
Abstract
Voltage imaging is a powerful technique for studying neuronal activity, but its effectiveness is often constrained by low signal-to-noise ratios (SNR). Traditional denoising methods, such as matrix factorization, impose rigid assumptions about noise and signal structures, while existing deep learning approaches fail to fully capture the rapid dynamics and complex dependencies inherent in voltage imaging data. Here, we introduce CellMincer, a novel self-supervised deep learning method specifically developed for denoising voltage imaging datasets. CellMincer operates by masking and predicting sparse pixel sets across short temporal windows and conditions the denoiser on precomputed spatiotemporal auto-correlations to effectively model long-range dependencies without large temporal contexts. We developed and utilized a physics-based simulation framework to generate realistic synthetic datasets, enabling rigorous hyperparameter optimization and ablation studies. This approach highlighted the critical role of conditioning on spatiotemporal auto-correlations, resulting in an additional 3-fold SNR gain. Comprehensive benchmarking on both simulated and real datasets, including those validated with patch-clamp electrophysiology (EP), demonstrates CellMincer’s state-of-the-art performance, with substantial noise reduction across the frequency spectrum, enhanced subthreshold event detection, and high-fidelity recovery of EP signals. CellMincer consistently outperforms existing methods in SNR gain (0.5–2.9 dB) and reduces SNR variability by 17–55%. Incorporating CellMincer into standard workflows significantly improves neuronal segmentation, peak detection, and functional phenotype identification, consistently surpassing current methods in both SNR gain and consistency.
Similar content being viewed by others
Introduction
Voltage imaging utilizes fluorescent reporters, either small-molecule dyes or genetically encoded proteins, to measure the membrane potential of electrically active cells. Compared to traditional patch-clamp electrophysiology (EP), voltage imaging offers higher throughput and is less invasive. This technique has been used to monitor neuronal electrical activity during behavioral assays in vivo1, as well as to characterize the functional effects of pharmacological and genetic perturbations in primary and iPSC-derived mammalian neurons in vitro2,3. The increased throughput, control, and flexibility of voltage imaging have enabled significant advances in our understanding of biology. Recent developments have improved the brightness of both voltage-sensitive dyes4 and heterologously expressed voltage-sensitive proteins5. However, the achievable signal-to-noise ratio (SNR) remains limited compared to conventional patch-clamp techniques due to factors such as dye quantum yield, short exposure times (<2 ms) needed to capture neuronal action potentials, and constraints on excitation intensity to prevent sample damage.
Limitations on SNR have two practical effects. First, small-magnitude electrical events of interest, such as subthreshold post-synaptic potentials, could be lost in the background temporal noise. Previous work powered by tracking the timing of action potential firing between neurons provided some insight to how neurons might wire together in small circuits. However, the site of inter-neuronal communication is the synapse. A measure of synaptic connectivity, demonstrated as subthreshold activity measured at the soma, would provide a greater understanding of how neuronal circuits are formed and how synaptic connections are modified during different forms of plasticity. Second, cells expressing relatively low amounts of fluorescent reporters can be lost in a comparatively high autofluorescent background, lowering the effective throughput of voltage imaging.
These technical challenges have motivated the development of data-denoising algorithms to computationally enhance the SNR and enable the recovery of obscured and subtle fluorescent signals. Matrix factorization is an effective class of algorithms for fluorescence image denoising6,7, as the sparse and static signal sources (e.g. neurites) in these imaging assays create an ideal setting for approximating entire fluorescence recordings as low-rank decompositions. Principal component analysis (PCA), non-negative matrix factorization (NMF), and penalized matrix decomposition (PMD)8 are popular implementations of this concept. These approaches, while being highly efficient and effective at data denoising, suffer from a number of caveats. These include: (1) implicit parametric assumptions on the nature of the noise that are theoretical approximations of the actual complex data-generating process; (2) usage of spatiotemporal regularizations to encourage robustness and model identifiability, such as total variation penalty or temporal continuity, that are often violated (e.g. spike events, spatially heterogeneous expression of the fluorescent reporter); (3) making strong assumptions about the background fluorescence component to allow their approximate subtraction as a simple data preprocessing step. These modeling assumptions, while laying a strong foundation, ultimately hamper the expressivity of conventional denoising algorithms.
We envision that the ideal denoising algorithm should minimize the explicit assumptions made about the noise process while maximizing the potential to learn the complex spatiotemporal relationships that govern the signal. Deep neural networks (DNNs), which have no theoretical limit to complexity, can in principle solve the issue of denoising model expressivity. However, deep learning denoising models pretrained on large datasets of natural images9 are ill-equipped to operate in the low-SNR regime of fluorescence imaging10, requiring a suitable model to be trained from scratch for this data domain. This immediately poses a challenge for supervised learning approaches which require clean images as a learning target, which are not available in voltage imaging. A powerful recent training strategy, called self-supervised denoising, circumvents the requirement of having clean ground truth data by exploiting a key property of many noise processes: by appropriately partitioning the raw data into compartments, and predicting one compartment from the other, it is often possible to eliminate predictors of noise while retaining the ability to predict the underlying signal. Noise2Noise (N2N)11, Noise2Self (N2S)12, and Noise2Void13 are prominent examples of self-supervised denoising techniques proposed for images. These methods have consistently been shown to produce state-of-the-art results, including in fluorescence imaging, even compared to counterparts that are trained on pairs of noisy and clean data10. In particular, the Noise2Self algorithm, the foundation upon which we built our method, operates on the following elegant and simple principle: suppose a sparse set of pixels are masked out from a noisy image, and a neural network is trained to predict the value of the sparsely masked pixels from the rest of the image, i.e. the majority of pixels. Assuming that the noise in the masked pixels is uncorrelated with the rest of the pixels, the optimal predictor can at best predict the noiseless signal component; in practice, it can excel at this task given the strong spatial correlations and redundancy in biological images. It follows that the optimal masked pixel predictor in turn behaves as an optimal pixel denoiser. Noisy data itself provides the needed evidence for teasing out the signal component, circumventing the need for clean training data.
One of the main challenges in extending self-supervised image denoising approaches to spatiotemporal data, such as voltage imaging recordings, is that these datasets contain thousands of frames, and that each frame is individually too signal-deficient to self-supervise its own denoising. At the same time, GPU hardware memory constraints and efficient training considerations prevent us from ingesting and processing entire voltage imaging movies with neural networks to exploit frame-to-frame correlations. The middle ground strategy adopted by several authors is to process the movie in overlapping and truncated local denoising temporal contexts, i.e. chunks of adjacent frames. For instance, Li et al.14 developed DeepCAD-RT, a Noise2Self-like denoising method based on their earlier DeepCAD15 method which reconstructs whole masked frames from temporally downsampled movie chunks, and they demonstrated its capacity to restore a high imaging SNR from low-SNR calcium imaging recordings. Lecoq et al.16 developed DeepInterpolation, a Noise2Noise-like whole-frame interpolation-based deep learning method acting on small temporal windows which also allowed them to increase the SNR and retrieve a significantly higher fraction of neuronal segments from calcium imaging. Zhang et al.17 developed DeepSeMi, a self-supervised-learning-based denoising framework which applies an asymmetric convolutional kernel to several isometric transformations of a given data patch to predict input pixels without including them in their own predictive contexts, and demonstrated its capacity to increase the signal-to-noise by 12 dB over various imaging conditions. Platisa et al.18 developed DeepVID, a deep convolutional neural network simultaneously trained under self-supervision to predict whole frames from a short window of pre- and post-frames and individual pixels from the remaining same-frame context, which enabled high-speed, deep-tissue imaging in active mice. Eom et al.19 developed SUPPORT, a self-supervised learning method for predicting pixels from their full spatiotemporal contexts, which was able to achieve precise denoising of various forms of fast microscopy imaging.
These existing approaches are sub-optimal for one or more of the following important reasons. (1) Unless the local denoising context is impractically large and contains hundreds of movie frames, the neural network is incapable of estimating long-range pixel-to-pixel temporal correlations that are arguably key to effective signal extraction and noise removal. As we will show in later sections, explicitly precomputing and supplementing the short-context local denoiser with such information results in a striking boost in the denoising performance. (2) Methods relying on leave-frame-out denoising approach, including DeepInterpolation, DeepCAD-RT, and DeepVID, are best suited for denoising calcium imaging data. The performance of these methods degrade strikingly when applied to voltage imaging data (see “CellMincer outperforms existing methods at denoising simulated volt-age imaging data”). The much faster temporal dynamics of voltage imaging data compared to calcium imaging implies that each movie frame contains unique signal that cannot be inferred from the adjacent frames with high fidelity. For instance, the evidence for a neuronal spike is most prominently present in a single frame. This issue has been independently acknowledged and addressed in SUPPORT19 and DeepSeMi17.
In this work, we introduce CellMincer, a self-supervised deep-learning method specifically designed for denoising voltage imaging datasets based on the Noise2Self denoising framework. CellMincer introduces several key refinements over the currently existing self-supervised movie denoising methods to address the aforementioned caveats. The key methodological contributions of CellMincer include: (1) development of an efficient and expressive two-stage spatiotemporal data processing deep neural network architecture, comprising a frame-wise 2D U-Net module for spatial feature extraction, followed by a pixelwise 1D convolutional module for temporal data post-processing; (2) replacing the common task of whole-frame prediction with masking and predicting a sparse set of pixels from a small number of adjacent frames; this training methodology allows the denoiser to have access to the unique information contained in any individual frame as well as the supporting context in its neighboring frames; (3) precomputing spatiotemporal auto-correlations at multiple length scales, and providing such precomputed statistics as a conditioner to the denoiser neural network (that otherwise processes smaller spatiotemporal regions of the movie at a time); (4) developing and leveraging a physics-based simulation framework to generate highly realistic pairs of clean ground truth and noisy recording realization for hyperparameter optimization and performing ablation studies to tease apart the roles of various modeling choices in a controlled setting.
Using benchmarking experiments performed on simulated data and real voltage imaging data with paired patch-clamp EP recordings as a proxy for ground truth, we show that CellMincer yields state-of-the-art results as measured in terms of several practical metrics. These include a modal peak signal-to-noise ratio (PSNR) gain of 23.3 dB compared to raw data simulated over a range of noise conditions (an increase of 1.7–2 dB over the next best-benchmarked methods), a 14 dB reduction in high-frequency (>100 Hz) noise (a further reduction of 3–10.5 dB from the next best methods), a 2–6 percentage point increase of F1-score in detecting sub-threshold events compared to the benchmarked methods across all voltage magnitudes in the 0.5–10 mV range (in which the baseline F1-score ranges from 5% to 14%), and an 8% increase in the cross-correlation between low-noise EP recordings and voltage imaging. A striking result from our ablation study is the pivotal role of conditioning the denoiser on precomputed global features, resulting in a nearly 5 dB (or approximately 3-fold) boost in average PSNR gain, as well as a highly-concentrated distribution of PSNR gain across all frames and electrical stimulation amplitudes (see Fig. 1e). Finally, to demonstrate the utility of CellMincer to real end-to-end biological hypothesis testing, we compare the voltage imaging of chronically tetrodotoxin-treated and unperturbed cultured hPSC-derived neurons, and demonstrate that CellMincer denoising enables reliable identification and segmentation of nearly 2-fold as many neurons as in the raw data, improved identification of spiking events, and ultimately significantly enhanced statistical separation between the two functional phenotypes.

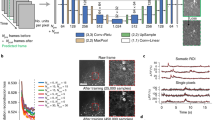
a A simplified schematic diagram of a typical optical voltage imaging experiment (left). The spatially resolved fluorescence response is recorded over time to produce a voltage imaging movie. A key component of CellMincer’s preprocessing pipeline is the computation of spatial summary statistics and various auto-correlations from the entire recording, which are concatenated into a stack of global features (right). b An overview of CellMincer’s deep learning architecture. c The conditional U-Net convolutional neural network (CNN). At each step in the contracting path, the precomputed global feature stack is spatially downsampled in parallel (\({\mathscr{F}}\to {{\mathscr{F}}}^{{\prime} }\to {{\mathscr{F}}}^{{\prime}{\prime}}\to \ldots\)) and concatenated to the intermediate spatial feature maps. d The temporal post-processor neural network. The sequence of pixel embeddings are convolved with a 1D kernel along the time dimension, producing a single vector of length C. A multilayer perceptron subsequently reduces this vector to a single value. e A comparison of model performance on simulated data before and after introducing global features as a U-Net conditioner. Using global features confers an average increase of 5 dB to the denoiser, roughly corresponding to a 3-fold noise reduction. The presented data consists of several segments in which the simulated recording was performed under several neuron stimulation conditions, which are reported as separate distributions of PSNR gain. For further elaboration, see “Optimizing CellMincer network architecture and training scheduleusing Optosynth-simulated datasets” in “Methods”.
