
Abstract
Quality control processes with automation ensure that customers receive defect-free products that meet their needs. However, the performance of real-world surface defect detection is often severely hindered by the scarcity of data. Recently, few-shot learning has been widely proposed as a solution to the data sufficiency problem by leveraging a limited number of base class samples. However, achieving discriminative and generalization capabilities with few samples remains a challenging task in various surface defect detection scenarios. In this paper, we propose a sparse cross-transformer network (SCTN) for surface defect detection. Specifically, we introduce a residual layer module to enhance the network’s ability to retain crucial information. Next, we propose a sparse layer module within the cross-transformer to increase computational efficiency. Finally, we incorporate a squeeze-and-excitation network into the cross-transformer to enhance the attention mechanism between local patches outputted by the transformer encoder. To verify the effectiveness of our proposed method, we conducted extensive experiments on the cylinder liner defect dataset, the NEU steel surface defect dataset, and the PKU-Market-PCB dataset, achieving the best mean average precision of 62.73%, 85.29%, and 88.7%, respectively. The experimental results demonstrate that our proposed method achieves significant improvements compared to state-of-the-art algorithms. Additionally, the results indicate that SCTN enhances the network’s discriminative ability and effectively improves generalization across various surface defect detection tasks.
Similar content being viewed by others


Introduction
The quality of manufactured products is extremely easily affected by deficiencies in some factors, such as production technology and working conditions in the industrial production process. Surface defects are the most intuitive manifestation of product quality being affected. Therefore, it is important to detect product surface defects to guarantee the reliable quality1. Human checking is generally the mainstream method. It suffers from time-consuming, high labor intensity, and human subjective factors. Instead, over the last decade, several surface defect detection methods based on classical machine vision have been proposed2. Compared to human checking, these methods greatly reduce the workload. However, they suffer from the low-accurate detection problem.
With the development of GPUs, deep learning has been attempted to address the above-mentioned limitations of manual detection methods3. Obtaining a high-performance deep learning model normally requires a massive number of surface defect samples with defect labels for training. However, collecting abundant annotated data in industrial domain is time-consuming, expensive, and almost infeasible. Therefore, the scarcity of data easily leads to poor detection performance. Recently, several few-shot learning methods have been proposed to address the scarce data problem in surface defect detection4,5,6. A few-shot surface defect detection framework was proposed through pre-training models using data relevant to the target task4. Liu et al.5 proposed a detection model based on a meta feature learner, a feature matching module and a bounding box prediction module for steel surface defect detection. Wang et al.6 proposed end-to-end meta-learning for photovoltaic module defect detection with a salience highlighting network, measuring the similarity between features from a prototype vector extractor and query feature map. These methods demonstrate that few-shot learning methods can be quickly adapted to new tasks using a limited labeled data. However, current few-shot detection methods continue to struggle with distinguishing fine-grained differences between novel classes, particularly in surface defect detection. Moreover, the redundancy and computational overhead reduce their practicality in industrial settings.
In this article, we propose a new few-shot learning framework to improve the discriminative ability and generalization ability for surface defect detection in various tasks. The backbone of our proposed method is a cross-transformer7, which exploits cross-attention mechanism for aggregating the key information from the two branches with different batch sizes. Residual layer module is used to capture crucial information. Additionally, to improve computational efficiency, a sparse layer is proposed to suppress redundant features. Furthermore, a squeeze and excitation module8 is incorporated to learn stronger global attention based on local attention features for optimizing the discriminative ability of cross-transformer. For detection, the detection head model is based on Faster R-CNN9. Overall, our main contributions are summarized as follows:
-
We propose a sparse cross transformer network (SCTN) specifically for surface defect detection. The primary innovation of SCTN lies in its capacity to bolster the correlation between local and global attentions while simultaneously strengthening the connection between the support and query sets. This enhancement is instrumental in improving the model’s ability to effectively detect surface defects in scenarios with limited data.
-
We introduced a residual layer module to extract the low-level and high-level information. Additionally, we proposed a sparse layer module to reduce the computational complexity of the cross-transformer and eliminate redundant features. Lastly, we incorporated a squeeze and excitation module into the transformer’s encoder module to enhance the learning of strong global attention, thus optimizing the visual transformer. All these strategies contribute to the improved performance of the cross-transformer framework.
-
The SCTN significantly enhances the detection of surface defects by addressing data scarcity and computational inefficiency through a residual layer, a novel sparse layer, and enhanced attention mechanism. Experimental results show that SCTN considerably improves performance in surface defect detection compared to the state-of-the-art methods.
The remainder of this paper is organized as follows. In Sect. 2, literature closely related to our proposed method is presented. In Sect. 3, the proposed method for surface defect detection is presented. Section 4 discusses the experimental results on the three surface defect databases and ablates the role of each module. In Sect. 5, this paper is concluded.
Related work
Surface defect detection
Classical machine vision methods have been extensively applied in surface defect detection, due to their low cost and high efficiency. These methods are generally categorized into supervised and unsupervised approaches. Supervised approaches10,11,12 rely on human-labeled samples to train detection models and extract regions of interest (RoI) using techniques like sliding windows. Molodova et al.10 employed sliding windows and the maximum stable extremal region to extract subregion features, subsequently training K-nearest neighbors to identify defects within these subregions. Tolba et al.11 proposed a novel multiscale and multidirectional autocorrelation function for defect detection in homogeneous web surfaces. Mentouri et al.12 introduced a multiresolution method utilizing binarized statistical image features to identify surface defects.
In contrast, unsupervised approaches13,14,15 employ image processing methods to detect defects without relying on labeled data. Timm et al.13 proposed a nonparametric Weibull-based method for defect detection by computing two parameters of a Weibull fit for the distribution of image gradients in a local region. Dubey et al.15 developed a maximally stable extremal region technique to identify the geometrical features of defective regions. Li et al.14 introduced a local Michelson-like contrast measure with a learnable threshold to differentiate defects from the background, where the threshold is learned using the proportion-emphasized maximum entropy thresholding algorithm.
Despite their widespread application, classical methods suffer from poor robustness and generalization in challenging environments. They often fail to capture the intricate patterns of surface defects, particularly when the defects exhibit significant variations in appearance or when the environmental conditions are not ideal.
