
Abstract
The human capacity for facial mimicry plays a vital role in social bonding and emotional comprehension. This study investigates the role of facial mimicry in preference formation. To do so, One-hundred and six participants, comprising of fifty-three dyads engaged in a preference-based paradigm where in each trial participants had to listen and then choose between two movie synopses, while their facial muscle activity was recorded using wearable facial electromyography (EMG) electrodes. In the first part of the experiment, one participant read aloud the two synopses, and in the second part both participants listened to a pre-recorded actress. Our findings revealed that speaker-listener facial mimicry of muscles associated with positive emotions was linked with increased likelihood of selecting that synopsis. In addition, listener’s choice was better predicted by speaker-listener’s facial mimicry than by individuals’ facial expressions alone. Notably, these results were maintained even when only smiling mimicry was measured with the pre-recorded actress, highlighting the robustness of this effect. Our findings reveal the central role facial mimicry plays in preference formation during social interaction.
Similar content being viewed by others

Introduction
Imagine you are in a courtroom observing a juror closely watching a witness’s testimony. Could you predict the juror’s stance by observing her facial expressions? Previous literature suggests a positive answer, with facial expressions both providing an indication of one’s internal emotional state and containing emotional messages one wants to convey to others1,2,3,4. As humans naturally use facial mimicry as a sophisticated communicative tool5, this study explores whether mimicry of facial expressions between individuals also offers predictive insights with respect to subsequent choices. Returning to the juror, could the extent to which she mimics the witness’s expressions provide a clue to her eventual ruling?
Facial expressions hold valuable information that could help predict one’s preferences6. The predictive direction of specific facial muscles varies according to their typical emotional associations. Muscles responsible for pulling the lip corners (linked to smiling) and raising the cheeks (associated with happiness) serve as strong positive predictors of preference6,7. Conversely, muscles that raise the upper eyelid, often associated with negative emotions like fear and surprise, act as negative predictors6, as do muscles associated with frowning7. These muscle-specific patterns have enabled researchers to predict various preference types, including voters’ political choices8 and individuals’ music preferences9. Moreover, facial expressions associated with happiness have been shown to correlate with the perceived effectiveness of highly and moderately amusing advertisements. However, this was not the case for low-amusing advertisements, suggesting that predicting emotional responses through facial expressions becomes more difficult when the differences in stimuli are subtle or less extreme10.
Research has largely focused on testing the association between individuals’ facial expressions and their preferences in a non-social context, but we argue for the importance of attending to the social facets of this process, as preference formation is often social11. For example, we tend to prefer the perfume that an actor wears in a commercial or to choose to watch a movie that is most liked by our friends. Facial expressions are a communicative signal that can help us interpret what others like continuously and non-verbally12,13. Thus, testing the role of facial mimicry—a social act—can deepen our understanding of preference within social interactions.
Facial mimicry denotes the unconscious replication of emotional facial expressions observed in others14 and represents spontaneous, automatic but goal-dependent imitation of the interaction partner’s emotional display involving a time-locked response by the mimicker following the initiator’s expression5. It was shown that facial mimicry starts as early as a child is born15, and is related to empathy16,17 and fostering affiliation18,19. Individuals tend to imitate others more when they view the target individual positively20 or as the group leader21, when they belong to the same social group22 or when cooperating.23,24 Moreover, mimicry is linked to affiliation5, we feel more positive towards someone who mimics us25,26, and experience greater neural reward responses when allowed to mimic others—compared to when restricted27. Notably, facial mimicry of smiling is observed even in audio stimuli, where the person that is being mimicked is unseen28,29,30.
Facial mimicry is considered a precursor and a key mechanism underlying emotional contagion—the interpersonal transfer of affect20,31,32 (but see33). Another theoretical perspective of facial mimicry is offered by embodiment theory, which holds that cognitive processes are grounded in bodily and sensorimotor states4,34. In the emotional domain, observers often embody others’ expressions via facial mimicry, partially simulating the corresponding emotional state and thus facilitating intuitive emotion recognition. This embodied simulation supports rapid, nonverbal social understanding35,36,37,38. Building on these theories, the ability to mimic facial expressions is claimed to be important for relating to other people’s emotions39,40, and to facilitate our understanding of others41. Although this literature often portrays mimicry as a largely automatic process, an alternative view suggests that mimicry may also involve higher-level interpretations of the social context.
Hess and Fischer’s5,42,43 Emotional Mimicry in Context model, a core theory in the research of mimicry, argues that facial mimicry is not a mere perceptual-motor reflex, but a socially embedded response shaped by the meaning of the expression and the relational context. Importantly, the model posits a bidirectional relationship between mimicry and affiliation: while mimicry is influenced by the affiliative stance between individuals, it also actively promotes affiliation and influences social judgements44. Rather than being uniformly automatic, mimicry depends on the observer’s goals, intentions, and interpretation of the social interaction. Consistent with this account, recent work demonstrates that facial mimicry is finely tuned to situational affordances: people suppress mimicry when an expression clashes with its setting (e.g., smiling at a funeral or frowning at a wedding19), when emotion recognition is impaired by face masks that obscure critical facial cues45, and when others’ laughter is judged inappropriate or non-affiliative within a scene46. Following this perspective, we suggest that the occurrence of facial mimicry may reflect higher-order evaluative processes, serving as a potential signal of preference formation.
Facial mimicry has been examined in the context of social decisions. For example, two studies using iterated Prisoner’s Dilemma games with virtual characters demonstrated how facial mimicry shapes social decisions: Hoegen et al.47 showed that agents’ mimicry and counter-mimicry influenced participants’ smiling behavior and cooperative choices, whereas Ravaja et al.48 found that participants’ mimicry responses, measured via facial electromyography (EMG), varied depending on whether they had previously chosen to cooperate or not. In yet another economic game, mimicry was modulated by fairness, with increased angry mimicry toward unfair partners49. Complementing these findings, it was found that mimicry is sensitive to self-relevance, with stronger smile mimicry for faces associated with monetary outcomes for the self, suggesting that value-based associations modulate mimicry even without active choice50. Extending this line of research, and in line with the idea that mimicry is context-dependent5,42,43, the current study examines whether mimicry can predict preference, based on the idea that we mimic facial expressions we implicitly agree with, in a context-dependent manner.
This study aims to test whether facial mimicry can predict preference, using a pairwise comparison paradigm embedded in natural dyadic interactions and recorded with high-resolution facial EMG. To explore facial mimicry’s role in preference formation, we studied dyads of participants in two types of storytelling interactions aiming to predict the listener’s subsequent preference: (1) “reading condition”: one participant read two movie synopses aloud while the other listened, after which they switched roles; and (2) “listening condition”: both participants listened together to two pre-recorded synopses read by an actress. After each trial, the participants chose their preferred synopsis.
Based on the context-dependent nature of facial mimicry5,42,43 in the reading phase, we hypothesize that (i) facial mimicry can predict listeners’ subsequent choice and that (ii) facial mimicry will be a stronger predictor of listeners’ choice than facial expressions alone. This second hypothesis is supported by observations that facial expressions are altered in the presence of strangers51,52, which might interfere with the inference of preference in such situations. Also, our stimuli were chosen to be equally and mildly interesting, and facial expressions were found to be less distinctive indicator with low-amusing stimuli10.
Finally, to further test the robustness of our two main hypotheses, we introduced a control context with reduced social motivation by presenting participants with pre-recorded audio of synopses read by an unfamiliar actress who was neither seen nor known to them. We hypothesized that, in this listening phase, (iii) facial mimicry toward the actress would predict listeners’ subsequent choices more strongly than facial expressions alone.
Methods
Sample size and power analysis
To determine the required sample size, we conducted an a priori power analysis using the ‘pwr’ library in R53 for a logistic regression with four predictors. We calculated the sample size needed to detect a moderate odds ratio of 1.2 (converted to an approximate f² of 0.067 for the power calculation) with 80% power. The analysis indicated a required sample size of 179 observations. Since our study employed a nested structure, with each dyad yielding 4 observations within each of the two experimental parts, we adjusted the sample size for clustering using a design effect calculation.54 Using an intraclass correlation coefficient (ICC) of 0.05 and a cluster size of 4 (the number of choices per dyad per experimental part), we obtained an adjusted requirement for 206 total observations for each experimental part. Thus, recruiting at least 52 dyads (each contributing 4 observations per part, totalling 208 observations per part) ensured that the sample size requirements were met or slightly exceeded for both experimental parts. This experiment was not preregistered.
Participants
A total of 120 women (gender was determined by self-identification) aged 19–40 (Mean = 23.48, SD = 2.41 years), comprising 60 dyads, participated in this study. No race or ethnicity data were collected. The study was approved by Tel Aviv University’s ethics committee. All participants provided written informed consent to participate in the study and received monetary compensation or course credit for their time. Dyads were carefully selected to ensure no prior acquaintance between members. The gender-specific selection was guided by the need to avoid interference from facial hair with EMG electrode readings. To ensure EMG signal quality and identify faulty channels, we used data recorded during the calibration phase. Faulty channels (owing to high impedance) were identified as having no apparent EMG activity during commanded facial muscle activation. Following this analysis step, we excluded dyads in which one participant had 4 or more faulty channels. Seven dyads were excluded from the analysis, resulting in data from 53 dyads in both the reading and listening parts. Out of these 53 dyads, one dyad was included in the reading part analysis but excluded from the listening part analysis because one participant’s device was not sufficiently charged beforehand, while another dyad was included in the listening part analysis but excluded from the reading part analysis due to a noisy signal during the reading phase.
