
Abstract
Flood-induced risks increasingly disrupt interdependent infrastructure systems. However, how these risks propagate, cluster or diverge across interconnected systems is unclear. To bridge this gap, this study constructs a multi-tiered risk-weighted network to disentangle interactions and reveal risk communities. UK-wide flood events from 2003 to 2023 were simulated using CaMa-Flood. Using these simulations, a flood-specific risk resistance surface, incorporating device, spatial, and external disturbance dimensions, was used to construct an adjacency graph for 29,697 EV charging points, yielding a risk-weighted network with 192,862,650 annual edges. This integrated framework enables a unified examination of flood-driven interaction pathways across scales. We find: (1) Flood risk propagation is driven respectively by spatial amplification (63.8%) at the node level, hybrid natural–built coupling (45.3%, 49.6%) at the buffer scale, and impact-driven dynamics (49.0%, 23.6%, 27.0%) at the disturbance layer, representing the relative contributions of entropy-weighted factor groups that form each resistance layer; (2) Risk propagation is governed not by group size, but by the interplay among structural coherence, spatial buffering, and fragmentation constraints across scales; and (3) Risk propagation emerges in fragmented, outward-oriented communities, where spatial geographical interplay, rather than path length, shapes intergroup cascades. These findings highlight multi-scale structural mechanisms driving flood-induced cascade behaviour.
Similar content being viewed by others
Introduction
Flooding is one of the most globally widespread and damaging natural hazards and is also the UK’s most severe natural hazard. Recurrent floods in the UK have caused widespread disruption: flooding event in 2007 killed 13 and damaged over 48,000 homes and 7000 businesses1; in 2012, heavy rainfall shut down Newcastle’s transport system2; in 2013 and 2015, storms caused flooding in Northern Ireland, Scotland3 and 16,000 homes in Cumbria4. Compounding flood risks threaten the stability of the emerging low-carbon infrastructure, underscoring the urgent need for reliable energy systems in the transition to sustainable transport. A key challenge to electric vehicle (EV) adoption is ensuring a dense, secure, and climate-adaptive charging network because urban pluvial floods can cause both direct physical damage and indirect disruption. Flood-driven inundation of low-lying parts of the charging and power infrastructure causes systemic failures, including power outages and disruption to urban mobility5,6,7,8. The Making Space for Water strategy, launched in March 2005, marked a decisive shift by the UK and Welsh governments toward a more integrated approach to flood management9. Despite growing attention from policymakers, the way in which flood risks move through spatial and infrastructure systems remains poorly understood, thus hindering efforts to design effective strategies.
Flood risk assessment has undergone significant methodological development over the past decade, with increasing emphasis on analytical frameworks that capture both hazard dynamics and infrastructure vulnerability. Recent advances include physics-informed surrogate models for rapid urban flood prediction10, integrated urban flood-risk assessment and management frameworks11, and ensemble-learning approaches designed to enhance infrastructure resilience under compound flooding conditions12. These studies demonstrate the sophistication of contemporary flood-risk assessment methods, yet most remain focused on direct physical impacts rather than on how risks propagate across interconnected infrastructure systems. This limitation highlights the need for approaches capable of capturing cross-scale transmission pathways and system-level interactions.
Building on this foundation, a growing body of research has explored the systemic impacts of flood hazards on critical infrastructure8,13,14, including road network absorptive capacity13, disaster impact frameworks15, residual service levels and cascading failures. Since 2010, interest in cascading dynamics has increased within network science16,17, particularly through the use of multilayer18 and multiplex network16 models. Network risk assessment methods are typically19 grouped into model-based, scenario-based and strategy-optimisation approaches20. Core model-based approaches include Bruneau’s integral formulation21 and resilience triangles22. Scenario-based methods assess how network functionality shifts across predefined disruption levels. Strategy-optimisation methods minimise worst-case losses, while simulations assess the capacity to adapt under multi-hazard uncertainty. To evaluate interdependencies in critical networks, the EU-funded STREST project proposed a probabilistic framework for assessing vulnerability and risk in transport and utility systems, targeting (a) individual high-risk sites; (b) distributed assets with high potential impact; and (c) multiple low-impact sites with collective risk, thus highlighting the role of key components in system robustness. Extending system-level frameworks, INFRARES focuses on multi-hazard interactions—including compound, sequential and interrelated events—and quantifies risk uncertainty via correlation-based probabilistic models23. Traditionally, regional risk assessments have used damage functions focusing on physical loss and repairs to the infrastructure, but recent work has highlighted the need to take environmental costs and climate projections into account as well24,25. However, conventional probabilistic approaches, such as quantitative risk assessments, often fall short when climate risk data are unavailable or incomplete, and become less applicable when the effectiveness of control or mitigation measures is highly uncertain.
Spatial risks and internal structural linkages in large-scale infrastructure systems can amplify the overall impacts, yet these interactions remain poorly understood. Previous studies have largely focused on load effectiveness in physical power grids26,27, intersystem cascades28,29, or power–transport stability under climate stress. Most of these address isolated components or regions, overlooking defence strategies for emerging transport–power systems and climate–infrastructure interactions across urban scales. As a result, critical gaps persist regarding a lack of a network-scale perspective that integrates node resilience, inter-regional coordination, and external disturbance. Research on flood-prone transport infrastructure, especially EV charging networks, remains sparse, with little insight into structural vulnerabilities or risk propagation. These gaps reflect broader challenges in terms of capturing how risks traverse complex, multi-layered systems, where internal structure and external stressors interact non-linearly, shaped by modular and hierarchical community patterns. Quantifying these dynamics requires integrated models and detailed identification of subgroup risk behaviours.
To bridge these gaps, this study develops a risk-weighted network framework that enables multi-level identification of risk-based community patterns. Specifically, the framework quantifies how the regional characteristics of individual components shape their contributions to the overall network risk. Based on this weighted network, we detect communities at risk and quantify their structural complexity and propagation dynamics. Comparative analyses reveal both shared and distinct risk profiles across communities, thus supporting more targeted intervention strategies. The resulting point–group–region hierarchy captures cascading interactions within the system and offers a structural basis for enhancing network-level flood resilience. Ultimately, this framework could be used to inform precise, system-scale decisions for flood risk management.
Results
To define risk propagation shaped by embedded coupling across node, buffer and external layers, a resistance surface is constructed to integrate all three dimensions into a risk-weighted network. Two rounds of community detection then reveal structural and propagation patterns within the system.
Risk network derived from a resistance surface integrating device, spatial and external dimensions
The resistance surface for constructing the risk-weighted network is grounded in the three dimensions proposed by the STREST project: (1) node-level resistance, reflecting a station’s ability to withstand flooding; (2) regional buffering, capturing spatial mitigation across connected areas; and (3) external disturbance, measuring environmental stress and inter-regional support. Risk factors under the aforementioned three dimensions were selected based on relevant literature30,31,32,33,34,35,36, and the risk weights for each layer were calculated using the entropy weighting method. To capture cascading risk relationships, node-level results were incorporated into the regional layer, and regional outcomes into the external disturbance layer, allowing each layer to be weighted in parallel (see Table 1 and Supplementary Table S1 for full version).