Deep learning-based surface defect detection
The advent of deep learning, particularly convolutional neural networks (CNNs), has revolutionized surface defect detection by enabling automatic feature extraction. Approaches such as those by Cha et al.16 and He et al.17 have utilized CNNs to detect multiple types of defects. Cha et al.16 employed faster R-CNN9 to detect various defect types simultaneously. He et al.17 used a CNN to generate feature maps at each stage and proposed a multilevel feature fusion network to combine these hierarchical features into a single feature for surface defect detection. To address the challenges posed by significant variations in defect appearance and similarities between interclass parts, Dong et al.18 proposed a pyramid feature fusion and global context attention network. Li et al.19 introduced a detection system comprising feature extraction, feature fusion and classifier modules for micromotor armature surface defect detection, where a channel attention was integrated into the feature fusion module.
The introduction of Transformer-based architectures, such as the Vision Transformer20, has further pushed the boundaries by capturing long-range dependencies and offering a more holistic understanding of defect patterns. To explore the extensibility of the Transformer, Gao et al.21 explored the extensibility of Transformer by proposing a variant Swin Transformer for surface defect detection, which includes a window shift scheme to enhance feature transfer between windows. Luo et al.22 utilized a cross-attention transformer within an encoder-decoder network and developed a cross-attention refinement module to optimize the coarse saliency maps.
While deep learning models have shown great promise in surface defect detection, they face challenges in balancing computational efficiency with detection accuracy. The complexity of these models often results in high resource consumption, which limits their applicability in real-time scenarios. Additionally, current models struggle to generalize effectively across various defect types and environmental conditions.
Few-shot object detection
Few-shot object detection aims to generalize novel classes within minimal supervision and limited annotated examples. Based on model architecture, existing methods can be broadly classified into single-branch and dual-branch architectures23. Single-branch methods typically resemble generic detectors when trained on novel categories, reducing the number of learnable parameters24,25. However, because parameters are pretrained on the base domain and then frozen for novel classes, single-branch architectures may underutilize novel category data. In contrast, dual-branch approaches usually employ a Siamese-like network with query and support networks26,27,28. Comparing with single-branch methods, the later one is commonly used in few-shot object detection, as they enable fast adaptation for novel classes without fine-tuning, requiring only a simple forward pass. Koch et al.26 introduced a Siamese network consisting of twin networks sharing weights, where each network receives a support image and a query image. The distance between the query and its support is learned by using logistic regression. Kang et al.27 proposed a feature re-weighting module to aggregate query and support features. Recently, some works28 have employed advanced transformers to improve similarity learning between the two inputs. Despite these advancements, current few-shot detection methods still struggle to capture fine-grained distinctions between novel classes, particularly in the context of surface defect detection. The redundancy and computational overhead associated with dual-branch architectures further limit their practicality in industrial applications.
In summary, to address these gaps, we propose the sparse cross-transformer network (SCTN), a novel architecture specifically designed for the detection of various surface defect. SCTN integrates a residual layer module to enhance the model’s capacity to learn deep and complex representations, improving feature extraction even with limited data. By incorporating cross-attention with a sparse layer and squeeze-and-excitation module, SCTN effectively balances computational efficiency with high detection accuracy, making it suitable for real-time applications. Additionally, SCTN’s architecture is designed to improve generalization across various defect types and conditions, providing a robust solution to the challenges identified in previous works.

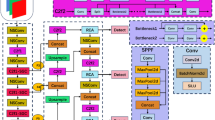
The architecture of SCTN, where RL is the residual layer module, patch embed means patch embedding module, and SSE is the sparse cross transformer with squeeze and excitation module.
Methodology
A few-shot learning framework is used in our surface defect detection method, where the dataset is split into base classes \(C_{b}\) and novel classes \(C_{n}\), with \(C_{b}\bigcap C_{n}=\emptyset\). The base classes \(C_{b}\) contains training samples and annotations, while the novel classes \(C_{n}\) are defined by a limited number of samples. According to the method outlined by Wang et al.29, each network input is treated as a task \(T_i\), consisting of a query set and a support set. The training process is carried out in three phases. First the single-branch network is trained exclusively on \(C_{b}\). In the second phase, the proposed dual-branch sparse cross transformer architecture is introduced and trained on \(C_{b}\). Finally, in the third stage, few-shot fine-tuning is performed on \(C_{n}\) in a k-shot setting, where each novel class contains only k annotations.
Overview
We proposed a few-shot learning model for surface defect detection, as shown in Fig. 1. In our proposed network, the first/second/third stage consists of a residual layer (RL) module, patch embedding module, and sparse cross transformer with squeeze-and-excitation (SSE) module. Each stage jointly performs feature extraction on the input query set and support set images. In last stage, proposal generator is additionally incorporated to generate the region candidate.
Given a query set \(I_q\in R^{N_{q}\times H_{q}\times W_{q}\times 3}\) and a support set \(I_s\in R^{N_{s}\times H_{s}\times W_{s}\times 3}\), where \(N_q=1\), \(N_s \ge 1\), H and W are the height and width of the image, respectively, all images are fed into an RL to extract low-level features \(F_q\in R^{{\hat{H}}_{q}\times {\hat{W}}_{q}\times K}\) and \(F_s\in R^{{\hat{H}}_{s}\times {\hat{W}}_{s}\times K}\) for the query and support sets, respectively, and convolutional feature maps are evenly split into \(4\times 4 \times K\) patches in the first stage, where K is the channel number of a convolutional feature map. Each flattened patch is further linearly projected to the C-dimension by going through a linear patching embedding layer, outputting \(X_{q}\in R^{D_q\times C}\) and \(X_{s}\in R^{D_s\times C}\), where \(D_q=\frac{{\hat{H}}_{q}\times {\hat{W}}_{q}}{4}\) and \(D_s=\frac{{\hat{H}}_{s}\times {\hat{W}}_{s}}{4}\). Subsequently, the projected patch sequences are fed into the SSE module. SSE consists of multi-head asymmetric batch cross-attention with a sparse layer and MLP, followed by a squeeze-and-excitation module. The same architecture applies to other stages, gradually decreasing patch sequence length and increasing channel dimensions. In Stage 4, besides patch embed and SSE modules, a proposal generator based on region proposal generator network is further used to generate the proposal feature. Lastly, a pairwise matching and Faster R-CNN like network head are used to predict bounding box in the detection stage.
Proposed method
The SCTN architecture consists of an residual layer module, patch embedding module, and Sparse cross transformer with Squeeze-and-Excitation module.
