
Abstract
Photonic neural networks (PNNs) have emerged as a promising platform for high-speed, parallel, and low-latency computing by harnessing the linear propagation of optical signals. However, scaling up PNNs faces significant challenges due to hardware errors caused by fabrication variations and environmental factors. Traditional approaches, such as offline error correction and online training, either rely on complex control systems or suffer from local optima convergence issues, resulting in limited scalability and efficiency. Here, we propose a hybrid on-offline configuration (HOOC) algorithm for programmable optical processors. This innovative approach combines offline initial value presetting with online perturbed optimization iteration algorithm, enabling precise and highly efficient error correction. We benchmark the algorithm’s performance in complex-valued matrix configuration and classification tasks, demonstrating robust error correction capabilities, including high reconstruction fidelity (≥98%), rapid convergence (≤10 iterations), and reduced dependence on detection devices. Furthermore, numerical simulations of high-order coherent processors demonstrate that our HOOC algorithm effectively avoids local optima, a common limitation of the conventional in-situ training method, thus simultaneously improving the scalability and robustness. These results underscore the viability and efficiency of the HOOC algorithm for scalable and robust PNN implementations, paving the way for scalable optical computing in artificial intelligence applications.
Similar content being viewed by others

Introduction
Driven by the rapid development of deep neural networks to address computation-intensive tasks in various applications1,2, numerous types of computing hardware have emerged as accelerators for artificial intelligence3,4,5,6,7,8,9. Among these frontier schemes, photonic neural networks (PNNs) have attracted a great deal of attention for their advantages of high speed, high parallelism, and low latency10,11,12. By leveraging the linear propagation of optical signals in optical devices, various fundamental operations in neural networks can be efficiently performed in the optical domain, including dot-product13, matrix multiplication14, convolution15, Fourier transforms16, and so on. This capability enables PNNs to deliver computational power surpassing that of their electrical counterparts. Meanwhile, photonic integrated circuits (PICs), as CMOS-compatible hardware platforms, facilitate compact on-chip integration of optical devices while enabling large-scale, cost-effective manufacturing of photonic chips17,18. These advancements have also ensured the practical implementation of PNN models19. To date, several studies have demonstrated large-scale, multilayer PNNs based on programmable on-chip optical processors14,20,21,22, showcasing their potential in applications such as image recognition13,23, natural language processing24, signal processing25,26, and complicated model solving27, etc.
However, scaling up PNNs remains challenging due to the precise encoding requirements of interferometers, which rely on analog operations28. Unlike digital circuits, which exhibit some tolerance to manufacturing errors29, integrated photonic chips, as analog devices, are more susceptible to errors arising from fabrication process variations30,31 and temperature fluctuation32,33. Current PNN implementations typically rely on pre-trained neural networks, which require offline simulation of the ideal model on classical computing equipment. However, discrepancies between the ideal model and actual PICs introduce significant hardware errors that accumulate as the on-chip circuits scale up. While several local error correction methods have been developed to improve matrix accuracies34,35,36,37,38, addressing device imbalance errors34, waveguide losses28,36, and thermal crosstalk36,37,38, these approaches typically require high-precision multiple sampling and complex control systems, presenting substantial experimental challenges35,36,39.
To overcome the limitations of offline error correction methods, significant efforts have been made to develop online weight configuration approaches for PNNs40. One promising solution is in-situ backpropagation41, which dynamically adjusts weights in real time by transmitting bidirectional optical signals through the mesh on the chip. However, these methods that rely solely on in-situ training require the real-time monitoring of signal strength at each node and a complex peripheral electrical system42. Alternative online training methods, such as physics-agnostic algorithms such as genetic algorithm43, particle swarm optimization44, and in-situ perturbed optimization iteration (POI) method36,45, update on-chip weights without relying on gradients or prior knowledge of the chip. While these methods eliminate the need for gradient-based optimization, they are prone to local optima and face challenges in converging to global optima46. This defect arises from random initialization strategies that may position the initial parameters within the basin of attraction of suboptimal solutions, increasing the possibility of convergence to local minima. While scaling the population size can partially mitigate this issue, it introduces significant computational inefficiency due to iterative iterations. Besides, pruning strategies and enhanced initialization techniques can partially alleviate the risk of local optima24,47, however, iterative optimization procedures starting from random initial configurations still demand significant computational overhead and prolonged training durations to achieve convergence towards application-specific target matrices36. These problems grow exponentially in high-dimensional space48, and highlight the critical need for an accurate and efficient training method for PNNs.