At the node level, the weighted contributions reveal that spatial factors (63.8%) have stronger influence on flood risk than device water resistance (36.2%), underscoring the primacy of physical context over intrinsic attributes (Table 1). From a spatial distribution perspective, high-risk nodes cluster in both densely built urban cores and hydrologically stressed regions, exhibiting centralised and zonal patterns (Fig. S1). This reflects two key mechanisms: risk accumulation in hazard-prone areas, such as floodplains or regions exposed to extreme weather, and heightened vulnerability in dense urban zones with limited capacity to absorb flood impacts. These patterns underscore the role of the environmental context in shaping node-level exposure. At the regional level, natural and built-environment factors contribute a similar proportion (45.3% and 49.6%), indicating that they play a balanced role in regional buffering. High-risk zones are primarily driven by terrain (weight = 0.3388), surface permeability(0.2749), and spatial resistance(0.1393) (Table 1). These zones reveal the limits of device protection under extreme stress. The regional layer not only reinforces node-level spatial patterns, but also detects high-risk areas driven by environmental exposure despite highly-rated device resilience, highlighting the need for spatially adaptive flood responses (Fig. S2). At the external disturbance layer, flood risk is shaped by asymmetric impact dynamics (49.0%, 23.6%, 27.0%), underscoring the need to target dominant stressors (Table 1). The measure used to assess the external disturbance layer builds on the node- and region-level risk, integrating data on the intensity, extent, and depth of flood impadts over a period of 21 years, to generate the final resistance surface for constructing the risk-weighted network (Fig. S3). Over time, high-risk values first declined and then rose, peaking in 2014 (4.3164) and 2017 (3.0700), with lows reached in 2007 (1.3772) and 2011 (1.0002). Notably, 2007 and 2017 exhibited synchronised regional extremes. Spatially, risk clustered in major urban hubs (e.g. London, Manchester), while secondary hotspots (e.g. Cambridge and Bristol) were more volatile. These patterns reflect compound external dynamics and underscore this layer’s value in revealing persistent spatial vulnerability in urban flood systems.
Based on the above results, a 21-year sequence of resistance surfaces was generated, supporting the construction of 192,862,650 edges from 29,697 EV charging nodes via adjacency graphs (2003–2023). Annual edge weights were used to capture the evolving risk propagation under flood events. Node-level risks were grouped into 19 classes via Jenks natural breaks to explore spatiotemporal linkages. Figure S4 shows that low-risk EV charging nodes exhibit stronger and expanding levels of risk propagation, with more evident temporal and spatial increases in edge weights. High-risk nodes remain relatively isolated with weak connectivity, while low-risk nodes are clustered more tightly and form denser transmission pathways. Anomalies are apparent in several years: in 2004 and 2019, low-risk groups showed sustained increases with exceptionally high edge weights. In 2006, despite an earlier decline, all groups remained above the global mean. High-risk nodes recorded the lowest edge weights in 2006 and 2023. These outlier years reflect flood-specific shocks with uneven network effects. While no persistent spatial correlation was found between node and edge risk, medium- and high-risk nodes are typically associated with weaker edges, suggesting more effective risk containment in these zones.
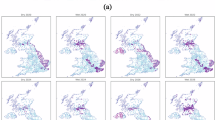
Building on the risk-weighted network, spatial coupling between node- and edge-level risks was examined by aggregating EV infrastructure data into 0.1° × 0.1° grids across the UK. Gaussian Mixture Models were used to cluster regions based on normalised weights, revealing joint spatial risk patterns (Fig. 1a–c). Colour coherence indicates the spatial alignment of node and edge risks. Synchronous clusters form elongated, diffuse bands, while asynchronous ones are more compact. Distinct patterns emerge across the UK: synchronous or asynchronous dominance appears in regions such as central Northern Ireland, the Scottish border, and mid-Wales. Urban core areas (e.g. London, Oxford) show elevated edge risks, whereas peripheral areas (e.g. Isle of Wight, Wealden) exhibit higher node risks. In semi-central zones (e.g. Lancaster), the risks for both rise, but edge risks accelerate. Northern peripheries (e.g. Orkney, Eilean Siar) show dominant, sharply increasing node risks.

a Four node–edge types: both high (>0.5), both low (<0.5), node high and edge low, and node low and edge high; b ln(1 + x) transformation applied to smooth risk gradients; and c Node–edge differences; negative values indicate higher edge risk.
Conventional wisdom often equates large-scale concentrations of high-risk devices with elevated risk transmission. However, this risk-weighted network construction method challenges that assumption, by uncovering the fundamental distinctions between device-level, spatial, and regional risk. These objectively occurring scenarios are as follows: (1) high device-level risk without regional clustering; (2) low individual risk but elevated regional risk; (3) high device risk with strong spatial concentration; and (4) low, dispersed device risk with no regional aggregation (Table S2).
Layer 1 risk communities patterns and feature identification
First-layer communities across 21 annual networks were detected using Louvain and Infomap, enhanced by GCN embeddings and KMeans consensus. Each network was partitioned into 12 communities (Fig. 2), enabling group-level index comparisons to be made. At the first-layer level, community structures broadly align with UK administrative regions. In terms of group size dynamics, Community 1 consistently has the largest share across the 21 years, with 18,878 members and a concentration of structurally critical nodes, indicating centrality but limited propagation. Community 2 experienced a dip–rebound pattern in size but remained close to a stable baseline, with strong internal similarity and a relatively high propagation index. Community 4 maintains high propagation across the 21 years, grows faster than Community 3, and ranks just behind Communities 1 and 2 in terms of clustering, centrality, and similarity - highlighting both momentum and cohesion. Several groups—5, 8, 9, 10, and 11—remain stable. Notably, Community 11, although the smallest and weakest in terms of global metrics, consistently exhibits high internal similarity and transmission potential. Unlike most communities, Community 8 exhibits a reverse pattern: despite relatively low similarity, it maintains high propagation, suggesting that internal coherence is not its main driver. Communities 7 and 12 show greater fluctuation, with Community 12 experiencing more frequent fragmentation and larger index variability across specific years (Fig. 3 and Supplementary Fig. S5 [full series]).

Community size and index variation in first-layer network communities.

(Full time-series results are shown in Supplementary Fig. S5).
In terms of spatial structure, Community 1 forms a compact urban core with concentrated high-risk stations, while Community 2 is more dispersed but shows risk clustering in the northern interior area. Communities 3 and 4 feature multi-centred formations, where localised risk hubs lead to outward diffusion across subgroups. Communities 6–9 show banded structures with parallel, spatially separated subgroup centres. Larger clusters often split into enclosed units—either inward-wrapping or outward-encircling. Due to their geographical positioning, Communities 5 and 10 exhibit greater spatial independence with weaker intergroup links. Community 5, being larger, shows clearer internal risk stratification. Communities 11 and 12 display the most unstable spatial patterns, consistently occupying peripheral network regions with parallel but non-centralised risk layouts. In 2005, 2008, 2019, and 2022, both groups expanded in size, largely influenced by surrounding major clusters, and showed abnormal index shifts. Notably, in 2008, Community 11 recorded the highest propagation index of all the groups. The first-layer communities reflect structurally diverse risk dynamics, whereby size and cohesion do not consistently predict propagation behaviour.
