
Abstract
Only few studies of Allostatic Load (AL) have been conducted in Latin-American cohorts. Here, we replicated a recently proposed comprehensive algorithm (ALCS) to derive an AL index in a Chilean cohort of cognitive healthy adults. Using data from the GERO cohort (n = 166, age 76.92 ± 5.07 years) we generated an ALCS AL index through and compared for model fit with a purely sample distribution l algorithm (ALES). ALCS largely improved when some clinical values were corrected for ages ≥65, although failed to achieve sufficient goodness of fit. A final inclusion of an additional inflammatory biomarker resulted in further improvement of ALES, but not on ALCS. The ALES algorithm, which do not include clinical thresholds, achieved satisfactory fit after correcting for sample disparities between sexes. This suggests the need to consider the suitability of clinical thresholds developed in younger populations and the need to develop specific thresholds for assessing older adults.
Similar content being viewed by others
Introduction
Allostatic Load (AL) describes the wear and tear resulting from physiological responses caused by stress exposure1. It reflects a process of maintaining homeostasis upon environmental demands, through transient changes in the basal activity of several physiological systems1,2. Nonetheless, if the response is sustained through extensive time, the organism’s resources will deplete and damage the multiple systems involved. To date, evidence shows positive relationship between AL and risk of developing several pathological conditions, such as major depression, brain structure deterioration, cardiovascular disease, diabetes type 2, cancer, functional decline, and dementia3. Although evidence reports important ethnic modulatory effect on AL4, most studies have been performed in white-caucasian cohorts from high-income countries, and only few reports can be found in Latin/Hispanic populations, usually among Mexican or Central-American immigrants within the US5,6,7,8, with very little evidence from South American cohorts9,10,11.
Initially, AL indexes included physiological biomarkers of neuroendocrine, metabolic, immune, and cardiovascular activity, classifying them as primary mediators, released as the first response of the hypothalamic-pituitary axis (HPA) upon stress exposure; and the secondary outcomes, activated by the primary mediators, such as glycemia, blood pressure or cholesterol levels12. Novel approaches have excluded the primary neuroendocrine mediators, and there is a broad consensus that at least one biomarker for the cardiovascular, metabolic, and inflammatory components must be included for AL estimation13. However, there is still no clear agreement regarding the algorithm to calculate the AL index, with up to 18 different equations described so far13, although several studies favour more comprehensive approaches that include prescribed medications, clinical thresholds and sex differences among biomarkers3,14,15,16,17.
In a recent study, we proposed a comprehensive composite to calculate an AL index a British cohort18. The algorithm included the high-quartile approach derived from sex-specific sample distribution, clinical reference values specific for age and sex when available, and current medications treatments that could potentially mask the values of some biomarkers. The algorithm showed better model fit criteria when compared to the purely empirical method and revealed strong associations with structural brain deterioration in a mid-life healthy population. Here, we aimed to replicate and validate this comprehensive approach to derive an AL scoring in non-demented, middle and older old participants from the Chilean GERO cohort19. This cohort is composed by a heterogenous group of Chilean participants, with a social context different from most published cohorts. This makes it attractive to study stressor factors, stress response and the mechanisms underlying dementia development in a different environmental and social context from those mostly analysed to date, especially as evidence shows that ethnicity and even geographical diversity can affect certain biomarkers used to estimate AL4,15,20,21. Accordingly, given the GERO population is older than the usually reported in previous AL studies and high cardiovascular and obesity risk is reported for Chile by recent OECD publications22, modifications had to be performed to improve the original algorithm.
Given that AL is a widely accepted measurement of physiological decline used to predict several outcomes related to healthy ageing and deterioration, an accurate derivation of an AL index is the first step to investigate several age-related outcomes in this cohort.
Results
Participants
The analytical sample included 166 participants from the GERO cohort (80.12% females), with an average age of 76.92 (SD = 5.07) years old (females: 77.04, SD = 5.27), and a mean of 9.02 (SD = 4.79) years of education (females: 8.79, SD = 4.66). No significant differences were found by sex in age (Mann–Whitney U test: U = 2268.5, p = 0.764) or education (Mann–Whitney U test: U = 1957, p = 0.33, full statistical results detailed in Supplementary Table S3). Demographic characteristics of the GERO participants included the analyses are detailed in Table 1.
AL algorithm selection and validation
Following the original proposal, comprehensive AL score (ALCS) and the empirical AL score (ALES) were calculated following the algorithm flowchart described in Supplementary Fig. S1, generating final AL categories of very-low, low, medium, and high from percentiles obtained from sex-specific distributions of total scores. Both categorical scores were separately regressed on the covariates sex, age, and years of education through multinomial logistic regressions (MLR), for algorithm selection based on best model fit criteria. Surprisingly, likelihood ratio tests revealed poor model fit for both original ALCS (χ²(9) = 10.371, p = 0.321), and ALES (χ²(9) = 16.309, p = 0.061; Table 2a, top row).
