
Abstract
Physics-informed neural networks have proven to be a powerful approach for addressing both forward and inverse problems by integrating the governing equations’ residuals and data constraints within the loss function. However, their performance significantly declines when interior data is sparse. In this study, we propose a new approach to address this issue by combining the Gated Recurrent Units with an implicit numerical method. First, the input is fed into the neural network to produce an initial solution approximation over the entire domain. Next, an implicit numerical method is employed to simulate the time iteration scheme based on these approximate solutions, wherein the unknown parameters of the partial differential equations are initially assigned random values. In this approach, the physical constraints are integrated into the time iteration scheme, allowing us to formulate mean square errors between the iteration scheme and the neural network’s approximate solutions. Furthermore, mean square errors comparing sparse interior data points and the network’s corresponding predictions are incorporated into the loss function. By minimizing this combined loss, the unknown parameters are identified, and the complete solution is obtained. The algorithm’s effectiveness is demonstrated in various numerical experiments, such as Burgers’ equation, Allen–Cahn equation, and non-linear Schrödinger equation.
Similar content being viewed by others

Introduction
Inverse problems arise in many scientific and engineering applications, where the goal is to infer unknown parameters or functions from indirect and often incomplete observations. These problems are inherently ill-posed, as small errors in data can lead to large deviations in the solution, making them challenging to solve using traditional methods. In this paper, we focus on simultaneously reconstructing the full spatio-temporal solution of a system governed by partial differential equations (PDEs) and estimating unknown parameters, using only limited boundary or internal measurements.
In recent years, machine learning approaches, especially neural networks, have gained significant attention for solving inverse problems. They offer a flexible and data-driven framework to capture complex dependencies in high-dimensional spaces, where classical methods struggle. In particular, Physics-informed neural networks (PINNs) have garnered significant attention for solving PDEs and inverse problems in the rapidly expanding field of scientific machine learning1,2,3,4. By embedding the governing mathematical model directly into the loss function, PINNs enforce constraints on the network’s output, ensuring that the predicted solutions adhere to the underlying PDEs. This approach allows for the solution of both forward and inverse problems by leveraging limited observational data while exploiting the structure of the physical laws. The emergence of automatic differentiation5,6, along with advances in computational power, made the implementation of these concepts more accessible and scalable.
Data-driven approaches for discovering PDEs have gained significant traction due to advances in deep learning techniques7. Presents PDE-Net, a deep learning model that learns both differential operators and nonlinear responses from data to predict system dynamics and uncover the underlying partial differential equations (PDEs). By constraining convolutional filters based on wavelet theory, PDE-Net identifies the governing PDEs while maintaining strong predictive capabilities, even in noisy environments8. Proposes a new framework combining neural networks, genetic algorithms, and adaptive methods to address challenges in discovering PDEs from sparse, noisy data. A physics-encoded discrete learning framework for uncovering spatio-temporal PDEs from limited and noisy data, utilizing a deep convolutional-recurrent network to embed prior physics knowledge and reconstruct high-quality data, followed by sparse regression to identify the governing PDEs9. These approaches represent a major step forward in data-driven PDE discovery, offering robust and flexible tools for tackling real-world problems in complex environments.
The success of a neural network can hinge on its architecture. Various applications often necessitate distinct architectures. For instance, the Convolutional Neural Networks10 are effective in handling image recognition while the Recurrent Neural Networks (RNNs)11 is crucial for modeling sequential data. According to the universal approximation theorem12, any continuous function can be arbitrarily closely approximated by a sufficiently large perception13. However, determining the proper parameters of networks to solve some complicated PDEs is difficult14. The selection of suitable architectures is essential for improving the performance. Ying et al.15 approximate the iteration scheme by using the fully connected neural network. In this work, we mainly implement the RNNs in estimating time-dependent PDEs. The RNNs have the gradient vanishing problem hindering the model’s ability to capture long-range dependencies16. To address this problem, two advanced variants, Long Short-Term Memory (LSTM)17 and Gated Recurrent Unit (GRU)18, are designed. Their update and reset gating mechanisms, along with improved memory cell structures, make GRUs well-suited for various sequential data tasks.