The presence or absence of centrality in first-layer communities depends on spatial form, cohesion, and size. Smaller, banded clusters with low structural indices often lack clear risk centres, while larger, cohesive groups tend to form pronounced cores. Under typical conditions, a high degree of internal similarity promotes risk transmission, with central nodes more likely to serve as hubs. This reinforces the contrasts between core and periphery risks, with large, compact clusters being more structurally stable than similarly sized banded ones. Community 4 exhibits the highest risk propagation along with strong internal similarity. Although Community 1 is larger in size and has a more centralised distribution than Communities 4 and 2, its risk propagation remains lower (Fig. S6). This suggests that transmission is shaped less by the number or proximity of high-risk nodes than by structural features, which govern interactions with external buffers and flood defences. The joint pattern of risk propagation and spatial divergence reflects the dependence of flood resilience on external environmental conditions. In Community 1, high-risk nodes exhibit limited outward spread, while Communities 10 and 12 have fluctuating high Local Clustering Coefficients (LCC), reflecting locally dense interconnections that facilitate short-range, rapid cascades of risk transmission within sub-networks. In contrast, Community 2, which has high regional aggregation, spreads more slowly but systemically, thus posing a greater long-range cascade risk. Compared to other isolated island-based groups like Community 10, Community 5 has a higher internal transmission rate, indicating more efficient risk channels among high-risk stations in Northern Ireland and a greater likelihood of cascading failures. Overall, a high structure with a low RPI may signal suppressed transmission that could escalate if protections fail, while a high RPI with low cohesion suggests localised vulnerability that needs rapid intervention. A high similarity and node importance imply systemic uniformity or critical-node risk, warranting continued monitoring.
Layer 2 Patterns and feature identification of communities at risk
Further subdividing first-layer communities reveals localised risk chains and key nodes, with refined second-layer partitions exposing sharper inter- and intra-group differences to support targeted mitigation and early intervention to curb multi-scale transmission. Changes in second-layer community size reflect modularity shifts: growth signals fragmentation and localised risk, while shrinkage implies integration and broader systemic exposure. Second-layer communities are derived from first-layer communities, with subdivision proceeding until optimal silhouette coefficient and Davies-Bouldin Index scores are reached. To enable clearer visualisation, the data were filtered in two stages, retaining high-risk edges for futher analysis (Fig. 4 and Supplementary Fig. S7 [full series]).

(Full time-series results are shown in Supplementary Fig. S7).
In terms of community size, large-scale clusters (Community 2, 4) and small-scale clusters (Community 6, 7, 11) show greater structural fusion or fragmentation in certain years (Fig. 5). Of these, Community 7 exhibits marked internal variation, with most charging stations forming a large cluster, while a few disperse into smaller groups located at varying distances from the main cluster. Although structurally similar to Community 7, Community 5 remains stable over the 21 year period, most likely due to its low overall risk and higher proportion of high-connectivity nodes. High-risk devices are concentrated in the centre of Community 1, while Communities 5 and 6, which have many high-connectivity nodes, greatly influence risk transmission. As expected, small-scale clusters have isolated points, all in Community 10, which has consistently contained two low-risk isolated groups with minimal transmission. Unlike Communities 5 and 9, which are also geographically isolated, Community 10 maintains stronger spatial and structural isolation, with fewer interlinked high-connectivity nodes (Supplementary Figs. S8 and S9). Notably, only a few communities (e.g. 1–2) consistently exhibit both a high degree and high weighting across the 21 year period (Supplementary Fig. S10, red box), suggesting they may serve as high-risk transmission hubs. High modularity does not require large-scale clusters; key diffusion nodes often lie in withmedium-sized groups, dispersed across clusters and interwoven with others. This highlights the partial mismatch between centrality(degree) and risk(weight), underscoring the need to consider both when identifying intervention targets.

(Inner rings show the number of subgroups per community; outer rings indicate node proportions within subgroups, with bar height scaled accordingly. Dashed lines indicate 0%, 50%, and 100%).
In terms of community characteristics, communities with high degree are concentrated from high to low in Communities 5, 6 and 7 (Supplementary Fig. S10). By contrast, high-risk charging stations are located mainly in Community 1, but the risk transmission index ranks from mid-to-low in all the communities (Supplementary Fig. S11). Notably, within Community 1, the larger sub-community 1-2 exerts greater influence on risk transmission than the sub-community 1-1 (Supplementary Fig. S12). Small, geographically isolated communities show stronger risk transmission when they are further divided into smaller sub-groups at the second level. For example, sub-communities 9-2 and 10-3, despite having a lack of risk transmission influences from high-risk devices or key nodes affecting other clusters, still exhibit a high level of local risk. In contrast, Community 5-1, although geographically isolated with fewer sub-groups, does not show the same high risk levels as the above groups. Conversely, sub-communities 2-2 and 3-1 exhibit an elevated risk level due to the combined effect of high node importance, modularity, and regionality values, and a higher proportion of high-risk device groups. In small-scale communities, isolated nodes exhibit higher risk transmission behaviours and maintain high risk homogeneity within the group (e.g. sub-communities 12-2 and 12-4). In large-scale communities with a risk-focused distribution, newly classified sub-groups (e.g. 4-4 and 4-5) often form concentrated risk hotspots, with stronger structural cohesion and significantly higher modularity and regional aggregation than other sub-groups in the same community. This suggests that nodes within these sub-groups are densely connected, with limited interaction between sub-groups, thereby creating cohesive internal structures and relative external independence. These connections enable the rapid spread of risk within high-modularity, regionally aggregated sub-groups, forming transmission ‘hotspots’ or ‘bottlenecks’ during risk events. In medium-sized communities, newly split sub-groups tend to form consistent levels of risk transmission within the original risk-focused clusters. However, unlike the larger communities, they do not bear the full risk burden. Instead, in low-risk sub-communities they play a role in isolating risk (e.g. 7-3, 7-4). Overall, communities with greater fluctuation in sub-community splits and mergers tend to highlight greater risk uncertainty. They are more prone to revealing risk sources and amplifying equipment-driven risks in spatial contexts. In contrast, stable sub-community clusters often maintain consistent risk levels over time and exhibit steady transmission patterns, thereby reducing the regional influence of equipment-related risks (Fig. 6 and Supplementary Fig. S9 [full series]).

(Full time-series results are shown in Supplementary Fig. S9).