Here, we demonstrate a hybrid on-offline configuration (HOOC) algorithm for programmable optical processors. By combining offline initial value presetting with an online POI algorithm, this approach achieves precise and highly efficient hardware error correction for programmable PNNs. Specifically, offline presetting requires only approximate initial values, eliminating the need for high-precision measurement equipment typically used in traditional offline correction methods. The online calibration process, based on inverse design and Frobenius norm normalization, effectively addresses various hardware errors such as insertion loss, imbalance, and crosstalk. Together, the hybrid configuration enhances device characterization efficiency and avoids the local extrema issues commonly associated with traditional physics-agnostic algorithms. The algorithm is also applicable to complex-valued matrix configurations and can be extended to other symmetric topological structures.
To experimentally validate the proposed method, we design and fabricate two photonic chips with Clements49,50 and FFT meshes51,52. We demonstrate several proof-of-principle tasks, including complex-valued matrix configuration and the classification of the Iris and Vowel datasets. The HOOC algorithm exhibit exceptional performance across all tasks. For complex-valued matrix configuration, the algorithm achieves a fidelity greater than 0.98 for 4th-order matrices with fewer than 10 optimization iterations. In contrast to traditional online error correction methods, which typically reach a steady state by around 100 round trips and are prone to becoming trapped in local optima, our algorithm demonstrates a significantly faster convergence rate and achieves a superior convergence value. Given that matrix configuration is a core operation in neural networks, this algorithm can be directly applied to PNNs for classification tasks. Using the Clements mesh, the measured accuracies for the Iris and Vowel datasets converged to 91.18 ± 0.98% and 72.55 ± 1.96%, respectively, demonstrating excellent agreement with the numerical testing accuracies. Similarly, with the FFT-based mesh, the accuracies converged to 83.21 ± 1.96% and 72.98 ± 3.54%, respectively. These results demonstrate the viability and effectiveness of the HOOC algorithm.
Results
Concept and principle
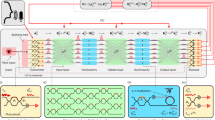
In this work, the HOOC algorithm is employed to achieve high-fidelity optical circuit performance on imperfect hardware platforms. The schematic of the algorithm, depicted in Fig. 1, consists of two primary components: offline preset and online calibration. As shown in Fig. 1a, the offline preset is a forward design process used for circuit initialization, in which the core operation is the mapping between neural network and physical hardware. In this phase, the connections between layers, represented by the weight matrix W in a typical electronic neural network, are decomposed using singular value decomposition (SVD) as W = UΣV†, where U and V are unitary matrices, and Σ is a diagonal matrix. This decomposition is then encoded into programmable optical architectures, such as the Clements mesh49,50 and FFT mesh51,52, which are composed of Mach-Zehnder interferometer (MZI) units (see Supplementary Note 1 for detailed matrix decomposition methods). Subsequently, the phase shifters in MZIs are calibrated by adjusting the voltage supplied to thermo-optic heaters, and the theoretical parameters derived from matrix decomposition (e.g., θi) are encoded into the optical processor upon power activation, while the output signals are collected by monitors and transmitted to the computer. Notably, the calibration curve in the offline preset process does not require high precision; instead, sampling a small set of voltage values is sufficient to complete the calibration. This approach significantly reduces the calibration time, which was previously a time-consuming task.

a The offline preset process relies on matrix decomposition and the characterization of on-chip discrete devices. Target matrices, derived from a trained network, are mathematically decomposed into phase shifts corresponding to the on-chip architecture. These phase shifts are then mapped to individual devices using measured transfer curves, establishing the theoretical configurations. b Illustration of the forward propagation flow within the coherent optical processor and associated electrical equipment. c The online calibration process further refines the implemented matrices using a POI algorithm. Through multiple iterations, the impact of hardware errors on the matrix is minimized, enabling the calibrated configuration to converge toward the target matrices.
After completing the offline preset process, the initial values are encoded into the optical processor, and the monitored outputs are subsequently used for online calibration. Figure 1b illustrates the forward propagation process in the coherent optical processor and its associated electrical equipment. Previous works have provided a theoretical foundation to mitigate hardware errors caused by beam splitter imbalances by adjusting the phase shift values34. Building on this insight, we develop an online calibration algorithm designed to effectively address various hardware errors in optical processors, including device insertion loss, beam splitter imbalances, and thermal crosstalk. Figure 1c conceptually shows the online calibration process of our HOOC algorithm. To efficiently optimize the configuration of the on-chip MZI mesh, we employ the POI algorithm, a type of inverse design algorithm, to compensate for discrepancies between the practical matrices and the target matrices. During each iteration, the phase shift value θi is perturbed to compute the forward difference \(\nabla {{{\mathcal{L}}}}({\theta }_{i})\), which represents the loss gradient with respect to the weight matrix (see Supplementary Note 2 for further details on the updating process). To ensure that the calibration process can cover errors caused by device loss, the loss function \({{{\mathcal{L}}}}\) of the perturbation optimization algorithm is defined as
where \(\hat{{{{\bf{A}}}}}\) is matrix obtained by normalizing A using the Frobenius norm, Atarget is the target matrix, and AMZI is the matrix implemented by MZI mesh. During each round of online calibration of the Nth-order MZI grid, each row of the Nth-order identity matrix is coded as the input signal, and the corresponding output vector is collected to reconstruct the Nth-order matrix realized by the MZI grid. This approach allows the online calibration algorithm to accurately estimate the forward deviation of the MZI mesh while accounting for the device loss, thereby providing accurate gradient direction for perturbation optimization. Since the online calibration process begins with a relatively rough initial value obtained from the offline presets, online calibration can quickly approach the target matrix with few iterations. Additionally, by adopting Frobenius norm normalization, the global proportional relationships between matrix elements are preserved, preventing any single element from dominating the whole structure. By utilizing global matrix-level information rather than relying solely on individual device calibration, the robustness of the system is significantly enhanced. As a result, our HOOC algorithm does not over-rely on highly accurate control systems. It is worth noting that the normalization and loss function calculation methods described above are equally applicable to complex-valued matrices, as \(\hat{{{{\bf{A}}}}}\) in Equation (1) may assume complex values.