Residual layer module
In surface defect detection, where defects vary significantly in size, shape, and texture, the ability to detect subtle differences in visual features is crucial. The bottleneck residual block, introduced by He et al.30, has proven effective in enabling deep networks to learn complex and nuanced representations, thereby enhancing accuracy in image classification. This block efficiently captures essential features without overwhelming the network with excessive parameters. Additionally, the skip connection preserves the original input features by directly adding them to the output, ensuring that critical low-level information is retained throughout the network layers. Building on the advantages of the bottleneck residual block, we propose incorporating a shortcut connection to capture both low-level details and high-level features. This approach allows the network to focus on learning residuals, thereby improving its ability to accurately identify defects.
The residual layer module in SCTN, as shown in Fig. 2, is structured as a residual block. Given an input x, it passes through a series of \(1\times 1\) and \(3\times 3\) convolutional layers, each followed by batch normalization and ReLU activation. This processed output then undergoes additional processing through another \(1\times 1\) convolution and batch normalization before being added back to the original input x, followed by a final ReLU activation. In SCTN, the residual layer module plays a crucial role in enabling the network to learn deeper and more complex representations, which significantly improves feature extraction. This is evidenced by the higher detection accuracy in our ablation study (Sect. 3). The inclusion of the residual layer module consistently enhances performance across various shot settings, highlighting its importance in improving the network’s ability to learn from limited data.

The architecture of residual layer module, where \(\bigoplus\) means element-wise addition.
Patch embedding module
For the query and support branches, two position embeddings \(E^{pos}_{q}\in R^{D_{q}\times C}\) and \(E^{pos}_{s}\in R^{D_{s}\times C}\) are added to the input patch sequences \(X_{q}\) and \(X_{s}\), respectively. At the same time, branch embedding information \(E^{bra}_{q}\in R^{1\times C}\) and \(E^{bra}_{s}\in R^{1\times C}\) are considered in query and support branches, respectively. For the sake of simplicity, k represents the query branch or support branch, i.e., \(k\in \{q, s\}\). \(X_{k}\) can be re-formulated as follows:
SSE module
The SSE module is shown Fig. 3. Following the Q-K-V attention in the transformer20, the patch sequences of \(X'_{k}\) are projected to \((Q_{k}^{i}\), \(K_{k}^{i}\), \(V_{k}^{i})\), respectively, where \(k\in \{q, s\}\), \(i=1,\ldots ,h\), and h represents the number of heads. Additionally, a spatial-reduction operation is used to sub-sample the feature maps of \(X'_{k}\) for K and V, thus reducing the computational complexity of the attention.

The architecture of Sparse cross transformer with squeeze-and-excitation module, where \(\bigoplus\) means element-wise addition.
-
1.
Cross-attention with sparse layer
Since the query and support branches have inconsistent batch sizes, normally, for the query branch, the size is 1, a cross-attention layer aggregates K-V pairs of both branches to increase attention. To match the input size of the query branch, an average pooling operation is performed on the support branch to aggregate the key and value from the support branch to the query branch, that is, \({\hat{K}}_{s}^i=\frac{1}{N_{s}}\sum _{N_{s}}K_{s}^{i}\) and \({\hat{V}}_{s}^i=\frac{1}{N_{s}}\sum _{N_{s}}V_{s}^{i}\). Additionally, the Key and Value vectors of the query branch are repeated \(N_s\) times along the batch dimension, that is \({\hat{K}}_{q}^i=\underbrace{[K_q^i,\ldots ,K_q^i]}_{N_s}\) and \({\hat{V}}_{q}^i=\underbrace{[V_q^i,\ldots ,V_q^i]}_{N_s}\). The K-V pair of the two branches are concatenated, summarized as \(K_{q_{cat}}^{i}=\bigg [ K_{q}^{i},{\hat{K}}_{s}^i \bigg ]\) and \(V_{q_{cat}}^{i}=\bigg [ V_{q}^{i},{\hat{V}}_{s}^i \bigg ]\) for the query branch, and \(K_{s_{cat}}^{i}=\bigg [{\hat{K}}_{q}^i,K_s^i \bigg ]\) and \(V_{s_{cat}}^{i}=\bigg [{\hat{V}}_{q}^i,K_s^i \bigg ]\) for the support branch. Then, the multi-head attention for query and support sets are represented by \(head_{k}^{i}={\mathscr {F}}(Q_k^i,K_{k_{cat}}^i,V_{k_{cat}}^i)\), respectively, where \({\mathscr {F}}(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d}})V\), \(head_{k}^{i}\in R^{d_h}\).

The mechanism of cross-attention with sparse layer.
The cross-attention between the query branch and support branch significantly enhances the discriminative ability of dual-branch network. However, this improvement can come at the cost of computational efficiency due to the presence of redundant tokens. Recently, Xue et al.31 proposed a method to drop some essential tokens, retaining only a small number of important and useful ones, thereby increasing the computational efficiency without sacrificing performance of facial expression recognition. This strategy enables a network to focus on the most critical features within input data, significantly enhancing its ability to detect subtle defects. By reducing the number of active features, it effectively filters out irrelevant or redundant information, allowing the model to concentrate on the most salient aspects of the data. This selective focus is particularly beneficial in defect detection, where the goal is to identify small, localized anomalies in materials or surfaces. By emphasizing the unique features associated with defects while suppressing common patterns in non-defective areas, the network can better distinguish between normal and defective regions. This results in a more discriminative feature set, improving the network’s ability to detect even the most subtle defects that might otherwise be overlooked. Therefore, we propose incorporating a sparse layer (SL) in the cross-transformer network, as shown in Fig. 4, to suppress superfluous tokens between the query and support branches, thus increasing the computational efficiency of the network. By incorporating sparsity, SCTN focuses its resources on the most relevant features for defect detection, enhancing its ability to identify subtle anomalies that might be missed by a more densely connected network. This leads to improved accuracy and robustness in defect detection tasks, particularly in scenarios where defects are small, rare, or visually similar to non-defective regions.
Sparse layer module aims to emphasize the most critical features in the input data while ignoring redundant information. This selective focus not only reduces computational load but also improves the efficiency of the network. In detail, with multi-head attention between the support branch and query branch, we define a thresholding function to refine more important tokens. Here we suppose that if one head cross-attention between the query branch and support branch becomes significant, it means that both branches along this head have strong semantic relationship, otherwise, the relationship is relatively weak. Therefore, to drop the less informative token, a mask mechanism for the query branch/support branch is defined as follows:
where i is the index of the head, and \(\lambda\) is a threshold. Our results show that the introduction of sparse layers leads to better performance in surface defect detection. Sparse layer module helps the network concentrate on essential features, thereby enhancing its ability to detect subtle defects.
