
Abstract
Ensemble learning can effectively mitigate the risk of model overfitting during training. This study aims to evaluate the performance of ensemble learning models in predicting tumor deposits in rectal cancer (RC) and identify the optimal model for preoperative clinical decision-making. A total of 199 RC patients were analyzed, with radiomic features extracted from T2-weighted and apparent diffusion coefficient images and selected through advanced statistical methods. After that, the bagging-ensemble learning model (random forest), boosting-ensemble learning model (XGBoost, AdaBoost, LightGBM, and CatBoost), and voting-ensemble learning model (integrating 5 classifiers) were applied and optimized using grid search with tenfold cross-validation. The area under the receiver operator characteristic curve, calibration curve, t-distributed stochastic neighbor embedding (t-SNE), and decision curve analysis were adopted to evaluate the performance of each model. The voting-ensemble learning model (VELM) performs best in the testing cohort, with an AUC of 0.875 and an accuracy of 0.800. Notably, Calibration plots confirmed VELM’s stability and t-SNE visualization illustrated clear clustering of radiomic features. Decision curve analysis further validated the VELM’s superior net benefit across a range of clinical thresholds, underscoring its potential as a reliable tool for clinical decision-making in RC.
Similar content being viewed by others


Introduction
Rectal cancer (RC) is a significant contributor to global cancer-related mortality, accounting for ~ 30–50% of all colorectal cancer cases1,2. Tumor deposits (TDs) refer to isolated tumor foci located in the pericolic or perirectal fat or within the adjacent mesentery that are distinct from the primary tumor and do not involve lymph nodes3,4. Several investigations have demonstrated the correlation between TDs in RC and aggressive tumor progression, diminished disease-free survival, and overall survival rates, along with an increased likelihood of local recurrence and distant metastasis5,6,7. T lesions with negative regional lymph node metastasis (LNM) but positive TDs are classified as N1c. Hence, the prospect of pretherapeutic TDs prediction offers promise in optimizing treatment approaches and patient outcomes, affording clinicians invaluable insights for tailored interventions8. However, the diagnosis of TDs currently relies on post-surgical pathological assessment, limiting its immediate clinical utility. Given that treatment decisions typically hinge on clinical and imaging data, the ability to predict TDs preoperatively poses a challenge.
Magnetic resonance imaging (MRI) is instrumental in the evaluation of RC, providing critical insights into extramural venous invasion (EMVI) status, circumferential resection margin (CRM) involvement, and the depth of direct tumor invasion. These imaging capabilities not only predict prognosis but also guide the selection of optimal treatment strategies. A study with a limited sample size highlighted MRI’s potential in predicting TDs; however, the radiomics analysis in this study was restricted to single-slice T2-weighted imaging (T2WI)9. Radiomics enables the extraction of high-dimensional quantitative features from medical images that are challenging to discern through visual inspection. By integrating radiology, computer vision, and machine learning (ML), radiomics provides insights into the underlying pathophysiology10. Numerous studies have utilized radiomics for cancer prognosis prediction, demonstrating the potential of radiomic features to improve clinical decision-making11. Leveraging artificial intelligence, including ML, radiomics offers a promising tool for diagnosis, therapeutic response assessment, and outcome prediction in various tumor types12. Guo et al. proposed an ensemble learning method for diagnosing COVID-19 based on CT images, employing ordinal regression13. Ensemble learning is a ML technique that integrates multiple individual classifiers to enhance predictive performance. By integrating various ML models into a single cohesive model, ensemble learning mitigates the risk of overfitting and promotes the generalization of the predictive algorithm14. This methodological fusion leverages the strengths of each classifier, thereby improving the robustness and accuracy of the overall prediction15.
Among the prevailing ensemble learning techniques, three primary methods have garnered significant attention: bagging, boosting, and voting. Bagging reduces variance by training multiple instances of a model on various subsets of the data. Boosting sequentially trains models, each correcting the errors of its predecessor, thereby improving bias and overall predictive performance. Bagging reduces model variance, and boosting reduces model deviation. Voting, unlike bagging and boosting, aggregates predictions by averaging the outputs of multiple different models on the same dataset to form a final prediction, typically enhancing stability and accuracy.
