecules with active prediction probabilities exceeding the threshold of 0.5 imposed by the QSAR model (Tables 2, 3, and 4). In addition to these metrics, to confirm the depth of the MCTS, the proportions of the reaction steps for the generated compounds were investigated (Fig. 5). A uniqueness analysis revealed that TRACER efficiently generated compounds that were distinct from those in the USPTO database across all target proteins. The efficiency of generating compounds with QSAR values exceeding 0.5 was significantly influenced by the starting compound. For DRD2 and AKT1, when the starting material had a high QSAR value, the structural exploration process started from scaffolds similar to those of the active compounds learned by the QSAR model, leading to a higher ratio of discovered molecules with high reward values. However, even when starting with compounds possessing low QSAR values, TRACER successfully generated compounds with high QSAR values by adjusting the beam width of the transformer. It was difficult to discover optimized compounds for CXCR4 when starting from compounds with low QSAR values (starting materials 11 and 12). However, when starting from compounds 13-15, our model successfully generated compounds with QSAR values exceeding 0.5 at a rate of approximately 15%. Starting from compounds 11, 12, and 15, it was challenging to improve the QSAR value. This is likely because the number of known CXCR4 ligands is relatively small, and few scaffolds are similar to the active compounds learned by the QSAR model that can access from these starting materials, thus limiting the opportunities for further development.

The figure shows the distribution of reaction step counts for generated compounds, obtained via the transformer with inference beam widths ranging from 10 to 50.
Overall, the optimal beam width for the conditional transformer model was found to vary depending on the starting compound. As shown in Fig. 5, increasing the beam width led to a reduced depthwise exploration process. In contrast, a narrower beam width was observed to increase the depth, leading to a greater number of reaction steps. These results indicated that, in some cases, promoting depthwise exploration by narrowing the tree width was more effective for discovering molecules with high reward values than dispersing the nodes to be explored by widening the tree width (starting materials 2-3, 6, 9, and 11). Conversely, in other cases, increasing the beam width facilitated the generation of high-reward molecules by promoting breadth-wise exploration (starting materials 4, 10, and 13). These findings demonstrate that TRACER is capable of performing structural optimization when starting from various initial compounds by optimizing the beam width.
To investigate the potential impact of increasing the beam width on the diversity of the generated molecules, the internal diversity of the compound sets that exceeded the threshold was calculated. In some cases, decreasing diversity trends were observed when the beam width was increased (starting materials 1, 3, 7, 9, and 12), whereas no notable influences were observed for the other materials.
In our model, since some reactants are treated implicitly, the reactants that are newly added to the input compounds were also investigated. For all pathways generated in Tables 2, 3, and 4, a total of 20,765 diverse reactants were identified, enabling this model to generate molecules with unique structures relative to those of the USPTO dataset.
Reaction pathways generated by the model
Figure 6 shows the compounds with the highest reward values and their synthesis routes for each of the starting materials. In these synthetic pathways, all reactants were not explicitly addressed. Therefore, the availability of the building blocks shown in these figures was investigated via Reaxys52, and all the starting materials were found to be commercially available (Supplementary Figs. 2–16). This result indicated that a wide range of reactants in USPTO are purchasable or synthesizable and that the conditional transformer captured this feature even though the model implicitly learned part of the reactants.

The compound with the highest reward value and its synthesis pathway, generated from experiments starting with compounds 1–5, which were selected to target DRD2.
Starting from 1, a series of reactions, including a nucleophilic attack of an alcohol on an aryl chloride and reductive amination were selected; this resulted in the generation of 1c with a QSAR value of 0.962. During the synthesis of 1a, the aryl fluoride scaffold of 1 and the newly added 2-chloropyrazine (Supplementary Fig. 2) could compete in an aromatic nucleophilic substitution reaction. However, several similar reactions are contained in the USPTO dataset, where aliphatic alcohols react with chloropyrazine, and an actual patents also exist53. This result indicates that TRACER correctly predicted the selectivity of the aromatic nucleophilic substitution reaction by learning real chemical reactions. Predicting such selectivity is extremely difficult with reaction template-based methods that determine applicable reaction templates without considering real chemical reactions. For compound 2, sulfonamidation of the amine was utilized to synthesize 2a, followed by conducting nucleophilic substitution and a nucleophilic attack on the alkyl halide to yield 2c. In the case of 3, 3a was generated by amidation with pivaloyl chloride. 3a was converted to 3b via Friedel-Crafts acylation. Generally, when an sp3 carbon is bonded to an aromatic ring, Friedel-Crafts reactions proceed selectively at the para position54, which the conditional transformer model successfully predicted. The derivation from 4 involved the amidation and two subsequent nucleophilic attacks of heteroatoms on alkyl halides to produce 4c. When 5 was used as the starting material, the introduction of the aliphatic amine moiety on the piperazine nitrogen using a phthalimide derivative provided 5b, and subsequent amidation provided 5c with a QSAR value of 0.994.
The results of the experiments conducted using the QSAR models of AKT1 and CXCR4 are shown in Figs. 7 and 8, respectively. Several examples were found in these reaction pathways, where the selectivities of the chemical reactions were correctly predicted. In the transformation from 8a to 8b, a method for reducing a nitro group while retaining a cyano group has been reported55. During the synthesis of 8d, the substitution at the 3-position of pyridine and the ortho-para directing effect of an aniline were correctly predicted. In the synthesis from 9a to 9b, similar reactions in which the ortho position of the amide groups in the substrates is halogenated using a metal catalyst56,57 have been reported. For 11a, the exact same reaction has been reported, in which reductive amination occurs while the alcohol is retained58. In the transformation from 11a to 11b, the aryl fluoride undergoes a substitution reaction while retaining the aldehyde of the newly added building block; indeed, several such examples exist59,60. As shown in these examples, TRACER can predict the selectivity of chemical reactions by explicitly learning actual chemical reactions.

The compound with the highest reward value and its synthesis pathway, generated from experiments starting with compounds 6–10, which were selected to target AKT1.

The compound with the highest reward value and its synthesis pathway, generated from experiments starting with compounds 11–15, which were selected to target CXCR4.
Although the structural optimization process using an unconditional transformer was explored, the generated synthetic routes proved impractical due to the use of several unreasonable transformations, such as multiple-step reactions performed in a single inference, the insertion of carbon atoms into alkyl chains, and a disregard for selectivity. Therefore, the retention rate of the Murcko scaffold61 of the reactants was investigated for the routes generated via structural optimization, with the QSAR model of DRD2 as a reward function. The retention rate was 94.5% for the conditional transformer, whereas it was 43.3% for the unconditional transformer. Considering these results together with the perfect accuracy investigation conducting in Section 5.3, it can be concluded that conditioning on chemical reactions is crucial.
