
Abstract
Advancements in memristive devices have given rise to a new generation of specialized hardware for bio-inspired computing. However, most of these implementations draw only partial inspiration from the architecture and functionalities of the mammalian brain. Moreover, the use of memristive hardware is typically restricted to specific elements within the learning algorithm, leaving computationally expensive operations to be executed in software. Here we demonstrate reinforcement learning through an actor–critic temporal difference algorithm implemented on analogue memristors, mirroring the principles of reward-based learning in a neural network architecture similar to the one found in biology. Memristors are used as multipurpose elements within the learning algorithm: they act as synaptic weights that are trained online, they calculate the weight updates associated with the temporal difference error directly in hardware and they determine the actions to navigate the environment. Owing to these features, weight training can take place entirely in memory, eliminating data movement. We test our framework on two navigation tasks—the T-maze and the Morris water maze—using analogue memristors based on the valence change memory effect. Our approach represents the first step towards fully in-memory and online neuromorphic computing engines based on bio-inspired learning schemes.
Similar content being viewed by others
Main
With its ability to adapt to new situations, process large amounts of data and generalize from past experiences, the human brain is a beacon of efficiency and computational power. Adjustments in brain connectivity are governed by ‘learning rules’1 that can be classified as two- or three-factor rules2. Although two-factor rules such as Hebbian learning or spike-timing-dependent plasticity1,3,4 are useful to learn representations of features based on the statistics of the input stream5,6,7, they lack a mechanism to incorporate neuromodulatory feedback signals that condition learning on reward, punishment or novelty8,9. By contrast, three-factor rules such as reward-modulated spike-timing-dependent plasticity (R-STDP)10 not only respond to input statistics but also incorporate an additional modulatory signal, allowing synaptic plasticity to be regulated based on behavioural context. Specifically, three-factor rules rely on Hebbian signals locally available at each synapse combined with a global broadcast signal (third factor)2,8,9. Three-factor learning rules are closely linked to reinforcement learning (RL)10, a machine learning approach in which artificial agents acquire knowledge by interacting with their surroundings, striving to maximize cumulative rewards11, similar to biological agents12. Software implementations of deep RL13,14 have excelled at complex games, for example, the game of Go15, and at navigation-related tasks such as autonomous robots, drones and cars14,16,17. However, the computational demands and power consumption of such software-based RL systems remain substantial, particularly when deployed in real-time, resource-constrained environments. Moreover, the necessity of deep RL to rely on the backpropagation algorithm makes it not only biologically implausible18 but also difficult to implement in energy-efficient hardware.
Implementing three-factor learning directly in hardware offers an alternative towards more efficient and scalable learning systems19,20. Such neuromorphic computing approaches21,22,23,24 have been realized using both complementary metal–oxide–semiconductor (CMOS) and memristive technologies. Although CMOS-based platforms are more mature in terms of integration25, they typically rely on digital architectures with physically separated memory and processing units, resulting in energy and latency bottlenecks in large-scale systems24. By contrast, memristors offer unique capabilities such as analogue, tunable synaptic weights and in-memory matrix–vector multiplications via crossbar arrays26,27,28,29,30, making them particularly attractive in energy-efficient, bio-inspired computing applications. However, to fully exploit these advantages, it is crucial that as many operations as possible are carried out directly on the memristive hardware itself31,32.
So far, only few memristor-based implementations of three-factor learning have been reported33,34,35,36, all limited to the use of individual devices only. Sarwat et al. implemented reward-based three-factor learning on memristors by combining light and voltage signals33. However, as the devices display only digital switching, they could not replicate the analogue nature of biological synapses, preventing fine-grained synaptic modulation essential for three-factor learning. An alternative to this approach is memristor-based circuits implementing R-STDP34,35,36. However, R-STDP has been shown to be less powerful than, for example, temporal difference (TD) learning rules10,11, which are optimally suited to navigation tasks37,38. Most importantly, an in situ approach in which memristive weights are trained online (that is, trained during runtime27) is still lacking.
Here we propose a framework for memristor-based TD learning. Specifically, we use the so-called TD error as a third factor, analogous to the reward prediction error delivered by the neurotransmitter dopamine in the mammalian brain8,39,40. The TD error signal is calculated in the critic module of an actor–critic network, which has been proposed as a fundamental architecture for reward-based learning in the brain41,42,43,44,45. Notably, and contrary to previous demonstrations of RL on memristors, our combination of a biologically plausible network architecture and three-factor learning enables the execution of all critical operations in hardware. Our memristors (1) serve as synaptic weights that are trained online and in memory; (2) they determine the next actions of the network; and (3) they compute the weight updates associated with the TD error. As such, our approach minimizes external recourse to software and allows full in-memory training, which enhances the processing speed and efficiency of artificial neural networks46. We demonstrate the applicability of our framework in two common neuroscience navigation tasks, the T-maze and the Morris water maze47,48,49. Our implementation relies on analogue valence change memories (VCM) consisting of a dielectric HfO2 layer combined with a conductive metal oxide (CMO)50,51,52,53; however, it is independent of the memristor type.
Results
Memristor-based actor–critic TD learning
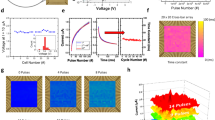
As a testbed for our bio-inspired three-factor learning framework on memristors, we consider the T-maze and Morris water maze navigation tasks (Fig. 1a,b, respectively). Both mazes are widely used to gain insight into the spatial learning and memory of animals47,48,49. In both experiments, a biological agent (mouse) initially moves randomly (trial 1), but gradually learns to take an efficient (direct) path to a predefined reward (trial n). The improvement in the mouse’s spatial navigation, trial by trial, is an example of reward-based learning37,38. Here we formulate both navigation tasks in a biologically plausible actor–critic network (Fig. 1c)42,43,44,45.

a, Sketch of a T-maze experiment. A biological agent (mouse) is navigating through a maze to find a reward (cheese). The T-maze consists of a stem and two lateral arms, with a reward at the end of one arm. The biological agent is placed at the bottom of the maze and can take a sequence of actions: going forwards or backwards, and, at the junction of the T-maze, turning right or left. Initially, the action choice is random (black trajectory), but the agent learns to choose actions that maximize the future reward (blue trajectory). b, Sketch of the Morris water maze experiment. A biological agent (mouse) is placed at a random location in the pool and strives to escape from the cold water onto a hidden platform (reward). The mouse is free to move in any direction. The mouse starts by swimming in circuitous paths (black trajectory) before learning over many trials to approach the platform on a nearly direct path (blue trajectory). c, Artificial agent with actor–critic TD learning (schematic). Place cells (state neurons; left) represent the momentary state st (position) of the agent and are connected via a weight matrix θ to actor neurons, which encode the probabilities πi for choosing action i. The place cells are also connected via the weight vector w to a critic neuron representing the value V(s) of the current state. The TD error (3rd) is a reward prediction error, analogous to the dopamine signal in biology8,11. It is used to update the weights in the actor–critic network (w, θ). d, Illustration of a memristor used as an artificial synapse in the actor–critic network. Memristors implement both weights w and θ. They perform online weight updates, compute the actions and are used for the in-memory calculation of the weight updates Δw and Δθ. e, Flowchart of the proposed bio-inspired actor–critic RL algorithm split into a software and hardware part. The hardware part employs the memristors to perform all operations highlighted in d. The software part mostly emulates the role of the environment by taking steps and returning rewards. Dedicated software calculations are kept minimized and only comprise sampling the actions, calculating the number of voltage update pulses from the corresponding weight updates, and computing the RBFs of the input representation. The combination of an online learning algorithm and continuous in-memory weight update calculation enables error-correcting weight updates as errors caused by the device non-idealities are compensated for in the next learning iteration. Panels a and b created with BioRender.com.
The network has two main parts, an actor and a critic component. The critic computes the value of each spatial position or state11, which measures its proximity to the reward, whereas the actor network represents the learned action choices. The actor–critic architecture exhibits multiple similarities with the functions of certain brain areas54,55,56,57 (Supplementary Fig. 1) and with widely used computational neuroscience models37,38,58,59. At time t, the agent’s position in the two-dimensional environment is given by the state st = (sx, sy), where sx and sy are Cartesian coordinates. This position is encoded by n place cells60 with activities (x1; x2…xn) = xt. Place cells are implemented as radial basis functions (RBFs) and form a fixed input layer to the actor–critic network (Methods). Given the agent’s position in the place-cell representation, a single actor–critic layer is sufficient to learn complex navigation tasks61,62, thereby reducing the size and complexity of typical RL networks.
In our network, the connection from any place cell j and the critic neuron(s) (a single one in our model) is characterized by a weight wj. The activity of the critic neuron V(st) = ∑jwjxj assigns a value V(st) to each state st. In the actor network, each neuron i encodes a different action ai, such as moving forwards, left or right (Methods provides details on the action selection). The weights, labelled θij, connect the place cells j (pre-synaptic neurons) to the actions i (post-synaptic neurons). The weights of both networks are adjusted by a neo-Hebbian three-factor rule2,9,63,64, which depends on the activity of the pre-synaptic (j) and post-synaptic (i) neuron via a ‘Hebbian’ coincidence detection ‘H’ (Methods) and a third factor called 3rd:
where α is a learning rate parameter and the superscripts act and cri refer to actor and critic, respectively. The third factor 3rd is related to phasic dopamine signals in the brain8,54 and represents the TD error δt (ref. 11):
Here r(st) is the reward received at time t, the parameter γ ≤ 1 is a discount factor, V(st) is the value of the state s at time t and V(st+1) is the value of the next state at time t + 1 after an action has been taken. The discount factor influences the relative importance of distant to immediate rewards13. This architecture and learning rule differ from a previously reported memristor-based actor–critic network65 employing backpropagation and gradient descent algorithms—two less biologically plausible techniques than those implemented here18.
