
Abstract
Glioma is a highly heterogeneous and aggressive brain tumour that demands an integrated understanding of its molecular and immunological landscape. We collected multi-omics data from 575 TCGA diffuse-glioma patients (156 IDH-wild-type WHO-grade 4 glioblastomas and 419 IDH-mutant WHO-grade 2/3 diffuse gliomas) together with two validation cohorts (CGGA n = 970; GEO n = 110). Using the MOVICS framework, we derived three integrative molecular subtypes—CS1, CS2 and CS3. Ten machine-learning algorithms in MIME were benchmarked, and the Lasso + SuperPC combination yielded an eight-gene GloMICS (Glioma Multi-Omics Consensus Signature) prognostic score. The subtypes display discrete biology: CS1 (astrocyte-like) is characterized by glial lineage features, immune-regulatory signaling, and relatively favorable prognosis; CS2 (basal-like/mesenchymal) shows epithelial-mesenchymal transition, stromal activation, and high immune infiltration, including PD-L1 expression; CS3 (proneural-like/IDH-mut metabolic) exhibits metabolic reprogramming (OXPHOS, hypoxia) and an immunologically cold tumour microenvironment (TME). CS2 is associated with the worst overall survival, whereas CS1 confers the most favourable outcome. Dual checkpoint blockade or T-cell-rejuvenation strategies may benefit CS2 tumours, while metabolic inhibitors could prove effective in CS3. The eight-gene GloMICS score outperformed 95 published prognostic models (C-index 0.74–0.66 across TCGA, CGGA and GEO). TME deconvolution, immune checkpoint profiling and TIDE analysis indicate that high-risk GloMICS tumours harbour immunosuppressive fibroblast-rich niches and exhausted CD8⁺ T cells. Connectivity-map screening nominated dabrafenib, irinotecan and three additional CTRP/PRISM compounds as candidate agents for the high-risk group. Our study establishes robust glioma subtypes and a transferable prognostic signature, offering a blueprint for biomarker-guided therapy. Future work should include single-cell and immunohistochemical validation of subtype hallmarks and prospective trials stratified by GloMICS score.
Similar content being viewed by others
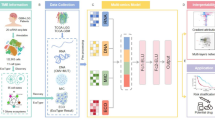

Introduction
Glioma—the most common primary malignancy of the central nervous system—remains a formidable clinical challenge because of its extreme molecular heterogeneity and dismal prognosis1. Under the 2021 WHO Classification of Tumours of the Central Nervous System2, the first molecular branch-point is the isocitrate-dehydrogenase (IDH) mutation: IDH-mutant diffuse astrocytoma/oligodendroglioma (WHO grades 2–4), and IDH-wild-type glioblastoma (GBM, WHO grade 4). Although IDH-mutant grade 2/3 tumours usually progress more slowly than IDH-wild-type GBM, a sizeable fraction ultimately evolves into grade 4 astrocytoma, culminating in therapeutic resistance and a median survival that rarely exceeds 15 months despite aggressive multimodal therapy. These sobering figures highlight the need for more incisive prognostic tools and biology-guided treatments.
Molecular diagnostics have already reshaped routine practice: IDH mutation and 1p/19q co-deletion are now compulsory diagnostic criteria, whereas MGMT-promoter methylation informs alkylator sensitivity2,3.. Yet these single-marker read-outs capture only a slice of the complex genomic, epigenomic and immunological landscape of diffuse glioma. Response rates to emerging modalities—especially immune checkpoint blockade—remain modest for most patients4, partly because genetic alterations, epigenetic rewiring and the immune micro-environment interact in ways that current single-omic stratifiers cannot resolve5,6. A comprehensive, multi-omics view is therefore essential to uncover second-level heterogeneity within each WHO-defined group.
Integrative multi-omics analyses that combine transcriptomic, epigenomic and mutational layers can reveal hidden biological subtypes, prognostic biomarkers and actionable vulnerabilities7,8. However, the high dimensionality of such data demands sophisticated computational strategies. Recent machine-learning advances—especially ensemble and transfer-learning algorithms—offer robust solutions for patient clustering and risk modelling9.
Here, we apply a multi-omics + machine-learning pipeline to a large cohort of IDH-wild-type WHO-4 glioblastomas and IDH-mutant WHO-2/3 diffuse gliomas. Using the MOVICS framework, we delineate three integrative molecular subtypes and build an eight-gene GloMICS (Glioma Multi-Omics Consensus Signature) score via systematic algorithm benchmarking in MIME. We further dissect tumour-micro-environment (TME) states, predict immunotherapy benefit, and nominate subtype-specific therapeutic compounds. Our results provide a refined stratification scheme and a transferable prognostic tool that may inform biomarker-guided clinical trials in diffuse glioma.
Materials and methods
Data acquisition
We collected multi-omics data from 575 diffuse glioma patients in The Cancer Genome Atlas (TCGA), including 156 IDH-wild-type WHO grade 4 glioblastomas and 419 IDH-mutant WHO grade 2/3 diffuse gliomas10. These data were downloaded from the UCSC Xena platform (https://xenabrowser.net/), encompassing transcriptome profiles (mRNA, lncRNA, and miRNA), DNA methylation (450K array), somatic mutation (Mutect2 MAF), and detailed clinical annotations.
To validate the robustness of our findings, we incorporated two external microarray datasets from the Gene Expression Omnibus (GEO: GSE74187, n = 60; GSE83300, n = 50), and a large RNA-seq dataset from the Chinese Glioma Genome Atlas (CGGA, n = 970; http://www.cgga.org.cn/)11. To reduce non-biological variance across platforms and batches, the ComBat function from the R package sva was applied12. The effectiveness of batch correction was confirmed using Principal Component Analysis (PCA) 13.
Multi-omics data preprocessing and integrative subtyping
Multi-omics integration was performed using the MOVICS R package (v1.0.3), which provides a unified interface for feature selection, multi-platform clustering, and subtype biomarker evaluation14. In line with the 2021 WHO CNS classification2, we stratified gliomas into two molecular groups: IDH-mutant WHO grade 2/3 diffuse gliomas and IDH-wild-type WHO grade 4 glioblastomas. All downstream analyses, including subtype discovery, were performed within this unified molecular framework.
For expression data, log₂-transformed TPM values of protein-coding mRNAs, lncRNAs, and miRNAs were used. For each transcriptomic layer, the top 1,500 mRNAs, 1,500 lncRNAs, and 200 miRNAs with the highest median absolute deviation (MAD) were selected using the getElites() function. Methylation data were restricted to probes targeting promoter-associated CpG islands (450K array), from which the top 1500 variable loci were retained. Somatic mutation data from Mutect2-processed MAF files were binarized (mutated = 1) and filtered to retain the top 5% of genes with the highest mutation frequency.
To reduce dimensionality and focus on clinically relevant features, univariate Cox proportional-hazards regression was applied to each omics layer to identify prognostically significant variables (P < 0.05). The filtered features were used as input for integrative clustering.
