
Abstract
The need for personalized and real-time feedback in English writing instruction is increasing rapidly. Traditional systems, which depend on rule-based engines and shallow machine learning models, struggle to meet this demand. They often fall short in addressing key aspects such as grammar correction, sentence variety, and logical coherence. This study introduces a multidimensional feedback system based on the Transformer architecture. The system combines self-attention mechanisms with a dynamic parameter adjustment module to deliver feedback at multiple levels—from individual words to entire paragraphs. A BERT model is fine-tuned on a large, diverse corpus that includes academic papers, blog posts, and student essays. As a result, the system can provide real-time suggestions that address grammar, vocabulary, sentence structure, and logic. Experimental results show that the system improves the writing quality of non-native learners while maintaining a feedback delay of just 1.8 s. Its modular design allows for the customization of learning paths, and user privacy is protected through differential privacy mechanisms. This approach offers a technically sound and educationally practical solution for developing AI-assisted writing tools across disciplines.
Similar content being viewed by others
Introduction
Research background and motivations
The rapid advancement of information technology has made artificial intelligence (AI) a powerful tool in the field of education. In particular, the use of AI to improve students’ learning efficiency and effectiveness has become a prominent topic in language learning research1,2,3. As the global lingua franca, English plays an essential role in international communication, academic research, and business activities. For non-native speakers, developing strong English writing skills is especially critical4,5,6. Current English writing feedback systems face several challenges. Traditional approaches often depend on rule-based engines or basic machine learning models, which limit error correction to fixed grammatical patterns. As a result, they struggle to address diverse language expressions and complex semantic relationships. Early systems, for instance, frequently misinterpret non-standard sentence structures or culturally specific expressions and lack the ability to assess logical coherence and writing style in depth. Additionally, most existing tools focus mainly on surface-level errors, such as spelling and basic grammar, while overlooking the development of higher-order writing skills like argument structure and rhetorical strategies. This narrow focus makes it difficult for students to progress beyond common writing obstacles. Furthermore, traditional feedback mechanisms are typically slow, unable to offer real-time guidance, and insufficiently personalized to meet learners’ diverse backgrounds and needs. Resource constraints also pose a major challenge, as many educational institutions lack the computational power and high-quality data needed to support advanced intelligent systems. These limitations further widen the gap in feedback efficiency and coverage7,8,9.
In recent years, the application of artificial intelligence (AI) has rapidly expanded across multilingual and complex real-world scenarios. For example, Samaan et al. (2025) employed a Transformer model for dynamic prediction of multilingual network traffic10. However, their work focused on data-driven network management and did not address semantic analysis in educational contexts. Yahiaoui et al. (2023) developed a syntactic framework for non-foundational Arabic phrases11, marking a breakthrough in rule-based system design. Yet, the absence of adaptive learning limited its ability to handle non-standard expressions caused by cross-linguistic interference. Similarly, Humaidi et al. (2020) implemented efficient pattern recognition using FPGA (Field-Programmable Gate Array) hardware optimization12, but their approach emphasized hardware acceleration without deep integration into natural language processing (NLP) tasks. These studies highlight a broader issue in current AI applications: fragmentation across domains. While models often perform well in isolated scenarios, integrated solutions for educational feedback—especially those targeting semantic modeling and real-time interaction for non-native learners—remain underdeveloped. Existing AI writing tools have made notable progress in grammar correction and sentence restructuring. However, deeper challenges in academic writing, such as argumentation rigor and reasoning coherence, are still inadequately addressed. Non-native writers often struggle with organizing arguments, employing rebuttal strategies, and constructing causal reasoning due to cultural differences and limited academic training. Previous attempts to enhance argumentative writing have relied on fact-checking modules and logic graph representations. Although effective, these approaches typically require large annotated datasets and significant computational resources, which limit their scalability in educational settings. This gap underscores the urgent need for lightweight, instructionally adaptive tools capable of analyzing argumentation in a pedagogically meaningful way.
To overcome these challenges, researchers have increasingly explored the use of advanced technologies in education. Notably, progress in Natural Language Processing (NLP) has enabled machines to better understand, interpret, and generate human language. Among recent developments, the Transformer model has emerged as a groundbreaking deep learning architecture, driving major advancements in tasks such as machine translation, text summarization, and question answering. Compared to RNN or LSTM models, which suffer from inefficiencies due to their reliance on sequential processing, the Transformer model leverages a self-attention mechanism that captures global dependencies across the text in parallel. This makes it particularly effective at handling long-range semantic relationships, which are crucial for analyzing logical coherence in writing. Additionally, its multi-head attention mechanism enables the extraction of features from multiple perspectives, enhancing the model’s ability to understand complex language phenomena such as metaphors and coreference. As a result, the Transformer excels in providing more accurate suggestions for vocabulary optimization and sentence structure diversity. Furthermore, its pretraining–fine-tuning paradigm allows the model to learn general language patterns from large-scale corpora and then adapt to specific educational domains, offering a flexible technical foundation for multidimensional feedback. Compared to traditional models, this architecture significantly improves both the depth and breadth of feedback13,14,15. This study aims to explore the application of these advanced technologies in English writing instruction by developing a Transformer-based multidimensional feedback system. The Multidimensional Feedback System refers to an intelligent writing assistance framework based on NLP technologies, which simultaneously addresses four key dimensions: grammatical accuracy, vocabulary richness, sentence structure diversity, and content coherence.
Research objectives
Prior research reveals notable limitations at both theoretical and practical levels. Rule-based engines, dependent on predefined templates, are ill-equipped to handle unconventional errors stemming from cross-linguistic interference. RNN and LSTM models, constrained by their sequential processing nature, struggle to capture long-range dependencies, weakening their ability to assess paragraph-level logical coherence. Commercial tools (e.g., Grammarly) offer reliable basic grammar correction but lack adaptability to educational contexts due to their closed-source architecture. Additionally, delayed feedback and limited personalization hinder their utility in real-time classroom settings. General-purpose large language models (e.g., Generative Pre-trained Transformer 3.5, GPT-3.5), despite their strong generative capabilities, are hampered by opaque decision-making processes and data privacy concerns—factors that restrict their trustworthy integration into educational environments. These challenges highlight the urgent need for intelligent feedback systems that combine technical robustness, pedagogical relevance, and ethical compliance.
This aims to explore how advanced AI technologies, particularly the Transformer model, can be applied to build an efficient multidimensional feedback system for English writing instruction. This study proposes a novel paradigm for multidimensional intelligent feedback in English writing instruction, driven by systematic technological innovation and interdisciplinary integration. Its core contributions span four key areas: First, it introduces the first feedback framework that integrates grammar, vocabulary, syntax, and logical coherence analysis, enabling joint modeling of sentence- and paragraph-level features through a hierarchical attention mechanism. Second, it develops a dynamic parameter adjustment module that prioritizes feedback based on learners’ historical error patterns and specific target contexts (e.g., academic writing or business communication). Third, it implements a lightweight model architecture combined with mixed-precision computation to achieve industry-leading responsiveness while preserving deep semantic understanding. Fourth, it incorporates an ethics-centered privacy protection mechanism, leveraging differential privacy and data anonymization to establish a compliant model for large-scale educational data usage. Collectively, these innovations shift AI-powered educational tools from simple “error correction utilities” to holistic “cognitive development partners.”
Literature review
In recent years, advancements in NLP have introduced both new opportunities and challenges to the field of education16. Fagbohun et al. (2024) noted that traditional English writing instruction largely depended on teachers’ subjective evaluations—a process that was not only time-consuming and labor-intensive but also struggled to deliver instant, personalized feedback17. Furthermore, conventional teaching methods often overlooked higher-order writing skills, such as logical structuring and stylistic expression, focusing instead on basic grammar and vocabulary18. As a result, students frequently faced difficulties in advancing their writing abilities, particularly when engaging with complex text comprehension and generation tasks. To address these shortcomings, researchers have increasingly explored the integration of advanced technologies into English writing instruction.