Then, the attention of multi-heads of the query branch / support branch are updated by \({\hat{head}}^i_{k}=mask^i_{k}*head^i_{k}.\) Therefore, the new cross-attention mechanism is summarized as follows:
where \({\mathscr {G}}\) is the concatenation operation, and \(W_o\in R^{hd_h\times C}\) is the shared weight by the two branches, which projects attention back to the original feature space.
-
2.
Feature enhancement module.
The recalibration process in SCTN is crucial for enhancing the network’s ability to distinguish between relevant and irrelevant features, directly contributing to higher detection accuracy. To increase the network’s sensitivity to informative features, the SE block8 is employed. This process allows the network to dynamically adjust the importance of different feature channels based on their relevance to surface defect detection. It begins with the “squeezing” step, where global spatial information is condensed into a more compact form, summarizing the global context of each channel. This is followed by the “excitation” step, where each feature channel is weighted according to its importance. This selective emphasis enables the network to prioritize the most relevant features while suppressing less critical ones, thereby improving overall detection accuracy.
The SE block functions as a channel-wise attention module and optimizes the network through a two-step process: squeeze and excitation, before filter responses are fed into the MLP. As shown in Fig. 5, the SE block is simple yet effective, utilizing significantly fewer parameters than the self-attention block, as it incorporates only two fully connected layers and a single point-wise multiplication operation. The SE module recalibrates feature maps by explicitly modeling channel-wise dependencies. This process allows the network to dynamically adjust the importance of each feature map, enhancing the network’s sensitivity to critical features. The inclusion of SE modules significantly boosts detection performance, improving the network’s ability to differentiate between relevant and irrelevant features, thus leading to higher detection accuracy and robustness.

The architecture of the squeeze-and-excitation block, where GAP and FC mean global average pooling and fully connected layers, respectively. \(\odot\) means element-wise multiplication.
Squeeze part averages feature along spatial information to generate channel-wise statistics. Formally, the m-th channel of squeezed \(Z_{k,m}^{''}\) is calculated by:
Following the squeeze part, the excitation part is designed based on several fully connected layers, the ReLu function, and Sigmoid activation, which is formulated as follows:
where \(W_1\) and \(W_2\) represent fully connected layers with n neurons and \(\frac{n}{4}\) neurons, respectively, and n is the length of \(Z_{k}^{''}\).
With the excitation part, the SE part is realized by using the dot product operation, formulated as follows:
where \(\odot\) is a element-wise multiplication.
SE follows the Transformer encoder, which aims at optimizing the learning of the ViT by learning more global attention relations between extracted local attention features. Finally, the MLP and LN layers are applied to each patch with stronger feature representations:
In SCTN, the SE module is particularly effective as it enhances the network’s ability to focus on the subtle and nuanced features that are crucial for identifying surface defects. By selectively amplifying the importance of these key features, SCTN can more accurately differentiate between defective and non-defective regions, even when faced with noise or complex backgrounds. This targeted emphasis on the most informative aspects of the input data ensures that the network captures the intricate details characteristic of surface defects, leading to more precise and reliable detection outcomes.
Detection head
After the support and query sets pass through the SSE module, the RoIAlign module32 is used, which jointly extracts and then aligns the RoI features of proposals before the final detection. Following the procedure7, all support images are averaged to reduce the computational complexity. For final detection, we used a pairwise matching network33 and Faster R-CNN detection head without the FPN34. For the few-shot object detection methods based on dual branches, the FPN module is discarded. The binary cross-entropy loss and bounding box regression loss function are employed during training. The final loss function for SCTN is formulated as follows:
where \(L_{att\_rpn}\) and \(L_{matching}\) are the binary cross-entropy loss function and bounding box regression loss function, respectively.
Experiment
In this section, we conduct experiments on three different datasets to comprehensively evaluate the performance of the proposed model, SCTN, in surface defect detection. We also compare SCTN with several state-of-the-art models to benchmark its effectiveness. Furthermore, we design and perform an ablation study to critically analyze the contribution and impact of each individual model within the SCTN architecture.
Dataset
In this subsection, we describe the three surface defect databases utilized in our experiments.
Cylinder Liner Defect (CLD) dataset 35: This dataset was collected from industry sources and meticulously annotated by two experts. It contains 1,179 images, each with a resolution of \(256\times 256\) pixels, and includes various defect types such as scratch, sand hole, and wear.
NEU Steel Surface Defect dataset 36: This dataset focuses on automatic recognition of defects in hot-rolled steel strips. It comprises 1,800 grayscale images, each with a resolution of \(200\times 200\) pixels, representing six defect classes: patches (Pa), crazing (Cr), pitted surface (Ps), inclusions (In), scratches (Sc), and rolled-in scale (Rs).
PKU-Market-PCB dataset 37: This dataset contains 693 PCB defect images and their corresponding annotation files, covering six defect types: missing hole (Mh), mouse bite (Mb), open circuit (Oc), short (Sh), spur (Sp), and spurious copper (Sco). The number of defects of each class is 497, 492, 482, 491, 488, and 503.
In our experiments, we adhere to the protocol outlined by Wang et al.29, utilizing a few-shot object detection dataset (FSOD)38 as the base set for evaluation. We use mean average precision (mAP) at IoU=0.5, F1, Recall, and Precision as performance metric, with mAP specifically used in the ablation study. We employ 3-way, 6-way, and 2-way strategies for CLD dataset, NEU Steel Surface Defect dataset, and PKU-Market-PCB dataset, respectively. During training, we utilize the AdamW optimizer with an initial learning rate of \(10^{-3}\) with a weight decay of 0.0002. The maximum iteration limit is set at 40k, with a mini-batch size of 8. Experiments are conducted using PyTorch 1.6 on two NVIDIA RTX GPUs, each with 24GB of memory, and we report the average results from three runs.
