
Abstract
Monocular depth estimation plays a crucial role in many downstream visual tasks. Although research on monocular depth estimation is relatively mature, it commonly involves strategies that entail increasing both the computational complexity and the number of parameters to achieve superior performance. Particularly in practical applications, enhancing the accuracy of depth prediction while ensuring computational efficiency remains a challenging issue. To tackle this challenge, we propose a novel and simple depth estimation model called SimMDE, which treats monocular depth estimation as an ordinal regression problem. Beginning with a baseline encoder, our model is equipped with a Deformable Cross-Attention Feature Fusion (DCF) decoder with sparse attention. This decoder efficiently integrates multi-scale feature maps, markedly reducing the quadratic complexity of the Transformer model. For the extraction of finer local features, we propose a Local Multi-dimensional Convolutional Attention (LMC) module. Meanwhile, we propose a Wavelet Attention Transformer (WAT) module to achieve pixel-level precise classification of images. Furthermore, we also conduct extensive experiments on two widely recognized depth estimation benchmark datasets: NYU and KITTI. The experimental findings unequivocally demonstrate that our model attains exceptional accuracy in depth estimation while upholding high computational efficiency. Remarkably, our framework SimMDE, extending from AdaBins, demonstrates enhancements, resulting in substantial improvements of 11.7% and 10.3% in the absolute relative error (AbsRel) on the NYU and KITTI datasets, respectively, with fewer parameters.
Similar content being viewed by others


Introduction
Monocular depth estimation aims to recover depth information for each pixel from a single static image, which is crucial for understanding the three-dimensional world. Many applications, including virtual and reality1, three-dimensional reconstruction2, and robot navigation3, heavily rely on depth estimation. However, with the diversification of application scenarios, the demand for depth estimation is increasing4. Not only are high-precision depth estimates required, but real-time processing capabilities and the ability to operate in computationally constrained environments are also expected from the model. Balancing computational burden while ensuring exceptional performance remains a pivotal concern in the realm of depth estimation.
In practical applications, depth estimation encounters a trade-off between complexity and accuracy, such as in autonomous driving and robot navigation. Achieving high accuracy often demands complex algorithms and substantial computational resources, which may not be feasible in resource-constrained embedded systems or real-time scenarios. Current research aims to achieve model lightweight design through various methods5,6,7,8. These methods enhance computational efficiency, but they often compromise accuracy, which is unacceptable in applications requiring precise depth information. Such one-sided optimization strategies fail to meet the demand for both efficient and accurate depth estimation algorithms.
Nowadays, the core idea of most depth estimation decoders is to expand the multi-scale features generated by the encoder to a specific size and fuse them through convolutional operations9. However, this approach may not fully capture all the details in the image, especially in regions with edges or complex textures. Therefore, many studies have started adopting Transformer-based decoders to capture finer-grained features10. Nevertheless, this approach inevitably introduces the quadratic complexity of the Transformer. To facilitate better integration of multi-scale features and mitigate the quadratic complexity associated with Transformers, we propose the Deformable Cross-Attention Feature Fusion (DCF) Decoder. This decoder reduces computational complexity by incorporating a deformable attention mechanism11 and offers more flexible feature sampling and fusion strategies.
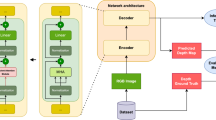
Furthermore, we transform the depth estimation problem into an ordinal regression task12 and propose SimMDE, a monocular depth estimation network architecture that balances complexity and accuracy. The network architecture comprises two branches: a probability prediction branch and a pixel classification branch.

Compares the number of trainable parameters against the AbsRel performance on the NYU and KITTI datasets’ test sets. Represented by blue dots are previous models. Our models employ advanced techniques and utilize significantly fewer parameters, achieving remarkable precision.
While dynamic convolution has introduced attention mechanisms to enhance its performance, its design primarily concentrates on the number of convolutional kernels, neglecting the critical dimensions of input and output channel numbers. In essence, existing works have not fully exploit the potential of dynamic convolutional properties, thus leaving considerable room for enhancing model performance. To handle this limitation, we propose the Local Multi-dimensional Convolution Attention (LMC) module to achieve more accurate probability prediction. This module applies attention mechanisms to all convolution kernels across three dimensions: the number of convolution kernels, input channels, and output channels. This dynamic mechanism endows the convolution kernel weights with sample adaptability. LMC facilitates the enhancement of effective channels without increasing the number of model parameters, while suppressing relatively less important channels, thereby significantly enhancing the feature extraction capability of the fundamental operation of convolutional neural networks (CNNs) operation.
To capture global information and accurately classify pixels, we propose the Wave Attention Transformer (WAT) module. While Transformer13 architectures have made breakthroughs in various aspects, their self-attention mechanism, which exhibits quadratic complexity in relation to the number of input patches, leads to high computational costs. To tackle this issue, some existing solutions often employ downsampling operations, such as average pooling, on the key and value to reduce computational overhead. However, this aggressive downsampling approach inevitably results in information loss, particularly for high-frequency components in images, such as texture details, as they are crucial for preserving rich image information. To more effectively retain high-frequency information, we introduce a lossless downsampling method using wavelet transforms14. Compared to traditional downsampling, wavelet transforms preserve high-frequency information in images and avoid the loss of texture details, while also capturing long-range dependencies without increasing computational complexity.
In conclusion, the following are our primary contributions:
-
1.
We propose a novel depth estimation model named SimMDE, which effectively balances the relationship between computational complexity and accuracy.
-
2.
We propose the Deformable Cross-Attention Feature Fusion (DCF) decoder with sparse attention, which flexibly captures detailed and structural information in images.
-
3.
To extract finer local features, we propose Local Multi-dimensional Convolution (LMC) attention to provide more refined feature extraction capabilities.
-
4.
We propose Wavelet Attention Transformer (WAT) to achieve precise pixel-level classification of images.
-
5.