Although model ensemble was an important strategy to optimize models, most of those studies focused on evaluating one of the ensemble learning approaches, whereas only a minority have compared the effects of different ensemble ML methods, especially in the field of predicting of TDs in RC16. Moreover, to the best of our knowledge, there remains a significant gap in MRI radiomics analyses that utilize multiparametric MR sequences, particularly in leveraging three-dimensional (3D) lesion features from T2WI and apparent diffusion coefficient (ADC) images to preoperatively assess TDs status. To address this, we sought to evaluate and compare the performance of different ensemble learning models, including bagging, boosting, and voting, using MRI radiomics features (ADC + T2WI) for the preoperative detection of TDs in RC, and to identify which model performs best for predicting TDs. Although the main focus of the article is the evaluation of prediction performance using different machine learning models based on ROIs extracted from MRI images, existing methods for automatic ROI segmentation already enable predictions to be made directly from MRI images without the need for annotations. Therefore, we can combine segmentation models (e.g., UNet) with radiomics classification algorithms, allowing the MRI image to be directly inputted to generate prediction results. As a result, this process is not particularly challenging for radiologists, and using this approach would offer significant time benefits. Figure 1 provides an overview of the radiomics analysis workflow.

The framework of our proposed radiomics model.
Materials and methods
Patients
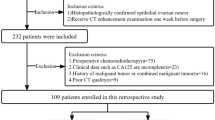
This retrospective study was approved by the institutional ethics review board of Wuhan Tongji Hospital, with a waiver of informed consent. 199 cases with RC were enrolled in this study, who were hospitalized at Wuhan Tongji Hospital from April 2018 to May 2022, and all patients’ private information had been de-identified. Pathological evaluation following surgical resection is regarded as the gold standard for diagnosing TDs. The clinicopathological characteristics are summarized in Table 1. The inclusion and exclusion criteria are illustrated in Fig. 2 and Supplementary Table S1. The patients were enrolled and allocated into training (n = 139) and testing (n = 60) cohorts. The pathologic features of all patients were retrieved from their medical records. The methods were performed according to relevant guidelines and regulations.

Inclusion and exclusion criteria.
Image acquisition and tumor segmentation
Prior to surgical intervention, patients were scanned using a 3.0 T MRI system (Verio 3.0, Siemens Medical Solutions, Germany) equipped with an eight-channel phased-array body coil. The imaging protocol included fat-suppressed T2WI and DWI sequences enhanced by respiratory gating techniques. T2WI images were acquired using conventional T2-weighted imaging to capture the differences in water content and tissue structure. DWI images were obtained by applying different b-values to assess the diffusion properties of water molecules within tissues, resulting in a series of diffusion-weighted images. Subsequently, these DWI images were processed to generate ADC maps, providing quantitative diffusion information. The radiomics features extracted from ADC and T2WI images formed the foundation of our study aimed at preoperatively identifying TDs in RC. The standard MRI protocol parameters are summarized in Supplementary Table S2.
Furthermore, upon meticulous analysis of the MR images from all participants, metrics such as the depth of tumor invasion as indicated by MRI (mT-stage), nodal involvement (mLN-status), CRM, and EMVI were meticulously documented by a duo of radiologists, each boasting over a decade of expertise in rectal carcinoma diagnostics. Discrepancies were harmonized through joint deliberation and mutual concordance between the diagnosticians.
Two readers manually and independently segmented the rectal tumors using ITK-SNAP (version 3.8.0) software. The segmentation was performed by two radiologists. The detailed information of the two radiologists and the details of the segmentation are shown in Supplementary Table S3. During the segmentation process, neither radiologist had access to the clinical or pathological information.
