
Abstract
Biomolecular condensates are found throughout a diversity of eukaryotic cell types and cellular compartments, playing roles in various cellular functions. A given protein generally forms functionally and compositionally heterogeneous condensates, but the underlying regulatory mechanisms are unknown. Here, we found that different RNA motifs modulate the formation of heterogeneous mRNA-protein condensates via riboregulation. Fragile X-related 1 (FXR1), an RNA-binding protein interacting with nuclear pores, assembles distinct localized subcellular mRNP condensates linked to cytosolic accumulation of G-quadruplex-containing pluripotent mRNAs and the localized translation of nucleoporin mRNAs at nuclear pores. The diverse locations of FXR1 condensates depend on the unique RNA-protein interaction modules of its two RNA binding domains, and the opposing effects of different RNA motifs on the affinity of FXR1 for nuclear pores. Notably, reduced FXR1 levels and impaired nuclear pore function lead to the nuclear accumulation of transcribed RNAs, facilitating fate transition in human embryonic stem cells. Preventing this decline would result in impaired hESC differentiation.
Similar content being viewed by others

Introduction
Biomolecular condensates are found throughout a diversity of eukaryotic cell types and cellular compartments, including in the nucleus, cytoplasm, and on membranes. They are involved in a variety of cellular functions, organizing molecules that act in processes ranging from chromatin organization and transcription to RNA metabolism and signaling1,2. The discovery of biomolecular condensates has moved our understanding of gene regulation away from traditional models of linear molecular interactions towards an understanding of how spatial compartmentalization leads to non-linear regulatory behaviors3. Early work in the field showed that multivalent interaction-driven phase separation is an important organizing principle for biomolecular condensates1,4. In recent years, scientific attention has focused on understanding condensate functions. In images captured of condensates within cells, we often see that a given protein can form condensates of different sizes and distributions5,6, and these condensates are likely to be functionally and compositionally heterogeneous. However, their dynamic composition, localization, function, and the regulatory mechanisms behind them remain largely unknown.
RNA-binding proteins (RBPs) are important molecular chaperones of RNA that regulate RNA metabolism and function throughout their life cycle7,8 and are extensively involved in biomolecular condensate formation due to their richness in intrinsically disordered regions (IDRs)9,10,11,12. RBPs are often multifunctional, with one RBP binding to multiple RNA molecules and regulating different processes of RNA metabolism simultaneously7. Some RBPs may exert their diverse functions by forming distinct biomolecular condensates, so it is apt to focus on RBPs when studying the heterogeneity of biomolecular condensates formed by the same protein. RBPs can interact with RNA to regulate RNA metabolism and function, and conversely, RNA can bind to RBP to affect its fate and function in a process called riboregulation13. Riboregulation has been demonstrated to modulate the glycolytic enzyme activity of ENO113, RNA polymerase activity14, and even the oligomerization state of autophagy receptors15. However, the role of riboregulation in RNA metabolism and condensate formation is less well studied, even though the mutual influence between RBP and RNA must be critical for RBP functioning.
mRNA nuclear export is an important step in RNA metabolism and is required for its translation into a functional protein. When mRNA passes through a nuclear pore with the assistance of a series of transport factors, it undergoes mRNA-protein complex (mRNP) remodeling, which is critical for mRNA fate determination after nuclear export16,17. The nuclear-exported mRNAs can be rapidly translated, transported to a particular location before translation, temporarily stored, or degraded18,19. However, it is not well understood how these different fates are coordinated and how the mutual regulation between mRNAs and RBPs affects their fate.
Here, we revealed a series of RBPs that regulate RNA nucleocytoplasmic distribution by capturing the nuclear pore complex (NPC) interactome. One RBP, FXR1, was found to interact with the cytoplasmic fibers of the NPC and regulate mRNA localization. More interestingly, FXR1 was shown to form distinct subcellular localized RNP condensates that are associated with the cytosolic accumulation of G-quadruplex-containing mRNAs and mediate the localized translation of nucleoporin mRNAs at the nuclear pore. The diverse locations of FXR1 condensates depended on the different RNA-protein interaction modules of its two RNA-binding domains (RBDs), as well as the opposing influences on the affinity of FXR1 with NPC after RNA binding. Moreover, we discovered that the FXR1-mediated repression of nucleoporin mRNA translation and nuclear pore activity during human embryonic stem cell (hESC) differentiation is required for its response to cell fate transition, revealing a previously unrecognized layer to our understanding of the regulation of hESC pluripotency.
Results
Systematic characterization of nuclear-pore-interacting RBPs in hESCs
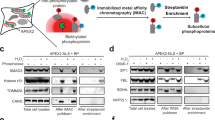
To comprehensively characterize the RBPs involved in mRNP remodeling during mRNA export, we employed an antibody targeting nucleoporin family members to capture NPCs, followed by co-immunoprecipitation (Co-IP) coupled with mass spectrometry (MS) analysis and the separate isolation of nuclear and cytoplasmic fractions (Fig. 1a and Supplementary Fig. 1a; Supplementary Data 1). This approach yielded 387 proteins, including all 30 known human nucleoporins. Notably, high-enrichment interactors were closely associated with nucleocytoplasmic transport and nuclear export processes, while medium and low-enrichment interactors were linked to RNA splicing, DNA metabolism and cytoplasmic translation, respectively (Fig. 1b). Of these, 113 (35%) were mainly distributed on the nucleoplasmic side, 156 (48%) were distributed on the cytoplasmic side, and 57 (17%) were dual distribution. Particularly, high enrichment interactors were mainly distributed on the nucleoplasmic side (Fig. 1c and Supplementary Fig. 1b). Statistically, enzymes, transporters, DNA-binding proteins, RBPs, and ribosomal proteins represented the most abundant categories of the interactome (Fig. 1d and Supplementary Fig. 1c, d). For many of these proteins, interactions with the nuclear pore were experimentally validated as partially RNA-dependent (Supplementary Fig. 1e, f).

a Strategies for capturing nuclear pore-interacting RNA-binding proteins (RBPs) and imaging screening; NPC nuclear pore complex, Nuc. nucleus, Cyto. cytoplasm, hESC human embryonic stem cell. b Box plot of nucleoporins (NUPs) and interactors enrichment in the NPC interactome, with functional enrichment analysis stratified by enrichment level, box plots indicate median (middle line), 25th, 75th percentile (box) and 5th and 95th percentile (whiskers) as well as outliers (single points). c Distribution of NPC-interactors with varying enrichment levels. d Composition, subcellular localization, and quantity of NPC interactome. e Subcellular distribution of NPC-enriched canonical RBPs. f RNA-binding domains in RBPs from (e) and functional enrichment of these RBPs. g Image-based screening workflow assessing the effects of RBPs on mRNA nucleo-cytoplasmic distribution. h The mean nucleocytoplasmic mRNA ratios were determined for the top 15 RBPs (analyzed in two experimental rounds) and other RBPs (data from the first round) after 72 h of RBP knockdown. i FISH images and line scan graphs of OCT4 mRNA nucleocytoplasmic localization following 72 h knockdown of top 5 RBPs and NXF1. j Pluripotency assessment by alkaline phosphatase (AP) staining and colony formation assay after 72 h RBPs knockdown; n = 3 biologically independent replicates. k Colocalizations between the RBPs and the nuclear pore, as detected by immunofluorescence, images representative of three experiments. Data represent the mean ± SEM. P values were determined by Student’s unpaired two-tailed t test (j). Source data are provided as a Source Data file.
A total of 44 canonical RBPs were identified as NPC interactors (Fig. 1d), with approximately 50% overlapping with those detected by APEX-based approaches20,21 (Supplementary Fig. 1g), validating the reliability of our identification. Spatially, nearly half of these RBPs were distributed mainly in the nucleus, and approximately one-quarter showed nucleo-cytoplasmic colocalization (Fig. 1e). Structurally, the majority of these RBPs harbored RNA-recognition motifs, K homology (KH) and zinc finger domains, as well as an RGG box, with several containing multiple RBDs. These modular combinations permit them to orchestrate binding to RNA targets, thereby regulating multiple RNA metabolic processes (Fig. 1f). Notably, most of these proteins were not previously known to interact with the NPC (Supplementary Fig. 1h), and their potential roles in RNA transport remain to be elucidated.
Image screening of RBPs responsible for mRNA nucleo-cytoplasmic distribution
Next, we performed image-based screening to test the effects of these RBPs on mRNA transport using OCT4 mRNA fluorescence in situ hybridization (FISH) (Fig. 1g). Given the absence of high-throughput image-screening tools, we constructed individual short-hairpin (sh)RNAs to knock down each RBP, along with the positive control mRNA transporter NXF1 in hESCs, then captured confocal images and quantitatively analyzed the nucleus and cytoplasm signals (Fig. 1g). Initially, we confirmed that NXF1 knockdown significantly increased the nuclear-to-cytoplasmic ratio of OCT4 mRNA and three other mRNAs (Supplementary Fig. 2a, b). After two rounds of screening (Supplementary Fig. 2c), we ranked the RBPs based on their impact on the nuclear-to-cytoplasmic ratio of OCT4 mRNA and demonstrated that knockdown of most RBPs led to an increased nuclear-to-cytoplasmic ratio of OCT4 mRNA, while a few RBPs (e.g., RBMX) decreased it (Fig. 1h).
We further focused on the top five RBPs whose knockdown increased the nuclear-to-cytoplasmic ratio of OCT4 mRNA. In all cases, cytoplasmic OCT4 mRNA signals decreased while nuclear signals increased, with little change in total OCT4 mRNA levels; these effects were not observed in negative control RBPs (e.g., SFPQ) (Fig. 1i and Supplementary Fig. 2d, e). This nucleocytoplasmic redistribution of OCT4 mRNA ultimately led to a decline in OCT4 protein levels (Supplementary Fig. 2g). Among them, FUS, HNRNPM, and PTBP1 also affected OCT4 mRNA stability, which may contribute to the altered nuclear-to-cytoplasmic ratio (Supplementary Fig. 2f). In contrast, FXR1 and G3BP2 had no effect on OCT4 mRNA stability and likely influenced the nuclear-to-cytoplasmic ratio primarily by facilitating OCT4 mRNA nuclear export (Supplementary Fig. 2f). Further investigation revealed that knockdown of these RBPs significantly increased the nuclear-to-cytoplasmic ratio of multiple pluripotent transcripts (Supplementary Fig. 2h), reduced hESC colony numbers, and resulted in differentiated colonies, whereas the control RBPs did not have this effect (Fig. 1j and Supplementary Fig. 2i). Time-course experiments with NXF1 depletion revealed that changes in RNA nuclear-to-cytoplasmic distribution may precede hESC differentiation (Supplementary Fig. 2j), implying that differentiation may be driven by the dysregulated RNA partitioning.
Lastly, we validated the interactions between these RBPs and nuclear pores through co-immunoprecipitation and proximity ligation assays, with most of these interactions being RNA-independent (Supplementary Fig. 2k, l). Immunofluorescence experiments further revealed that FUS, HNRNPM, and PTBP1 are colocalized with nuclear pores on the nucleoplasmic side, implicating their potential roles in early mRNA export steps, such as nuclear basket docking or export receptor recruitment (Fig. 1k). In contrast, G3BP2 and FXR1 colocalize with nuclear pores on the cytoplasmic side, consistent with potential functions in cytoplasmic mRNP remodeling (Fig. 1k). Notably, FXR1 had accumulated around the nuclear pore and formed microscopically visible particles, suggesting that it may regulate mRNA nuclear–cytoplasmic distribution by forming mRNP condensates.