Experimental setup and validation
Figure 2 a illustrates the schematic of the testing system to validate the HOOC algorithm experimentally. The testing system comprises several key components: a tunable continuous-wave light source, an integrated optical processor chip, a photon detector, and a near-field projecting system. The process begins with a continuous laser light at a wavelength of 1550 nm, which is directed through fiber arrays into a polarization controller to adjust the input light mode to ensure alignment with the transmission mode, and then goes into the integrated optical processor chip. The resulting output photons are then collected by a fiber array and transmitted to the photon detector. To enhance the efficiency of rapid phase shifter characterization during the offline preset stage, a near-field projecting system is added. Light from the designed monitoring ports on the chip passes through a Fourier lens system and is captured by a shortwave infrared (SWIR) camera for calibration. During this process, detected photons are converted into photocurrents and further collected by a data acquisition (DAQ) broad, together with programmable phase shifters to be controlled by a classical computer, which also manages the updating process of the POI algorithm. The chip is packaged optically and electrically, with electrodes mounted to a printed circuit board via wire bonding, as demonstrated in Fig. 2b.

a Testing system of the HOOC algorithm. The light generated by a tunable C-band laser and amplified by an erbium-doped fiber amplifier (EDFA) is directed through a polarization controller (PC) and into the photonic chip. The optical signals from the monitor ports within the MZI mesh are captured by a shortwave infrared (SWIR) camera. The output signals from the fiber array (FA) are converted into photocurrent and collected by a data acquisition (DAQ) board. b Image of the photonic chip packaged to the printed circuit board (PCB) and fiber array. FFT: fast Fourier transform; IFFT: inverse fast Fourier transform; BDUs: balanced detection units. Photographs of the fabricated photonic chips with the FFT-based MZI mesh (c) and the Clements-based MZI mesh (d).
We fabricate two types of programmable photonic chips with programmable MZI meshes to experimentally validate the HOOC algorithm. The micrographs of the fabricated chips, based on the FFT-based scheme51 and the Clements scheme49, are shown in Fig. 2c, d, respectively. The FFT-based scheme integrates a fast Fourier transform in the optical domain using butterfly-style MZI meshes with a single column of MZIs, enabling the realization of a one-layer neural network with a 4th-order circulant matrix connection. On the other hand, the Clements-based scheme incorporates two 4th-order unitary matrices and one diagonal matrix, enabling the multiplication of arbitrary unitary matrices. For the Clements structure, 8 MZI units are added into both the top and bottom optical paths to compensate for inter-path insertion loss variations while simultaneously providing additional monitor ports. For the FFT-based scheme, 1% tap ports are symmetrically introduced into all propagating paths, serving as power monitors. Additionally, on-chip balanced detection units are included to extract the real and imaginary parts of the output signals, which are essential for demonstrating the HOOC algorithm in the complex-valued domain. A detailed description of the on-chip balanced detection unit is provided in Supplementary Note 2.
To evaluate the performance of our HOOC algorithm and validate its design for hardware error correction, we first investigate the reconfigurability of the arbitrary transformation by generating and implementing random complex-valued matrices within two MZI-based meshes. The process begins with the calibration of phase shifters in the MZIs during the offline preset stage, accomplished through near-field detection. Figure 3a displays the near-field image captured by the SWIR camera, with the spot areas corresponding to the monitoring grating couplers highlighted by red dotted boxes. The image within the red dotted box is further converted into a normalized intensity distribution for phase shifter calibration, as illustrated in Fig. 3b. The calibration results using near-field detection are represented by gray dots in Fig. 3c. For comparison, the calibration curve of a complete 2π modulation cycle using the traditional output light detection method is plotted as a blue line in Fig. 3c. It is evident that the data obtained from the SWIR camera closely matches the transmission values from the traditional method but requires significantly less calibration time and fewer sampling points, thereby enhancing the efficiency of the offline presetting process. In addition, although the calibration of all heaters is necessary to account for fabrication-induced phase variations, the availability of multiple monitoring ports enables parallel calibration, preserving overall efficiency. The resulting calibration curves are stored and subsequently used for arbitrary matrix encoding. Further details on the offline calibration procedure are provided in Supplementary Note 3.