In our actor–critic learning scheme, analogue memristors act as the artificial synapses θij and wj (Fig. 1d). The memristor weights are not only employed to statically encode the learned actions and values but they also (i) compute the actions, (ii) determine the weight updates based on the TD error (in-memory weight update calculation) and (iii) are updated in an online fashion according to equation (1) (online learning). Importantly, the same memristors are employed to perform all these tasks, highlighting their multifunctional role. Moreover, our implementation does not require any weight read-outs, which reduces data movement. The flowchart in Fig. 1e summarizes a single time step of the algorithm, segmented into its software and hardware components. Some operations are still performed in software but are limited to the interaction of the agent with its environment, a few computationally inexpensive operations (that is, action sampling, conversion of weight update into pulses) and the evaluation of RBFs to obtain place-cell representations.
Executing the majority of the algorithm in memory, as here, is known to enhance the processing speed and lower the energy consumption of learning processes on crossbar arrays46. By contrast, conventional RL implementations on memristive hardware only partially exploit in-memory computing. Typically, (1) the action and the weight update computation—both complex operations—are carried out in software and (2) the memristor weights are continuously read-out in case of write–verify schemes66,67,68. Supplementary Table 1 compares our TD learning hardware implementation with previous demonstrations of RL algorithms on memristors. As the TD error is calculated at each step, errors due to imperfect weight updates on memristors are trained away in the next iteration, providing error-correcting capabilities. With our online learning strategy, the errors are automatically incorporated into the in-memory weight update calculation. The learning loop is detailed in the ‘In-memory learning loop’ section.
Analogue memristor synapses as active components of actor–critic networks
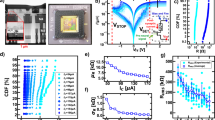
Our actor–critic framework relies on analogue memristors as hardware components consisting of a W/TiN/CMO/HfO2/TiN stack and operating on the VCM effect (Fig. 2a). Both HfO2 and CMO layers are involved in the switching process: a conductive filament grows through the HfO2 layer, whereas the CMO acts as an oxygen reservoir layer52,69,70. This CMO–HfO2 bilayer film offers better analogue switching characteristics than Ti–HfO2 stacks52.

a, Schematic of the material composition and biasing scheme. The active layers consist of HfO2 and a CMO. Our memristors are operated by grounding the TiN bottom electrode (BE) and applying an electrical signal to the W top electrode (TE). A conductive filament (CF) is initially created during a forming step by applying a negative voltage at the TE (Supplementary Fig. 2). b, Scanning electron microscopy image providing an angled view of the vertical VCM stack. The active area of the artificial synapse is given by the overlap of the top and bottom electrodes. c, Focused-ion-beam (FIB) cross-section image cut along the dotted line shown in b. The inset shows the deposited material stack including the active HfO2–CMO bilayer of the VCM memristor. d, Resistance–voltage (R–V) characteristics displaying the resistive switching behaviour of the fabricated devices. They exhibit reproducible switching with gradual and quasi-symmetrical set and reset processes. e, Dynamic measurements displaying the synaptic potentiation and depression curves as a function of the number of applied pulses. Data from ten distinct cycles, along with the mean, are shown. Identical pulse trains were used to perform this measurement: 200 set pulses at 2.5 V with a 1.5-μs pulse width for potentiation and 200 reset pulses at –2.7 V with a 10-μs pulse width for depression. The pulse parameters (amplitude and duration) were specifically chosen to achieve a good compromise between the linearity of potentiation/depression and the noise in weight updates. f, Histograms showing the deviations of both potentiation and depression measurements from their respective means for 27 distinct devices.
The fabrication procedure, which employs processes compatible with CMOS and back-end-of-line (BEOL) technologies, closely follows the method presented in ref. 52, differing only by the use of electron-beam lithography instead of optical lithography steps. A detailed description of the fabrication process is provided in Extended Data Fig. 1. Our memristors have an active area of 600 × 600 nm2 (Fig. 2b). The focused-ion-beam cross-section image (Fig. 2c) displays the deposited material stack.
Under direct current (d.c.) operation, the HfO2–CMO bilayer exhibits reproducible resistive switching properties, as demonstrated by the resistance–voltage (R–V) characteristics (Fig. 2d). Both transitions from the high-resistance state to the low-resistance state and from the low-resistance state to the high-resistance state are gradual. Such a behaviour originates from the modulation of oxygen vacancies within the CMO layer, and from the confinement of the electric field and temperature within the HfO2–CMO bilayer71. This confinement, in turn, enables controlled and continuous changes in electrical conductivity52,72. We also investigated synaptic potentiation and depression by stimulating our devices with identical pulse trains. Figure 2e reports ten full potentiation/depression cycles together with their mean values. The measurement data demonstrate a gradual and controlled switching during pulsed operations, resulting in multiple reproducible non-volatile states that represent the actor (θij) and critic (wj) weights in our actor–critic network (Fig. 1c).
We quantified the noise level in the potentiation and depression curves for multiple devices by subtracting the measurement data from their respective means (Fig. 2f). The obtained histogram serves as a measure of the update noise within our devices. The noise can be attributed to the read operation68, cycle-to-cycle variability and the measurement setup (Methods and Supplementary Fig. 3). Although protons and water molecules could be incorporated during layer deposition and are known to play a crucial role in the switching operation73, no detailed analysis was performed, as endurance measurements (not shown here) demonstrated reliable operation up to 108 programming cycles. The same applies to interfacial reactions, such as the possible oxidation of the TiN electrodes.
In-memory learning loop
Our actor–critic RL framework supports learning, that is, the adaptation of θij and wj, on both hardware and in-software-emulated memristors. The training of critic weights (actor weights work analogously) is depicted in Fig. 3a in the case of one-hot encoding: only one place cell is active at a time (Supplementary Note 1), which is effective if the state space is limited.

a, The learning procedure starts with the in-memory calculation of the desired weight update Δwdes through a subnetwork including three weights wfixed, wt+1 and wt. On the basis of the current location of the agent, the voltages U3 and U2 are applied to the two critic devices storing wt = V(st) and wt+1 = V(st+1). The value of Δwdes is then translated into the corresponding number Δp of update pulses, followed by the actual weight update on the memristor wt. Two sources of errors are introduced during the update: an error ϵ1 because of the nonlinear dependence of the weight update on the number Δp of applied voltage pulses and an error ϵ2 because of the inherent noise in the memristor updates. During the subsequent iteration, both error terms are taken into account and, therefore, compensated through the in-memory calculation of the next desired weight update (feedback). The update loop, thus, has capabilities to correct errors. b, Experimentally measured in-memory weight updates (Δwdes,meas) as a function of the expected software weight updates (Δwdes,exp). Δwdes,meas were measured out of the subnetwork in a, for various weights wt and wt+1, unit-free values within the range of 0–1, whereas wfixed has a fixed value of 1. Δwdes,exp was calculated with equation (3) using the values V(st+1) and V(st), within the range of 0–1, whereas r(st) has a fixed value of 1. The measured values of Δwdes are in good agreement with the calculated values, with their absolute difference never exceeding 0.03 (or 3%). Note that for both experiments and theory, a value of α = 0.2 was used, which, according to equation (3), implies that the weight updates cannot be larger than 0.2. c, Mean and error bars for the standard deviation of critic weights are compared between the cases with and without the error-correcting feedback as a function of the episode number. The results are extracted from 1,000 distinct simulated runs using an actor–critic RL scenario. The plot highlights the impact of the error correction mechanism on the variability of the learned weights.
The learning process begins with the calculation of the desired weight update in hardware (Fig. 3a(i)), denoted as Δwdes. This is done in memory by performing an in situ vector–vector multiplication using two critic memristors (wi and wi+1) along with a fixed-value resistor (wfixed) that has a weight equal to 1. Since in one-hot encoding, each critic weight stores the value V(s) of one state, wi and wi+1 are chosen such that they correspond to V(st) (current state) and V(st+1) (next state) and, thus, labelled wt and wt+1, respectively. In other words, the same memristors store the critic weights and are used to calculate the weight update. By applying the voltages U1 = α × r(st), U2 = α × γ and U3 = −α, to wfixed, wt+1 and wt, respectively, the desired weight update is obtained for the memristor storing wt:
The update is determined by measuring the total output current Itot resulting from the vector–vector multiplication. The detailed derivation is provided in the Methods and Supplementary Note 2, whereas the general case of beyond one-hot encoding with higher-dimensional input activations is discussed in Supplementary Note 7.
In the second part of the learning algorithm (Fig. 3a(ii)), the desired weight update Δwdes is converted into the number of update pulses Δp = Δwdes × N, assuming a linear potentiation and depression of the memristor conductance. Here Δwdes corresponds to the extracted output current Itot = Δwdes, and N is the total number of pulses, which is a constant (200 in our case). This conversion is currently done in software, but could be directly implemented on chip24,74,75.
