
Abstract
Compute-in-memory based on resistive random-access memory has emerged as a promising technology for accelerating neural networks on edge devices. It can reduce frequent data transfers and improve energy efficiency. However, the nonvolatile nature of resistive memory raises concerns that stored weights can be easily extracted during computation. To address this challenge, we propose RePACK, a threefold data protection scheme that safeguards neural network input, weight, and structural information. It utilizes a bipartite-sort coding scheme to store data with a fully on-chip physical unclonable function. Experimental results demonstrate the effectiveness of increasing enumeration complexity to 5.77 × 1075 for a 128-column compute-in-memory core. We further implement and evaluate a RePACK computing system on a 40 nm resistive memory compute-in-memory chip. This work represents a step towards developing safe, robust, and efficient edge neural network accelerators. It potentially serves as the hardware infrastructure for edge devices in federated learning or other systems.
Similar content being viewed by others

Introduction
As the global embodied artificial intelligence (AI) and artificial intelligence of things (AIoT) market experiences rapid growth, there is an increasing demand for edge devices that are low-power, lightweight, and safe. The security of these devices is of paramount importance, as they process private information and are vulnerable to attack1,2. However, the limited on-chip resources hinder the implementation of complex encryption algorithms, highlighting the need for a balance between efficiency and safety3,4. The fast-developing federated learning technique at edge nodes also demands efficiency and safety5,6,7,8. In recent years, researchers have developed innovative technologies to improve AIoT devices and edge learning efficiency. One such technique is Compute-in-Memory (CIM)9. By performing Multiply-Accumulate (MAC) operations directly within memory bit cells, CIM significantly reduces the cost of data loading and provides an energy-efficient solution10,11,12. AIoT devices can store trained neural network parameters locally in the CIM module, enabling AI computation with low latency and high efficiency. Furthermore, the advent of Resistive Random-Access Memory (ReRAM) technology has opened up new avenues for edge AI CIM acceleration. ReRAM’s unique characteristics – non-volatility, high density, and low-cost fabrication – have propelled ReRAM-based CIM to the forefront of promising AIoT computing solutions13,14,15,16.
However, deploying ReRAM-based CIM faces severe security and private-protecting challenges at edge nodes17. The nonvolatility of ReRAM is a mixed blessing: on the one hand, the standby power consumption is minimal and ReRAM bit cells maintain data persistently on the chip even after the chip is powered off. On the other hand, weight data on the chip are prone to being stolen by simply reading the memory data through the legal IO ports. Even in federated learning devices, AI inference still has to perform with the weights stored in the hardware chip. The nonvolatility of ReRAM CIM processors leaves two major aspects of theft threats. First, the trained parameters (or weights) of the neural networks are the model providers’ intellectual properties (IP). Direct storage of neural network weights in the CIM core for efficient computing leaves a backdoor for model theft. Unauthorized users could extract the weights from hardware and reproduce the neural network IP. Second, the side-channel attacks could easily restore the input data of the CIM core, which is owned by the regular memory physical designs, causing exposure to the users’ private information18,19. The input information leakage causes severe vulnerability because private user information can be extracted locally as soon as the AIoT device works. Therefore, developing a safe ReRAM CIM scheme is in urgent need.
Although the existing methods could encrypt neural network parameters, such as XOR cipher20,21,22, advanced encryption standard (AES)23, and homomorphic encryption24, they may inflict large on-chip area overheads. The AES scheme includes multiple steps to encrypt or decrypt. It is complicated for edge devices and costs a large chip area and high power (29.8 mW at 28 nm node)23 while many always-on medical applications only consume only 1 mW~100 mW on average25,26,27,28. XOR cipher is a lightweight solution that protects deep learning models. This scheme requires the weights to be encrypted off-chip with an assigned key. It only encrypts parts of weights since the cost of encrypting all data is high. The physical unclonable function (PUF) is a device that provides unique information for each entity using its intrinsic stochasticity29. It is a powerful and lightweight scheme for the security and authentication of AIoT hardware. There are many kinds of PUF designs in the literature30,31,32,33,34,35,36,37,38 for memory-only applications. To protect CMOS hardware security, the CMOS-compatible PUFs are frequently used. These PUFs include resistive RAM (ReRAM)30,31,34,35,36, MRAM39, phase-change memory (PCM)40, SRAM33,37, embedded DRAM32, Flash memory41, etc.
Efficient PUF specially designed for AI computation in CIM hardware is still rare. Previous PUF works emphasize the performance of PUF encoding and decoding, neglecting the protection for the weights, structure of the neural networks, and intermediate information30,34,42. A previous work presents SRAM-based CIM assisted by PUF, but it uses a simple XOR operation for encryption and the 10T-SRAM causes low density for AIoT chips43. Prior ReRAM-based PUF exploiting the intrinsic stochasticity during the conductive filament formation works for memory-only applications30. Nevertheless, they are not convenient to be directly used in CIM scenarios due to the different circuit structures of memory and CIM macros. A more efficient implementation of integrating PUF and CIM cores is needed to provide safe AI computation.
In this article, we fuse ReRAM-based PUF into a ReRAM CIM chip, which enhances the safety of the ReRAM CIM chip with minimal area overhead. We present “RePACK”, a safe CIM scheme that fundamentally deploys the PUF into a CIM module that uniquely encrypts every chip and does not induce additional computing clock cycles for CIM computation. We propose an encryption technique, the bipartite-sort (BS) code to encrypt CIM with PUF responses in RePACK. RePACK is an encryption technique that self-encrypts the ReRAM CIM with the randomness of ReRAM itself (‘packing’ the ReRAM CIM with self-encryption). This encryption scheme is fully on-chip. It performs encryption for both AI inference and weight storage. In RePACK, every chip implicitly and uniquely encrypts neural network data, without extra computing clock cycles. RePACK can also serve as a hardware infrastructure for edge learning systems, such as federated learning and micro-learning, and it can work parallelly with software encryptions. Experimentally, we develop a high-density ReRAM-based PUF, providing each bit of PUF code with only one one-transistor-one-ReRAM (1T1R) bit-cell. We built a closed-loop prototype system based on the proposed RePACK scheme. As a demonstration, the system successfully resolves the privacy protection in the edge AI healthcare scene. Comprehensive experiments prove the robustness of the ReRAM-based PUF on the chip. The BS code exhibits comprehensive advantages over other encryption schemes in the comparison. Comparisons with former works9,20,22,30,34,35,36,39,43,44,45,46,47,48 prove the supremacy of the RePACK system, BS code, and the ReRAM PUF in this work. The system shows strong resilience against attacks. Experimental results show that direct reading and side-channel attacks fail to steal information from CIM with the RePACK scheme. This work resolves the significant safety issue existing in the state-of-the-art CIM system. It is the first work that proposes a comprehensive on-chip fusion of PUF and CIM.