We demonstrate the effectiveness of our proposed model through extensive experiments on two widely used depth estimation benchmark datasets, NYU and KITTI. The proposed SimMDE model, depicted in Fig. 1, outperforms state-of-the-art methods, achieves performance comparable to existing state-of-the-art methods while maintaining only 30.9M trainable parameters.
Ralated work
Supervised monocular depth estimation
Supervised Monocular Depth Estimation has made significant strides in recent years. Eigen et al.15 pioneered the use of deep neural networks for monocular depth estimation tasks. They introduced a novel approach employing two depth networks to address depth estimation tasks: one for global prediction and the other for local refinement. TransDepth16 was the first to incorporate Transformer into monocular depth estimation tasks. It proposed an architecture combining Transformer and convolutional neural networks aimed at tackling continuous pixel-level prediction problems such as monocular depth estimation and surface normal estimation. DORN17 was the first to introduce the transformation of the depth estimation problem into an ordinal regression task for more effectively handling uncertainty in depth estimation. AdaBins12 dynamically adjusts the depth range partitioning based on the characteristics of the input image, enabling it to handle depth estimation problems in different scenarios with significant achievements. IEBins18 introduced the novel Iterative Elastic Bins method, utilizing a classification-regression-based approach to search for high-quality depth. NeWCRFs19 significantly reduces the enormous computational burden brought by global CRFs by partitioning feature maps into small windows and computing CRFs within local windows, while leveraging shift windows to associate different local windows. LifelongDepth20 introduces an efficient multi-head architecture that facilitates lifelong, cross-domain, and scare-aware monocular depth learning. SADC21 proposes a robust depth completion method based on semantic aggregation, which aims to address the challenge of the robustness of the completion model due to variations in the effective pixel density in sparse depth maps. ASNDepth22 proposed a unified scheme to estimate depth and surface normal in the guidance of geometric context. DINOv223 is a self-supervised vision transformer that learns rich and generalizable visual representations, enabling strong performance across various downstream tasks, including depth estimation. SQLDepth24 utilizes an innovative Self Query Layer (SQL) to construct a self-cost volume and infer depth from it, rather than inferring depth from feature maps. Depth-Anything25 is a versatile depth estimation model that leverages large-scale pretraining and multi-modal learning to achieve high generalization across diverse scenes and tasks. PatchFusion26 is an end-to-end tile-based framework designed for high-resolution monocular metric depth estimation, which effectively fuses local and global depth cues to achieve accurate and scalable depth predictions. Marigold27 repurposes diffusion-based image generators for monocular depth estimation by leveraging the strong priors learned in generative models to produce high-quality depth predictions from single images. TIE-KD28 achieves efficient knowledge transfer without requiring architectural similarity between teacher and student models by introducing an interpretable Depth Probability Map. Metric3Dv229 achieves accurate estimation of zero-shot metric depth and surface normals by proposing a canonical camera space transformation and a joint depth-normal optimization module. However, these methods either achieve higher depth estimation accuracy at the cost of increased model complexity or sacrifice accuracy excessively to improve efficiency. In contrast, our proposed method effectively balances depth estimation accuracy and model efficiency by designing a simple encoder-decoder network combined with a convolutional attention module and a wavelet attention Transformer module.
Transformer
Transformer13, as a neural network architecture based on self-attention mechanism, has made significant breakthroughs in the field of natural language processing in recent years and has gradually extended to other domains such as computer vision. The introduction of Vision Transformer (ViT)30 marks the successful application of Transformer in the field of computer vision. ViT divides images into multiple small patches and treats them as sequential inputs, utilizing self-attention mechanism to learn feature representations in images, achieving comparable or even superior image classification performance compared to CNNs. Data-efficient Image Transformer (DeiT)31 employs a distillation-based training strategy to enhance the performance of small student models by learning knowledge from larger teacher models. Multiscale Visual Transformer (MViT)32 adopts a multi-scale feature hierarchy, enabling it to capture and represent information from high to low resolution more efficiently in videos. Focal Transformer33 enhances computational efficiency and model performance by focusing more finely on information close to the current position and coarsely on information far from the current position. Pyramid vision transformer (PVT)34 successfully improves the performance of the original ViT on dense prediction tasks by combining pyramid structure, local contiguous features, and flexible position encoding. Swin Transformer35 improves computational efficiency and scalability by introducing sliding window operations to limit the computational range of self-attention. Swin Transformer V236 enhances the original Swin Transformer35 by introducing scaled cosine attention, log-spaced continuous position bias, and improved training stability, enabling it to handle higher capacity and resolution for various vision tasks. U-DiTs37 introduce a U-shaped architecture for diffusion transformers that strategically downsamples tokens, improving efficiency and scalability while preserving rich hierarchical representations for high-quality image generation and understanding. PIIP38 introduce a novel hierarchical framework that inverts the conventional parameter allocation in image pyramids, enhancing Transformer-based models with improved efficiency and multi-scale feature representation. Current Transformers often employ pooling strategies to reduce the computational burden, inevitably leading to information loss. However, our proposed WAT, through wavelet transform, achieves lossless downsampling without sacrificing crucial information, thus striking a better balance between computational cost and performance.

The overview of the proposed SimMDE. The input RGB images are subject to feature extraction and fusion via our innovative encoder-decoder module. Upon the decoder completing feature reconstruction, the resulting feature map is sent to two branches: one for probability prediction incorporating LMC module, and the other for pixel classification utilizing WAT module. By reframing depth estimation as an ordinal regression problem, the final depth estimation is determined using the combined outputs from both branches.
Methodology
In this section, we first outline our proposed depth estimation architecture, SimMDE. Subsequently, we delve into the key components of the architecture, including the Deformable Cross-Attention Feature Fusion (DCF) decoder, the Local Multi-dimensional Convolutional Attention (LMC) module, the Wave Attention Transformer (WAT) module, and the depth estimation module. Finally, we introduce the loss function.

