
Abstract
CD8+ T cells can rapidly produce effector molecules following activation. This activation triggers rapid changes in gene expression that rely on the control of mRNA levels via multiple mechanisms, including RNA modifications. N6-methyladenosine (m6A) is an abundant post-transcriptional modification that promotes the decay of messenger RNAs in the cytosol. However, how recognition of m6A sites is integrated with other regulatory mechanisms that alter the fate of immunoregulatory mRNAs in CD8+ T cells remains unexplored. Here, we apply the m6A-iCLIP and GLORI methods to identify the importance of m6A sites flanked by AU-rich elements (AREs) within the 3’UTRs of CD8+ T cell mRNAs. Presence of such ARE-flanking m6A motifs predicts meta-unstable mRNAs that rapidly decay upon CD8+ T cell activation. We demonstrate interdependent effects of mutations in the identified AREs and RRACHs on TNF mRNA stability. The ARE-flanking m6A sites in these mRNAs show particularly high iCLIP crosslinking of YTHDF proteins, which are also identified by proteomic interactome analyses along with additional novel RNA-binding proteins. Our study reveals a crosstalk between m6A and ARE-dependent mechanisms in CD8+ T cells, providing new approaches for modulating mRNA decay in T cell activation.
Similar content being viewed by others
Introduction
CD8+ T cells, also known as cytotoxic or killer T cells, play a crucial role in the immune response against malignant and virally infected cells1. When CD8+ T cells encounter infected or malignant cells, they proliferate and differentiate into effector cells (Teff), which produce high levels of effector molecules to kill target cells. After target cell clearance, most Teff cells undergo apoptosis, but importantly, a subset differentiates into memory cells (TM), which persist and provide long-term immunity2. When activated, CD8+ T cells undergo rapid changes in gene expression that rely on finely-tuned control of messenger RNA (mRNA) levels3. An important determinant of mRNA stability in CD8+ T cells are the adenylate-uridylate-rich elements (AU-rich elements; AREs)4, abundant sequences in the 3’ untranslated region (3’UTR) of many mRNAs; these are particularly prominent in cytokine mRNAs5,6. AREs recruit RNA-binding proteins (RBPs) that promote either RNA stabilisation (e.g., HuR) or degradation (e.g., ZFP36L1/L2), thus representing an important mechanism of regulation of effector molecule production by TM cells after T-cell activation3,7.
Another determinant of cellular mRNA stability is N6-methyladenosine (m6A) methylation. The m6A modification is co-transcriptionally deposited on mRNAs by the core methyltransferase complex METTL3/METTL14/WTAP8, which plays widespread regulatory roles in mRNA metabolism; these include nuclear export, splicing, stability, translation, and compartmentalisation8,9,10,11,12. m6A demethylation is catalysed by α-ketoglutarate (αKG)-dependent dioxygenases, which include FTO and ALKBH5 demethylases13,14. Deposition of m6A is largely associated with accelerated mRNA metabolism through the activity of m6A reader proteins, including YTHDF proteins (YTHDF1, YTHDF2 and YTHDF3), that promote mRNA decay in the cytoplasm and P-bodies15,16. Recognition of m6A-modified RNAs is crucial in cell differentiation and development17,18, and dysregulation of m6A deposition has been reported in leukaemia, aging and neurodegeneration19,20,21.
Various next-generation sequencing (NGS) methods enable the transcriptomic profiling of individual m6A modifications by applying chemical, enzymatic, or antibody-based recognition of modified ribonucleosides and/or direct RNA sequencing to detect m6A residues on mRNAs22,23,24. One of these methods for profiling m6A at single-nucleotide resolution is miCLIP (also known as m6A-CLIP)25,26. This method relies on the use of anti-m6A antibodies for the immunoprecipitation of m6A-modified RNA fragments, which form covalent crosslinks with the antibody upon exposure to UV-C light. Insights from miCLIP and other methods demonstrate that m6A is primarily present in consensus RRACH (R, purine; H, not G) sequences, with greatest enrichment near stop codons at the start of 3’ untranslated regions (3’UTRs) of mRNAs25,26,27,28. Several methods have also reported signals in non-RRACH motifs, with variation between cell types and methodologies used. For instance, non-RRACH pentamers such as GGAUU were reported by the miCLIP2 study in HEK293T and C643 lines29. Direct RNA sequencing revealed 187 m6A sites in AGAUU in Arabidopsis mRNAs30. However, the roles of such non-RRACH sites in the m6A-dependent regulation of mRNA metabolism have not been systematically investigated.
Evidence shows that m6A modification is an important factor in immune-modulatory responses, including antitumor immunity31. Deletion of the reader protein YTHDF1 in mouse dendritic cells enhances antitumor responses through increased tumour antigen presentation to CD8+ T cells32. Deletion of METTL3 blocks mouse CD4+ T cell differentiation by keeping the cells in a naïve state33. However, we do not yet fully understand how the recognition of m6A sites is integrated with other regulatory mechanisms to control mRNA stability during T cell activation. It is clear that diverse RNA-binding proteins (RBPs), in addition to canonical YTH domain m6A readers, can regulate mRNA stability in m6A-dependent ways9,16. For instance, m6A mRNA methylation can either promote or inhibit the binding of HuR to transcripts such as SOX234 and FOXM135, or to various regions in a single mRNA18. It is thus important to characterise how m6A deposition might interact with various regulatory motifs to control the fate of immunoregulatory mRNAs in T cells.
Here, we used an improved iCLIP protocol (iiCLIP)36 in the context of miCLIP to profile m6A in human CD8+ T cells before and after activation. As expected, the strongest enrichment of the miCLIP signal was found in RRACH motifs (miCLIP-RRACH), but we have also identified enrichment within ARE motifs (miCLIP-ARE). Absolute quantification of m6A sites using the antibody-independent GLORI method37 revealed that miCLIP-ARE sites contain RRACH motifs within ± 4 nucleotides of AREs, which may represent a distinct functional subclass of m6A sites.
Through measurements of mRNA stability, we showed that mRNAs in which we identified ARE-flanking m6A sites are meta-unstable, so that they become rapidly degraded in activated CD8+ T cells. Interestingly, these mRNAs encode late-effector and memory proteins. Through supervised learning of mRNA half-life data, we found that the combined miCLIP and GLORI signal in ARE-flanking m6A sites is more effective at predicting meta-instability than either signal in canonical RRACH motifs alone. We investigated these relationships further by manipulating the m6A machinery and with reporter assays. We found that METTL3 inhibition increases the stability of target mRNAs harbouring ARE-flanking m6A sites, such as IL7R and TNF. We also demonstrated that the impact of mutations in miCLIP-ARE sites on the stability of the 3'UTR-TNF mRNA depends on mutations in RRACH sites. Finally, we showed that miCLIP-ARE sites were enriched in iCLIP crosslink sites of YTHDF proteins and newly identified ARE-bound RBPs uncovered in this study, particularly members of the LSM family. These findings indicate that canonical m6A-modified RRACH motifs and the ARE-flanking m6A sequences represent functionally distinct m6A sites, bound by different m6A-reader RBPs. Together, they likely coordinate the meta-decay of mRNAs involved in key regulatory functions of CD8+ T cells.
Results
ARE-flanking m6A sites revealed by motif integration of miCLIP and GLORI profiling
We applied a methylation-improved iCLIP (miCLIP)25,26,36 assay to study m6A methylation in non-activated and activated CD8+ T cells, where an anti-m6A antibody was used to immunoprecipitate fragmented RNA isolated from primary human CD8+ T cells subjected to in vitro activation with aCD3/aCD28 beads (Fig. 1A and Supplementary Fig. S1A). Our miCLIP workflow introduces several features to identify motifs at anti-m6A crosslinks with high specificity: (a) m6A immunoprecipitation with or without UV irradiation of the m6A antibody to RNA to account for the technical impact of UV crosslinking38; (b) sequencing of fragmented input RNAs with the same protocol, to account for the technical biases of cDNA ligation and other aspects of the protocol39 and allow us to normalise data by RNA abundance40,41; (c) use of UMIs and the iCLIP analysis approach to identify unique cDNA molecules; and (d) use of positionally enriched k-mer analysis (PEKA)42 to identify the motifs enriched around high-confidence (thresholded) crosslinks, i.e., crosslinks located within peaks of high crosslink density, relative to crosslinks located outside peak regions; peaks were determined using either Clippy or Paraclu43 (Methods) (Fig. 1A). Hierarchical clustering of 5-mers based on PEKA scores of thresholded sites revealed enrichment of crosslinks in GGACU and other variants of the RRACH consensus as well as motifs corresponding to the WWAWW consensus (W = A or U), reminiscent of the AU-rich elements (AREs) (Fig. 1B). The two sets of motifs were enriched at the starts of miCLIP reads for non-activated (noAct), Day1- and Day5-activated CD8+ T cell samples but not at the starts of cDNAs prepared from input RNA (Fig. 1B). Noticeably, both the RRACH and WWAWW consensus sequences were enriched at the start of miCLIP reads in the absence of UV crosslinking (Fig. 1B), although some W-rich sequences were UV-dependent (Fig. 1B). This finding suggested that UV irradiation only partially promotes the crosslinking of nearby uridines to the anti-m6A antibody.

A The miCLIP workflow for identification of high-confidence crosslinks: (1) primary human CD8+ T cells subjected to in vitro activation with aCD3/aCD28 beads; (2) RNA enrichment and experimental controls, including m6A immunoprecipitation without UV irradiation (noUV) and input RNA samples; (3) SDS‒PAGE purification of RNA fragments crosslinked to the anti-m6A antibody followed by RNA isolation; (4) library preparation; (5) iCLIP analysis for determination of uniquely mapped crosslinks; (6) determination of peaks, i.e., regions with high density of crosslinks; (7) ‘positionally enriched k-mer analysis’ (PEKA) to extract sequences in high-confidence (‘thresholded’) miCLIP crosslinks. B Hierarchical clustering of 5-mers based on standardised PEKA scores at ‘thresholded sites’; here, crosslinks and Clippy peaks were used for PEKA. The median PEKA score of each miCLIP or Input group (noAct, Day1 or Day5) was calculated for all 5-mers, and the unique sets of the 20 most enriched and variant 5-mers were plotted on the heatmap. C Metagene distribution of GLORI-determined m6A counts at miCLIP sites (top) and number-matched control sites randomly selected from the 3’UTR (bottom), centred on RRACH, WWAWW and CRACH pentamers; GLORI counts show the effect of the METTL3 inhibitor at each position, and represent the average across two CD8+ T cell replicates. D Metagene distribution of GLORI-determined m6A counts centred on miCLIP-ARE sites that contain nearby RRACH motifs (left) or lack RRACH motifs (right), showing the effect of the METTL3 inhibitor. Stratification by distance highlights the spatial relationship between m6A deposition and RRACH proximity. The WWAWW + RRACH sites refer to miCLIP-ARE sites containing at least one RRACH motif within ≤ 50nt. E Density plot showing the motif-specific distribution of PEKA crosslinks in the miCLIP and Input samples around scaled mRNA regions. For all panels, CD8+ T cells from healthy donors were isolated; not activated (noAct; n = 4), Day1 after activation (Day1; n = 5), Day5 after activation (Day5; n = 4), Mock (n = 12), noUV (n = 3). Panel (A) was created in BioRender. Foskolou, I. (2026) https://BioRender.com/ h18sinc. Source data are provided as a Source Data file.
The metagene distribution of motifs around the starts of miCLIP cDNAs demonstrated direct alignment with the A motif corresponding to GGACU (and RRACH consensus) and proximal to UUAUU (and WWAWW consensus), but not those corresponding to CRACH consensus (e.g., CGACU) (Supplementary Fig. S1B), which is in agreement with reports showing that METTL3 does not exhibit in vitro activity on CGACU-containing RNA probes44. The starts of iCLIP reads can be enriched at uridines due to nucleotide biases of UV crosslinking, but the starts of miCLIP reads were aligned within two nucleotides from A, both at the RRACH and WWAWW motif centres (Fig. 1B and Supplementary Fig. S1B). On one hand, the UV independence of motif enrichment, and alignment of cDNA starts with As, indicates that the RNA-bound part of the antibody is carried over throughout the miCLIP procedure and can induce cDNA truncation at its RNA contact sites even when it is not UV crosslinked. This is surprising, since the procedure involves high-salt washing of the IP mixture, separation of the antibody-RNA complex via SDS‒PAGE, transfer to a membrane and treatment with proteinase K to release an antibody peptide bound to RNA. Accordingly, we detected an infrared signal on the membrane in all the miCLIP and noUV samples that were immunoprecipitated with the anti-m6A antibody but not in the UV-crosslinked samples immunoprecipitated with a control IgG isotype (Supplementary Fig. S1C). Notably, the m6A antibody was developed against a monomer of N6-methyladenosine conjugated to a keyhole limpet haemocyanin lacking any WWAWW motifs; therefore, we speculated that contacts with AREs might be mediated by the presence of m6A on these sites.
Typical iCLIP relies on the analysis of cDNA starts as signatures of cDNA truncations induced by the crosslinked peptide45,46. Moreover, less frequent readthrough of reverse transcriptase (RT) across cross-linked peptides can lead to deletions and insertions, which can be analysed for cross-linking-induced mutation sites (CIMS)25,47. Expectedly, the incidence of deletions was higher in miCLIP than in input samples (Supplementary Fig. S1D). In this regard, it is documented that m6A-modified RRACHs result in CIMS characterised by C > T substitutions25. To assess motif-specific CIMS, we expanded the CIMS analysis to include C > T, T > A and A > T transitions to account for transitions in the ARE sites. While C > T substitutions were enriched at the genomic coordinates of RRACHs, T > A substitutions were enriched within AREs, but not detected at CRACH centres (Supplementary Fig. S1E). These substitutions were enriched regardless of whether UV was used in miCLIP. This indicates that the bound antibody peptide might be able to maintain bound to the RNA fragments throughout the CLIP procedure and form direct contacts with RRACHs and AREs, so that it can affect the mutation and truncation rate of reverse transcription at these motifs.