Results
The RePACK framework enables the design of secure edge AI processors for perception applications, as depicted in Fig. 1a. The hardware developer designs the processor based on ReRAM technology, which is fabricated by a chip foundry without performing forming operations internally. Instead, the developer uses a two-step forming scheme to generate a unique PUF for each chip. The trained neural network models are downloaded from the cloud or trained through distributed learning and loaded onto the ReRAM CIM cores, with weights arranged according to each chip’s unique PUF. Each chip’s CIM core can only conduct computation successfully when its correct PUF response is loaded. This design ensures that only authorized chips can perform computations, thereby preventing potential attackers from exploiting the system. The RePACK framework provides a robust hardware-level security mechanism for edge AI processors, enabling secure and reliable operation in perception applications. In many real-world scenes, the edge devices work in a distributed AI system, such as a federated learning system. RePACK serves as an important hardware-level protection for privacy-preserved learning in this scene. Its distinctive advantages include: (1) It is physically unclonable. (2) It protects the chip from hardware attacks. (3) It provides supremacy in energy efficiency. Therefore, it is indispensable even though software encryptions can work in edge learning systems (see Supplementary Section 19 and Supplementary Fig. 31 for detailed explanations).

a The application scenario of RePACK-based edge devices. In this scenario, the foundry provides the chips with identical designs. The edge device developer receives the chips and loads AI models to the chips with the RePACK scheme. The RePACK makes every chip a unique chip and gives these chips resilience against attack. b The attack model and the protections against these attacks include layer encryption, weight encryption, and input encryption. c An example of the encryption in this work. An original input is encrypted before sending it to the CIM module. The encrypted data successfully hides its details which are crucial to the user’s privacy. d The hardware architecture of the edge AI processor is based on the RePACK scheme. The CIM tiles include CIM cores, a TRNG core, and a PUF core. These cores are all made of 1T1R ReRAM array. This reduces the cost of design and fabrication and also provides reconfigurability.
In this work, we consider that the AIoT chip faces three types of potential hardware attacks on the deep learning network structure, the weights, and the inputs of the on-chip neural network. The structure and weight of neural networks are the IPs of developers and trainers in the distributed system; the inputs of the on-chip neural networks are the end-user’s privacy. The attackers can access all IO ports of the chip and we assume that the attackers cannot destructively access the circuits inside the chip for future continuous usage. In this case, the attackers can directly read the data stored in the ReRAM CIM core or deploy a side-channel attack on the chip, such as measuring the power consumption19. To prevent these attacks, we apply the proposed RePACK scheme on both PUF-guided inference (layer encryption), PUF-guided weight redistribution (weight encryption), and PUF-guided input (input encryption), as shown in Fig. 1b49. They are oblique to each other and can be applied simultaneously for better protection. In all these sub-schemes, the PUF responses are sent to the CIM cores implicitly inside the chip and we especially design the PUF data path so that the attackers cannot access this information. Figure 1c50 shows the input encryption of an actual image. When an unauthorized attacker uses wrong PUF responses to recover data, the system only outputs a disordering image whose details are thoroughly erased.
The whole edge AI processor with RePACK is composed of a CIM tile, data buffer, and digital logic processing circuits (Fig. 1d). The CIM tile is made of 1T1R ReRAM cores, including CIM cores and PUF cores, facilitated by the digital logic and data buffer on the chip. Each ReRAM core can be reconfigured to perform different functions since the same 1T1R ReRAM array structure realizes the CIM and PUF functions. In this section, we elaborate on reliable PUF generation as hardware foundation, the BS code, and the threefold data protection with experimental demonstration, respectively.
Two-step ReRAM 1T1R PUF Generation as the Hardware Foundation
The on-chip PUF plays a crucial role in this work, serving as a unique private key for each chip. In this work, we use the device-to-device resistance variation of the ReRAM device as the entropy source to deploy PUF. The one-step forming can provide enough entropy but cannot keep the stability for reproduction. A two-step forming scheme helps enhance the PUF stability, providing reliable and effective PUF responses. The PUF programming starts from an unformed array where the devices’ conductances are ~ 0µS (Fig. 2a, b). The first step is a pseudo-forming, a forming step but with a lower compliant current. After pseudo-forming, the devices in an array are programmed to the states with comparatively lower conductances (Fig. 2c, d). The second step chooses all devices with higher conductance than the median conductance (see Supplementary Fig 14 and Supplementary Table 10 for programming details). Half of the devices in the array are selected. This step includes a strong forming on these devices. It separates the conductances into two states while maintaining the original randomness introduced by pseudo-forming (Fig. 2e, f). After the stepwise programming, the devices in an array show ~5 ON/OFF ratio (Fig. 3a). In the PUF programming, the pseudo-forming step generates a continuous distribution around a median value, utilizing device-to-device variation as the entropy source (Figs. 2d and 3a inset). The strong forming step enhances the ON/OFF ratio between PUF bit ‘0’ and ‘1’. This step does not affect the stochasticity provided by the pseudo-forming step (see Supplementary Section 15, 16 and Supplementary Figs. 14, 15 for details). This programming scheme eliminates the requirement of additional reset steps while maintaining the adequate ON/OFF ratio of the ReRAM array. It is a simpler way to generate PUF data and saves programming time. The system simply compares the readout current of each ReRAM cell with a pre-defined reference current and generates 0 and 1 in the PUF response.

a The conductances of an unformed 128 × 128 ReRAM array. b The conductance distribution of an unformed 128 × 128 ReRAM array. All conductances are ~ 0µS. c The conductances of the ReRAM array after pseudo-forming. d The conductance distribution of the ReRAM array after pseudo-forming. e The actual conductance mapping of a generated PUF based on a 128 × 128 ReRAM array after the two-step PUF generation. f The conductance distribution of the ReRAM array after the two-step PUF generation.

a The distribution of conductances, including high-resistance state (HRS) and low-resistance state (LRS), after programming the ReRAM chip to produce the PUF. The inset schematic shows the pseudo-forming step and the strong-forming step. b The distribution of both inter-chip and intra-chip Hamming Distances (HD). The inter-chip HD is close to 0.50, indicating high uniqueness between chips, while the intra-chip HD is close to 0, suggesting consistency within a single chip. The ReRAM-based PUF in this work shows high uniqueness and uniformity. c The stability of PUF response reproduction over various VDD2. d The stability of PUF response reproduction over various VDD1. e The stability of PUF response reproduction over numerous consecutive read operations. The bit error rate (BER) of the PUF response remains 0.00% ( < 6.1 × 10-5) even after 108 read cycles, showing high stability. f The retention test of PUF response. The PUF response remains unaffected after 106 seconds. g The stability of PUF response reproduction over various temperatures. The PUF response remains unaffected from −50 °C to 125 °C. h The stability of PUF response reproduction after high-temperature baking. After 100 hours of baking at 125°C, the BER of PUF response remains 0.00% ( < 6.1 × 10-5).