Comparative analysis with molecular generation models that incorporate synthetic route generation
To evaluate TRACER, structural optimization experiments were conducted on the QSAR models of DRD2, AKT1, and CXCR4 along with benchmark models (the Molecule Chef45, DoG-Gen46, CasVAE37, and SynFlowNet43). A comparison among these models is presented in Table 5. The specification of starting compounds, which is a crucial function in drug discovery, is supported only by our framework. Furthermore, the models that are capable of explicitly learning chemical reactions are limited to TRACER, the Molecule Chef, and DoG-Gen. Notably, the Molecule Chef is applicable only to single-step reactions. Despite the fact that CasVAE and SynFlowNet, which are rule-based methods that utilize reaction templates, can perform structural optimization accompanied by the generation of reaction pathways, they are unable to consider actual chemical reactions. The optimization methods proposed by each model are described in the following section.
Molecule chef
In the Molecule Chef, the reactants involving in chemical reactions are vectorized via graph neural networks (GNNs). A network for mapping to a latent space is learned by utilizing a “bag of reactants”, which is obtained by summing these vectorized representations. In the original paper, a property predictor was connected to the latent space, and the coordinates were updated by calculating the gradient of the latent variable to generate optimized molecules. For comparative experiments, the property predictor was trained by precalculating the QSAR values of the training dataset used in the original paper, which was derived from USPTO dataset.
DoG-Gen
DoG-Gen is the only model among the benchmark models in this comparative study that is capable of explicitly learning chemical reactions and handling multistep transformations. The mapping to the latent space was learned by encoding reaction trees, constructed from the USPTO dataset, with a two-stage Gated Graph Neural Network (GGNN). In the benchmark experiments, following the methodology of the original paper, 30 rounds of operations were performed. Each round involved sampling 7000 reaction trees from DoG-Gen and conducting fine-tuning twice with the top 1500 molecules ranked by their QSAR values. The same training dataset as that employed in the original paper, which was derived from USPTO, was used in this experiment.
CasVAE
In CasVAE, separate latent spaces are constructed for compounds and reaction trees, utilizing the pathways obtained by decomposing the molecules in the USPTO dataset with a reaction template-based retrosynthesis model62. Decoding is performed by using the latent variables sampled from each space. As per the original implementation, five batches of 3000 molecules were generated by applying Bayesian optimization to the latent space of the molecules.
SynFlowNet
SynFlowNet is a GFlowNet-based model that was designed to sample data points with a probability proportional to a reward value. The tasks of predicting applicable reaction templates for compounds and reaction partners for bimolecular reaction templates are performed via neural networks, and the structure expansion procedure based on chemical reactions is modeled as a Markov process. The original paper utilized building blocks derived from Enamine building blocks63. In this comparative experiment, the training data were replaced with the USPTO dataset using the same preprocessing procedure as the original paper to standardize the conditions. The experimental conditions were set to be identical to those in the original implementation; the batch size during the generation step was 64, the temperature parameter was 32, and the number of training steps was 1000.
Experimental results
For all the benchmarked models, their compound generation effects were investigated via QSAR models of DRD2, AKT1, and CXCR4 (Table 6). For TRACER, the optimized beam widths for each starting material presented in Tables 2–4 were used in combination. As additional evaluation metrics beyond those used in Section 2.2, the proportion of unique generated compounds (uniqueness) and the Fréchet ChemNet distance (FCD)64 were calculated to evaluate the similarity between the generated compound set and the training dataset. Cases where the numbers of unique compounds were less than 5,000 were excluded because the FCD was shown to be unreliable in the original paper when the number of compounds was small, particularly when it was below this threshold.
When DRD2 was targeted, TRACER presented the greatest compound uniqueness and the largest proportion of generated USPTO-unique molecules. SynFlowNet generated a substantial number of duplicate compounds, resulting in only 10.9% unique compounds. DoG-Gen exhibited a USPTO-unique compound ratio of 41.3%, indicating a large number of generated compounds overlapping with the training data due to its learning of a mapping from the reaction trees to the latent space. Furthermore, the FCD values of both the Molecule Chef and DoG-Gen were low, suggesting that methods that construct latent spaces via reaction trees tend to explore regions that are close to the training data. SynFlowNet exhibited the highest FCD, which can be attributed to its reaction template-based approach, where various reaction templates can be applied to the starting materials to increase the FCD. A high FCD of 14.3 was also observed for TRACER, suggesting its success in the challenging task of generating compounds that are dissimilar to the training data while explicitly learning chemical reactions. CasVAE showed the best results in terms of the proportion of compounds with QSAR values greater than 0.5 and the overall diversity. This is likely because CasVAE performs Bayesian optimization solely on the latent space of the compound structures, thus performing a simpler task that does not consider the latent representations of reaction trees. Consequently, as shown in Section 2.4.3, CasVAE attempted to generate 15,000 reaction trees but yielded only 615 valid trees. This was mainly due to the selection of incorrect reaction templates during the reaction tree generation process and the failure to construct complete reaction pathways, resulting in a lack of high-throughput capabilities.
When targeting AKT1 and CXCR4, TRACER presented the highest values for the USPTO-unique compound ratio and FCD. This result indicates that TRACER robustly explored a vast chemical space with respect to the reward function while considering real chemical reactions. With respect to the proportion of compounds exceeding the QSAR threshold, CasVAE presented the highest value for AKT1, whereas DoG-Gen presented the highest proportion for CXCR4. As described in Section 5.2, the numbers of active compounds for DRD2, AKT1, and CXCR4 were 9,913, 4,035, and 925, respectively. This suggests that the performance of CasVAE was significantly influenced by the number of known ligands, which made it difficult to discover optimized molecules for CXCR4. DoG-Gen exhibited the highest degree of diversity, which is presumably attributed to the absence of an initial compound selection phase, allowing for a greater degree of freedom when exploring the chemical space. TRACER attained moderate performance in terms of the proportions of compounds generated with high QSAR values (17.0% for DRD2, 25.5% for AKT1, and 13.5% for CXCR4) compared with those of DoG-Gen and CasVAE. Notably, this ability significantly depends on the initially selected compounds. To evaluate the optimization ability of our framework with respect to the reward function, compounds with low QSAR values were intentionally set as the starting compounds. However, the other methods do not have such strong constraints, allowing for a greater degree of flexibility during the search process.