The proposed encoder-decoder structure. (a) provides an overall view of both the encoder and decoder. (b) delves into the specifics of the decoder, showcasing its intricate details.
Framework overview
The overall network results are depicted in Fig. 2. We utilize the encoder structure from39 to extract multiscale features. For an RGB image of size \(H \times W \times C\), we design four depth feature extraction stages: (i) \(\frac{H}{4} \times \frac{W}{4} \times {C}_1\), (ii) \(\frac{H}{8} \times \frac{W}{8} \times {C}_2\), (iii) \(\frac{H}{16} \times \frac{W}{16} \times {C}_3\), (iv) \(\frac{H}{32} \times \frac{W}{32} \times {C}_4\), where \(C_i\) denotes the number of channels at each stage. The DCF decoder progressively extends multiscale encoder features from \(\frac{H}{32} \times \frac{W}{32}\) to \(\frac{H}{4} \times \frac{W}{4}\) layer by layer. It utilizes deformable cross-attention to deeply fuse encoder features and decoder features at different levels. After feature reconstruction by the decoder, the output feature map bifurcates into two streams: one is fed into the probability prediction branch, and the other guides the pixel classification branch. (I) Probability Prediction Branch: Initially, LMC is applied to the feature map to enhance the focus on important features and suppress irrelevant information. Subsequently, the feature map is reprocessed through a Softmax function to obtain a probability distribution of N depth intervals. (II) Pixel classification branch: The processing flow for each pixel begins with an embedding layer. Subsequently, the features processed by the embedding layer are transported to our proposed Wave Attention Transformer msodule. The WAT module precisely analyzes the features of each pixel by capturing global information, enabling accurate pixel classification. Ultimately, the results from the probability prediction branch and the pixel classification branch are aggregated by the depth estimation module to generate the final predicted depth map12.
Deformable cross-attention feature fusion decoder
In current practice, the majority of decoder architectures rely on a fusion approach combining bilinear upsampling and convolution operations9. This method aims to recover the intricate details and structural information of images. However, traditional convolution-based methods for feature fusion often struggle to fully capture and reconstruct fine variations in images, especially in complex scenes and with dynamic objects. Despite the existence of many decoders based on standard Transformers13, they inevitably suffer from the quadratic complexity of standard Transformers.
To overcome these limitations, we introduce Deformable Attention into feature fusion, constructing our Deformable Cross-Attention Feature Fusion (DCF) Decoder. Unlike standard Transformers, deformable attention11 significantly reduces computational complexity by focusing only on a small subset of key sampling points around reference points. This localized attention strategy avoids the quadratic complexity problem in standard Transformers, empowering our decoder to handle high-resolution images more efficiently. The structure diagram is presented in Fig. 3.
For the outputs from the four different stages of the encoder, we utilize a deformable cross-attention mechanism to deeply integrate them with decoder features at various levels. As an illustration, let’s consider the fusion of outputs from consecutive stages i and \(i+1\) in the decoder. Suppose the respective output feature maps are denoted as \(X_{i} \in \mathbb {R}^{h \times w \times c_{1}}\) and \(X_{i+1} \in \mathbb {R}^{h_{1} \times w_{1} \times c_{2}}\). Initially, a bilinear interpolation operation is applied to \(X_{i+1}\) to expand its size, generating a new feature map \(Y_{i} \in \mathbb {R}^{h \times w \times c_{2}}\). Subsequently, \(X_{i}\) and \(Y_{i}\) are fed into the DCF module, which outputs the fused feature map, \(Z_{i} \in \mathbb {R}^{h \times w \times c}\).
The deformable attention mechanism focuses on a set of local key sampling points around reference points, regardless of the spatial dimensions of the feature map. By assigning a limited number of key points for each query point, we effectively address the convergence issue of the model and the challenge of feature space resolution. To elaborate, we initially apply \(1 \times 1\) convolutional processing to \(X_{i}\) and \(Y_{i}\) to obtain feature maps \(\widehat{X}\), \(\widehat{Y} \in \mathbb {R}^{h \times w \times c }\). Subsequently, positional encoding is applied to \(\widehat{X}\) to derive \(X^{pos} \in \mathbb {R}^{h \times w \times c}\). The resulting \(X^{pos}\) is then element-wise added to \(\widehat{X}\), yielding the \(query \in \mathbb {R}^{h \times w \times c }\). This feature map serves as the query input for computing deformable cross-attention, while \(\widehat{Y}\) itself acts as the value input. Given two input feature maps \(x \in \mathbb {R}^{h \times w \times c }\) and \(y \in \mathbb {R}^{h \times w \times c }\), the mathematical expression for deformable cross-attention is as follows:
where, K represents the number of attention heads, M represents the number of samples(\(M<< HW\)), \(W_k\), \(W_{mqk}\), and \(W_p\) represent the learnable weights. \(\bigtriangleup f_{mqk}\) and \(\sigma (W_{mqk}x)\) denote the sampling offset and attention weight of the k-th sampling point in the m-th attention head, respectively. q indexes a characteristic query element of \(c_{q}\). \(\sigma\) represents the Softmax function.

Illustration of the LMC’s approach to progressively multiplying three distinct attention types with convolutional kernels. LMC module employs a unique multi-dimensional attention mechanism to simultaneously compute attentions \(A_i\), \(B_i\), and \(C_i\) for \(W_i\), each corresponding to a different dimension within the kernel space.
Local multi-dimensional convolutional attention module
Recent research has unveiled the significant enhancement of network processing capabilities through the integration of attention mechanisms within convolutional neural networks40,41. Following this42,43, introduced the concept of dynamic convolution. By embedding attention mechanisms, they successfully addressed the inherent limitations of traditional static convolution, which relies on fixed and invariant convolutional kernels for all input signals. Dynamic convolution41, employing multiple sets of convolutional kernels and their associated weight factors, effectively boosts the network’s adaptability and flexibility in handling input features.