Optimal cluster number (k) was determined using the getClustNum() function, which incorporates Clustering Prediction Index, Gap Statistics, and Silhouette scores. Integrative consensus clustering was then performed with ten algorithms (including iClusterBayes, CIMLR, SNF, IntNMF, and others) through the getMOIC() function. Final subtype labels were derived using the getConsensusMOIC() function, yielding a robust molecular stratification across IDH-defined glioma subgroups.
Immune pathway and tumor microenvironment analysis
Gene Set Variation Analysis (GSVA) was used to assess immune-related and therapy-relevant pathway activities, based on curated gene sets from literature and public databases15. Enrichment scores were standardized and visualized to highlight subtype-specific patterns16,17. Transcriptional regulatory networks (RTNs) were reconstructed using the RTN package, focusing on key transcription factors and chromatin regulators18. Tumor-infiltrating lymphocyte (MeTIL) scores were computed from DNA methylation profiles19, while immune and stromal scores were inferred using ESTIMATE20.The composition of immune cells in the tumor microenvironment (TME) was profiled using CIBERSORT, and immune checkpoint gene expression was compared across subtypes21. Classification robustness was evaluated through concordance among consensus clustering, NTP, and PAM using Kappa statistics.
Comprehensive characterisation of somatic variants
Somatic mutation data from TCGA-GBMLGG were curated using maftools, with synonymous variants excluded. Candidate drivers were defined exclusively from the IntOGen “Compendium Cancer Genes” list (GBM, LGGNOS, HGGNOS) and mapped to HGNC symbols. Subtype-specific MAF objects (CS1–CS3) were generated and visualised with oncoplots of the ten most recurrent IntOGen drivers. Ninety-six–channel SNV counts were obtained with trinucleotideMatrix; de-novo signatures were extracted by NMF and assigned to COSMIC SBS v3.4 when cosine similarity > 0.85, after which per-sample exposures were retained. Within each subtype, co-occurrence and mutual exclusivity among the twenty most mutated IntOGen genes were tested by Fisher’s exact test with Benjamini–Hochberg correction (q < 0.05). Neo-antigen burden was predicted with pVACseq (NetMHCpan 4.1) following Optitype HLA typing, counting peptides with rank < 0.5%; burdens were compared across clusters by Kruskal–Wallis with Dunn’s post-hoc adjustment.
Prognostic modeling using MIME-integrated machine learning algorithms
To construct a robust prognostic model, we utilized MIME, a flexible machine-learning framework designed for high-dimensional omics data analysis22. MIME integrates ten algorithms—including Lasso, Elastic Net, Random Forest, CoxBoost, SuperPC, and others—enabling comprehensive modeling and feature selection in survival-based studies.
Transcriptomic features (mRNA only) that were significantly associated with overall survival in univariate Cox regression (P < 0.01) were used as the input feature matrix. Prior to modeling, gene expression data across all training cohorts were standardized using Z-score normalization. The MIME preprocessing module ensured uniform scaling and removed batch-related effects across different platforms.
During model construction, we benchmarked all ten integrated algorithms using tenfold cross-validation within the TCGA cohort. Model performance was evaluated primarily using Harrell’s concordance index (C-index) and time-dependent ROC curves at 1-, 3-, and 5-year survival endpoints. The optimal model, based on a Lasso + SuperPC ensemble strategy, yielded the highest predictive accuracy and was selected as the final GloMICS (Glioma Multi-Omics Consensus Signature) prognostic model. Hyperparameters were automatically tuned using MIME’s internal grid-search engine.
To evaluate the generalizability of the GloMICS model, we applied it to two external validation cohorts (CGGA, n = 970; GEO, n = 110). Model performance was compared against 95 previously published glioma prognostic signatures using the C-index across all cohorts.
Finally, model explainability was assessed through feature importance scoring, Kaplan–Meier risk stratification, and time-dependent ROC curves. These visualizations facilitated interpretation of the prognostic impact of each gene within the signature.
Prognostic value of GloMICS and clinical application
To assess the prognostic relevance of the Glioma Omics-based Consensus Signature (GloMICS), we conducted univariate and multivariate Cox proportional hazards regression analyses using clinical and molecular variables. Univariate analysis was performed on factors including age, sex, tumor mutation burden (TMB), study-defined molecular subtype (CS1–CS3)and the GloMICS score. Variables with statistically significant associations were included in a multivariate Cox model to evaluate their independent effects on overall survival.
A nomogram was constructed based on the multivariate Cox regression model to estimate the probability of 1-, 2-, and 3-year survival. Model calibration was performed using calibration curves. Time-dependent concordance index (C-index) curves were generated to assess the discriminative ability of the model over time. Decision curve analysis (DCA) was further employed to evaluate the potential clinical utility of incorporating GloMICS into survival prediction.
Multi-omics analysis of immune characteristics in glioma patients
To investigate the immune landscape associated with glioma, we applied multiple deconvolution algorithms—including CIBERSORT, EPIC, xCell, and MCPcounter—to RNA-seq data from TCGA glioma patients. These methods were used to estimate the relative abundance of various immune cell types within the tumor microenvironment. Additionally, single-sample Gene Set Enrichment Analysis (ssGSEA) was used to compute immune-related gene signature scores.
Immune features such as tumor mutation burden (TMB), tumor neoantigen burden (TNB), and CD8⁺ T cell proportion were calculated or obtained from public resources. These variables were integrated with GloMICS scores to characterize the immune contexture of each patient. Statistical analyses, including Kaplan–Meier survival analysis, Wilcoxon rank-sum tests, and Spearman correlation, were conducted to evaluate associations between GloMICS and immune variables. Multivariate Cox regression was performed to assess the prognostic relevance of immune-related factors in combination with the GloMICS score. All visualizations, such as survival curves, boxplots, density distributions, and scatter plots, were generated using the ggplot2 package in R.
Drug response prediction and enrichment analysis
Differential gene expression analysis between high- and low-risk groups defined by the GloMICS score was conducted using the limma R package. The resulting gene expression profiles were used to perform Gene Set Enrichment Analysis (GSEA) based on hallmark and KEGG gene sets to identify enriched biological pathways. The visualization of core enriched genes was conducted using the clusterProfiler and enrichplot packages in R.
For drug sensitivity analysis, pharmacogenomic data from the Cancer Therapeutics Response Portal (CTRP) and PRISM Repurposing dataset were retrieved23. These datasets include drug response metrics, such as area under the curve (AUC), across a broad range of cancer cell lines. Gene expression data of glioma patients were integrated with the drug response profiles through linear modeling and correlation analysis. Statistical assessments, including Spearman correlation and Wilcoxon rank-sum tests, were performed to examine associations between GloMICS-defined risk groups and predicted drug sensitivities. Drug-specific analyses, including evaluation of Temozolomide response, were further examined in relation to MGMT expression status3.
