
Abstract
Reinforcement learning models focus on reward prediction errors as the driver of behavior. However, recent evidence indicates that deviations from emotion expectations, termed affective prediction errors, also crucially shape behavior. Whether there is neural separability between emotion and reward signals remains unknown. We employ electroencephalography during social learning to investigate the neural signatures of reward and affective prediction errors. Behavioral results reveal that affective prediction errors are associated with choices when little is known about how a partner will behave. This behavioral evidence is mirrored neurally by engagement of separate event-related potentials. More specifically, the feedback-related negativity is largely and consistently indexed by reward prediction errors, while the P3b is more consistently tracked by affective prediction errors. The P3b in particular is linked to subsequent choices, highlighting the mechanistic influence of emotion during social learning. These findings present evidence for a neurobiologically viable emotion learning signal that is partially distinguishable, at both the behavior and neural levels, from reward.
Similar content being viewed by others


Introduction
Reward prediction errors (PE)—the difference between expected and experienced reward—serve as the dominant mechanism for explaining how people learn to make adaptive, value-based decisions1,2,3,4,5,6. Reward PEs function within a reinforcement learning (RL) framework, illustrating how people adjust their actions based on past experiences to achieve more successful outcomes7. This framework has been successfully applied to explain a host of simple behaviors such as avoiding financial losses1 and navigating new environments8, to more complex behaviors, such as determining who can be trusted9. While the term reward is frequently used to explain learning, the fact that ‘rewards’ in the social world are abstract, difficult to quantify, and shaped by multiple features of a social situation, suggests a gap between the externally rewarding reinforcers encountered (e.g., money, smiles) and how the brain interprets them as value. A critical unresolved question thus centers around what exactly is reward and how does the brain represent it? Here, we examine how the human brain computes external rewards into internal value during a social learning paradigm.
An intuitive possibility for how external reinforcers are transformed into internal value comes from the field of emotion. Decades of work indicate that emotions play a vital role in the decision-making process10,11, where stress inductions12, mood inductions13 and emotion regulation14 can all impact choice. Indeed, several affective theories propose that emotions are the evaluation of external rewards, and thus possess the capacity to influence future behavior15,16,17,18. Building on this theory, our previous research operationalized affect within an RL framework, which led to the hypothesis that violations of emotion expectations—known as affective prediction errors (PEs)—influence choice. By formally quantifying affective PEs as the difference between expected and experienced emotion, we observed that affective PEs exhibit an independent effect that is stronger than monetary reward PEs in predicting one-shot choices during a social exchange task19. The distinction between emotion and reward was further exhibited in an independent sample, where individuals at risk of depression demonstrated selective impaired use of affective PEs but fully intact use of reward PEs in a behavioral economic game.
Although this dissociation suggests affective PEs are central in guiding socially adaptive behaviors, it remains unknown whether they also act as critical signals during trial-by-trial learning, where knowledge about others must be continually updated to adjust future choices. Many theories propose that the brain functions as a prediction machine20,21, primarily aimed at minimizing error or uncertainty. There is growing evidence that the brain processes not only reward PEs but also sensory22, interpersonal23, and other learning-related error signals. However, there is no evidence showing that the brain encodes both affective and reward error signals, or that these types of PEs can be characterized neurobiologically. Demonstrating neural differentiation—at the temporal, functional, or localization levels—between affective and reward PEs would be strong evidence that emotion serves as a distinct learning signal, one that may be both psychologically and neurally separate from reward, and thus able to transform external rewards into internal, subjective value.
To test whether affective and reward PEs are critical for learning and are neurally identifiable, we used a repeated social exchange paradigm in conjunction with electroencephalography (EEG). EEG was chosen for its superior temporal resolution capable of capturing unfolding neural processes on the order of milliseconds. We a priori identified three potential event-related potentials (ERPs) known to reflect changes in EEG activity in response to feedback or reward processing. In particular, the feedback-related negativity (FRN) is an ERP thought to reflect the evaluation of surprising events24,25 and is theorized to be the neural basis of reward PE processing26. Additionally, the P3a and P3b are commonly linked to various aspects of feedback processing, including reward magnitude27, reward valence28, and rare, surprising outcomes29. Given the mixed evidence of how these ERPs map onto the construct of reward, we were agnostic as to which neural signal would preferentially index reward or affective PEs.
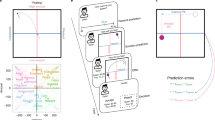
EEG was recorded during a repeated Ultimatum Game (UG), where participants (N = 41) interacted with three different partner types offering a range of fair to unfair monetary offers (fair, unfair, neutral; see Methods and Fig. 1B). The repeated nature of the UG, five trials in a row per partner, allowed participants to update their expectations of a partner based on the history of offers with that person. We included two key measurements to enhance our understanding of how rewards and emotions influence feedback processing and updating (Fig. 1A). First, rather than using computational models to infer participants’ reward expectations30,31, we asked them to report the amount of money they expected to receive on each trial (ranging from $0 to $10). This allowed us to compute trial-by-trial reward PEs as the discrepancy between the actual offer and the expected one. Second, participants used a 2D affect grid to predict how they thought they would feel after receiving an offer (affect expectation), and to express how they actually feel once the offer was received (affective experience)19,32. This measure captures participant’s core affect, a consciously accessible facet of subjective feelings that categorizes feelings into core dimensions of valence (pleasantness) and arousal (alertness/intensity). We computed affective PEs for both arousal and valence dimensions as the difference in participant’s expectation and experience on a trial-by-trial basis (Fig. 1C). Together, these measurements allow us to map all three empirical PEs (reward, valence, and arousal) onto behavior and examine whether there are corresponding neural EEG signatures expressed during repeated social interactions (Fig. 1D).

A Trial design. Participants are partnered with another individual and play five rounds of a repeated UG. Participants first see a photograph and name of their partner (Partner Face), before being asked to report how much money they expected to receive in an offer (Reward Expectation) and how they expected to feel after the offer (Affect Expectation). Next, participants received an offer showing the proposed amount for the participant as well as the amount kept by the partner (Offer). After receiving the offer, participants indicated how they felt (Affective Experience) before deciding to accept or reject the offer (Decision). Timings show the average maximum duration of each of the stages, with “until response” meaning the program waited until the participant gave a response. B Partner offers. Unknown to participants, offers were determined by different normal distributions per partner type. On average, unfair partners gave $1, neutral gave $3, and fair gave $5; all partners’ normal distributions used a standard deviation of $0.50. C Prediction errors (PEs). On each trial we compute three empirical PEs: a reward PE (δ), a valence PE (ν) and an arousal PE (α). In the equations, \(\hat{{{{\rm{y}}}}}\) refers to an individual’s prediction about the reward or emotion they would experience, while \({{{\rm{y}}}}\) refers to their actual experience. D EEG offer activity. Our analyses focus on the EEG activity occurring after the offer presentation. The average EEG activity at electrode FCz in response to offers is shown alongside a topography of the average activity across electrodes between 200 ms to 250 ms where the black dot marks the FCz.
