
Abstract
Publications related to experimentation with Large Language Models (LLMs) in healthcare are rapidly increasing. While human evaluation remains the gold standard for evaluating LLMs, there is still a lack of standardization in its implementation. In this review article, we systematically examine studies involving LLMs in healthcare that have conducted human evaluations. We analyze the metrics used, assess their variability across studies. We also propose a standardized framework along with an interactive open web application HumanELY, to facilitate human evaluation. We believe that use of HumanELY will provide an opportunity for consistent, comprehensive, reliable, reproducible, and measurable human evaluations of LLM in healthcare. HumanELY is publicly available at https://www.brainxai.com/humanely.
Similar content being viewed by others
Introduction
Large Language Models (LLMs) have demonstrated remarkable potential in solving complex tasks across diverse domains1,2. The proliferation of LLMs, coupled with the interest in applying them in healthcare, has led to an increasing number of publications3,4,5,6,7. Despite the significant advancement of LLMs, several challenges remain, including hallucination, lack of contextual understanding, ethical and legal concerns, limited interpretability, bias and error propagation6,8,9. These challenges highlight an urgent need for comprehensive evaluation of LLM for delivering high-quality care and ensuring patient safety in healthcare applications. Evaluating LLMs is a challenging task, as there is no one-size-fits-all evaluation method10,11. Evaluation mechanisms are broadly categorized into quantitative metrics, automated benchmarks, and human evaluations12,13,14. While quantitative metrics provide objective measurements, human evaluation remains the gold standard and most trustworthy approach for evaluating LLM performance, particularly for healthcare applications15,16,17. Of late, a few human evaluation frameworks have been proposed to address the significant variation that has been observed in both the criteria for human evaluations and how these assessments are performed15,16,18,19.
In a recent systematic review of LLM evaluations, the authors observed wide variation in the evaluation criteria. Notably, bias, fairness, toxicity, robustness, and implementability were the least frequently addressed dimensions15. Similarly, in another literature review of 142 studies, the researchers found gaps in human evaluation processes in dimensions related to reliability, generalizability, and applicability16.
Healthcare-specific human evaluation frameworks have also been proposed recently to address the gaps in assessment of LLM outputs. In a pilot testing of a standardized assessment tool termed CLEAR, the authors aimed to test four key themes of the quality of health information delivered by AI-based models: completeness of content, lack of false information in the content, evidence supporting the content, appropriateness of the content, and relevance20. Similarly, XLingEval has been proposed as a comprehensive cross-lingual framework to assess the behavior of LLMs, especially in high-risk domains such as healthcare. This framework emphasizes the evaluation of correctness, consistency, and verifiability across different languages and models21. QUEST is another recently proposed comprehensive and practical framework for the human evaluation of LLMs designed with five proposed assessment domains: quality of information, understanding and reasoning, expression style and persona, safety and harm, and trust and confidence16.
Despite several efforts to establish human evaluation as a standard approach for evaluating LLMs, many studies have either not performed human evaluation in their LLM experiments or have done so without following any standardized framework. This inconsistency highlights the need to analyze existing gaps and challenges in human evaluation, and to encourage the development of both theoretical and practical frameworks. There is a strong need for an interactive system that enables researchers to conduct human evaluations effectively, engage with the process intuitively, and collaborate seamlessly with other researchers. In this review study, we have done the following:
-
Conducted a systematic literature review to understand the variation in metrics used for human evaluation of LLMs in healthcare.
-
Provided an exhaustive list of metrics commonly employed in human evaluation.
-
Introduced an open-source framework for performing human evaluation, called HumanELY (Human Evaluation of LLM Yield).
Our study aims to bring greater transparency, consistency, and reproducibility and scalability to the evaluation of LLMs in healthcare. We hope HumanELY will serve as a community-driven platform to support best practices and promote collaborative advancements in this evolving field.
Results
In this section, we present findings from our systematic review of studies that employed human evaluation in evaluating LLMs within the healthcare domain, and compare them against our proposed HumanELY (Fig. 1) framework.

