
Abstract
Machine learning (ML) is increasingly being developed to support individualized risk assessment and de-escalation in acute psychiatry. However, ML algorithms have been shown to exhibit unfair behavior based on protected characteristics, such as an individual’s sex or ethnicity. The fairness of ML-based predictions of aggression in acute psychiatry has received limited investigation. To address this gap, we trained an ML algorithm to predict aggressive incidents from structured electronic health records corresponding to 17,703 patients at a large psychiatric hospital between January 2016 and May 2022 (n = 42,719 observation days). We analyzed predictions for fairness by assessing disparities in false positive rates (FPR) and true positive rates (TPR), based on patient race/ethnicity, gender, admission mode, citizenship, and housing status, as well as intersections of race/ethnicity and gender. A random forest algorithm attained ROC-AUC = 0.81. Fairness analyses revealed significant disparities in FPR and TPR across subgroups: FPR was higher for Middle Eastern and Black patients, men, those admitted into emergency care by the police, and those with unstable or supportive forms of housing. Our analysis demonstrates the potential for ML algorithms to reinforce and amplify known social and structural inequities, highlighting the importance of considering and addressing model fairness prior to clinical implementation.
Similar content being viewed by others


Introduction
Patient aggression is a major concern in clinical settings, such as acute psychiatry, and encompasses a range of behaviors including verbal abuse, sexual harassment, and physical violence. It has adverse effects on the quality of care, patient and staff safety, and public perceptions of mental health care1,2,3. However, coercive interventions used to manage the risk of aggression can be similarly problematic: the administration of medications (i.e., chemical restraints) and physical restraints to manage aggression have been shown to negatively impact a patient’s experience of care in a potentially traumatizing way4,5. Machine learning (ML) has increasingly been applied to predict the risk of patient aggression in psychiatric and forensic settings, as it can leverage complex datasets to generate more individualized predictions to enable earlier and more targeted de-escalation using non-coercive forms of intervention. Previous studies have trained ML algorithms on diverse datasets, from clinical data to neuroimaging scans, with these algorithms often exceeding the predictive performance of current clinical instruments6. However, there has been limited investigation of the fairness of these models in acute psychiatry—that is, whether their predictions display any prejudice or favoritism towards an individual or group based on certain inherent or acquired characteristics, such as race or sex (i.e., a protected group)7.
Algorithmic fairness has been a growing area of focus in ML research, and widely used algorithms for criminal recidivism prediction and healthcare resource allocation have been shown to be unfair towards racially marginalized groups, such as Black or lower-income individuals8,9,10, as well as the intersections of underserved groups, like Hispanic females11. The potential for algorithmic unfairness is particularly concerning in the context of predicting aggression in acute psychiatry because of pervasive inequities embedded in the training data. Inequities can be structural (interpersonal and systemic processes which create inequities in power and resources12) and social (disparities relating to an individual’s proximal social, political, and economic environment12). These include racial profiling in police apprehensions for involuntary psychiatric admission, gendered biases in clinician perceptions of inpatient violence risk, and disparities in access to quality mental health care based on socioeconomic status13,14,15. Inequities defined by the intersection of race, ethnicity and gender are also a significant concern, given the well-documented challenges Black men face in accessing and receiving mental health care16,17,18. These inequities can be readily embedded in the data used to train ML algorithms. Evidence of performance disparities in ML-based predictions of violence against hospital providers have emerged in one prior study, suggesting less accurate predictions for Asian and Native Hawaiian patient groups, but the analysis only examined fairness stratified by patient race, and the ability to draw conclusions was limited by small sample sizes19. There is a need to better assess how both proximal social indicators, like race/ethnicity and sex, as well as upstream factors, such as policing or housing are related to the fairness of ML-based predictions of aggression.
This analysis, which was part of a larger mixed-methods study protocolled in Sikstrom et al. 20 dissecting the construction and use of predictive care tools, had three main objectives. First, we used demographic and clinical features to train a supervised ML algorithm to predict whether a patient would become aggressive on a given day and validated its performance on an internal test set. Second, we performed a fairness assessment, examining the algorithm’s performance stratified by demographic characteristics of patients, focusing on gender, race/ethnicity, citizenship, admission mode, and housing status. Third, we characterized how the model performs for groups of patients defined by the intersection of both race/ethnicity and gender11. Overall, by examining algorithmic unfairness in ML predictions of aggression, our findings highlight the importance of assessing fairness across diverse social and demographic factors during model development and evaluation, to prevent the deployment of ML models in acute psychiatry that can harm specific populations.
Methods
Study population
This analysis utilized electronic health records (EHRs) from ten inpatient care units at the Center of Addiction and Mental Health (CAMH), a large mental health and addictions hospital in Toronto, Canada, between January 2016 and May 2022. This constituted a large, clinically heterogenous dataset that enabled sufficient sample sizes (n > 50) for fairness analysis of each demographic subgroup. Only patients who were admitted to inpatient units via the hospital’s emergency department (ED) were included, to enable consideration of admission mode (e.g., apprehension for admission by police). Patients were excluded from analysis if they were referred from a corrections facility or another hospital. However, we did not exclude patients with prior acute care visits, so the analysis included multiple inpatient hospitalizations from unique patients.
All demographic data were obtained from patient-reported forms routinely collected at admission, and include age, gender, sexual orientation, citizenship, housing status, income, highest education level, language, ethnicity, and marital status. All clinical and contextual factors that were documented at patient intake were also extracted, including primary psychiatric diagnosis assessed by ED psychiatrists via a brief diagnostic interview, presence of substance-induced symptoms, mode of admission, and inpatient unit location. Finally, risk assessment data included ratings on the Dynamic Appraisal of Situational Aggression (DASA), a clinically validated instrument that assesses each patient’s risk of aggression over the next 24 h. Assessment is based on seven dichotomous items which capture behavioral and interpersonal factors related to this risk (e.g., agitation, sensitivity to provocation, verbal threats)21,22. At CAMH, DASA scores are generated by nurses each morning that a patient is on the unit, based on their clinical observations and relevant information from a chart review of the past 24 h.