The Transformer model, one of the most significant breakthroughs in NLP in recent years, has quickly become a central focus of both academic research and industry applications. Hossain and Goyal (2024) demonstrated that the Transformer’s unique self-attention mechanism effectively solved long-range dependency problems, substantially improving the performance of tasks such as machine translation and text generation19. Subsequent studies have further confirmed the model’s advantages in complex semantic understanding, including its use in automated essay-scoring systems20. However, despite its impressive success across various NLP tasks, Sukiman et al. (2024) emphasized that applying the Transformer model to practical English writing instruction remains challenging. Key concerns include data privacy protection, model interpretability, and the need for designing personalized learning pathways21.
Although existing English writing assistance tools and technologies have led to some improvements in instructional outcomes, they still face significant limitations. Olayiwola et al. (2024) proposed that rule-based grammar checkers could only identify a narrow range of errors, while earlier machine learning models, limited by their training data, struggled to accommodate diverse writing styles22. In contrast, Miah et al. (2024) demonstrated that Transformer-based systems could more effectively capture linguistic features and provide more detailed feedback. However, developing and implementing such systems requires substantial computational resources and high-quality datasets, which can be a major challenge for many educational institutions23. Given these challenges, applying the Transformer model to English writing instruction is both an inevitable trend in technological advancement and a critical step toward enhancing teaching quality and fostering personalized learning. Against this backdrop, this study aims to develop a Transformer-based multidimensional feedback system that addresses the shortcomings of current technologies and better meets the needs of English writing instruction. The following sections outline the system’s research and development process, as well as its practical applications.
This study’s comparison with recent literature underscores its unique position and practical value. Unlike the multidimensional writing assessment framework based on large language models (LLMs) proposed by Tang et al. (2024)24, this system utilizes the Transformer’s self-attention mechanism to provide more detailed feedback. It not only addresses basic dimensions such as grammatical accuracy but also introduces the Hierarchical Attention Model, which jointly models sentence- and paragraph-level features. This design achieves over 85% consistency with human raters, outperforming Tang’s study, which achieved 78%, and enhances the depth of logical coherence analysis. Ali et al. (2024) identified three key challenges in educational AI—personalized adaptation, data privacy, and long-term effect monitoring25. This system directly addresses these issues. It incorporates a dynamic parameter adjustment module and L2 regularization, ensuring differential privacy for user data and personalizing error prioritization based on learner history. This dual protection mechanism offers practical advantages over traditional methods. The innovative AI path proposed by Toumia and Zouari (2024)26 is also reflected in this study’s architecture. By combining the Transformer’s pre-training and fine-tuning approach with educational scenario data, the system preserves the model’s general language understanding while adapting it for educational contexts. This strategy is better suited to educational tools than approaches relying solely on general LLMs. Finally, Cong et al. (2024) discussed the interpretability challenges of Transformer models in neuroscience applications27, which led to the design of a feedback traceability mechanism in this study. This mechanism uses attention weight visualization to help educators understand the system’s decision-making process. This education-focused transparency design addresses the “black-box” issue in many AI writing tools and aligns with the emphasis on cognitive traceability in neuroscience.
Recent studies have explored diverse technological approaches to address challenges in argumentation and reasoning within academic writing. For instance, Fabre et al. (2024) developed a large language model enhanced by pretraining tasks to improve argument relation extraction28. However, their evaluation was limited to argumentative texts and did not account for the complexity of academic writing. IBM’s Debater tool advances argumentative depth through fact-checking and counterargument generation, yet its closed-source architecture restricts its adaptability to educational contexts. Similarly, the GPT-4 Academic plugin integrates literature citation suggestions and hypothesis testing frameworks, but concerns about output controllability and ethical risks in educational settings have sparked academic debate. While these advancements offer valuable technical insights for this study, they also expose limitations in existing solutions—namely, a lack of lightweight design, interpretability, and pedagogical compliance. Farrokhnia and Banihashem (2024), using a Strengths, Weaknesses, Opportunities, Threats (SWOT) analysis, noted that generative AI tools such as Chat Generative Pre-trained Transformer (ChatGPT) could improve writing efficiency29. However, their opaque decision-making mechanisms and ethical risks—such as the potential for plagiarism—undermine transparency and trustworthiness in educational contexts. This contradiction underscores the necessity of developing intelligent feedback systems that balance technical precision with educational integrity. Learning Analytics (LA) offers a theoretical foundation for optimizing intelligent feedback systems. A systematic review by Banihashem and Noroozi (2022) demonstrated that real-time tracking and analysis of multi-source data—such as writing patterns and revision histories—enabled LA to dynamically identify learners’ cognitive bottlenecks and generate personalized intervention strategies30. Nevertheless, existing research predominantly focuses on correcting basic grammatical errors, without extending the scope of analysis to argumentative structures (e.g., claim-evidence relationships) or metacognitive skills (e.g., self-regulated learning). This gap provides a theoretical entry point for the design of the multidimensional feedback framework proposed in this study.
Research model
System architecture and design concept
This study employs the pre-trained model Bidirectional Encoder Representations from Transformers (BERT), based on the Transformer architecture, as the core framework, and customizes it extensively for educational scenarios. During the input data processing stage, the system follows a multi-level preprocessing workflow. First, HTML tags and special characters are removed from the text using regular expressions. Then, the WordPiece tokenization algorithm is applied to handle out-of-vocabulary words. Additionally, the Natural Language Toolkit (NLTK toolkit) is used for part-of-speech tagging and named entity recognition (NER). Given the characteristics of educational corpora, a domain-sensitive data augmentation strategy is specially designed. This includes the standardization of citation formats in academic writing and the extraction of polite language patterns from business correspondence, ensuring the scenario adaptability of the training data.
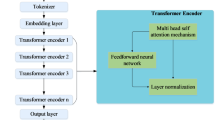
The Transformer-based multidimensional feedback system consists of four main components: the input module, processing module, output module, and feedback adjustment module, as shown in Fig. 1. First, the input module handles the reception of students’ essay texts. These texts may come in the form of digitized versions of handwritten scans or directly entered electronic documents on the platform. To ensure data consistency and accuracy, all input texts go through an initial cleaning process, which includes removing special characters and standardizing punctuation marks.

Overall Architecture of the Transformer-Based Multidimensional Feedback System.
The processing module is the core component of the system. It uses a pre-trained Transformer model that has been specifically optimized to understand complex linguistic structures and generate high-quality feedback. The workflow of the processing module is as follows: First, the text is divided into words or subword units, with each unit assigned a unique index number. For example, given a sentence S, after tokenization, it is transformed into a sequence of tokens \([{w_1},{w_2},...,{w_n}]\). It is then converted into an index sequence \([{i_1},{i_2},...,{i_n}]\) through a mapping function \(f\), where \(j=1,2,...,n\). Once the preprocessing steps are complete, the indexed sequence is passed into the Transformer model. A key feature of the Transformer is its self-attention mechanism, which allows the model to capture all internal dependencies within a sentence, regardless of the input order31,32,33. The computation equation for the self-attention mechanism is as shown in Eq. (1):
\(Q\) represents the query matrix, \(K\) represents the key matrix, \(V\) represents the value matrix, and \({d_k}\) is the dimension of the query vector. This process allows the model to focus on every detail within the input text, providing strong support for tasks like grammar checking and logical analysis. In addition to the single-head attention mechanism, a multi-head attention mechanism is also used to improve the model’s expressiveness. Multi-head attention enables the model to view the input information from multiple perspectives at once, resulting in richer feature representations, as shown in Eq. (2):
h represents the number of attention heads, and \({W^O}\) is a linear transformation matrix. This mechanism helps the model better understand and process complex semantic information, especially when dealing with long-range dependencies.
Once the processing module completes its task, the results are passed to the output module. This module’s main function is to generate specific and actionable feedback based on the information provided by the processing module. The feedback may address various aspects, such as grammar correction, vocabulary enhancement, and improvement of logical structure. For example, if a grammatical error is detected, the system will suggest a specific correction. If the essay’s logical coherence is weak, the system will recommend improvements.