We have proposed five major factors for conducting human evaluation: Relevance, Coverage, Coherence, Comparison, and Harm. We have developed a set of survey-based questions to evaluate these five categories. Additionally, we are providing a WebApp that allows for evaluation by simply uploading a file with reference text and human-generated text. The graphs and numbers in the figures are for illustrative purposes only and do not represent real data.
Search results
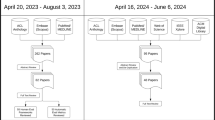
The initial search across two electronic databases PubMed and Scopus returned a total of 904 articles (PubMed = 508; Scopus = 396). After removing 223 duplicates (13 identified manually and 210 by Covidence), 681 articles remained for screening. Following title and abstract screening, 305 articles were excluded, leaving 376 articles for full-text review. No articles were excluded due to full-text retrieval issues. Among the 376 full-text articles assessed for eligibility, 190 were excluded for the following reasons: no use of LLMs (n = 5), case study design (n = 16), review articles (n = 20), absence of human evaluation (n = 115), not healthcare-related (n = 9), outside the eligible date range (n = 1), use of uncommon evaluation criteria (n = 15), image-based studies using human evaluation (n = 8), and correction papers to previously published studies (n = 1). A total of 186 studies met the inclusion criteria and were included in the final review. The complete screening process and reasons for exclusion are illustrated in (Fig. 2).

PRISMA flowchart for screening and evaluation of LLM in healthcare publications.
Comparative analysis of human evaluation metrics in healthcare LLM studies
We analysed 186 screened (Table 1) articles to explore gaps and challenges in human evaluation in LLMs, specifically within the healthcare domain. Our analysis focused on understanding the variation in human evaluation metrics used across studies, differences in the number and expertise of evaluators, and the most frequently studied LLMs. In all our analyses we have considered HumanELY (Fig. 1) matrices as a benchmark. Explanations of the HumanELY matrices and submatrices are provided in Table 2. Our findings revealed substantial variation in the use of human evaluation metrics. While some studies employed a comprehensive set of metrics aligned with HumanELY, many others used only a limited subset, reflecting an overall lack of standardization in evaluation practices across the literature.
Variation of human evaluation metrics evaluated across studies
Our analysis demonstrated significant variation in the applications of metrics of human evaluation (Fig. 3A). Relevance and coherence were the most frequently used metrics, while harm was the least assessed. Within relevance, accuracy was evaluated in 180 (96.77%) studies, comprehensiveness in 142 (76.34%) studies, and reasoning in 116 (62.36%) studies. Coverage-related metrics were evaluated in a moderate proportion of studies: key points 110 (59.13%), retrieval 105 (56.45%), and missingness 83 (44.62%). Coherence-related dimensions were less frequently assessed: fluency 69 (37.09%), grammar 63 (33.87%), and organization 67 (36.02%). Ethical and harm-related aspects were the least frequently evaluated: bias 23 (12.36%), toxicity 9 (4.83%), privacy 0, and hallucination 13 (6.98%). Bias was the most measured harm-related aspect. Comparison metrics included human (format) 28 (15.05%), human (content) 65 (34.94%), and LLM 66 (35.48%).

A Variations in metrics used for human evaluation of LLM outputs. B Composition of annotator types involved in evaluations (C) Top 10 model types used in publications related to LLMs in healthcare with human evaluation. D Number of models evaluated per study, highlighting the predominance of single-model evaluations.
Diversity, number, and professional background of evaluators
We found that 179 (96%) out of 186 studies reported the details and characteristics of the evaluators. Among the 186 studies analyzed, 124 (66.6%) used specialist physicians as evaluators. Other evaluator categories included medical trainees 24 (12.9%), generalist physicians 10 (5.4%), nurses 7 (3.8%), and others 47 (25.3%), which included various healthcare professionals. Patients or lay persons participated in 18 (9.7%) of the evaluations. Also, 39 (21%) of the studies used more than one evaluator type, with the maximum number of evaluators being 255 (median value = 3) (Fig. 3B).
Types and distribution of models evaluated across selected studies
Our analysis revealed that 67 different types of models were used across the selected studies. Almost all studies incorporated some version of OpenAI’s GPT model series, including GPT-422 77 (41.39%), GPT-3.523 78 (41.93%), and GPT 30.1%. The GPT category includes all GPT models prior to GPT-3.5 or those GPT models where the exact model type was not specified in the publication. Beyond OpenAI’s GPT models, Google’s Bard 2324 (12.3%) was the second most preferred, followed by Meta’s LLaMA-225 8 (4.3%) and Microsoft’s Bing26 7 (3.76%) (Fig. 3C).
