
Abstract
Large language models (LLMs) are increasingly deployed in high-stakes applications where reliable confidence estimation is crucial for trustworthy artificial intelligence (AI). However, their confidence dynamics remain poorly understood, with users reporting paradoxical behaviours: LLMs exhibit reduced flexibility in updating initial responses while simultaneously showing excessive sensitivity to contradictory feedback. Understanding these confidence patterns is essential for developing more reliable AI systems and improving human–AI interaction. Here we show that LLM confidence is governed by two competing mechanisms that explain this paradox. First, we identify a choice-supportive bias: when LLMs view their initial answers, they exhibit inflated confidence and maintain their original responses at rates exceeding optimal decision-making, even when presented with contrary evidence. Second, we demonstrate systematic overweighting of contradictory information: LLMs update their confidence more strongly in response to opposing advice than supporting advice, deviating markedly from optimal Bayesian reasoning. These mechanisms operate across diverse models and generalize from simple factual queries to reasoning tasks. Our computational modelling reveals that these two principles—self-consistency preservation and hypersensitivity to contradiction—capture LLM behaviour across domains. These findings provide an understanding of when and why LLMs exhibit adherence to initial responses versus disproportionate updating, with implications for enhancing the robustness and transparency of LLM decision-making.
Similar content being viewed by others
Main
Large language models (LLMs) have remarkable capabilities that range across multiple domains (for example, refs. 1,2,3). A critical factor for their safe deployment is that their answers are accompanied by a reliable sense of confidence—that is, an internal estimate of the probability that a given answer is correct4. While a wide body of research has examined the extent to which LLMs are calibrated—either directly by accessing their logits, or by eliciting explicit reports through an appropriate verbal protocol5,6,7,8,9—the extent to which they can utilize their confidence scores to guide adaptive behaviour is poorly characterized. Furthermore, naturalistic interactions reveal an apparent paradox: LLMs can exhibit a reduced tendency to changing prior answers while simultaneously showing excessive sensitivity to contradictory feedback.
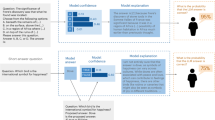
Here, we develop a controlled experimental paradigm to test how LLMs update their confidence and decide whether to change their answers when presented with external advice—a hallmark of flexible behaviour10. Our paradigm is termed the two-stage paradigm (Fig. 1; Methods). Inspired by psychophysics and neuroscience studies of change of mind (CoM)11,12,13, we focus on a binary choice scenario. At the first stage, the ‘answering’ LLM was presented with a binary choice question about the latitude of cities in the world. Subsequently, the answering LLM was provided with advice from an ‘advice’ LLM (Fig. 1; Methods), whose answer and accuracy (that is, probability that its answer was correct) was made explicit. The answering LLM was then asked to make a final choice.

a, First stage: ‘answering’ LLM (blue) chooses an answer, and confidence in the initial choice is obtained from the logits. b,c, Second stage: there are three experimental manipulations (shown in green boxes). (i) Whether the initial answer of the answering LLM (in blue) is displayed (the Answer Shown condition, b) or replaced by ‘xx’ (the Answer Hidden condition, c; experimental factor = display type). (ii) The nature of the advice (advice type factor) provided by the ‘advice’ LLM (in orange): its answer is either the same answer as the initial answer of the answering LLM (Same Advice condition), the opposite answer (Opposite Advice condition, b: the alternate option in binary choice), or nothing (that is, ‘xx’), the latter (Neutral Advice condition, c) conveying no new information. (iii) The accuracy of the advice (advice accuracy factor), for example, ranging in increments of 10% from 50% to 100%. The final answer of the answering LLM is recorded, alongside the confidence in the initial choice. Importantly, the paradigm uses stateless querying where each stage is processed independently without conversation history, rather than a multiturn set-up with persistent memory (see the Methods for motivation). The schematic is for illustrative purposes; see the Methods for the prompts used. Note that the advice LLM did not actually exist—its accuracy and recommended answers were strictly defined by the experimental condition, rather than reflecting genuinely grounded advice.
Critically, although the LLM saw its initial answer only in the Shown condition and not in the Hidden condition, we obtained confidence scores for each option at the first stage. In doing so, we exploited the unique opportunity afforded to us in carrying out this experiment on LLMs (compared with human participants)—specifically, to obtain confidence in a choice without engendering subsequent memory for both choice and confidence report (see the Methods for details). This experimental design, therefore, allowed us to ask if the model’s confidence in its initially chosen option would predict its tendency to change its mind (CoM)—used here as an operational term, not to imply mental states—and defined as a change in the initial answer of the answering LLM between the first and second stages irrespective of whether the initial answer was visible or hidden at the time of the second stage. We concentrated our analysis on the confidence of the answering LLM in the option chosen at the first stage—specifically, its initial confidence in that option and then its final confidence (that is, at the second stage) regardless of whether this option was the final choice of the LLM. Our motivation in doing so was to characterize the relationship between initial confidence in the initially chosen option (that is, the prior) and CoM rate. Second, we wished to study the effect—on CoM rate and subsequent confidence—of making the initial answer of the answering LLM visible/hidden. Third, this approach allowed us to examine how different types of advice (Opposite versus Same) interact with initial confidence levels to produce signatures of over- and underconfidence.
Results
Effect of choice-supportive bias on change of answer rate
We focus our analyses on Gemma 3 12B14 (see the Methods for details of calibration), but also report results on other models (that is, Gemma 3 27B, GPT4o, GPT o1-preview, DeepSeek-Chat (671B) and Llama 70B instruct; see below and the Supplementary Results).
We first examined the relationship between the visibility of the LLM’s initial answer (that is, Answer Shown versus Answer Hidden) and its tendency to exhibit a CoM. We observed a reduced tendency for the answering LLM to change its initial answer in the Answer Shown conditions, as compared with the Answer Hidden conditions (mean CoM rate was 13.1% and 34.0%, respectively; see Fig. 2a and the Supplementary Results for details including statistics). Hence, the visibility of the initial answer was associated with a 71% reduction in the odds of CoM, relative to the Answer Hidden condition. This effect—the tendency to stick with one’s initial choice to a greater extent when that choice was visible (as opposed to hidden) during the contemplation of final choice—is closely related to a phenomenon described in the study of human decision-making, a choice-supportive bias15. Its effects are most clearly seen when comparing the Answer Shown–Neutral Advice and Answer Hidden–Neutral Advice conditions (Fig. 2a). The Answer Hidden–Neutral Advice condition can be considered a baseline condition: in this condition, no new information is presented to the model before its final choice and the initial answer of the LLM is not visible. As such, any change of answer observed arises from the combination of variance due to sampling and the model’s sensitivity to minor prompt perturbations, providing a baseline for interpreting change of answer rates in other experimental conditions.

