
Abstract
The grading of non-muscle invasive bladder cancer (NMIBC) continues to face challenges due to subjective interpretations, which affect the assessment of its severity. To address this challenge, we are developing an innovative artificial intelligence (AI) system aimed at objectively grading NMIBC. This system uses a novel convolutional neural network (CNN) architecture called the multi-scale pyramidal pretrained CNN to analyze both local and global pathology markers extracted from digital pathology images. The proposed CNN structure takes as input three levels of patches, ranging from small patches (e.g., \(128 \times 128\)) to the largest size patches (\(512 \times 512\)). These levels are then fused by random forest (RF) to estimate the severity grade of NMIBC. The optimal patch sizes and other model hyperparameters are determined using a grid search algorithm. For each patch size, the proposed system has been trained on 32K patches (comprising 16K low-grade and 16K high-grade samples) and subsequently tested on 8K patches (consisting of 4K low-grade and 4K high-grade samples), all annotated by two pathologists. Incorporating light and efficient processing, defining new benchmarks in the application of AI to histopathology, the ShuffleNet-based AI system achieved notable metrics on the testing data, including 94.25% ± 0.70% accuracy, 94.47% ± 0.93% sensitivity, 94.03% ± 0.95% specificity, and a 94.29% ± 0.70% F1-score. These results highlight its superior performance over traditional models like ResNet-18. The proposed system’s robustness in accurately grading pathology demonstrates its potential as an advanced AI tool for diagnosing human diseases in the domain of digital pathology.
Similar content being viewed by others
Introduction
Bladder cancer is the most common malignancy in urologic systems, and it can be widely separated into two major types: muscle-invasive bladder cancer (MIBC) and non-muscle-invasive bladder cancer (NMIBC). NMIBC carries a risk of progressing to MIBC that may be as high as 50% if left untreated1,2,3. The cornerstone of bladder cancer diagnosis is the system of pathological staging and grading, essential for the effective disease management as well as in mitigating the risks of recurrence and progression4,5. Pathological markers thus assume an essential role in the prognosis and treatment strategies for bladder cancer since there is often the need to estimate the aggressiveness of the tumor5.
The majority of bladder cancer cases are NMIBC. Among these, high-grade tumors have a propensity to progress to MIBC, while low-grade tumors are more likely to recur4. Therefore, the grading of NMIBC is a critical prognostic factor that aids in personalizing treatment to reduce the rates of recurrence or progression, especially considering the high costs associated with diagnosis and treatment6. The gold standard method for pathological diagnosis is transurethral resection of bladder tumor (TURBT), which is strongly recommended by European Association of Urology (EAU) guidelines7. NMIBC tumors are graded according to World Health Organization standards, with either the the 1973 version or 2004/2016 version being currently recommended for use8. An improved grading system may bring about an improved treatment protocol which lowers disease-associated mortality and also deters the economic burden of this disease9.
There are challenges faced by pathologists in interpreting data, which arise due to the scarcity of experienced professionals, the workload, and inter-observer variability. These challenges not only prolong the time required to evaluate pathology data but also impact the effort involved significantly. Digital pathology has emerged as a revolutionary solution to these issues by enabling the scanning of pathological slides through various scanners, transforming traditional hematoxylin and eosin (H &E) stained slides into digital data, i.e., whole slide images (WSI). WSI can be easily viewed and analyzed on computers, heralding a significant advancement in the medical field10. The application of artificial intelligence (AI) to digital pathology has yielded promising results in reducing subjectivity and enhancing both diagnostic and predictive performance. Most notably, deep learning (DL) techniques are extensively employed across a range of applications, including tumor detection11,12,13, grading13,14,15,16,17,18, subtyping19, survival12,20, mutation19, response prediction21, and prognosis22,23. However, among these studies, only a select few have specifically focused on bladder cancer grading13,14,15,16,17,18, with their accuracy influenced by various factors such as scanner type, which directly affects image quality24, the necessity for color normalization in stained images25, and the variability in magnification levels across different sites26. These differences necessitate external validation, a common limitation across related studies13,16.
WSI are generated as a set of tiles or patches, which may range in number from hundreds to millions. A WSI classification model for general use must be able to deal with data sets of such variable size. Modern applications have significantly aided pathologists in identifying regions of interest (ROI) and segmenting these into patches, thereby reducing the time and effort required for this process. Despite the availability of numerous tools for the WSI annotation, it remains a time-consuming process according to all recent studies13,14,15,16,17,18. Furthermore, the effectiveness of the AI models employed also plays a critical role in the outcomes achieved.