Most studies used a single model 119 (63.9%) for calculating results, followed by two models 39 (20.9%), three models 15 (8.0%), four models 9 (4.8%), and a smaller proportion using five or more models (Fig. 3D).
Discussion
Despite being the gold standard, performance of human evaluation of LLM outputs in healthcare is a significant challenge. Our analysis demonstrates vast variability in how human evaluation of LLM output is performed and what domains are assessed. Accuracy (180[96.77%]), comprehensiveness (142[76.34%]) and reasoning (116[62.36%]) are important metrics for relevance of the output and are most commonly measured. Metrics related to coverage, key points (110[59.13%]), retrieval (105[56.45%]), and missingness (83[44.62%]) are not assessed often enough as they are many times assumed with the measurement of submetrics relevance. Lower levels of measurement of coherence, fluency (69[37.09%]), grammar (63[33.87%]), and organization (67[36.02%]) might be due to high levels of coherent responses with GPT models, which were the most frequently used LLM. However, for many other LLMs, incoherent outputs can be concerning in healthcare space, because readability and understandability of the outputs are of key importance for both clinicians and patients. Harm metrics are still poorly assessed, with biasness (23[12.36%]) being measured most commonly, and despite all the concerns for hallucinations (13[6.98%]) by LLM, it is not frequently measured and perhaps once again assumed to be addressed by an assessment of accuracy and reasoning. This is concerning since in healthcare, there is already a significant apprehension related to biases in AI algorithms, privacy, harm to patients with the use of toxic language, and safety concerns with misinformation generated from hallucinating LLM output or targeted attacks9,15. Since most of the data used for these studies is not from real clinical scenarios, it is not unexpected that private information leaks were not measured15. With recommendations for the use of real patient data in the future and the sensitivity towards leakage of private information in healthcare, privacy needs to be monitored more closely with the use of LLMs. While many have used two or more models (67/186) studies, possibly increasing the number of models trialed in an experiment may provide more insights into model behaviors. This makes a comparison of these assessments challenging, and the results are not comparable.
There is a lack of consistent metrics, definitions for those metrics, frameworks, and tools to perform human evaluation effectively, and non-uniformity in assessments and evaluators. While other researchers have highlighted the issue of variability in the use of the metrics, variability in the definitions of these metrics is also a concern. Tesller et al., used relevance as a metric, but based on the proposed HumanELY definitions, it measures coverage27. Similarly, even for the most frequently used metric of accuracy, there is variability in what it is assessing. Termed accuracy as a metric by Ito et al., the measurement corresponds more with reasoning (“GPT-4 was also queried for its reasoning and reasons behind the diagnoses.”) based on HumanELY definition28. Infrequently used metrics are also used for evaluations such as “factual consistency”, used by Xie et al., which measures whether the source documents substantiate the statement29.
Although Likert was the most common evaluation scale used, we observed significant variation in the scales used for the assessment of the LLM outputs30,31. Elangovan et al., shared how cognitive biases can conflate fluent information and truthfulness, and how cognitive uncertainty affects the reliability of rating scores such as Likert32. Also, these scales might have inverse interpretations where the lower end of the scales might imply least applicable for some metrics and inverse for others. Consistent scaling becomes an important part of measurement once the metrics and definitions have been standardized. Most frequent use of the GPT group of models is not unexpected, as GPT can commonly be used directly from the web application, even by those who do not perform programming. Use of specialty healthcare data trained models was rare (e.g., Med-PaLM used 2 times), but is likely to increase in the future as they get developed and become open source33. Our analysis also found that most of the studies used specialist physicians for assessments and generalist physicians, patients, trainees, and other healthcare professionals where appropriate. There is still a greater opportunity to design studies engaging patients and include readability and understandability assessments. While many have experimented with LLMs and compared the output with human-generated content and other LLM outputs, there is a significant lack of comparison with ground truth. Variations in scoring of the LLM results, to some extent, can be addressed by assigning these assessments to the appropriate level of human reviewers and measuring inter-rater variability of the assessments performed.