FXR1 regulates mRNA localization and localized translation near nuclear pores
FXR1 is a member of the Fragile X-related (FXR) gene family22 and has been shown to regulate mRNA translation by interacting with ribosomes23,24, facilitating the recruitment of translation initiation factors19, and undergoing phase separation25. To clarify how FXR1 regulates mRNA localization, we conducted separate RNA sequencing of the nuclear and cytoplasmic fractions of hESCs with FXR1 depletion, and enhanced cross-linked immunoprecipitation and sequencing (eCLIP-seq) of FXR1 (Fig. 2a and Supplementary Fig. 3a, b; Supplementary Data 2). The deletion of FXR1 increased the nuclear-to-cytoplasmic ratio of a substantial number of mRNAs (Fig. 2b), including pluripotency, translation and cell cycle-related transcripts, and significantly reduced the corresponding protein levels (Fig. 2c and Supplementary Fig. 3c, d; Supplementary Data 3). FXR1 deletion also decreased the nuclear-to-cytoplasmic ratio of a subset of genes, but the number was around half that of the former, and these genes were expressed at low levels (Fig. 2b and Supplementary Fig. 3e, f). We further focused on a specific subset of mRNAs that are directly bound to FXR1 (Fig. 2d). Nuclear-cytoplasmic separation coupled with qPCR and RNA FISH collectively confirmed that depletion of FXR1 significantly increased the nuclear-to-cytoplasmic ratio of multiple pluripotent transcripts, including MDFI, DDIT4, PHF5A, and TRAPPC3 mRNAs (Fig. 2e, f). RNA-seq analysis further revealed significant nuclear retention accompanied by moderate cytoplasmic depletion of these mRNAs, with unchanged total mRNA abundance (Supplementary Fig. 3g). Notably, FXR1 depletion did not alter the half-lives of these transcripts (Supplementary Fig. 3h), but led to pronounced decreases in encoded protein levels (Supplementary Fig. 3i). This highlights the potential role of FXR1 in promoting the cytosolic accumulation of pluripotent transcripts.

a Schematic diagram of nucleocytoplasmic fractionation RNA-seq and FXR1 eCLIP-seq of hESCs. b Quantification of transcripts showing altered nucleocytoplasmic ratios following 72 h FXR1 depletion. c The protein level changes and nucleocytoplasmic ratio alterations for nuclear-retained transcripts upon FXR1 depletion. d Changes in nucleocytoplasmic ratios of transcripts directly bound to FXR1 after FXR1 depletion. e qPCR validation of nucleocytoplasmic ratio alterations for pluripotency transcripts after FXR1 depletion; n = 3 independent replicates. f FISH images and quantitation of pluripotent transcript distribution upon FXR1 depletion; MDFI n(cell) per group = 144, 187, 205; DDIT4 n(cell) per group = 224, 266, 178; PHF5A n(cell) per group = 141, 166, 257; TRAPPC3 n(cell) per group = 125, 155, 171, respectively. Images representative of three experiments. g Functional annotation of transcripts directly bound by FXR1. h Number and proportion of FXR1-binding nucleoporin mRNAs among nucleocytoplasmic transport gene terms and among all FXR1-binding transcripts. i Nucleocytoplasmic ratio changes of FXR1-bound nucleoporin mRNAs after FXR1 depletion. j Heat map showing enrichment of FXR1-bound nucleoporin mRNAs at nuclear pores in hESCs. k Changes in the enrichment of FXR1-bound nucleoporin mRNAs at nuclear pores after FXR1 knockdown. l FISH detection of location of NUP358 and AHCTF1 mRNAs, and jitter plots showing positions of indicated mRNA foci relative to nuclear pores after FXR1 depletion; NUP358 n(cell) per group = 26, 25, 25; AHCTF1 n(cell) per group = 25, 26, 25; Images are representative of cells from 3 independent experiments. m Puromycin-based proximity ligation assay detecting nascent nucleoporin peptides and quantification of translation events; NUP358 n(cell) per group = 36, 37; AHCTF1 n(cell) per group = 37, 37; Images are representative of cells from 3 independent experiments. n Stimulated emission depletion (STED) microscopy super-resolution images of nuclear pores and quantification of NPC fluorescence intensity and density; NC group n(cell) = 20; FXR1 KD group n(cell) = 23; Images are representative of cells from two independent experiments; Box plots indicate median (middle line), 25th, 75th percentile (box) and 5th and 95th percentile (whiskers) as well as outliers (single points). Data represent the mean ± SEM. P values were determined by Student’s unpaired two-tailed t test (e, f, n), and two-tailed Wilcoxon rank sum test (l, m). Source data are provided as a Source Data file.
FXR1 was observed to bind other RNAs, predominantly nucleocytoplasmic transport-associated transcripts (Fig. 2g), 13 of which were nucleoporin mRNAs that accounted for 42% of all nucleoporin mRNAs (Fig. 2h). Moreover, the binding potencies were the strongest and enrichment ratios were the highest among the transcripts of giant intracellular complexes, indicating the specificity of FXR1 binding with nucleoporin mRNAs (Supplementary Fig. 3j). Unexpectedly, FXR1 depletion did not affect the nuclear-to-cytoplasmic ratio of most FXR1-bound nucleoporin mRNAs (Fig. 2i). Nucleoporin transcripts in yeast cells gather at nuclear pores to undergo localized translation26. Thus, we were curious as to whether they do this in hESCs and whether FXR1 mediates them. To answer this question, we conducted the RNA immunoprecipitation of nuclear pores in hESCs and found that most nucleoporin mRNAs were indeed enriched (Fig. 2j). Puromycin-based proximity ligation assays27,28 revealed that nascent nucleoporins were synthesized near nuclear pores, with their abundance significantly reduced upon cycloheximide treatment, indicating active local translation (Supplementary Fig. 3k). Furthermore, nucleoporin mRNAs such as NUP358 and AHCTF1 localization and local translation at nuclear pores was clearly reduced with FXR1 inhibition (Fig. 2k–m and Supplementary Fig. 3l). Polysome profiling qPCR further corroborated these findings, revealing translational downregulation of most nucleoporin mRNAs after FXR1 depletion, that correlated with decreased protein expression, but not their mRNAs (Supplementary Fig. 3m–o). Finally, we observed individual nuclear pores by super-resolution stimulated emission depletion (STED) microscopy and transmission electron microscopy, and found that FXR1 depletion led to a significant decrease in the fluorescence intensity, density, and diameter of the nuclear pores (Fig. 2n and Supplementary Fig. 3p). These results indicated that FXR1 mediates the localization of nucleoporin mRNAs at nuclear pores and assists in their subsequent local translation. Taken together, FXR1 plays a dual role in potentially facilitating the cytosolic accumulation of pluripotent mRNAs and localized translation of nucleoporin mRNAs.
FXR1 forms mRNP condensates associated with both RNA localization and localized translation through distinct partners
To further dissect the dual function of FXR1, we first detected the colocalization of FXR1 with its two classes of mRNA targets using RNA FISH combined with FXR1 immunofluorescence. Staining results showed that FXR1 formed microscopically visible mRNP condensates with its mRNA targets (Fig. 3a). We also noticed that the FXR1 transport-associated condensates that colocalized with pluripotency gene transcripts were more widely distributed in the cytoplasm, whereas FXR1 local translation-associated condensates colocalized with nucleoporin mRNAs were more tightly aggregated around the nuclear membrane (Fig. 3b).

a Colocalization of FXR1 with target mRNAs in fixed hESCs, and red arrows indicate representative colocalized puncta; Images are representative of cells from three independent experiments. b Distance of mRNP condensates from the nuclear membrane; MDFI n(condensate) = 200; PHF5A n(condensate) = 200; DDIT4 n(condensate) = 200; TRAPPC3 n(condensate) = 200; AHCTF1 n(condensate) = 200; NUP358 n(condensate) = 200; NUP153 n(condensate) = 177; NUP214 n(condensate) = 82. c Workflow for FXR1-interacting protein enrichment and proteomic characterization. d Functional enrichment of FXR1-interacting proteins. e Relative abundance of translation- (blue) and transport-related (purple) proteins identified by FXR1 Co-IP/MS. f Immunofluorescence showing FXR1 colocalization with transport or translation factors, and red arrows indicate representative colocalized puncta. g Immunofluorescent labeling combined with FISH showing colocalization of FXR1 with its target transcripts and cofactors; Images representative of three experiments. h qPCR analysis of nucleocytoplasmic ratios for pluripotency transcripts after TUBG1 or MYL12A knockdown 72 h; n = 3 independent replicates. i Puro-PLA detection of nascent nucleoporin peptides near nuclear pores following EIF5B or PABPC1 knockdown. j Quantification of perinuclear translation events from (i); NUP358 n(cell) per group = 49, 85, 54; AHCTF1 n(cell) per group = 32, 72, 49; NUP214 n(cell) per group = 36, 83, 85. Data represent the mean ± SEM. P values were determined by Student’s unpaired two-tailed t test (b, h, j); Box plots indicate median (middle line), 25th, 75th percentile (box) and 5th and 95th percentile (whiskers) as well as outliers (single points) (b, j). Source data are provided as a Source Data file.
Considering that mRNP particles typically incorporate multiple proteins to synergistically regulate mRNA fate, we employed immunoprecipitation followed by MS analysis to further identify potential cofactors of FXR1 in the different mRNP condensates (Fig. 3c; Supplementary Data 4). A total of 314 FXR1-interacting proteins were identified, including established RNA transporters such as mRNA export adapter Aly/REF export factor, microtubule components, and myosin (Fig. 3d, e). FXR1 recruits these transport factors in the cytoplasm to form transport-associated condensates (Fig. 3f and Supplementary Fig. 4a). In addition, FXR1 bound to a number of translation factors, including several translational initiation factors, ribosomal proteins, and poly(A)-binding proteins (Fig. 3e). In contrast to the former, FXR1 recruits these translation factors around the nuclear membrane to form localized translation-associated condensates (Fig. 3f and Supplementary Fig. 4a).
To determine whether FXR1 recruits distinct cofactors for its two classes of mRNA targets, we performed high-resolution microscopic analysis to assess the triple colocalization of FXR1, its cofactors, and target mRNAs (Fig. 3g). Super-resolution imaging revealed specific co-assembly of FXR1 with pluripotent mRNAs and RNA transport factors within cytoplasmic condensates. This is in contrast to the behavior of FXR1 at nuclear pores, where it formed condensates with nucleoporin mRNAs and a set of translation factors (Fig. 3g and Supplementary Fig. 4b). Depletion of transport factors TUBG1 and MYL12A significantly reduced the cytoplasmic-to-nuclear ratio of FXR1-regulated pluripotent transcripts (Fig. 3h and Supplementary Fig. 4c, d). Conversely, depletion of translation factors EIF5B and PABPC1, disrupted the localized synthesis of nucleoporins (Fig. 3i, j and Supplementary Fig. 4c, d). Collectively, these results demonstrate that FXR1 assembles two distinct types of condensates: perinuclear condensates associated with translation machinery, and dispersed cytosolic condensates associated with transport proteins.
FXR1 undergoes phase separation in vitro and forms distinct mRNP condensates in hESCs
Mouse FXR1 has been found to undergo phase separation to activate the translation of stored mRNAs in spermiogenesis25. Therefore, we investigated whether human FXR1 also undergoes phase separation in vitro and forms functional mRNP condensates in hESCs. Firstly, an IDR was identified at the C-terminal end of human FXR1 that overlapped with its RGG domain and was separate from the Agenet domain and KH domain (Fig. 4a). Secondly, to test the phase separation ability of human FXR1 and to determine which domain primarily contributes to this, we purified fluorescently-labeled full-length FXR1 and different domain truncations (Fig. 4b). The full-length FXR1, the RGG domain, and the KH domain formed spherical droplets in vitro in a concentration-dependent manner, whereas the Agenet domain protein and the enhanced green fluorescent protein (EGFP) protein failed to do so (Fig. 4c–e). The KH domain formed spherical droplets in vitro at a relatively high concentration compared to the full-length FXR1 and the RGG domain, suggesting that the RGG domain primarily contributes to the phase separation of FXR1, and the KH domain may only play a supporting role. In fluorescence recovery after photobleaching (FRAP) analysis, the FXR1 droplets recovered most of the fluorescence signal within 40 s after photobleaching (Fig. 4f and Supplementary Fig. 4e).