This study was approved by the CAMH research ethics board (REB #053-2021). Direct patient consent was not required for this study, as was approved by the CAMH research ethics board. All patient EHR data was processed in adherence with protocols reviewed by the CAMH Privacy Department and research ethics board.
Prediction task
The prediction outcome included aggressive incidents involving patients, as documented by any attending staff (e.g., nurses, clinicians, security guards or program assistants) in CAMH’s reporting tool. Incidents were included as outcomes if they were categorized by staff as either “abuse/assault/violence” or “physical/sexual/verbal behaviors and assaults”. Any documented use of any combination of chemical restraints, physical restraints, or seclusion due to “harm to others” or “harm to both self and others” was included as an outcome since these interventions are only used when violence or aggression is deemed imminent20,23. This method of encoding outcome was applied for all demographic groups.
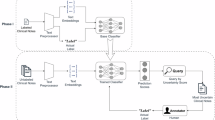
Because patients are assessed using the DASA for the risk of imminent aggression (e.g. within the next 24 hours), predictions were made on each day of the acute care stay (Fig. 1). As such, the prediction time (i.e., when a model prediction was made) was based on the time at which DASA ratings were recorded in the morning. The prediction window (i.e., the time duration after the prediction time over which the outcome was being predicted) ended either when an outcome occurred, or when the next DASA was recorded (approximately 24 hours after the prediction time). The predictor/observation window (i.e., the time duration of predictors that were used for prediction) encompassed the data collected at admission, as well as the previous 24 hours of admission or the inpatient stay, which informed the DASA score given for that day.

*If the outcome (1) occurs on a given day, no further risk assessment data (i.e., DASA scores) will be included in ML modeling for that visit. Figure adapted from Sikstrom et al. 20.
Most outcomes were expected to occur on the first three days that a patient was receiving acute care24. For this reason, we included up to three days or prediction windows for each visit. If one or more outcomes occurred during a given visit, we only included data collected until the first occurrence, since interventions used to manage the outcome may alter risk. In other words, each patient had up to three prediction windows of approximately 24 hours, starting at their first DASA assessment and ending at the next DASA assessment.
Clinical, sociodemographic and admission data was only collected once at admission for each visit, so it was repeated across the three days for each visit and patient. An outcome (i.e., aggressive incident, restraint, or seclusion) occurring before the first DASA assessment on that same visit (i.e., occurring before admission into inpatient care units, such as during transport to CAMH or during their ED course) was treated as a predictor (i.e., a binary variable indicating whether the incident occurred prior to the first DASA), that was repeated across the three days for each visit and patient.
Data processing
All variables were manually reviewed to verify the quality and clinical relevance of each predictor. Additionally, the intake demographic questionnaire contained open-ended response options for variables that were categorized as ‘other’, which were all manually categorized into the existing categories, in consultation with CAMH acute care clinicians. Gender was grouped into three categories: male, female, and gender expansive. Race/ethnicity was grouped into Black, Asian, South Asian, Indigenous, Latin-American, Middle Eastern, Mixed, and White. Each of the seven DASA items was included as an individual dichotomous variable to retain information about specific aggression-related factors. Primary diagnoses appeared as a descriptive field in the EHR; they were grouped by the study team and in consultation with clinicians into ten diagnosis types, guided by the DSM-5 categories (Supplementary table 2). The final predictor dataset included 16 categorical variables.
A 70%/30% train-test split was performed. Randomization for the train-test split was done by patient, as opposed to by observation-day, to ensure that different inpatient days or multiple presentations to acute care for the same patient were not split between the two sets. No functions were fitted on the test set, which was withheld until the final performance and fairness evaluation. All variables with missing responses were imputed based on the proportion of missingness. Variables with ≤ 20% missing were imputed by the mode, and following Suchting and colleagues23, missing values for variables with > 20% missing were imputed with a new “missing” category to preserve the potential informativeness of high missingness, which may reflect underlying social factors. Non-binary variables were one-hot-encoded in preparation for model training.
Addressing class imbalance
In the study population, the outcomes were imbalanced by almost a ratio of 33:1, with significantly greater cases with no incident. To prevent the decision boundary from greatly favoring the majority class at the expense of the fidelity of minority class predictions (e.g., by making almost exclusively negative predictions), F1 score was used as the primary evaluation metric, which is calculated based on the balance between precision and recall, thereby offering a more reliable evaluation of imbalanced data classification. Additionally, a range of resampling algorithms were tested as part of the model tuning process, where the training set was either undersampled by removing cases from the majority class or oversampled by adding synthetic cases to the minority class to balance the distribution of positive and negative cases.
Model selection and optimization
Model selection and optimization was performed on the training set using 5-fold cross validation, optimizing for F1 score based on a classification probability threshold of 0.5. Logistic regression, naïve bayes, random forest, gradient boosting, support vector machine, decision tree, and simple neural network were evaluated as candidate classification models. Additionally, no resampling, random undersampling, nearmiss undersampling, and SMOTE oversampling were evaluated as candidate resampling methods in combination with all candidate models.
Model selection and optimization was carried out in two steps. First, an initial search to determine an optimal classifier and resampler was conducted by training a model for every possible classifier-resampler combination. For each model, hyperparameters were loosely tuned using 5-fold CV across 100 iterations of a randomized hyperparameter search. (Supplementary table 5). Second, more extensive hyperparameter optimization was conducted on the top three-performing model architectures identified in the previous step, using 5-fold CV across a comprehensive grid search. (Supplementary table 6) The architecture and hyperparameters of the top performing model by F1 score were used for the final model.