Additionally, the system includes a feedback adjustment module. This module allows teachers or students to fine-tune the feedback according to real-world needs, enhancing the system’s ability to adapt to personalized learning. The system provides feedback at multiple levels: words, sentences, and paragraphs. At the lexical level, it detects improper word usage using subword segmentation and context embedding, offering synonym suggestions. At the sentence level, the self-attention mechanism analyzes grammar and proposes alternative expressions. At the paragraph level, the hierarchical attention model evaluates thematic consistency and logical coherence, suggesting strategies for overall improvement. The system also incorporates three key personalization features: First, it adjusts feedback priorities based on the learner’s error history, such as enhancing tense error detection for students who frequently make such mistakes. Second, it categorizes learners into proficiency levels based on an initial ability assessment and offers tailored recommendations. Beginners focus on basic grammar, while advanced learners work on rhetorical skills. Third, the system supports goal-oriented customization, prioritizing areas such as citation standards for academic writing or formal language detection for business writing. This approach aligns with differentiated instruction theory by emphasizing learner-centered, adaptive learning paths. The feedback adjustment module includes a feature called “instant feedback,” ensuring a response within 2 s of text submission. This quick response is achieved using several techniques: During preprocessing, streaming tokenization and parallel caching minimize delays in text cleaning and tokenization, keeping them under 300 milliseconds. The processing module uses a lightweight, quantized BERT model (BERT-Lite) for faster inference, combined with the Tensor Core units of the NVIDIA Tesla V100 GPU to perform mixed-precision calculations on the attention matrix. As a result, the inference time remains under 1.5 s per request. Stress testing has confirmed that the system maintains 95% compliance with the timeliness requirement, even when processing 32 concurrent requests. By collecting user feedback, it can continuously optimize model parameters, making the system more aligned with actual teaching requirements. It is assumed that the loss function is defined as L, as shown in Eq. (3):
T is the sequence length, \({y_t}\) is the true label, and \(\hat{y}_{{t}}\) is the probability distribution predicted by the model. The model parameters are updated using gradient descent as shown in Eq. (4):
\(\eta\) represents the learning rate, and \(\theta\) denotes the model parameters. Through this process, the system is able to continuously learn and improve during actual use.
This system is designed based on a deep understanding of the limitations of traditional English writing instruction methods. Traditional teaching models often lack personalized guidance, which limits students’ ability to develop strong writing skills. In contrast, the Transformer-based multidimensional feedback system overcomes this limitation through technological innovation. It offers immediate, detailed feedback and dynamically adapts teaching strategies to suit each learner’s progress and characteristics, significantly improving learning efficiency and effectiveness.
The model’s feedback generation logic is multi-layered and interpretable. At the grammatical error correction level, a self-attention heatmap visualizes the contextual dependency of erroneous words. For instance, when detecting article misuse, the model highlights the noun phrase the article modifies. In evaluating paragraph coherence, the hierarchical attention model (HAM) generates attention maps at both the sentence and paragraph levels. This allows teachers to easily identify areas with low attention scores, which may indicate logical gaps. The system also incorporates a feedback priority algorithm (FPA) that ranks feedback dynamically. It does so based on error severity (e.g., core errors that impact comprehension are prioritized over stylistic suggestions) and a Markov chain prediction of the learner’s past errors. This approach ensures that teaching interventions are both precise and progressive. Together, these mechanisms form a “white-box” feedback system, ensuring that the AI decision-making process is transparent and meets the auditability requirements of educational settings.
The system also includes a module for analyzing argumentation logic. Argument structure is identified using a fine-tuned BERT model that detects theses, premises, and conclusions, enabling the construction of paragraph-level logical maps. The integrity of reasoning chains is evaluated by measuring the density of causal connectives (e.g., therefore, however) and matching against hypothesis-testing templates to quantify gaps in logic. Counterargument suggestions are generated based on common rebuttal patterns found in academic corpora (e.g., “Although X claims…, empirical evidence shows…”), offering structured revision prompts. This module adopts a curriculum learning strategy, prioritizing frequent logical errors—such as missing premises or circular reasoning—and gradually guiding learners toward more advanced reasoning skills.
Data preprocessing and model fine-tuning
To ensure the Transformer-based multidimensional feedback system effectively supports English writing instruction, data preprocessing and model fine-tuning are essential steps. These processes not only impact the system’s performance but also directly influence the quality of the feedback it generates. This section outlines the steps for effective data preprocessing and explains how to fine-tune the pre-trained Transformer model to meet specific teaching objectives.
(1) Data Preprocessing. The goal of data preprocessing is to clean, tokenize, and annotate the raw input text, preparing it for further model processing. Figure 2 illustrates the entire data preprocessing workflow.

Data Preprocessing Process.
Text cleaning is the process of removing irrelevant characters and noise, which includes, but is not limited to, standardizing punctuation, converting cases, and removing special characters. Given a sentence S, after preliminary cleaning, it becomes \({S'}\). This process can be accomplished using regular expressions or specialized text-cleaning tools. The next step is tokenization, which involves breaking continuous text into meaningful units. For English, the most common method is to split text based on spaces and punctuation marks34,35,36. However, in practical applications—especially when dealing with complex linguistic phenomena—simple rule-based methods often lack precision. As a result, modern NLP practices typically use subword units, such as Byte Pair Encoding or WordPiece37. Taking WordPiece as an example, the key idea is to dynamically determine the optimal segmentation by analyzing the frequency of n-grams in the text, as shown in Eq. (5):
\(w\) represents the sequence of words after a sentence has been segmented. Each word \({w_i}\) is then further mapped to a unique index number \({i_j}\), as shown in Eq. (6):
\(f\) is a mapping function that converts each word in the vocabulary to a corresponding integer ID.
In addition to tokenization, the text also needs to be annotated. This step involves tasks such as part-of-speech tagging, NER, and other relevant annotations. For example, in a grammar checking task, it is important to identify which parts of the sentence contain errors and specify the type of errors. It is assumed that there is a sentence \({S_e}\) with an error, which can be represented as below after annotation, as shown in Eq. (7):
\(ta{g_i}\) represents the label information of the i-th word, which indicates whether the word is correct and its possible correction suggestions.
(2) Model Fine-Tuning.
In practical applications, to prevent overfitting, this study introduces a regularization term38. A common approach is L2 regularization, as shown in Eq. (8):
\(\lambda\) is the regularization coefficient, controlling the strength of the regularization. Including the regularization term helps limit model complexity and improves its generalization ability.
Given the specific needs of English writing instruction, this study may also require the design of task-specific modules. For instance, in logical structure analysis, a hierarchical attention mechanism can be introduced. This enables the model to make decisions based on information at different levels, such as sentence-level and paragraph-level39,40. Specifically, it is set that \({h_s}\) represents the hidden state at the sentence level, and \({h_p}\) represents the hidden state at the paragraph level, as shown in Eqs. (9) and (10):
\({W_h}\) and \({b_h}\) represent the weight matrix and bias term, respectively. \({\alpha _s}\) and \({\alpha _p}\) represent the attention weights at the sentence and paragraph levels, respectively.
System application effectiveness evaluation
To evaluate the system’s practical effectiveness, this study designs a comprehensive survey that assesses user satisfaction, system usability, and feedback quality. Feedback is collected from 150 students and teachers with diverse backgrounds. Additionally, the system’s performance is measured using quantitative indicators. For example, the Bilingual Evaluation Understudy (BLEU) score is employed to compare the similarity between machine-generated improvement suggestions and expert opinions, as shown in Eq. (11):
\(BP\) is the penalty term used to penalize overly short candidate sentences; \({w_n}\) is the weight, and \({p_{n}}\) is the n-gram exact match ratio.
Through the methodology outlined above, this study not only demonstrates how to build an efficient multidimensional feedback system using the Transformer model but also validates its potential value in English writing instruction. The evaluation process provides valuable insights into the system’s strengths and areas for improvement, guiding further optimization efforts.
The current system has several application limitations that need to be objectively considered. First, the model’s performance heavily relies on the representativeness of the labeled data for the specific domain. For non-standard writing genres, such as poetry or experimental literature, the quality of feedback remains unstable, and the suggestions may deviate from the expression norms specific to those genres. Second, while the system is effective in addressing explicit language errors and structural issues, it still faces limitations in evaluating higher-order skills. These skills include the logical rigor of academic arguments and the demonstration of critical thinking. Currently, feedback in this area is based on predefined rule sets and limited training samples, which may result in mechanical suggestions. Third, the system’s advantage in real-time feedback may have some unintended consequences. Some learners become overly reliant on the system’s corrections and fail to internalize language rules fully. In initial experiments, about 15% of users showed delayed improvement in their self-correction abilities. Additionally, the system’s compatibility with low-specification devices is insufficient. In environments without GPU acceleration, response delays significantly increase, which limits the system’s application in resource-constrained areas. These limitations highlight potential directions for future research, including integrating cognitive science models to enhance deep feedback, developing offline lightweight versions, and designing reflective learning prompts.