Results
CellMincer self-supervised denoising framework
The CellMincer denoising pipeline involves three stages: (1) data preprocessing and global feature extraction; (2) self-supervised pretraining of the denoising neural network; (3) inference of denoised movie. In the preprocessing step, we take a recording X(t, x, y) represented as a three-dimensional tensor with shape T(time) × W(width) × H(height). We treat each pixel as a separate time series of T samples, fit a low-order polynomial function to each, and thereby decompose the movie as a sum of smooth trend and detrended residual tensors. The trend tensor primarily represents the background fluorescence, whereas the residual detrended tensor represents a noisy measurement of the electrical activity. This step, in contrast with the trained neural network component of our pipeline, is merely a heuristic to improve model performance by removing what the user would reasonably deem irrelevant to the signal of interest. Going forward, we apply a scaling factor to the detrended data before performing inference over the normalized result, after which we invert the scaling factor and add back the smooth trend component. This detrending and scaling step is critical for model training stability, as the presence of a high-magnitude background obscures the functional component of the data, preventing the network from disentangling the small-scale signal from the even smaller-scale noise. This both prevents the issue of floating-point underflow induced by a high-magnitude input and allows the model to generalize better to out-of-sample data, the background activity of which is likely to differ substantially from that of the training data.
To set the stage for self-supervised pretraining, we calculate various summary statistics for each pixel, including temporal mean, temporal variance, and all bidirectionally lagged spatiotemporal auto-correlations with adjacent pixels. These statistics are computed separately for both the slow moving average and the fast residual components of the detrended movie, and at two different spatially downsampled resolutions to account for auto-correlations with longer spatial lags. Finally, we concatenate these precomputed statistics as a tensor \({\mathscr{F}}\) of shape F × W × H to represent pixelwise global statistics, where F = 74 is the total number of computed statistics per pixel. “CellMincer preprocessing and global feature extraction details” in “Methods” fully describes our preprocessing and feature extraction stage. This step is schematically referred to as global featurizer in Fig. 1a.
We present the denoising strategy we employ in CellMincer in two stages for clarity. First, we describe the architecture of the DNN that we purport to be capable of performing efficient denoising. Next, we describe the self-supervised training strategy a la Noise2Self that allows the denoiser to train without clean targets.
Our proposed denoising DNN takes as input a series of 2τ + 1 consecutive frames, corresponding to time points t − τ, …, t − 1, t, t + 1, …t + τ, from the detrended movie and aims to predict a denoised reconstruction of the frame in the middle, at time point t. We refer to τ as the temporal order, and to 2τ + 1 as the context size of the local denoiser. Crucially, the DNN additionally takes the precomputed global feature stack \({\mathscr{F}}\) as a conditioner to supplement the local denoiser with long-range spatiotemporal statistics. The architecture of the denoising DNN consists of a single-frame spatial feature extractor followed by a temporal post-processor (see Fig. 1b). The spatial component is implemented as a U-Net convolutional neural network (CNN) with a small but consequential modification: to condition the convolutional operations on \({\mathscr{F}}\), we concatenate an appropriately spatially downsampled copy of \({\mathscr{F}}\) prior to each convolution block on the contracting path (see Fig. 1c). The conditional U-Net extracts deep, native-resolution C-channel single-frame embeddings from each of the 2τ + 1 consecutive frames (see Fig. 1b). The resulting embeddings are concatenated into a 4D tensor of shape (2τ + 1) × C × W × H:
where ⋀ denotes concatenation along the time dimension. This intermediate tensor is routed to the temporal post-processor, which consists of a series of temporal convolutional layers, reducing each set of pixel embeddings across all frames to a final output pixel. The output of the temporal post-processor represents a denoised reconstruction of the middle frame:
Note that the temporal post-processor treats pixels (x, y) as independent, only operating on time and U-Net feature channels (see Fig. 1d). This two-stage constrained network design enables efficient spatiotemporal data processing by logically compartmentalizing the flow of information; the U-Net facilitates information mixing across pixels within individual frames, while the post-processor convolves information across frames for individual pixels. Refer to “CellMincer neural network design, training schedule, and implemen-tation details” in “Methods” for architectural details.
We train the CellMincer denoiser in a self-supervised fashion as follows. At the beginning of each training iteration, pixels chosen at random in the frame at time t are replaced with Gaussian noise with pixel-specific in-distribution mean and variance before the frame is fed into the network:
Here, \({\mathsf{M}}(x,y)\) is a binary mask containing a sparse number of ones, and μ(x, y) and σ(x, y) correspond to the temporal mean and standard deviation of the detrended movie at position (x, y). These masked pixels are then used as the training targets, where the Lp loss is computed between the network’s predicted values and their pre-masked values with the following loss function:
where \({{\mathsf{NN}}}_{{\rm{CellMincer}}}={{\mathsf{NN}}}_{{\rm{post}}\text{-}{\rm{processor}}}\circ {{\mathsf{NN}}}_{{\rm{U}}\text{-}{\rm{Net}}}\) (see Fig. 1b). Here, … ∣ and ∣ … refer to the τ preceding and the τ following frames surrounding the frame at time t, respectively. As for a choice of pixel loss function, we have experimented with both p = 1 and 2 and found the latter to result in higher PSNR (see “Optimizing CellMincer network architecture and training scheduleusing Optosynth-simulated datasets” in “Methods”). Even though these pre-masked target values do not represent actual ground truth but noisy realizations, their noise contribution cannot be predicted by the neural network provided that the masking mechanism decorrelates the pixel noise between masked and unmasked compartments (\({\mathcal{J}}\)-invariance, see ref. 12). In fluorescence imaging, the main source of noise is pixelwise Poisson-Gaussian noise, which is uncorrelated across pixels, allowing us to satisfy the \({\mathcal{J}}\)-invariance condition as a matter of masking individual pixels. CellMincer’s implementation additionally permits the use of alternate masking mechanisms (e.g. inclusion of margin around each masked pixel) if needed to account for correlated noise. Crucially, the training protocol includes only the masked pixels in its prediction task, directing the network to solely infer pixel values without their noise components. At inference time, this function is applied across all pixels uniformly, yielding our desired denoising outcome without additional masking. This training strategy allows CellMincer to operate very efficiently at inference time, when we feed the noisy detrended movie in (2τ + 1)-length overlapping sliding windows to the network and denoise each window’s entire middle frame. To avoid the typical practice of producing truncated results, we augment all model inputs with appropriate spatial padding at training and inference time, and we pad the beginning and end of the denoised movie with τ copies of its first and last frame respectively.
Our implementation of CellMincer can jointly train on many datasets across multiple GPUs to produce a highly generalizable model, but satisfactory results can be achieved by training on a single voltage imaging dataset with as few as 5000 frames. For a more detailed exploration of the effect of training data size and imaging resolution on CellMincer’s performance, see Sec. 2 and Sec. 3 in Supplementary Material. Owing to the model’s self-supervised training scheme, the dataset to be denoised can also serve as the model’s only training data.
Architecture optimization of CellMincer via realistic physics-based simulations
To optimize the architecture and hyperparameters of CellMincer and study the impact of various design choices on the baseline denoising performance, one needs noiseless ground truth voltage imaging data. While experimental sourcing of true noiseless data is impractical due to technical limitations (e.g. the trade-off between signal-to-noise ratio and sampling rate, photo-bleaching and sample heating at higher illumination), we can aim to generate such ground truth recordings and their noisy realizations via carefully crafted simulations. These simulated data can then be used to study and optimize the model architecture and serve as a benchmark to evaluate the performance of CellMincer compared to other denoising methods.
To these ends, we developed Optosynth, a methodology for generating physics-based synthetic optical voltage imaging data using single-neuron morphological reconstructions and paired EP measurements from the Allen Brain Patch-seq dataset20,21,22. In brief, Optosynth simulates a noiseless voltage imaging readout by sampling neurons from a Patch-seq dataset, arranging them on a synthetic imaging field, and modeling the fluorescence signal density as an appropriate conversion function of the measured membrane potential. To produce realistic voltage imaging readouts, we additionally include low-passing of EP to the fluorescence sensor sampling rate, action potential wavefront propagation and decay, variability in fluorescent reporter expression, point spread function (PSF), and static and dynamics background autofluorescence. We generate noisy readings from noiseless simulations by adding Poisson shot noise and Gaussian sensor thermal noise. Optosynth’s simulations are highly customizable, enabling generation of synthetic datasets that can represent a wide range of experimental conditions, noise levels, and magnifications. A detailed description of Optosynth is provided in “Simulating realistic voltage imaging datasets using Optosynth” in “Methods”.
The CellMincer model is specified by a large set of hyperparameters which determine the architecture of the underlying DNNs, the self-supervised training parameters, and the optimizer scheduling. To optimize over this hyperparameter space, we first identified a baseline configuration that specifies a design empirically capable of denoising our Optosynth datasets and training it to sufficient convergence. We then constructed a series of single-hyperparameter variations of the baseline configuration and evaluated their performance on Optosynth data. Our hyperparameter variations included the inclusion or exclusion of global features \({\mathscr{F}}\), the length of the denoising window 2τ + 1, the U-Net parameters (depth, number of channels), the temporal post-processor architecture, the loss function, and the rate of pixel masking during self-supervised training. Our evaluation procedure consisted of training the model on a subset of our Optosynth data, denoising both the training data and unseen data (biological replicates generated using Optosynth) with our trained model, and computing the denoised imaging’s peak signal-to-noise ratio (PSNR) with respect to the ground truth. These results determined our final selection of hyperparameters used in subsequent benchmarking experiments. While our greedy hyperparameter search procedure is unlikely to locate the globally optimal model configuration given the dependencies between CellMincer’s hyperparameters, we believe that this process produced a suitable optimum where a complete grid search would be computationally infeasible. In particular, our central finding that the inclusion of precomputed global features largely overshadows all other optimizations suggests to us that there is relatively little room for further model improvement. A more thorough elaboration of these optimization experiments can be found in “Optimizing CellMincer network architecture and training scheduleusing Optosynth-simulated datasets” in “Methods”.
Foremost, we found that conditioning the U-Net on global features produced the most significant improvement by wide margins, up to 5 dB gain in PSNR (see Fig. 6b, rows 1–3). Without inclusion of global features, model performance gains relied heavily on increasing the local denoising temporal context windows (see Fig. 6b, rows 1, 4–7; the context size is varied from 5 to 21 frames ~10−42 ms). We note that such large temporal context sizes exceed the observed temporal correlation lengths in voltage imaging (see lagged cross-correlations in Fig. 2d and Fig. 3c), suggesting that the unconditioned denoiser is taking advantage of large context sizes to infer pixel-to-pixel spatial correlations rather than temporal correlations. To further underscore this point, we note that PSNR gains of a denoiser explicitly conditioned on precomputed global auto-correlations saturate between 5 and 9 frames ~10−18 ms, which coincides with the typical temporal correlation length in neuronal activity (see Fig. 6e, rows 1–5). Clearly, precomputing global features and conditioning the denoiser is a much more effective and computationally efficient alternative to using longer denoising context windows.

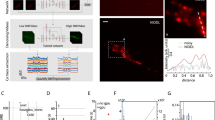
a Sample denoised frame visualizations (grayscale images) and their residuals with respect to simulated ground truth imaging (red/blue images). Both the denoised and residual images are shown as relative change in fluorescence ΔF/F with respect to a frame-averaged polynomial regression of the baseline (see “CellMincer preprocessing and global feature extraction details” in “Methods”). b Sample denoised ROI-averaged neuron traces (color), overlaid with the ground truth (black). c Distributions of single-frame PSNR gain achieved through denoising. Each distribution corresponds to a different value of simulated photon-per-fluorophore count Q (shown in the legend), which is the measure of raw data SNR in Optosynth simulations (see “Simulating realistic voltage imaging datasets using Optosynth” in “Methods”). The dashed vertical line over the top four rows is a guide for the eye and indicates the mode of CellMincer’s PSNR gain distribution for the lowest SNR data (corresponding to Q = 5). The plot at the bottom row shows the SNR distributions of the raw datasets at different Q levels. d Distributions of lagged cross-correlations between denoised single-neuron traces and their ground truths. Their medians are overlaid with peak correlations at Δt = 0 labeled. Abbreviations: GT (ground truth).