Studies concerning histological grading of bladder cancer have leveraged machine learning or statistical approaches to enhance diagnostic accuracy. Various machine learning techniques have been employed, including supervised learning methods as demonstrated by Pan et al.13, Habibi et al.15, and Jansen et al.16; semi-supervised learning in Wenger et al.14; and unsupervised learning approaches employed by García et al.18. The work of Slotman et al.27 explored the combination of supervised learning models with traditional statistical methods. Some studies have implemented transfer learning approaches, leveraging pre-trained models such as ScanNet13, VGG-1614,15,16, Inception, InceptionResNet, and Xception15, and U-net27. These approaches significantly show the importance of building new deep learning models, particularly beneficial for analyzing the vast data sizes of WSI.
Jansen et al.16 performed free-hand annotation of WSI to identify ROI of \(572\times 572\) pixels from U-net segmentation models, and patches of \(224\times 224\) pixels to feed into the VGG-16 network. Despite the data variability across sites, the study reported specificity and sensitivity rates of 76% and 71%, respectively. Pan et al.13 annotated pathological WSI at both the patch level and whole slide level, with ROI sized at \(2048 \times 2048\) pixels downsampled to \(128 \times 128\) pixels for computational efficiency. Their model, trained on a ScanNet architecture derived from an earlier study28, underwent validation across patch-level, slide-level, and in comparison with pathologists, demonstrating robustness albeit with a decreased sensitivity of 0.743 at the slide-level. The model notably outperformed junior and intermediate pathologists in accuracy but was less effective compared to senior pathologists.
In their study, Habibi et al.15 fully annotated different WSI for analysis using five models: VGG-16, Inception, InceptionResNet, Xception, and a custom convolutional neural network (CNN). The highest test accuracy was found with the VGG-16 model, thus indicating the model’s efficacy may be contingent on the pathologist’s input. Their approach justified using a limited number of slides due to the extensive number of patches derived from each WSI, emphasizing the potential to streamline the annotation process by excluding background regions, a common limitation in prior research.
Wenger et al.14 explored the use of digital pathology, creating patches of \(512 \times 512\) pixels in a semi-supervised learning (SSL) framework combining labeled and unlabeled data on input to the VGG-16 network. Their findings highlighted the performance benefits of using a larger dataset of labeled data, achieving a high accuracy with a mix of 16,000 labeled and 14,000 unlabeled patches. The study also found the use of gray scale patches vs. color did not necessarily threaten the performance of the model. There needs to be further investigate of the efficacy of using RGB data in SSL methods.
García et al.18 achieved 90.3% accuracy using 136 unlabeled WSI of a patch size of \(512 \times 512\) pixels with the help of deep convolutional embedded attention clustering (DCEAC) method. This method used an attention module-powered autoencoder as a learning function, thereafter feeding to the decoder for result analysis such that the pathologist excludes ROI from the background to optimize of computational resources.
Lastly, Slotman et al.27 utilized U-net for tumor segmentation and annotation of morphological features of nuclei in each WSI. Feature of cell nuclei comprised area, perimeter, and mitotic index, among others. These features were integrated into multivariate linear and logistic regression models for automatic grading, revealing that nuclear area and mitotic index were particularly predictive of tumor grade. Despite achieving an accuracy of 88% and an AUC of 94%, the study acknowledged the challenge of data imbalance, with a dataset skewed towards low-grade tumors affecting overall results.
This detailed examination of current literature underscores the dynamic and evolving nature of AI applications in histological grading of bladder cancer, highlighting both the achievements and limitations faced by recent studies.
The primary contribution of our research lies in the development of an AI-driven system (Fig. 1) utilizing a fully annotated, balanced dataset within a pyramidal WSI29 supervised learning model for the grading of NMIBC using a multi-scale pyramidal CNN architecture. This approach uniquely integrates multiple patch sizes to capture both local and global pathological features, enhancing the robustness and accuracy of the grading process. In addition, transfer-learning technique based on ShuffleNet architecture is employed, rather than custom-designed CNN architecture, to ensure that we started from a pre-trained network, which assures that the final trained data has no bias and avoid overfitting. Furthermore, the employment of an ensemble learning algorithm (Random Forests (RF)), rather than the simple majority voting criteria, to fuse the outputs of individual CNNs significantly reduces the effect of inter-rater reliability and subjectivity in diagnosis, providing an automated, objective, and highly accurate diagnostic tool. This innovation represents a substantial advancement in the field of AI-driven pathology, with the potential to revolutionize current practices, improve patient outcomes, and enhance the personalized management of NMIBC.

The proposed workflow. For illustrative purposes, the figure shows a small selection of WSI patches, while our method actually performs comprehensive WSI annotation. The HR, MR, and LR prediction models stand for high resolution, medium resolution, and low resolution, respectively.
Materials
Study design and patient population
We conducted a prospective study involving high-risk NMIBC patients recruited from the Urology & Nephrology Center at Mansoura University, Egypt. Eligible participants were those diagnosed with either high-grade (HG) or low-grade (LG) Ta/T1 NMIBC, having undergone no prior Bacillus Calmette-Guérin (BCG) therapy. Participation in the study was contingent upon the provision of informed consent, obtained in alignment with the principles outlined in the Declaration of Helsinki. This study protocol received approval from the Institutional Review Board (IRB) of the Faculty of Medicine at Mansoura University.