To assess the signal in AREs in other datasets, we analysed the published miCLIP2 data, where 661 m6A sites were reported in non-DRACH sequences29. By assessing the distribution of PEKA crosslinks around relevant motifs, we found significant enrichment of miCLIP2 crosslinks centred at GGACU and UUAUU pentamers, but not CGACU, in miCLIP2 data from both mouse embryonic stem cells (mESCs) and human cell lines (HEK293T and C643) (Supplementary Fig. S1F, S1G). In mESCs, the PEKA crosslinks were Mettl3 dependent at GGACU centres, but the signal at UUAUU centres was less affected by Mettl3 loss (Supplementary Fig. S1F). Antibody-independent methods also enable m6A profiling with single-base resolution, although some are experimentally tailored to specifically probe RRACH or related subset sequences, such as MAZTER-seq48 and m6A-REF-seq49 that rely on endoribonuclease recognition of ACA sequences. Among these methods, the recently developed GLORI features glyoxal- and nitrite-mediated deamination of unmodified adenosines, enabling the absolute quantification of m6A sites with high specificity37. By analysing GLORI-processed data in HEK293T cells, we observed that m6A peaks were enriched at RRACH and depleted directly at WWAWW pentamers enriched in their vicinity (Supplementary Fig. S1H). We further interrogated m6A sites previously identified using the antibody-free MePMe-seq method in HeLa cells50; these sites were also mildly enriched within 10 nucleotides from WWAWW pentamers but depleted directly at the ‘A’ centre (Supplementary Fig. S1I). Conversely, both antibody-independent methods showed that m6A sites were depleted at the ‘A’ centre yet not enriched in the vicinity of CRACH pentamers, with fivefold lower counts at each position when compared to WWAWW motifs (Supplementary Fig. S1H, S1I). Thus, our miCLIP data and that of Kortel et al.29 revealed WWAWW-centred (ARE-like) motifs, which we denoted miCLIP-ARE sites. Conversely, two antibody-free methods in immortalised cell lines showed that m6A sites are enriched in RRACH motifs and proximal to WWAWW motifs, yet depleted at the WWAWW-centred A (Supplementary Fig. S1H, S1I). This led us to hypothesise that miCLIP-ARE sites may represent canonical RRACH motifs flanked by AREs in their immediate vicinity. To test this in a METTL3-dependent manner, we performed GLORI in primary CD8+ T cells under activation conditions, with or without a competitive METTL3 inhibitor51. GLORI-detected m6A sites (GLORI-m6A counts) were highly enriched in miCLIP-RRACH sites (Fig. 1C). Notably, a substantial fraction (10%) of GLORI-m6A counts localised within ± 4 nucleotides of miCLIP-ARE sites, with signal peaking just 2 nucleotides downstream, while remaining low at the central A of WWAWW motifs (Fig. 1C). These signals were METTL3-dependent and most reduced in the non-activated T cells, suggesting functional roles (Fig. 1C – orange line). Importantly, the GLORI-m6A sites were more enriched around miCLIP-ARE sites (i.e., 8056 thresholded sites) than around randomly sampled 3’UTR ARE sites (i.e., 8056 control sites). Conversely, the GLORI signals at miCLIP-RRACH sites showed a similar enrichment pattern to those at randomly sampled RRACH sites, albeit with higher overall signal intensity (Fig. 1C). The data strongly suggest that miCLIP-ARE sites correspond to canonical RRACH motifs with flanking AREs within (±) 4 nucleotides of the ‘A’ centre.
To further dissect this motif relationship, we stratified miCLIP-ARE sites based on the proximity of RRACH motifs within ± 5, 25 and 50 nucleotides. In agreement with the preceding meta-analyses, the GLORI-m6A counts were enriched at miCLIP-ARE sites with flanking RRACHs, but not at miCLIP-ARE sites lacking nearby RRACH motifs (Fig. 1D and Supplementary Fig. S1J). Together, these findings uncover a class of m6A sites corresponding to RRACH motifs flanked by AREs – termed ARE-flanking m6A sites. Finally, consistent with previous reports, the overall miCLIP signal was most enriched around stop codons (Fig. 1E). Moreover, miCLIP-ARE sites displayed specific enrichment at the start of 3’UTRs, which contrasted the input signal in AREs, which was more evenly distributed across the entire 3’UTR (Fig. 1E). Importantly, the omission of UV crosslinking from miCLIP (noUV) had very little effect on motif distribution, consistent with antibody-RNA complex detection by SDS-PAGE. Thus, ARE-flanking m6A sites (miCLIP-AREs) may represent a distinct functional subclass when compared to canonical miCLIP-RRACH sites.
Meta-instability of 3’UTRs with ARE-flanking m6A sites upon T cell activation
The m6A modification promotes mRNA decay in various cell types, but its effects on individual mRNAs vary significantly9. In this respect, which m6A sites play a role in fine-tuning transcript levels for dynamic and stimulus-dependent responses is not well understood. To assess mRNA-specific features in CD8+ T cells, we partitioned the miCLIP and input signal into RRACH and ARE motifs, normalised the counts using the DESeq2 model, and compared the hierarchical clustering of 3’UTRs across miCLIP and input samples. First, principal component analysis (PCA) of miCLIP counts across the top 1000 most variable 3’UTRs showed that miCLIP-RRACH and miCLIP-ARE motifs were clearly separated along the first two principal components (Supplementary Fig. S2A). Second, we observed that the miCLIP counts were poorly correlated with input counts in the respective motif (Supplementary Fig. S2B – light squares), indicating that changes in the miCLIP signal do not arise from changes in mRNA expression or stability3. Hierarchical clustering of mRNA 3’UTRs revealed 4 clusters characterised by different miCLIP signatures across different CD8+ T cell states: 3’UTRs with high miCLIP-ARE signal and low miCLIP-RRACH signal (cluster 1), lowly expressed 3’UTRs with high miCLIP-ARE and miCLIP-RRACH signal (cluster 2), 3’UTRs with low miCLIP-ARE and high miCLIP-RRACH signal (cluster 3), and highly expressed 3’UTRs with varied degrees of miCLIP signal in AREs or RRACHs (cluster 4) (Fig. 2A). Cluster 4, defined by highly expressed mRNAs mainly in activated CD8+ T cells (Fig. 2A), contained mRNAs typically upregulated during T cell activation; these included genes involved in macromolecule biosynthetic processes (e.g., RPL15, RPL23, RPL31, RPL38, EIF4G1, MRPL3), MHC II class (HLA-A), glycolysis (PGK1), lactate dehydrogenase (LDHA and LDHB), and granzyme B (GZMB) (Supplementary Fig. S2C and Supplementary Data 1). In contrast, cluster 2 included mRNAs involved in immunoregulation and mRNA metabolism. For example, cluster 2 contained mRNAs that play a crucial role in regulating cytokine production (ZFP36L1, ZFP36L2), immune activation (CD28, CD69, TNFAIP3, GBP1), and T cell memory (BCL2, CXCR4, IL7R, TCF7), TNF signalling genes (TNF, TNFRSF1B, TNFAIP8, TNFRSF9), other interleukins and cytokine-related genes (e.g., IL7R, IL10RA, IL27RA, CXCR6, CCR4, CCL3), RNA splicing (SRSF4), and relevant RNA processing (LSM1) and stress granule assembly factors (G3BP2) (Supplementary Fig. S2C and Supplementary Data 1)3. Conversely, cluster 3 included mRNAs that regulate ribosomal processing and biogenesis (DDX54, DEDD2, EIF6, RRP36), T cell activation and innate immunity response (e.g., CXCR3, GZMH, CD74, CD7, CD44) (Supplementary Fig. S2C and Supplementary Data 1).

A Heatmap of miCLIP (PEKA crosslinks) and input counts in 3′UTRs, normalised using DESeq2 size factors. The top 1000 most variable 3′UTRs across noAct (n = 4), Day1 (n = 5), Day5 (n = 4), and input (n = 12) samples are shown, clustered into four groups (c1–c4) defined by unsupervised learning. B Cumulative distributions of mRNA half-lives for miCLIP clusters (c1–c4) and transcripts without miCLIP crosslinks (genes.nomiCLIP), across noAct, Day1 and Day5 CD8⁺ T cells. Two two-sided Kolmogorov–Smirnov (KS) tests were used for statistical significance. C Cumulative distributions of mRNA half-lives for transcripts containing GLORI-identified m⁶A sites at RRACH motifs, stratified by distance to adjacent ARE (WWAWW) motifs. Top: all RRACH sites; Bottom: RRACH sites overlapping miCLIP-ARE peaks. Two-sided KS tests were applied. D KS test statistics comparing mRNA half-lives between transcripts lacking GLORI signal and those harbouring GLORI m⁶A sites at RRACH motifs, binned by distance to AREs. E Heatmap of GLORI m⁶A counts in 3′UTRs, normalised by DESeq2, for the 1000 most variable transcripts across RRACH-only and RRACH-flanking-ARE sites. GLORI clusters (ci, cii) were defined by unsupervised clustering. F Box plots of mRNA half-lives for miCLIP clusters, GLORI clusters, and corresponding no-signal controls across noAct, Day1 and Day5. Boxes represent the interquartile range (IQR), centre lines show medians, whiskers extend to 1.5 × IQR, and minima/maxima are shown as individual points. Two-sided KS tests were used for pairwise comparisons. G Sankey diagram showing the flow between CD8⁺ gene modules, Day5 mRNA half-life categories, and miCLIP/GLORI clusters. H t-SNE projection of transcripts grouped into short (< 3 h) and long (> 5.3 h) half-life classes using miCLIP and genomic features. I Variable importance from 30 conditional Random Forest (cRF) models predicting mRNA stability classes using miCLIP/GLORI cluster identity, genomic features and CD8⁺ T cell annotations. J Performance metrics of the final cRF classifier and 10-fold cross-validation. Box plots defined as in (F). K, L ROC (K) and precision–recall (L) curves for test data and each cross-validation fold. N denotes the number of mRNAs tested in (B), (F) and (G).
To assess the effect of CD8+ T cell activation on mRNA stability and its links to dynamic m6A sites, we performed SLAM-seq (thiol(SH)-linked alkylation for metabolic sequencing of RNA)52 and determined mRNA half-lives in noAct, Day1 and Day5 activated CD8+ T cells. We performed a pulse-chase design of 24 h labelling with 4-thiouridine (4SU) pulsed every 4 h, followed by washout with uridine for 0, 0.5, 1, 3, 6 and 16 h. By fitting the T > C transitions over time to an exponential decay model and applying a goodness of fit cutoff (R2 > 0.5), we determined reliable half-life estimates (t1/2 = ln(2) / k, k = decay constant) for 4158, 5585 and 5866 transcripts in noAct, Day1 and Day5 activated CD8+ T cells, respectively (Supplementary Fig. S2D and Supplementary Data 1). The median mRNA half-life was reduced in activated CD8+ T cells, from 3.6 h in noAct to 3.2 h in Day1 and 2.2 h in Day5 activated T cells (Supplementary Fig. S2D). The mRNA half-lives determined via SLAM-Seq agree with previously published mRNA half-lives in other mammalian cells52,53,54 and with the expected high mRNA turnover in activated T cells55. Comparing mRNA half-lives between the miCLIP clusters revealed that mRNAs with miCLIP-ARE and miCLIP-RRACH sites (cluster 2) had shorter half-lives when compared to mRNAs with low miCLIP signal (i.e., nomiCLIP, ≤ 2 miCLIP counts averaged across samples) included in the DESeq2 model (Fig. 2B). Conversely, highly expressed mRNAs with low miCLIP-RRACH signal (cluster 4) had the longest half-lives (Fig. 2B). We next examined mRNA half-life distributions in relation to GLORI-determined m⁶A sites (GLORI sites), stratified by the proximity of ARE motifs (WWAWW) located within ± 3, 5, 15, 25 or 50 nucleotides of a RRACH motif. Consistent with our miCLIP data, RRACH-flanking ARE sites were associated with significantly shorter mRNA half-lives compared to RRACH sites lacking nearby AREs (i.e., no WWAWW motifs within ± 50 nt) (Fig. 2C). Notably, in Day 5 activated T cells, the mRNA half-lives progressively decreased as the distance between RRACH and ARE motifs narrowed (Fig. 2C, D). The significance threshold (P = 0.05) separated clearly the RRACH-flanking versus RRACH-lacking ARE sites within ±50 nucleotides (Fig. 2D). Relative to genes with low miCLIP (nomiCLIP) or low GLORI (noGLORI) signal, the miCLIP-cluster 2 and GLORI-cluster i were the most destabilised in Day5 activated T cells (Fig. 2C), even though all mRNAs were overall destabilised following CD8+ T cell activation (Supplementary Fig. S2E). Therefore, the datasets support the notion that activation of CD8+ T cells leads to faster decay of mRNAs that harbour ARE-flanking m6A sites (miCLIP-cluster 2 and GLORI-cluster i).
To test whether GLORI-determined m6A sites exhibit similar regulatory patterns, we stratified them into two classes: RRACH-only sites and ARE-flanking m6A sites (i.e., RRACH motifs with at least one ARE within ± 50 nucleotides). Differential expression analysis using DESeq2 showed a clear distinction between the two m6A subclasses in activated T cells (Fig. 2E), with RRACH-flanking ARE sites associated with significantly shorter half-lives compared to RRACH-only sites (Supplementary Fig. S2F). These short-lived transcripts (GLORI-cluster i) showed a 29% overlap with miCLIP-cluster 2, characterised by strong miCLIP-ARE and miCLIP-RRACH signals (Fig. 2A), and included immunoregulatory mRNAs such as CXCR4, CXCR6, G3BP2, IL7R, IL10RA, LSM1, TNFAIP3, TNFAIP8, and ZFP36L2 (Supplementary Data 1). Although the GLORI-cluster ii displayed similar half-life distributions when compared to the noGLORI group (Supplementary Fig. S2F), it still overlapped by 19% with miCLIP-cluster 2 and included several short-lived mRNAs such as TNF and TNFRSF1B (Supplementary Data 1). These findings suggest that ARE-flanking m6A sites and isolated m6A sites are functionally distinct in terms of mRNA stability during T cell activation. Moreover, the two m6A subclasses may contribute differently to post-transcriptional regulation relevant to T cell immune functions.
To test for associations between these m6A signatures and T cell subtype-specific roles, we interrogated mRNAs half-lives within transcriptional modules known to be co-activated in effector versus memory T cells56. Noticeably, the gene modules with shorter half-lives in the SLAM-seq data comprised late effector- and memory-related mRNAs (Supplementary Fig. S2G - modules C, D and F), as defined by Best et al.56 and these were the most destabilised mRNAs during CD8+ T cell activation (Supplementary Fig. S2H). We next grouped mRNA half-lives based on their quartile distribution, < 2.3 (25%), 2.3−3.5 (50%), 3.5−5.3 (75%) and > 5.3 h (100%) in Day5 activated T cells and analysed how they connect to both m6A signatures (miCLIP and GLORI clusters) and CD8+ gene modules (Fig. 2G). Indeed, the late effector, memory precursor and naïve/late effector/memory genes (modules C, D and F) contained more shorter-lived (< 2.3 and 2.3–3.5 hr) than long-lived (3.5–5.3 and > 5.3 hr) mRNAs, which were enriched in miCLIP-cluster 2 and GLORI-cluster i (Fig. 2G – red and green lines). In contrast, the control groups (nomiCLIP and noGLORI) contained mainly cell cycle/division genes, which were overall longer lived (> 2.3 hr) (Fig. 2G – blue lines). These data suggest that ARE-flanking m6A sites in the 3’UTR is a feature of highly unstable – or meta-unstable – mRNAs with T cell memory roles in the activated state.