a PONDR-predicted intrinsically disordered region in FXR1, dashed line indicates disorder threshold. b Schematic of truncated FXR1 protein structures. c In vitro droplet formation assays showing full-length FXR1488 and truncation mutants at indicated concentrations in buffer containing 50 mM NaCl and 10% PEG-8000. d Phase diagram showing the turbidity of FXR1488 and different domain truncations. e Condensate areas of FXR1488 and different domain truncations; n(FXR1488 condensate) = 0, 0, 9, 35, 77, 72, 76, 82; n(RGG488 condensate) = 0, 0, 0, 0, 0, 4, 61, 61, 158, 158; n(KH488 condensate) = 0, 0, 0, 0, 0, 0, 0, 13, 22, 67, 67, 93; n(AGE488 condensate) = 0, 0, 0, 0, 0, 0, 0, 0, 0, 12, 9, 23; n(EGFP condensate) = 0. f Fluorescence recovery after photobleaching (FRAP) analysis of FXR1488 droplets in vitro; n = 10 droplets. g Live-cell imaging of hESCs expressing EGFP (diffuse) or EGFP-FXR1 (punctate), arrows indicate different condensates. h Number and area of cytoplasmically dispersed and perinuclear EGFP-FXR1 condensates per cell; n(cell) = 22, 22, 22; n(condensate) = 254, 234. i FRAP analysis of cytoplasmically dispersed and perinuclear EGFP-FXR1 condensates in hESCs, the fluorescent intensity was plotted over recovery time following photobleaching; n(cytoplasmically dispersed droplets) = 13; n(perinuclear droplets) = 9. Data represent the mean ± SEM. P values were calculated by Student’s unpaired two-tailed t test (h), and two-way repeated measures ANOVA (i). Source data are provided as a Source Data file.
To further test whether FXR1 forms biomolecular condensates with different functions and distributions within the cell, we transiently transfected EGFP-labeled FXR1 into hESCs. We observed that EGFP-FXR1 aggregated as mobile condensates around the nuclear membrane and scattered throughout the cytoplasm, recapitulating the endogenous FXR1 localization pattern in Fig. 1k, whereas EGFP protein was diffusely distributed throughout the cell (Fig. 4g). Approximately 40 such FXR1 condensates were formed per cell, and there were more cytoplasmically dispersed condensates than perinuclear condensates, although there was no significant difference in the area covered by the two kinds of condensates (Fig. 4h). FRAP analysis showed that the recovery rate of the condensates was highly dynamic within the same cell. Perinuclear-localized condensates exhibited weaker recovery and mobility than the cytoplasmically dispersed ones (Fig. 4i), indicating there were stronger interactions within the perinuclear FXR1 condensates. We therefore concluded that FXR1 proteins can undergo phase separation in vitro, and form spatially specific mRNP condensates in hESCs.
FXR1 regulates mRNA nucleocytoplasmic localization and localized translation in a manner dependent on different RNA-binding domains
Next, we aimed to unveil the underlying mechanisms by which FXR1 forms distinct condensates at the nuclear pores, respectively. First, we compared the signatures of FXR1 binding to these two classes of mRNAs. Intriguingly, FXR1 exhibited preferential binding to the CDS region of nucleoporin mRNAs as well as to the 3’ UTR region of transported mRNAs, and the FXR1-binding peaks of transported mRNAs had higher GC content and lower minimum free energy (Fig. 5a and Supplementary Fig. 5a). Given that FXR1 contains KH and RGG domains that tend to recognize different RNA motifs29,30, we further analyzed the proportion of known KH- and RGG-domain-binding motifs in the FXR1-binding peaks. We found that they rarely appeared simultaneously in the same transcripts, and more often appeared separately in different transcripts bound to FXR1 (Supplementary Fig. 5b). It is worth noting that the RGG-domain-binding motif, including RNAfold30 predicted G-quadruplex and experimentally validated G-quadruplex31 (Fig. 5b, c and Supplementary Fig. 5c), was significantly more enriched in the transported mRNA peaks than nucleoporin mRNAs, while KH-domain-binding motifs, including AGAA and CAAU, etc., exhibited the opposite trend (Fig. 5b, c).

a FXR1-binding region and GC content of nucleoporin mRNAs and transported mRNAs; Box plots indicate median (middle line), 25th, 75th percentile (box) and 5th and 95th percentile (whiskers) as well as outliers (single points); n(peak) per group = 17, 17, respectively. b Proportions of known KH- and RGG-domain-binding motifs among FXR1-binding NUPs and transported mRNAs. c Positions of representative motifs on NUPs and transported mRNAs. d Electrophoretic mobility shift assay for binding of FXR1 KH or RGG domain to AGAA×5 and G-quadruplex (G4) RNA; The EMSA blot shown is representative of three independent experiments, all yielding consistent results. e Biolayer interferometry measurement of FXR1 KH- or RGG-domain binding affinity with G-quadruplex or AGAA×5 RNA. Kd value represents binding affinity. f Quantitative analysis of association (Kon) and dissociation (Koff) rates from (e). g In vitro phase separation of purified KH488 or RGG488 with increasing concentrations of AGAA×5 and G-quadruplex RNA, and the microscope image shows a representative image of RNA at 1000 nM; n = 3 biologically independent replicates. h Schematic diagram of FXR1 truncates lacking the KH or RGG domain. i Perinuclear localization efficiency of NUP mRNAs in cells expressing FXR1 truncation mutants; NUP358 n(cell) per group = 53, 53, 45, 48, 48; AHCTF1 n(cell) per group = 45, 48, 32, 53, 47, respectively. j Detection of nascent peptides of nucleoporins using proximity ligation assays and associated statistical analysis; NUP358 n(cell) per group = 53, 50, 51, 47, 46; AHCTF1 n(cell) per group = 29, 33, 26, 29, 25, respectively. k FISH images and fluorescence signal statistics revealing the subcellular distribution of PHF5A and MDFI transcripts; PHF5A n(cell) per group = 330, 157, 157, 157, 154; MDFI n(cell) per group =250, 175, 168, 159, 215, respectively. l Cyto./Nuc. ratio of PHF5A and MDFI transcripts detected by qPCR; n = 3 independent replicates. m Schematic diagram of FXR1-RNA binding dynamics in the two types of condensates. Data represent the mean ± SEM. Statistics used were Student’s unpaired two-tailed t test (a, k, l), Chi-squared test (b), two-way repeated measures ANOVA (g), and Chi-squared test (i, j). Source data are provided as a Source Data file.
To investigate how the KH and RGG domains of FXR1 interact with RNA and exert distinct roles, we used the truncated FXR1 mutants (Fig. 4b) and examined their propensity to bind to different RNA motifs by electrophoretic mobility shift assay (EMSA) and biological layer interferometry (BLI). We found that the KH domain of FXR1 was able to bind to both AGAA×5 and G-quadruplex RNA probes but had a stronger affinity for AGAA×5, whereas the RGG domain only bound to the G-quadruplex RNA probe and exhibited a much higher Kd value for AGAA×5, suggesting the absence of binding (Fig. 5d, e and Supplementary Fig. 5d, e). The negative control Agenet domain did not bind to any RNA (Supplementary Fig. 5f). These findings were further corroborated by molecular dynamics (MD) simulations, which demonstrated that the KH domain had lower binding free energy and greater stability when interacting with AGAA×5 compared to G-quadruplex RNA, the opposite was true for the RGG domain, which exhibited stronger binding and stability with G-quadruplex RNA (Supplementary Fig. 5g, h). Moreover, we were surprised to find that the kinetic characteristics of KH- and RGG-domain binding to RNA were totally different, which coincides with their distinct functions (Fig. 5f and Supplementary Fig. 5e). The rapid RNA binding and dissociation of the RGG domain make it suitable for transporting RNA, while the slow, stable RNA binding and dissociation of the KH domain are suitable for mediating RNA localization. This concept is supported by evidence showing a close correlation between the binding kinetics of RBP-Deleted in Azoospermia-Like (Dazl) and its functional roles in mRNA regulation32. Consistent with this, in vitro phase separation experiments showed that the purified KH domain favored the assembly of AGAA×5 RNA, whereas the RGG domain favored the assembly of G-quadruplex RNA into mRNP condensates (Fig. 5g).
To determine whether the two RBDs of FXR1 function differently upon binding to RNA, we constructed additional truncated FXR1 mutants and overexpressed them in FXR1-knockout hESCs carrying a heterozygous deletion of exons 3–6 (Fig. 5h and Supplementary Fig. 5i, j). The results of FISH, NPC RIP, puromycin-based PLA and IF consistently demonstrated that full-length FXR1 and RGG-domain-deficient FXR1 restored the perinuclear localization of nucleoporin mRNAs, exemplified by NUP358 and AHCTF1 mRNAs (Fig. 5i and Supplementary Fig. 5k), as well as their local translation at this site (Fig. 5j and Supplementary Fig. 5l). Conversely, KH-domain-deficient FXR1 failed restoration for most nucleoporin mRNAs (Fig. 5i, j and Supplementary Fig. 5k, l), suggesting that the KH domain is primarily responsible for FXR1’s role in mediating localized translation of most nucleoporin mRNAs. Additionally, the results of FISH and nuclear-cytoplasmic separation-coupled qPCR consistently showed that both full-length FXR1 and KH-domain-deficient FXR1 rescued the suppressed mRNA cytosolic accumulation resulting from FXR1 depletion, whereas the RGG-domain-deficient FXR1 did not (Fig. 5k, l and Supplementary Fig. 5m, n). This illustrates that the RGG domain is required for FXR1’s role in mRNA nucleocytoplasmic distribution. Therefore, we concluded that, within distinct condensates, FXR1 employs its KH domain to slowly and stably recruit nucleoporin mRNAs, ensuring their precise localization and localized translation. This is in stark contrast to its use of the RGG domain to rapidly engage and release G-quadruplex-containing mRNAs and facilitate their efficient nucleocytoplasmic translocation (Fig. 5m).
Riboregulation determines the different subcellular localization of FXR1 condensates and controls mRNA fate
We then explored how the different RBD binding strategies of the two classes of mRNAs mediate the distinct localization of FXR1 condensates and lead to different mRNA export fates. First, we examined the binding of FXR1 with cytoplasmic nucleoporins and identified NUP88 and NUP98 as potential interacting partners (Fig. 6a). The interactions were further verified by reverse Co-IP, in which NUP88 had a strong signal and NUP98 had no signal (Supplementary Fig. 6a). Based on these findings, we focused our subsequent mechanistic investigations on the FXR1-NUP88 interaction. To clarify which domain of FXR1 was responsible for its binding to NUP88, we conducted NUP88 pull-down experiments using truncated FXR1 proteins in vitro. The results showed that, although both the Agenet and KH domains of FXR1 interacted with NUP88, the KH domain bound more protein (Fig. 6b). NUP88 immunoprecipitation was performed in hESCs with truncated FXR1 overexpression, which showed that deletion of any domain reduced the potency of FXR1 binding to NUP88, while KH-domain deletion completely prevented their binding (Supplementary Fig. 6b). Co-phase separation of NUP88 and truncated FXR1 also showed that the KH domain completely fused and colocalized with NUP88 in the same droplet, whereas this was not the case for the RGG domain, which encapsulated NUP88 (Supplementary Fig. 6c-e). These results indicated that the KH domain of FXR1 is more essential than the other domains for its binding to NUP88.

