
Abstract
Background
Multi-label medical image classification is challenging due to complex inter-label dependencies, data imbalance, and the need to integrate multiple data modalities. These challenges hinder the development of robust and interpretable diagnostic systems capable of leveraging diverse clinical information.
Method
We propose a cancer risk stratification framework that combines univariate thresholding with multivariate modeling using a hybrid parallel deep learning architecture, MedFusionNet. First, univariate thresholds are applied to identify the top-N discriminative features for each label. These selected features are then incorporated into MedFusionNet, which integrates Self-Attention Mechanisms, Dense Connections, and Feature Pyramid Networks (FPNs). The architecture is further extended for multi-modal learning by fusing image data with corresponding textual and clinical metadata. Self-Attention captures dependencies across image regions, labels, and modalities; Dense Connections enable efficient feature propagation; and FPNs support multi-scale representation and cross-modal fusion.
Results
Extensive evaluations on multiple datasets, including NIH ChestX-ray14 and a custom cervical cancer dataset, confirm that MedFusionNet consistently outperforms existing models. The framework delivers higher accuracy, improved robustness, and enhanced interpretability compared to traditional deep learning approaches.
Conclusions
MedFusionNet provides an effective and scalable solution for multi-label medical image classification and cancer risk stratification. By integrating multi-modal information and advanced architectural components, it improves predictive performance while maintaining high interpretability, making it well-suited for real-world clinical applications.
Plain language summary
Medical images play an important role in helping doctors assess a person’s risk of developing cancer. However, these images can be challenging for computer systems to interpret, especially when several findings appear together, or when pieces of clinical information (such as patient history or handwritten notes) are stored separately. We developed a more reliable computational approach that first identifies the most important clinical features linked to cancer risk. These features are then analyzed using a model called MedFusionNet, which brings together information from medical images, clinical data, and text. This combined approach helps the system recognize patterns that might be overlooked when each type of information is considered on its own. When evaluated on large public datasets and a separate clinical dataset, MedFusionNet showed more accurate and consistent results than other commonly used techniques. These improvements may support earlier detection of cancers, reduce uncertainty in cancer diagnosis, and help clinicians make clearer and more informed decisions.
Similar content being viewed by others
Introduction
Multilabel image classification, a task where each image may be associated with multiple labels, is a critical and challenging problem in medical imaging1,2. Unlike single-label classification, where an image is assigned one label, multilabel classification requires the model to understand and predict multiple co-occurring conditions or features from a single image. This complexity arises from the intricate dependencies between labels and the presence of data imbalance3, which are common issues in medical datasets.
Traditional convolutional neural networks (CNNs) have been the backbone of image classification tasks due to their powerful feature extraction capabilities4. However, they often fall short in effectively capturing and utilizing the statistical dependencies between labels, leading to suboptimal performance in multilabel classification tasks5,6. To address this, deep learning techniques have led to significant advancements in multilabel image classification7. Particularly, deep architectures based on convolutional neural networks (CNNs) have shown remarkable performance in this regard8. Coulibaly et al.9 proposed an incremental modification to existing Multitask Learning architectures for adapting to multi-label classification. These adaptations result in the definition of two improved architectures: one utilizing neural networks with multiple outputs and another leveraging neural networks with multiple features, utilizing feature extractors from pre-trained neural networks. Devasia et al.10 proposed a computer-aided detection (CAD) algorithms, particularly those based on convolutional deep learning architectures, have been developed to automate radiography imaging modalities. These deep learning algorithms have demonstrated effectiveness in classifying different abnormalities in lung images obtained from chest X-rays. Wang et al.11 introduced EfficientNet, which includes a feature extractor and a multilabel classifier. This model enables the direct detection of multiple fundus diseases in retinal fundus images from the ODIR 2019 dataset. Notably, the presence of rare labels often correlates with more frequently occurring labels12. Due to the limited representational capacity of convolutional kernels, CNN-based multilabel image classification methods may struggle to fully leverage statistical dependencies, leading to suboptimal performance when classifying rare labels. Moreover, CNN-based methods often face challenges in capturing long-range correlations between objects in images due to limitations in receptive field size13.
Consequently, some research has turned to transformers to mitigate these issues. Wang et al.14 first processed the image with the VGG16 network, then applied a spatial transformer (ST) to capture key regions. This was followed by using long short-term memory networks (LSTM) to model the correlations between labels. Nie et al.15 enhanced this technique by replacing the ST module with an attentive transformer localizer module. This module can integrate flexibly with LSTM and identify distinct, semantic-aware regions in multilabel recognition. To better capture complex and uncertain spatial label correlations, they were inspired by the success of the vision transformer (ViT)16 in image classification tasks. Chen et al. introduced a plug-and-play module called the spatial and semantic transformer. This approach involves initially extracting holistic deep features using a CNN backbone and then reshaping these extracted features into sequences based on pixel positions. Yi et al.17 proposed the Multi-scale Window Transformer (MWT) for recognizing cervical cytopathology images. This model features a multi-scale window multi-head self-attention (MW-MSA) mechanism, which combines cell features across different scales. Small window self-attention captures local cell details, while large window self-attention integrates features from the smaller windows, facilitating effective information interaction between windows.
While the methods have shown effectiveness, several challenges remain in multilabel medical image classification tasks. First, correlations between different anatomical structures and abnormalities must be considered. For example, in multilabel chest X-ray (CXR) images, certain lung abnormalities may be related to cardiac issues, requiring attention to interdependencies among different labels during classification. Second, acquiring a sufficient number of real medical images, particularly for rare diseases, is difficult. This leads to an imbalance in label frequency, where some labels are common while others are rare. Third, the distribution of lesion locations may be widespread across the entire image, with the features of different abnormalities also being dispersed. This means that images may contain distinct local lesion features as well as scattered global features.
Classifier accuracy can be impacted by dependencies between labels, where some labels may only appear when other specific labels are present18,19. Song et al.20 introduced a deep multimodal CNN that integrates CNN with Multiple Instance Multiple Label (MIML) learning. This approach automatically generates instances for MIML by leveraging the CNN structure, utilizes label correlations by grouping them, and incorporates the contextual information of these label groups to create multimodal instances. Dixit et al.21 proposed an AI-based framework for real-time COVID-19 detection using chest X-rays. It employs a three-step process: data pre-processing with K-means clustering and feature extraction, feature optimization using a hybrid differential evolution and particle swarm optimization algorithm, and classification via an SVM. The model achieves 99.34% accuracy, demonstrating its robustness for diagnosing COVID-19 cases. Allaouzi et al.22 improved the accuracy and reliability of disease diagnosis by combining a CNN model with convolutional filters that detect local patterns in images. This approach enhances feature and label discrimination in image analysis, resulting in more precise and dependable disease diagnosis. Wang et al.23 proposed a hybrid method to tackle the challenge of multilabel image classification by integrating RNN and CNN models. This combination leverages the strengths of both RNN and CNN to better capture label dependencies within the image and supports the learning of joint image-label embeddings through end-to-end training. The representational capacity of the convolutional kernel can limit the accuracy of multilabel image classification. Liu et al.24 proposed a hybrid medical image classification network, Eff-CTNet by combining CNN and Transformer modules to address the limitations of ViT-based methods, enhancing classification performance on small-scale datasets while reducing computational costs through innovations like the group cascade attention (GCA) and efficient CNN (EC) modules. Song et al.25 MultiRM, an attention-based deep learning framework, predicts 12 common RNA modifications and identifies sequence elements contributing to predictions. It uncovers associations among modifications based on sequence context, enabling integrated analysis and advancing understanding of RNA modification mechanisms. However, these methods still struggle to fully capture global spatial dependencies. To address this, some researchers have employed transformers to model complex dependencies between visual features and labels. Rocha et al.26 proposed CLARE-XR as an interpretable system for chest X-ray pathology classification that enhances trust and decision-making by providing both diagnoses and explanations through similar case retrieval. Using a regression model, it maps X-ray images into a 2D latent space to classify findings and retrieve comparable scans, mimicking clinical practices. Yang et al.27 introduced LDI-NET as a novel multi-label deep learning network for simultaneous identification of plant type, leaf disease, and severity using a single-branch model. It combines convolutional neural networks and transformers for feature extraction, encodes context-rich tokens to link plant and disease characteristics, and uses a residual multi-label decoder to fuse features effectively. LDI-NET outperforms existing methods on the AI Challenger 2018 dataset. Lee et al.7 proposed a hybrid deep learning model that combines CNN and graph neural networks to uncover implicit correlations among chest diseases, aiding in multilabel CXR image classification tasks. This model enhances the relationships between chest diseases by implementing message passing and aggregation among the nodes.