To improve model fitting, algorithms were corrected for two main features of the sample: the large disparity between the number of male and female participants, and their age distribution (min = 69, max = 92 years). For the former, we generated the final AL categories based on percentiles from the whole sample distribution instead of a sex-specific approach. This modification was supported as no significant differences were found between sex in the ALCS (two-tailed unpaired t-test; t(164) = 0.223) or ALES raw scores (Mann–Whitney U test: U = 2223.5, p = 0.91, full statistical results detailed in Supplementary Table S3). For the latter, available age-specific clinical thresholds were included for the ERS, CRP and RHR biomarkers (see details in Supplementary Table S1).
Corrected ALCS and ALES categories were regressed on the covariates, with only corrected ALES showing significant model fit (χ²(9) = 19.012, p = 0.025), whereas corrected ALCS evidenced a large but not significant improvement (χ²(9) = 17.098, p = 0.047; (Table 2a, middle row).
On a final approach, IL-6 was included as an additional inflammatory biomarker to prevent a possible overload of the cardiovascular component, as suggested by previous health reports for the Chilean population. Preserving previous sex and age corrections, MLR showed a significantly improved model fit for the ALES-corrected+IL-6 algorithm (likelihood ratio test: χ²(9) = 20.844, p = 0.013), but no changes were evidenced in the ALCS-corrected+IL-6 model (likelihood ratio test: χ²(9) = 16.952, p = 0.049; Table 2a, bottom row).
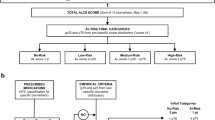
Showing the best model fit, ALES-corrected, and ALES-corrected+IL-6 algorithms were further compared for final selection (Table 2b). Although only slight differences favoured the ALES-corrected+IL-6 in Mc-Fadden’s pseudo-R² (ΔR² = 0.006) and log-likelihoods (ΔLL = 6.178), it showed a substantial decrease of the Bayesian Information Criterion (ΔBIC = −12.356), compared to ALES-corrected. Further analysis between the ratios of correct classification into AL categories showed no overall significant differences among the algorithms, although middle category was significantly better ranked by the ALES-corrected+IL-6 scores (pooled p̂ = 0.682, p < 0.001). Inter-rater reliability test showed a high level of agreement between algorithms (Cohen’s kappa test for 4 measures and 2 scorers: κ = 0.798, z-transformed = 17.199, p < 0.001). Altogether, the empirical AL score corrected for sex disparities and inclusion IL-6 resulted in the best algorithm for further analysis in the GERO cohort. The final algorithm flowchart is described in Fig. 1.

Final algorithm flowchart for AL scoring and AL categories construction.
Associations between AL index and demographic variables
Associations between AL categories from the selected algorithm, demographic covariates, and engagement in stimulating activities were estimated through MLR and very-low AL as reference category (Table 3). The overall model showed satisfactory fitting (χ²(30) = 49.531, p = 0.014), with significant model effects only for sex (χ²(3) = 8.076, p = 0.044), and years of education (χ²(3) = 9.78, p = 0.021). Education was inversely associated with AL load, with significantly increased odds of being in low (aOR = 0.54, p = 0.038), medium (aOR = 0.53, p = 0.033) and high AL (aOR = 0.53, p = 0.035). No significant associations were found between AL categories and sex, age, household income, APOEε4 genotype status, engagement in cognitive, social, recreational, physical, or productive stimulating activities. Collinearity analyses among the significant predictor years of education was assessed through a linear regression with education as dependent variable and sex, age, income, APOEε4 genotype and engagement in stimulating activities as predictors. All Variance Inflation Factors (VIFs) were below the most conservative threshold value of 5, which might indicate the presence of multicollinearity. Therefore, no collinearities were found among variables used to assess for associations with AL categories (see details in Supplementary Table S4).
Discussion
The present study is the first evaluation of AL in a Chilean cohort, based on a previously published comprehensive approach for AL scoring18, assessing the replicability and validation of this algorithm to derive an AL index and categories. In the attempt to replicate this proposal, important considerations emerged regarding the demographic characteristics of the studied population, which led to need to correct the original algorithms to achieve an adequate model fit.
First, to account for the large disparity between female and male participants in the GERO cohort, percentiles for AL categorization were generated from the whole sample scores distribution instead of the original gender-specific proposal. Second, given the studied population was significantly older (76.92, SD = 5.07, min = 70) than the one used to derive the original ALCS (51.3, SD = 5.48)18, available clinical thresholds for individuals ≥65 and ≥70 years old were included in the comprehensive algorithm. Both corrections largely improved both the ALCS and the ALES, but only the latter showed satisfactory model fit when regressed against similar demographic covariates used to validate the original proposal. The lack of model fit consistently shown by ALCS is considered an important finding related to the replicability of the algorithm to a much older cohort, compared to the one used in the original proposal. This lack of fit was assessed repeatedly after adjusting for sex imbalances and the few available age-specific clinical ranges for some biomarkers to evaluate potential improvements against ALES. Although these adjustments largely improved ALCS to achieve statistical significance lower than α = 0.05, a p = 0.047 could be still considered a weak model fit as it shows that there is only a 0.3% more probability that the observed results are not due to random variation and mathematically can be rounded to the non-significant value of 0.05. Conversely, the purely empirical algorithm ALES performed better than ALCS after adjustments for sex imbalance, with a stronger significance value of 0.025. These findings suggest that when applying the ALCS algorithm to an older cohort than the one used to validate the original proposal18 the use of age-specific clinical cut-off values is critical to calculate an optimal AL index and, given the limited availability of normal ranges for all the biomarkers in older populations, AL scores and categories are best derived using empirical distribution percentiles only.