This led us to assess the most unstable (< 3.0 hr, 30 pth) and stable (> 5.3 hr, 30 pth) mRNAs in our SLAM-seq data based on the motif-specific m6A signatures. To this end, we trained conditional random forest (cRF) models to classify mRNAs as unstable (N = 230) or stable (N = 230) based on eight experimental features in our miCLIP dataset: (1–6) cluster identity, i.e., presence or absence of mRNA in each miCLIP cluster (c1 to c4) or GLORI cluster (ci and cii); (7) CD8+ state (noAct, Day1 and Day5) as a categorical variable; (8) CD8+ gene modules (A to G) as a categorical variable; and two 3’UTR features, (9) frequency of RRACH pentamers and (10) frequency of ARE (WWAWW) pentamers. First, we determined that two t-distributed stochastic neighbour embedding (t.SNE) dimensions could partly resolve unstable and stable mRNAs based on the ten features considered (Fig. 2H), suggesting that a binary classifier may perform well in predicting the two mRNA classes. To determine the best predictive features of unstable and stable mRNAs, we used a conditional variable importance measure that computes the change in prediction accuracy (number of mRNAs classified correctly) when each predictor is permuted in a conditional manner (i.e., using a within-groups permutation that accounts for correlated variables)57. By determining the conditional variable importance on the 30 cRF models (3 repeats of 10-fold resampled iterations each) in the training set (75% of mRNAs), we showed that CD8+ gene modules, miCLIP-cluster 2 and ARE frequency in the 3’UTR were among the most important features in its unique contribution to the cRF models (Fig. 2I). Noticeably, the frequency of ARE motifs within 3’UTRs varied more substantially across clusters than did the frequency of RRACH motifs (Supplementary Fig. S2I). Particularly, GLORI-cluster i was enriched for AREs, whereas GLORI-cluster ii was comparatively depleted of AREs relative to noGLORI mRNAs (Supplementary Fig. S2I).
To evaluate the performance of the cRF classifier, we assessed the predictions from the i) 10-fold cross-validation (CV) during training (training performance) and ii) final model on a held-out test set (25% of mRNAs) in terms of the following metrics: accuracy, specificity, precision, recall (or sensitivity), positive predictive value (PPV), negative predictive value (NPV) and F1 measure. The test set performance of the cRF classifier was 75–83% for each metric, indicating good predictive performance for the positive class (unstable mRNAs) (Fig. 2J – green points). Thus, the cRF classifier showed strong performance in predicting truly unstable mRNAs (PPV), and the high specificity indicates accurate identification of both unstable and stable mRNAs.
In addition, the balanced F1 score on the test set (78%) highlights the model’s overall effectiveness in balancing sensitivity and precision in the classification of unstable mRNAs (Fig. 2J), with CD8+ gene modules and interlinked AREs being important features in this prediction (Fig. 2I). Across the 10-CV folds, the training performance was 65–67% for each metric on averaged (Fig. 2J), which suggests that the 30 cRF models can be improved by being trained on more comprehensive data. Importantly, the receiving operating characteristic (ROC) and precision-recall (PR) curves confirmed that all 10-CV folds performed above a random classifier at all classification cutoff points (Fig. 2K, L), confirming the performance consistency across folds. Similarly, the ROC and PR curves from the final test predictions confirmed the generalisation capacity of the model (Fig. 2K, L). While the combined predictors did not fully account for mRNA instability in the test set (balanced accuracy = 79%) (Fig. 2J), these data indicate that ARE-flanking m6A sites (miCLIP-cluster 2) are better predictors of meta-unstable mRNAs than RRACH-only m6A sites (miCLIP-cluster 3 and GLORI-cluster ii). These findings support a model in which the presence of AREs within 3’UTR enhances m6A-dependent mRNA decay during T cell activation.
Assessment of m6A-interlinked ARE sites on CD8+ T cell essential mRNAs
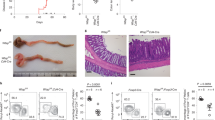
To confirm our transcriptomic findings on essential genes for CD8+ T cel biology, we assessed the stability of newly transcribed mRNAs harbouring ARE-flanking m6A sites and RRACH-only m6A sites (Fig. 2A - cluster 2). To this end, we treated CD8+ T cells with DMSO or METTL3 inhibitor and, on Day 5 after activation, we blocked de novo transcription with actinomycin D and measured mRNA decay over time. METTL3 inhibition increased mRNA stability for IL7R (T cell memory marker58), TNF (essential effector molecule) mRNAs and a trend increase in CD69 (T cell activation marker59) (Fig. 3A and Supplementary Fig. S3A). METTL3 inhibition/deletion also showed an overall increase in total mRNA levels of several mRNAs linked to memory formation (e.g., IL7R) and chemokines and cytokines important for CD8+ T cell function (CCL4, TNF, IFNG) (Fig. 3B and Supplementary Fig. S3B, S3C).

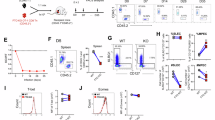
A Actinomycin D experiments showing % of remaining mRNA in CD8⁺ T cells treated with DMSO or METTL3inhibitor. Mean ± SD; n = 3 (one donor provided material for 0,2 h). Mixed-effects model (REML), p-values indicate treatment effects. Donors were processed in parallel. Representative results from three independent experiments (IL7R, TNF). B mRNA levels IL7R (n = 5), CCL4 (n = 5), CD69 (n = 4), CD28 (n = 4), TCF7 (n = 3), ZFP36L1 (n = 3), TNF (n = 4), IFNG (n = 4) in CD8⁺ T cells treated with METTL3inhibitor. Fold change relative to DMSO (grey line). Reference gene 18S. Mean ± SD; paired two-tailed t tests on ΔCt values. For TNF, one Grubbs-identified outlier is displayed but excluded from statistics. C, D Representative flow cytometry plots illustrating IL7Rα gating (C) and quantification of IL7Rα⁺CD8⁺ T cells (D) (n = 10). Paired two-tailed t tests. E, F Representative histogram (E) and quantification (F) of IL7Rα median fluorescence intensity (MFI) in IL7Rα⁺ cells treated with METTL3inhibitor relative to DMSO (grey line) (n = 10). Mean ± SD; one-sample two-tailed t test. G GFP MFI in T cells transduced with GFP-3’UTR constructs (S3H) after treatment with FTO inhibitor followed by PMA/ionomycin activation relative to DMSO (n = 3). One-way ordinary ANOVA. H, I IFNγ (H) and TNFα (I) protein levels measured by ELISA in DMSO (0 μM) or FTOinhibitor treated cells (n = 3). RM one-way ANOVA. J, K Representative amplification curves (ΔRn) and Ct quantification for reference (J) and miCLIP-ARE (K) amplicons in control (grey) and METTL3-KO (pink) samples (n = 3). Mean ± SD. L Fold-change expression (ΔΔCt) for the miCLIP-ARE site in METTL3-KO and FTO-KO cells relative to control (grey line). Mean ± SEM; unpaired two-tailed t test comparing METTL3-KO and FTO-KO; paired t test for control vs METTL3-KO on ΔCt values; (n = 3). M–P mRNA levels (M) and GFP protein levels (N–P) in CD8+ T cells transduced with GFP-3′UTR constructs (S3O). mRNA levels normalised to 3′UTR-TNF_WT (grey line) (n = 10); one-way ANOVA with Holm–Šídák correction (M). Representative plots of resting or PMA/ionomycin-activated cells (N). GFP MFI quantification in activated cells (O, P) (n = 15); paired two-tailed t tests. Box-and-whisker plots (min–max, median, 25th–75th percentiles). All n values reflect distinct donors. Source data are provided as a Source Data file.
IL7Rα is an essential receptor for CD8+ T cells, whose surface expression serves as a marker for long-lived memory CD8+ T cells60. Particularly, the IL7R mRNA showed high-confidence miCLIP-RRACH and miCLIP-ARE sites (Supplementary Fig. S3D), also detected by GLORI as an ARE-flanking m6A within 50nt of a RRACH (GAACU) sequence (Fig. 2E – cluster i). In agreement with previous results (Figs. 1 and 2), we determined higher IL7R mRNA stability and total mRNA levels upon METTL3 inhibition (Fig. 3A, B), as well as an increased population of CD8+ T cells expressing this surface marker and with higher intensity (Fig. 3C–F). These data indicate that m6A levels in ARE-flanking RRACH sites contribute to destabilisation of meta-unstable mRNAs, such as IL7R (t1/2 = 2.3 hr), that characterise memory-precursor functions in activated CD8+ T cells (Fig. 2G – module D, Supplementary Data 1).
Other important genes for CD8+ T cell function include cytokines such as TNFα and IFNγ, essential for target clearance but also highly toxic, thus requiring a fined-tuned regulation of their expression. Memory CD8+ T cells accumulate pre-formed mRNAs of IFNG and TNF, which can be rapidly translated upon activation without the need of de novo transcription61. Both TNF and IFNG mRNAs exhibited miCLIP-AREs, and the TNF had a clear miCLIP-RRACH site (Supplementary Fig. S3E, F), with METTL3 inhibition causing an increase in their steady-state levels (Fig. 3B). We used GFP reporter assays to further investigate the effect of m6A on TNFα and IFNγ expression, where GFP was fused with either the 3’UTR of IFNG, TNF or GzmB mRNA, and the median fluorescence intensity (MFI) measured (Supplementary Fig. S3E–H). CD8+ T cells were transduced with the constructs, rested, and treated with increasing concentrations of the FTO inhibitor meclofenamic acid (MA) for 7 h, followed by overnight CD8+ T cell activation62. The GzmB mRNA was used as a negative control, as it harbours a short 3’UTR, a feature previously associated with enhanced stability in T cells63. This was confirmed by SLAM-seq, which showed a t1/2 of 12 h in no Act and 11 h in Day 5 activated CD8+ T cells (Supplementary Data 1). In addition, the GZMB 3’UTR contained only one high-confidence miCLIP-RRACH site in activated T cells (Supplementary Fig. S3G). As expected, FTO inhibition had no effect on the proportion of GFP-positive cells (Supplementary Fig. S3I). Noticeably, the MFI was significantly reduced in cells expressing the 3′UTR-IFNG and 3′UTR-TNF constructs upon treatment with MA (Fig. 3G and Supplementary Fig. S3J). In contrast, GFP levels from the 3′UTR-GzmB construct remained unaltered by FTO inhibition (Fig. 3G and Supplementary Fig. S3J–K). In line with these results, secretion of endogenous IFNγ and TNFα proteins was also decreased following FTO inhibition during CD8+ T cell activation (Fig. 3H–I), without compromising overall T cell viability (Supplementary Fig. S3L). Although the GzmB 3′UTR did contain a putative miCLIP-ARE site, its signal intensity was comparable to that of the input control site, suggesting this site is not reliably associated with m6A modification (Supplementary Fig. S3G). These results indicate that m6A methylation promotes the decay of short-lived cytokine mRNAs, thereby attenuating effector protein expression in activated CD8⁺ T cells.
Interplay of miCLIP-ARE sites in the control of TNF mRNA levels
The impact of m⁶A on RNP assembly may depend on the additional regulatory motifs beyond the RRACH, including AREs. To independently validate whether ARE-flanking m6A sites can be directy m6A modified, we applied the single-base elongation and ligation-based qPCR amplification (SELECT) method, which exploits the decreased activity of DNA polymerases and nick ligation to m6A bases64. We focused on the 3′UTR of the TNF mRNA, given the importance of the cytokine TNFα for CD8+ T cell function3,7 and because it contains a clear miCLIP-ARE site (AUUUAUUA) located within 15 nucleotides of a RRACH (AGACA) motif (Supplementary Fig. S3E). We designed SELECT primers for the TNF 3’UTR that targeted the miCLIP-ARE site and a distal unmodified adenosine (A) as a reference site, located within 5 nucleotides of a high-confidence miCLIP-RRACH site and 85 nucleotides away from the miCLIP-ARE site (Supplementary Fig. S3E). For SELECT experiments, we adjusted the amount of input RNA based on the qPCR amplification. We then compared the SELECT qPCR amplification curves of primary human CD8+ T control cells and CD8+ T cells with knockout (KO) of either METTL3 methyltransferase (METTL3-KO) or FTO demethylase (FTO-KO) (Supplementary Fig. S3B). While we did not observe differences in amplification curves between control and METTL3-KO CD8+ T cells at the reference site (Fig. 3J), we found greater amplification at the target miCLIP-ARE site in METTL3-KO cells (Fig. 3K, L), indicating lower m6A levels in the absence of METTL3. Conversely, comparison of WT and FTO-KO CD8+ T cells revealed reduced amplification at the miCLIP-ARE site (Supplementary Fig. S3M, N). We also observed a significant difference in amplification between METTL3-KO and FTO-KO cells at this site (Fig. 3L). These results show that the changes detected in the amplification curves were m6A dependent and sensitive to both METTL3 and FTO expression. These data provide orthogonal evidence for the existence of METTL3-dependent m6A modifications at specific RRACH-flanking ARE sites, suggesting these composite motifs function as a distinct m⁶A regulatory unit. We then sought to determine the role of motif-specific m6A signatures identified in our miCLIP on transcript expression. We used the GFP reporter system to further investigate the role of each motif-specific miCLIP site in the 3’UTR of TNF. Specifically, we used either the GFP construct fused with the WT 3’UTR of TNF (3’UTR-TNF_WT) or with mutated forms of miCLIP sites (Supplementary Fig. S3O). The mutated TNF 3’UTRs we used had either a point mutation (A > G) at the miCLIP-ARE site (3’UTR-TNF_AREmut), a point mutation (A > G) at the miCLIP-RRACH site (3’UTR-TNF_RRACHmut) or two-point mutations at both sites (3’UTR-TNF_AREmut/RRACHmut) (Supplementary Fig. S3O). We then retrovirally transduced CD8+ T cells with the GFP 3’UTR-TNF constructs. To account for differences in transduction efficiency, we simultaneously transduced the CD8+ T cells with a construct that expressed Katushka under no 3’UTR control (Supplementary Fig. S3O). After transduction, the cells were rested (kept in culture for an additional 7–10 days), and the RNA levels of GFP and Katushka were measured. We found higher GFP mRNA levels in the presence of mutant miCLIP-ARE compared to mutant miCLIP-RRACH (Fig. 3M and Supplementary Fig. S3P). When both sites were mutated, we observed lower (P = 0.0546) mRNA levels compared to the mutant miCLIP-ARE (Fig. 3M and Supplementary Fig. S3P). To test the effect of the mutations on protein expression, we reactivated the transduced CD8+ T cells with PMA/ionomycin for 16 h and measured GFP levels before and after activation (Fig. 3N–P). As expected, GFP was undetectable in resting CD8+ T cells (Fig. 3N), although we could quantify GFP mRNA levels in the resting state (Fig. 3M). In contrast, following 16 h of activation, GFP protein levels increased across all conditions tested (Fig. 3N), with a higher intensity of GFP under mutant miCLIP-ARE conditions when compared to WT (P = 0.0508) and mutant miCLIP-RRACH (Fig. 3O, P). Katushka levels remained unchanged across conditions both before and after activation of transduced CD8+ T cells (Supplementary Fig. S3Q–T). These results showed that the RRACH-flanking ARE site enhances mRNA decay only in the presence of intact RRACH sites capable of m6A modification. Interestingly, mutation of the RRACH site alone was insufficient to alter TNF mRNA levels, contrary to expectations based on the established role of RRACH in mRNA destabilization9. Collectively, these data lead to the hypothesis that the functional impact of m6A modifications may in some cases, depend on combinatorial recognition of methylated RRACH alongside its flanking ARE sites.
miCLIP-AREs recruit YTHDF and other unique RNA processing factors
To investigate whether miCLIP-ARE sites modulate the recruitment of RBPs, we first examined the local enrichment of m6A in RNAs bound by specific ARE-binding proteins. We performed CLIP experiments in Jurkat T cells using antibodies against canonical m6A-readers (YTHDF1 and YTHDF2) and ARE-binding proteins relevant to T cell biology (HuR, ZFP36). Crosslinked RNA fragments were isolated and analysed by tandem mass spectrometry (LC‒MS/MS) to quantify m6A and adenosine (A) levels (LC‒MS/MS) (Supplementary Fig. S4A). Use of Jurkat T cells in these experiments provided sufficient material to reproducibly detect m6A ribonucleosides by LC-MS/MS, which could not be achieved with primary T cells due to lower RNA yield (see note in Methods). We found that the m6A/A ratio was elevated in RNAs bound to YTHDF1/2, HuR and ZFP36, compared to those bound by the polyA-binding protein (PAPB), which preferentially interacts with A-rich sequences. This indicates that m6A is enriched in RNA regions bound by both m6A-readers and ARE-binding RBPs. Of note, the input RNA (total crosslinked RNA) showed an intermediate m6A/A ratio relative to the PABP-bound RNAs (Supplementary Fig. S4A).