The means and standard deviations of the SA scores and molecular weights for the compounds generated by each model are shown in Table 7. With respect to the SA scores, all the models exhibited comparable performance, except for SynFlowNet, which targeted CXCR4. Although the SA score includes a size penalty term17, which was designed to penalize larger molecules, TRACER generated compounds with higher molecular weights than those of the Molecule Chef and DoG-Gen while maintaining comparable SA scores.
Structural optimization experiments involving the QSAR model starting from unseen molecules
Structural optimization experiments designed to simulate the actual drug discovery process were conducted. A dataset consisting of nonpatented-like compounds was obtained from the ZINC database as described in Section 5.3. The compounds with the highest ligand efficiency (LE), which is defined as the absolute docking score normalized by the number of heavy atoms, were then selected as the starting materials for each protein. As a result, 16 was selected for DRD2 (docking score = − 5.1, LE = 0.729) and AKT1 (docking score = − 4.5, LE = 0.643), whereas 17 was selected for CXCR4 (docking score = − 4.7, LE = 0.671) (Fig. 9).

These compounds were selected from a dataset created by removing compounds used to train transformer and QSAR models from the ZINC dataset. For each target protein, compounds in the dataset were docked, and the one with the highest ligand efficiency was selected as the starting compound.
The results of the experiments conducted using compounds 16 and 17 as starting materials are presented in Table 8. Although these initial compounds exhibited high LE, their QSAR values were 0.00, 0.01, and 0.01 for DRD2, AKT1, and CXCR4, respectively. However, TRACER enhanced the reward values by optimizing the structures of these compounds. Through a beam width investigation, compounds with QSAR values exceeding the threshold were generated at rates of 11.2% (beam width = 10) for DRD2, 24.5% (beam width = 10) for AKT1, and 9.81% (beam width = 50) for CXCR4. Consistent with the results presented in Section 2.2, the majority of the generated compounds were not included in the training dataset.
For each target protein, the compound sets generated by TRACER were compared with known ligands. Pairwise Tanimoto coefficients were calculated between the known ligands and the compounds generated by TRACER with QSAR values greater than 0.5. The compound pairs with the highest similarity, the synthetic routes for the generated compounds, and the docking poses are shown in Fig. 10. Although these known ligands were not included in the training data, compounds with Tanimoto similarities of 0.838, 0.588, and 0.552 were generated for DRD2, AKT1, and CXCR4, respectively. For these generated compounds, TRACER generated synthetic routes consisting of 2, 3, and 4 steps. Although the QSAR model does not explicitly consider docking scores, these generated compounds exhibit comparable binding potential to active ligands. These results indicate that our framework can effectively generate optimized compounds for the reward function, even when starting from molecules that are not included in the training dataset. Furthermore, compounds that are structurally similar to active ligands that were not included in the training dataset could be generated via the QSAR model, along with by the generation of reaction pathways.

The left column displays compounds found in known ligand datasets, and the right column shows compounds generated by TRACER. The figure also includes synthetic routes with reaction templates generated by our model, Tanimoto similarity scores for each compound pair, and docking scores.
Conclusions
In this study, a conditional transformer model was developed for the prediction of diverse chemical reactions. Compared with the unconditional model, the proposed model was shown to significantly improve the accuracy of the output product predictions. By incorporating reaction template information, the model was able to generate molecules through a wide variety of chemical reactions.
TRACER, which is a combination of a conditional transformer, a GCN, and an MCTS, was investigated for its ability to optimize compounds targeting specific proteins through the generation of synthetic pathways. MCTS-based molecule generation experiments using the QSAR model to predict the activity of DRD2, AKT1, and CXCR4 demonstrated the applicability of the conditional transformer in terms of drug discovery. MCTSs with various search widths showed that, in some cases, widening the search width enabled the efficient generation of compounds with high reward values. In contrast, in other cases, narrowing the search width facilitated a deeper search process, leading to the discovery of molecules with high reward values. Furthermore, the model performed structural transformations by appending commercially available building blocks, although it implicitly learned some of the reactants in the dataset. In benchmarking experiments, TRACER explored a chemical space farther from the training data than the other models did. Moreover, TRACER successfully generated compounds with high reward values, even when starting from compounds that were absent in the training data and with QSAR values close to zero. These results indicate the robustness of our framework against variations in the starting compounds and target proteins. The integration of additional models, such as a reaction condition recommendation model65,66 or a multiobjective optimization model67 for lead optimization, is expected to further accelerate the process of optimizing novel compounds in drug discovery tasks. Future work is needed to improve the robustness of the proposed approach by optimizing the model with larger datasets and exploring its potential applications involving diverse reward functions.
Methods
Figure 11a shows the procedure used by the proposed model to generate feasible products from the given reactant and to optimize the structure on the basis of virtual chemical reactions. First, a graph convolutional network (GCN) is used to predict the applicable reaction templates for the reactant. To filter mismatched templates, those with no substructures that match the reactant are removed at this time. Second, the transformer performs molecular generation under the conditions of the reaction type predicted for the reactant. This operation enables the model to be aware of how the reactant should be transformed into a product by learning real chemical reactions that correspond to the conditional templates. The number of outputs for each reaction type is examined in Section 2. The reaction templates with only one suitable product, such as the deprotection of nucleophilic substituents, are manually annotated with indices of the reaction templates. These templates are assumed to generate only a single molecule. Fig. 11b shows an overview of the optimization framework using an MCTS. In this study, the MCTS uses simulations to selectively grow a search tree and determine the most promising actions, in conjunction with the transformer and GCN. It searches for the optimal compounds through four steps: selection, expansion, simulation, and backpropagation. In the selection step, the most promising molecule is determined via the upper confidence bound (UCB) score described in Section 4.3. In the expansion step, the applicable reaction templates for the molecule are expanded, and the transformer performs conditional forward synthesis-based prediction for each reaction template. In the simulation step, the potential of the newly generated molecules is evaluated by further exploring the tree. Finally, the estimated values are propagated back to the root node, ensuring that molecules with higher values are more likely to be selected in the next cycle. The computing environment for all the experiments was an Ubuntu 22.04 OS, an Intel(R) Xeon(R) Gold 5318Y CPU, 128 GB of RAM, and an NVIDIA GeForce RTX 4090 GPU (with 24 GB of memory).

a Single-step forward synthesis enumeration. b An exploration process involving multistep synthesis pathway generation via an MCTS.