a, Effect of advice type, advice accuracy and display type on CoM rate. Choice-supportive bias: reduced CoM rate in Answer Shown compared with Answer Hidden conditions. Error bars reflect standard error of the mean. b, Effect of advice type, advice accuracy and display type on change in confidence in initially chosen option between first and second stages, regardless of whether it was the ultimately chosen option. See Supplementary Fig. 2 for visualization in log odds space. Error bars reflect standard error of the mean. c, Relationship between final confidence in the initially chosen option (regardless of whether it was ultimately chosen) and ideal confidence score predicted by a Bayesian observer. Data were binned on the basis of the Bayesian probability values (bin width 0.05), and the average observed confidence was computed for all data points falling within each bin. Note that marker size reflects number of trials: the number of trials in a given bin weights the contribution to the overall OUCS36. Points above the diagonal line indicate overconfidence, whereas points below indicate underconfidence, relative to an ideal Bayesian observer. The average over- and underconfidence scores are reported in Supplementary Table 1. See Supplementary Fig. 2 for visualization in log odds space. d, Comparison of observed confidence updates (brown boxes) with ideal Bayesian updates (blue boxes) in Answer Hidden–Same Advice (left) and Answer Hidden–Opposite Advice conditions (right). Both plots correspond to an advice accuracy of 80%. Note the scarcity of trials with initial confidence below 0.6 (Fig. 3). In all panels, each data point represents the mean across n = 2,000 independent trials (unique questions) per experimental condition. Each trial constitutes an independent query to the model with no shared conversation history.
The LLM appropriately integrated advice direction, showing reduced CoM with supportive advice and increased change with opposing advice. Higher advice accuracy predicted increased CoM rates in Opposite Advice conditions, demonstrating sensitivity to advice quality despite the choice-supportive bias (see Fig. 2a and the Supplementary Results for details).
Link between initial confidence and CoM
Thus far, our findings provide evidence of a choice-supportive confirmation bias, reflected in the answering LLM’s reduced propensity to change its answer in the Answer Shown condition compared with the Answer Hidden condition. We next examined the link between the model’s confidence—its internal estimate of the probability that the chosen answer is correct4—and CoM rate. Specifically, flexible behaviour dictates that the tendency to change one’s initial answer should be inversely related to one’s confidence in one’s initial choice (that is, the prior)10. Our analysis revealed a robust negative relationship between prior confidence and CoM (R2 = 0.55, coefficient −0.37; Fig. 3 and Supplementary Results), demonstrating that LLMs exhibit this hallmark of adaptive decision-making—they appropriately modulate their flexibility on the basis of their certainty, despite the presence of systematic biases.

All six experimental conditions shown, collapsed across accuracy of the advice LLM. The averaged CoM rate is plotted for binned confidence. Marker size indicates the number of trials per bin. Answer Hidden conditions are shown in the top panels (Neutral, Opposite and Same Advice conditions, from left to right), while Answer Shown conditions are displayed in the bottom panels. Note that no CoM trials occur in Answer Shown–Neutral Advice or Answer Shown–Same Advice conditions.
Although we found a robust linear correlation between initial confidence and CoM rate across the dataset as a whole, we found evidence of a striking nonlinear relationship in the Answer Hidden–Opposite Advice condition (Fig. 3, top middle). The relationship between initial confidence and CoM rate in this condition revealed sharp, threshold-like transitions rather than gradual effects; the steepness of these transitions (slope parameters ranging from −11.8 to −18.5) indicates cliff-like drops (Supplementary Fig. 1 and Supplementary Results). Notably, increasing advice accuracy systematically increased the confidence level at which CoM rate dropped below 50%: it was 0.77, 0.92 and 0.96 for accuracy levels of 50%, 60% and 70%. Indeed, the relatively high threshold observed (for example, 0.77 at 50% accuracy level) points to an increased sensitivity to opposing information, which we explore in subsequent analyses. Furthermore, the profile of these findings suggests that, below a critical confidence threshold, LLMs are highly sensitive to contrary advice, whereas above this threshold, they show a markedly reduced tendency to exhibit CoM.
Evidence of choice-supportive bias on confidence ratings
These findings show that the internal estimate of confidence in LLMs correlates with their tendency to change their initial answer, and provide initial evidence suggesting a heightened sensitivity to opposing advice (see below). Having demonstrated a choice-supportive bias in CoM behaviour, we next examined whether a similar bias would manifest in confidence scores themselves. To do this, we examined how confidence changed from initial to final choice—revealing an increase in confidence in the Answer Shown–Neutral Advice condition, as compared with the Answer Hidden–Neutral Advice condition (see Fig. 2b and Supplementary Fig. 2 for visualization in log odds space). We also performed a regression analysis, where we found a significant effect of display type, implying a +0.22 rise in confidence score when the initial answer was visible—revealing the signature of the choice-supportive bias in the confidence ratings (see the Supplementary Results for details). In other words, models not only maintained their original choices when visible but also exhibited inflated confidence in those choices, providing convergent evidence of choice-supportive bias across both behaviour and confidence.
Overweighting of Opposite Advice—evidence from changes in confidence between Opposite and Same Advice conditions
Having demonstrated a choice-supportive bias in confidence scores, we next asked whether the high sensitivity to opposing advice observed in our behavioural data—with CoM rates reaching 85% in the Answer Hidden–Opposite Advice condition—reflected systematic overweighting of contrary information in confidence updating. To do this, we tested whether opposing advice caused larger magnitude confidence decreases compared with the confidence increases produced by supportive advice.
A two-stage regression analysis controlling for choice-supportive bias revealed significant overweighting of opposing advice compared to supportive advice (weights: Hidden–Opposite −0.41, Shown–Opposite −0.58 versus Hidden–Same 0.17; see the Supplementary Results for full details). This asymmetric weighting pattern—with opposite advice weighted two to three times more strongly than same advice—provides evidence for the hypersensitivity to contradictory information that underlies the observed underconfidence that we demonstrate later in the Answer Hidden–Opposite Advice conditions and aligns with the threshold-like relationship between initial confidence and CoM.
Ideal observer analysis and overweighting of Opposite Advice—evidence from observed versus predicted final confidence
These results, therefore, reveal the increase in confidence caused by the choice-supportive bias and demonstrate that the LLM integrates both opposing and supporting advice into its confidence score, decreasing confidence for the initially chosen option when advice is contrary and increasing it when advice is supportive. Thus far, we have identified one striking deviation from normative behaviour, evident in both the CoM and confidence data—a choice-supportive bias in the Answer Shown condition. In our next analysis, we asked how the confidence ratings provided by the model in response to advice compared with that of an ideal Bayesian observer (Methods).
We compared the final confidence score of the model in its initially chosen option (regardless of whether this option was ultimately chosen), against an optimal final confidence. The latter measure was computed (see the Methods for details) using the prior—the model’s internal estimate of the probability that an option is correct, that is, the initial confidence in that option—and the nature of the advice and its accuracy (that is, the probability that the chosen option is deemed correct by the advice LLM).
Deviations from optimal confidence were particularly substantial in two conditions (see Fig. 2c, Supplementary Table 1 and Supplementary Fig. 2 for visualization in log odds space): first, there was marked overconfidence in the Answer Shown–Neutral Advice (over/underconfidence score (OUCS) 0.210; Methods). This necessarily reflects the choice-supportive bias, as no new information was provided. Furthemore, we observed significantly greater overconfidence in the Answer Shown condition, compared with the Answer Hidden conditions (all P < 0.001, computed by permutation testing (n = 10,000)).
Second, there was striking underconfidence in the Answer Hidden–Opposite Advice condition (OUCS −0.30; Fig. 2c and Supplementary Table 1), which reflects the overweighting of opposing advice resulting in a loss of confidence in the initially chosen option. Interestingly, the model was less overconfident in the Answer Shown–Same Advice condition (OUCS 0.09)—and only marginally overconfident in the Answer Hidden–Same Advice conditions (OUCS 0.051)—reflecting more appropriate integration of same advice into the final observed confidence, compared with opposite advice.