a Distribution of cytoplasmic filament nucleoporins and their interactions with FXR1, as detected by FXR1 Co-IP. b In vitro interactions between NUP88 and truncated FXR1 proteins from (4b), as detected by NUP88 protein pull-down; Black arrows, the strongest interactions. c Interaction between NUP88 and FXR1 upon addition of different RNA motifs of decreasing concentrations; quantitative grayscale values are shown below. d, e Biolayer interferometry detection of binding affinity of FXR1 with G-quadruplex RNA (d) or NUP88 protein (e). f Phase separation co-assembly quantified by Pearson’s correlation coefficient between FXR1488 and NUP88647 condensates with varying RNA concentrations. g Representative images of FXR1488 and NUP88 droplets upon addition of different RNA motifs. h FRAP analysis of droplets containing FXR1488 and G-quadruplex RNA; FXR1488 and AGAA×5 RNA; or FXR1488, AGAA×5 RNA, and NUP88 protein; n = 10 droplets. i Representative images of EGFP-FXR1 condensates with overexpressed RNA motifs, and their distance from NPCs; n(condensate) = 300, 281, 300. j Super-resolution images of spatially segregated FXR1 condensates with transport or translation factors. k Co-IP analysis of FXR1-cofactor interactions upon RNA motif overexpression. l FXR1 RIP-qPCR quantification of FXR1FL, FXR1KH−, and FXR1RGG− binding to target mRNAs; n = 3 biologically independent replicates. m Representative immunofluorescence images showing subcellular distribution of FXR1 truncation mutants, and quantitative analysis of the distance between FXR1 granules and nuclear pores; n = 200 condensates per group. n Schematic representation of mediation of different localized FXR1 condensates by riboregulation. Data represent the mean ± SEM. Statistics used were Student’s unpaired two-tailed t test (f, l), two-way repeated measures ANOVA (h), and one-way ANOVA with False Discovery Rate (FDR) correction (i, m); Box plots indicate median (middle line), 25th, 75th percentile (box) and 5th and 95th percentile (whiskers) as well as outliers (single points) (i, m). Data shown are representative of 3 identical replicates and uncropped blots in Source Data (a–c, k). Source data are provided as a Source Data file.
Given that the KH domain of FXR1 can also bind to RNA, we were curious to ascertain the relationship between its RNA- and protein-binding functions. Therefore, we added conserved RNA probes to an NUP88 pull-down assay to test this. Surprisingly, the AGAA×5 probe did not compete with, but rather enhanced, the binding between FXR1 and NUP88. Conversely, the G-quadruplex RNA probe weakened the binding between them, and the attenuation was dose-dependent (Fig. 6c and Supplementary Fig. 6f). This was also supported by the greater affinity between FXR1 and G-quadruplex RNA than that between FXR1 and NUP88 in the BLI experiments (Fig. 6d, e). In vitro phase separation showed that FXR1 assembled both AGAA×5 RNA and G-quadruplex RNA into mRNP particles (Supplementary Fig. 6g, h). Incorporation of AGAA×5 RNA facilitated the colocalization of FXR1 and NUP88 and resulted in the formation of larger condensates in a dose-dependent manner, whereas the incorporation of G-quadruplex RNA inhibited their co-localization and phase separation (Fig. 6f, g). FRAP analysis showed that FXR1 condensates containing G-quadruplex RNA were the most mobile, whereas condensates containing both AGAA×5 RNA and NUP88 proteins were the least mobile, probably due to the stronger and more stable intermolecular interactions (Fig. 6h). This recapitulated what we observed in the cell: the FXR1 condensates localized at nuclear pores were less mobile than those distributed through the cytoplasm (Fig. 4i).
We further transfected EGFP-FXR1-overexpressing cells with the two types of RNA. The addition of AGAA×5 RNA led to a greater enrichment of FXR1 condensates in the periphery of the nucleus, whereas the addition of G-quadruplex RNA led to FXR1 condensates being dispersed through the cytoplasm (Fig. 6i). Correspondingly, the addition of AGAA×5 RNA gave rise to recruitment of more translation-related proteins such as EIF5B to FXR1 condensates surrounding the nucleus, whereas the addition of G-quadruplex RNA resulted in recruitment of more transport-related proteins such as TUBG1 to FXR1 condensates in the cytoplasm (Fig. 6j, k). To further substantiate our findings, we complementarily overexpressed full-length FXR1 and truncated mutants with defects in distinct RNA-binding domains. Full-length FXR1 bound both G4- and AGAA-containing mRNAs. However, the KH domain-deficient FXR1 selectively bound G4-containing mRNAs, while the RGG domain-deficient one only bound AGAA-containing mRNAs (Fig. 6l). These RNA-binding alterations repositioned FXR1 condensates: the KH domain-deficient FXR1 dispersed condensates throughout the cytoplasm, whereas the RGG domain-deficient one aggregated condensates around nuclear pores (Fig. 6m). Functionally, the KH domain-deficient FXR1 reduced nucleoporin mRNA localization and local translation at nuclear pores (Supplementary Fig. 6i-k), while the RGG domain-deficient one significantly impaired target mRNA cytosolic accumulation (Supplementary Fig. 6l). This illustrated the direct effect of the target RNAs on the localization and function of FXR1 condensates. Taken together, these findings revealed that the riboregulation of FXR1 modulates the fluidity and localization of its condensates, thereby mediating the localized translation of nucleoporin mRNAs at nuclear pores and the cytosolic accumulation of G-quadruplex-containing mRNAs (Fig. 6n).
Changes in FXR1-mediated nuclear pore activity are required for hESC differentiation
Given the established involvement of FXR1 condensates in mRNA localization and translational regulation, we further investigated its role in maintaining hESC pluripotency. Deleting FXR1 expression in hESCs repressed pluripotent gene expression and decreased alkaline phosphatase (AP) activity and colony formation ability, and led to an overall repression of cell cycle and stem cell maintenance-related gene expression and teratoma formation in vivo (Fig. 7a-c, Supplementary Fig. 7a). The results clearly indicate that FXR1 is required for hESC self-renewal.

a Expression of FXR1 and pluripotency genes in heterozygous FXR1 knockout (KO) hESCs; Data shown are representative of 3 identical replicates and uncropped blots in Source Data. b AP staining and colony formation assay of wildtype and heterozygous FXR1-KO hESCs; n = 5 biologically independent replicates. c Gene set enrichment analysis of mitotic cell cycle process and stem cell population maintenance proteins in heterozygous FXR1 KO hESCs. d Expression of FXR1 and NPCs during hESC differentiation towards mesoderm, as detected by immunofluorescent labeling; STED microscopy images show individual NPCs. e Relative fluorescence intensity, density, and diameter of individual NPCs from (d); n(cell) for Day 0, 1, 2, 3, 4, 5, and 6 groups respectively: 20, 23, 22, 22, 22, 22, 22. f Nucleocytoplasmic ratio dynamics of expressed genes during mesoderm differentiation; Line styles (solid/dotted) represent TPM thresholds; colors (purple/blue) denote early/late differentiation time points. g Diagram depicting dynamics of nuclear pore activity and subcellular localization of total RNA during hESC differentiation. h, i Impact of overexpressing full-length FXR1 and FXR1 mutants with specific functional defects on NPC intensity during hESC differentiation; n(cell) = 6. j Lollipop chart illustrating the impact of full-length FXR1 overexpression on mRNA nucleocytoplasmic distribution on day 2 of hESC differentiation. k Heatmaps of mRNA nucleocytoplasmic distribution changes (day 2/day 0) upon full-length FXR1 or truncations overexpression; Data from qPCR, n = 3 biologically independent replicates. l AP staining reveals differential pluripotency maintenance in hESCs overexpressing FXR1 truncation mutants; n = 3 biologically independent replicates. m–o Formation efficiency and representative images (m), weight and volume (n), and OCT4 immunohistochemical staining (o) of mouse teratomas derived from WT and full-length FXR1-OE hESCs. Representative OCT4-positive regions are shown; n(WT group teratomas) = 12; n(FXR1 OE group teratomas) = 9. p Model diagram of how FXR1 controls mRNA fate through riboregulation to mediate the fate transition of hESCs. Data represent the mean ± SEM. P values were calculated by Student’s unpaired two-tailed t test (b, e, f, i, l, n). Box plots indicate median (middle line), 25th, 75th percentile (box) and 5th and 95th percentile (whiskers) as well as outliers (single points) (e, i). Source data are provided as a Source Data file.
FXR1 expression and condensate numbers decreased sharply during hESC differentiation and began to recover on differentiation day 6 (Fig. 7d). Our data have indicated that FXR1 condensates regulate the localized translation of nucleoporin mRNAs at nuclear pore and thereby influence the overall expression of NPCs (Fig. 2). In line with this, the expression of nuclear pores noticeably declined in the early stages of differentiation and recovered in the late stages, as indicated by a reduction in the fluorescence intensity, density, and diameter of individual nuclear pores (Fig. 7d, e and Supplementary Fig. 7b, c). This was also validated by an immunoblot of nucleoporins and MS data (Supplementary Fig. 7d, e). A similar decrease in FXR1 and nucleoporin expression was also observed during the exit from pluripotency and the mesoderm and endoderm differentiation of hESCs (Supplementary Fig. 7f, g)33,34, suggesting that the changes in nuclear pore activity controlled by FXR1 may be a general phenomenon necessary for the fate transition of hESCs. Consistent with the dynamic changes observed in nuclear pore expression, global mRNA nuclear-to-cytoplasmic ratio clearly increased in the early stages of differentiation, especially the transcripts of highly expressed genes, but gradually recovered in the later stages (Fig. 7f and Supplementary Fig. 7h; Supplementary Data 5). It is worth noting that the pluripotency- and differentiation-associated transcripts showed similar trends, suggesting that the blockage of mRNA nucleocytoplasmic trafficking at this stage was not selective but global (Supplementary Fig. 7i; Supplementary Data 5). Therefore, we hypothesized that hESCs downregulated the activity or expression of nuclear pores during their differentiation to retain transcribed mRNAs in the nucleus and dissolve the existing gene regulatory network to achieve cell fate transition (Fig. 7g).
To test this hypothesis, we overexpressed full-length FXR1 and FXR1 mutants with specific functional defects during hESC differentiation to prevent downregulation of nuclear pore activity and examined the effect on hESC pluripotency. As expected, overexpression of both full-length FXR1 and RGG-domain-deficient FXR1(which retains the KH domain) prevented the reduction in nuclear pore intensity, whereas the KH-domain-deficient FXR1 did not (Fig. 7h, i). This prevention led to a decrease in the nuclear-to-cytoplasmic ratio of favorable mRNA during hESCs differentiation (Fig. 7j, k; Supplementary Data 6). Although overexpression of the KH-domain-deficient FXR1 did not alter nuclear pore activity, it significantly enhanced the cytoplasmic distribution of multiple FXR1 target RNAs, including pluripotency gene mRNAs (Fig. 7k). Consistent with these changes in mRNA nuclear-cytosolic distribution, AP staining showed significantly more undifferentiated colonies in hESCs overexpressing full-length FXR1 or FXR1 mutants after 12 h of differentiation (Fig. 7l). Furthermore, full-length FXR1 overexpression led to a delayed decrease in pluripotency gene expression, while the increase in differentiation gene expression was suppressed (Supplementary Fig. 7j–m; Supplementary Data 7). Moreover, overexpression of full-length FXR1 suppressed embryoid body formation in vitro and teratoma formation in vivo (Fig. 7m–o and Supplementary Fig. 7n, o), strongly supporting the hypothesis that full-length FXR1 overexpression resulted in the reduced pluripotency and differentiation deficiency of hESCs. These data led us to propose, for the first time, that stem cells can respond to fate transition by controlling RNA subcellular localization patterns.