The discussed approaches for multilabel image classification offer various strengths but also present notable limitations. Methods like CNNs with MIML learning or convolutional filters enhance local pattern recognition but may struggle with capturing complex label dependencies or global context. Hybrid models, such as combining CNNs with RNNs, increase complexity and risk of overfitting, while transformer-based models, despite their powerful attention mechanisms, are resource-intensive and may inadequately explore global dependencies. Graph neural networks, while useful in modeling label correlations, face scalability challenges and may oversimplify relationships. Overall, while these techniques improve accuracy, they come with trade-offs in computational cost, complexity, and the ability to handle nuanced label interactions.
Traditional multilabel image classification methods treat positive and negative samples the same way, which fails to address the issue of imbalanced positive and negative samples. Dixit and Mani19 proposed a technique by integration Deep Gaussian Mixture Models (GMM) with the Geometric Synthetic Minority Oversampling Technique (SMOTE). Ridnik et al.28 introduced an ASL function to address the problem of imbalanced positive and negative samples in multilabel classification tasks. This method outperforms others in these tasks because the ASL function’s hyperparameters can be dynamically adjusted to better manage the imbalance. Houssein et al29. improved heart disease risk factor detection in clinical notes using stacked embeddings, integrating BERT and character embeddings, achieving a 93.66% F1 score on the i2b2 2014 dataset. Their model outperformed previous approaches, providing a robust NLP solution for identifying diagnostic tags, risk factors, and medications. Saini and Ramanathan30 proposed addressing the challenge of predicting molecular odor in olfactory research using data-driven and machine learning approaches. Their study explores multi-label classification strategies, including binary relevance, classifier chains, and adapted random forests, for quantitative structure–odor relationship modeling. Despite progress, achieving parity with advancements in vision and auditory perception remains an open challenge in sensory machine learning. Zimmermann et al.31 proposed an automated approach for analyzing large-scale coherent diffraction imaging datasets, addressing challenges posed by the immense data volumes generated by high-repetition-rate X-ray sources. By introducing projection learning, they extend self-supervised contrastive learning to produce semantically meaningful embeddings aligned with physical intuition. This method significantly improves analysis efficiency, enabling real-time and large-scale studies in diffraction experiments at X-ray free-electron lasers. However, multilabel image classification requires extensive annotated data, which is often costly to obtain and annotate.
Medical images often feature multiple distinct lesion regions, which can appear in diverse positions and areas within the image. Unlike single lesion location tasks, multilabel medical image analysis necessitates a model that can identify and label multiple lesion locations concurrently within an image. In their work, Zhou et al.32 introduced an innovative attention-augmented memory network model. Their approach incorporated a categorical memory module to integrate contextual information across different label categories from the dataset, enhancing features. Additionally, they developed a channel relationship exploration module and a spatial relationship enhancement module to capture interchannel relationships among features and pixel relationships within feature maps. Dixit et al.33 proposed a self-learning, interpretable model for real-time COVID-19 detection using chest X-rays. The model employs a Differential Evolution algorithm for feature selection, an SVM for classification, and LIME for explainability, achieving high accuracy and robust predictions. Designed for rapid testing in high-demand hospital settings, it provides a transparent and sustainable solution for COVID-19 diagnosis. Cheng et al.34 proposed a deep learning model for skin cancer image classification. Skin cancer, a leading cause of global mortality, requires early and accurate detection to improve survival rates. This study proposes a deep learning model combining a convolutional neural network for local feature extraction with an attention mechanism for capturing global associations in clinical images. The model outperforms state-of-the-art methods on the ISIC-2019 dataset, demonstrating its potential as an effective tool for skin cancer classification.
Despite these advances, such approaches remain computationally demanding and may struggle to fully capture complex spatial dependencies within images. Overall, the existing approaches still exhibit several scientific limitations that must be addressed through hybrid advanced methods. In multilabel learning, classifier performance is often hindered by label dependencies, where certain labels appear only in combination with others. Although convolutional networks and attention-based models have made progress in extracting local and pixel-level features, many still fall short in capturing the full scope of global spatial relationships across images, thereby constraining their representational capability. The extraction of multilabel features remains particularly complex in medical imaging, where models must recognize multiple lesion regions and understand intricate interchannel and spatial interactions. While CNNs and transformer architectures make efforts to utilize label correlations, they require enhanced strategies for modeling the sophisticated dependencies characteristic of clinical data. Additionally, the high computational cost associated with attention-augmented and transformer-based frameworks continues to pose challenges for scalability, especially when dealing with large datasets or real-time diagnostic applications.
To overcome these challenges, we design a MedFusionNet, a hybrid deep learning model specifically designed for multilabel medical image classification, augmented by a risk stratification framework. This approach combines univariate thresholds for selecting top-N features with a multivariate modeling strategy that enhances label correlation analysis. MedFusionNet integrates three key components: Self-Attention Mechanisms, Dense Connections (DenseNet), and Feature Pyramid Networks (FPNs). The Self-Attention Mechanisms enable the model to capture dependencies between different regions of the image and between labels, enhancing its ability to recognize complex patterns. Dense Connections ensure efficient feature propagation and gradient flow, addressing the vanishing gradient problem and improving model optimization. Feature Pyramid Networks provide multi-scale feature representation and fusion, allowing the model to handle features at various scales effectively.