As the third step of the learning loop, the conductance of the targeted memristor is updated by applying Δp pulses (Fig. 3a(iii)). The assumed linear ‘Δw versus Δp’ relationship during the calculation of Δp introduces an update error ϵ1 because of the nonlinearity of our memristors’ potentiation/depression curves (Fig. 2e). This error ϵ1 is particularly pronounced near the devices’ minimum and maximum conductance values (saturation regions), where deviations from linear weight updates are the largest (Extended Data Fig. 2). A second error ϵ2 arises because of update noise, as introduced in Fig. 2f. Both errors are automatically taken into account and, therefore, compensated for by the in-memory weight update calculation in the next iteration of the learning loop (Fig. 3a(iv)), leading to an error correction mechanism (Methods and Supplementary Note 4). The learning loop for in-software-emulated memristors is discussed in Supplementary Note 3.
Although ϵ1 impacts the weight update, the assumption of a linear update offers substantial advantages over more complex schemes76. In particular, it avoids read-outs of the current weights to determine the position within the potentiation/depression model curves and eliminates the need to store the true weight update curves of each memristor. Hence, faster and more energy-efficient in situ weight update processes are possible27.
The calculation of Δwdes in hardware assumes a linear ‘resistance versus voltage’ relationship and includes the measurement noise. We, thus, empirically verify the accuracy of the in-memory weight update evaluation through a comparison between the measured (Δwdes,meas) and expected (Δwdes,exp) weight updates (Fig. 3b) for different weight combinations of the two memristors involved, namely, wt and wt+1. In all combinations tested, we found good agreement between the experimental measurements and theoretical expectations, with an error below 3%.
To further examine the error-correcting properties of our approach, we consider the standard deviation of the trained critic weights across 1,000 independent training runs in a simulated actor–critic RL task (Fig. 3c; Methods). The incorporation of the error terms ϵ1 and ϵ2 into the calculation of the desired weight update is responsible for the error-correcting feedback loop. This results in reduced variability in the learned weights, as indicated by the lower standard deviation compared with the case in which the error terms are not compensated for: the errors do not accumulate over several episodes, but are trained away at every iteration. Furthermore, with error correction, the error bars become narrower, corresponding to a smaller spread in the weights.
Learning in discrete space using analogue memristors
The aforementioned analogue memristors are used to solve the T-maze navigation task (Fig. 1a) in discrete space. It involves an agent navigating through the maze and adapting its policy to locate a reward. The environment consists of nine states labelled 0–8 with the reward located in the left corner of the T-maze (state 6). The limited state space allows for the use of one-hot encoding to represent the agent’s current position in the maze. This means that only one place cell in Fig. 1c is active at a time, which directly corresponds to the agent’s location. This encoding eliminates the need for RBFs, and the activation xt is equal to the state st. Each place cell is then connected to two actor neurons that encode the possible actions and one critic neuron that computes a value estimate of the current location. The actions can either be ‘moving forwards/backwards’ (all states except state 4) or ‘moving left/right’ (state 4).
The concepts of online learning, in-memory weight update calculation and error correction presented in Fig. 3 are combined to realize bio-inspired learning in an actor–critic network. The latter comprises 27 synaptic weights, including 9 × 2 = 18 actor weights (θij) and 9 × 1 = 9 critic weights (wj). Each of these weights is implemented by a different hardware memristor (Methods). For every run, two out of the nine critic weights are represented by physical memristors and updated in hardware via online training. The same two hardware devices additionally implement the in-memory weight update calculation introduced in Fig. 3a. The outcome is the learned policy and the corresponding value map (Fig. 4a).

a, An agent must navigate through a T-maze environment made of nine states labelled 0–8 to reach a reward (state 6). Place cells represent the position of the agent and each of them corresponds to a distinct state in the environment (one-hot encoded). Two actor neurons encode forwards/backwards (all states except 4) or left/right movements (state 4). The single critic neuron computes an estimate of the value of a given state. The ideal policy and value maps are illustrated at the bottom. The synaptic weights connecting place cells to actor neurons (θij) and place cells to the critic neuron (wj) are implemented by memristors. For each run, two out of the nine critic memristors are implemented in hardware, whereas the behaviour of the other critic and all actor weights is emulated in software. Therefore, five distinct configurations were investigated to measure all critic weights in hardware: (w0, w1), (w2, w3), (w4, w5), w6 and (w7, w8), where each wj corresponds to a distinct device. The hardware memristors are updated in an online manner and perform the in-memory calculation of the desired update Δwdes. b, Measured critic weights w0–w8 (orange) over 200 episodes compared with the ideal software case (blue). The software curves correspond to the average of 1,000 distinct runs, with light blue indicating two standard deviations101. Each critic weight was implemented by a different memristor. c, Number of steps per episode required to reach the reward as a function of the episode number, extracted as the mean value from all the configurations shown in b. The learned policy approaches the optimal one (six steps between the initial position and the reward). d, Mean and error bars of the critic weights after 200 episodes for runs with in-software-emulated memristors (blue) compared with the experimental values (yellow crosses). The values of emulation are the average of 1,000 distinct runs, with the error bars indicating two standard deviations. e, Histogram showing the error between the measured (Δwdes,meas) and expected (Δwdes,exp) theoretical values for the in-memory calculation of the weight update. Δwdes,meas is obtained using equation (8) (Methods). f, Comparison between the experimental update error (top) and the update noise (bottom) extracted from the corresponding potentiation and depression curves. The update error is smaller or equal to the extracted update noise. The resulting accuracy allows for an exact tuning of the analogue memristor weights, thereby confirming the feasibility of in-memory/online learning. The dashed lines in the top histogram denote the hardware error limits shown in e. Panel a created with BioRender.com.
The measurements of the learned critic weights w0–w8 as a function of the episode number are displayed in Fig. 4b, together with the software runs that use ideal synaptic weights (continuous, linear and no noise). The measured curves follow the software runs, with the agreement being better for critic weights associated with states closer to the reward. Deviations between the measurements and ideal runs can be attributed to fluctuations related to the nonlinear potentiation/depression curves (error term ϵ1) and update noise (error term ϵ2). This non-ideal behaviour is the most evident at the start of training and for weights that remain small during training (that is, w0 – w2), where ϵ1 is the most pronounced. However, since these errors are fed back into the in-memory weight update calculation in subsequent iterations, they are gradually corrected over time.
We also tested the implementation of all actor weights in hardware using 18 different memristors (Supplementary Note 6). Extended Data Figure 3 presents the potentiation and depression curves of the memristors utilized for the hardware critic and actor weights. Overall, in-memory training, including online weight updates and weight update calculations, consumes 28.2 μJ of energy (Supplementary Note 8).
The agent initially finds the reward through random exploration, subsequently through the reinforcement of successful trajectories. With an increasing number of episodes, the agent predominantly exploits the stereotypical trajectory it has learned to reach the target. This behaviour can also be observed in Fig. 4c, which illustrates the number of steps required to reach the reward as a function of the episode number. At the beginning of the learning experiment, the number of steps is high because the actor weights are still small, resulting in random action choices. As the learning experiment progresses, the number of steps converges to the optimal trajectory of six steps (Fig. 4c, black dotted line). Even after the correct path has been learned (that is, after around 50 episodes), the finite temperature of the softmax action selection ensures continued exploration via random actions, thereby addressing the exploration–exploitation dilemma (Supplementary Fig. 4)11 and inducing slight fluctuations in the number of steps.
The values of the trained critic weights after the last episode are shown in Fig. 4d. The experimental data are compared with results from runs using only in-software-emulated memristors. All measurements fall within the error bars of the simulated values, proving that the in-software-emulated memristors closely replicate the learning of their physical counterparts.
Importantly, in our measured runs, the weight updates (Δwdes) are directly calculated in hardware, allowing for the entire learning loop to remain in memory. Hence, the algorithm operates without explicit read-outs of the weight values at any point, minimizing off-device computations. We only measured the critic weights for visualization purposes during training.
The in-memory weight update calculations introduce only minimal deviations from the targeted values (Fig. 4e), which reports the difference between the measured (Δwdes,meas) and expected (Δwdes,exp) in-memory weight update values. The absolute error stays below 0.04, consistent with the reference measurement shown in Fig. 3b. It becomes even more evident that the error in Δwdes is small, when compared with its counterpart introduced by the memristor weight update processes (Fig. 4f, top). Finally, we relate this update error to the overall update noise (Fig. 4f, bottom). The latter is extracted from the corresponding potentiation and depression characteristics of the measured memristors. The update error is smaller than or equal to the extracted update noise, suggesting that weight updates within the analogue programming process of our devices are very accurate, establishing the feasibility of online learning for our memristors.
Learning in continuous space using in-software-emulated memristors
To demonstrate that our framework can be applied to more complex problems and scaled up to larger memristor arrays, we set up the two-dimensional Morris water maze experiment (Fig. 1b)10,37,38,47 and perform simulations exclusively on the previously validated in-software-emulated memristors (Methods). In this task, the agent is randomly placed at a starting location in a water maze. Its goal consists of reaching a reward in the form of a hidden platform (Fig. 5a). Once this happens, a reward signal is released and the episode ends.