Taken together, the evidence shows that the RBP FXR1 interacts with cytoplasmic fibers of the NPC. When nucleoporin mRNAs pass through the nuclear pore, they interact with the KH domain of FXR1, which enhances the binding of FXR1 with the NPC, resulting in the formation of localized translation-associated FXR1 condensates around nuclear pores. When G-quadruplex-containing mRNAs pass through the nuclear pore, they interact with the RGG domain of FXR1, which weakens the binding of FXR1 with the NPC, resulting in the release of FXR1 mRNP condensates from nuclear pores and their dispersal in the cytoplasm. Functionally, FXR1 is highly expressed in hESCs to maintain their self-renewal activities, and a decrease in FXR1 and the resulting nuclear pore activity repression are required for hESC differentiation (Fig. 7p).
Discussion
In our research, we uncovered evidence that FXR1 located on the cytoplasmic side of the nuclear pore controls mRNA fate and is able to assemble bi-condensates that exercise distinct functions: one is associated with the localized translation of nucleoporin mRNAs, while the other is associated with the cytosolic accumulation of G-quadruplex-containing mRNAs. The formation and potential function of FXR1 bi-condensates are riboregulated by distinct RNA motifs. These findings have revealed the biological function and regulatory mechanism of heterogeneous condensate formation by a given protein and provided critical insights into the multiple functions of RBPs.
How a given protein aggregates into condensates of different sizes, compositions, and functions is not fully understood. Recent research has highlighted post-translational modifications as key factors in regulating biomolecular condensate formation12,35,36,37. In this study, we found that distinct RNA motifs can modulate the formation of heterogeneous FXR1 condensates. Specifically, the interaction of RNA molecules with FXR1 reduces its solubility and thus promotes its aggregation, further affecting its interaction with other proteins, and distinct RNA sequences produce different effects. For example, the binding of G-quadruplex-containing RNA weakens FXR1’s association with the nuclear pore, whereas nucleoporin mRNA strengthens this association, resulting in the differential localization of the two FXR1 condensates. Distinct RNA sequences may also influence the recruitment of translational factors by FXR1, as the RGG domain binds to RNA and concurrently recruits translation initiation complexes19, leading to different functions for the two FXR1 condensates. Thus, RBP binding to distinct RNA motifs can assemble complexes with very different compositions, resulting in the formation of heterogeneous mRNP condensates with different localization patterns and functions, and this may serve as a pervasive regulatory mechanism.
The function model of FXR1’s ability to determine RNA fate in a manner dependent on different RBDs also offers critical insights into multifunctional RBPs. Single RBPs typically possess multiple RBDs, and their arrangement can enhance the RNA-binding ability of RBP in a coordinated manner29,38. Our findings indicate that the presence of multiple RBDs within an RBP constitutes the fundamental structural basis for its diverse functions. Specifically, the distinct functions of FXR1 depend on its KH and RGG domains recognizing different RNA motifs, binding to different functional regions of transcripts, and possessing individual binding kinetics. Binding kinetics, in particular, are a prominent feature of the FXR1 regulation of target genes. Indeed, while the molecular details of how individual RBDs recognize RNA have been elucidated by biochemical and structural studies29,38,39,40, this study was the first to link these details with RBP molecular functions. It is fascinating that, based on these binding mechanics, mRNA ligands appear to regulate FXR1’s function in a manner reminiscent of riboregulation13. The activity of this regulatory module provides a fresh perspective on the RNA-ligand regulation of protein function. It is possibly a universal mechanism for RNA-regulated RBP function, but has not been widely recognized due to technical limitations.
While subcellular protein localization is essential for function, its regulatory mechanisms remain incompletely understood. Recent studies have identified intrinsic amino acid sequences as molecular “codes” that determine protein localization41. Our study extends this concept by demonstrating that the localization of FXR1 depends not only on its intrinsic amino acid sequences but more critically on the modular interactions between its RNA-binding domains and specific RNA molecules. These interactions generate dynamic “interaction codes” that dictate both subcellular localization and function of RBPs. Specifically, FXR1 localizes to the perinuclear region via “KH domain-AGAA mRNA” pairing, and to the cytoplasm via “RGG domain-G-quadruplex mRNA” interactions. This finding expands the concept of protein localization codes from mere amino acid sequences to dynamic protein-RNA interaction networks. Second, this mechanism is likely conserved among RBPs, offering a critical framework to explain the multi-localization phenomena of proteins. Most importantly, this modular and programmable localization control mechanism provides valuable insights into the spatiotemporal regulation of proteins during cell differentiation and development, and lays a theoretical foundation for precise protein localization manipulation in synthetic biology.
Lastly, transcriptional regulation is widely acknowledged to be a key regulatory player in controlling cell fate and organ development42,43,44. Recently, researchers provided important evidence that emphasized the significance of post-transcriptional regulation in hESC exit from pluripotency45,46. Our findings also provide support for the critical role of post-transcriptional regulation in stem cell differentiation. We found that FXR1 condensates controlled the repression of nuclear pore expression required for hESC differentiation, and this led to nuclear accumulation of transcribed mRNAs and ultimately dissolved the existing gene regulatory network. This corresponds to the emerging perspective that the activity of nuclear pores is critical in regulating cell fate transition47,48.
Methods
Please refer to Supplementary Data 8 for a complete list of sequences and materials utilized in this study. All reagents, including oligonucleotides and plasmids, are available upon request from the corresponding author.
Human embryonic stem cell culture
Human ESC line H1 was maintained in mTeSR1 (StemCell Technologies) on matrigel (Corning)-coated plates. The medium was changed every day, and cells were passaged every 5–7 days by ReLeSR (StemCell Technologies) for maintenance. When the cell density reached 30–60%, they induced their differentiation towards the mesoderm. The basal induction medium consisted of IMDM medium (Gibco), 10% fetal bovine serum (Gibco), 2 mM glutamine (Gibco), 50 μg/mL ascorbic acid (StemCell Technologies), and 0.1 μM monothioglycerol (Sigma). 10 ng/mL BMP4 (StemCell Technologies) was added on the first day of induction, and basic fibroblast growth factor (bFGF) (2.5 ng/mL, StemCell Technologies) was incubated simultaneously from the second day of induction for 3–5 days before the experiment. For the pluripotency exit assay, 24 h after seeding, mTeSR1 medium was replaced with the following differentiation medium: −bFGF, −TGFβ condition (mTeSR1 Medium w/o Select Factors CUSTOM (Stem Cell Technologies)). Cells were incubated in differentiation medium for 120 h. Medium was then replaced with mTeSR1 and incubated for an additional 24 h before conducting western blot analysis.
CRISPR/Cas9-mediated gene knockout
The single guide RNA (sgRNA) sequences corresponding to the region between FXR1 exons 3 and 6 were chosen to minimize the likelihood of off-target cleavage based on the publicly available online tool (http://crispor.tefor.net/). sgRNA was synthesized, and the annealed oligos were cloned into lentiGUIDE-GFP. Packaged lentiCRISPR v2 and lentiGUIDE-GFP lentiviruses using 293 T cells were co-infected into H1 hESCs. Cells were selected with puromycin for 7 days, followed by fluorescence-activated cell sorting (FACS) to isolate cells expressing GFP. These sorted cells were then replated as single cells. hESC colonies were collected on the 7th day after single-cell plating. Genomic DNA was extracted from cells, and PCR was performed to validate the gene knockout. We designed two primer sets: internal primers (F1/R1) amplifying a 960 bp band from the wildtype allele and external primers (F2/R2) amplifying a 660 bp band from the knockout allele. Sanger sequencing of the 660 bp F2/R2 band from the knockout allele confirmed successful exon deletion.
Plasmids and lentivirus package
All lentiviral vectors used for the 36 RBPs knockdown experiments were designed within the pLKO.1 vector (Kindly provided by Dr Ge Shan, University of Science and Technology of China). The sequence of truncations (FXR1FL-Flag, FXR1KH−-Flag, FXR1RGG−-Flag, FXR1AGE−-Flag) were designed within the V2869 PCDH-EF1-MCS-3xFlag-T2A-puro vector (Tianyi Huiyuan Biotechnology). Lentivirus was packaged by co-transfection of each pLKO.1 shRNA vector or PCDH overexpression vector with the packaging vectors pMD2.G (Addgene) and psPAX2 (Addgene) in a 4:1:3 ratio into 293 T cells. The supernatant was collected 48 h after transfection and passed through a 0.45 μm filter. Lentivirus infection was performed during hESC passage. Subsequent experiments were performed 72 h post-infection unless otherwise specified.
Alkaline phosphatase staining and colony formation assay
Alkaline phosphatase activity assays were performed using the leukocyte alkaline phosphatase kit (Sigma) following the manufacturer’s protocol. The main step included washing cells with PBS, fixing cells with 4% paraformaldehyde, washing twice with TBST, preparing the alkaline phosphatase staining solution, staining at room temperature for 30 min, washing once with TBST, and suspending the cells in PBS containing 20% glycerol for storage. For colony formation assay, 5000 hESCs per well were seeded on a 12-well plate in Matrigel-coated plates. After 5–7 days of cell culture, the cells were stained with an alkaline phosphatase kit, and positive colonies were counted.
Embryoid body formation
Embryoid bodies (EBs) were formed from WT hESCs or hESCs overexpressing FXR1FL-Flag. Briefly, cultured hESCs were dissociated with accutase. 105 cells were inoculated into 2 ml of EB formation medium supplemented with 10 μM Y-27632 (StemCell Technologies) and added uniformly to one well of a pre-warmed and washed microwells (StemCell Technologies) plate. Immediately centrifuge the microwell plate, observe cells under a microscope to confirm the even distribution of cells within the wells, change the cell medium daily, and continue culturing for 6–8 days.
Teratoma formation assay
For teratoma formation assay, at least 1 × 106 cells were injected into one site of SCID beige mice by subcutaneous injection, 10–12 sites per cell line. Teratoma size was measured about one month after injection and then measured every 3–4 days. Teratomas were picked 5–8 weeks after injection, washed with PBS and fixed in 4% paraformaldehyde, paraffin-embedded and sectioned. Then the sections were stained with hematoxylin, eosin and immunohistochemistry.
RNA fluorescence in situ hybridization
For the FISH assay, hESCs were seeded on chamber slides, washed with PBS then treated according to the RNAscope® Fluorescent Multiplex Reagent Kit User Manual (ACD). In simple terms, the samples were fixed at room temperature in 4% paraformaldehyde for 30 min, followed by dehydration and permeabilization with Proteinase 3. Subsequently, RNA probes were added and incubated at 40 °C in a humidity-controlled hybridization oven for 2 h. After removing excess liquid, AMP1 was applied for 30 min, AMP2 for 30 min, and AMP3 for 15 min, with two 2-minute wash buffer washes between each reagent change. Following this, HRP-C1 was applied for 15 min, Opal 520 was incubated for 40 min, and HRP blocking was performed before mounting on slides. Images were captured using a fluorescent microscope. Statistical analyses and plots were performed with CellProfiler49 and Prism 8. When image color balance adjustment was needed, all comparable images were processed in the same manner.