a Sample denoised ROI-averaged neuron traces (color), aligned to the EP-derived ground truth (black). b Inlays of subthreshold activity as indicated in the previous column, magnified. c Distributions of lagged cross-correlations between denoised single-neuron traces and their corresponding aligned EP signals. Their medians are overlaid with peak correlations at Δt = 0 labeled. d Average noise reductions at varying frequency ranges achieved through denoising. e Peak-calling accuracy F1-scores over a range of EP peak prominence levels, using the EP signal as ground truth. Abbreviations: ROI (region of interest).
Another advantage of conditioning the denoiser on precomputed global features is achieving more robust PSNR gain characteristics across different stimulation amplitudes. This can be seen by comparing the violin plots of PSNR gain distributions for unconditioned and conditioned denoisers in Fig. 6. The PSNR gain distribution of the unconditioned denoiser (baseline, first row, panel b-c)) varies from +16 dB to +23 dB, and is highly variable in particular for recordings at lower electrical stimulation amplitudes (shown in blue). This observation further underscores that the performance of an unconditioned denoiser relies on its ability to infer correlations solely from the local context, which can be unreliable when neurons are not active under low stimulation. In contrast, the PSNR gain distributions of all conditioned model variants (rows 2–2, panel b–c, and all rows of panel e–f) are tightly concentrated from +22 dB to +24 dB.
Besides the crucial importance of conditioning the denoiser on global features, we find that other design decisions (like U-Net depth, number of channels, loss function selection, and the amount of masked pixels) have a surprisingly small effect on model performance. This indicates that CellMincer works reliably and does not require extensive parameter fine-tuning when used with other voltage imaging datasets. A more detailed description of these optimization experiments and their results are provided in “Optimizing CellMincer network architecture and training scheduleusing Optosynth-simulated datasets” in “Methods”.
CellMincer outperforms existing methods at denoising simulated voltage imaging data
For our benchmark evaluations, we included a selection of denoising algorithms applicable to spatiotemporal data. Importantly, the algorithms share the precondition that clean reference data for training is not needed. SUPPORT19 is a self-supervised learning method for removing Poisson-Gaussian noise from voltage imaging data. DeepVID18, a deep convolutional neural network trained under self-supervision to predict whole frames and individual pixels in voltage imaging data. DeepSeMi17 is a self-supervised-learning-based framework that uses blind-spot kernels in training to denoise voltage imaging data. DeepCAD-RT14 is a self-supervised deep-learning algorithm for denoising calcium imaging data. Penalized matrix decomposition (PMD)8 is a training-free algorithm based on a regularized, low-rank factorization of the data. As a baseline, we also include the original implementation of Noise2Self (N2S)12 for images, which denoises movie frames individually.
To cover a range of scenarios characterized by differing noise conditions, we chose four different SNRs by varying the number of photons-per-fluorophore Q in simulations (see “Simulating realistic voltage imaging datasets using Optosynth” in “Methods”). With this design choice, our aim was to conduct a broad evaluation of each method across a range of imaging qualities, which in practice can vary widely with the choice of fluorescent reporter, the stimulation protocol, and the sensor characteristics, among other factors. For each level of SNR, denoted in increasing order as Q = 5, 10, 50, 200, we generated five synthetic datasets using Optosynth at an imaging rate of 500 Hz with associated ground truth. For each of the benchmark methods, we decided whether to provide the data in its original form or as the pixelwise detrended version produced by CellMincer’s preprocessing step. From early empirical results, we found that the baseline algorithms PMD and N2S perform significantly better on detrended data, while the various self-supervised voltage imaging denoisers contain their own preprocessing steps and were thus given the original data. We then trained CellMincer and each of the other training-based denoising methods on three of the five datasets and subsequently used them to denoise all five datasets. PMD, which is a single-sample denoising algorithm, was used to individually denoise the five datasets instead. With these denoised datasets along with the original noisy datasets, we conducted a series of evaluations centered on comparing them to our ground truth imaging. We present our Optosynth benchmarks in Fig. 2. Of the methods benchmarked here, DeepVID and DeepSeMi did not produce comparable results, leading us to omit them from Fig. 2. Their results are included in the extended Optosynth benchmark in Fig. 4 in Supplementary Materials.

control hPSC-derived neurons with raw and CellMincer-denoised Optopatch voltage imaging data. a Raw and denoised versions of a sample frame, colored with the neuron components identified in their corresponding datasets. b Corresponding ROI-averaged single-neuron traces detected in both versions of the above frame. c Spike count distributions, separated by neuron population and stimulation intensity. Spikes were identified in each detected neuron’s trace and binned by their stimulation intensity. The separation between the sets of green (TTX-treated) and purple (Control) boxplots in each respective plot indicates the degree to which we were able to identify the difference in spiking activity in the data. d Detected neuron counts in the raw and denoised versions of each dataset. e Statistical power of the Wilcoxon Rank Sum test applied to the neuron population differentiation hypothesis, reported as the negative logarithm of its p-value.
To visualize imaging quality, our first benchmark evaluation compared the results of denoising a single movie frame in both absolute intensity and residual intensity with respect to ground truth, of which CellMincer, SUPPORT, and PMD exhibit notably cleaner residual frames (Fig. 2a). CellMincer and PMD exhibited slight and moderate misjudgements of certain neuron spiking intensities respectively, while DeepCAD-RT and N2S were less effective at removing noise throughout the frame. Our next evaluation explored the resolution of single-neuron signals from the imaging. To extract these signals, we inferred single-neuron masks from the raw data (refer to “Procuring fluorescence intensity traces and aligning to joint electro-physiology data” in “Methods”) and used them to produce ROI-averaged traces. We overlaid these traces with their respective ground truth for a sample neuron (Fig. 2b) and observed significantly less noise from CellMincer, SUPPORT, and DeepCAD-RT. We noted that CellMincer occasionally overstates the intensity of action potentials, SUPPORT at times fails to register subthreshold events, and DeepCAD-RT does not fully reconstruct spiking events.
After establishing a visual evaluation of CellMincer and the compared methods, we sought to quantify these differences with the PSNR metric. In column c, we compared the distributions of single-frame PSNR gain achieved by denoising. Each frame PSNR was computed over the union of pixels contained in the neuron ROIs gathered from all five datasets, and only frames during stimulation periods were considered. These restrictions mitigated the influence of background pixels in our performance metric. We found that CellMincer demonstrates a consistent lead in PSNR gain over the other algorithms. Additionally, CellMincer is more consistent across our range of input SNRs, while the other methods yield a clear reduction in PSNR gain for higher-quality datasets. This is consistent with one of our core findings that the inclusion of global features, unique to CellMincer, acts as an equalizing factor for data with varying SNR. This finding ties in with our ablation study on the impact of global features (Fig. 1e), in which we see that a CellMincer model without global features exhibits a similarly overdispersed PSNR gain distributions at different neuron stimulation amplitudes, correlated with large jumps in SNR. Quantitatively, the modal PSNR gain describes the effectiveness of a method for a “typical” frame, while the (mode-centered) interquartile range (IQR) encapsulates the general variance around this point. In Table 1, we provide the mean PSNR, modal PSNR, and IQR for each method’s PSNR gain distributions, which we briefly summarize here. Compared to the best competing method SUPPORT, CellMincer exhibits an improvement in modal PSNR of +0.5 dB at SNR level Q = 5, an improvement of +1.01 dB at Q = 10, +2.93 dB at Q = 50, and +2.32 dB at Q = 200. Additionally, CellMincer exhibits a reduction in IQR from SUPPORT of 52% at Q = 5, 55% at Q = 10, 33% at Q = 50, and 17% at Q = 200. For reference, the SNR distribution of the raw datasets are given at the bottom of column c for each of the four simulated scenarios.
Finally, we aimed to show that CellMincer does indeed reconstruct the activity exhibited in the ground truth single-neuron traces without temporal bias. In column d, we computed the distributions of lagged cross-correlations between the denoised and ground truth traces over the Optosynth neurons at Q = 10 and overlaid the median. All cross-correlations sharply peaked at Δt = 0, and CellMincer exhibited a zero-lag median cross-correlation of ρ = 0.81, comparable with that of SUPPORT (0.82) and significantly higher than of DeepCAD-RT (0.68) and PMD (0.65).
CellMincer improves the detection of subthreshold events in real voltage imaging data with paired electrophysiology
To extend our evaluation of CellMincer to real data, we further evaluated CellMincer on 26 external datasets from a previously published study with simultaneous voltage imaging with chemically-synthesized voltage-sensitive fluorophore, BeRST23,24, and patch-clamp EP recordings, the latter of which can be repurposed as a high-confidence source of ground truth. BeRST is a chemically-synthesized far-red voltage-sensitive fluorophore. Previously, we showed that BeRST can be used in cultured rat hippocampal neurons to track changes in neuronal activity in models of development and disease25. Data from that study contained simultaneous recordings of BeRST fluorescence (voltage imaging) and single-cell patch clamp recordings (EP) that could serve as a ground truth for benchmarking of CellMincer. Please refer to “Simultaneous BeRST fluorescence voltage imaging and single-cellpatch-clamp EP recording experimental procedure” in “Methods” for the details of the experimental procedure.
Our aim in the following benchmarking experiments was to extract single-neuron denoised imaging traces and compare them to their associated patch-clamp EP signals. While both modalities operate on the same underlying neural activity, they differ substantially in sampling rate, noise characteristics, and artifacts. It is thus necessary for us to minimally resolve these data modality incompatibilities by applying a series of common filters and transformations to map them onto a shared scale. These include removing a slowly-varying trend from both measurements, temporal alignment of the two recordings, and performing a global affine transformation on the detrended fluorescence recordings to make them comparable in scale to EP recordings (in mV). See “Procuring fluorescence intensity traces and aligning to joint electro-physiology data” in “Methods” for a detailed description of our alignment procedure.
Using an analogous approach to that presented in our simulated data benchmarking, we trained the deep learning-based models on as many as all 26 of the available joint datasets, depending on the capabilities of the model implementations. DeepCAD-RT was excluded from this benchmark due to difficulties with training it on large quantities of data, as well as its previously noted poor performance in reconstructing spiking events (see Fig. 2). With these trained models, we identified a subset of 22 datasets exhibiting discernible activity suitable for benchmarking purposes. Each model was used to denoise these benchmarking datasets, while PMD, as before, denoised each dataset individually. From the resulting denoised datasets, we extracted ROI-averaged traces and aligned them to their corresponding EP signals. The concordance between these aligned traces to the underlying EP activity forms the basis of our benchmark results, shown in Fig. 3.
Our first step was to visualize the quality of our imaging traces after mapping them to the EP scale. From plotting these traces against their corresponding EP signals (Fig. 3a), we found that CellMincer again exhibited significantly less noise than the other algorithms while aligning to the baseline more accurately than SUPPORT. The improvement is particularly apparent when examining the baseline trace relative to subthreshold activity (Fig. 3b). To characterize this noise reduction, we computed the spectral power, binned by frequency, of the residual signal before and after denoising for each algorithm (“Metrics for evaluating denoising performance on real voltage imagingwith paired EP” in “Methods”). We plot the reduction in power of these residuals, measured in dB, across the frequency range (Fig. 3d). At frequencies above 100Hz, CellMincer achieves an average noise reduction of 13.9 dB, greater than that of SUPPORT (10.9), PMD (3.2) and N2S (0.6). This quantifies the visually identifiable differences in performance from the inset traces (Fig. 3b), which contributes to the resolution of low-magnitude signals from the noisy baseline. Using a process analogous to that in our simulated data benchmark, we also compared the distributions of lagged cross-correlations between the voltage imaging and EP data (Fig. 3c). CellMincer similarly exhibited a higher median cross-correlation (ρ = 0.90), comparable to that of SUPPORT (0.91), while the other algorithms remained on par with the raw data (0.83).