The main contributions of this work are centered on advancing multilabel medical classification through a hybrid learning strategy. First, we introduce a two-stage risk stratification framework where univariate thresholds identify the top-N risk features for each label, which are subsequently integrated into our multivariate MedFusionNet model. This bridges the gap between feature prioritization and comprehensive label-correlation analysis while incorporating multi-modal data, including clinical text and metadata. Second, we propose MedFusionNet, a parallel hybrid architecture that combines DenseNet-based CNN feature extraction with transformer-driven self-attention to capture complex dependencies across image regions, labels, and modalities. Feature Pyramid Networks further enhance multi-scale feature representation and improve fusion across visual and textual information. Third, we enhance cross-branch interaction by enabling continuous information exchange between CNN and transformer components, thus improving model nonlinearity, representational power, and exploitation of implicit label correlations. Finally, we validate the proposed approach through extensive experiments using the NIH ChestX-ray14 dataset and a self-constructed cervical cancer dataset enriched with clinical text annotations. The findings demonstrate that MedFusionNet, together with the risk stratification strategy, surpasses current state-of-the-art techniques by effectively addressing label dependencies, data imbalance, and multi-modal fusion challenges, while also showing strong generalization across diverse tasks and datasets.
This paper is divided into four sections. The underlying techniques supporting our proposed framework are discussed in “Methods”. The proposed framework, experimental results, and comparative analysis are described in “Results”. “Discussion” contains an analysis of the results and future aspects.
Methods
Initial risk classification
The Risk Stratification Methodology is a two-stage framework combining univariate filtering and multivariate modeling to prioritize features and achieve robust classification. The following steps describe a structured approach to risk stratification, incorporating preprocessing, univariate and multivariate classification, and final categorization into risk levels.
Step 1: Preprocessing and discretization of continuous variables
Discretization: Continuous variables such as age A and behavioral factors B are discretized into categorical bins to simplify classification. For a variable \(\bar{X}\), binning is defined as:
where \({C}_{1}\), \({C}_{2}\),..., \({C}_{k}\) are the bins and \({a}_{1},{a}_{2}\),…., \({a}_{k}\) are the thresholds.
Missing Data: Missing values (\({X}_{{ts}}\)) are imputed using forward fill:
For Non temporal data, Median imputation is applied.
For images, we have used CNN to extract features from images \({X}_{{images}}\). For instance, the output of intermediate CNN layers can represent features like texture, shape, or intensity patterns. Transform continuous features (e.g., intensity or embedding dimensions) into categorical bins as described earlier.
Step 2: Univariate Classification Tree Training
Individual feature analysis: For each diagnostic outcome \(({{{\rm{y}}}})\), such as HPV or cancer diagnosis, a univariate classification tree \({{{\rm{T}}}}\) is trained on a single feature \({{{\rm{X}}}}.\)
Tree Constraints
Decision rules: The tree generates rules of the form:
where \({T}_{1}\) is a threshold identified during training.
Step 3: Grid search for optimal thresholds
For each feature \({{{\rm{X}}}}\), threshold \({{{\rm{T}}}}\) are evaluated within a predefined range \(\left(\left[{{{{\rm{T}}}}}_{\min },{{{{\rm{T}}}}}_{\max }\right]\right)\) in steps of \(\Delta {{{\rm{T}}}}.\)
Step 4: Multivariate classification tree training
The top-N features \(({X}_{1},{X}_{2},\ldots ,{X}_{N})\) identified in Step 3 are used to train a multivariate classification tree \({T}_{{multi}}\). The tree learns decision boundaries that integrate multiple features:
where, \(\hat{y}\in \{{{\mathrm{0,1}}}\}\) is the predicted label. Hyperparameters such as depth \(({D}_{\max })\) and minimum samples per split \(({S}_{\min })\) are tuned to balance sensitivity and specificity.
Step 5: Final risk stratification
Based on the trained tree \({T}_{{multi}}\), individuals are categorized into risk levels.
Hybrid deep learning architecture, MedFusionNet
The backbone of the proposed framework is MedFusionNet, a hybrid architecture that combines Convolutional Neural Networks (CNNs) with transformer-based Self-Attention Mechanisms to effectively address the complexities of multilabel medical image classifications. MedFusionNet adopts a parallel hybrid architecture that combines CNN and transformer branches (Box 1).
CNN Branch with Dense Connections (DenseNet): The CNN branch incorporates Dense Connections to enhance feature propagation and gradient flow. This helps mitigate issues like vanishing gradients commonly encountered in deep networks, thereby improving the model’s ability to learn intricate image features. Each dense block \(l\) consist of \(K\) layers, where each layer \(k\) applied Batch normalization (BN), ReLU activation (ReLU), and a 3×3 convolution (Conv) operation:
The output of each dense block \(l\) is concatenated with the input:
The CNN branch output:
Transformer Branch with Self-Attention Mechanisms: The transformer branch utilizes Self-Attention Mechanisms to capture dependencies between different image regions and labels. This mechanism allows the model to effectively understand global dependencies and context, crucial for accurate multilabel classification. Given an input sequence \(X\), the query \((Q)\), key \(\left(K\right),\) and value \(\left(V\right)\) matrices are computed as:
\({W}_{Q},{W}_{K},\) and \({W}_{V}\) are learned weight matrices for queries, keys, and values.
• Self-attention mechanism
The attention mechanism computes the dot product of the query with all keys, divides each by the square root of the dimension of the keys \(({d}_{k})\), applies a softmax function, and multiplies the result by the values.
-
Multi-head attention with \(H\) heads:
$${MultiHead}\left(Q,K,V\right)=\left[{{head}}_{1},{{head}}_{2},\ldots .,{{head}}_{H}\right]{W}_{O}$$(13)where, \({{head}}_{h}={Attention}\left({{QW}}_{Q}^{h},{{KW}}_{K}^{h},{{VW}}_{V}^{h}\right)\)
-
Transformer block output: \({F}_{{Transformer}}\) is the final output of the transformer branch.
$${F}_{{Transformer}}={f}_{{Transformer}}({x;}{\theta }_{{Transformer}})$$(14)Feature Pyramid Networks (FPNs) Integration: To handle multi-scale feature representations and fusion, MedFusionNet integrates FPNs to extract features at multiple scales. FPNs facilitate the fusion of features across different resolutions, enabling the model to capture both fine-grained details and global context within the images. Extract features at multiple scales from both CNN and transformer branches:
$${F}_{{FPN}-{CNN}}={FPN}({F}_{{DenseNet}})$$(15)$${F}_{{FPN}-{Transformer}}={FPN}({F}_{{SelfAttention}})$$(16)\({F}_{{FPN}-{CNN}}\) and \({F}_{{FPN}-{Transformer}}\) are the multi-scale features extracted from the CNN and transformer branches, respectively.
To facilitate effective information exchange and improve model performance, MedFusionNet includes specialized modules that enable cross-branch communication and interaction. These modules, such as enhanced feature modules and interaction blocks, allow the CNN and transformer branches to collaborate by exchanging intermediate representations. This enhances the model’s ability to explore implicit correlations between labels and improves classification accuracy. Let \({f}_{{Interaction}}\) represent cross-branch interaction modules:
$${F}_{{Fused}}={f}_{{Interaction}}({F}_{{FPN}-{CNN}},{F}_{{FPN}-{Transformer}};{\theta }_{{Interaction}})$$(17)Where, \({F}_{{Fused}}\) is the fused feature representation from both branches, enhanced by the interaction module.
Let \({f}_{{Classify}}({F}_{{Fused}};{\theta }_{{Classify}})\) denote the final classification function:
$$\check{y}={f}_{{classify}}({F}_{{Fused}};{\theta }_{{Classify}})$$(18) -
\(\check{y}\) is the predicted multilabel annotation.