Performance comparison with state-of-the-art methods
In this section, we conduct a comparative analysis of our proposed method against several state-of-the-art methods, including MetaRCNN39, TFA24, FSCE40, AttentionRPN41, FSDetView42, MPSR43, QA-FewDet44, DeFRCN25, and FCT7. To ensure fairness and consistency, the default parameters specified in these state-of-the-art algorithms are used during training. The performance comparison on the CLD dataset, NEU steel surface defect dataset, and PKU-Market-PCB dataset is reported in Table 1.
Comparison in the CLD dataset
Among all the baselines, FCT achieves the highest mAP (59.81%) in the 30-shot scenario, while our method achieves a mAP of 62.73%. Compared to FCT, our method consistently outperforms it by 1-3% across various scenarios. Additionally, when compared to the other nine benchmarks, our method achieves state-of-the-art performance across all shot numbers. Additionally, our method is quantitatively compared with other approaches, and the attention maps are visualized in Fig. 6. Notably, compared to algorithms such as TFA, which struggle to identify defects in the image, our method considerably highlights the defect regions, as shown in red in the attention maps. In contrast, even when using DeFRCN, some attentions shift towards normal regions. Moreover, Fig. 7 illustrates the detected results of our proposed method. SCTN accurately identifies defects such as wear, highlighting its precision. These observations demonstrate that our proposed approach provides more theoretically meaningful results compared to state-of-the-art algorithms. In SCTN, the residual layer effectively addresses non-overlapping issues while preserving fine-grained low-level features, enhancing the network’s ability to retain crucial information and improve accuracy. Additionally, the sparse layer within the cross-transformer network reduces computational complexity by eliminating redundant features, enabling the network to focus on the most informative parts of the image. The squeeze-and-excitation (SE) module further enhances the network’s ability to capture significant features by strengthening the relationship between global and local attention mechanisms. These combined improvements result in better defect detection accuracy, with SCTN outperforming other methods by a margin of 2% to 14.83% in 30-shot scenarios, demonstrating its robustness in handling diverse defect patterns.
The performance comparison in terms of various metric and defect classes in the 30-shot scenario is reported in Table 2. The experimental results clearly demonstrate the superiority of our proposed method over existing state-of-the-art algorithms on the CLD dataset in the 30-shot scenario. Our method achieves the highest mAP of 62.73%, surpassing the second-best performance by FCT, which stands at 59.81%. This significant improvement in mAP indicates our method’s robust capability in accurately identifying surface defects across different classes. Furthermore, our method attains the highest F1 score of 0.8057, reflecting an optimal balance between precision and recall, which are also the highest among all compared methods at 76.38% and 85.24%, respectively. These metrics collectively underscore the effectiveness of our approach in maintaining high accuracy and reliability in defect detection.
Additionally, our method shows superior performance across individual defect classes, achieving mAP scores of 65.06% for scratch, 59.88% for sand hole, and 63.25% for wear. These scores are consistently higher than those of other methods, highlighting the generalizability and robustness of our approach in handling various defect types. Compared to the next best-performing method, FCT, which achieves class mAP scores of 60.11%, 56.62%, and 62.7%, respectively, our method demonstrates clear advantages. This comprehensive performance boost can be attributed to the novel integration of cross transformer networks and advanced feature extraction mechanisms, which collectively enhance the model’s ability to capture and differentiate defect features effectively.

Comparison in attention map between our proposed method and the state-of-the-art techniques. An image is from CLD dataset.

Qualitative results of defect detection on CLD dataset. (a) Ground truth; (b) detected results using our proposed method.
Comparison in the NEU steel surface defect dataset
Figure 8 shows the ground truth and the corresponding detected results of strip steel surface image using our method. It is evident that our method excels at detecting long-shape surface defects as well as irregularly shaped defects. For example, in the third column, our method accurately identified a defect observed by a human. According to Table 1, in the 30-shot scenario, SCTN achieves a mAP of 85.29%, which is 2.98% higher than that of FCT. SCTN outperformed other methods by a margin of 2.98 to 19.12%, demonstrating its robustness in handling diverse defect patterns. It demonstrated that RL, SL, and SE modules promisingly contribute to SCTN. Residual layer improves accuracy by addressing non-overlapping issues and preserving fine-grained features, while the sparse layer reduces computational complexity by eliminating redundant features. Additionally, the squeeze-and-excitation module enhances defect detection by strengthening the relationship between global and local attentions.

Qualitative results of surface defect detection on NEU surface defect dataset, where (a) is the original images alongside their corresponding ground truths, (b) is the detected results achieved using our proposed method.
The experiment results on the NEU steel surface defect dataset in the 30-shot scenarios are reported in Table 3. The results illustrate the clear superiority of our proposed method compared to existing state-of-the-art algorithms. Our method achieves the highest mAP of 85.29%, significantly outperforming the second-best performance by FCT, which is 83.58%. This remarkable increase in mAP underscores the efficacy of our approach in accurately detecting defects. Moreover, our method achieves the highest F1 score of 0.8788, alongside superior precision and recall values of 85.62% and 90.27%, respectively. These results indicates that our method maintains an excellent balance between precision and recall, ensuring both high accuracy and robustness in surface defect detection.
Furthermore, our method excels in class-specific performance metrics, achieving impressive mAP scores for all six classes: 86.52% for crazing, 89.47% for inclusion, 90.9% for patches, 88.95% for pitted surface, 90.28% for rolled-in scale, and 86.08% for scratches. These scores are consistently higher than those of other methods, demonstrating our method’s robustness and effectiveness across various surface defect types. For example, compared to FCT, which achieves mAP scores of 81.41%, 82.05%, 83.73%, 82.5%, 89.74%, and 76.17% for the respective classes, our method shows substantial improvement. This superior performance can be attributed to the innovative integration of cross-transformer networks with RL, SL, and SE modules, which enhance the model’s ability to capture and distinguish defect features effectively.
Comparison in the PKU-Market-PCB dataset
According to Table 1, STCN improves the mAP of MetaRCNN (69.34%) to 88.7% in the 30-shot scenario. In all shots, our proposed method outperforms all state-of-the-art algorithms. When compared with FCT, our method shows an average performance improvement of 6.1% in the 30-shot scenario. Even in 1-shot scenerio, there is a 2% improvement over FCT. Notably. our method significantly outperforms Feature enhancement module and multi-scale fusion module (FPFM)29. When compared to FPFM, STCN shows promising performance improvements of 11.94%, 14.73%, 8.94%, 9.29%, 4.08%, and 9.84% for 1-shot, 2-shot, 3-shot, 5-shot, 10-shot, and 30-shot scenarios, respectively. Furthermore, the performance improvement becomes more pronounced as the shot number increases.