Despite the integration of attention mechanisms to enhance performance, the design of dynamic convolution primarily emphasizes the number of convolutional kernels, neglecting the crucial role of input and output channel dimensions. While replacing conventional convolution with dynamic convolution can enhance processing capacity, it results in an increase in total parameters by a factor of k, where k represents the number of kernel groups. This increase significantly increases model complexity.
Drawing inspiration from40,41,44, we introduce a module called Local Multi-dimensional Convolutional Attention (LMC). The diagram in Fig. 4 illustrates the structure. This module adaptively learns attention weights across three crucial dimensions: the number of convolutional kernels, input channels, and output channels. This innovative approach aims to amplify the effectiveness of convolutional operations across various facets. Employing a parallel strategy, the LMC module learns attention across these dimensions concurrently. Furthermore, the attention mechanisms applied to these dimensions are mutually reinforcing, collaboratively bolstering the feature extraction capabilities of convolutional neural networks without imposing additional parameters.
Initially, an input feature map \(X^{f}\) is fed into a \(7 \times 7\) convolutional layer to extract local features efficiently. To minimize computational complexity, depth-wise convolution (DWConv)45 and the Gaussian Error Linear Unit (GELU)46 are judiciously applied, yielding a further refined feature map \(X^{t} \in \mathbb {R}^{h \times w \times C_{in}}\). Subsequently, \(X^{t}\) is condensed into a feature vector \(X^{c} \in \mathbb {R}^{C_{in} \times 1}\) via average pooling. Following this, its dimensions are reduced to 1/8 of the original size through a fully connected layer (FC) with Rectified Linear Unit (ReLU)47. An attention layer is then introduced at the output of the ReLU function. This layer divides the input \(X^{c}\) into three branches, each tasked with computing attention across convolutional kernel size, input channel number, and output channel number. After processing through their respective branches, the resulting feature vector dimensions are \(n \times 1\), \(C_{in} \times 1\), and \(C_{out} \times 1\), respectively. The branch for kernel size is subjected to a Softmax layer, while the branches for input and output channel numbers undergo Sigmoid layers to normalize attention weights \(A_{i}\), \(B_{i}\), and \(C_{i}\). Subsequently, the attention weights \(B_{i}\) are multiplied by \(X^{t}\) and reshaped to create a new feature map \(X^{t'}\). Additionally, the attention weights \(A_{i}\) are multiplied by learnable parameters \(P_{i}\), and after element-wise addition, multiply the result as the convolution kernel \(W_{i}\) with \(X^{t'}\), and finally multiplied by attention weights \(C_{i}\). This result is then combined with shortcut operations to generate the output of the probability branch. For n convolutional kernels, the definition of the LMC module can be articulated as follows:
where \(A_{i} \in {\mathbb {R} ^ {n \times 1}}\) represents the kernel dimension attention, \(P_{i} \in {\mathbb {R} ^ {n \times 1}}\) represents the learnable parameters , \(B_{i} \in {\mathbb {R} ^ {C_{in} \times 1}}\) represents the input channel attention, \(C_{i} \in {\mathbb {R} ^ {C_{out} \times 1}}\) represents the output channel attention, and \(\odot\) represents multiplication operations.
Wave attention transformer module

Diagrammatic representation of WAT module. Our WAT module utilizes Discrete Wavelet Transform (DWT) and Inverse DWT (IDWT) to implement lossless downsampling.
Given the prevailing use of pooling operations in current Vision Transformer architectures to reduce computational load48, this inevitably leads to information loss. Although pooling effectively reduces the number of model parameters and computational complexity, this process is irreversible and sacrifices valuable details and contextual information. On the other hand, avoiding downsampling would drastically increase the computational burden of the model due to the quadratic growth of feature dimensions, rendering it impractical for real-world applications. Inspired by49,50, we propose the Wave Attention Transformer module, aiming to extract global information from images without loss while controlling computational overhead. By cleverly leveraging the multi-resolution analysis capability of wavelet transformation, the Wave Attention Transformer effectively compresses feature space without sacrificing vital information. With this technique, our model accurately computes the bins-widths of each image. Figure 5 illustrates the architecture of the Wave Attention Transformer.
Initially, the input of the pixel classification branch denoted as \(X \in \mathbb {R}^{h \times w \times C_{\text {in}}}\), passes through a linear mapping to obtain \(query \in \mathbb {R}^{ \frac{h}{2} \times \frac{w}{2} \times C_{in}}\). Simultaneously, a linear transformation is applied to X by multiplying it with the matrix \(W^{d} \in \mathbb {R}^{C_{\text {in}} \times \frac{C_{\text {in}}}{4}}\), resulting in \(X^{a}=X W^{d} \in \mathbb {R}^{h \times w \times \frac{C_{\text {in}}}{4}}\). Subsequently, we apply the discrete wavelet transform (DWT)51 to \(X^{a}\), downsampling it and reducing its dimensionality to one-fourth of the original, corresponding to four distinct wavelet subbands. Taking inspiration from49, the Discrete Wavelet Transform operation utilizes a high-pass filter \(f^{H}= \left( \frac{1}{\sqrt{2}},- \frac{1}{\sqrt{2}}\right)\) and a low-pass filter \(f^{L}= \left( \frac{1}{\sqrt{2}}, \frac{1}{\sqrt{2}}\right)\). This results in four embedded matrices: \(W^{LL}, W^{LH}, W^{HL}, W^{HH} \in \mathbb {R}^{2 \times 2}\). By employing \(W^{LL}\), \(W^{LH}\), \(W^{HL}\), \(W^{HH}\), \(X^{a}\) is transformed into \(X^{LL}\), \(X^{LH}\), \(X^{HL}\), \(X^{HH} \in \mathbb {R}^{\frac{h}{2} \times \frac{w}{2} \times \frac{C_{in}}{4}}\). Where \(X^{LL}\) captures the low-frequency information of basic object structures at a coarse level, while \(X^{LH}\), \(X^{HL}\), and \(X^{HH}\) reveal the high-frequency information of object textures preserved at finer levels. Subsequently, they are concatenated to obtain a downsampled result \(X^{dwt} \in \mathbb {R}^{ \frac{h}{2} \times \frac{w}{2} \times C_{in}}\) that integrates all details without information loss, effectively covering every detail of the image. When handling \(X^{dwt}\), the process follows two pathways. Initially, one pathway performs linear projection on \(X^{dwt}\), generating \(key, value \in \mathbb {R}^{ \frac{h}{2} \times \frac{w}{2} \times C_{in}}\), which are utilized for subsequent processing.