Statistical analysis
Statistical analyses were conducted using R software version 4.4.0. For comparisons between two groups, normally distributed variables were assessed using unpaired Student’s t-tests, while non-normally distributed variables were analyzed with the Wilcoxon rank-sum test. For multiple group comparisons, one-way ANOVA and Kruskal–Wallis tests were used for parametric and non-parametric variables, respectively. Contingency tables were evaluated with a two-sided Fisher’s exact test. Multi-omics clustering was performed using the MOVICS package, and the optimal cutoff for the GloMICS score was determined using the surv_cutpoint function from the survminer package. Differential expression analysis was carried out with the limma package, and drug sensitivity was predicted by correlating data from the CTRP and PRISM platforms with GloMICS scores using Spearman correlation and Wilcoxon rank-sum tests. Gene set enrichment analysis (GSEA) was conducted with the clusterProfiler package, and multiple comparisons were adjusted using the Benjamini–Hochberg method.
Result
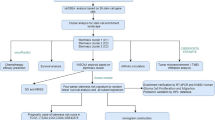
Identification and classification of subtypes in glioma patients
We used CPI and gap statistical analysis to identify three subtypes in glioma patients, with the optimal average number of gliomas determined to be three. Consequently, we classified glioma patients into three subtypes (CS 1, CS 2 and CS 3), demonstrating the robustness of the classification system. The silhouette scores for the subtypes were 0.56 for CS 1, 0.69 for CS 2, and 0.73 for CS 3, confirming a clear separation and distinction between the subtypes. Each subtype exhibited unique molecular patterns spanning transcriptomic (mRNA, lncRNA, and miRNA), epigenetic methylation, and somatic mutation data (Fig. 1A–C). Additionally, we compared the clinical prognostic outcomes of glioma patients across the three subtypes. Notably, CS 2 patients had significantly shorter overall survival compared to CS 1 and CS 3, with overall survival (OS) being highly significant (p < 0.001; Fig. 1D). Among all subtypes, CS 2 demonstrated the most favorable survival outcomes.

Multi-omics clustering and survival analysis of glioma patients. (A) Integrated multi-omics clustering reveals distinct molecular subtypes based on mRNA, lncRNA, miRNA expression, DNA methylation, and mutation status. (B) Clustering consistency was assessed across ten different methods, with the top annotation representing the final consensus subtypes. (C) Consensus heatmap showing clustering stability of glioma patients across three subtypes. Darker colors indicate higher consensus scores. (D) Kaplan–Meier survival curves comparing overall survival between the molecular subtypes identified by consensus clustering.
Molecular characterisation, regulatory landscapes, and immune contexture across subtypes
To elucidate the molecular heterogeneity of glioma, we performed an integrative analysis of transcriptomic, epigenetic, and mutational profiles. Gene set variation analysis (GSVA) revealed distinct pathway activation patterns across subtypes (Fig. 2A). CS1 showed enrichment in glial differentiation, Notch, and TGF-β signaling, indicating a lineage-committed astrocytic state with moderate mitotic and Wnt pathway activity. CS2 exhibited robust activation of epithelial-mesenchymal transition (EMT), glycolysis, apoptosis, PI3K-AKT-mTOR signaling, and hypoxia pathways, consistent with a mesenchymal-like, invasive, and metabolically reprogrammed phenotype. CS3 was characterised by oxidative phosphorylation, myelination, and fatty acid metabolism, suggesting a proneural-like, metabolically active state with limited inflammatory activation.

Molecular Subtype Characterization and Immune Landscape Analysis in Glioma (A). Heatmap showing immune pathway enrichment scores across GloMICS subtypes of glioma. (B). Heatmaps depicting transcriptional regulatory networks (TRN) and chromatin remodeling activities across GloMICS subtypes in glioma patients. (C). Heatmaps illustrating the immune landscape of glioma subtypes, focusing on immune checkpoint expression and tumor microenvironment (TME) infiltration. (D–E). Heatmaps generated by Nearest Template Prediction (NTP) analysis, classifying samples from both the CCGC and GEO cohorts into molecular subtypes based on TCGA-derived subtypes. (F–G). Survival analysis of across three subtypes in both the CCGC and GEO cohorts. (H–I). Consistency heatmaps comparing molecular subtypes assigned by Nearest Template Prediction (NTP) and partitioning around medoids (PAM) clustering in both the CCGC and GEO cohorts.
Subtype-specific transcription factor and chromatin regulator activity patterns further reinforced these biological distinctions (Fig. 2B). CS1 was defined by elevated NFIA, SMAD3/4, and SOX2 activity, alongside chromatin modifier KDM4A, supporting astrocytic differentiation and TGF-β signaling. CS2 was dominated by WWTR1 (TAZ), ETV4, E2F1, SOX9, and STAT3, which are associated with proliferative, mesenchymal, and inflammatory programs. In contrast, CS3 showed prominent activation of SIRT3, EPAS1, TET1, PARP2, and ETV5, indicating hypoxia adaptation, DNA demethylation, and metabolic regulation.
The tumor immune microenvironment (TME) also exhibited clear subtype-specific features (Fig. 2C). CS2 had the highest MeTIL scores, stromal content, and CD8 + T-cell infiltration, alongside elevated expression of immune checkpoint molecules such as PD-L1 (CD274) and PD-L2 (PDCD1LG2), suggesting an immunologically hot but potentially exhausted TME. CS1 and CS3 showed lower overall immune activation. Specifically, CS1 displayed reduced PD-1 and CTLA-4 expression and diminished NK cell activity, implying an immunosuppressive state. CS3, though enriched in activated memory CD4 + T cells, had generally low checkpoint gene expression, suggesting immune quiescence rather than active evasion.
The robustness of these molecular subtypes was validated across external cohorts using Nearest Template Prediction (NTP). Subtypes mapped consistently in the CCGC and GEO datasets (Fig. 2D–E), with survival differences reproduced in both (log-rank p < 0.001 and p = 0.003, respectively; Fig. 2F–G). High concordance with PAM clustering further confirmed classification stability (p < 0.001; Fig. 2H–I). Together, these findings establish three biologically and immunologically distinct glioma subtypes, each with prognostic and therapeutic relevance.
Somatic mutation landscape and neoantigen load across glioma subtypes
To characterize the genomic alterations across molecular subtypes, we performed a comprehensive somatic mutation analysis in the TCGA-GBMLGG cohort (Fig. 3). Classical driver genes displayed subtype-specific distributions: CS1 was enriched for IDH1 (97%), TP53 (93%), and ATRX (74%) mutations; CS2 showed higher frequencies of EGFR (28%), PTEN (25%), and TP53 (22%) mutations; and CS3 featured frequent alterations in IDH1 (91%), CIC (63%), and FUBP1 (25%) (Fig. 3A, D–F). Analysis of mutational signatures revealed distinct etiologies: CS1 was associated with SBS11 and SBS1, suggestive of prior treatment exposure and age-related mutations; CS2 exhibited SBS1 combined with SBS10b, implying aging and potential POLE activity; CS3 was marked by SBS1 and SBS6, indicative of aging and mismatch repair deficiency (Fig. 3B). Notably, SBS1 exposure was significantly higher in CS2 than in the other subtypes (Fig. 3C, p< 2.2e − 16).