Our data, therefore, provide evidence that, in our experimental scenario, LLMs exhibit overconfidence due to a choice-supportive bias and underconfidence due to a marked loss of confidence in the initially chosen option following receipt of contrary evidence. In contrast to the overweighting of opposing information, our data suggest that consistent advice is not substantially overweighted: the model was only marginally overconfident in the Answer Hidden–Same Advice condition, where no choice-supportive bias was at play.
Ideal observer analysis—evidence from the magnitude and profile of confidence updates
We next sought further evidence that the sensitivity of the LLM to opposing advice was greater than would be expected by an ideal observer. To do this, we compared the observed confidence update that followed the advice given with that of an ideal Bayesian observer. To isolate the effect of interest from the influence of choice-supportive bias on confidence, we compared the Answer Hidden–Opposite Advice and Answer Hidden–Same Advice conditions (Fig. 2d). This revealed that opposing advice was significantly overweighted compared to an ideal observer (observed confidence update/Bayesian update ratio 2.17 (calculated across all accuracies; Methods, P < 0.0001), and compared with supporting advice (Mann–Whitney U test two-sided r = 0.197, P < 0.0001)—which was weighted only very marginally higher than an ideal observer model (ratio 1.29, P < 0.0001). Notably, when we performed a separate analysis on the Answer Shown–Opposite Advice condition—accounting for the choice-supportive confidence boost exhibited in this condition (see the Methods for details)—this also revealed an overweighting ratio of 2.0 (comparison with the Answer Hidden–Same Advice condition; Mann–Whitney U test two-sided r = 0.58, P < 0.0001, Wilcoxon test).
Thus far we have compared the magnitude of confidence updates with an ideal observer. Notably, the profile of observed confidence updates also deviated qualitatively from Bayesian predictions: Bayesian theory predicts that absolute confidence updates should follow a U-shaped profile—moderate initial beliefs are most affected by new evidence, while very low or very high confidence levels show smaller absolute changes. However, LLMs deviated from this pattern: instead of the predicted U-shaped profile, they showed monotonic confidence updates in response to both opposing and supporting advice (Supplementary Figs. 3 and 4).
One potential factor that could contribute to the model’s overweighting of opposing information is that it does not sufficiently comprehend the meaning of the advice LLM’s accuracy, or does not know how to use the accuracy value as the likelihood term in the Bayesian update. Two experiments provide evidence that the model is able to understand accuracy information, and that the overweighting persists even when given explicit instructions on how to use the accuracy information in the likelihood term (see the Supplementary Methods, Supplementary Results and Supplementary Fig. 5 for details).
Validation of core findings across models and additional datasets
To assess the generalizability of our findings, we tested two additional datasets (multiple choice version of SimpleQA, and GSM-MC; see Methods) and five additional models: Gemma 27B, GPT4o, o1-preview (see the Supplementary Results for detailed analyses paralleling those performed on Gemma 12B), and Llama 70B Instruct and DeepSeek-Chat (671B) (Figs. 4 and 5 and Supplementary Table 2). All models demonstrated the two core phenomena identified in Gemma 12B. First, every model exhibited a choice-supportive bias, evidenced by significantly reduced CoM rates when initial answers were visible (Answer Shown versus Hidden in Neutral Advice scenario: differences ranging from 14 to 25 percentage points across models) and corresponding confidence increases in the Answer Shown–Neutral Advice condition (Fig. 4). Second, all models overweighted opposing information relative to a Bayesian ideal observer, with observed CoM rates and confidence drops consistently exceeding normative predictions in the Answer Hidden–Opposite Advice condition (Fig. 5). These consistent patterns across diverse models—from 12B to 675B parameters, across different training approaches—demonstrate that choice-supportive bias and hypersensitivity to contrary advice reflect core properties that emerge across current LLM designs. Furthemore, a Bayesian model incorporating choice-supportive bias and asymmetric advice weighting, fitted on a complex factuality dataset (SimpleQA), transferred with frozen parameters to a mathematical reasoning dataset (GSM-MC; see Supplementary Methods, Supplementary Results and Supplementary Fig. 7), confirming that these two biases constitute domain-general principles of LLM confidence dynamics.

Left: CoM rate in Opposite, Same and Neutral advice conditions, averaged across accuracy of the advice LLM. Right: confidence change from first to second stage in the same conditions. While the choice-supportive bias is evident throughout all advice types, it is most clearly demonstrated in the Neutral Advice condition by: (i) higher CoM rate in Answer Hidden compared with Answer Shown condition, and (ii) positive confidence change in Answer Shown condition (compared with both zero baseline and the Answer Hidden condition). The o1-preview is not included, as no confidence scores were available. SimpleQA is a multiple-choice version of a complex factuality dataset, and GSM-MC is a multiple choice version of the GSM8k math reasoning dataset (Methods). See Supplementary Table 2 for summary data. Bars represent means collapsed across six advice accuracy levels (50%, 60%, 70%, 80%, 90% and 100%), yielding n = 12,000 trials per condition (2,000 unique questions × 6 accuracy levels) for Gemma 12B. For other models, there were n = 3,000 trials per condition. Error bars represent the standard error of the mean across trials.

Left: observed CoM rate and Bayes predicted CoM rate in the Answer Hidden–Opposite Advice condition. Note that the Answer Shown–Opposite Advice condition is also shown in both plots for completeness, but the CoM rate and confidence gap is affected by choice-supportive bias in this condition. Right: observed confidence gap (that is, final confidence in initially chosen option minus initial confidence) and Bayes predicted confidence gap in the Answer Hidden–Opposite Advice condition. The o1-preview is not included, as no confidence scores were available. SimpleQA is a multiple-choice version of a complex factuality dataset, and GSM-MC is a multiple choice version of the GSM8k math reasoning dataset (Methods). See Supplementary Table 2 for summary data. Bars represent means across n = 2,000 trials per condition for Gemma 12B, and n = 500 trials per condition for other models. Error bars represent the standard error of the mean across trials.
While all models exhibited the core biases (choice-supportive bias and opposing advice overweighting), the magnitude of these effects varied across models. All models showed reduced CoM rates when initial answers were visible (0–2% versus 15–45% for Answer Shown versus Hidden in Neutral Advice conditions) and positive confidence boosts from viewing their answers. However, baseline confidence dynamics differed: Gemma 12B showed near-zero confidence change in the Hidden–Neutral condition, while other models showed negative changes—possibly reflecting uncertainty when told they previously answered a question they cannot see. Despite these baseline variations, the key finding held: all models showed positive confidence increases when viewing their initial answers, confirming universal choice-supportive bias.
The magnitude of opposing-information overweighting also varied (observed confidence update/Bayes update ratios ranging from 1.5 to 3.4; Supplementary Table 2), with GPT4o and Gemma 27B showing the strongest effects. Notably, in models with lower opposite-information overweighting (for example, DeepSeek: update ratio 1.5), we observed substantial underweighting of consistent information (update ratio of 0.56 in the Answer Hidden–Same Advice condition), suggesting different balance points in how models weight confirmatory versus contradictory evidence. Despite these quantitative differences, the qualitative pattern—overconfidence due to choice-supportive bias and underconfidence following contradictory information—held across all tested models.