Radiomics feature extraction and selection
Radiomics feature extraction was performed using Python (version 3.9.18) and the PyRadiomics package to obtain 3D features from T2WI and ADC images17. Prior to extraction, all images were normalized using the z-score method and resampled to a voxel size of 1 × 1 × 1 mm. Specifically, the z-score normalization was performed using the zscore function from Python’s scikit-learn package (version 3.1.2). This method involves subtracting the mean and dividing by the standard deviation for each feature. The entire process, including image processing and feature extraction, was fully automated to ensure consistent results.
1702 radiomic features were extracted, spanning seven categories, were initially extracted for analysis. To account for inter-reader variability in radiomics feature extraction, reliability analysis was conducted using the intra-class correlation coefficient (ICC)18. Features demonstrating excellent reproducibility (ICC ≥ 0.8) were retained, resulting in a refined subset of 1202 features for subsequent model development. To construct a robust radiomics signature and identify the most relevant features from this subset, a two-step feature selection process was employed. Initially, we conducted Max-Relevance and Min-Redundancy (mRMR) with a K threshold of 150 to identify and eliminate redundant features. To mitigate bias from unbalanced data in the training cohort, the synthetic minority oversampling technique (SMOTE) was employed during the construction of the predictive model19. Subsequently, features were selected based on the least absolute shrinkage and selection operator (LASSO), a method specifically designed to prevent overfitting and well-suited for analyzing radiomic features20. The 10-fold cross-validation method was employed to evaluate the overall performance of the model in the LASSO framework., shown in Supplementary Fig. S1. Ultimately, 21 features were selected and retained for subsequent analysis, shown in Supplementary Table S4.
Model construction and evaluation
Bagging-ensemble learning model
The bagging-ensemble learning model generates multiple sub-datasets through bootstrap sampling, trains base models, and aggregates their predictions to reduce variance and enhance generalization. Figure 1 illustrates the structural diagram of the bagging. First, m training samples are drawn from the original dataset. After T rounds of sampling, T distinct training sets are generated, which are then used to train individual weak learners. The outcome is derived by combining the results of these weak learners through either averaging or voting. Random forest (RF), a representative decision tree-based algorithm, is a bagging ensemble technique that utilizes bootstrap sampling21. RF creates multiple subsets through bootstrap sampling from the training data and trains various models on these subsets. The final prediction is obtained by averaging the outputs of all submodels. As the number of trees increases, RF effectively avoids overfitting and is less influenced by outliers22. Additionally, RF demonstrates superior predictive power compared to other ML algorithms, even with imbalanced classes. Given these strengths, this study employs RF as a bagging-ensemble learning model to enhance the overall model’s generalization ability and robustness.
Boosting-ensemble learning model
The boosting-ensemble learning model is renowned for its exceptional predictive performance. Boosting is an iterative ensemble technique where each calculation step is influenced by the preceding one. This forward-distributed algorithm adjusts the weights of misclassified samples, enhancing their significance to boost the model’s overall predictive accuracy23. As shown in Fig. 1, the initial training of weak learner 1 is conducted on the original dataset. Based on its prediction results, the training sample distribution is adjusted to create training cohort 2. Subsequently, weak learner 2 is trained on training cohort 2. This process is repeated iteratively until the termination condition is met. The final prediction is obtained by computing the weighted sum of each base learner’s output. Representatively, there are extreme gradient boosting (XGBoost)24, light gradient boosting machine (LightGBM)25, Adaptive Boosting (AdaBoost)26 and Categorical Boosting (CatBoost)27. Hence, the boosting-ensemble learning model was done using these four ML classification algorithms.