a The near-field image captured by the SWIR camera, highlighting the grating couplers used for intensity measurement. b Intensity distribution of the diagonal unit (Σ unit) highlighted within the red dotted box in a. The output signal is derived by integrating the intensity across each region of the grating coupler. c Normalized transmission curve of an MZI unit. d Illustration of a random complex-valued matrix configuration using Clements-based mesh. e The experimental testing results of fidelity and loss versus rounds of the POI algorithm for the Clements-based mesh. f Illustration of a random complex-valued matrix configuration using FFT-based mesh. g The experimental testing results of fidelity and loss versus rounds of the POI algorithm for the FFT-based mesh.
Next, we validate the HOOC algorithm by applying it to reconstruct weight matrices upon programmable optical processors. The target matrices used for validation are numerically generated random normed matrices with 4 × 4 modes, constructed without theoretical approximations. These matrices serve as ideal benchmarks to assess the reconstruction accuracy on Clements-based and FFT-based MZI meshes, as shown in Fig. 3d, f. In these figures, color bars represent experimental results, while opaque bars with solid-dashed borders denote theoretical results. Significant errors between the uncorrected matrix and the target matrix are observed in both the real and imaginary parts. However, after applying online calibration, the corrected matrix shows a substantial reduction in errors, converging closely to the target matrix in both its real and imaginary components, demonstrating the effectiveness of our correction method. In Supplementary Note 4, we provide a detailed procedure of the online calibration based on the POI algorithm.
As a result of the matrix deployment, the fidelity \(F=| Tr({\hat{{{{\bf{A}}}}}}_{\,{\mbox{MZI}}\,}^{{{\dagger}} }{\hat{{{{\bf{A}}}}}}_{{{{\rm{target}}}}}){| }^{2}\) is calculated, and its distribution, along with the corresponding loss function, is plotted as a function of iteration rounds in Fig. 3e, g for the Clements and FFT-based MZI meshes, respectively. The matrix fidelity based solely on the offline preset Funco is 0.79 and 0.71, respectively. After applying the online calibration method, these values improve to 0.98 ± 0.06 and 0.98 ± 0.08 within just 10 iterations. Simultaneously, the matrix losses decrease from 5.26 and 3.51 to 0.70 ± 0.18 and 0.69 ± 0.30 after the same number of iterations, respectively. This improvement stems from correcting static component errors including beam splitter imbalance ratios and inter-path insertion loss variations. In addition, local thermal crosstalk causes functional discrepancies between the on-chip device performances during actual operation and the measured results obtained during the offline presetting stage. Such a performance-limiting factor in our thermally programmable matrix processor can also be compensated by employing the online calibration. In our experiments, fabricated chips for the Clements and FFT-based schemes contain 48 and 28 on-chip phase shifters, respectively. Given the multi-channel voltage source with an update rate of 100 Sa s−1 in our experimental system, the online calibration process requires ~1 s per iteration for the Clements-based chip and ~0.6 s for the FFT-based chip. The 50 iterations in Fig. 3e, g take ~50 s and 30 s, respectively, with each achieving a fidelity exceeding 0.97 within 10 iterations. These results demonstrate that the HOOC algorithm can reconstruct the matrix with high accuracy and efficiency, which can further be applied into the complicated classification tasks.
Classification tasks
In this section, the HOOC algorithm is further applied to optical neural networks, demonstrating its capability to enhance classification performance across various tasks, such as the Iris and Vowel datasets, as illustrated in Fig. 4a. For the Iris dataset, which comprises four features (sepal and petal lengths and widths) and three categories (setosa, versicolor, and virginica), the entire dataset of 150 samples is split into a training set of 99 samples and a test set of 51 samples. A one-layer neural network with a weight matrix W4×3 (Fig. 4b) is trained on both Clements-based and FFT-based MZI meshes. The numerical testing accuracies for the two MZI meshes are 92.16% and 74.51%, respectively. During the offline preset stage, the testing samples are experimentally evaluated on both hardware chips with classification accuracies below 75%. Subsequently, the online calibration of the HOOC algorithm is employed to correct hardware errors, updating the real and imaginary parts of the trained weight matrix through iterative optimization on the two MZI meshes, as depicted in Figs. 4d, e, g, h. After error correction, the classification accuracies improve to 91.18 ± 0.98% and 72.55 ± 1.96%, respectively, demonstrating convergence towards the values obtained in the numerical simulation.