For risk managers, changes in these indicators could serve as potential early warning signals. Modularity changes indicate the degree of community fragmentation or merging, while shifts in average path length and network diameter reflect transmission path length. Shorter paths suggest are accelerated spread. The variance or entropy of community size distribution measures whether risk is concentrated in a few groups, thus helping to identify tipping points from latent to explosive risk. Detecting adverse network changes (e.g. lower modularity, shorter paths) enables timely interventions to be made. Conversely, high fragmentation signals the need to monitor for hidden risk accumulation.
Discussion
The structural correlation between the first and second-level networks makes community structure evolution a leading signal for risk evolution. Comparing risk transmission across the two layers shows that communities with frequent changes and more subgroups are more likely to be risk transmission hotspots. Consistent with previous research, excessive interconnections within the network can be harmful37,38,39. As sub-communities are divided, their contribution to first-level indices becomes more differentiated (Supplementary Fig. S12). This suggests that sub-communities exhibit diverse network structural characteristics and clear risk heterogeneity across clusters. Over the 21-year period, with the exception of 2008 when Community 11 moved to the forefront in terms of risk transmission, Communities 4 and 2 consistently led in relation to risk transmission, followed by Communities 5 and 9. Notably, sub-communities 9-2, 2-2, 5-1, and 11-1 (in 2008) significantly contributed to their respective communities’ high-risk levels, thus amplifying risk transmission. In addition to the aforementioned sub-communities’ contribution to the high-risk levels of their respective first-level communities, Community 4, with its broader consistent risk transmission behaviour and wider degree distribution, increases the risk vulnerability of the intra-group interdependent network40. Undoubtedly, the high degree of reach in Communities 5, 3, and 11 accelerates risk transmission. However, Communities 6 and 7, despite having similarly high degrees of reach and widespread high-risk devices, are less vulnerable due to their smaller size and stable distribution. This further supports the theory that broad degree distributions are linked to network vulnerability. However, this theory should be tested hierarchically across multi-scale groups, taking both node-level risk distribution and consistent inter-node transmission behaviour into consideration. Doing so would provide a more effective way of revealing risk transmission mechanisms. Although isolated nodes (sub-community 10-3) exhibit homogeneous high-risk transmission behaviour beyond their group, as expected, the layered isolation still confines risk within second-layer communities, thus preventing broader network-level links. Similarly, although geographically isolated Community 3 shows risk transmission levels not inferior to those of other communities, it clearly has limited influence on adjacent groups. This indicates that geographical isolation suppresses the spread of large-scale risk and creates a natural ‘boundary effect’41. Beyond differences in group scale and geographic location, distant subgroups (e.g. 2-2, 10-3, 3-1, 5-1, 9-1) exhibit synchronised high-frequency risk transmission and jointly form a backbone that shapes local interactions and network connectivity.
It is worth considering whether differences in risk transmission across groups of varying sizes reflect deeper patterns. In large-scale groups, do more fragmented subclusters signal higher risk or greater transmission potential than in medium- and small-scale groups? In fact, large-scale communities are more prone to fragmentation under disturbances. Their advantage in terms of scale concentrates risk, necessitating the dispersion and burden-sharing of subgroups. For example, Community 4 is larger and riskier than Community 2. Its persistent fragmentation and stable location within the same risk zone probably contribute to its elevated risk. Despite experiencing sharp risk fluctuations in 2008, Community 11 notably reversed its status, saw a surge in membership, and reappeared in a zone similar to Community 4. This highlights the critical role played by geography in relation to risk. Communities such as 5 and 9, despite their moderate size and isolated spatial features, have consistently shown high risk levels often surpassing those of larger groups. Despite exhibiting the most active fragmentation and integration dynamics, the risk levels of Communities 6 and 7 remain confined to moderate, due to their limited scale. This further suggests that the number of group members can to some extent define the upper boundary of risk thresholds, but it does not ensure that the lower boundary remains consistently high. A certain scale of group size is therefore not a necessary condition for high risk. Moreover, the correlation between subgroup fragmentation and elevated risk appears to be modulated by overall group size. In addition, a community’s structural orientation - whether inward or outward—clearly influences its impact on other communities’ risk, echoing weak tie theory and core–periphery structures42,43. Outward-oriented communities are more likely to act as bridges in cross-group risk transmission, whereas inward-oriented communities primarily amplify risk locally. Some communities are inwardly cohesive with few external links44. Community 1, for instance, forms a centralised, self-contained cluster. Its risk level remains largely independent of neighbouring communities, which exert minimal influence. Even adjacent high-risk (Community 4), moderate-risk (7 and 8), and fluctuating (11) groups did not trigger secondary transmission. Outward-oritented communities lacking spatial cohesion tend to disperse risk across neighbouring groups. For instance, Community 4 triggered intergroup transmission to Community 2, intensifying the uneven risk within its subgroups. Although subcommunity 2-2, despite having stronger cohesion, modularity, and aggregation than its elongated counterpart, bears more risk probably due to its proximity to Community 4.
How does risk propagation relate to the structural and geographical characteristics of clusters at different scales? High structural scores indicate risk amplification, while indicators such as similarity and RPI affect secondary risk spread. When node importance, similarity, and LCC are high, tightly clustered structures facilitate hotspot formation and rapid internal transmission. However, if protective measures are effective and RPI stays low, risk transmission may be temporarily contained even in structurally vulnerable communities. Those with high node importance and similarity tend to have critical hubs and uniformly high risk, making them prone to systemic failures and cascading spread. Communities with high node importance but low similarity contain a few critical hubs amid diverse risk levels, where risk tends to concentrate in key nodes, and surrounding low-risk nodes help to buffer cascading spread. Conversely, communities with low node importance but high similarity exhibit uniform risk levels without dominant hubs. When overall risk is high, diffusion may occur slowly in a homogeneous fashion; when low, the system tends to remain stable. Communities with both low node importance and low similarity often exhibit fragmented and heterogeneous structures, lacking dominant hubs or consistent risk profiles. Risk spread is typically localised, with low cascade potential, though local disruptions may still occur. By contrast, Communities with high RAI and LCC concentrate risk structurally, enabling rapid local spread within closed loops. Even with low RPI, tightly clustered networks may still harbour latent ignition points. Communities with low RAI but high RPI are less spatially concentrated, yet strong edge-level transmission can lead to localised “point-like” risk outbreaks in scattered areas. Large, highly structured communities can cause widespread impact even with low RPI, and thus require global monitoring and local alerts. In small, high-RPI communities, risk spreads rapidly through strong edge transmission and requires swift local intervention. It was found that true risk damage equals inherent infrastructure risk minus the environmental threshold, which is consistent with prior research45. It is worth adding that environmental risk exposure has a disproportionate spatial impact: it is stronger at closer distances, especially in the case of flexible, point-based infrastructure. This effect is less evident for linear or area-based systems, highlighting the need to consider spatial risk by infrastructure type. Our findings show that charging infrastructure exhibits strong spatial dependence, shaped by elevation (e.g. above/below ground, flood-prone zones) and local flood resilience (e.g. sheltered or exposed setups). Points in terrain-defined ‘flood-risk critical zones’, based on