Given the variability due to the small sample size, a 10-fold cross-validation approach was employed. The dataset was randomly split into 10 equal parts, with 9 parts used for training and the remaining 1 part for testing28. This step was repeated 10 times. The mean value from 10 experiments, along with the corresponding 95% confidence interval (CI), was used as the evaluation standard. The data were divided into training and testing cohorts at a 7:3 ratio. The split was automatically generated in a stratified manner. Hyperparameter optimization, or tuning, involves identifying a set of hyperparameter values that enable an ML algorithm to fit the data more effectively, achieving optimal performance based on a predefined metric in a cross-validation set29. Hyperparameter optimization is crucial for enhancing the prediction accuracy of ML algorithms. Various automated hyperparameter optimization algorithms have been proposed, such as grid search30, random search30, Bayesian search31, gradient-based search32, and multi-fidelity search methods33. In our study, we employed the grid search optimization available in the open-source software ML library Scikit-Optimize on each ML algorithm after completing the feature selection process. Supplementary Table S5 details the hyperparameter settings for each ML algorithm, optimized through grid search.
Voting-ensemble learning model
The VELM is an ML model ensemble that combines predictions from multiple other models. It has demonstrated superiority over single models in both predictive power and generalization capability by enhancing weak classifiers to achieve improved outcomes34. The core principle of this model is to enhance robustness and generalizability by combining predictions from multiple weak learners rather than relying on a single predictor35. VELM includes hard voting and soft voting. Its learning capability enables the weighted combination of predictions from different algorithms, compensating for their weaknesses and leading to more accurate and robust predictions. Our VELM employed five ML models and then integrated them using a soft voting strategy. The VELM is both fast and straightforward, as it generates prediction results on the test dataset without requiring model retraining. The methodologic details are presented in the supplemental materials.
After evaluating and selecting the base estimator, several ML base algorithms were constructed for the VELM by adjusting various parameters. In this study, LR, XGBoost, SVM, CatBoost, and MLP were selected for the voting-ensemble learning model36. The parameters and weight of the VELM were optimized by a random search strategy. The predicted probabilities from each ML classifier were then fed into the voting ensemble classifier, which performed voting based on the argmax of the sum of predicted class label probabilities35. Likewise, this model performed 10-fold cross-validation and calculated the associated evaluation metrics. We experimented with voting using each of the algorithms listed in Table 2 as the base estimator.
Multiple experiments were conducted using the features selected by the aforementioned feature selection methods, and we used the Youden index to confirm the optimal thresholds. The average performance on the training and testing cohort were all recorded in Tables 3 and 4.
Statistical analysis
All statistical analysis were conducted using Python (version 3.9.18). The “glmnet” package was used to implement the LASSO logistic regression analysis. To evaluate the models’ performance, area under the receiver operating characteristic (AUC-ROC), accuracy, specificity, sensitivity, PPV, and NPV were considered. It should be emphasized that the optimal classification threshold was determined using the Youden index. Shapley Additive Explanations (SHAP) value analysis, a method rooted in cooperative game theory, was employed to enhance the interpretability of the best-performing model by assigning importance values to each feature for specific predictions. This analysis was conducted using the “shap” open-source Python library37. Moreover, t-distributed Stochastic Neighbor Embedding (t-SNE) was applied for the visualization of high-dimensional radiomic features, providing insights into the intrinsic clustering patterns and separation among distinct groups. Decision curve analysis (DCA) was performed to appraise the clinical utility of the models by examining the net benefit across a continuum of decision thresholds. Supplementary Table S6 lists the major Python packages used in this study.
Results
Clinical characteristics
199 patients were included in our study. Among them, no significant differences were observed in histologic grade (P = 0.993), mT-stage (P = 0.376), and mLN-status (P = 0.682) between positive and negative groups within the training cohort. Similarly, within the testing cohort, no significant differences were observed in these parameters, with histologic grade (P = 0.674), mT-stage (P = 0.468), and mLN-status (P = 0.497) remaining consistent across groups. Patient characteristics, summarized in Table 1, showed no significant differences between the training and testing cohorts, except for histologic grade and CRM. Additionally, no difference in the TDs positive rate was observed between the training and testing cohorts (37.4% (52/139) vs. 36.7% (22/60), respectively; P = 0.92).