In this study, we employ the Gated Recurrent Units (GRU) network to solve time-dependent PDEs and identify the unknown parameters using sparse data. The neural network serves as an approximation for time iteration schemes, and we introduce the Adams–Moulton implicit method to guide convergence to solutions during network training. Integration of sparse data as a regulatory component enhances the model’s accuracy significantly. The efficacy of this algorithm is demonstrated through numerous numerical experiments, encompassing scenarios such as Burgers, Allen–Cahn, and non-linear Schrödinger equations, validating its feasibility and performance across diverse applications.
Outline of paper: In “Methodology” section, the architecture of our model is described, and the algorithm is presented. “Numerical experiments” section presents the results of numerical experiments. The conclusion is mentioned in “Conclusion” section.
Methodology
“Methodology” section primarily presents the algorithm for solving time-dependent PDEs.
Problem setup
Consider the time-dependent PDE of the form:
subject to initial and boundary conditions,
where \(u = u(t, {\textbf{x}})\) is the latent solution of Eq. (1), and f is a function of u, t, u and its partial derivatives of u with respect to \({\textbf{x}}\). Here, \({\textbf{x}}_{1}\) and \({\textbf{x}}_{2}\) denote the lower and upper bounds of \({\textbf{x}}\) respectively. \(\varvec{\tau }\) represents unknown parameters in Eq. (1). We aim to propose a neural network to approximate the \(u({\textbf{x}},t)\) and estimate the unknown parameters \(\varvec{\tau }\) using only a few interior observations with initial conditions.
Algorithm
In this section, we mainly describe our algorithm. The architecture is comprised of one layer of GRUs and several fully connected layers. We utilize the finite difference to approximate the partial derivatives of Eq. (1) so we can discretize the domain into a \(M\times N\) mesh grid, defined by \(x_{i}, i = 0,1,2,\dots , M-1\) and \(t_{j}, j = 0,1,2,\dots , N-1\), with step size \(\Delta x\) and \(\Delta t\).
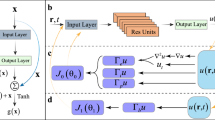
The flow chart of our approach is presented in Fig. 2. From the left side of this figure, we use a neural network, denoted by \({\bar{u}}(t,u;\varvec{\theta })\), to approximate u(t, u), and \(\varvec{\theta }\) represents the parameters of neural network. The number of neurons for each layer is set to N, with each neuron providing an estimation of the solution at \(t_{j}\). The different neurons of the output layer generate the approximations \({\bar{u}}(t_{j},u;\varvec{\theta })\) at \(t_{j}, j = 0,1,2,\dots , N-1\).
As for spatial discretization of the governing partial differential equation, we considered several finite difference schemes, including forward, backward, and upwind approximations. Ultimately, the central difference scheme was selected due to its second-order accuracy, which offers a more precise approximation of spatial derivatives compared to the first-order accuracy of the forward and backward schemes19. While upwind differences are commonly employed in advection-dominated problems to enhance numerical stability and suppress spurious oscillations20, we are not focusing on strongly convection-driven problems. As a result, the central difference scheme provided a favorable balance between accuracy and computational efficiency. A stability analysis was also conducted using von Neumann analysis, confirming that the central difference scheme, in combination with the chosen time-stepping method, yields a stable and convergent numerical solution within the tested parameter regime21.
Figure 1 presents a geometric interpretation of finite difference approximations for the first derivative of a smooth function u(x). The function is evaluated at three points: \(x-\Delta x, x, x + \Delta x\), corresponding to the locations of points A, P, and B, respectively. The secant line between A and P approximates the backward difference, while the secant between P and B represents the forward difference. The line connecting A and B captures the central difference approximation:
with an error of order \(\Delta x^{2}\). This figure illustrates how central differencing provides a more symmetric and accurate estimate of the derivative at x by leveraging function values on both sides of the point.