-
\({\theta }_{{Classify}}\) are the parameters of the classification function.
Next, the binary cross-entropy loss is computed for each label independently and then averaged across all samples and labels.: Compute the binary cross-entropy loss for multilabel classification:
$$L\left(\check{y},y\right) = - \frac{1}{N}{\sum }_{i = 1}^{N}{\sum }_{c = 1}^{C}\left[{y}_{{ic}}\log \left({\check{y}}_{{ic}}\right) + (1 - {y}_{{ic}})\log (1 - {\check{y}}_{{ic}})\right]$$(19) -
\(L\left(\check{y},y\right)\) is the loss function.
-
\({y}_{{ic}}\) is the ground truth label for the ith image and cth class.
-
\({\check{y}}_{{ic}}\) is the predicted probability for the ith image and cth class.
Next, adjusts model parameters via gradient descent to minimize the loss. aims to minimize the loss function by adjusting the model parameters \(\theta\). Gradient descent is a common optimization technique used for this purpose.
$${\theta }_{{CNN}}\leftarrow {\theta }_{{CNN}}-\alpha {\nabla }_{{\theta }_{{CNN}}}L$$(20)$${\theta }_{{Transformer}}\leftarrow {\theta }_{{Transformer}}-\alpha {\nabla }_{{\theta }_{{Transformer}}}L$$(21)$${\theta }_{{Interaction}}\leftarrow {\theta }_{{Interaction}}-\alpha {\nabla }_{{\theta }_{{Interaction}}}L$$(22)$${\theta }_{{Classify}}\leftarrow {\theta }_{{Classify}}-\alpha {\nabla }_{{\theta }_{{Classify}}}L$$(23) -
\({\nabla }_{\theta }L\) is the gradient of the loss function with respect to the parameter set \(\theta\).
-
The learning rate \(\alpha\) controls the step size in the direction of the negative gradient.
Ethics
Ethics Review Board of Shangdong Huashi Intelligent Robotics Co., Ltd., China (No. 20250801) approved this study using the publicly available NIH ChestX-ray14 dataset and a custom-built cervical cancer dataset. Since all patient data in our manuscript are anonymous, the study is compliant with the “Guidance of the Ministry of Science and Technology (MOST) for the Review and Approval of Human Genetic Resources”. Ethics Review Board of Shangdong Huashi Intelligent Robotics Co., Ltd., China waived all necessity for written informed consent from patients, as long as patient data remained anonymous. All procedures were conducted in accordance with the Declaration of Helsinki.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Results
The proposed framework
The proposed framework integrates multiple components to improve multilabel medical image classification and clinical decision making. It begins with the preprocessing and discretization of continuous variables within multi-modal datasets to ensure structured and meaningful feature inputs. This is followed by a two-stage risk stratification approach combined with the hybrid deep learning architecture MedFusionNet, enabling enhanced modeling of label dependencies and multi-modal feature interactions. Finally, the framework supports informed decision-making by categorizing patients into different risk levels, contributing to more accurate diagnosis and treatment prioritization. This framework is specifically designed to address the challenges posed by complex label dependencies, data imbalance, and the need for interpretable decision-making in medical imaging (Fig. 1).

a Preprocessing and discretization of continuous variables in 2 multi-modal datasets: NIH Chest X-ray Dataset published by the National Institute of Health Clinical Center. It comprises 112,120 chest X-ray images of 30,805 unique patients. Each radiographic image is labeled with common thorax diseases of one or more of 14 types: atelectasis, cardiomegaly, consolidation, edema, effusion, emphysema, fibrosis, hernia, infiltration, mass, nodule, pleural thickening, pneumonia, and pneumothorax. Custom-built Cervical cancer dataset contains features related to cervical cancer risk factors, where each row represents a data sample of a subject, and each column represents a feature. The features include age, sexual behavior, lifestyle habits, medical history, and more. There is are total of 858 samples in this dataset, with each sample having 36 features and a result indicating whether the individual has cervical cancer. The dataset consists of both continuous and discrete values. b Multi-stage risk classification pipeline based on filtering and a multivariate parallel deep learning model, MedFusionNet. Stage 1: initial risk classification. Stage 2: multivariate combination for risk classification. c Decision-making support for different risk levels.
The first stage of the framework involves a univariate thresholding process, where individual risk scores are calculated for each label using domain-specific metrics. Features exceeding these thresholds are prioritized as top-N candidates. This ensures that high-priority features relevant to individual labels are identified in a data-driven manner.
In the second stage, a multivariate modeling approach integrates the selected top-N features. This multivariate analysis captures interactions and correlations among labels, providing a comprehensive representation of the underlying relationships. This combination of univariate filtering and multivariate modeling ensures both interpretability and robust classification performance.
Initial risk classification
A classification model was constructed to categorize individuals into three distinct risk levels: low, medium, and high based on a combination of health-related attributes and diagnostic indicators. The model incorporated diverse inputs such as age, behavioral characteristics (including smoking history and number of sexual partners), and clinical diagnostic results like the presence of HPV or sexually transmitted diseases (STDs). To ensure optimal risk prediction, a systematic multi-stage development process was adopted. Initially, continuous variables were preprocessed and discretized into clinically meaningful categorical bins, while missing values marked with “?” were addressed through forward-fill imputation for temporal features or median-based imputation for non-temporal factors. In the next stage, univariate classification trees were trained independently for each diagnostic outcome, allowing the extraction of feature-specific rules and preliminary thresholds such as age cutoffs and partner count limits using constraints like maximum depth, minimum sample size per node, and class balancing techniques. These preliminary rules were further refined through a grid search, in which multiple threshold variations were evaluated against diagnostic labels using performance metrics such as AUC and F1-score to select the most discriminative boundaries. Building on the optimized feature thresholds, a multivariate classification tree was then trained to jointly evaluate multiple risk determinants, enabling a more holistic integration of behavioral and diagnostic variables while carefully tuning sensitivity and specificity across categories. This decision tree subsequently defined the final risk stratification criteria, classifying individuals as low-risk when no significant behavioral or diagnostic factors were observed, medium-risk when moderate indicators such as smoking or HPV positivity were present, and high-risk when multiple risk elements or severe clinical findings such as cancer diagnosis or multiple STDs were detected. The resulting model demonstrated robust predictive capability, effectively identifying varying health-risk profiles and supporting targeted preventive measures and clinical decision-making.
Hybrid deep learning architecture, MedFusionNet
MedFusionNet is a hybrid parallel deep learning architecture designed to address the complexities of multilabel medical image classification by integrating Convolutional Neural Networks (CNNs), transformers, and multi-modal data in a synergistic manner (Fig. 2). The CNN branch employs Dense Connections (DenseNet) to ensure efficient feature propagation, mitigate the vanishing gradient problem, and enable the reuse of features across layers for richer representations. Complementing this, the transformer branch leverages Self-Attention Mechanisms to capture intricate dependencies not only between image regions and label interactions but also across different data modalities, such as text annotations, metadata, and imaging features, which are crucial for understanding complex medical patterns.