After demonstrating that CellMincer, by way of its enhanced noise reduction, could potentially resolve signals of a smaller magnitude than that which can be seen by the other algorithms, we sought an approach to quantify this small-signal reconstruction fidelity. Due to difficulties with reliably processing these imaging traces with tools designed for EP signals, we devised an analytic method based on peak-calling (“Metrics for evaluating denoising performance on real voltage imagingwith paired EP” in “Methods”). From this analysis, we plotted the peak-calling accuracy of each algorithm as an F1-score, binned over several ranges of peak magnitudes (Fig. 3e), and found that CellMincer exhibited a 12–194% increase in F1-score over the other benchmarked algorithms and the raw data across peak magnitudes between 0.5 and 3 mV. At the 0.5–2 mV and 5–10 mV ranges, only CellMincer and SUPPORT show any statistically significant improvement over the raw data, with CellMincer outperforming SUPPORT significantly for small-magnitude events. In the higher magnitude regime in which peaks are more easily differentiated from the noisy baseline, SUPPORT’s performance approaches that of CellMincer. These evaluations demonstrated that on real voltage imaging, CellMincer produces significant quantitative improvements in the reconstruction of single-neuron traces when compared to traces derived from the raw data and from data denoised by standard algorithms. These improvements have meaningful implications for the potential uses of CellMincer denoising to recover underlying subthreshold activity using voltage imaging data.
CellMincer improves neuron segmentation and detection of subtle changes in neural activity
To demonstrate the utility of CellMincer in a representative end-to-end biological hypothesis testing workflow, we present a complete such analysis with and without CellMincer as a data-denoising component, and we quantify the impact of CellMincer on improving the detection of subtle phenotypic changes. Specifically, we compare the spiking activity of unperturbed and chronically tetrodotoxin (TTX)-treated cultured hPSC-derived neurons via Optopatch voltage imaging. TTX is a voltage-gated sodium channel blocker that, when used to treat cultured neurons, prevents them from firing action potentials. Prolonged silencing with TTX increases intrinsic excitability of neurons26. This homeostatic plasticity is also displayed in hPSC-derived neurons3. We incubated hPSC-derived neuronal cultures in 500 nM TTX for 48 h and washed it out prior to Optopatch recordings. Parallel unperturbed cultures were incubated in TTX-free media. In both cases, we subjected the neurons to eight stimulation periods in increasing intensity and measured their action potential via Optopatch voltage imaging. Please refer to “Optopatch voltage imaging of chronically TTX-treated and unper-turbed hPSC-derived neurons” in “Methods” for the details of the experimental procedure.
We analysed the obtained recordings as follows. We performed a pixelwise detrending preprocessing step on both raw and denoised datasets, computed independent spatial components using a PCA/ICA decomposition approach27, and identified neuronal components through careful comparative review of the obtained components and the activity traces. We finally derived an ROI-averaged trace from each identified neuron for downstream analysis, which focused on counting and comparing the statistics of high-amplitude action potential spikes. Additional details are provided in “Methods for segmenting and spike-counting voltage imaging datasets” in “Methods”.
Figure 4 showcases a segmentation of identifiable neurons on a sample frame from the raw and CellMincer-denoised analysis. It is evident that: (1) among the neurons that are reliably identifiable in both the raw and denoised dataset, CellMincer more clearly delineates their boundaries. This is particularly evident among the cluster of overlapping neurons shown on the left side of the field of view in Fig. 4a); (2) CellMincer enables better separation and detection of more neuronal components, in particular neurons with fainter fluorescence signal, as well as more reliable spike-counting. To substantiate the latter, we plotted the ROI-averaged traces from three neurons side-by-side in Fig. 4b (color-matched to the neuron components shown in Fig. 4a). As explored in the previous experiments, the most salient improvement brought about by CellMincer is in the form of a significant reduction in the background noise (see Fig. 3c). In the present context, this has the effect of highlighting subtler spiking events and enabling them to be called with greater confidence (compare the raw and denoised traces shown in Fig. 4b). The total number of confidently detected neurons are shown in Fig. 4d and establishes that in most recordings, CellMincer denoising allows identification of twice or more as many neurons with distinct spiking patterns. As a result of improved neuron segmentation and spike counting following denoising, aggregating spike statistics over more neurons results in a larger statistical separation between the control and chronically TTX-treated populations. This can be visualized by comparing the boxplots shown in Fig. 4c. To further quantify this finding, we performed a Wilcoxon rank sum test, the result of which is shown in Fig. 4e. Notably, CellMincer denoising yields significantly greater statistical power to separate the two conditions, with this separation increasing at higher stimulation intensities, as evidenced in the tail-end of Fig. 4e. Interestingly, the lowest stimulation intensity shows a deviation from this trend, yet it still aligns with the overall conclusion that chronically TTX-treated neurons exhibit heightened excitability.
Discussion
We introduced CellMincer, a self-supervised deep learning method specifically designed for denoising voltage imaging datasets, and discussed several key methodological refinements over the existing approaches. These include: (1) an efficient and expressive two-stage spatiotemporal data processing deep neural network architecture, comprising a frame-wise 2D U-Net module for spatial feature extraction, followed by a pixelwise 1D convolutional module for temporal data post-processing; (2) performing self-supervised training by masking a sparse set of pixels rather than entire frames, allowing the model to access both intra- and inter-frame information as needed for effective denoising of voltage imaging datasets; (3) conditioning local denoisers on a set of precomputed spatiotemporal auto-correlations at multiple length scales, resulting in a significant boost in denoising accuracy; (4) introducing a physics-based simulation framework to generate highly realistic pairs of clean and noisy voltage imaging movies for the purpose of hyperparameter optimization and ablation studies. We evaluated CellMincer’s performance on both simulated and real datasets, including an external previously published dataset comprising 30 voltage imaging experiments with simultaneous patch-clamp EP recordings25, and established that CellMincer outperforms the existing denoising approaches. Finally, we demonstrated the utility of CellMincer in downstream analyses, resulting in a more robust identification of neurons and spiking events and ultimately a higher statistical power for separating neuron populations based on functional phenotypes.
CellMincer denoising holds the potential to advance the study of complex neuronal communication through multiple avenues. Firstly, traditional methods often involve measuring postsynaptic potentials at the cell body to understand synaptic transmission. However, the inherent biophysical properties of synapses, coupled with the intricate dendritic morphology, such as shape, branching, and diameter, can distort electrical signals originating at the synapse. Consequently, the activity recorded at the soma may not accurately depict events at the synapse. This discrepancy poses a challenge in electrophysiological techniques, which predominantly require recordings at the soma. CellMincer, however, presents a promising solution by facilitating the direct examination of electrical activity at the synapse through voltage imaging techniques and computational SNR enhancement. Secondly, CellMincer denoising enables the collection of usable data even from low magnification recordings with low signal-to-noise ratios (SNRs). For instance, enough data was acquired in seconds to clearly separate the TTX-treated groups (Fig. 4). This stands in contrast to single cell recordings either by patch-clamp EP or high magnification voltage imaging, which would take multiple recording days.
CellMincer’s improved performance over similar denoising methods largely stems from precomputing global movie features and using these features as a conditioner for the denoiser network that otherwise operates on small temporal contexts. The inclusion of global spatial features alongside CellMincer’s localized context processing allows the algorithm to exploit persistent long-range correlations in the data without directly ingesting the entire dataset with a neural network, an intractable computational operation. These carefully crafted features (see “CellMincer preprocessing and global feature extraction details” in “Methods”) meaningfully contribute to data modeling because the neuron signal sources are generally fixed in space, making the behavior of individual pixels, as well as pixel-pixel relationships, highly consistent. Our ablation studies reveal that providing global features to the denoiser results in a striking 3-fold boost in the PSNR (or approximately a 5 dB gain). While increasing the denoising context size endows the local denoiser with more global information and improves its performance, we notice that there is still a ~4 dB gap between an unconditioned denoiser with a context size of 21 frames and a conditioned denoiser with a context size of only 9 frames, see Fig. 6.
Another advantage of leveraging precomputing global features in conditioning short-context denoisers is computational efficiency. Existing denoising methods that rely on long contexts to achieve satisfactory denoising performance will inevitably demand relatively larger computational resources. For instance, when extended to a training corpora of 26 datasets (“CellMincer improves the detection of subthreshold events in real volt-age imaging data with paired electrophysiology”), DeepCAD-RT’s computational resource demands exceeded our limits and we had to exclude it from the benchmarking. Likewise, DeepInterpolation16, another self-supervised deep neural network denoiser, could not be made to process our datasets and was thus also not included in benchmarking. In contrast, we were able to efficiently train CellMincer on our largest training corpora using widely-available commodity GPUs.
While the performance gap between CellMincer and SUPPORT is smaller compared to the gap between CellMincer and the other evaluated algorithms, we find that CellMincer demonstrates more consistent performance across different frames and varying noise levels. As shown in the PSNR distributions in Fig. 2c and summarized in Table 1, CellMincer outperforms all other benchmark methods by achieving a substantially better combination of a higher modal PSNR gain and a smaller interquartile range (IQR). This indicates that for a “typical" frame, CellMincer is the superior denoiser by a significant margin. We hypothesize that this performance advantage stems from the use of global features as a conditioner in our denoiser model, as supported by our optimization study (see Fig. 6). In that study, model variants lacking global features (a–c) exhibit highly overdispersed and multimodal PSNR gain distributions, whereas variants incorporating global features (d–f) produce sharp unimodal distributions-a distinction not observed with any other hyperparameter variation examined in the experiment.
The pre-training approach we employed to train the CellMincer model on voltage imaging data might not be optimally tailored to handle other functional imaging modalities, such as calcium imaging, characterized by substantially different spatiotemporal dynamics. A characteristic difference in the dynamics of voltage imaging and calcium imaging is the presence of single spiking events occurring within 5 to 10 frames. The performance gap between CellMincer and DeepCAD-RT on voltage imaging suggests that the most effective fluorescence imaging denoisers are highly specific to their target domains. CellMincer’s architecture uses a context window length on par with the timescale of a typical voltage imaging spiking event, and its training scheme maximizes the utility of this context by enabling inference from same-frame pixels. Conversely, DeepCAD-RT predicts whole frames from a large, temporally downsampled neighborhood of frames, a strategy that foregoes mutual information carried by proximal pixels in exchange for training scalability. Our hypothesis of the specificity of the model (and self-supervision task) to the data domain is further reinforced by an experiment in which we compare the performance of CellMincer and DeepCAD-RT on calcium imaging data (refer to Sec. 1 in Supplementary Materials). Both algorithms were trained on seven low-SNR calcium imaging datasets14, and their denoised outputs were compared to high-SNR versions of the same datasets. We noticed a significant drop in the performance of CellMincer on denoising calcium imaging data, and improved performance of DeepCAD-RT, which is opposite to our findings on fast voltage imaging data. We concluded that CellMincer’s capacity to model short-term fluctuations becomes a hindrance when the underlying signal has inherently slow dynamics, whereas DeepCAD-RT’s whole-frame masking and the implicit bias of slow dynamics become advantageous.
A notable difficulty in conducting the analysis of neuron imaging traces in relation to corresponding EP activity is the lack of available tools for analyzing waveforms that diverge from the highly specific characteristics of EP. The Electrophys Feature Extraction Library (EFEL)28, one such tool, can extract a variety of EP features such as spike half-widths but is much less conclusive when the input signals are adapted from fluorescence imaging. Our solution, prominence-thresholded peak calling, is motivated by the biological significance of partial and total depolarization events, indicative of subthreshold activity and action potentials respectively. Thus, identifying peaks in the EP represents a sensible first-order approximation for the locations of these events and can function as a task to which we subject our imaging traces. While most action potentials stand in such stark contrast to the surrounding baseline that they are evident in any form of the trace, the elevated baseline noise in the traces produced by PMD, N2S, and the raw data is likely to hide less pronounced EP events and introduce more false positives. Although the absolute peak-calling performance across all methods is low, primarily owing to the inherent incompatibilities between the 50 kHz EP signal and its derived 500 Hz imaging, our assessment is that for EP peaks between 2 and 5 mV, there is indeed information in the raw data that corresponds to this activity but is not immediately visible, and CellMincer is distilling this information to allow for more confident judgments.
