
Abstract
We propose the X3Z3 Floquet code, a dynamical code with improved performance under biased noise compared to other Floquet codes. The enhanced performance is attributed to a simplified decoding problem resulting from a persistent stabiliser-product symmetry, which surprisingly exists in a code without constant stabilisers. Even if such a symmetry is allowed, we prove that general dynamical codes with two-qubit parity measurements cannot admit one-dimensional decoding graphs, a key feature responsible for the high performance of bias-tailored stabiliser codes. Despite this, our comprehensive simulations show that the symmetry of the X3Z3 Floquet code renders its performance under biased noise far better than several leading Floquet codes. To maintain high-performance implementation in hardware without native two-qubit parity measurements, we introduce ancilla-assisted bias-preserving parity measurement circuits. Our work establishes the X3Z3 code as a prime quantum error-correcting code, particularly for devices with reduced connectivity, such as the honeycomb and heavy-hexagonal architectures.
Similar content being viewed by others
Introduction
Quantum error correction (QEC)1,2,3,4 should be understood as occurring both in space and time5. Taking advantage of the temporal dimension, Floquet codes6,7,8,9,10,11,12,13,14,15,16,17,18,19,20, or more generally dynamical codes21,22,23, form a large class of quantum error-correcting codes, which can achieve competitive fault-tolerant performance6,8,9,10,11,12,13,14,15,16,17 while reducing the weights of check measurements performed for the error correction. Several of these codes7,9,13,18 also benefit from being defined on a lattice with sparser connectivity than that for the surface code24,25: each qubit is only connected to three other qubits. In architectures where two-qubit parity check measurements are native, Floquet codes could achieve higher thresholds8,10,17 and lower space-time overheads8,10 than the surface code. Without requiring additional connectivity, such codes can be deformed around defective components caused by highly noisy qubits or gates15,26. Moreover, dynamical codes allow for implementations of arbitrary Clifford, and even some non-Clifford gates, through low-weight parity check measurements21. In addition, dynamical measurement schedules can result in certain errors being self-corrected in the Floquet-Bacon-Shor code20—this code was recently demonstrated in superconducting qubit experiments27.
Although Floquet codes (in particular, the honeycomb code) have been studied under various noise models9,28, there have not been any Floquet codes that are specifically tailored for an improved performance under biased noise. A biased noise model is one in which a specific type of error, for example, phase errors, occurs more frequently than other errors, such as bit flip errors. This biased noise is typical to most quantum platforms, for example, bosonic “cat” qubits29,30, spin-optical17,31, neutral atoms32, quantum-dot spin qubits33,34 and Majorana qubits35,36. In these platforms, biased noise can arise due to different predominant error mechanisms. For example, by increasing the photon number of the resonators, the cat qubits29,30 can be made exponentially protected against the bit-flip error at the expense of only a linear increase in the phase-flip error. For the spin qubits in both spin-optical17 and quantum dot architectures33,34, the noise is predominantly dephasing due to the short spin coherence time, T2. Moreover, the two-qubit gates of quantum-dot spin qubits have also been experimentally shown to exhibit phase-biased noise which is caused by the T2 dephasing, non-Markovian error sources, AC-Stark shift, and calibration errors34. In neutral-atom qubits, detailed modelling of the experiment shows that the two-qubit gate noise is predominantly phase-biased due to the short Rydberg state \({T}_{2}^{* }\) lifetime caused by finite atomic temperature and light-shift fluctuations of the lasers32. Lastly, for Majorana qubits, the noise is expected to be biased due to residual coupling between the Majoranas and thermal fluctuations that excite the qubit to an above-gap quasiparticle state37.
For enhanced performance, quantum-error-correcting codes need to be designed such that they possess symmetries that can be utilised to simplify the error-syndrome decoding problem given the noise structure38,39,40,41,42,43,44,45,46,47. While there have been a number of proposals for bias-tailored static codes39,40,41,42,42,43,44,45,46,47,48,49,50,51,52,53,54,55, designing Floquet codes for high performance under biased noise is still an open problem. Owing to the experimental relevance of biased noise and given the ease of implementation of Floquet codes, which require only two-qubit parity measurements that can be implemented even in architectures with sparse connectivity, it is therefore imperative to tailor Floquet codes for biased noise and study how the performance of such dynamical codes can be improved.
In this paper, we present the X3Z3 bias-tailored Floquet code, a Clifford-deformed46 version of the Calderbank-Shor-Steane (CSS) Floquet code13,18. Despite not having a fixed stabiliser group (as static codes have), remarkably the X3Z3 Floquet code possesses a stabiliser-product symmetry under infinitely phase-biased noise, simplifying decoding in biased noise regimes. We perform an in-depth study of this code, along with the CSS Floquet code13,18, and two types of honeycomb codes: one introduced by Hastings and Haah6 and the other by Gidney et al.8. We simulate all codes under biased-noise models, and find that the X3Z3 code has the best performance. Using a matching decoder, we find that, as the noise changes from fully depolarising to pure dephasing, the X3Z3 Floquet code threshold increases from 1.13% to 3.09% under a code-capacity noise model and increases from 0.76% to 1.08% under a circuit-level noise model mimicking hardware with noisy direct entangling measurements. Furthermore, we show that its sub-threshold performance is also substantially better under biased noise than other Floquet codes.
Compared to its static counterparts, the X3Z3 Floquet code has an advantage that it can be realised using only two-qubit parity check measurements. This makes it particularly suitable for devices with constrained connectivity, such as the honeycomb and heavy-hexagonal lattice (currently IBM’s preferred superconducting-qubit architecture)56,57. Moreover, we demonstrate that the two-qubit parity measurements of the Floquet code can be performed in a bias-preserving way even in hardware without direct entangling measurements, thus enabling high performance implementation in such devices. Crucially, we show that even in the presence of mid-gate errors which degrade noise bias in the target qubits of conventional CNOT gates58, two of the three required parity-check circuits, built using these conventional gates, can be made fully Z-bias preserving, i.e., sustain the Z noise bias on both data qubits, while the other one is partially phase-bias preserving, i.e., protects the Z noise bias in only one of the data qubits.
We argue that other dynamical codes defined on the same architecture, and built from two-body measurements, would likely not have drastically improved performance compared to the X3Z3 Floquet code. To support this argument, we prove that decoding graphs of such dynamical codes under infinitely phase-biased noise have connectivities that are too high for the decoding problem to be reduced to a simple decoding of repetition codes, as is the case for static codes42,46. This can be understood as resulting from the fact that error syndromes of dynamical codes possess less symmetry than their static code counterparts.
The paper is laid out as follows. In the Results section, we first review the basics of Floquet codes together with two widely studied examples: honeycomb and CSS Floquet codes. Readers who are already familiar with Floquet codes can skip directly to the section in which we discuss our X3Z3 Floquet code. Crucially, we show that there exists a persistent symmetry in the code’s error syndrome under pure dephasing noise that allows for a simplified decoding. Subsequently, we introduce ancilla-assisted bias-preserving parity measurement circuits that allow for high-performance code implementation in devices without native entangling measurements. We then provide the simulation results for memory experiments. We provide two theorems showing that the decoding hypergraphs of dynamical codes cannot be reduced to 1D graphs. Finally, we conclude and present future research directions in the Discussion section. In the Methods section, we provide the description of our noise models, details of numerical simulations and proofs of the no-go theorems. In the Supplementary Information, we provide a more thorough review of the basics of honeycomb and CSS Floquet codes, details of our parity check circuits, plots for determining thresholds, details of hyperedges in the honeycomb codes, and results for Floquet codes with elongated dimension and twisted periodic boundary conditions.
Results
Dynamical and Floquet codes
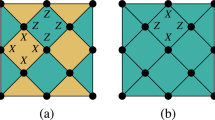
We begin by defining dynamical and Floquet codes. Here we consider the Floquet codes to be defined on the lattice of a two-dimensional colour code, which is trivalent and three-colourable. A trivalent lattice has each vertex incident to three edges, and a three-colourable lattice has every face assigned one of three colours in such a way that there are no two adjacent faces of the same colour. Throughout this paper, we will use the honeycomb lattice as an example of such a lattice (see Fig. 1).

a CSS and (b, c) X3Z3 Floquet codes. a, b Left: Hexagonal lattice with qubits sitting on vertices and opposite boundaries identified. Plaquettes and edges are assigned one of three colours [red, green, blue; examples are shown in (a)] and one of two types (X- or Z-type for CSS and A- or B-type for X3Z3). a Right: CSS Floquet code measurement schedule. b Left: The X3Z3 Floquet code is obtained from the CSS code via Hadamard gates applied to shaded domains' qubits. Right: Plaquette and edge (check) operators are A- or B-type, depending on their support basis on the shaded/unshaded domains. c The X3Z3 Floquet code measurement schedule. Arrows indicate the type and colour of the edge operator measured at each step, where the edges just measured (members of the ISG) are highlighted in the lattice. Uncoloured plaquettes host only a single type of stabiliser, either A or B, indicated by the letters in the plaquettes, while coloured plaquettes host both A- and B-type stabilisers in the ISG. One set of anti-commuting logical operators is shown by yellow and brown strings, where their qubit supports are depicted using big circles and stars, respectively, with the X (Z) bases highlighted by red (blue) colouring. The other set (not shown) is similar to the set shown but offset by three measurement subrounds and with an X ↔ Z interchange of the qubit supports' bases.
We define qubits as residing on the vertices of the lattice and error-correction is performed by measuring two-qubit operators defined on edges of the lattice (i.e., acting on qubits incident to a given edge). Each edge is coloured the same as the plaquettes it connects [see e.g., the coloured edges in the middle right of the lattice in Fig. 1a]. We perform error-correction by measuring edge operators in a particular sequence. After any given subround of edge measurements, the system will be in the +1-eigenstate of the operators in an “instantaneous stabiliser group” (ISG), which will change at each time step. The ISG at time step t + 1 is defined as
In the above, \({{\mathcal{M}}}_{t+1}\) is the set of “check” measurements performed at time step t + 1. The ISGt+1 also includes “plaquette stabiliser operators” S ∈ ISGt which commute with all \(M\in {{\mathcal{M}}}_{t+1}\). The check measurement operators are chosen in such a way that those check operators at time t that have overlapping qubit supports with check operators at t + 1 anti-commute. For Floquet codes, the measurement sequence is periodic, such that \({{\mathcal{M}}}_{t+T}={{\mathcal{M}}}_{t}\) for some integer T. For such a code, we will be performing quantum memory experiments with mT time steps, for some integer m. We will refer to m as the number of “QEC rounds” in the experiment, while we will refer to mT as the number of “measurement subrounds” in the experiment.