Comprehensive somatic-mutation landscape in Glioma. (A) Driver-gene mutation bar charts across CS1–3. (B) Stacked exposure of COSMIC v3.4 single-base-substitution signatures per sample. (C) Violin plot comparing SBS1 exposure among clusters. (D–F) OncoPrints for CS1-3, respectively (top 10 mutated genes). (G–I) Pairwise co-occurrence/ exclusivity matrices for CS1-3. (J) Heat-map of driver-gene mutation frequency by cluster. (K) Neo-antigen load per cluster.
We further explored the interaction patterns among frequently mutated genes. CS1 and CS2 exhibited broad co-occurrence patterns (e.g., TP53–ATRX, EGFR–PTEN), while CS3 displayed a mix of co-mutations (e.g., CIC–FUBP1) and mutual exclusivity (e.g., IDH1–PIK3CA) (Fig. 3G–I). A heatmap of driver mutation frequencies across clusters confirmed subtype-enriched patterns, such as CIC and FUBP1 in CS3, EGFR and NF1 in CS2, and ATRX in CS1 (Fig. 3J). Finally, neoantigen prediction revealed that CS2 tumors exhibited significantly higher predicted neoantigen loads compared to CS1 and CS3 (Kruskal–Wallis p = 0.012), supporting the immunologically active nature of this subtype (Fig. 3K).
Development of the GloMICS prognostic model
We identified prognostically relevant genes from three independent datasets (TCGA, CGGA, and GEO) using univariate Cox regression analysis (p < 0.001). The intersecting set of survival-associated genes across these datasets was used to construct the GloMICS prognostic model. In the TCGA training cohort, we benchmarked 117 machine learning combinations using the MIME package. Among these, the Lasso + SuperPC algorithm demonstrated the best performance based on the average concordance index (C-index) across all validation cohorts (Fig. 4A). Meta-analysis of univariate Cox results further confirmed the consistency of hazard ratios across cohorts (Fig. 4B), with the Lasso + SuperPC model showing minimal overfitting and strong predictive accuracy (C-index: 0.74 in TCGA, 0.73 in CGGA, 0.66 in GEO; Fig. 4C).

Evaluation of Prognostic Model Performance and Gene Significance Across TCGA, CCGC, and GEO Cohorts. (A) C-index distribution for various models trained on TCGA and validated on CCGC and GEO datasets. (B) Meta-analysis of univariate Cox regression results for survival prediction across TCGA, CCGC, and GEO datasets. (C) C-index distribution for the "Lasso + SuperPC" model across TCGA, CCGC, and GEO datasets. (D) Coefficient estimates from multivariate Cox regression analysis for selected genes identified by the Lasso + SuperPC model. (E) Forest plot of hazard ratios (HR) and 95% confidence intervals (CI) from univariate Cox regression analysis for selected genes across TCGA, CCGC, and GEO datasets. (F). Kaplan–Meier survival curves for the TCGA, CCGC, and GEO datasets based on the "Lasso + SuperPC" model.
The eight selected prognostic genes were consistently significant across multiple cohorts (Fig. 4D–E). Combined analysis using both random- and fixed-effect models showed robust hazard ratios: HR = 3.55 (95% CI 2.81–4.48, p < 0.001) and HR = 3.77 (95% CI 3.26–4.35, p < 0.001), respectively. Kaplan–Meier survival analysis stratified by the GloMICS score revealed significantly worse outcomes for high-risk patients across all cohorts (Fig. 4F), supporting the robustness of the GloMICS model for glioma prognostication.
Performance comparison and validation of the GloMICS prognostic model
We benchmarked the GloMICS model against 95 published glioma prognostic signatures from the MIME database. In terms of concordance index (C-index), GloMICS ranked sixth in the TCGA cohort, second in CGGA, and first in the GEO cohort, outperforming the majority of existing models (Fig. 5A). Kaplan–Meier analysis further confirmed that high GloMICS scores were significantly associated with worse overall survival across all datasets (Fig. 5B).

Comprehensive Evaluation of the "Lasso + SuperPC" Model Across Multiple Databases and Metrics. (A and B). Comparison of the C-index and HR for our model versus existing models in the MIME package across TCGA, CCGC, and GEO databases. (C) Results from multivariate Cox regression analysis, identifying significant predictors of prognosis. (D) A nomogram that estimates 1-year, 3-year, and 5-year survival probabilities. (E). Calibration plot comparing observed versus nomogram-predicted overall survival (OS) at multiple time points, confirming the model’s accuracy. (F) Decision curve analysis (DCA) that quantifies the clinical usefulness of different predictive factors used in the model. (G) Trends in the C-index over a 10-year period, comparing two prognostic models for assessing long-term outcomes in glioma patients.
To assess the independent prognostic value of GloMICS, we performed univariate Cox regression incorporating age, sex, tumor mutation burden (TMB), tumor neoantigen burden (TNB), and molecular subtype (CS1–CS3), Age, and GloMICS risk score (RS) were significant predictors (p < 0.05) and were subsequently entered into a multivariate Cox model (Fig. 5C). Based on the multivariate results, we constructed a prognostic nomogram to estimate 1-, 2-, and 3-year survival probabilities (Fig. 5D). Calibration curves showed good concordance between predicted and observed outcomes (Fig. 5E).
Decision curve analysis (DCA) demonstrated that the nomogram provided greater net clinical benefit than models based on single variables such as age or RS (Fig. 5F). Furthermore, time-dependent C-index comparison confirmed the superior predictive performance of the nomogram compared to other representative models such as CMLS (Fig. 5G).
Tumor microenvironment and immune features in glioma based on GloMICS
To explore the immunological landscape of glioma, we analyzed the tumor microenvironment (TME) in relation to GloMICS risk groups using the IOBR framework. High-risk GloMICS patients exhibited significantly elevated infiltration of fibroblasts and regulatory T cells (Tregs), alongside a marked increase in exhausted CD8⁺ T cell subsets, such as CD8_c2_Teff and CD8_c6_Tcm (Fig. 6A). In contrast, low-risk patients showed higher levels of cytotoxic and naïve CD8⁺ T cells (e.g., CD8⁺ naive, CD8_c3_Tn) and NK cell populations, suggesting a more immunoreactive TME associated with better prognosis.

Analysis of Tumor Microenvironment Molecular Characteristics in High and Low GloMICS Patients. (A) Distribution of TME immune cell type signatures between patients with high and low GloMICS levels. (B) Distribution of immune suppression signatures among high and low GloMICS groups. (C) Distribution of immune exclusion signatures among high and low GloMICS groups. (D) Differences in immunotherapy biomarkers between high and low GloMICS patients. (E) Distribution of Tumor Mutation Burden (TMB) between high and low GloMICS groups. (F) Distribution of Tumor Neoantigen Burden (TNB) between high and low GloMICS groups. (G) Distribution of M1 macrophages in high and low GloMICS groups. (H) The relationship between GloMICS levels and CD8 T cells. (I–K) Survival analysis combining GloMICS with TMB, TNB, and CD8 T cell indicators.