The ReRAM-based PUF only utilizes a 1T1R cell to represent a PUF bit, providing high data density. The PUF programming step excludes write-verify to save programming time. The ON/OFF ratio requirement of the ReRAM cell in the PUF function is to secure the read margin so that there is no error during reproduction. Though the device’s ON/OFF ratio without write-verify is lower, it is sufficient for PUF applications. As shown in Fig. 3b, the produced PUF code provides high-quality uniqueness and uniformity (see Supplementary Section 1, 2 for detailed information). As shown in Fig. 3e, the 1T1R PUF in this work reaches a < 6.78×10-6 bit error rate (BER) after 108 read cycles (zero error in 144 K bits), showing high stability after large reproducing amounts. The generated PUF response successfully passes the NIST test (see Supplementary Table 1 for details). Comprehensive reliability tests prove the PUF stability on varying VDD (Fig. 3c, d), iterative reproduction (Fig. 3e), retention (Fig. 3f), varying temperature (Fig. 3g), and long-time baking (Fig. 3h). The BERs in these circumstances remain at 0.0000% (zero error in the array). These tests comprehensively prove the randomness and robustness of the ReRAM-based PUF in this work (see Supplementary Section 16 and Supplementary Figs. 16, 28 for detailed reliability tests). This work achieves comparatively eminent PUF properties among other works in literature (see Supplementary Section 21 and Supplementary Table 8 for details).
Bipartite-sort code for RePACK encryption
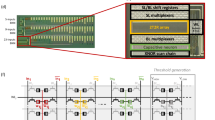
In RePACK, we develop a bipartite-sort (BS) coding scheme for minimizing the peripheral processing circuits (Fig. 4). It is the essential technique to map the weight data and the input data with the PUF response in the CIM macro. The BS code especially utilizes equal amounts of “1”s and “0”s in the PUF response to bipartite the data and sort them with the randomness provided by the PUF. The PUF-guided weight redistribution and PUF-guided input both use the BS code scheme. The BS scheme redistributes the data of a vector according to a given sequence, usually the PUF response (see Supplementary Section 3 for mathematical explanations). It first separates each datum word in the vector into two equal parts. In this step, a word can be partitioned into LSB/MSB parts, differential pairs, or other formats, depending on the data features. We refer to this step as “bipartition”. Here we define the two parts as “1”-part and “0”-part. Then, a binary sequence with binary bits is used to redistribute the data. The length of this binary sequence is the same as the length of the vector after bipartition. An illustrative example is depicted in Fig. 4a. After the bipartition of the vector, its elements undergo redistribution guided by a binary sequence. Elements categorized as “1”-parts are situated at positions corresponding to “1”s within the binary sequence, while those classified as “0”-parts are positioned at “0”s. Notably, the internal ordering of elements within each category (“1”-parts or “0”-parts) remains unaltered during this redistribution process. After this process, the vector is encrypted in the bipartite-sort code format, guided by the binary sequence which always refers to the PUF response in this work.

a The schematic of bipartite-sort code. b A simplified example of bipartite-sort code. c The process of how the physical unclonable function (PUF) response guides the results of positive columns (1-parts). d The process of how the PUF response guides the results of negative columns (0-parts).
Figure 4b gives a simplified example to illustrate the bipartite-sort code. The BS code encrypts a vector with a length of 5. It is partitioned into 10 elements. Following the redistribution process guided by a PUF response, a precise alignment emerges between the vector elements and the PUF response. Each element Wi+ occupies a position corresponding to a “1” within the PUF response, while elements Wi- align with 0 s. This intricate correlation effectively encrypts the vector, harnessing the inherent uniqueness and unpredictability of the PUF response as a cryptographic mechanism. As shown in Fig. 4c, d, the data of the BS code format can be reconstructed to the normal format by using certain reconstruction circuits (see Supplementary Section 4 for detailed information). Only when the PUF responses for encryption and decryption are identical, the data after reconstruction will be identical to the original data. Compared to conventional hardware encryption codes, including XOR cipher, AES, and homomorphic encryption, the proposed BS code achieves the highest figure of merit (FoM) on Complexity / (Power × Area × Latency), with 2 ~ 3 orders of magnitude higher than other techniques. This proves that BS code could provide high encryption complexity with low energy cost and low latency (see supplementary Section 20 and Supplementary Table 7 for detailed information).
Threefold data protection in RePACK
PUF-guided inference scheme can successfully protect unauthorized users from using the chip to infer and extract the structural information of the neural network. It could induce fake weights for an entire layer or an entire CIM core (Fig. 5a). The layer of fake weights and the layer of real weights are arranged together using the PUF response. Each layer is assigned a one-bit PUF response. Only when the response is “1”, is a certain layer to use. Otherwise, the layer is skipped. The discriminator receives the one-bit PUF response and makes the choice. In an ideal case, the real layers are arranged to the “1” PUF response, and the fake layers are arranged to the “0” PUF response. To save on-chip memory, the fake weights do not use memory space. Instead, they are generated using a simple hash function on the PUF response and the weight data (Fig. 5b). The hash function is \({Output}=f({Input\; address},{PUF\; response},{Weight\; data})\). This function provides stationary pseudo-random fake weights for a certain address (see Supplementary Section 5 for detailed information). When an edge device receives layers of neural network weights, it stores these layers according to the local PUF response. During inference, only when the PUF response is precisely reproduced can the neural network use all real weights to compute. Otherwise, random numbers may replace some layers, and thus the inference fails.

a The schematic of layer encryption (PUF-guided inference). The neural network inference uses real weights or fake weights depending on the PUF response. PUF: physical unclonable function. CIM: compute-in-memory. b The hardware implementation of PUF-guided inference. A discriminator is used to detect the PUF response and decide whether to use the real multiply-and-accumulate (MAC) results from the ReRAM CIM core or the random bitstream from TRNG. c The schematic of weight encryption (PUF-guided weight redistribution). The weights are stored in a ReRAM-based CIM core as differential pairs. The sequence of these differential pairs is redistributed according to the PUF response. During the CIM computation, the positive/negative columns are computed alternately in a clock cycle. CLK: clock signal. TIA: transimpedance amplifier. S&H: sample and hold circuit. ADC: analog-to-digital converter. d The hardware implementation of PUF-guided weight redistribution. The multiplexers at the output side of the ReRAM-based CIM core use PUF response to select the CIM results to the partial sum registers. e The schematic of input encryption (PUF-guided input). In this scheme, the input data is encrypted before sending to the CIM macro. After CIM computation, the output data is decrypted. f The hardware implementation of PUF-guided input. The input sequence of columns in the input data is redistributed according to the PUF response.