The logical operators at time t are given by \({\mathcal{C}}({{\rm{ISG}}}_{t})/{{\rm{ISG}}}_{t}\), where \({\mathcal{C}}({{\rm{ISG}}}_{t})\) is the centraliser of ISGt, i.e., the group of Pauli operators commuting with all S ∈ ISGt. A (potentially trivial) logical operator “representative” is some member of \({\mathcal{C}}({{\rm{ISG}}}_{t})\). Each lowest-weight nontrivial logical operator representative for the codes considered will be a string-like Pauli operator at each time step [see Fig. 1c]. To avoid anti-commuting with the next-subround edge measurements, certain check measurement results along a logical operator’s path have to be multiplied into that logical operator. Hence, the logical operators will evolve from one time step to the next. As an illustration, take for example the vertical logical operator immediately after the gB checks are applied, i.e., the operator on the yellow string in the top-centre panel of Fig. 1(c). This operator is obtained by multiplying the vertical green-B checks on the vertical logical operator’s path [the two green edges on the yellow path shown in the top-centre panel of Fig. 1c] into the previous time-step vertical logical operator [the operator shown by the yellow string in the top-left panel of Fig. 1(c)]. Note that after the multiplication, the logical operator commutes with the next check measurements, which are the blue-A edge measurements.
We can detect errors if we can find sets of measurements, called detectors, that always multiply to the value +1 in the absence of noise, thus registering no error. Over some number of QEC rounds we will have extracted several detector outcomes. A detector (or decoding) hypergraph is formed by first defining a node for each (independent) detector in the code’s history. Subsequently, for each potential fault (e.g., Pauli or measurement errors) that might have occured, a (hyper)edge is drawn between the detectors whose signs are flipped by this fault. Each (hyper)edge is assigned a weight based on the probability of the corresponding error occurring59. The codes we will be examining are amenable to minimum-weight perfect matching decoding60, upon decomposing hyperedges into edges. Given a “syndrome” (a set of detectors whose measurements return −1 rather than +1), the decoder attempts to pair up the triggered detectors to determine a highest-probability correction operation. The decoder succeeds if the error combined with the correction is a trivial logical operator.
Having discussed the general idea of Floquet codes, we now briefly review the commonly studied examples: two variants of the honeycomb code6,8 and the CSS Floquet code13,18. We will later modify the CSS Floquet code to achieve the bias-tailored X3Z3 Floquet code. More details of the honeycomb and CSS Floquet codes are presented in Supplementary Sec. I of the Supplementary Information61.
Honeycomb codes
We begin by first discussing the honeycomb codes. The first variant we review is due to Gidney et al.8, which we call the P6 Floquet code, since its plaquette operators are six-body operators of the form P⊗6 for P = X, Y, Z. We define edge operators of three types: on red edges we define an XX operator, on green edges a YY operator and on blue edges a ZZ operator. We measure edge operators in the periodic sequence r → g → b. When this code is defined with periodic boundary conditions it stores two logical qubits (it is equivalent to the toric code concatenated with a two-qubit repetition code at each time step6). The code’s logical operators evolve through the measurement cycle (see Supplementary Sec. IA of the Supplementary Information61). While the measurement sequence has period 3, the logical operators only return to their initial values (up to signs) with period 6.
We define one stabiliser operator for each plaquette, where red, green, and blue plaquettes host the X⊗6, Y⊗6, and Z⊗6 operators, respectively. These plaquette operator eigenvalues are inferred from edge measurements in two consecutive subrounds. Detectors are formed from consecutive plaquette operator measurements.
The second honeycomb code variant, which we call the XYZ2 honeycomb code, is due to Hastings and Haah6. It differs from the P6 code by single-qubit Clifford rotations acting on the qubits. While the XYZ2 code’s edges are still coloured the same as the P6 edges, the XYZ2 code’s edge operators have their Pauli bases defined according to their orientations within each T junction, i.e., horizontal edges are of Z type while the X and Y checks are respectively those edges which are 90° clockwise and counter-clockwise rotated from the horizontal edges (see Supplementary Sec. IA of the Supplementary Information61). All plaquettes have the same stabiliser operator, i.e., the XYZ2 operator. While the logical operators of the XYZ2 code have the same qubit supports as those of the P6 code, the qubit support bases of the XYZ2 logical operators are not uniform throughout, but involve X, Y, and Z Paulis6. We note that even though these honeycomb code variants have been studied by several works in the literature (e,g., refs. 6,7,8,9), there have not been any studies comparing the performance of these two codes under biased noise.
CSS Floquet code
Having discussed the honeycomb codes, we now give a brief review of another type of Floquet code, the CSS Floquet code, which was first presented in refs. 13,18. We refer the readers to Supplementary Sec. IB of the Supplementary Information61 for more details on the code. The CSS Floquet code is defined on the same honeycomb lattice. We show the code’s measurement cycle in Fig. 1(a). We measure operators defined on edges using the r → g → b cycle, but alternate between measuring XX and ZZ operators on these edges. Hence, this code has a period-6 measurement cycle, and its logical operator evolutions also have period-6 (see Supplementary Fig. 2 of the Supplementary Information61 for an illustration). Even though the honeycomb code’s measurement schedule has only a period of 3, for consistency, we will define 1 QEC round to be 6 measurement subrounds for all codes studied in this paper. The check operators, stabilisers and logicals all are either X- or Z-type and, for this reason, the code is called the CSS Floquet code.
Unlike the honeycomb codes, the CSS Floquet code has no persistent stabiliser operators. Instead, each plaquette stabiliser is repeatedly reinitialised and measured out, with subsequent measurement values compared to form a detector. In contrast to the honeycomb codes where the values of the plaquette stabilisers are inferred from measurements of check operators in two consecutive subrounds, here the plaquette operator measurements take only a single subround13,18. Because of these single-step measurements, at each measurement subround, there is always one type of plaquette operator that anti-commutes with the check measurements, and hence their values are undetermined (see Supplementary Sec. IB of the Supplementary Information61). These “inactive” plaquettes, however, will be reinitialised at the next measurement subround. As a result, at each time step, the ISG contains X-type and Z-type stabiliser operators defined on two of the three colours of plaquette and either an X-type or a Z-type operator defined on the other colour. For instance, after measuring the red-X checks, the ISG contains X⊗6 and Z⊗6 operators on both blue and green plaquettes, but only X⊗6 red plaquette operators, since Z⊗6 red plaquette operators anti-commute with the red-X checks (see Supplementary Sec. IB of the Supplementary Information61 for more details).
The CSS Floquet code is naturally suited to a minimum-weight perfect matching (MWPM) decoding, since single-qubit (X or Z) Pauli and measurement errors all lead to graph-like syndromes13: they each trigger a pair of detectors. There are two decoding graphs formed from the Z-type and X-type detectors. Only Y errors form hyperedges that need to be decomposed into edges in the two detector graphs.
X3Z3 bias-tailored Floquet code
We now describe the X3Z3 bias-tailored Floquet code, which is shown in Fig. 1b, 1c. This code is related to the CSS Floquet code by Hadamard gates applied to the qubits in alternating strips [i.e., the grey strips in Fig. 1b] along vertical non-trivial cycles of the lattice, and is a Floquetified version of the domain wall colour code46. As in the CSS Floquet code, the X3Z3 code also has two types of plaquettes and edges: one originates from the Pauli X and the other from the Pauli Z plaquettes and edges in the CSS code before the Hadamard deformation. We refer to these modified operators as A-type and B-type, respectively; these are shown in Fig. 1b. The measurement sequence is analogous to the CSS Floquet code sequence: rA → gB → bA → rB → gA → bB, where cA represents the measurement of A-type check operators along c-coloured edges, and similarly for cB. Just as with the CSS Floquet code13, this code can also be defined on a planar lattice with boundary.
The decoding of the X3Z3 Floquet code under Z-biased noise is simplified by the presence of a symmetry in the decoding graphs, which we will explain below. This is a space-time analogue of the symmetries present in bias-tailored static codes such as the XZZX code42 and the domain wall colour code46. In such codes, under the infinitely phase-biased code-capacity noise model (with only single-qubit Z errors, for example), syndromes are forced to come in pairs along one-dimensional (1D) strips of the lattice. This results from strips of stabilisers multiplying together to the identity along one domain and commuting with all Z errors on all qubits: these are 1D symmetries of the stabiliser code under infinitely phase-biased noise. We will refer to (plaquette) stabilisers in the ISG that are flipped by an error as anyons. In bias-tailored static codes, anyons can propagate within strips but cannot move outside the strip without changing their Pauli type. We will show that there also exists a similar symmetry in the bias-tailored Floquet code.
As in the CSS Floquet code, there are two disjoint decoding graphs for the X3Z3 Floquet code: the A-type and B-type graphs, whose edges correspond to single-qubit Pauli errors. In even measurement subrounds, we perform B-type measurements and form detectors for the B-type graph while in odd measurement subrounds, we only form detectors for the A-type graph. Note that under a more complicated noise model, such as one that includes measurement or two-qubit errors, edges can exist between the A- and B-type graphs and they are no longer disjoint.
Persistent stabiliser-product symmetry and two-dimensional decoding of the X3Z3 Floquet code under biased noise
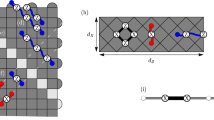
There is no constant stabiliser group when viewing the X3Z3 Floquet code as a subsystem code (in a subsystem code, the stabiliser group is defined as the centre of the gauge group, which, in our case, is generated by all edge operators)13,18. Surprisingly, despite this fact, at every time step, there do exist operators that form a symmetry under pure dephasing noise (without measurement errors). An example of such a symmetry is shown in Fig. 2. It is a symmetry on one of the unshaded domains and it is formed by the product of A-type plaquettes. A similar symmetry can also be found on the shaded strips which are formed by the product of B-type plaquettes.

a An example of such a symmetry along a single unshaded strip of the lattice, together with a Pauli-Z error, is shown throughout the measurement cycle. Arrows indicate the type of check (cA or cB for some colour c) measured at each subround. A-type plaquette operators whose product forms the symmetry at that subround are highlighted in darker colours. Plaquettes indicated by coloured dots are the locations of syndromes that would be triggered if the Z error shown were to occur at that measurement subround. b An example of a stabiliser-product symmetry just before gB checks are measured is the product of red and blue A-type plaquettes shown. Since this product is the identity along the vertical unshaded strip and commutes with Z errors on all qubits, the syndromes/anyons [coloured dots in (a)] must appear in pairs along the vertical strips.
To see why such symmetries exist, consider one particular time step, e.g., just before the green B-type measurements, and one vertical unshaded domain in the lattice. This is shown in Fig. 2b. As depicted, the product of red and blue A-type plaquettes in the ISG is the identity on all qubits in the domain, and yields Pauli Z operators on some qubits in the neighbouring shaded vertical domains. To be more concrete, consider the plaquettes that can detect Z errors along the unshaded vertical domain \({\mathcal{D}}\) at time step t. These are the A-type plaquette operators with support in \({\mathcal{D}}\). For a plaquette stabiliser operator S, which is measured in a time step \(t^{\prime} > t\), to form a detector (i.e., a node in the detector graph), it has to be in ISGt and ISGt+1, since it must commute with at least the next measurement subround. We can define \({{\rm{ISG}}}_{\left(t,t+1\right)}^{A,{\mathcal{D}}}\) as the subgroup of ISGt ∩ ISGt+1 formed from A-type plaquettes with non-trivial supports on domain \({\mathcal{D}}\). We then have
where \({\bar{{\mathcal{D}}}}_{Z,t}\) and \({\bar{{\mathcal{D}}}}_{I,t}\) are some subsets of qubits in the domains adjacent to domain \({\mathcal{D}}\) on which the product of the A-type plaquette stabilisers yields Pauli Z and the identity, respectively [for the example given in Fig. 2b, the domain \({\mathcal{D}}\) is the unshaded vertical strip, the domains \({\bar{{\mathcal{D}}}}_{Z,t}\) and \({\bar{{\mathcal{D}}}}_{I,t}\) comprise the qubits in the neighbouring shaded vertical strips with Z-circled label and no label, respectively]. We use a subscript t in the notations \({\bar{{\mathcal{D}}}}_{Z,t}\) and \({\bar{{\mathcal{D}}}}_{I,t}\) to indicate that the qubits belonging to these two subsets depend on the time step t. Note that we suppress the identity factors outside of \({\mathcal{D}}\) and its adjacent domains. In particular, by restricting this operator to domain \({\mathcal{D}}\), we have the following persistent stabiliser-product symmetry:
which implies that the error syndrome obeys a conservation law in the domain \({\mathcal{D}}\): the syndrome comes in pairs along this strip. At each subround, there also exists a similar symmetry on the shaded domains, which is formed by the product of B-type plaquettes. Therefore, for the pure Z Pauli noise model, we can perform minimum-weight perfect matching decoding within each domain.