The experimental results on the PKU-Market-PCB dataset in the 30-shot scenario, reported in Table 4, reveal the outstanding performance of our proposed method compared to the state-of-the-art algorithms. Our method achieves the highest mAP of 88.70%, a substantial improvement over the best method, DeFRCN, which achieves a mAP of 83.28%. This significant increase in mAP underscores the superior defect detection capabilities of our approach. Furthermore, our method achieves the highest F1 score of 0.8853, along with the highest precision and recall values of 87.34% and 89.75%, respectively. These metrics demonstrate that our method not only excels in precision but also maintains a high recall rate, ensuring reliable and accurate detection of defects.
In addition to overall performance, our method excels in class-specific performance metrics, achieving impressive mAP scores across all six classes: 86.52% for missing hole (Mh), 89.47% for mouse bite (Mb), 90.9% for open circuit (Oc), 88.95% for short circuit (Sh), 90.28% for spur (Sp), and 86.08% for spurious copper (Sco). These scores are consistently higher than those of other methods, demonstrating our method’s robustness and effectiveness in identifying a wide range of defect types. For instance, compared to DeFRCN, which achieves class mAP score of 76.38%, 82.57%, 88.72%, 81.63%, 89.46%, and 80.92%, respectively, our method shows considerable improvement. This superior performance is attributed to the advanced integration of cross-transformer networks and sophisticated sparse and SE layers, which enhance the model’s ability to capture and distinguish defect features with high precision and reliability.
Discussion
The empirical results demonstrate the effectiveness of SCTN in achieving both high accuracy and efficiency. Compared against various state-of-the-art methods, SCTN consistently achieves the highest mAP score of 62.73%, 85.29%, and 88.70% across three datasets.
The success of our approach is primarily attributed to the contributions of the residual layer, sparse layer, and squeeze-and-excitation modules. The residual layer effectively addresses the non-overlapping issue while preserves fine-grained low-level features, which enhances the network’s ability to retain crucial information and improve accuracy. Additionally, the sparse layer within cross-transformer network reduces computational complexity by eliminating redundant features, allowing the network to focus on the most informative parts of the image. The squeeze-and-excitation module further enhances the network’s ability to capture significant features by strengthening the relationship between global and local attentions, leading to improved defect detection accuracy.
Overall, our proposed SCTN significantly advances surface defect detection by tackling challenges related to data scarcity and computational inefficiency through residual layer, a novel sparse layer and enhanced attention mechanism.
Ablation study
To evaluate the effectiveness of our proposed SCTN, we conduct an ablation study by systematically adding or removing key module–namely, the Residual Layer (RL), Sparse Layer (SL), and Squeeze-and-Excitation (SE) module–and combining them in different configuration. The results, summarized in Table 5, are measured in terms of accuracy across 1-shot, 2-shot, 5-shot, and 10-shot scenarios. Below, we discuss the impact of each module, focusing on the 10-shot scenario.
Impact of RL The addition of the residual layer (RL) module consistently improves performance across all scenarios. When the RL is omitted (No. 1), there is a noticeable performance drop in mAP of 0.66%, 1.51%, 1.55%, 0.55%, and 0.54% for 1-shot, 2-shot, 3-shot, 5-shot, and 10-shot scenarios, respectively, compared to when it is included (No. 2). Furthermore, comparing No. 5 and No. 6 with No. 3 and No. 4, respectively, shows performance increases from 45.85% to 46.71%, and from 46.68% to 46.95%. These results highlight the RL’s critical role in addressing the non-overlapping problem and preserving fine-grained low-level features in the patch embedding stage of SCTN. The RL enhances the network’s ability to retain crucial information, contributing to better accuracy. The ablation study shows that incorporating RL improves mAP across all shots, underscoring its importance in enhancing feature extraction and representation.
Impact of SL The sparse layer (SL) module also contributes to a modest improvement in performance. As indicated in Table 5, the baseline performance improves from 45.62% (No. 1) to 45.85% (No. 3) when the SL is employed in the 10-shot scenario. Notably, the SL yields a similar performance gain of 0.55% and 0.14% compared to No. 2 and No. 4, respectively. Additionally, the SL reduces the Floating Point Operations (FLOPs) of PvTv2 from 192.6 G to 153.5 G, demonstrating its efficiency in reducing computational complexity. These experiments show that the SL helps the model focus on more discriminative patches, reducing the impact of irrelevant information introduced by noisy patches. As illustrated in Fig. 9, the influence of \(\lambda\) value on the 2-shot and 10-shot scenarios shows that increasing \(\lambda\) improves performance, with the best results achieved when \(\lambda\) reached 0.5, yielding mAP values of 31.92% and 47.21%, respectively. Therefore, we set \(\lambda\) to 0.5 for all our experiments. The SL module effectively reduces redundant information, allowing the network to concentrate on more relevant features.

Performance evaluation under different \(\lambda\) for sparse layer.

t-SNE plots corresponding to the 768-dimensional features of (a) No. 1 and (b) No. 4. The features correspond to the CLD images.
Impact of the SE module The SE module has significant impact on improving performance. Comparing No. 1–4 shows performance gains of 0.76%, 0.82%, and 0.98% in accuracy upon introducing the SE module. Moreover, as shown in Fig. 10, the t-SNE visualization of the extracted features (No. 1 vs. No. 4) reveals that the SE module substantially improves the model’s discrimination ability by maximizing intra-cluster distances. This comparison highlights the SE module’s role in enhancing local attention feature extraction by identifying global attention relations. The SE module significantly enhances feature attention, leading to improved detection accuracy.
Combination of two kinds of modules Adding both RL and SL modules (No. 5) improves further performance compared to using each module individually. This highlights their complementary roles, leading to a performance increase to 26.12% (1-shot) and 46.71% (10-shot). Additionally, combination the RL and SE modules (No. 6) yields better results than using RL alone, with accuracy reaching 26.38% (1-shot) and 46.95% (10-shot), demonstrating the significant contribution of SE module. Lastly, the combination of SL and SE modules (No. 7) shows a marked improvement over using SL module alone, with accuracy increasing to 26.13% (1-shot) and 46.82% (10-shot).