a, Illustration of the task objective. An artificial agent is placed at a random location in the maze (starting position; blue) and navigates through the maze (trajectory; blue) until it reaches the reward (hidden platform; red). To make the task more challenging, a U-shaped obstacle (grey) forces the agent to reach the reward from above10. For each step in the maze, the agent can select one out of eight actions (inset). The two-dimensional continuous state space is mapped to a grid of 11 × 11 overlapping place cells (black dots denote the centre of place cells). The closer the location of the agent to a place cell, the larger the input activation, given by Gaussian RBFs (green circles correspond to one standard deviation of the Gaussian function). b, Mean and standard deviation of the number of steps per episodes for 100 random seeds learned on in-software-emulated memristors (light blue) compared with the case in which the update noise is set to the minimum of all memristors (dark blue). The black dotted line indicates the mean and standard deviation achievable by a noiseless, ideal learner. Note that a random walk policy would take the agent 450 steps on average to find the reward. c, Mean policy map after training on in-software-emulated memristors. Each arrow points towards the average direction taken by the agent. The colour and length of these arrows are scaled according to the probability of taking the shown direction. From any initial position, actions leading to the target area are learned with increasing probabilities closer to the reward, as expected from ref. 10. d, Mean state value map after training. The closer the value is to the reward area, the higher is the learned value.
Figure 5b displays the number of required steps to reach the reward versus the episode number. Despite the presence of initially large fluctuations probably caused by the update error of the in-software-emulated memristors, the number of steps gradually converges to a mean value close to its optimum of around 6.5 steps obtained through software runs (black dotted line). We attribute this noise resilience to the error correction mechanism of our approach. Reducing the update noise of each device to the minimum value among all 27 memristors, while keeping the same potentiation/depression curves, allows the agent to more rapidly attain the reward and drastically reduce the number of episodes for convergence (Fig. 5b, dark blue line). A VCM technology with better controlled noise level, such as that demonstrated in ref. 77, would, therefore, lead to a faster convergence of the learning process, as indicated by the simulation results shown in Extended Data Fig. 4. Moreover, additional simulations revealed that more linear weight update curves are beneficial (Extended Data Fig. 5 and Supplementary Fig. 5).
To gain further insight into the learning process of in-software-emulated memristors, we examine their synaptic weights for the actor (policy map) and critic (value map) networks after training. Figure 5c displays the mean policy map at every possible position of the agent. The vectors represent the most likely action to be chosen at each location in the maze, whereas their length and colour correspond to the probability of that action. Regardless of the starting position, the learned actions lead the agent directly towards the reward. As expected, the action probability is higher for positions close to the reward10. Although the maze is symmetric, the action vector field shows slight asymmetries, which are attributed to the nonlinearity of the weight update curves and to the update noise. The corresponding state values at each position are plotted as a colour map (Fig. 5d).
These software results indicate that our framework can potentially be implemented on a physical VCM crossbar array to perform the Morris water maze navigation task. A possible realization is proposed in Supplementary Note 7. Its energy consumption for operations executed on memristors is estimated to be 20 times (39 times) lower than that of a standard memristor (GPU) RL implementation using the backpropagation algorithm (Extended Data Table 1 and the ‘Energy consumption and latency estimation of a crossbar-level implementation’ section).
Discussion
We implemented actor–critic TD learning on analogue memristors to mimic biological reward-based learning. In contrast to other memristor-based systems (Methods and Supplementary Table 1), our approach takes advantage of a local three-factor learning rule, which allows for full in-memory training with memristors acting as synaptic weights and directly calculating weight updates. We demonstrated learning on our analogue computing platform by first implementing the T-maze navigation task. For that purpose, we made use of the controllable and gradual switching properties of our devices and showed that the learned weights are close to the ideal values obtained in software. A quantification of the error in the in-memory weight update calculation proved that our approach is highly accurate. Although our framework was tested with HfO2–CMO bilayer memristors, it is compatible with any memristive hardware. As an outlook for future work, we applied our framework to a complex biologically plausible learning task with a two-dimensional continuous state space, inspired by the Morris water maze experiment. Overall, our results lay the groundwork for full in-memory operations of neuromorphic chips and for the realization of computing engines that are built similar to their biological counterparts. For example, we envision that our framework could be utilized for real-time navigation in autonomous robots. First, our memristors should be integrated into crossbar arrays, allowing for larger-scale demonstrations of TD learning, where all actor and critic weights are stored and updated simultaneously in hardware. Our scheme could also be extended with eligibility traces9,11, a biologically inspired technique to accelerate the convergence time of RL experiments.
Methods
Place cells
The position of the RL agent is encoded by n place cells60 with activities (x1; x2…xn) = xt, which serve as the input layer to the actor–critic network shown in Fig. 1c. Their construction and functionality are described elsewhere60,78. We adopt the same principles here to encode the spatial information. Specifically, in continuous spatial environments, an effective input representation of the environment is achieved through a fixed layer using RBFs, where each place cell is active in a specific region. The use of place cells is instrumental in reducing the size and complexity of actor–critic networks. Given the position of the agent in the place-cell representation, a single subsequent layer is sufficient to learn complex navigation tasks. This contrasts with deep RL networks, which require the training of potentially many hidden layers to achieve useful input representations79.
Action selection and Hebbian term
The actor network assigns a synaptic weight θij to the connection of place cells j (pre-synaptic) to the actor neurons i (post-synaptic), where each neuron i represents a different action ai. The activity of an action neuron i is given by
where xj denotes the pre-synaptic activity (that is, activity of the place cells). hi determines the probability of selecting action ai in the momentary state st through the softmax policy π(i∣st) (ref. 11):
where k is the number of possible actions and T is the softmax temperature parameter. The latter determines the balance between exploration (executing random actions) and exploitation (application of the learned actions)11, with a higher value resulting in increased exploration. In our actor–critic framework, actions are dynamically learned and become increasingly more certain over time as the actor weights grow. Together with the temperature parameter, which ensures continued exploration, even if the actor network favours a particular action, these two mechanisms help prevent the overexploitation of suboptimal trajectories.
The Hebbian term H(i, j) in equation (1) is a combination of signals that are locally available to the synapse, namely, the pre-synaptic activity xj and the post-synaptic activity hi. It is defined in our model as
where i* is the post-synaptic action neuron that fired following the chosen action.
Experimental setups
The d.c. characterization of the memristors were performed with the B2912A source measure unit from Keysight. The bottom electrode (TiN) was grounded, whereas the top electrode (W) was biased with a positive or negative voltage. Neither current compliance nor external series resistor was used during the d.c. measurements as the current passing through the device was self-limited by the active layers of the memristor. The electrical measurements of the dynamic characterization were conducted using the 33500B arbitrary waveform generator from Keysight in combination with the RTE1102 oscilloscope from Rhode & Schwarz and a 10-kΩ series resistance. The conductance states of the potentiation and depression curves were determined via the voltage drop across the resistor. For the hardware weight update calculation and the weight updates, two 33500B arbitrary waveform generators from Keysight were combined with the DHPCA-100 amplifier from FEMTO and the RTE1102 oscilloscope from Rhode & Schwarz. More details about the different experimental setups are given in Supplementary Figs. 3 and 7. All the memristor weight updates were performed using identical pulses: 2.5 V with 1.5-μs width for potentiation, and –2.7 V with 10-μs width for depression, with 200 pulses spanning the full conductance range.
Derivation of the in-memory weight update calculation
The formulas for the in-memory weight update calculation used in the T-maze task are summarized in this section. The learning rule for the critic weight can be rewritten as a scalar product:
Here α represents the learning rate, r(st) is the reward at state st, γ is the discount factor, V(st+1) and V(st) are the value estimates and Hcri(j) is the Hebbian term of the critic. The latter is equal to 1 (that is, Hcri(j) = 1) in the case of one-hot encoding, as only one entry of the input vector xt is non-zero. As shown in Fig. 3a, this scalar product can be implemented with two memristors wt+1 and wt from the critic network and one resistor wfixed, which are wired together in one row. In this manner, the first vector of the weight update can be mapped to the input voltages U1 = α × r(st), U2 = α × γ and U3 = − α and the second vector to the weights wfixed = 1, wt+1 = V(st+1) and wt = V(st).
Since the reward term α × r(st) is a feedback signal from the environment of the navigation task, it is implemented by the applied voltage U1 and requires wfixed to be equal to one. A resistor is, thus, chosen to represent this constant term, but it could also be implemented using another memristor with a fixed conductance. In practice, the memristor conductances need to be converted to normalized weights, which results in adjusted input voltages U1–U3. A detailed explanation of the mathematical derivation of these voltages is provided in Supplementary Note 2.
Error correction mechanism
In navigation tasks, when moving between states in its environment, an agent strives to choose actions that maximize the amount of reward it collects. A difference between the actual (the immediate reward the agent receives) and expected (the predicted reward the agents anticipates if it follows its current strategy) reward leads to a non-zero TD error 3rd (equation (2)), which updates the actor θij and critic weights wj according to equation (1). This iterative adjustment of the weights drives the agent’s learning process towards a near-optimal set of state values V(st) and policy π(i∣st).
Our actor–critic RL framework calculates the weight updates Δwdes directly in hardware through a subnetwork of two critic memristors (wt and wt+1) along with a fixed-value resistor (wfixed) (Fig. 3a). Two sources of errors are introduced during the actual update: an error ϵ1 because of the nonlinear dependence of the weight update on the number Δp of applied voltage pulses and an error ϵ2 because of the inherent noise in the memristor updates. Neither ϵ1 nor ϵ2 are known during the hardware update and are, therefore, contained in the new weight after the update. However, as the new weights directly represent the value estimates of the current (V(st)) and next (V(st+1)) state through wt and wt+1, respectively, both error terms are taken into account during the subsequent iteration and, therefore, compensated through the in-memory calculation of the next desired weight update (Fig. 3a(iv)). They are, thus, trained away by the algorithm11, leading to an error correction mechanism. Similar mechanisms are present in other online training algorithms on memristors. However, these implementations require an external computation of the weight update to account for these error terms (that is, the gradient of the loss function in backpropagation is computed in software), preventing full in-memory training. By contrast, in our approach, the weight updates are computed in hardware according to equation (3) and implemented by the scheme shown in Fig. 3a. A mathematical description of the error correction mechanism is provided in Supplementary Note 4.