a Photonic neural network designed for various tasks, including complex-valued weight configuration, classification of the Iris dataset, and classification of the Vowel dataset. b Pre-trained network for Iris task and its encoding strategies. x1 ~ x4 represent the four features of each sample, y1 ~ y3 represent the three classes. The weight matrix (W4×3) is encoded in either the real or imaginary part of the complex-valued matrix (WMZI). c Pre-trained network for Vowel task and its encoding strategies. x1 ~ x8 represent the eight features of each sample, y1 ~ y4 represent the four classes. The weight matrix of the first hidden layer (W8×8) is divided into blocks and restructured into complex-valued matrices (WMZI1 and WMZI2). d–f The calibration results of the two tasks using a 4 × 4 Clements-based MZI mesh. g–i The calibration results of the two tasks using a 4 × 4 FFT-based MZI mesh. j Histogram comparing the fidelity of weight matrices implemented using only the initial preset versus those corrected through online calibration.
A more complicated task, Vowel task, is further used to validate the HOOC algorithm’s ability to mitigate hardware errors and improve classification performance. A two-layer PNN model integrated with the HOOC algorithm is employed for this task. As shown in Fig. 4c, the PNN model consists of a hidden layer W8×8 and an output layer W8×4. During matrix encoding, the hidden layer weight matrix is partitioned into four 4 × 4 blocks. The Vowel dataset includes 11 categories, each characterized by 10 features. To manage this complexity, a subset of 4 categories (“hid”, “hId”, “hEd”, and “hAd”) and the first eight features are selected, with the dataset divided into a training set of 196 samples and a test set of 144 samples. The training process of the HOOC algorithm on the two chips is illustrated in Figs. 4f, i, respectively. We perform the hidden layer W8×8 with our HOOC algorithm in the optical domain, and the output layer W8×4 is performed on the electrical computer. The fidelity of the trained weight matrices, shown in Fig. 4j and summarized in Table 1, demonstrates significant improvement after applying the HOOC algorithm. Upon completion of the HOOC process, the accuracy of the experimental testing increased from 52.08% to 83.21 ± 1.96% for the Clements-based MZI mesh and from 53.47% to 72.98 ± 3.54% for the FFT-based MZI mesh.
Performances under high-order coherent processor
As illustrated in the above sections, our HOOC algorithm has been experimentally validated to effectively correct hardware errors in both 4th-order Clements-based and FFT-based MZI meshes. To investigate the scalability of the HOOC algorithm further, this section presents numerical simulations of the two MZI meshes under fabrication imperfections. The primary sources of hardware errors in an MZI mesh include: (1) Insertion loss (αBS) and imbalance (βMMI) of the beam splitter; (2) Insertion loss (αCross) and crosstalk (βCross) of the cross coupler; (3) Insertion loss of the waveguide (αWG); (4) Metal absorption loss (αmetal) and (5) environmental fluctuations. Among them, the metal absorption loss (αmetal) for each phase shifter is set to 0.06 ± 0.1 dB, according to the simulation results based on the geometric dimensions of the titanium nitride (TiN) heaters (300 μm × 3 μm) in our fabricated chip53. Other losses are estimated from experimental measurements and summarized in Table 2. In Supplementary Note 5, we provide a detailed description of the characterizations for the on-chip devices. In addition, to account for environmental fluctuations in practical conditions, we introduce a 5% random noise to the phase shift values.
Using these parameters, we conduct three simulations for circuit sizes N = 4, 8, 16 on both Clements-based and FFT-based MZI meshes. Each set involved 200 randomly generated complex-valued matrices for hardware configuration. The simulation results are evaluated based on matrix fidelity, as shown in Figs. 5a, b. For N = 4, both MZI meshes achieved a matrix fidelity exceeding 0.97 with the HOOC algorithm. While the fidelity of both pre-correction and post-calibration matrices decreases for larger N, a significant improvement in fidelity is consistently observed after calibration, underscoring the scalability and feasibility of our approach. Notably, our simulations assume a minimum detectable optical power of −30 dBm (corresponding to the 7-bit resolution of our control system), demonstrating that the scheme maintains a robust performance without requiring ultra-high-precision external electronics. Furthermore, a comparative analysis between our HOOC algorithm and traditional online error correction methods43,45, detailed in Supplementary Note 6, demonstrates that the HOOC algorithm achieves both a faster convergence rate and a higher convergence value. Meanwhile, our HOOC algorithm exhibits good robust performance in avoiding the local optimization problem, which ensures its scalability for high-scale circuits containing a large number of physical parameters. In Supplementary Note 6, we provide detailed simulation analysis of the performance of our HOOC algorithm under varying levels of random initial phase noise.

The histograms show the fidelity of random complex-valued matrices before and after online calibration for the Clements-based MZI mesh (a) and FFT-based MZI mesh (b) with N = 4, 8, 16. Each group includes 200 random complex-valued matrices.