To address all these variabilities, we have proposed HumanELY as a framework and as an interactive web application for consistent, comprehensive, comparable, and efficient human evaluation of LLM output. While all metrics may not be applicable to all the assessments, if any of the metrics are not used, we do recommend an explanation of why it was not used. In addition, additional metrics used for the purpose of the study can be used in the framework with a consistent Likert scale based scoring and assessment. We have provided a free web-based tool that is available to all users for efficient evaluation. While the question of who should be performing the assessment is best addressed by the users, consistency and clarity in definitions, provision of easy to use scale, even for those who cannot perform computer programming was our goal. The design of HumanELY follows the recommendations of the ConSiDERS framework and its six proposed pillars of Consistency, Scoring Criteria, Differentiating, User Experience, Responsible, and Scalability32. Building upon this, several key recommendations emerge for future research practices.
-
1.
Consistency in evaluation metrics and their definitions: Going beyond the recommendations for standardization of evaluation metrics, we also need consistent definitions of these metrics.
-
2.
Uniformity in experimentation: Consensus guidelines need to be developed to provide uniformity in evaluation experimentations as recommended by Bedi S, et al.15.
-
3.
Adoption of guidelines, frameworks, and recommendations: Assessing LLMs is a challenging task, as there is no one-size-fits-all evaluation method10,11. HELM (Holistic Evaluation of Language Models) framework provides a comprehensive assessment of LLMs by evaluating them across various aspects, including language understanding, generation, coherence, context sensitivity, common-sense reasoning, and domain-specific knowledge18. HELM provides for measuring seven metrics, including accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency. Similarly, for healthcare, QUEST provides a framework for evaluations of LLM output16. International consensus recommendations for research in LLM, such as HUMANE for AI in general, are still lacking and need to be developed for global adoption34.
-
4.
Efficient and effective human evaluation of LLM outputs: Adoption of open source tools for human evaluation of LLM outputs such as HumanELY is needed.
We also acknowledge several limitations, such as our publication search in the systematic review including missing evaluations beyond the end date of the search, use of two search engines which do not include publications from computer science conferences, and the search methodology, such as the inclusion of English language publications only. The lack of tools for evaluation of biases and quality assessment tools for LLM-related publications limits our assessments for the same. The proposed HumanELY metrics and definitions are from a single but diverse research group, including both practicing clinicians, AI researchers, and trainees from across the world. Lastly, human evaluation of LLMs itself suffers from many limitations, including cost, limited correlations between human evaluators, biases, and lack of scalability. Also, there are automation and scalability issues with human evaluation of LLMs. The limitations of scalability are likely to be overcome by use of LLM-as-a-judge, though we believe a human-in-loop will still be required. HumanELY framework can provide consistency in the evaluation criteria used by LLMs to perform assessments at scale and to optimize their performance in alignment with human judgments. By offering clearly defined matrices and submatrices, HumanELY facilitates the creation of structured and standardized prompts for LLM-as-a-judge approaches. Future research is needed to ensure that these approaches are reliably aligned with human values.
In conclusion, Human evaluation of LLM output in healthcare is variable. Experiments so far have used inconsistent metrics, definitions, and methodologies. To perform consistent, comprehensive, reliable, reproducible, and measurable evaluations of LLM in healthcare, frameworks, and tools must be developed and adopted. Scaling of evaluations will need automation of these accepted definitions and frameworks.
Methods
Search
This systematic review adheres to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) reporting guidelines35 (Supplementary Data 2). Our literature search was performed using a PubMed and Scopus database search from January 1, 2020 to July 15, 2024, on July 19, 2024. Our detailed search methodology is included in Supplementary Information 1. In the article search, we excluded article types: Comment, Preprint, Editorial, Letter, Review, Scientific Integrity Review, Systematic Review, News, Newspaper Article, and Published Erratum. We also excluded animal-based studies or those not published in the English language.