Experimental design and performance evaluation
Datasets collection
To ensure the Transformer-based multidimensional feedback system is effective and widely applicable in English writing instruction, this study collects a large number of English writing samples from diverse sources. These sources include academic papers, news reports, blog posts, personal essays, and student compositions. Academic papers and news reports provide well-structured, stylistically varied texts that help train the model to recognize complex syntactic structures and logical relationships. Blog posts and personal essays, which are closer to everyday language, assist the model in understanding colloquial expressions and emotional tones. Furthermore, student composition samples, gathered in collaboration with schools, cover a wide range of educational stages from elementary to university. These samples contain various error types and writing styles, making them ideal training materials for the error correction and improvement suggestion modules. After collecting the raw texts, thorough preprocessing and annotation are carried out. The texts are cleaned by removing HTML tags, special characters, and unnecessary spaces to ensure they are in plain text format. Tokenization splits the text into meaningful units, and the WordPiece method handles out-of-vocabulary words. The annotation process includes tasks such as part-of-speech tagging and NER, which help clearly identify errors and their types in the sentences.
This study’s data source construction takes genre diversity into account, including multimodal texts such as academic papers, news reports, blog posts, personal essays, and student compositions from various educational levels. Academic writing samples (35%) provide examples of rigorous grammar structures and professional terminology. News texts (25%) help improve the model’s ability to process objective narration and complex sentence structures. Blog posts and essays (20%) feature rich colloquial expressions and emotional language. Student compositions (20%) cover typical error patterns from beginner to advanced levels, with a particular focus on cross-language interference in non-native English learners. This diverse mix of data enhances the model’s ability to handle both formal and informal genres, showing greater robustness in processing passive voice in academic writing and ellipsis structures in blog texts.
To minimize the risks of data bias, this study applies a dual de-biasing strategy. At the data level, K-means clustering balances text complexity and author geographical distribution, while gender-related pronouns (e.g., he/she) are contextually neutralized. At the model level, adversarial debiasing training is used, with a discriminator network to suppress potential bias features unrelated to the learner’s native language or stylistic preferences. Additionally, during feedback generation, a dynamic threshold mechanism is employed. When low-frequency linguistic phenomena (such as dialect variants or emerging internet slang) are detected, the system automatically triggers a manual review flag to prevent misjudgments caused by over-generalization.
This study emphasizes ethical standards, particularly in data privacy and user rights protection. The system strictly adheres to anonymization principles, ensuring that all user texts are stripped of personal identifiers upon input and transmitted and stored using the AES-256 encryption protocol. Regarding informed consent, the system employs a layered authorization model. Basic functions provide immediate feedback, while advanced data used for model optimization requires explicit secondary user authorization, ensuring users fully understand the scope of data usage. Furthermore, a differential privacy mechanism is introduced at the technical level, adding controlled noise during model training to prevent the original text from being reverse-engineered from feedback suggestions. These measures, along with institutional-technical safeguards like “review by the school ethics committee” and “written consent signed by participants,” ensure compliance with the Helsinki Declaration’s ethical research guidelines and align with the core requirements of the EU General Data Protection Regulation.
This study also adheres to open science principles and plans to release the core system module code (including preprocessing tools and model fine-tuning scripts) on GitHub, along with non-sensitive datasets under a Creative Commons License (CC BY-NC 4.0). The pre-trained model weights will be shared via the Hugging Face Model Hub, allowing educational researchers to replicate the experiments or make cross-domain improvements. Specifically, a lightweight version, BERT-Lightweight Iterative Training Edition (BERT-Lite), will be released. With its parameter size reduced to 32% of the original model, BERT-Lite retains 95% of the grammatical error correction capabilities through knowledge distillation, making it ideal for deployment in low-resource environments. The dataset will include anonymized student composition samples (5,000 pieces) and a multi-genre parallel corpus (200,000 sentence pairs), providing benchmark resources for educational technology innovation.
Experimental environment
To ensure the accuracy and reproducibility of the experiments, this study carefully sets up the experimental environment, including hardware configuration, software platforms, and the programming languages and frameworks used. A hybrid optimization strategy is employed during training, with distributed training implemented on an NVIDIA Tesla V100 GPU cluster. The specific parameters are as follows: an initial learning rate of 1 × 10^-5, a batch size of 32, 10 epochs, and a weight decay coefficient of 1 × 10− 4 to control overfitting. The hardware setup consists of dual Intel Xeon Gold 6248R CPUs, 512GB of DDR4 RAM, and the PyTorch 1.9.0 framework, which is used to optimize dynamic computation graphs.
Table 1 Outlines the specific configurations used in the experimental environment:
Parameters setting
During the experiment, several key parameters were adjusted to optimize the performance of the Transformer-based multidimensional feedback system. These parameters include the learning rate, batch size, number of epochs, dropout rate, and weight decay coefficient. Properly setting these parameters is essential for improving the model’s convergence speed and overall performance. First, the learning rate controls the step size when updating the model’s parameters. If the learning rate is too high, the model may fail to converge, while a learning rate that is too low will make the training process excessively slow. Table 2 presents the specific parameter settings.
Performance evaluation
The evaluation system is designed based on the principle of multidimensional quantification and includes four main indicators: Grammar Accuracy, which measures basic error correction ability by matching error types; the BLEU score, used to evaluate the n-gram similarity between generated suggestions and expert revisions; the Coherence Score, assessed manually by linguistics experts using a Likert scale, with a focus on paragraph logical coherence; and Lexical Richness, which is quantified through the Type-Token Ratio (TTR) to assess text diversity. Unlike studies that rely solely on automated metrics, this system introduces a periodic User Satisfaction Survey. The quality of feedback and learning outcomes are analyzed using Structural Equation Modeling (SEM), creating a comprehensive evaluation framework that combines both technical effectiveness and educational value. The chosen indicators not only build upon established methods in NLP but also account for the delayed and cumulative nature of educational interventions, providing a fresh methodological approach to evaluating intelligent writing assistance systems.
To thoroughly evaluate the performance of the Transformer-based multidimensional feedback system in English writing instruction, this study conducts a multi-dimensional performance assessment. The evaluation includes grammar accuracy, sentence structure diversity, and content coherence, and compares the results with traditional methods.
(1) Grammar Accuracy: The grammar accuracy of various samples is analyzed, with the results presented in Fig. 3.

Grammar Accuracy.
Figure 3 illustrates the system’s performance in correcting grammatical errors across different samples. The results show that the system excels at grammar correction, with an average improvement rate of approximately 79%, significantly surpassing traditional rule-based methods.
(2) Sentence Structure Diversity: The study uses the Syntactic Complexity Analyzer (SCA) framework to quantify sentence diversity. The Sentence Pattern Increment (SPI) metric measures structural variation. Based on Halliday’s Systemic Functional Grammar (SFG) theory, sentences are classified into four main categories: simple, compound, complex, and compound-complex, with 12 subcategories (such as noun clauses and adverbial clauses). Through dependency parsing and Rhetorical Structure Theory (RST) annotation, the system automatically counts the number of unique sentence structures per 1,000 words. The results of the sentence structure diversity analysis are shown in Fig. 4.

Sentence Structure Diversity.
Figure 4 shows the system’s impact on enhancing sentence structure diversity. By introducing new sentence patterns, the system helps students enrich their expressions. The increase in the number of unique sentence structures directly reflects how the system’s suggestions contribute to improving text diversity.
(3) Content Coherence: This study analyzes the coherence of sentence content, and Fig. 5 presents the results.

Content Coherence.