In this work, we demonstrate that affective PEs are crucial for social learning, even when accounting for reward PEs. The influence of affective PEs is strongest when uncertainty about social partners is high, and the influence of affective PEs gradually decreases with learning. Our neural data reveal separate neural correlates and temporal dynamics for reward and affective learning signals. Furthermore, we find that the P3b stands out as the primary neural predictor of social choice, reflecting a reliance on emotion error signals during learning. Ultimately, our findings highlight that a comprehensive understanding of human decision-making and social learning requires considering violations of expectations of both external rewards and internal emotions.
Results
Reward and affective PEs exhibit separable behavioral effects
Given our prior work found that valence, compared to reward PEs, exert a stronger influence on one-shot decisions to punish norm violators19, we began by examining the strength of reward, valence, and arousal PE signals when deciding to punish in a social learning context. This additive linear mixed-effects model (LMM) represents a strict test of our theory since each PE type is included in the model, and therefore competes with all others to explain variance during learning, and the resulting beta coefficients represent the unique effect of each PE type. Replicating our prior research, we found that both valence (\(\beta=-0.76\pm 0.11,z=-6.65,p < {0.001,95}\%{CI}[-1.00,-0.53]\)) and reward PEs (\(\beta=-0.67\pm 0.14,z=-4.75,p < {0.001,95}\%{CI}[-0.96,-0.38]\)) have independent contributions when learning when to punish. That is, participants punished at higher rates when experiencing more unpleasantness (valence) or less reward than expected. While the valence and reward PEs are correlated at the intra-individual level (\({r}_{{rm}}=.68,p < 0.001\)), the variance inflation factor statistics indicate low collinearity between these predictors in our model (see Supplement for all comparisons) and therefore produce reliable estimates of how strongly these PEs affect choice. Unlike our prior results19, we observed no unique contribution of arousal PEs on decisions to punish (\(\beta=0.13\pm 0.11,z=1.14,p={0.26,95}\%{CI}[-{0.10,0.36}]\)) once valence and reward PEs are accounted for. When we control for the experiences of reward and affect in these regressions, experience diminishes the predictive power of all PE types. Specifically, inclusion of the offer (i.e., reward experience) weakens the reward PE (although reward PE still remains significant), while most of the predictive power of valence PEs appears to come from valence experiences (see Supplementary Table 1). We note that unlike reward, valence expectations and experiences are both reported by the participant; meaning the participant’s valence experience may already be in relation to their expectations, and thus, could potentially already represent part of the affective PE.
To examine how the relationship between each PE type and choice changes during learning, we interact PE type with round number. We observe that the strength of reward and valence PEs change in opposite directions overtime, while arousal PEs are not predictive of behavior, once we control for the other PE types (Table 1; Fig. 2A). Valence PEs exert the strongest relationship to choice on the first round when uncertainty is greatest, and significantly weakens over time as uncertainty about a partner’s behavior is slowly resolved. In contrast, reward PEs do not significantly interact with round number. Directly pitting both reward and valence PEs against one another reveals that valence PEs have a significantly stronger impact on motivating punitive choices on the first round compared to reward PEs (\(\beta\) coefficient test: \(z=-1.70,p=0.04\)), while reward PEs have a stronger, albeit not-significant, influence on the final round (when compared to valence PEs: \(z=1.05,p=0.15\)). This reversal in predictive power amongst the PE types reveals how valence PEs are more influential early on when uncertainty is greatest. This finding is robust across analyses, including additional analyses that control for block number or when we subset the data to only include the first and last rounds (see Supplementary Table 6).

A Valence and reward PEs predict choice differently across rounds. The data on each graph reflect the probability of rejecting the offer from Table 1 and the colour of each line indicates the round number (1 – 5) of the Ultimatum Game. Negative values reflect negative PEs, indicating less pleasantness (valence), arousal, and money (reward) than expected. B Relationship between ERP and choice over round. The data on each graph reflect the probability of rejecting the offer from Table 2 and the colour of each line indicates the round number (1 – 5) of the Ultimatum Game. Positive values reflect positive EEG amplitudes, indicating a greater P3b, P3a or FRN (N2) effect. Data are presented as mean values and shaded areas reflect \(\pm\)1 S.E. All statistical tests are two-sided with no adjustments for multiple comparisons. ***P < .001, **P < .01, *P < .05.
Reward and affective PEs indexed by separate neural signals
We next investigated if each PE—reward, valence, and arousal—is represented by unique neural architecture, and whether they are, in any way, linked to choice (Fig. 2B). We follow the same analysis pipeline as our behavioral results: first we standardize all PEs at the group level and used all three PEs (valence, arousal, and reward) as independent variables in linear mixed effects regressions for each a priori ERPs of interest separately: the FRN, P3a, and P3b (see Methods). The FRN is known to encode both signed and unsigned PEs26,33. Reward PE effects on the P3 component are also somewhat ambiguous as to what exactly they index34, potentially reflecting the magnitude of the PE rather than the valence27. Although affective PEs have not, until now, been neurally identified, prior research examining the neural correlates of emotional stimuli suggest they are unsigned35. Given the lack of clarity around what exactly these ERPs index, we test multiple different models for how absolute or signed PEs predict the ERPs of interest. Across multiple analysis and models, we find more evidence that ERPs represent absolute rather than signed PEs (see Supplementary Tables 3–4 and Supplementary Figs. 4 and 5). Thus, our neural analyses include the absolute value of all three PEs (valence, arousal, and reward).
To assess the link between each ERP and each PE type, we begin by modeling the FRN as a function of all three possible PEs such that each PE controls for the variance of the other. We find that both valence (\(\beta=0.03\pm 0.01,t=2.37,p={0.02,95}\%{CI}[{0.01,0.06}]\)) and reward PEs (\(\beta=-0.04\pm 0.01,t=-2.75,p={0.006,95}\%{CI}[-0.06,-0.01]\)) predict the FRN, but in opposite directions. The direction of the reward PE effect is consistent with some prior literature—i.e., larger magnitude reward PEs indicate larger and more negative FRNs. The positive direction of the valence PE was more unusual, which led us to run follow up analyses. We separately modeled the FRN as a function of valence or reward PEs, therefore representing their unconditional effects. Results illustrate that valence PEs do not have any predictive value on the FRN (unconditional effect: \(p=0.36\)), while reward PEs predict the FRN in a similar manner (unconditional effect: \(p=0.047\)). This means that the observed relationship between FRN and valence PEs is contingent on reward PEs, while reward PEs are more consistently linked to the FRN (in both the conditional and unconditional models).