Conditional transformer model
In recent years, the development of compound generation models based on transformer architectures48 has significantly advanced68,69. These models utilize attention mechanisms to learn long-range dependencies in sequential data such as SMILES strings. Notably, the Molecular Transformer47 achieved high accuracy in forward chemical reaction prediction tasks. It was trained on the USPTO dataset to predict the products from the given reactants. Unlike the previously developed forward synthesis prediction models that generate products when provided with all starting materials, our model was developed to predict compounds that can be synthesized from a single starting material through various chemical reactions.
The conditional transformer was employed to control the diversity of virtual chemical reactions. Previous studies on transformer models have reported that the properties of generated molecules can be successfully controlled by appending conditional tokens corresponding to the desired properties70,71,72. In this study, indices of the 1,000 reaction templates extracted from the USPTO 1k TPL dataset73 were added to the beginning of the input SMILES sequences, and the transformer was trained to predict the product corresponding to the reaction (Fig. 12). These manipulations were performed to control the diversity of the chemical reactions by conditioning various reaction templates on the reactants. As described in the Section 5.1, the reaction dataset considers only a single reactant as an explicit input. However, in most cases where partner compounds exist, they can be determined from the reaction template and the structural differences between the reactant and the product. This training approach enabled the model to learn all the necessary information for describing the chemical reactions while avoiding the need to select partner compounds from tens of thousands of potentially existing molecules. Consequently, the model is expected to generate plausible structural transformations in reference to real chemical reactions.

The index of the reaction template is added to the beginning of the input SMILES sequence as a conditional token. In this example, the model implicitly learns the propionyl chloride from the information of the reaction template, the reactant, and the product.
To clarify the effect of the conditional tokens, conditional and unconditional transformer models were implemented via PyTorch74 and torchtext libraries. The hyperparameters were determined according to the original transformer model48 as follows: the batch size was 128, the dimensionality of the model was 512, the dropout ratio was 0.1, the numbers of layers in the encoder and decoder were 6, the dimensionality of the feedforward network was 2048, the activation function was a rectified linear unit (ReLU), and the number of attention heads was 8.
Graph convolutional network (GCN)
The GCN model75 was implemented on the basis of a previous study that predicted reaction templates from the SMILES representations of compounds76. Molecules with n nodes are represented as \({{{\mathcal{M}}}}\equiv (A,E,F)\), where A ∈ {0, 1}n×n is the adjacency matrix, \(F\in {{\mathbb{R}}}^{n\times d}\) is the matrix of the node features, and E ∈ {0, 1}n×n×T is the edge tensor when T types of bonds are present. Using these representations and A = {A(t)∣t ∈ T}, the molecules can be represented as \({{{{\mathcal{M}}}}}^{{\prime} }\equiv ({{{\bf{A}}}},F)\), where \({({{{{\bf{A}}}}}^{(t)})}_{i,j}=1\) if a bond of type t is present between nodes i and j. The architecture of a GCN typically consists of convolution layers, dense layers, and aggregation layers.
Graph convolution layer
A graph convolution is computed as follows:
where \({\tilde{{{{\bf{A}}}}}}^{(t)}\) is a normalized adjacency matrix for bond type t, X(l) is the input matrix of the lth layer, and \({{{{\bf{W}}}}}_{t}^{(l)}\) is the parameter matrix for the lth layer with a bond type t.
Dense layer
After applying the graph convolution, the output X(l+1) is typically passed through a dense layer, which is also known as a fully connected layer. The dense layer independently applies a linear transformation to the features of each node. The output X(l+1) can be expressed as follows:
where X(l) is the input matrix, and W(l) is the weight matrix of the dense layer.
Aggregation layer
After the graph convolution and dense layers, the resulting node representations need to be aggregated to obtain a graph-level representation. Following previous work76, sum aggregation was employed. The output is calculated as follows:
where \({\left({{{{\bf{X}}}}}^{(l+1)}\right)}_{j}\) is the jth element of the vector representation. The graph-level representation X(l+1) obtained through sum aggregation can be further processed to produce the final output of the GCN model. Additional dense layers are applied to predict the reaction templates. The overall architecture of the GCN model is shown in Fig. 13.
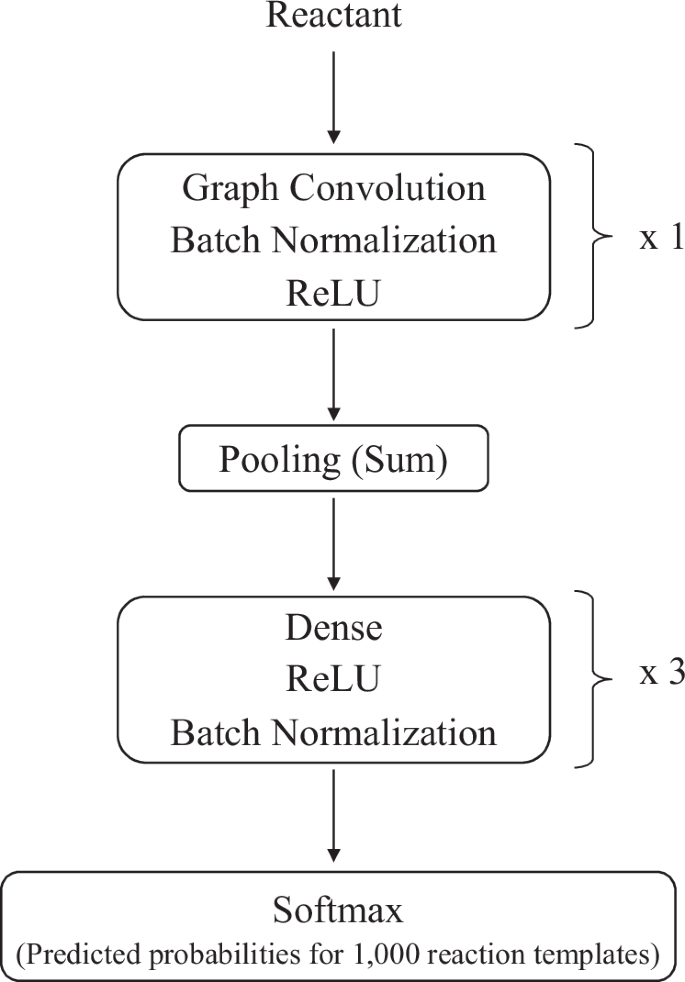
The number of convolution layers and dense layers was determined using Optuna.The output dimension of the final layer was set to 1000 to predict reaction templates.