Materials
Sixteen book synopses sourced from GoodReads.com were selected as stimuli for the study. To generate the stimuli set we first selected 25 synopses, derived from books released around the time of selection and possessing no prior Hebrew translation or notable popularity in Israel. These synopses were then translated into Hebrew and adapted to approximately 90 seconds of reading time. To select synopses for the experiment we performed an online pre-test with 30 participants (22 females). These participants rated the synopses for interest using a Visual Analog Scale (VAS). We then chose a subset of 16 synopses that elicited similar (averaged) interest. Following this selection, the synopses were grouped into pairs, ensuring that each pair comprised synopses with closely matched interest ratings. Although originally drawn from books, the synopses were introduced to participants as movie synopses to match the framing of the experimental task. Half of the synopses were pre-recorded by an actress, 23 years old, with a Samsung galaxy tab 6 tablet and EMG electrodes applied, at the same settings of the experiment. All synopses' interest ratings and details are available in the supplementary materials. (Supplemental Table 1).
Procedure
Upon arriving at the laboratory, participants provided their consent by completing an agreement to participate. The experimenter then applied EMG electrodes on their faces and explained the experimental procedure. The experimenter placed electrodes following the protocol described in Funk et al.55 Channels 1–15 were positioned on the right side of the face, and channel 16 on the left forehead. A ground electrode was positioned on the right mastoid. Details regarding electrode type and specific muscle sites are provided below.
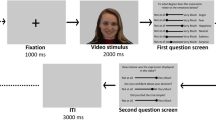
The experiment began with an initial calibration phase focused on instructed facial imitation. During this phase, participants stood in front of a television screen and imitated an actor in a video while the actor smiled three times. They then imitated the actor frowning three times, followed by imitating the actor’s blinking. This calibration phase was used to validate annotation timing and ensure signal quality. Following this calibration, the participants sat face to face, with a screen placed behind one of them, so that only one participant could view the screen at a time (See Fig. 1).

Each dyad went through a calibration phase, reading phase where they each read aloud two pairs of synopses and then switched places, and listening phase where they both listened to four pairs of movie synopses pre-recorded by an actress. Photos in the “calibration” phase were taken with permission, and illustrations in the “reading” and “listening” phases were adapted from Vecteezy.com.
In the initial part of the experiment, the reading phase, on each trial, the participant who was facing the screen read aloud two movie synopses that appeared sequentially, while the other participant, seated opposite and unable to see the screen, listened while observing the reader’s face without visual obstruction. After both synopses were read, each participant used a numpad to indicate which movie they would prefer to watch in a theater (1 for the first movie, 2 for the second). Participants then switched seats, so that the former listener became the reader. Each participant served twice as a reader and twice as a listener, for a total of four trials.
In the second part of the experiment, the listening phase, both participants remained seated face to face and listened to two synopses that were pre-recorded by an actress (audio only). In two of the four trials, they were instructed to indicate which movie they personally preferred; in the other two, they were asked to guess which movie they thought their partner would prefer. This manipulation was included both to promote attention toward the other participant and to probe social judgment. However, data from the trials in which participants guessed their partner’s preference were not included in the present analyses, as the primary focus of our paper is to predict the listener’s own preferences using the listener’s mimicry toward the reader.
We chose a real-life, dyadic EMG paradigm as dynamic stimuli like moving facial expressions elicit more natural mimicry than static images56,57,58 and facial EMG has been utilized to measure facial mimicry in real-life dyadic interactions59. Moreover, related research designs studying co-viewing and clinical interviews have used similar approaches to offer valuable insight into interpersonal dynamics60,61.
Whereas the setup does not replicate a fully natural conversation, it resembles everyday interactions—such as when one friend reads aloud two options and asks the other for input. Our design offers a compromise between ecological validity and the experimental control needed in studies of social interaction. To measure subjective preferences in such settings, pairwise comparison provides an intuitive and simple method for capturing evaluative judgments. It has been widely adopted in preference learning62, supports consistent selections in uncertain contexts63, and has already been employed in studies combining pairwise comparisons with facial expression data9.
Following the completion of the experiment, participants completed several additional questionnaires. The Interpersonal Reactivity Index64 was included as a measure of subjective empathy, due to its relevance for capturing individual differences in social sensitivity and emotional responsiveness. The Autism-Spectrum Quotient65 was administered in light of prior findings linking autistic traits to reduced mimicry, which could provide insights into interpersonal variability. The Inclusion of Other in the Self Scale66 assessed perceived closeness within a dyad. This measure has previously been used as an index of affiliation, a factor identified as influencing facial mimicry responses (e.g.,5,42,43,45). Lastly, the Consciousness of Appropriateness Scale67 was used to measure social self-monitoring, a trait known to modulate expressive behavior. Although the data from these questionnaires were not included in the present analyses, their collection was intended to support exploratory and future investigations into the social and individual factors underlying facial mimicry.
Electromyography
To accurately capture real-life interactions with high temporal precision, we utilized the X-trodes facial surface EMG (sEMG) electrode arrays. This system employs screen-printed carbon electrodes (X-trodes Ltd.) connected to a miniature wireless data acquisition unit (DAU). The DAU supports up to 16 unipolar channels at 4,000 samples/second with 16-bit resolution, an input range of ±12.5 mV, and an input impedance of \({10}^{7}\) Ω. Dry electrode impedance values vary with size, body location and frequency range68. For the electrodes used in this study, located at the face, and in the EMG frequency range, impedance values are typically in the 50 kΩ range, low enough to guarantee reliable EMG recordings. In rare cases of bad skin-electrode contact, flat signals were observed, and relevant sessions were omitted from further analysis. A 620 mAh battery supported up to 16 hours of operation while a Bluetooth module enabled continuous data transfer. An Android application controlled the DAU, with data stored on both a built-in SD card and cloud servers for analysis. The system also included a 3-axis inertial sensor to measure head acceleration during recordings. This wearable technology allowed us to continuously track the dynamic flow of facial muscle activity during social interaction55.
Preprocessing of EMG data
Firstly, we used a method of removing powerline interference69, to remove 50 Hz DC noise. Subsequently, we applied SciPy’s Butterworth 4th-order bandpass filter70 with a range of 35 to 350 Hz, as outlined in Gat et al.71 To further refine the signal and remove additional noise artifacts, we utilized a wavelet-based approach. This method involved calculating an approximate wavelet representation of the signal using Debauchies 15 (db15) with a five-level decomposition, applying a hard threshold to the wavelet coefficients, and then reconstructing the signal using the Inverse Discrete Wavelet Transform (IDWT) via the PyWavelets Python library72. We chose to use wavelet transforms due to their effectiveness in approximating human biological signals, particularly in the context of surface electromyography73,74. We then whitened and centred all signal channels to enhance the effectiveness of the subsequent independent component analysis (ICA) decomposition.
For each participant, we conducted ICA individually using the Sickit-learn library in Python75. Since surface electrodes record data from multiple muscles simultaneously, it is necessary to separate the recorded values into distinct sources, which represent independent components. This ICA method effectively reduces crosstalk caused by muscle activity76,77. This algorithm yields a weight matrix that, when multiplied with the original electrode matrix, produces the independent components. By utilizing the corresponding rows in this matrix, we generated heatmaps for each component based on the geometric layout of the electrodes. These heatmaps allow the automatic identification of the primary muscle targeted by each independent component. (See Fig. 2).
To enable reliable cross-participant comparison, we used a standardized facial muscle Atlas developed by Man et al.78 This atlas implements an automated, machine-learning-based classification algorithm that maps each participant’s unique facial muscle activity patterns to a common reference framework. This approach allowed us to classify each participant’s independent components (ICs) into consistent muscle groups based on spatial similarity, ensuring valid between-subject comparisons of facial muscle activity patterns during the experiment tasks. If a particular IC’s activity pattern did not match any of the predefined clusters, the corresponding cluster was marked as NA/null in that participant’s data. As each Atlas cluster was associated with facial muscles78, after the classification, we refer to the group of ICs (across all participants) that were attributed to a specific cluster as muscle cluster.
The resulting classification yielded sixteen distinct muscle clusters, each corresponding to a specific set of underlying facial muscles as defined by the atlas78: Cluster 1 comprised the orbicularis oris, depressor anguli oris, and depressor labii inferior; Cluster 2 included the platysma and buccinator; Cluster 3 was associated with the zygomaticus major and masseter; Cluster 4 contained the buccinator and risorius; Cluster 5 & Cluster 6 corresponded to the zygomaticus major; Cluster 7 included the zygomaticus major and zygomaticus minor; Cluster 8 was associated with the levator labii superioris, levator labii superioris alaeque nasi, and levator anguli oris; Cluster 9 included the levator labii superioris alaeque nasi, orbicularis oculi, pars inferioris (medial), and levator labii superioris; Cluster 10 reflected the orbicularis oculi and its pars orbitalis (inferior and lateral); Cluster 11 comprised the zygomaticus minor and zygomaticus major; Cluster 12 included the temporalis, orbicularis oculi, and pars orbitalis (lateral); Cluster 13 was associated with the orbicularis oculi, temporalis, and frontalis lateralis; Cluster 14 included the orbicularis oculi, pars orbitalis (superior), and frontalis lateralis; Cluster 15 and Cluster 16 reflected the frontalis, corrugator supercilii, and orbicularis oculi.