elevation, slope, openness, and regional vulnerability, are identified as key features if their risk level ranks in the top 25%. A comparison group from the non-‘flood-risk critical zones’ category was then used to test the association with final risk impact values. The results showed that only 2.18% of nodes fall within a ‘flood-risk critical zone’, with a median risk impact of 1.01876. However, 54.94% of the nodes outside these zones exceed this median, highlighting broader vulnerability beyond terrain-defined areas. This further explains why some high-risk nodes in flood-prone areas may experience less impact than nearby nodes due to localised physical barriers. It also reaffirms spatially layered risk diffusion and highlights how the point-based layout of charging stations shapes their risk dynamics. An interesting yet counterintuitive finding is that while high clustering (e.g. a high Local Clustering Coefficient or regional aggregation) typically amplifies local risk, shorter average path lengths do not necessarily lead to stronger transmission - even in clusters with many important or high-risk nodes. This highlights the role of geographical factors as barriers to risk diffusion, rather than relying solely on physical proximity within a simple spatial cross-section. Despite the robustness of the proposed framework, several methodological limitations should be acknowledged. First, the construction of the travel-based network is grounded in simplified behavioural assumptions, including typical driving ranges, fixed recharging intervals, and deterministic traversal rules. These abstractions capture general mobility tendencies but may not fully reflect heterogeneous or stochastic travel behaviour in real-world contexts. Second, although the framework performs reliably for point-based EV charging networks, extending it to other infrastructure systems may require further adaptation to account for differences in spatial organisation, operational processes, and exposure patterns. These considerations do not undermine the overall findings but highlight directions for future refinement through improved behavioural modelling, higher-resolution datasets, and cross-system validation. Overall, this study develops a robust three-layer risk-weighted network to better identify multi-modal risk clusters and optimise cascading risk control. It corrects the misconception that high levels of risk propagation are solely the result of large-scale clustering of high-risk devices and spatial aggregation, and clarifies the distinction between device- and spatial-level risks. It finds that: (1) Flood risk propagates through three mechanisms—spatial clustering at the node level, natural—built environment coupling at the buffer scale, and impact-driven forces at the disturbance layer - which together form four distinct archetypal risk scenarios. Based on this weighted framework, the study further identifies multiscale risk community patterns through two rounds of classification. (2) Group size shapes risk boundaries but is not a sufficient condition for high vulnerability. Risk rises with structural fragmentation, yet stability depends more on form - compact clusters resist disruption better than linear or sparse ones. As centrality (degree) and vulnerability (weight) often diverge, both must guide intervention. Crucially, risk propagation reflects not just node proximity but the interplay between structure, scale, and spatial barriers. (3) Communities with frequent subgroup fragmentation are often frontline risk carriers. The theory of degree-wide vulnerability must be validated through multi-scale, layered assessments of node-level risk distribution and inter-node transmission consistency. Structural orientation, whether inward or outward, shapes external influence, while high clustering or short paths alone do not guarantee high transmission. Overall, infrastructure risk propagation is shaped not only by physical proximity but also by multiscale risk distribution, behavioural consistency, spatial buffering, and inter-group cascades, thus challenging traditional distance-based assumptions. The proposed framework Fig. 7 is broadly applicable across infrastructure types. Point-based systems may exhibit unexpected local amplification, while linear or areal systems may not, highlighting the need for type-specific risk strategies to be used in future assessments.

Research framework.
Methods
Flood model simulation
In this study, we applied the CaMa-Flood model (version 4.20; [https://hydro.iis.u-tokyo.ac.jp/~yamadai/cama-flood/]) to simulate large-scale floodplain dynamics. CaMa-Flood employs a one-dimensional local inertia equation that accounts for backwater effects by neglecting inertial terms in the momentum balance. River widths are derived from a global database for major channels46, while widths and depths of smaller rivers (<300 m) are estimated using empirical runoff-based relationships47. The model routes runoff between grid cells using simplified shallow-water equations and explicitly represents sub-grid topography, allowing for the simulation of water levels and flood inundation depths47.In our configuration, CaMa-Flood was implemented on the global 1 arc-min river-routing grid (≈1.8 km at the equator and ≈1.1 km over the UK domain), which was clipped to the study area. The model was forced using ERA5-Land hourly surface runoff at 0.1° spatial resolution, which was temporally aggregated to daily runoff to match CaMa-Flood’s daily hydrodynamic routing scheme. River–floodplain connectivity parameters, including channel geometry and floodplain storage capacity, were derived from MERIT-DEM at 30-arc-s (~1 km) resolution. Consequently, the model produces daily water levels and flood-inundation depths on the 1 arc-min routing grid for the period 2003–2023.
Construction of the risk-weighted network (Risk factors – resistance surface – network formation – edge weighting)
Specific risk factors were selected based on three dimensions: node-level resistance, surrounding resistance, and external disturbance (see Table 1). Network construction incorporates continuous regional influence via resistance surface integration. All risk factor classification was based on value ranges observed in areas of the UK and applied the Natural Breaks method, which was selected because it minimises within-class variance and maximises between-class separation, making it suitable for heterogeneous geospatial variables such as elevation, slope, drainage density, and hydrological disturbance indicators. In the case of charging stations, due to the sharp risk decline beyond a certain threshold, classification followed IP (Ingress Protection) and NEMA (National Electrical Manufacturers Association) protection standards. At each location, up to eight connector types were recorded. As flood risk is more closely linked to device structure than quantity, the average protection level of all connector types was used to determine overall equipment stability. Lifespan was based on first installation records, and usage intensity was derived from local population density and traffic flow. Rainfall intensity and wind speed were represented by 21-year averages, which were used to characterise long-term background environmental disturbance conditions rather than event-scale variability. This treatment follows standard practice in regional exposure assessment and avoids double-counting because event-specific spatial heterogeneity is already represented through CaMa-Flood hydrodynamic outputs (water level, inundation depth, and flood extent) rather than through climatological indicators. Flood impact, as part of the external risk disturbance module, was assessed using multiple quantitative indicators derived from the CaMa-Flood model’s 01 min simulations. As the dataset spans 21 years, all secondary factors were evaluated based on long-term mean values. The surrounding-area risk resistance module assessed drainage capacity under both natural and built environments. For natural spaces, topography, soil texture (0–5, 5–15, 15–30 cm), and vegetation were considered. For built areas, surface paving, flood infrastructure, and building density were evaluated. The multi-level risk factors incorporated both quantitative risk metrics and qualitative risk indicators with relative grading and higher uncertainty. A complete list of literature sources for all mathematical formulations used in this section (Eqs. 1–15) is provided in Supplementary Table S3.
In the risk weighting process, node-level weights were used to evaluate the inherent risk resistance of charging stations. All node attributes were normalised to the [0,1] range to eliminate dimensional inconsistencies48,49.
\({x}_{{ij}}^{{\prime} }\,\) represents the normalised value of the\({i}^{{th}}\) sample on the\({j}^{{th}}\) indicator, while \({x}_{{ij}}\) denotes the original value. Subsequently, entropy weighting50,51 was applied to quantify the importance of each attribute based on its degree of dispersion— attributes with higher variability were assigned greater weights, reflecting their stronger contribution to node-level risk resistance.