Screening
Screening was conducted by six independent reviewers (A.A.1., A.A.2., S.M., H.A., I.D., and A.C.) using an online tool (Covidence, 2024) (Fig. 2). The reviewers were trained on the use of online tools as well on the different evaluation instruments and their definitions. Studies were retained if they evaluated LLMs in health care tasks. Title and abstract screening was performed and we excluded studies that were duplicates, or not related to human or healthcare LLM tasks. A broad range of studies was included for a comprehensive review. The final screening was performed by seven independent reviewers ((A.A.1, A.A.2, A.A.3, A.A.4, S.M., H.A., and A.C.) using Covidence to eliminate studies criteria that excluded most of the studies without use LLM, case studies, review publications, publications without human evaluation, publications not based on healthcare, and publications which did not use standard LLM evaluation metrics or used clinical evaluation metrics (Fig. 2).
HumanELY: open-source human evaluation framework for LLMs
HumanELY is an open-source web application designed to facilitate structured and reproducible human evaluation of LLM outputs. As illustrated in (Fig. 2) HumanELY offers a systematic framework for evaluating various aspects of LLM-generated content through an intuitive and customizable interface. The framework is organized around five major evaluation dimensions: (1) Relevance, (2) Coverage, (3) Coherence, (4) Comparison, and (5) Harm, each consisting of an exhaustive set of sub-metrics. These sub-metrics are rated using Likert-scale, survey-based questions which ensures consistency and comparability across evaluation scores. The reason for selection of 5- point Likert scale is for its ease of use by human evaluators, decrease in subjectivity of interpretation when using a larger scale, and for consistency in measurement of the human evaluation. A comprehensive explanation of all evaluation metrics, sub-metrics, and their definitions is provided in (Table 2). A key consideration is that different evaluation metrics may overlap; for example, an inaccurate answer can be both harmful and unsafe (Supplementary Fig. 1). HumanELY allows evaluators to upload their data files, conduct evaluations within the web application, and download the scored results in widely used formats such as CSV, Excel, and PDF. HumanELY supports the scalability and reproducibility of human evaluations and enables downstream quantitative analysis of evaluation scores. Importantly, HumanELY does not collect or store any user-uploaded data on its servers, thereby safeguarding user privacy. However, in order to improve the tool and support future research, we do retain user feedback and associated evaluation scores excluding any uploaded content. A step-by-step guide on how to use the HumanELY tool is provided in the Supplementary Information 2, Supplementary Fig. 2.
Data extraction
For each of the 186 studies, the reviewers extracted data from their published manuscripts and added their assessment related to the metrics of evaluation based on HumanELY metrics, additional assessment metrics, information about the evaluators, type, and number of LLMs used for evaluation, and any other pertinent information helpful to the review. This was done using consensus by three reviewers(P.M., S.M., and R.A.) (Table 2).
Statistical analysis
Descriptive statistics were used to summarize the distribution of studies across key dimensions of human evaluation. Frequencies and percentages were calculated for several categories, including the types of human evaluation metrics used (e.g., accuracy, reasoning, bias), the professional backgrounds of evaluators (e.g., specialist physicians, medical trainees), the number of models assessed per study, and the types of LLMs evaluated. All calculations were performed using the Pandas and NumPy packages in Google Colab with Python 3.9.
Code availability
The HumanELY webapp is publicly available at https://www.brainxai.com/humanely.
References
Jumper, J. et al. Highly accurate protein structure prediction with AlphaFold. Nature 596, 583–589 (2021).
Raza, M., Jahangir, Z., Riaz, M. B., Saeed, M. J. & Sattar, M. A. Industrial applications of large language models. Sci. Rep. 15, 1–23 (2025).
Ray, P. P. Timely need for navigating the potential and downsides of LLMs in healthcare and biomedicine. Brief Bioinform. 25, bbae214 (2024).
Park, Y.-J. et al. Assessing the research landscape and clinical utility of large language models: a scoping review. BMC Med. Inf. Decis. Mak. 24, 72 (2024).
Dennstädt, F., Hastings, J., Putora, P. M., Schmerder, M. & Cihoric, N. Implementing large language models in healthcare while balancing control, collaboration, costs and security. npj Digital Med. 8, 1–4 (2025).
Busch, F. et al. Current applications and challenges in large language models for patient care: a systematic review. Commun. Med. 5, 1–13 (2025).