In the second pathway, the inverse DWT (IDWT) is applied to \(X^{dwt}\), to restore it to \(X^{idwt} \in \mathbb {R}^{ h \times w \times {\frac{C_{in}}{4}}}\). According to wavelet theory, this process can faithfully reconstruct all detailed information from the original image X without loss. Unlike traditional single \(k \times k\) convolutional operations, the integration of DWT, convolution, and IDWT throughout the process effectively extends the model’s perceptual range without introducing additional computational burden or memory requirements.
Ultimately, each head output, containing long-range contextual information, is combined with \(X^{idwt}\), which contains local contextual information, integrating contextual information across different scales. Subsequently, a linear transformation is applied to generate the final output of the wavelet transform, facilitating comprehensive extraction and utilization of image insights.
In summary, the formulation for WAT can be expressed as follows:
where \(W_{o}\) is the transformation matrix.
Depth esimation module
In this module, we compute the final depth estimation by integrating the outputs from both the probability prediction branch and the pixel classification branch. The output \(X^{w} \in \mathbb {R} ^ {N}\) generated by the pixel classification branch provides a probability distribution for each pixel position as the center of N depth intervals. Through the following straightforward steps, we can obtain:
where \(c(b_{i})\) denotes the center depth of the i-th bin, \(d_{min}\) and \(d_{max}\) represent the minimum and maximum valid depth values in the dataset. The output \(X_{w} \in \mathbb {R} ^ {H \times W \times N}\) from the probability prediction branch represents the probability \(p_{k}\) for each depth interval. The final depth value is determined by a linear combination of \(c(b_{i})\) and \(p_{k}\):
Loss function
We utilize a modified version of the Scale-Invariant (SI) loss15:
where N represents the count of valid pixels, d stands for the predicted depth, and d indicates the ground truth depth. Drawing from prior research52, we opted for \(\lambda = 0.85\) and \(\alpha = 10\) as hyperparameters for our model.

Qualitative comparison on the NYU dataset.
Experiments
Datasets
NYU Dataset. The NYU dataset53 consists of 464 indoor scenes, each featuring 120,000 images paired with corresponding depth maps at a resolution of \(640 \times 480\). In our methodology, we meticulously adhere to the official data splitting guidelines: 24231 image-depth pairs are designated for training, while 654 images are held out for testing purposes. Depths within the scenes span from 0 to 10 meters.
KITTI Dataset. The KITTI dataset54 encompasses a total of 61 scenes, each featuring RGB images with an approximate resolution of \(1241 \times 376\) pixels. Our network is trained on a carefully curated subset of around 26000 images captured from the left view, including scenes identified within the 697-image test set specified by15. Depths within the scenes vary from 0 to 80 meters.
SUN RGB-D Dataset. The SUN RGB-D Dataset55 is an indoor dataset comprising approximately 10,000 images capturing a wide range of scenes, obtained from four distinct sensors. Here we use the 5050 test images of the official segmentation.
iBims-1 benchmark. The iBims-1 benchmark56 is a high-quality RGB-D dataset captured using a digital single-lens reflex camera and precise laser scanner. We employ 100 images from this dataset for testing purposes.
DIODE Dataset. The DIODE dataset57 is a high-resolution dataset containing depth maps obtained from LiDAR sensor measurements. We utilize the complete validation split, comprising 325 indoor samples and 446 outdoor samples.
The main datasets we use to train SimDepth are NYU dataset53 for indoor scenes and KITTI dataset54 for outdoor environments.
To illustrate the capacity to generalize, we assess zero-shot performance on several additional datasets: SUN RGB-D55, iBims56 and DIODE Indoor57 for the indoor scenario; DIODE Outdoor57 for the outdoor environments.
Training setting and evaluation metrics
Training details. Our models are developed using PyTorch64 and trained on an Nvidia GTX 3090 GPU equipped with 24 GB of memory. Training the entire model was conducted with a batch size of 9, employing a learning rate set to \(10^{-4}\). We utilized the AdamW65 optimizer with a weight decay of \(10^{-2}\). Additionally, the learning rate was scheduled using a cosine annealing strategy. For all reported results, the models were trained for 30 epochs.
Evaluation Metrics of Depth Estimation. We conduct a quantitative comparison of our method with state-of-the-art approaches and employ eight standard metrics, as outlined in15, to evaluate the performance of the predicted depth. These metrics encompass five error metrics and three accuracy metrics. Specifically, we utilize metrics such as relative absolute error (AbsRel), relative squared error (SqRel), root mean squared error (RMSE), root mean squared logarithmic error (RMSElog), log10 error (log10), and threshold accuracy at various deltas (\(\delta < 1.25\), \(\delta < 1.25^2\), \(\delta < 1.25^3\)).
Comparison to the state-of-the-art
We conducted a comprehensive comparison of our proposed method with other leading monocular depth estimation models. To meticulously evaluate our approach’s performance, we specifically selected the highly-regarded Adabins12 as our primary competitor. To ensure fairness and accuracy in the comparison, we replicated the code of Adabins and utilized the pre-trained models provided by the authors to obtain their generated depth images. Additionally, to obtain results from other leading models, we directly ran their official code. Through this series of rigorous comparative experiments, we aim to comprehensively demonstrate the strengths and characteristics of our proposed method. The qualitative comparisons can be observed in Figs. 6 and 7. In a complex environment with many objects, AdaBins12, NewCRFs19, and IEbins18 are inferior to SimMDE in depth prediction. For example, carpets, fallen books, and street lamps.