\({p}_{{ij}}\) denotes the normalised proportion of the \({i}^{{th}}\) sample on the \({j}^{{th}}\) indicator, and \({e}_{{node},i}\) the entropy of indicator i. The comprehensive node weight \({w}_{{node}}\) represents the overall risk resistance of each node. Here, m is the number of nodes, n is the number of indicators, and k is the normalisation constant in the entropy method. The final node-level score was obtained by computing the weighted sum of attribute values and their corresponding weights.
In the static resistance surface weighting52,53 based on surrounding-area risk resistance, the resistance surface influences the connection weights between nodes, especially when charging stations are linked across different geographical regions. The regional resistance capacity directly affects the risk weight of these connections. All factors were normalised using min–max scaling (Eq. 1). Entropy weights were then computed following the same procedure described in Eqs. (2)–(4), with the notation adapted for resistance indicators. The final static resistance score was calculated as the weighted sum of factor values:
Dynamic resistance surface weighting was used to capture external risk disturbances that may arise in specific regions and influence edge weights within the network. To reflect temporal variability in these risk factors, a dynamic resistance surface was constructed. Spatial and temporal dimensions54,55,56 were first decoupled for separate evaluation.
Calculation of temporal dimension weights:
Calculation of spatial dimension weights:
Spatiotemporal fusion weights:
Composite dynamic resistance score:
Where \({e}_{{time},{\rm{k}}}\) and \({e}_{{space},k}\) represent the temporal and spatial entropy values of the \({k\,}_{{th}}\) dynamic factor, respectively. \({w}_{{time},k}\) and \({w}_{{space},,k}\) are the time and space weights for the \({k\,}_{{th}}\) dynamic factor, while a is the balance coefficient between time and space, ranging from 0 to 1. \({w}_{{dynamic},,k}\) is the composite weight of the \({k\,}_{{th}}\) dynamic factor.
Construction of the resistance surface based on external risk disturbance:
Where \({w}_{{node}}\), \({w}_{{static}}\) and \({w}_{{dynamic}}\) are the weights for the first, second, and third layers, respectively, determined through entropy-based weighting57. The proportional relationship between layers is structured such that the output from the first layer is used as an input in the second layer, where it is combined with other factors to compute the corresponding weights. Similarly, the second layer’s output is integrated with the third layer’s factors for subsequent weight calculation. \({r}_{{final}}\left(x,y,t\right)\) represents the composite resistance value at spatial location(\(x,y,\)) and time \(t\). After calculating the weight values of the risk resistance factors, risk dynamic resistance surfaces for 21 individual years were generated.
In the context of network construction, the charging station capacity is a micro-scale issue. Therefore, this section focuses on the scientific layout and construction of the charging station network. By simulating real-world short- and long-distance travel behaviour and considering energy replenishment needs during transit, the node traversal order and edge construction steps were scientifically defined. This approach integrates the typical driving range of mainstream EVs, the shortest charging station spacing set by charging station providers, driving habits, and range anxiety. It was assumed that, after departing from any given point, a charging station would be needed at least once within every 100 km. As the distance increases, another charging station is required within the next 100 km, and so on, until the destination is reached. Simultaneously, by systematically traversing all points and simulating the travel behaviour for each, an authentic travel network for charging stations is constructed. In the actual implementation, an adjacency graph construction algorithm is employed to establish edges between nodes. The weight of each edge58 is then determined by integrating two key factors: a normalised travel distance and a risk resistance value derived from previous analyses. The result is a comprehensive charging station network annotated with risk weight attributes.
Subsequently, a genetic algorithm (GA)59 framework is established to support the overall optimisation process. The balancing coefficient between distance and resistance, denoted as α, is treated separately because it functions as a linear scaling parameter rather than a structural optimisation variable. Since α controls the proportional contribution of distance and resistance and its effect on the combined edge weight is monotonic and approximately linear, its optimal value can be efficiently estimated using ordinary least squares instead of evolutionary search. This separation allows the GA to focus on high-dimensional non-linear structural optimisation while α is obtained through a stable closed-form solution provided by linear regression. Initially, a linear regression approach is applied to automatically derive the optimal balancing parameter α, under the assumption that the distance weight coefficient and the resistance weight coefficient satisfy the following relationship:
Due to the inherent characteristics of the data—where directly combining distance and resistance does not yield a clear minimum (minimising one factor causes the other to dominate excessively)—this design ensures that both factors contribute in a balanced manner. Based on this relationship, the edge weight from charging station i to charging station j is defined as:
Here, \({{Distance}}_{{ij}}\) denotes the actual road distance between charging station i and j, while \({{Resistance}}_{{ij}}\) is obtained via bilinear interpolation from the dynamic resistance surface data (computed for the period 2003–2023). Ultimately, all edge weights will vary in accordance with the annual changes in the resistance surface.
Risk-weighted network structural features and risk cluster identification
It is necessary to identify network communities with high synergy and tight interconnections, which exhibit strong associations and collaborative effects in functionality, behaviour, and risk propagation. These communities consist of nodes with cooperative relationships or shared characteristics that form spatial, temporal, or functional linkages, allowing their intrinsic properties and external impacts to be quantified. To rapidly identify densely interconnected node clusters within the network, a static community detection method was initially applied for preliminary grouping. The objective of community detection is to reveal clusters with high internal connectivity and sparse external connections based solely on network topology. For this purpose, the Louvain algorithm—optimised via modularity—is employed due to its efficiency in handling large-scale networks. Subsequently, to further validate the accuracy of the community assignments, the Infomap algorithm was used as a complementary approach. Infomap leverages random walk dynamics to partition the network by optimising the flow of information, making it particularly suitable for analysing the propagation patterns of information or risk across the network.
The Louvain algorithm60,61 evaluates community partitions by maximising the modularity Q, defined as:
Where \({A}_{{ij}}\) is the weight of the link between nodes i and j, \({K}_{i}{K}_{j}\) is the product of the degrees of nodes i and j. m is the total edge weight in the network, and \(\delta ({c}_{i},{c}_{j})\) equals 1 if nodes i and j belong to the same community and 0 otherwise. Applying the Louvain algorithm to network G yields a community label \({c}_{i}\) for each node, forming the label set C = [c1,c2,…,cn].
To further extract node features and refine the initial community partition, a graph convolutional network (GCN)62 is employed for embedding optimisation. By aggregating information from neighbouring nodes, the GCN captures deeper relational features within the network. The basic propagation rule is expressed as:
Where \({H}^{(l)}\) is the node feature matrix at the \({l}_{{th}}\) layer, \(\widetilde{A}\) is the normalised adjacency matrix with self-loops, \(\widetilde{D}\) is its corresponding degree matrix, \({W}^{(l)}\) is the trainable weight matrix at the \({l}_{{th}}\) layer. and \(\sigma\) denotes the nonlinear activation function. The resulting node embeddings in this latent space can then be used for further identification of cohesive communities. To unify outputs from the Louvain, Infomap, and GCN approaches across multiple time periods, we performed a consensus clustering step with the number of clusters fixed at k = 12. This value was selected using standard consensus-clustering diagnostics. The cumulative distribution function (CDF) of the consensus values exhibited clear stabilisation for \(k > 10\), and the consensus matrix for \(k=12\) showed high within-cluster coherence while avoiding excessive fragmentation. A light sensitivity check across k = 10–14 yielded consistent spatial patterns and community boundaries, indicating that the final results are robust to small variations in the choice of k. This choice, guided by domain knowledge and preliminary tests, balances interpretability and granularity, facilitating straightforward cross-year comparisons.