Performance of different ensemble methods
The performance of each model can be further evaluated using a calibration plot (Fig. 3a,b). The dashed line represents perfect calibration; therefore, the closer a model’s calibration curve is to this diagonal line, the more accurate its predictive performance. Notably, the VELM demonstrates the best calibration, closely following the diagonal line, indicating a high consistency between predicted and actual probabilities.

Calibration plot for different models in the training (a) and testing cohort (b). The y-axis represents the predicted value, while the x-axis denotes the fraction of positive. The different colored lines correspond to the calibration curves of various models, with the dashed line serving as the reference line for an ideal classifier. Notably, our model, represented by the blue line, is closer to the diagonal dashed line, indicating superior predictive performance of VELM.
Figure 4a and b depicts the ROC curves of each ensemble model on the training and testing cohorts. A grid search, using the area under the ROC curve (AUC) as the objective, was conducted to optimize the parameters of all base estimators. Notably, our VELM (the blue line) is the closest to the upper left corner, demonstrating slightly higher sensitivity and a lower false positive rate compared to most other models. Of these models evaluated, VELM achieves the best performance, which indicates that this model can accurately predict recurrence outcomes. The ROC curves of these three models are close to the left and top axes. Obviously, on the testing cohort, the auc of the VELM is the highest (auc = 0.875), then the boosting-ensemble learning model falls into the range of (0.781–0.804) and the bagging-ensemble learning model (auc = 0.747) rank successively. On the training cohort, CatBoost achieves the highest auc, with an auc of 0.988, followed by VELM (auc = 0.972).

(a,b) Display the ROC curves and corresponding AUCs for all models in the training and testing cohorts, respectively.
The diagnostic performances of the bagging-ensemble learning model, boosting-ensemble learning model, and VELM on the training and testing cohorts are summarized in Tables 3 and 4. Notably, the VELM exhibits significantly superior classification accuracy compared to both bagging and boosting approaches across the training and testing cohorts, proving that VELM can combine the advantages of individual classifiers and obtain better performance. The classification results are presented as SD across repeated runs.
Feature importance analysis and SHAP explanation
In Supplementary Fig. S3, the distribution of three important features: “wavelet-HLL_glcm_InverseVariance_T2”, “wavelet-HHH_glcm_Imc1_ADC” and “wavelet-LLL_glcm_Correlation_T2” is shown in a boxplot, respectively. It reveals a central distribution with medians around zero, varying interquartile ranges indicating different levels of dispersion, and significant outliers suggesting the presence of extreme values, particularly notable in “wavelet-HLL_glcm_InverseVariance_T2” and “wavelet-LLL_glcm_Correlation_T2”, highlighting the need for potential data normalization or outlier treatment in subsequent analyses. Figure 5 illustrates the contribution of individual radiomics features to the predicted value for a single sample, presented as a waterfall plot. The plot elucidates that “wavelet-HLL_glcm_InverseVariance_T2” is the most influential feature, significantly enhancing the model’s predictions with high positive SHAP values, while “wavelet-HLL_firstorder_Skewness_ADC” and “wavelet-HLL_glcm_MaximumProbability_ADC” also substantially contribute, highlighting the complex interplay of top features in driving model outcomes and underscoring the necessity for their careful consideration in predictive analytics.

The waterfall plot for a single sample prediction displays the feature names on the y-axis, with the corresponding feature values listed next to each name. The numbers within the plot indicate the contribution of each feature to the prediction result.
Discussion
This study facilitates prediction based on MRI images, enabling preoperative detection of deposits. Such an approach contributes to precise clinical staging, thereby informing decisions regarding the necessity for preoperative adjuvant chemotherapy/radiotherapy and the extent of surgical resection. Consequently, the adoption of this method is expected to yield substantial time benefits. Radiomics has emerged as a powerful tool for image analysis, transforming medical images into quantitative descriptors38. To our knowledge, several studies have underscored the critical role of ML techniques in enhancing clinical decision-making and prognostic accuracy in RC. Zhang et al. established and validated radiomics models based on multiparametric MRI of RC by comparing different ML algorithms. The LR algorithm emerged as the best-performing model, achieving AUCs of 0.827 and 0.739 in the training and testing cohorts, respectively39. Sun et al. used RF, SVM, and Deep Learning models, with the AUC of 0.854 and 0.923 for the training and validation set, respectively40. However, few studies compared the predictive performance of several ensemble models for the preoperative identification of TDs in RC. Our findings were essential to improve the predictive performance in facilitating the preoperative evaluation of TDs status.