Following the separation into different clusters, we applied the Root Mean Square (RMS) technique to each component. RMS is a widely used signal processing method in EMG analysis, providing an assessment of the overall signal amplitude. This is particularly advantageous because raw EMG signals are often contaminated by noise and interference, whereas the RMS values are believed to contain all the necessary amplitude information, including significant details for classifying facial expressions79. In our analysis, we selected a window size of 50 milliseconds for the RMS, as this value is recommended for accurately capturing rapidly changing facial expressions80. We then down-sampled the signal to 200HZ using SciPy library’s resample function that avoids aliasing.
Computing mimicry
Interpreting correlational algorithms as facial mimicry (and not synchrony)
Interpersonal synchrony denotes the temporally organized coordination of partners’ behavior during interaction. Facial synchrony involves mutual coordination measured in both interactants over time, may occur simultaneously, and does not require isomorphic matching of specific facial actions, unlike facial mimicry which can be unilateral and involves an individual reproducing another’s expression in a time-locked manner5.
Although correlation-based algorithms such as cross-correlation, windowed cross-lagged correlation (WCLC), and windowed time-lagged cross-correlation (WTLCC) are used to index synchrony81,82—these same procedures can be applied for mimicry when specific methodological constraints are applied. Facial mimicry requires the reproduction of a partner’s specific facial movements with temporal contingency83. Accordingly, we (i) correlated only homologous EMG facial muscle clusters to ensure matched expressions, (ii) retained only positive time lags so that listener activity followed the speaker’s, and (iii) used temporally constrained sliding windows (3 seconds) to capture short-lived, time-locked responses. This analytic approach is based on previous studies that implemented similar correlational methods and explicitly interpreted their results as facial mimicry59,83,84,85.
WTLCC parameters
For each dyad, we analyzed data from the same muscle components using the WTLCC analysis. We set the window size at 3 seconds with a maximum lag of 3 seconds, and a step size of 5 milliseconds, utilizing Pearson’s r-value as the correlation function between each two windows. The choice of window and maximal lag is supported by previous synchrony studies. Golland et al.60 who applied a similar WTLCC approach, used a 3-second maximal lag. In addition, Behrens et al.86 using WTLCC method as in our study, systematically compared parameter configurations and identified a 3-second window with a 3-second lag as one of the most effective settings for the algorithm during interactive storytelling (see Figures 5 and 7 of Behrens et al.86).
Choosing window size and maximum lag in WTLCC is inherently difficult because relevant interpersonal dynamics unfold at different time scales, so there is no universal standard87. Windows that are too short fail to capture sufficient information, whereas overly long windows can cancel shifting leads and lags. Similarly, lags that are too small miss response delays, while lags that are too large risk correlating unrelated events. Given the lack of established standards and ongoing calls to determine which parameter combinations yield valid results, a transparent approach is to report WTLCC estimates across a reasonable range of windows and lags87,88. Accordingly, we include a supplementary table that summarizes our main analyses across multiple parameter settings (Supplemental Table 5).
Operational procedure
Each synopsis was segmented into consecutive 3 seconds windows. For every muscle component and window, we fixed the speaker’s segment and slid the listener’s segment forward up to 3 seconds, recording the highest correlation value and the lag at which it occurred. We then averaged these peak correlations and their associated lags across windows to yield, for each muscle and synopsis, an average mimicry value and an average lag. In addition, we computed mean activation for each participant and muscle over the full synopsis. During the listening phase, mimicry was computed between each participant and the actress who narrated the synopses.
Reading phase cluster-level comparison of chosen and unchosen synopses
We conducted two-tailed paired t-tests and calculated paired Cohen’s d effect sizes across all clusters, separately for mimicry scores and activation scores, grouping values as “chosen” or “unchosen” based on the listener’s selection (data distribution was assumed to be normal but this was not formally tested). This approach allowed us to present the full distribution of results across all clusters, rather than focusing only on specific effects, thereby offering a comprehensive view of the data. However, due to substantial overlap and redundancy in EMG cluster activity (See “Deep learning based expression reconstruction” and Table 1 in Man et al.78), we next applied two complementary dimensionality-reduction strategies: (i) valence-guided theory-driven grouping (ii) data-driven feature selection grouping.
Variable preparation for dimensionality reduction analysis
For each muscle cluster i within every synopsis, we computed two primary metrics: mimicry(i), i.e. mimicry value yielded by the WTLCC algorithm between the speaker and the listener (hereafter referred to as the mimicry score), and listener_mean_activation(i), i.e. listener’s mean EMG activation for that cluster during the synopsis. To convert these single-synopsis values into comparative predictors, we subtracted the score for synopsis 2 from that for synopsis 1, creating mimicryDif(i) = mimicrysynopsis2(i)—mimicrysynopsis1(i) and listenerActivationDif(i) = listener_mean_activationsynopsis2(i)—listener_mean_activationsynopsis1(i). Thus, positive values indicate that synopsis 2 elicited greater mimicry or higher listener activation in cluster i, whereas negative values indicate the opposite. These difference variables, were generated for each pair of synopses on all muscle clusters.
Reading-phase cross muscle averaged predictors
As an initial step, we created two composite predictors by averaging the mimicry difference scores (mimicryDif(i)) and activation difference scores (listenerActivationDif(i)) across all muscle clusters. These composite variables were then entered as predictors in logistic regression models to examine whether a global facial mimicry or activation measure could predict listener choice prior to applying theory-driven or data-driven grouping approaches.
Reading-phase valence-guided theory-driven grouping
After computing the cluster-level difference variables (mimicryDif(i) and listenerActivationDif(i)) for each synopsis pair, we grouped the muscle clusters by their typical emotional valence based on previous literature. The positive muscle set included the muscle cluster associated with cheek raising (cluster 10), the muscle cluster associated with eyebrow flashing (cluster 14), and the muscle cluster associated with pulling the lip corners (cluster 6). These muscles are commonly involved in expressions of happiness, interest, and affiliative approach58,89,90,91,92. The negative muscle set comprised the muscle cluster associated with lip stretching (cluster 2), the muscle cluster associated with depressing the lip corners (cluster 4), and the muscle cluster associated with nose wrinkling (cluster 9), which is typically linked to expressions of disgust and food rejection92,93,94,95,96. While we acknowledge that these muscles may participate in a range of facial expressions, our grouping is intended as a suggestive framework based on their prototypical valence associations. We averaged the relevant difference scores within each set to derive four composite predictors—positiveMimicryDif, negativeMimicryDif, positiveListenerActivationDif, and negativeListenerActivationDif —which were entered into a logistic regression model predicting the listener’s choice.
Using these four composites, we built two binary logistic-regression models in which the outcome variable was the listener’s choice (0 = first synopsis, 1 = second synopsis). Our primary model contained the two mimicry composites (positiveMimicryDif, and negativeMimicryDif) and their interaction as predictors, capturing the between-synopsis difference of mimicry in positive and negative muscle sets. To determine whether a listener’s own facial activity carried predictive value, we estimated a second model, using the two activation composites (positiveListenerActivationDif, and negativeListenerActivationDif) and their interaction. We compared these models with the Akaike Information Criterion (AIC), treating lower AIC as indicating better model fit. A difference in AIC greater than 10 was considered strong evidence in favor of the model with the lower AIC97.
Reading-phase data-driven feature selection grouping
To reduce dimensionality while retaining the shared variance among highly correlated clusters, we applied Relative Weight Analysis (RWA)98 separately to the mimicry-difference scores (mimicryDif(i)) and to the activation-difference scores (listenerActivationDif(i)). RWA partitions the total predictive variance into signed, rescaled weights that quantify each cluster’s unique contribution plus the variance it shares with the other clusters—an advantage when predictors are collinear. After obtaining the 16 signed weights, clusters with positive weights (indicating that larger mimicry score favored the listener’s eventual choice) were grouped into a positive subset, and clusters with negative weights into a negative subset; the sign here refers to the direction of association rather than emotional valence. We then constructed composite predictors by calculating a weighted mean of the cluster-level difference scores within each subset, using the absolute RWA weights as multipliers. Subsequently, we standardized these predictors using z-score.
We evaluated these composites predictive utility through two logistic-regression models: (i) a mimicry model containing the positive and negative mimicry composites, and their interaction; and (ii) an activation model containing the positive and negative muscle-activation composites and their interaction. Since this method is subjected to overfitting, and to test the significance of the models’ accuracy and coefficients, we ran a 10,000-iteration permutation test, inspired by previous studies99,100,101. In each iteration the outcome variable (listener’s choice) was randomly shuffled, the entire RWA procedure was repeated, new composite variables were calculated and standardized, and the relevant logistic model was refitted. Recording the models’ classification accuracies and regression coefficients across permutations yielded empirical null distributions against which we compared the observed estimates, providing permutation-based p-values for each model’s accuracy score and regression coefficients.