Histopathological data collection and analysis
Histopathological specimens were acquired via TURBT, performed by a senior urologist with over five years of experience. Following resection, specimens were prepared on slides and stained with H &E for microscopic examination. To ensure unbiased findings, two expert pathologists, blinded to each other’s assessments, independently reported their findings. Their evaluations adhered to the WHO 2004/2016 classification system for tumor grading. In cases of disagreement, a consensus was sought through discussion. If consensus could not be achieved, the judgment of the more experienced pathologist was given precedence. This approach ensured that the final pathological outcomes were determined with the highest level of expertise and agreement.
Data de-identification and digital slide preparation
Prior to further analysis, all patient identifiers were removed from the slides to ensure confidentiality. The de-identified slides were then digitized using a Motic Easy-Pro scanner at a 40x magnification, courtesy of the Nile Higher Institute For Engineering & Technology. For this study, a total of 21 WSI were obtained from 21 different patients (11 LG and 10 HG tumors). Each WSI was exported in TIFF format, facilitating subsequent digital pathology analyses.
Methods
Our AI system’s workflow (Fig. 1) is designed for the grading of NMIBC into HG and LG categories. This process involves several critical steps, detailed below:
-
1.
Full annotation of each WSI was performed post-scanning, creating a new dataset for use in supervised deep learning models. This included the extraction of ROI.
-
2.
ROI were tiled using patches of three sizes: \(512 \times 512\), \(256 \times 256\), and \(128 \times 128\) pixels. These patches serve as the primary inputs for our models.
-
3.
Preprocessing of these scaled tiles was conducted to optimize the data for use in deep learning CNN models.
-
4.
Generation of three individual CNN models, each corresponding to a different patch size.
-
5.
Integration of outcomes from the three models using a fusion ML algorithm to achieve final grade classification.
WSI annotation and pyramidal patching
Each WSI underwent a comprehensive annotation process by a senior pathologist, utilizing the Qupath software program30. This process involved the meticulous identification of three key tissue types: tumor, stroma, and carcinoma in situ (CIS), using the brush tool for precise demarcation. To facilitate compatibility with Qupath and streamline data handling, WSI initially in TIFF format were converted to pyramidal OME-TIFF format using the Bio-Formats command-line tool31.
Our primary focus was on distinguishing between HG and LG tumors, essential for the study’s objectives. Given the relative scarcity of CIS cases and the non-relevance of stroma regions to our specific research goals, we exclusively looked at ROI with the “tumor” annotation, opting to exclude other tissue types from further analysis. This approach ensured a concentrated examination of tumor regions, which inherently included various cellular compositions such as inflammatory cells and blood vessels. Importantly, the presence of crushed cells within the tumor annotations was acknowledged for its potential impact on the analysis results.
We included patches that contained a mix of tumor tissues and adjacent elements as a deliberate strategy to improve the robustness and generalizability of our model. This is expected to provide more context for the learning of the model and enable other subtle and inclusive future research on bladder cancer prognosis. Now that the dataset has been annotated thoroughly, it is readily available for future work in supervised learning applications on NMIBC.
WSI are by nature very high dimensional data with upward of one billion pixels, hence the mammoth difficulties in CNN model generation and also difficulties encountered in CNN model deployment. For this, we used an algorithmic pyramidal patching approach using the Qupath software with Groovy scripting, to efficiently dissect large histopathological images into smaller, analyzable patches. From this process three scales of patches emerged: large at \(512 \times 512\) pixels, medium at \(256 \times 256\) pixels and small at \(128 \times 128\) pixels. The rationale behind selecting these specific sizes stemmed from an extensive review of relevant literature, where \(512 \times 512\) pixels emerged as the most frequently adopted dimension for ROI in similar studies. This dimension was thus chosen for the largest patch size, with the medium and small scales proportionally derived to facilitate a comprehensive analysis encompassing both local and global tissue structures.
To ensure the empirical validity of these sizes, a grid search technique was applied, taking into account both the literature review and consultations with pathologists and urologists. This collaborative and data-driven approach ensured the selection of patch sizes that are both scientifically grounded and practically relevant to clinical experts. Additionally, we imposed stringent selection criteria for these patches, allowing a maximum of 25% background presence to ensure the integrity of the tissue analysis. Moreover, to maintain consistency across scales, we ensured co-centric alignment of patches without any overlap, facilitating a coherent and integrated examination of histological features.