Immunofluorescence (IF)
For IF assay, hESCs were seeded on chamber slides, washed with PBS and fixed with 4% paraformaldehyde, then permeabilized with 0.5% Triton X-100 for 10 min, and blocked with blocking solution (PBST, 1% BSA, 22.52 mg/mL glycine) for 30 min at room temperature. Cells were incubated with primary antibodies for 1 h or overnight at 4 °C, washed three times with PBS, then incubated with fluorescent secondary antibody for 1 h at room temperature and protected from light. Then nuclei were labeled by DAPI and observed by a confocal fluorescence microscope. STED microscopy and analysis immunolabeling procedure for STED super-resolution light microscopy was similar to conventional IF assay as described above, with several optimizations: Prolong Gold (Thermo Fisher), but not DAPI, was used for DNA staining. Samples were mounted under high-performance cover glass (#1.5, 0.17 mm ± 0.005 mm thickness). STED microscopy was performed on Leica TCS SP8 gSTED 3X microscope. For the same target in one batch, all parameters, including but not limited to excitation laser, depletion laser, delay time, gating time and image capturing settings, were identical for parallel comparison between samples at different stages. Statistical analyses and plots were performed with CellProfiler, ZEN and Prism 847. For IF combined FISH assays, IF blocking and subsequent steps are performed immediately after the FISH step, HRP blocking.
Proximity ligation assay (PLA)
For PLA assay, hESCs were seeded onto chamber slides, washed twice with PBS and fixed with 4% paraformaldehyde, then permeabilized with 0.1% Triton X-100. After blocking with a blocking buffer, the cells were incubated overnight at 4 °C with primary antibodies. Proximity ligation was performed using a Duolink in situ PLA kit for mouse/rabbit antibodies (Sigma-Aldrich) according to the manufacturer’s protocol. The oligonucleotides and antibody–nucleic acid conjugates used were those provided in the Sigma-Aldrich PLA kit. Fluorescence was detected using a Leica microscope at ×40 magnification. The relative PLA stain signal was obtained by normalizing the PLA signal to the signal obtained from the primary IgG antibody-only control to account for the background signal. For the puromycin-based PLA (as described in refs. 27,28), the protocol differs from the aforementioned method in that hESCs were treated with 2 µM puromycin for 10 min before fixation with 4% paraformaldehyde, then incubated overnight with primary antibodies against puromycin (mouse) and nucleoporin (rabbit).
RNA stability assay
To assess RNA stability, hESCs infected with the virus for 72 h were seeded at a density of 1 × 10⁶ cells per well in a 6-well plate. After 24 h of cell attachment, the cells were treated with 10 μg/mL actinomycin D to inhibit transcription and subsequently collected at designated time points. Total RNA was extracted using TRIzol reagent. cDNA was synthesized from equal volumes of RNA inputs using reverse transcriptase, and the levels of target transcripts were quantified by RT-qPCR with gene-specific primers. The RNA half-life was calculated by fitting the decay curves to a first-order kinetic model.
Co-immunoprecipitation
For Co-IP assays, 107 WT hESCs or hESCs overexpressing FXR1 variants were lysed in ice-cold buffer (20 mM Tris-HCl pH 8.0, 137 mM NaCl, 2 mM EDTA, 5% glycerol, 1% NP-40, 1× protease inhibitor cocktail, 1 mM PMSF) for 30 min at 4 °C with rotation. Lysates were clarified by centrifugation (12,000 × g, 15 min, 4 °C), and supernatants were incubated with 5 μg antibody or IgG overnight at 4 °C, followed by 4 h incubation with protein A Dynabeads. Beads were magnetically captured, washed three times with wash buffer (10 mM Tris-HCl pH 7.4, 150 mM NaCl, 1 mM EDTA, 1 mM EGTA, 5% glycerol, 1% NP-40, 1× protease inhibitor cocktail, 1 mM PMSF). For RNase-treated samples, beads were washed three times for 10 min each at 25 °C with wash buffer containing 2 ng/ml RNase A, followed by a final wash with 200 U/mL SUPERase In. Beads were then eluted in 50 μL of 2× SDS loading buffer by boiling for 10 min. The eluate was used for Western blot or mass spectrometry analysis.
Nucleo-cytoplasmic fractionation
A nuclear/cytosol fractionation kit (Thermo Fisher) was used to separate cytoplasmic and nuclear cell fractions. 5 × 106 hESCs were washed twice with PBS and then treated according to the manufacturer’s protocol. After removing PBS, cells were treated with an appropriate volume of CER I based on cell volume (maintaining the volume ratio of CER I:CER II: NER reagents at 200:11:100 µL). The cells were then resuspended and incubated on ice for 10 min. Ice-cold CER II was added, and after resuspending the cells for 5 seconds, they were incubated on ice for 1 min. The suspension was then vortexed for 5 seconds, followed by centrifugation at 16,000 × g for 5 min. The supernatant, which contains the cytoplasmic extract, was immediately transferred to a clean pre-chilled tube. The pellet was resuspended in ice-cold NER, incubated on ice for 40 min, and centrifuged at 16,000 × g for 10 min. The resulting supernatant represents the nuclear extract. Then the samples were used for mass spectrometry after Coomassie Blue Staining (Beyotime) or qPCR detection.
Polysome profiling
For polysome profiling analysis, hESCs infected with virus for 72 h were treated with 100 μg/mL cycloheximide for 15–30 min at 37 °C to arrest translating ribosomes, then lysed in polysome extraction buffer (100 mM KCl, 50 mM HEPES, 2 mM MgCl2, 1% Triton X-100, 10% Glycerin, 100 μg/mL cycloheximide, 1 mM DTT, RNase inhibitor). Lysates were clarified by centrifugation (12,000 × g, 10 min, 4 °C), layered onto 20–50% sucrose gradients, and ultracentrifuged (100,000 × g, 3 h, 4 °C). Gradients were fractionated using a density gradient fractionator while monitoring absorbance at 254 nm to isolate monosome and polysome fractions. RNA from each fraction was extracted using TRIzol and reverse-transcribed into cDNA. Target mRNA distribution across fractions was quantified by qPCR with gene-specific primers, normalized to spike-in controls or total RNA input, and expressed as relative abundance in polysomal (actively translating) versus all fractions.
Enhanced UV crosslinking immunoprecipitation (eCLIP) and sequencing
FXR1 eCLIP was conducted based on an established protocol, with slight modifications50. 2 × 107 cells were UV cross-linked on a 10 cm plate with 3 ml cold PBS at 150 mJ and 254 nm. Then, cells were lysed with lysis buffer (50 mM Tris–HCl pH 7.4, 100 mM NaCl, 1% NP-40, 0.1% SDS, 0.5% sodium deoxycholate and 1 × protease inhibitor cocktail, Roche) followed by further RNase A (Promega), and Turbo DNase treatments. The lysate was incubated with FXR1 antibody overnight at 4 °C for immunoprecipitation. 50 μL protein A Dynabeads (Invitrogen) were added and incubated for 2 h. After the end repair and the 3’ adaptor ligation, Nupage 4–12% Bis-Tris protein gel was used for sizing selection and then transferred to the nitrocellulose membrane. RNAs on nitrocellulose were collected and reverse-transcribed using SuperScript III (Thermo Fisher). cDNA libraries were then prepared and sequenced by using Illumina NovaSeq 6000 with strand-specific paired-end 150 bp read length.
RNA immunoprecipitation (RIP)
For RIP, 40 μL Protein A Dynabeads (Thermo Fisher) were washed three times with RIP buffer (20 mM HEPES pH 7.9, 150 mM NaCl, 0.5 mM EDTA pH 8.0, 10 mM KCl, 1 M MgCl2, 0.5% NP-40, 10% glycerin, 1.5 mM DTT, 1× Protease Inhibitor cocktail, 10 U/ml RNase Inhibitor) and then incubated with 5 μg anti-NPC antibody (Abcam) and normal mouse IgG (Millipore) for 4–6 h. 107 hESCs were resuspended in 500 μL cold RIP lysis buffer and lysed for 30 min, and then centrifuged for 30 min. The supernatants were used for RNA immunoprecipitation with antibody-Dynabeads complex by rotating at 4 °C overnight. After that, Dynabeads were washed two times, and RNA was isolated from the beads and input samples (5% of the lysate) for qPCR to detect interaction.
Native PAGE assay and circular dichroism
RNA oligonucleotides (Sangon Biotech) were dissolved in nuclease-free water at a concentration of 20 µM. RNA oligonucleotides were heated to 95 °C for 5 min in a buffer containing various concentrations of KCl and then cooled slowly at room temperature to obtain G-quadruplex formation. Further dilutions of samples to working concentrations were made with the relevant buffer immediately prior to use. For the native PAGE assay, RNA was resolved in an 8% native polyacrylamide gel, and then RNA species were visualized with SYBR Gold. For the spectroscopy measurements, Circular Dichroism of RNA oligonucleotides was determined at 20 °C by a Chirascan Plus spectropolarimeter equipped with a temperature controller. Circular Dichroism spectra ranging from 220 to 320 nm were recorded in a 0.1-mm path length cuvette at a scan rate of 50 nm/min with a 2-sec response time, 1.00-nm bandwidth, and continuous scan mode.
Electrophoretic mobility shift assay
The biotin-labeled RNA probes, as well as corresponding cold probes, were synthesized by Sangon Biotech company (China). For RNA probes to form a G-quadruplex, a process of annealing followed by slow cooling was performed. For AGAA×5 RNA probes, they were heated to 95 °C for 5 min and placed on ice immediately, then incubated with truncation protein (KH-his, RGG-his), which was purchased from CUSABOI company (China), using the LightShift™ Chemiluminescent RNA EMSA Kit (Thermo Fisher) according to the manufacturer’s protocol. The reactions were incubated at room temperature for 25 min before adding RNA loading dye and separated by native 8% PAGE.
Biolayer Interferometry
BLI was carried out on a Fortebio Octet system according to the user guide. Streptavidin or Ni-NTA (NTA) biosensors (Fortebio) were hydrated for 10 min prior to the experiment in the buffer containing 0.02% Tween-20 and 0.1% BSA. Biotin-labeled RNA samples were diluted to 200 nM (His-labeled protein samples were diluted to 100 nM), and protein (or RNA) samples were diluted to different concentrations in the same buffer. After loading and quenching, the sensors with fixed biotin-labeled RNA were applied to measure the binding affinity of different protein samples. The binding affinity (Kd) values, dissociation rate (Koff) and association rate (Kon) were calculated.
Protein-protein pull down
For NUP88 pull-down assays, equal amounts of FXR1 FL-his, AGE-his, KH-his, RGG -his, his-tag and NUP88-Flag proteins (Origene) bound to protein A Dynabeads were incubated with Flag antibody for 4 h at 4 °C. For RNA competition group, FXR1 FL-his protein was incubated with RNA for 2 h at 4 °C, then NUP88-Flag proteins, protein A Dynabeads and flag antibody incubated 2 h at 4 °C. After extensive washing, the proteins bound to the beads were resolved on SDS-polyacrylamide gels and detected by western blot analysis.
Phase separation assay
Purified FXR1 and truncation proteins (KH-his, RGG-his, Agenet-his) were purchased from CUSABOI company (China). And they were labeled by Alexa Fluor® 488 Conjugation Kit before the in vitro phase-separation assay. NUP88 protein was purchased from Origene company and labeled with Alexa Fluor® 647 Conjugation Kit. RNA probes were labeled Cy3 by Sangon Biotech company.
For the in vitro phase separation assay, 50mM NaCl was added to make up the phase separation buffer (working concentration: 50mM Tris-HCl, PH 7.5, 10% (v/v) glycerol, 1mM DTT, 10% (v/v) PEG8000). The purified proteins ranging between 0.03 and 68.8 µM were added to the buffer solution to observe droplet formation. The sample solution was loaded onto a confocal dish (3.5 cm, aperture 15 mm) and imaged with Leica Stellar Leica Stellaris 5 Confocal Microscope equipped with immersion objectives of 63erve droplet form. phase separation assays of purified proteins at various amounts and with increasing concentrations of RNAs in 50 mM NaCl were performed with the same operation. Statistical analyses were performed with Image J.
For intracellular phase separation, the sequence of full-long FXR1 was designed within the PCDH-EF1-EGFP-MCS-3xFlag-T2A-puro vector. 2–5 µg of EGFP-FXR1 expression vector was transfected into hESCs alone or co-transfected with different Cy3-tagged RNAs, then imaged with Leica Stellaris 5 Confocal Microscope.