Facial mimicry with recorded narrator
In the listening phase we limited our analysis to smiles, as in this part we measured mimicry between listeners and an offline speaker (the actress that read the synopses, which participants could only hear her voice). This choice was motivated by evidence that smiles, in particular, are discernible from vocal cues alone102,103,104,105 and that listeners may spontaneously mimic smiles they hear28,106. We focused on the two muscle clusters in our array most strongly associated with smiling: cluster 6 (orbicularis oculi; pars orbitalis (inferior and lateral), cheek-raiser) and cluster 10 (zygomaticus major, lip-corner-puller). For every synopsis pair we therefore computed four difference predictors—mimicryDif(6), mimicryDif(10), listenerActivationDif(6) and listenerActivationDif(10). The first two terms capture the relative mimicry of the listener with the prerecorded actress for each muscle, whereas the latter two terms quantify the listener’s own relative activation. These predictors were entered into mixed-effects logistic regression models that included a random intercept for the first synopsis in each pair (8 levels). By structuring the model hierarchically in the listening phase, we were able to control for both item-level differences in the synopses and potential order effects introduced by which synopsis was presented first in each pair. This hierarchical structure was applied because, in the listening phase, all participants were exposed to the exact same set of audio stimuli, narrated by the same actress (identical prosody, pacing, emphasis and emotions conveyed) across trials. This uniformity justified modelling the synopses as a shared source of variance across participants.
Statistical analysis
All logistic regression analyses were performed using R version 4.1.0107, with the ‘glm’ function from the ‘stats’ library and ‘glmer’ from ‘lme4’ library108. RWA was calculated using ‘rwa’ library109.
For all logistic regression analyses, we report odds ratios (OR) with 95% confidence intervals (CI) for the predictors; Where applicable, we also provide model‑fit indices—the Akaike Information Criterion (AIC) and Tjur’s R², a coefficient of discrimination suited to binary outcomes110, and, for mixed-effects models, the Nakagawa-Schielzeth marginal and conditional R² values111. We assessed multicollinearity across all models using Variance Inflation Factors (VIF); all values were below 5, indicating the assumption of no multicollinearity was met. Threshold for statistical significance was set at p < 0.05 for all analyses.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Results
We studied dyadic interaction to test the role of facial mimicry in preference formation. The study contained two parts—a reading part—where one of the participants (the reader) read aloud two movie synopses and the other participant (the listener) listened to the synopses. Subsequently, they both chose separately which synopsis they preferred. In the listening part, both participants were listening to an offline actress reading pairs of synopses and chose which synopsis they preferred. Participants’ facial muscles activity was recorded during the whole experiment, as well as the actress facial muscles activity when reading offline. We tested whether both listener mimicry of the speaker and listener’s own muscle activation predicted the listener’s choice, using multiple analytic approaches.
Reading phase cluster-level comparison of chosen and unchosen synopses
To test the contribution of each facial muscle cluster to listeners’ choices, we conducted two-tailed paired-sample t-tests comparing both mimicry and listener’s facial activation scores for chosen versus unchosen synopses across all 16 EMG clusters (See Fig. 2). For mimicry, significant differences were found in cluster 8, t(163) = 2.52, 95% CI [0.0014, 0.0112], p = 0.013, Cohen’s d = 0.2; cluster 10, t(199) = 2.17, 95% CI [0.0005, 0.0112], p = 0.032, Cohen’s d = 0.15; and cluster 14, t(199) = 2.07, 95% CI [0.0002, 0.0076], p = 0.040, Cohen’s d = 0.15. For muscle activation, a significant difference emerged in cluster 6, t(189) = 2.11, 95% CI [0.0011, 0.0326], p = 0.036, Cohen’s d = 0.15, and a marginally significant difference in cluster 10, t(205) = 1.96, 95% CI [−0.0001, 0.0238], p = 0.051, Cohen’s d = 0.14. All other clusters showed no significant effects (See Supplemental Table 2). Mimicry and activation values were analyzed per cluster, with NA values assigned where components were missing due to noise. This analysis provides a comprehensive overview of the predictive signals embedded in each facial region prior to dimensionality reduction. Descriptives for mimicry and muscle activation values per cluster are available in the supplementary material (Supplemental Table 3).

A Mimicry scores and B activation scores. Bars display the paired Cohen’s d, calculated from the within-subject differences for each cluster, and are ordered by effect size; whiskers show the 95% CI of Cohen’s d. Asterisks flag clusters whose paired t-test p-value < 0.05. Positive Cohen’s d values indicate greater mimicry (A) or activation (B) values in the chosen synopses. C A standardized facial muscle atlas was developed using an algorithm by Man et al.78 based on EMG data collected during the reading phase from all participants. Independent Component Analysis (ICA) was applied separately to each participant’s EMG recordings, and the resulting unmixing matrix (W) was used to generate spatial heatmaps of muscle activation per IC. Each subfigure displays the average of these IC heatmaps across participants, grouped into “muscle clusters” based on distinct and consistent spatial activation patterns. Muscle clusters are sorted and numbered from 1 (near the mouth) to 16 (at the forehead), according to the vertical arrangement of the electrode array. The variable N indicates the number of participants contributing an IC heatmap to each cluster. If a participant’s IC did not sufficiently match any cluster, it was considered noise and excluded from analysis, with an NA recorded in the corresponding cluster position for that participant. Consequently, N varies across subfigures and is lower than the total number of participants. See the Methods section for the full association between muscle clusters and facial muscles. Consent was obtained for the publication of the image in (C).
Reading-phase cross muscle averaged predictors
To evaluate whether a model treating facial mimicry and muscle activation averaged across all facial muscle clusters as uniformly predictive of listener choice would be effective, we fitted a logistic regression using two composite predictors: (i) the average mimicry difference score calculated across all facial muscle clusters and (ii) the average activation difference score across all facial clusters. Neither of these predictors significantly contributed to the model, and model fit statistics showed no meaningful improvement over the null model (χ²(2) = 3.51, p = 0.17, Tjur’s R² =0.015, AIC = 295.46), suggesting no credible evidence that facial mimicry or activation averaged across all facial clusters predicts listener’s choice.
Reading-phase valence-guided theory-driven grouping
To test whether facial mimicry and facial muscles activation predicted the listener’s choice, we computed difference scores between the two synopses for selected muscle clusters. Clusters were grouped by emotional valence into positive (clusters 6, 10 and 14) and negative (clusters 2, 4 and 9) sets. We then averaged the mimicry and activation differences within each set, yielding four composite predictors: positiveMimicryDif, negativeMimicryDif, positiveListenerActivationDif, and negativeListenerActivationDif. These were entered into logistic regression models predicting the listenr’s choice.
The first model included composite difference scores for positive and negative mimicry and their interaction. This model significantly explained variance in listener decisions, χ²(3) = 19.92, p <0.001, Tjur’s R² = 09, with a residual deviance of 267.74 and AIC = 275.74. Greater positive mimicry in a synopsis was associated with increased likelihood of it being chosen (β = 0.70, SE = 0.19, z = 3.64, p <0.001; OR = 2.02, 95% CI for OR [1.38, 2.95]) (See Fig. 3). The interaction between positive and negative mimicry was also significant (β = 0.32, SE = 0.13, z = 2.44, p = 0.015; OR = 1.38, 95% CI for OR [1.06, 1.78]). Negative mimicry did not reach significance (β = –0.28, SE = 0.17, z = –1.68, p = 0.093; OR = 0.76, 95% CI for OR [0.55, 1.05]) (See Fig. 3). Further examination of different window and maximum lag parameter configurations for this analysis is provided in Supplemental Table 5.

A Heatmaps of the selected facial muscle clusters, categorized into positive (blue box) and negative (red box) sets based on their prototypical emotional valence. B, C Logistic regression results (n = 106 participants) predicting listener choice based on facial mimicry with the live reader. Trend lines illustrate the relationship between relative positive mimicry (B, blue) and relative negative mimicry (C, red) and the predicted probability of choosing synopsis 2 (coded as 1; synopsis 1 coded as 0). Shaded areas represent pointwise 95% confidence intervals. Greater positive mimicry significantly increased the likelihood of choosing that story, whereas greater negative mimicry showed a trend toward decreased likelihood of choosing that story. Black ticks represent the listeners’ choice in each data point. Consent was obtained for the publication of the image in (A).
The second model included composite difference scores for positive and negative listener muscle activation and their interaction. This model showed a weaker fit (residual deviance = 283.47; AIC = 291.47), did not reach significance (χ²(3) = 6.96, p = 0.073, Tjur’s R² = 0.029) and no main effects were significant. A comparison of the models confirmed that the mimicry-based model provided a better fit to the data, as reflected in a lower AIC (275.74 vs. 291.47). A difference in AIC greater than 10 is generally considered strong evidence in favor of the model with the lower AIC.97 Overall, these results demonstrate that facial mimicry during a synopsis, was a stronger and more consistent predictor of listeners’ subsequent choice than listeners’ muscle activation.