All modules combined The combination of all three modules (RL, SL, and SE) achieves the best performance, delivering the highest accuracy across all scenarios: 26.53% (1 shot) and 47.21% (10 shot). This demonstrates the synergistic effect of integrating RL, SL, and SE within the SCTN framework.

Attention maps of No. 1–8 described in Table 5 from the output CLS tokens to the RGB image input space.
Attention visualization Figure 11 presents seven attention maps for a CLD image, with each map generated by iteratively introducing a different module into our proposed method. Comparing these maps to No. 1, it’s evident that they increasingly focus on the defect part, while still considering some background areas. By combining more than two modules, these attention maps become even more robust and accurate. In contrast to the baseline, all the introduced modules guide the model to suppress background areas and concentrate on surface defects. These visualizations offer strong evidence that our approach holds theoretical significance.
Discussion Our SCTN achieves superior performance due to its unique architecture and the synergistic effect of its modules. The RL effectively resolves the non-overlapping issue while maintaining fine-grained low-level features, which helps the network retain crucial information and improve accuracy. SL enhances the models’ ability to focus on relevant parts of the input, improving detection accuracy with fewer parameters. The SE module recalibrates feature maps, emphasizing crucial features and improving overall accuracy. Specifically, the introduction of the sparse layer significantly reduces the computational burden, allowing real-time defect detection without compromising accuracy. This efficiency is particularly beneficial in industrial applications where processing speed is crucial. However, the effectiveness of the sparse layer is somewhat dependent on the threshold parameter \(\lambda\), which requires careful tuning for optimal performance. On the other hand, by incorporating the SE module, our network gains a stronger ability to differentiate between defect and non-defect regions, improving detection precision. However, the addition of the squeeze and excitation module slightly increase the model complexity, which might necessitate additional computational resources during training. Future work could explore optimizing the integration of these modules or experimenting with other architectures to further enhance performance.
In summary, the ablation study demonstrates that each module-Residual Layer, Sparse Layer, and Squeeze and Excitation module-contributes to the improved performance of the SCTN. The combination of these modules results in the highest accuracy, validating their effectiveness in enhancing surface defect detection.
Summary
The combination of residual layer, sparse layer, and squeeze-and-excitation module in sparse cross-transformer network (SCTN) creates a synergistic effect that significantly enhances the network’s overall performance in surface defect detection. Each module uniquely contributes to the network’s ability to capture and process critical features, and when integrated, they complement one another to produce a more powerful and efficient model.
Residual layer allows the network to learn more complex representations by enabling the flow of information across layers. By providing shortcut connections that bypass certain layers, these layers help maintain the integrity of the features being learned, ensuring that critical information is retained and refined as it propagates through the network. This leads to more robust and accurate feature representation, essential for identifying subtle defects. The sparse layer, on the other hand, focuses the network’s attention on the most important features by reducing the complexity of the input data. This reduction in complexity is achieved by selectively activating only the most relevant neurons, effectively filtering out noise and irrelevant information. This sparsity not only reduces the computational load but also enhances the network’s ability to detect fine details, as it can allocate more resources to processing the most critical aspects of the input. Finally, the squeeze-and-excitation modules dynamically recalibrate the feature channels, adjusting their importance based on their relevance to the task at hand. This recalibration ensures that the network emphasizes the most informative features while suppressing those that are less useful, further refining the feature representation.
When these three modules are combined, the residual layer provides a solid foundation for deep learning by preserving and enhancing important features, the sparse layer focuses the network’s capacity on critical information, and the squeeze-and-excitation module fine-tunes the feature representation for maximum relevance. Together, they create a network that is not only capable of learning complex and nuanced features but is also highly efficient and focused, leading to superior performance in surface defect detection.
Conclusion
In this paper, we revisit cross-transformer architecture and propose a sparse cross transformer network for surface defect detection. SCTN leverages the cross-transform module to extract interaction between the K-V pairs of the query and support branches, preserving an important information even as the number of network layers increases. Furthermore, the sparse layer is proposed to increase efficiency of cross-transformer by concentrating essential features. Additionally, the squeeze-and-excitation module is incorporated into the network to extract more discriminative attention features. Performance evaluation was extensively conducted on three surface defect databases from different industrial field. Experiment results demonstrate not only the considerable performance but also the generalization capabilities of our proposed method across real-world applications. These results collectively demonstrate the effectiveness of our method. In conclusion, SCTN substantially advances the state-of-the-art in surface defect detection through its innovative use of sparse cross-transformers and enhanced attention mechanisms. Future work will explore optimizing parameter settings and reducing model complexity without sacrificing performance.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
De Vitis, G. A., Foglia, P. & Prete, C. A. Row-level algorithm to improve real-time performance of glass tube defect detection in the production phase. IET Image Process. 14, 2911–2921 (2020).
Werghi, N., Berretti, S. & Del Bimbo, A. The mesh-lbp: A framework for extracting local binary patterns from discrete manifolds. IEEE Trans. Image Process. 24, 220–235 (2014).
Cui, L. et al. Sddnet: A fast and accurate network for surface defect detection. IEEE Trans. Instrum. Meas. 70, 1–13 (2021).
Wang, H., Li, Z. & Wang, H. Few-shot steel surface defect detection. IEEE Trans. Instrum. Meas. 71, 1–12 (2021).
Liu, Z., Guo, Z., Li, C., Gao, C. & Huang, N. Few-shot steel surface defect detection based on meta learning. In Proc. ICCPR, 113–119 (2021).
Wang, S., Chen, H., Liu, K., Zhou, Y. & Feng, H. Meta-FSDet: A meta-learning based detector for few-shot defects of photovoltaic modules. J. Intell. Manuf. 34, 1–15 (2022).
Han, G., Ma, J., Huang, S., Chen, L. & Chang, S.-F. Few-shot object detection with fully cross-transformer. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 5321–5330 (2022).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 7132–7141 (2018).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process Syst. 28 (2015).
Molodova, M., Li, Z., Núñez, A. & Dollevoet, R. Monitoring the railway infrastructure: Detection of surface defects using wavelets. In Proc. ITSC, 1316–1321 (2013).
Tolba, A. S. A novel multiscale-multidirectional autocorrelation approach for defect detection in homogeneous flat surfaces. Mach. Vis. Appl. 23, 739–750 (2012).
Mentouri, Z., Moussaoui, A., Boudjehem, D. & Doghmane, H. Steel strip surface defect identification using multiresolution binarized image features. J. Fail. Anal. Prev. 20, 1917–1927 (2020).
