
Abstract
Accurately predicting agricultural commodity prices is crucial for India's economy. Traditional parametric models struggle with stringent assumptions, while machine learning (ML) approaches, though data-driven, lack automatic feature extraction. Deep learning (DL) models, with advanced feature extraction and predictive abilities, offer a promising solution. However, their application to agricultural price data ignored the exogenous factors. Hence, the study explored advanced versions of the well-known univariate models, NBEATSX and TransformerX. The research employed price data for essential crops like Tomato, Onion, and Potato (TOP) from major Indian markets and complemented it with corresponding weather data (precipitation and temperature). To provide a comprehensive analysis, the study also evaluated traditional statistical methods (ARIMAX and MLR) and a suite of ML algorithms (ANN, SVR, RFR, and XGBoost). The performance of these models was rigorously evaluated using error metrics like RMSE, MAE, sMAPE, MASE and QL. The findings were significant indicating DL models, particularly when augmented with exogenous variables, consistently outshone other methods with NBEATSX and TransformerX showing an average RMSE of 110.33 and 135.33, MAE of 60.08 and 74.92, sMAPE of 22.14 and 24.00, MASE of 1.02 and 1.32 and QL of 30.04 and 34.07, respectively. They exhibited lower error metrics, as compare to the statistical and ML models underscoring their effectiveness and potential in agricultural crop price forecasting. This study not only bridged a crucial research gap but also highlighted the robust potential of DL models in enhancing the accuracy of agricultural commodity price predictions in India.
Similar content being viewed by others
Introduction
In India, tomatoes, onions, and potatoes, collectively known as TOP crops, are the most widely cultivated, produced, and consumed vegetables. India is the second-largest producer of these three vegetables globally, next to China. According to the second advance estimates (2021–22) of horticultural crop production, vegetable production in India is projected to reach 204.61 million tonnes, an increase from the previous year's 200.45 million tonnes in 2020–21 (Agricultural and Processed Food Products Export Development Authority, 2022). Specifically, onion production is estimated to be 31.70 million tonnes, an increase from 26.64 million tonnes in the previous year, while potato production is anticipated to be 53.58 million tonnes, slightly lower than the 56.17 million tonnes. Additionally, tomato production is likely to be 20.34 million tonnes, a decrease from 21.18 million tonnes (Press Information Bureau, 2022). However, this surplus in production has not brought much relief to farmers. Instead, they are grappling with challenges such as overproduction, leading to distress sales, crop wastage, and even dumping crops on roadsides. The challenges in adequately supporting our farmers arise from various factors, such as fragmentation in the value chain, price volatility, quality and quantity losses, and insufficient processing levels, all prevalent in the Indian horticultural market. These issues have weakened India's position in the global horticulture trade and have resulted in low returns for farmers. This discrepancy highlights the challenges within the Indian horticultural sector that need to be addressed to ensure fair returns for farmers and sustainable growth in the industry1,2.
The fluctuations in agricultural commodity prices pose significant challenges for various stakeholders, including farmers, the government, industry participants, and financial markets3,4. Price forecasting plays a crucial role in commodity trading and price analysis within the agricultural sector. Researchers have focused on studying forecasts related to production and prices in agricultural commodity markets, considering the unpredictability influenced by natural disasters like droughts, floods, and pest attacks5,6. The agricultural sector's dependence on rainfall, particularly affecting small farmers, highlights the need for effective modeling and prediction, as variations in rainfall patterns can disrupt the market7,8. In response to low prices, governments often increase minimum support prices, while high prices may prompt restrictions on exports. In India, commodity exchanges have been introduced as market-based solutions, influenced by both domestic and international markets9,10. Commodity futures markets in horticulture, with nationwide coverage, involve speculators and hedgers in the value chain, facilitating price discovery and risk management11,12. The unique dynamics of agricultural pricing, influenced by factors like weather, seasonality, crop production cycles, and the inelastic relationship between supply and demand, set it apart from other goods and services13. Understanding the complex interplay of internal and external factors leading to abnormal fluctuations in agricultural prices is crucial14,15. Weather changes, a significant external factor, can impact the entire process of vegetable cultivation, harvest, transportation, and sales, disrupting supply and demand dynamics16. Therefore, studying the dynamic impacts of weather changes on agricultural price fluctuations is of theoretical and practical significance in India.
To address these challenges, time-series models like ARIMA and its variations, including SARIMA and ARIMAX, have been widely used to capture underlying relationships in variables17. However, addressing nonstationary, nonlinear, and noisy financial time series data has led researchers to explore advanced intelligence systems such as machine learning (ML) and deep learning (DL) models18,19. DL, with its automated feature learning capabilities, has emerged as a robust solution, effectively handling large-scale, noisy, and unstructured data in time series forecasting20,21. While most DL models focus on univariate time series datasets, developing models capable of handling multiple variables and assessing their impact on the target variable remains a challenge22.