Conclusion
In this work, we propose and demonstrate an HOOC algorithm for the efficient configuration of programmable optical processors. By combining the advantages of offline presetting and online calibration, this approach integrates rapid offline characterization with the POI algorithm. The offline presetting stage provides a time-efficient method for initializing optical processor values without requiring the high-precision device characterization used in previous works. The online calibration stage employs the POI algorithm to achieve global matrix optimization. Utilizing Frobenius normalization, our calibration algorithm effectively mitigates errors caused by various hardware imperfections, including insertion loss, imbalance, and crosstalk. This addresses a key limitation of traditional calibration algorithms, which are typically restricted to handling a single type of error. Furthermore, by starting with offline-preset initial values, our online calibration avoids the local extrema issues commonly encountered in traditional physics-agnostic algorithms.
We validate the HOOC algorithm through extensive experiments and simulations. Two photonic chips, based on Clements and FFT-based MZI meshes, are fabricated and integrated into a closed-loop testing system. Through a series of experiments, we demonstrate the algorithm’s outstanding performance in diverse scenarios, including complex-valued matrix configuration and the implementation of PNNs for classification tasks such as Iris and Vowel datasets. Specifically, the algorithm achieves high fidelity (≥98%) in matrix reconstruction with remarkably few iterations (≤10 iterations), while experimental accuracies for classification tasks closely match numerical testing results. Simulation experiments further validate the algorithm’s applicability to large-scale on-chip optical processors, highlighting its reliability and scalability.
Although we demonstrate the HOOC algorithm on Clements-based and FFT-based MZI meshes, its applicability extends to other on-chip symmetric topological structures. For asymmetric designs, such as the Reck54 and Diamond55 configurations, the algorithm can be adapted by compensating for propagation path loss to mitigate optical power attenuation. Moreover, the offline pre-configuration and online calibration strategies of our algorithm are highly versatile in programmable photonics. By modifying the decomposition strategy and loss function variables, our method can be extended to various applications, including optical interconnects56, microwave photonics57, and topological beamforming58, among others. This adaptability highlights the potential of our algorithm to enhance functionality in systems supporting hundreds of modes, offering a promising pathway for scaling up programmable photonics and enabling transformative applications across diverse industries.
Methods
Fabrication and packaging
The 4th-order Clements-based and FFT-based MZI mesh is fabricated on the silicon-on-insulator (SOI) platform with a 220-nm-thick silicon top layer and a 2-μm-thick buried oxide. Subsequently, a thin layer of titanium nitride (TiN) is then deposited to serve as the resistive material for the heaters, followed by the patterning of a thin aluminum film to form electrical connections to the electrodes and heaters. To minimize power consumption, isolation trenches are etched around the TiN phase shifters through the SiO2 top cladding and Si substrate. The entire fabrication process is carried out using CMOS-compatible techniques. Detailed analysis of the average power consumption per MZI unit and the loss characteristics of each unit is provided in Supplementary Note 5. For optical packaging, UV-curable glue is employed to attach the fiber array to the chip, with index-matched oil applied to enhance coupling efficiency. The measured coupling loss is ~3.5 dB per facet. For electrical packaging, a two-layer wire-bonding technique is utilized to connect the electrical pads on the chip to the corresponding pads on the PCB.
Experimental setup
The light source is a Santec-570 tunable laser, providing C-band input light. Next, an erbium-doped fiber amplifier (EDFA) is connected to the laser, amplifying the optical power up to 20 dBm. A polarization controller is employed to optimize the coupling efficiency of the light source to the photonic chip. Input and output signals are coupled using a 12-channel fiber array with a uniform spacing of 127 μm. The encoding of input signals and matrix configurations is achieved using an NI-PCI-6704 multi-channel voltage source, controlled via MATLAB, which updates voltages at a rate of ~100 Sa s−1. Light emitted from the monitor ports of the photonic chip is captured using a YM-SC640 shortwave infrared camera. To capture the output optical signals below 14 dBm, eight photodetectors (LSIPD-LD50, 0.9 mA mW−1) convert the optical output signals into electrical signals, which are then transformed into sampling voltages using 62-kΩ resistors. A data acquisition board (DAQ, NI-USB-6210, 250 kS s−1) is utilized to collect the sampling voltages for further processing.
Data availability
The data that support the findings of this study are available from the corresponding author upon request.
Code availability
The codes that support the findings of this study are available from the corresponding author upon request.
References
Jordan, M. I. & Mitchell, T. M. Machine learning: trends, perspectives, and prospects. Science 349, 255–260 (2015).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Reuther, A. et al. Survey of machine learning accelerators. in Proc. IEEE High Performance Extreme Computing Conference (HPEC), 1–12 (IEEE, 2020).
Koilia, N. & Kachris, C. Hardware acceleration of LLMs: a comprehensive survey and comparison. Preprint at arXiv: 2409.03384v1 (2024).