Qualitative comparison on the KITTI dataset.
Results on NYU. We compare our SimMDE with previous works on the indoor dataset NYU, and the quantitative results are shown in Table 1. Despite the long-standing saturation of state-of-the-art performance on the NYU dataset, our method has demonstrated remarkable superiority across evaluation metrics. Compared to AdaBins12, our approach demonstrates a 11.7% improvements in AbsRel, a 9.1% improvements in RMSE, and, a 2.0% improvements in \(log_{10}\) error.
Results on KITTI. Table 2 presents the quantitative results for the KITTI outdoor dataset. In comparison to the previous state-of-the-art, our proposed model exhibits clear performance advantages. Additionally, when compared to the monocular depth method that relies on the Swin–Large35 encoder, our model achieves comparable accuracy while boasting reduced parameters and complexity. Specifically, in comparison with12, our method results in an approximately 10.2% increase in RMSE score, a 10.3% increase in AbsRel score, and a 17.9% increase in SqRel score.
Notice that our model has only 15.2% of the model parameters of Metric3Dv229, yet achieves nearly identical depth estimation accuracy.
Zero-shot generalization
We evaluate the generalization capability of the proposed method by analyzing its zero-shot performance on three unseen indoor datasets and an outdoor datasets, without any fine-tuning. Comprehensive qualitative results can be found in Table 3.
Even without fine-tuning on additional datasets, our model surpasses the performance of the previous state-of-the-art model. Impressively, it outperforms in the majority of datasets, underscoring its robustness and effectiveness.
Ablation studies
We conducted ablation experiments on the NYU dataset to validate the effectiveness of our method, and the results are presented in Table 4. Initially, we adopted MSCAN39 along with a bilinear upsampling decoder as our baseline architecture. Subsequently, we systematically replaced this architecture with our proposed decoder. Finally, we sequentially incorporated our proposed LMC module and WAT module. While our proposed decoder did not yield significant improvements in the experimental results, it reduced the number of parameters to some extent. The experimental findings indicate that each of the introduced modules contributes to improvements in the experimental outcomes to varying extents.

Impact of varying the number of bins (N) on the Absolute Relative Error metric, indicating performance changes.
For fairness and accuracy of the experiments, we maintained consistency in both encoder and decoder architectures, with the only variation being the replacement of the MLP, mViT12 and MSA (window attention)35 modules by our proposed WAT module. According to the experimental results shown in the Table 5, our proposed WAT module consistently outperforms mViT, MSA, and MLP in various performance metrics. Although the parameter count of our WAT module slightly increases compared to the MSA module, the overall improvement in performance sufficiently demonstrates the effectiveness and superiority of our WAT module design.
Similarly, to verify the effectiveness of our proposed LMC module, we conducted comparative experiments by replacing the LMC module in the same with three different convolutional attention modules: SENet67, CABM68, and SCConv69. As shown in Table 6, although our proposed LMC module does not have the lowest parameter count, it still achieves the best performance across all evaluation metrics. This is because the LMC module learns the attention mechanism from three dimensions, enabling the model to focus more effectively on important regions, thus enhancing the accuracy of probability prediction. These results further validate the rationality and superiority of the LMC module design.
To delve deeper into the impact of the number of bins (N) on the model’s performance, we systematically trained models using AbsRel as the evaluation metric for different N values (32, 64, 128, 256, 384, 512). As depicted in Fig. 8, it was observed that initially, as N increased, the error decreased, leading to a improvement in AbsRel. However, as N continued to increase, the error also increased, resulting in an increment in AbsRel. Based on a comprehensive analysis of the experimental data, we determined to set \(N=256\) in the final model to achieve optimal performance.
In this series of experiments, we meticulously explore the subtle impact of the Wavelet Attention Transformer (WAT) on the efficacy of our network model, we opted to focus on the AbsRel metric for evaluation. Through meticulous experimentation, we systematically trained the model while varying the stacking times of WAT. The detailed experimental results are elaborated in Table 7. Following a thorough analysis and careful consideration of the experimental data, we arrived at the decision to set the stacking times to 2. This choice was made to ensure that the model could attain optimal performance levels, effectively balancing computational efficiency with accuracy.
In Table 8, we present a thorough comparison between our proposed method and Adabins, NeWCRFs, LifelongDepth, IEBins, and Metric3Dv2, focusing on key metrics across both the KITTI and NYU datasets: the number of model parameters, computational complexity (GFLOPs), and frame rate (FPS). To ensure the comparability and objectivity of our experimental results, we consistently utilized the Nvidia GTX 3090 GPU as our testing platform. From the collected data, it is evident that our method achieves a substantial reduction in the number of model parameters, leading to faster inference speeds and a more streamlined and efficient model architecture. In essence, our method demonstrates significant advantages in both performance and efficiency.
Finally, we conducted a detailed comparison of our proposed DCF, LMC, and WAT modules against other mainstream modules in terms of time complexity and parameter count, as shown in Table 9. From the results, it is evident that although our proposed modules do not have the smallest parameter counts, they still achieve a superior balance between performance and computational complexity with a relatively reasonable number of parameters. These findings clearly demonstrate that our proposed modules can effectively enhance model performance while maintaining an excellent trade-off between computational efficiency and accuracy.
Conclusions
We introduce SimMED, a novel monocular depth estimation network that effectively balances complexity and accuracy. Through extensive experimentation and rigorous validation, we have demonstrated the strong performance of our model in achieving high-precision depth estimation while notably reducing computational complexity and resource utilization. At the core of our approach is the Deformable Cross-Attention Feature Fusion (DCF) Decoder, an architecture equipped with sparse attention mechanisms, effectively enhancing model performance while minimizing the number of parameters. Moreover, to further refine accuracy, we introduce two additional modules: the Local Multi-dimensional Convolutional Attention (LMC) module, dedicated to probability prediction, and the Wave Attention Transformer (WAT) module, focusing on pixel-level precise classification. Through comprehensive evaluation on benchmark datasets such as NYU and KITTI, we validate the effectiveness and robustness of our proposed model.