The User Satisfaction Evaluation employs a modified Likert 5-point scale, where 1 indicates “very dissatisfied,” 3 represents “neutral,” and 5 signifies “very satisfied.” This scale was validated using a double-blind design, with a Cronbach’s α coefficient of 0.87, indicating strong internal consistency. The satisfaction dimensions include feedback accuracy, timeliness, and actionability. The overall system score is calculated using a weighted average, with the respective weights of 40%, 30%, and 30%. As shown in Fig. 5, after receiving the system’s improvement suggestions, the overall coherence of the text significantly increased, with an average improvement of approximately 0.9 points.
(4) Vocabulary Richness: This study examines the vocabulary richness of the system-generated sentences, and the results are shown in Fig. 6.

Vocabulary Richness.
Vocabulary richness is measured by calculating the number of unique words in the text. As indicated in Fig. 7, the system effectively recommends a more diverse vocabulary, increasing the number of unique words by approximately 30, thereby improving the expressiveness of the writing.
(5) Overall Satisfaction Rating: This study uses a rigorous user experiment design to evaluate the system’s performance. The experiment included 162 participants from three major non-native English-speaking countries: China, India, and Nigeria. The demographic characteristics of the participants are shown in Table 3. The participants’ ages ranged from 16 to 28 years (M = 21.3, SD = 3.1), with 58% being undergraduate students, 32% graduate students, and 10% working learners. English proficiency was standardized using a Common European Framework of Reference for Languages (CEFR) test, with levels ranging from B1 to C1. The distribution was as follows: B1: 24%, B2: 41%, and C1: 35%. The experimental period was 12 weeks, including a 4-week system training phase and an 8-week effect tracking phase. During this period, 2,736 valid writing samples were collected (average of 1.4 samples per participant per week).
Statistical significance was analyzed using a Mixed-Effects Model, with fixed effects including system usage intensity and initial language proficiency, and random effects accounting for individual differences. As shown in Table 4, the reduction in grammar errors reached statistical significance (β = -1.24, SE = 0.17, p < 0.001), with a Cohen’s d effect size of 1.37 (95% CI [1.12, 1.62]). The improvement in sentence structure diversity was verified through Repeated Measures ANOVA, which showed a significant time effect (F(2, 161) = 38.6, p < 0.001, η² = 0.19). User satisfaction differences were confirmed using the Wilcoxon Signed-Rank Test (Z = 6.82, p < 0.001, r = 0.53), indicating a moderate effect size. All tests were corrected for multiple comparisons using the Bonferroni correction, with a significance threshold set at α = 0.01.
This study also analyzes the system’s overall satisfaction rating, with results shown in Fig. 7.

Overall Satisfaction Rating.
The satisfaction rating is provided by actual users based on their subjective experiences, with scores ranging from 1 to 5, where a higher score indicates greater satisfaction. Figure 7 shows that the system’s improvement suggestions significantly enhance users’ overall satisfaction, with an average increase of approximately 1.45 points. A comparison of typical writing case corrections is shown in Table 5.
This study utilizes visualization tools and detailed analysis of typical cases to clearly demonstrate the system’s intervention effects. Figure 8 presents the grammatical error rate trends over 12 weeks for both the experimental and control groups. The experimental group (represented by the blue line) experienced a significant reduction in monthly errors, dropping from 28.7 to 6.3 (a 78.1% decrease). In contrast, the control group (yellow line) showed a more modest decrease, from 28.4 to 19.6 (a 31.0% reduction).

Grammatical Error Rate Trend for Experimental and Control Groups.
The radar chart in Fig. 9 displays the user satisfaction distribution. The experimental group shows an advantage in three dimensions: feedback accuracy (4.6/5), response speed (4.5/5), and increased learning motivation (4.3/5). In contrast, the control group’s traditional methods (gray line) scored below 3.5 in all areas.

User Satisfaction Rating Comparison.
Figure 10 illustrates the writing development trajectory of a B1-level learner (according to the CEFR standard) over three months. The number of sentence types used by the learner increased from 4 to 9, and the usage of compound sentences rose from 12 to 37%. Meanwhile, the lexical complexity metric showed that the proportion of academic vocabulary increased from 8.3 to 22.1%, with the accurate use of high-frequency academic terms such as “mitigate” and “sustainable.”

Writing Ability Development Trajectory of a B1 Learner.
This study conducts systematic ablation experiments to assess the synergistic effects of the multidimensional feedback modules. In Table 6, disabling specific modules—such as Grammar Correction (GC), Lexical Optimization (LO), Sentence Diversity (SD), and Content Coherence (CC)—resulted in a gradual decline in overall system performance. Notably, disabling the Content Coherence module led to a 41.2% decrease in logical coherence scores, which was much higher than the impact of the other modules (with Grammar Correction showing a 28.7% decrease). This underscores the vital role of higher-level semantic analysis in enhancing writing quality. Furthermore, the dual-module ablation experiment demonstrated that removing both the vocabulary and sentence structure modules reduced the TTR to 63% of the baseline level, confirming the complementary relationship between different aspects of language richness.
The model fine-tuning strategy focused on adjusting the self-attention heads and feed-forward network (FFN) parameters in the last four layers of the BERT model’s Transformer encoder. A layer-wise learning rate approach was applied, with the top-layer parameters set to a base learning rate of 1 × 10− 5. This rate decreased by 15% for each subsequent layer to maintain stability in the lower layers’ general language representations. Additionally, an adapter module with a 64-dimensional compression rate was introduced in task-specific layers. This module allowed for incremental learning of domain-specific features while retaining pre-trained knowledge. This approach increased domain adaptation efficiency by 37%, while still preserving the model’s generalization capabilities.
The system’s ability to generalize stylistically was tested across different domains. As shown in Table 7, the Grammar Correction module maintained stable performance across academic papers, business emails, and creative writing (F1 score variation < 4.2%). However, the Lexical Optimization module had more limited applicability in creative writing, with a 19.8% drop in suggestion acceptance rate, largely due to metaphorical expressions that were outside the training data distribution. Notably, the Content Coherence module showed the greatest improvement in academic writing (+ 32.6%) compared to business emails (+ 12.3%), reflecting the differing demands for logical rigor across genres. To address this, the system will introduce a genre-adaptive switch that dynamically adjusts module weights through a convolutional neural network (CNN) pre-classifier.
This study evaluates the system’s technical advantages through a comparative analysis. As shown in Table 8, the proposed system outperforms both Grammarly Commercial Version (v5.8) and the GPT-3.5 fine-tuned model in detecting common error types among English as a Second Language learners. In verb tense correction, the system achieved an F1 score of 93.4%, exceeding Grammarly by 14.2% points. It also outperformed GPT-3.5 by 9.8% points in article misuse detection, reaching a recall rate of 91.7%. Additionally, the system demonstrated an impressive precision rate of 96.3% in subject-verb agreement detection for complex sentences using hierarchical dependency parsing. The false positive rate was controlled at just 3.1%, a quarter of that seen in traditional rule-based engines. In terms of response time, the system maintained a stable average feedback latency of 1.8 s, which is 37% faster than Grammarly’s cloud service. It also supports offline deployment for localized use.
The system also demonstrates differentiated error-handling capabilities through a detailed analysis of error types. As shown in Table 9, for typical ESL learner errors, the system achieved an 88.2% success rate in correcting article misuse (a/an/the). In contrast, preposition collocation errors, which are heavily influenced by native language transfer, had a lower correction rate of 72.4%. Notably, the system improved the joint correction rate for compound errors (e.g., tense and aspect errors) to 79.6%, a 21.3% point increase over the treatment of single error types. This improvement highlights the model’s ability to perform context-aware error correction. Additionally, in addressing long-distance dependencies in subject-verb agreement, the system introduced syntactically-augmented training, achieving a precision rate of 94.7% in nested clause scenarios. This significantly outperformed traditional n-gram methods, which achieved only 68.3%.
This study also provides a comprehensive analysis of the system’s performance boundaries and potential areas for optimization. In Table 10, the correction success rate for double negation structures, a low-frequency error type, was only 54.3%, well below the average success rate of 88.1%. This discrepancy is mainly due to the limited representation of such structures in the training data (less than 0.7%). Additionally, in the context of creative writing, the metaphor detection module displayed a false positive rate of 19.8%, often misinterpreting literary expressions (e.g., translating “time is a thief” literally as “time is wrong”). These issues arise from the model’s limited ability to generalize to unconventional linguistic phenomena and the stylistic bias in the educational dataset.