We would like to contrast our approach to model optimization and benchmarking, i.e., using Optosynth simulated data and voltage imaging with paired electrophysiology, with the more standard approach of using paired low-SNR and high-SNR recordings. While high-SNR recordings could plausibly substitute for the theoretical ground truth imaging, in practice they suffer from two drawbacks: (1) they are laborious to acquire at scale, limiting the range of imaging conditions on which the model can be tested, and (2) the source of noise in high-SNR recordings, while diminished in magnitude, remains the same as that of their low-SNR counterparts, making it possible for models tuned and evaluated in this manner to favor the retention of these shared noise components-an outcome antithetical to the primary objective in voltage imaging denoising. The use of Optosynth as an imaging simulation framework permits the mass generation of realistic imaging data with clean ground truth, where imaging and noise conditions can be freely varied through parameterization. Furthermore, using simultaneously measured “gold standard" electrophysiology to gauge signal reconstruction from image-denoising circumvents concerns regarding the retention of undesired voltage imaging artifacts, while also allowing us to address questions related to high-frequency and low-amplitude electrophysiological behavior, such as subthreshold events.
A limitation of CellMincer’s default self-supervised training scheme is that in uniformly sampling random crops of the training data, CellMincer spends an overwhelming majority of its computation time on static background pixels as opposed to pixels containing meaningful neuronal activity. We introduced an option in CellMincer to increase its sampling efficiency without introducing network bias by oversampling such meaningful data crops, defined as exceeding the top n% of average luminosity across all crops in the dataset for n chosen between 0.1 and 1, to 50% of each training batch (importance sampling). We can then correct the loss calculation knowing the constructed ratio of meaningful samples. While this feature was not incorporated into the models used in our main benchmarking experiments, we found that it reduced the performance gap between CellMincer and DeepCAD-RT on calcium imaging. We expect further exploration of this direction, namely adaptive sampling and hard sample mining in the context of self-supervised training, will find applications beyond the present domain.
Precomputation of global features should be carried out with additional considerations in situations where either neuron locations or noise characteristics could be non-stationary (e.g. certain in vivo recordings). In such cases, the temporal distributional shift along a long recording interval may render any one set of precomputed global features less relevant to variable local contexts of the recording. Since CellMincer’s objective function is unbiased (see Eq. (4)), conditioning on poor (or even irrelevant) global features will not degrade the performance of the method. Indeed, this is again evidenced by the concentration and unimodality of our PSNR gain distributions around the modal performance (see Fig. 6), as this outcome would not arise if CellMincer was overwhelmingly favoring certain frames at the detriment of others for which the global features are less relevant. We can thus estimate an upper bound on CellMincer’s performance degradation for non-stationary recordings of −5 dB, which is the difference in performance between CellMincer with and without global features. While SUPPORT and DeepSeMi both claim to denoise non-stationary recordings effectively, CellMincer’s performance bound still exceeds the reported performance of DeepSeMi, while a direct comparison with SUPPORT would require further experimentation. However, to take full advantage of the notion of feature-conditioning, we stipulate that a more effective strategy in denoising non-stationary data would be to pre-segment the movie into approximately stationary intervals and denoising each section separately using its own precomputed features. This is streamlined by CellMincer’s ability to pre-train on and denoise an arbitrary collection of recordings.
We believe that CellMincer’s architecture is adequately powered for denoising many forms of fluorescence imaging modalities of electrically active cells. Optimizing the hyperparameters and training schedule of CellMincer for related data domains (e.g. calcium imaging) would be a natural avenue for future work. While our analysis shows that CellMincer satisfactorily operates on a single dataset (both for training and denoising), we hypothesize that training a generalist large-scale CellMincer foundation model on a large and diverse biomedical imaging corpora (and perhaps using more scalable architectures such as the Vision Transformer29) is another promising area of future research. Intriguingly, inspecting and building on the saliency and attention maps underlying the Vision Transformer could lay a novel roadmap for segmenting a wide range of functional imaging datasets into functional units, much like the recently demonstrated utility of self-supervised models of natural images (e.g. DINOv230) in segmenting natural images and performing various other image-based downstream tasks.
Throughout its development and benchmarking, CellMincer has been tested on voltage imaging data from multiple institutions, recorded using both older and newer technologies. As a result, CellMincer is highly versatile, capable of ingesting TIF, BIN, and NumPy formats without the need for conversion. Unlike other voltage imaging denoising algorithms that require fixed patch and stride sizes, CellMincer processes entire frames at inference time without fixed dimension specifications. This flexibility allows models trained on data of a particular dimension to perform inference on datasets of varying sizes seamlessly. These implementation features contribute to a level of accessibility and ease of deployment that surpasses our experiences with other denoising methods.
Additionally, the CellMincer code release was designed with a strong emphasis on usability and ease of deployment. We have incorporated various diagnostic feedback mechanisms to assist users, including plots to visualize the trend-fitting preprocessing step and previews of the denoised output as .AVI movie files. To address dependency issues commonly encountered with similar tools, we have provided a stable Docker image for public use. In our experience with CellMincer on datasets of approximately 5000–7000 frames, preprocessing typically takes 5 min, with inference time around 10 min per dataset. Furthermore, we have prepared workflows on the Terra platform to facilitate easy, parallelizable remote execution of the tool, offering an additional avenue for accessing CellMincer.
We have made available separate pre-trained CellMincer models on synthetic Optosynth data from “CellMincer outperforms existing methods at denoising simulated volt-age imaging data”, the BeRST voltage imaging data from “CellMincer improves the detection of subthreshold events in real volt-age imaging data with paired electrophysiology”, and the Optopatch voltage imaging data from “CellMincer improves neuron segmentation and detection of subtlechanges in neural activity”. Even though training a CellMincer model from scratch can take 10–12 h on a typical dataset and publicly available commodity GPU (see “CellMincer neural network design, training schedule, and implemen-tation details” in “Methods”), using one of the pre-trained models as is or fine-tuning it presents a faster and less computationally intensive approach to the adoption of our method. In the future, we hope that the availability pre-trained CellMincer foundation models on a large and diverse voltage imaging dataset, combined with efficient model selection and fine-tuning strategies, will further reduce the computational cost of using CellMincer.
Methods
CellMincer neural network design, training schedule, and implementation details
The neural network architecture of CellMincer consists of a U-Net which produces deep embeddings of individual frames and a temporal post-processor which reduces a sequence of frame embeddings into a single denoised frame (see Fig. 1b).
Our U-Net design allows for the augmentation of the input frame with our precomputed global features. This augmentation can occur either by concatenating the two before passing it through the U-Net or by repeating this concatenation at each step of the U-Net’s contracting path, iteratively downsampling the global features in tandem with the frame embedding (see Fig. 1). We find that this repeat global feature augmentation reinforces the network bias toward using the global features, improving downstream performance. In addition, our U-Net implementation is not limited to a specific input dimension (as often required by conventional implementations), as demonstrated by our protocol of training on small imaging crops while using whole frames at evaluation time. This allows the model to train on imaging corpora with mixed dimensions and generalize to arbitrarily sized inputs without needing to dissect the input into uniformly-sized patches. Without padding each convolution layer, our U-Net produces image contraction, so we apply reflection padding to the input to achieve our desired output dimensions.
The temporal post-processor takes as input a short window of frame embeddings from the U-Net, convolves the time dimension, and collapses the feature dimension, producing a single output for each pixel. In this manner, no further spatial entanglement is introduced, so we do not include global features at this computation step (see Fig. 1d).
Through optimization trials, we determined an Adam optimizer with standard momentum parameters (β1 = 0.9, β2 = 0.999) was most effective for training CellMincer. We applied a cosine-annealed learning rate with linear warmup31, parameterized at \({\eta }_{\max }=1{0}^{-4}\). To increase the diversity of imaging used to train our model, we configured our training samples to consist of small 62 × 62 crops padded with 30 pixels on each side, striking a balance between the minibatch diversity and the training signal that comes from each entry in the minibatch. With this configuration, we were able to maximize GPU utilization by training on minibatches of 20 samples per GPU (reduced to 10 samples for our largest model variant). We found that 50,000 training iterations generally led to sufficient model convergence when using a training set of limited size (1–5 recordings). More investigation is needed to determine whether a longer training period is needed to make full use of a larger training set.
In the course of CellMincer’s development, we explored a series of variations on its architecture and training schemes, some of which are reported in detail in “Optimizing CellMincer network architecture and training scheduleusing Optosynth-simulated datasets” in “Methods”. Of those omitted from our results, we considered single U-Net architectures that combined spatial and temporal processing, either by using a 3D U-Net to model time or by concatenating the frame sequence within the feature dimension. While our time as features model was computationally more efficient, we could not reach the expressivity and performance afforded by our current two-stage design. We also experimented with the choice of learning rate schedule, opting for an empirically validated cosine annealing with 10% linear warmup31. This schedule mitigates early instability while the model performance is highly variant while improving convergence near the end of training. In addition, we briefly explored the use of stochastic weight averaging32, and discovered that it had a paradoxically negative impact on performance. Our hypothesis is that the contours of our model’s loss landscape are highly nonconvex so that an averaging of local optima removes us from the optimal parameter manifold.
We implemented CellMincer as a CLI tool in the PyTorch Lightning framework, which offers ease of scalability with multi-GPU training. To offer a sense of training costs and runtime, a CellMincer model trained on a single dataset using one NVIDIA Tesla T4 GPU for a standard 50,000 iterations would take 12–16 h to finish, while a larger operation using 26 datasets and 4 GPUs may take 6–7 days. In practice, we found that training a fresh model to denoise a new dataset is not necessary. For instance, in our end-to-end hypothesis testing experiment (“Methods for segmenting and spike-counting voltage imaging datasets” in “Methods”), we simply used a model previously trained on a different voltage imaging corpus (recorded under similar conditions) and did not involve any of the datasets in the experiment. Denoising a typical dataset with CellMincer, by contrast, takes no more than a few minutes on any GPU setup.
CellMincer preprocessing and global feature extraction details
Before a voltage imaging movie X(t, x, y) is received as input to a CellMincer model, our pipeline applies several preprocessing steps to: (1) approximately isolate the background fluorescence; (2) normalize the dynamic range of background-subtracted data prior to denoising; (3) precompute a number of global movie statistics for conditioning the local denoiser. In this section, we detail the data preprocessing and global feature extraction stages of the CellMincer pipeline.
Data preprocessing and trend isolation
Background fluorescence is a dynamic imaging artifact both highly individual to its source dataset and magnitudes larger than the true fluorescence signal, so removing it aids the network in identifying neuron action potentials. To model this background activity separately for each (x, y) pixel, we temporally interpolate each pixel’s trace with a low-order polynomial (with a default value of npoly = 3) to obtain the following decomposition:
By design, Xtrend approximately captures the smooth temporal trend and DC bias offset in the recording, whereas Xdetrended represents the normalized residual fluorescence signal. When specified by the user, we obtain the smooth trend fit only from the resting periods (typically the beginning and the end segments of a recording segment). When such resting periods are not included in the recording, we regress over the entire recording and use a lower order polynomial (npoly = 1) to avoid overfitting to the neural activity. We note that normalizing the detrended component by its standard deviation over all pixels and time points, σdetrended, allows CellMincer to train over multiple datasets and data sources (see Eq. (5)). After denoising such a detrended dataset, CellMincer applies a reconstituting step in which the scaling factor is inverted and the removed trend is added back (Eq. (5)). This process generates denoised data at the original raw capture scale, making it suitable for any downstream analysis pipeline that ingests raw data. Additionally, CellMincer outputs the detrended component of the denoised data, which can be utilized in downstream applications that benefit from such input, such as segmentation.
Precomputing global features
After the preprocessing stage of the CellMincer pipeline, we precompute the global features as follows. First, we further decompose Xdetrended(t, x, y) into slow and fast components:
where \({X}_{\,\text{detrended}}^{\text{slow}\,}(t,x,y)\) is the moving average of Xdetrended(t, x, y) over a short window. For a 500 Hz recording, we calculate the moving average over 10 frames, corresponding to 20 ms. The goal here is to separate the neural activity into fast transients (e.g. spikes) and slower features (e.g. subthreshold activity). We calculate the same set of global features from the two components independently. We define the general spatially-resolved temporal auto-correlation function as such:
The first three global features are: (1) the square root of \(\rho [{X}_{\,\text{detrended}}^{\text{slow}\,};0,0,0](x,y)\), i.e. the pixelwise slow temporal variability; (2) the square root of \(\rho [{X}_{\,\text{detrended}}^{\text{fast}\,};0,0,0](x,y)\), i.e. the pixelwise fast temporal variability; (3) the temporal mean of \({X}_{\,\text{detrended}}^{\text{slow}\,}(t,x,y)\), i.e. the mean pixelwise slow activity. In addition to these, we include 17 other normalized and spatially-resolved auto-correlation functions as follows:
for Δx, Δy ∈ {−1, 0, 1}, Δt ∈ {0, 1}, and excluding Δx = Δy = Δt = 0. Put together, these amount to 37 feature maps. Next, we spatially downsample both \({X}_{\,\text{detrended}}^{\text{slow}\,}\) and \({X}_{\,\text{detrended}}^{\text{fast}\,}\) by a factor of two, such that each image-space pixel corresponds to the average signal over a two native-resolution pixels. We calculate the same set of 37 features maps, and upsample the obtained feature map by a factor of two back to the original resolution. The rationale is to bring more distant spatially-lagged auto-correlations into a feature map in the native resolution. In principle, this procedure can be repeated multiple times to capture further dilated and averaged auto-correlations. We stop the procedure at the second level, obtaining F = 2 × 37 = 74 spatial feature maps in total which we collect and concatenate into a F × H × W tensor. Conveniently, the F channels of this tensor encode a standardized set of spatiotemporal auto-correlations at different lengthscales, which can be used by the model to infer covarying groups of pixels without having access to the full movie.