To assess how the presence of m6A influences RNA–protein interactions close to AREs, we performed quantitative mass spectrometry-based RNA interactome capture using synthetic RNA probes designed to mimic key sequence contexts identified by miCLIP and GLORI profiling, as previously described65. Specifically, we tested RNA oligonucleotides containing either the canonical m6A-modified RRACH motif (GGACU) or a composite motif in which a UUAUU (ARE) pentamer was immediately flanked upstream by a RRACH sequence. Unmethylated versions of each probe served as controls. The methylation was placed directly on the central adenosine of the ARE (AGACU-Um⁶AUU), inspired by the original miCLIP signal. Although GLORI data showed that m6A sites are located within RRACH rather than ARE, our probes nevertheless capture the composite architecture of ARE-flanking RRACH sites to allow comparison with RRACH-only probes. We performed a forward pulldown, wherein immobilised A and m6A probes were first incubated with human T cell lysates. After incubation and washes, bound proteins were digested and then differentially labelled with light (A bait pull-down) and medium (m6A bait pull-down) dimethyl isotopes, respectively. We also performed a label swap experiment, which serves as a replicate measurement (reverse). We determined the M/L ratio of bound proteins for the forward and reverse pulldowns, such that m6A-readers are depicted in the upper right quadrant (high forward M/L ratio; low M/L ratio in the reverse experiment) (Fig. 4A, B and Supplementary Fig. S4B). As a control, we confirmed that YTH domain-containing proteins (YTHDF1, YTHDF2, YTHDC1 and YTHDC2) were more strongly bound to the m6A-modified GGACU probe than to the unmethylated GGACU probe (Fig. 4A), showing that one repeat of the m6A consensus sequence GGACU is sufficient to capture canonical m6A readers in T cells65. Conversely, we found that various members of the LSM family of RNA-binding proteins (LSM1, LSM2, LSM3, LSM4, and LSM6) specifically bound to m6A-modified UUAUU relative to the unmodified UUAUU probe (Fig. 4B and Supplementary Fig. S4B). Interestingly, all the YTHDF paralogues were also significant readers of m6A-modified UUAUU sequences, whereas several more proteins were repelled by the m6A-modified UUAUU than by the unmodified GGACU probe (Fig. 4B and Supplementary Fig. S4B). It has been reported that LSM proteins assemble into RNPs that facilitate pre-mRNA splicing and mRNA degradation66. To test whether miCLIP-ARE sites recruit specific RBPs in a biological sequence context, we performed pulldown experiments targeting the TNF 3’UTR, where the m6A-modified (and unmodified) probes contained a UUAUU pentamer surrounded by a sequence (15 nt upstream and downstream) corresponding to the respective region of the TNF 3’UTR. The TNF 3’UTR probe contained the miCLIP-ARE site flanked downstream by a RRACH site (UUm6AUUACCCCCUCCUUCAGACA, see complete probe in Methods), as assayed above (Supplementary Fig. S3E).

A–C Proteomic interactome screening using RNA pulldowns with m6A-modified and unmodified probes. Shown are log₂ fold-changes in protein abundance for RNA-binding proteins (RBPs) binding to: (A) an m⁶A-modified GGACU probe, (B) an m⁶A-modified UUAUU (ARE) probe, and (C) an m⁶A-modified region of the TNF 3′UTR. Fold-changes were calculated relative to the corresponding unmethylated probe. Data represent one representative experiment from pooled human T cells (n = 9 donors). D Metagene distribution of published CLIP data for m6A-reader proteins67 at endogenous miCLIP-defined sites. Left: CLIP signal centred at miCLIP-ARE sites, stratified by whether a RRACH motif occurs within ± 50 nt. Right: CLIP signal centred at miCLIP-RRACH sites, stratified by whether an ARE occurs within ± 50 nt. E Model illustrating how canonical (RRACH-only) versus composite (ARE-flanking m6A) motifs differentially regulate mRNA decay. Composite motifs, defined by m⁶A at RRACH elements positioned within ± 4 nt of ARE pentamers, promote rapid mRNA destabilisation during T cell activation. These composite sites recruit a distinct set of RBPs compared to canonical RRACH-only m6A sites, enabling selective decay of immunoregulatory mRNAs in activated T cells. Parts of panel (E) were created in BioRender. Foskolou, I. (2026) https://BioRender.com/ m18fugc. Source data are provided as a Source Data file.
Similarly to Fig. 4B, YTH paralogues and the LSM family of proteins were found to bind specifically to the m6A-modified TNF probe (Fig. 4C and Supplementary Fig. S4C). Finally, to determine whether the high-confidence ARE-flanking m6A sites identified by miCLIP and GLORI profiling could serve as binding sites for canonical m6A readers, we checked the iCLIP data for YTHDF, YTHDC paralogues, RBM15 and RBM15b67. We observed that YTHDF1 binding sites, as defined by published unique iCLIP tags67, were enriched at both miCLIP-ARE and miCLIP-RRACH sites, but not at control ARE or RRACH sites lacking miCLIP signal (Fig. 4D and Supplementary Fig. S4D, E). Control sites were expression-matched to the miCLIP sites by selecting 3’UTRs from the DESeq2 model that were expressed in CD8+ T cells but showed low miCLIP signal for the respective motifs (Supplementary Fig. S4D). Surprisingly, unique YTHDF tags were also detected at miCLIP-CRACH sites, however, due to their low number, it is difficult to interpret this distribution (Supplementary Fig. S4D). Notably, YTHDF1 binding showed a prominent central peak at miCLIP-AREs flanked by RRACH ( ≤ 50nt) but not at isolated miCLIP-AREs (Fig. 4D). Enriched central peak was observed at both classes of miCLIP-RRACH sites, but we noticed somewhat broader crosslinking profile at RRACHs that were proximal to ARE motifs (Fig. 4D and Supplementary Fig. S4E). Collectively, these data show that m6A-modified AREs can recruit LSM proteins and YTHDF proteins, which may cooperatively alter mRNA decay through YTHDF-dependent pathways. These findings support a model in which RRACH-flanking AREs form composite m6A motifs that assemble distinct RNP complexes to more strongly promote mRNA destabilisation in activated CD8⁺ T cells as compared to the RRACH-only m6A sites (Fig. 4E).
Discussion
The degradation of mRNAs is an essential aspect of the regulation of transcript numbers68. This is ever more important for dosage-sensitive genes, such as cytokines, for which small fluctuations in rates of mRNA decay can have significant effects on mRNA and protein abundance6. In T cells, the tight regulation of cytokine expression is required to ensure early and transient responses, since aberrant cytokine production can lead to severe autoimmune diseases, while insufficient cytokine levels cause impaired antitumor responses3. Here, through a motif discovery analysis and supervised learning approach on miCLIP/GLORI and SLAM-seq data, we have identified ARE-flanking m6A motifs that mark immunoregulatory mRNAs for rapid decay in activated CD8+ T cells.
In this study, we apply an improved miCLIP protocol, motif discovery analysis (PEKA) and GLORI profiling to find that m6A-modified RRACHs are often flanked by AREs (Fig. 1C, D). The closest arrangement is a RRACH sequence (e.g., GAACU) directly next to an ARE (e.g., AUUUA) to form a hypothetical AUUUAGAACU or GAACUAUUUA motif. The sequence required for METTL3-dependent m6A methylation44,48 can thus partly overlap with an ARE-like sequence, likely an atypical class III ARE4.
The molecular effects of m6A-modified RRACHs on mRNA degradation range from subtle to profound9,53. Understanding the specificity of this process would enable more precise identification of m6A variants that regulate basic cell functions. We reasoned that a low frequency of m6A sites in non-RRACH motifs does not indicate a lack of biological importance, since cellular responses may require subsets of mRNAs whose stability depends on different regulatory mechanisms. CD8+ T cell activation is a crucial process that relies on the tight control of cytokine and inflammatory mRNA levels and is largely achieved by ARE-binding proteins3,7. However, how ARE-mediated mRNA decay is integrated with other mechanisms, including RNA modifications, to define T cell functions is not understood. Through a supervised learning approach on miCLIP/GLORI and SLAM-seq data, we revealed that CD8+ T cell activation leads to faster decay of mRNAs harbouring ARE-proximal m6A modifications. We refer to these highly unstable transcripts as meta-unstable mRNAs, reflecting their dynamic reduction in half-life. This reduction occurs predominantly upon CD8⁺ T cell activation. This group includes key essential mRNAs for CD8+ T cell function (Fig. 2A – cluster 2, 2E – cluster i, Supplementary Data 1). Notably, the meta-unstable mRNAs were more accurately predicted by ARE-proximal m6A sites than by remaining m6A sites. This composite m6A motif, defined by RRACH-flanking ARE sites, may constitute a distinct regulatory unit for m6A-dependent mRNA decay. We tested this model using orthogonal approaches and targeted assays focused on key immunoregulatory genes. We employed SELECT studies to add orthogonal evidence of the presence of m6A in a specific RRACH-flanking ARE site in the TNF 3’UTR (Supplementary Fig. S3E). GFP reporter assays showed that a single-nucleotide mutation of the ARE site of 3'UTR-TNF led to increased mRNA levels only in the presence of an intact RRACH site, but not when mutating both the RRACH and ARE sites. It should be noted that the reporter assays are insufficient to fully disentangle m6A-dependent effects from other sequence-dependent influences on mRNA levels (Fig. 3). Notably, some ARE-binding RBPs, such as HuR69 may be able to bind to both the wild-type ARE (UUAUU) and its mutant (UUGUU) sequences in the reporter. On the other hand, it is possible that the A > G mutation in the 3’UTR-TNF_AREmut may impair the binding of ARE-binding RBPs regardless of m6A status. Nevertheless, our findings show that mRNA meta-instability of the TNF and other immunoregulatory mRNAs likely depends on the interplay between RBPs binding to m6A sites and their flanking ARE motifs.
We present two lines of evidence that ARE-flanking m6A sites and canonical RRACHs have different efficacy on mRNA decay CD8+ T cells, likely due to the formation of somewhat distinct m6A-dependent ribonucleoprotein (RNP) complexes. First, using cellular extracts of T cells, we show that ARE-flanking m6A sites recruit YTHDF paralog proteins along with additional RBPs, especially the LSM proteins66. Importantly, LSM4, a highly enriched RBP according to our interaction screening, was recently shown to bind TNF mRNA in T cells after activation70. Second, analysis of YTHDF1/2/3 binding profiles67 showed that YTHDF paralogs show a somewhat broader crosslink profile to the composite sites with AREs flanked by the methylated RRACH sites when compared to isolated RRACH sites, consistent with Arabidopsis iCLIP data showing that m6A-modified RRACH motifs are favoured in pyrimidine-rich regions71. While all three YTHDF paralogs are known to contribute to the degradation of m6A-modified mRNAs, two studies have indicated that YTHDF2 plays a main role in mRNA decay through two pathways: (1) the endoribonucleolytic-cleavage pathway via RNaseP/MRP72 and (2) the CCR4/NOT deadenylation pathway73. However, whether and to what degree the RnaseP/MRP and CCR4/NOT pathways operate differently on meta-unstable mRNAs with different m6A signatures has not been addressed here. Moreover, whether m6A-interlinked ARE and RRACH sites work cooperatively or in opposing ways on specific mRNAs was not determined, and merits further consideration.
Beyond the molecular basis of mRNA decay, our study links m6A to meta-unstable mRNAs that are involved in memory and late effector functions (Fig. 2)56,74. Since m6A and TNFα play important roles in antitumor immunity, it will be relevant to assess whether ARE sites functionally linked to m6A influence T cell differentiation and activity. Taken together, the findings support a model whereby ARE-flanking m6A sites recruit distinct regulatory RNP assemblies that enable selective decay of memory precursor and late effector transcripts in T cells. This context-dependent m6A code reveals how combinatorial RNA motifs can fine-tune transcript stability in response to activation cues in CD8+ T cells. Further understanding of the mechanisms mediating the combinatorial recognition of m6A and its flanking ARE sites could lead to valuable approaches for fine-tuning the immune system.
Methods
Reagents and resources
All reagents (chemicals, antibodies, bacterial strains, cell lines, biological samples, peptides, recombinant DNA, oligonucleotides and CRISPR-Cas9 crRNAs) are provided in the “Key Resources Table” in Supplementary Information.
Human T cells
Human CD8+ T cells were isolated either directly after blood donation (8-12 h after blood collection) or cryopreserved and used after cryopreservation. PBMCs were isolated through Ficoll-Paque PLUS density gradient separation (GE Healthcare). The cells were incubated in 21% oxygen and 5% carbon dioxide at 37 °C. Sex, gender or age were not determined for any of the donors.
For miCLIP and SLAM-Seq experiments, human CD8+ T cells were isolated with MACS Miltenyi kits (total CD8+ T cells: 130-096-495; total CD8+ MicroBeads: 130-045-201; and total FcR-blocking: 130-059-901) following the manufacturer’s instructions. CD8+ T cells were activated with aCD3/CD28 beads (1:1 bead-to-cell ratio) (11132D, Gibco) in fresh complete RPMI media (52400-025; Gibco) containing 10% FBS, 1% penicillin‒streptomycin and IL-2 (30 μ/ml; Roche).
For GLORI experiments, human CD8+ T cells were isolated with the MACS Miltenyi kit (total CD8+ MicroBeads: 130-045-201) following the manufacturer’s instructions. CD8+ T cells were either kept non-activated for 1 day or were activated with aCD3/CD28 beads (1:1 bead-to-cell ratio) (11132D, Gibco) in fresh complete RPMI media (52400-025; Gibco) containing 10% FBS, 1% penicillin‒streptomycin and IL-2 (30 μ/ml; Clinigen) for 1 or 5 days. Non-activated and Day1 activated cells were treated for 24 h with DMSO or 4 µM METTL3 inhibitor (MedChemExpress, cat. no. HY-134836), while Day5 activated T cells were treated with the same inhibitor for 5 days. For Day 5 activated samples, beads were removed at day 4 and fresh medium was replenished twice during culture.