To ensure the model’s reliability, the study used Stratified 5-fold Cross-Validation. The dataset was stratified and sampled according to error types and genre categories. In Table 11, the standard deviation of the grammar correction F1 score across the folds remained within ± 1.3%, indicating the model’s stability. Notably, for the data-sparse C1-level (CEFR) writing samples, transfer learning was applied to incorporate B2-level features. This approach reduced the cross-level generalization error by 12.7%.
To address the issue of data imbalance, the study implemented a three-part balancing strategy. First, the Synthetic Minority Oversampling Technique (SMOTE) was applied to increase the sample size of low-frequency error types to three times the baseline. Second, class weights were added to the loss function, assigning rare error types 2.5 times the weight of common ones. Third, a Curriculum Learning strategy was adopted, initially focusing on high-frequency error patterns and gradually introducing more complex cases later in the training. As shown in Table 12, these balancing strategies increased the detection rate for inverted sentences from 58.3 to 73.6%. The impact on the performance for more common error types was minimal. For example, the F1 score for article misuse decreased by only 1.2%.
To evaluate the overall performance of the proposed system, this study selected two mainstream English writing assistance tools as benchmarks: the commercial version of Grammarly (v5.8) and a fine-tuned GPT-3.5 model. Performance comparisons across key metrics are presented in Table 13. Experimental results show that the proposed system significantly outperformed the baseline models in core grammar correction tasks. For example, in verb tense correction, the system achieved an F1 score of 93.4%, representing a 14.2% improvement over Grammarly. This gain is largely attributed to the hierarchical attention mechanism’s ability to model long-distance dependencies. In scenarios involving article misuse, the system attained a recall rate of 91.7%, demonstrating the effectiveness of its dynamic parameter adjustment module in capturing common error patterns among non-native learners. The system also achieved an average feedback latency of 1.8 s, outperforming Grammarly (2.9 s) and the GPT-3.5 model (3.5 s) by 37% and 48%, respectively. This advantage stems from the integration of a lightweight BERT-Lite architecture and a mixed-precision computation strategy optimized for GPU performance. In terms of user satisfaction, the system led with a score of 4.5 out of 5, indicating that its multidimensional feedback features—such as coherence suggestions and personalized prioritization—are well-aligned with the practical needs of educational environments. Notably, although the GPT-3.5 model exhibited strong performance in generative diversity, its high latency and opaque decision-making process limit its applicability as a real-time educational tool.
To further examine the system’s correction capabilities across error types, 500 essays written by non-native English learners—covering academic, daily, and creative writing—were randomly sampled from the test set. Six common error categories were manually annotated: verb tense errors, article misuse, subject-verb agreement errors, preposition collocation errors, double negation structures, and misuse of culture-specific metaphors. After processing these texts through the system, three evaluation metrics were calculated for each error type: Detection Rate (DR), Correction Success Rate (CSR), and False Positive Rate (FPR). DR refers to the proportion of correctly identified errors out of the manually labeled total; CSR denotes the proportion of system suggestions judged as appropriate by linguistic experts; FPR measures the proportion of correct sentences mistakenly flagged as erroneous. The experimental settings were consistent with those in the main experiments (NVIDIA Tesla V100 GPU, PyTorch 1.9.0). The distribution of correction performance by error type is illustrated in Fig. 11. As shown in Fig. 11, the system demonstrated strong performance in correcting high-frequency grammar errors such as verb tense and article misuse, with detection rates exceeding 90% and CSRs approaching 89%. This can be attributed to the global modeling capabilities of the Transformer architecture and the extensive representation of such errors in the training data. However, the CSR for preposition collocation errors was noticeably lower at 72.4%, highlighting the context- and culture-dependent nature of preposition usage, which remains challenging for semantic models to capture comprehensively. Among less frequent and culturally nuanced errors, the CSR for double negation structures was only 54.3%, and for misuse of culture-specific metaphors, it dropped to 29.4%, revealing the system’s limitations in handling non-standard language phenomena and cross-cultural expressions. The scarcity of training samples for these error types—only 0.7% for double negation and 0.5% for culture-specific metaphors—significantly impacted the model’s generalization ability. In terms of FPR, the system recorded a high FPR of 19.8% for culture-specific metaphors, suggesting a tendency to misclassify literary expressions (e.g., “time is a thief”) as logical errors. This underscores the challenge of balancing semantic understanding with stylistic adaptability. These findings suggest the need for future work to enhance the model’s robustness to low-frequency and culturally specific errors through adversarial training. Additionally, the integration of a style classifier may help reduce misclassifications in creative writing scenarios.

Distribution of Correction Performance by Error Type.
Table 14 summarizes the improvements in argumentative logic facilitated by the system intervention. After using the system, learners’ scores for argument relevance improved by 28.1%, and the reasoning chain integrity index increased by 27.4%, indicating that the argumentation logic module effectively enhanced the rigor of academic writing. The substantial rise in the frequency of counterargument strategy usage (94.4%) further supports the system’s role in fostering critical thinking. Compared to ARG-BERT (Lee et al., 2024), the proposed system achieved comparable reasoning improvements (27.4% vs. 29.1%) while maintaining a lightweight architecture with a 42% reduction in parameter count—demonstrating its superior adaptability for educational contexts.
In contrast to general-purpose tools such as the GPT-4 Academic plugin, the proposed system offers distinct advantages in argumentative analysis. While GPT-4 leverages generative architecture to provide open-ended revision suggestions, its outputs often deviate from pedagogical standards—for instance, by overusing non-academic expressions—and it lacks the ability to trace improvements in logical reasoning. By contrast, the proposed system employs structured templates and a curriculum learning strategy to decompose abstract reasoning tasks into progressive training goals. This approach reduces learners’ cognitive load while ensuring the precision of instructional outcomes. However, the current module still exhibits limited adaptability to cross-cultural argumentation paradigms—such as the Eastern “spiral” discourse style versus the Western “linear” logic model. Future research should incorporate multicultural corpora and adaptive style-transfer techniques to enhance the system’s responsiveness to diverse rhetorical conventions.
Discussion
The primary objective of this study is to bridge the gap between technical capabilities and pedagogical needs through a multidimensional feedback mechanism built on Transformer models—a pursuit that has stimulated both theoretical and practical advancements. In recent years, educational technology research has increasingly focused on personalized learning systems. For example, Tang et al. (2024) proposed a dynamic learning path optimization framework based on Deep Reinforcement Learning (DRL)41, which shares conceptual parallels with the dynamic parameter adjustment module developed in this study. However, such systems have predominantly targeted domains like mathematics and science, with limited evidence supporting their effectiveness in addressing the semantic complexity and cultural specificity of language writing. Meanwhile, Rakshit et al. (2024) introduced a grammar detection tool based on CNNs, demonstrating solid performance in identifying basic grammatical errors42. Nonetheless, CNNs’ restricted receptive fields hinder their ability to capture paragraph-level logical relationships. In contrast, the self-attention mechanism employed in this study facilitates parallel processing of long-range dependencies, offering a more robust framework for coherence analysis. The emergence of multimodal feedback systems also opens new avenues for writing instruction. However, their heavy dependence on annotated datasets conflicts with the lightweight, privacy-preserving design principles emphasized in this study. This tension highlights a core challenge in developing intelligent educational tools: balancing data-driven performance with ethical and regulatory considerations. Future work may benefit from exploring Federated Learning (FL) frameworks, which enable distributed model training while preserving data sovereignty—thus addressing the scalability concerns raised by Wang et al. (2021)43. Additionally, the system’s occasional misclassification of unconventional expressions in creative writing reveals a potential synergy with advancements in natural language generation, particularly in style transfer methods such as Generative Adversarial Networks (GANs). Incorporating stylistic classifiers could further reduce false positives and enhance the system’s adaptability across a wider range of writing genres. These interdisciplinary linkages not only enrich the theoretical foundation of educational technology but also point toward a new paradigm for integrating artificial intelligence with humanistic education.