Simulating realistic voltage imaging datasets using Optosynth
In order to optimize the architecture and hyperparameters of a data denoising technique and study the impact of various design choices on the bottom line denoising performance, one needs noiseless or high-SNR ground truth data. To generate such ground truth recordings and their noisy realizations, we developed a physics-based simulation companion software called Optosynth in which we aimed to carefully model salient aspects of the phenomenology of voltage imaging. We briefly describe the key steps involved in Optosynth simulations as follows (see Fig. 5 for a graphical overview).

a Single-neuron paired morphology and EP data downloaded from Allen Brain Atlas; b Generating experiment manifest, including selecting neurons and sweeps for each segment of the experiment, and random sampling and precomputing various simulation accessories; c Schematic illustration of the generation process of a movie frame: depending on the position of a pixel on a given neuron, an action potential wavefront propagation delay is read off from the precomputed delay map and is used to select the appropriately delayed timepoint on the EP voltage trace. The voltage value is converted to fluorescence amplitude in combination with the precomputed reporter heterogeneity and spike decay maps. This process is repeated within an efficient vectorized algorithm for all pixels for a given neuron and for all other neurons in the simulation. A background frame is generated and added to the total fluorescence amplitude map generated by the neurons. A point spread function (Gaussian blur) is applied to the total fluorescence map to generate a clean movie frame. The application of pixelwise Poisson-Gaussian noise with specified parameters (thermal noise strength, quantum yield) generates a noisy movie frame. This process is repeated for each frame in the stimulation segment and for all other segments in the simulation. d From top to bottom: (1) neuronal masks juxtaposed in different colors; (2) a simulated frame before the addition of background and PSF; (3) the same frame after the addition of background and PSF; (4) the same frame after the addition of Poisson-Gaussian noise.
Data procurement and preprocessing
We used Allen SDK33 to access Allen Brain Atlas data, and procured 485 neurons from mouse primary visual cortex (VISp) from the Allen cell types database with paired morphology and EP data (Patch-seq)21,22,34. We minimally preprocess reconstructed morphology data as follows. We scale the image-space pixel from the original 0.1144 μm/pixel by a factor of 10 to 1.144 μm/pixel, representative of the typical magnification of voltage imaging experiments. We project the 3D morphology into a 2D binary mask. Allen morphology reconstructions only provide the location and radius of the soma. We use this information to generate a synthetic soma shape circumscribed by a random Fourier curve with 3 frequency components and a wiggle amplitude of no more than 20% of the soma radius. We also minimally preprocess the EP data by truncating the sweeps to 2 s in duration, amounting to 0.5 s of resting recording, 1 s of electrical stimulation, followed by another 0.5 s of resting recording. For each neuron, we keep track of the stimulation current amplitude (pA) and the membrane potential (mV) time series.
Setting up the simulation
The Optosynth simulation configuration is used to generate a manifest for the experiment. The key user input is the number of desired stimulation segments for the full experiment, and is given to the tool as a list of \([{I}_{\min },{I}_{\max }]\) stimulation amplitude intervals. Based on this specification, we filter the pool of available Patch-seq neurons to the subset of neurons that have at least one sweep within each stimulation interval. Relaxing the stimulation current to fall within an interval (in contrast with matching a specific value) allows more flexibility in choosing neurons for simulation, because not all Patch-seq neurons have received the same set of stimulation amplitudes.
Simulating the neuron fluorescence density
For each neuron, we precompute a spike decay map α(r), a delay map τ(r), and a fluorescent reporter spatial density map ρ(r) as follows:
Here, r is a 2D position vector, rsoma refers to the soma location of the neuron of interest, ℓdecay is a specified signal decay lengthscale, vprop is the action potential propagation velocity3,35. We sample ρ(r) from a Gaussian process with zero mean and an isotropic Gaussian kernel with lengthscale ℓreporter. The fclamp function linearly rescales the dynamic range of the randomly generated density map to the specified lower and upper limit, \({\rho }_{\,\text{reporter}\,}^{(\min )}\) and \({\rho }_{\,\text{reporter}\,}^{(\max )}\), respectively. We randomly place each neuron on the imaging field, together with a random rotation, displacement, and scale factors. To this end, we take the initial binary mask of the i’th neuron and apply a general isotropic affine transformation on the mask to obtain the final mask on the imaging field, which we refer to as \({{\mathsf{M}}}^{(i)}({\bf{r}})\in [0,1]\). The precomputed spatial maps and the geometric placements on the imaging field are held constant for all stimulation segments in the experiment, as well as potentially other simulated trials involving the same neurons.
The spatial fluorescence density emanating from a pixel at position r at time t emanating from the i’th neuron, F(i)(r, t), is calculated as follows:
First, we apply a low-pass Fourier filter \({{\mathcal{F}}}_{{\rm{LP}}}\) with cutoff frequency fLP on the patch-clamp EP recording of i’th neuron, V(i)(t), to obtain \({V}_{\,\text{LP}\,}^{(i)}(t)\). This provision is to simulate the lagged response of one’s choice of fluorescent reporter to voltage transients. To obtain the effective spatial membrane potential of the neuron, V(i)(r, t), we linearly admix the resting potential V0 ≈ −70 mV and the appropriately time-delayed and low-passed EP recording, see Eq. (11). Finally, the fluorescence density is obtain by converting the spatial membrane potential to fluorescence and multiplying by the precomputed reporter density and neuron mask, see Eq. (12). We use a sigmoid function to convert voltage to fluorescence, and set the sigmoid slope β ≪ 1 to work mostly in the linear regime. The two parameters F∞ and Vrise are automatically determined by the user’s specification of two points on the voltage conversion curve, (V1, F1) and (V2, F2).
Simulating the background fluorescence density
Typical voltage imaging recording is often accompanied by a source background fluorescence, including the static autofluorescence from the cell culture, and a dynamic slowly-varying component due to convection currents associated with sample heating by the stimulation laser. We simulate the background noise by first sampling a set of patterns from a zero-mean Gaussian process with anisotropic Gaussian kernels:
where \({\ell }_{{\rm{static}}}^{(x,y)}\) and \({\ell }_{{\rm{dynamic}}}^{(x,y)}\) denote the spatial variation lengthscales of static and dynamic background patterns along the x and y axes, and K is the number of dynamic patterns. For each dynamic pattern, we additionally sample a slowly-varying temporal amplitude:
where fdynamic is the dynamic background variation frequency. We finally compose the full background as follows:
Generating the clean and noisy recordings
The total fluorescence density is the sum of fluorescence density associated with the neurons and the background:
We interpret the fluorescence density F(r, t) as the density of excitable fluorophores per voxel, such that the reporter fluorescence laser converts F(r, t) to an emitted photon count per imaging interval via a conversation factor Q. To account for point spreading due to imaging optics, we further convolve F(r, t) with a normalized Gaussian point spread function (PSF) with lengthscale ℓPSF to obtain the clean fluorescence density:
The clean recording is given as:
where R is the sensor voltage gain per absorbed photon, Q is the photon emission rate per excited fluorophore, and Δdc is a dc offset (characteristic of typical sensor readouts). The noisy recordings are obtained by applying a Poisson-Gaussian noise and quantizing to integer counts:
Note that the SNR is implicitly controlled by the two parameters Q (number of photons per fluorophore) and σsensor (sensor noise). The default values for all the parameters are shown in Table 1 in Supplementary Materials.
To generate multiple simulated recordings from the same neurons, we simply repeat the simulation process multiple times while keeping the experiment manifest constant (including choice of Patch-seq neurons, as well as their geometries and precomputed spatial maps).
Optimizing CellMincer network architecture and training schedule using Optosynth-simulated datasets
We performed an extensive hyperparameter exploration to study the role of various modeling choices and identify optimal settings. Simulated data produced by Optosynth was an ideal setting for optimization experiments and ablation studies because of the access to ground truth imaging and its capacity to simulate a range of imaging conditions. The ground truth imaging enabled the direct computation of performance metrics for model evaluation, while the simulation versatility allowed us to test the model on data imaged at various SNR without the overhead associated with real-world data collection. Using Optosynth, we generated five datasets under the same neuron density and SNR conditions, three of which were allocated to the training set while the other two were set aside for testing.
Because a complete grid search was not feasible, we chose a baseline configuration that produced a viable model and varied the parameters around this baseline one at a time. Some choices, such as the use of an Adam optimizer, the learning rate scheme, and the number of training iterations, were decided in the baseline model and do not appear in our optimization experiments. We determined variations on each of the other hyperparameters of interest to apply to our baseline model and trained a CellMincer model with each of the resulting configuration variants. These models were subsequently used to denoise both the training and testing datasets, and we computed the distribution of PSNR gain over each frame within the active stimulation periods. The distributions of these PSNR gains and all of our model variants are summarized in Fig. 6. We emphasize that our main objective with these experiments was not to exhaustively identify every incremental improvement to our architecture, but to rather study the role of key model hyperparameters and produce a strongly tuned model configuration within reasonable computational resources. While beyond the scope of this work, further investment into model optimization could take the form of repeating these single-parameter variation experiments on the current configuration optimum, in which we would expect more deviations to lead to worse outcomes. Repeating this process until all such variations worsen model performance would produce a locally optimal model configuration.

Each model was evaluated on both its training data (b, e) and unseen test data (c, f). a–c Initial series of experiments using no global features as a baseline. d–f Followup iteration of experiments using repeated global features as a baseline. The global features setting determines whether the precomputed global features is not used (0), used to augment the U-Net input only at the beginning (1), or used to augment repeatedly at every contracting path step (R). The included temporal post-processor variants refers to the architecture of the ultimate multilayer perceptron component: C → C/2 → C (A), C → C → C/2 → 1 (B), and C → C → C → 1 (C). The architectural variants are ordered in increasing complexity. The pixel masking setting refers to the Bernoulli parameter used to decide whether each pixel is masked, a sampling process repeated for each training iteration. The second set of experiments adjusts the original baseline model to use a conditional U-Net with repeated global features.
Our key finding was that the inclusion of global features produced a dominating gain in PSNR. On both training data and unseen test data, CellMincer models incorporating global features exhibited an additional 5 dB gain in PSNR over the baseline model (i.e. a striking 3-fold increase in SNR), in contrast with other architectural variations that yielded 0–1.5 dB over the baseline (see Fig. 6a–c). In addition, we noted that the performance of CellMincer models without global features was highly sensitive to the stimulation conditions of each dataset segment, while the variant using global features is significantly more consistent, as summarized in Fig. 1e. We believe this to be an outcome of the increased intensity at higher stimulations, which in turn yields a higher baseline SNR. This explanation for CellMincer underperforming on higher stimulation segments is further supported by the tendency of our other benchmark methods to underperform on higher SNR datasets (see Fig. 2c).
Indeed, we found that the baseline model performance (which did not include the global features) was highly sensitive to changes in the temporal window length (i.e. the denoising context size), with longer windows significantly improving performance. It is evident that both modifications to this baseline model address the limited temporal context it is provided, of which global features is by far the more effective and computationally efficient option. To determine the architectural settings that best synergize with the inclusion of global features, we performed this optimization experiment again with a parallel set of CellMincer variations, all of which included repeat global features (see Fig. 6d–f). While most of the model performance variation remained consistent with our results in the first iteration, we observed that the performance gain induced by larger temporal contexts plateaued at a window length of 13 frames, comparable in size to our baseline window of 9 frames. This further supports our hypothesis that very long temporal windows can be exploited by a model without global features as a compensatory measure, and by explicitly including global features, we removed the need for long contexts. The result is a network architecture that requires comparatively fewer input frames for denoising, allowing it to denoise datasets in a fraction of the computational time needed by comparable deep learning architectures like DeepCAD-RT.