Despite comparable Treg levels across risk groups, the high GloMICS group was enriched for cancer-associated fibroblasts (CAFs) and extracellular matrix (ECM) components (Fig. 6B–C), suggesting an immunosuppressive niche driven by stromal remodeling and immune exclusion. These TME features may contribute to immune evasion and therapy resistance.
Consistent with this, multiple immunotherapy-related gene signatures, including immune checkpoints, were upregulated in the high-risk group (Fig. 6D), indicating potential benefit from targeted immunotherapeutic approaches such as dual checkpoint inhibition or T cell rejuvenation strategies.
Analysis of genomic correlates revealed that tumor mutational burden (TMB) was significantly higher in the high GloMICS group, whereas tumor neoantigen burden (TNB) showed minimal variation (Fig. 6E–F). Furthermore, the abundance of CD8⁺ T cells was paradoxically elevated in the high-risk group (Fig. 6G–H), likely reflecting dysfunctional or exhausted phenotypes.
Survival stratification by immune-related variables demonstrated that GloMICS provided additional prognostic resolution beyond TMB, TNB, and M1 macrophage levels (Fig. 6I–K). Notably, patients with low GloMICS scores and concurrently low TMB, TNB, or CD8⁺ T cell infiltration had the most favorable survival outcomes.
Evaluation of GloMICS and immune response in glioma immunotherapy
To investigate the relevance of GloMICS to immunotherapy response, we analyzed the IMvigor210 cohort, which provides survival and treatment response data for patients receiving immune checkpoint blockade24,25. Patients in the low GloMICS group exhibited improved survival at 3 months post-treatment (p = 0.03), whereas the difference at 12 months was not statistically significant (p = 0.41) (Fig. 7A–B). Notably, GloMICS scores were significantly lower in immune responders compared to non-responders (Fig. 7C), indicating that lower GloMICS scores may predict better response to immunotherapy.

The Utility of GloMICS in Predicting Immunotherapy Responses in MUC Patients. (A) Differences in restricted mean survival time (RMS) at 6 months and 1 year after treatment between high and low GloMICS groups. (B) Differences in long-term survival (LTS) 3 months post-treatment between high and low GloMICS groups. (C) Distribution of GloMICS across different immunotherapy response categories. (D) Variations in activation levels at each step of the TIP between high and low GloMICS groups. (E) TIDE-based prediction of immunotherapy response. (F) TIDE algorithm predictions of TIDE scores between low and high GloMICS groups. (F) TIDE algorithm predicts CD8 T-cell levels in high and low GloMICS groups. (G) Survival analysis in the GSE78220 dataset comparing high and low GloMICS groups. (H) Survival analysis in the GSE135222 dataset comparing high and low GloMICS groups. (I) Distribution of GloMICS across different immunotherapy response categories in the GSE91061 dataset.
We further explored the underlying immunological mechanisms using the tumor immune phenotype (TIP) tracking framework. Immune activation processes, such as T cell recruitment (Step 4), infiltration (Step 5), and tumor cell killing (Step 7), were more pronounced in the low GloMICS group, particularly in CD4⁺ and CD8⁺ T cell-related steps (Fig. 7D), suggesting a more robust anti-tumor immune response in these patients26.
TIDE analysis revealed that non-responders had significantly higher TIDE scores than responders (p < 0.001), and high GloMICS patients were more likely to be non-responders (70.13%) compared to low GloMICS patients (Fig. 7E). In line with this, CD8⁺ T cell levels were significantly elevated in low GloMICS tumors (p < 0.0001), while the expression of immunotherapy response-related markers was also enriched in the high-risk group (Fig. 7F–G), suggesting functional exhaustion27.
Validation in independent immunotherapy-treated cohorts (GSE78220, GSE135222, and GSE91061) further supported the predictive capacity of GloMICS. High GloMICS scores were consistently associated with poorer post-treatment survival (e.g., GSE135222, p < 0.001; GSE78220, p = 0.002), while low-risk groups demonstrated improved outcomes (GSE91061, p = 0.062) (Fig. 7H–J).
Identification and screening of potential drugs
To explore potential therapeutic strategies for glioma patients stratified by GloMICS, we performed Gene Set Enrichment Analysis (GSEA) to identify pathways differentially enriched between high- and low-risk groups. The high GloMICS group showed significant enrichment in pathways related to epithelial–mesenchymal transition (EMT), TNF signaling, interferon-gamma response, and coagulation (Fig. 8A), indicating enhanced tumor microenvironment remodeling and inflammatory signaling.

Exploration of Potential Therapeutic Agents for Patients with High GloMICS (A) Gene Set Enrichment Analysis (GSEA) investigates the distribution and significance of differentially expressed genes within known biological pathways. (B) Demonstrating the predicted sensitivity of the chemotherapy drug Temozolomide for glioblastoma multiforme (GBM) samples. (C) The workflow for screening potential therapeutic agents. (D and E) Correlation and differential analysis of drug sensitivity for potential drugs screened from the CTRP and PRISM datasets.
Given the established role of MGMT in mediating resistance to temozolomide (TMZ), we analyzed MGMT expression and found that patients with low MGMT expression were significantly more sensitive to TMZ treatment (Fig. 8B), consistent with previous findings.
We further screened potential therapeutic compounds for high GloMICS patients by integrating transcriptomic profiles with pharmacogenomic data from the CTRP and PRISM databases. Six CTRP-derived compounds were identified, including atorvastatin (HMGCR inhibitor), CGM097 (MDM2 inhibitor), dabrafenib (BRAF inhibitor), ingenol mebutate (PKC activator), irinotecan (topoisomerase I inhibitor), and MK-2461 (MET inhibitor) (Fig. 8C–D). Additionally, five PRISM-derived compounds were prioritized: BRD-K37390332(uncharacterized screening compound), dasatinib (SRC/ABL inhibitor), GDC-0879 (ERK inhibitor), PRIMA-1 (TP53 reactivator), and TG-100–115 (PI3Kγ inhibitor) (Fig. 8E). These compounds may offer therapeutic opportunities for high-risk glioma patients with poor prognosis.
Discussion
Advancing glioma stratification through integrated multi-omics
Traditional glioma classification often relies on single-omics data such as transcriptomics or DNA methylation28,29,30. While informative, these approaches capture only limited aspects of tumor biology and often fail to resolve the full heterogeneity of gliomas. Our study improves upon these limitations by integrating five omics layers—including mRNA, lncRNA, miRNA, DNA methylation, and somatic mutations—using a consensus ensemble clustering framework31. This strategy leverages the complementary nature of each data type, enabling more biologically coherent and clinically relevant subtype identification32.