Central difference approximation22.
Then, we apply the central difference scheme to approximate the second-order spatial derivatives23,
Multistep methods are particularly well-suited to recurrent frameworks because both approaches leverage information from multiple previous states to compute the next state. In recurrent neural networks, the hidden state at each time step depends on past hidden states. Similarly, in multistep numerical methods, the next solution value is computed as a function of several previous time steps24. This shared structure allows multistep methods to naturally align with the sequential and memory-based nature of recurrent systems.
Also, when dealing with sequential data on recurrent neural networks, multi-step methods are highly effective due to their superior stability, accuracy, and reliability as compared to the one-step multi-stage method. Let \(h = f(x,{\bar{u}},{\bar{u}}_{x},{\bar{u}}_{xx})\), then h is employed to approximate the new time iteration scheme \({\tilde{u}}(x,t)\) by applying the Adams–Moulton Implicit methods25. For instance, the one-step implicit method or trapezoidal rule:
Then, one component of the loss function can be constructed as the mean square error between the \({\bar{u}}\) and \({\tilde{u}}\).

Flowchart of the algorithm for identifying parameters of PDEs using sparse data.
As for the right side of Fig. 2, we randomly select some sparse observations represented by \(u_{data}\) at first. Correspondingly, the \(x_{data}\) is denoted as values at these selected spatial points. The \({\bar{u}}_{data}(t_{0},x_{data}), \dots , {\bar{u}}_{data}(t_{N-1},x_{data})\) are the output of the neural network. Then, inspired by26, we apply \(\lambda\) as a weighting factor on the data term in the loss function to emphasize data fidelity, ensuring the neural network closely fits the data points. This hyperparameter balances the trade-off between fitting the data and other loss components.
We also incorporate the initial condition into the loss function.
The total loss function is comprised of these three terms.
In Fig. 2, the neural networks on both sides use identical parameters, meaning they share the same weights and biases across all layers. This ensures that both networks produce consistent outputs for the same inputs. By incorporating randomly selected known data points into the loss function, we enforce the network to align its predictions with the given data, guaranteeing consistency and agreement at these selected points. Algorithm 1 describes the procedures mentioned above.

Approximate the unknown parameters from sparse data using GRU neural network
Numerical experiments
In this section, we present the results of Burgers’ equation, Allen–Cahn equation, and non-linear Schrödinger to validate the effectiveness of our method. We utilize the numerical method or analytical solution to generate the synthetic data and randomly pick sparse data at each time step. Our model infers the complete spatio-temporal solutions of these equations while also approximating the unknown parameters. The architecture comprises one layer of GRUs and some dense layers, and each cell or neuron of the output layer will give the prediction at \(t_{j}\). Thus, each layer’s number of cells or neurons depends on the \(\Delta t\). We train the network by applying the Adam optimizer27, and then followed by L-BFGS28 to minimize the loss function. The idea behind this is that the Adam optimizer avoids the local minimum, and then the solutions can be refined by the L-BFGS optimizer29. We adopt the Tanh function as the activation function for neural networks. We utilize the Learning Rate decay30, which started with a relatively large learning rate and reduced it after a certain number of iterations. The Algorithm 1 is implemented by utilizing the computing package PyTorch31. To further evaluate the performance of our algorithm, we introduce Gaussian noise into the data and rerun the program. This allows us to assess the robustness of the model and its ability to estimate parameters accurately under realistic conditions with data imperfections.