Metrics for evaluating denoising performance on Optosynth simulated datasets
Peak signal-to-noise ratio (PSNR), measured in decibels, is a metric of similarity between a clean image and its noisy realization and is defined as:
where \({I}_{\max }\) is the maximum possible value for the signal intensity. Many of our results are reported in PSNR gain, in which we use the PSNR between the raw noisy data and the clean data as a baseline. Reporting the results in terms of PSNR gain is more meaningful and comparable across different settings as it does not depend on \({I}_{\max }\). Structural similarity index measure (SSIM) is another metric describing the perceived quality of noisy digital images. We chose to reports on results in terms of PSNR given the flexibility it affords (e.g. the ability to be restricted over arbitrary spatial regions such as foreground or background pixels), as well as its wide adoption in the fluorescence imaging community.
Procuring fluorescence intensity traces and aligning to joint electrophysiology data
Our analyses of single-neuron traces are contingent on identifying representative ROIs over which the fluorescent signal is averaged, which is also a common practice in the field. To determine neuronal ROIs, we select a small set of seed pixels that belong to a neuron’s soma and calculate cross-correlations between these pixels and every other pixel in the raw recording. On the resulting cross-correlation map, we choose a manually tuned threshold that captures the soma region and apply the watershed algorithm to add spatial continuity. The resulting ROI is then used to compute traces for the raw recording as well as its denoised counterparts.
Our ROI-extracted fluorescence trace can be interpreted as a noisy affine transformation of the neuron’s electrophysiological activity. In the absence of a calibration dataset, we rely on an optimization-based approach to align the obtained fluorescence traces (in arbitrary units) to the EP data (in mV). We first remove the trend from the imaging trace by median filtering with a moving one-second window (which is short enough to correct for pipette movement but long enough to retain the actual signal). We also removed high-frequency jitter from the patch-clamp EP by applying a Savitzky-Golay cubic filter with a 51-point window. These post-filter signals are more easily imposed over one another following several linear transformations. By matching corresponding peaks in both signals, the intensity trace can be transferred onto the EP timescale. This allows us to evaluate intervals between peaks in absolute time and to downsample the EP signal with interpolation. We then find the affine transformation of our intensity trace that minimizes L2 error with the EP signal, producing an aligned voltage imaging trace. Our subsequent analyses center on evaluating the reconstruction quality of these aligned traces. Refer to Fig. 3b for the results of this alignment method.
Metrics for evaluating denoising performance on real voltage imaging with paired EP
Quantifying residual noise power using short-time Fourier transform
To compute the spectral noise power of a residual aligned fluorescence trace, we apply a short-time Fourier transform (STFT) parameterized by window length 64 and overlap 48. While voltage imaging, which exhibits a relative downsampling factor of 100, cannot fully capture the underlying EP signal, the peaks of spiking events are particularly high-magnitude points of uncertainty, making them ill-suited for this analysis. To remove spiking events from consideration, we exclude time intervals in which the EP signal’s total spectral power exceeds a chosen threshold. For the remaining time intervals, we convert the spectral powers to noise intensity (dB) and average them in each frequency bin to produce the average noise at that frequency. By repeating this process for each denoised signal and the raw signal, we can compute the reductions in noise intensity, yielding the results shown in Fig. 3d. A typical spectrogram is also shown here in Fig. 7, in which we clearly notice spiking events as and the attenuated high-frequency noise in the inter-spike interval in the CellMincer-denoised results. In contrast, the spectrogram of the raw data is visually akin to that of white noise.

A sample spectral power map (dB) of a residual voltage imaging recording before and after denoising with CellMincer.
Prominence-based peak calling
We can formulate the notion of quantifying signal reconstruction quality as a peak-calling problem. We consider peaks in the EP signal and classify them by their prominence, as most spikes exceed 20 mV in prominence while peaks in the subthreshold activity fall below 10 mV. A visualization of prominence as a signal peak feature is shown in Fig. 8. Let XEP(t) and XVI(t) refer to the filtered and aligned traces derived from the patch-clamp EP and the voltage imaging (VI) respectively, and let Sp(X) be the set of peak time-points in signal X(t) thresholded above a certain prominence p. We express our problem as an evaluation of similarity between Sp(XEP) and \({S}_{{p}^{{\prime} }}({X}_{{\rm{VI}}})\) for \({p}^{{\prime} }\simeq p\). As our set elements comprise points along a continuous time interval, we need to adapt the notions of precision and recall to allow for fuzzy matching of nearby peaks. More explicitly, we define:
We calculate the F1-score as usual:
As our definitions suggest, we determine peaks to be correctly called when a corresponding peak occurs within a Δt separation. In our evaluations, we set Δt = 2 ms, corresponding to a one-frame discrepancy in 500 Hz voltage imaging. To introduce tolerance around particular choices of prominence thresholding, we further define:
and we set Δp = 0.2 mV. We average this quantity over bins of prominences p to produce Fig. 3e, which is the ultimate result of this analysis.

A moderate prominence threshold would exclude transient peaks produced by noise fluctuations (green), and a larger threshold would exclude subthreshold activity (blue), leaving only the true action potentials (red).
Methods for segmenting and spike-counting voltage imaging datasets
We extract single-neuron segments from each raw movie and its denoised counterpart using a PCA/ICA-based approach27. Similar to CellMincer’s data preprocessing step, our first step is to enhance pixel-pixel correlations by detrending the movie, leaving only the signal component stemming from neural activity. Through experimentation with various signal filters, we found that a rolling circle filter parameterized with width 3.2 frames (6.4 ms) and height 16 (fluorescence a.u.), followed by a threshold filter to collapse values between ±15 (fluorescence a.u.) to zero, was effective at isolating spiking events in the denoised data. We could not achieve similar success using various combinations of filters on the raw data, so we left those datasets unchanged. Using movie pixels as samples and time frames as features, PCA reduces the dimension of each pixel from Ntime ~104 to NPCA = 200. These components correspond to groups of covarying pixels but not necessarily to individual neurons. For this reason, ICA is used to subsequently unmix the principal components into an independent component set containing our neuron segment candidates. To detect neurons of varying signal strengths, we use a range of parameterizations NICA ∈ {10, 20, 50, 100} to produce the components from which our neuron segments are selected through manual filtering, including a careful study of ICA spatial components together with the associated temporal trace around spike-like events.
Following the extraction of these segments, we compute inner products between a segment mask and each movie frame and apply median filtering with window length of 51 frames to generate its corresponding trace. From these traces, we identify spiking events through manual filtering. This process is aided by a peak-finding algorithm to determine spike candidates and a segmented movie visualization to resolve ambiguous spiking sources. These spikes are tallied across stimulation intensities, and statistical separation between the spiking activity of unperturbed and chronically TTX-treated neurons is computed with a Wilcoxon rank sum test.
It should be noted that through the process of computationally and manually filtering segments, candidates with no discernible activity were excluded from analysis, even though they may have been real neurons that failed to express either the light-gated ion channel or fluorescent reporter. This distinction was considerably more apparent in the denoised movies, potentially causing some neurons to be discarded from the denoised count and included in the raw count despite the overall neuron count favoring the denoised data.
Optopatch voltage imaging of chronically TTX-treated and unperturbed hPSC-derived neurons
hPSC-derived neuron differentiation was performed as previously described36,37, followed by Optopatch voltage imaging also as previously described38. Methods are reproduced below for completeness.
hPSC culture
Human ESCs were maintained on plates coated with Geltrex (Life Technologies, A1413301) in mTeSR Plus medium (StemCell Technologies, 100-1130) and passaged with Accutase (Gibco, A11105). All cell cultures were maintained at 37 °C, 5% CO2.
Neuronal induction
hPSC-derived neurons were differentiated from an hPSC line (H1/WA01) using combined NGN2 programming with SMAD and WNT inhibition in the presence of mouse astrocytes36,37. On day 0, hPSCs were differentiated in N2 medium (500 mL DMEM/F12 [1:1] [Gibco, 11320-033]), 5 mL Glutamax (Gibco, 35050-061), 7.5 mL sucrose (20%, Sigma, S0389), 5 mL N2 supplement B (StemCell Technologies, 07156) supplemented with SB431542 (10 μM, Tocris, 1614), XAV939 (2 μM, Stemgent, 04-00046), and LDN-193189 (100 nM, Stemgent, 04-0074) along with doxycycline hyclate (2 μg.mL−1, Sigma, D9891) and Y27632 (5 mM, Stemgent 04-0012). On day 1 and 2 media was changed to N2 medium supplemented with SB431542 (5 μM, Tocris, 1614), XAV939 (1 μM, Stemgent, 04-00046), and LDN-193189 (50 nM, Stemgent, 04-0074) with doxycycline hyclate (2 μg.mL−1, Sigma, D9891) and Zeocin (1 μg.mL−1, Invitrogen, 46-059). On Day 3 neuronal precursor cells were passaged with Accutase into Neurobasal media (500 mL Neurobasal [Gibco, 21103-049], 5 mL Glutamax [Gibco, 35050-061], 7.5 mL Sucrose [20%, Sigma, S0389], 2.5 mL NEAA [Corning, 25-0250 Cl]) supplemented with B27 (50x, Gibco, 17504-044), BDNF, CTNF, GDNF (10 ng.mL−1, R&D Systems 248-BD/CF, 257-NT/CF, and 212-GD/CF) and doxycycline hyclate (2 μg.mL−1, Sigma, D9891) in a 24-well format and infected with lentiviral optogenetic constructs (HT076, hSyn Cre-off Archon-TS-darkCitrine-TSx3-ER) at 2 MOI. On day 7, the cells were passaged with Accutase onto 10mm glass coverslip bottom dishes precoated with Geltrex containing a monolayer of mouse cortical astrocytes. Estimated neuron/astrocyte ratio was 1:2 with 80k neurons plated per 10 mm dish. Cell were matured in Neurobasal media supplemented with B27 (50x, Gibco, 17504-044), BDNF, CTNF, GDNF (10 ng.mL−1, R&D Systems 248-BD/CF, 257-NT/CF, and 212-GD/CF) and doxycycline hyclate (2 μg.mL−1, Sigma, D9891) with 50% media changes twice a week.
TTX treatment and Optopatch imaging
On Day 35,500 nM TTX (Tocris) was added to the culture media and cultures were returned to the incubator for additional 48 hours. Parallel control cultures were kept in TTX-free media. 10 min prior to recording the cultures were washed 3 times in pre-warned recording solution (125 mM NaCl, 2.5 mM KCl, 3 mM CaCl2, 1 mM MgCl2, 15 mM HEPES, 30 mM glucose (pH 7.3) and adjusted to 305–310 mOsm with sucrose) to wash out the TTX. Recordings were obtained in recording solution in the absence of TTX at 23 °C. Cellular activity was recorded on custom-built wide-field microscope equipped with oblique illumination lens and a wide 20× objective. The cells were stimulated with 500 ms blue light (488 nm) at 1 Hz of increasing intensity (20 to 120 mW/cm2) for 6 s, while firing patterns were recorded under continuous red light (635 nm) illumination at 1 kHz.
Simultaneous BeRST fluorescence voltage imaging and single-cell patch-clamp EP recording experimental procedure
Simultaneous BeRST imaging and single-cell patch-clamp EP recordings were performed as described previously25. Methods are reproduced below for completeness.
Cell culture
All animal procedures were approved by the UC Berkeley Animal Care and Use Committees and conformed to the NIH Guide for the Care and Use of Laboratory Animals and the Public Health Policy.