A comparative analysis was conducted on various forecasting models in agricultural and environmental contexts. Anggraeni et al.23 compared ARIMAX and VAR models for rice price prediction in Thailand, with ARIMAX showing superior performance. Alam et al.15 explored hybrid models (ARIMAX-ANN and ARIMAX-SVM) incorporating weather variables, which outperformed the conventional ARIMAX model in rice yield forecasting. Medar et al.24 proposed a novel approach for sugarcane yield prediction in Karnataka, combining LTTS, weather, soil attributes, NDVI, and SVR, demonstrating high accuracy. Zhang et al.25 focused on rainfall forecasting in Odisha, using SVR and MLP models, with SVR proving efficient for accurate predictions. Sun et al.26 provided a comprehensive review of agricultural product price forecasting methods, emphasizing the importance of combined models and the integration of structured and unstructured data for accurate predictions. Yuan and Ling27 introduced a comprehensive agricultural software employing Long Short-Term Memory (LSTM) for price forecasting, integrating weather data and facilitating trade. Cho et al.28 integrated attention-based LSTM and ARMA models for tomato yield prediction, outperforming existing methods. Olivares et al.29 developed NBEATSx, an extension of the NBEATS model, enhancing forecast accuracy in electricity price prediction. Souto and Moradi30 compared NBEATSx with other models for daily stock realized volatility, demonstrating its superior accuracy and robustness. Panja et al.31 proposed XEWNet for dengue outbreak prediction, incorporating wavelet transformation, ensemble neural networks, and exogenous climate variables, offering flexibility, interpretability, and computational efficiency in forecasting dengue incidence. Mohanty et al.32 proposed an efficient ML framework integrating various factors for agricultural commodity price prediction, while Ben Ameur et al.33 explored the efficacy of DL algorithms, particularly LSTM for analysing Bloomberg Commodity Index, revealing insights for investors and policymakers. Tami and Owda34 introduced an LSTM-based model showcasing superior performance over traditional methods for modeling five essential commodities namely bread, meat, milk, oil, and petrol35. HT et al.35 conducted a comparative analysis of time series models for onion price forecasting, highlighting the superiority of the TBATS model. Rana et al.36 demonstrated LSTM's superiority over ARIMA and Random Forest models for predicting agricultural commodity prices, while Sari et al.37 proposed a novel forecasting model using the extreme learning machine technique optimized with genetic algorithm, providing insights for effective agricultural policy management. Avinash et al.38 developed Hidden Markov guided DL models to forecast highly volatile agricultural commodity prices, demonstrating improved accuracy over baseline DL models.
This study addresses a significant gap in existing research by focusing on forecasting agricultural prices using both the target variable and its associated exogenous variables39,40. Unlike previous studies that predominantly concentrate on forecasting price series alone, our approach incorporates DL models designed to handle multivariable complexity. We introduce DL models that seamlessly integrate exogenous variables with the target variable, aiming to enhance forecasting performance. Furthermore, our research conducts a comprehensive comparative analysis of these DL models with various ML techniques, including Artificial Neural Networks (ANNs), Support Vector Regression (SVR), Random Forest Regression (RFR), and XGBoost, alongside statistical models such as Autoregressive Integrated Moving Average with Exogenous variables (ARIMAX) and Multiple Linear Regression (MLR). The study aims to introduce DL models for improved price forecasting incorporating exogenous variables, assess forecasting performance utilizing individual and combined weather variables and conduct a comprehensive comparison of DL models with other ML and statistical counterparts.
The paper follows this structure: Section "Materials and methods" outlines the materials and methods, Section "Study methodology" elaborates on the study methodology, Section "Experiment and results" presents the empirical study using real datasets (TOP price series), and Section "Discussion" concludes with findings, remarks, and future prospects, followed by a list of references.
Materials and methods
Autoregressive integrated moving average with exogenous inputs (ARIMAX)
ARIMAX, an extension of the well-known ARIMA model, integrates external predictors to enhance time series forecasting. ARIMA models are effective in capturing temporal patterns within data, denoted as ARIMA \(\left(p,d, q\right)\) where 'p' signifies autoregressive order, 'd' represents differencing order, and 'q' indicates moving average order. ARIMAX introduces exogenous variables, external factors influencing the time series data, broadening its applicability. ARIMAX models are estimated by fitting the autoregressive, differencing, and moving average components to the historical time series data and incorporating the exogenous variables. The inclusion of exogenous inputs allows the model to account for external factors that can impact the time series, enhancing the accuracy of the forecasts23. ARIMAX models are particularly useful when the time series data exhibit a clear temporal pattern, and there are additional variables that can contribute valuable information for prediction.