For the CRISPR/Cas9 and SELECT experiments, human CD8+ T cells were isolated with MACS Miltenyi kits (total CD8+ T cells: 130-096-495; total CD8+ MicroBeads: 130-045-201; and total FcR-blocking: 130-059-901) following the manufacturer’s instructions. CD8+ T cells were activated in 24-well plates precoated overnight at 4 °C with 2 μg/ml anti-mouse IgG2a (BioLegend) in phosphate-buffered saline (PBS). The plates were washed and coated for > 3 h with 1 μg/ml a-CD3 (HIT3a, Biolegend) at 37 °C. The CD8+ T cells were then seeded in plates supplemented with 1 μg/ml soluble a-CD28 (CD28.2; Biolegend) in fresh complete RPMI media (52400-025; Gibco) supplemented with 10% FBS, 1% penicillin‒streptomycin and IL-2 (30 μ/ml; Clinigen).
For RNA pull-down and GFP construct transduction experiments, human T cells (both CD4+ and CD8+) were activated in 24-well plates that were precoated overnight at 4 °C with 2 μg/ml anti-mouse IgG2a (BioLegend) in phosphate-buffered saline (PBS). The plates were washed and coated for > 3 h with 1 μg/ml a-CD3 (HIT3a, Biolegend) at 37 °C. The CD8+ T cells were then seeded in plates supplemented with 1 μg/ml soluble a-CD28 (CD28.2; Biolegend) in fresh complete RPMI media (52400-025; Gibco) supplemented with 10% FBS, 1% penicillin‒streptomycin and IL-2 (30 μ/ml; Clinigen). For GFP construct transduction experiments, the number of GFP-positive or Katushka-positive CD8+ T cells was determined via flow cytometry. For the RNA pull-down experiment, T cells were isolated from 9 donors, activated and expanded separately for 7 days. On day 7, the cells were pooled in three falcons (3 donors in each pool). After centrifugation, the cells were resuspended in RIPA buffer (150 mM NaCl, 50 mM Tris (pH 8), 1 mM EDTA, 10% glycerol, 1% NP-40, 1 mM DTT, and 1 x protease inhibitor), incubated on a rotator at 4 °C for 2 h, and centrifuged, after which the supernatant was collected in new tubes that were snap frozen.
For inhibitor treatments, T cells were treated with either DMSO or 6 µM METTL3 inhibitor (4 µM for GLORI datasets) (MedChemExpress, cat no. HY-134836) for 4 to 5 days. Media refreshment was done every 1-2 days. For the FTO inhibitor, T cells were treated with DMSO or increasing concentrations of Meclofenamate62 (sodium salt, Cayman Chemical, Item No. 70550) for 6-7 h before 16 h activation with PMA/ionomycin (for GFP reporter assays) or treated overnight (18 h) before 4 h activation (for ELISA assays).
Cloning
For the Katuska construct, the pMIG-w (Addgene) plasmid was used as a backbone, and the Katushka sequence was integrated by using the NcoI and PacI restriction enzymes. For GFP 3’UTR-IFNγ, 3’UTR-TNFα and 3’UTR-GzmB plasmids, the full-length 3’UTR of each gene was amplified from human genomic DNA and cloned into BamHI and NotI sites of pRETRO-SUPER GFP downstream of GFP, as previously described70. The single and double mutants were generated by site-directed mutagenesis via Twist Bioscience (https://www.twistbioscience.com). The sequences were verified by sequencing.
Retroviral transduction of human T cells
The viral supernatant was collected after transfecting FLYRD18 cells (retroviral packaging cells) with the GFP-3’UTR or Katushka plasmids using GeneJammer as a transfection reagent. The viral supernatant was collected 2 days after transfection. T cells were isolated and activated as described above. After 2 days of activation, T cells were co-transduced with retrovirus containing one of the GFP-3’UTR constructs or with retrovirus containing the Katushka construct at a ratio of 1:1. Nontissue culture–treated 24-well plates were coated overnight with 50 μg/ml RetroNectin (Takara) and washed once with PBS prior to the addition of both viral supernatants. The plates were centrifuged for 30 min at 4 °C and 2820 x g. The viral supernatant was removed, and 0.5 × 106 T cells were added to each well. The cells were harvested 1-2 days after transduction and cultured at a concentration of 1 × 106 cells/ml for an additional 6–8 days. Rested cells (not reactivated) were collected for RNA isolation and RT‒PCR analysis. For flow cytometry analysis of protein levels, cells were either reactivated with PMA (10 ng/ml) or ionomycin (1 μM) for 16 h or left non-activated. Flow cytometry was performed as described below.
Quantitative real-time PCR (qRT–PCR)
Total RNA was extracted from isolated T cells using TRIzol (Invitrogen), Direct-zol RNA Miniprep Kits (Zymo Research, R2052), or Quick-RNA Miniprep Kit (Zymo Research, R1055), and 300–500 ng of RNA was used for cDNA synthesis (SuperScript III, Invitrogen or Maxima First Strand cDNA Synthesis Kit for RT-qPCR, K1641, Thermo Fisher). All kits were used according to the manufacturer’s instructions. Samples were run in technical triplicates. qRT‒PCR was performed using SYBR Green on a StepOne Plus system (Applied Biosystems). Ct values were normalised to HPRT or 18S levels. The primer sequences can be found in the “Key Resources Table”.
Actinomycin D treatment
Peripheral blood mononuclear cells (PBMCs) were thawed, and CD8+ T cells were isolated using a CD8⁺ isolation kit (CD8+ MicroBeads, 130-045-201, Miltenyi biotec). Isolated cells were activated using anti-CD3/CD28 activation beads (Dynabeads™ Human T-Activator CD3/CD28 for T Cell Expansion and Activation, 11131D, ThermoFisher Scientific) and cultured in T cell medium (RPMI 1640 supplemented with L-glutamine and 25 mM HEPES (ThermoFisher Scientific, cat no. 52400-025) supplemented with 10% FCS, 10,000 μ/ml penicillin-10 mg/ml streptomycin (Sigma, cat no P4333), and human IL-2 (30 μ/mL). Cells were treated with either DMSO or 6 µM METTL3 inhibitor (MedChemExpress, cat no. HY-134836) for 4 or 5 days. Media refreshment was done every 1-2 days. Activation beads were removed on day 4. On day 5, cells were treated with 5 μg/mL actinomycin D (Sigma-Aldrich, Cat. No A9415) for 0, 1, 2, 3, or 4 hrs to assess RNA stability. Subsequently, cells were washed with cold PBS, centrifuged, and the resulting pellets were snap-frozen and stored at − 80 °C until further analysis. RNA was extracted as mentioned above and qRT-PCR followed for quantification of mRNA levels.
ELISA
Secreted IFNγ and TNFa levels of CD8+ T cells were determined using ELISA. Assays were performed with uncoated ELISA kits (Catalog No. 88-7316-88; 88-7346-88 ThermoFisher Scientific), according to the manufacturer’s instructions. Absorbance was determined using a microplate reader (Sunrise, Tecan) at a wavelength of 450 nm.
Genetic modification of T cells with Cas9 RNPs
crRNAs were designed in Benchling (https://benchling.com) and are listed in the “Key Resources Table”. The Alt-R crRNA and tracr-RNA were reconstituted to 100 μM in nuclease-free duplex buffer (Integrated DNA Technologies). As a negative control, the nontargeting negative control crRNA #1 was used (Integrated DNA Technologies). Oligos were mixed at equimolar ratios (i.e., 4.5 μl of total crRNA + 4.5 μl of tracrRNA) in nuclease-free PCR tubes and denatured by heating at 95 °C for 5 min in a thermocycler. The nucleic acids were cooled to room temperature prior to mixing with 30 μg of TrueCut Cas9 V2 (Invitrogen) to produce Cas9 ribonuclear proteins (RNPs). The mixture was incubated at room temperature for at least 10 min prior to nucleofection. For nucleofection, human CD8+ T cells were activated for 48 h as described above. Cells were electroporated in 16-well strips in a 4D Nucleofector X unit (Lonza) with the programme EH100 for human T cells with P2 Primary Cell buffer (Lonza). Knockout efficiency was determined on days 7–10 after electroporation by Western blot.
SELECT
The elongation and ligation-based qPCR amplification method SELECT was used as previously described64. Specifically, CD8+ T cells were isolated from healthy individuals, activated and cultured as described above. On day 2 after activation, the cells were genetically modified with CRISPR/Cas9 as described above and further cultured for an additional 8–12 days. The amount of RNA for each sample and each target was previously verified by quantitative real-time PCR (qRT–PCR), and the same amount of RNA was used for SELECT (normalised to the WT control). Specifically, to validate a presumed m6A site, two primers (up and down primers) were designed to flank the site of interest via Benchling (https://benchling.com). A nonm6A site on the same mRNA was also tested as a reference control (Reference Up and Down primers). The sequences of all primers used are listed in the “Key Resources Table”. Total RNA (1.5 μg) was used per experiment. The RNA was mixed with 40 nM Up Primer, 40 nM Down Primer and 5 μM dTTP in a total of 17 μl of 1 × CutSmart buffer (NEB). The RNA and primers were annealed by incubating the mixture at a temperature gradient of 90 °C for 1 min, 80 °C for 1 min, 70 °C for 1 min, 60 °C for 1 min, 50 °C for 1 min, and 40 °C for 6 min. Subsequently, 3 μl of a mixture containing 0.01 U of Bst 2.0 DNA polymerase, 0.5 U of SplintR ligase and 10 nmol of ATP was added to the former mixture to a final volume of 20 μl. The final reaction was incubated at 40 °C for 20 min, denatured at 80 °C for 20 min and kept at 4 °C. Quantitative real-time PCR (qPCR) was subsequently performed with the primers qPCR_F and qPCR_R for SELECT (200 nM; sequences at “Key Resources Table”) and with PowerUp SYBR Green on a StepOne Plus system (Applied Biosystems). For the qPCR, 2–4 μl of the elongation and ligation samples were used. qPCR was performed under the following conditions: 95 °C, 5 min; 95 °C, 10 s; 60 °C, 35 s, 40 cycles; 95 °C, 15 s; 60 °C, 1 min; 95 °C, 15 s (for which the fluorescence was collected at a ramping rate of 0.05 °C/s); and 4 °C. The data were analysed by Design & Analysis 2 (DA2) Software v2.6.0 (Thermo Scientific).
Flow cytometry
The cells were pelleted by centrifugation and stained with antibodies in FACS Buffer (5% FBS, 2 mM EDTA in PBS) at 4 °C for 30–60 min. The stained cells were washed with FACS buffer 2–3 times and processed for flow cytometry. The emission spectra “spillover” were corrected by compensation using compensation beads (01-1111-41; OneComp eBeads) mixed with each fluorescent probe. The BD LSR-Fortessa and BD FACSymphony flow cytometers and the Sony Spectra Analyser were used. The flow cytometry data were analysed using FlowJo (BD Biosciences, version 10). The antibodies used can be found in the “Key Resources Table”.
Western blotting
Human CD8+ T cells were isolated, activated and engineered by CRISPR/Cas9 as described above. A total of 3 × 106 cells were collected, washed and pelleted. The cell pellets were incubated with urea-tris buffer (8 mol/L urea, 50 mmol/L Tris-HCl (pH 7.5), 150 mmol/L β-mercaptoethanol) and centrifuged at 14,000 × g and 4 °C for 15 min. The proteins were separated via SDS‒PAGE and subsequently transferred to PVDF membranes. The membranes were then blocked in 5% milk prepared in PBS supplemented with 0.05% Tween 20 and incubated with primary antibodies overnight at 4 °C and HRP-conjugated secondary antibodies for 1 h at room temperature the next day. Following ECL exposure (Invitrogen), the membranes were imaged using an iBrightCL1000 (Thermo Fisher). The antibodies used can be found in the “Key Resources Table”.
miCLIP library preparation
We applied miCLIP (methylation individual-nucleotide-resolution crosslinking and immunoprecipitation)25,26 to profile m6A using the latest improved iCLIP protocol (iiCLIP)36 to produce cDNA libraries with increased efficiency and minimal loss of material. Compared to previous (m)iCLIP versions, this protocol features (i) the use of DMSO (and no DTT) for improved ligation efficiency; (ii) infrared imaging of the RNA:anti-m6A antibody complex, as in irCLIP75; (iii) reverse transcription (RT) with SSIV and RT primers that contain carbon spacers, as in irCLIP; (iv) ampure bead-based purification of cDNAs; and (v) circularisation with commercial circligase II with betaine additive. The miCLIP protocol is completed from UV crosslinking to amplify cDNA libraries within 4 days.
RNA extraction and fragmentation (Day 0): Total RNA was extracted from CD8+ T cells using the mirVana isolation kit according to the manufacturer’s instructions (Thermo Fisher Scientific, #AM1560), purified polyadenylated RNA was extracted using two rounds of poly(A) tail hybridisation with Oligo-dT magnetic Dynabeads (Thermo Fisher Scientific, #61002), and fragmented (750–1000 ng) in a buffered zinc acetate solution (pH 5.3) at 70 °C for 15 min (pH 5.3).
Immunoprecipitation (IP), UV crosslinking and SeqRv adaptor ligation (Day 1): The fragmented polyadenylated RNA was subjected to IP using an anti-m6A antibody (Ab) (Abcam, catalogue no. ab151230) conjugated to protein A/G Dynabeads (Thermo Fisher Scientific, catalogue no. 88803) for 2 h at 4 °C. The RNA:Ab complex was irradiated twice with 150 mJ/cm2 UV at 254 nm, and the cDNA library was prepared as described previously36. After IP, the (protein A/G) beads were washed twice in high-salt buffer (50 mM Tris-HCl, pH 7.4, 1 M NaCl, 1 mM EDTA, 1% Igepal, 0.1% SDS, 0.5% sodium deoxycholate) and twice in PNK (20 mM Tris-HCl, pH 7.4, 10 mM MgCl2, 0.2% Tween-20) buffer. The samples were incubated at 37 °C for 40 min for 3’ end dephosphorylation; the beads were washed with 1 x ligation buffer (50 mM Tris-HCl (pH 7.5) and 10 mM MgCl2), and 3’ end ligation to an infrared dye-conjugated and biotinylated L3 adaptor (SeqRv) was performed on the beads overnight at 16 °C with shaking at 150 g.