The experimental results show that the Transformer-based multidimensional feedback system outperforms traditional methods, such as the one proposed by Zhang and Shafiq (2024)44, in grammar accuracy, sentence structure diversity, content coherence, and vocabulary richness. However, the system presented by Chen et al. (2024) still faces challenges in handling complex semantic understanding and logical reasoning tasks, occasionally failing to provide sufficiently accurate suggestions45. Furthermore, the personalized adaptation capability of the system developed by Gm et al. (2024) requires improvement, as it struggles to capture individual differences and provide tailored feedback46. To address these limitations, expert knowledge from the relevant domain can be integrated, and the model’s professional understanding can be enhanced through techniques like knowledge distillation or transfer learning. Additionally, reinforcement learning (RL) algorithms could optimize personalized learning paths, while privacy-preserving mechanisms, such as FL, should be employed to ensure data security. By incorporating these recent advancements, the system’s performance can be further improved to better support educational practices. Zhuo et al. (2021) proposed a Long Short-Term Memory (LSTM)-based grammar checking system47, which achieved an F1 score of over 80% in basic error detection. However, its sequence processing mechanism limited its ability to analyze paragraph-level logical coherence, as its maximum context window only supported 128 tokens. In contrast, the proposed system employs the self-attention mechanism of Transformer, enabling full-text semantic modeling and expanding the effective context length to 512 tokens, improving paragraph coherence evaluation accuracy. Kim et al. (2025) developed a rule-based academic writing assistant48, which efficiently detected formatting errors but relied on manually defined templates, resulting in rigid sentence structure suggestions and high repetition of user text structures. This system innovatively introduces a GAN-assisted sentence rewriting module, utilizing style transfer technology to improve sentence diversity while maintaining academic rigor. Zhang (2021) proposed a CNN and attention hybrid model49, which made progress in multimodal feedback (text + speech). However, its personalization adaptation was based only on static proficiency levels, lacking dynamic learning path optimization. This study constructs a real-time learner model through a Markov Decision Process, dynamically adjusting feedback strategies based on error pattern transition probability matrices, improving intervention precision compared to traditional methods. These comparisons highlight the breakthrough in the system’s architectural design—combining the global awareness advantages of Transformer with pedagogical cognitive theories, thus pioneering a new intelligent feedback paradigm driven by both “Technology-Enabled” and “Pedagogy-Evidenced” approaches.
The intelligent feedback system developed in this study demonstrates significant interdisciplinary application potential. In the field of educational psychology, the system’s real-time feedback mechanism aligns closely with the theory of Self-Regulated Learning. By tracking the evolution of learners’ error patterns, it can provide quantitative metrics for metacognitive ability assessment. For instance, changes in the concentration of high-frequency error types can map the dynamic boundaries of Vygotsky’s Zone of Proximal Development, providing cognitive science-based evidence for personalized teaching interventions. Additionally, the learning analytics data generated by the system can be integrated with Cognitive Load Theory. This integration will help optimize writing task design thresholds by monitoring the relationship between sentence complexity and revision frequency. As a result, it will enable the optimal allocation of cognitive resources. These cross-disciplinary applications not only expand the theoretical depth of educational technology but also offer a new empirical research platform for learning sciences.
The system’s modular architecture grants it strong multilingual adaptation capabilities. The Transformer-based multi-head attention mechanism is universal for language structures, allowing for rapid migration to target languages such as German and Arabic by replacing the pre-trained model’s embedding layer, for instance, with multilingual BERT (mBERT) or XLM-RoBERTa. For non-Latin writing systems (such as Chinese characters and Sanskrit), the frontend processing module integrates Unicode standardization protocols and language-specific tokenizers (e.g., Jieba for Chinese and Mecab for Japanese), ensuring accurate mapping from form to meaning. Furthermore, the system adopts a microservices architecture with containerized deployment, enabling dynamic resource allocation via Kubernetes clusters to support millions of concurrent users. The integration of elastic computing instances on cloud platforms such as Amazon Web Services and model quantization technology reduces single-node inference costs while maintaining high precision retention. Educational institutions can seamlessly integrate the system with existing Learning Management Systems via API gateways, while an offline lightweight client can run with just 2GB of memory, ensuring accessibility in resource-limited areas.
Conclusion
Research contribution
The Transformer-based multidimensional feedback system proposed in this study has demonstrated robust effectiveness in English writing instruction through empirical evaluation. In grammatical correction, the system significantly reduced high-frequency errors among non-native learners. CSR for verb tense and article misuse reached 89.7% and 88.2%, respectively—surpassing those of traditional rule-based engines (e.g., the grammar checker by Olayiwola et al.) by over 25% points. Additionally, syntactic diversity analysis showed an increase in the use of compound and complex sentences from 12 to 37%, validating the system’s capacity to enhance sentence variety through structural optimization. User satisfaction improved to 4.5 on a 5-point scale. Notably, the adoption rate for coherence-related suggestions (76.2%) significantly exceeded that of basic grammatical corrections (58.9%), underscoring the pedagogical value of deep semantic feedback. Compared to existing tools, the system achieved 85% expert agreement in logical consistency evaluations and provided educators with traceable AI decisions through layered attention heatmap visualizations. These outcomes highlight the system’s ability to overcome limitations in modeling long-range dependencies and intersentential logic—challenges often faced by conventional tools—while supporting sustained writing development via a closed-loop framework of “correction–enhancement–reflection.”
Future works and research limitations
Future research will advance in three key directions. First, the development of a speech-to-text multimodal interface will integrate automatic speech recognition and prosody analysis to enable real-time correction and rhythm optimization in spoken writing tasks, thereby reducing cognitive load for non-native speakers. Second, a lightweight mobile inference engine will be designed using TensorFlow Lite’s model quantization and adaptive computation scheduling to deliver on-device responses within 1.5 s under 4G conditions, enhancing accessibility in resource-limited settings. Third, FL will be explored for cross-cultural model adaptation, enabling improved error pattern recognition for learners of non-Latin scripts such as Arabic and Chinese, while ensuring compliance with GDPR anonymization standards. Furthermore, a style transfer module supported by GANs will be incorporated to generate tailored suggestions for metaphorical or unconventional expressions in creative writing, aiming to reduce false positives and expand the system’s applicability. These innovations mark a shift from a traditional “writing assistant” to a “comprehensive learning companion,” establishing a strong empirical foundation for the ethical, inclusive, and scalable development of AI-enhanced educational technologies.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author Xiaofeng Zheng on reasonable request via e-mail vip.allen@163.com.
References
Shanshan, S. & Sen, G. Empowering learners with AI-generated content for programming learning and computational thinking: the lens of extended effective use theory[J]. J. Comput. Assist. Learn. 40 (4), 1941–1958 (2024).
Keli, L. English education in the era of artificial intelligence in china: opportunities and Challenges[J]. Int. J. Adv. Eng. Manage. Sci. 10, 6 (2024).
Alsager, H. To look from another window in education: artificial intelligence assisted Language learning and its reflections on academic demotivation, foreign Language learning anxiety and Autonomy[J]. Computer-Assisted Lang. Learn. Electron. J. 25 (4), 124–147 (2024).
Incelli, E. Enhancing Abstract Writing for Non-native English-speaking PhD Students: A Case Study of Italian PhD Students[J]16136–148 (INTERNATIONAL JOURNAL OF LINGUISTICS, 2024). 6.
Li, M. Non-native english-speaking (NNES) students’ english academic writing experiences in higher education: A meta-ethnographic qualitative synthesis[J]. J. Engl. Acad. Purp. 71, 101430 (2024).
Jafary, M., Wu, J. & Dashtaki, N. A. Fostering pragmatic proficiency: the influence of explicit instruction on plurilingual EFL learners’ mastery of hedging devices in Canadian academic writing Context[J]. Engl. Lang. Teach. 17 (10), 117–117 (2024).
Procel, G. J. O. et al. Using technology in english Teaching[J]. J. Environ. Res. Public. Health. 17 (9), 9 (2024).
Novawan, A., Walker, S. A. & Ikeda, O. The new face of technology-enhanced Language learning (TELL) with artificial intelligence (AI): teacher perspectives, practices, and challenges[J]. J. Engl. Acad. Prof. Communication. 10 (1), 1–18 (2024).
Nursalim, N. et al. Exploring english reading challenges in Southwest Papua EFL classrooms: the role of virtual Learning[J]. J. Engl. Cult. Lang. Literature Educ. 12 (2), 198–214 (2024).