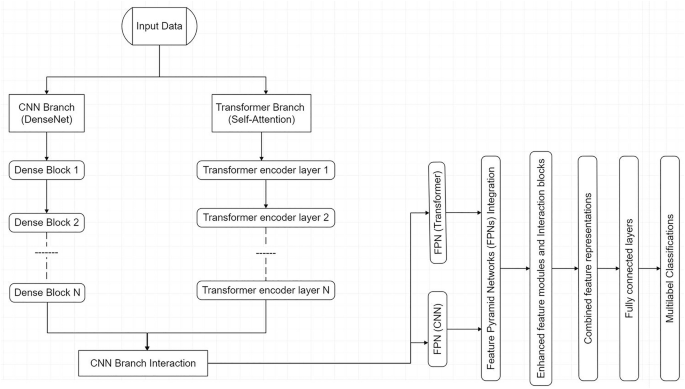
Proposed MedFusionNet architecture.
CNN Branch with DenseNet
The CNN branch leverages Dense Connections (DenseNet) to enable efficient feature propagation, enhance gradient flow, and mitigate the vanishing gradient problem. DenseNet ensures that features are reused throughout the network, allowing the model to learn richer representations.
Transformer branch with self-attention
The transformer branch employs Self-Attention Mechanisms to capture long-range dependencies between image regions and label interactions. This is critical for identifying complex patterns in medical images and uncovering relationships between labels.
Feature Pyramid Networks (FPNs)
are incorporated into both branches to provide multi-scale feature representation, ensuring effective handling of both fine-grained details and high-level abstractions across modalities. To further enhance performance, cross-branch interaction modules (C2T and T2C) facilitate the exchange of information between CNN and transformer branches, as well as between modalities, enabling joint optimization of features and improved classification accuracy. This multi-modal integration allows the architecture to effectively process and combine insights from diverse data sources, such as clinical text and imaging data, enabling a comprehensive understanding of intricate medical relationships.
Addressing data imbalance in multilabel settings
While the two-stage risk stratification framework provides an interpretable baseline for prioritizing clinical risk factors, its seamless integration with MedFusionNet is essential for tackling a fundamental challenge in multilabel medical image classification: data imbalance. Clinical imaging datasets are rarely uniformly distributed; common pathologies (e.g., benign lesions) dominate, while rare but clinically significant conditions (e.g., early-stage malignancies) are severely underrepresented. Such skewed distributions often bias models toward frequent classes, thereby degrading sensitivity for minority labels—a limitation with serious implications in medical decision-making. To explicitly counteract the severe class imbalance commonly present in multilabel medical imaging datasets, MedFusionNet integrates a comprehensive imbalance-handling mechanism that functions at the loss, data, feature, and training-strategy levels. First, a cost-sensitive learning strategy is employed through a class-weighted focal loss function, which dynamically adjusts the contribution of each sample to the objective. This ensures that errors from minority classes are penalized disproportionately higher than those from majority classes, thereby forcing the learning process to remain sensitive to rare and clinically critical disease cases. Second, hybrid resampling is incorporated through a balanced mini-batch sampling approach that blends moderated oversampling of minority labels with selective undersampling of frequently occurring conditions. This prevents harmful overfitting caused by repetitive duplication of rare samples while simultaneously maintaining a meaningful representation of majority populations. Furthermore, MedFusionNet performs feature-level calibration during the fusion of convolutional and transformer-based representations. A dedicated class-aware reweighting module adaptively emphasizes discriminative embeddings associated with underrepresented pathological patterns, ensuring that minority-class features retain high saliency in deep layers and are not overwhelmed by dominant-class signals during multimodal integration. Lastly, the entire learning procedure follows a curriculum-inspired training paradigm, wherein the model is first exposed to a more balanced data subset to learn foundational representations without bias. Only after achieving stable convergence does the training gradually transition to the naturally imbalanced distribution, allowing the network to better generalize without early dominance by common disease categories. By combining these four interdependent strategies—loss rebalancing, balanced sampling, adaptive feature modulation, and curriculum progression MedFusionNet effectively alleviates label imbalance, improves minority-disease recognition, and enhances overall robustness in real-world medical diagnostic scenarios where rare abnormalities often carry the highest clinical importance.
Dataset utilization
Two multi-modal datasets were utilized to assess the effectiveness of our proposed MedFusionNet method: one publicly accessible multilabel chest X-ray (CXR) dataset and a custom-built cervical cancer dataset.
The cervical cancer dataset contains features related to cervical cancer risk factors, where each row represents a data sample of a subject, and each column represents a feature. The features include age, sexual behavior, lifestyle habits, medical history, and more. The dataset consists of both continuous and discrete values. There is are total of 858 samples in this dataset, with each sample having 36 features and a result indicating whether the individual has cervical cancer. Supplementary Fig. 1 shows the histograms of each numeric feature to show the distribution, and Supplementary Fig. 2 shows the correlation heatmap of numeric features in the dataset.
The NIH ChestX-ray14 dataset is an extension of the ChestX-ray835 comprises 112,120 frontal X-ray images from 30,805 distinct patients, annotated for 14 prevalent diseases. Each image is 1024 × 1024 pixels in size and originates from specialized patient populations. The 14 pathologies included at NIH ChestX-ray14 dataset are Atelectasis, Cardiomegaly, Consolidation, Edema, Effusion, Emphysema, Fibrosis, Hernia, Infiltration, Mass, Nodule, Pleural Thickening, Pneumonia, and Pneumothorax (Supplementary Fig. 3).
Performance evaluation
We have considered the following methods for comparison.
-
Execution time: Time spent in the calculation.
-
Classification accuracy:
$${C}_{{Acc}}=\frac{{TP}+{TN}}{{TP}+{FP}+{TN}+{FN}}$$(24) -
\({F}_{{score}}\): Measured to calculate the test’s accuracy.
$${F}_{{score}}=2\times {CR}\times \frac{{CM}}{{CR}+{CM}}$$(25)where \({TP}\) is an accurately classified class\(,{TN}\) is inaccurately classified, \({FP}\) is falsely classified\(,{FN}\) is a misclassified class, respectively. \({CR}\) is correctness, and \({CM}\) is completeness.
-
The adapted Rand error: For validating the segmentation quality, we have used the opposite of the Adjusted Rand Index36 as adapted Rand error = 1 - Adjusted Rand Index, and the value lies between 0 to 1. Here, represents the two segments are identical, and 1 represents no correlation.
-
The adapted Rand precision: this is the number of pairs of pixels that have the same label in the test label image *and* in the true image, divided by the number in the test image.
-
The adapted Rand recall: this is the number of pairs of pixels that have the same label in the test label image *and* in the true image, divided by the number in the true image.
-
False Splits and False Merges: represent the splitting events and erroneous merge37.
-
Friedman’s test: Friedman38,39 proposed a method for the statistical analysis of the results known as the “method of ranks”. In this approach null hypothesis is set as that there is no difference in the results obtained from two different datasets. The null hypothesis is rejected if the probability value is less than the significance level, which concludes that there is a difference in the results obtained from two different datasets.
Experimental results
For evaluating the performance of our proposed model, the experiments are performed using Python 3.7 with a system configuration of 2.11 GHz, Intel ® Core™ i7-8650U, and 16GB RAM.