PUF-guided weight redistribution scheme protects the weights with the most minor area overhead (Fig. 5c). Since the hardware attackers could easily read out the weight data through available I/O ports, it is a must to encrypt neural network weights. To fit CIM with ReRAM-PUF, we develop a ReRAM-PUF-compatible CIM core structure. It uses a differential pair to store a single weight similar to the prior works15,51. The positive and negative parts of each weight are stored separately in the CIM core according to the BS code. Each bit of PUF response is assigned to each column in the CIM macro (Fig. 5d). The columns with PUF code “1” store positive parts of weights, while the columns with PUF code “0” store negative parts of weights. Because the PUF response has an equal distribution of “1”s and “0”s, the redistributed weights may just fit in the CIM macro. After the computation in the CIM core, the reconstruction circuits reconstruct the output partial sums in the right order.
The PUF-guided input scheme aims to shield the streaming data on the chip from privacy theft during execution. Although the private data as neural network inputs, such as medical images, are often encrypted by algorithms during communication. Yet when those data are processed on AIoT hardware, they are vulnerable to hardware attacks (Fig. 5e). In the proposed PUF-guided input scheme, the input data are sent to the CIM module in a bit-serial manner. Each input integer is partitioned into the MSB part and the LSB part. The input orders of these MSB parts and LSB parts are redistributed by the PUF responses, according to the BS code (Fig. 5f). Thus, the input data cannot be directly extracted without the PUF response. After the computation of the whole input data on the CIM module, the reconstruction circuit reconstructs the partial sums according to the PUF response for input data. The implementation includes the circuits for three levels of encryptions, working concurrently with different PUF responses.
Experimental demonstration of RePACK on the ReRAM-based CIM chip
In this work, we developed a closed-loop system to show the potential of real-world applications of the proposed scheme. To build this system, we designed and fabricated a ReRAM-based chip on a 40 nm technology platform (Fig. 6a). This chip includes 13 ReRAM modules. Each ReRAM module adopts the 1T1R cell structure, supporting the reconfigurability for CIM or PUF (Fig. 6b). The ReRAM devices integrate on a CMOS platform with a back-end-of-line (BEOL) process. The device is stable enough to secure reliable PUF reproduction (see Supplementary Section 24 for details). These ReRAM modules together build up a multi-core CIM tile with PUF. The system includes a field programmable gate array (FPGA), a customized ReRAM CIM chip, and a personal computer (PC) (Fig. 6c and Supplementary Movie 1). As shown in Fig. 6d, inside the ReRAM CIM module, the ReRAM array stores a matrix, and it performs the vector-matrix multiplication (VMM) in parallel according to Kirchhoff’s law. The detailed system architecture is shown in Fig. 7. The system includes a PUF array and 12 CIM arrays, with read & write ports and a communication interface (see Supplementary Section 6 for detailed information). In the proposed system, the attacker is not able to access the PUF key through I/O ports and the PUF responses do not directly connect to the bus (see supplementary Section 17 and Supplementary Fig. 29 for details of key management). To comprehensively evaluate the performance of the RePACK, we implemented various neural network models across different classes. These models include standard deep neural networks (DNNs), convolutional neural networks (CNNs), and recurrent neural networks (RNNs). Specifically, we investigated the framework’s suitability for image segmentation tasks by employing a U-Net architecture as a visualized example.

a The photo of fabricated 40 nm ReRAM chip. There are several ReRAM modules on a single chip that could build up a ReRAM tile. b The microscopic photo of one ReRAM module. The array size of one typical ReRAM module is 128 × 128. The ReRAM module can be configured for the PUF/TRNG/CIM function. c The closed-loop system in this work. The system consists of the ReRAM chip, the AMD VC707 FPGA, the printed circuit board (PCB), and an Aardvark I2C/SPI adapter. The adapter further connects to the personal computer (PC). FPGA: Field Programmable Gate Array. SPI: Serial Peripheral Interface. BL: bit-line. WL: word-line. ADC: analog-to-digital converter. d The schematic of one ReRAM-based CIM module in this system.

The ReRAM chip includes 13 ReRAM arrays. In this work, one 128 × 128 1T1R ReRAM array serves as the physical unclonable function (PUF) array. The other 12 arrays can be used as the compute-in-memory (CIM) arrays. The PUF array works implicitly in the system and it provides the PUF response for the threefold encryption of the RePACK scheme. The computing system uses Read & Write ports and the memory configuration module to initiate the memory setup of the system. An SPI interface working at 1 MHz clock frequency connects to the outside of the system. The typical size of the ReRAM CIM array is 128 × 128. It is encrypted by the RePACK scheme. The reconstruction circuit reconstructs the computing results to the right sequence. The computing results are further sent to the output buffer. ADC: analog-to-digital converter. SPI: Serial Peripheral Interface. MUX: multiplexer.
PUF-guided inference scheme (layer encryption) in RePACK protects the trained neural network model from unauthorized users’ malicious usage. Here we take U-Net with integer weights as a typical example to visualize its effectiveness (see Supplementary Section 10 for detailed information). As shown in Fig. 8a, taking the input convolutional layers in the model as an example, the neural network with correct weights can reach high accuracy (Dice). After any single CIM core is replaced by a fake weight core, the accuracy drops to 0.000% ~ 39.236% and the loss becomes high. The model is not able to correctly identify and predict the input medical tumor images (Fig. 8b). During inference, as the bit missing ratio (BMR) of the provided PUF response increases, the inference accuracy sharply drops to nearly 0% (see Supplementary Table 4 for detailed information). Besides integer weights, the results of PUF-guided inference with floating-point weights are also promising (see Supplementary Figs. 4, 5 for detailed information). It proves the effectiveness of PUF-guided inference to protect the chip against malicious usage and structural information extraction.