Arimoto, Y. & Ishiwara, H. Current status of ferroelectric random-access memory. MRS Bull. 29, 823–828 (2004).
Lv, H. et al. DNA-based programmable gate arrays for general-purpose DNA computing. Nature 622, 292–300 (2023).
Kitayama, K.-I. et al. Novel frontier of photonics for data processing-Photonic accelerator. APL Photonics 4, 090901 (2019).
Khurgin, J., Bykov, A. Y. & Zayats, A. V. Hot-electron dynamics in plasmonic nanostructures: fundamentals, applications and overlooked aspects. eLight 4, 15 (2024).
Wang, X. et al. Exploiting universal nonlocal dispersion in optically active materials for spectro-polarimetric computational imaging. eLight 4, 1–13 (2024).
Zhou, H. et al. Photonic matrix multiplication lights up photonic accelerator and beyond. Light Sci. Appl. 11, 30 (2022).
Huang, C. et al. Prospects and applications of photonic neural networks. Adv. Phys. X 7, 1981155 (2022).
Ning, S. et al. Photonic-electronic integrated circuits for high-performance computing and AI accelerators. J. Lightwave Technol. 42, 7834–7859 (2024).
Xu, S. et al. Optical coherent dot-product chip for sophisticated deep learning regression. Light Sci. Appl. 10, 221 (2021).
Shen, Y. et al. Deep learning with coherent nanophotonic circuits. Nat. Photon. 11, 441–446 (2017).
Zhu, Y. et al. Silicon photonic neuromorphic accelerator using integrated coherent transmit-receive optical sub-assemblies. Optica 11, 583–594 (2024).
Wang, Z. et al. On-chip wavefront shaping with dielectric metasurface. Nat. Commun. 10, 3547 (2019).
Dong, P. et al. Silicon photonic devices and integrated circuits. Nanophotonics 3, 215–228 (2014).
Shekhar, S. et al. Roadmapping the next generation of silicon photonics. Nat. Commun. 15, 751 (2024).
Bogaerts, W. et al. Programmable photonic circuits. Nature 586, 207–216 (2020).
Zhu, H. H. et al. Space-efficient optical computing with an integrated chip diffractive neural network. Nat. Commun. 13, 1044 (2022).
Zhang, H. et al. An optical neural chip for implementing complex-valued neural network. Nat. Commun. 12, 457 (2021).
Fu, T. et al. Photonic machine learning with on-chip diffractive optics. Nat. Commun. 14, 70 (2023).
Xu, Z. et al. Large-scale photonic chiplet Taichi empowers 160-TOPS/W artificial general intelligence. Science 384, 202–209 (2024).
Cheng, J. et al. Multimodal deep learning using on-chip diffractive optics with in situ training capability. Nat. Commun. 15, 6189 (2024).
Huang, C. et al. A silicon photonic-electronic neural network for fibre nonlinearity compensation. Nat. Electron. 4, 837–844 (2021).
Romero, P. M.-C. et al. Integrated microwave photonics coherent processor for massive-MIMO systems in wireless communications. IEEE J. Sel. Top. Quantum Electron. 29, 1–12 (2023).
Xu, X.-Y. et al. Reconfigurable integrated photonic processor for NP-complete problems. Adv. Photon. 6, 056011 (2024).
Shafiee, A. et al. Analysis of optical loss and crosstalk noise in MZI-based coherent photonic neural networks. J. Lightwave Technol. 42, 4598–4613 (2024).
Gerakis, V. et al. A low-cost, robust and tolerant, digital scheme for post-bond testing and diagnosis of TSVs. J. Electron. Test. 37, 191–203 (2021).
Mirza, A. et al. Characterization and optimization of coherent MZI-based nanophotonic neural networks under fabrication non-uniformity. IEEE Trans. Nanotechnol. 21, 763–771 (2022).
Bahadori, M. et al. Comprehensive design space exploration of silicon photonic interconnects. J. Lightwave Technol. 34, 2975–2987 (2016).
Padmaraju, K. et al. Thermal stabilization of a microring modulator using feedback control. Opt. Express 20, 27999–28008 (2012).
Ning, N. et al. Thermal flux manipulation on the silicon photonic chip to suppress the thermal crosstalk. APL Photon. 9, 046108 (2024).
Bandyopadhyay, S. et al. Hardware error correction for programmable photonics. Optica 8, 1247–1255 (2021).
Zhang, W. et al. Silicon microring synapses enable photonic deep learning beyond 9-bit precision. Optica 9, 579–584 (2022).
Bandyopadhyay, S. et al. Single-chip photonic deep neural network with forward-only training. Nat. Photon. 18, 1335–1343 (2024).
Teofilovic, I. et al. Thermal crosstalk modelling and compensation methods for programmable photonic integrated circuits. J. Lightwave Technol. 42, 7816–7824 (2024).