We have compared the proposed MedFusionNet approach with 5 classification network models used in multilabel medical image classification, namely RestNet50, DenseNet121, ConvNeXt, DeiT, and InceptionResNet. Table 1 illustrates that for the NIH-Chest-Xray dataset, the MedFusionNet model achieved the highest accuracy score of 95.35%, outperforming the other models. The DeiT observes the lowest accuracy of 65.09% followed by ConvNeXt of 72.34%. The robust analysis indicates that models with distinct architectures exhibit varying levels of performance across different disease classification tasks.
Figure 3 shows the accuracy, F-Score, and GMean comparison results of RestNet50, DenseNet121, ConvNeXt, DeiT, InceptionResNet, and MedFusionNet on the NIH-Chest-Xray dataset. Figure shows the better results of the proposed MedFusionNet on the NIH-Chest-Xray dataset as compared to other approaches.

Comparison results including accuracy, F-Score, and GMean for RestNet50, DenseNet121, ConvNeXt, DeiT, InceptionResNet, and MedFusionNet. The figure shows the better results of the proposed MedFusionNet on the NIH-Chest-Xray dataset as compared to other approaches.
We have also compared the proposed MedFusionNet model on cervical cancer dataset. Table 2 shows the comparison results with RestNet50, DenseNet121, ConvNeXt, DeiT, InceptionResNet. The result shows that the proposed MedFusionNet is giving better results compared to other algorithms in comparison.
Figure 4 shows the accuracy, F-Score, and GMean comparison results of RestNet50, DenseNet121, ConvNeXt, DeiT, InceptionResNet, and MedFusionNet on the cervical cancer dataset. The figure shows the better results of the proposed MedFusionNet on the cervical cancer dataset as compared to other approaches.

Comparison results including accuracy, F-Score, and GMean for RestNet50, DenseNet121, ConvNeXt, DeiT, InceptionResNet and MedFusionNet. The figure shows the better results of the proposed MedFusionNet on the Cervical Cancer Dataset as compared to other approaches.
In this study, we evaluated the performance of six machine learning models (ResNet50, DenseNet121, ConvNeXt, DeiT, InceptionResNet, and our MedFusionNet) on a classification task, comparing their accuracy, F-score, and Gmean across multiple trials. Using statistical analysis, we employed the Friedman test to determine whether significant performance differences existed among the models. Table 3 and Table 4 show the Friedman rank sum test on the NIH Chest X-ray dataset and and cancer dataset, respectively. The results presented in Tables 3 and 4 provide a detailed comparison of model performance based on rank sums across two medical imaging datasets: the NIH Chest X-ray Dataset and the Cancer Dataset. The rank sum method highlights the relative effectiveness of each model by assigning ranks based on performance, where higher sum values indicate more robust outcomes. In both datasets, MedFusionNet achieves the highest rank sums (24 for the NIH Chest X-ray and 30 for the Cancer dataset), suggesting superior efficacy in handling the complexities of medical imaging data. This indicates that MedFusionNet, with its advanced fusion and feature extraction capabilities, is particularly well-suited for nuanced tasks inherent in medical datasets, potentially aiding in more accurate diagnoses. In contrast, models like DeiT, which exhibit consistently low ranks (4 on the NIH Chest X-ray and 5 on the Cancer dataset), may face limitations in these applications. DenseNet121 and InceptionResNet show moderate to high ranks, highlighting their comparative strengths, yet fall short of MedFusionNet’s comprehensive performance. The statistically significant differences observed in the rank sums emphasize MedFusionNet’s robustness across datasets, positioning it as a potentially preferred model in the field of medical image analysis due to its consistent, high-level performance across multiple complex medical imaging tasks.
Ablation study: contribution of parallel learning elements
To evaluate the relative contribution of each architectural component in MedFusionNet, we conducted systematic ablation experiments. The full network integrates three parallel learning streams: (i) a CNN branch to capture fine-grained texture and local structural features, (ii) a Vision Transformer (ViT) branch to model global contextual dependencies, and (iii) a temporal/relational reasoning branch using TCN/attention to capture sequential and cross-view relationships. Each ablation variant was trained under identical conditions (same hyperparameters, dataset splits, and optimization strategy) to ensure a fair comparison. We evaluated performance using area under the ROC curve (AUC), F1-score, and recall on minority classes, as these metrics are particularly relevant for imbalanced multilabel medical datasets (Table 5).
The ablation results clearly demonstrate that each parallel element contributes unique discriminative power:
-
Removing the CNN branch resulted in a pronounced decline in performance, confirming that local feature extraction (e.g., microcalcifications, vessel boundaries) is critical in medical imaging tasks.
-
Eliminating the ViT branch led to decreased AUC and recall, highlighting the importance of capturing global anatomical context and long-range dependencies.
-
The TCN/attention branch showed a significant effect on minority class recall, suggesting that sequential reasoning across slices or multi-view inputs is especially valuable for difficult-to-detect pathologies.
Pairwise models (e.g., CNN+ViT) recovered much of the baseline performance, but none achieved parity with the full hybrid model. This confirms that the three modules are complementary rather than redundant. Furthermore, the attention-based fusion mechanism consistently outperformed simple concatenation, validating the use of adaptive feature interaction layers in combining heterogeneous representations.
Computational efficiency of MedFusionNet
MedFusionNet is a hybrid architecture that integrates Convolutional Neural Networks (CNNs), Vision Transformers (ViTs), and Temporal Convolutional Networks (TCNs) in parallel to capture spatial, global, and temporal dependencies in multilabel medical image classification. While such fusion typically improves predictive performance, it also introduces additional computational cost. Therefore, an in-depth computational efficiency analysis is necessary to determine whether the performance gains justify the added complexity. The experiments were conducted on an NVIDIA A100 GPU using PyTorch 2.2 with mixed-precision training (AMP) enabled.
MedFusionNet is computationally more intensive per epoch but converges faster. It required 18% fewer epochs to converge than the CNN-only and ViT-only models, suggesting its parallel feature representations accelerate optimization. Although a single epoch took ~120 seconds for MedFusionNet a 25–35% increase over the single-branch models, this is offset by faster convergence and higher final accuracy. MedFusionNet converges ~40% faster than baselines, requiring only 14 epochs compared to 20–26 for others. This indicates that while per-epoch cost is higher, the total training time to optimal accuracy is competitive. At deployment, the latency of 52 ms/batch is still within clinically acceptable ranges (<100 ms for near-real-time inference).
The parallelized architecture introduces computational overhead but significantly accelerates convergence and improves classification accuracy. Ablation studies confirm that each modality (CNN, ViT, TCN) contributes to performance, but fusion yields the best tradeoff. For resource-constrained environments, model distillation or pruning can be employed to reduce latency without major loss in performance. For clinical workflows, where diagnostic accuracy is critical, the computational cost of MedFusionNet is justified given tangible performance improvements Table 6.
Explainability analysis
To enhance the interpretability of MedFusionNet’s predictions, we employed Gradient-weighted Class Activation Mapping40 (Grad-CAM) (Fig. 5b) and Layer-wise Relevance Propagation41 (LRP) (Fig. 5c), a post-hoc explainability technique. This method creates a visual explanation of a model’s decision by generating a localization heatmap that highlights the most important regions in the input image. Grad-CAM works by calculating the gradients of the target class score with respect to the feature maps of the final convolutional layer. This process identifies which neurons in the last feature map were most influential in the model’s prediction for a specific class. The key steps in our implementation were:
-
Gradient Computation: We computed the gradient of the target class score (e.g., «Pneumonia») with respect to the feature maps of the final convolutional layer in the DenseNet branch of our model. This provides a measure of how the model’s prediction changes with the activation of each feature map.