The ARIMAX \({\left(p,d, q\right)\left(P, D,Q\right)}_{s}\) model can be expressed mathematically as:
Here, \({Y}_{t}\) represents the observed value at time \(t\), \(c\) is a constant term, \({\phi }_{1}, {\phi }_{2},\dots , {\phi }_{p}\) are autoregressive coefficients, \({\varepsilon }_{t-1}, {\varepsilon }_{t-2}, \dots ,{\varepsilon }_{t-q}\) are error terms from past time steps, \({X}_{t}\) represents the exogenous input variables at time \(t\), \(\beta\) represents the coefficients for the exogenous variables, and \({\varepsilon }_{t}\) is the error term at time \(t\).
Multiple linear regression (MLR)
MLR is a fundamental statistical method used for modeling the relationship between a dependent variable \(\left(y\right)\) and two or more independent variables \(\left({x}_{1}, {x}_{2},\dots , {x}_{n}\right)\). The model assumes a linear relationship between the predictors and the response variable, represented mathematically as:
Here, \({\beta }_{0}\) is the intercept, \({\beta }_{0}, {\beta }_{1},{\beta }_{2}, \dots , {\beta }_{n}\) are the coefficients representing the influence of each independent variable, \({x}_{1}, {x}_{2}, \dots ,{x}_{n}\), and \(\varepsilon\) represents the error term accounting for unexplained variability in the data. The goal of Multiple Linear Regression is to estimate the coefficients \(\left({\beta }_{0}, {\beta }_{1},{\beta }_{2}, \dots , {\beta }_{n}\right)\) that minimize the sum of squared differences between the observed \(\left(y\right)\) and predicted \(\widehat{y}\) values.
The regression coefficients are estimated using the method of least squares, where the objective is to minimize the residual sum of squares (RSS), defined as:
where \(N\) is the number of observations. The regression model calculates the predicted values \({\widehat{y}}_{i}\) by multiplying each independent variable \(\left({x}_{1}, {x}_{2}, \dots ,{x}_{n}\right)\) with its corresponding coefficient \(\left({\beta }_{0}, {\beta }_{1},{\beta }_{2}, \dots , {\beta }_{n}\right)\), adding the intercept \(\left({\beta }_{0}\right)\), and accounting for the error term \(\varepsilon\). MLR is widely used in various fields to understand the relationships between multiple variables, making it a valuable tool for predictive modeling and data analysis7,41.
Artificial neural networks (ANN)
ANNs represent a category of ML models inspired by the interconnected neurons in the human brain. Particularly proficient in regression tasks, ANNs excel at capturing intricate patterns within data. Comprising layers of interconnected nodes, ANNs include an input layer, one or more hidden layers, and an output layer41. Every connection between nodes possesses a specific weight, and each node processes the weighted sum of its inputs through an activation function.
For regression, the output layer typically consists of a single node, representing the predicted continuous value \(\left(\widehat{y}\right)\). During training, ANNs adjust their weights through a process called backpropagation42,43. This involves computing the error between the predicted output and the actual target values \(\left(y\right)\) and then updating the weights to minimize this error. The objective function minimized during training is often the Mean Squared Error (MSE), which measures the average squared difference between predicted and actual values:
Here, \(n\) represents the number of data points, \({\widehat{y}}_{i}\) is the predicted value for the \(i\)-th instance, and \({y}_{i}\) is the actual target value.
A fundamental operation in an ANN involves computing the weighted sum of inputs \(\left({z}_{i}\right)\) and subsequently applying an activation function \(\left({a}_{i}\right)\). Activation functions such as the sigmoid function, hyperbolic tangent (tanh), and rectified linear unit (ReLU) are commonly used. These functions introduce non-linearities, allowing ANNs to grasp intricate relationships within the data, enhancing their ability to learn complex patterns. The output \(\left({\widehat{y}}_{i}\right)\) of the \(i\)-th node in the network is computed as:
ANNs are capable of learning intricate patterns from data, making them suitable for various regression tasks. By adjusting the weights and biases through the training process, ANNs can approximate complex functions, allowing them to model and predict continuous outcomes accurately44,45. Their ability to capture non-linear relationships makes them a valuable tool in regression analysis within diverse fields.
Support vector machines (SVM)
Support Vector Regression (SVR) stands as a potent ML algorithm extensively employed for regression tasks. In SVM regression, the primary aim is to identify a hyperplane that optimally fits the data while maximizing the margin, defined as the distance between the hyperplane and the nearest data points, referred to as support vectors. The objective involves minimizing prediction errors while accommodating a specified margin of tolerance46,47.