We can apply the same modeling logic to the P3b. When we model the P3b as a function all three possible PEs, where each PE controls for the variance of the others, only valence PE is predictive \((\beta=0.06\pm 0.02,t=3.98,p < {0.001,95}\%{CI}[{0.03,0.09}])\). In contrast, reward PEs are not statistically significant (\(\beta=0.03\pm 0.02,t=1.34,p={0.19,95}\%{CI}[-{0.01,0.07}]\)). While valence PEs are the only significant predictor, a beta-comparison test reveals that the difference between valence and reward PEs and their relationship to the P3b is not statistically significant \(\left(z=1.46,p=0.07\right)\). When using unconditional models (where only a single PE is entered into the model to predict the P3b), both reward (unconditional effect: \(p < 0.001\)) and valence (unconditional effect: \(p < 0.001\)) are significant. A beta-coefficient test comparing the unconditional effect of valence and reward shows a similar non-significant difference between valence and reward \(\left(z=1.32,p=0.09\right)\). The same series of models applied to the P3a reveals that no PE is predictive when accounting for the other (all \(p > 0.07\); however, separate models reveal main effects of both reward (unconditional effect: \(p=0.02\)) and arousal PEs (unconditional effect: \(p=0.01\)). Exploratory analyses (see Supplementary Fig. 10) suggests that the P3a may be best explained by offer extremity which may account for these reward and arousal PE effects. In short, the FRN is consistently linked to reward PEs (both when considering reward PEs on their own and when controlling for the other PE types), while the P3b is consistently predicted by valence PEs (both when considering valence PEs on their own and when controlling for the other PE types).
To ensure we did not miss any other potential PE effects and to further scrutinize the robustness of our ERP findings, we analyze each ERP as a function of both signed and absolute value PEs in the same regression model. We find evidence that signed reward PEs (\(\beta=-0.04\pm 0.01,t=-2.74,p={0.006,95}\%{CI}[-0.06,-0.01]\)) and absolute value valence PEs (\(\beta=0.06\pm 0.02,t=3.86,p < {0.001,95}\%{CI}[{0.03,0.09}]\)) is associated with changes in P3b amplitude. No other PE predictors, signed or unsigned, are significant (all \(p > 0.38\)). To further understand when these effects come online, we conduct a follow-up region of interest (ROI)-based time course analysis that granularly examines how these two predictors relate to the average amplitude of the P3b electrodes for the entire timeseries. Specifically, we run regressions with all three signed and absolute value PEs for each 20 ms bin which should reveal when these predictors emerge during a time course. Results show clusters associated with absolute valence PE (using a threshold of \(p < 0.05\), uncorrected for multiple comparisons), while signed reward PEs do not significantly predict P3b amplitudes in any individual time bin (Fig. 3B). Upon further scrutiny, the signed reward PE effect observed in the P3b described above fails significance testing with a more fine-grained analysis. We apply this same technique to examine the ROI window for the FRN, noting that its identification is based on its relative timing with the N2 and P2 components (see Supplementary Fig. 12).

A Regression models of each ERP. The data in each graph reflect the beta coefficient from linear mixed-effects models (LMMs) examining the unique link between the absolute value of each PE type and each ERP: the FRN, P3a, and P3b for N = 41 participants. Statistical tests are two-sided with no adjustments for multiple comparisons. B P3b ROI time course. Beta coefficients from the LMMs predicting P3b amplitude as a function of all signed and absolute value PEs for valence, reward, and arousal are plotted for each 20 ms time window. Predictor type is indicated by color where blue is absolute valence PE and green is signed reward PE (other predictors are not shown for ease of viewing). The bar at the bottom represents timepoints where the predictors are significant (P < .05) and shows two clusters for absolute valence PEs with no clusters for signed reward PEs. Statistical tests are two-sided with no adjustments for multiple comparisons. C Separate spatiotemporal clusters for reward and valence PEs. Data reflect t-statistic heatmaps from the mass univariate analysis (see Methods). Spatiotemporal clusters were formed using a cluster-forming threshold of P < .01 and corrected for multiple comparisons. The time and channel corresponding to the maximum absolute t-statistic for each cluster are depicted with a black circle and visualized using a topographical plot. The time of the peak cluster expression for each electrode is plotted in the dashed line. Statistical tests are two-sided with permutation testing to adjust for multiple comparisons. Data are presented as mean values and error bars reflect \(\pm\)1 S.E. ***P < .001, **P < .01, *P < .05.
To ensure that we are capturing all possible electrophysiological signatures of reward, valence, and arousal PEs (which we might have missed with an ERP approach) we additionally employ a data-driven, mass univariate method that does not rely on the experimenter to predefine the signals36. We regress each participant’s offer-locked EEG signal at every timepoint and channel against variables reflecting the standardized absolute reward, valence, and arousal PEs values, allowing us to determine the unique contribution of each PE, and determine clusters of significant electrodes and timepoints which survive multiple comparisons (see Methods). Results from this data-driven approach reveal separate clusters for reward and valence PEs, with no significant clusters for arousal PEs—aligning with our ROI results reported above. Valence PEs are represented by a positive cluster spanning 460 to 670 ms after offer onset, with the most pronounced signal in the parietal area (Fig. 3C). This cluster aligns with the timing and direction of the P3b response, illustrating further evidence that the P3b is likely the neural representation of valence PEs. Average feedback-locked event related potentials in the P3 electrode (the center of the P3b ROI) reveals a positive deflection for positive and negative valence PEs. Conversely, reward PEs were linked to a negative cluster ranging from 326 to 790 ms, with the most robust signal in the frontal areas, including an EEG signal consistent with the timing, direction, and topography of the FRN response. Collectively, these results strengthen and provide converging evidence for the interpretation that reward and valence PEs are separately encoded in the brain.
To assess the neural learning effects on choice, especially given our behavioral findings showing that the relationship between PEs and choice varies with round number, we next allowed each ERP to interact with round. Results reveal a significant simple effect of P3b on choice, as well as an interactive effect between P3b and round on choice (Table 2; Fig. 2B). This indicates that the P3b is the primary neural signal influencing choice, and the strength of this neural signal decreases over time as more information is acquired about a partner’s behavior and uncertainty about how they will behave diminishes. When considered alongside our behavioral result—which shows that the relationship between signed valence PEs and choice diminishes with round (Fig. 2A)—it suggests that the common feature between brain and behavior is likely an attenuating surprise signal that tracks how a participant feels as they learn more about their partners’ offers. The interaction between FRN and round was not statistically significant. Collectively, these findings illustrate that both FRN and P3b uniquely track reward and affective learning signals, but that only the P3b affective PEs, most consistently indexed by affective PEs, are relevant for choice.