However, in this study, we adopted the bins division method from previous literature, which relies solely on the output from the last decoder layer for depth range prediction. This approach does not effectively integrate multi-scale feature information, resulting in a lack of precision and sophistication in the bins division. Moreover, the use of single-scale features often struggles to adequately handle depth variations in complex scenes, thereby limiting further improvements in prediction accuracy. Therefore, future research will focus on developing a more refined and adaptive bins division strategy capable of effectively integrating multi-scale features to better capture detailed information across different scales, thus further enhancing the depth prediction performance of the model.
In the future, while maintaining a proper balance between complexity and accuracy, our research will expand beyond monocular depth estimation to explore the applicability of our approach in a broader range of computer vision tasks, such as 3D reconstruction, object detection, and semantic segmentation. We aim to validate the versatility and effectiveness of our model across various datasets and real-world scenarios, ensuring its robustness and generalization ability. Additionally, we plan to further optimize the network architecture and training process to enhance performance without compromising the trade-off between complexity and accuracy.
Data availability
NYU-v2 Benchmark:https://cs.nyu.edu/~fergus/datasets/nyu_depth_v2.html KITTI Benchmark: https://www.cvlibs.net/datasets/kitti
References
Dickson, A. et al. User-centred depth estimation benchmarking for vr content creation from single images. In: PG (Short Papers, Posters, and Work-in-Progress Papers), 71–72 (2021).
Kim, S. B., Kim, S., Ahn, D. & Ko, B. C. Btd-rf: 3d scene reconstruction using block-term tensor decomposition. Appl. Intell. 1–14 (2024).
Wang, O., Finger, J., Yang, Q., Davis, J. & Yang, R. Automatic natural video matting with depth. In: 15th Pacific Conference on Computer Graphics and Applications (PG’07), 469–472 (IEEE, 2007).
Zhou, Y. et al. Resolution-sensitive self-supervised monocular absolute depth estimation. Appl. Intell. 54, 4781–4793 (2024).
Liu, S., Yang, L. T., Tu, X., Li, R. & Xu, C. Lightweight monocular depth estimation on edge devices. IEEE Internet Things J. 9, 16168–16180 (2022).
Huynh, L., Nguyen, P., Matas, J., Rahtu, E. & Heikkilä, J. Lightweight monocular depth with a novel neural architecture search method. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision, 3643–3653 (2022).
Feng, C. et al. Rt-monodepth: Real-time monocular depth estimation on embedded systems. arXiv preprint arXiv:2308.10569 (2023).
Zhang, N., Nex, F., Vosselman, G. & Kerle, N. Lite-mono: A lightweight cnn and transformer architecture for self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18537–18546 (2023).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In: Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, 234–241 (Springer, 2015).
Li, Z., Wang, X., Liu, X. & Jiang, J. Binsformer: Revisiting adaptive bins for monocular depth estimation. arXiv preprint arXiv:2204.00987 (2022).
Zhu, X. et al. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159 (2020).
Bhat, S. F., Alhashim, I. & Wonka, P. Adabins: Depth estimation using adaptive bins. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 4009–4018 (2021).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inform. Process. Syst. 30 (2017).
Yao, T., Pan, Y., Li, Y., Ngo, C.-W. & Mei, T. Wave-vit: Unifying wavelet and transformers for visual representation learning. In: European Conference on Computer Vision, 328–345 (Springer, 2022).
Eigen, D., Puhrsch, C. & Fergus, R. Depth map prediction from a single image using a multi-scale deep network. Adv. Neural Inform. Process. Syst. 27 (2014).
Yang, G., Tang, H., Ding, M., Sebe, N. & Ricci, E. Transformer-based attention networks for continuous pixel-wise prediction. In: Proceedings of the IEEE/CVF International Conference on Computer vision, 16269–16279 (2021).
Fu, H., Gong, M., Wang, C., Batmanghelich, K. & Tao, D. Deep ordinal regression network for monocular depth estimation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 2002–2011 (2018).
Shao, S. et al. Iebins: Iterative elastic bins for monocular depth estimation. In: Advances in Neural Information Processing Systems (NeurIPS) (2023).
Yuan, W., Gu, X., Dai, Z., Zhu, S. & Tan, P. Neural window fully-connected crfs for monocular depth estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 3916–3925 (2022).
Hu, J. et al. Lifelong-monodepth: Lifelong learning for multidomain monocular metric depth estimation. IEEE Trans. Neural Networks Learning Syst. (2023).
Fu, Z. et al. Robust depth completion based on semantic aggregation. Appl. Intell. 54, 3825–3840 (2024).
Long, X. et al. Adaptive surface normal constraint for geometric estimation from monocular images. arXiv preprint arXiv:2402.05869 (2024).
Oquab, M. et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023).
Wang, Y., Liang, Y., Xu, H., Jiao, S. & Yu, H. Sqldepth: Generalizable self-supervised fine-structured monocular depth estimation. In: Proceedings of the AAAI Conference on Artificial Intelligence 38, 5713–5721 (2024).
Yang, L. et al. Depth anything: Unleashing the power of large-scale unlabeled data. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10371–10381 (2024).
Li, Z., Bhat, S. F. & Wonka, P. Patchfusion: An end-to-end tile-based framework for high-resolution monocular metric depth estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10016–10025 (2024).
Ke, B. et al. Repurposing diffusion-based image generators for monocular depth estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9492–9502 (2024).
Choi, S., Choi, D. & Kim, D. Tie-kd: Teacher-independent and explainable knowledge distillation for monocular depth estimation. Image Vision Comput. 148, 105110 (2024).
Hu, M. et al. A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation. arXiv (2024). 2404.15506.
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
Touvron, H. et al. Training data-efficient image transformers & distillation through attention. In: International conference on machine learning, 10347–10357 (PMLR, 2021).