In all, this meticulous approach led to the generation of 120,192 patches in all, uniformly split between LG (60,279) and HG (59,913) categories where each patch size category contained 40,064 patches. In order to maintain the integrity of histological information, patches were kept at full resolution with no downsampling and in the RGB color space. The patches were then exported from Qupath in OME-TIFF format, arranged in twenty one main folders corresponding to each WSI ID. Within each WSI’s folder, three sub-folders represented the patch sizes (512, 256, 128), containing the respective patch images. This organizational structure not only facilitated easy access and identification of patches but also ensured a balanced representation of LG and HG cases across all sizes. Crucially, by exporting tiles with their WSI ID and coordinates (x, y), we guaranteed that the patches remained aligned and centered relative to their origin within the WSI, supporting accurate and reliable analysis.
Patch pre-processing
Normalization is required in the process of pyramidal tiling so that patches have similar contrast throughout the dataset. Uniform image quality is key for any machine model to work optimally32. Although every WSI came from the same scanner, differences in contrast were noticed with periodical dial changes of the scanner’s gamma settings. This variability would significantly affect the performance of the model, potentially increasing a rate of false positives due to unusually high contrast of some images.
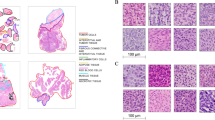
For addressing this issue, the contrast in all images was normalized to match a target image selected by the pathologist for having optimal contrast in their professional opinion. Normalization was done via histogram matching. A portion of patches are shown before and after this normalization process in Fig. 2, specifically to highlight the contrasting differences, as well as the existence of crushed cells adjacent to tumor regions. These features point out the challenges which are inherent to preprocessing and highlight the necessity of normalization of images to produce useful training data.
Most importantly, the effect is observed in Fig. 3, which illustrates a set of images before and after histogram matching. The subset of images above shows the highly variable contrast of the original patches while the one below represents uniformity achieved post-normalization displaying a significant improvement in the image consistency across the dataset.
Following normalization, all the patches were resampled to our CNN architecture’s required input size, i.e., \(224 \times 224\) pixels. Then the dataset was partitioned into a training set (80%) and a testing set (20%). This amounted to 32,179 images for training and 7,885 images for testing within each patch size model. The structured approach to data preparation—with careful normalization and resizing of patches—lays a very good foundation for the subsequent model training and evaluation stages.

Samples from the dataset showing the variation in contrast among patches from 11 unique LG patients and 10 HG patients, prior to normalization. The presence of crushed cells and the variability in image quality highlight the preprocessing challenges and the importance of normalization to achieve consistent contrast across the dataset.

Demonstration of the normalization effect on a random batch of pyramidal images. The first subset shows images before normalization, illustrating the variability in contrast. The second subset, post-normalization, reveals the uniformity in contrast achieved, underscoring the critical role of histogram matching in preprocessing for consistent image analysis.
Model baseline architecture
We used the ShuffleNet CNN33 as the base. This network is known for being high accuracy, lightweight, and efficient in terms of computation. Since the dataset that we used was large, the motivation for using this architecture was dual. Firstly, the computation involved with a large dataset incurs a trade-off with classification performance vs. execution speed. Using transfer learning, we adopted a ShuffleNet model pre-trained on the ImageNet dataset34. Use of the pre-learned weights can greatly reduce the initialization time. This approach underscores our model’s adaptability to various CNN architectures, contingent on the computational resources available.
The proposed model
Our model architecture was meticulously designed to accommodate the unique characteristics of NMIBC grading. We trained three distinct CNN models, each tailored to process patches of specific sizes: \(512 \times 512\), \(256 \times 256\), and \(128 \times 128\) pixels. As depicted in Fig. 4, each model follows the same structured pipeline:
-
An Initial 2D Convolution Block: Starting with the resized pyramidal patches (\(112 \times 112 \times 3\)), this block utilizes 24 filters, a \(3 \times 3\) kernel, batch normalization, and ReLU activation, culminating in a dimension reduction to \(56 \times 56\) pixels via max-pooling.
-
Inverted Residual Blocks: These blocks feature multiple convolution layers, batch normalization, ReLU activation, and, crucially, inverted residual layers that perform channel shuffling and pointwise grouping of convolutions (Fig. 5). This design significantly reduces the model’s parameter count while capturing essential features, balancing computational efficiency with grading accuracy.
-
A Final 2D Convolution Block: With 1024 filters and a \(1 \times 1\) kernel size, this block feeds into a fully connected layer that outputs the binary classification of LG or HG.
The training loss was computed using the cross-entropy loss function, defined as:
where L represents the loss per training sample, y the true label, and \(\hat{y}\) the predicted probability of being LG. This loss function emphasizes penalization for incorrect predictions, facilitating effective model learning. The model underwent 40 epochs of training with a batch size of 128, using Adam’s optimizer and a learning rate of 0.001. Notably, our model architecture employs fewer parameters than the original ShuffleNet, enhancing its suitability for real-time applications.

Proposed CNN pipeline.

The inverted residual block of the model, it aggregates grouping of convolutions and shuffle the RGB channels of input.