Reward and affective PEs are resolved through different mechanisms
Although most PEs are no longer predictive by the final round—indicating rapid learning—it remains unclear which component of the prediction error (i.e., experience or expectation) drives the error signal. On one hand, participants might adjust their expectations to make upcoming events less surprising. This aligns with reinforcement learning accounts which predominantly emphasize adjusting PEs by altering expectations (i.e., increasing Q-value of an action to anticipate a greater reward next time). On the other hand, participants could alter their experiences (perhaps by employing emotion regulation tactics) to lessen an event’s impact. While research on affective forecasting suggests that accurately predicting future emotional events is challenging37,38, one could use emotion regulation strategies to modify responses to events like unfair offers39. These two accounts present divergent theories about how affective and reward PEs might drive learning.
To explore the theory that modifying expectation can reduce both affective and reward PEs, we examine how reward, valence, and arousal expectations change throughout the task. As expected, participants exhibit the largest update in both reward and affective expectations between the first and second rounds (Table 3, Fig. 4), clear evidence of learning on both reward and affective dimensions. We then probe how expectations change between rounds two through five to understand if participants continue to adapt after an initial surprise. Reward expectations during this period reveal that participants continue to refine beliefs about their partners, indicating ongoing reward learning (Table 3, rounds 2–5 updating). In contrast, expectations about valence and arousal remain consistent across all partner types between rounds two through five, suggesting participants do not continue to adjust their affective expectations after the initial round. We used a LMM to test whether these effects of reward and valence expectations across rounds are significantly different from each other. The interaction between round and PE type (valence or reward) is not significant for either the fair (\(p=0.99\)) or neutral partner (\(p=0.54\)) but is significant for the unfair partner (\(p=0.008\); see Supplement). In other words, only reward—and not affective—PEs are resolved by altering expectations about someone behaving unfairly. We can also examine whether experiences change across the task. We find that participant’s subjective reports of their valence and arousal experiences change significantly over rounds. Specifically, negative reactions to unfair offers wane over time, and the intensely positive feelings associated with receiving a fair offer also diminish as participants learn more about the fair partner (Table 3, Fig. 4). Given that monetary offers are fixed by task design and do not significantly vary across rounds, we can use the same approach to compare reward and valence experiences; results demonstrate that the interaction between round and PE type (valence or reward) is significant for the fair (\(p < 0.001\)), neutral (\(p=0.04\)) and unfair partners (\(p < 0.001\); see Supplement). This suggests that the experience of valence and reward are clearly separable. Thus, these results highlight a clear distinction in how affective and reward PEs are leveraged for learning: after an initial large update of expectations, reward PEs are resolved by adjusting reward expectations (dovetailing with the RL literature), whereas affective PEs are managed by aligning emotional experiences with prior predictions.

Measurements are plotted by round number, as a function of experience (left panel), expectation (middle panel), and PE (the difference between experience and expectation; right panel). A Valence. Valence PEs are calculated as the difference between valence experience and expectations for each round. Valence ratings are between −250 (very unpleasant) and 250 (very pleasant). B Arousal. Arousal PEs are calculated as the difference between arousal experience and expectations for each round. Arousal ratings are between −250 (low intensity) and 250 (high intensity). C Reward. Reward prediction errors (PEs) are calculated as the difference between reward offer and reward expectations for each round. Reward is defined by experimental design. All data are averaged within and then across participants (N = 41) for each round and partner type. All error bars reflect \(\pm\)1 S.E. Statistical tests (main effects) are shown in Table 3 (see Supplement for valence-reward interactions). All statistical tests are two-sided with no adjustments for multiple comparisons. ***P < 0.001, **P < 0.01, *P < 0.05.
Discussion
While it is well-known that emotions influence learning and decision-making in some domains (e.g., fear learning, value-based choice)40, most reinforcement learning models do not explicitly incorporate affective experiences. Instead, these models emphasize reward PEs as the driver of behavior. This may be in part attributable to the fact that it is notoriously difficult to dissociate emotion and reward (although there are examples from real-world negotiations where they may not move in tandem41), or, because it is assumed that reward conceptually encompasses emotion (or vice versa). Here, we ask a basic question about whether RL models of social learning benefit from the inclusion of emotion, and whether emotional error signals might be neurobiologically instantiated in a way that is separate from reward. We leverage the fast temporal resolution of EEG to determine if emotions are neurally indexed in a repeated economic game where one can learn about the intentions and behaviors of others over time.
Our behavioral results show that affective PEs have an independent and stronger effect on choice, especially when there is significant uncertainty about a partner’s actions. As this uncertainty decreases with experience, reward PEs begin to have a greater impact on choice. At the neural level, a priori ERPs are largely associated with distinct PEs: the FRN corresponds most closely to and consistently with reward PEs, the P3b with valence PEs, and the P3a possibly indexes arousal about offer extremity. While these findings suggest that reward and emotion learning signals largely have separate neural correlates with different temporal trajectories, the fact that neural separability depends on whether we control for other PE types in the model, suggests that on some level, reward and valence PEs have some dependency on one another. Moreover, when we separately model reward PE as a function of each ERP, we find that reward PEs indiscriminately engage all ERPs, suggesting more widespread neural encoding that differs from the more selective encoding of affective PEs. This implies a nuanced relationship, where valence and reward PEs may track similar information in the environment, but when controlling for the presence of each PE, their relative contributions become more distinguishable. Finally, at the trial level, that the temporal trajectory of the FRN comes online first and is then followed by the P3b, suggests that monetary offers are likely initially evaluated based on how surprising the reward is (e.g., “How does this monetary offer differ from my reward expectations?”) and only later are violations of emotion expectations incorporated (e.g., “I feel better/worse than anticipated”).
In contrast to reward-centric accounts that dominate the learning literature42, our findings underscore that violations of affective expectations are important for social learning, and that social learning cannot be explained by rewards alone. Although rewards may be sufficient for building successful artificial agents, there is growing concern about whether reward functions (as typically instantiated in RL) are enough to explain the breadth and flexibility of human decision-making43, and it has been suggested that internal, emotional signals might bridge this gap44,45,46. Indeed, our results fit nicely with recent theoretical accounts which argue that emotions can be thought of as computations for evaluating rewarding outcomes47. Importantly, we also show that reward as an error signal still performs an algorithmic role in how the brain learns about the environment, specifically what monetary offer to expect from a partner. While prior affective research has primarily explored long-term affective forecasting errors38 or contexts absent of trial-by-trial learning19, here we provide a direct assessment of affective learning signals at the neural level. We find that the P3b component, which tracks valence PEs, stands as the main neural predictor of social learning. This aligns with prior work showing that the P3b integrates information from multiple mechanisms relevant for decision policy changes36,48. While far less influential, reward PEs still contribute to learning26,33,49,50, and our findings show that the FRN indexes monetary reward PEs—even when controlling for affective signals. In summary, a comprehensive explanation of human decision-making necessitates consideration of both rewards and emotions.