Burgers’ equation
The viscous Burgers’ equation is the fundamental nonlinear PDEs in fluid dynamics and shock waves. The Burgers’ equation with periodic boundary condition is given by
where \(\tau /\pi\) is the viscosity coefficient, and \(\tau\) will be estimated by using the Algorithm 1. We set the time-step \(\Delta t = 0.01\) and obtain 10000 uniformly spaced x values from \(-\)1 to 1. The observations are obtained by solving the Eq.(3) numerically, given that \(\tau = 0.01\). We randomly select 20 data points for each time step, and after several experiments, the corresponding \(\lambda\) is set to 25. The network consists of a single GRU layer followed by two dense layers, each with 100 neurons. Initially, \(\tau\) is set to 1. Then, we implement the Algorithm 1 to estimate the \(\tau\) and the complete solution across the entire domain. The model is trained in 6000 epochs with the Adam optimizer at a learning rate of 0.005, followed by an additional 6000 epochs with a learning rate of 0.001, and subsequently refined using L-BFGS to achieve convergence. The approximated parameter \({\bar{\tau }}\) and solution \({\bar{u}}\) are utilized to construct the loss function. Firstly, we calculate
Then, we apply the Adams–Moulton Three-Step implicit method to obtain:
The loss function can be expressed as follows:
Figure 3 illustrates the results at several selected time values, providing a comparison between the predicted solution and the exact solution. In the figure, the blue data points represent randomly selected points that are used for regularization in the loss function. From the comparison, it is evident that the predictions made by our neural network align closely with the exact solution, demonstrating the model’s ability to accurately capture the underlying dynamics of the problem. This strong agreement between the predicted and exact solutions highlights the effectiveness of our network in solving the given task.
The vanilla PINN is applied to solve this inverse problem under the same conditions for comparison with our method. The network consists of five hidden layers, each with 200 neurons, and uses the Tanh activation function. The model undergoes training in the same manner as our approach. Let \({\hat{u}}\) be the output of the network, representing the network’s output, with partial derivatives computed via automatic differentiation. The loss function is formulated as follows:
where \({\hat{\tau }}\) is the approximation of parameter \(\tau\) by PINN, and \(\lambda\) is set to 40. Table 1 presents the results of PINN and Algorithm 1. The first row presents the relative \(L_{2}\) errors between the solutions obtained using a numerical PDE solver and those predicted by the neural network, calculated using Eq. (14). The second row displays the parameters estimated by the two methods. As shown in the Table 1, Algorithm 1 achieves lower relative \(L_{2}\) errors and more accurate parameter identification compared to PINN. The Table 2, shows good performance of Algorithm 1 under low noise levels, where the estimated parameters are close to the exact values. As noise increases, errors grow, and the parameter estimates deviate further, but the results remain acceptable for moderate noise levels.

Burgers’ equation: snapshots of the predicted solutions and exact solutions at \(t = \{0.0,0.3,0.5,0.7,0.9,1.0\}\).
Allen–Cahn equation
To further validate the effectiveness of our method, we implement the Algorithm 1 to solve the Allen–Cahn PDE, which is a reaction-diffusion equation. It describes the phase separation process in multi-component alloy systems, including order-disorder transitions. The Allen–Cahn PDE is given as follows:
where D is the diffusion rate, and R is the reaction term coefficient. We set the time-step \(\Delta t = 0.005\) in this experiment and use the same x values. Let \(D = 0.00001\) and \(R = 5\), the synthetic data is obtained using the numerical PDE solver. We randomly pick 15 data points from each time step. Considering the smaller \(\Delta t\) in this case so that there are more collocation data points, we increase the \(\lambda\) to 40. The network is constructed by one GRUs layer and three dense layers with 201 neurons per layer, it is trained for 5000 epochs using the Adam optimizer with a learning rate of 0.005, followed by another 5000 epochs with a learning rate of 0.001, and then further optimized using L-BFGS to reach convergence. Both D and R are initially set to one. After we obtaining \({\bar{u}}\), and approximated \({\bar{D}}\) and \({\bar{R}}\), we calculate
where \(u_{x}\) and \(u_{xx}\) are calculated by finite difference. The Adams–Moulton Four-Step implicit method is adopted to calculate \({\tilde{u}}\). Then, the loss function is constructed as follows:
Figure 4 shows the comparison between the predicted and exact solutions of a system at different time steps. The solid lines are the predicted solutions, the dashed lines represent the numerical solutions, and the scatter points are randomly selected data points. The lines for both time steps show a close alignment between the predicted and exact solutions, indicating that the network model provides an accurate approximation for both time steps.