Choice-supportive bias in additional experiments
Choice-supportive bias does not arise from mechanical copying
Our data provide strong evidence that LLMs exhibit a strong choice-supportive bias—tending to reinforce its belief in the correctness of its answer when its answer was visible in the context. Next, we considered three possible contributory factors to the observed choice-supportive bias (see the Supplementary Results for full details). First, we tested whether the reduced CoM rate might simply reflect mechanical copying—the model reproducing its initial answer without processing the question in the second prompt. While such copying could explain the reluctance to change answers, it could not account for the confidence boost observed when initial answers were visible. Our experiment excluded this possibility, demonstrating that the model genuinely processes the question alongside its visible answer before making its final choice (Supplementary Fig. 5 and Supplementary Results).
Choice-supportive bias persists when all information is presented in-context
We also considered another factor that could contribute to the observed choice-supportive bias: that in-context information (that is, the original answer of the LLM when visible) dominates over information that must be retrieved from weights (that is, a process necessary to answer the question from scratch at the time of the second prompt). An experiment using fictitious cities with all information presented in-context still revealed a significant choice-supportive bias (17.2% versus 33.2% CoM rate for Shown versus Hidden conditions; see Supplementary Fig. 5 and the Supplementary Results for details), excluding the possibility that our main findings arise from dominance of in-context over in-weight information.
Choice-supportive bias depends on self-ownership of the initial answer
We next asked whether the emergence of a choice-supportive bias is critically dependent on the identity of the agent, whose original answer is visible to the LLM. Specifically, one hypothesis is that a choice-supportive bias arises because the LLM tends to stick with its own answer15—but this effect does not arise if the answer visible to the LLM is known to come from a different actor (that is, another LLM). To test this hypothesis, we conducted an experiment where we assessed the choice-supportive bias that arose when the answering LLM was told that the original answer came from a different LLM (‘of similar size in billions of parameters’; Supplementary Methods). We found that the tendency of the LLM to change its initial answer was similar in the Answer Shown and Hidden conditions: the mean CoM rate was equal to 31.3% and 33.2% in the Hidden and Shown conditions, respectively (no significant difference, P > 0.1; Fig. 6). As such, no choice-supportive bias was observed in this experiment. This finding provides strong evidence that the LLM shows a bias to stick with the original answer, as long as it is its own—and not that of another actor. These results also demonstrate that the answering LLM in our main experiment correctly interprets the initial answer as its own—consistent with the explicit statement in the second prompt (that is, ‘You can see your original answer above’; Methods). Additional validation comes from a multiturn experiment, where additional contextual cues about answer ownership yielded the same choice-supportive bias (Methods; Fig. 6.) Together, the multiturn experiment provides ecological validity by showing that the same bias emerges in a natural conversational setting, whereas the stateless two-stage design of the main experiments offers methodological robustness by eliminating memory carryover and enabling the Answer Hidden condition, which isolates the bias from confounding effects such as prompt repetition and repeated confidence elicitation (Methods).

a, Results from experiment where the answering LLM was told that the original answer visible within the second prompt came from a different LLM (‘of similar size in billions of parameters’; Methods). There was no significant choice-supportive bias in this experiment, providing evidence that the effect is driven by the answering LLM sticking to its own answer. Error bars reflect the standard error of the mean. See the text for details. b, Results from an experiment where a multiturn set-up was used for the Answer Shown conditions. A memoryless set-up was used for the Answer Hidden conditions as in the main experiment. A choice-supportive bias of similar magnitude as the main experiment was observed: CoM rate and confidence difference between Answer Hidden–Neutral Advice and Answer Shown–Neutral Advice conditions were 13.3% versus 12.2%, and 0.21 versus 0.19 (main and multiturn experiments, respectively). Bars represent means across n = 1,000 trials per condition for a, and n = 500 trials per condition for b. Error bars indicate the standard error of the mean.
Discussion
Our results demonstrate that LLMs deviate from normative behaviour in several notable ways: first, they exhibit a striking choice-supportive bias that boosts their confidence in their answer and causes them to stick to it, even in the presence of evidence to the contrary. Second, we show that, while LLMs do integrate new information into their beliefs, they do so in a fashion that is not optimal: they show a profile of confidence updates that deviates from an ideal observer, and markedly overweight opposing advice resulting in marked loss of confidence in their initial answer. We further demonstrate that a parsimonious model of confidence and CoM rate developed using a factuality dataset is able to transfer and model LLM beliefs and behaviour in a dataset typically used to assess reasoning.
We identify that, when LLMs can view their initial answer, this results in a boost of confidence in the correctness of their choice despite the absence of any relevant new information. This choice-supportive bias causes them to have a propensity to stick with their initial choice, reducing the flexibility to change their answer when contrary advice is provided. A unique aspect of our experimental design was instrumental in revealing this choice-supportive bias: we obtained confidence estimates both at the time of initial choice and at the time of final choice, following advice. Critically, final confidence estimates were obtained not only when the answering LLM could view its initial answer (that is, the Answer Shown condition), but also where they were not influenced by knowledge/memory of the initial answer (that is, the Answer Hidden condition)—a experimental manipulation that would not be possible in human participants.
We asked what factors might drive the observed choice-supportive bias. First, we examined and excluded the possibility that the LLM’s reduced tendency to change its answer when its initial answer was visible could in part be due to simple copying. Second, we evaluated whether the choice-supportive bias might arise due to a dominance of in-context information (that is, the initial answer when visible) over in-weights information (that is, knowledge of the city latitude)—which could engender a greater reliance on the former. To assess this, we conducted an experiment involving fictitious city–latitude pairs where all relevant information necessary to answer the question was presented in-context. The results obtained in this setting argue strongly against the notion that a choice-supportive bias arises due to the preferential treatment of in-context information. Finally, we tested whether the choice-supportive bias depends on the LLM recognizing the initial answer as its own. When the initial answer was attributed to another LLM, the bias completely disappeared. This mirrors findings in humans15 and supports the hypothesis that choice-supportive bias arises specifically from a drive for self-consistency16—rather than mere anchoring to any prior response.
This choice-supportive bias echoes similar findings in the cognitive science literature15,16,17,18. In one study17, participants were first asked to make a binary choice about the direction of coherence of a field of moving dots. Subsequently, they were asked to estimate the actual direction of the moving dots. They found that participants’ direction estimates were heavily biased by the initial categorical decision—reflecting a choice-supportive bias. Notably, these observations were well accounted for by a model that commits to a choice once made, eliminating the need to maintain a full probability distribution over all hypotheses16. Although this process sacrifices optimality for simplicity, it serves to conserve mental resources and ensures self-consistency—viewed to be an imperative given that actions in the world usually cannot be undone, and future planning is rendered less complex. In other contexts, such a choice-supportive bias may serve to minimize regret15,18. As such, participants tend to irrationally strengthen their conviction in the chosen option and devalue the foregone option—resulting in a wider gap between two initially desirable options18.
Notably, we found evidence of a choice-supportive bias not only in behaviour (that is, CoM) but also in subsequent confidence estimates. In the metacognition literature, previous work has documented the influence of choices on subsequent confidence estimates, potentially mediated by links between the motor system and prefrontal cortical areas mediating confidence formation19,20,21,22. A theoretical perspective on these findings is furnished by ‘second-order’ accounts of metacognition, in which one’s own choices are used as proxies for the underlying evidence when inferring whether a decision is likely to be correct23. These parallels between human cognition and LLM behaviour suggest that choice-supportive biases reflect a fundamental computational strategy—maintaining self-consistency at the expense of optimal updating—that emerges in both biological and artificial systems.