Model training
The final model and sampler was refit on the entire training set and its performance was measured based on its predictions on the hold-out test set. No resampling was performed on the test set (Fig. 2). Final model performance on the test set was quantified using F1 score, PR-AUC, ROC-AUC, accuracy, sensitivity, and specificity. Standard deviations and confidence intervals for all performance and fairness metrics were calculated by training the model five times using five different random seeds, then applying each to the test set11. Feature importances were extracted using impurity-based importance as implemented in Sci-kit learn. Model recalibration was not performed, as we wished to examine the fairness characteristics of the classifier without any post-hoc group-specific adjustment.

Methodology for model training and fairness analysis.
Fairness assessment
Fairness analysis was conducted using observational criteria based on post-hoc analysis of model outputs, true outcome, and sensitive attributes. In our paper, we operationalize fairness using the equalized odds criteria, which requires that a fair model must have equal false positive rate (FPR) and true positive rate (TPR) between subgroups of sensitive attributes, where \({FPR}=\frac{{FP}}{{FP}+{TN}({\rm{Actual\; negatives}})}\) and \({TPR}=\frac{{TP}}{{TP}+{FN}({\rm{Actual\; positives}})}\)7. Given that false positives (i.e., incorrectly flagging individuals as being at high risk of aggression) carries the most potential harm with respect to reinforcing social and structural inequities, we primarily focus our assessment on FPR, which represents the disparate mistreatment criterion of fairness25. To understand the fairness behavior of the algorithm more thoroughly, group-specific F1-score, ROC curves, and calibration curves were also assessed.
Attributes that were analyzed for fairness include race/ethnicity, gender, admission mode, citizenship, and housing status. Intersectional fairness analysis was performed for the intersection of gender and race/ethnicity. When performing fairness analysis for a given feature, individuals with imputed values for that feature were excluded from that analysis. This ensures the results of the fairness analysis reflect only real-world observations without being affected by any potential bias introduced by imputation.
Results
Sample characteristics
Across all observation days, there were a total of 41447 “no incident” cases (i.e., observation days on which a violent or aggressive incident was not reported) to 1272 “incident” cases (i.e., days on which such an incident was reported) corresponding to 17703 total unique patients. These patients were split into 29879 cases in the train set (n = 12398 unique patients) and 12840 in the test set (n = 5305 unique patients).
Patients were relatively evenly distributed across age categories, but they were predominantly male, White, single, and of Canadian citizenship. The most common diagnoses were psychotic disorders, and patients were most commonly accompanied during ED admission by family or friends. Citizenship, Housing, Marital status, and Admission mode had proportions of missing observations above 20%, thereby requiring imputation with a “missing” category. All features differed significantly when comparing no incident vs incident populations (p < 0.001). Sample characteristics at the level of observation days in the overall data can be found in Table 1. Sample characteristics at the level of unique patients can be found in supplementary table 3, and characteristics by train/test set is reported in supplementary table 4.
Model performance
The best-performing model on the train set was a 200-estimator random forest (RF) with no oversampling or undersampling. Model performance for other candidate models are reported in supplementary tables 5 and 6. On the hold-out test set, the random forest obtained a F1 score of 0.2213 ± 0.0031, a PR-AUC of 0.1301 ± 0.0025, an ROC-AUC of 0.8120 ± 0.0016, and an accuracy of 0.9323 ± 0.0004 (Fig. 3A, B). The model had a sensitivity/TPR of 0.3265 ± 0.0057 and a specificity of 0.9507 ± 0.0005 at a probability threshold of 0.5. Feature importance extracted from the RF revealed that the DASA items, especially irritability, as well as the presence of a violent/aggressive incident or restraint occurring prior to admission into acute care, are highly important for predictions. (Fig. 3D).

A Precision recall curve – Area under curve (PR-AUC), B Receiver operating curve – Area under curve (ROC-AUC), C Confusion matrix based on a prediction threshold of 0.5, D Model feature importances, based on impurity-based importance.
Fairness assessment
With respect to race/ethnicity, Middle Eastern individuals had the highest FPR among all ethnic groups (FPR [standard deviation] = 0.0801 [0.0048]) followed by Black (0.0694 [0.002]), Indigenous (0.0552 [0.0037]), Mixed (0.0525 [0.0021]), White (0.0404 [0.0008]), South Asian (0.0356 [0.0019]), Asian (0.0322 [0.0028]), and Latin American (0.0313 [0.0028]) individuals (Fig. 4, Supplementary table 7). There was also significant variation in TPR: Latin American (TPR [standard deviation] = 0.3846 [0.0000]) and Middle Eastern (0.3778 [0.0222]) had the highest TPR, and Asian (0.2381 [0.0000]) and South Asian (0.2571 [0.0350]) had the lowest TPR (Supplementary table 7). Predictive accuracy was highest in Middle Eastern individuals (F1 score [standard deviation] = 0.2372 [0.0158]). ROC curves reveal significant differences in the TPR-FPR trade-offs between groups, with Black individuals having considerably higher FPR for any TPR (Supplementary Fig. 1).

A Rates stratified by ethnicity; B Rates stratified by gender; C Rates stratified by admission mode; D Rates stratified by citizenship; and E Rates stratified by housing status.
Men (0.0542 [0.0005]) had higher FPR than women (0.0426 [0.0009]) and gender expansive individuals (0.0418 [0.006]). TPR, F1 score and ROC-AUC are all lower in men compared to women. At conservative prediction thresholds, men have higher FPR for any given TPR compared to women and gender expansive individuals.
Examining fairness by admission mode, individuals who were admitted by police had significantly higher FPR than any other group label (0.0941 [0.0019]), followed by other (0.0547 [0.002]), mobile crisis (0.0476 [0.0000]), self (0.0326 [0.0007]), case worker/nurse (0.0303 [0.0007]), and friend/family (0.0264 [0.0011]). Police admissions also had relatively high TPR (0.4174 [0.0165]) and F1 score (0.2405 [0.0158]).