A similar PINN is utilized to solve the inverse problem of the Allen–Cahn equation. The loss function is
where \({\hat{D}}\) and \({\hat{R}}\) are PINN’s approximated diffusion rate and reaction term coefficient, respectively, and \(\lambda = 40\). From Table 3, the first row displays the relative \(L_{2}\) errors between the numerical solution and the predictions from the two networks. The second row presents the estimated diffusion rate, while the third row shows the reaction coefficients obtained by the two methods. The error in the diffusion rate appears relatively large because the true diffusion value is very small, which amplifies the relative error. Additionally, Algorithm 1 demonstrates better performance in this experiment. Similarly, Table 4 shows that for smaller noise levels, the Algorithm 1 provides accurate approximations and parameter estimates close to the true values.

Allen–Cahn equation: snapshots of the predicted solutions and exact solutions at different time steps.
Non-linear schrodinger equation
The non-linear Schrödinger equation, describing the behavior of complex-valued wavefunctions, is chosen as another example to validate the effectiveness of our methodology further. The equation with the periodic boundary conditions is given as follows:
where h is complex, and D is the diffusion rate. Then, Eq. (19) can be redefined as \(h(x,t) = u(x,t) + iv(x,t)\), where u(x, t) represents the real part and v(x, t) represents the complex part. The split equations are as follows:
Let the time-step size be \(\Delta t = \pi /400\) with \(D = 0.5\), and 10,000 x-collocation points between \(-\)5 and 5. The PDE solver is used to solve Eq. (20) and generate the synthetic data. For each time step, 20 data points are randomly selected. Two networks are employed to approximate u and v respectively. Each network is constructed by one layer of GRUs and three dense layers with 200 neurons per layer. The activation function of hidden layers is Tanh, and the ReLU is applied to the output layer to keep the values non-negative. Then, the output \({\bar{u}}\) and \({\bar{v}}\) are used to get
Then, combined with the Adams–Moulton implicit methods, \(f_{u}\) and \(f_{v}\) are utilized to calculate the \({\tilde{u}}\) and \({\tilde{v}}\). The parameters of these two networks are learned by adopting 6000 iterations of Adam with a learning rate 0.005 and 6000 iterations of \(L-BFGs\) with a learning rate 0.5 to minimize the loss functions \(loss = loss_{{\bar{u}}} + loss_{{\bar{v}}}\).
Figure 5 presents the comparison between the prediction \(|h| = \sqrt{{\bar{u}}^{2} + {\bar{v}}^{2}}\) and numerical solution. It demonstrates that the network’s predictions closely align with the numerical solution. The regular PINN is applied to solve the Schrödinger equation for comparison. The neural network architecture includes 6 dense layers, each with 200 neurons. The input and output layers both contain two neurons, where the output layer produces \({\hat{u}}\) and \({\hat{v}}\). The loss function is defined as:
\(\lambda\) is set to 50. The total loss, defined as \(loss_{{\hat{u}}} + loss_{{\hat{v}}}\), is minimized using 2000 iterations of the Adam optimizer with a learning rate of 0.005, followed by 8000 iterations with a learning rate of 0.001. The solution is then further refined using the L-BFGS algorithm. Table 5 provides a more accurate parameter approximation and smaller relative \(L_{2}\) errors compared to the PINN. From Table 6, the Algorithm 1 performs well with small noise, with parameter estimates aligning closely with the exact values.

Schrodinger equation: snapshots of the predicted solutions and exact solutions at \(t = \{0,\frac{\pi }{12},\frac{2\pi }{12},\frac{3\pi }{12},\frac{4\pi }{12},\frac{\pi }{2}\}\).