For the reactants included in the training data, the GCN model was trained to predict the correct reaction templates from 1,000 available templates. This implies that the random selection of a reaction template would result in an accuracy of 0.001. The hyperparameters of the GCN model were determined via Optuna77 (Table 9). Finally, the trained GCN model was evaluated on the test data, yielding a top-1 accuracy of 0.483, a top-5 accuracy of 0.771, and a top-10 accuracy of 0.862.
Monte Carlo Tree Search (MCTS)
The MCTS algorithm78 was utilized to generate optimized compounds for the reward function. MCTSs integrated with RNNs, genetic algorithms, or matched molecular pairs5,6,7,79,80,81 have been demonstrated to be effective in molecular optimization tasks. In our framework, the nodes represent molecules, and the paths involving any nodes represent synthetic routes. The MCTS algorithm consists of four steps, each of which is detailed below.
-
1.
Selection: Child nodes are iteratively selected by starting from the root node based on its estimated value and visit count. The tree policy, which is a score function for selecting child nodes, plays an important role in the performance of the MCTS. One commonly used metric is the UCB score, which was originally proposed for multiarm bandit problems. This approach balances the exploration of nodes with fewer visits and the exploitation of promising nodes. The UCB score for the node i is calculated via the following formula:
where Q(s) represents the mean estimated value of state s for its child nodes and N(s) denotes the number of visits to state s. The states of each node i and its parent node are represented as si and sp, respectively. Cp balances the trade-off between exploitation and exploration. The first term in the UCB score corresponds to exploitation which encourages the selection of nodes with higher estimated values. The second term corresponds to exploration, which promotes the selection of the less-visited nodes. This selection policy guides the search toward the most valuable regions of the search space, enabling the discovery of the molecules that are likely to have the desired properties.
-
2.
Expansion: The products generated via virtual chemical reactions using the transformer are added as new child nodes to the selected node. In the conditional transformer, the reaction templates that pass the substructure matching filter after sampling from the GCN are used as conditional tokens. In the unconditional transformer, the model simply predicts the products without considering the reaction templates. A beam search, which is a heuristic search algorithm that explores a graph by expanding the most promising nodes, is employed to obtain the feasible products, and the influence of the beam width on the molecular optimization process is investigated.
-
3.
Simulation: The values of the child nodes generated in the expansion step are estimated. Virtual chemical reactions are repeatedly performed by the transformer a predetermined number of times. The number of reaction templates sampled during the simulation step is set to 5, and a single molecule is generated for each reaction template. The number of reaction steps explored is set to 2, and the maximum reward value among the generated compounds (25 or fewer) is set as the value for each node.
-
4.
Backpropagation: The values calculated via the simulation step are propagated for all nodes along the path from the generated nodes to the root node, and the cumulative scores are calculated. The nodes in the direction of the promising compounds contained within the search tree are highly evaluated by this step; this step enables the efficient generation of compounds that are optimized for the evaluation function.
In this study, the quantitative structure-activity relationship (QSAR) model, which predicts the activity probability of a target protein from a chemical structure within the range from 0 to 1, was used as the reward function. The diversity of the generated compounds was evaluated via the following equation, as described in a previous benchmark study of molecular generative models82:
where G is the set of valid compounds generated and T is the Tanimoto similarity between compounds m1 and m2 calculated by ECFP4 (2048-bit).
QSAR model
The activity prediction models developed for dopamine receptor D2 (DRD2), AKT serine/threonine kinase 1 (AKT1), and C-X-C motif chemokine receptor 4 (CXCR4) were used as the reward functions for the MCTS. A random forest classifier was trained to predict the probability of an active compound on the basis of 2048-bit ECFP6 via active/inactive labeled datasets for each protein described in Section 5.2. The training dataset consisted of 9006 active and 306,457 inactive compounds for DRD2, 3623 active and 14,814 inactive compounds for AKT1, and 853 active and 3051 inactive compounds for CXCR4. The hyperparameters of these models were optimized via Optuna77 (Table 10). The performance of the trained model was evaluated by the area under the curve (AUC), which is a performance metric that evaluates the ability of a binary classification model to identify classes across a classification threshold, on a test dataset consisting of 907 active and 33,943 inactive compounds for DRD2, 412 active and 1,636 inactive compounds for AKT1, and 72 active and 355 inactive compounds for CXCR4. The models achieved an accuracy of 0.984 and an AUC of 0.703 for DRD2, an accuracy of 0.958 and an AUC of 0.897 for AKT1, and an accuracy of 0.974 and an AUC of 0.924.
Selection of the starting compounds for the MCTS
The starting materials used by the MCTS for compound generation in Section 2.2 were randomly sampled from the distribution of the QSAR values for DRD2, AKT1, and CXCR4. Molecules with more than 8-membered rings and molecular weights ≥ 300 were removed from the USPTO 1k TPL dataset. Since reactants require functional groups that readily undergo chemical reactions, those not containing halogens, carbonyl groups, unsaturated bonds, or nucleophilic substituents were also removed; this decreased the number of compounds from 890,230 to 374,675. For each protein target, five initial compounds were selected as follows: the QSAR values of the filtered compounds were calculated, and one molecule was randomly sampled from each QSAR value bin including of 0–0.1, 0.1–0.2, 0.2–0.3, 0.3–0.4, and 0.4–0.5. These selected compounds are described in Section 2.2.
Data
USPTO dataset
In this study, the USPTO 1k TPL dataset reported by Schwaller et al. in their reaction classification work73 was used as a chemical reaction dataset. USPTO 1k TPL was derived from the USPTO database created by Lowe83 and consists of 445,000 reactions and corresponding reaction templates. The reaction templates were curated by selecting the 1000 most frequent template hashes obtained through atom mapping and template extraction via RxnMapper84. Certain reagents and solvents (e.g., hydrochloric acid, ethyl acetate, and dichloromethane) were removed from the dataset to further preprocess the data. The molecular pairs with the highest Tanimoto similarity between the reactants and products of each reaction were subsequently formed, indicating a structural transformation from the reactants to the products. The index of the labeled reaction template for each data point was appended to the beginning of the SMILES string of the reactants. The source code of TRACER, the activity prediction model, and the curated dataset are available in our public repository at https://github.com/sekijima-lab/TRACER.