Finally, considering recent reports of high cardiovascular and obesity risk in Chilean population22, IL-6 was included as additional inflammatory biomarker to prevent a possible bias of the scores by the cardiovascular component. The result was a further increase in model fit criteria when compared to the corrected ALES with no significant improvement in the corrected ALCS algorithm (p = 0.049). While it could be argued that both ALCS-corrected and ALCS-corrected + IL6 achieved theoretical statistical significance, the better performance of ALES-corrected (p = 0.025) and much better after including IL6 (ALES-corrected + IL6, p = 0.013) indicated that both should be preferred over ALCS for further assessment and final selection.
Although these findings seem to contradict the previously reported validity of the comprehensive approach18, they point to the biggest difference in how both ALCS and ALES algorithms are constructed: the inclusion of clinical reference values and the suitability for the studied population. The large improvement in model fit from the original to the corrected ALCS (likelihood ratio tests p values 0.321 and 0.047, respectively), reveals the importance of setting specific laboratory ranges for older cohorts when determining threshold values. The lack of improvement seen in ALCS compared to ALES after adding IL-6 can be explained given the absence of a single, universally agreed clinical cut-off value for this biomarker in older adults23, although evidence has shown that IL-6 serum concentration increases with age24 along with other inflammatory biomarkers25, and elevated IL-6 levels in older adults have been related to increased risk of mobility-disability, frailty, and cardiovascular mortality23,26,27. This evidence supports our conclusions, highlighting the need to include specific clinical thresholds for older populations to derive a valid comprehensive AL score.
Additionally, given this work is construct-validity as the analyses performed assesses how well the two versions of AL behaves in relation to theoretical expectations and their relationship with key predictors. Therefore, as one version of the index produces better model fit- stronger associations with relevant predictors, it suggests that that version reflects the underlying construct better.
While global population significantly ages and new classifications for young-old (65–74), middle-old (75–84), and oldest-old (≥85) have been proposed28,29, clinical thresholds are usually established in young adults aged 20–4030,31. Yet, increased amount of evidence reports that some changes from established reference values are expected in elderly healthy people, such as increased fasting serum glucose and erythrocyte sedimentation rates, or decreased serum creatinine levels30,32,33, suggesting that some abnormalities may be relevant pathological signs whereas other could just reflect a normal aging process34. Thus, it should not surprise that our AL categories were not associated with age, as it happens in younger cohorts9,18. Although some longitudinal studies performed in British and US cohorts35,36 report a linear increase of AL through age, van Deurzen et al., showed that such trajectory in later life was highly associated with date of birth cohort and the cumulative socioeconomical disadvantages36. Conversely, an earlier cross-sectional study preformed in 18,000 participants between 20 and 90 years old showed that AL was strongly associated with age until 60 years old, after which scores stabilized with very slight variations37, suggesting that there might be a point when AL cannot be considered as a predictor of age-related physiological decline. However, in this study, some biomarkers were scored using clinical thresholds not adjusted for older ages, leaving open the question of how valid these ranges are for establishing a reliable AL score in these populations.
Finally, while higher AL was strongly predicted by lower levels of education, no associations were found with household income, APOEε4 genotype status, or engagement in stimulating activities. Although sex was found to be a significant predictor to the overall MLR model (likelihood ratio tests p value = 0.044), no differences were found in the odds of being among higher AL categories compared to very-low AL level. Although this could be attributable to the large disparity between the number of males and females in the analytical sample, the lack of significant differences reported by the independent samples comparisons of raw AL scores suggest that this imbalance did not influence the final results and support the use of a whole sample instead of a sex-specific distribution approach to derive categories of AL level. However, the lack of significant effects of sex among the AL categories should be interpreted carefully and low statistical power cannot be discarded given the wide confidence intervals (CIs) reported for the adjusted ORs. This is likely due to the low number of cases in the categories to compare males and females, as the cohort is composed of a large majority of females.
The absence of significant associations between AL and APOEε4 has been previously reported in similar studies18,38 and should not be interpreted as evidence against a relationship to cognitive decline, given that APOEε4 was assessed as predictor of AL and not as a covariate to predict the effect of AL on cognition. Similarly, the lack of direct associations found between AL and engagement in cognitive and stimulating activities has also been previously reported39, although indirect effects mediated by other factors such as sleep or resilience cannot be discarded.
The lack of association to household income somehow disagree with previous studies performed in Latin-American cohorts, where AL was highly related to a range of socio-economic disadvantages, such as housing conditions, social or religious support and neighbourhood characteristics5,40. Nonetheless, it should be noted that according to recent demographic analyses, educational level is not correlated with per-capita income in the Chilean population41, thus it is not surprising that education shows a significant association while income does not in our sample.