Two-dimentional heat equation
We then applied Algorithm 1 to the 2D Heat Equation with Neumann boundary conditions. The equation is given by
where \(\alpha\) is thermal diffusivity. Under the given initial and boundary conditions, the analytical solution is
We set \(\alpha = 4\), the step-sizes \(\Delta t = 0.005\), \(\Delta x = 0.002\), and \(\Delta y = 0.002\). The analytical solution described in Eq. 25 generates the data, from which 20 data points are randomly selected at each time step. The neural network architecture consists of a single layer of GRUs, followed by five fully connected dense layers, each containing 200 neurons. The Tanh activation function is applied to each dense layer, except for the final output layer, where the activation function is not applied. To construct the loss function, we first calculate
where the \({\bar{\alpha }}\) is the estimated thermal diffusivity by neural network. As presented in the Algorithm 1, \({\tilde{u}}\) is calculated using the four-step Adams-Moultto implicit method. The loss function is constructed as
The \({\bar{\alpha }}\) represents the approximated thermal diffusivity by minimizing the loss function Eq. (27), and we set \(\lambda = 20\). Figure 6 presents heatmaps comparing the predicted and exact solutions for a 2D time-dependent PDE at \(t=\{0.0, 0.05, 0.1\}\). The heatmaps of the predicted solutions (left column) and exact solutions (right column) visually demonstrate the accuracy of the predictions. The optimization process begins with 2000 iterations of the Adam optimizer at a learning rate of 0.005, followed by 8000 iterations at a reduced learning rate of 0.001. Subsequently, the solution is further refined using the L-BFGS algorithm. As shown in Table 7, this approach yields more accurate parameter approximations and smaller relative \(L_{2}\) errors compared to the PINN. For the 2D heat equation in Table 8, the Algorithm 1 provides accurate parameter estimates under small noise, closely matching the exact values. However, errors and deviations increase with higher noise levels, highlighting limitations under excessive noise.

2D heat equation: snapshots of the predicted solutions and exact solutions at \(t = \{0,0.05, 0.1\}\).
Conclusion
The Gated Recurrent Units neural network is designed to handle time-series data, while the implicit numerical method estimates values at the next time step. Additionally, physical laws are embedded directly into the loss function. This seamless integration of time-series modeling, implicit numerical techniques, and physics-informed learning creates a robust framework for parameter identification and deriving the full solution across the domain using sparse data. Initially, neural networks are employed to approximate the iterative scheme for solving partial differential equations. The finite difference method is then applied to compute derivatives, followed by the formulation of new iteration schemes through the implicit approach. By minimizing the discrepancy between the original and newly derived schemes, the network effectively converges to the solution of the partial differential equation and identifies unknown parameters. Sparse interior observation data acts as a regularizer, improving the network’s convergence. The non-Linear Schrödinger equation is transformed into a system of equations, demonstrating the effectiveness of our proposed method for solving such systems. Across all examples, the results indicate that Algorithm 1 consistently generates accurate approximations from sparse data even with moderate Gaussian noise. However, if the noise becomes excessively large, the Algorithm 1 struggles to produce reliable approximations. Additionally, the current predictions of parameters are static. Future work will focus on extending the methodology to handle parameters of partial differential equations that vary dynamically in both space and time. Another important consideration for future exploration is the scenario where the entire solution or the parameters to be predicted exhibit discontinuities, which presents additional numerical and modeling challenges.
Data availability
The datasets generated and/or analyzed during the current study are not publicly available due to their synthetic nature, created using a numerical partial differential equation (PDE) solver to simulate specific research conditions, but are available from the corresponding author on reasonable request.
References
Raissi, M., Perdikaris, P. & Karniadakis, G. E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 378, 686–707 (2019).
Raissi, M., Perdikaris, P. & Karniadakis, G. E. Machine learning of linear differential equations using Gaussian processes. J. Comput. Phys. 348, 683–693 (2017).
Raissi, M., Perdikaris, P. & Karniadakis, G. E. Inferring solutions of differential equations using noisy multi-fidelity data. J. Comput. Phys. 335, 736–746 (2017).