Dataset for QSAR modeling
The dataset for the QSAR modeling process targeting DRD2 was extracted from ExCAPE85 and ChEMBL86. In addition to the active/inactive labeled dataset derived from ExCAPE, a set of compounds from ChEMBL was added as active compounds. On the basis of the literature87, the active compounds retrieved from ChEMBL underwent filtration with the following parameters: standard relation equal to “=”, pChEMBL > = 6.0, and molecular weight < 750. The AKT1 and CXCR4, active/inactive labeled datasets acquired from DUD-E88 were combined with active compounds from ChEMBL. The active compounds obtained from ChEMBL were preprocessed via the same filtering criteria as those applied to DRD2. The final DRD2 dataset consisted of 9913 active and 340,400 inactive compounds, the AKT1 dataset consisted of 4035 active and 16,450 inactive compounds, and the CXCR4 dataset consisted of 925 active and 3406 inactive compounds.
Dataset and docking simulations for structural optimization starting from unseen molecules
To demonstrate the ability of our framework to generate optimized compounds when starting from unseen molecules, a dataset of molecules not included in the training set was created. This dataset was constructed by removing the compounds used for training the transformer and QSAR models from the building blocks that were available in the ZINC database89,90. After applying the same filtering process described in Section 4.5, docking simulations were performed via Vina-GPU 2.091 with DRD2 (PDB ID: 6CM4), AKT1 (PDB ID: 3CQW), and CXCR4 (PDB ID: 3ODU). The compounds with the highest ligand efficiency (absolute docking score divided by the number of heavy atoms) were then selected as the starting materials for each protein.
Data availability
The activity prediction model and the curated dataset utilized in this study are available in our public repository at https://github.com/sekijima-lab/TRACER.
Code availability
The source code and trained models for TRACER have been released under the MIT license and are available in our public repository at https://github.com/sekijimalab/TRACER.
References
DiMasi, J. A., Grabowski, H. G. & Hansen, R. W. Innovation in the pharmaceutical industry: new estimates of r&d costs. J. Health Econ. 47, 20–33 (2016).
Wouters, O. J., McKee, M. & Luyten, J. Estimated research and development investment needed to bring a new medicine to market, 2009-2018. JAMA 323, 844 (2020).
Bleicher, K. H., Böhm, H.-J., Müller, K. & Alanine, A. I. Hit and lead generation: beyond high-throughput screening. Nat. Rev. Drug Discov. 2, 369–378 (2003).
Jiménez-Luna, J., Grisoni, F. & Schneider, G. Drug discovery with explainable artificial intelligence. Nat. Mach. Intell. 2, 573–584 (2020).
Yang, X., Zhang, J., Yoshizoe, K., Terayama, K. & Tsuda, K. Chemts: an efficient python library for de novo molecular generation. Sci. Technol. Adv. Mater. 18, 972–976 (2017).
Erikawa, D., Yasuo, N. & Sekijima, M. Mermaid: an open source automated hit-to-lead method based on deep reinforcement learning. J. Cheminform. https://doi.org/10.1186/s13321-021-00572-6 (2021).
Erikawa, D., Yasuo, N., Suzuki, T., Nakamura, S. & Sekijima, M. Gargoyles: An open source graph-based molecular optimization method based on deep reinforcement learning. ACS Omega 8, 37431–37441 (2023).
Loeffler, H. H. et al. Reinvent 4: Modern ai–driven generative molecule design. J. Cheminformatics 16, 20 (2024).
Gómez-Bombarelli, R. et al. Automatic chemical design using a data-driven continuous representation of molecules. ACS Cent. Sci. 4, 268–276 (2018).
Lim, J., Ryu, S., Kim, J. W. & Kim, W. Y. Molecular generative model based on conditional variational autoencoder for de novo molecular design. J. Cheminform. https://doi.org/10.1186/s13321-018-0286-7 (2018).
Sanchez-Lengeling, B. & Aspuru-Guzik, A. Inverse molecular design using machine learning: Generative models for matter engineering. Science 361, 360–365 (2018).
Prykhodko, O. et al. A de novo molecular generation method using latent vector based generative adversarial network. J. Cheminform. https://doi.org/10.1186/s13321-019-0397-9 (2019).
Ozawa, M., Nakamura, S., Yasuo, N. & Sekijima, M. Iev2mol: Molecular generative model considering protein–ligand interaction energy vectors. J. Chem. Inf. Modeling 64, 6969–6978 (2024).
Chiba, S. et al. A prospective compound screening contest identified broader inhibitors for sirtuin 1. Sci. Rep. https://doi.org/10.1038/s41598-019-55069-y (2019).
Yoshino, R. et al. Discovery of a hidden trypanosoma cruzi spermidine synthase binding site and inhibitors through in silico, in vitro, and X-ray crystallography. ACS Omega (2023).
Schneider, G. & Clark, D. E. Automated de novo drug design: are we nearly there yet? Angew. Chem. Int. Ed. 58, 10792–10803 (2019).
Ertl, P. & Schuffenhauer, A. Estimation of synthetic accessibility score of drug-like molecules based on molecular complexity and fragment contributions. J. Cheminformatics 1, 1–11 (2009).
Chen, S. & Jung, Y. Estimating the synthetic accessibility of molecules with building block and reaction-aware sascore. J. Cheminformatics 16, 83 (2024).
Stanley, M. & Segler, M. Fake it until you make it? generative de novo design and virtual screening of synthesizable molecules. Curr. Opin. Struct. Biol. 82, 102658 (2023).
de Almeida, A. F., Moreira, R. & Rodrigues, T. Synthetic organic chemistry driven by artificial intelligence. Nat. Rev. Chem. 3, 589–604 (2019).
Strieth-Kalthoff, F. et al. Artificial intelligence for retrosynthetic planning needs both data and expert knowledge. J. Am. Chem. Soc. https://doi.org/10.1021/jacs.4c00338 (2024).
Coley, C. W., Rogers, L., Green, W. H. & Jensen, K. F. Scscore: synthetic complexity learned from a reaction corpus. J. Chem. Inf. Model. 58, 252–261 (2018).
Voršilák, M., Kolár^, M., Čmelo, I. & Svozil, D. Syba: Bayesian estimation of synthetic accessibility of organic compounds. J. Cheminformatics 12, 1–13 (2020).
Thakkar, A., Chadimová, V., Bjerrum, E. J., Engkvist, O. & Reymond, J.-L. Retrosynthetic accessibility score (rascore)–rapid machine learned synthesizability classification from ai driven retrosynthetic planning. Chem. Sci. 12, 3339–3349 (2021).
Yu, J. et al. Organic compound synthetic accessibility prediction based on the graph attention mechanism. J. Chem. Inf. Model. 62, 2973–2986 (2022).
Wang, S., Wang, L., Li, F. & Bai, F. Deepsa: a deep-learning driven predictor of compound synthesis accessibility. J. Cheminformatics 15, 103 (2023).