To explain this more concretely, we use the anyon picture. These anyons, shown in Fig. 2a, are interpreted as having locations given by the detectors that would be flipped if the corresponding error were to occur at that time step. For example, if the Z error shown in Fig. 2a occurs just before the green B-check measurements (top-left panel of the figure), it will trigger a red A detector after two measurement subrounds and a blue A detector after a further two subrounds. As a result of each of the symmetries, Pauli-Z errors create anyons in pairs along each vertical strip. An example of such anyons, which are formed due to a Pauli Z error at a particular measurement subround, is shown in Fig. 2a. While the plaquette locations of the anyons, triggered by the Z error occurring on the same qubit, change every other subround, they always respect the symmetry, i.e., are aligned along the domain (see Fig. 2).
Unlike the symmetry in static stabiliser codes, this stabiliser-product symmetry does not allow for 1D decoding even when measurement errors are absent. While in static codes, only measurement errors produce “time-like” edges, in Floquet codes, even Pauli errors produce time-like edges (between detectors formed at different times). To demonstrate this, we display in Fig. 3 a portion of the A-type detector graph under infinitely phase-biased single-qubit noise with no measurement errors. As can be seen, there is a disconnected subgraph defined along one unshaded domain of the code lattice. Even considering this simple noise model, the decoding graph in the infinite bias regime is two-dimensional (i.e., the graph is planar). This results from the fact that neighbouring plaquettes are measured at different times. We emphasise that although the above discussion is based on Z errors, the same analysis also holds for X errors because X and Z operators are interchangeable for the X3Z3 code. As a result, the performance of the X3Z3 code under X-biased noise is expected to be the same as that under the Z-biased noise model.

Only a single vertical strip [e.g., that supporting the stabiliser-product symmetry in Fig. 2b] is shown. The illustrated part of the graph is disconnected from those of neighbouring strips. Arrows represent only the A-type measurements. The B-type subrounds are not shown, since they do not influence the detectors in this graph. Each node (representing a detector) is placed in the centre of a plaquette and at the subround in which the corresponding detector is formed. For example, the bottom layer corresponds to the blue A-check measurements, at which time the red A-type plaquettes are measured.
Bias-preserving parity-check circuits
While two-body measurements are native to certain architectures, for example, Majorana10,62,63 and photonic17,64 platforms, most architectures require quantum circuits to carry out such measurements. To maintain the high-performance of bias-tailored codes in these hardware, the parity-check measurement circuits need to be constructed in a phase-bias preserving manner, such that they do not propagate frequently-occurring errors to rarely-occurring errors. To this end, we design two-qubit parity check circuits that preserve the Z bias on data qubits. That is, the probability of X and Y errors on data qubits after these circuits remains small (proportional to single-qubit X or Y error probabilities). Our bias-preserving parity check measurement circuits are constructed by using an ancilla circuit connecting two data qubits, which can be realised even in devices with minimal connectivity, such as the heavy-hexagonal layout56,57.
For a circuit to be bias preserving, it can be constructed using only gates that do not change the error type under conjugation. For example, one way to construct bias-preserving circuits is to use only CNOT gates in the measurement circuits as they only propagate errors to others with the same Pauli type. For the X3Z3 code, we need to construct bias-preserving circuits for three different kinds of parity checks: ZZ, XX and ZX. All these three circuits can be constructed using only CNOT gates as shown in Fig. 4. As depicted, these circuits also include resets and measurements of the ancilla qubit in the three Pauli bases, i.e., Z, X and Y bases for ZZ, XX and ZX checks, respectively. Note that the circuits are still phase-bias-preserving even if the resets/measurements in the X and Y bases are compiled in terms of resets/measurements in the Z basis with additional single-qubit Clifford gates. This is because a Z error on any qubit at any time step in the compiled circuits still propagates to data qubits as a Z error, or as a check operator about to be measured.

For the circuits to be bias-preserving, the CNOT gates in the circuits need to be also bias-preserving. Shown are the circuits for (a) Z1Z2, (b) X1X2, and (c) Z1X2 checks circuits, where the ancilla qubit is reset and later measured in the Z, X and Y bases, respectively.
The parity-check circuits shown in Fig. 4, however, may not preserve the noise bias if errors happen during the CNOT gates. This is because a Z error occurring on the target qubit during the application of a conventional (non-bias preserving) CNOT gate may result in a combination of Z and X errors on the target qubit after the CNOT gate58. One way to remedy this problem is to use bias-preserving CNOT gates58. These gates, however, are available only in specific platforms such as cat qubits. Here, we propose a more general approach to constructing Z-bias preserving parity check circuits without requiring the bias-preserving gates. While our proposed circuits can preserve only a specific type of noise bias, i.e., the Z bias, these circuits are built using conventional (which may not be phase-bias preserving) two-qubit gates and thus can be implemented in many different architectures.
Our proposed phase-bias preserving parity-check circuits are depicted in Fig. 5. For the ZZ and ZX check measurement circuits, they are constructed using either CZ gates or CNOT gates targeting ancilla qubits, which propagate Pauli errors on the ancilla qubits only as Z errors on the data qubits. In other words, these circuits do not leave any residual Pauli X or Y errors occurring with probability \({\mathcal{O}}({p}_{Z})\) and therefore do not degrade the Z noise bias on the data qubits. This is true even if we consider mid-gate Pauli errors (see Supplementary Sec. II in the Supplementary Information61 for details). The XX measurement circuit shown in Fig. 5b, however, is not fully Z-bias preserving in the presence of mid-gate errors. This circuit degrades the Z bias on one of the data qubits, i.e., the data qubit that is the target of the classically-controlled X gate. (Note that instead of implementing the classically controlled X gate, we may alternatively perform a CNOT gate, with the control being the ancilla qubit and target being data qubit 1, immediately preceding the ancilla measurement). However, since the XX parity-check circuit shown in Fig. 5b degrades the Z-bias on only one data qubit, it has a better Z-bias-preserving performance compared to the XX check circuit in Fig. 4b, which degrades the Z-bias on both data qubits due to the fact that both data qubits are used as target qubits of the CNOT gates in the circuit.

Shown are (a) ZZ, (b) XX, and (c) Z1X2 check circuits. The circuits in (a) and (c) preserve the Z noise bias on data qubits even in the presence of mid-gate errors. The circuit in (b) includes a classically controlled X gate targeting one of the data qubits, which is non-Z bias preserving. Data qubits are labelled by Data1 and Data2, while the middle qubit in each circuit is a measurement ancilla. In (c), the first equality can be checked by noting that the depth-3 circuit before and after the mid-circuit measurement performs a next-nearest-neighbour CZ gate, if the measurement ancilla is initially in the \(\left\vert +\right\rangle\) state. The second equality can be checked by commuting all gates past the measurement. The grey measurements can be optionally included to provide flag information.
We now elaborate on how the parity-check circuits work. We begin by noting that while the ZZ parity check measurements [Fig. 5a] are performed by reading out the ancilla qubits like in standard syndrome extraction circuits, the XX and ZX parity values [Fig. 5b, c] are obtained by measuring the data qubits after some two-qubit gates are applied on them. These two-qubit gates are required for the parity measurements so as not to reveal each individual data qubit’s state. For the XX parity-check circuit, the two mid-circuit X-measurements in Fig. 5b, are equivalent to reading out the X1Xa and X2Xa parity values, where the Pauli operator Xa acts on the ancilla qubit which is prepared in the \(\left\vert 0\right\rangle\) state. Hence, the product of these two measurement outcomes is the required X1X2 parity check outcome. We can disentangle the ancilla qubit by performing a final Za measurement (which requires correcting a potential bit flip on one of the data qubits with the classically controlled X gate), or by using a CNOT gate (not shown) before the Za measurement (see Supplementary Sec. II of the Supplementary Information61 for details).
The mixed-type Z1X2 parity circuit can be constructed using CZ gates between the data qubits, as shown in Fig. 5c. If the connections between the data qubits are not available in the device such as in hardware with a heavy-hexagonal lattice, these CZ gates have to be implemented using ancilla qubits in-between the data qubits. We show such an implementation of next-nearest-neighbour CZ gates in the first equality of Fig. 5c (this is adapted from ref. 56). This circuit also includes optional measurements, coloured in grey, which provide “flag information” for detecting Z errors on the ancilla qubit that may have propagated to the data qubits. Such flag measurements can assist in decoding57. In the second equality of Fig. 5c, we reset the ancilla qubit in the \(\left\vert 0\right\rangle\) state instead of the \(\left\vert +\right\rangle\) state, allowing for a shorter-depth circuit to implement the Z1X2 measurement. This comes at the cost of removing one flag measurement. To see that this circuit works as intended, we can commute the two-qubit gates past the X2 measurement, resulting in a Z1ZaX2 parity measurement. From the result of this measurement, together with the fact that Za value is set to be +1 at the ancilla reset, we can then infer the value of Z1X2.
We emphasise that, even if the X measurements in the parity-check circuits above are implemented using Z measurements sandwiched by Hadamard gates, this does not degrade the bias, since a Z error occurring between those Hadamard gates is harmless. Specifically, a Z error happening before the measurement is immediately absorbed by the Z measurement without flipping its outcome, and a Z error after the measurement is a stabiliser of the state (up to a sign), so does nothing. Moreover, the circuit will not change the noise bias significantly even if the Hadamard gates are noisy, since in many architectures, the single-qubit gate errors are not the predominant error source and are usually much smaller than the two-qubit gate errors65,66,67,68.
In Supplementary Sec. II of the Supplementary Information61, we show in more detail how the parity check circuits preserve the noise bias. We also show that the phase-bias preserving parity-check circuits presented in this paper have optimal circuit depth.