a The effect of wrong PUF responses on inference accuracy (Dice) and loss value in the PUF-guided inference task. Any layer with fake weights can cause failed inference. In this test, the data format of weight is an 8-bit integer. b The results predicted by the original model and predicted by the model with wrong PUF response in PUF-guided inference. The model could not complete correct predictions after replacing the real weight layer with the fake weight layer. c The effect of wrong PUF response on inference accuracy (Dice) and loss value in the PUF-guided weight redistribution. The BMR of the PUF response applied for each layer is controlled at 6.25%. The accuracy drops significantly with comparatively low BMR. d Conductance mapping of ReRAM devices. Top: Normal conductance mapping. Bottom: Conductance mapping after PUF-guided weight redistribution. e The schematic of the BS code generation for 32-bit floating-point data. The high 16 bits and the low 16 bits are partitioned in this scheme. f The effect of wrong PUF response on inference accuracy and loss value in the PUF-guided weight redistribution. The data format of weight in this test is 32-bit floating point.
PUF-guided weight redistribution scheme (weight encryption) in RePACK helps protect neural network weights from being stolen. In this demonstration, the precision of weight is an 8-bit integer. Each 8-bit integer weight parameter is separated into a high 4-bit part and a low 4-bit part, respectively. The PUF responses predefine the column storage order of the high 4-bit part and the low 4-bit part in each macro. As an example, we evaluate PUF-guided weight redistribution on a U-Net model with integer-type weights. Figure 8c shows a sharp drop in inference accuracy when wrong PUF responses with 6.25% BMR are inputted to a specific layer. The accuracy drops to ~0% when two or more layers are applied with 6.25% BMR PUF responses. This result indicates that PUF interference from comparatively low BMR can significantly disrupt the model’s inference task (see Supplementary Section 7 and Supplementary Table 5 for detailed information). Disturbance of multiple layers also indicates serious failure. It shows that the PUF-based weight redistribution requires a highly accurate PUF response, which helps secure the safety of the chip. We experimentally implemented the tests on the ReRAM chip. As shown in Fig. 8d, the direct weight mapping (upper) and the BS code mapping (lower) on the ReRAM array show a significant difference. In the hardware implementation, the PUF-guided weight redistribution does not require additional clock cycle to reconstruct the results after the MAC operation, showing an advantage in timing. The reconstruction circuits are pure combinatorial logic. They cost 3032.0 µm2 area and 0.4596 mW power, which is considerably low in the CIM core. A quantitative comparison shows that the BS code circuit only costs 1.6% area and 7% power of an ordinary ReRAM CIM macro. Its latency can hide implicitly in a normal 100 MHz computing frequency (see Supplementary Section 22 and Supplementary Table 9 for details).
With the development of AI models, high data precision is also required in certain fields and the floating-point format is gaining importance. In this work, the RePACK scheme and BS code not only support integer data but also work for float-point data, showing a broader range of usage (Fig. 8e). As shown in Fig. 8f, the PUF-guided weight redistribution performs even better for FP32 weights, because of the nonlinear behavior of interfering floating-point data (see Supplementary Section 8 and Supplementary Fig. 13 for detailed information). This verifies the effectiveness of the BS code and PUF-guided weight redistribution in both integer format and floating-point format.
To attack the neural network, an attacker might directly read the stored data and try to reconstruct them through enumeration (see Supplementary Section 7 for detailed information). The number of data columns of the ReRAM array is denoted by n, and then the time complexity for enumeration to extract the correct weights from the ReRAM array is \({{\boldsymbol{O}}}({{\boldsymbol{C}}}_{{{\boldsymbol{2n}}}}^{{{\boldsymbol{n}}}})\), according to the BS code. For example, considering the ReRAM array with 128 numbers in each row, the attacker needs to perform 5.77 × 1075 tests to complete the whole enumeration. Assuming that each inference takes 1 ms, it takes 5.77 × 1072 s to obtain the correct weight matrix. The time required for enumeration on BS code is not acceptable for attackers, in terms of both hardware and time expenditure. The BS code reaches high encryption complexity with low-cost hardware (see supplementary Section,20 and Supplementary Table 7 for detailed information). Besides the image segmentation task, evaluations of the RePACK scheme on a range of neural networks also prove effective (see Supplementary Section 9 for detailed information).
PUF-guided input is also crucial in the threefold encryption. In this work, we define the encryption that includes all three levels of encryption as threefold encryption. It uses three different PUF responses for the three levels of encryptions. Threefold encryption can induce more PUF code bits on a certain neural network scale and thus increase the safety against enumeration or other attacks. Different from other encryption techniques, the BS code enables overlapping multiple encryptions on the same macro because of its low hardware cost.
We deployed the threefold encryption scheme on the LeNet-5 network as a demonstration. The weights and inputs are encrypted by PUF response 1&2 while PUF response 3 protects the layers (see Supplementary Section 10 for detailed information). As shown in Fig. 9a, after the CIM computation of each partial sum, PUF response 1 and PUF response 2 are both used for partial sum reconstruction. During the whole inference process, the PUF response 3 guides the layer-level encryption. Figure 9b demonstrates the supremacy of threefold encryption (see Supplementary Section 11 for detailed information). When performing inference tasks with the threefold encryption scheme, it only takes one additional clock cycle in one macro to complete the partial sum redistribution (Fig. 9c). The time complexity of reconstruction in threefold encryption is only \({{\boldsymbol{O(1)}}}\), showing a negligible impact on the computation speed.

a Diagram of the encryption when both weights and inputs are encrypted. Two physical unclonable function (PUF) responses encrypt weights and inputs respectively. Together with the layer encryption, the scheme performs a threefold encryption behavior. b Effectiveness of the threefold encryption scheme based on the RePACK scheme. With the same PUF response BMR, threefold encryption can further lower the inference accuracy by 7.62%. c The timing diagram of the CIM module with threefold encryption. The reconstruction process after CIM computation includes input-level partial sum reconstruction and weight-level partial sum reconstruction. w1 and w2 are the partial sum reconstruction results at the weight level in the computation process. The weight-level reconstruction is performed after each CIM cycle. This process is implemented on combinatorial logic. i1 and i2 are the partial sum results according to the high 4-bit part and the high 4-bit part of the input data, respectively. The input-level reconstruction is performed after the whole computation. i3 refers to the final partial sum reconstruction results after the whole computation. The whole reconstruction process only induces one extra clock cycle. d Multi-level conductance distribution based on ReRAM devices. e Multi-level conductance mapping of the encrypted convolutional layer in U-Net with RePACK. f The parameters are stored using ReRAM multi-values: The effect of wrong PUF response on inference accuracy and loss value in the PUF-guided weight redistribution.