Pyramidal fusion algorithm
The final stage in our methodology involves the integration of predictive outputs from three CNN models, tailored to patches of sizes \(512 \times 512\), \(256 \times 256\), and \(128 \times 128\) pixels, through a supervised machine learning Random Forest (RF) classifier. This ensemble method, detailed in Algorithm 1, serves to amalgamate the nuanced insights from each model into a unified prediction.
Predicted probabilities for being labeled as LG are obtained from each CNN model:
-
P1: Probability from CNN for \(512 \times 512\) patches,
-
P2: Probability from CNN for \(256 \times 256\) patches,
-
P3: Probability from CNN for \(128 \times 128\) patches.
Given the complementary nature of HG probabilities, we consolidate these predictions into a single feature set to capture triple-scale features effectively during training and testing phases.
Recall the dataset had been partitioned into an 80% training subset and a 20% testing subset, with labels consistent across CNN models due to the patches at different scales being aligned. The RF model, constructed from multiple decision trees, each trained on unique subsets of the data, predicts the LG likelihood, culminating in a majority vote for the final classification (as delineated in Algorithm 1).

Random Forest Fusion Algorithm
Hyperparameter optimization
Having fixed the architecture of both the fixed-scale and fusion models, we embarked on a systematic optimization of their hyperparameters. This process was guided by a grid search methodology, meticulously exploring a multitude of parameter configurations to identify the settings that maximized model accuracy and generalizability. The grid search process involved systematically varying hyperparameters such as learning rate, batch size, and the number of layers, among others, within predefined ranges. This enabled us to empirically assess the performance implications of different hyperparameter combinations, facilitating an informed selection based on quantitative evaluation metrics. The selection criteria for the optimal hyperparameters were grounded in achieving the best balance between model accuracy and computational efficiency, ensuring that each model is both effective in its diagnostic capability and practical for deployment in clinical settings. Notably, this optimization process revealed that a singular set of hyperparameters emerged as optimal across all three individual models. This unexpected uniformity not only streamlined the model training process but also highlighted the intrinsic coherence of the dataset across different resolutions.
The optimization of the RF fusion model was similarly conducted with precision, focusing on parameters critical to its integrative function, such as the number of decision trees, maximum tree depth, and node splitting criteria. Through this careful calibration, we ensured the fusion model effectively leveraged the diverse input from the individual models to produce a unified, accurate diagnostic output.
To ensure the integrity and reproducibility of our findings, the grid search was conducted under a consistent experimental framework, with each model variant subjected to the same training and validation protocols. This rigorous approach not only underscores the empirical basis of our hyperparameter selection process but also reflects our commitment to leveraging data-driven insights to inform model development, thereby enhancing the robustness and reliability of our AI-based system. This refined approach to the model’s baseline architecture, its specialized development for NMIBC grading, and the innovative fusion algorithm for final classification ensures a robust, efficient, and accurate system for distinguishing between LG and HG NMIBC cases.
Results
The implementation of our proposed multi-scale pyramidal AI system was carried out using Python 3.6 within a Jupyter Notebook environment. Our CNN architectures were developed leveraging TensorFlow (v2.12). The computational experiments were conducted on an Intel(R) Xeon(R) Gold 628R CPU @ 3.00GHz with 64 GB RAM. During the training phase, cross-entropy loss was calculated at each epoch alongside the optimization of other training parameters. This monitoring allowed us to plot the training loss throughout the fitting procedure, ensuring our model was neither underfitting nor overfitting. Figure 6 presents the confusion matrices generated from the testing phase to evaluate our model’s performance on pathological images.

Confusion matrices of the individual models, illustrating the performance across different CNN architectures. Columns represent the predicted labels, while rows indicate the true labels, allowing for the assessment of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN).
To assess the model’s efficacy, we employed several evaluation metrics: accuracy, sensitivity, specificity, and the F1-score, derived from the observed true positive (TP), true negative (TN), false negative (FN), and false positive (FP) rates derived from the confusion matrix. These metrics facilitated a comprehensive understanding of our model’s grading capabilities in distinguishing between HG and LG NMIBC. All the experiments were repeated 100 times and the evaluation metrics were reported in terms of (\(mean \pm standard\) deviation). Data were shuffled between each iteration to ensure robust and reliable results.
Our comparison of CNN architectures35,36,37,38, as detailed in Table 1, reveals that the proposed model utilizing ShuffleNet architecture significantly outperforms the ResNet-18 model. Additionally, when compared with two state-of-the-art methodologies proposed by Pan et al.13 and Slotman et al.27 for grading NMIBC, our model demonstrates superior performance metrics, including higher sensitivity, specificity, and overall accuracy. This comparison underscores the efficacy of ShuffleNet in histopathological image classification tasks within our specific study context.