One limitation of our study is the underrepresentation of men, which is a common limitation for recruitment in similar studies of subjective cognitive decline42, highly influencing the disposition to participate and the attrition levels during the follow-up. Conversely, the observed overrepresentation of women (80.12%) reflects a common pattern in aging research, where older women are both more prevalent in the population and more inclined to participate in voluntary health studies. Stratified sampling by sex was not used to select participants for biomarker collection. Therefore, it is important to note that our results might be more generalizable to women and further research should prioritize recruitment of men to expand the scope of our finding. However, the unique features of the sample which include low educational level, urban origin and public health system users, should be considered relevant for accurate representation of the epidemiological profile of elderly people in Chile.
Understanding AL in older adults is crucial to predict vulnerability to age-related diseases and to develop interventions and care plans to improve their quality of life. As the first evaluation of AL in a Chilean population, we expect this study will serve as first step for future assessments of age-related outcomes in the GERO cohort. Given the small number of similar reports in Latin-American populations, our results will help to expand the existing evidence linking AL with cognitive decline and dementia risk established in white-caucasian cohorts. Although our cohort has a limited sample size, our results can set foundations for future analysis and to establish new insights into South American populations. Future research should focus in addressing four key areas: (i) to conduct a longitudinal analysis in the GERO cohort to assess the predictive validity of the proposed AL index for age-related outcomes; (ii) to explore additional factors, such as diet or psychosocial stressors, relevant to the Chilean context; (iii) to validate the algorithm in other Latin American cohorts to assess its generalizability; and (iv) to develop or adapt clinical thresholds specific to older Latin American populations, in collaboration with regional health organizations.
Methods
Participants
Data from the first assessment (T1) from the GERO cohort were used19. Participants were recruited between October 2017 and July 2021 from the general population through a door-to-door strategy across three districts in Santiago–Chile (Macul, Peñalolen and La Reina), assigned to three primary healthcare centres and selected according to their socioeconomic heterogeneity. According to the Chilean Index of Social Priority (Indice de Prioridad Social - IPS), a composite of income, education and health access indicators used to prioritize government interventions for community development, the selected districts were categorized as medium-low (Peñalolen), low (Macul), and no social priority (La Reina), representing 57,2%, 46,3%, and 36,2% of the population within the fourth income decile, respectively43. Taking together, these figures show a reliable indicator of diversity for our cohort in terms of socioeconomic stratification. Moreover, considering that all the participants are affiliated to the public health system, the sample can be considered representative of urban and low-educated Chilean population in risk of dementia.
Given our research strategy, multidimensional and extensive evaluations were prioritized under time and budget constraints, limiting the cohort size to satisfy two main criteria to fulfil our aims: (i) to achieve adequate statistical power to explore multiple associations with outcomes and (ii) the feasibility to perform a wide range of assessments on each participant assuming costs and logistics. Both criteria meant a trade-off between the tolerance to uncertainty around the parameters to be estimated and the number of assessments that would be investigated throughout the study.
Eligible participants were ≥70-year old, without dementia diagnosis and cognitive complaint either self-reported or by a close informant. Eligible participants underwent a first evaluation to confirm inclusion criteria after signing a written informed consent.
Biomarkers collection
Fourteen biomarkers were used to derive an AL index. The inflammatory component included Creatinine, albumin, C-reactive protein (CRP) and Erythrocyte Sedimentation Rate (ESR). The latter was included as a reliable proxy measure to replace serum fibrinogen44 used in the original composite. ESR is a widely used nonspecific measure of inflammation in biomedical research45 which increases proportionally with fibrinogen levels as the latter contributed to red blood cell aggregation. Given the large wealth of evidence showing a strong positive correlation between both biomarkers46,47,48, it can be used reliably as proxy of plasma fibrinogen when this is not available.
Cardiovascular included systolic blood pressure (SBP), diastolic blood pressure (DBP), resting heart rate (RHR), and waist-to-hip ratio (WHR), and metabolic system included total cholesterol, high-density lipoprotein (HDL) cholesterol, low-density lipoprotein (LDL) cholesterol, glycemia, triglycerides, and body-mass index (BMI). Interlukin-6 (IL6), also commonly used for AL score creation11,49, was selected as additional inflammatory biomarker for potential model corrections. Samples were taken between 9 A.M. and 11 A.M. and peripheral blood was processed within 2 h. Whole blood, buffy coat, plasma, and serum were collected in a fasted state at baseline evaluation and processed according to the guidelines published previously50. Subsequently, blood samples were stored in the GERO biobank for long-term storage at −80 °C at the Faculty of Medicine of the University of Chile. IL-6 and CRP inflammatory biomarkers were analysed using Luminex platform at the University of Chile (see full details in Slachevsky 202019).