Memory experiment simulation
To study the performance of our proposed X3Z3 code, we perform quantum memory experiment simulations under two biased noise models. These noise models are the generalisations of the standard code-capacity and standard depolarising entangling measurement (SDEM3) noise models (see the Methods section for details of the noise models). We simulate the X3Z3 code along with three other codes: CSS, P6 and XYZ2 Floquet codes, with varying degrees of noise bias η (see the Methods section for details of our numerical simulations). The noise bias η = pZ/(pX + pY) is defined as the ratio of the Z-error pZ to other errors where the total physical error rate is p = pX + pY + pZ. As the noise asymmetry increases, the noise bias η increases from η = 0.5, which corresponds to fully depolarising noise (pX = pY = pZ = p/3), to η = ∞, corresponding to a pure Z-biased noise (pZ = p, and pX = pY = 0).
Thresholds
Figure 6 shows the thresholds of all codes for various levels of noise bias η calculated for (a) code-capacity and (b) SDEM3 noise models. Each threshold is obtained from the intersection of the logical failure probabilities pL vs physical error rate p curves of different code distances deff ≡ d/2 = 6, 8, 10, and 12. Here, the effective distance deff is defined as the minimum number of faults under SDEM3 depolarising noise that produce a logical error. This is half of the distance d of the code-capacity noise model. For the methods and plots used to determine the thresholds, see the Methods section and Supplementary Figs. 5–8 of the Supplementary Information61. We also provide the threshold data in ref. 69.

Codes studied are X3Z3 (blue), CSS (green), P6 (red) and XYZ2 (orange). Results are computed for two different noise models: (a) code-capacity and (b) SDEM3. a Inset: Zoom-in threshold plots for the P6 (red) and XYZ2 (orange) codes. For better visualisation, we fit all curves with quadratic splines.
Since the code-capacity noise model, which considers only single-qubit noise, is a more benign model than the SDEM3 noise model, which also includes two-qubit and measurement errors, the code performance calculated under the code-capacity noise is better than that of the SDEM3 noise. For both noise models, as shown in Fig. 6a, b, the performance of the X3Z3 code becomes increasingly better than those of all other tested codes as the noise bias increases. In particular, as the noise changes from fully depolarising to a pure dephasing type, the X3Z3 Floquet code’s threshold increases from ≈ 1.13% to ≈ 3.09% for the code-capacity noise and from ≈ 0.76% to ≈ 1.08% for the SDEM3 noise model. The threshold therefore increases by a factor of 2.7 and 1.4 for the code capacity and SDEM3 noise models, respectively.
It is interesting to note that for the fully depolarising code-capacity noise, all codes have the same threshold. This is because at every measurement subround under this noise model, all the above codes have two types of errors at each fault location (occurring with a total probability 2p/3) that give rise to edges in the detector graph and one type (occurring with probability p/3) that produces hyperedges. For the CSS and X3Z3 codes, these hyperedges result from Y Pauli errors. On the other hand, the hyperedge errors in the P6 and XYZ2 codes are those that anti-commute with the check measurements that occur just before and immediately after the errors12,22. Therefore, the Pauli type of the hyperedge errors for the honeycomb codes varies between measurement subrounds. For example, Z errors create hyperedges only when they occur between the XX and YY checks of the honeycomb codes. In summary, all the above codes have the same performance for fully depolarising code-capacity noise because their (weighted) detector hypergraphs are all equivalent.
As shown in Fig. 6a, b, while the CSS Floquet code has the same threshold as the X3Z3 code when the noise is fully depolarising, its threshold decreases with increasing noise bias, where its value is 0.752% and 0.668% at infinite bias for the code-capacity and SDEM3 noise, respectively. This decrease is due to the fact that the CSS Floquet code has pure X and pure Z detectors where in the presence of biased noise, half of the detectors, i.e., those with the same type of the dominant error, will become less useful in detecting the biased errors.
Figure 6a, b shows that the thresholds for the honeycomb codes have only minor improvements as the noise bias increases, where the thresholds for both honeycomb codes increase only by ≤6 × 10−4. Specifically, the thresholds of the honeycomb codes at η = ∞ are only about 1.03 − 1.08 times larger than their thresholds at η = 0.5 (where their fully-depolarising noise thresholds are 1.13% and 0.585% for the code-capacity and SDEM3 models, respectively). We note that for the SDEM3 noise, the thresholds of both honeycomb codes are lower than those of the X3Z3 and CSS Floquet codes at all noise biases. This is partly explained by noting that the SDEM3 noise model contains measurement errors which give rise to hyperedges in the decoding hypergraphs of the honeycomb codes12 but only graph-like edges for the CSS and X3Z3 Floquet codes13. As we explain below, these hyperedges degrade the MWPM decoder performance.
We find that there are differences, albeit modest ones, between the performance of the XYZ2 and P6 honeycomb codes under biased noise; these differences have not been pointed out before in the literature. While the XYZ2 honeycomb code has a better performance than the P6 honeycomb code for the code-capacity noise model, we find that its performance is inferior to that of the P6 Floquet code for the SDEM3 noise model. This is surprising, considering the similarity of the former to the bias-tailored XYZ2 static code49. However, owing to stabilisers being measured in two measurement subrounds, the XYZ2 Floquet code no longer possesses all the symmetries of the static version making the dynamical code not able to inherit all the benefits of its static counterpart.
The performance difference between the XYZ2 and P6 honeycomb codes can be understood from the distribution of hyperedge-like syndromes (namely, those with four triggered detectors) in the detector hypergraphs under the biased SDEM3 noise model. These hyperedges generally degrade the code’s performance when using a matching decoder since they must be decomposed into edges (see ref. 12 for a detailed description of the decoding in a hyperbolic version of the honeycomb code). An infinitely phase-biased SDEM3 noise model that includes Pauli noise but no measurement errors can already form hyperedges in the honeycomb codes’ detector hypergraphs. In particular, the P6 code can have hyperedges resulting from Z errors occurring only after the red check measurement subrounds, while the hyperedges in XYZ2 code can result from certain Z errors happening in any subround. While there is no difference in the overall number of hyperedges resulting from single-qubit Z errors in the two hypergraphs, the different arrangement of the hyperedges due to the single-qubit errors in these two codes gives rise to different kinds of syndromes for the two-qubit ZZ errors. Specifically, ZZ errors can lead to hyperedge syndromes in the XYZ2 Floquet code but only edge-like syndromes for the P6 code (see Supplementary Sec. IV of the Supplementary Information61 for details). As a result, in an infinitely phase-biased regime, where Pauli errors after MPP gates are evenly distributed between Z1, Z2 and Z1Z2, there are more hyperedge syndromes triggered in the XYZ2 code than in the P6 code. This is the reason underlying the difference in the thresholds, as shown in Fig. 6b, of the two honeycomb codes under the SDEM3 noise. Since honeycomb codes are prone to hyperedge errors, better performance of the honeycomb codes might be expected using a correlated MWPM decoder such as the one used in ref. 8.
Subthreshold performance
As a result of the shift of the thresholds with the noise bias, the subthreshold performance of the codes changes accordingly. As shown in Fig. 7a, b, the subthreshold logical failure probability improves significantly for the X3Z3 code, while it becomes only slightly better for the honeycomb codes and deteriorates for the CSS code. In general, one expects the subthreshold performance of the codes to improve by increasing the code distance along the direction where the biased errors most likely form logical strings. For example, for the Z biased noise considered here, it would be by increasing the vertical code distance dV. To this end, we study the subthreshold performance of elongated CSS and X3Z3 Floquet codes with dV > dH, where dV and dH are the vertical and horizontal code distances, respectively. The details are given in Supplementary Sec. V of the Supplementary Information61.

Codes studied are X3Z3 (blue), CSS (green), P6 (red) and XYZ2 (orange). Results are computed for two different noise models: (a) code-capacity and (b) SDEM3. Inset: Zoom-in subthreshold performance plots of the P6 (red) and XYZ2 (orange) codes. Results are calculated using (a) lattice size 20 × 30 (d = 20) for 30 QEC rounds with p = 0.72% and (b) lattice size 24 × 36 (deff = 12) for 36 QEC rounds with p = 0.5%. Each data point is averaged over 106 − 108 Monte Carlo shots. For better visualisation, we fit all curves with quadratic splines. For each of the noise models, we choose the largest code distance and the smallest subthreshold physical error rate that can be simulated given our computational resources.
Besides thresholds, another quantity of importance is the scaling of the code sub-threshold performance with the code distance. We plot the sub-threshold logical failure probability as a function of d or deff for varying levels of noise bias in Fig. 8. As shown, the logical failure probabilities for all codes decrease exponentially with the code distance, i.e., \({p}_{L}\propto \exp (-\gamma d)\) or \({p}_{L}\propto \exp (-\gamma {d}_{{\rm{eff}}})\). Among all codes presented, the X3Z3 code has the largest logical error suppression rate γ. At higher noise bias, this error suppression rate becomes significantly larger for the X3Z3 code, moderately increases for the two honeycomb codes and decreases for the CSS Floquet code. The reason is that as the noise bias increases, a fixed subthreshold physical error rate moves relatively with respect to the shifting threshold, so that it becomes much further below the threshold for the X3Z3 Floquet code, moves moderately away from the threshold for the two honeycomb codes and becomes closer to the threshold for the CSS code [see Fig. 6a, b].

We use code distances d or deff depending on the noise model and compare different Floquet codes: CSS (green), XYZ2 (orange), P6 (red), and X3Z3 (blue). Results are calculated for different noise models: (a, b) code-capacity and (c, d) SDEM3 noise models, with a subthreshold physical error rate p = 0.55%, which is small enough, yet can still be simulated using our computational resources up to code distance d = 24 or deff = 12, for all the different codes and parameters corresponding to different curves in the plots. The same physical error rates are chosen for all curves such that the subthreshold performance under different noise bias strengths and noise models can be compared. Plots are computed using two different bias strengths; one representing noise near the depolarizing regime: (a,c) η = 1 and the other representing noise in the strongly dephasing regime: (b, d) η = 99. All curves can be fitted to an exponential decay function \(f\propto \exp (-\gamma d)\) or \(f\propto \exp (-\gamma {d}_{{\rm{eff}}})\) where γ depends on the bias strength η and is an increasing function of (pth − p). Each data point is averaged over 105 − 109 shots.
We also numerically simulate the performance of the X3Z3 Floquet code with a twisted periodic boundary condition. This twisted code has a pure Z-type logical operator with a length that scales quadratically with the code distance of the untwisted code. As a result, we find better thresholds and more favourable subthreshold performance for the twisted code over the untwisted one. While these performance benefits hold for the infinite-bias code-capacity noise, they do not apply to other noise biases and models tested (See Supplementary Sec. VI of the Supplementary Information61 for details).
While in this paper, we focus on Floquet codes with periodic boundary conditions, we expect similar qualitative performance of the Floquet codes under open boundary conditions. As shown in ref. 9 for the honeycomb code with depolarizing noise, the boundary conditions (whether periodic or open) do not significantly impact the threshold and subthreshold performance of the code. This should be expected even more so for the CSS and X3Z3 Floquet codes, because the boundary condition does not affect the measurement schedule for the codes. We leave the simulations of the codes under open boundary conditions to future works.