Compared to previous studies that used a single data modality, our multi-omics approach captures cross-layer regulatory interactions and provides a more robust stratification. The integration of diverse molecular signals allows for finer delineation of subtypes within existing classifications, uncovering hidden heterogeneity among tumors that would otherwise appear similar. This is particularly important in glioma, where traditional histological and single-gene markers have shown limited prognostic precision.
By aligning molecular subtypes with distinct biological features and clinical outcomes, our framework enhances prognostic evaluation and lays the groundwork for personalized therapeutic strategies. This approach represents a methodological advancement over prior single-omics models and offers a more comprehensive lens through which to understand and manage diffuse gliomas.
Integration of machine learning in multi-omics prognostic modeling for personalized glioma treatment
Traditional glioma prognostic models often rely on single-omics data and limited biomarkers, limiting their predictive accuracy. In this study, we employed a multi-omics approach integrated with the MIME framework, which systematically benchmarks ten machine learning algorithms to construct a robust prognostic model22. By leveraging transcriptomic, epigenomic, and mutational data, we identified an eight-gene signature (GloMICS) that demonstrated superior predictive performance across multiple cohorts.
Unlike previous models, our method captures the complex interplay between diverse molecular alterations, enhancing prognostic precision and clinical utility33. The multi-algorithm consensus strategy mitigates the instability of individual methods, ensuring generalizability and reproducibility34. Moreover, the incorporation of molecular subtype (CS1–CS3) into our nomogram provides an additional layer of biological context for risk stratification35.
This integrative modeling framework offers a valuable tool for guiding personalized treatment decisions in glioma36. Future studies should incorporate more real-world clinical and omics data—such as proteomics or radiogenomics—to further refine predictions and support prospective clinical applications37,38.
Tumor microenvironment and immune response variations in GloMICS subtypes
Our study revealed distinct immune profiles across the GloMICS subtypes, which can inform therapeutic strategies. In the high-risk GloMICS group (CS2), immune checkpoint molecules like PD-L1 and PD-L2 were highly expressed, suggesting an immunologically “hot” tumor microenvironment (TME) with significant CD8⁺ T cell infiltration39. However, the presence of immune exhaustion markers, such as PD-1 and CTLA-4 expression, indicates an impaired immune response and possible resistance to standard immunotherapy40. Similar findings were reported by previous studies on mesenchymal subtypes, which show both high immune infiltration and exhausted T cells, particularly relevant for therapies targeting the PD-1/PD-L1 axis41.
In contrast, the low-risk GloMICS group (CS1 and CS3) demonstrated lower levels of immune checkpoint expression and better T cell functionality, suggesting that these patients might benefit from immune checkpoint inhibitors aimed at rejuvenating T cell activity. Additionally, the relatively less immune-active CS3 subtype, characterized by metabolic dysregulation and neuroendocrine-like features, may require more specific treatments targeting metabolic pathways or immune modulation42.
Overall, GloMICS provides insight into immune heterogeneity across glioma subtypes, with CS2 displaying immune suppression despite high immune infiltration, while CS1 and CS3 may respond better to immunotherapy, especially when combined with strategies targeting immune checkpoint pathways or metabolism.
Biological characterization and comparison with TCGA subtypes
The three GloMICS subtypes (CS1, CS2, and CS3) demonstrate clear parallels with TCGA’s classical, mesenchymal, and proneural subtypes, though with important distinctions. CS1 (Classical / Astrocyte-like) aligns with the Classical subtype of TCGA. This subtype is characterized by mutations in IDH1, TP53, and ATRX, presenting a well-differentiated, glial lineage with immune-regulatory features. Consequently, these tumors exhibit a less aggressive phenotype, which may suggest better prognosis and potential responsiveness to therapies aimed at differentiation or immune modulation43,44. On the other hand, CS2 (Basal-like / Mesenchymal) closely resembles the Mesenchymal subtype of TCGA. It is marked by EGFR activation and deletions of PTEN and NF1, which are indicative of an inflammatory, invasive, and epithelial-to-mesenchymal transition (EMT)-driven phenotype45. Additionally, the elevated expression of immune checkpoints such as PD-L1 suggests that CS2 tumors may benefit from immunotherapies, particularly those targeting the PD-1/PD-L1 axis, although immune exhaustion in this subtype remains a significant challenge46. In contrast, CS3 (Proneural-like / IDH-mut Metabolic) exhibits features akin to the Proneural subtype of TCGA. Defined by IDH1 mutations, this subtype shows a strong reliance on metabolic pathways related to hypoxia and oxidative phosphorylation, along with alterations in CIC and FUBP144. This phenotype is accompanied by an immunologically cold tumor microenvironment (TME) and metabolic dysregulation, necessitating alternative therapeutic strategies, such as those targeting metabolic pathways or hypoxia adaptation47.
Potential therapeutic strategies and challenges for high GloMICS glioma patients
In light of the poor prognostic response to immunotherapy observed in the high GloMICS group, we undertook a comprehensive screening of potential therapeutic agents. This systematic approach led us to identify dabrafenib and irinotecan as promising candidates for enhancing treatment outcomes in high GloMICS patients. Dabrafenib, a selective BRAF inhibitor, has shown promise in targeting specific mutations prevalent in glioma48. Its effectiveness is supported by studies demonstrating significant tumor burden reduction when combined with anti-PD-1 therapies in preclinical models. Integrating dabrafenib into immunotherapy regimens may enhance the therapeutic response in high GloMICS patients. Additionally, irinotecan, frequently used in glioma treatment, acts through topoisomerase inhibition, effectively damaging DNA in rapidly dividing tumor cells. This makes it a valuable option for high GloMICS patients who may experience aggressive tumor growth. However, challenges remain in the screening and application of these agents. The complexity of glioma biology, characterized by its heterogeneity, poses significant barriers to identifying universally effective treatments.
Future directions and clinical implications
As we navigate the evolving landscape of glioma treatment, the integration of multi-omics analysis and machine learning approaches presents unprecedented opportunities for advancing personalized medicine. The distinct biological characteristics and immune responses identified among the GloMICS subtypes underscore the necessity for tailored therapeutic strategies. Future research should focus on elucidating the mechanisms underlying the immune microenvironment variations in glioma, particularly the role of exhausted CD8 + T cells in the high GloMICS group. Understanding these dynamics will be crucial for developing effective interventions aimed at restoring T cell functionality. Moreover, the application of advanced screening techniques and clinical trial methodologies is essential for assessing the efficacy of identified therapeutic candidates such as dabrafenib and irinotecan. Investigating combination therapies that incorporate these agents alongside immunotherapies could lead to synergistic effects, improving outcomes for patients with high GloMICS scores. Furthermore, the incorporation of real-world data (RWD) into our research framework can enhance the clinical relevance of our findings, allowing us to better understand treatment responses across diverse patient populations.