Reading phase data-driven feature selection grouping
To assess the predictive contribution of data-driven composite facial mimicry variables, we applied Relative Weight Analysis (RWA) to the mimicry difference scores (mimicryDif(i)) across 16 facial clusters. This method grouped clusters into positive and negative subsets based on the sign of their RWA weights, reflecting whether greater mimicry in a cluster was associated with the chosen synopsis (preference). Weighted composite scores for positive and negative mimicry were computed and standardized using z-score. This process was repeated 10,000 times with shuffled outcomes (listeners’ choice) to generate empirical null distributions of model accuracy and coefficients, allowing for permutation-based significance testing.
A logistic regression model including the RWA-derived positive and negative subsets of mimicry composites and their interaction predicted listener choices with 66.5% accuracy, which was significantly above chance based on a 10,000-iteration permutation test (p = 0.03). The positive mimicry predictor was associated with a greater likelihood of a synopsis being chosen (β = 0.87, SE = 0.20, z = 4.23, p < 0.001; OR = 2.38, 95% CI for OR [1.59, 3.55]), and this effect was also significant under permutation testing (p = 0.029; 95% bootstrap CI for β [0.28, 0.9]). The negative mimicry predictor showed a significant negative effect in the model (β = –0.54, SE = 0.19, z = –2.92, p = 0.004; OR = 0.58, 95% CI for OR [0.40, 0.84]), but this effect did not reach significance in the permutation test (p = 0.51; 95% bootstrap CI for β [−0.9, −0.29]). The interaction term was not significant (β = 0.19, SE = 0.14, z = 1.29, p = 0.196; OR = 1.20, 95% CI for OR [0.91, 1.60]), and this was consistent with the permutation-based result (p = 0.13; 95% bootstrap CI for β [−0.24, 0.27]).
These findings indicate that positive mimicry, as identified through a data-driven grouping of facial clusters, was a reliable predictor of listener preference, whereas negative mimicry and the interaction term did not show significant effects under permutation testing (See Fig. 4).

Histograms show the distribution of permutation-based regression coefficients and model accuracies across 10,000 iterations: model classification accuracy (first column), positive beta (second column), negative beta (third column) and the interaction term (fourth column). (n = 106 participants). Top row: Results based on facial mimicry. The logistic regression model predicted listener choices significantly above chance (66.5% accuracy, p = 0.03). The positive mimicry predictor was significant (p = 0.029), whereas the negative mimicry and interaction terms did not reach significance under permutation testing. Bottom row: Results based on listeners’ facial muscle activation. The model’s accuracy (54.2%) did not exceed chance level (p = 0.978). Neither positive nor negative activation contributed significantly to the prediction, though the interaction term was significant (p = 0.028). These findings highlight the predictive value of facial mimicry forecasting listener preference.
Next, we applied the same data-driven procedure to the activation difference scores (listnerActivationDif(i)). Clusters were grouped into positive and negative subsets based on the sign of their RWA weights, and weighted composite scores for positive and negative activation were computed and standardized using z-score for each trial. This process was repeated 10,000 times with shuffled outcomes (listeners’ choice) to generate empirical null distributions of model accuracy and coefficients, allowing for permutation-based significance testing.
A logistic regression model including the positive activation composite, the negative activation composite, and their interaction predicted listener choices with an accuracy of 54.2%, which did not exceed chance based on a 10,000-iteration permutation test (p = 0.978). Although the positive (preference-based) activation predictor was associated with higher likelihood of a synopsis being chosen (β = 0.81, SE = 0.30, z = 2.70, p = 0.007; OR = 2.25, 95% CI for OR [1.25, 4.04]), this effect was not significant under permutation testing (p = 0.447; 95% bootstrap CI for β [0.39, 1.36]). The negative activation predictor had a significant negative coefficient in the model (β = –0.57, SE = 0.27, z = –2.12, p = 0.034; OR = 0.57, 95% CI for OR [0.34, 0.96]) but was also non-significant under permutation testing (p = 0.827; 95% bootstrap CI for β [−1.36 −0.38]). The interaction between positive and negative activation was not significant in the model (β = 0.24, SE = 0.13, z = 1.79, p = 0.073; OR = 1.27, 95% CI for OR [0.98, 1.65]) but reached significance in the permutation test (p = 0.028; 95% bootstrap CI for β [−0.19, 0.22]). However, drawing conclusions from individual predictors is questionable without adequate model fit112,113. Together, these results indicate that, the activation-based predictors provided limited predictive value for listener choice (See Fig. 4).
Facial mimicry with recorded narrator
To further test the robustness of our findings regarding the role of mimicry in predicting preferences, we tested our two main hypotheses—namely, that facial responses predict listener preferences, and that mimicry is a better predictor than facial activation—during the listening phase, in which participants listened to synopses read by an offline actress. We tested mimicry and activation only in smile-related muscles, as prior research suggested that smiles can be detected from vocal cues alone102,103,104,105 and that listeners may spontaneously mimic smiles they hear28,106. We focused on cluster 6 (zygomaticus major) and cluster 10 (orbicularis oculi; pars orbitalis (inferior and lateral)) and compared two separate logistic regression models—one including mimicry predictors and the other including activation predictors—using mixed-effects models with a random intercept for the first synopsis in each pair. Descriptives for mimicry and muscle activation values for clusters 6 and 10 are available in the supplementary material (Supplemental Table 4).
A model including mimicry predictors (with a random intercept for the first synopsis) significantly explained variance in listener decisions compared to a null model with the same random structure, χ²(2) = 7.61, p = 0.022; AIC = 229.8; marginal R² = 0.05, conditional R² = 0.33. Greater mimicry in cluster 10—the cheek-raising component of a smile—was significantly associated with increased likelihood of a synopsis being chosen (β = 0.49, SE = 0.20, z = 2.41, p = 0.016; OR = 1.62, 95% CI [1.09, 2.41]). Mimicry in cluster 6 did not significantly predict choice (β = –0.02, SE = 0.20, z = –0.10, p = 0.92; OR = 0.98, 95% CI [0.66, 1.45]). In contrast, the activation-based model did not significantly improve fit over its null model, χ²(2) = 0.09, p = 0.96; AIC = 237.3; marginal R² = 0.01, conditional R² = 0.27, and neither activation predictors were significant (cluster 6: β = 0.07, SE = 0.24, z = 0.28, p = 0.778; cluster 10: β = –0.03, SE = 0.22, z = –0.12, p = 0.906). These findings indicate that listener preferences during the listening phase were better predicted by mimicry than by facial activation, and specifically by mimicry of the cheek-raising component of a smile.
Discussion
In this study, we examined the role of facial mimicry in preference formation within the context of dyadic interactions. Our findings revealed that facial mimicry significantly predicted individuals’ preferences. Participants tended to choose synopses during which they showed greater mimicry in muscles associated with positive expressions. This effect persisted in both live interactions and with pre-recorded stimuli, where the mimicry was to an unseen actress, emphasizing its robustness. Notably, facial mimicry outperformed mean muscles activation levels in predicting choices.
Our findings provide compelling evidence that facial mimicry predicts listeners’ preferences, offering support for the view that mimicry reflects more than just automatic emotional contagion. Whereas classic theories emphasized mimicry as a reflexive, low-level mechanism14,20, our results resonate with more recent frameworks (e.g., refs. 5,42,43) that conceptualize mimicry as a socially contextualized, goal-sensitive behavior. In our study, mimicry predicted choices even when participants were explicitly instructed to express their personal preferences, independent of social evaluation. This suggests that facial mimicry serves as an implicit cue of agreement with the content, revealing how subtle embodied responses can forecast subjective preferences. By establishing mimicry as a reliable predictor of evaluative decisions, we extend its functional role beyond social rapport to include individual preference formation.
Facial muscle activations were previously found to be predictors of preferences, with their impact varying based on the emotions they typically convey9. Muscles associated with positive emotions, such as smiling, tend to positively predict preferences, while those linked to negative emotions often act as negative predictors6. In our study, facial expressions alone were not significant predictors of listener’s choice. This result aligns with previous research which found that for less amusing stimuli, facial expressions alone did not predict preferences10, and with our use of stimuli that were intentionally selected to be moderately engaging and closely matched in interest level within each pair. Our study suggests that in a naturalistic and relatively neutral dyadic interaction, facial mimicry is more informative of individual’s preference than facial expressions per se.
Facial mimicry can ease emotion recognition via embodied simulation, with behavioral and causal evidence showing that allowing (or amplifying) feedback facilitates selecting the correct label, whereas constraining or disrupting it impairs performance114,115,116,117 (but see ref. 5). Because choosing an emotion label may be considered as a decision, embodiment also plausibly supports related social decisions—e.g., judging smile genuineness or calibrating affiliative responses—by adding proprioceptive evidence to support fine-grained judgments36. In this light, our findings are consistent with the idea that, under ambiguity or between closely related categories, mimicry-related signals add proprioceptive evidence that accompanies the decision process; however, our correlational design cannot establish directionality.