It is well known that overfitting is a typical fault of ML models, where the model captures random noise in the data rather than identifying underlying patterns or trends41. To construct the radiomic signature and mitigate overfitting, the most relevant variables were selected using mRMR, Lasso and SMOTE methods. We constructed three ensemble learning models (bagging, boosting and voting), employing grid search to optimize parameters based on 21 radiomics features. RF is a representative bagging ensemble method, while XGBoost, AdaBoost, CatBoost and LightGBM are state-of-the-art boosting ensemble methods42. Compared to the other two ensemble models, the VELM demonstrates surprisingly outstanding performance on almost all indexes in our study, auc, accuracy, PPV, and NPV are significantly higher.
VELM can be applied to any ML model and is often considered a meta-model, enhancing predictive performance by leveraging multiple algorithms. In hard voting, the final prediction is determined by the majority class label from individual models. However, soft voting offers several advantages over hard voting. This is because, based on the probabilities predicted by various classifiers, the soft voting classifier categorizes input data with higher accuracy than a hard voting classifier due to its flexibility in assigning determination. Specifically, the prediction is made by averaging the probabilities from each classifier and selecting the class with the highest average probability35,42,43. By averaging these probabilities, the soft voting strategy effectively leverages the strengths of all the included classifiers, resulting in improved predictive performance. Given these benefits, we developed a VELM that integrates five ML classifiers using a combined strategy of soft voting, which can provide quantitative analysis support for clinical decision-making.
The results (Tables 3 and 4) clearly show that VELM does not improve the specificity metric compared to other algorithms (the specificity of RF = 97.6%, the specificity of CatBoost = 100%, while the specificity of VELM = 95.1% on the testing cohort). The reason for this is that during model training, we aim for auc optimality, and therefore, cannot take into account other metrics, such as specificity. Thus, we conclude that combining classifiers through voting may not always lead to improved performance. In practice, by adjusting the optimization objective, the model can obtain better results on the specified indicators.
Conclusion
Pathological evaluation following surgical resection is considered the gold standard for diagnosing tumor deposits (TDs). However, it can only be obtained postoperatively. In this study, we proposed an ensemble learning strategy utilizing efficient radiomics feature representation (ADC + T2WI) was proposed for the preoperative prediction of TDs status in RC patients. This approach helps guide decisions on the necessity of preoperative adjuvant chemotherapy/radiotherapy and the extent of surgical resection. Compared to ultrasound and radiological examinations, MRI-based prediction of TDs demonstrates higher concordance with pathological diagnosis. In conclusion, our study investigated and validated the VELM based on efficient radiomics feature representation that could predict TDs status in RC patients with good accuracy on both training and testing cohorts. The VELM with manual optimization can serve as a clinical decision support system, aiding clinicians in selecting the most appropriate initial treatment for RC patients, thereby reducing unnecessary surgical resection and minimizing patient harm.
Data availability
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.
References
Bailey, C. E. et al. Increasing disparities in the age-related incidences of colon and rectal cancers in the United States, 1975–2010. JAMA Surg. 150, 17–22 (2015).
Siegel, R. L., Miller, K. D., Fuchs, H. E. & Jemal, A. Cancer statistics, 2022. CA Cancer J. Clin. 72, 7–33 (2022).
Chen, L.-D. et al. Preoperative prediction of tumour deposits in rectal cancer by an artificial neural network-based US radiomics model. Eur. Radiol. 30, 1969–1979 (2020).