In conclusion, our findings highlight the importance of a comprehensive multi-omics approach and machine learning integration in stratifying glioma patients and tailoring treatment strategies. By addressing the unique characteristics of each subtype and utilizing advanced therapeutic options, we can aspire to improve clinical outcomes and develop more effective treatment paradigms for glioma patients in the future. Continuous exploration in this domain will be pivotal in overcoming the current challenges and optimizing patient care in glioma management.
Conclusion
In this study, we established a comprehensive multi-omics and machine learning framework to stratify diffuse glioma patients into three robust molecular subtypes—CS1 (Classical/Astrocyte-like), CS2 (Basal-like/Mesenchymal), and CS3 (Proneural-like/IDH-mut Metabolic)—each with distinct genomic alterations, immune landscapes, and prognostic implications. We further developed the GloMICS score, an eight-gene prognostic model that outperformed 95 existing glioma signatures across three independent cohorts. Our findings underscore the clinical value of integrating transcriptomic, epigenetic, and mutational data for precision classification and prognosis. Moreover, by linking GloMICS subtypes to immune responsiveness and drug sensitivity, we propose subtype-specific therapeutic strategies, including immunotherapy for CS2 and metabolic targeting for CS3. Together, our work provides a refined glioma taxonomy and a transferable prognostic tool that may inform biomarker-driven clinical decision-making and future stratified trials.
Data availability
Multi-omic data for glioblastoma and lower-grade glioma were obtained from TCGA-GBM and TCGA-LGG cohorts via UCSC Xena (https://xenabrowser.net/). Validation datasets are available under GEO accession codes GSE74187 and GSE83300. Additional glioblastoma transcriptomic data were retrieved from the CGGA database (http://www.cgga.org.cn/).
References
Nicholson, J. G. & Fine, H. A. Diffuse glioma heterogeneity and its therapeutic implications. Cancer Discov. 11(3), 575–590. https://doi.org/10.1158/2159-8290.CD-20-1474 (2021).
Louis, D. N. et al. The 2021 WHO classification of tumors of the central nervous system: A summary. Neuro-Oncol. 23(8), 1231–1251. https://doi.org/10.1093/neuonc/noab106 (2021).
Hegi, M. E. et al. mgmt gene silencing and benefit from temozolomide in glioblastoma. N. Engl. J. Med. 352(10), 997–1003. https://doi.org/10.1056/NEJMoa043331 (2005).
Liu, J., Peng, J., Jiang, J. & Liu, Y. Clinical immunotherapy in glioma: Current concepts, challenges, and future perspectives. Front. Immunol. 15, 1476436. https://doi.org/10.3389/fimmu.2024.1476436 (2024).
Lin, H. et al. Understanding the immunosuppressive microenvironment of glioma: mechanistic insights and clinical perspectives. J. Hematol. Oncol. J. Hematol. Oncol. 17(1), 31. https://doi.org/10.1186/s13045-024-01544-7 (2024).
Barzegar Behrooz, A. et al. Integrating multi-omics analysis for enhanced diagnosis and treatment of glioblastoma: A comprehensive data-driven approach. Cancers 15(12), 3158. https://doi.org/10.3390/cancers15123158 (2023).
Hasin, Y., Seldin, M. & Lusis, A. Multi-omics approaches to disease. Genome Biol. 18(1), 83. https://doi.org/10.1186/s13059-017-1215-1 (2017).
Zhao, Y., Gao, Y., Xu, X., Zhou, J. & Wang, H. Multi-omics analysis of genomics, epigenomics and transcriptomics for molecular subtypes and core genes for lung adenocarcinoma. BMC Cancer 21(1), 257. https://doi.org/10.1186/s12885-021-07888-4 (2021).
Min, S., Lee, B. & Yoon, S. Deep learning in bioinformatics. Brief. Bioinform. https://doi.org/10.1093/bib/bbw068 (2016).
Weinstein, J. N. et al. The cancer genome atlas pan-cancer analysis project. Nat. Genet. 45(10), 1113–1120. https://doi.org/10.1038/ng.2764 (2013).
Zhao, Z. et al. Chinese glioma genome atlas (CGGA): A comprehensive resource with functional genomic data from chinese glioma patients. Genom Proteom Bioinf 19(1), 1–12. https://doi.org/10.1016/j.gpb.2020.10.005 (2021).
Leek, J. T., Johnson, W. E., Parker, H. S., Jaffe, A. E. & Storey, J. D. The sva package for removing batch effects and other unwanted variation in high-throughput experiments. Bioinformatics 28(6), 882–883. https://doi.org/10.1093/bioinformatics/bts034 (2012).
Nyamundanda, G., Poudel, P., Patil, Y. & Sadanandam, A. A novel statistical method to diagnose, quantify and correct batch effects in genomic studies. Sci. Rep. 7(1), 10849. https://doi.org/10.1038/s41598-017-11110-6 (2017).
Lu, X., Meng, J., Zhou, Y., Jiang, L. & Yan, F. MOVICS : An R package for multi-omics integration and visualization in cancer subtyping. Bioinformatics 36(22–23), 5539–5541. https://doi.org/10.1093/bioinformatics/btaa1018 (2021).
Hänzelmann, S., Castelo, R. & Guinney, J. GSVA: Gene set variation analysis for microarray and RNA-Seq data. BMC Bioinf 14(1), 7. https://doi.org/10.1186/1471-2105-14-7 (2013).
Mariathasan, S. et al. TGFβ attenuates tumour response to PD-L1 blockade by contributing to exclusion of T cells. Nature 554(7693), 544–548. https://doi.org/10.1038/nature25501 (2018).
Hu, J. et al. Siglec15 shapes a non-inflamed tumor microenvironment and predicts the molecular subtype in bladder cancer. Theranostics 11(7), 3089–3108. https://doi.org/10.7150/thno.53649 (2021).
Lu, X. et al. Multi-omics consensus ensemble refines the classification of muscle-invasive bladder cancer with stratified prognosis, tumour microenvironment and distinct sensitivity to frontline therapies. Clin. Transl. Med. 11(12), e601. https://doi.org/10.1002/ctm2.601 (2021).
Jeschke, J. et al. DNA methylation-based immune response signature improves patient diagnosis in multiple cancers. J. Clin. Invest. 127(8), 3090–3102. https://doi.org/10.1172/JCI91095 (2017).
Yoshihara, K. et al. Inferring tumour purity and stromal and immune cell admixture from expression data. Nat. Commun. 4(1), 2612. https://doi.org/10.1038/ncomms3612 (2013).
Chen, B., Khodadoust, M. S., Liu, C. L., Newman, A. M. & Alizadeh, A. A. Profiling tumor infiltrating immune cells with CIBERSORT. In Cancer systems biology methods in molecular biology (ed. Von Stechow, L.) 243–259 (Springer, New York, New York, 2018).
Liu, H. et al. Mime: A flexible machine-learning framework to construct and visualize models for clinical characteristics prediction and feature selection. Comput. Struct. Biotechnol. J. 23, 2798–2810. https://doi.org/10.1016/j.csbj.2024.06.035 (2024).