Building on the first-layer partition, each community is subjected to further subdivision. Specifically, for each community, we first extract node-level features - comprising one-hot encodings of their Louvain and Infomap labels, node weight, degree, and weighted degree—to construct the feature matrix. Depending on the community’s size, hierarchical clustering (Agglomerative Clustering) is employed for those with more than five nodes, whereas smaller communities are standardised, reduced via principal component analysis (PCA), and subsequently clustered with K-means. To determine the optimal number of clusters k, we iterate k from 2 to min (community size−1,10) and compute the Silhouette coefficient alongside the Davies–Bouldin index (DBI) for each candidate partition, selecting the one that maximises the Silhouette coefficient (and cross-checking DBI as a secondary indicator). The best-performing partition is then assigned to each node in that community, yielding a refined second-layer label. Notably, this implementation does not involve weakening sparse links or performing multiple iterative evaluations for incremental metric improvement; rather, it executes a single pass over possible values of k and retains the most favourable outcome. In cases where a community is too small or fails to yield a valid result, its first-layer label is preserved. Overall, this approach balances flexibility for varying community sizes with a quantitative assessment of clustering quality, thus offering a more granular delineation of internal heterogeneity and external cohesion. Refining community structures in this way facilitates more precise risk assessment and targeted intervention strategies.
Building on these refined two-layer communities, we next derive several advanced metrics—namely, the regional aggregation degree61,63, standard local clustering coefficient64, node importance index65, risk propagation index18, and similarity index66—to deepen our understanding of how risks diffuse through the network. In so doing, we capture the distribution of risk sources, the intensity of interconnections, and potential cascade effects, thus providing a robust scientific basis for developing tiered, precise, and efficient defence strategies. Detailed methodologies for computing these indices are provided in Table S4.
Data sources
The data sources employed in this study are summarised in Table S5. Notably, among the charging station nodes, 78 are located in territories under the British Crown that fall outside the official administrative boundaries of the United Kingdom, and 2 nodes are situated in New York, USA. In addition, 24 nodes exhibit missing or anomalous values. Consequently, the initial dataset comprised 43,126 charging station nodes (including instances where multiple charging points share the same geographical coordinates); however, after removing duplicates based on coordinate data, 29,697 unique charging station nodes remained.
Data availability
The derived datasets generated in this study will be deposited in an open-access repository upon acceptance of the manuscript, and a DOI will be provided. Original charging-infrastructure data were obtained from the UK National Chargepoint Registry (NCR) and other third-party providers listed in Table S5. The NCR dataset was originally released under the UK Open Government Licence but has since been decommissioned, and the authors are therefore unable to redistribute the raw data. Access to third-party datasets may also be subject to licensing restrictions. After removing duplicates and anomalous entries, 29,697 unique charging-station nodes were retained for analysis.
Code availability
The custom Python scripts developed for constructing the risk-weighted network, performing multi-level community detection, and conducting the risk propagation analysis in this study are available from the first author upon reasonable request. Due to licensing restrictions on the proprietary input data, these scripts cannot be executed independently without the underlying datasets, but they are provided to ensure transparency and to facilitate the replication of the analytical workflow.
References
Pitt, S. M. Learning Lessons from the 2007 Floods. Cll Group 1-3 (Pitt Review, 2008).
Pregnolato, M. et al. The impact of flooding on road transport: a depth-disruption function. Transp. Res. Part D. 55, 67–81 (2017).
Thorne, C. Geographies of UK flooding in 2013/4. Geogr. J. 180, 297–309 (2014).
Marsh, T. et al. The Winter Floods of 2015/2016 in the UK-A Review. (NERC/Centre for Ecology & Hydrology, 2016).
Ganin, A. A. et al. Resilience and efficiency in transportation networks. Sci. Adv. 3, e1701079 (2017).
Hong, L. et al. Vulnerability assessment and mitigation for the Chinese railway system under floods. Reliab. Eng. Syst. Saf. 137, 58–68 (2015).
Huang, X. et al. Robustness of interdependent networks under targeted attack. Phys. Rev. E 83, 065101 (2011).
Serre, D. et al. Assessing and mapping urban resilience to floods with respect to cascading effects through critical infrastructure networks. IJDRR 30, 235–243 (2018).
Hall, J. W. et al. Integrated flood risk management in England and Wales. Nat. Hazard. Rev. 4, 126–135 (2003).
Bhattarai, Y., Bista, S., Talchabhadel, R., Duwal, S. & Sharma, S. Rapid prediction of urban flooding at street-scale using physics-informed machine learning-based surrogate modeling. npj Urban Sustain. 12, 200116 (2024).
Li, J., Gao, J., Li, N., Yao, Y. & Jiang, Y. Risk assessment and management method of urban flood disaster. Water Resour. Manag. 37, 2001–2018 (2023).
Bhattarai, Y., Chaudhary, V., Walker, C., Talchabhadel, R. & Sharma, S. Ensemble learning for enhancing critical infrastructure resilience to urban flooding. Sci. Rep. 15, 36901 (2025).
Lhomme, S. et al. Analyzing resilience of urban networks: a preliminary step towards more flood resilient cities. Nat. Hazards Earth Syst. Sci. 13, 221–230 (2013).
Pescaroli, G. Perceptions of cascading risk and interconnected failures in emergency planning: implications for operational resilience and policy making. IJDRR 30, 269–280 (2018).
Hereld, M. et al. in Resilience Week (RWS) 170-176 (IEEE, 2017).
Gao, J. et al. Networks formed from interdependent networks. Nat. Phys. 8, 40–48 (2012).
Gao, J. et al. Robustness of a network of networks. Phys. Rev. Lett. 107, 195701 (2011).
Barrat, A. et al. Dynamical Processes on Complex Networks (Cambridge University Press, 2008).
Cohen, R. et al. Complex Networks: Structure, Robustness and Function (Cambridge University Press, 2010).
Haghighi, N. et al. A multi-scenario probabilistic simulation approach for critical transportation network risk assessment. Netw. Spat. Econ. 18, 181–203 (2018).
Bruneau, M. et al. A framework to quantitatively assess and enhance the seismic resilience of communities. Earthq. spectra 19, 733–752 (2003).
Hosseini, S. et al. A review of definitions and measures of system resilience. Reliab. Eng. Syst. Saf. 145, 47–61 (2016).