SeqRv adaptor removal, SDS‒PAGE and RNA purification (Day 2): The 3’ end-ligated RNA:Ab complex on the beads was washed twice in high-salt buffer and twice in PNK wash buffer, and the excess SeqRv adaptor was removed by resuspending the beads in a mixture of 5’ deadenylase (NEB) and RecJf exonuclease (NEB) for 30 min at 30 °C followed by 30 min at 37 °C while shaking at 150 g. The beads were washed twice with high-salt buffer and once with PNK buffer, and the protein‒RNA complexes were eluted in 1x NuPAGE loading buffer (supplemented with 100 mM DTT) at 70 °C for 1 min. The protein‒RNA complexes were separated via SDS‒PAGE in a 4‒12% Bis‒Tris gel (Invitrogen), transferred to a nitrocellulose membrane for 2 h at 30 V, and visualised via infrared imaging. The RNA:Ab complex was excised from the membrane, treated with proteinase K (which leaves only a short peptide at the crosslinking site) for 1 h at 50 °C with shaking at 150 g, and the RNA was purified by adding a (25:24:1) mixture of phenol:chloroform:isoamyl alcohol (Sigma‒Aldrich). The mixture was subsequently transferred to a prespun 2 ml Phase Lock Gel tube and incubated for 5 min at 30 °C with shaking at 150 g. The samples were centrifuged for 5 min at 21,000 × g, chloroform was added to the top (aqueous) phase of the biphasic solution, and the tubes were inverted to mix and centrifuged for 5 min at 21,000 × g. The aqueous layer was transferred into a new tube, and the RNA was precipitated overnight in 70% ethanol containing 300 mM sodium acetate and 1 μl of glycogen blue (15 mg/ml).
Reverse transcription, cDNA purification and circularisation (Day 3): The RNA pellets were washed twice in 70% ethanol, resuspended in water and reverse transcribed into cDNA with barcoded RT primers (which contained a sequence complementary to the SeqRv adaptor) using the Superscript IV (SSIV) Kit. To minimise technical variations in library preparation, we multiplexed up to four CLIP libraries after the RT step using barcoded RT primers. We did not perform RT primer removal because this step was not tested or incorporated into the iiCLIP protocol at the time of this study. The cDNAs were purified using Agencourt AMPure XP beads, circularised using CircLigase II with betaine additive, purified again using the AMPure XP beads, eluted in water and stored at − 20 °C.
PCR amplification (Day 4) – The cDNA was amplified using an optimal number of cycles in PhusionHF Master Mix containing P3/P5 Illumina sequencing primers.
We applied a similar protocol to generate input libraries, in which 750–1000 ng of polyadenylated RNA was fragmented, directly processed for 3’ end dephosphorylation, converted into cDNA and amplified as described above.
miCLIP data analysis
The miCLIP and input data were uploaded and analysed on the FlowBio platform (https://app.flow.bio) using a standardised iCLIP analysis described therein76: demultiplexing (https://app.flow.bio/pipelines/447171969201517470/) followed by the CLIP-Seq (https://app.flow.bio/pipelines/960154035051242353/) pipeline. Using the CLIP-Seq pipeline as described previously https://docs.flow.bio/docs/clip-pipeline-1.0/, (1) the 3’ end of the reads were trimmed for the 3’ end adaptor sequence (AGATCGGAAGAGCGGTTCAG) by TrimGalore; (2) the reads were pre-mapped to an index of rRNA and tRNA sequences using Bowtie; (3) the unmapped reads were mapped to the human genome (GRCh38) using STAR; (4) the aligned reads were deduplicated based on the unique molecular identifiers (UMI) and start position; (5) the start position minus one in uniquely mapped reads was used as a proxy for the crosslink position, i.e., the most likely site of the methylated base25,47, and crosslink bed files were produced; and (6) the peaks were determined using Paraclu and Clippy peak callers. The GRCh38 GENCODE annotation was used for all human data. Other summary files reporting total crosslink counts in genes and RNA biotypes and quality control metrics presented as a MultiQC report were generated by the CLIP-Seq pipeline; all files from the miCLP and Input samples are retrievable at https://app.flow.bio/projects/663588932565340992/. We applied positionally enriched k-mer analysis (PEKA) to extract motifs that were enriched in proximity to high-confidence crosslink sites, i.e., ‘thresholded crosslinks’, located within crosslink peaks and with high counts relative to low-count crosslink sites located outside the peaks42. We used crosslinks and peaks (generated by Paraclu or Clippy) as inputs for PEKA; we ran PEKA by setting the proximal window to 10 nt (-w 10), the distal window to 150 nt (-dw 150), the k-mer length to 5 nt (-k 5), the smoothing window to 6 nt (-s 6), the percentile parameter for assignment of thresholded crosslinks to 0.7 (-p 0.7), and without subsampling of foreground and background crosslinks (https://github.com/ulelab/peka). Each k-mer at the “thresholded crosslink” position was assigned a PEKA score42, and the top 20 k-mers were plotted based on the PEKA scores and P-value of less than 0.01 (Fig. 1B, Supplementary Fig. S1B). We defined “PEKA crosslinks” as the number of crosslinks that overlap with the genomic positions of ‘thresholded PEKA crosslinks’. To check the alignment at motif centres (Fig. 1), the PEKA crosslinks were normalised at each meta position in the 3’UTR by the total number of crosslinks in the 3’UTR. We used PEKA crosslinks in the 3’UTR for all other analyses (Fig. 2) unless otherwise noted.
GLORI library preparation and data analysis
Human CD8⁺ T cell pellets from 6 donors were lysed in TRIzol, and total RNA was isolated using Direct-zol RNA Miniprep Kits (Zymo Research, cat. no. R2052) according to the manufacturer’s instructions. RNA quality was assessed with a Bioanalyzer (Agilent). The RNA of donors was pooled in 2 (not activated) or 3 (Day 1 and Day 5 activated) samples. GLORI libraries were prepared using the NEBNext Ultra II Directional RNA Library Prep Kit for Illumina (New England Biolabs, cat. no. E7760S). The protocol uses a dUTP-based method for second-strand synthesis, resulting in strand-specific libraries in which Read 2 corresponds to the sense strand of the original RNA. Library preparation was carried out according to the manufacturer’s instructions, and sequenced on an Illumina NovaSeq 6000 by the Advanced Sequencing Facility at The Francis Crick Institute. Downstream analyses were performed using the second read (L5_2) of each pair, which contains the chemically informative read for m⁶A detection. Adaptor trimming was performed using Trim Galore (v0.6.7) with the following parameters: -q 20 --stringency 1 -e 0.3 --length 20. Reads shorter than 20 nucleotides after trimming were discarded. The remaining high-quality reads were aligned to an A > G converted version of the human genome (GRCh38) using GLORI-tools (https://github.com/liucongcas/GLORI-tools), which accommodates the chemical reactivity-based profiling of m6A through misincorporation signals. Strand-specific pileups for all four nucleotides (A, C, G, T) were generated directly from the resulting BAM files. Per-base coverage and A-to-G or T-to-C conversion ratios were computed and exported as both BigWig and BedGraph files to facilitate visualisation in IGV or related genome browsers. Conversion ratios were calculated as A/(A + G) for the forward strand and T/(T + C) for the reverse strand. To identify putative m6A sites, pileup data were processed in R using the GenomicRanges package, focusing on positions with reference A or T located within ± 2 kb of annotated protein-coding genes (Ensembl release 113). These positions were further annotated for overlap with canonical m6A motifs (GAC, GAAC) and their reverse complements. Transcript-level mapping was performed using the annotatePeakInBatch() function from ChIPpeakAnno, enabling transcript-level annotation. Given that a single site can map to multiple transcripts or genes, redundancy was handled by tracking unique “position_id” fields to identify and filter duplicate entries. Additional genomic context was assigned using genomicElementDistribution() (ChIPpeakAnno), classifying sites at three hierarchical levels: transcript-level regions (promoter, downstream, gene body), exon–intron boundaries, and exon subtypes (5′UTR, CDS, 3′UTR, or other noncoding exons within protein-coding genes). To increase specificity, we applied two filtering criteria: (i) a minimum read depth of ≥ 15 for A + G (or T + C on the reverse strand) and (ii) a minimum base conversion ratio (A/(A + G) or T/(T + C)) of ≥ 0.1. The resulting datasets were saved as GRanges objects in.rds format for downstream meta-analysis in R. Supporting files, including gene annotations in GTF format, motif coordinates, genomic distribution plots, and conversion rate boxplots, were made for visualisation and further analysis. This integrated pipeline enabled the identification and annotation of GLORI-defined m6A sites across the CD8+ T cell transcriptome.
SLAM-Seq library preparation and determination of mRNA half-lives
SLAM-Seq experiments were conducted as previously described52 with certain modifications. Specifically, CD8+ T cells were isolated from two healthy donors as described above. The cells were either not activated or activated with aCD3/CD28 beads (1:1 bead-to-cell ratio). Both non-activated and activated cells were cultured in fresh complete RPMI media supplemented with 10% FBS, 1% penicillin‒streptomycin and IL-2 (30 μ/ml). Approximately 10 × 106 cells were used per condition. For non-activated and day 1 activated cells, 100 μM 4SU (T4509; Sigma) was added to the culture medium every 4 h for 24 h in total. The cells were then collected and washed with warm media. After centrifugation, the cells were plated in fresh RPMI media supplemented with 10% FBS, 1% penicillin‒streptomycin, IL-2 and 100 mM uridine (U3750; Sigma). After the addition of uridine, the cells were further cultured for 0, 0.5, 1, 3, 6 and 16 h. At each of the above time points, 1-2 × 106 cells were harvested, the activation beads were removed, and the RNA was isolated. For day 5 of activation, CD8+ T cells were activated for 4 days, after which the activation beads were removed, and 4SU was added as described above. After 24 h of 4SU, the cells were washed, further cultured with uridine and harvested at 0, 1, 3, 6 and 16 h. Total RNA was extracted from human CD8⁺ T cells after each chase time point using TRIzol reagent, followed by column-based purification. RNA integrity was assessed by Bioanalyzer (Agilent). SLAM-seq libraries were generated as previously described52, with minor modifications. In brief, thiol-modified RNA was chemically alkylated to introduce T > C mutations detectable by NGS. Libraries were prepared from total RNA using the Lexogen QuantSeq 3′ mRNA-Seq Library Prep Kit FWD, V2 (Cat. No. 191.96, Lexogen GmbH), which produces forward-stranded Illumina-compatible libraries enriched for the 3′ ends of polyadenylated transcripts. The workflow consists of oligo(dT)-primed reverse transcription from the poly(A) tail, selective degradation of RNA, and second-strand synthesis primed by random oligonucleotides carrying Illumina linker sequences to preserve strand specificity. Final cDNA libraries were PCR-amplified, purified, quantified, assessed for quality using an Agilent Bioanalyzer, and sequenced on an Illumina HiSeq 4000 by the Advanced Sequencing Facility at The Francis Crick Institute. To calculate mRNA T > C conversions, the analysis pipeline was implemented using Snakemake 5.3.077. Sequencing reads were demultiplexed with Cutadapt 1.18, with no allowed mismatches in the barcodes, quality-filtered with a cutoff of Q20, trimmed of the barcodes (cut 12), and short reads were discarded (length 16). Polyadenylated stretches (> 4) at the 3’ end were trimmed to 20 tandems without indels or mismatches. The trimmed reads were aligned to the reference human genome (GRCh38) using the Slamdunk map 0.3.378 with local alignment, allowing up to 100 multimapping reads (-n 100). Aligned reads were filtered to retain only those with a minimum identity of 95% and at least 50% of the read bases mapped. Reads ambiguously mapping to more than one 3’ UTR were discarded using the UTR annotation pipeline (https://github.com/AmeresLab/UTRannotation). SNPs were identified using VarScan 2.4.179 with default parameters, establishing a 10-fold coverage cutoff and a variant fraction cutoff of 0.8 (-c 10-f 0.8). T > C conversions overlapping with SNPs required a minimum base quality (Phred score) of 26. T > C conversions were counted in rolling windows, normalised by T content and coverage of each position, and averaged per possible transcript 3’ UTR. The quality of the T > C conversions was assessed using Slamdunk Alyoop 0.3.378. To calculate mRNA half-lives, T > C conversions were background-subtracted, normalised to the chase uridine treatment and fitted to an exponential decay model using the R package minpack.lm 1.280. The mRNA half-lives that correlated with the model (R² > 0.5) under all the experimental conditions were determined by t1/2 = ln(2)/k, where k is the decay constant in the monoexponential model. Using this approach, we determined accurate half-lives for 4158, 5585 and 5866 transcripts in activated CD8+ T cells on day 1 and day 5, respectively.
Motif-specific analysis of miCLIP, GLORI and input counts and half-life classification
The total number of PEKA crosslinks per 3’UTR was normalised using the DESeq2 model (DESeq factor), transformed using the variance stabilisation function (vst) and standardised (centred and scaled). The top 1000 3’UTRs with the highest variability of DESeq2-normalised counts across samples were clustered based on the Euclidean distance of counts and plotted on the heatmap. DESeq2 normalisation was applied to the number of PEKA crosslinks in each motif class (RRACH or WWWWW pentamers; a ‘W” centre was considered for DESeq2 analyses, instead of ‘A’), summed across the 3’UTR and to the corresponding input counts, i.e., input reads that started at the same coordinates, also summed across the 3’UTR. We excluded four input replicates from the DESeq2 model (noAct, replicate 1 and 2; Day1, replicate 1; and Day5, replicate R3), due to the low number of counts (< 500) in the 3’UTR. All the miCLIP replicates (13 WWAWW and 13 RRACH samples) were considered for DESeq2 analysis. The same procedure was carried out for differential analysis of GLORI-determined m6A counts using the DESeq2 model. To classify mRNA half-lives, we considered all 3’UTRs in DESeq2 clusters that had reliable half-lives and selected the most unstable (< 3.0 h, 30 pth) and most stable (> 5.3 h, 70 pth) mRNAs. Using the caret package (6.0.94) in R, we trained a conditional random forest (cRF) model to classify unstable (N = 230) and stable (N = 230) mRNAs based on the following miCLIP features: 1–6) cluster identity, where the presence (1) or absence (0) of mRNA in each DESeq2 cluster was coded as a dummy variable (using the ifelse() function), 7) the CD8+ state (noAct, Day1 and Day5) and 8) CD8+ gene modules (A–G) as categorical variables, and two genomic features: 9) frequency of RRACH pentamers and 10) frequency of ARE (WWAWW) motifs. We generated 30 conditional random forest (cRF) models by randomly splitting the training set (75% of mRNAs) into 10 subsamples (k folds) of the same size (10-fold cross-validation) and computing the performance metric (accuracy) for each fold (k), with the remaining (k-1) of the folds used as training data; this process was repeated 3 times. The control parameters for the caret training were defined using the ‘caret::trainControl’ function, with the main arguments (method = “repeatedcv”, number = 10, search = “random”, repeats = 3, p = 0.75, sampling = “down”, summaryFunction = twoClassSummary, classProbs = TRUE), and the cRF models (train object) generated using the ‘caret::train’ function with arguments (method = ‘cforest’, trControl = fit.control, metric = “Accuracy”, maximise = T, tuneLength = 10), with ‘fit.control’ representing the R object with the control parameters defined above, and the number of predictors (mtry) was tuned for optimal model accuracy. The variable importance in the cRF models was determined using the ‘caret::varImp’ function with arguments (scale = T, conditional = T). The cross-validation performance of the cRF models was determined using the ‘caret::confusionMatrix’ function. The final class predictions of the cRF models were made by applying the “stats::predict” function to the test set (25% of the mRNAs). We generated cRF models to classify destabilised (log2-fold < − 0.73) and stabilised (log2-fold > 0.30) mRNAs in Day5-activated CD8+ T cells using the same approach, and the cross-validation performance was determined as above.