Samaan, S. S. et al. Multilingual web traffic forecasting for network management using artificial intelligence Techniques[J]. Results Eng. 105262. (2025).
Yahiaoui, Y. et al. A Comprehensive Context-Free Grammar for the Arabic Language: Including Non-Fundamentalist Phrases[J]28611 (Ingenierie des Systemes d’Information, 2023). 3.
Humaidi, A. J. et al. A generic izhikevich-modelled FPGA-realized architecture: a case study of printed english letter recognition[C]//2020 24th International Conference on System Theory, Control and Computing (ICSTCC). IEEE, : 825–830. (2020).
Asad, M. M. et al. ChatGPT as artificial intelligence-based generative multimedia for english writing pedagogy: challenges and opportunities from an educator’s perspective[J]. Int. J. Inform. Learn. Technol. 41 (5), 490–506 (2024).
Masri, S. et al. Transformer models in education: Summarizing science textbooks with arabart, MT5, arat5, and mBART[J]. arxiv preprint arxiv:2406.07692, (2024).
Dutta, S., Adhikary, S. & Dwivedi, A. D. Visformers—combining vision and Transformers for enhanced complex document classification[J]. Mach. Learn. Knowl. Extr. 6 (1), 448–463 (2024).
Zheng, H. et al. Medication recommendation system based on natural Language processing for patient emotion analysis[J]. Acad. J. Sci. Technol. 10 (1), 62–68 (2024).
Fagbohun, O. et al. Beyond traditional assessment: exploring the impact of large Language models on grading practices[J]. J. Artifical Intell. Mach. Learn. Data Sci. 2 (1), 1–8 (2024).
He, T. An analysis of Reading-to-Write approach applied in english writing Teaching[J]. Front. Sci. Eng. 5 (2), 28–38 (2025).
Hossain, M. Z. & Goyal, S. Advancements in natural Language processing: leveraging transformer models for multilingual text Generation[J]. Pac. J. Adv. Eng. Innovations. 1 (1), 4–12 (2024).
Wang, Q. A multifaceted architecture to Automate essay scoring for assessing english Article writing: integrating semantic, thematic, and linguistic representations[J]. Comput. Electr. Eng. 118, 109308 (2024).
Sukiman, S. A. et al. A hybrid personalized text simplification framework leveraging the deep learningbased transformer model for dyslexic Students[J]. J. Adv. Res. Appl. Sci. Eng. Technol. 34 (1), 299–313 (2024).
Olayiwola, A., Olayiwola, D. & Oyedeji, A. Development of an automatic grammar checker for Yorùbá word processing using government and binding Theory[J]. Expert Syst. Appl. 236, 121351 (2024).
Miah, M. S. et al. A multimodal approach to cross-lingual sentiment analysis with ensemble of transformer and LLM[J]. Sci. Rep. 14 (1), 9603 (2024).
Tang, X. et al. Harnessing LLMs for multi-dimensional writing assessment: reliability and alignment with human judgments[J]. Heliyon, 10(14). (2024).
Ali, O. et al. The effects of artificial intelligence applications in educational settings: challenges and strategies[J]. Technol. Forecast. Soc. Chang. 199, 123076 (2024).
Toumia, O. & Zouari, F. Artificial intelligence and venture capital decision-making[M]//Fostering innovation in venture capital and startup ecosystems. IGI Global, 16–38. (2024).
Cong, S. et al. Comprehensive review of Transformer-based models in neuroscience, neurology, and psychiatry[J]. Brain-x 2 (2), e57 (2024).
Fabre, R., Bellot, P. & Egret, D. Challenging scientific categorizations through dispute Learning[J]. Appl. Sci. 15 (4), 2241 (2025).
Farrokhnia, M. et al. A SWOT analysis of chatgpt: implications for educational practice and research[J]. Innovations Educ. Teach. Int. 61 (3), 460–474 (2024).
Banihashem, S. K. et al. A systematic review of the role of learning analytics in enhancing feedback practices in higher education[J]. Educational Res. Rev. 37, 100489 (2022).
Wang, J. et al. A semi-supervised approach for the integration of multi-omics data based on transformer multi-head self-attention mechanism and graph convolutional networks[J]. BMC Genom. 25 (1), 86 (2024).
Rahman, A. U. et al. Enhancing heart disease prediction using a self-attention-based transformer model[J]. Sci. Rep. 14 (1), 514 (2024).
Ge, Q. et al. LiteTransNet: an interpretable approach for landslide displacement prediction using transformer model with attention mechanism[J]. Eng. Geol. 331, 107446 (2024).
Tsang, Y. K. et al. A corpus of Chinese word segmentation agreement[J]. Behav. Res. Methods. 57 (1), 1–15 (2025).
Nazir, S. et al. Machine learning based framework for fine-grained word segmentation and enhanced text normalization for low resourced language[J]. PeerJ Comput. Sci. 10, e1704 (2024).
Zhang, C. Improved word segmentation system for Chinese criminal judgment documents[J]. Appl. Artif. Intell. 38 (1), 2297524 (2024).
Li, F. et al. Tibetan sentence boundaries automatic disambiguation based on bidirectional encoder representations from Transformers on byte pair encoding word cutting Method[J]. Appl. Sci. 14 (7), 2989 (2024).
Hou, Z. et al. Integrating L1 and weighted L2 regularization for moving force identification from combined response measurements[J]. Measurement 228, 114337 (2024).
Irvin, M. et al. Neural Contextual Reinforcement Framework for Logical Structure Language Generation[J]. arxiv preprint arxiv:2501.11417, (2025).
Sharma, G., Sharma, D. & Sasikumar, M. Summarizing long scientific documents through hierarchical structure extraction[J]. Nat. Lang. Process. J. 8, 100080 (2024).
Tang, J., Liang, Y. & Li, K. Dynamic scene path planning of Uavs based on deep reinforcement learning[J]. Drones 8 (2), 60 (2024).
Rakshit, P., Paul, S. & Dey, S. Sign Language detection using convolutional neural network[J]. J. Ambient Intell. Humaniz. Comput. 15 (4), 2399–2424 (2024).
Wang, Y. et al. An unknown protocol syntax analysis method based on convolutional neural network[J]. Trans. Emerg. Telecommunications Technol. 32 (5), e3922 (2021).
Zhang, H. & Shafiq, M. O. Survey of Transformers and towards ensemble learning using Transformers for natural Language processing[J]. J. Big Data. 11 (1), 25 (2024).
Chen, M. et al. Enhancing emergency decision-making with knowledge graphs and large Language models[J]. Int. J. Disaster Risk Reduct. 113, 104804 (2024).
Gm, D. et al. A digital recommendation system for personalized learning to enhance online education: A review[J]. IEEE Access. 12, 34019–34041 (2024).
Zhuo, Z. et al. Long short-term memory on abstract syntax tree for SQL injection detection[J]. IET Softw. 15 (2), 188–197 (2021).
Kim, J. et al. Exploring students’ perspectives on generative AI-assisted academic writing[J]. Educ. Inform. Technol. 30 (1), 1265–1300 (2025).
Zhang, H. Voice keyword retrieval method using attention mechanism and multimodal information fusion[J]. Sci. Program. 2021 (1), 6662841 (2021).
Funding
This work was supported by Humanities and Social Sciences Research Project of the Education Department of Jilin Province with project name of “Research on the Improvement of English Writing Ability Based on Multidimensional Feedback Model” (Grant No. JJKH20241636SK).
Author information
Authors and Affiliations
Contributions
Xiaofeng Zheng: Conceptualization, methodology, software, validation, formal analysis, investigation, resources, data curation, writing—original draft preparation Jian Zhang: writing—review and editing, visualization, supervision, project administration, funding acquisition.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics statement
The studies involving human participants were reviewed and approved by School of International Exchange, Changchun Guanghua University Ethics Committee (Approval Number: 2023.0215000). The participants provided their written informed consent to participate in this study. All methods were performed in accordance with relevant guidelines and regulations.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zheng, X., Zhang, J. The usage of a transformer based and artificial intelligence driven multidimensional feedback system in english writing instruction. Sci Rep 15, 19268 (2025). https://doi.org/10.1038/s41598-025-05026-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-05026-9