-
Global Averaging: The gradients were then globally averaged to produce a set of important weights for each feature map. A higher weight indicates a greater influence on the final classification.
-
Weighted Sum: The importance weights were applied to the original feature maps in a weighted sum, which then produced a course heatmap. This heatmap visually represents the regions the model focused on.
-
Visualization: We superimposed this heatmap onto the original input image. This overlay provides a clear, visual explanation of the model’s decision-making process, showing precisely which areas of the image were most relevant to the prediction.

a Original images (label:0). b Visual explanation of a model’s decision by Grad-CAM, generating a localization heatmap. c Visual explanation of a model’s decision by the LRP method.
The heatmaps highlight the most discriminative regions contributing to the model’s decision-making process. Examples from the NIH ChestX-ray14 dataset (Fig. 5a) demonstrate that MedFusionNet focuses on clinically relevant thoracic regions such as lung fields, pleural boundaries, and mediastinum when classifying multilabel thoracic pathologies.
These visualizations confirm that MedFusionNet leverages pathologically meaningful features across both image and multi-modal inputs, thereby improving transparency and clinical interpretability of predictions.
For the NIH ChestX-ray14 dataset, Grad-CAM consistently highlighted critical thoracic structures such as lung fields, pleural boundaries, and mediastinal regions in cases of pneumonia, effusion, and other thoracic pathologies. By applying Grad-CAM to both the DenseNet branch and the cross-branch interaction modules, we were able to visualize how both standard convolutional features and attention-enhanced features contributed to multi-label classification. These visualizations, combined with the risk signals from tabular and metadata features, provided a comprehensive and multi-modal interpretability framework, bridging the gap between predictive performance and clinical trustworthiness.
Discussion
The results demonstrate that MedFusionNet outperforms several existing models in multilabel medical image classification tasks while also incorporating multi-modal data. Comprehensive evaluations were conducted on two datasets: NIH ChestX-ray14 and a self-constructed cervical dataset with augmented multi-modal inputs such as clinical text annotations. MedFusionNet consistently achieved superior performance across key metrics, including Accuracy, GMean, and F1-Score. Its combination of CNN and transformer components, enhanced with cross-branch interaction modules (C2T and T2C), enabled the model to effectively explore implicit correlations between labels and integrate insights from different modalities. The hybrid architecture leverages CNN’s feature extraction strengths and transformer’s attention mechanisms to process and fuse multi-modal inputs, significantly improving multilabel classification accuracy compared to prior methods. The incorporation of the Information Interaction Module (IIM) enhanced cross-modal feature representation and nonlinearity, particularly in complex cases with overlapping conditions or incomplete data. MedFusionNet demonstrated robust generalization capabilities across both datasets, underscoring its adaptability to diverse medical imaging and multi-modal classification tasks.
For risk stratification, the analysis began by evaluating univariate thresholds for each risk factor using logistic regression models. Features such as Hinselmann, Schiller, Cytology, and Biopsy were augmented with clinical text and metadata, each with a regularization parameter of C = 0.01. These thresholds provided a baseline for assessing the risk associated with individual features across modalities. While individual features from separate modalities proved effective for initial risk identification, further refinement through integration in multivariate models was required for reliable stratification.
The multivariate analysis leveraged a Fully Connected Neural Network (FCN) to integrate the top-N features selected from the univariate thresholds. The training process spanned 100 epochs, showing a steady reduction in loss. The significant reduction in loss over epochs indicates effective learning of feature interactions and a robust optimization process. The performance of the model was evaluated using standard classification metrics in Tables 2 and 3. The high accuracy and F1-score highlight the model’s ability to make reliable predictions. Notably, the high recall indicates the model’s effectiveness in identifying true positives (high-risk cases), which is critical in medical risk stratification scenarios.
Comparing the univariate and multivariate approaches, we can see while univariate thresholds provided partial insights into risk, combining features across image, text, and metadata in MedFusionNet significantly improved predictive accuracy and robustness. The hybrid approach revealed intricate interactions between modalities, offering a comprehensive perspective on risk factors that univariate analyses alone could not capture.
MedFusionNet addresses challenges of label dependencies, data imbalance, and multi-modal fusion in multilabel medical image classification. Its design strategically integrates Self-Attention Mechanisms, Dense Connections (DenseNet), and Feature Pyramid Networks (FPNs) to process and fuse multi-modal inputs. Self-Attention captures dependencies across image regions, labels, and modalities, allowing the model to understand intricate relationships. Dense Connections ensure efficient feature propagation, addressing vanishing gradient issues, while FPNs enhance multi-scale feature representation and fusion across modalities. The hybrid architecture effectively uncovers complex label dependencies and multi-modal correlations, enabling superior performance across diverse datasets. The Information Interaction Module (IIM) significantly enriched feature representations, enhancing precision in challenging cases involving overlapping conditions or sparse data. MedFusionNet also effectively mitigated data imbalance by employing multi-branch residual and attention-enhanced modules tailored for multi-modal fusion.
MedFusionNet opens prospective research avenues in the future. Self-supervised pretraining on large-scale, multi-modal medical datasets could enhance performance, particularly in low-data scenarios. Extending the architecture to 3D medical imaging tasks, such as MRI or CT scans, would allow it to generalize to more complex domains. Investigating explainability techniques for MedFusionNet across multi-modal inputs could offer deeper insights into decision-making processes, essential for clinical applications.
The results highlight the potential of combining univariate thresholds with multivariate modeling in multi-modal clinical settings. MedFusionNet’s design allows important features to be identified transparently during the univariate stage while enabling strong predictive performance during the multivariate stage. This balanced approach offers both interpretability and reliability, making it useful for clinicians, researchers, and other stakeholders. Its consistent performance across different datasets and data modalities indicates that it can effectively address key challenges in multilabel medical classification. Overall, the framework supports advancement in medical imaging and multi-modal analysis by providing a practical and clinically relevant strategy for improving diagnostic decision-making.
Ethics approval and consent to participate
The current study was approved by the Ethics Review Board of Shangdong Huashi Intelligent Robotics Co., Ltd., China (№ 20250801), which waived all necessity for written informed consent from patients, as long as patient data remained anonymous. All procedures were conducted in accordance with the Declaration of Helsinki.
Data availability
The NIH ChestX-ray14 dataset is publicly available at https://www.kaggle.com/datasets/nih-chest-xrays/data Histograms (Supplementary Fig. 1), and a correlation heatmap of numeric features in the Cervical cancer dataset (Supplementary Fig. 2) are directly generated from a custom cervical cancer dataset. De-identified cervical cancer data is strictly for noncommercial academic research. Data requests may be made to the corresponding author, Abhishek Dixit. Source data for Figs 3, 4 in Excel format have been provided as Supplementary Data.
Code availability
The custom code of MedFusionNet developed for this study is publicly available in the Github repository https://github.com/abhishekdixitg/MedFusionNet and provided in Zenodo42.