ReRAM-based multi-level storage provides a high-density solution for CIM. This work uses the 2-bit ReRAM cell as an example. Four 2-bit ReRAM cells represent an 8-bit integer in the RePACK scheme (see Supplementary Section 18 and Supplementary Fig. 30 for details). The conductance distribution of 2-bit ReRAM is shown in Fig. 9d. The 4 conductance states separate with adequate margins, representing 4 digital values. We experimentally deployed the 2-bit ReRAM-based CIM with RePACK (Fig. 9e). As shown in Fig. 9f, the protection results prove effective (see Supplementary Section 12 for detailed information). The multi-level storage strategy with RePACK can effectively improve the storage density of AI models while maintaining safety. In this work, we realize the PUF-guided encryption on multi-value ReRAM parameter storage for the first time, demonstrating the safe and compact CIM implementation. The RePACK scheme continuously supports the CIM encryption when the cell bits increase.
In summary, we have proposed a safe CIM scheme, RePACK. This scheme uses the chip’s intrinsic randomness to encrypt the weights stored in the CIM module and only induces little area overhead and low computation latency. It achieves the best performance on CPAL FoM. It is a fully on-chip self-encryption technique. We have theoretically illustrated the effectiveness of RePACK and tested it on various AI models. Furthermore, we have experimentally fabricated a ReRAM-based CIM chip that successfully implemented the RePACK scheme. As a hardware foundation, we have achieved both compact and robust on-chip PUF implementation. Based on this, we implemented the ReRAM-based safe edge AI system and measured its effectiveness under attacks. The proposed RePACK framework offers a general solution for enhancing the security of edge AI systems. Extending RePACK to threefold encryption allows for comprehensive protection, safeguarding both stored data and incoming inputs. Serving as a hardware infrastructure, it can work collaboratively with software encryption algorithms or encrypted communications for distributed edge AI systems. This establishes a fundamental approach for intellectual property protection on AIoT devices.
Discussion
In this section, we also discuss some potential limitations of RePACK
Destructive detection: The hardware architecture of the RePACK scheme does not prevent destructive detection. Theoretically, attackers can read the PUF data by destructively detecting the PUF data paths as long as they can access the chip physically. Although this method can acquire PUF data, it may seriously hinder the reuse of the same chip. To resolve this limitation, future work might design an obfuscation structure in chip layout to prevent the chip from destructive reading further.
Model training: This work does not involve encrypted model training since RePACK is mainly designed for safe inference in AIoT chips, but it illustrates its potential usage in federated learning and other distributed systems. Future work could combine federated learning with PUF-based secret sharing and the RePACK scheme to support model training. The weight pattern during training can also benefit from software-hardware co-design.
BS code implementation: The proposed BS code scheme is a key component to realize in-memory computing operation with PUF protection. It is a hardware implementation scheme instead of a brand-new encryption coding algorithm. Therefore, the realization of BS code as a hardware component is orthogonal to standard encryption algorithms, such as AES.
Methods
Programming of ReRAM chip
The programming system comprises a test board, an AMD VC707 FPGA, and a personal computer (PC). The VC707 FPGA, as the control unit of the programming system, connects to the test board through the FPGA Mezzanine Card (FMC) module in the extended FPGA I/O port. The FPGA communicates with the PC through JTAG (program and debug) and UART protocols (data transfer). It receives instructions from the PC and sends computing results to the PC. The ASD7057 (differential) and MCP33131 (single-ended) ADC modules on the test board measure the ReRAM conductance, assisted with a sampling resistor. The test board’s DAC8168 (8 channels) provides programming voltage for ReRAM devices. By controlling the voltages of the source line (SL), word line (WL), and bit line (BL) ports of the ReRAM array, the system can successfully compute the programming of ReRAM devices. There are at most three DACs included, serving as voltage sources for SL, WL, and BL, respectively. The voltage pulse width is controlled through multiplexers on the chip instead of varying DAC voltage to avoid ramps of DAC voltage. During the Forming and Set process, DAC2 provides VWL on WL. DAC1 provides Vset/Vforming, the write voltage, on BL, and the SL is grounded. During the Reset process, DAC2 provides VWL on WL. DAC1 provides Vset/Vforming, the reset voltage, on SL, and BL is grounded. As for the reading device’s conductance, DAC2 provides VWL to WL, and DAC1 provides read voltage Vread to BL. SL can connect to a sampling resistor directly or through a current mirror, passing its current to the sampling resistor. The voltage value of the sampling resistor is sampled through ADC. Thus, the system can successfully calculate the conductance of the ReRAM cell by measuring the sampling resistor.
PUF programming of ReRAM chip
To improve efficiency and reliability, a stepwise forming scheme is used to complete the programming operation. First, a pseudo-forming operation is performed on the ReRAM array with a lower-than-normal forming voltage (Vpseudo-forming) to ensure a low-compliant current. The pseudo-forming step generates adequate stochasticity through device-to-device variation. From the post-pseudo-forming conductance distribution, the median conductance (Gmedian) is determined. Second, device conductance values (G) are compared to Gmedian. For devices with G <Gmedian, no forming operation is performed, and they spontaneously relax. For devices with G > Gmedian, strong forming is performed. After strong forming, write-verify selects devices with conductance values outside the target range. These devices undergo repeated strong-forming operations until their conductance values fall within the target range. The strong forming step and write-verify ensure the ON/OFF ratio and enhance the PUF reliability without interfering with the stochasticity. Write-verify is not always required since usually one round of strong forming steps can succeed in the programming.
Multilevel ReRAM programming
The multilevel ReRAM is implemented by iterative write-verify programming. First, different forming operations are performed on array sections with different write voltages. Device conductance after forming is measured by reading voltage. The target conductance value (Gtarget) determines the acceptable range [GL, GH]. If the conductance value is within range, no extra programming is needed. If outside, iterative programming is required. For devices with G lower than GL, a SET voltage is applied for a SET operation. Conductance is read again and compared to GL. Coordinates with conductance lower than GL are updated for the next SET operation. Similarly, when G exceeds GH, a RESET voltage is applied for a RESET operation. Conductance is read again and compared to GH, updating coordinates with conductance higher than GH for the next RESET operation. This process continues until conductance falls within the acceptable range for the target conductance.
Closed-loop system implementation
The closed-loop system comprises a field programmable gate array (FPGA), a customized ReRAM CIM chip, and a personal computer (PC). The FPGA serves as a controlling module and controls the operation of the ReRAM chip. It also communicates with the PC through the SPI interface. The ReRAM chip plays a role as a neural network accelerator, employing the RePACK technique to safely store neural network weights, enhancing the security of the whole system. The PC sends data to FPGA before the computation and receives results from FPGA after the computation. Additionally, we use an Aardvark I2C/SPI host adapter to facilitate the SPI communication between the PC and the FPGA.
Data availability
The ReRAM testing data that support this study’s findings are available in Zenodo with the identifier https://doi.org/10.5281/zenodo.1395027352. All data are available in the main text or the supplementary materials.