Quantification of m6A levels in RNP complexes (CLIP-MS)
For CLIP–MS analysis of RBP-bound ribonucleosides, Jurkat T cells were UV-crosslinked, processed by CLIP, and the RNA was isolated and hydrolysed to ribonucleosides for LC-MS/MS analysis, as described below. The detected m6A ion counts were in the 0.5–5 fmol range, with signal-to-noise ratios of 15–30 relative to blanks. Although RBP abundance and regulation differ quantitatively between Jurkat and primary T cells, their qualitative RNA-binding profiles are broadly conserved across cell types (given similar expression)81, supporting the use of Jurkat T cells as a reductionist model for mechanistic studies of RBP binding and m6A methylation. The RNA:RBP complexes for the 4 RBPs (HuR, ZFP36L1, YTHDF1 and PABP) were purified from Jurkat T cells using the iiCLIP protocol, with the following specifications. Jurkat T cells were cultured in twelve 15 cm culture plates (3 plates per RBP tested) until 80% confluence, irradiated twice with 0.15 J/cm2 UV at 254 nm, harvested by scraping, and centrifuged at 500 × g at 4 °C for 5 min. The cell pellets were subsequently lysed in iCLIP lysis buffer (50 mM Tris-HCl, pH 7.4, 100 mM NaCl, 1% Igepal, 0.1% SDS, 0.5% sodium deoxycholate) supplemented with complete protease inhibitor cocktail (Roche). To generate RNA fragments of optimal size and digest genomic DNA, we incubated 9 mg (at 1 mg/ml) of Jurkat T cell lysates with 1 μ/ml of RNase 1 and 2 μl of Turbo Turbo DNase (Invitrogen) in CLIP lysis buffer for 3 min at 37 °C with shaking at 150 g. The cell lysates were centrifuged for 10 min at 21,000 × g, and the supernatants were immunoprecipitated with 5 μg of antibody conjugated to protein A/G Dynabeads for 3 h at 4 °C. We kept 150 μl of supernatant as an ‘input’ control; this mixture was not subjected to IP and was directly purified by SDS‒PAGE. The RNA:RBP complexes were purified by SDS‒PAGE and excised from the membrane as described above (miCLIP-Day2), and the isolated RNA was digested into nucleosides, after which the m6A levels were quantified by LC‒MS/MS82. In brief, we digested the purified RNA into ribonucleosides using one unit of nuclease P1 in 25 μl of 25 mM NaCl, 2.5 mM ZnCl2 and 10 mM NaCH3COO (pH 5.3) and incubated for 2 h at 37 °C. Subsequently, NH4HCO3 (100 mM) and 5 units of alkaline phosphatase were added, and the sample was incubated for 2 h at 37 °C. Formic acid was added at 0.1% v/v in a final volume of 50 μl, the samples were filtered (0.22 μm, Millipore), and 15–20 μl was analysed in duplicate by LC–MS/MS. The ribonucleosides were separated using a C18 reversed-phase column (100 × 2.1 mm, 3 μm particle size; Chromex Scientific) and detected by a TSQ Quantiva Triple Quadrupole mass spectrometer (TSQ Quantiva, Thermo Scientific) operating in positive ionisation mode with a capillary voltage of 3500 V, a sheath gas flow rate of 7.35 l/min, and a gas temperature of 325 °C. The retention time, mass transitions (m/z) and collision energies were ~4.1 min, 268.1 - > 136.1 m/z and 20 V, respectively, for adenosine and ~ 8.7 min, 282.1 - > 150.1 m/z, and 20 V, respectively, for m6A. A mixture of ribonucleoside standards of each ribonucleoside was run for absolute quantification. The data were recorded using Xcalibur 4.0.27 software (Thermo Fisher Scientific), and the areas under the adenosine and m6A peaks were determined using Skyline.
RNA pulldowns with dimethyl labelling
RRACH, ARE, and TNFα pulldowns were performed with dimethyl labelling65,83. All buffer solutions were prepared with RNase-free reagents. For each RNA pulldown experiment, four individual pulldowns were performed. For each individual pulldown, 20 µl of streptavidin Sepharose high-performance slurry beads (Cytiva, 50% v/v) was used. The beads were washed with RNA-binding buffer (RBB, 50 mM HEPES-HCl (pH 7.5), 150 mM NaCl, 0.5% NP40 (v/v), and 10 mM MgCl2) and centrifuged. All pulldown centrifugation steps were performed at 1,500 × g for 2 min at 4 °C. The beads were then incubated with the RNase inhibitor RNasin plus (Promega) in RNA binding buffer (100 µl of RBB with 0.8 units of RNasin/µl) for 15 min on ice. After centrifugation, the beads were pre-blocked with yeast tRNA (Invitrogen, 100 μg tRNA in 1 ml RBB) for 1 h at 4 °C on a rotation wheel, followed by one wash with RBB. Then, the beads were incubated with either a control or m6A probe at a final concentration of 0.67 μM in 600 µl of RBB for 30 min at 4 °C while rotating. The probe sequences used for the RNA pulldowns can be found in the “Key Resources Table” (oligonucleotides). After probe incubation, the beads were washed once with RBB and twice with protein incubation buffer (PIB, 10 mM Tris-HCl (pH 7.5), 150 mM KCl, 1.5 mM MgCl2, 0.1% (v/v) NP-40, 0.5 mM DTT, and complete protease inhibitors (Roche)). The beads containing the immobilised RNA probes were then incubated with 1 mg of whole-cell lysate pooled from 9 donors in 600 µl of PIB supplemented with 0.4 units of RNasin/µl and 30 μg of tRNA for 30 min at RT, followed by 90 min at 4 °C. Unbound and unspecific proteins were removed by washing three times with PIB followed by two 1 x PBS washes. The remaining liquid was removed with a syringe. For on-bead digestion, 50 µl of elution buffer (100 mM Tris, pH 8.5; 2 M urea; and 10 mM DTT) was added to the beads, which were subsequently incubated for 20 min at RT in a thermoshaker at 200 g. To prevent the reformation of disulphide bonds, iodoacetamide was added to a final concentration of 50 mM, and the mixture was incubated for 10 min in the dark at RT (200 × g). This was followed by partial digestion of proteins from the beads by the addition of 250 ng of trypsin and incubation for 2 h at RT at 200 g. in the dark. After centrifugation, the supernatant containing the cleaved peptides was collected, and the remaining peptides were collected by adding 50 µl of new elution buffer to the beads and incubating them for 5 min at 200 g before the supernatant was added to the previously collected supernatant. Next, 100 ng of trypsin was added to the eluates, and the proteins were further digested overnight at RT. The eluted peptide samples were then prepared and desalted for mass spectrometry analysis via the C18 StageTip method84. StageTips were prepared by placing a double C18 plug in a 200 µl pipette tip free of polymers. The disk was then washed with 50 µl of methanol, 50 µl of buffer B (0.1% formic acid, 80% acetonitrile), and two washes of 50 µl of buffer A (0.1% formic acid). All washes were performed by centrifugation at 1500 × g, after which the StageTips were placed in adaptors suitable for centrifugation and collection of the flowthrough. The eluted peptides were then loaded on the StageTips and centrifuged at 1000 × g for 10 min to allow the peptides to bind to the disk and the liquid to flow through. Peptides were then labelled by either light or medium (0.2% CH2O or 0.2% CD2O in 10 mM NaH2PO4, 35 mM Na2HPO4 and 32 mM NaBH3CN) dimethyl isotopes by labelling with 150 µl of the isotope labelling buffer and centrifugation of 1000 × g for 5 min twice83.
Mass spectrometry (MS) analysis of RNA pulldown samples
After peptide elution from the StageTips, individual peptide samples were combined, resulting in forward and reverse reactions, which served as two technical replicates: the forward reaction included the control probe CH2O (light) combined with the m6A probe CD2O (medium); the reverse reaction included the control probe CD2O (medium) combined with the m6A probe CH2O (light). Elution of both the forward and the reverse reactions was performed using 30 µl of buffer B (0.1% formic acid, 80% acetonitrile), followed by an additional elution using 10 µl. After speedvac centrifugation to reduce the sample to 5 µl, 7 µl of buffer A (0.1% formic acid) was added. For the measurements, 5 µl of each sample was loaded on an Easy-nLC1000 connected online to an Orbitrap Exploris 480 (Thermo Fisher Scientific), and the data were acquired in a 60 min gradient. A 43 min acetonitrile gradient (12% to 30%) was used, followed by washes at 60% and 95% for a total of 60 min of data acquisition. The spray voltage was set to 2100 V in positive ion mode. The scans were collected in a data-dependent mode and collected in the top 20 data-dependent acquisition modes. The dynamic exclusion was enabled and set to 45 s. The Orbitrap resolution for a full scan was set to 120,000 in a scan range of 350–1300 m/z.
Mass spectrometry analysis of protein abundance
The RNA pulldown results were processed using MaxQuant 1.6.6.085. The DimethylLys0 and DimethylNter0 labels were selected, as were DimethylLys4 and DimethylNter4 (light and medium, respectively). Peptide identifications were restricted to tryptic peptides with no more than two missed cleavages. The minimal peptide length was set at 7. Carbamidomethyl cysteine was set as a fixed modification, and oxidised methionine and protein N-acetylation were searched as variable modifications. Database searching was performed with a main-search precursor mass tolerance of 4.5 ppm and a fragment ion mass tolerance of 20 ppm. FDR was controlled at 1% at the peptide-spectrum match (PSM) and protein levels. The re-quantification function was enabled, and the UniProt human FASTA database from June 2017 was used as a search database. Perseus v1.6.15.086 was used to filter and analyze the data. Proteins identified as identified only by site, reverse and potential contaminants were removed. Finally, proteins were filtered if at least two peptides were identified with at least one unique peptide. To identify and visualise significant interactors, forward and reverse ratios were log2 and -log2 transformed, respectively, and a ratio of both forward and reverse of 1 was used as a cutoff. Scatter plots were generated in R.
Quantification and statistical analysis
The results are shown as the mean ± SEM or mean ± SD as stated in the figure legends. Statistical analysis was performed using R or Prism-10 software (GraphPad). p < 0.05 indicated statistical significance, and the statistical tests applied are stated in the figure legends.
Ethical approvals
Peripheral blood mononuclear cells (PBMCs) were obtained from healthy donors at Cambridge Bioscience, National Health Service (NHS) Blood and Transplant (NHSBT: Addenbrooke’s Hospital, Cambridge, UK) or Sanquin (Amsterdam, NL). The study was performed according to the Declaration of Helsinki (seventh revision, 2013). Ethical approval was obtained from the Eastern England-Cambridge Central Research Ethics Committee (06/Q0108/281), and consent was obtained from all the subjects. Written informed consent was obtained (Cambridge Bioscience, Cambridge, UK; NHSBT Cambridge, UK; Sanquin Research, Amsterdam, NL).
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The data supporting the findings of this study are available from the corresponding authors upon request. The data generated in this study are publicly available. Specifically:
• miCLIP - sequencing data ArrayExpress (E-MTAB-15643); sequence raw and processed files: https://app.flow.bio/projects/663588932565340992/
• GLORI - sequencing data ArrayExpress (E-MTAB-15649); sequence raw and processed files: https://app.flow.bio/projects/127418738102891967/
• SLAM-Seq - sequencing data ArrayExpress (E-MTAB-15648); sequence raw and processed files: https://app.flow.bio/projects/783560763419435859/ (SLAM-Seq).
• The mass spectrometry proteomics data have been deposited to the ProteomeXchange Consortium via the PRIDE87 partner repository with the dataset identifier PXD059083.
• Flow cytometry, western blots and analysed data are available at Mendeley Data: Mendeley Data, V1, https://doi.org/10.17632/bhgn4bn5ks.1
• Source data for the figures and Supplementary Figs. are provided as a Source Data file. Source data are provided in this paper.
Code availability
Custom R scripts used to process crosslink data and generate metaprofiles shown in Fig. 1, 4D and Supplementary Fig. S1, S4D were developed for this study. The scripts execute standard data loading, normalisation, and plotting functions using publicly available R packages. Given their simplicity and reliance on existing libraries, the code is not deposited in a public repository but is available from the corresponding author upon request.
References
Raskov, H., Orhan, A., Christensen, J. P. & Gögenur, I. Cytotoxic CD8 + T cells in cancer and cancer immunotherapy. Br. J. Cancer 124, 359–367 (2021).
Kaech, S. M. & Cui, W. Transcriptional control of effector and memory CD8 + T cell differentiation. Nat. Rev. Immunol. 12, 749–761 (2012).
Salerno, F., Turner, M. & Wolkers, M. C. Dynamic post-transcriptional events governing CD8 + T cell homeostasis and effector function. Trends Immunol. 41, 240–254 (2020).
Barreau, C., Paillard, L. & Osborne, H. B. AU-rich elements and associated factors: Are there unifying principles? Nucleic Acids Res. 33, 7138–7150 (2005).
Caput, D. et al. Identification of a common nucleotide sequence in the 3’-untranslated region of mRNA molecules specifying inflammatory mediators. Proc. Natl. Acad. Sci. USA 83, 1670–1674 (1986).
Winzen, R. et al. The p38 MAP kinase pathway signals for cytokine-induced mRNA stabilization via MAP kinase-activated protein kinase 2 and an AU-rich region-targeted mechanism. EMBO J. 18, 4969–4980 (1999).
Anderson, P. Post-transcriptional control of cytokine production. Nat. Immunol. 9, 353–359 (2008).
Zhao, B. S., Roundtree, I. A. & He, C. Post-transcriptional gene regulation by mRNA modifications. Nat. Rev. Mol. Cell Biol. 18, 31–42 (2017).
Lee, Y., Choe, J., Park, O. H. & Kim, Y. K. Molecular mechanisms driving mRNA degradation by m6A modification. Trends Genet. 36, 177–188 (2020).
Han, S. H. & Choe, J. Diverse molecular functions of m6A mRNA modification in cancer. Exp. Mol. Med. 52, 738–749 (2020).
Wang, X. et al. N6-methyladenosine-dependent regulation of messenger RNA stability. Nature 505, 117–120 (2014).
Wang, X. et al. N6-methyladenosine Modulates messenger RNA translation efficiency. Cell 161, 1388–1399 (2015).
Jia, G. et al. N6-Methyladenosine in nuclear RNA is a major substrate of the obesity-associated FTO. Nat. Chem. Biol. 7, 885–887 (2011).
Zheng, G. et al. ALKBH5 Is a mammalian RNA demethylase that impacts RNA metabolism and mouse fertility. Mol. Cell 49, 18–29 (2013).
Zou, Z., Sepich-Poore, C., Zhou, X., Wei, J. & He, C. The mechanism underlying redundant functions of the YTHDF proteins. Genome Biol. 24, 17 (2023).
Zaccara, S. & Jaffrey, S. R. A unified model for the function of YTHDF proteins in regulating m6A-modified mRNA. Cell 181, 1582–1595 (2020).