Canadian citizens had higher FPR and TPR (FPR = 0.0427 [0.004], TPR = 0.3145 [0.0072]) than non-citizens (FPR = 0.0210 [0.0024], TPR = 0.2696 [0.0174]). There is a significant mismatch in the ROC curves between the two groups, with Canadian citizens having higher FPR rates for any given TPR at conservative prediction thresholds.
With respect to housing, those who were in unstable forms of housing or unhoused (0.0829 [0.0014]) or were living in supportive housing (0.0502 [0.0017]) had higher FPR than those who had other forms of housing, such as owning (0.0344 [0.002]), renting (0.0318 [0.0007]), and living with family (0.0273 [0.001]). Individuals living in supportive housing have considerably lower predictive accuracy than other groups, with the lowest TPR (0.2308 [0.0243]), F1 score (0.1356 [0.0123]) and ROC-AUC (0.7651 [0.0048]).
Intersectional fairness assessment
Intersectional analysis was performed for the intersection of ethnicity and gender (Fig. 5; Supplementary table 8). The gender expansive group was excluded due to low sample sizes (N < 15 observations) for all races/ethnicities except White. All other intersectional groups had more than 50 observations. Middle Eastern men had the highest FPR (FPR [standard deviation] = 0.0933 [0.0074]) and a highly pronounced gender-specific effect; Middle Eastern women had a significantly lower FPR (0.0372 [0.0047]). However, both genders were similar in terms of their TPR. Black men (0.0759 [0.0026]) and Indigenous men (0.0747 [0.0062]) also had a relatively high FPR, and their TPRs also tended to be higher as compared to Black women (TPR [standard deviation] = 0.2353 [0.0372]) and Indigenous women (0.2500 [0.0000]). Across all races/ethnicities, men had an intersectional FPR equal to or greater than that of women.

A True positive rate (TPR), B false positive rate (FPR).
Discussion
In this study, we assessed whether ML predictions of inpatient aggression in acute psychiatric care are unfair. To our knowledge, this is the most comprehensive fairness assessment of ML as related to this outcome, and builds on previous work by Dobbins et al. 19 by examining a wider range of social determinants and applying an intersectional approach. A random forest model was trained on a range of demographic, clinical, admission, and risk assessment data, yielding an F1 score of 0.22, a PR-AUC of 0.13, and a ROC-AUC of 0.81. Although maximizing predictive performance was not an emphasis of this study, the model achieved comparable performance to ML algorithms reported in prior research trained on tabular data in clinically heterogenous psychiatric populations (ROC-AUC obtained in Suchting et al. = 0.7823, Menger et al. = 0.7626, Wang et al. = 0.6327, Danielsen et al. = 0.8728). The fairness assessment revealed the algorithm violates both disparate mistreatment and equalized odds: there were significant disparities in FPR, TPR, and ROC-AUC curves across race/ethnicity, gender, admission mode, citizenship, and housing status. Relative to other groups, FPR was elevated in individuals who are Middle Eastern and Black, those who identify as male, are admitted into emergency care by the police, Canadian citizens, and with unstable or supportive forms of housing. Intersectional analyses revealed that Middle Eastern men had the highest FPR among all groups. There were significant differences in TPR and ROC-AUC curves in relation to the FPR of each group, suggesting the nature of algorithmic unfairness differs between groups. For example, in the case of patients who are Middle Eastern, in unstable or no housing, or admitted by police, FPR and TPR were both elevated relative to other groups, suggesting the model was calibrated to increase overall predictive accuracy at the expense of higher FPR. Conversely, for other groups like Black patients, models had high FPR and low TPR, suggesting poor overall performance.
Importantly, observational measures of unfairness, such as TPR and FPR are merely outcome measures that do not explain how unfair predictions arise. Rather, these results must be understood in the context of underlying social and structural inequities that can give rise to unfair predictions in the first place, such as racial profiling in the criminal justice system, racial residential segregation, or barriers to accessing mental healthcare29. We discuss some of these parallels in the section below.
Black individuals are less likely to receive adequate outpatient psychiatric treatment, they are more likely to be involuntarily admitted into inpatient treatment, and they may also present with more severe psychotic symptoms, compared to White individuals13,14. Black men in particular face significant barriers in accessing mental health care, and they are more likely to be misdiagnosed with psychotic disorders, as compared to White men16,17,18. Interpersonal bias is also possibility, where structurally reinforced stereotypes may lead to higher risk perceptions for racially marginalized individuals on clinical risk instruments like the DASA, though research is largely inconclusive on whether these instruments are themselves biased. Both male gender and Black race have been found to be significantly associated with violence in psychiatric settings. Findings from our study suggest that these associations can become embedded in clinical datasets, which may lead to unfair treatment by ML algorithms, both via increased false positive predictions and poorer performance in identifying at-risk individuals2,30.
Police apprehension for admission into the ED is also communicated among clinicians to be a relevant factor in risk assessment due to an increased likelihood of aggression in patients admitted involuntarily, and/or referred by the police2,31. It is therefore perhaps not surprising that this mode of admission was associated with the highest FPR of any other predictor in the fairness assessment. Patients apprehended by police for admission into emergency psychiatric care are indeed more likely to become violent or aggressive, which is likely to account for relatively high FPRs and TPRs for this group32. At the same time, racially marginalized and Indigenous groups have increased rates of involuntary admissions into psychiatric care by police, likely due to various factors, such as barriers to accessing mental health care or racial profiling31,33,34,35. This tendency may in part explain the finding of higher FPRs among Black men, and potentially Middle Eastern and Indigenous individuals as well.