Skoraczyński, G., Kitlas, M., Miasojedow, B. & Gambin, A. Critical assessment of synthetic accessibility scores in computer-assisted synthesis planning. J. Cheminformatics 15, 6 (2023).
Klingler, F.-M. et al. SAR by space: Enriching hit sets from the chemical space. Molecules 24, 3096 (2019).
Grygorenko, O. O. et al. Generating multibillion chemical space of readily accessible screening compounds. iScience 23, 101681 (2020).
Nicolaou, C. A., Watson, I. A., Hu, H. & Wang, J. The proximal lilly collection: Mapping, exploring and exploiting feasible chemical space. J. Chem. Inf. Model. 56, 1253–1266 (2016).
Hu, Q. et al. Pfizer global virtual library (pgvl): a chemistry design tool powered by experimentally validated parallel synthesis information. ACS Combinat. Sci. 14, 579–589 (2012).
Vinkers, H. M. et al. Synopsis: synthesize and optimize system in silico. J. Med. Chem. 46, 2765–2773 (2003).
Hartenfeller, M. et al. Dogs: reaction-driven de novo design of bioactive compounds. PLoS Comput. Biol. 8, e1002380 (2012).
Spiegel, J. O. & Durrant, J. D. Autogrow4: an open-source genetic algorithm for de novo drug design and lead optimization. J. Cheminformatics 12, 1–16 (2020).
Button, A., Merk, D., Hiss, J. A. & Schneider, G. Automated de novo molecular design by hybrid machine intelligence and rule-driven chemical synthesis. Nat. Mach. Intell. 1, 307–315 (2019).
Gao, W., Mercado, R. & Coley, C. W. Amortized tree generation for bottom-up synthesis planning and synthesizable molecular design. In International Conference on Learning Representations https://openreview.net/forum?id=FRxhHdnxt1 (2022).
Nguyen, D. H. & Tsuda, K. Generating reaction trees with cascaded variational autoencoders. J. Chem. Phys. 156, 044117 (2022).
Noh, J. et al. Path-Aware and Structure-Preserving generation of synthetically accessible molecules. In Chaudhuri, K. et al. (eds.) Proceedings of the 39th International Conference on Machine Learning, vol. 162 of Proceedings of Machine Learning Research, 16952-16968 (PMLR, 2022).
Gottipati, S. K. et al. Learning to navigate the synthetically accessible chemical space using reinforcement learning. In International conference on machine learning, 3668-3679 (PMLR, 2020).
Horwood, J. & Noutahi, E. Molecular design in synthetically accessible chemical space via deep reinforcement learning. ACS Omega 5, 32984–32994 (2020).
Fialková, V. et al. Libinvent: Reaction-based generative scaffold decoration for in silico library design. J. Chem. Inf. Modeling 62, 2046–2063 (2021).
Swanson, K. et al. Generative ai for designing and validating easily synthesizable and structurally novel antibiotics. Nat. Mach. Intell. 6, 338–353 (2024).
Cretu, M., Harris, C., Roy, J., Bengio, E. & Liò, P. Synflownet: Towards molecule design with guaranteed synthesis pathways. In ICLR 2024 Workshop on Generative and Experimental Perspectives for Biomolecular Design (2024).
Wang, Y., Zhang, H., Zhu, J., Li, Y. & Feng, L. Rgfn: Recurrent graph feature network for clickbait detection. In 2021 International Conference on High Performance Big Data and Intelligent Systems (HPBD&IS), 151-156 (IEEE, 2021).
Bradshaw, J., Paige, B., Kusner, M. J., Segler, M. & Hernández-Lobato, J. M. A model to search for synthesizable molecules. Adv. Neural Inf. Process. Syst. 32, 12000–12010 (2019).
Bradshaw, J., Paige, B., Kusner, M. J., Segler, M. & Hernández-Lobato, J. M. Barking up the right tree: an approach to search over molecule synthesis dags. Adv. neural Inf. Process. Syst. 33, 6852–6866 (2020).
Schwaller, P. et al. Molecular transformer: A model for uncertainty-calibrated chemical reaction prediction. ACS Cent. Sci. 5, 1572–1583 (2019).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 6000–6010 (2017).
Weininger, D. Smiles, a chemical language and information system. 1. introduction to methodology and encoding rules. J. Chem. Inf. Computer Sci. 28, 31–36 (1988).
Brown, T. et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 33, 1877–1901 (2020).
Yoshikai, Y., Mizuno, T., Nemoto, S. & Kusuhara, H. Difficulty in chirality recognition for transformer architectures learning chemical structures from string representations. Nat. Commun. 15, 1197 (2024).
Reaxys. https://www.reaxys.com.
Yi, X. et al. Substituted Oxaborole Antibacterial Agents. WO Patent 2011/17125 A1 (2011).
Sartori, G. & Maggi, R. Use of solid catalysts in friedel- crafts acylation reactions. Chem. Rev. 106, 1077–1104 (2006).
Quinn, J. F., Bryant, C. E., Golden, K. C. & Gregg, B. T. Rapid reduction of heteroaromatic nitro groups using catalytic transfer hydrogenation with microwave heating. Tetrahedron Lett. 51, 786–789 (2010).
Kianmehr, E. & Afaridoun, H. Nickel (ii)-and silver (i)-catalyzed c–h bond halogenation of anilides and carbamates. synthesis 53, 1513–1523 (2021).
Singh, H., Sen, C., Sahoo, T. & Ghosh, S. C. A visible light-mediated regioselective halogenation of anilides and quinolines by using a heterogeneous cu-mno catalyst. Eur. J. Org. Chem. 2018, 4748–4753 (2018).
Legnani, L. & Morandi, B. Direct catalytic synthesis of unprotected 2-amino-1-phenylethanols from alkenes by using iron (ii) phthalocyanine. Angew. Chem. Int. Ed. 55, 2248–2251 (2016).
Cantello, B. C. et al. [[. omega.-(heterocyclylamino) alkoxy] benzyl]-2, 4-thiazolidinediones as potent antihyperglycemic agents. J. Med. Chem. 37, 3977–3985 (1994).
Fan, Y.-H. et al. Structure–activity requirements for the antiproliferative effect of troglitazone derivatives mediated by depletion of intracellular calcium. Bioorg. Med. Chem. Lett. 14, 2547–2550 (2004).
Bemis, G. W. & Murcko, M. A. The properties of known drugs. 1. molecular frameworks. J. Med. Chem. 39, 2887–2893 (1996).