While research indicates that emotional stimuli, such as faces or words, are sometimes processed relatively early51,52,53, our results indicate that evaluations of emotionally charged social exchanges are initially evaluated based on reward. While at first blush this might appear as a discrepancy, emotional experiences unfold over time, which include initial attention to the event and subsequent evaluation54. Because we probe participants’ self-reports of their affective experience following the offer, this approach may align more consistently with the evaluation of an affective experience rather than initial attention. This account aligns with other EEG work showing that late neural components, such as the Late Positive Potential (LPP), are associated with emotional stimuli35. Interestingly, the LPP shares similar morphology with the P3b, is sensitive to a stimulus’s emotional saliency55, can be influenced by cognitive reappraisal or attentional shifts56, and is also known to modulate attention during late-stage processing57,58. Taken together, this suggests that emotional processing that unfolds on later temporal trajectories can still be influential for higher cognition.
Our data also suggests that affective experiences habituate with repeated experiences, giving rise to smaller prediction errors over time. The consequence of blunted affective responses through experience (i.e., reduced prediction errors) means that the emotional experiences of an initial interaction with a social partner is amplified compared to subsequent encounters. This pattern is consistent with normative prescriptions for learning in uncertain and dynamic environments59,60,61, highlighting the possibility that the attenuation of affective experience might serve an important role in optimizing learning under uncertainty. Our results underscore the complexity of social behaviors, which likely relies on multiple signals—monetary rewards, affective experiences, and their violations. There could of course be other candidate variables that are interrelated, such as confidence48 or state uncertainty estimation62. This is supported by the fact that neural ERPs were largely predicted by unsigned PEs, which reflect the magnitude of the PE, regardless of sign. This opens avenues for future research to investigate the neural mechanisms by which unsigned PEs are transformed into signed PEs. While we emphasize the importance of affect in learning, we think future work could manipulate a broader array of factors that influence normative learning dynamics, such as outcome stochasticity60,63, volatility59,63, and temporal structure36,64.
By taking the simple, albeit innovative, step of incorporating emotion as an error signal into a framework, we reveal the importance of affective PEs in driving social learning. With the precise temporal neural time course of EEG, we provide evidence for early processing of reward PEs and the later processing of affective PEs when learning about other people. Although violations of emotion expectations are integrated relatively late in the decision process, they most strongly predict social choice—providing evidence of a neurobiologically plausible separate emotion error signal.
Methods
Participants
Participants (N = 41, 25 female, mean age = 20.8\(\pm\)4.4) provided informed consent and received either monetary compensation ($15 per hour) or course credits. The study was approved by Brown University’s Institutional Review Board under protocol 1607001555. The sample’s sex distribution was representative of the general population, but its age distribution was not and skewed younger. Participants self-reported their sex, which was not analyzed because this study was not powered to detect sex-based differences. A power analysis of the unique effect of valence prediction error on choice in our prior work19 revealed that 18 participants would be sufficient to detect this effect with an alpha of 0.05 and power (beta) of 0.80. Accordingly, we aimed to exceed this and collected a sample of 40 participants which matches sample sizes of recent EEG studies focusing on the FRN and P30036,48.
Task and procedure
Participants played an adapted repeated Ultimatum Game65,66 that included quantitative subjective emotion and reward ratings19,32. Participants were told they were playing with past participants who gave offers across five rounds, conditional on participant’s choices to accept or reject each offer—similar to strategy methods used in economics67. Unknown to participants, their partner’s offers were generated from one of three normal distributions representing three types of proposers: (1) unfair proposers gave offers according to a normal distribution with a mean of $1 and SD of 0.50; (2) neutral proposers gave $3 on average with a SD of 0.50; and (3) fair proposers who gave $5 on average with a SD of 0.50. Participants played with 36 unique partners, 12 of each type and all five offers from each partner were randomly drawn from their respective normal distribution. We used faces from the 74 image MR2 database68 to represent partners and 36 faces were pseudo-randomly pulled from this database per participant to achieve a balanced distribution of images of men and women of European, African, and East Asian ancestry. Importantly, partner faces were never repeated beyond the five repeated trials, meaning participants knew partners would not later reappear. Subjective affective predictions and experiences were reported using a 500-500 pixel two-dimensional affect grid where the horizontal axis was valence (unpleasant/pleasant feelings) and the vertical axis was arousal (low/high intensity feelings). Both dimensions range from –250 to +250. To familiarize participants with this affect grid, participants completed an emotion classification task prior to the repeated UG. Participants made affect ratings of 20 canonical emotion words (for example, angry, sad, and surprised) on the grid, twice for each word, in a randomized order. Training participants to interpret this subjective affect grid has shown strong convergent validity with other approaches for emotion ratings69.
We calculated affective prediction errors (PEs) on a trial-by-trial basis by measuring the discrepancy between participants’ actual affective experiences and their affect expectations. affective PEs can be defined on both valence and arousal dimensions. A valence PE was computed by subtracting the predicted level of (un)pleasantness of an offer from the actual experienced (un)pleasantness, while an arousal PE was the difference between the expected arousal and actual experienced arousal. For instance, if a participant felt unpleasant about receiving an offer (e.g., rating it –200) but had anticipated feeling slightly pleasant (e.g., rating it +40), the valence PE would be –240 (–200 minus +40). Similarly, reward PEs were calculated by subtracting the predicted monetary reward from the actual offer given to the participant for each trial.
For our generalized linear mixed effects regression models we follow the recommended approach to keep the random effect structure maximal70. We fit the maximal random effect structure, when possible, but if a model is overly specified (e.g., modeling random effects for interactions per subject is often not possible) we use singular value decomposition to simplify the random effect structure until the model converges.
The was UG comprised of nine blocks of four partners each (20 trials per block), with self-paced rests between blocks for a total of 180 trials. Participants additionally completed pre-UG and post-UG likability ratings for all 36 partners on a visual analog scale (0–10, in increments of 0.01, see Supplementary Fig. 7). The experiment was delivered in Matlab (The MathWorks, Inc.) using the Psychtoolbox-3 package and included stimulus presentation, event, and response logging. A standard computer mouse and keyboard were used for response registration.