The fairness assessment also highlights housing as a potential source of algorithmic unfairness, specifically for those with unstable or supportive forms of housing. On a social level, unstable housing has been associated with psychiatric conditions, such as trauma and substance use, as well as a lower educational attainment and disrupted support networks36,37. Conditions of unstable housing may contribute to food or water insecurity, sleep deprivation, and hyper vigilance, which can lead to the expression of behaviors that are rated as precursors of aggression on clinical instruments, such as the DASA (e.g., irritability, sensitivity to provocation, and unwillingness to follow instructions). Structurally, current psychiatric care systems are not well-equipped to meet the constellation of needs of unhoused individuals, which may contribute to their increased ED use and higher false positive predictions for the risk of violence in inpatient care37,38,39,40,41. Supportive housing services for people with severe mental illness offer more stability, but they are in high demand and extremely under-resourced, often unable to meet complex, individual needs42.
We also identified performance disparities that are not linked to well-researched inequities. For example, while qualitative analyses have shown a general distrust of biomedical mental health services among Middle Eastern individuals, there is a considerable research gap in characterizing how they interact with these systems43. Although our analyses suggest that high FPR for Middle Eastern patients may be in part related to improved model TPR/sensitivity, social and structural determinants likely play a role in the way their risk of violence or aggression is perceived; these may be related to cultural communication barriers, or expressions of distrust manifesting as increased irritability or an unwillingness to follow instructions. However, the gender discrepancy in FPR (but not in TPR) for this group suggests this effect may only extend to men. Similarly, the algorithm displayed modest FPR differences based on citizenship, which is also not a well-documented demographic feature in the psychiatric literature. Nevertheless, citizenship may be an important factor to consider in future fairness assessments of ML models in healthcare, given its impact on access to community, social, and health services.
These findings highlight the importance of thoughtful documentation and processing of demographic data, which is a strength of our study. Specifically, access to high-quality and diverse sociodemographic information is necessary for evaluating ML models for fairness, making it critical that these data are measured or not lost during processing44. Middle Eastern ethnicity, for example, does not appear to be commonly encoded as a unique racial or ethnic category in research datasets, which inevitably precludes the discovery of important trends in this population as identified in our study45. Demographics in our dataset were drawn from CAMH’s health equity form, which was designed to capture a range of rich features which are not frequently characterized, such as specific ethnic and gender minorities46.
Overall, our results suggest that if fairness is not properly considered, the deployment of ML algorithms to support the prediction of aggression in acute psychiatric care and other clinical settings has the potential to cause significant harms with respect to both disparate mistreatment and equalized odds in socially and structurally disadvantaged groups45. Bias in ML algorithms has already been shown to reduce clinician accuracy47; in psychiatric risk assessment, the unwarranted use of interventions based on a false positive prediction can lead to unnecessary distress, disruption of trust in a therapeutic relationship or the health system, and may even precipitate violent or aggressive incidents when they otherwise would not have occurred48. Furthermore, there is extensive literature highlighting the cyclical nature of algorithmic unfairness: algorithms can reproduce and amplify existing inequalities, which can then become embedded in new datasets used to develop ML algorithms or inform care45,49. Even if an unfair recommendation is not followed, disagreement between providers and ML algorithms may lead providers to fear legal implications against them, which may negatively impact care50. Given these concerns, algorithmic unfairness is recognized by both patients and providers as a major barrier in the clinical implementation of predictive risk models50,51.
There exists a range of algorithmic methods to improve a model’s fairness, such as integrating fairness benchmarks into optimization criteria during model training, resampling the input data itself to improve fairness, or enforcing specific fairness criteria using group-specific prediction thresholds52. Several studies have now applied “debiasing” methods to clinical ML algorithms, demonstrating promising results53,54,55. Our findings highlight the necessity to properly assess fairness so that these measures can be applied as appropriate to predictive risk models before they are deployed. An important consideration, however, is that most debiasing methods use the ground truth outcome label as a benchmark to determine whether a model is fair56. In other words, most methods seek to faithfully replicate “the world as it is” – no more, but no less unfair than the input data. However, we have discussed how data relating to inpatient aggression, particularly the administration of coercive interventions, is deeply intertwined with societal inequities. As such, debiasing metrics and methods in this context must use some “true” notion of fairness that represents “the world as it should be”. Algorithmic interventions, therefore, do not constitute a complete solution. To enable algorithmic debiasing approaches, practitioners first must define how a fair and equitable ML algorithm should behave – this is a social question, not a technical one.
Ultimately, ML systems do not operate in a vacuum, but rather as part of highly complex sociotechnical systems where algorithms and societal inequities interact in complex ways. We highlight that ML fairness assessments can identify inequities across large, complex datasets to help target further investigation. However, fairness analysis alone cannot deeply characterize these social and structural drivers of unfairness, nor the exact processes by which they ultimately result in unfair predictions. When seeking to understand algorithmic fairness, therefore, it is important to characterize and understand these biases and inequities on a social level, such as through qualitative approaches that reveal patient and provider experience57,58.
It is also important to note that there is no single optimal way to assess the fairness of ML algorithms. There are over 70 definitions of fairness, many of which are conflicting, making it impossible to simultaneously satisfy all possible definitions59. We restricted our analysis to a single a priori perspective of what constitutes a fair ML model with a focus on disparate mistreatment and equalized odds, making it possible that our analysis missed other relevant fairness considerations or perspectives. For example, in contrast to the group notion of fairness used in this study, individual fairness postulates that similar individuals should receive similar ML predictions, drawing from philosophies of consistency and individual justice rather than anti-discrimination frameworks49,60. Individual fairness often relies on counterfactual or explanation-based ways to define fairness, neither of which were assessed in this study60. Additionally, our investigation examined the fairness of only one model architecture, since our aim was to evaluate models that could be advanced for further testing and implementation (i.e., those performing best on training or validation data). Although underlying societal inequities are likely to impact different types of ML models in similar ways, there is evidence that fairness performance can vary based on model architecture55,61. As such, future research could consider how fairness characteristics differ between model types, and investigate impacts of integrating fairness considerations into model selection itself62,63.