Code availability
The source codes to realize BS code decoding are available in Zenodo with the identifier https://doi.org/10.5281/zenodo.1395027352.
References
Pise, A. A. et al. Enabling Artificial Intelligence of Things (AIoT) Healthcare Architectures and Listing Security Issues. Computational Intell. Neurosci. 2022, 1–14 (2022).
Qiu, H. et al. Toward secure and efficient deep learning inference in dependable IoT systems. IEEE Internet of Things Journal 8, 3180–3188 (2021).
Liu, Y. et al. An 82nW 0.53pJ/SOP Clock-Free Spiking Neural Network with 40µs Latency for AloT Wake-Up Functions Using Ultimate-Event-Driven Bionic Architecture and Computing-in-Memory Technique. in 2022 IEEE International Solid- State Circuits Conference (ISSCC) 372–374 (IEEE, San Francisco, CA, USA, 2022).
Liu, C. et al. VO2 memristor-based frequency converter with in-situ synthesize and mix for wireless internet-of-things. Nat. Commun. 15, 1523 (2024).
Ali, M., Naeem, F., Tariq, M. & Kaddoum, G. Federated learning for privacy preservation in smart healthcare systems: a comprehensive survey. IEEE J. Biomed. Health Inform. 27, 778–789 (2023).
Li, L., Fan, Y., Tse, M. & Lin, K.-Y. A review of applications in federated learning. Computers Ind. Eng. 149, 106854 (2020).
Boenisch, F. et al. Reconstructing Individual Data Points in Federated Learning Hardened with Differential Privacy and Secure Aggregation. in 2023 IEEE 8th European Symposium on Security and Privacy (EuroS&P) 241–257 (IEEE, Delft, Netherlands, 2023).
Truex, S. et al. A Hybrid Approach to Privacy-Preserving Federated Learning. in Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security 1–11 (ACM, London United Kingdom, 2019).
Ye, L. et al. The challenges and emerging technologies for low-power artificial intelligence IoT systems. IEEE Trans. Circuits Syst. I: Regul. Pap. 68, 4821–4834 (2021).
Verma, N. et al. In-memory computing: advances and prospects. IEEE Solid-State Circuits Mag. 11, 43–55 (2019).
Le Gallo, M. et al. A 64-core mixed-signal in-memory compute chip based on phase-change memory for deep neural network inference. Nat. Electron 6, 680–693 (2023).
Yin, X. et al. Ferroelectric compute-in-memory annealer for combinatorial optimization problems. Nat. Commun. 15, 2419 (2024).
Aguirre, F. et al. Hardware implementation of memristor-based artificial neural networks. Nat. Commun. 15, 1974 (2024).
Wang, Z. et al. Fully memristive neural networks for pattern classification with unsupervised learning. Nat. Electron 1, 137–145 (2018).
Yao, P. et al. Fully hardware-implemented memristor convolutional neural network. Nature 577, 641–646 (2020).
Wan, W. et al. A compute-in-memory chip based on resistive random-access memory. Nature 608, 504–512 (2022).
Zou, M. et al. Security enhancement for RRAM computing system through obfuscating crossbar row connections. in 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE) 466–471 (IEEE, 2020).
Wang, Z., Meng, F., Park, Y., Eshraghian, J. K. & Lu, W. D. Side-channel attack analysis on in-memory computing architectures. IEEE Transactions on Emerging Topics in Computing (2023).
Wang, Z. et al. PowerGAN: a machine learning approach for power side‐channel attack on compute‐in‐memory accelerators. Adv. Intell. Syst. 5, 2300313 (2023).
Huang, S., Jiang, H., Peng, X., Li, W. & Yu, S. XOR-CIM: compute-in-memory SRAM architecture with embedded XOR encryption. Proc. 39th Int. Conf. Computer-Aided Des. 1, 6 (2020).
Li, W., Huang, S., Sun, X., Jiang, H. & Yu, S. Secure-RRAM: A 40nm 16kb compute-in-memory macro with reconfigurability, sparsity control, and embedded security. in 2021 IEEE Custom Integrated Circuits Conference (CICC) 1–2 (IEEE, 2021).
Huang, S., Jiang, H., Peng, X., Li, W. & Yu, S. Secure XOR-CIM engine: compute-in-memory SRAM architecture with embedded XOR encryption. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 29, 2027–2039 (2021).
Shan, W. et al. Machine learning assisted side-channel-attack countermeasure and its application on a 28-nm AES circuit. IEEE J. Solid-State Circuits 55, 794–804 (2019).
Li, X. et al. First Demonstration of Homomorphic Encryption using Multi-Functional RRAM Arrays with a Novel Noise-Modulation Scheme. in 2022 International Electron Devices Meeting (IEDM) 33–35 (IEEE, 2022).
Tu, F. et al. 16.4 TensorCIM: A 28nm 3.7nJ/Gather and 8.3TFLOPS/W FP32 Digital-CIM Tensor Processor for MCM-CIM-Based Beyond-NN Acceleration. in 2023 IEEE International Solid-State Circuits Conference (ISSCC) 254–256 (2023).
Tu, F. et al. A 28nm 29.2TFLOPS/W BF16 and 36.5TOPS/W INT8 reconfigurable digital CIM processor with unified FP/INT pipeline and bitwise in-memory booth multiplication for cloud deep learning acceleration. 2022 IEEE Int. Solid-State Circuits Conf. (ISSCC) 65, 1–3 (2022).
Yan, B. et al. A 1.041-Mb/mm2 27.38-TOPS/W signed-INT8 dynamic-logic-based ADC-less SRAM compute-in-memory macro in 28nm with reconfigurable bitwise operation for AI and embedded applications. IEEE Int. Solid-State Circuits Conf. (ISSCC) 65, 188–190 (2022).
Wang, Z. et al. A 148-nW reconfigurable event-driven intelligent wake-up system for AIoT nodes using an asynchronous pulse-based feature extractor and a convolutional neural network. IEEE J. Solid-State Circuits 56, 3274–3288 (2021).
Gao, Y., Al-Sarawi, S. F. & Abbott, D. Physical unclonable functions. Nat. Electron. 3, 81–91 (2020).
Gao, B. et al. A unified PUF and TRNG design based on 40-nm RRAM with high entropy and robustness for IoT security. IEEE Trans. Electron Devices 69, 536–542 (2022).
Pang, Y. et al. 25.2 A reconfigurable RRAM physically unclonable function utilizing post-process randomness source with<6\times 10- 6 native bit error rate. in 2019 IEEE International Solid-State Circuits Conference-(ISSCC) 402–404 (IEEE, 2019).