During the UG, participants were first shown a picture of their partner for 1000 ms, followed by a fixation cross (500 ms, same timing for all fixations). Participants were then given cues for reward predictions ($?) or affect predictions (E?; 1000 ms each); these cues indicate that participants will be making the required response on the next screen. Reward predictions (how much participants expect the partner to offer) are reported on a visual analog scale ($0–$10) and participants have unlimited time to respond. Affect predictions (how participants expect to feel after the offer) are reported on the valence-arousal grid and participants are required to answer within 5 s. The order of predictions was counterbalanced and separated by fixations. Following predictions, the offer was given (2000 ms) in dollar and cent format (e.g., $2.37) and followed by another fixation. Participants were then given an affective experience rating cue (E; 1000 ms), which indicated that they should rate how they felt about the offer using the affect-grid (required within 5 s). A fixation followed and then participants were given a choice cue (C; 1000 ms) indicating they would need to make their choice. The choices to accept or reject were presented on the screen (e.g., [A] [R]), and the order of these options was counterbalanced. When participants were matched with a new partner, they were presented with a waiting screen for 1–4 s before starting the next trial.
Prior to experiment, participants filled in the following two personality questionnaires: the 20-item Toronto Alexithymia Scale71 and the Temporal Experience of Pleasure Scale72. These measures were registered as potential control variables and for other purposes not addressed here. Participants were then seated in a shielded EEG cabin. Prior to completing the emotion classification and UG task, participants performed practice trials.
Psychophysiological recording and processing
EEG was recorded using BrainVision recorder software (Brain Products, München, Germany) at a sampling rate of 500 Hz from 64 Ag/AgCl electrodes mounted in an electrode cap (ECI Inc.). Data was collected using Cz as a reference channel and re-referenced to average reference offline. Electrodes below the eyes (IO1, IO2) and at the outer canthi (LO1, LO2) recorded vertical and horizonal ocular activity. At the end of the experiment, we recorded prototypical eye movements (20 trials of each: up, down, left, and right) for offline ocular artifact correction. We kept electrode impedance below 10 kΩ.
EEG data were processed using Matlab (The MathWorks Inc.) using the EEGlab toolbox73 as done in prior research48 and included the following steps: (1) re-referencing to average reference and retrieving the Cz channel, (2) removal of blink and eye movement artifacts using BESA74, (3) bandpass filtering of 0.1–40 Hz, (3), (4) epoching the ongoing EEG from –200 to 800 ms relative to offer onset, (5) removal of segments containing artifacts, based on values exceeding ±150 µV and gradients larger than 50 µV between two adjacent sampling points. Baselines were corrected to the 200 ms pre-stimulus interval (offer onset) using the regression method in subsequent analyses75.
To define the time windows for single-trial analyses of FRN, P3a and P3b amplitudes, we first determined the grant average peak latencies of FCz, FCz, and Pz, respectively. Accordingly, the FRN was quantified on single trials as the average voltage within an interval from 315 to 415 ms after offer onset across all electrodes within a fronto-central region of interest including F3, Fz, F4, FC3, FCz, FC4, C3, Cz, C427. To control for P2 effects on the FRN, the P2 amplitude was also extracted within each trial as the average voltage between 199 and 299 ms across fronto-central electrodes F1, Fz, F2, FC1, FCz, FC2, C1, Cz, C2, and included as a regressor in the analyses. P3a amplitude was quantified on single trials as the average voltage within a 363–463 ms interval post-offer across fronto-central electrodes F1, Fz, F2, FC1, FCz, FC2, C1, Cz, C248. P3b amplitude was quantified on single trials as the average voltage within a 530–630 ms interval post-offer within a parietally-focused region of interest including CP1, CPz, CP2, P1, Pz, P2, PO3, POz, PO448.
We also employ a data-driven method known as a mass univariate analysis that lets us identify potential electrophysiological signatures of reward, valence, and arousal PEs without the need to rely on predefined signals36. We regressed each participant’s offer-locked EEG signal (at every timepoint and channel) against separate variables reflecting the standardized reward, valence, and arousal PEs values, allowing us to determine the unique contribution of each PE. The beta coefficient for each PE, across every electrode (64) and timepoint (500) between –200ms and 800 ms with a step size of 2 ms, was calculated for each participant and then aggregated into a t-statistic representing the predictor variable’s strength for the entire group. Spatiotemporal clusters were formed using a cluster-forming threshold at a p-value of p < 0.01 and the mass of each cluster was computed as the sum of the absolute t-statistics within the cluster. To control for multiple comparisons, we permuted subject betas via sign flipping to create 1000 permutations of our original data, their corresponding t-maps, and spatiotemporal clusters. A null distribution for cluster mass was created by selecting the largest cluster mass value from each permutation. Cluster significance was assessed by examination of actual cluster mass values relative to this null distribution – clusters in the 97.5th percentile were considered significant, essentially implementing a two-tailed test.
Analyses
Reward PEs (RPE) were determined as the offer minus the reward prediction given by participants Valence and Arousal PEs were determined similarly: the affective experience participants reported upon receiving the offer minus participant’s affective prediction for how they would feel after the offer. Prior to analyses, reward, valence, and arousal PEs were standardized but not mean centered, as zero represents a meaningful value on these scales (predicted and actual experiences are the same). Inspection of the behavioral data identified four trials in which impossible affect ratings were given (valence or arousal ratings outside of the 500 by 500-pixel grid) and these data were excluded from relevant analyses.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Processed behavioral, ERP, and continuous EEG data are publicly available at https://github.com/jpheffne/2025_epe_eeg or Zenodo at https://doi.org/10.5281/zenodo.15739721. Uncleaned raw data will be made available upon request to the corresponding author.
Code availability
Data analysis scripts for reproducing manuscript results are publicly available at https://github.com/jpheffne/2025_epe_eeg or Zenodo at https://doi.org/10.5281/zenodo.15739721.
References
Pessiglione, M., Seymour, B., Flandin, G., Dolan, R. J. & Frith, C. D. Dopamine-dependent prediction errors underpin reward-seeking behaviour in humans. Nature 442, 1042–1045 (2006).
King-Casas, B. et al. Getting to know you: reputation and trust in a two-person economic exchange. Science 308, 78–83 (2005).
Schultz, W., Dayan, P. & Montague, P. R. A neural substrate of prediction and reward. Science 275, 1593–1599 (1997).
Schultz, W. & Dickinson, A. Neuronal coding of prediction errors. Annu. Rev. Neurosci. 23, 473–500 (2000).
Daw, N. D., Gershman, S. J., Seymour, B., Dayan, P. & Dolan, R. J. Model-based influences on humans’ choices and striatal prediction errors. Neuron 69, 1204–1215 (2011).