Additionally, there are limitations within the dataset used for this study. Our algorithm was trained using an urban Canadian population—although underlying inequities appear pervasive across populations, our findings may not generalize to other populations64. Moreover, the analysis relied on EHR data which is known to vary in quality. For instance, it is possible that some aggressive incidents were not documented, or modes of admission were mislabelled. Following prior work23, we included restraints in the outcome under the assumption that they were only applied when aggressive incidents were imminent, which may not always hold. Additionally, segmentation of the dataset into subgroups reduced the sample size for the fairness assessment, especially with respect to minority and intersectional groups. For example, limited sample sizes necessitated us to collapse granular descriptions of ethnic heritage into “Black” as a big-bucket category, which may mask additional disparities in ML fairness within this heterogenous group65. Similar limitations were present with gender, as we grouped all genders that were not male or female into a single category, which still lacked the sufficient size to perform intersectional analysis. We were also limited in our exploration of other indicators of socioeconomic status beyond housing, such as income or area-level deprivation and marginalization, which may have offered valuable insights into how these features impact model fairness. As such, we encourage future ML studies in this context to perform fairness assessments, particularly by leveraging rich dataset features, such as granular ethnic breakdowns, larger sample sizes for intersectional groups, and including multiple indicators of socioeconomic status. This will enable a more nuanced and thorough understanding of algorithmic fairness and how it may differ across populations.
In conclusion, ML predictions of aggression in acute psychiatric care and other clinical settings have the potential to be unfairly biased. However, this is not meant to be an argument against the use of ML in such contexts. Rather, we suggest that it is critical to be aware of fairness-related considerations prior to their implementation, and illustrate how performing such analyses can shed light on underlying inequities. To this end, we encourage future ML work in psychiatry to consider fairness as a critical element of evaluation and to conduct further research to interrogate these identified inequities.
Data availability
The dataset is restricted as it comprised confidential EHRs. Inquiries about the data can be directed to the corresponding author. The code and prediction model supporting this study is not publicly available but can be shared upon reasonable request from the corresponding author.
Code availability
The code and prediction model supporting this study is not publicly available but can be shared upon reasonable request from the corresponding author.
References
Itzhaki, M. et al. Exposure of mental health nurses to violence associated with job stress, life satisfaction, staff resilience, and post-traumatic growth. Int. J. Ment. Health Nurs. 24, 403–412 (2015).
Iozzino, L., Ferrari, C., Large, M., Nielssen, O. & Girolamo, G. de. Prevalence and risk factors of violence by psychiatric acute inpatients: a systematic review and meta-analysis. PLoS ONE 10, e0128536 (2015).
Pescosolido, B. A., Manago, B. & Monahan, J. Evolving public views on the likelihood of violence from people with mental illness: stigma and its consequences. Health Aff. 38, 1735–1743 (2019).
Zaheer, J. Documenting Restraint: Minimizing Trauma. in Interrogating Psychiatric Narratives of Madness: Documented Lives (eds. Daley, A. & Pilling, M. D.) 111–135 (Springer International Publishing, 2021). https://doi.org/10.1007/978-3-030-83692-4_5.
Lu, W., Mueser, K. T., Rosenberg, S. D., Yanos, P. T. & Mahmoud, N. Posttraumatic reactions to psychosis: a qualitative analysis. Front. Psychiatry 8, 129 (2017).
Parmigiani, G., Barchielli, B., Casale, S., Mancini, T. & Ferracuti, S. The impact of machine learning in predicting risk of violence: a systematic review. Front. Psychiatry 13, 1015914 (2022).
Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K. & Galstyan, A. A survey on bias and fairness in machine learning. ACM Computing Surveys (CSUR). 54, 1−35 (2021).
Julia, A., Larson, J., Surya, M. & Lauren, K. Machine Bias. Machine Bias https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing (2016).
Obermeyer, Z., Powers, B., Vogeli, C. & Mullainathan, S. Dissecting racial bias in an algorithm used to manage the health of populations. Science 366, 447–453 (2019).
Chen, I. Y., Szolovits, P. & Ghassemi, M. Can AI help reduce disparities in general medical and mental health care? AMA J. Ethics 21, E167–E179 (2019).
Seyyed-Kalantari, L., Zhang, H., McDermott, M. B. A., Chen, I. Y. & Ghassemi, M. Underdiagnosis bias of artificial intelligence algorithms applied to chest radiographs in under-served patient populations. Nat. Med. 27, 2176–2182 (2021).
National Collaborating Centre for Determinants of Health. Glossary of essential health equity terms. (NCCDH, 2022).
Hairston, D. R., Gibbs, T. A., Wong, S. S. & Jordan, A. Clinician Bias in Diagnosis and Treatment. in Racism and Psychiatry: Contemporary Issues and Interventions (eds. Medlock, M. M., Shtasel, D., Trinh, N.-H. T. & Williams, D. R.) 105–137 (Springer International Publishing, 2019). https://doi.org/10.1007/978-3-319-90197-8_7.
Smith, C. M. et al. Association of black race with physical and chemical restraint use among patients undergoing emergency psychiatric evaluation. Psychiatr. Serv. Wash. DC 73, 730–736 (2022).
Kirkbride, J. B. et al. The social determinants of mental health and disorder: evidence, prevention and recommendations. World Psychiatry 23, 58–90 (2024).
Motley, R. & Banks, A. Black males, trauma, and mental health service use: a systematic review. Perspect. Soc. Work J. Dr. Stud. Univ. Houst. Grad. Sch. Soc. Work 14, 4–19 (2018).
Olbert, C. M., Nagendra, A. & Buck, B. Meta-analysis of Black vs. White racial disparity in schizophrenia diagnosis in the United States: do structured assessments attenuate racial disparities? J. Abnorm. Psychol. 127, 104–115 (2018).