The error correction mechanism can compensate for non-idealities such as update noise or conductance drift. As such, it can also adapt to potential device degradation that occurs over long timescales. If conductance values change over time, the TD error is no longer equal to zero, naturally triggering retraining and thereby mitigating other hardware non-idealities as well. However, this requires that devices remain reprogrammable after degradation, that is, no permanent device failure has occurred.
We also investigated the impact of read accuracy (Fig. 3b) during the hardware weight update calculation on convergence. Specifically, we analysed how variations in this accuracy affect the convergence in the Morris water maze task (Supplementary Fig. 6). The simulation results show that our measured read accuracy has a negligible impact on the convergence and performs similarly to the ideal case with perfect accuracy.
Evaluation of the error correction mechanism
The error correction mechanism was tested by solving the T-maze navigation task illustrated in Fig. 4 with in-software-emulated memristors and by inspecting the resulting standard deviation of the critic weights wj as a function of the episode number. Specifically, we compared the case in which the errors ϵ1 (resulting from linear updates on nonlinear potentiation/depression curves) and ϵ2 (update noise) were included in the in-memory weight update calculation of the next iteration (with feedback) to the case in which they were omitted (no feedback). In the case where ϵ1 and ϵ2 were not fed back, errors were accumulated over different iterations of the learning algorithm, resulting in a higher standard deviation of the learned weights and a larger spread in the weights. We conducted 1,000 distinct simulated runs and extracted the mean along with error bars representing two standard deviations.
Implementation of the T-maze experiment
The algorithm used for the T-maze experiment is based on the equations of TD learning presented in the ‘Analogue memristor synapses as active components of actor–critic networks’ section. The TD error (equation (2)) adapts the actor and critic synapses based on the learning rules given in equation (1) with the adjustable learning parameters α, γ and T. The reward function r(st) is equal to 1 for state 6 (where a reward is present) and 0 otherwise. In all the runs, we set the discount factor γ to 0.9. Moreover, the optimal parameters for the learning rate and softmax temperature are determined through a grid search of simulated runs using in-software-emulated memristors (Supplementary Note 5), which yields α = 0.2 and T = 0.3, respectively. For all the experiments, the reward was placed in the left corner of the T-maze (state 6). Although the task involved a static reward, our actor–critic framework is also capable of learning in dynamic environments in which the reward location changes slowly over time, either smoothly or abruptly. In such cases, the actor and critic weights would slowly adapt through updates driven by the TD error. The speed of relearning could be increased further by the use of a global signal conveying uncertainty or surprise37,80,81.
As mentioned in the main text, the actor–critic network comprises 27 synaptic weights in total, including 9 × 2 = 18 actor weights (θij) and 9 × 1 = 9 critic weights (wj). Each of these weights is implemented by a different hardware memristor. In each run, two out of the nine critic weights are represented by physical devices and updated in hardware via online training. Due to experimental constraints (Supplementary Fig. 7), we are limited to operating and training only two memristors per run at the same time. The behaviour of the other critic and actor weights is, thus, emulated in software. Each of them relies on the fitted characteristics of a distinct memristor, including its potentiation/depression curves, cycle-to-cycle variability, nonlinearity and update noise (Extended Data Fig. 6 shows the measured potentiation and depression curves of all 27 in-software-emulated memristors). The same two hardware devices additionally implement the in-memory weight update calculation, as introduced in Fig. 3a.
Due to experimental constraints, including the availability of only four probe needles on the probe station and a limited number of output channels on the arbitrary waveform generators, we were restricted to operating and updating two memristors in parallel per run.
Implementation of the Morris water maze experiment
As the simulated environment is continuous, Gaussian RBFs are used as the input layer of our actor–critic network (Fig. 1c). They create a representation of the current agent’s location in the maze, which is encoded by the activation xt of 121 overlapping RBFs that are centred at evenly spaced grid points in an 11 × 11 layout. The components of xt become larger as the agent moves closer to the corresponding grid point. The representation of positions through an RBF input layer enables to solve the complex water maze navigation task in continuous space by learning actions and state values in a single subsequent layer, thereby substantially reducing the required neural network size compared with multilayer networks11,37,38. Our choice of a fixed RBF grid with evenly spaced grid points is sufficient for the types of task analysed in this work, where the reward location is static and the environment obstacles placed uniformly across the space. However, if it is not known a priori where higher spatial resolution is needed, a more flexible place-cell representation would be advantageous. For example, self-organizing maps or similar unsupervised algorithms could be employed, as they typically rely on local learning rules58,61,82, and are, therefore, fully compatible with our in situ, local learning framework.
To navigate through the maze, the agent chooses among eight possible actions (Fig. 5a). Following the actor–critic network shown in Fig. 1c, each place cell is connected to one critic neuron and eight action neurons. In total, the actor–critic network comprises 1,089 synaptic weights, including 121 × 1 critic weights and 121 × 8 = 968 actor weights. The behaviour of all these weights is emulated in software, with all the weights initialized to zero, which showed the fastest convergence (Supplementary Fig. 8). We use the same 27 potentiation/depression measurements as in the T-maze (Extended Data Fig. 6) as the basis for the in-software-emulated memristors. Although the number of weight update curves is much smaller than the total number of synaptic weights, device-to-device variability is captured by randomly assigning these measured curves to the network weights. For each device, the emulated weight updates incorporate cycle-to-cycle variability, nonlinearity and update noise. Compared with the T-maze case in which distinct cycles were chosen at each iteration, here cycle-to-cycle variability and update noise are combined within a single error term \(\sigma\). For each memristor, this parameter is extracted from overlapping all ten measurement potentiation/depression cycles (similar to Fig. 2f). By varying \(\sigma\), we can properly investigate the effect of the total update error on our simulation runs. Moreover, we analysed the impact of actor weight initialization and granularity (that is, the number of pulses between minimum and maximum conductance) on the convergence speed (Supplementary Fig. 8).
Extension to deep networks
In our navigation framework, a single RBF-based input layer is sufficient to encode a representation of the environment. This representation is rich enough for learning actions and state values in a single subsequent layer, making deep RL unnecessary58,61,62. A representation with approximate RBFs could be the result of a generic preprocessing pipeline, for example, with a deep convolutional neural network that serves as a foundation model and transforms arbitrary input images, or other sensor data, into high-level representations61,83,84,85. All weights of the preprocessing pipeline could be mapped onto memristors, with each layer implemented as a crossbar array. Only the last layer—the actor–critic one—would be trained in situ on a specific task, using our three-factor learning rule and in-memory weight update scheme.
One limitation of the proposed approach is the limited adaptability to new environments due to the fixed input layer(s). The application of three-factor learning rules with local plasticity to the case of self-supervised representation learning provides an alternative to extend our approach to deep neural networks84,86,87. These biologically inspired learning rules rely on layer-specific loss functions and eliminate the need for the backpropagation of error signals. To illustrate this, we have used the local three-factor rule, named CLAPP84,88, in simulation in a deep network comprising six layers. The deep network was pretrained on the STL10 database. We then kept the weights fixed and applied inputs from simulated views of a three-dimensional T-maze environment with images on the walls (Supplementary Fig. 9). The representation layer (layer 6 of the deep network) was rich enough that it could be used as input to our simulated (one-layer) actor–critic network, which learns the navigation task in fewer than 20 trials. However, these rules are currently an active field of research and it is too early to attempt an implementation memristor-based architectures.
Comparison with other RL algorithms and local learning rules based on backpropagation approximations
The actor–critic TD learning algorithm lends itself particularly well to an in-memory implementation compared with the most-common RL algorithms such as Q-learning, SARSA or Monte Carlo methods11. Whereas Monte Carlo methods are not compatible with online learning11, Q-learning is an online, although off-policy method, which prevents efficient in-memory weight updates. SARSA theoretically allows for a similar hardware implementation as TD learning with actor–critic networks, but the latter directly learns and updates the action policy over time, a feature that makes it both resistant to function approximation errors and better suited to complex environments11. Since our bio-inspired algorithm employs RBFs to represent the agent’s location, a single subsequent layer combined with a local learning rule is sufficient to learn both actions and state values, realizing complex navigation tasks38,58,61. Owing to the local learning rule, only individual weight updates on a small subset of all memristor devices are performed.
Within our developed framework, hardware memristors are not only employed as synaptic weights for online learning but also for the calculation of weight updates. Compared with existing in-memory weight update calculations, where updates are solely based on the sign of the weight change and thus imprecise31,32, our method computes exact weight updates. When updating the memristors, no additional error mitigation schemes such as write–verify algorithms are necessary as opposed to other weight update schemes89,90, thereby simplifying the control circuitry27,31,91. Hence, the proposed approach minimizes off-device computations and avoids weight read-outs so that the main task of the software reduces to environment interactions.