The error suppression rate γ is related to the error suppression factor Λ introduced in ref. 70 which is defined as the reduction factor in the logical failure probability as the code distance increases by 2. Mathematically, it is given by
for the code-capacity noise and similarly for the SDEM3 noise model, but with d replaced by deff. For a noise model where the error is characterised by a single error rate p and threshold value pth, when p ≪ pth, QEC suppresses the logical error exponentially as the code distance increases, i.e., \({p}_{L}\approx {(p/{p}_{{\rm{th}}})}^{d/2}\). Since Λ ≡ pL(d)/pL(d + 2), we then have Λ ≈ pth/p. At the thresholds, we have Λ(pth) ≈ 1. The value of Λ increases as the physical error rate p moves further below the threshold pth. For physical error rate below the threshold, Λ > 1 and larger Λ means greater error correction. Since the threshold depends on the noise bias η, Λ depends on both η and p. In Table 1, we list the values of Λ corresponding to the γ values shown in Fig. 8.
Performance optimality of X3Z3 Floquet code and no-go theorems
As seen above, although the performance of the X3Z3 Floquet code is significantly better compared to other Floquet codes, its threshold under infinitely phase-biased code-capacity noise does not reach the 50% threshold of its bias-tailored static version46. To explain this, we show that there are fewer symmetries in the decoding graphs of dynamical codes, which restricts the code performance. The key feature resulting in the high performance of bias-tailored static codes (i.e., their decoding can be understood as decoding a series of repetition codes39,40,42,46) is not possible for dynamical codes built from two-qubit parity measurements, as we will show below.
We argue that due to the above limiting constraint, the symmetry of the X3Z3 Floquet code has likely rendered its performance close to optimal under a matching decoder, despite the fact that even for the most favourable case of infinitely phase-biased code-capacity noise, its decoding can only be reduced to at most a series of disjoint 2D (planar) graphs. We formalise this by proving two no-go theorems for the decoding graphs of dynamical codes. We begin with the following informal statement of our first theorem:
Theorem 1
(Informal) A dynamical code (not necessarily a Floquet code) on the honeycomb lattice operated over a sufficiently large number of time steps cannot have a 1D decoding graph under an infinitely biased code-capacity noise model, so long as it obeys the following properties:
-
(a)
At each time step, two-body Pauli operators on edges of a given colour are measured. Measurements in consecutive time steps occur on edges of different colours and anti-commute.
-
(b)
Detectors are supported on plaquettes.
-
(c)
All non-trivial errors are detectable and produce syndromes of weight > 1.
In principle, a 1D graph [such as the one shown in Fig. 9a] could still result in better code performance than a general planar decoding graph. The fact that this type of graph is not possible suggests that planar graph decoding is already optimal for dynamical codes on the honeycomb lattice.

We display examples of the decoding graphs (under an infinitely biased code-capacity noise model; edges correspond to Z errors and vertices to detectors) that are forbidden by (a) Theorem 1 for dynamical codes on the honeycomb lattice and (b) Theorem 2 for general dynamical codes.
To generalise this result beyond codes defined on the honeycomb lattice, we provide the following theorem for general dynamical codes built from two-qubit parity measurements.
Theorem 2
(Informal) A dynamical code (not necessarily a Floquet code) operated over a sufficiently long time scale cannot have a decoding graph, under an infinitely biased code-capacity noise model, equivalent to that of a collection of repetition codes [see Fig. 9b], so long as: all measurements are two-qubit parity measurements, each qubit is in the support of one measurement in each time step, overlapping measurements in consecutive time steps anti-commute, and errors produce syndromes of weight > 1.
This theorem shows that (given reasonable and typical assumptions) the decoding graphs of general dynamical codes cannot be decomposed into a collection of 1D repetition-code decoding graphs, which could otherwise allow them to achieve higher thresholds.
We provide the formal statements of the above two theorems and their proofs in the Methods section. We display the decoding graphs prohibited by the above two theorems in Fig. 9.
Discussion
In this paper, we introduce the X3Z3 Floquet code, the first bias-tailored dynamical code based on two-qubit parity check measurements. We show that, despite having no constant stabilisers, the code possesses a persistent stabiliser-product symmetry under pure dephasing (or pure bit-flip) noise which allows for a simplified decoding. This results in a substantially improved threshold and sub-threshold performance under biased noise, when compared to other Floquet codes. We demonstrate the enhanced performance through our simulation results obtained from using a fast matching decoder and two error models: a simplistic code-capacity noise model and a noise model approaching realistic circuit-level errors. Besides the superior performance of the X3Z3 Floquet code, our results also show that there are differences, albeit modest ones, in the threshold and subthreshold performance between the XYZ2 and P6 honeycomb codes under biased noise.
To explain why the X3Z3 Floquet code does not reach the same high performance as the bias-tailored static codes, we prove that a dynamical code on the honeycomb lattice (obeying certain assumptions common to standard Floquet codes) cannot have a 1D decoding graph, the crucial requirement for the high performance of static codes. Despite this limitation, the bias-tailored X3Z3 Floquet code has the advantage over its static counterpart in that it requires only lower-weight measurements. Specifically for devices without native two-qubit parity measurements, we devise phase-bias preserving parity check measurement circuits for any qubit architecture, which allow for high-performance implementation of the code. Our work therefore demonstrates that the X3Z3 Floquet code is a leading quantum error correction code especially for devices with limited connectivity such as the hexagonal and heavy-hexagonal architectures.
We now give several directions for future work. Since the decoding of any general Floquet codes with two-qubit parity measurements can be reduced, at most, to a 2D decoding problem, it would be interesting to investigate the performance improvements of the X3Z3 Floquet code using a more accurate decoder (such as a tensor network decoder) and to consider ways to analytically derive the best achievable thresholds for the X3Z3 Floquet code. Future studies may also investigate fault-tolerant logic in the X3Z3 code, via lattice surgery7, aperiodic measurement sequences21, twist braiding71, or transversal gates72. Finally, it will be of interest to study the performance of memory experiments and fault-tolerant logical gate implementations in hardware where parity checks are implemented using bias-preserving circuits such as the circuits presented in this paper and compare them to the performance in hardware with native direct multi-Pauli product measurements.
Methods
Noise models
In this paper, we consider two noise models: code-capacity and entangling measurement (SDEM3) noise models. In the code-capacity noise model, we apply single-qubit Pauli noise on all the data qubits independently at every measurement subround. The single-qubit Pauli noise channel is given by
Here, p ≡ pX + pY + pZ is the total error probability. As in the literature, we define the noise bias as η = pZ/(pX + pY) and assume pX = pY. Several values of η are worth listing:
-
1.
η = 0 → pZ = 0, and pX = pY = p/2,
-
2.
η = 0.5 → pX = pY = pZ = p/3,
-
3.
η = ∞ → pZ = p, and pX = pY = 0.
We note that, since for Floquet codes one QEC round consists of several measurement subrounds, the single-qubit noise channel in the code-capacity model is applied several times in one QEC round instead of just once as is the case with static codes. The code-capacity noise model is often used as a preferred initial noise model to study before going to a more involved model as its simplicity often offers insight into understanding the code performance.
On the other hand, the SDEM3 model is a more elaborate error model involving single-qubit noise channels after every single-qubit gate, measurement and reset, a two-qubit noise channel after every multi-Pauli product (MPP) parity measurement gate, and a classical flip after each measurement. As in ref. 9, we assume that each of these error channels occurs with a total probability p. The SDEM3 noise model is therefore close to standard circuit-level noise and would be a more accurate description of a realistic noise channel, particularly in hardware with native two-qubit measurements, for example, Majorana10,62,63 and photonic17,64 architectures.
To take into account biased noise, we generalise the SDEM3 model for depolarising noise used in refs. 9,15. Here, the single-qubit noise channel has the same form as given in Eq. (5) for the code-capacity noise model. On top of the single-qubit errors, this model also has a two-qubit noise channel applied after each of the MPP gates, which is given by
To conform with how the bias is defined for the single-qubit noise channel, we also use η to characterize the bias of the two-qubit noise channel. Specifically, we define the bias η for the two-qubit noise channel such that
-
1.
η = 0 → pZZ = pIZ = pZI = 0 and each of the other probabilities is p/12,
-
2.
η = 0.5 → each of the Pauli errors occurs with p/15, and
-
3.
η = ∞ → pZZ = pIZ = pZI = p/3, and the other probabilities are 0.
Just as for the single-qubit noise, the above definition of η ensures that the two-qubit noise at the three special points, η = 0, η = 0.5 and η = ∞, are Z-error free, depolarising, and pure dephasing, respectively. Given that the two-qubit error probabilities at these η values must satisfy the conditions above, we define ζ ∈ [0, 1] and write the two-qubit Pauli error probabilities as
with η and ζ related via:
Note that Eq. (7) is defined such that the total probability of all the Pauli errors \({\sum }_{O\in {\{I,X,Y,Z\}}^{\otimes 2}\backslash \{I\otimes I\}}{p}_{O}=p\) for all noise biases η. Apart from the single- and two-qubit Pauli noise channels, we also apply a classical flip of the measurement results with probability p after each of the single and two-qubit measurements. These measurement flips are uncorrelated with the single and two-qubit noise channels. We summarise the description of the SDEM3 noise model and its noisy gate set in Tables 2 and 3, respectively.
Stabiliser circuits
We simulate the circuits and generate the error syndromes using Stim73; example Stim circuits are provided at ref. 69. We construct Stim circuits from various quantum operations (resets, measurement gates, etc.) with noise channels associated with each quantum operation (i.e., with error probabilities set by the noise models introduced above), detectors and logical observable updates. From these circuits, Stim can generate the detector error models which list the error mechanisms, the associated syndromes, and the logical observables flipped by the errors. A detector error model is fed to the decoder which then predicts the most likely error based on a given syndrome. We refer the reader to ref. 73 for more details on Stim.
MWPM decoder
To decode the error syndromes, we apply a minimum-weight perfect matching (MWPM) decoder74, which is implemented using PyMatching60. The syndrome decoding is mapped by the MWPM decoder onto a graph problem, which is subsequently solved by utilizing Edmonds’ algorithm75,76 for finding a perfect matching which has minimal weight, i.e., finding a minimum-total-weight set of edges, for which every vertex is incident to exactly one edge77.
Details of numerical simulations
Our simulations are performed for four different Floquet codes using different values of physical error rates p and various strengths of noise bias η. Moreover, we consider two different noise models: code-capacity and SDEM3 noise models. For each code, the simulations are run with effective distances deff ≡ d/2 = 4, 6, 8, 10, 12, where the effective distance deff is defined as the minimum number of faults under SDEM3 depolarising noise that produce a logical error. This is half of the distance d of the code-capacity noise model. The calculated effective distance differs between noise models since in the SDEM3 noise model, two-qubit errors occurring after an MPP parity gate count as a single fault, while under the code-capacity noise model they would count as two faults.
We choose lattices with periodic boundary conditions. For most simulations, we choose lattice sizes L × 3L/2, where L = d = 2deff is the lattice length which varies with respect to the code distance. We choose lattice sizes L × 3L/2 such that the horizontal and vertical code distances are the same, as can be inferred from the minimum weight of the horizontal and vertical logical operators (see e.g., Fig. 1(c) for lattice length L = 4). We simulate the memory experiments for 3deff QEC rounds or 18deff measurement subrounds (1 QEC round consists of 6 measurement subrounds). For Supplementary Sec. V of the Supplementary Information61 where we study elongated codes, we use lattice sizes of dH × 3dV/2 where dV ≥ dH. Here, dH and dV are the minimum weights of the logical operators in the horizontal and vertical directions, respectively. We simulate the horizontal and vertical logical memory experiments for 3dH/2 and 3dV/2 rounds, respectively.