Karatzetzou, A. et al. Unified hazard models for risk assessment of transportation networks in a multi-hazard environment. IJDRR 75, 102960 (2022).
Wang, T. et al. How can the UK road system be adapted to the impacts posed by climate change? By creating a climate adaptation framework. Transp. Res. D 77, 403–424 (2019).
Ji, T. et al. The impact of climate change on urban transportation resilience to compound extreme events. Sustainability 14, 3880 (2022).
Johansson, J. et al. An approach for modelling interdependent infrastructures in the context of vulnerability analysis. Reliab. Eng. Syst. Saf. 95, 1335–1344 (2010).
Rocchetta, R. et al. Risk assessment and risk-cost optimization of distributed power generation systems considering extreme weather conditions. Reliab. Eng. Syst. Saf. 136, 47–61 (2015).
Arrighi, C. et al. Indirect flood impacts and cascade risk across interdependent linear infrastructures. Nat. Hazards Earth Syst. Sci. 21, 1955–1969 (2021).
Wang, W. et al. An approach for cascading effects within critical infrastructure systems. PHYSICA A 510, 164–177 (2018).
Kumar, D. R. et al. Integrating GIS, MCDM, and Spatial Analysis for ComprehensiveFlood Risk Assessment and Mapping in Uttarakhand, India. Geol. J. 60, 2263-2280 (2025).
Abishek, S. R. et al. Assessing urban flood risk in Thoothukudi city: a GIS and remote sensing-based approach to climate change. Econ. Disaster Clim. Change 9, 263–287 (2025).
Sarhadi, A. et al. Physics-based hazard assessment of compound flooding from tropical and extratropical cyclones in a warming climate. Earths Future 13, e2024EF005078 (2025).
Thelen, T. et al. Wind and rain compound with tides to cause frequent and unexpected coastal floods. Water Res. 266, 122339 (2024).
Sohn, W. et al. How does increasing impervious surfaces affect urban flooding in response to climate variability? Ecol. Indic. 118, 106774 (2020).
Osman, S. A. et al. GIS-based flood risk assessment using multi-criteria decision analysis of Shebelle River Basin in southern Somalia. SN Appl. Sci. 5, 134 (2023).
Breinl, K. et al. Understanding the relationship between rainfall and flood probabilities through combined intensity-duration-frequency analysis. J. Hydrol. 602, 126759 (2021).
Brummitt, C. D. et al. Suppressing cascades of load in interdependent networks. PNAS 109, E680–E689 (2012).
Rosas-Casals, M. et al. Topological vulnerability of the European power grid under errors and attacks. Int. J. Bifurc. Chaos 17, 2465–2475 (2007).
Crucitti, P. et al. Error and attack tolerance of complex networks. Physica A 340, 388–394 (2004).
Buldyrev, S. V. et al. Catastrophic cascade of failures in interdependent networks. Nature 464, 1025–1028 (2010).
Gastner, M. T. et al. The spatial structure of networks. Eur. Phys J. B 49, 247–252 (2006).
Borgatti, S. P. et al. Models of core/periphery structures. Soc. Netw. 21, 375–395 (2000).
Granovetter, M. S. The strength of weak ties. Am. J. Socio. 78, 1360–1380 (1973).
Kitsak, M. et al. Identification of influential spreaders in complex networks. Nat. Phys. 6, 888–893 (2010).
Nieuwenhuijsen, M. J. Exposure Assessment in Environmental Epidemiology (OUP Us, 2015).
Yamazaki, D. et al. Regional flood dynamics in a bifurcating mega delta simulated in a global river model. Geophys. Res. Lett. 41, 3127–3135 (2014).
Yamazaki, D. et al. A physically based description of floodplain inundation dynamics in a global river routing model. Water Resour. 47, 1–21 (2011).
Malczewski, J. & Rinner, C. Multicriteria Decision Analysis in Geographic Information Science (Springer, 2015).
Jain, A., Nandakumar, K. & Ross, A. Score normalization in multimodal biometric systems. Pattern Recogn. 38, 2270–2285 (2005).
Shannon, C. E. A mathematical theory of communication. Bell Syst. Tech. J. 27, 379–423 (1948).
Liu, Q. et al. China’s municipal public infrastructure: estimating construction levels and investment efficiency using the entropy method and a DEA model. Habitat Int. 64, 59–70 (2017).
Malczewski, J. GIS and Multicriteria Decision Analysis (John Wiley & Sons, 1999).
Greene, R. et al. An approach to GIS-based multiple criteria decision analysis integrating exploration and evaluation phases: case study in a forest-dominated landscape. Ecol. Manag. 260, 2102–2114 (2010).
Tzeng, G.-H. & Huang, J.-J. Multiple Attribute Decision Making: Methods and Applications. (CRC Press, 2011).
Goodchild, M. F. The quality of big (geo) data. Dialogues Hum. Geogr. 3, 280–284 (2013).
Leibovici, D. G. et al. Local and global spatio-temporal entropy indices based on distance-ratios and co-occurrences distributions. Int. J. Geogr. Inf. Sci. 28, 1061–1084 (2014).
McRae, B. H. et al. Using circuit theory to model connectivity in ecology, evolution, and conservation. Ecology 89, 2712–2724 (2008).
Deb, K. Multi-objective Optimization Using Evolutionary Algorithms (John Wiley & Sons, 2001).
Goldberg, D. E. Genetic Algorithms in Search, Optimization, and Machine Learning (Addison-Wesley, 1989).
Blondel, V. D., Guillaume, J.-L., Lambiotte, R. & Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. 2008, P10008 (2008).
Newman, M. E. J. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 103, 8577–8582 (2006).
Kipf, T. N. & Welling, M. Semi-supervised classification with graph convolutional networks. Preprint at https://doi.org/10.48550/arXiv.1609.02907 (2016).
Newman, M. E. et al. Finding and evaluating community structure in networks. Phys. Rev. E 69, 026113 (2004).
Watts, D. J. et al. Collective dynamics of ‘small-world’networks. Nature 393, 440–442 (1998).
Albert, R. & Barabási, A.-L. Statistical mechanics of complex networks. Rev. Mod. Phys. 74, 47 (2002).
Schütze, H. et al. Introduction to Information Retrieval Vol. 39 (Cambridge University Press, 2008).
Acknowledgements
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
Yunshan Wan: Conceived and designed the experiments; Performed the experiments; Analysed the data; Contributed materials/analysis tools; Wrote the paper. Rong Xia: Conceived and designed the experiments; Performed the experiments; Wrote the paper. Yuerong Zhang: Analysed the data; Contributed materials/analysis tools; Wrote the paper. Qiwei He: Performed the experiments; Contributed materials/analysis tools; Wrote the paper. Mengqiu Cao: Conceived and designed the experiments; Performed the experiments; Analysed the data; Contributed materials/analysis tools; Wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wan, Y., Xia, R., Zhang, Y. et al. Multiscale flood-driven risk propagation across urban charging infrastructure. npj Urban Sustain 6, 37 (2026). https://doi.org/10.1038/s42949-026-00344-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s42949-026-00344-x