Original and corrected comprehensive AL algorithm (ALCS)
166 participants from a total of 291 were selected for inclusion to the GERO cohort, with participants excluded if they had missing data in the variables used to create the AL index (n = 125). All biomarkers were scored to create a comprehensive AL index (ALCS), as previously described18. Initial categories for “no-AL” (zero points), “AL” (one point), and “high AL” (two points) were defined for each marker, based on both clinical reference values provided by Hospital Salvador (Santiago, Chile) and quartile calculations based on sex-specific sample distribution. When clinical upper limit (clinical-up) was higher than the 75th percentile, AL category was defined between ≥p75 - ≤clinical-up (no-AL: <p75 and high-AL: >clinical-up). When clinical upper limit was lower than p75, AL was defined between ≥clinical-up - ≤p75 (no-AL: <clinical-up, high-AL: >p75). For reverse biomarkers (albumin, HDL cholesterol), if clinical lower limit (clinical-low) was below the 25th percentile (p25), AL was defined as ≤clinical-low - ≥p25 (no-AL: >p25 and high-AL: <clinical-low).
Current medication treatments were assessed during the medical interview, where participants were asked to provide either their last physical prescription or to self-report the name, dose, reason and origin of currently prescribed medications. Medication treatments coded through the Anatomic Therapeutic Chemical (ATC) classification system51 were scored as high-AL (two points) as could potentially mask some biomarkers values, as follows: total cholesterol, triglycerides and LDL for lipid modifying agents (C10); systolic and diastolic blood pressure for anti-hypertensive medication (C02, C03, C09); resting heart rate for beta-blockers (C07) or calcium blockers (C08); and glycemia for insulin or analogues (A10).
After summing the scores and given only three female participants scored 0 points, percentiles of total scores – including zeros - were calculated from sex-specific distributions, to generate final AL categories: Very-low: 0 - <p5; Low: ≥p5 - ≤p25; Medium: >p25 - <p75; High: ≥p75. The decision algorithm is detailed in Supplementary Fig. S1a.
Given the age of the sample, age-corrected clinical thresholds were included for ESR52, CRP53 and age and gender categories for RHR provided by the British Cardiovascular Society. These age-specific thresholds were determined from available evidence based on scientific agreement. Given these studies were mostly performed in white-Caucasians populations, previous research describing potential discrepancies with Hispanic/Latin-American individuals were investigated before adjusting values to age-corrected ranges. While most studies focus on racial differences between white and black individuals, the few reports found comparing Hispanic and white adults show no significant differences among the reference intervals used for the biomarkers included in our AL index calculation54. Particularly, the use of the age and gender categories for RHR provided by the British Cardiovascular Society and used by in original ALSC publication18, was preserved as evidence of racial differences in this biomarker is not consistent. While one study reports a slightly lower RHR in older Hispanic and Latino adults compared to non-Hispanic White individuals55, research performed in adolescents did not find significant differences between Hispanic and Caucasians56, and most available studies highlight the relevance of age and sex differences in RHR variabilities, above race covariance.
Finally, high and low quartiles were calculated from the whole sample distribution of total scores to generate final AL categories. Clinical thresholds and quartiles values are detailed in Supplementary Table S1.
Original and corrected empirical AL algorithm (ALES)
Following the empirical approach57, a purely quartile-based AL index was derived from sex-specific distributions. Biomarkers were awarded 1 point if their value was ≥p75, or ≤p25 for albumin and HDL cholesterol. After scoring for medications, AL categories were generated from total scores by the same method used in ALCS. Corrected ALES final categories were generated by calculating percentiles from the whole sample distribution of total scores. The decision algorithm is detailed in Supplementary Fig. S1b.
Covariates
Demographic covariates included age, sex, and years of education. Household income was assessed as self-reported estimated total income in Chilean pesos from all members of the household, categorized from 65,000 to over 1,650,000 in variable ranges of 50,000, 100,000 or 200,000, according to criteria from the National Health Survey. For APOEε4 genotype status, DNA was extracted using the protocol Q suggested by the international human microbiome standards (IHMS SOP 06 V1). Given only 25 participants (15.1% from total sample, 19 females and 6 males) were heterozygous for APOEε4 gene, and only 2 APOEε4 homozygous females (15.1% from total sample), binary categories were generated where 0 = no APOEε4 allele and 1 = one or both APOEε4 alleles.
As an additional modulator of AL, self-reported frequency of engagement in stimulating activities was assessed through a 15-item reverse-coded Likert scale (see details in Supplementary Table S2), with points ranging from 1 to 5 for “several times a week” to “never” (Thumala et al. Article in preparation). Activity types were sub-divided as cognitive, social, recreational, physical, and productive, each comprising the sum of 3 items. Thus, the score for each type of activity ranges between 3 (several times a week) and 15 (never), with lower scores indicating higher frequency of engagement.
Statistical analysis
All analyses were conducted using IBM SPSS Statistics v.27.058. Statistical differences between sex for age, years of education and original AL raw scores were evaluated by two-tailed unpaired t-test when normality and homoscedasticity were above the rejection value of <0.05 (estimated by Shapiro–Wilk and Levene’s tests, respectively). Otherwise, Mann–Whitney U rank sum test was used for non-parametric unpaired two-sample comparison.