Timm, F. & Barth, E. Non-parametric texture defect detection using weibull features. In Image Processing: Machine Vision Applications IV, 7877, 150–161 (SPIE, 2011).
Li, Q. & Ren, S. A visual detection system for rail surface defects. IEEE Trans. Syst. Man Cybern. C Appli. 42, 1531–1542 (2012).
Dubey, A. K. & Jaffery, Z. A. Maximally stable extremal region marking-based railway track surface defect sensing. IEEE Sens. J. 16, 9047–9052 (2016).
Cha, Y.-J., Choi, W., Suh, G., Mahmoudkhani, S. & Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput-Aided Civ. Inf. 33, 731–747 (2018).
He, Y., Song, K., Meng, Q. & Yan, Y. An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Trans. Instrum. Meas. 69, 1493–1504 (2019).
Dong, H. et al. Pga-net: Pyramid feature fusion and global context attention network for automated surface defect detection. IEEE Trans. Industr. Inform. 16, 7448–7458 (2019).
Li, Y. et al. A channel attention-based method for micro-motor armature surface defect detection. IEEE Sens. J. 22, 8672–8684 (2022).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2010).
Gao, L., Zhang, J., Yang, C. & Zhou, Y. Cas-VSwin transformer: A variant swin transformer for surface-defect detection. Comput. Ind. 140, 103689 (2022).
Luo, Q. et al. Cat-ednet: Cross-attention transformer-based encoder-decoder network for salient defect detection of strip steel surface. IEEE Trans. Instrum. Meas. 71, 1–13 (2022).
Köhler, M., Eisenbach, M. & Gross, H.-M. Few-shot object detection: A comprehensive survey. IEEE Trans. Neural. Netw. Learn. Syst. (2023).
Wang, X., Huang, T. E., Darrell, T., Gonzalez, J. E. & Yu, F. Frustratingly simple few-shot object detection. Proc. ICML 1–10 (2020).
Qiao, L. et al. Defrcn: Decoupled faster r-cnn for few-shot object detection. In Proc. IEEE Int. Conf. Comput. Vis., 8681–8690 (2021).
Koch, G., Zemel, R. & Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In ICML deep learning workshop, vol. 2 (2015).
Kang, B. et al. Few-shot object detection via feature reweighting. In Proc. IEEE Int. Conf. Comput. Vis., 8420–8429 (2019).
Hou, R., Chang, H., Ma, B., Shan, S. & Chen, X. Cross attention network for few-shot classification. Adv. Neural Inf. Process Syst. 32 (2019).
Wang, H., Xie, J., Xu, X. & Zheng, Z. Few-shot pcb surface defect detection based on feature enhancement and multi-scale fusion. IEEE Access 10, 129911–129924 (2022).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
Xue, F., Wang, Q., Tan, Z., Ma, Z. & Guo, G. Vision transformer with attentive pooling for robust facial expression recognition. IEEE Trans. Affect, Comput., (2022).
He, K., Gkioxari, G., Dollár, P. & Girshick, R. Mask r-cnn. In Proc. IEEE Int. Conf. Comput. Vis., 2961–2969 (2017).
Fan, Q., Zhuo, W., Tang, C.-K. & Tai, Y.-W. Few-shot object detection with attention-rpn and multi-relation detector. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 4013–4022 (2020).
Lin, T.-Y. et al. Feature pyramid networks for object detection. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2117–2125 (2017).
Liu, Q., Huang, X., Shao, X. & Hao, F. Industrial cylinder liner defect detection using a transformer with a block division and mask mechanism. Sci. Rep. 12, 10689 (2022).
Song, K. & Yan, Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl. Surf. Sci. 285, 858–864 (2013).
Huang, W. & Wei, P. A pcb dataset for defects detection and classification. arXiv preprint arXiv:1901.08204 (2019).
Fan, Q., Zhuo, W., Tang, C.-K. & Tai, Y.-W. Few-shot object detection with attention-rpn and multi-relation detector. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 4013–4022 (2020).
Yan, X. et al. Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proc. IEEE Int. Conf. Comput. Vis., 9577–9586 (2019).
Sun, B., Li, B., Cai, S., Yuan, Y. & Zhang, C. Fsce: Few-shot object detection via contrastive proposal encoding. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 7352–7362 (2021).
Fan, Q., Zhuo, W., Tang, C.-K. & Tai, Y.-W. Few-shot object detection with attention-rpn and multi-relation detector. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 4013–4022 (2020).
Xiao, Y., Lepetit, V. & Marlet, R. Few-shot object detection and viewpoint estimation for objects in the wild. IEEE Trans. Pattern Anal. Mach. Intell.45, 3090–3106 (2022).
Wu, J., Liu, S., Huang, D. & Wang, Y. Multi-scale positive sample refinement for few-shot object detection. In Proc. of ECCV, 456–472 (2020).
Han, G., He, Y., Huang, S., Ma, J. & Chang, S.-F. Query adaptive few-shot object detection with heterogeneous graph convolutional networks. In Proc. IEEE Int. Conf. Comput. Vis., 3263–3272 (2021).
Acknowledgements
This research was in part supported by National Natural Science Foundation of China (Grant No. 62076122), the Talent Startup project of NJIT (No. YKJ201982), Graduate Education Teaching Reform Project of NJIT (2023YJYJG07), Basic Science (Natural Science) research project of higher education institutions in Jiangsu Province (24KJA520003), the Fundamental Research Funds for the Central Universities (No. 2242024k30027), the Opening Project of Advanced Industrial Technology Research Institute, Nanjing Institute of Technology (No. XJY202102), the Opening Project of Jiangsu Province Engineering Research Center of IntelliSense Technology and System (No. ITS202102) and Key project of Jiangsu Province Teaching Science Planning (B/2022/01/80).
Author information
Authors and Affiliations
Contributions
X.H. conceived the methodology, X.H. acquired the funding, Y.L. and Y.B. conducted the experiments, X.H. wrote the main manuscript text, Y.L. and Y.B. prepared all figures, X.Z. reviewed and edited manuscript text and analyzed the results, Y.L. was in charge of database description.
Corresponding author
Ethics declarations
Competing interests
The author(s) declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Huang, X., Li, Y., Bao, Y. et al. Sparse cross-transformer network for surface defect detection. Sci Rep 14, 24731 (2024). https://doi.org/10.1038/s41598-024-75680-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-75680-y