The approach of separating positive and negative facial signals has been successfully applied in recent studies examining the relationship between facial expressions and preferences6,7. Building on established research showing that people do mimic both positive and negative expressions—but in a strongly context-dependent manner19,45,46,118—we extend this literature by considering mimicry of positive and negative expressions as separate, directionally specified predictors in the same choice model. Prior studies identified sadness mimicry as an empathic, help-oriented response when contextually appropriate19, whereas other “negative” displays (e.g., disgust) can elicit reduced or non-genuine mimicry118. In our data, mimicry of negative expressions trended toward predicting reduced preference, underscoring that its informational value in choice settings can diverge from its affiliative function in interpersonal contexts. Although this negative predictor did not reach statistical significance, its separation from positive mimicry was theoretically important and the distinction significantly improved model performance.
Our study revealed that the smiling mimicry between participants and the pre-recorded actress also predicted listener’s preferences. Ample evidence supports that humans can reliably detect smiles through vocal cues alone102,103,104,105, and that they may unconsciously mimic smiles they hear28,29,106. In this study, we demonstrated that such mimicry appears to carry communicative value—not merely as an automatic motor response, but as an index of agreement. In our study we specifically demonstrated a connection between auditory dependent facial mimicry of smiles to one’s preference. Even though the actress was unknown and unseen—which provided a setting with reduced social motivation—mimicry of the actress’s smiles still correlated with participants’ choices. This suggests that our brains are wired to mimic context dependent emotional cues, which may in turn influence our choices.
When examining associations between individual muscles’ mimicry and activation values and listeners’ choices, mimicry values showed stronger associations with listener preferences than activation values (See Fig. 2). Interestingly, zygomaticus major was the only muscle where activation predicted preferences more consistently than mimicry, likely due to contamination from speech signals affecting the mimicry values in the zygomaticus muscle data. Although these patterns are intriguing, the current study was not sufficiently powered to support firm conclusions about specific muscle-level effects. One compelling future direction is to examine whether different smile configurations—such as Duchenne versus non-Duchenne smiles—differentially predict preferences, as prior research has shown that Duchenne smiles which includes activity in both zygomaticus major and orbicularis oculi has been linked to the expression of enjoyment119,120,121. Moreover, orbicularis oculi is more tightly linked to reward-related positive affect, whereas zygomaticus major frequently supports communicative management during speech and politeness. This functional asymmetry provides a principled account for differences in the social impact of smiles involving orbicularis oculi compared with those driven primarily by zygomaticus major89,119,122. More broadly, future studies could investigate alternative combinations of facial muscle activation and mimicry to assess their role in social decision-making. We believe that our study provides a useful basis for such work.
Limitations: Despite the strength of these findings, there are limitations to consider. The study focused exclusively on women to avoid potential interference of facial hair with EMG measurements. Although the electrodes function equally well on shaved male participants, the local fashion at the time of data collection—favoring male facial hair—resulted in very few men volunteering. As a result, we proceeded with women-only dyads, which controlled for gender effects but limits the generalizability of the findings across genders. Moreover, this study was conducted in a naturalistic setting, which, although providing ecological validity, limits our ability to establish causal relationships regarding facial mimicry. Future research could address this limitation by inducing facial mimicry and testing its effect on individual’s preferences. Finally, the choice of WTLCC parameters remains an open methodological issue in the field. Although our main effects were robust across a reasonable range of window sizes and maximum lags, different parameterizations can emphasize different interpersonal timescales and may shift absolute effect sizes.
In conclusion, this study adds to the growing body of research on facial mimicry by demonstrating its predictive value for human preferences. Our findings suggest that facial mimicry is a powerful non-verbal cue that is correlated to and might influence agreement, interpersonal judgments and preferences, offering important implications for understanding the mechanisms behind social cognition and interaction.
Data availability
All data are available at: https://github.com/Liramic/facial_mimicry_predicts_preference and also at https://zenodo.org/records/17314670123.
Code availability
Code for the analyses is available at: https://github.com/Liramic/facial_mimicry_predicts_preference and also at https://zenodo.org/records/17314670123.
References
Crivelli, C. & Fridlund, A. J. Facial displays are tools for social influence. Trends Cogn. Sci. 22, 388–399 (2018).
Ekman, P. An argument for basic emotions. Cogn. Emot. 6, 169–200 (1992).
Keltner, D. & Kring, A. M. Emotion, social function, and psychopathology. Rev. Gen. Psychol. 2, 320–342 (1998).
Niedenthal, P. M. Embodying emotion. Science 316, 1002–1005 (2007).
Hess, U., Fischer, A. Emotional mimicry. Automatic Imitation. 41–60 Springer Nature Switzerland: Cham, 2024.
Sato, Y., Horaguchi, Y., Vanel, L. & Shioiri, S. Prediction of image preferences from spontaneous facial expressions. Interdiscip. Inf. Sci. 28, 45–53 (2022).
Kirsch, L. P., Snagg, A., Heerey, E. & Cross, E. S. The impact of experience on affective responses during action observation. PloS ONE 11, e0154681 (2016).
McDuff, D., El Kaliouby, R., Kodra, E., & Picard, R. Measuring voter’s candidate preference based on affective responses to election debates. In 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, pp. 369–374 (2013).
Tkalčič, M. et al. Prediction of music pairwise preferences from facial expressions. In Proceedings of the 24th international conference on intelligent user interfaces, pp. 150–159 (2019).
Lewinski, P., Fransen, M. L. & Tan, E. S. Predicting advertising effectiveness by facial expressions in response to amusing persuasive stimuli. J. Neurosci. Psychol. Econ. 7, 1 (2014).
Cialdini, R. B. & Goldstein, N. J. Social influence: compliance and conformity. Annu. Rev. Psychol. 55, 591–621 (2004).
McDuff, D., El Kaliouby, R., Cohn, J. F. & Picard, R. W. Predicting ad liking and purchase intent: Large-scale analysis of facial responses to ads. IEEE Trans. Affect. Comput. 6, 223–235 (2014).
Zhi, R., Wan, J., Zhang, D. & Li, W. Correlation between hedonic liking and facial expression measurement using dynamic affective response representation. Food Res. Int. 108, 237–245 (2018).
Dimberg, U. Facial reactions to facial expressions. Psychophysiology 19, 643–647 (1982).
Meltzoff, A. N., & Moore, M. K. Newborn infants imitate adult facial gestures. Child Dev. 54, 702–709 (1983).
Sonnby–Borgström, M. Automatic mimicry reactions as related to differences in emotional empathy. Scand. J. Psychol. 43, 433–443 (2002).
Drimalla, H., Landwehr, N., Hess, U. & Dziobek, I. From face to face: the contribution of facial mimicry to cognitive and emotional empathy. Cogn. Emot. 33, 1672–1686 (2019).
Fischer, A. & Hess, U. Mimicking emotions. Curr. Opin. Psychol. 17, 151–155 (2017).
Kastendieck, T., Mauersberger, H., Blaison, C., Ghalib, J. & Hess, U. Laughing at funerals and frowning at weddings: top-down influences of context-driven social judgments on emotional mimicry. Acta Psychol. 212, 103195 (2021).
McIntosh, D. N. Spontaneous facial mimicry, liking and emotional contagion. Pol. Psychol. Bull. 37, 31 (2006).
Dindar, M., Järvelä, S., Ahola, S., Huang, X. & Zhao, G. Leaders and followers identified by emotional mimicry during collaborative learning: a facial expression recognition study on emotional valence. IEEE Trans. Affect. Comput. 13, 1390–1400 (2020).
Bourgeois, P. & Hess, U. The impact of social context on mimicry. Biol. Psychol. 77, 343–352 (2008).
Blocker, H. S. & McIntosh, D. N. Automaticity of the interpersonal attitude effect on facial mimicry: it takes effort to smile at neutral others but not those we like. Motiv. Emot. 40, 914–922 (2016).
Frenzel, A. C., Dindar, M., Pekrun, R., Reck, C. & Marx, A. K. Joy is reciprocally transmitted between teachers and students: evidence on facial mimicry in the classroom. Learn. Instr. 91, 101896 (2024).
Kühn, S. et al. Why do I like you when you behave like me? Neural mechanisms mediating positive consequences of observing someone being imitated. Soc. Neurosci. 5, 384–392 (2010).
Kulesza, W. M. et al. The face of the chameleon: the experience of facial mimicry for the mimicker and the mimickee. J. Soc. Psychol. 155, 590–604 (2015).
Hsu, C. T., Sims, T. & Chakrabarti, B. How mimicry influences the neural correlates of reward: an fMRI study. Neuropsychologia 116, 61–67 (2018).
Arias, P., Bellmann, C. & Aucouturier, J. J. Facial mimicry in the congenitally blind. Curr. Biol. 31, R1112–R1114 (2021).
Chan, L. P., Livingstone, S. R. & Russo, F. A. Facial mimicry in response to song. Music Percept. Interdiscip. J. 30, 361–367 (2012).
Viswanathan, N. K., de Klerk, C. C., Wass, S. V. & Goupil, L. Learning to imitate facial expressions through sound. Dev. Rev. 73, 101137 (2024).