Fluorescence recovery after photobleaching (FRAP) assay
In vitro FRAP experiments were prepared according to the phase separation assay and performed photobleaching with a laser at 488 nm (0.8 s/repeat × 4, 100% intensity), and images were captured every 0.8 s. For intracellular FRAP experiments, hESCs transfected with EGFP-tagged FXR1 were seeded in a 35-mm confocal dish. Laser stimulation at 488 nm was performed using a confocal microscope. The images were also taken every 0.8 s after the region of interest was photobleached. The fluorescence intensity of the bleaching region was analyzed and determined using the manufacturer’s software (LAS X). The data were then normalized and exported to be analyzed by Graphpad Prism.
MS datasets analysis
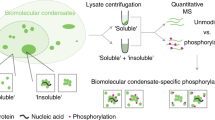
The MS spectrometry data were analyzed by Proteome Discoverer 1.4 (Thermo Fisher Scientific) supported by the Center of Biomedical Analysis (Tsinghua University, Beijing, China). The protein score was used to estimate the reliability of protein identification, which was evaluated by peptide spectrum matches (PSMs–the number of identified peptide spectra matched for the proteins in second-order MS), matching rate, and peptide FDR confidence level. The area value represented the relative quantity of protein defined by the peak area of peptides on chromatography. In Fig. 1 and Supplementary Fig. 1, for data generated from NPC Co-IP (n = 2 biological replicates) and nucleo-cytoplasmic fractionation assay (n = 3 biological replicates), we filtered out proteins with a score <5. The area ratio was calculated by the formula [(IP abundance × 10−5 + 1) / (IgG abundance × 10−5 + 1)], and represented the relative enrichment of each protein at the nuclear pore. We retained the NPC interactome proteins with area ratio (IP/IgG) > 1.5. For nucleo-cytoplasmic fractionation data, the formula [(abundance of cytoplasm × 10−5 + 1)/(abundance of (cytoplasm + nucleus) × 10−5 + 1)] was used to calculate the ratio of protein abundance in cytoplasm. Combined with the protein score and the cyto. ratio, proteins were divided into three classifications: nuclear enriched proteins (cyto. Ratio ≤ 0.33), cytoplasmic enriched proteins (cyto. ratio ≥ 0.67), and colocalized proteins (0.33 <cyto. ratio <0.67). For data generated from FXR1 inhibition assay (n = 2 biological replicates) in Fig. 2 and Supplementary Fig. 3, we filtered proteins with score > 5, and differential protein expression analysis was conducted by the ratio of average area value of proteins in the FXR1 inhibition and NC data. For FXR1 Co-IP MS data (n = 2 biological replicates) in Fig. 3 and Supplementary Fig. 4, the calculation was the same as NPC Co-IP data. In Supplementary Fig. 7 for MS data of hESC differentiation (n = 2 biological replicates)33,34, relative expression of NUPs was the ratio of the protein abundance on day 3/5/6 to the protein abundance on day 0.
RNA-seq datasets analysis
RNA-seq libraries (n = 2 biological replicates) were constructed using the poly (A) non-stranded protocol for Illumina sequencing with the paired-end 150-nt mode. In Fig. 2, for nucleo-cytoplasmic fractionation RNA-seq data, all reads were aligned to human genome (Ensembl GRCh38.83) using STAR51 with the parameter “--outFilterMultimapNmax 1 --outFilterMultimapScoreRange 1 --outFilterScoreMin 10 --outBAMsortingThreadN 5 --quantMode TranscriptomeSAM GeneCounts”, and uniquely mapped reads were retained for calculating gene counts by RSEM52. For RNA-seq data of hESC differentiation into mesoderm in Fig. 7, all reads were aligned to human genome (Ensembl GRCh38.83) using STAR51 with the parameter “--outFilterMultimapNmax 1 --outFilterMultimapScoreRange 1 --outFilterScoreMin 10 --outBAMsortingThreadN 5”. Then, uniquely mapped reads were retained for calculating gene counts by FeatureCounts53 and normalized for transcripts per million (TPM) using in-house scripts. The nucleocytoplasmic ratio of gene was conducted using DESeq254 and differential gene N/C ratio analysis was conducted using DESeq254 with the p value < 0.05 and |log2 (Fold change)| > log2 (1.2). All genes with TPM ≥ 1 in any sample were considered.
eCLIP-seq dataset analysis
The eCLIP-seq datasets (n = 2 biological replicates) were processed in accordance with previous studies50, and the pipeline was available at “https://github.com/YeoLab/eclip”. The raw reads with distinct inline barcodes were demultiplexed using in-house scripts, and the 10-mer random sequence was appended to the reads name in bam files for following analyses. Cutadapt55 was used to trimming low quality reads and adapters. Reads were aligned with the sequence of human repetitive elements in the RepBase database (https://www.girinst.org/) by STAR to remove the repetitive reads and obtain the cleaned reads. Cleaned reads were then mapped to the human genome (Ensembl GRCh38.83) using STAR51. Removing PCR duplicate reads by an in-house script based on sharing an identical random sequence. Two biological replicates were merged by SAMtools56 “merge” for subsequent analyses. Peak calling and downstream data analysis were performed by clipper57. Peak normalization performed using “Peak_input_normalization_wrapper.pl” tool, which was available at “https://github.com/YeoLab/eclip”. The visualization peaks were generated by Integrative Genomics Viewer (IGV) software58. MEME-ChIP tool on MEME online suite were used for FXR1 RNA binding motif discovery59, and FIMO tools was used to match known motifs and FXR1-binding sequences (http://meme-suite.org/). RNAfold software was used to predict the G-quadruplex structure and the minimum free energy of the FXR1-binding regions60.
Gene functional enrichment analysis
Gene ontology (GO) functional enrichment analysis was performed by Metascape (http://metascape.org/) with default settings. Gene set enrichment analysis (GSEA) was performed on a list of genes ranked by fold change using GSEA software61.
Structure prediction and molecular dynamics simulations
Protein sequences for FXR1 were available from UniPort (https://www.uniprot.org/), RNA G-quadruplex structure was download from PDB database with entry ID 5DE562. The protein-RNA complex structures predicted by AlphaFold363 were protonated using the PDBFixer program (https://github.com/openmm/pdbfixer). Subsequently, molecular dynamics (MD) simulations were performed using GROMACS (version 2025.0)61, with each complex system simulated for 100 ns. Proteins and RNA were parameterized with the AMBER ff14SB + parmbsc1 force field64,65, solvated in a cubic box with TIP3P water model66, and neutralized with Na⁺ and Cl⁻ ions at 0.15 M salt concentration. Simulations included energy minimization (EM), the canonical ensemble (NVT) equilibration (0–300 K over 1 ps), and the isothermal-isobaric ensemble (NPT) equilibration (300 K, 1 atm for 2 ns). Finally, a 600 ns production MD simulation used V-rescale temperature coupling67, C-rescale pressure coupling68, and the particle mesh Ewald (PME) electrostatics with a 1.0 nm cutoff. The binding free energy was calculated with gmx_MMPBSA69 using the MM/GBSA method, with the “GB-Neck2” model, at 0.15 M ion concentration.
lmaging data analysis
In Figs. 2 and 5, Supplementary Figs. 2 and 5, for mRNA cytoplasm-nucleus translocation assay, human C-N translocation pipeline of CellProfiler49 was used to measure mRNA content in the nucleus and cytoplasm, and then calculate the ratio as a measure of translocation. Nuclear edges were identified by DAPI signals. For localization assay in Figs. 2–3 and 5–6, Supplementary Fig. 3 and Supplementary Figs. 5–6, the fluorescence signals of RNA, proteins and nascent peptides outside the nucleus are recognized. In Figs. 3 and 6, for mRNA transport and localized translation assay, FXR1 condensates were identified by fluorescence signals overlapping FXR1 proteins and other RNAs. Calculate the distance between each signal or condensate and the nearest nucleus edge. All of this was done using ImageJ software, while the plotting was done with R.
Intrinsically disordered region prediction
The online tool PONDR (http://pondr.com/) was used to predict disordered regions of FXR1 and NUP88 proteins.
Statistics and reproducibility
Statistical parameters are reported either in individual figures or corresponding figure legends. Quantification data are in general presented as bar/line plots, with the error bar representing mean ± SEM, or a boxplot, showing the median (middle line), and first and third quartiles (box boundaries). The data from experimental sources were assumed to be normally distributed unless stated otherwise; however, this was not formally tested. The normality and equivariance tests of the data distribution from sequencing sources are carried out, and the suitable test methods are selected. Student’s t test and Wilcoxon rank sum test were used for analyses of two populations. For multiple-comparison testing, the p values were determined using one-way or two-way ANOVA with correction, and the Chi-square test was used for statistical tests among multiple groups of frequencies. All statistical analyses were done in R and Graphpad Prism 6.0. All experiments were independently repeated at least three times with consistent results.
Reference datasets
The information regarding the gene functions and groupings in Fig. 2, Supplementary Figs. 1, 3, and 7 was all derived from the Gene Ontology database (http://geneontology.org/). NPC interactome data were accessible from previously published experiments20,21. For analyses involving experimentally defined G-quadruplex sequences, data were taken from previously published experiments31. Protein sequences for FXR1 and NUP88 are available from UniPort database (https://www.uniprot.org/), which was used to predict disordered regions of proteins. The RBP dataset was supported by RBPDB and EuRBPDB (http://eurbpdb.syshospital.org/). Furthermore, the gene names and Ensembl IDs in these databases have been corrected manually.
Ethics & Inclusion statement
We declare that we have complied with all relevant ethical regulations and that all necessary animal experiments and human embryonic stem cell experiments have been approved by the Ethics Committee of the Institute of Basic Medicine, Chinese Academy of Medical Sciences.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The raw data and processed data of RNA-seq and eCLIP-seq generated in this study have been deposited in the GEO database under accession code GSE245777. The mass spectrometry data generated in this study have been deposited in the OMIX database under accession code OMIX011273. Raw data supporting the findings of this study are available in the Supplementary Information/Source Data files, which include uncropped blot images, raw data corresponding to each figure. RNA-seq and MS data of hESC differentiation into mesoderm or endoderm were publicly accessible from the GEO or PRIDE database with accession numbers GSE206328, PXD008554, and PXD032904, respectively34,51. Source data are provided with this paper.
References
Banani, S. F. et al. Biomolecular condensates: organizers of cellular biochemistry. Nat. Rev. Mol. Cell Biol. 18, 285–298 (2017).
Alberti, S. & Hyman, A. A. Biomolecular condensates at the nexus of cellular stress, protein aggregation disease and ageing. Nat. Rev. Mol. Cell Biol. 22, 196–213 (2021).
Lyon, A. S., Peeples, W. B. & Rosen, M. K. A framework for understanding the functions of biomolecular condensates across scales. Nat. Rev. Mol. Cell Biol. 22, 215–235 (2021).
Li, P. et al. Phase transitions in the assembly of multivalent signalling proteins. Nature 483, 336–340 (2012).
Hanazawa, M., Yonetani, M. & Sugimoto, A. PGL proteins self-associate and bind RNPs to mediate germ granule assembly in C. elegans. J. Cell Biol. 192, 929–937 (2011).
Sehgal, P. B. Biomolecular condensates in cancer cell biology: interleukin-6-induced cytoplasmic and nuclear STAT3/PY-STAT3 condensates in hepatoma cells. Contemp. Oncol.23, 16–22 (2019).
Clarke, J. P., Thibault, P. A., Salapa, H. E. & Levin, M. C. A comprehensive analysis of the role of hnRNP A1 function and dysfunction in the pathogenesis of neurodegenerative disease. Front. Mol. Biosci. 8, 659610 (2021).