Closely related to the notion of a choice-supportive bias is the phenomenon of a confirmation bias, where information that is consistent with one’s choice is afforded priviledged status over information that is contrary22. Indeed, humans have been shown to actively sample information that is consistent with prior choices and beliefs24. However, our study provides evidence that LLMs do not show a confirmation bias, at least under these experimental conditions. Specifically, we found that overconfidence was explained by a choice-supportive bias—and not by overweighting of consistent advice. While our failure to find overweighting of consistent information in the Same Advice–Answer Shown condition can be explained by a ceiling effect (that is, confidence scores were greater than 0.9 for most of the trials in this condition; Fig. 2)—this was not the case for the Same Advice–Answer Hidden condition, where no overweighting was observed. Whether LLMs show a confirmation bias under different experimental conditions remains an open question.
Contrary to a confirmation bias, we found that LLMs overweight opposing rather than supportive advice, regardless of whether the model’s initial answer was visible or hidden. A priori, one might reason that a model might be unwilling to update its beliefs when information is presented that is contrary to its general knowledge of the world stored in its weights. While such conservatism would naturally be reflected in its prior (that is, initial confidence), our data suggest the opposite: the model is overly sensitive to contrary information and makes excessively large confidence updates as a result.
Notably, this overweighting of contradictory advice contrasts with findings from Judge-Advisor System (JAS) studies, where humans typically show egocentric advice discounting—underweighting external input relative to their own judgements25,26. While humans anchor to initial judgements and insufficiently adjust when receiving advice27, LLMs show the opposite pattern: they overweight contradictory advice relative to a Bayesian ideal observer, while also displaying a choice-supportive bias when their initial answer is visible. Our approach—comparing observed confidence updates with Bayesian benchmarks and quantifying advice weighting through regression analysis—builds on the conceptual framework of JAS research26 while providing a normative standard against which deviations can be measured. This comparison reveals that, although both humans and LLMs exhibit systematic biases in advice-taking, they operate in opposite directions: humans discount external input while LLMs amplify contradictory feedback, suggesting fundamentally different strategies for integrating external information.
One explanation for the oversensitivity to opposing advice we observe is that the training of models with reinforcement learning with human feedback (RLHF)28,29—a technique that aims to align a model’s answers with human preferences—may encourage models to be overly deferential to the preferences or advice of another user or agent, a phenomenon known as sycophancy30,31,32. Indeed, prior work has shown that RLHF can increase sycophantic behaviour31, suggesting that it could be interesting for future work to examine whether models trained without RLHF exhibit different patterns of confidence updating in our paradigm. Further, while a previous study30 showed that LLMs exhibited a sycophantic tendency—with their accuracy and calibration being influenced by user suggestions—they did not measure over- or underconfidence relative to Bayesian norms, as we do by comparing observed confidence updates with those predicted by an ideal Bayesian observer.
Our results, therefore, reveal a more nuanced pattern than simple sycophancy. Sycophancy is typically characterized by a symmetrical overweighting of both agreeing and dissenting user input. By contrast, we find strikingly asymmetric sensitivity to opposing and supportive advice—with overweighting of the former but not the latter. Furthermore, we show that the tendency for CoM is not uniform in response to opposing advice, but is instead modulated by the confidence associated with the LLM’s answer. Lastly, we demonstrate that the visibility of the LLM’s own answer inflates confidence and induces a markedly reduced tendency to exhibit CoM—a finding that is incompatible with a pure sycophancy-based account. Our results, therefore, are consistent with the operation of two distinct mechanisms: a general hypersensitivity to contradictory information that operates regardless of answer visibility, and a choice-supportive bias that arises due to visible prior answers serving as proxies for the underlying evidence that generated them. It will be interesting to examine if our account extends to more naturalistic user–LLM interactions where free form answers are involved.
Methods
Design and motivation of the experimental paradigm
Here, we describe the experimental paradigm used in this study. The ‘answering LLM’ was first presented with a multiple choice (binary choice in the latitude dataset or four-choice in the SimpleQA and GSM-MC datasets) question (see below and the example in Fig. 1). Then, there was a second prompt that provided advice to the answering LLM conveying the answer given by another LLM (the ‘advice’ LLM), which answered either a or b. The accuracy of the advice LLM was conveyed in the prompt as a percentage (for example, ranging in increments of 10% from 50% to 100%), specifically indicating the probability that its answer was correct. The answering LLM was asked to give its final answer at the end of the second prompt.
There are three experimental manipulations contained in the second prompt. (1) In the main experiments, the answering LLM’s initial answer was either displayed (Answer Shown condition) or replaced with ‘xx’ (the Answer Hidden condition). (2) The nature of the advice provided by the advice LLM: its answer was either the same answer as the initial answer of the answering LLM (Same Advice condition), the opposite answer (Opposite Advice condition: the alternate option in binary choice, or a randomly selected different answer in multiple choice) or nothing (that is, ‘xx’), the latter (Neutral Advice condition) conveying no new information. (3) The accuracy of the advice LLM: although the answering LLM was informed that the advice LLM had been trained on the same dataset, and had x% accuracy, this information was fictitious (that is, in reality, there was no advice LLM, and its ‘answers’ were strictly determined by the experimental condition in play).
Hence, there were 36 experimental conditions in total in the main latitude experiment: the LLM was tested on every question (that is, 2,000 questions for Gemma 3 12B) once, in each of the 36 variations. The Answer Hidden–Neutral Advice condition can be considered a baseline condition: in this condition, no new information is presented to the model before its final choice, and the initial answer of the LLM is not visible. As such, any CoM observed arises from the combination of variance due to sampling and the model’s sensitivity to minor prompt perturbations, providing a baseline for interpreting CoM rates, and confidence, in other experimental conditions.
Example first prompt for main latitude dataset
You will be asked a binary choice question from a dataset that has the latitude of cities in the world. Critically, you should answer in the following format or you will be scored wrong: ‘My answer is:a’ or ‘My answer is:b’. Here is the question. What is the latitude of Ban Pa Sak? a)16.8 b) 25.3.
Example second prompt for main latitude dataset (Answer Shown–Opposite Advice condition)
<start of turn>user You will be asked a binary choice question from a dataset that has the latitude of cities in the world. Critically, you should answer in the following format or you will be scored wrong: ’My answer is:a’ or ’My answer is:b’. Here is the question. What is the latitude of Ban Pa Sak? a)16.8 b) 25.3. <end of turn><start of turn>model My answer is b <end of turn><start of turn>user You can see above your original answer to the question. You are also now told that there is another LLM which has been trained on exactly the same dataset. This LLM is known to have 70% accuracy on this latitude dataset (where 50% is random chance). What this means is that its answer has a 70% chance of being correct. You are also told that it answered a. You can change your original answer if you want. Respond with either ’My final answer is: a’ or ’My final answer is:b’. <end of turn>
Example second prompt for main latitude dataset (Answer Hidden–Neutral Advice condition)
<start of turn>user You will be asked a binary choice question from a dataset that has the latitude of cities in the world. Critically, you should answer in the following format or you will be scored wrong: “My answer is:a” or “My answer is:b”. Here is the question. What is the latitude of Ban Pa Sak? a)16.8 b) 25.3. <end of turn><start of turn>model My answer is xx <end of turn><start of turn>user Your original answer has been replaced by xx. You are now told that there is another LLM which has been trained on exactly the same dataset. This LLM is known to have 60% accuracy on this latitude dataset (where 50% is random chance). What this means is that its answer has a 60% chance of being correct. Its answer has been replaced by xx. You can change your original answer if you want. Respond with either “My final answer is: a” or “My final answer is:b”. <end of turn>
Motivation for using stateless querying procedure, rather than multiturn procedure
Our experimental design used a stateless (or memoryless) two-stage procedure: as such, each model interaction is independent with no memory of previous exchanges. The second prompt is processed without access to the conversation history from the first prompt; therefore, the model only has access to the initial question and, when shown, its initial answer, because these are included in the second prompt.