Huo, B. et al. Large language models for chatbot health advice studies: a systematic review. JAMA Netw. Open 8, e2457879 (2025).
Ullah, E., Parwani, A., Baig, M. M. & Singh, R. Challenges and barriers of using large language models (LLM) such as ChatGPT for diagnostic medicine with a focus on digital pathology – a recent scoping review. Diagn. Pathol. 19, 43 (2024).
Ong, J. C. L. et al. Ethical and regulatory challenges of large language models in medicine. Lancet. Digit. Health 6, e428–e432 (2024).
Chan, C.-M. et al. Chateval: Towards better llm-based evaluators through multi-agent debate. arXiv preprint arXiv:2308.07201 (2023).
Zhang, X. et al. Wider and deeper llm networks are fairer llm evaluators. arXiv preprint arXiv:2308.01862 (2023).
Blagec, K., Dorffner, G., Moradi, M., Ott, S. & Samwald, M. A global analysis of metrics used for measuring performance in natural language processing. In Proceedings of NLP Power! The First Workshop on Efficient Benchmarking in NLP 52–63 (2022).
Wang, A. et al. Superglue: A stickier benchmark for general-purpose language understanding systems. Adv. Neural Inf. Processing Systems 32, 3266–3280 (2019).
Workshop, B. et al. Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100 (2022).
Bedi, S. et al. Testing and evaluation of health care applications of large language models: a systematic review. JAMA 333, 319–328 (2025).
Tam, T. Y. C. et al. A framework for human evaluation of large language models in healthcare derived from literature review. npj Digital Med. 7, 258 (2024).
Chang, Y. et al. "A survey on evaluation of large language models." ACM Trans. Intell. Syst. Technol. 15,1-45 (2024).
Liang, P. et al. Holistic evaluation of language models. arXiv preprint arXiv:2211.09110 (2022).
Yuan, J., Zhang, J., Wen, A. & Hu, X. The science of evaluating foundation models. arXiv preprint arXiv:2502.09670 (2025).
Sallam, M., Barakat, M. & Sallam, M. Pilot testing of a tool to standardize the assessment of the quality of health information generated by artificial intelligence-based models. Cureus 15, e49373 (2023).
Jin, Y. et al. Better to ask in english: Cross-lingual evaluation of large language models for healthcare queries. Proc. ACM Web Conf. 2627–2638 (2024).
Achiam, J. et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
Brown, T. et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 33, 1877–1901 (2020).
Gemini. Gemini https://gemini.google.com/app.
Touvron, H. et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
Rugged peaks and wild waters. Search - Microsoft Bing https://www.bing.com/?form=HPFBBK&ssd=20250424_0700&mkt=en-US.
Tessler, I. et al. ChatGPT’s adherence to otolaryngology clinical practice guidelines. Eur. Arch. Otorhinolaryngol. 281, 3829–3834 (2024).
Ito, N. et al. The accuracy and potential racial and ethnic biases of GPT-4 in the diagnosis and triage of health conditions: evaluation study. JMIR Med. Educ. 9, e47532 (2023).
Website. https://doi.org/10.1093/jamia/ocae100.
Makrygiannakis, M. A., Giannakopoulos, K. & Kaklamanos, E. G. Evidence-based potential of generative artificial intelligence large language models in orthodontics: a comparative study of ChatGPT, Google Bard, and Microsoft Bing. Eur. J. Orthod. https://doi.org/10.1093/ejo/cjae017 (2024).
Tang, L. et al. Evaluating large language models on medical evidence summarization. npj Digital Med. 6, 1–8 (2023).
Elangovan, A., Liu, L., Xu, L., Bodapati, S. & Roth, D. ConSiDERS-The-Human Evaluation Framework: Rethinking Human Evaluation for Generative Large Language Models. https://doi.org/10.18653/v1/2024.acl-long.63 (2024).
Peng, C. et al. A study of generative large language model for medical research and healthcare. npj Digital Med. 6, 1–10 (2023).
Deo, N. et al. HUMANE: Harmonious Understanding of Machine Learning Analytics Network—global consensus for research on artificial intelligence in medicine. Open Exploration 2, 157–166 (2019).
Page, M. J. et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. Rev. Esp. Cardiol. (Engl. Ed.) 74, 790–799 (2021).