Choi, Y. et al. Time-resolved profiling of RNA binding proteins throughout the mRNA life cycle. Mol. Cell 84, 1764–1782.e10 (2024).
Wang, J. et al. A molecular grammar governing the driving forces for phase separation of prion-like RNA binding proteins. Cell 174, 688–699.e16 (2018).
Xiao, Y. et al. Regulation of zebrafish dorsoventral patterning by phase separation of RNA-binding protein Rbm14. Cell Discov. 5, 1–17 (2019).
Shao, W. et al. Phase separation of RNA-binding protein promotes polymerase binding and transcription. Nat. Chem. Biol. 18, 70–80 (2022).
Guo, Y. E. et al. Pol II phosphorylation regulates a switch between transcriptional and splicing condensates. Nature 572, 543–548 (2019).
Huppertz, I. et al. Riboregulation of Enolase 1 activity controls glycolysis and embryonic stem cell differentiation. Mol. Cell 82, 2666–2680.e11 (2022).
Wassarman, K. M. & Storz, G. 6S RNA regulates E. coli RNA polymerase activity. Cell 101, 613–623 (2000).
Horos, R. The small non-coding vault RNA1-1 acts as a riboregulator of autophagy. Cell 176, 1054–1067.e12 (2019).
Weirich, C. S. et al. Activation of the DExD/H-box protein Dbp5 by the nuclear-pore protein Gle1 and its coactivator InsP6 is required for mRNA export. Nat. Cell Biol. 8, 668–676 (2006).
Montpetit, B. et al. A conserved mechanism of DEAD-box ATPase activation by nucleoporins and InsP6 in mRNA export. Nature 472, 238–242 (2011).
Das, S., Vera, M., Gandin, V., Singer, R. H. & Tutucci, E. Intracellular mRNA transport and localized translation. Nat. Rev. Mol. Cell Biol. 22, 483–504 (2021).
Fernandopulle, M. S., Lippincott-Schwartz, J. & Ward, M. E. RNA transport and local translation in neurodevelopmental and neurodegenerative disease. Nat. Neurosci. 24, 622–632 (2021).
James, C. et al. Proteomic mapping by rapamycin-dependent targeting of APEX2 identifies binding partners of VAPB at the inner nuclear membrane. J. Biol. Chem. 294, 16241–16254 (2019).
Liu, C.-H. et al. Combining proximity labeling and cross-linking mass spectrometry for proteomic dissection of nuclear envelope interactome. J. Proteome Res. 19, 1109–1118 (2020).
Zhang, Y. et al. The fragile X mental retardation syndrome protein interacts with novel homologs FXR1 and FXR2. EMBO J. 14, 5358–5366 (1995).
Siomi, M. C., Zhang, Y., Siomi, H. & Dreyfuss, G. Specific sequences in the fragile X syndrome protein FMR1 and the FXR proteins mediate their binding to 60S ribosomal subunits and the interactions among them. Mol. Cell Biol. 16, 3825–3832 (1996).
Datta, C. et al. Ribosome changes reprogram translation for chemosurvival in G0 leukemic cells. Sci. Adv. 8, eabo1304 (2022).
Kang, J.-Y. et al. LLPS of FXR1 drives spermiogenesis by activating translation of stored mRNAs. Science 377, eabj6647 (2022).
Lautier, O. et al. Co-translational assembly and localized translation of nucleoporins in nuclear pore complex biogenesis. Mol. Cell 81, 2417–2427.e5 (2021).
Fenton, A. R. et al. FMRP regulates MFF translation to locally direct mitochondrial fission in neurons. Nat. Cell Biol. 26, 2061–2074 (2024).
Tom Dieck, S. et al. Direct visualization of newly synthesized target proteins in situ. Nat. Methods 12, 411–414 (2015).
Cléry, A. & Allain, F. H.-T. From structure to function of RNA binding domains. In Madame Curie Bioscience Database [Internet] (Landes Bioscience, 2013).
Goering, R. et al. FMRP promotes RNA localization to neuronal projections through interactions between its RGG domain and G-quadruplex RNA sequences. eLife 9, e52621 (2020).
Guo, J. U. & Bartel, D. P. RNA G-quadruplexes are globally unfolded in eukaryotic cells and depleted in bacteria. Science 353, aaf5371 (2016).
Sharma, D. et al. The kinetic landscape of an RNA-binding protein in cells. Nature 591, 152–156 (2021).
Wolling, H. et al. Quantitative secretomics reveals extrinsic signals involved in human pluripotent stem cell cardiomyogenesis. Proteomics 18, e1800102 (2018).
Genuth, N. R. et al. A stem cell roadmap of ribosome heterogeneity reveals a function for RPL10A in mesoderm production. Nat. Commun. 13, 5491 (2022).
Ambadipudi, S., Biernat, J., Riedel, D., Mandelkow, E. & Zweckstetter, M. Liquid-liquid phase separation of the microtubule-binding repeats of the Alzheimer-related protein Tau. Nat. Commun. 8, 275 (2017).
Hofweber, M. et al. Phase separation of FUS is suppressed by its nuclear import receptor and arginine methylation. Cell 173, 706–719.e13 (2018).
Chen, Y. et al. O-GlcNAcylation determines the translational regulation and phase separation of YTHDF proteins. Nat. Cell Biol. 25, 1676–1690 (2023).
Lunde, B. M., Moore, C. & Varani, G. RNA-binding proteins: modular design for efficient function. Nat. Rev. Mol. Cell Biol. 8, 479–490 (2007).
Gerstberger, S., Hafner, M. & Tuschl, T. A census of human RNA-binding proteins. Nat. Rev. Genet. 15, 829–845 (2014).
Hentze, M. W., Castello, A., Schwarzl, T. & Preiss, T. A brave new world of RNA-binding proteins. Nat. Rev. Mol. Cell Biol. 19, 327–341 (2018).
Kilgore, H. R. et al. Protein codes promote selective subcellular compartmentalization. Science 387, 1095–1101 (2025).
Joung, J. et al. A transcription factor atlas of directed differentiation. Cell 186, 209–229.e26 (2023).
Fang, Y. et al. Histone crotonylation promotes mesoendodermal commitment of human embryonic stem cells. Cell Stem Cell 28, 748–763.e7 (2021).
Melcer, S. et al. Histone modifications and lamin A regulate chromatin protein dynamics in early embryonic stem cell differentiation. Nat. Commun. 3, 910 (2012).
Di Stefano, B. et al. The RNA helicase DDX6 controls cellular plasticity by modulating p-body homeostasis. Cell Stem Cell 25, 622–638.e13 (2019).
Frye, M. & Blanco, S. Post-transcriptional modifications in development and stem cells. Development 143, 3871–3881 (2016).
Shen, W. et al. Comprehensive maturity of nuclear pore complexes regulates zygotic genome activation. Cell 185, 4954–4970.e20 (2022).
Han, L. et al. Changes in nuclear pore numbers control nuclear import and stress response of mouse hearts. Dev. Cell 57, 2397–2411.e9 (2022).
McQuin, C. et al. CellProfiler 3.0: next-generation image processing for biology. PLoS Biol. 16, e2005970 (2018).
Van Nostrand, E. et al. Robust transcriptome-wide discovery of RNA-binding protein binding sites with enhanced CLIP (eCLIP). Nat. Methods 13, 508–514 (2016).
Dobin, A. et al. STAR: ultrafast universal RNA-seq aligner. Bioinformatics 29, 15–21 (2013).
Li, B. & Dewey, C. N. RSEM: accurate transcript quantification from RNA-Seq data with or without a reference genome. BMC Bioinformatics 12, 323 (2011).
Liao, Y., Smyth, G. K. & Shi, W. featureCounts: an efficient general purpose program for assigning sequence reads to genomic features. Bioinformatics 30, 923–930 (2014).
Love, M. I., Huber, W. & Anders, S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 15, 550 (2014).
Kechin, A., Boyarskikh, U., Kel, A. & Filipenko, M. cutPrimers: a new tool for accurate cutting of primers from reads of targeted next generation sequencing. J. Comput. Biol. 24, 1138–1143 (2017).
Li, H. et al. The sequence alignment/map format and SAMtools. Bioinformatics 25, 2078–2079 (2009).
Lovci, M. T. et al. Rbfox proteins regulate alternative mRNA splicing through evolutionarily conserved RNA bridges. Nat. Struct. Mol. Biol. 20, 1434–1442 (2013).
Thorvaldsdóttir, H., Robinson, J. T. & Mesirov, J. P. Integrative Genomics Viewer (IGV): high-performance genomics data visualization and exploration. Brief. Bioinform. 14, 178–192 (2013).
Buske, F. A., Bodén, M., Bauer, D. C. & Bailey, T. L. Assigning roles to DNA regulatory motifs using comparative genomics. Bioinformatics 26, 860–866 (2010).
Lorenz, R. et al. ViennaRNA Package 2.0. Algorithms Mol. Biol. 6, 26 (2011).
Van Der Spoel, D. et al. GROMACS: fast, flexible, and free. J. Comput. Chem. 26, 1701–1718 (2005).
Vasilyev, N. et al. Crystal structure reveals specific recognition of a G-quadruplex RNA by a β-turn in the RGG motif of FMRP. Proc. Natl. Acad. Sci. USA 112, E5391–E5400 (2015).
Abramson, J. et al. Accurate structure prediction of biomolecular interactions with AlphaFold 3. Nature 630, 493–500 (2024).
Maier, J. A. et al. ff14SB: improving the accuracy of protein side chain and backbone parameters from ff99SB. J. Chem. Theory Comput. 11, 3696–3713 (2015).
Ivani, I. et al. Parmbsc1: a refined force field for DNA simulations. Nat. Methods 13, 55–58 (2016).
Srivastava, D. K. et al. Structure of the human dopamine transporter and mechanisms of inhibition. Nature 632, 672–677 (2024).
Bussi, G., Donadio, D. & Parrinello, M. Canonical sampling through velocity rescaling. J. Chem. Phys. 126, 014101 (2007).
Bernetti, M. & Bussi, G. Pressure control using stochastic cell rescaling. J. Chem. Phys. 153, 114107 (2020).
Hess, B. P-LINCS: a parallel linear constraint solver for molecular simulation. J. Chem. Theory Comput. 4, 116–122 (2008).
Acknowledgements
We would like to express our gratitude to Professor Ge Shan of the University of Science and Technology of China for providing the RBP knockdown plasmids. Thanks to Yue Huang Laboratory, Institute of Basic Medicine, Chinese Academy of Medical Sciences, for the gift of H1 hESCs. We thank the State Key Laboratory of Common Mechanism Research of Major Diseases Platform for consultation and instrument availability that supported this work, and the High-performance Computing Platform at the Center for Bioinformatics, Institute of Basic Medical Sciences, Chinese Academy of Medical Sciences. This work was supported by the National Key Research and Development Program of China, Y.M. (2021YFA0805703), the National Natural Science Foundation of China, J.Y. (92268205, 82330007) and Y.M. (32470847), and the CAMS Innovation Fund for Medical Sciences, J.Y. (2021-I2M-1-019, 2024-I2M-ZH-021).
Author information
Authors and Affiliations
Contributions
J.Y. and Y.M. conceived and directed the study; J.B.Y. designed and performed most of the experiments; Z.C. performed the bioinformatics analysis; J.H. and B.Z. constructed the FXR1 knockout cell lines; Y.S. provided technical support; J.Y., Y.M., and J.B.Y. edited the manuscript with input from all authors. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Niels Gehring and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yang, J., Chen, Z., He, J. et al. Modular RNA interactions shape FXR1 condensates involved in mRNA localization and translation. Nat Commun 16, 8589 (2025). https://doi.org/10.1038/s41467-025-63700-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-63700-y