Greene, F. L. Tumor deposits in colorectal cancer: A moving target. Ann. Surg. 255, 214 (2012).
Ueno, H. et al. Peritumoral deposits as an adverse prognostic indicator of colorectal cancer. Am. J. Surg. 207, 70–77 (2014).
Lin, Q. et al. Tumor deposit is a poor prognostic indicator in patients who underwent simultaneous resection for synchronous colorectal liver metastases. OncoTargets Ther. 8, 233–240 (2015).
Lord, A. C. et al. Significance of extranodal tumour deposits in colorectal cancer: A systematic review and meta-analysis. Eur. J. Cancer 82, 92–102 (2017).
Glynne-Jones, R. et al. Corrections to “Rectal cancer: ESMO clinical practice guidelines for diagnosis, treatment and follow-up”. Ann. Oncol. 29, 263 (2018).
Yan-song, Y. et al. High-resolution MRI-based radiomics analysis to predict lymph node metastasis and tumor deposits respectively in rectal cancer. Abdom. Radiol. 46, 873–884 (2021).
Zhou, M., Xiong, X., Drummer, D. & Jiang, B. Molecular dynamics simulation and experimental investigation of the geometrical morphology development of injection-molded nanopillars on polymethylmethacrylate surface. Comput. Mater. Sci. 149, 208–216 (2018).
Cha, Y. J. et al. Prediction of response to stereotactic radiosurgery for brain metastases using convolutional neural networks. Anticancer Res. 38, 5437–5445 (2018).
Bi, W. L. et al. Artificial intelligence in cancer imaging: Clinical challenges and applications. CA Cancer J. Clin. 69, 127–157 (2019).
Guo, X. et al. An ensemble learning method based on ordinal regression for COVID-19 diagnosis from chest CT. Phys. Med. Biol. 66, 244001 (2021).
Dorani, F., Hu, T., Woods, M. O. & Zhai, G. Ensemble learning for detecting gene–gene interactions in colorectal cancer. PeerJ 6, e5854 (2018).
Pearson, R., Pisner, D., Meyer, B., Shumake, J. & Beevers, C. G. A machine learning ensemble to predict treatment outcomes following an Internet intervention for depression. Psychol. Med. 49, 1–12 (2018).
Ritter, Z. et al. Two-year event-free survival prediction in DLBCL patients based on in vivo radiomics and clinical parameters. Front. Oncol. 12, 820136 (2022).
Van Griethuysen, J. J. M. et al. Computational radiomics system to decode the radiographic phenotype. Cancer Res. 77, e104–e107 (2017).
Xue, C. et al. Radiomics feature reliability assessed by intraclass correlation coefficient: A systematic review. Quant. Imaging Med. Surg. 11, 4431460–4434460 (2021).
Umer, M. et al. Scientific papers citation analysis using textual features and SMOTE resampling techniques. Pattern Recognit. Lett. 150, 250–257 (2021).
Park, Y. W. et al. Radiomics with ensemble machine learning predicts dopamine agonist response in patients with prolactinoma. J. Clin. Endocrinol. Metab. 106, e3069–e3077 (2021).
Mukherjee, S. et al. Radiomics-based machine-learning models can detect pancreatic cancer on prediagnostic computed tomography scans at a substantial lead time before clinical diagnosis. Gastroenterology 163, 1435-1446.e3 (2022).
Javed, A. A. et al. Accurate non-invasive grading of nonfunctional pancreatic neuroendocrine tumors with a CT derived radiomics signature. Diagn. Interv. Imaging 105, 33–39 (2024).
Lin, S. et al. Comparative performance of eight ensemble learning approaches for the development of models of slope stability prediction. Acta Geotech. 17, 1477–1502 (2022).
Chen, T. & Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 785–794 (Association for Computing Machinery, New York, 2016).
Ke, G. et al. LightGBM: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems, vol. 30 (Curran Associates, Inc., 2017).