Song, J. et al. A 3T eDRAM in-memory physically unclonable function with spatial majority voting stabilization. IEEE Solid-State Circuits Lett. 5, 58–61 (2022).
Shifman, Y., Miller, A., Keren, O., Weizman, Y. & Shor, J. An SRAM-based PUF with a capacitive digital preselection for a 1E-9 key error probability. IEEE Trans. Circuits Syst. I: Regul. Pap. 67, 4855–4868 (2020).
Gao, B. et al. Concealable physically unclonable function chip with a memristor array. Sci. Adv. 8, eabn7753 (2022).
Nili, H. et al. Hardware-intrinsic security primitives enabled by analogue state and nonlinear conductance variations in integrated memristors. Nat. Electron. 1, 197–202 (2018).
Oh, J. et al. Memristor-based security primitives robust to malicious attacks for highly secure neuromorphic systems. Adv. Intell. Syst. 4, 2200177 (2022).
Taneja, S., Rajanna, V. K. & Alioto, M. In-memory unified TRNG and multi-bit PUF for ubiquitous hardware security. IEEE J. Solid-State Circuits 57, 153–166 (2021).
John, R. A. et al. Halide perovskite memristors as flexible and reconfigurable physical unclonable functions. Nat. Commun. 12, 3681 (2021).
Chiu, Y.-C. et al. A CMOS-integrated spintronic compute-in-memory macro for secure AI edge devices. Nat. Electron 6, 534–543 (2023).
Zhang, L., Kong, Z. H. & Chang, C.-H. PCKGen: A phase change memory based cryptographic key generator. in 2013 IEEE International Symposium on Circuits and Systems (ISCAS) 1444–1447 (IEEE, 2013).
Wang, Y. et al. Flash memory for ubiquitous hardware security functions: True random number generation and device fingerprints. in 2012 IEEE Symposium on Security and Privacy 33–47 (IEEE, 2012).
Li, D. et al. PUF-Based Intellectual Property Protection for CNN Model. in Knowledge Science, Engineering and Management: 15th International Conference, KSEM 2022, Singapore, August 6–8, 2022, Proceedings, Part III 722–733 (Springer, 2022).
Chen, Z. et al. PUF-CIM: SRAM-Based Compute-In-Memory With Zero Bit-Error-Rate Physical Unclonable Function for Lightweight Secure Edge Computing. IEEE Transactions on Very Large Scale Integration (VLSI) Systems (2023).
Beckmann, K., Manem, H. & Cady, N. C. Performance enhancement of a time-delay PUF design by utilizing integrated nanoscale ReRAM devices. IEEE Trans. Emerg. Top. Comput. 5, 304–316 (2017).
Schultz, T., Jha, R., Casto, M. & Dupaix, B. Vulnerabilities and reliability of ReRAM based PUFs and memory logic. IEEE Trans. Rel. 69, 690–698 (2020).
Wilson, T., Jain, S., Garrard, J., Cambou, B. & Burke, I. Characterization of ReRAM arrays operating in the pre-formed range to design reliable PUFs. In Intelligent Computing. SAI 2024. Lecture Notes in Networks and Systems (ed. Arai, K.) 328–350 (Springer, 2024).
Larimian, S., Mahmoodi, M. & Strukov, D. Lightweight integrated design of PUF and TRNG security primitives based on eFlash memory in 55-nm CMOS. IEEE Trans. Electron Devices 67, 1586–1592 (2020).
Shan, W., Fan, A., Xu, J., Yang, J. & Seok, M. A 923 Gbps/W, 113-Cycle, 2-Sbox energy-efficient AES accelerator in 28nm CMOS. in 2019 Symposium on VLSI Circuits C236–C237 (IEEE, Kyoto, Japan, 2019).
Pedano, N. et al. The Cancer Genome Atlas Low Grade Glioma Collection (TCGA-LGG). The Cancer Imaging Archive https://doi.org/10.7937/K9/TCIA.2016.L4LTD3TK (2016).
Kermany, D. et al. Labeled optical coherence tomography (OCT) and chest x-ray images for classification. Mendeley https://doi.org/10.17632/RSCBJBR9SJ.2 (2018).
Liu, Q. et al. 33.2 A Fully Integrated Analog ReRAM Based 78.4TOPS/W Compute-In-Memory Chip with Fully Parallel MAC Computing. in 2020 IEEE International Solid-State Circuits Conference - (ISSCC) 500–502 (2020).
Yue, W. et al. Physical unclonable in-memory computing for simultaneous protecting private data and deep learning models. Zenodo https://doi.org/10.5281/ZENODO.13950273 (2024).
Acknowledgements
This work was supported by the National Key R&D Program of China (2023YFB4502200), National Natural Science Foundation of China (61925401, 92064004, 61927901, 92364102, 8206100486, 92164302), Beijing Natural Science Foundation (L234026) and the 111 Project (B18001). Fund 2023YFB4502200, 61925401, 92064004, 61927901, 92164302, and L234026 are awarded to Y. Y. Fund 8206100486 is awarded to Y. T. Fund 92364102 is awarded to B. Y. The authors thank Minglang Gao, Daijing Shi, and Anjunyi Fan for their helpful discussions.
Author information
Authors and Affiliations
Contributions
W.Y., B.Y., Y.T., T.Z., R.H., and Yuchao Yang conceived the project. W.Y. designed the ReRAM chip and proposed the RePACK scheme. K.W., Z.W., and X.Y. performed the simulations and analyzed the results. W.Y., K.W., L.Y., Z. Li, and J.Z. conducted the experiments. Y.W., W.B., S.W., X.H., and Yuxiang Yang optimized the ReRAM devices. K.W. and Z.W. filmed the demonstration video. B.Y. and Yuchao Yang supervised the project. W.Y. and B.Y. wrote the manuscript, and K.W. contributed to some figures. W.Y., B.Y., and Yuchao Yang revised the manuscript. All authors reviewed and edited the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Peer review
Peer review information
Nature Communications thanks Cheol Seong Hwang, Omid Kavehei and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yue, W., Wu, K., Li, Z. et al. Physical unclonable in-memory computing for simultaneous protecting private data and deep learning models. Nat Commun 16, 1031 (2025). https://doi.org/10.1038/s41467-025-56412-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-56412-w
This article is cited by
-
A reconfigurable photosensitive split-floating-gate memory for neuromorphic computing and nonlinear activation
Nature Communications (2026)
-
Self-Rectifying Memristors for Beyond-CMOS Computing: Mechanisms, Materials, and Integration Prospects
Nano-Micro Letters (2026)
-
A Review on Resistive RAM: From Material Properties to Switching Characteristics, Reliability, Models and Applications
Transactions on Electrical and Electronic Materials (2025)