Chen, B., Li, C., Dai, H. & Song, L. Retro*: learning retrosynthetic planning with neural guided a* search. In International conference on machine learning, 1608–1616 (PMLR, 2020).
Enamine building blocks. https://enamine.net/building-blocks/building-blocks-catalog. Accessed on 2024/11/05.
Preuer, K., Renz, P., Unterthiner, T., Hochreiter, S. & Klambauer, G. Fréchet chemnet distance: a metric for generative models for molecules in drug discovery. J. Chem. Inf. Model. 58, 1736–1741 (2018).
Gao, H. et al. Using machine learning to predict suitable conditions for organic reactions. ACS Cent. Sci. 4, 1465–1476 (2018).
Shim, E. et al. Predicting reaction conditions from limited data through active transfer learning. Chem. Sci. 13, 6655–6668 (2022).
Fu, T., Xiao, C., Li, X., Glass, L. M. & Sun, J. Mimosa: Multi-constraint molecule sampling for molecule optimization. In Proceedings of the AAAI Conference on Artificial Intelligence, 35, 125–133 (2021).
Pang, C., Qiao, J., Zeng, X., Zou, Q. & Wei, L. Deep generative models in de novo drug molecule generation. J. Chem. Inf. Modeling 64, 2174–2194 (2023).
Yang, X. et al. Gpmo: Gradient perturbation-based contrastive learning for molecule optimization. In IJCAI, 4940-4948 (2023).
Yang, Y. et al. SyntaLinker: automatic fragment linking with deep conditional transformer neural networks. Chem. Sci. 11, 8312–8322 (2020).
Wang, J. et al. Multi-constraint molecular generation based on conditional transformer, knowledge distillation and reinforcement learning. Nat. Mach. Intell. 3, 914–922 (2021).
He, J. et al. Transformer-based molecular optimization beyond matched molecular pairs. J. Cheminformatics. https://doi.org/10.1186/s13321-022-00599-3 (2022).
Schwaller, P. et al. Mapping the space of chemical reactions using attention-based neural networks. Nat. Mach. Intell. 3, 144–152 (2021).
Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Infor. Process. Syst. 32, 8024–8035 (2019).
Kipf, T. N. & Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR ’17 https://openreview.net/forum?id=SJU4ayYgl (2017).
Ishida, S., Terayama, K., Kojima, R., Takasu, K. & Okuno, Y. Prediction and interpretable visualization of retrosynthetic reactions using graph convolutional networks. J. Chem. Inf. modeling 59, 5026–5033 (2019).
Akiba, T., Sano, S., Yanase, T., Ohta, T. & Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2623-2631 (2019).
Browne, C. B. et al. A survey of monte carlo tree search methods. IEEE Trans. Comput. Intell. AI games 4, 1–43 (2012).
Jensen, J. H. A graph-based genetic algorithm and generative model/monte carlo tree search for the exploration of chemical space. Chem. Sci. 10, 3567–3572 (2019).
Sun, M. et al. Molsearch: search-based multi-objective molecular generation and property optimization. In Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining, 4724-4732 (2022).
Suzuki, T., Ma, D., Yasuo, N. & Sekijima, M. Mothra: Multiobjective de novo molecular generation using monte carlo tree search. J. Chem. Inf. Model. 64, 7291–7302 (2024).
Polykovskiy, D. et al. Molecular sets (MOSES): A benchmarking platform for molecular generation models. Front. Pharmacol. 11, 565644 (2020).
Lowe, D. Chemical reactions from u.s. patents (1976-sep2016), 2017.https://figshare.com/articles/dataset/Chemical_reactions_from_US_patents_1976-Sep2016_5104873.
Schwaller, P., Hoover, B., Reymond, J.-L., Strobelt, H. & Laino, T. Extraction of organic chemistry grammar from unsupervised learning of chemical reactions. Sci. Adv. 7, eabe4166 (2021).
Sun, J. et al. Excape-db: an integrated large scale dataset facilitating big data analysis in chemogenomics. J. Cheminformatics 9, 1–9 (2017).
Zdrazil, B. et al. The chembl database in 2023: a drug discovery platform spanning multiple bioactivity data types and time periods. Nucleic acids Res. 52, D1180–D1192 (2024).
Papadopoulos, K., Giblin, K. A., Janet, J. P., Patronov, A. & Engkvist, O. De novo design with deep generative models based on 3d similarity scoring. Bioorg. Medicinal Chem. 44, 116308 (2021).
Mysinger, M. M., Carchia, M., Irwin, J. J. & Shoichet, B. K. Directory of useful decoys, enhanced (dud-e): better ligands and decoys for better benchmarking. J. Medicinal Chem. 55, 6582–6594 (2012).
Irwin, J. J. et al. Zinc20-a free ultralarge-scale chemical database for ligand discovery. J. Chem. Inf. Model. 60, 6065–6073 (2020).
Zinc database. https://files.docking.org/bb/.
Ding, J. et al. Vina-gpu 2.0: further accelerating autodock vina and its derivatives with graphics processing units. J. Chem. Inf. Model. 63, 1982–1998 (2023).
Acknowledgements
This work was partially supported by a Grant-in-Aid for Transformative Research Areas (A) “Latent Chemical Space” JP24H01760 for M.S. from the Ministry of Education, Culture, Sports, Science and Technology, Japan; the Research Support Project for Life Science and Drug Discovery (Basis for Supporting Innovative Drug Discovery and Life Science Research (BINDS)) from AMED under Grant Number JP24ama121026 for M.S.; the Japan Society for the Promotion of Science (JSPS) under KAKENHI Grant Number JP20H00620 for M.S.; and JST SPRING Grant Number JPMJSP2106 for S.N. We would like to thank Springer Nature Author Services for their professional English language editing (Verification code: 9754-750B-ED41-C1BD-E29P).
Author information
Authors and Affiliations
Contributions
S.N. designed the research and M.S. supervised the computational study. S.N. developed the software, and N.Y. guided the experiments. S.N. wrote the manuscript. All authors critically reviewed and revised the manuscript draft and approved the final version for submission.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Communications Chemistry thanks Fang Bai and the other, anonymous, reviewers for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nakamura, S., Yasuo, N. & Sekijima, M. Molecular optimization using a conditional transformer for reaction-aware compound exploration with reinforcement learning. Commun Chem 8, 40 (2025). https://doi.org/10.1038/s42004-025-01437-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s42004-025-01437-x
This article is cited by
-
MolMod: a molecular modification platform for molecular property optimization via fragment-based generation
Molecular Diversity (2025)