Tegnerowicz, J. “Maybe It Was Something Wrong With Me”: On the Psychiatric Pathologization of Black Men. in Inequality, Crime, and Health Among African American Males vol. 20 73–94 (Emerald Publishing Limited, 2018).
Dobbins, N. J. et al. Deep learning models can predict violence and threats against healthcare providers using clinical notes. Npj Ment. Health Res. 3, 61 (2024).
Sikstrom, L. et al. Predictive care: a protocol for a computational ethnographic approach to building fair models of inpatient violence in emergency psychiatry. BMJ Open 13, e069255 (2023).
Ogloff, J. R. P. & Daffern, M. The dynamic appraisal of situational aggression: an instrument to assess risk for imminent aggression in psychiatric inpatients. Behav. Sci. Law 24, 799–813 (2006).
Lantta, T., Kontio, R., Daffern, M., Adams, C. E. & Välimäki, M. Using the dynamic appraisal of situational aggression with mental health inpatients: a feasibility study. Patient Prefer. Adherence 10, 691–701 (2016).
Suchting, R., Green, C. E., Glazier, S. M. & Lane, S. D. A data science approach to predicting patient aggressive events in a psychiatric hospital. Psychiatry Res 268, 217–222 (2018).
Weltens, I. et al. Aggression on the psychiatric ward: prevalence and risk factors. A systematic review of the literature. PLoS ONE 16, e0258346 (2021).
Zafar, M. B., Valera, I., Rodriguez, M. G. & Gummadi, K. P. Fairness Beyond Disparate Treatment & Disparate Impact: Learning Classification without Disparate Mistreatment. In Proceedings of the 26th International Conference on World Wide Web 1171–1180 (2017). https://doi.org/10.1145/3038912.3052660.
Menger, V., Spruit, M., van Est, R., Nap, E. & Scheepers, F. Machine learning approach to inpatient violence risk assessment using routinely collected clinical notes in electronic health records. JAMA Netw. Open 2, e196709 (2019).
Wang, K. Z. et al. Prediction of physical violence in schizophrenia with machine learning algorithms. Psychiatry Res 289, 112960 (2020).
Danielsen, A. A., Fenger, M. H. J., Østergaard, S. D., Nielbo, K. L. & Mors, O. Predicting mechanical restraint of psychiatric inpatients by applying machine learning on electronic health data. Acta Psychiatr. Scand. 140, 147–157 (2019).
El-Azab, S. & Nong, P. Clinical algorithms, racism, and “fairness” in healthcare: a case of bounded justice. Big Data Soc 10, 20539517231213820 (2023).
Watts, D., Leese, M., Thomas, S., Atakan, Z. & Wykes, T. The prediction of violence in acute psychiatric units. Int. J. Forensic Ment. Health 2, 173–180 (2003).
Maharaj, R., Gillies, D., Andrew, S. & O’brien, L. Characteristics of patients referred by police to a psychiatric hospital. J. Psychiatr. Ment. Health Nurs. 18, 205–212 (2011).
Dharma, C. et al. Examining systemic and interpersonal bias in violence risk assessments of patients in acute psychiatric care. Psychiatr. Serv. 76, 326–335 (2025).
Meerai, S., Abdillahi, I. & Poole, J. An introduction to anti-black sanism. Intersect. Glob. J. Soc. Work Anal. Res. Polity Pract. 5, 18–35 (2016).
Bhui, K. et al. Ethnic variations in pathways to and use of specialist mental health services in the UK. Systematic review. Br. J. Psychiatry J. Ment. Sci. 182, 105–116 (2003).
Chow, J. C.-C., Jaffee, K. & Snowden, L. Racial/ethnic disparities in the use of mental health services in poverty areas. Am. J. Public Health 93, 792–797 (2003).
Schreiter, S. et al. Housing situation and healthcare for patients in a psychiatric centre in Berlin, Germany: a cross-sectional patient survey. BMJ Open 9, e032576 (2019).
Narendorf, S. C. Intersection of homelessness and mental health: a mixed methods study of young adults who accessed psychiatric emergency services. Child. Youth Serv. Rev. 81, 54–62 (2017).
Amato, S., Nobay, F., Amato, D. P., Abar, B. & Adler, D. Sick and unsheltered: Homelessness as a major risk factor for emergency care utilization. Am. J. Emerg. Med. 37, 415–420 (2019).
Kushel, M. B., Perry, S., Bangsberg, D., Clark, R. & Moss, A. R. Emergency department use among the homeless and marginally housed: results from a community-based study. Am. J. Public Health 92, 778–784 (2002).
Serper, M. R. et al. Predictors of aggression on the psychiatric inpatient service. Compr. Psychiatry 46, 121–127 (2005).
Mauri, M. C. et al. Aggressiveness and violence in psychiatric patients: a clinical or social paradigm? CNS Spectr 24, 564–573 (2019).
Sanford, S., Roche, B., Molina, I., Weston N. A. & Sirotich, F. Toronto supportive housing growth plan: Needs assessment. Toronto, ON: Wellesley Institute & Canadian Mental Health Association-Toronto. (2022).
Tahir, R., Due, C., Ward, P. & Ziersch, A. Understanding mental health from the perception of Middle Eastern refugee women: a critical systematic review. SSM - Ment. Health 2, 100130 (2022).
Andrus, M., Spitzer, E., Brown, J. & Xiang, A. What We Can’t Measure, We Can’t Understand: Challenges to Demographic Data Procurement in the Pursuit of Fairness. in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency 249–260. https://doi.org/10.1145/3442188.3445888 (Association for Computing Machinery, 2021).
Soliman, L., Jain, A., Rozel, J. & Rachal, J. Safe spaces: mitigating potential aggression in acute care psychiatry. FOCUS 21, 46–51 (2023).