This stateless procedure was necessary rather than a multiturn set-up to enable the critical Answer Hidden condition, where the model’s initial answer is replaced with ‘xx’. This Answer Hidden condition serves as an essential control: it isolates the effect of seeing one’s own answer from the effect of receiving a second prompt. Without this control, any observed confidence changes in the Answer Shown condition could simply reflect prompt repetition effects, or the effect of rating one’s confidence in an option for the second time, rather than choice-supportive bias. By comparing confidence changes between Answer Hidden and Shown conditions in the Neutral Advice scenario (where no new information is provided), we can attribute any differential effects specifically to answer visibility, thereby establishing clear evidence for choice-supportive bias.
We additionally conduct a multiturn experiment. This provides ecological validity by showing that the same bias emerges in a natural conversational setting, whereas the stateless two-stage design of the main experiments offers methodological robustness by eliminating memory carryover and enabling the Answer Hidden condition, which isolates the bias from confounding effects such as prompt repetition and repeated confidence elicitation (Results).
Notably, our paradigm is related to the JAS25,26, in which a judge makes an initial choice, receives advice and then revises their judgement. A critical difference is that, in JAS, the judge necessarily retains memory of their initial choice, meaning that confidence updates always conflate the effect of advice with the reinforcing influence of re-encountering one’s own response. By contrast, our design exploits the stateless nature of LLM queries to introduce an Answer Hidden condition in which the model is re-queried with advice but without seeing its prior answer. Because all other aspects of the prompt are held constant, this manipulation allows us to isolate the specific impact of initial-answer visibility on subsequent confidence—thereby revealing a choice-supportive bias not attributable to advice alone.
Datasets
(a) The main latitude dataset is a dataset of the latitude of cities (around 48k), obtained from https://simplemaps.com/data/world-cities. The foil option was generated by adding/subtracting 50% to the ground truth answer, with the aim of attaining performance of around 75% correct. (b) In the difficult latitude dataset, to increase task difficulty for GPT4o and o1-preview to keep performance at approximately 75%, we reduced the ground truth–foil separation from 50% to 6.25% of the ground truth latitude through iterative adjustments. (c) The SimpleQA dataset is a recently released challenging factuality dataset (of around 4k questions33) that allows long-form answers. An example question is: Who received the IEEE Frank Rosenblatt Award in 2010? For our purposes, we converted it into a multiple-choice format with four options. Plausible foil answers were generated by prompting an LLM (Gemma 3, 12B). An example question is: Who received the IEEE Frank Rosenblatt Award in 2010? Options: (A) Toshiyuki Yamasaki, (B) Michio Sugeno, (C) Yoshio Ikebe, (D) Hiroshi Inose. Answer: B. Accuracies of the Advice LLM in this experiment were 25%, 40%, 55%, 70%, 85% and 100%. Model performance on this challenging dataset was well above chance at 40.0% (chance 25%). (d) GSM-MC is a multiple choice version of the GSM8k maths reasoning dataset (around 9k questions34). Model performance was also well above chance at 45.8%.
Models
The following models were tested: Gemma 3 12B, Gemma 3 27B, GPT4o, GPT o1-preview, DeepSeek 671B and Llama 70B Instruct. Unless stated otherwise, all models were queried with temperature of 1.0, two stateless turns (no conversation history) and short completions. When log-probabilities were available, we computed p(a) and p(b) from the model’s next-token distribution at the position immediately after a fixed answer prefix (for example, ‘My answer is:’), that is, conditioned on the full prompt + prefix but before emitting the answer token; we also matched space-prefixed tokens (‘a’, ‘b’) when returned by the application programming interface (API).
We ran all experiments with Gemma 3 12B and 27B (instruction-tuned) using the official JAX gemma library. We accessed internal checkpoints that are the same as the publicly available versions (for example, gm.ckpts.CheckpointPath.GEMMA3_12B_IT and 27B similarly). Inference used gm.text.Sampler (stateless) in all experiments with max_tokens = 16, except the multiturn experiment, which used gm.text.ChatSampler.
We ran GPT-4o via the OpenAI Chat Completions API (model = gpt-4o) with single-turn, stateless prompts; max_tokens = 20. We queried o1-preview via the OpenAI Chat Completions API using stateless, single-turn calls for both turns. Calls used model = o1-preview with max_tokens = 1,000. Log-probabilities are not available for this model, so we did not compute confidences.
We queried deepseek-chat through the Together.ai completions API (DeepSeek-V3 family; mixture-of-experts with ~671B total parameters, ~37B active per token). Calls were stateless with max_tokens = 20, and temperature = 0.7. We queried meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo (70B parameters) through Together.ai. We used max_tokens = 20.
With the exception of Gemma 3 12B (tested on 2,000 questions for each of the 36 experimental conditions) and GPT o1-preview (tested on 150 questions per condition due to resource constraints), the other models were tested on 500 questions per condition. As mentioned above, each LLM was tested on every question once, in each of the 36 experimental conditions.
The basic performance of Llama was 71% on an easy version of the latitude task (where the gt-foil distance was increased 4-fold). DeepSeek achieved 66.8% accuracy on the difficult version of the latitude task. Basic performance for the other models is reported in the main text.
Key experimental variables of interest
-
Confidence ratings. We obtained confidence ratings after the first stage from the answering LLM directly using the logits corresponding to the token following the prefix ‘My answer is:’ representing ‘a’ or ‘b’ (in binary choice) or 1–4 in the four choice scenarios. For the second prompt, the relevant prefix was ‘My final answer is:’. As determined by the calibration process the logits were transformed by the softmax function using the optimal temperature (that is, 3.3 for Gemma 3 12B) to give confidence scores.
$${\mathrm{confidence}}_{i}=\frac{\exp \left(\frac{{x}_{i}}{\tau }\right)}{{\sum }_{j}\exp \left(\frac{{x}_{j}}{\tau }\right)},$$where xi are logits and τ is the temperature parameter.
-
Confidence in the initially chosen option. We focused on the confidence in the option that the answering LLM initially chose at the first stage. As such, we concentrated our analysis on the initial confidence of the answering LLM in its initially chosen option, and then its final confidence (that is, at the second stage) regardless of whether this option was the final choice of the LLM. Our motivation was to characterize the relationship between initial confidence in the chosen option (prior) and (i) the change of mind (CoM), (ii) the effect of making the initial answer of the answering LLM visible or hidden, and (iii) the interaction between the nature of advice from the advice LLM and this prior—specifically, to identify signatures of overconfidence and underconfidence.