Our methodology contrasts with modern deep RL methods such as deep Q-networks and proximal policy operation (PPO) that rely on error backpropagation across multiple layers11 and are, therefore, less biologically plausible18 than our actor–critic TD learning approach, where both actions and state values are learned using a single layer. We note that deep RL methods14 train all layers on a given task or set of tasks13. However, in our approach, we assume that a good representation of the environment can be achieved independently of the task, using, as preprocessing, a foundation model trained with modern self-supervised learning algorithms92,93,94,95 on large datasets. In line with existing foundation models, we expect that a representation built by the foundation model is useful for many different tasks. Most importantly, although deep RL algorithms have demonstrated strong performance in many deep RL tasks13, they go beyond what is needed to solve navigation tasks38,58,61. In Extended Data Fig. 7, we directly compare our actor–critic TD learning algorithm with PPO and R-STDP implementations on the Morris water maze task, using the same RBF input representation and an identical network structure consisting of a single layer. While the software implementations of actor–critic TD learning and PPO achieve similar performance, the memristor emulation performs slightly worse due to the presence of non-idealities in the weight updates, and R-STDP does not converge at all. Unlike TD learning, where weight updates happen whenever a non-zero TD error (a reward prediction error) is present, updates in R-STDP only take place when the reward is reached.
As an alternative to directly implementing local three-factor learning rules, yet avoiding the biological limitations of backpropagation, several approximations of the backpropagation algorithm have emerged in recent years18. A notable example is the proposed memristor-based architecture employing direct feedback alignment96. Although these methods are compelling, it is important to highlight a key distinction: in our framework, the TD error acts as a scalar, one-dimensional global error signal, in contrast to the high-dimensional error signals used in both backpropagation and direct feedback alignment. This scalar error enables fully local learning by eliminating the need for network-wide error propagation (as required in direct feedback alignment) and allows the same modulatory signal to be broadcast uniformly to all synapses, unlike the synapse-specific feedback used in approaches such as that in ref. 96.
Energy consumption and latency estimation of a crossbar-level implementation
The energy consumption and latency of the actor–critic TD learning algorithm was calculated, focusing specifically on the operations that can be performed in hardware to highlight the potential of a crossbar implementation of our framework (Extended Data Table 1). We compared three different cases: ‘this work’, ‘hybrid’ and ‘software’, where ‘hybrid’ refers to other works that employ memristors within the RL algorithm and ‘software’ to an implementation without memristors. Each algorithmic operation performed in ‘software’ is assumed to be executed on an NVIDIA A100 40-GB GPU. The operations performed in ‘hardware’ are assumed to be implemented on a crossbar array, namely, the one proposed in Supplementary Note 7. For both GPU and memristor operations, we consider a ‘standard’ case and an ‘optimal’ case, as well as a ‘compute’ scenario specifically for the GPU. The GPU is ideally fully utilized (‘optimal’ case), which results in the lowest latency and energy consumption, whereas ‘standard’ is a more realistic utilization scenario, such as that in ref. 97. ‘Compute’ provides a reference for the energy consumed solely by computation, excluding any overhead from fetching or storing weights in memory. As basis for the energy and latency calculations, we employ the values presented in Table 2 and Supplementary Table S1 of ref. 97. For the memristor implementations, we consider a standard case using the pulse widths employed in this work, as well as an optimal case with a 60-ns pulse width for all the operations, similar to what has been demonstrated in the past for the same HfO2–CMO cells98 (Supplementary Note 8 provides more details on the effect of the pulse width on energy consumption). Furthermore, we assume all memristors to be in the low-resistance state of 50 μS, and that each weight update consists of three reset pulses of 10 μs (standard case) or four set pulses of 60 ns (optimal case), each representing the worst-case scenario in terms of energy consumption during the water maze emulation. For all vector–matrix and vector–vector calculations, we consider the same mapping that we used in the hardware calculation of Δw in the T-maze, which results in a maximum voltage of 0.1 V applied to a memristor. Here we assume that 0.1 V is applied to all memristors during the vector–matrix and vector–vector calculations.
In the analysis of energy consumption and latency, we did not include the contribution of the peripheral circuitry. Analogue-to-digital digital-to-analogue converters are typically the main contributors to the energy consumption of memristor-based systems99. To minimize their negative impact, our framework avoids converting data between the digital and analogue domains by computing as many components of the algorithm as possible in memory. This is expected to further reduce the energy consumption and latency compared with other memristor-based systems.
Data availability
The figure files used in this study are available via Zenodo at https://doi.org/10.5281/zenodo.15740718 (ref. 100), whereas the datasets for the T-maze and Morris water maze experiments are available via GitHub at https://github.com/ztill/TD_learning_on_memristors/.
Code availability
The source code for the TD learning framework is available via Zenodo at https://doi.org/10.5281/zenodo.17315889 (ref. 101) and via GitHub at https://github.com/ztill/TD_learning_on_memristors/.
References
Caporale, N. & Dan, Y. Spike timing–dependent plasticity: a Hebbian learning rule. Annu. Rev. Neurosci. 31, 25–46 (2008).
Frémaux, N. & Gerstner, W. Neuromodulated spike-timing-dependent plasticity, and theory of three-factor learning rules. Front. Neural Circuits 9, 85 (2016).
Markram, H., Gerstner, W. & Sjöström, P. J. Spike-timing-dependent plasticity: a comprehensive overview. Front. Synaptic Neurosci. 4, 2 (2012).
Rathi, N., Agrawal, A., Lee, C., Kosta, A. K. & Roy, K. Exploring spike-based learning for neuromorphic computing: prospects and perspectives. In Proc. IEEE International Electron Devices Meeting (IEDM) 902–907 (IEEE, 2021).
Olshausen, B. A. & Field, D. J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 381, 607–609 (1996).
Kempter, R., Gerstner, W. & van Hemmen, J. L. Hebbian learning and spiking neurons. Phys. Rev. E 59, 4498–4514 (1999).
Zenke, F., Agnes, E. & Gerstner, W. Diverse synaptic plasticity mechanisms orchestrated to form and retrieve memories in spiking neural networks. Nat. Commun. 6, 6922 (2015).
Schultz, W., Dayan, P. & Montague, P. R. A neural substrate of prediction and reward. Science 275, 1593–1599 (1997).
Gerstner, W., Lehmann, M., Liakoni, V., Corneil, D. & Brea, J. Eligibility traces and plasticity on behavioral time scales: experimental support of neohebbian three-factor learning rules. Front. Neural Circuits 12, 53 (2018).
Frémaux, N., Sprekeler, H. & Gerstner, W. Reinforcement learning using a continuous time actor-critic framework with spiking neurons. PLoS Comput. Biol. 9, e1003024 (2013).
Sutton, R. S. & Barto, A. G. Reinforcement Learning: An Introduction (MIT Press, 2018).
Neftci, E. O. & Averbeck, B. B. Reinforcement learning in artificial and biological systems. Nat. Mach. Intell. 1, 133–143 (2019).
Mnih, V. et al. Human-level control through deep reinforcement learning. Nature 518, 529–533 (2015).
Li, Y. Deep reinforcement learning: an overview. Preprint at https://arxiv.org/abs/1701.07274 (2017).
Silver, D. et al. Mastering the game of Go without human knowledge. Nature 550, 354–359 (2017).
Kaufmann, E. et al. Champion-level drone racing using deep reinforcement learning. Nature 620, 982–987 (2023).
AlMahamid, F. & Grolinger, K. Reinforcement learning algorithms: an overview and classification. In Proc. IEEE International Conference on Big Data (Big Data) 1–7 (IEEE, 2021).
Lillicrap, T. P., Santoro, A., Marris, L., Akerman, C. J. & Hinton, G. Backpropagation and the brain. Nat. Rev. Neurosci.21, 335–346 (2020).
Xia, Q. & Yang, J. J. Memristive crossbar arrays for brain-inspired computing. Nat. Mater. 18, 309–323 (2019).
Gokmen, T. & Vlasov, Y. Acceleration of deep neural network training with resistive cross-point devices: design considerations. Front. Neurosci. 10, 333 (2016).
Mead, C. Neuromorphic electronic systems. Proc. IEEE 78, 1629–1636 (1990).
Furber, S. Large-scale neuromorphic computing systems. J. Neural Eng. 13, 051001 (2016).
Christensen, D. V. et al. 2022 roadmap on neuromorphic computing and engineering. Neuromorph. Comput. Eng. 2, 022501 (2022).
Sebastian, A., Le Gallo, M., Khaddam-Aljameh, R. & Eleftheriou, E. Memory devices and applications for in-memory computing. Nat. Nanotechnol. 15, 529–544 (2020).
Orchard, G. et al. Efficient neuromorphic signal processing with Loihi 2. In Proc. IEEE Workshop on Signal Processing Systems (SiPS) 254–259 (IEEE, 2021).
Mehonic, A. et al. Memristors—from in-memory computing, deep learning acceleration, and spiking neural networks to the future of neuromorphic and bio-inspired computing. Adv. Intell. Syst. 2, 2000085 (2020).
Yu, S. Neuro-inspired computing with emerging nonvolatile memorys. Proc. IEEE 106, 260–285 (2018).
Li, Y., Wang, Z., Midya, R., Xia, Q. & Yang, J. J. Review of memristor devices in neuromorphic computing: materials sciences and device challenges. J. Phys. D: Appl. Phys. 51, 503002 (2018).
Yang, J. J., Strukov, D. B. & Stewart, D. R. Memristive devices for computing. Nat. Nanotechnol. 8, 13–24 (2013).
Emboras, A. et al. Opto-electronic memristors: prospects and challenges in neuromorphic computing. Appl. Phys. Lett. 117, 230501 (2020).