Saeidnia, H. R., Kozak, M., Lund, B. D. & Hassanzadeh, M. Evaluation of ChatGPT’s responses to information needs and information seeking of dementia patients. Sci. Rep. 14, 1–12 (2024).
Crook, B. S., Park, C. N., Hurley, E. T., Richard, M. J. & Pidgeon, T. S. Evaluation of online artificial intelligence-generated information on common hand procedures. J. Hand Surg. 48, 1122–1127 (2023).
Lang, S. et al. Are large language models valid tools for patient information on lumbar disc herniation? The spine surgeons’ perspective. Brain Spine 4, 102804 (2024).
Guo, E. et al. neuroGPT-X: toward a clinic-ready large language model. J. Neurosurg. 140, 1041–1053 (2023).
Coşkun, Ö, Kıyak, Y. S. & Budakoğlu, I. İ ChatGPT to generate clinical vignettes for teaching and multiple-choice questions for assessment: A randomized controlled experiment. Med. Teach. 47, 268–274 (2025).
Retrieval-Augmented Large Language Models for Adolescent Idiopathic Scoliosis Patients in Shared Decision-Making. https://dl.acm.org/doi/10.1145/3584371.3612956.
Criteria2Query 3.0: Leveraging generative large language models for clinical trial eligibility query generation. J. Biomed. Inform. 154, 104649 (2024).
Tie, X. et al. Personalized impression generation for PET reports using large language models. J. imaging Inform. Med. 37, 471–488 (2024).
Zhang, J., Zhao, Y., Saleh, M. & Liu, P. J. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. Proceedings of the 37th International Conference on Machine Learning, PMLR. 119 11328-11339 (2020).
Onder, C. E., Koc, G., Gokbulut, P., Taskaldiran, I. & Kuskonmaz, S. M. Evaluation of the reliability and readability of ChatGPT-4 responses regarding hypothyroidism during pregnancy. Sci. Rep. 14, 1–8 (2024).
Anastasio, A. T., Mills, F. B., Karavan, M. P. & Adams, S. B. Evaluating the quality and usability of artificial intelligence-generated responses to common patient questions in foot and ankle surgery. Foot Ankle Orthopaedics 8, 24730114231209919 (2023).
Currie, G., Robbie, S. & Tually, P. ChatGPT and Patient Information in Nuclear Medicine: GPT-3.5 Versus GPT-4. J. Nucl. Med. Technol. 51, 307–313 (2023).
Kooraki, S. et al. Evaluation of ChatGPT-generated educational patient pamphlets for common interventional radiology procedures. Acad. Radiol. 31, 4548–4553 (2024).
Wang, G. et al. Potential and limitations of ChatGPT 3.5 and 4.0 as a Source of COVID-19 information: comprehensive comparative analysis of generative and authoritative information. J. Med. Internet Res. 25, e49771 (2023).
Acknowledgements
We acknowledge that we did not get any funding for this research.
Author information
Authors and Affiliations
Contributions
Raghav Awasthi: conceptualization, data curation, formal analysis, investigation, writing, supervision; Atharva Bhattad: formal analysis, investigation, writing; Sai Prasad Ramachandran, Izabella DiRosa, Hajra Arshad, and Aarit Atreja: data curation, writing; Shreya Mishra: conceptualization, data curation, formal analysis, investigation, writing; Ashish K Khanna, Jacek B Cywinski, Kamal Maheshwari, and Francis A. Papay: conceptualization, writing; Dwarikanath Mahapatra: conceptualization, investigation, writing; Anabelle Cohen, Asma Alshukaili, Aryan Vohra: data curation; Nishant Singh: formal analysis, investigation, writing; Ashish Atreja: formal analysis, writing, supervision; Rahul Kashyap: conceptualization, formal analysis, investigation, writing, supervision; Piyush Mathur: conceptualization, data curation, formal analysis, investigation, writing, supervision.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Awasthi, R., Bhattad, A., Ramachandran, S.P. et al. Human evaluation of large language models in healthcare: gaps, challenges, and the need for standardization. npj Health Syst. 2, 40 (2025). https://doi.org/10.1038/s44401-025-00043-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44401-025-00043-2