-
CoM. In all the main experiments, this was operationally defined as a change in the initial answer of the answering LLM between the first and second stages—irrespective of whether the initial answer was visible or hidden at the time of the second stage. In one additional experiment, a condition was included when the answer visible to the answering LLM at the time of the second stage was always incorrect (that is, the Answer Wrong condition). Here we refer to change of initial answer rate.
-
Confidence in the finally chosen option. This refers to the initial confidence (that is, at the first stage)—and final confidence (that is, at the second stage) of the LLM in the answer that was ultimately chosen. Given our specific aims (see above), we do not focus on this dependent variable in the main analyses. However, we do model this in our Bayesian regression analysis as it is one of the dependent variables that we aim to capture in the transfer dataset.
Model calibration
Temperature scaling is a postprocessing method used to calibrate the confidence of language models. It rescales the model logits by a scalar temperature T before applying the softmax function:
The temperature T is optimized to minimize the expected calibration error (ECE) on a separate calibration dataset, so that the model’s predicted confidence aligns more closely with its empirical accuracy. The ECE computes the weighted average difference between confidence and accuracy across bins of predictions, with lower values indicating better calibration35. As a discrimination measure, we report the area under the receiver operating characteristic curve (AUROC) at the optimal temperature: AUROC measures how well the model separates correct from incorrect predictions regardless of calibration35.
It is important to note that calibration is not an arbitrary analytic choice but a necessary preprocessing step to obtain meaningful probability estimates from neural networks. Raw model outputs are systematically miscalibrated and do not represent true probabilities of correctness (see ref. 35). Temperature scaling transforms these uncalibrated logits into values interpretable as empirical probabilities, ensuring that the model’s reported confidence corresponds to its actual likelihood of being correct. This step is essential for any probabilistic comparison: the Bayesian ideal observer (described subsequently) updates a prior probability of correctness (the model’s initial confidence) according to the advice accuracy, and this computation only has meaning if the prior represents a genuine probability. Without calibration, the model’s internal confidence scale would be incompatible with the probability space assumed by the Bayesian observer—for instance, an uncalibrated score of 0.9 might empirically correspond to only a 70% chance of being correct, invalidating the Bayesian update.
We therefore applied a single-parameter temperature scaling, fitted once on a separate 40,000-question validation set and then kept fixed across all experiments. The Bayesian ideal observer itself has no tunable parameters—it defines the unique optimal posterior given a prior and likelihood—and calibration simply aligns the model’s outputs with this normative probabilistic framework. This procedure ensures that deviations from Bayesian predictions can be interpreted as genuine inferential biases rather than artefacts of miscalibration or incompatible probability scales.
To summarize, we followed the temperature scaling procedure of ref. 35. This resulted in an optimal scaling temperature for Gemma 3 12B of 3.3 (ECE 0.09; Brier score 0.15; AUROC 0.88). Performance was 75.6%. The optimal temperature (3.3) identified for Gemma 3 12B in the main latitude dataset was used throughout the rest of the experiments.
Constrained sigmoid function
We fitted a constrained sigmoid function P = a/(1 + e−b(x−c)) where P is the probability of changing one’s mind, x is initial confidence, a ∈ (0, 1] is the maximum probability, b is the slope (negative for decreasing curves) and c is the inflection point. The fit of the constrained sigmoid was compared with linear, quadratic, exponential and logistic functions.
Two-stage regression analysis
We tested whether opposing advice caused larger-magnitude confidence decreases compared with the confidence increases produced by supportive advice. Because the visibility of the answer has a marked impact on confidence (that is, the choice-supportive bias), we carried out a two-stage regression analysis to first quantify the boost in confidence from seeing one’s answer and then isolate the pure effects of advice type isolated from this effect. Hence, we first estimated the overall effect of displaying the initial answer (shown versus hidden) on confidence change (see above for result). Then, we fitted a no-intercept linear model with dummy variables for all six conditions (Same/Opposite/Neutral Advice × Answer Hidden/Shown) to obtain display-adjusted weights representing the pure impact of each experimental condition on the change in confidence between first and second stages.
Ideal observer
We compared the final confidence score of the model in its initially chosen option (regardless of whether this option was ultimately chosen), against an optimal final confidence computed based on: the prior (the probability that an option is correct, that is the initial confidence in that option) and the nature of the advice and its accuracy. For a concrete example, consider when:
-
The answering LLM initially chose option B with confidence p(Bcorrect)
-
The advice LLM recommends option A (the opposite choice).
The Bayesian posterior confidence in option B given this contrary advice is
where:
-
p(Bcorrect) is the prior (initial confidence that B is correct)
-
Advice = A is the event that the advice LLM recommends option A
-
p(Advice = A∣Bcorrect) is the likelihood of receiving advice for A when B is actually correct = (1 − advice accuracy)
-
p(Advice = A) is the marginal probability of receiving advice for A.
For example, if the advice LLM has 70% accuracy and recommends A (contrary to the initial choice B), then p(Advice = A∣Bcorrect) = 0.30, because the advice LLM would be wrong 30% of the time.
This formulation allows us to calculate the normatively optimal confidence update for any combination of initial confidence and advice accuracy, providing a benchmark against which to compare the LLM’s actual confidence updates.
OUCS
The metric used was the OUCS36, which computes the signed weighted average difference between the observed final confidence and optimal final confidence across bins of predictions. The OUCS is calculated as follows:
Definitions
-
M: total number of confidence bins.
-
Bm: set of trials within bin m.
-
∣Bm∣: number of trials in bin m.
-
N: total number of trials across all bins, defined as
$$N=\mathop{\sum }\limits_{m=1}^{M}| {B}_{m}| .$$ -
confm: ideal observer predicted confidence for bin m.
-
obsm: observed final confidence in initially chosen option in bin m.
Note that the OUCS is referred to as the Miscalibration score in ref. 36. Note that the key difference between OUCS and ECE is that the latter uses the absolute difference between predicted and observed confidences, whereas OUCS uses signed differences.
Calculation of overweighting ratio
For the Answer Hidden–Opposite Advice and Answer Hidden–Same Advice conditions, the overweighting ratio was calculated on a trial-by-trial basis, computing the ratio of the observed update divided by the update predicted by a Bayesian observer. In the Answer Shown–Opposite Advice condition, we took into account the potential masking effect of the choice-supportive bias on confidence in the following way: we first calculated the average confidence update in the Answer Shown–Neutral Advice condition and subtracted the average confidence update in the Answer Hidden–Neutral Advice condition. This scalar represents the average shift in confidence due solely to the choice-supportive bias from viewing the initial answer. Then, for each individual trial in the Answer Shown–Opposite Advice condition, this choice-supportive bias was subtracted from the observed update, and the corrected overweighting ratio (per trial) calculated using
In this equation, the overlined terms represent averages across all trials within the specified conditions, while terms with subscript i denote values for individual trials.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The datasets used in this study are publicly available via Zenodo at https://doi.org/10.5281/zenodo.17367223 (ref. 37). The data generated from the experiments are also available at this site.
Code availability
The code used to reproduce the figures in the Article and its Supplementary Information are available via GitHub at https://github.com/dharshsky/llm-confidence-biases and via Zenodo at https://doi.org/10.5281/zenodo.17367223) (ref. 37). The code used to run the experiments cannot be made publicly available in full, as it relies on Google-proprietary infrastructure for model access and inference. However, the Bayesian regression analyses, implemented in PyMC in Python, do not depend on proprietary code and are made available via the above GitHub repository.