Rat hippocampal neurons
Hippocampi were dissected from embryonic day 18 Sprague Dawley rats (Charles River Laboratory) in cold sterile HBSS (zero Ca2+, zero Mg2+). All dissection products were supplied by Invitrogen, unless otherwise stated. Hippocampal tissue was treated with trypsin (2.5%) for 15 min at 37° C. The tissue was triturated using fire polished Pasteur pipettes, in minimum essential media (MEM) supplemented with 5% fetal bovine serum (FBS; Thermo Scientific), 2% B-27, 2% 1 M D-glucose (Fisher Scientific) and 1% GlutaMax. The dissociated cells (neurons and glia) were plated onto 12 mm diameter coverslips (Fisher Scientific) pre-treated with PDL at a density of 30–40,000 cells per coverslip in MEM supplemented media (as above). Cells were maintained at 37 °C in a humidified incubator with 5% CO2. At 1 day in vitro (DIV), half of the MEM supplemented media was removed and replaced with FBS-free media to supress glial cell growth (Neurobasal media containing 2% B-27 supplement and 1% GlutaMax). Functional imaging was performed on 8–15 DIV neurons to access neuronal excitability and connectivity across different stages of development. References to biological replicates, or “n,” refer to the number of dissections data were collected from.
VoltageFluor/BeRST 1 stocks and cellular loading
For all imaging experiments, BeRST 1 was diluted from a 250 μM DMSO stock solution to 0.1–1 μM in HBSS (+Ca2+, +Mg2+, -phenol red). To load cells with dye solution, the media was first removed from a coverslip and then replaced with the BeRST-HBSS solution. The dye was then allowed to load onto the cells for 20 min at 37 °C in a humidified incubator with 5% CO2. After dye loading, coverslips were removed from the incubator and placed into an Attofluor cell chamber filled with fresh HBSS for functional imaging at room temperature (20–23 °C).
Voltage imaging with BeRST
Voltage imaging was performed on an upright AxioExaminer Z-1 (Zeiss) or an inverted Zeiss AxioObserver Z-1 (Zeiss), both equipped with a Spectra-X light engine LED light (Lumencor), and controlled with Slidebook (3i). Images were acquired using a W-Plan-Apo/1.0 NA 20x water immersion objective (Zeiss) or a Plan-Apochromat/0.8 NA 20x air objective (Zeiss). Images (2048 px × 400 px, pixel size: 0.325 μm × 0.325 μm) were collected continuously on an OrcaFlash4.0 sCMOS camera (sCMOS; Hamamatsu) at a sampling rate of 0.5 kHz, with 4 × 4 binning, and a 631 nm LED (13 mW/mm2, SpectraX) with a 631/28 nm excitation bandpass. Emission was collected after passing through a quadruple bandpass dichroic (432/38 nm, 509/22 nm, 586/40 nm, 654 nm LP and quadruple bandpass emission filter (430/32 nm, 508/14 nm, 586/30 nm, 708/98 nm).
Electrophysiology
For electrophysiological experiments, pipettes were pulled from borosilicate glass (Sutter Instruments, BF150-86-10), with a resistance of 5−8 MΩ, and were filled with an internal solution; (in mM) 115 potassium gluconate, 10 BAPTA tetrapotassium salt, 10 HEPES, 5 NaCl, 10 KCl, 2 ATP disodium salt, 0.3 GTP trisodium salt (pH 7.25, 275 mOsm). Recordings were obtained with an Axopatch 200B amplifier (Molecular Devices) at room temperature. The signals were digitized with a Digidata 1440A, sampled at 50 kHz and recorded with pCLAMP 10 software (Molecular Devices) on a PC. Fast capacitance was compensated in the on-cell configuration. For all electrophysiology experiments, recordings were only pursued if the series resistance in voltage clamp was less than 30 MΩ. For whole-cell, current clamp recordings in hippocampal neurons, following membrane rupture, resting membrane potential was assessed and recorded at I = 0 and monitored during the data acquisition.
Data availability
All data used to conduct the benchmarking experiments with Optosynth data, BeRST voltage imaging with paired EP data, and Optopatch datasets for chronically TTX-treated and unperturbed hPSC-derived neurons can be accessed either directly from the Google Cloud bucket found at gs://broad-dsp-cellmincer-data, or through notebooks in the paper analysis GitHub repository: https://github.com/cellarium-ai/CellMincerPaperAnalysis.
Code availability
The code repository containing the CellMincer pipeline can be found at https://github.com/cellarium-ai/CellMincer. The repository containing the Optosynth simulation framework can be found at https://github.com/cellarium-ai/Optosynth. An auxiliary repository with reproductions of the analysis used to produce the figures can be found at https://github.com/cellarium-ai/CellMincerPaperAnalysis.
References
Adam, Y. et al. Voltage imaging and optogenetics reveal behaviour-dependent changes in hippocampal dynamics. Nature 569, 413–417 (2019).
St-Pierre, F. et al. High-fidelity optical reporting of neuronal electrical activity with an ultrafast fluorescent voltage sensor. Nat. Neurosci. 17, 884–889 (2014).
Hochbaum, D. R. et al. All-optical electrophysiology in mammalian neurons using engineered microbial rhodopsins. Nat. Methods 11, 825–833 (2014).
Kulkarni, R. U. & Miller, E. W. Voltage imaging: pitfalls and potential. Biochemistry 56, 5171–5177 (2017).
Lin, M. Z. & Schnitzer, M. J. Genetically encoded indicators of neuronal activity. Nat. Neurosci. 19, 1142–1153 (2016).
Huang, S., Zhao, Y. & Qin, B. Two-hierarchical nonnegative matrix factorization distinguishing the fluorescent targets from autofluorescence for fluorescence imaging. Biomed. Eng. Online 14, 116 (2015).
Aonishi, T. et al. Imaging data analysis using non-negative matrix factorization. Neurosci. Res. 179, 51–56 (2022).
Witten, D. M., Tibshirani, R. & Hastie, T. A penalized matrix decomposition, with applications to sparse principal components and canonical correlation analysis. Biostatistics 10, 515–534 (2009).
Zhang, K., Zuo, W., Chen, Y., Meng, D. & Zhang, L. Beyond a gaussian denoiser: residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 26, 3142–3155 (2017).
Zhang, Y. et al. A Poisson-Gaussian denoising dataset with real fluorescence microscopy images. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11710–11718 (2019).
Lehtinen, J. et al. Noise2Noise: Learning image restoration without clean data. In Proc. 35th International Conference on Machine Learning Research, 80, 2965–2974, (2018). Available from https://proceedings.mlr.press/v80/lehtinen18a.html.
Batson, J. & Royer, L. Noise2Self: Blind Denoising by Self-Supervision. In Proc. 36th International Conference on Machine Learning Research, 97, 524–533, (2019). Available from https://proceedings.mlr.press/v97/batson19a.html.
Krull, A., Buchholz, T. O. & Jug, F. Noise2void-learning denoising from single noisy images. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2129–2137 (2018).
Li, X. et al. Real-time denoising enables high-sensitivity fluorescence time-lapse imaging beyond the shot-noise limit. Nat. Biotechnol. 41, 282–292 (2023).
Li, X. et al. Reinforcing neuron extraction and spike inference in calcium imaging using deep self-supervised denoising. Nat. Methods 18, 1395–1400 (2021).
Lecoq, J. et al. Removing independent noise in systems neuroscience data using DeepInterpolation. Nat. Methods 18, 1401–1408 (2021).
Zhang, G. et al. Bio-friendly long-term subcellular dynamic recording by self-supervised image enhancement microscopy. Nat. Methods 20, 1957–1970 (2023).
Platisa, J. et al. High-speed low-light in vivo two-photon voltage imaging of large neuronal populations. Nat. Methods 20, 1095–1103 (2023).
Eom, M. et al. Statistically unbiased prediction enables accurate denoising of voltage imaging data. Nat. Methods 20, 1581–1592 (2023).
Gouwens, N. W. et al. Integrated morphoelectric and transcriptomic classification of cortical GABAergic cells. Cell 183, 935–953.e19 (2020).
Lee, B. R. et al. Scaled, high fidelity electrophysiological, morphological, and transcriptomic cell characterization. Elife 10, e65482 (2021).
Berg, J. et al. Human neocortical expansion involves glutamatergic neuron diversification. Nature 598, 151–158 (2021).
Huang, Y.-L., Walker, A. S. & Miller, E. W. A photostable silicon rhodamine platform for optical voltage sensing. J. Am. Chem. Soc. 137, 10767–10776 (2015).
Milosevic, M. M., Jang, J., McKimm, E. J., Zhu, M. H. & Antic, S. D. In vitro testing of voltage indicators: Archon1, ArcLightD, ASAP1, ASAP2s, ASAP3b, Bongwoori-Pos6, BeRST1, FlicR1, and Chi-VSFP-Butterfly. eNeuro 7, https://doi.org/10.1523/ENEURO.0060-20.2020 (2020).
Walker, A. S. et al. Optical spike detection and connectivity analysis with a far-red voltage-sensitive fluorophore reveals changes to network connectivity in development and disease. Front. Neurosci. 15, 643859 (2021).
Desai, N. S., Rutherford, L. C. & Turrigiano, G. G. Plasticity in the intrinsic excitability of cortical pyramidal neurons. Nat. Neurosci. 2, 515–520 (1999).
Mukamel, E. A., Nimmerjahn, A. & Schnitzer, M. J. Automated analysis of cellular signals from large-scale calcium imaging data. Neuron 63, 747–760 (2009).
Creators Ranjan, Rajnish1 Van Geit, Werner1 Moor, Ruben1 Rössert, Christian1 Riquelme, Juan Luis1 Damart, Tanguy1 Jaquier, Aurélien1 Tuncel, Anil1 Show affiliations 1. Blue Brain Project, EPFL. eFEL.
Dosovitskiy, A. et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. https://arxiv.org/abs/2010.11929 (2021).
Oquab, M. et al. DINOv2: Learning robust visual features without supervision. https://doi.org/10.48550/arXiv.2304.07193 (2023).
Loshchilov, I. & Hutter, F. SGDR: Stochastic gradient descent with warm restarts. https://arxiv.org/abs/1608.03983 (2017).
Izmailov, P., Podoprikhin, D., Garipov, T., Vetrov, D. & Wilson, A. G. Averaging weights leads to wider optima and better generalization. https://arxiv.org/abs/1803.05407 (2018).
for Brain Science, A. I. Allen software development kit (allen sdk). https://allensdk.readthedocs.io (2023).
Gouwens, N. W. et al. Integrated morphoelectric and transcriptomic classification of cortical gabaergic cells. Cell 183, 935–953 (2020).
Stuart, G., Spruston, N., Sakmann, B. & Häusser, M. Action potential initiation and backpropagation in neurons of the mammalian CNS. Trends Neurosci. 20, 125–131 (1997).
Nehme, R. et al. Combining ngn2 programming with developmental patterning generates human excitatory neurons with nmdar-mediated synaptic transmission. Cell Rep. 23, 2509–2523 (2018).
Berryer, M. H. et al. Robust induction of functional astrocytes using ngn2 expression in human pluripotent stem cells. Iscience 26, 106995 (2023).
Fan, L. Z. et al. All-optical synaptic electrophysiology probes mechanism of ketamine-induced disinhibition. Nat. Methods 15, 823–831 (2018).
Acknowledgements
This work was supported by a grant from SFARI (#890477, SLF, RN), by the National Institute of Mental Health (R01 MH128366-01A1, SLF, RN; R21 MH120423, SLF; and U01MH115727, MB, RN), by the National Institute of Health (R01 NS098088, ASW, EWM), by the Stanley Center for Psychiatric Research, by a SPARC award from Broad Institute (year 2019–2020, TM, MB, SLF), and by a BroadIgnite award from Broad Institute (2021–2022, BW, MB). The template HT076 was a gift from Dr. Adam Cohen. The authors thank Luca D’Alessio for insightful comments during various stages of the development and testing of CellMincer.
Author information
Authors and Affiliations
Contributions
M.B. conceived and supervised the execution of the project; M.B., B.W., S.J.F., and T.M. developed the CellMincer and Optosynth codebases; M.B. and B.W. wrote the main manuscript text and prepared the figures, with significant contributions from S.L.F., E.W.M., R.N., and A.W.; B.W. performed all of the data analyses in support of the manuscript, with contributions from T.C., T.N., E.C., and V.V.; S. L.F., R.N., and V.V. conducted the TTX homeostatic plasticity voltage imaging experiments; E.S.M. and A.W. conducted the paired BerST and EP recording experiments. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
Author M.B. is a consultant and a scientific advisory board member of Hepta Bio. The other authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, B., Ma, T., Chen, T. et al. Robust self-supervised denoising of voltage imaging data using CellMincer. npj Imaging 2, 51 (2024). https://doi.org/10.1038/s44303-024-00055-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44303-024-00055-x