Table 2 contrasts the proposed model against individual CNN models based on patch size, showcasing the comprehensive performance enhancement achieved through our pyramidal approach.
Additionally, to identify the optimal machine learning classifier for our fusion algorithm, alternative classifiers were evaluated, including Adaboost, K-nearest neighbour (KNN), and multi-layer perceptron (MLP), alongside our RF approach. The optimal hyperparameters for each classifier were determined using grid search, with the results presented in Table 3.
The exhaustive evaluation underscores the efficacy of the RF classifier in harmonizing the diverse insights offered by the pyramidal CNN models, thereby affirming the significant advantage of our fusion approach in enhancing NMIBC grade classification accuracy.
It is worth noting that according to the pathological guidelines, the WHO 2022 classification considers all subtypes (LG and HG) with more than 5% of HG, as a HG tumor39. That means, the grade of tumor in a slide assigned as HG if at least 5% of the total tissue (patches) in the WSI is found to be HG, otherwise it is considered as LG. To ensure that the proposed approach produces accurate results with no bias, we evaluated the computing performance on the patch level against the whole slide level. Remarkably, in a LG slide with a total number of 1132 patches for each patch-level size, the proposed AI-driven system misclassified 5 out of 1132 patches as HG. That represents only 0.004% proportion of the entire patches of the slide, less than the 5% standard. As a results, the accuracy of the proposed system classifying this WSI as LG is 100%. Likewise, in another LG slide, 2216 patches were correctly classified as LG out of 2154 patches, ending up with an accuracy of 97.2%. That means only 2.8% of the patches were classified as HG, less than the 5% standard. That means the accuracy of the proposed system classifying this WSI as LG is 100%. Meanwhile, we tested some HG WSIs and the same accuracy of 100% following the same pathological guidelines of the 5% standard were obtained.
Discussion
Indeed, by the press of precision in the management of a condition currently characterized by highly limited efficacious interventions like BCG40, the search for improved NMIBC grading systems is more of a clinical imperative than an academic exercise. Against this backdrop, traditional diagnostic/grading protocols that are majorly dependent upon interpretative skills of the pathologists themselves tend to remain intrinsically a giant hurdle due to subjectivity and interobserver variability. These issues not only contribute to the difficulty of accomplishing diagnostic consistency, but they also have huge potential to lead treatment pathways off-track and critically impact patient outcomes.
This present paper presents a novel AI system to overcome these barriers by means of a deep learning framework utilizing histopathological images at all spatial resolutions. As such, it is a paradigm shift to far more objective, reliable, and efficient NMIBC grading and not just an incremental advancement in digital pathology. Integration of three distinct pyramidal sized patches in our analysis paves the way for consideration of full-scale histopathological images, bridging cellular feature analysis with intercellular features. This multiscale view emulates the pathologist process starting from macroscopic to ending on a microscopic examination that elevates up to five percent the grading accuracy of this model.
The uniqueness of our system is realized through the ensemble machine learning algorithm which fuses CNN outputs. This methodological choice is validated by our results, which demonstrate superior performance in terms of sensitivity, specificity, and overall accuracy when compared to existing models like ResNet-18, ScanNet model proposed by Pan et al.13, and U-net model of Slotman et al.27. The success of ShuffleNet in our study, as illustrated in Table 1, not only highlights the efficiency of lightweight models in processing complex histopathological data but also emphasizes the significance of architectural design in achieving high diagnostic performance.
Moreover, our exploration of various machine learning algorithms for output fusion, detailed in Table 3, underscores the Random Forest classifier’s effectiveness over other techniques. This finding is pivotal, suggesting that the right fusion strategy can significantly amplify the predictive power of AI systems in cancer diagnostics, transcending the capabilities of individual models.
To summarize, this study makes several noteworthy contributions to the field of digital pathology and the grading processes for NMIBC, specifically:
-
Analyzed three empirically chosen different patch sizes to capture and integrate both local and global pathological features, enhancing diagnostic accuracy and providing a nuanced understanding of tissue morphology.
-
Developed a pyramidal AI-driven system that utilizes multi-scale ShuffleNet architectures rather than custom-designed CNN architectures for objective NMIBC grading, addressing the challenge of diagnostic subjectivity and avoid overfitting problems.
-
Demonstrated the efficacy of integrating outputs from multiple CNN models through an ensemble machine learning fusion algorithm, significantly enhancing grading accuracy with a standout accuracy of 94.25% ± 0.70%.
-
Established the superiority of the proposed AI system over traditional models and recent state-of-the-art approaches, through comprehensive performance metrics including sensitivity, specificity, and F1-score.
-
Laid the groundwork for future advancements in personalized cancer care, providing a scalable framework for extending the proposed system to other types of cancer diagnostics.
Hence, this study serves as a critical next step in the evolution of digital pathology in the era of AI, offering a scalable/adaptable framework that may well revolutionize the landscape of NMIBC management and beyond.