Rouhani, N. & Niv, Y. Signed and unsigned reward prediction errors dynamically enhance learning and memory. eLife 10, e61077 (2021).
Sutton, R. S. & Barto, A. G. Reinforcement learning: An introduction 2nd ed. (The MIT Press, 2018).
Sosa, M. & Giocomo, L. M. Navigating for reward. Nat. Rev. Neurosci. 22, 472–487 (2021).
Lamba, A., Frank, M. J. & FeldmanHall, O. Anxiety impedes adaptive social learning under uncertainty. Psychol. Sci. 31, 592–603 (2020).
Lerner, J. S., Li, Y., Valdesolo, P. & Kassam, K. S. Emotion and decision making. Annu. Rev. Psychol. 66, 799–823 (2015).
Phelps, E. A. Emotion and cognition: insights from studies of the human amygdala. Annu. Rev. Psychol. 57, 27–53 (2005).
FeldmanHall, O., Raio, C. M., Kubota, J. T., Seiler, M. G. & Phelps, E. A. The effects of social context and acute stress on decision making under uncertainty. Psychol. Sci. 26, 1918–1926 (2015).
Stanton, S. J., Reeck, C., Huettel, S. A. & LaBar, K. S. Effects of induced moods on economic choices. Judgm. Decis. Mak. 9, 167–175 (2014).
Martin, L. N. & Delgado, M. R. The influence of emotion regulation on decision-making under risk. J. Cogn. Neurosci. 23, 2569–2581 (2011).
Frijda, N. H. Emotion, cognitive structure, and action tendency. Cogn Emot. 1, 115–143 (1987).
Lowe, R. The feeling of action tendencies: on the emotional regulation of goal-directed behavior. Front. Psychol. 2 https://doi.org/10.3389/fpsyg.2011.00346 (2011).
Barrett, L. F. The theory of constructed emotion: an active inference account of interoception and categorization. Soc. Cogn. Affect. Neurosci. 12, 1–23 (2017).
Heimer, O., Kron, A. & Hertz, U. Temporal dynamics of the semantic versus affective representations of valence during reversal learning. Cognition 236, 105423 (2023).
Heffner, J., Son, J.-Y. & FeldmanHall, O. Emotion prediction errors guide socially adaptive behaviour. Nat. Hum. Behav. 5, 1391–1401 (2021).
Friston, K. & Kiebel, S. Predictive coding under the free-energy principle. Philos. Trans. R. Soc. Lond. B Biol. Sci. 364, 1211–1221 (2009).
Clark, A. Whatever next? Predictive brains, situated agents, and the future of cognitive science. Behav. Brain Sci. 36, 181–204 (2013).
Tseng, Y. -w, Diedrichsen, J., Krakauer, J. W., Shadmehr, R. & Bastian, A. J. Sensory prediction errors drive cerebellum-dependent adaptation of reaching. J. Neurophysiol. 98, 54–62 (2007).
Lohrenz, T., Bhatt, M., Apple, N. & Montague, P. R. Keeping up with the Joneses: interpersonal prediction errors and the correlation of behavior in a tandem sequential choice task. PLoS Comput. Biol. 9, e1003275 (2013).
Hauser, T. U. et al. The feedback-related negativity (FRN) revisited: new insights into the localization, meaning and network organization. NeuroImage 84, 159–168 (2014).
Hayden, B. Y., Heilbronner, S. R., Pearson, J. M. & Platt, M. L. Surprise signals in anterior cingulate cortex: neuronal encoding of unsigned reward prediction errors driving adjustment in behavior. J. Neurosci. 31, 4178–4187 (2011).
Holroyd, C. B. & Coles, M. G. H. The neural basis of human error processing: reinforcement learning, dopamine, and the error-related negativity. Psychol. Rev. 109, 679–709 (2002).
Yeung, N. & Sanfey, A. Independent coding of reward magnitude and valence in the human brain. J. Neurosci. 24, 6258–6264 (2004).
Hajcak, G., Holroyd, C. B., Moser, J. S. & Simons, R. F. Brain potentials associated with expected and unexpected good and bad outcomes. Psychophysiology 42, 161–170 (2005).
Mars, R. B. et al. Trial-by-trial fluctuations in the event-related electroencephalogram reflect dynamic changes in the degree of surprise. J. Neurosci. 28, 12539 (2008).
Ting, X., Terry, L. & Montague, P. R. Computational substrates of norms and their violations during social exchange. J. Neurosci. 33, 1099 (2013).
Xiaosi, G. et al. Necessary, yet dissociable contributions of the insular and ventromedial prefrontal cortices to norm adaptation: computational and lesion evidence in humans. J. Neurosci. 35, 467 (2015).
Heffner, J. & FeldmanHall, O. A probabilistic map of emotional experiences during competitive social interactions. Nat. Commun. 13, 1718 (2022).
Sambrook, T. D. & Goslin, J. A neural reward prediction error revealed by a meta-analysis of ERPs using great grand averages. Psychol. Bull. 141, 213 (2015).
San Martín, R. Event-related potential studies of outcome processing and feedback-guided learning. Front Hum. Neurosci. 6, 304 (2012).
Rahman, A. Facing good and evil: early brain signatures of affective biographical knowledge in face recognition. Emotion 11, 1397–1405 (2011).
Nassar, M. R., Bruckner, R. & Frank, M. J. Statistical context dictates the relationship between feedback-related EEG signals and learning. eLife 8, e46975 (2019).
Gilbert, D. T., Pinel, E. C., Wilson, T. D., Blumberg, S. J. & Wheatley, T. P. Immune neglect: a source of durability bias in affective forecasting. J. Personal. Soc. Psychol. 75, 617–638 (1998).
Wilson, T. D. & Gilbert, D. T. Affective forecasting: knowing what to want. Curr. Dir. Psychol. Sci. 14, 131–134 (2005).
Xiao, E. & Houser, D. Emotion expression in human punishment behavior. Proc. Natl Acad. Sci. USA 102, 7398–7401 (2005).
Phelps, E. A., Lempert, K. M. & Sokol-Hessner, P. Emotion and decision making: multiple modulatory neural circuits. Annu. Rev. Neurosci. 37, 263–287 (2014).
FeldmanHall, O. & Heffner, J. A generalizable framework for assessing the role of emotion during choice. Am. Psychol. 77, 1017–1029 (2022).
Silver, D., Singh, S., Precup, D. & Sutton, R. S. Reward is enough. Artif. Intell. 299, 103535 (2021).
Shenhav, A. The affective gradient hypothesis: an affect-centered account of motivated behavior. Trends Cogn. Sci. 28, 1089–1104 (2024).