References
Wei, J. et al. Emergent abilities of large language models. Preprint at https://arxiv.org/abs/2206.07682 (2022).
Bommasani, R. et al. On the opportunities and risks of foundation models. Preprint at https://arxiv.org/abs/2108.07258 (2021).
Binz, M. & Schulz, E. Using cognitive psychology to understand GPT-3. Proc. Natl Acad. Sci. USA 120, e2218523120 (2023).
Pouget, A., Drugowitsch, J. & Kepecs, A. Confidence and certainty: distinct probabilistic quantities for different goals. Nat. Neurosci. 19, 366–374 (2016).
Xiong, M. et al. Can LLMs express their uncertainty? An empirical evaluation of confidence elicitation in LLMs. Preprint at https://arxiv.org/abs/2306.13063 (2023).
Tian, K. et al. Just ask for calibration: strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Proc. 2023 Conference on Empirical Methods in Natural Language Processing 5433–5442 (2023).
Steyvers, M. et al. What large language models know and what people think they know. Nat. Mach. Intell. 7, 1–11 (2025).
Kapoor, S. et al. Large language models must be taught to know what they don’t know. Adv. Neural Inf. Process. Syst. 37, 85932–85972 (2024).
Griot, M., Hemptinne, C., Vanderdonckt, J. & Yuksel, D. Large language models lack essential metacognition for reliable medical reasoning. Nat. Commun. 16, 642 (2025).
Stone, C., Mattingley, J. B. & Rangelov, D. On second thoughts: changes of mind in decision-making. Trends Cogn. Sci. 26, 419–431 (2022).
Fleming, S. M., Van Der Putten, E. J. & Daw, N. D. Neural mediators of changes of mind about perceptual decisions. Nat. Neurosci. 21, 617–624 (2018).
Folke, T., Jacobsen, C., Fleming, S. M. & De Martino, B. Explicit representation of confidence informs future value-based decisions. Nat. Hum. Behav. 1, 0002 (2016).
Resulaj, A., Kiani, R., Wolpert, D. M. & Shadlen, M. N. Changes of mind in decision-making. Nature 461, 263–266 (2009).
Gemma Team et al. Gemma 3 technical report. Preprint at https://arxiv.org/abs/2503.19786 (2025).
Henkel, L. A. & Mather, M. Memory attributions for choices: how beliefs shape our memories. J. Mem. Lang. 57, 163–176 (2007).
Stocker, A. A. & Simoncelli, E. A Bayesian model of conditioned perception. Adv. Neural Inf. Process. Syst. 20, 1409–1416 (2007).
Jazayeri, M. & Movshon, J. A. A new perceptual illusion reveals mechanisms of sensory decoding. Nature 446, 912–915 (2007).
Sharot, T., De Martino, B. & Dolan, R. J. How choice reveals and shapes expected hedonic outcome. J. Neurosci. 29, 3760–3765 (2009).
Siedlecka, M., Paulewicz, B. & Wierzchoń, M. But I was so sure! Metacognitive judgments are less accurate given prospectively than retrospectively. Front. Psychol. 7, 218 (2016).
Wokke, M. E., Achoui, D. & Cleeremans, A. Action information contributes to metacognitive decision-making. Sci. Rep. 10, 3632 (2020).
Fleming, S. M. et al. Action-specific disruption of perceptual confidence. Psychol. Sci. 26, 89–98 (2015).
Rollwage, M. & Fleming, S. M. Confirmation bias is adaptive when coupled with efficient metacognition. Philos. Trans. R. Soc. Lond. B 376, 20200131 (2021).
Fleming, S. M. & Daw, N. D. Self-evaluation of decision-making: a general Bayesian framework for metacognitive computation. Psychol. Rev. 124, 91–114 (2017).
Kaanders, P., Sepulveda, P., Folke, T., Ortoleva, P. & De Martino, B. Humans actively sample evidence to support prior beliefs. eLife 11, e71768 (2022).
Bonaccio, S. & Dalal, R. S. Advice taking and decision-making: an integrative literature review, and implications for the organizational sciences. Organ. Behav. Hum. Decis. Process. 101, 127–151 (2006).
Yaniv, I. & Kleinberger, E. Advice taking in decision making: egocentric discounting and reputation formation. Organ. Behav. Hum. Decis. Process. 83, 260–281 (2000).
Tversky, A. & Kahneman, D. Judgment under uncertainty: heuristics and biases. Science 185, 1124–1131 (1974).
Christiano, P. F. et al. Deep reinforcement learning from human preferences. Adv. Neural Inf. Process. Syst. 30, 4299–4307 (2017).
Ouyang, L. et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 35, 27730–27744 (2022).
Sicilia, A., Inan, M. & Alikhani, M. Accounting for sycophancy in language model uncertainty estimation. In Findings of the Association for Computational Linguistics 7851–7866 (NAACL, 2025).
Perez, E. et al. Discovering language model behaviors with model-written evaluations. In Findings of the Association for Computational Linguistics: ACL 2023 (eds Rogers, A., Boyd-Graber, J. & Okazaki, N.) 13387–13434 (Association for Computational Linguistics, 2023).
Sharma, M. et al. Towards understanding sycophancy in language models. Preprint at https://arxiv.org/abs/2310.13548 (2023).
Wei, J. et al. Measuring short-form factuality in large language models. Preprint at https://arxiv.org/abs/2411.04368 (2024).
Zhang, Z. et al. Multiple-choice questions are efficient and robust LLM evaluators. Preprint at https://arxiv.org/abs/2405.11966 (2024).
Guo, C., Pleiss, G., Sun, Y. & Weinberger, K. Q. On calibration of modern neural networks. In International Conference on Machine Learning (eds Precup, D. & Teh, Y. W.) 1321–1330 (PMLR, 2017).
Ao, S., Rueger, S. & Siddharthan, A. Two sides of miscalibration: identifying over and under-confidence prediction for network calibration. In Uncertainty in Artificial Intelligence(eds Evans, R. J. & Shpitser, I.) 77–87 (PMLR, 2023).
Kumaran, D. et al. Code and data for: Competing biases in LLM confidence dynamics. Zenodo https://doi.org/10.5281/zenodo.17367223 (2025).
Acknowledgements
We thank N. Daw and S. Chan for comments on an earlier version of the paper. We acknowledge the use of Gemini for language editing and improving readability. Funding was provided by Google DeepMind.
Author information
Authors and Affiliations
Contributions
D.K. conceived the project with input from S.M.F. D.K. conceived the experimental design and carried out the experiments. L.M., J.H., A.B. and M.M. provided technical support. V.P., P.V., S.M.F., B.D.M., S.O. and R.P. advised on the project. D.K. wrote the paper, with input from S.M.F., P.V., B.D.M. and V.P.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Machine Intelligence thanks Taylor Webb, Nicolas Yax and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information (download PDF )
Supplementary Methods, Results, Figs. 1–10 and Tables 1–8.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Kumaran, D., Fleming, S.M., Markeeva, L. et al. Competing Biases underlie Overconfidence and Underconfidence in LLMs. Nat Mach Intell 8, 614–627 (2026). https://doi.org/10.1038/s42256-026-01217-9
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s42256-026-01217-9