For validation, original, corrected and IL6-included ALCS and ALES algorithms were analysed separately, including age, sex, and years of education as covariates in Multinomial Logistic Regression (MLR) models, with the very-low category used as reference. Algorithms showing satisfactory model fit (Likelihood ratio χ² tests with α = 0.05) were further assessed for final selection by highest Mc Fadden’s pseudo-R²57, the Bayesian Information Criterion difference (ΔBIC) > -1059, and highest log-likelihood parameters. Mc Fadden’s pseudo-R² is an index between 0 and 1 that measures how well a logistic regression model fits the data, with higher values indicating better fit. The BIC (Bayesian Information Criterion) is another index that balances goodness of fit and parsimony. Lower values of the BIC are indicator of better models.
Classification tables were used to compare the accuracy of correct classification into each AL category, and differences were assessed through pooled probabilities and z-transformations. Inter-rater reliability was evaluated through contingency tables and Cohen’s kappa index. After model validation, an MLR was fitted to assess relationships between AL categories generated from the selected algorithm and age, sex, years of education, household income, APOEε4 genotype status, and engagement in cognitive, social, recreational, physical, and productive stimulating activities. Collinearity analyses among the significant predictors were assessed through a linear regression to calculate Variance Inflation Factors (VIFs). The presence of multicollinearity was discarded if respective VIFs between variables were below the most conservative threshold value of 560.
Ethics
The Geroscience Center for Brain Health and Metabolism Research Project N° 1140423 and informed consents were approved in May 2015 by the Scientific Ethics Committee (SEC) of the Western Metropolitan Health Service (WMHS, Santiago, Chile), which operates according to the Helsinki Declaration of 1975 (and as revised in 1983) Study Number: NCT04265482. Written informed consent to participate in the study is obtained for all participants of the GERO cohort. All data were appropriately anonymized before the present analysis.
Data availability
The data supporting the findings of this study are available on request from the corresponding author. The data are not publicly available due to privacy or ethical restrictions.
References
McEWEN, B. S. Stress, adaptation, and disease: allostasis and allostatic load. Ann. N. Y. Acad. Sci. 840, 33–44 (1998).
Schulkin, J. Rethinking Homeostasis (The MIT Press, 2002). https://doi.org/10.7551/mitpress/5928.001.0001.
Guidi, J., Lucente, M., Sonino, N. & Fava, G. A. Allostatic load and its impact on health: a systematic review. Psychother. Psychosom. 90, 11–27 (2021).
Borrell, L. N., Rodríguez-Álvarez, E. & Dallo, F. J. Racial/ethnic inequities in the associations of allostatic load with all-cause and cardiovascular-specific mortality risk in U.S. adults. PLoS One 15, e0228336 (2020).
D’Alonzo, K. T. et al. Estresse de aculturação e carga alostática entre mulheres imigrantes mexicanas. Rev. Lat. Am. Enfermagem 27, e3135 (2019).
Niño, M. D. & Chavez, Y. Z. Stress and allostatic load among Latina/os: evidence from the Hispanic Community Health Study/Study of Latina/os. J. Immigr. Minor. Heal. 23, 895–903 (2021).
Rodriquez, E. J. et al. Allostatic load, unhealthy behaviors, and depressive symptoms in the Hispanic Community Health Study/Study of Latinos. SSM Popul. Heal. 16, 100917 (2021).
McClain, A. C., Xiao, R. S., Tucker, K. L., Falcón, L. M. & Mattei, J. Depressive symptoms and allostatic load have a bidirectional association among Puerto Rican older adults. Psychol. Med. 52, 3073–3085 (2022).
Soria, C. A., Remedi, C., D’Alessio, L. & Roldán, E. J. A. Sex and age-related differences in neuroticism and allostatic load index in urban patients with general anxiety disorder treated with alprazolam. Open J. Psychiatry 08, 212–232 (2018).
Freire, A. D. N. F., Barbosa, J. F. S., Pereira, D. S., Gomes, C. D. S. & Guerra, R. O. Allostatic load and stress biomarkers in a sample of community-dwelling older adults. Arch. Gerontol. Geriatr. 87, 104006 (2020.
Germano, M. L. et al. Allostatic load and physical performance in older adults: findings from the International Mobility in Aging Study (IMIAS). Arch. Gerontol. Geriatr. 109, 104961 (2023).
Seeman, T. E., Singer, B. H., Rowe, J. W., Horwitz, R. I. & McEwen, B. S. Price of adaptation-allostatic load and its health consequences. MacArthur studies of successful aging. Arch. Intern. Med. 157, 2259–2268 (1997).
Duong, M. T., Bingham, B. A., Aldana, P. C., Chung, S. T. & Sumner, A. E. Variation in the calculation of allostatic load score: 21 examples from NHANES. J. Racial Ethn. Heal. Disparities 4, 455–461 (2017).
Rodriquez, E. J. et al. Relationships between allostatic load, unhealthy behaviors, and depressive disorder in U.S. adults, 2005–2012. Nhanes. Prev. Med.110, 9–15 (2018).
Rodriquez, E. J., Kim, E. N., Sumner, A. E., Nápoles, A. M. & Pérez-Stable, E. J. Allostatic load: importance, markers, and score determination in minority and disparity populations. J. Urban Heal. 96, 3–11 (2019).