Zhang, W. et al. Edge learning using a fully integrated neuro-inspired memristor chip. Science 381, 1205–1211 (2023).
Gao, B. et al. Memristor-based analogue computing for brain-inspired sound localization with in situ training. Nat. Commun. 13, 2026 (2022).
Sarwat, S. G., Moraitis, T., Wright, C. D. & Bhaskaran, H. Chalcogenide optomemristors for multi-factor neuromorphic computation. Nat. Commun. 13, 2247 (2022).
Sun, Y. et al. Ferroelectric polarized in transistor channel polarity modulation for reward-modulated spike-time-dependent plasticity application. J. Phys. Chem. Lett. 13, 10056–10064 (2022).
Shi, C., Lu, J., Wang, Y., Li, P. & Tian, M. Exploiting memristors for neuromorphic reinforcement learning. In Proc. IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS) 1–4 (IEEE, 2021).
Vlasov, D. et al. Memristor-based spiking neural network with online reinforcement learning. Neural Netw. 166, 512–523 (2023).
Foster, D., Morris, R. & Dayan, P. Models of hippocampally dependent navigation using the temporal difference learning rule. Hippocampus 10, 1–16 (2000).
Arleo, A. & Gerstner, W. Spatial cognition and neuro-mimetic navigation: a model of hippocampal place cell activity. Biol. Cybern. 83, 287–299 (2000).
Amo, R. et al. A gradual temporal shift of dopamine responses mirrors the progression of temporal difference error in machine learning. Nat. Neurosci. 25, 1082–1092 (2022).
Schultz, W. Dopamine reward prediction error coding. Dialogues Clin. Neurosci. 18, 23–32 (2016).
Averbeck, B. & O’Doherty, J. P. Reinforcement-learning in fronto-striatal circuits. Neuropsychopharmacology 47, 147–162 (2022).
Joel, D., Niv, Y. & Ruppin, E. Actor–critic models of the basal ganglia: new anatomical and computational perspectives. Neural Netw. 15, 535–547 (2002).
Barto, A. G. in Models of Information Processing in the Basal Ganglia 215–232 (MIT Press, 1995).
Houk, J. C., Adams, J. L. & Barto, A. G. in Models of Information Processing in the Basal Ganglia 249–270 (MIT Press, 1995).
Takahashi, Y., Schoenbaum, G. & Niv, Y. Silencing the critics: understanding the effects of cocaine sensitization on dorsolateral and ventral striatum in the context of an actor/critic model. Front. Neurosci. 2, 282 (2008).
Kim, D. et al. An overview of processing-in-memory circuits for artificial intelligence and machine learning. IEEE J. Emerg. Sel. Top. Circuits Syst. 12, 338–353 (2022).
Morris, R. G. Spatial localization does not require the presence of local cues. Learn. Motiv. 12, 239–260 (1981).
D’Hooge, R. & De Deyn, P. P. Applications of the Morris water maze in the study of learning and memory. Brain Res. Rev. 36, 60–90 (2001).
Wenk, G. L. Assessment of spatial memory using the T maze. Curr. Protoc. Neurosci. 4, 8.5B (1998).
Wu, W. et al. Improving analog switching in HfOx-based resistive memory with a thermal enhanced layer. IEEE Electron Device Lett. 38, 1019–1022 (2017).
Stecconi, T. et al.Filamentary TaOx/HfO2 ReRAM devices for neural networks training with analog in-memory computing. Adv. Electron. Mater. 8, 2200448 (2022).
Falcone, D. F. et al. Physical modeling and design rules of analog conductive metal oxide-HfO2 RERAM. In Proc. IEEE International Memory Workshop 1–4 (IEEE, 2023).
Stecconi, T. et al. Role of conductive-metal-oxide to HfOx interfacial layer on the switching properties of bilayer TaOx/HfOx ReRAM. In Proc. IEEE 52nd European Solid-State Device Research Conference (ESSDERC) 297–300 (IEEE, 2022).
Watabe-Uchida, M., Eshel, N. & Uchida, N. Neural circuitry or reward prediction error. Annu. Rev. Neurosci. 40, 373–394 (2017).
Dhawale, A. K., Wolff, S. B., Ko, R. & Ölveczky, B. P. The basal ganglia control the detailed kinematics of learned motor skills. Nat. Neurosci. 24, 1256–1269 (2021).
Kelley, A. & Domesick, V. The distribution of the projection from the hippocampal formation to the nucleus accumbens in the rat: an anterograde- and retrograde-horseradish peroxidase study. Neuroscience 7, 2321–2335 (1982).
Trouche, S. et al. A hippocampus-accumbens tripartite neuronal motif guides appetitive memory in space. Cell 176, 1393–1406 (2019).
Sheynikhovich, D., Chavarriaga, R., Strosslin, T., Arleo, A. & Gerstner, W. Is there a geometric module for spatial orientation? Insights from a rodent navigation model. Psychol. Rev. 116, 540–566 (2009).
Geerts, H., Chersi, F., Stachenfeld, K. & Burgess, N. A general model of hippocampal and dorsal striatal learning and decision making. Proc. Natl Acad. Sci. USA 117, 31427–31437 (2020).
O’Keefe, J. & Dostrovsky, J. The hippocampus as a spatial map: preliminary evidence from unit activity in the freely-moving rat. Brain Res. 34, 171–175 (1971).
Strösslin, T., Sheynikhovich, D., Chavarriaga, R. & Gerstner, W. Robust self-localisation and navigation based on hippocampal place cells. Neural Netw. 18, 1125–1140 (2005).
Wu, Y., Wang, H., Zhang, B. & Du, K.-L. Using radial basis function networks for function approximation and classification. Int. Sch. Res. Not. 2012, 324194 (2012).
Lisman, J., Grace, A. & Duzel, E. A neoHebbian framework for episodic memory; role of dopamine-dependent late LTP. Trends Neurosci. 34, 536–547 (2011).
Roelfsema, P. & Holtmaat, A. Control of synaptic plasticity in deep cortical networks. Nat. Rev. Neurosci. 19, 166–180 (2018).
Wu, N., Vincent, A., Strukov, D. & Xie, Y. Memristor hardware-friendly reinforcement learning. Preprint at https://arxiv.org/abs/2001.06930 (2020).
Wang, Z. et al. Reinforcement learning with analogue memristor arrays. Nat. Electron. 2, 115–124 (2019).
Bianchi, S. et al. A self-adaptive hardware with resistive switching synapses for experience-based neurocomputing. Nat. Commun. 14, 1565 (2023).
Lin, Y. et al. Uncertainty quantification via a memristor Bayesian deep neural network for risk-sensitive reinforcement learning. Nat. Mach. Intell. 5, 714–723 (2023).
Sekar, D. C. et al. Technology and circuit optimization of resistive RAM for low-power, reproducible operation. In Proc. IEEE International Electron Devices Meeting (IEDM) 28.3.1–28.3.4 (IEEE, 2014).
Cüppers, F. et al. Exploiting the switching dynamics of HfO2-based ReRAM devices for reliable analog memristive behavior. APL Mater. 7, 091105 (2019).
Falcone, D. F. et al. Analytical modelling of the transport in analog filamentary conductive-metal-oxide/HfOx ReRAM devices. Nanoscale Horiz. 9, 775–784 (2024).
Galetta, M. et al. Compact model of conductive-metal-oxide/HfOx analog filamentary ReRAM devices. In Proc. IEEE European Solid-State Electronics Research Conference (ESSERC) 749–752 (IEEE, 2024).
Valov, I. & Tsuruoka, T. Effects of moisture and redox reactions in VCM and ECM resistive switching memories. J. Phys. D: Appl. Phys. 51, 413001 (2018).
Yao, P. et al. Fully hardware-implemented memristor convolutional neural network. Nature 577, 641–646 (2020).
Shafiee, A. et al. ISAAC: a convolutional neural network accelerator with in-situ analog arithmetic in crossbars. ACM SIGARCH Comput. Archit. News. 44, 14–26 (2016).
Portner, K. et al. Analog nanoscale electro-optical synapses for neuromorphic computing applications. ACS Nano 15, 14776–14785 (2021).
Rao, M. et al. Thousands of conductance levels in memristors integrated on CMOS. Nature 615, 823–829 (2023).
Lowe, D. & Broomhead, D. Multivariable functional interpolation and adaptive networks. Complex Syst. 2, 321–355 (1988).
Gupta, J. K., Egorov, M. & Kochenderfer, M. J. Cooperative multi-agent control using deep reinforcement learning. In Proc. International Conference on Autonomous Agents and Multiagent Systems Workshops 66–83 (Springer, 2017).
Yu, A. & Dayan, P. Uncertainty, neuromodulation, and attention. Neuron 46, 681–692 (2005).
Xu, A., Modirshanechi, A., Lehmann, M., Gerstner, W. & Herzog, M. Novelty is not surprise: human exploratory and adaptive behavior in sequential decision-making. PLOS Comput. Biol. 17, e1009070 (2021).
Kohonen, T. Physiological interpretation of the self-organizing map algorithm. Neural Netw. 6, 895–905 (1993).
Sünderhauf, N., Shirazi, S., Dayoub, F., Upcroft, B. & Milford, M. On the performance of ConvNet features for place recognition. In Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 4297–4304 (IEEE, 2015).
Illing, B., Ventura, J., Bellec, G. & Gerstner, W. Local plasticity rules can learn deep representations using self-supervised contrastive predictions. Adv. Neural Inf. Process. Syst. 34, 30365–30379 (2021).