Seashore-Ludlow, B. et al. Harnessing connectivity in a large-scale small-molecule sensitivity dataset. Cancer Discov. 5(11), 1210–1223. https://doi.org/10.1158/2159-8290.CD-15-0235 (2015).
Rosenberg, J. E. et al. Atezolizumab in patients with locally advanced and metastatic urothelial carcinoma who have progressed following treatment with platinum-based chemotherapy: A single-arm, multicentre, phase 2 trial. Lancet 387(10031), 1909–1920. https://doi.org/10.1016/S0140-6736(16)00561-4 (2016).
Powles, T. et al. Atezolizumab versus chemotherapy in patients with platinum-treated locally advanced or metastatic urothelial carcinoma (IMvigor211): A multicentre, open-label, phase 3 randomised controlled trial. Lancet 391(10122), 748–757. https://doi.org/10.1016/S0140-6736(17)33297-X (2018).
Xu, L. et al. TIP: A web server for resolving tumor immunophenotype profiling. Cancer Res. 78(23), 6575–6580. https://doi.org/10.1158/0008-5472.CAN-18-0689 (2018).
Jiang, P. et al. Signatures of T cell dysfunction and exclusion predict cancer immunotherapy response. Nat. Med. 24(10), 1550–1558. https://doi.org/10.1038/s41591-018-0136-1 (2018).
Ptashne, M. & Gann, A. Transcriptional activation by recruitment. Nature 386(6625), 569–577. https://doi.org/10.1038/386569a0 (1997).
Li, E. & Zhang, Y. DNA methylation in mammals. Cold Spring Harb. Perspect. Biol. 6(5), a019133–a019133. https://doi.org/10.1101/cshperspect.a019133 (2014).
Zaib, S., Rana, N. & Khan, I. Histone modifications and their role in epigenetics of cancer. Curr. Med. Chem. 29(14), 2399–2411. https://doi.org/10.2174/0929867328666211108105214 (2022).
Du, Z. et al. A multi-omics analysis-based model to predict the prognosis of low-grade gliomas. Sci. Rep. 14(1), 9427. https://doi.org/10.1038/s41598-024-58434-8 (2024).
Vieira, F. G., Bispo, R. & Lopes, M. B. Integration of multi-omics data for the classification of glioma types and identification of novel biomarkers. Bioinforma. Biol. Insights 18, 11779322241249564. https://doi.org/10.1177/11779322241249563 (2024).
Yang, H. et al. From multi-omics data to the cancer druggable gene discovery: A novel machine learning-based approach. Brief. Bioinform. 24(1), bbac528. https://doi.org/10.1093/bib/bbac528 (2023).
Ching, T. et al. Opportunities and obstacles for deep learning in biology and medicine. J. R. Soc. Interface 15(141), 20170387. https://doi.org/10.1098/rsif.2017.0387 (2018).
Li, F. et al. Positive-unlabeled learning in bioinformatics and computational biology: A brief review. Brief. Bioinform. 23(1), bba461. https://doi.org/10.1093/bib/bbab461 (2022).
Schork, N. J. Personalized medicine: Time for one-person trials. Nature 520(7549), 609–611. https://doi.org/10.1038/520609a (2015).
Kourou, K., Exarchos, T. P., Exarchos, K. P., Karamouzis, M. V. & Fotiadis, D. I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 13, 8–17. https://doi.org/10.1016/j.csbj.2014.11.005 (2015).
Liu, F. & Panagiotakos, D. Real-world data: A brief review of the methods, applications, challenges and opportunities. BMC Med. Res. Methodol. 22(1), 287. https://doi.org/10.1186/s12874-022-01768-6 (2022).
Chen, D. S. & Mellman, I. Oncology meets immunology: The cancer-immunity cycle. Immunity 39(1), 1–10. https://doi.org/10.1016/j.immuni.2013.07.012 (2013).
Balakrishna, P., George, S., Hatoum, H. & Mukherjee, S. Serotonin pathway in cancer. Int. J. Mol. Sci. 22(3), 1268. https://doi.org/10.3390/ijms22031268 (2021).
Topalian, S. L. et al. Safety, activity, and immune correlates of anti–PD-1 antibody in cancer. N. Engl. J. Med. 366(26), 2443–2454. https://doi.org/10.1056/NEJMoa1200690 (2012).
Wherry, E. J. T cell exhaustion. Nat. Immunol. 12(6), 492–499. https://doi.org/10.1038/ni.2035 (2011).
Verhaak, R. G. W. et al. Integrated genomic analysis identifies clinically relevant subtypes of glioblastoma characterized by abnormalities in PDGFRA, IDH1, EGFR, and NF1. Cancer Cell 17(1), 98–110. https://doi.org/10.1016/j.ccr.2009.12.020 (2010).
Jiao, Y. et al. Frequent ATRX, CIC, FUBP1 and IDH1 mutations refine the classification of malignant gliomas. Oncotarget 3(7), 709–722. https://doi.org/10.18632/oncotarget.588 (2012).
Wang, Q. et al. Tumor evolution of glioma-intrinsic gene expression subtypes associates with immunological changes in the microenvironment. Cancer Cell 32(1), 42-56.e6. https://doi.org/10.1016/j.ccell.2017.06.003 (2017).
Wang, X., Wang, X. & Li, J. Overcoming T-Cell exhaustion in glioblastoma: A narrative review. Glioma 5(2), 56–61. https://doi.org/10.4103/glioma.glioma_16_22 (2022).
Sarantopoulos, A., Ene, C. & Aquilanti, E. Therapeutic approaches to modulate the immune microenvironment in gliomas. Npj Precis. Oncol. 8(1), 241. https://doi.org/10.1038/s41698-024-00717-4 (2024).
Shih, K. C. et al. Successful treatment with dabrafenib (GSK2118436) in a patient with ganglioglioma. J. Clin. Oncol. 32(29), e98–e100. https://doi.org/10.1200/JCO.2013.48.6852 (2014).
Author information
Authors and Affiliations
Contributions
Conceptualization, Jiandonng Wu. And Mian Ma; Methodology, Yi Ding. And Zhaiyue Xu.; Software, Yi Ding.; Validation, Mian Ma. And Peng Deng.; Formal Analysis, Wenjing Hu.; Data Curation, Yi Ding. and Zhaiyue Xu.; Writing – Original Draft Preparation, Yi Ding. And Zhaiyue Xu.; Writing – Review & Editing, Mian Ma.; Supervision, Yi Ding. And Zhaiyue Xu.; Project Administration, Jiandonng Wu. And Mian Ma.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.The author(s) declare financil support was received for research, authorship, and/or publication of this article. This study was supported by grants from the Suzhou Science and Technology Development Plan (syw2025049).
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ding, Y., Xu, Z., Hu, W. et al. Comprehensive multi-omics and machine learning framework for glioma subtyping and precision therapeutics. Sci Rep 15, 24874 (2025). https://doi.org/10.1038/s41598-025-09742-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-09742-0