Marchisio, A. et al. Comprehensive thermal crosstalk model of meshed MZI topologies for neuromorphic computing. in AI and Optical Data Sciences VI, Vol. 13375, 90–94 (SPIE, 2025).
Zhu, H. et al. A dynamically programmable quantum photonic microprocessor for graph computation. Laser Photon. Rev. 18, 2300304 (2024).
Buckley, S. M. et al. Photonic online learning: a perspective. Nanophotonics 12, 833–845 (2023).
Hughes, T. W. et al. Training of photonic neural networks through in situ backpropagation and gradient measurement. Optica 5, 864–871 (2018).
Pai, S. et al. Experimentally realized in situ backpropagation for deep learning in photonic neural networks. Science 380, 398–404 (2023).
Zhang, H. et al. Efficient on-chip training of optical neural networks using genetic algorithm. ACS Photon. 8, 1662–1672 (2021).
Zhang, T. et al. Efficient training and design of photonic neural network through neuroevolution. Opt. Express 27, 37150–37163 (2019).
Zhou, H. et al. Self-configuring and reconfigurable silicon photonic signal processor. ACS Photon. 7, 792–799 (2020).
Dang, D.-C. et al. Escaping local optima using crossover with emergent diversity. IEEE Trans. Evol. Comput. 22, 484–497 (2017).
Pai, S., Bartlett, B., Solgaard, O. & Miller, D. A. B. Matrix optimization on universal unitary photonic devices. Phys. Rev. Appl. 11, 064044 (2019).
Maring, N. et al. A versatile single-photon-based quantum computing platform. Nat. Photon. 18, 603–609 (2024).
Clements, W. R. et al. Optimal design for universal multiport interferometers. Optica 3, 1460–1465 (2016).
Zhao, Z. et al. Clements-enhanced complex-valued coherent mesh with balanced detection units for photonic neural networks. J. Lightwave Technol. 42, 6839–6849 (2024).
Gu, J. et al. Toward hardware-efficient optical neural networks: beyond FFT architecture via joint learnability. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 40, 1796–1809 (2020).
Feng, C. et al. A compact butterfly-style silicon photonic-electronic neural chip for hardware-efficient deep learning. ACS Photon. 9, 3906–3916 (2022).
Harris, N. C. et al. Efficient, compact and low loss thermo-optic phase shifter in silicon. Opt. Express 22, 10487–10493 (2014).
Reck, M. et al. Experimental realization of any discrete unitary operator. Phys. Rev. Lett. 73, 58–61 (1994).
Shokraneh, F. et al. The diamond mesh, a phase-error- and loss-tolerant field-programmable MZI-based optical processor for optical neural networks. Opt. Express 28, 23495–23508 (2020).
Cheng, Q. et al. Ultralow-crosstalk, strictly non-blocking microring-based optical switch. Photon. Res. 7, 155–161 (2019).
Catalá-Lahoz, C. et al. Self-configuring programmable silicon photonic filter for integrated microwave photonic processors. APL Photon. 8, 116103 (2023).
Wang, W. et al. On-chip topological beamformer for multi-link terahertz 6G to XG wireless. Nature 632, 522–527 (2024).
Acknowledgements
This work was supported by the National Key Research and Development Program of China (2024YFE0211800); National Natural Science Foundation of China (U22A2082); Ningbo Science and Technology Program (2023Z073); “Leading Goose" R&D Program of Zhejiang Province (2024C01112); “Vanguard" R&D Program of Zhejiang Province (2025C01043); Jinhua Science and Technology Program (2024-1-021); the National Natural Science Founda tion of China (No. 62205246 and 62475192); the National Key Research and Development Program of China (No. 2023YFF0613600); the Funda mental Research Funds for the Central Universities, and Shanghai Pilot Program for Basic Research.
Author information
Authors and Affiliations
Contributions
Z.C.Z., H.H.Z., Q.S.L., H.R.M., Y.H.W., and J.Y.Y. jointly conceived the idea. Z.C.Z., Q.S.L., Z.Y.F., and B.C. performed the numerical simulations and theoretical analysis. Z.C.Z., Q.S.L., H.R.M., Z.Y.F., and X.Y.J. did the experiments. Z.C.Z., H.H.Z., Q.S.L., H.R.M., and A.Q.L. were involved in the discussion and data analysis. Z.C.Z., Q.S.L., H.R.M., and Z.Y.F. prepared the manuscript. H.H.Z., Y.H.W., T.C., Y.Z.S., and J.Y.Y. supervised and coordinated all the work. All authors commented on the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Communications Physics thanks Silvia Ortin and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. [A peer review file is available.]
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhao, Z., Zhu, H., Liang, Q. et al. Efficient hardware error correction with hybrid on-offline configuration algorithm for optical processor. Commun Phys 8, 323 (2025). https://doi.org/10.1038/s42005-025-02247-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s42005-025-02247-2