Juster, R.-P. et al. Sex differences and gender diversity in stress responses and allostatic load among workers and LGBT people. Curr. Psychiatry Rep. 21, 110 (2019).
Kerr, P., Kheloui, S., Rossi, M., Désilets, M. & Juster, R.-P. Allostatic load and women’s brain health: a systematic review. Front. Neuroendocrinol. 59, 100858 (2020).
Buller-Peralta, I. et al. Comprehensive allostatic load risk index is associated with increased frontal and left parietal white matter hyperintensities in mid-life cognitively healthy adults. Sci. Rep. 14, 573 (2024).
Slachevsky, A. et al. GERO Cohort Protocol, Chile, 2017–2022: community-based cohort of functional decline in subjective cognitive complaint elderly. BMC Geriatr. 20, 505 (2020).
Beese, S., Postma, J. & Graves, J. M. Allostatic load measurement: a systematic review of reviews, database inventory, and considerations for neighborhood research. Int. J. Environ. Res. Public Health 19, 17006 (2022).
Howard, J. T. & Sparks, P. J. Does allostatic load calculation method matter? Evaluation of different methods and individual biomarkers functioning by race/ethnicity and educational level. Am. J. Hum. Biol. 28, 627–635 (2016).
Measuring distance to the SDG targets – Chile. In The Short and Winding Road to 2030 (OECD, 2022). https://doi.org/10.1787/44021a81-en.
Nicklas, B. J. et al. Exercise training and plasma C-reactive protein and interleukin-6 in elderly people. J. Am. Geriatr. Soc. 56, 2045–2052 (2008).
Maggio, M., Guralnik, J. M., Longo, D. L. & Ferrucci, L. Interleukin-6 in aging and chronic disease: a magnificent pathway. J. Gerontol. Ser. A 61, 575–584 (2006).
Rea, I. M. et al. Age and age-related diseases: role of inflammation triggers and cytokines. Front. Immunol. 9, 586 (2018).
Gómez-Rubio, P., Trapero, I., Cauli, O. & Buigues, C. Salivary IL-6 concentration is associated with frailty syndrome in older individuals. Diagnostics 12, 117 (2022).
Gager, G. M. et al. Interleukin-6 level is a powerful predictor of long-term cardiovascular mortality in patients with acute coronary syndrome. Vasc. Pharmacol. 135, 106806 (2020).
Alterovitz, S. S. R. & Mendelsohn, G. A. Relationship goals of middle-aged, young-old, and old-old internet daters: An analysis of online personal ads. J. Aging Stud. 27, 159–165 (2013).
Lee, S. B., Oh, J. H., Park, J. H., Choi, S. P. & Wee, J. H. Differences in youngest-old, middle-old, and oldest-old patients who visit the emergency department. Clin. Exp. Emerg. Med. 5, 249–255 (2018).
Vásárhelyi, B. & Debreczeni, L. A. Lab test findings in the elderly. EJIFCC 28, 328–332 (2017).
Schuff-Werner, P. Challenges of laboratory diagnostics in the elderly. LaboratoriumsMedizin 42, 105–107 (2018).
Kelso, T. Laboratory values in the elderly. Emerg. Med. Clin. North Am. 8, 241–254 (1990).
Risch, M., Sakem, B., Risch, L. & Nydegger, U. E. The SENIORLAB study in the quest for healthy elderly patients. LaboratoriumsMedizin 42, 109–120 (2018).
Lapin, A. & Böhmer, F. Laboratory diagnosis and geriatrics: more than just reference intervals for the elderly. Wien. Medizinische Wochenschr. 155, 30–35 (2005).
Tampubolon, G. & Maharani, A. Trajectories of allostatic load among older Americans and Britons: longitudinal cohort studies. BMC Geriatr. 18, 255 (2018).
van Deurzen, I. & Vanhoutte, B. A longitudinal study of allostatic load in later life: the role of sex, birth cohorts, and risk accumulation. Res. Aging 41, 419–442 (2019).
Crimmins, E. M., Johnston, M., Hayward, M. & Seeman, T. Age differences in allostatic load: an index of physiological dysregulation. Exp. Gerontol. 38, 731–734 (2003).
Crook, Z. et al. Apolipoprotein E genotype does not moderate the associations of depressive symptoms, neuroticism and allostatic load with cognitive ability and cognitive aging in the Lothian Birth Cohort 1936. PLoS One 13, e0192604 (2018).
Buller-Peralta, I. et al. The pivotal role of sleep in mediating the effects of life stressors and healthy habits on allostatic load in mid-life adults. Front. Hum. Neurosci. 18, 1509223 (2024).
Morales-Jinez, A. et al. Social factors contributing to the development of allostatic load in older adults: a correlational- predictive study. Aquichan 18, 298–310 (2018).
Prieto, J. Poverty traps and affluence shields: modeling the persistence of income position in chile. Res. Econ. Inequal. 29, 169–207 (2021).
Abdelnour, C. et al. Impact of recruitment methods in subjective cognitive decline. J. Alzheimers. Dis. 57, 625–632 (2017).