Prochazkova, E. & Kret, M. E. Connecting minds and sharing emotions through mimicry: a neurocognitive model of emotional contagion. Neurosci. Biobehav. Rev. 80, 99–114 (2017).
Hatfield, E., Bensman, L., Thornton, P. D., & Rapson, R. L. New perspectives on emotional contagion: a review of classic and recent research on facial mimicry and contagion. Interpersona 8, 2 (2014).
Olszanowski, M., Wróbel, M. & Hess, U. Mimicking and sharing emotions: a re-examination of the link between facial mimicry and emotional contagion. Cognit. Emot. 34, 367–376 (2020).
Gallese, V. Embodied simulation: from neurons to phenomenal experience. Phenomenol. Cogn. Sci. 4, 23–48 (2005).
Japee, S. On the role of sensorimotor experience in facial expression perception. J. Cogn. Neurosci. 36, 2780–2792 (2024).
Niedenthal, P. M., Wood, A., Rychlowska, M. & Korb, S. Embodied simulation in decoding facial expression. Sci. facial Expr. 14, 397–414 (2017).
Winkielman, P., Niedenthal, P. M., & Oberman, L. M. Embodied perspective on emotion-cognition interactions. In Mirror neuron systems: the role of mirroring processes in social cognition (pp. 235–257). Totowa, NJ: Humana Press (2008).
Wood, A., Lipson, J., Zhao, O., & Niedenthal, P. Forms and functions of affective synchrony. Handbook of embodied psychology: thinking, feeling, and acting, 381–402 (2021).
Lewis, M. B. The interactions between botulinum-toxin-based facial treatments and embodied emotions. Sci. Rep. 8, 14720 (2018).
Ponari, M., Conson, M., D’Amico, N. P., Grossi, D. & Trojano, L. Mapping correspondence between facial mimicry and emotion recognition in healthy subjects. Emotion 12, 1398 (2012).
daSilva, E. B. & Wood, A. How and why people synchronize: an integrated perspective. Personal. Soc. Psychol. Rev. 29, 159–187 (2025).
Hess, U. & Fischer, A. Emotional mimicry as social regulation. Personal. Soc. Psychol. Rev. 17, 142–157 (2013).
Hess, U. & Fischer, A. Emotional mimicry as social regulator: theoretical considerations. Cognit. Emot. 36, 785–793 (2022).
Mauersberger, H. & Hess, U. When smiling back helps and scowling back hurts: individual differences in emotional mimicry are associated with self-reported interaction quality during conflict interactions. Motiv. Emot. 43, 471–482 (2019).
Kastendieck, T., Dippel, N., Asbrand, J. & Hess, U. Influence of child and adult faces with face masks on emotion perception and facial mimicry. Sci. Rep. 13, 14848 (2023).
Mauersberger, H., Kastendieck, T., Hetmann, A., Schöll, A. & Hess, U. The different shades of laughter: when do we laugh and when do we mimic other’s laughter? Philos. Trans. R. Soc. B 377, 20210188 (2022).
Hoegen, R., Van Der Schalk, J., Lucas, G., & Gratch, J. The impact of agent facial mimicry on social behavior in a prisoner’s dilemma. In Proceedings of the 18th International Conference on Intelligent Virtual Agents (pp. 275–280) (2018).
Ravaja, N., Bente, G., Kätsyri, J., Salminen, M. & Takala, T. Virtual character facial expressions influence human brain and facial EMG activity in a decision-making game. IEEE Trans. Affect. Comput. 9, 285–298 (2016).
Hofman, D., Bos, P. A., Schutter, D. J. & van Honk, J. Fairness modulates non-conscious facial mimicry in women. Proc. R. Soc. B: Biol. Sci. 279, 3535–3539 (2012).
Forbes, P. A., Korb, S., Radloff, A. & Lamm, C. The effects of self-relevance vs. reward value on facial mimicry. Acta Psychol. 212, 103193 (2021).
Frith, C. Role of facial expressions in social interactions. Philos. Trans. R. Soc. B: Biol. Sci. 364, 3453–3458 (2009).
Wagner, H. L. & Smith, J. Facial expression in the presence of friends and strangers. J. Nonverbal Behav. 15, 201–214 (1991).
Champely, S. pwr: basic functions for power analysis. R. package version 1, 3–0 (2020).
Kish, L. Survey sampling. New York: John Wiley & Sons, Inc (1965).
Funk, P. F. et al. Wireless high-resolution surface facial electromyography mask for discrimination of standardized facial expressions in healthy adults. Sci. Rep. 14, 19317 (2024).
Sato, W. & Yoshikawa, S. Enhanced experience of emotional arousal in response to dynamic facial expressions. J. Nonverbal Behav. 31, 119–135 (2007).
Sato, W., Fujimura, T. & Suzuki, N. Enhanced facial EMG activity in response to dynamic facial expressions. Int. J. Psychophysiol. 70, 70–74 (2008).
Seibt, B., Mühlberger, A., Likowski, K. & Weyers, P. Facial mimicry in its social setting. Front. Psychol. 6, 121380 (2015).
Hess, U. & Bourgeois, P. You smile–I smile: emotion expression in social interaction. Biol. Psychol. 84, 514–520 (2010).
Golland, Y., Mevorach, D. & Levit-Binnun, N. Affiliative zygomatic synchrony in co-present strangers. Sci. Rep. 9, 3120 (2019).
Altmann, U., Brümmel, M., Meier, J. & Strauss, B. Movement synchrony and facial synchrony as diagnostic features of depression: a pilot study. J. Nerv. Ment. Dis. 209, 128–136 (2021).
Fürnkranz, J., Hüllermeier, E., Rudin, C., Slowinski, R. & Sanner, S. Preference learning (dagstuhl seminar 14101). Dagstuhl Rep. 4, 1–27 (2014).
Böckenholt, U. & Tsai, R. C. Individual differences in paired comparison data. Br. J. Math. Stat. Psychol. 54, 265–277 (2001).
Davis, M. H. Measuring individual differences in empathy: Evidence for a multidimensional approach. J. Pers. Soc. Psychol. 44, 113 (1983).
Baron-Cohen, S., Wheelwright, S., Skinner, R., Martin, J. & Clubley, E. The autism-spectrum quotient (AQ): Evidence from asperger syndrome/high-functioning autism, malesand females, scientists and mathematicians. J. Autism Dev. Disord. 31, 5–17 (2001).
Aron, A., Aron, E. N. & Smollan, D. Inclusion of other in the self scale and the structure of interpersonal closeness. J. Pers. Soc. Psychol. 63, 596 (1992).
Lennox, R. D. & Wolfe, R. N. Revision of the self-monitoring scale (1984).
Arché-Núñez, A. et al. Bio-potential noise of dry printed electrodes: physiology versus the skin-electrode impedance. Physiol. Meas. 44, 095006 (2023).
Heitler, W. J. A simple method for the removal of mains interference from pre-recorded electrophysiological data. Bioinformatics 12, 539–542 (1996).
Virtanen, P. et al. Fundamental algorithms for scientific computing in python and SciPy 1.0 contributors. SciPy 1.0. Nat. Methods 17, 261–272 (2020).
Gat, L., Gerston, A., Shikun, L., Inzelberg, L. & Hanein, Y. Similarities and disparities between visual analysis and high-resolution electromyography of facial expressions. PloS ONE 17, e0262286 (2022).
Lee, G., Gommers, R., Waselewski, F., Wohlfahrt, K. & O’Leary, A. PyWavelets: a Python package for wavelet analysis. J. Open Source Softw. 4, 1237 (2019).
Daubechies, I. The wavelet transform, time-frequency localization and signal analysis. IEEE Trans. Inf. Theory 36, 961–1005 (1990).
Phinyomark, A., Phukpattaranont, P., & Limsakul, C. The usefulness of wavelet transform to reduce noise in the SEMG signal. EMG methods for evaluating muscle and nerve function, 107–132 (2012).
Pedregosa, F. et al. Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Inzelberg, L., Rand, D., Steinberg, S., David-Pur, M. & Hanein, Y. A wearable high-resolution facial electromyography for long term recordings in freely behaving humans. Sci. Rep. 8, 2018 (2058).
Sato, W. & Kochiyama, T. Crosstalk in facial EMG and its reduction using ICA. Sensors 23, 2720 (2023).
Man, H. et al. Facial muscle mapping and expression prediction using a conformal surface-electromyography platform. npj Flex. Electron. 9, 71 (2025).
Nakayama, Y., Takano, Y., Matsubara, M., Suzuki, K. & Terasawa, H. The sound of smile: auditory biofeedback of facial EMG activity. Displays 47, 32–39 (2017).
Konrad, P. The ABC of EMG: a practical introduction to kinesiological electromyography. Neurologie 1, 30–35 (2005).
Boker, S. M., Rotondo, J. L., Xu, M. & King, K. Windowed cross-correlation and peak picking for the analysis of variability in the association between behavioral time series. Psychol. Methods 7, 338 (2002).