Fan, H. et al. Multiscale vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision, 6824–6835 (2021).
Yang, J. et al. Focal self-attention for local-global interactions in vision transformers. arXiv preprint arXiv:2107.00641 (2021).
Wang, W. et al. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In: Proceedings of the IEEE/CVF international conference on computer vision, 568–578 (2021).
Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF international conference on computer vision, 10012–10022 (2021).
Liu, Z. et al. Swin transformer v2: Scaling up capacity and resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 12009–12019 (2022).
Tian, Y. et al. U-dits: Downsample tokens in u-shaped diffusion transformers. arXiv preprint arXiv:2405.02730 (2024).
Zhu, X. et al. Parameter-inverted image pyramid networks. Adv. Neural Inform. Processing Syst. 37, 132267–132288 (2024).
Guo, M.-H. et al. Segnext: Rethinking convolutional attention design for semantic segmentation. Adv. Neural Inform. Process. Syst. 35, 1140–1156 (2022).
Yang, B., Bender, G., Le, Q. V. & Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. Adv. Neural Inform. Process. Syst. 32 (2019).
Chen, Y. et al. Dynamic convolution: Attention over convolution kernels. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11030–11039 (2020).
Lin, X., Ma, L., Liu, W. & Chang, S.-F. Context-gated convolution. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVIII 16, 701–718 (Springer, 2020).
Quader, N., Bhuiyan, M. M. I., Lu, J., Dai, P. & Li, W. Weight excitation: Built-in attention mechanisms in convolutional neural networks. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX 16, 87–103 (Springer, 2020).
Li, C., Zhou, A. & Yao, A. Omni-dimensional dynamic convolution. arXiv preprint arXiv:2209.07947 (2022).
Chollet, F. Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 1251–1258 (2017).
Hendrycks, D. & Gimpel, K. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415 (2016).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Commun. ACM 60, 84–90 (2017).
Wang, W. et al. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Visual Media 8, 415–424 (2022).
Liu, L. et al. Wavelet-based dual-branch network for image demoiréing. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIII 16, 86–102 (Springer, 2020).
Dang, J., Li, Z., Zhong, Y. & Wang, L. Wavenet: Wave-aware image enhancement. In: Proc. Pacific Conf. Comput. Graph. Appl, 21–29 (2023).
Mallat, S. G. A theory for multiresolution signal decomposition: the wavelet representation. IEEE Trans. Pattern Anal. Machine Intell. 11, 674–693 (1989).
Ranftl, R., Bochkovskiy, A. & Koltun, V. Vision transformers for dense prediction. In: Proceedings of the IEEE/CVF international conference on computer vision, 12179–12188 (2021).
Silberman, N., Hoiem, D., Kohli, P. & Fergus, R. Indoor segmentation and support inference from rgbd images. In: Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, October 7-13, 2012, Proceedings, Part V 12, 746–760 (Springer, 2012).
Geiger, A., Lenz, P., Stiller, C. & Urtasun, R. Vision meets robotics: The kitti dataset. The Int. J. Robotics Res. 32, 1231–1237 (2013).
Sohn, K. et al. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inform. Process. Syst. 33, 596–608 (2020).
Koch, T., Liebel, L., Fraundorfer, F. & Korner, M. Evaluation of cnn-based single-image depth estimation methods. In: Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 0–0 (2018).
Vasiljevic, I. et al. Diode: A dense indoor and outdoor depth dataset. arXiv preprint arXiv:1908.00463 (2019).
Lee, J. H., Han, M.-K., Ko, D. W. & Suh, I. H. From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv preprint arXiv:1907.10326 (2019).
Lee, S., Lee, J., Kim, B., Yi, E. & Kim, J. Patch-wise attention network for monocular depth estimation. In: Proceedings of the AAAI Conference on Artificial Intelligence 35, 1873–1881 (2021).
Patil, V., Sakaridis, C., Liniger, A. & Van Gool, L. P3depth: Monocular depth estimation with a piecewise planarity prior. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1610–1621 (2022).
Li, Z., Chen, Z., Liu, X. & Jiang, J. Depthformer: Exploiting long-range correlation and local information for accurate monocular depth estimation. Machine Intell. Res. 20, 837–854 (2023).
Ning, C. & Gan, H. Trap attention: Monocular depth estimation with manual traps. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5033–5043 (2023).
Xiang, M., Zhang, J., Barnes, N. & Dai, Y. Measuring and modeling uncertainty degree for monocular depth estimation. IEEE Trans. Circuits Syst. Video Technol. (2024).
Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inform. Process. Syst. 32 (2019).
Loshchilov, I. & Hutter, F. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017).
Bhat, S. F., Alhashim, I. & Wonka, P. Localbins: Improving depth estimation by learning local distributions. In: European Conference on Computer Vision, 480–496 (Springer, 2022).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 7132–7141 (2018).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. Cbam: Convolutional block attention module. In: Proceedings of the European conference on computer vision (ECCV), 3–19 (2018).
Li, J., Wen, Y. & He, L. Scconv: Spatial and channel reconstruction convolution for feature redundancy. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 6153–6162 (2023).
Acknowledgements
This work was partially supported by the Shenzhen Longhua Fundamental Research Program (No. 10162A20230325B73A546).
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. The implementations, data collection were performed by Mengdie Feng and Xueqi Guo. Xuanxuan Liu contributed to the design and implementation of the research, analyze the results, and wrote the main manuscript text. Thanks to Shuai Tang and Yan Wang for their revision of the manuscript. Yanru Zhang devised the project and supervised the research. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflicts of interest
The authors have no relevant financial or nonfinancial interests to disclose.
Ethics approval
No human subjects or animals are involved in this study.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, X., Tang, S., Feng, M. et al. A simple monocular depth estimation network for balancing complexity and accuracy. Sci Rep 15, 12860 (2025). https://doi.org/10.1038/s41598-025-97568-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-97568-1