We select a single logical qubit for each Floquet code (they all encode two logical qubits on a lattice with periodic boundary conditions) to test for the logical failure probability. Depending on the codes and parameter regimes, we run different numbers of Monte Carlo shots ranging from 105 − 1010 (larger number of shots for longer code distances and smaller physical error rates) for each of the horizontal and vertical logical observables, which give us the horizontal pH and vertical pV logical failure probabilities. We then report the combined logical error probability:
which is an estimate of the probability that either a vertical or a horizontal logical error occurs. Equation (9) assumes that the horizontal and vertical logical errors occur independently. For the infinitely phase-biased code-capacity noise model, one of the logical errors which is of pure Z-type or pure X-type has zero logical error probability, because the pure biased noise cannot form the other logical operator which is of mixed-type and hence cannot flip the pure-type logical operator. As a result, for the infinitely phase-biased code-capacity noise, the maximum combined logical error probability is pL = 0.5 [Eq. (9)]. This is in contrast to other noise biases and models where the maximum combined logical error probability is pL = 0.75 since pV, pH ≤ 0.5.
Determining the thresholds
To extract thresholds of the codes, we perform a finite-size collapse78,79 of the logical failure probability pL data taken for various physical error rates p and code distances. This is done by fitting the data to the curve A + Bx + Cx2 where x = (p − pth)d1/ν or \(x=(p-{p}_{{\rm{th}}}){d}_{{\rm{eff}}}^{1/\nu }\) for the code-capacity and SDEM3 noise models, respectively. Here, ν is the critical exponent, pth is the Pauli threshold, A, B, C are the fit parameters, d and deff are code distances under the code-capacity and SDEM3 noise models, respectively. This data is presented in Supplementary Figs. 5–8 of the Supplementary Information61.
No-go theorems for 1D decoding graphs of dynamical codes
Here, we provide formal statements and proofs for the two no-go theorems presented in the Results section. To this end, we begin by providing several definitions.
Definition 1
Let V be a set of detectors for a dynamical code. For every qubit and every time step (q, t), i.e., every fault location in the code, define a hyperedge e(q, t) = (v1, v2, …), where the vi ∈ V are detectors that return − 1 outcomes if a single Z error occurs at the fault location (q, t). The Z-detector hypergraph (ZDH) is defined as G = (V, E), where E = ⋃q,te(q, t) is the set of all hyperedges. A Z-detector graph (ZDG) is a Z-detector hypergraph in which all hyperedges are edges (their size is 2).
Definition 2
A 1D-decodable Z-detector graph is one in which all vertices have neighbourhoods of size no greater than 2.
Finally, we define dynamical codes on the honeycomb lattice in the following way:
Definition 3
A honeycomb dynamical code (HDC), with “duration” T and constant “initial(final)-time boundary offsets” ti (tf), is a finite-depth measurement circuit acting on qubits of the honeycomb lattice (without boundary). The sets of measurements in the circuit, \({{\mathcal{M}}}_{t}\) (t ∈ {1, …, T}), are composed of two-body Pauli measurements along coloured edges (either r, g, or b, for each time step) of the lattice, performed sequentially on a state stabilised by some group \({\mathcal{S}}\). The HDC obeys the following properties:
-
(a)
Overlapping measurements in consecutive time steps anti-commute and are supported on different edges.
-
(b)
Detectors (for time steps t > ti) are associated with plaquettes in the lattice (they have support only on qubits around their associated plaquette).
-
(c)
If a single-qubit or two-qubit error occurring in time steps ti < t < T − tf anti-commutes with future measurements, it is detectable, unless the two-qubit error is the same as an edge operator just measured or to be measured in the next time step.
-
(d)
All single-qubit errors in time steps ti < t < T − tf have syndromes of weight > 1.
Let us first comment on our definition of an HDC. The chosen properties are very natural. The anti-commutation of consecutive measurement subrounds ensures “local reversibility” of the code, so as to preserve the quantum information and its locality80 (although note that we do not require the code to have logical qubits in our definition). The requirement that consecutive sets of measurements are supported on different edges is not very restrictive: if two (anti-commuting) measurements act on the same edge in consecutive time steps, we can replace the second with a Clifford gate and commute that to the end of the circuit. This merely changes the bases of subsequent measurements without changing their (anti-)commutation. Since the Clifford gates are unimportant, we can ignore them and hence we end up with a shorter duration T. We restrict our attention to errors occurring in the temporal “bulk” of the code, ti < t < T − tf. This avoids complications due to errors occurring close to the initial and final-time boundaries where detectors here may be formed in different ways than the bulk detectors. Specifically, the detectors associated with errors at the initial and final time boundaries are obtained by comparing the edge or plaquette measurement values with the initial state and final read-out of the physical qubits, respectively. The exclusion of these final time boundary detectors is also required here since we do not include final read-out measurements in our definition of an HDC. In summary, we consider errors occurring in all “detection cells”13 that are completed before time step T and begin at time step t ≥ 1, where a detection cell consists of all the spacetime points at which a detector can identify errors.
We will show that an HDC cannot even have a 1D-decodable ZDG, which implies that its decoding graph cannot be equivalent to a collection of the much simpler repetition code’s graphs. Note that a repetition code graph is not only 1D-decodable but also has a maximum degree of 2, which means there are no double edges between neighbouring vertices. Here, however, we allow for these double edges in our definition of 1D-decodability, and show that this more general property is also impossible. Such double edges naturally arise in Floquet codes, where they correspond to two-qubit undetectable errors (i.e., edge operators just measured or about to be measured).
We begin by first proving the following lemma which is going to be used in the proof of Theorem 1.
Lemma 1
In a honeycomb dynamical code, at each time step t > 1, no detectors can be formed on neighbouring plaquettes.
Proof
Without loss of generality, suppose neighbouring plaquettes F1 and F2 are coloured red and blue, respectively. Suppose, for the sake of contradiction, that they both host detectors at a time step t > 1. Let \({{\mathcal{D}}}_{1},{{\mathcal{D}}}_{2}\subset {{\mathcal{M}}}_{t}\) be the sets of check measurements from \({{\mathcal{M}}}_{t}\) whose products around the plaquettes F1 and F2, respectively, form the detectors at the corresponding plaquettes at time t. That is, the measurements in \({{\mathcal{D}}}_{j}\) act only on qubits around Fj. Since at every time step, only edges of one particular colour are being measured and green edges are shared by blue and red plaquettes, the measurement set \({{\mathcal{M}}}_{t}\) at time t can contain only measurements on green edges. Otherwise, either \({{\mathcal{D}}}_{1}\) or \({{\mathcal{D}}}_{2}\) would have to be empty or they would include measurements on qubits not adjacent to F1 or F2, respectively, which is not allowed by the definition of \({{\mathcal{D}}}_{1}\) and \({{\mathcal{D}}}_{2}\).
To form detectors at both plaquettes, we require that, for all \(M\in {{\mathcal{M}}}_{t-1}\), \([M,{\prod }_{D\in {{\mathcal{D}}}_{j}}D]=0\), for j = 1, 2. Otherwise the plaquette operator outcomes would be indeterministic. However, from property (a) of Definition 3 of an HDC, for each \(D\in {{\mathcal{D}}}_{1}\), there is a measurement in \({{\mathcal{M}}}_{t-1}\) that anti-commutes with it. Therefore, \({\prod }_{D\in {{\mathcal{D}}}_{j}}D\) must have even overlap with all edge measurements in \({{\mathcal{M}}}_{t-1}\), for j = 1, 2. This condition can only be satisfied for both j = 1, 2 if all \(M\in {{\mathcal{M}}}_{t-1}\) are also on green edges (if they are supported on red edges, there will be one measurement with odd overlap with each \(D\in {{\mathcal{D}}}_{1}\), and similarly for \(D\in {{\mathcal{D}}}_{2}\) if they are supported on blue edges). But now both \({{\mathcal{M}}}_{t-1}\) and \({{\mathcal{M}}}_{t}\) are made up of measurements on green edges, contradicting property (a) of Definition 3.□
Using the properties of the HDC as defined above, we now present the first main theorem of our paper:
Theorem 1
A honeycomb dynamical code with duration more than 3tf + ti + 3 cannot have a 1D-decodable Z-detector graph, where ti and tf are the initial and final time-boundary offsets.
Since the proof of the theorem is quite long, here we begin by providing the sketch of the proof. We first show that the Z-detector graph of an HDC contains many more edges than vertices. This means the graph must contain many cycles. We will then find a subgraph of the ZDG in which no two vertices are connected by more than one edge, where for such a subgraph, the size of the neighbourhood of each vertex is equal to the number of edges incident to it. In particular, we will show that there exists at least one such subgraph that still possesses many more edges than vertices, meaning it is not possible for all vertices in the subgraph to have neighbourhoods of size ≤ 2 – if that were the case, then there would be at least as many vertices as edges. This, in turn, implies that the full ZDG must contain some vertices with neighbourhoods of size > 2.
The full proof of Theorem 1 is as follows.
Proof
We take an error occurring in time step t to mean that it occurs immediately after the measurements in \({{\mathcal{M}}}_{t}\). Suppose there are T time steps and n qubits in the HDC. Let us consider part of the ZDG that contains vertices corresponding to all detectors formed in time steps t > ti, but only those edges corresponding to detectable errors, i.e., those occurring in time steps ti < t < T − tf. We will call this subgraph \(\overline{{\rm{ZDG}}}\). The number of vertices in this subgraph, corresponding to the number of detectors formed, is at most n(T − ti)/6, since at each time step no detectors can be formed on neighbouring plaquettes (see Lemma 1), and there are n/6 such non-neighbouring plaquettes, which correspond to all plaquettes of a single colour, in the honeycomb lattice without boundary. Meanwhile, Z errors generate n edges between each time step, resulting in a total of n(T − 1 − ti − tf) edges in the \(\overline{{\rm{ZDG}}}\).
Let us now create a bipartition of the qubits into sets C and D such that no qubits in C are adjacent to one another, and similarly for qubits in D. This is possible since the honeycomb lattice is bipartite. Let us consider the subgraph of \(\overline{{\rm{ZDG}}}\), denoted by \({\overline{{\rm{ZDG}}}}_{C}\), that contains only edges corresponding to Z errors on qubits in C. The subgraph \({\overline{{\rm{ZDG}}}}_{C}\) therefore contains n(T − 1 − ti − tf)/2 edges. Suppose two vertices are connected in this graph by more than one edge. In such a scenario, we can choose any two from the collection of edges between these vertices. These two edges correspond to a weight-2 error, i.e, an error with support only on two qubits, in C, which is undetectable. This error is undetectable because the combination of the two errors, where each flips the values of the same two detectors, triggers no detector.