Ramseyer, F. & Tschacher, W. Nonverbal synchrony in psychotherapy: coordinated body movement reflects relationship quality and outcome. J. Consult. Clin. Psychol. 79, 284 (2011).
Riehle, M. & Lincoln, T. M. Investigating the social costs of schizophrenia: Facial expressions in dyadic interactions of people with and without schizophrenia. J. Abnorm. Psychol. 127, 202 (2018).
Blasberg, J. U., Kanske, P. & Engert, V. Little evidence for a role of facial mimicry in the transmission of stress from parents to adolescent children. Commun. Psychol. 3, 78 (2025).
Riehle, M., Kempkensteffen, J. & Lincoln, T. M. Quantifying facial expression synchrony in face-to-face dyadic interactions: Temporal dynamics of simultaneously recorded facial EMG signals. J. Nonverbal Behav. 41, 85–102 (2017).
Behrens, F., Moulder, R. G., Boker, S. M., & Kret, M. E. Quantifying physiological synchrony through windowed cross-correlation analysis: Statistical and theoretical considerations. BioRxiv, https://www.biorxiv.org/content/10.1101/2020.08.27.269746v1 (2020).
Moulder, R. G., Boker, S. M., Ramseyer, F. & Tschacher, W. Determining synchrony between behavioral time series: an application of surrogate data generation for establishing falsifiable null-hypotheses. Psychol. Methods 23, 757 (2018).
Schoenherr, D. et al. Quantification of nonverbal synchrony using linear time series analysis methods: lack of convergent validity and evidence for facets of synchrony. Behav. Res. Methods 51, 361–383 (2019).
Ambadar, Z., Cohn, J. F. & Reed, L. I. All smiles are not created equal: Morphology and timing of smiles perceived as amused, polite, and embarrassed/nervous. J. Nonverbal Behav. 33, 17–34 (2009).
Soleymani, M. & Mortillaro, M. Behavioral and physiological responses to visual interest and appraisals: Multimodal analysis and automatic recognition. Front. ICT 5, 17 (2018).
Grammer, K., Schiefenhövel, W., Schleidt, M., Lorenz, B. & Eibl-Eibesfeldt, I. Patterns on the face: the eyebrow flash in crosscultural comparison. Ethology 77, 279–299 (1988).
Larsen, J. T., Norris, C. J. & Cacioppo, J. T. Effects of positive and negative affect on electromyographic activity over zygomaticus major and corrugator supercilii. Psychophysiology 40, 776–785 (2003).
Wolf, K. et al. The facial pattern of disgust, appetence, excited joy and relaxed joy: an improved facial EMG study. Scand. J. Psychol. 46, 403–409 (2005).
Clark, E. A. et al. The facial action coding system for characterization of human affective response to consumer product-based stimuli: a systematic review. Front. Psychol. 11, 920 (2020).
Saluja, S. et al. Facial disgust in response to touches, smells, and tastes. Emotion 24, 2 (2024).
Nath, E. C., Cannon, P. R. & Philipp, M. C. An unfamiliar social presence reduces facial disgust responses to food stimuli. Food Res. Int. 126, 108662 (2019).
Burnham, K. P. & Anderson, D. R. Multimodel inference: understanding AIC and BIC in model selection. Sociol. Methods Res. 33, 261–304 (2004).
Tonidandel, S. & LeBreton, J. M. Relative importance analysis: a useful supplement to regression analysis. J. Bus. Psychol. 26, 1–9 (2011).
Finos, L., Brombin, C. & Salmaso, L. Adjusting stepwise p-values in generalized linear models. Commun. Stat.—Theory Methods 39, 1832–1846 (2010).
Harrell, F. E. Regression modeling strategies: with applications to linear models, logistic regression, and survival analysis (Vol. 608). New York: springer (2001).
Mannan, H. A practical application of a simple bootstrapping method for assessing predictors selected for epidemiologic risk models using automated variable selection. Int. J. Stat. Appl 7, 239–249 (2017).
Tartter, V. C. Happy talk: Perceptual and acoustic effects of smiling on speech. Percept. Psychophys. 27, 24–27 (1980).
Drahota, A., Costall, A. & Reddy, V. The vocal communication of different kinds of smile. Speech Commun. 50, 278–287 (2008).
Pell, M. D. & Skorup, V. Implicit processing of emotional prosody in a foreign versus native language. Speech Commun. 50, 519–530 (2008).
Vos, S., Collignon, O. & Boets, B. The sound of emotion: pinpointing emotional voice processing via frequency tagging EEG. Brain Sci. 13, 162 (2023).
Arias, P., Belin, P. & Aucouturier, J. J. Auditory smiles trigger unconscious facial imitation. Curr. Biol. 28, R782–R783 (2018).
R CoreTeam. (2021). A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/ (2021).
Bates, D., Mächler, M., Bolker, B. & Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67, 1–48 (2015).
Tonidandel, S. & LeBreton, J. M. RWA web: a free, comprehensive, web-based, and user-friendly tool for relative weight analyses. J. Bus. Psychol. 30, 207–216 (2015).
Tjur, T. Coefficients of determination in logistic regression models—a new proposal: The coefficient of discrimination. Am. Stat. 63, 366–372 (2009).
Nakagawa, S. & Schielzeth, H. A general and simple method for obtaining R2 from generalized linear mixed-effects models. Methods Ecol. Evol. 4, 133–142 (2013).
Hancock, G. R., Mueller, R. O., & Stapleton, L. M. The reviewer’s guide to quantitative methods in the social sciences. Routledge (2010).
Yzerbyt, V. Y., Muller, D. & Judd, C. M. Adjusting researchers’ approach to adjustment: on the use of covariates when testing interactions. J. Exp. Soc. Psychol. 40, 424–431 (2004).
Stel, M. & Van Knippenberg, A. The role of facial mimicry in the recognition of affect. Psychol. Sci. 19, 984 (2008).
Oberman, L. M., Winkielman, P. & Ramachandran, V. S. Face to face: blocking facial mimicry can selectively impair recognition of emotional expressions. Soc. Neurosci. 2, 167–178 (2007).
Neal, D. T. & Chartrand, T. L. Embodied emotion perception: amplifying and dampening facial feedback modulates emotion perception accuracy. Soc. Psychol. Personal. Sci. 2, 673–678 (2011).
Pitcher, D., Garrido, L., Walsh, V. & Duchaine, B. C. Transcranial magnetic stimulation disrupts the perception and embodiment of facial expressions. J. Neurosci. 28, 8929–8933 (2008).
Mauersberger, H., Kastendieck, T. & Hess, U. I looked at you, you looked at me, I smiled at you, you smiled at me—the impact of eye contact on emotional mimicry. Front. Psychol. 13, 970954 (2022).
Ekman, P., Davidson, R. J. & Friesen, W. V. The Duchenne smile: emotional expression and brain physiology: II. J. Pers. Soc. Psychol. 58, 342 (1990).
Frank, M. G., Ekman, P. & Friesen, W. V. Behavioral markers and recognizability of the smile of enjoyment. J. Personal. Soc. Psychol. 64, 83 (1993).
Krumhuber, E. G. & Manstead, A. S. Can Duchenne smiles be feigned? New evidence on felt and false smiles. Emotion 9, 807 (2009).
Rychlowska, M. et al. Functional smiles: tools for love, sympathy, and war. Psychol. Sci. 28, 1259–1270 (2017).
Amihai, L., Sharvit, E., Man, H., Hanein, Y. & Yeshurun, Y. Facial mimicry predicts preference. Zenodo https://doi.org/10.5281/zenodo.17314670 (2025).
Acknowledgements
We would like to thank Bara Levit for insights and assistance with EMG component extraction, Raz Danino, Ori Levit, Argaman Bell Meir, Daniel Toledano, Eden Elbaz, Tal Ohad, Guy Grinfeld, Nitzan Trainin, for statistical discussions, and Rania Qais, Neta Katz, Miri Goldman, Shani Schorr, Efi Izhar, Dina Eisenstadt and Daniel Dayan, for their help in running the experiment. We acknowledge the support of the Israel Science Foundation (grant No. 388/24, Y.Y.), European Research Council (grant No. 101053186, Y.H.) and Tel Aviv University Center for AI & Data Science (H.M.). The funders had no role in study design, data collection and analysis, decision to publish or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
L.A. conceptualization, methodology, software, analysis, investigation, data curation, validation, visualization, writing, project administration; E.S. investigation, project administration; H.M. methodology, writing; Y.H. methodology, writing. Y.Y. conceptualization, methodology, writing, funding, supervision.
Corresponding authors
Ethics declarations
Competing interests
Y.H. declares financial interest in X-trodes Ltd., which holds the licensing rights of the EMG skin technology cited in this paper. This does not alter her adherence to scientific and publication policies on sharing data and materials. The remaining authors declare no competing interests.
Peer review
Peer review information
Communications Psychology thanks Till Kastendieck, Jianyi Liu and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Primary Handling Editors: Yafeng Pan and Troby Ka-Yan Lui. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Amihai, L., Sharvit, E., Man, H. et al. Facial mimicry predicts preference. Commun Psychol 3, 176 (2025). https://doi.org/10.1038/s44271-025-00351-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44271-025-00351-1