Conclusion and future work
In conclusion, the proposed AI system represents ground-breaking opportunities for the grading of NMIBC in a novel manner by capitalizing on multi-scale CNN architectures as well as an innovative ML fusion algorithm to boost diagnostic accuracy and reliability. By addressing the critical challenges of interobserver variability and diagnostic subjectivity, the system sets a new standard for AI application in histopathology promising to improve patient management and treatment outcome by a significant margin.
While our study demonstrates significant advancements in the grading of NMIBC using a multi-scale pyramidal CNN architecture and ensemble learning, several limitations must be acknowledged. Firstly, the dataset used in this study is limited to images from a single institution, which may introduce biases related to imaging techniques, staining protocols, and patient demographics. To enhance the generalizability and robustness of our model, future studies should aim to validate it on multi-institutional datasets. Secondly, variations in image quality and the presence of artifacts could affect the model’s performance. Although our preprocessing steps mitigate these issues to some extent, further refinement and the incorporation of advanced image enhancement methods could improve accuracy. Moreover, while our model excels in differentiating between high-grade and low-grade NMIBC, it does not currently account for carcinoma in situ or other atypical pathological subtypes. Expanding the model’s capabilities to include these subtypes will provide a more comprehensive diagnostic tool. Lastly, importance of clinical trials will be to assess the actual practical impact of our AI system in real-life settings as well as make an evaluation on its potential to bring about a streamlining of diagnostic workflows together with an enhancement in their decision-making processes during treatment for NMIBC. Addressing these limitations in future research will ensure that our AI-driven system continues to contribute meaningfully to the field of AI-based pathology and ultimately improve clinical outcomes for patients with NMIBC. By acknowledging these limitations, we aim to provide a clear roadmap for future improvements, ensuring that our research continues to contribute meaningfully to the field of AI-driven pathology.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on a reasonable request.
References
Rouprêt, M. et al. European association of urology guidelines on upper urinary tract urothelial carcinoma: 2023 update. Eur. Urol. (2023).
Babjuk, M. et al. EAU guidelines on non-muscle-invasive bladder cancer (tat1 and cis). Eur. Urol. 71, 447–61 (2017).
van Hoogstraten, L. M. et al. Global trends in the epidemiology of bladder cancer: Challenges for public health and clinical practice. Nat. Rev. Clin. Oncol. 20, 287–304 (2023).
Magers, M. J. et al. Staging of bladder cancer. Histopathology 74, 112–134 (2019).
Beijert, I. J. et al. International opinions on grading of urothelial carcinoma: A survey among European association of urology and international society of urological pathology members. Eur. Urol. Open Sci. 52, 154–165 (2023).
Mossanen, M. et al. Evaluating the cost of surveillance for non-muscle-invasive bladder cancer: An analysis based on risk categories. World J. Urol. 37, 2059–2065 (2019).
Kim, L. H. & Patel, M. I. Transurethral resection of bladder tumour (turbt). Transl. Androl. Urol. 9, 3056 (2020).
van Rhijn, B. W. et al. Prognostic value of the WHO1973 and WHO2004/2016 classification systems for grade in primary TA/T1 non-muscle-invasive bladder cancer: A multicenter European Association of Urology non-muscle-invasive bladder cancer guidelines panel study. Eur. Urol. Oncol. 4, 182–191 (2021).
van der Kwast, T. et al. International society of urological pathology expert opinion on grading of urothelial carcinoma. Eur. Urol. Focus 8, 438–446 (2022).
Jiang, Y., Yang, M., Wang, S., Li, X. & Sun, Y. Emerging role of deep learning-based artificial intelligence in tumor pathology. Cancer Commun. 40, 154–166 (2020).
Yin, P.-N. et al. Histopathological distinction of non-invasive and invasive bladder cancers using machine learning approaches. BMC Med. Inform. Decis. Making 20, 1–11 (2020).
Zheng, Q. et al. Accurate diagnosis and survival prediction of bladder cancer using deep learning on histological slides. Cancers 14, 5807 (2022).
Pan, J. et al. An artificial intelligence model for the pathological diagnosis of invasion depth and histologic grade in bladder cancer. J. Transl. Med. 21, 42 (2023).
Wenger, K. et al. A semi-supervised learning approach for bladder cancer grading. Mach. Learn. Appl. 9, 100347 (2022).
Habibi, K. et al. ABC: Artificial intelligence for bladder cancer grading system. Mach. Learn. Appl. 9, 100387 (2022).
Jansen, I. et al. Automated detection and grading of non-muscle-invasive urothelial cell carcinoma of the bladder. Am. J. Pathol. 190, 1483–1490 (2020).
Eckstein, M. et al. Proposal for a novel histological scoring system as a potential grading approach for muscle-invasive urothelial bladder cancer correlating with disease aggressiveness and patient outcomes. Eur. Urol. Oncol. (2023).