Margineantu, D. D. & Dietterich, T. G. Pruning Adaptive Boosting (Morgan Kaufmann Publ. Inc, 1997).
Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V. & Gulin, A. CatBoost: Unbiased boosting with categorical features. in Advances in Neural Information Processing Systems vol. 31 (Curran Associates, Inc., 2018).
Wang, L. et al. Ensemble learning based on efficient features combination can predict the outcome of recurrence-free survival in patients with hepatocellular carcinoma within three years after surgery. Front. Oncol. 12, 1019009 (2022).
Eleftheriadis, V. et al. Radiomics and machine learning for skeletal muscle injury recovery prediction. IEEE Trans. Radiat. Plasma Med. Sci. 7, 830–838 (2023).
Bergstra, J. & Bengio, Y. Random Search for Hyper-Parameter Optimization.
Agnihotri, A. & Batra, N. Exploring Bayesian optimization. Distill 5, e26 (2020).
Foo, C., B., C. & Ng, A. Efficient multiple hyperparameter learning for log-linear models. In Advances in Neural Information Processing Systems, vol. 20 (Curran Associates, Inc., 2007).
Hu, Y.-Q. et al. Multi-fidelity automatic hyper-parameter tuning via transfer series expansion. Proc. AAAI Conf. Artif. Intell. 33, 3846–3853 (2019).
Kurnianingsih, K., Hadi, N. F. A. F., Wardihani, E. D., Kubota, N. & Chin, W. H. Ensemble learning based on soft voting for detecting methamphetamine in urine. In 2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) (2020).
Cao, J. et al. Class-specific soft voting based multiple extreme learning machines ensemble. Neurocomputing 149, 275–284 (2015).
Huang, Y. et al. Development and validation of a machine learning prognostic model for hepatocellular carcinoma recurrence after surgical resection. Front. Oncol. 10, 593741 (2021).
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems, vol. 30 (Curran Associates, Inc., 2017).
Lambin, P. et al. Radiomics: Extracting more information from medical images using advanced feature analysis. Eur. J. Cancer 48, 441–446 (2012).
Zhang, Y. et al. Preoperative prediction of microsatellite instability in rectal cancer using five machine learning algorithms based on multiparametric MRI radiomics. Diagnostics 13, 269 (2023).
Li, C. & Yin, J. Radiomics based on T2-weighted imaging and apparent diffusion coefficient images for preoperative evaluation of lymph node metastasis in rectal cancer patients. Front. Oncol. 11, 671354 (2021).
Parekh, V. & Jacobs, M. A. Radiomics: A new application from established techniques. Expert Rev. Precis. Med. Drug Dev. 1, 207–226 (2016).
Gao, G., Wang, H. & Gao, P. Establishing a credit risk evaluation system for SMEs using the soft voting fusion model. Risks 9, 202 (2021).
Kurian, B. & Jyothi, V. L. Breast cancer prediction using ensemble voting classifiers in next-generation sequences. Soft Comput. https://doi.org/10.1007/s00500-023-08658-z (2023).
Acknowledgements
This study was supported by the National Natural Science Foundation of China (Nos. 62072349).
Author information
Authors and Affiliations
Contributions
Jiayi Wang developed the concept, collected the data, analyzed the data, and wrote the paper. Fayong Hu, Liang Wang and Wenzhi Lv made substantial contribution to the conception or design of the work. Zhiyong Liu and Jin Li made contributions to the study supervision.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, J., Hu, F., Li, J. et al. Comparative performance of multiple ensemble learning models for preoperative prediction of tumor deposits in rectal cancer based on MR imaging. Sci Rep 15, 4848 (2025). https://doi.org/10.1038/s41598-025-89482-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-89482-3
Keywords
This article is cited by
-
Comparative analysis of algorithmic approaches in ensemble learning: bagging vs. boosting
Scientific Reports (2025)
-
MRI-based habitat, intra-, and peritumoral machine learning model for perineural invasion prediction in rectal cancer
Abdominal Radiology (2025)