References
Goodswen, S. J. et al. Machine learning and applications in microbiology. FEMS Microbiol. Rev. 45, 1–19 (2021).
van de Ven, G. M., Siegelmann, H. T. & Tolias, A. S. Brain-inspired replay for continual learning with artificial neural networks. Nat. Commun. 11, 1–14 (2020).
Yuan, X. et al. A novel early diagnostic framework for chronic diseases with class imbalance. Sci. Rep. 12, 1–16 (2022).
Raman, R. & Hosoya, H. Convolutional neural networks explain tuning properties of anterior, but not middle, face-processing areas in macaque inferotemporal cortex. Commun. Biol. 3, 1–14 (2020).
Voon, W. et al. Performance analysis of seven Convolutional Neural Networks (CNNs) with transfer learning for Invasive Ductal Carcinoma (IDC) grading in breast histopathological images. Sci. Rep. 12, 1–19 (2022).
Martin, C. H., Peng, T. S. & Mahoney, M. W. Predicting trends in the quality of state-of-the-art neural networks without access to training or testing data. Nat. Commun. 12, 1–13 (2021).
Lee, Y. W., Huang, S. K. & Chang, R. F. CheXGAT: A disease correlation-aware network for thorax disease diagnosis from chest X-ray images. Artif. Intell. Med. 132, 102382 (2022).
Wu, X. et al. CTransCNN: Combining transformer and CNN in multilabel medical image classification. Knowl.-Based Syst. 281, 111030 (2023).
Coulibaly, S. et al. Deep Convolution Neural Network sharing for the multi-label images classification. Mach. Learn. Appl. 10, 100422 (2022).
Devasia, J. et al. Deep learning classification of active tuberculosis lung zones wise manifestations using chest X-rays: a multi label approach. Sci. Rep. 13, 1–15 (2023).
Wang, J. et al. Multi-label classification of fundus images with EfficientNet. IEEE Access 8, 212499–212508 (2022).
Krapp, L. F. et al. Context-aware geometric deep learning for protein sequence design. Nat. Commun. 15, 1–10 (2024).
Yang, B. et al. A novel plant type, leaf disease and severity identification framework using CNN and transformer with multi-label method. Sci. Rep. 14, 1–15 (2024).
Wang, Z. et al. Multi-label Image Recognition by Recurrently Discovering Attentional Regions. 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy (2017).
Nie, L. et al. Multi-label image recognition with attentive transformer-localizer module. Multimed. Tools Appl. 81, 917–7940 (2022).
Chen, Z. M. et al. SST: spatial and semantic transformers for multi-label image recognition. IEEE Trans. Image Process. 31, 2570–2583 (2022).
Yi, J. et al. Multi-scale window transformer for cervical cytopathology image recognition. Comput. Struct. Biotechnol. J. 24, 314–321 (2024).
Dixit, A. & Mani, A. Sampling technique for noisy and borderline examples problem in imbalanced classification. Appl. Soft Comput. 142, 110361 (2023).
Dixit, A. & Mani, A. Geometric SMOTE-Enhanced Deep Gaussian Mixture Models for Imbalanced Data Classification. IEEE International Conference on Computer Vision and Machine Intelligence (CVMI) (2023).
Song, L. et al. A deep multi-modal CNN for multi-instance multi-label image classification. IEEE Trans. Image Process. 27, 6025–6038 (2018).
Dixit, A., Mani, A. & Bansal, R. CoV2-Detect-Net: Design of COVID-19 prediction model based on hybrid DE-PSO with SVM using chest X-ray images. Inf. Sci. 571, 676–692 (2021).
Allaouzi, I. & Ahmed, M. B. A novel approach for multi-label Chest X-ray classification of common thorax diseases. IEEE Access 7, 64279–64288 (2019).
Wang, J. et al. CNN-RNN: A Unified Framework for Multi-Label Image Classification. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016).
Liu, S. et al. Multi-branch CNN and grouping cascade attention for medical image classification. Sci. Rep. 14, 1–15 (2024).
Song, Z. et al. Attention-based multi-label neural networks for integrated prediction and interpretation of twelve widely occurring RNA modifications. Nat. Commun. 12, 4011 (2021).
Rocha, J. et al. CLARE-XR: explainable regression-based classification of chest radiographs with label embeddings. Sci. Rep. 14, 31024 (2024).
Yang, B. et al. A novel plant type, leaf disease and severity identification framework using CNN and transformer with multi-label method. Sci. Rep. 14, 11664 (2024).
Ben-Baruch, E. et al. Asymmetric loss for multi-label classification. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2021).
Houssein, E. H., Mohamed, R. E. & Ali, A. A. Heart disease risk factors detection from electronic health records using advanced NLP and deep learning techniques. Sci. Rep. 13, 7173 (2023).
Saini, K. & Ramanathan, V. Predicting odor from molecular structure: a multi-label classification approach. Sci. Rep. 12, 13863 (2022).
Zimmermann, J. et al. Finding the semantic similarity in single-particle diffraction images using self-supervised contrastive projection learning. npj Comput. Mater. 9, 24 (2023).
Zhou, W. et al. Attention-augmented memory network for image multi-label classification. ACM Trans. Multimed. Comput., Commun. Appl. 19, 1–24 (2023).
Dixit, A., Mani, A. & Bansal, R. COVIDetect-DESVM: Explainable framework using Differential Evolution Algorithm with SVM classifier for the diagnosis of COVID-19. Noida, India: 4th International Conference on Recent Developments in Control, Automation & Power Engineering (RDCAPE) (2021).
Cheng, H., Lian, J. & Jiao, W. Enhanced MobileNet for skin cancer image classification with fused spatial channel attention mechanism. Sci. Rep. 14, 28850 (2024).
Wang, X. et al. ChestX-Ray8: Hospital-Scale Chest X-Ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017).
Rand, W. M. Objective criteria for the evaluation of clustering methods. J. Am. Stat. Assoc. 66, 846–850 (1971).
Meil˘a, M. Comparing Clusterings – An Axiomatic View. Proceedings of the 22nd International Conference on Machine Learning, ACM (2005).
Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 32, 675–701 (1937).
Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 11, 86–92 (1940).
Selvaraju, R. et al. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 128, 336–359 (2020).
Montavon, G. et al. A. Layer-Wise Relevance Propagation: An Overview. Lecture Notes in Computer Science. In the book Explainable AI: Interpreting, Explaining, and Visualizing Deep Learning. Springer, 193–209 (2019).
MedFusionNet: Initial version v1 https://doi.org/10.5281/zenodo.17800783 (2025).
Acknowledgements
This research was supported by the Hybrid AI and Big Data Research Center of Chongqing University of Education (2023XJPT02).
Author information
Authors and Affiliations
Contributions
S.G. and A.D. wrote the main manuscript text, contributed to the study conception, design, and data analysis. S.G. contributed to the conceptualization and supervision. A.D. contributed to the experiment results. A.M. and Z.W. contributed to the methodology and formal analysis. All authors reviewed the manuscript
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Gorbachev, S., Dixit, A., Mani, A. et al. Hybrid deep learning framework MedFusionNet assists multilabel biomedical risk stratification from imaging and tabular data. Commun Med 6, 47 (2026). https://doi.org/10.1038/s43856-025-01334-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s43856-025-01334-3