Consider one such undetectable weight-2 error, \({Z}_{i,t}{Z}_{j,t^{\prime} }\), where Zi,t denotes an error that acts on qubit i at time step t and similarly for \({Z}_{j,t^{\prime} }\). We will show that for \({Z}_{i,t}{Z}_{j,t^{\prime} }\)not to be detectable, the two errors must act on the same qubit (i = j) but at adjacent time steps (\(t=t^{\prime} \pm 1\)). To this end, we begin by ruling out other possibilities. First, we show that if the qubits i, j ∈ C are different then the error \({Z}_{i,t}{Z}_{j,t^{\prime} }\) will anti-commute with some future measurements. This, along with the fact that Zi,tZj,t is not an operator just measured or about to be measured (since i and j are not connected by an edge), means that the error is detectable by property (c) of Definition 3 of an HDC. We begin by analysing the case where the two errors occur at the same time step (\(t=t^{\prime}\)). Suppose that this error commutes with all \(M\in {{\mathcal{M}}}_{t+1}\). Since every measurement in \({{\mathcal{M}}}_{t+1}\) must have support only on one qubit in C, then the two check measurements in \({{\mathcal{M}}}_{t+1}\), one with support on qubit i and the other on qubit j, must have Pauli Z operator supports on those respective qubits. Now consider the measurement \(M^{\prime} \in {{\mathcal{M}}}_{t+2}\) with support on qubit i. By property (a) of Definition 3, one measurement from the set \({{\mathcal{M}}}_{t+2}\) that has a support on qubit i cannot act as a Pauli Z operator on that qubit, since it has to anti-commute with the previous edge measurement from \({{\mathcal{M}}}_{t+1}\) that also has a Z support on the same qubit. Therefore, \(M^{\prime}\) will anti-commute with Zi,tZj,t which, according to property (c) of Definition 3, means that the error Zi,tZj,t is detectable. Similarly, if the errors occur on different qubits but at different time steps, they must also be detectable. To show this, we can argue using the reasons mentioned above that Zi,t must anti-commute with a future measurement in set \({{\mathcal{M}}}_{t+1}\) or \({{\mathcal{M}}}_{t+2}\). Since qubits i and j are not connected by an edge in the honeycomb lattice, the same measurement, however, cannot anti-commute with \({Z}_{j,t^{\prime} }\).
Using the above reasonings, we can infer that the only possibility for the weight-2 error to be undetectable is for the two errors to occur on the same qubit, but at different time steps, i.e., \({Z}_{i,t}{Z}_{i,t^{\prime} }\) (note that if the two errors on qubit i occur at the same time step then they cancel each other out, which is equivalent to there being no error at all). Suppose, without loss of generality, that \(t < t^{\prime}\). For the weight-2 error to be undetectable, the measurements in between them must commute with Zi. Since consecutive measurements with support on the same qubit anti-commute, the two errors acting on qubit i must be separated only by one measurement time step where the in-between measurement commutes with the two errors.
The above analysis implies that vertices in \({\overline{{\rm{ZDG}}}}_{C}\) can be connected by only at most two edges. All such edges would have to correspond to errors on the same qubit and if there were more than two, we could find a pair of edges that correspond to an undetectable error \({Z}_{i,t}{Z}_{i,t^{\prime} }\) with \(t^{\prime} > t+1\), which we have shown above to be impossible. Therefore, at most half of the edges in \({\overline{{\rm{ZDG}}}}_{C}\) can be removed without changing which vertices are connected. This means that there is a spanning subgraph of \({\overline{{\rm{ZDG}}}}_{C}\) with at least ⌈n(T − 1 − ti − tf)/4⌉ edges with no vertices in the subgraph connected by more than one edge.
All things considered, this implies that the full ZDG has a subgraph with ⌈n(T − 1 − ti − tf)/4⌉ edges and a number of vertices ≤ n(T − ti)/6, such that no two vertices are connected by more than one edge. For T > 3tf + ti + 3, there are more edges than vertices in this subgraph, which means that it cannot have all vertices with neighbourhoods of size ≤ 2. Therefore, some vertices in the full ZDG also must have neighbourhoods with size greater than 2.□
The above theorem implies that no matter how an HDC is bias-tailored, it likely can never achieve as high a threshold as the repetition code or the bias-tailored stabiliser codes. Indeed, for large T (T ≫ ti, tf), there will be at least approximately 6 times as many edges as vertices in the ZDG, and there is a subgraph with 3/2 as many edges as vertices without any pair of vertices sharing more than one edge. This means the graph must have many cycles with length at least three edges.
It is clear that the codes examined in this paper obey the properties of an HDC. In particular, any Floquet codes related to the CSS Floquet code by Hadamard gates applied to a subset of the qubits (as is the case for the X3Z3 Floquet code) do not have 1D-decodable ZDGs. The reason we have focused on dynamical codes that have ZDGs, e.g., Hadamard-deformed CSS codes, instead of codes with hyperedges in their Z-detector hypergraphs, is because their decoding graphs are immediate generalisations of that of the CSS code. The fact that 1D-decodable ZDGs are not possible for an HDC suggests that there are not enough independent symmetries to reduce its decoding graph to the extent possible for stabiliser codes. It is interesting to note that even with hyperedges in the Z-detector hypergraph, a stabiliser code can still be bias-tailored39 such that it possesses large enough symmetries to render its thresholds close to the hashing bound81,82. While such high-thresholds are possible for static codes, we do not believe this would be the case for HDCs.
Finally, we consider more general codes defined on an arbitrary graph G.
Definition 4
A general dynamical code (GDC) is a finite-depth measurement circuit acting on qubits associated with vertices of a graph G. It has a duration T and initial (final) time boundary offsets ti (tf), as defined above. The sets of measurements \({{\mathcal{M}}}_{t}\) are two-body Pauli measurements associated with edges of G (each qubit is in the support of one measurement in each time step), performed sequentially on a state stabilised by some group \({\mathcal{S}}\). A GDC obeys properties (a) and (d) of an HDC.
Having defined GDCs, we now provide the second main theorem of our paper:
Theorem 2
A GDC with a duration at least 2tf + ti + 2 (i.e., a constant), where ti and tf are the initial and final time-boundary offsets, respectively, cannot have a Z-detector graph equivalent to a collection of disjoint repetition codes.
Proof
Since there are n/2 measurements in a given time step, there can be at most n/2 independent detectors formed from such measurements.
However, there will in fact be far fewer for a GDC, because each individual measurement anti-commutes with a measurement from the previous time step resulting in a random value for each edge measurement. Therefore, a detector with a deterministic outcome must be formed from at least a product of two non-deterministic measurements within a time step. Suppose the GDC has a Z-detector graph (edges in the ZDG correspond to particular Z errors). Again, we consider the subgraph corresponding to Z errors occurring in time steps ti < t < T − tf, where T is the GDC’s duration, and detectors formed in time steps t > ti. There are < n(T − ti)/2 vertices and n(T − 1 − ti − tf) edges in this subgraph. Since the number of vertices of a collection of repetition code decoding graphs cannot be less than the number of edges, this means that the ZDG of a GDC cannot be a collection of repetition code graphs for T ≥ 2tf + ti + 2.□
Owing to this theorem, we do not expect to see thresholds in dynamical codes as high as 50%. The reason that static codes perform better than dynamical codes under biased noise is that they obey two separate symmetries under an infinitely phase-biased code-capacity noise model. There is a spatial symmetry that forces syndromes to appear in pairs along 1D strips of the lattice, but there is also a temporal symmetry: syndromes must appear in pairs within a given time slice. These two symmetries simplify the detector graph into a collection of disjoint repetition code decoding graphs, leading to a high performance (up to 50% threshold) of the static codes under biased noise. On the other hand, even for the case where measurement errors are not considered, GDCs necessarily break the temporal symmetry (for HDCs, this is a consequence of Lemma 1), leading to edges between vertices in different time slices of the detector graph (see Fig. 3). We thus expect that such codes can only possess a single symmetry under an infinitely phase-biased code-capacity noise model, as the X3Z3 Floquet code does.
Data availability
The threshold data is available in https://doi.org/10.5281/zenodo.14258878 (ref. 69). Other numerical data generated in this work is available from the authors upon reasonable request. The video talk on this manuscript is available in https://www.youtube.com/watch?v=nqQT-5IRC9w.
Code availability
Circuits used in the simulations are available in https://doi.org/10.5281/zenodo.14258878 (ref. 69).
References
Shor, P. W. Scheme for reducing decoherence in quantum computer memory. Phys. Rev. A 52, R2493–R2496 (1995).
Shor, P. W. Fault-tolerant quantum computation. In Proceedings of 37th Conference on Foundations of Computer Science, 56 https://ieeexplore.ieee.org/abstract/document/548464 (IEEE, 1996).
Calderbank, A. R. & Shor, P. W. Good quantum error-correcting codes exist. Phys. Rev. A 54, 1098 (1996).
Devitt, S. J., Munro, W. J. & Nemoto, K. Quantum error correction for beginners. Rep. Progress Phys. 76, 076001 (2013).
Gottesman, D. Opportunities and challenges in fault-tolerant quantum computation. In The Physics of Quantum Information, ed. David Gross, Alexander Sevrin, and Peter Zoller, Proceedings of the 28th Solvay Conference on Physics, 287–309 https://doi.org/10.1142/13369 (World Scientific, 2023).
Hastings, M. B. & Haah, J. Dynamically generated logical qubits. Quantum 5, 564 (2021).
Haah, J. & Hastings, M. B. Boundaries for the honeycomb code. Quantum 6, 693 (2022).
Gidney, C., Newman, M., Fowler, A. & Broughton, M. A fault-tolerant honeycomb memory. Quantum 5, 605 (2021).
Gidney, C., Newman, M. & McEwen, M. Benchmarking the planar honeycomb code. Quantum 6, 813 (2022).
Paetznick, A. et al. Performance of planar Floquet codes with Majorana-based qubits. PRX Quantum 4, 010310 (2023).
Higgott, O. & Breuckmann, N. P. Constructions and performance of hyperbolic and semi-hyperbolic Floquet codes. PRX Quantum 5, 040327 (2024).
Fahimniya, A. et al. Fault-tolerant hyperbolic Floquet quantum error correcting codes. arXiv:2309.10033 (2023).
Kesselring, M. S. et al. Anyon condensation and the color code. PRX Quantum 5, 010342 (2024).
Gu, S., Retzker, A. & Kubica, A. Fault-tolerant quantum architectures based on erasure qubits. Phys. Rev. Res. 7, 013249 (2025).
McLauchlan, C., Gehér, G. P. & Moylett, A. E. Accommodating fabrication defects on Floquet codes with minimal hardware requirements. Quantum 8, 1562 (2024).
Magdalena de la Fuente, J. C. et al. XYZ ruby code: making a case for a three-colored graphical calculus for quantum error correction in spacetime. PRX Quantum 6, 010360 (2025).
Hilaire, P. et al. Enhanced fault-tolerance in photonic quantum computing: Floquet code outperforms surface code in tailored architecture. arXiv:2410.07065 (2024).
Davydova, M., Tantivasadakarn, N. & Balasubramanian, S. Floquet codes without parent subsystem codes. PRX Quantum 4, 020341 (2023).
Dua, A., Tantivasadakarn, N., Sullivan, J. & Ellison, T. D. Engineering 3D Floquet codes by rewinding. PRX Quantum 5, 020305 (2024).