Batista, P. J. et al. m6A RNA Modification controls cell fate transition in mammalian embryonic stem cells. Cell Stem Cell 15, 707–719 (2014).
Wang, Y. et al. N6-methyladenosine modification destabilizes developmental regulators in embryonic stem cells. Nat. Cell Biol. 16, 191–198 (2014).
Su, R. et al. R-2HG Exhibits anti-tumor activity by targeting FTO/m 6 A/MYC/CEBPA signaling. Cell 172, 90–91 (2017).
Chen, X. et al. Down-regulation of m6A mRNA methylation is involved in dopaminergic neuronal death. ACS Chem. Neurosci. 10, 2355–2363 (2019).
Wu, Z. et al. METTL3 counteracts premature aging via m6A-dependent stabilization of MIS12 mRNA. Nucleic Acids Res. 48, 11083–11096 (2020).
Zhang, Y., Lu, L. & Li, X. Detection technologies for RNA modifications. Exp. Mol. Med. 54, 1601–1616 (2022).
Helm, M. & Motorin, Y. Detecting RNA modifications in the epitranscriptome: predict and validate. Nat. Rev. Genet. 18, 275–291 (2017).
Hendra, C. et al. Detection of m6A from direct RNA sequencing using a multiple instance learning framework. Nat. Methods 19, 1590–1598 (2022).
Linder, B. et al. Single-nucleotide-resolution mapping of m6A and m6Am throughout the transcriptome. Nat. Methods 12, 767–772 (2015).
Ke, S. et al. A majority of m6A residues are in the last exons, allowing the potential for 3’ UTR regulation. Genes Dev. 29, 2037–2053 (2015).
Meyer, K. D. et al. Comprehensive analysis of mRNA methylation reveals enrichment in 3’ UTRs and near stop codons. Cell 149, 1635–1646 (2012).
Dominissini, D. et al. Topology of the human and mouse m6A RNA methylomes revealed by m6A-seq. Nature 485, 201–206 (2012).
Körtel, N. et al. Deep and accurate detection of m6A RNA modifications using miCLIP2 and m6Aboost machine learning. Nucleic Acids Res. 49, e92–e92 (2021).
Parker, M. T. et al. Nanopore direct RNA sequencing maps the complexity of arabidopsis mRNA processing and m6A modification. Elife 9, 1–35 (2020).
Shulman, Z. & Stern-Ginossar, N. The RNA modification N6-methyladenosine as a novel regulator of the immune system. Nat. Immunol. 21, 501–512 (2020).
Han, D. et al. Anti-tumour immunity controlled through mRNA m6A methylation and YTHDF1 in dendritic cells. Nature 566, 270–274 (2019).
Li, H.-B. et al. m6A mRNA methylation controls T cell homeostasis by targeting the IL-7/STAT5/SOCS pathways. Nature 548, 338–342 (2017).
Visvanathan, A. et al. Essential role of METTL3-mediated m 6 A modification in glioma stem-like cells maintenance and radioresistance. Oncogene 37, 522–533 (2018).
Zhang, S. et al. m6A Demethylase ALKBH5 maintains tumorigenicity of glioblastoma stem-like cells by sustaining FOXM1 expression and cell proliferation program. Cancer Cell 31, 591–606 (2017).
Lee, F. C. Y., Chakrabarti, A. M., Hänel, H. & Monzón-casanova, E. An improved iCLIP protocol. Preprint at https://doi.org/10.1101/2021.08.27.457890 (2021).
Liu, C. et al. Absolute quantification of single-base m6A methylation in the mammalian transcriptome using GLORI. Nat. Biotechnol. 41, 355–366 (2023).
Smith, K. C. Physical and Chemical Changes Induced in Nucleic Acids by Ultraviolet Light. Radiat. Res. Suppl. 6, 54 (1966).
Hafner, M. et al. RNA-ligase-dependent biases in miRNA representation in deep-sequenced small RNA cDNA libraries. RNA 17, 1697–1712 (2011).
Capitanchik, C., Toolan-Kerr, P., Luscombe, N. M. & Ule, J. How do you identify m6 A methylation in transcriptomes at high resolution? a comparison of recent datasets. Front. Genet. 11, 398 (2020).
McIntyre, A. B. R. et al. Limits in the detection of m6A changes using MeRIP/m6A-seq. Sci. Rep. 10, 6590 (2020).
Kuret, K., Amalietti, A. G., Jones, D. M., Capitanchik, C. & Ule, J. Positional motif analysis reveals the extent of specificity of protein-RNA interactions observed by CLIP. Genome Biol. 23, 1–34 (2022).
Frith, M. C. et al. A code for transcription initiation in mammalian genomes. Genome Res. 18, 1–12 (2008).
Wang, X. et al. Structural basis of N6-adenosine methylation by the METTL3–METTL14 complex. Nature 534, 575–578 (2016).
Lee, F. C. Y. & Ule, J. Advances in CLIP Technologies for Studies of Protein-RNA Interactions. Mol. Cell 69, 354–369 (2018).
Haberman, N. et al. Insights into the design and interpretation of iCLIP experiments. Genome Biol. 18, 1–21 (2017).
Moore, M. J. et al. Mapping Argonaute and conventional RNA-binding protein interactions with RNA at single-nucleotide resolution using HITS-CLIP and CIMS analysis. Nat. Protoc. 9, 263–293 (2014).
Garcia-Campos, M. A. et al. Deciphering the “m6A Code” via antibody-independent quantitative profiling. Cell 178, 731–747 (2019).
Zhang, Z. et al. Single-base mapping of m6A by an antibody-independent method. Sci. Adv. 5, eaax0250 (2019).
Hartstock, K. et al. MePMe-seq: antibody-free simultaneous m6A and m5C mapping in mRNA by metabolic propargyl labeling and sequencing. Nat. Commun. 14, 7154 (2023).
Yankova, E. et al. Small-molecule inhibition of METTL3 as a strategy against myeloid leukaemia. Nature 593, 597–601 (2021).
Herzog, V. A. et al. Thiol-linked alkylation of RNA to assess expression dynamics. Nat. Methods 14, 1198–1204 (2017).
Rücklé, C. et al. RNA stability controlled by m6A methylation contributes to X-to-autosome dosage compensation in mammals. Nat. Struct. Mol. Biol. 30, 1207–1215 (2023).
Agarwal, V. & Kelley, D. R. The genetic and biochemical determinants of mRNA degradation rates in mammals. Genome Biol. 23, 245 (2022).
Raghavan, A. Genome-wide analysis of mRNA decay in resting and activated primary human T lymphocytes. Nucleic Acids Res. 30, 5529–5538 (2002).
Best, J. A. et al. Transcriptional insights into the CD8 + T cell response to infection and memory T cell formation. Nat. Immunol. 14, 404–412 (2013).
Strobl, C., Boulesteix, A. L., Kneib, T., Augustin, T. & Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 9, 1–11 (2008).
Micevic, G. et al. IL-7R licenses a population of epigenetically poised memory CD8 + T cells with superior antitumor efficacy that are critical for melanoma memory. Proc. Natl. Acad. Sci. USA 120, e2304319120 (2023).
Cibrián, D. & Sánchez-Madrid, F. CD69: from activation marker to metabolic gatekeeper. Eur. J. Immunol. 47, 946–953 (2017).
Huster, K. M. et al. Selective expression of IL-7 receptor on memory T cells identifies early CD40L-dependent generation of distinct CD8+ memory T cell subsets. Proc. Natl. Acad. Sci. USA 101, 5610–5615 (2004).
Salerno, F., Paolini, N. A., Stark, R., von Lindern, M. & Wolkers, M. C. Distinct PKC-mediated posttranscriptional events set cytokine production kinetics in CD8 + T cells. Proc. Natl. Acad. Sci. USA 114, 9677–9682 (2017).
Huang, Y. et al. Meclofenamic acid selectively inhibits FTO demethylation of m6A over ALKBH5. Nucleic Acids Res. 43, 373–384 (2015).
Sandberg, R., Neilson, J. R., Sarma, A., Sharp, P. A. & Burge, C. B. Proliferating cells express mRNAs with shortened 3’ untranslated regions and fewer microRNA target sites. Science 320, 1643–1647 (2008).
Xiao, Y. et al. An Elongation- and Ligation-Based qPCR Amplification Method for the Radiolabeling-Free Detection of Locus-Specific N6-Methyladenosine Modification. Angew. Chem. Int. Ed. 57, 15995–16000 (2018).
Edupuganti, R. R. et al. N6-methyladenosine (m6A) recruits and repels proteins to regulate mRNA homeostasis. Nat. Struct. Mol. Biol. 24, 870–878 (2017).
He, W. & Parker, R. Functions of Lsm proteins in mRNA degradation and splicing. Curr. Opin. Cell Biol. 12, 346–350 (2000).
Patil, D. P. et al. m6A RNA methylation promotes XIST-mediated transcriptional repression. Nature 537, 1–25 (2016).
Ross, J. mRNA stability in mammalian cells. Microbiol. Rev. 59, 423–450 (1995).
de Silanes, I. L., Zhan, M., Lal, A., Yang, X. & Gorospe, M. Identification of a target RNA motif for RNA-binding protein HuR. Proc. Nat.l Acad. Sci. USA 101, 2987–2992 (2004).
Popović, B. et al. Time-dependent regulation of cytokine production by RNA binding proteins defines T cell effector function. Cell Rep. 42, https://doi.org/10.1016/j.celrep.2023.112419 (2023).
Arribas-Hernández, L. et al. Principles of mRNA targeting via the Arabidopsis m6A-binding protein ECT2. Elife 10, https://doi.org/10.7554/elife.72375 (2021).
Park, O. H. et al. Endoribonucleolytic cleavage of m6A-containing RNAs by RNase P/MRP complex. Mol. Cell 74, 494–507 (2019).
Du, H. et al. YTHDF2 destabilizes m6A-containing RNA through direct recruitment of the CCR4–NOT deadenylase complex. Nat. Commun. 7, 12626 (2016).
Guo, W. et al. Mettl3-dependent m6A modification is essential for effector differentiation and memory formation of CD8 + T cells. Sci. Bull. 69, 82–96 (2024).
Zarnegar, B. J. et al. irCLIP platform for efficient characterization of protein-RNA interactions. Nat. Methods 13, 489–492 (2016).
Capitanchik, C. et al. Flow: a web platform and open database to analyse, store, curate and share bioinformatics data at scale. Preprint at https://doi.org/10.1101/2023.08.22.544179 (2023).
Köster, J. & Rahmann, S. Snakemake—a scalable bioinformatics workflow engine. Bioinformatics 28, 2520–2522 (2012).
Neumann, T. et al. Quantification of experimentally induced nucleotide conversions in high-throughput sequencing datasets. BMC Bioinform.20, 258 (2019).
Koboldt, D. C. et al. VarScan: variant detection in massively parallel sequencing of individual and pooled samples. Bioinformatics 25, 2283–2285 (2009).
Bates, D. M. & Chambers, J. M. Nonlinear Models. in Statistical Models in S 421–454 (Routledge, 2017).
Mukherjee, N. et al. Global target mRNA specification and regulation by the RNA-binding protein ZFP36. Genome Biol. 15, R12 (2014).
Gameiro, P. A., Encheva, V., Dos Santos, M. S., MacRae, J. I. & Ule, J. Metabolic turnover and dynamics of modified ribonucleosides by 13 C labeling. J. Biol. Chem. 297, 101294 (2021).
Boersema, P. J., Raijmakers, R., Lemeer, S., Mohammed, S. & Heck, A. J. R. Multiplex peptide stable isotope dimethyl labeling for quantitative proteomics. Nat. Protoc. 4, 484–494 (2009).
Rappsilber, J., Mann, M. & Ishihama, Y. Protocol for micro-purification, enrichment, pre-fractionation and storage of peptides for proteomics using StageTips. Nat. Protoc. 2, 1896–1906 (2007).
Cox, J. & Mann, M. MaxQuant enables high peptide identification rates, individualized p.p.b.-range mass accuracies and proteome-wide protein quantification. Nat. Biotechnol. 26, 1367–1372 (2008).
Tyanova, S. et al. The Perseus computational platform for comprehensive analysis of (prote)omics data. Nat. Methods 13, 731–740 (2016).
Perez-Riverol, Y. et al. The PRIDE database resources in 2022: a hub for mass spectrometry-based proteomics evidences. Nucleic Acids Res. 50, D543–D552 (2022).
Acknowledgements
We thank Richard Mitter for support with GLORI data analysis, Karen Davey, Natasja Kragten, Aurélie Guislain, Benoît P Nicolet and Ken GC Smith for valuable discussions and technical assistance; the Bioinformatics and Biostatistics Team and the Advanced Sequencing Facility (ASF) at the Francis Crick Institute for expert support; the Cambridge NIHR BRC Cell Phenotyping Hub; the flow cytometry facility from the School of the Biological Sciences; and the flow cytometry facility at Sanquin. This work was supported by the Wellcome Trust (103760/Z/14/Z) and the European Research Council (ERC; FP7/2007-2013/ERC grant agreement ID: 617837) awarded to J.U.; Wellcome Trust Principal Research Fellowship (214283/Z/19/Z), a Knut and Alice Wallenberg Scholar Award, the Swedish Medical Research Council (Vetenskapsrådet 2019-01485), the Swedish Cancer Fund (Cancerfonden, CAN2018/808), and the Swedish Children’s Cancer Fund (Barncancerfonden PR2020-007) awarded to R.S.J.; the HORIZON-MSCA grant (701730) awarded to P.A.G.; and the HORIZON-MSCA grant (101107176) awarded to I.P.F. Work in the lab of M.V. is supported by an NWO-VICI grant (VI.C.202.013). The laboratories of M.W. and M.V. are part of the Oncode Institute, which is partly funded by the Dutch Cancer Society.
Funding
Open Access funding provided by The Francis Crick Institute.
Author information
Authors and Affiliations
Contributions
Y.A.B. and A.A.M.M. contributed equally to this work. Conceptualisation, P.A.G., I.P.F., R.S.J., and J.U.; Methodology, P.A.G., I.P.F., Y.A.B., A.A.M.M., M.C.W., R.S.J., and J.U.; Software, P.A.G., K.K., I.R.dlM., N.D.Z., and R.F.; Investigation, P.A.G., I.P.F., Y.A.B., A.A.M.M., K.K., I.R.dlM., N.D.Z., Z.H., V.K., and R.F. Writing-Original Draft, P.A.G. and I.P.F.; Writing-Review & Editing, all authors; Funding Acquisition, P.A.G., I.P.F., R.S.J., and J.U.; Supervision, I.P.F., M.V., M.C.W., R.S.J., and J.U.; Project Administration, P.A.G., I.P.F., M.C.W., R.S.J., and J.U.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks the anonymous reviewers for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gameiro, P.A., Foskolou, I.P., Butt, Y.A. et al. Meta-unstable mRNAs in activated CD8+ T cells are defined by interlinked AU-rich elements and m6A mRNA methylation. Nat Commun 17, 160 (2026). https://doi.org/10.1038/s41467-025-67762-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-67762-w