García, G., Esteve, A., Colomer, A., Ramos, D. & Naranjo, V. A novel self-learning framework for bladder cancer grading using histopathological images. Comput. Biol. Med. 138, 104932 (2021).
Li, X., Cen, M., Xu, J., Zhang, H. & Xu, X. S. Improving feature extraction from histopathological images through a fine-tuning imagenet model. J. Pathol. Inform. 13, 100115 (2022).
Chen, S. et al. Clinical use of machine learning-based pathomics signature for diagnosis and survival prediction of bladder cancer. Cancer Sci. 112, 2905–2914 (2021).
Echle, A. et al. Deep learning in cancer pathology: A new generation of clinical biomarkers. Br. J. Cancer 124, 686–696 (2021).
Gavriel, C. G. et al. Assessment of immunological features in muscle-invasive bladder cancer prognosis using ensemble learning. Cancers 13, 1624 (2021).
Barrios, W. et al. Bladder cancer prognosis using deep neural networks and histopathology images. J. Pathol. Inform. 13, 100135 (2022).
Howard, F. M. et al. The impact of site-specific digital histology signatures on deep learning model accuracy and bias. Nat. Commun. 12, 4423 (2021).
Anghel, A. et al. A high-performance system for robust stain normalization of whole-slide images in histopathology. Front. Med. 6, 193 (2019).
Gupta, V. & Bhavsar, A. Breast cancer histopathological image classification: Is magnification important? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 17–24 (2017).
Slotman, A. et al. Quantitative nuclear grading: An objective, artificial intelligence-facilitated foundation for grading noninvasive papillary urothelial carcinoma. Lab. Investig. 103, 100155 (2023).
Lin, H. et al. Scannet: A fast and dense scanning framework for metastastic breast cancer detection from whole-slide image. In 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), 539–546. https://doi.org/10.1109/WACV.2018.00065 (2018).
Abdeltawab, H. et al. A pyramidal deep learning pipeline for kidney whole-slide histology images classification. Sci. Rep. 11, 20189 (2021).
Bankhead, P. et al. Qupath: Open source software for digital pathology image analysis. Sci. Rep. 7, 1–7 (2017).
The Open Microscopy Environment (OME). Bio-formats command-line tool—version 7.2.0. https://www.openmicroscopy.org/bio-formats. Accessed 10 Feb 2024 (2024).
Salvi, M., Molinari, F., Acharya, U. R., Molinaro, L. & Meiburger, K. M. Impact of stain normalization and patch selection on the performance of convolutional neural networks in histological breast and prostate cancer classification. Comput. Methods Programs Biomed. Update 1, 100004 (2021).
Zhang, X., Zhou, X., Lin, M. & Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 6848–6856 (2018).
Deng, J. et al. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255 (IEEE, 2009).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
Fang, S., Yang, J., Wang, M., Liu, C. & Liu, S. An improved image classification method for cervical precancerous lesions based on shufflenet. Comput. Intell. Neurosci. 2022 (2022).
Fu, X., Liu, S., Li, C. & Sun, J. Mclnet: An multidimensional convolutional lightweight network for gastric histopathology image classification. Biomed. Signal Process. Control 80, 104319. https://doi.org/10.1016/j.bspc.2022.104319 (2023).
Bungărdean, R. M., Şerbănescu, M.-S., Streba, C. T. & Crişan, M. Deep learning with transfer learning in pathology. Case study: Classification of basal cell carcinoma. Roman. J. Morphol. Embryol. 62, 1017 (2021).
Gontero, P. et al. EAU guidelines on non-muscle-invasive bladder-cancer. In Proceedings of the EAU Annual Congress, Milan, Italy, vol. 10 (2023).
Rifat, U. N. The implications of BCG shortage for the management of patients with non-muscle-invasive bladder cancers. J. Urol. Ren. Dis. 7, 1245 (2022).
Acknowledgements
This research is supported by Princess Nourah bint Abdulrahman University Researchers Partial Supporting Project Number (PNURSP2024R40), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
S.K., O.E., K.A., and D.G. recruited data for the study. A.S., A.A., M.S.,A.M., E.E., M.M. N.A, M.G., and A.E. performed the formal analysis for the study. A.S., A.A., M.S., A.M. and A.E. were responsible for the conceptualization. A.S. and A.A. were responsible for the software development. E.E., M.M. N.A, M.G., and A.E. were responsible for project administration. A.S., A.A., M.S., A.M, and A.E validated the results. A.S., A.A., and M.S. visualized the obtained results. A.S. made all the required figures. All authors were involved in the original draft writing and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Shalata, A.T., Alksas, A., Shehata, M. et al. Precise grading of non-muscle invasive bladder cancer with multi-scale pyramidal CNN. Sci Rep 14, 25131 (2024). https://doi.org/10.1038/s41598-024-77101-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-77101-6