Long, J., Khaliq, A. & Xu, Y. Physics-informed encoder-decoder gated recurrent neural network for solving time-dependent PDEs. J. Mach. Learn. Model. Comput 5, 3 (2024).
Paszke, A. et al. Automatic differentiation in pytorch. In: (2017).
Baydin, A. G., Pearlmutter, B. A., Radul, A. A. & Siskind, J. M. Automatic differentiation in machine learning: A survey. J. Marchine Learn. Res. 18, 1–43 (2018).
Long, Z., Lu, Y., Ma, X. & Dong, B. Pde-net: Learning pdes from data. In: International conference on machine learning. PMLR. (2018), pp. 3208– 3216
Xu, H., Zhang, D. & Zeng, J. Deep-learning of parametric partial differential equations from sparse and noisy data. Phys. Fluids 33, 3 (2021).
Rao, C., Ren, P., Liu, Y. & Sun, H. Discovering nonlinear PDEs from scarce data with physics-encoded learning. In: arXiv preprint arXiv:2201.12354 (2022).
Russakovsky, O. et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vision 115, 211–252 (2015).
Rumelhart, D. E., Hinton, G. E., Williams, R. J., et al. Learning internal representations by error propagation. (1985).
Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control Sig. Syst. 2(4), 303–314 (1989).
Hornik, K., Stinchcombe, M. & White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 2(5), 359–366 (1989).
Waheed, U., Haghighat, E., Alkhalifah, T., Song, C. & Hao, Q. PINNeik: Eikonal solution using physics-informed neural networks. Comput. Geosci. 155, 104833 (2021).
Li, Y., Zhou, Z. & Ying, S. DeLISA: Deep learning based iteration scheme approximation for solving PDEs. J. Comput. Phys. 451, 110884 (2022).
Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Internat. J. Uncertain. Fuzziness Knowledge-Based Syst. 6(02), 107–116 (1998).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997).
Chung, J., Gulcehre, C., Cho, K. & Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In: arXiv preprint arXiv:1412.3555 (2014).
LeVeque, R. J. Finite difference methods for ordinary and partial differential equations: Steady-state and time-dependent problems. SIAM, (2007)
Strikwerda, J. C. Finite difference schemes and partial differential equations. SIAM, (2004).
Iserles, A. A first course in the numerical analysis of differential equations Vol. 44 (Cambridge University Press, Cambridge, 2009).
Smith, G. D. Numerical solution of partial differential equations: Finite difference methods (Oxford University Press, Oxford, 1985).
Thomas, J. W. Numerical partial differential equations: Finite difference methods Vol. 22 (Springer Science & Business Media, Berlin, 2013).
Lambert, J. D. Numerical methods for ordinary differential systems: The initial value problem (John Wiley & Sons Inc, Hoboken, 1991).
Hairer, E., Nørsett, S. P. & Wanner, G. Solving ordinary differential equations. I: Nonstiff problems. 3rd corrected printing. In: Springer Series in Computational Mathematics 8, (2010), 528.
Wight, C. L. & Zhao, J. Solving Allen–Cahn and cahn-hilliard equations using the adaptive physics informed neural networks. In: arXiv preprint arXiv:2007.04542 (2020).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. In: arXiv preprint arXiv:1412.6980 (2014).
Liu, D. C. & Nocedal, J. On the limited memory BFGS method for large scale optimization. Math. Program. 45(1–3), 503–528 (1989).
Markidis, S. The old and the new: Can physics-informed deep-learning replace traditional linear solvers?. Front. Big Data 4, 669097 (2021).
Chollet, F. Deep learning with Python (Simon and Schuster, New York, 2021).
Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 32, (2019).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Long, J., Khaliq, A. & Furati, K.M. Parameter identification for PDEs using sparse interior data and a recurrent neural network. Sci Rep 15, 33828 (2025). https://doi.org/10.1038/s41598-025-02410-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-02410-3