Centre for Addiction and Mental Health. We Ask Because We Care: Answers to Frequently Asked Questions about Patient Demographic Data Collection [Internet]. Toronto, ON: Centre for Addiction and Mental Health. Available from: https://www.camh.ca/-/media/files/socio-demographic_patient_pamphlet-pdf.
Jabbour, S. et al. Measuring the impact of AI in the diagnosis of hospitalized patients: a randomized clinical vignette survey study. JAMA 330, 2275–2284 (2023).
Ling, S., Cleverley, K. & Perivolaris, A. Understanding mental health service user experiences of restraint through debriefing: a qualitative analysis. Can. J. Psychiatry Rev. Can. Psychiatr. 60, 386–392 (2015).
Caton, S. & Haas, C. Fairness in machine learning: a survey. ACM Comput. Surv. 56, 3616865 https://doi.org/10.1145/3616865 (2023).
Giddings, R. et al. Factors influencing clinician and patient interaction with machine learning-based risk prediction models: a systematic review. Lancet Digit. Health 6, e131–e144 (2024).
Sax, D. R., Sturmer, L. R., Mark, D. G., Rana, J. S. & Reed, M. E. Barriers and opportunities regarding implementation of a machine learning-based acute heart failure risk stratification tool in the emergency department. Diagnostics 12, 2463 (2022).
Feng, Q., Du, M., Zou, N. & Hu, X. Fair Machine Learning in Healthcare: A Survey in IEEE Transactions on Artificial Intelligence, Vol. 6, 493−507 https://doi.org/10.1109/TAI.2024.3361836.
Zhu, Y. et al. M$^3$Fair: Mitigating bias in healthcare data through multi-level and multi-sensitive-attribute reweighting method. arXiv.org https://arxiv.org/abs/2306.04118v1 (2023).
Yang, J., Soltan, A. A. S., Eyre, D. W., Yang, Y. & Clifton, D. A. An adversarial training framework for mitigating algorithmic biases in clinical machine learning. npj Digit. Med. 6, 1–10 (2023).
Li, F. et al. Evaluating and mitigating bias in machine learning models for cardiovascular disease prediction. J. Biomed. Inform. 138, 104294 (2023).
Hellström, T., Dignum, V. & Bensch, S. Bias in Machine Learning -- What is it Good for? Preprint at https://doi.org/10.48550/arXiv.2004.00686 (2020).
Chin, M. H. et al. Guiding principles to address the impact of algorithm bias on racial and ethnic disparities in health and health care. JAMA Netw. Open 6, e2345050 (2023).
Aquino, Y. S. J. et al. Practical, epistemic and normative implications of algorithmic bias in healthcare artificial intelligence: a qualitative study of multidisciplinary expert perspectives. J. Med. Ethics https://doi.org/10.1136/jme-2022-108850 (2023).
Kleinberg, J., Mullainathan, S. & Raghavan, M. Inherent Trade-Off s in the Fair Determination of Risk Scores. In 8th Innovations in Theoretical Computer Science Conference, Vol. 67, 43:1−43:23 (ITCS 2017).
Binns, R. On the apparent confl ict between individual and group fairness. In Proc. 2020 conference on fairness, accountability, and transparency 514−524 (2020).
Feng, C. H., Deng, F., Disis, M. L., Gao, N. & Zhang, L. Towards machine learning fairness in classifying multicategory causes of deaths in colorectal or lung cancer patients. Brief. Bioinform. 26, bbaf398 (2025).
Yang, Y. et al. A responsible framework for assessing, selecting, and explaining machine learning models in cardiovascular disease outcomes among people with type 2 diabetes: methodology and validation study. JMIR Med. Inform. 13, e66200 (2025).
Dang, V. N. et al. Fairness and bias correction in machine learning for depression prediction across four study populations. Sci. Rep. 14, 7848 (2024).
Silva, M., Loureiro, A. & Cardoso, G. Social determinants of mental health: a review of the evidence. Eur. J. Psychiatry 30, 259–292 (2016).
Movva, R. et al. Coarse race data conceals disparities in clinical risk score performance. In Proc. 8th Machine Learning for Healthcare Conference 443–472 (PMLR, 2023).
Acknowledgements
We thank members of CAMH's Data & Insights Team for their support with health record extraction and interpretation. This work was supported by a Dalla Lana School of Public Health Interdisciplinary Data Science Seed Grant (S.L.H, no award/grant number), the Krembil Foundation (L.S. and M.M.M., no award/grant number), the Social Sciences and Humanities Research Council Insight Development Grant (L.S.: #430- 2021-01166) and a Google Award for Inclusion Research (L.S. and S.L.H, no award/grant number).
Author information
Authors and Affiliations
Contributions
L.S., M.M.M., J.Z., and S.H. conceptualized the study and acquired funding for its completion. Y.W., Z.F., and R.Z. contributed to the interpretation and processing of data. Y.W., R.Z., M.M.M., L.S., and S.H. conceptualized the methods. Y.W. completed the analysis and visualizations and drafted the paper. All authors reviewed and contributed edits to the manuscript.
Corresponding author
Ethics declarations
Competing interests
S.L.H, J.Z., L.S., and M.M.M report financial support from the University of Toronto Dalla Lana School of Public Health. S.H, J.Z., L.S., and M.M.M. report financial support from the Social Sciences and Humanities Research Council of Canada. L.S. and S.L.H. report financial support from Google Research. These funders had no role in study conceptualization, design, implementation or dissemination of findings. The other authors do not have a competing interest.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Study registration
The study was not registered.
Public involvement
Two patient advisors with lived experience of mental illness and acute mental healthcare were consulted on the study aims and methods.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, Y., Sikstrom, L., Xiao, R. et al. Fairness analysis of machine learning predictions of aggression in acute psychiatric care. npj Mental Health Res 5, 16 (2026). https://doi.org/10.1038/s44184-026-00194-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44184-026-00194-6