Ministerio de Desarrollo Social y familia. Índice De Prioridad Social De Comunas 2022. Área Estud. e Inversiones Seremi Desarro. Soc. y Fam. Región Metrop. (2022).
Beydoun, M. A. et al. Systemic inflammation is associated with longitudinal changes in cognitive performance among urban adults. Front. Aging Neurosci. 10, 1–12 (2018).
Aldwin, C. M. & Nath, R. Erythrocyte sedimentation rate as a biomarker for stress and aging research. In Oxford Research Encyclopedia of Psychology (Oxford University Press, 2019). https://doi.org/10.1093/acrefore/9780190236557.013.354.
BAIN, B. J. Some influences on the ESR and the fibrinogen level in healthy subjects. Clin. Lab. Haematol. 5, 45–54 (2008).
Rooney, T. et al. Levels of plasma fibrinogen are elevated in well-controlled rheumatoid arthritis. Rheumatology 50, 1458–1465 (2011).
Yin, W., Xu, Z., Sheng, J., Xie, X. & Zhang, C. Erythrocyte sedimentation rate and fibrinogen concentration of whole blood influences the cellular composition of platelet-rich plasma obtained from centrifugation methods. Exp. Ther. Med. 14, 1909–1918 (2017).
Booth, T., Starr, J. M. & Deary, I. Modeling multisystem biological risk in later life: allostatic load in the lothian birth cohort study 1936. Am. J. Hum. Biol. 25, 538–543 (2013).
O’Bryant, S. E. et al. Guidelines for the standardization of preanalytic variables for blood-based biomarker studies in Alzheimer’s disease research. Alzheimers. Dement. 11, 549–560 (2015).
Nahler, G. anatomical therapeutic chemical classification system (ATC). In Dictionary of Pharmaceutical Medicine 8–8 (Springer, 2009). https://doi.org/10.1007/978-3-211-89836-9_64.
ISP. Recomendaciones para la medición de la velocidad hemática de sedimentación. Rol ISP 1–9 (2017).
Wener, M. H., Daum, P. R. & McQuillan, G. M. The influence of age, sex, and race on the upper reference limit of serum C-reactive protein concentration. J. Rheumatol. 27, 2351–2359 (2000).
Lim, E., Miyamura, J. & Chen, J. J. Racial/ethnic-specific reference intervals for common laboratory tests: a comparison among asians, blacks, hispanics, and white. Hawai’i J. Med. Public Heal. J. Asia Pac. Med. Public Heal. 74, 302–310 (2015).
Ostchega, Y., Porter, K. S., Hughes, J., Dillon, C. F. & Nwankwo, T. Resting pulse rate reference data for children, adolescents, and adults: United States, 1999–2008 (National Health Statistics Reports, 2011).
Hedger-Archbold, K., Sorensen, S. T., Goodwin, J. L. & Quan, S. F. Average heart rates of Hispanic and Caucasian adolescents during sleep: longitudinal analysis from the TuCASA cohort. J. Clin. Sleep. Med. 10, 991–995 (2014).
McLoughlin, S., Kenny, R. A. & McCrory, C. Does the choice of allostatic Load scoring algorithm matter for predicting age-related health outcomes?. Psychoneuroendocrinology 120, 104789 (2020).
IBM Corp. IBM SPSS Statistics for Windows (Version 27.0) (IBM Corp, 2020).
Raftery, A. E. Bayesian model selection in social research. Sociol. Methodol. 25, 111 (1995).
Kim, J. H. Multicollinearity and misleading statistical results. Korean J. Anesthesiol. 72, 558–569 (2019).
Acknowledgements
Servicio de Salud Metropolitano Oriente, Hospital del Salvador and CESFAM Santa Julia (Macul), CESFAM Ossandón (La Reina), CESFAM Juan Pablo II (La Reina), and CESFAM Cardenal Silvia Henríquez (Peñalolén) for their contribution to the realization of the study. The authors would like to express their gratitude to the participants and family members from the GERO cohort study. Funding was provided by ANID/FONDAP/15150012; A.S. is partially supported by ANID/FONDECYT Regular Fondecyt 1231839. The contents of this publication are solely the responsibility of the authors and do not represent the official views of these institutions. The funding body has no involvement in the design of the study and collection, analysis, and interpretation of data, and in manuscript writing.
Author information
Authors and Affiliations
Contributions
I.B.-P. reviewed the literature, designed the study, analysed, and interpreted data, G.M.-T. and A.S. supervised the study design, data analysis and interpretation.Designed the GERO study: P.L., C.G.-B., F.C., D.T. Field work and coordination of study: P.L., M.D., R.S., F.D., F.S., F.D., M.D., D.T., A.S. Draft manuscript: I.B.-P., G.M.-T., P.R., A.S. Wrote and revised the manuscript critically: I.B., G.M.T., A.S. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Buller-Peralta, I., Muniz-Terrera, G., Lillo, P. et al. Allostatic load calculation in a Chilean older-adults cohort reveals the need for age-specific clinical thresholds. npj Dement. 1, 26 (2025). https://doi.org/10.1038/s44400-025-00032-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44400-025-00032-0