Juechems, K. & Summerfield, C. Where does value come from?. Trends Cogn. Sci. 23, 836–850 (2019).
FeldmanHall, O. & Nassar, M. R. The computational challenge of social learning. Trends Cogn. Sci. 25, 1045–1057 (2021).
FeldmanHall, O. & Heffner, J. A generalizable framework for assessing the role of emotion during choice. Am. Psychologist 77, 1017–1029 (2022).
Emanuel, A. & Eldar, E. Emotions as computations. Neurosci. Biobehav. Rev. 144, 104977 (2023).
Frömer, R. et al. Response-based outcome predictions and confidence regulate feedback processing and learning. eLife 10, e62825 (2021).
Holroyd, C. B., Nieuwenhuis, S., Yeung, N. & Cohen, J. D. Errors in reward prediction are reflected in the event-related brain potential. Neuroreport 14, 2481–2484 (2003).
Cavanagh, J. F. Cortical delta activity reflects reward prediction error and related behavioral adjustments, but at different times. NeuroImage 110, 205–216 (2015).
Willis, J. & Todorov, A. First impressions: making up your mind after a 100-Ms exposure to a face. Psychol. Sci. 17, 592–598 (2006).
Baum, J. & Abdel Rahman, R. Emotional news affects social judgments independent of perceived media credibility. Soc. Cogn. Affect. Neurosci. 16, 280–291 (2021).
Phelps, E. A., Ling, S. & Carrasco, M. Emotion facilitates perception and potentiates the perceptual benefits of attention. Psychol. Sci. 17, 292–299 (2006).
Barrett, L. F. & Gross, J. J. in Emotions: Currrent Issues and Future Directions. Emotions and Social Behavior. 286–310 (The Guilford Press, 2001).
Brown, S., van Steenbergen, H., Band, G., de Rover, M. & Nieuwenhuis, S. Functional significance of the emotion-related late positive potential. Front. Hum. Neurosci. 6, https://doi.org/10.3389/fnhum.2012.00033 (2012).
DeCicco, J. M., O’Toole, L. J. & Dennis, T. A. The late positive potential as a neural signature for cognitive reappraisal in children. Dev. Neuropsychol. 39, 497–515 (2014).
Liu, Y., Huang, H., McGinnis-Deweese, M., Keil, A. & Ding, M. Neural substrate of the late positive potential in emotional processing. J. Neurosci. 32, 14563–14572 (2012).
Dennis, T. A. & Hajcak, G. The late positive potential: a neurophysiological marker for emotion regulation in children. J. Child Psychol. Psychiatry 50, 1373–1383 (2009).
Behrens, T. E., Woolrich, M. W., Walton, M. E. & Rushworth, M. F. Learning the value of information in an uncertain world. Nat. Neurosci. 10, 1214–1221 (2007).
Nassar, M. R., Wilson, R. C., Heasly, B. & Gold, J. I. An approximately Bayesian delta-rule model explains the dynamics of belief updating in a changing environment. J. Neurosci. 30, 12366–12378 (2010).
Yu, L. Q., Wilson, R. C. & Nassar, M. R. Adaptive learning is structure learning in time. Neurosci. Biobehav. Rev. 128, 270–281 (2021).
Nassar, M. R., McGuire, J. T., Ritz, H. & Kable, J. W. Dissociable forms of uncertainty-driven representational change across the human brain. J. Neurosci. 39, 1688 (2019).
Piray, P. & Daw, N. D. A model for learning based on the joint estimation of stochasticity and volatility. Nat. Commun. 12, 6587 (2021).
Razmi, N. & Nassar, M. R. Adaptive learning through temporal dynamics of state representation. J. Neurosci. 42, 2524–2538 (2022).
Cooper, D. J. & Dutcher, E. G. The dynamics of responder behavior in ultimatum games: a meta-study. Exp. Econ. 14, 519–546 (2011).
Güth, W., Schmittberger, R. & Schwarze, B. An experimental analysis of ultimatum bargaining. J. Econ. Behav. Organ. 3, 367–388 (1982).
Bahry, D. L. & Wilson, R. K. Confusion or fairness in the field? Rejections in the ultimatum game under the strategy method. J. Econ. Behav. Organ. 60, 37–54 (2006).
Strohminger, N. et al. The MR2: a multi-racial, mega-resolution database of facial stimuli. Behav. Res. Methods 48, 1197–1204 (2016).
Russell, J., Weiss, A. & Mendelsohn, G. Affect grid: a single-item scale of pleasure and arousal. J. Personal. Soc. Psychol. 57, 493–502 (1989).
Barr, D. J., Levy, R., Scheepers, C. & Tily, H. J. Random effects structure for confirmatory hypothesis testing: keep it maximal. J. Mem. Lang. 68 https://doi.org/10.1016/j.jml.2012.11.001 (2013).
Bagby, R. M., Parker, J. D. A. & Taylor, G. J. The twenty-item Toronto Alexithymia scale—I. Item selection and cross-validation of the factor structure. J. Psychosom. Res. 38, 23–32 (1994).
Gard, D. E., Gard, M. G., Kring, A. M. & John, O. P. Anticipatory and consummatory components of the experience of pleasure: a scale development study. J. Res. Personal. 40, 1086–1102 (2006).
Delorme, A. & Makeig, S. EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 134, 9–21 (2004).
Ille, N., Berg, P. & Scherg, M. Artifact correction of the ongoing EEG using spatial filters based on artifact and brain signal topographies. J. Clin. Neurophysiol. 19, 113–124 (2002).
Alday, P. M. How much baseline correction do we need in ERP research? Extended GLM model can replace baseline correction while lifting its limits. Psychophysiology 56, e13451 (2019).
Acknowledgements
The authors are grateful to all study participants. We thank Jae-Young Son for his assistance in modularizing the Matlab code used to run the EEG experiment. We extend our sincere gratitude to Isabella Aslarus and Amelia Michael for their invaluable help with data collection, and to Julia Baum for piloting the study. J.H. was supported by a Carney Institute for Brain Science Graduate Award in Brain Science. R.F. was funded through an AMS Springboard award and a subaward on NSF grant 2309022. O.F.H. was supported by NIH grant (P20GM103645).
Author information
Authors and Affiliations
Contributions
J.H., R.F., and O.F.H. conceptualized and designed the research. J.H. and R.F. collected the data. J.H., R.F., and M.N. analyzed the data. J.H. and O.F.H. drafted the manuscript, and all authors revised it.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Heffner, J., Frömer, R., Nassar, M.R. et al. Separable neural signals for reward and emotion prediction errors. Nat Commun 16, 7849 (2025). https://doi.org/10.1038/s41467-025-63135-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-63135-5