Novo, A., Lobon, F., Garcia de Marina, H., Romero, S. & Barranco, F. Neuromorphic perception and navigation for mobile robots: a review. ACM Comput. Surveys 56, 246 (2024).
Halvagal, M. S. & Zenke, F. The combination of Hebbian and predictive plasticity learns invariant object representations in deep sensory networks. Nat. Neurosci. 26, 1906–1915 (2023).
Kaiser, J., Mostafa, H. & Neftci, E. Synaptic plasticity dynamics for deep continuous local learning (DECOLLE). Front. Neurosci. 14, 424 (2020).
Delrocq, A. et al. Critical periods support representation learning in a model of cortical processing. Preprint at bioRxiv https://doi.org/10.1101/2024.12.20.629674 (2024).
Bayat, F. M. et al. Implementation of multilayer perceptron network with highly uniform passive memristive crossbar circuits. Nat. Commun. 9, 2331 (2018).
Kim, H., Mahmoodi, M., Nili, H. & Strukov, D. B. 4k-memristor analog-grade passive crossbar circuit. Nat. Commun. 12, 5198 (2021).
Yao, P. et al. Face classification using electronic synapses. Nat. Commun. 8, 15199 (2017).
van den Oord, A., Li, Y. & Vinyals, O. Representation learning with contrastive predictive coding. Preprint at https://arxiv.org/abs/1807.03748 (2019).
Bardes, A., Ponce, J. & LeCun, Y. VICReg: variance-invariance-covariance regularization for self-supervised learning. Preprint at https://arxiv.org/abs/2105.04906 (2022).
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations. In Proc. 37th International Conference on Machine Learning 1597–1607 (PMLR, 2020).
Garrido, Q., Chen, Y., Bardes, A., Najman, L. & LeCun, Y. On the duality between contrastive and non-contrastive self-supervised learning. Preprint at https://doi.org/10.48550/arXiv.2206.02574 (2023).
Payvand, M., Fouda, M. E., Kurdahi, F., Eltawil, A. & Neftci, E. O. Error-triggered three-factor learning dynamics for crossbar arrays. In Proc. IEEE 2nd AICAS—2020 IEEE International Symposium on Artificial Intelligence Circuits and Systems 218–222 (IEEE, 2020).
Weilenmann, C. et al. Single neuromorphic memristor closely emulates multiple synaptic mechanisms for energy efficient neural networks. Nat. Commun. 15, 6898 (2024).
Lombardo, D. G. F. et al. Read noise analysis in analog conductive-metal-oxide/HfOx ReRAM devices. In Proc. 2024 Device Research Conference (DRC) 1–2 (IEEE, 2024).
Aguirre, F. et al. Hardware implementation of memristor-based artificial neural networks. Nat. Commun. 15, 1974 (2024).
Portner, K. & Zellweger, T. Actor-critic networks with analogue memristors mimicking reward-based learning. Zenodo https://doi.org/10.5281/zenodo.15740718 (2025).
Zellweger, T., keportner & flavio-martinelli. ztill/TD_learning_on_memristors: first release actor-critic TD-learning on memristors. Zenodo https://doi.org/10.5281/zenodo.17315889(2025).
Acknowledgements
All authors acknowledge funding from the ALMOND project supported by the SNSF Sinergia program (grant number 198612). Funding from the Werner Siemens Foundation is acknowledged by K.P., T.Z., C.W., M.L. and A.E. This work was also supported in part by the Swiss State Secretariat for Education, Research, and Innovation (SERI) through the SwissChips research project. It was carried out at the Binnig and Rohrer Nanotechnology Center (BRNC) and at ETH Zurich. We thank the Cleanroom Operations Team of the BRNC for their help and support. We thank M. Stiefel for capturing the focused-ion-beam images.
Funding
Open access funding provided by Swiss Federal Institute of Technology Zurich.
Author information
Authors and Affiliations
Contributions
K.P., T.Z., M.L. and A.E. conceived the project. K.P., L.B.-L. and V.B. fabricated the devices. F.M. developed the RL simulations. K.P. and T.Z. performed the experiments. T.Z. designed the hardware implementation of the RL algorithm and developed the measurement setup. C.W. and O.H. helped on developing the measurement setup. D.J. helped with the device measurements. D.F.F., F.H., T.S., A.l.P., U.D. and A.O. contributed to the device fabrication. K.P., T.Z., M.L. and A.E. analysed the data and co-wrote the manuscript. W.G., F.M. and B.J.O. contributed to the writing of the manuscript. F.M. and W.G. contributed to the development of the concept. F.M., L.B.-L., V.B. and C.W. contributed to the data analysis. All authors contributed to the editing of the paper. M.L. and A.E. supervised the project.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Machine Intelligence thanks Tifenn Hirtzlin, Ilia Valov and Zhongrui Wang for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Detailed fabrication flow of the analogue memristors with Scanning Electron Microscopy (SEM) pictures.
(a) Deposition of the CMOS- and BEOL-compatible layers on a Si/SiO2 substrate. The TiN and HfO2 layers are deposited by a Plasma-Enhanced Atomic Layer Deposition (PEALD) process at 300 ∘C, without breaking the vacuum to prevent oxidation of the TiN. The Conductive Metal Oxide (CMO), TiN and W layers are then deposited by sputtering. During the transfer from the ALD chamber to the sputtering system, the layer stack experiences a brief exposure to the atmosphere, during which moisture and protons may be incorporated into the device stack73. (b) Etching of the top three layers. The etch defines the active area. (c) Encapsulation of the active area by SiN. This material is deposited via Plasma-Enhanced Chemical Vapour Deposition (PECVD) process at 300 ∘C. (d) Etching of the bottom two layers. The HfO2 and TiN are etched to define the bottom electrode (BE). (e) Encapsulation of the BE by SiN. (f) Via opening to provide access to the memristor device. For the top electrode (TE) via, SiN is etched, while for the bottom electrode (BE), both SiN and HfO2 are etched. (g) Sputtering and patterning of a W TE. A SEM picture of the final device is shown. The inset provides an angled view.
Extended Data Fig. 2 Estimation of the error ϵ1 arising from the difference between idealised (perfectly linear) and actual (non-linear) weight updates.
(a) Measured and fitted potentiation and depression curves of ten different cycles from a single memristor device. As mentioned in the main text, an error term ϵ1 is introduced due to the difference between the ideal (linear) potentiation/depression (black line) and non-ideal measurement curves (dark and light blue). This error ϵ1 is extracted by subtracting the measurement data (b) and the fits (c) from the ideal linear curve for all ten cycles. In both cases, the error is directly related to the non-linearity of the potentiation/depression and is largest at the beginning of the potentiation (light blue) and depression curves (dark blue), as indicated by the red circles. This implies that weight updates when the memristor conductance is close to the beginning of the potentiation and depression curves result in a larger error ϵ1. Because the weights in our actor-critic reinforcement learning tasks are generally more often increased than decreased (their initial value is zero), the problem is more severe in the case of potentiation than depression (see for example Fig. 4b in the main text). The first update of each weight is therefore the most impacted one.
Extended Data Fig. 3 Measured potentiation and depression curves of the memristor devices used for the hardware runs of the T-maze navigation task (Fig. 4 of the main text and Supplementary Note 7).
The 9 critic weights are denoted as wj and the 18 actor weights as θij.
Extended Data Fig. 4 Effect of the noise level on the convergence speed of the Morris water maze navigation task.
(a) Extracted update noise for both potentiation and depression curves of all in-software-emulated memristors. A single parameter σ, corresponding to the standard deviation of all 10 overlapped potentiation or depression measurement curves was extracted for each measured device. (b) Number of steps per episode plotted against the number of episodes for different noise levels, compared to the memristor emulation in the paper. The curves show the mean of 100 distinct simulation runs with an applied running average of 10 episodes to improve comparability between the runs. The in-software-emulated memristors exhibit noise levels between 2.9% and 10%, with a mean of 6.7%.
Extended Data Fig. 5 Effect of non-linearity on the convergence speed of the Morris water maze navigation task.
(a) Extracted non-linearity parameter β for both potentiation and depression curves from our 27 experimental devices, used in the corresponding software models. (b) Number of steps per episode plotted against the number of episodes for different non-linearity parameters β, compared to the memristor emulation in the paper. Each curve represents the average of 100 independent simulation runs, with an applied running average of 10 episodes to improve comparability between the runs.
Extended Data Fig. 7 Actor–critic TD learning (floating-point and memristor emulation) compared to PPO and rate-based R-STDP.
The performance of the actor-critic TD learning algorithm is comparable to PPO in the floating-point software implementation, whereas convergence slows down for the memristor emulation due to update noise (Extended Data Fig. 4). R-STDP does not converge, as updates effectively only happen when the reward is reached and not when a non-zero TD error is present. The memristor model represents the mean of 100 independent simulation runs, while the PPO results are averaged over five random seeds. A moving average over 10 episodes was applied to improve comparability between runs.
Supplementary information
Supplementary Information (download PDF )
Supplementary Figs. 1–17, Notes 1–8, Table 1 and references.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Portner, K., Zellweger, T., Martinelli, F. et al. Actor–critic networks with analogue memristors mimicking reward-based learning. Nat Mach Intell 7, 1939–1953 (2025). https://doi.org/10.1038/s42256-025-01149-w
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s42256-025-01149-w