Alam, M. S. & Rieffel, E. Dynamical logical qubits in the Bacon-Shor code. arXiv:2403.03291 (2024).
Davydova, M., Tantivasadakarn, N., Balasubramanian, S. & Aasen, D. Quantum computation from dynamic automorphism codes. Quantum 8, 1448 (2024).
Fu, X. & Gottesman, D. Error correction in dynamical codes. arXiv:2403.04163 (2024).
Aitchison, C. T. & Béri, B. Competing automorphisms and disordered Floquet codes. Phys. Rev. B 111, 235112 (2025).
Kitaev, A. Y. Fault-tolerant quantum computation by anyons. Ann. Phys. 303, 2 (2003).
Fowler, A. G., Mariantoni, M., Martinis, J. M. & Cleland, A. N. Surface codes: towards practical large-scale quantum computation. Phys. Rev. A 86, 032324 (2012).
Aasen, D., Haah, J., Bonderson, P., Wang, Z. & Hastings, M. Fault-tolerant Hastings-Haah codes in the presence of dead qubits. arXiv:2307.03715 (2023).
Sun, X. et al. Universal logical operations with a dynamical qubit in Floquet code. arXiv:2503.03867 (2025).
Hetényi, B. & Wootton, J. R. Tailoring quantum error correction to spin qubits. Phys. Rev. A 109, 032433 (2024).
Lescanne, R. et al. Exponential suppression of bit-flips in a qubit encoded in an oscillator. Nat. Phys. 16, 509–513 (2020).
Grimm, A. et al. Stabilization and operation of a Kerr-cat qubit. Nature 584, 205–209 (2020).
de Gliniasty, G. et al. A spin-optical quantum computing architecture. Quantum 8, 1423 (2024).
Evered, S. J. et al. High-fidelity parallel entangling gates on a neutral-atom quantum computer. Nature 622, 268 (2023).
Watson, T. et al. A programmable two-qubit quantum processor in silicon. Nature 555, 633 (2018).
Tanttu, T. et al. Assessment of the errors of high-fidelity two-qubit gates in silicon quantum dots. Nat. Phys. 20, 1804–1809 (2024).
Aasen, D. et al. Milestones toward Majorana-based quantum computing. Phys. Rev. X 6, 031016 (2016).
McLauchlan, C. & Béri, B. A new twist on the Majorana surface code: Bosonic and fermionic defects for fault-tolerant quantum computation. Quantum 8, 1400 (2024).
Aasen, D. et al. Roadmap to fault tolerant quantum computation using topological qubit arrays. arXiv:2502.12252 (2025).
Higgott, O., Bohdanowicz, T. C., Kubica, A., Flammia, S. T. & Campbell, E. T. Improved decoding of circuit noise and fragile boundaries of tailored surface codes. Phys. Rev. X 13, 031007 (2023).
Tuckett, D. K., Bartlett, S. D. & Flammia, S. T. Ultrahigh error threshold for surface codes with biased noise. Phys. Rev. Lett. 120, 050505 (2018).
Tuckett, D. K. et al. Tailoring surface codes for highly biased noise. Phys. Rev. X 9, 041031 (2019).
Tuckett, D. K., Bartlett, S. D., Flammia, S. T. & Brown, B. J. Fault-tolerant thresholds for the surface code in excess of 5% under biased noise. Phys. Rev. Lett. 124, 130501 (2020).
Bonilla Ataides, J. P., Tuckett, D. K., Bartlett, S. D., Flammia, S. T. & Brown, B. J. The XZZX surface code. Nat. Commun. 12, 2172 (2021).
Xu, Q. et al. Tailored XZZX codes for biased noise. Phys. Rev. Res. 5, 013035 (2023).
San Miguel, J. F., Williamson, D. J. & Brown, B. J. A cellular automaton decoder for a noise-bias tailored color code. Quantum 7, 940 (2023).
Dua, A., Kubica, A., Jiang, L., Flammia, S. T. & Gullans, M. J. Clifford-deformed surface codes. PRX Quantum 5, 010347 (2024).
Tiurev, K. et al. Domain wall color code. Phys. Rev. Lett. 133, 110601 (2024).
Forlivesi, D., Valentini, L. & Chiani, M. Quantum codes for asymmetric channels: ZZZY surface codes. IEEE Commun. Lett. 28, 2233–2237 (2024).
Sarvepalli, P. K., Klappenecker, A. & Rötteler, M. Asymmetric quantum codes: constructions, bounds and performance. Proc. R. Soc. Math. Phys. Eng. Sci. 465, 1645 (2009).
Srivastava, B., Frisk Kockum, A. & Granath, M. The XYZ2 hexagonal stabilizer code. Quantum 6, 698 (2022).
Roffe, J., Cohen, L. Z., Quintavalle, A. O., Chandra, D. & Campbell, E. T. Bias-tailored quantum LDPC codes. Quantum 7, 1005 (2023).
Claes, J., Bourassa, J. E. & Puri, S. Tailored cluster states with high threshold under biased noise. npj Quantum Inform. 9, 9 (2023).
Huang, E., Pesah, A., Chubb, C. T., Vasmer, M. & Dua, A. Tailoring three-dimensional topological codes for biased noise. PRX Quantum 4, 030338 (2023).
Sahay, K., Jin, J., Claes, J., Thompson, J. D. & Puri, S. High-threshold codes for neutral-atom qubits with biased erasure errors. Phys. Rev. X 13, 041013 (2023).
Sahay, K., Claes, J. & Puri, S. Tailoring fusion-based error correction for high thresholds to biased fusion failures. Phys. Rev. Lett. 131, 120604 (2023).
Forlivesi, D., Valentini, L. & Chiani, M. Logical error rates of XZZX and rotated quantum surface codes. IEEE J. Select. Areas Commun. 42, 1808 – 1817 (2024).
Hetényi, B. & Wootton, J. R. Creating entangled logical qubits in the heavy-hex lattice with topological codes. PRX Quantum 5, 040334 (2024).
Chamberland, C., Zhu, G., Yoder, T. J., Hertzberg, J. B. & Cross, A. W. Topological and subsystem codes on low-degree graphs with flag qubits. Phys. Rev. X 10, 011022 (2020).
Puri, S. et al. Bias-preserving gates with stabilized cat qubits. Sci. Adv. 6, eaay5901 (2020).
Dennis, E., Kitaev, A., Landahl, A. & Preskill, J. Topological quantum memory. J. Math. Phys. 43, 4452–4505 (2002).
Higgott, O. & Gidney, C. Sparse blossom: correcting a million errors per core second with minimum-weight matching. Quantum 9, 1600 (2025).
See Supplementary Information for details on the honeycomb and CSS Floquet codes, parity-check circuits, plots for determining thresholds, hyperedge errors, simulation results for Floquet codes with elongated dimension and a twisted boundary condition.
Karzig, T. et al. Scalable designs for quasiparticle-poisoning-protected topological quantum computation with Majorana zero modes. Phys. Rev. B 95, 235305 (2017).
McLauchlan, C. K. & Béri, B. Fermion-parity-based computation and its Majorana-zero-mode implementation. Phys. Rev. Lett. 128, 180504 (2022).
Paesani, S. & Brown, B. J. High-threshold quantum computing by fusing one-dimensional cluster states. Phys. Rev. Lett. 131, 120603 (2023).
Krantz, P. et al. A quantum engineer's guide to superconducting qubits. Appl. Phys. Rev. 6, 021318 (2019).
Bruzewicz, C. D., Chiaverini, J., McConnell, R. & Sage, J. M. Trapped-ion quantum computing: progress and challenges. Appl. Phys. Rev. 6, 021314 (2019).
Burkard, G., Ladd, T. D., Pan, A., Nichol, J. M. & Petta, J. R. Semiconductor spin qubits. Rev. Mod. Phys. 95, 025003 (2023).
Wintersperger, K. et al. Neutral atom quantum computing hardware: performance and end-user perspective. EPJ Quantum Technol. 10, 32 https://doi.org/10.1140/epjqt/s40507-023-00190-1 (2023).
Setiawan, F. & McLauchlan, C. Stim circuits and data for Tailoring Dynamical Codes for Biased Noise: The X3Z3 Floquet Code. https://doi.org/10.5281/zenodo.14258878.
Google Quantum AI. Exponential suppression of bit or phase errors with cyclic error correction. Nature 595, 383–387 (2021).
Ellison, T. D., Sullivan, J. & Dua, A. Floquet codes with a twist. arXiv:2306.08027 (2023).
Aliferis, P. & Cross, A. W. Subsystem fault tolerance with the Bacon-Shor code. Phys. Rev. Lett. 98, 220502 (2007).
Gidney, C. Stim: a fast stabilizer circuit simulator. Quantum 5, 497 (2021).
Dennis, E., Kitaev, A., Landahl, A. & Preskill, J. Topological quantum memory. J. Math. Phys. 43, 4452 (2002).
Edmonds, J. Maximum matching and a polyhedron with 0, 1-vertices. J. Res. Natl. Bur. Stand. B 69, 55 (1965).
Edmonds, J. Paths, trees, and flowers. Can. J. Math. 17, 449 (1965).
Fowler, A. G. Minimum weight perfect matching of fault-tolerant topological quantum error correction in average O(1) parallel time. Quantum Inform. Comput. 15, 145 (2014).
Wang, C., Harrington, J. & Preskill, J. Confinement-Higgs transition in a disordered gauge theory and the accuracy threshold for quantum memory. Ann. Phys. 303, 31 (2003).
Harrington, J. W. Analysis of quantum error-correcting codes: symplectic lattice codes and toric codes. PhD thesis, California Institute of Technology, Pasadena, California https://resolver.caltech.edu/CaltechETD:etd-05122004-113132 (2004).
Aasen, D., Haah, J., Li, Z. & Mong, R. S. Measurement quantum cellular automata and anomalies in Floquet codes. arXiv:2304.01277 (2023).
Lloyd, S. Capacity of the noisy quantum channel. Phys. Rev. A 55, 1613 (1997).
Devetak, I. The private classical capacity and quantum capacity of a quantum channel. IEEE Trans. Inform. Theory 51, 44–55 (2005).
Acknowledgements
We would like to thank our colleagues at Riverlane, especially Alexandra Moylett, Ophelia Crawford, and György Gehér for helpful discussions. We are also grateful to Ophelia Crawford and Hari Krovi for their comments on the manuscript. C.M. would like to thank Benjamin Brown for pointing out a useful circuit for performing next-nearest-neighbour entangling gates. C.M. acknowledges support from the Intelligence Advanced Research Projects Activity (IARPA), under the Entangled Logical Qubits programme through Cooperative Agreement Number W911NF-23-2-0223.
Author information
Authors and Affiliations
Contributions
F.S. developed the X3Z3 Floquet code and biased noise models. F.S. also performed the numerical simulations for all Floquet codes investigated. C.M. characterised the symmetry and decoding features of the codes tested. In addition, C.M. developed the bias-tailored circuits and the proofs of the no-go theorems. Both authors contributed to the writing of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Setiawan, F., McLauchlan, C. Tailoring dynamical codes for biased noise: the X3Z3 Floquet code. npj Quantum Inf 11, 149 (2025). https://doi.org/10.1038/s41534-025-01074-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41534-025-01074-1