Mathematically, SVM regression aims to find a function \(f\left(x\right)\) that predicts the target values \(\left(y\right)\) based on input features \(\left(y\right)\). The objective function for SVM regression is defined as follows:
Here, \(w\) represents the weights, \(C\) is the regularization parameter that controls the trade-off between minimizing the error and maximizing the margin, \(\epsilon\) is the margin of tolerance, and \(\left({x}_{i},{y}_{i}\right)\) are the input–output pairs in the training dataset. The function \(f\left(x\right)\) is determined by the dot product between the input features and the weights, i.e., \(f\left(x\right)=\langle w,x\rangle +b\), where \(b\) is the bias term.
SVR identifies the optimal hyperplane by solving a constrained optimization problem, ensuring that the errors are minimized while maintaining a balance between fitting the data and achieving a wide margin. The support vectors, which are the data points closest to the hyperplane, influence the final model. SVM regression is effective in capturing non-linear relationships through kernel functions, allowing the algorithm to map the input features into a higher-dimensional space where a linear hyperplane can be more effectively applied48. This ability to handle non-linear data patterns makes SVM regression a versatile technique for various regression tasks in different fields of research and analysis.
Random forest (RF)
RF is a robust regression technique widely used in data analysis. Unlike traditional regression methods, RF combines the predictive power of multiple Decision Tree (DT) algorithms to create an ensemble model. In RF regression, when provided with an input vector \(\left(x\right)\) containing various evidential features for a specific training area, RF constructs a set of \(K\) regression trees and averages their results. The RF regression predictor \(\left({\widehat{f}}_{k}\left(x\right)\right)\) for an input vector \(x\) is calculated by averaging the predictions of individual trees as follows:
Here, \(T\left(x\right)\) represents the individual regression trees grown by RF. To enhance diversity among these trees and prevent correlation, RF employs a technique called bagging. In bagging, training data subsets are created by randomly resampling the original dataset with replacement. This process involves selecting data points from the input sample to generate subsets \(\left\{h\left(x,{\Theta }_{k}\right),k=1, \dots , K\right\}\), where \(\left\{{\Theta }_{k}\right\}\) are independent random vectors with the same distribution. Some data points may be repeated, while others might not be used, increasing stability and prediction accuracy, especially in the face of slight variations in input data.
A notable characteristic of RF lies in its ability to select the optimal feature/split point from a randomly chosen subset of features for each tree, reducing inter-tree correlation and minimizing generalization errors. RF trees grow without pruning, ensuring computational efficiency, and utilize out-of-bag elements to evaluate performance without external test data. As the number of trees increases, the generalization error converges, preventing overfitting. Moreover, RF offers insights into the importance of different features, aiding accurate predictions in regression tasks49,50.
Extreme gradient boosting (XGBoost)
XGBoost, an advanced ML algorithm, stands out for its efficiency in regression tasks. Unlike traditional techniques, XGBoost employs a gradient boosting framework that sequentially builds multiple decision trees to refine predictions. In regression, XGBoost minimizes the objective function, which is the sum of a loss function and a regularization term, to find the optimal prediction model. The objective function for XGBoost regression is defined as follows:
Here, \({y}_{i}\) represents the actual target value, \({\widehat{y}}_{i}\) is the predicted value, and \(n\) is the number of data points. The term \(\Omega \left(f\right)\) represents the regularization function, and \(\lambda\) controls the regularization strength.
XGBoost's power lies in its iterative approach. It starts with an initial prediction \({\widehat{y}}_{i}^{\left(0\right)}\) and then updates it at each iteration by adding the prediction from a new decision tree:
Here, \(t\) denotes the current iteration, \({f}_{t}\left({x}_{i}\right)\) is the prediction from the \(t\)-th tree for input \({x}_{i}\), and \({\widehat{y}}_{i}^{\left(t\right)}\) is the updated prediction.
To build accurate trees, XGBoost optimizes the structure by selecting the best split points based on the gradient of the loss function. It calculates the first-order and second-order gradients for each instance and uses these values to find the optimal splits. Additionally, XGBoost incorporates a regularization term, controlling the complexity of individual trees, preventing overfitting, and enhancing generalization. By combining the predictions from multiple trees and continuously refining them, XGBoost provides highly accurate regression models, making it a powerful choice for various data analysis tasks51.
Neural basis expansion analysis for interpretable time series forecasting with exogenous variable (NBEATSX)
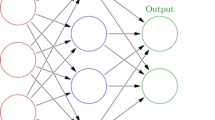
In a thorough examination, the NBEATSX framework dissects the target signal's objective by utilizing local nonlinear projections of the target data onto basis functions within specific blocks29. The model's architecture, as depicted in Fig. 1, consists of multiple blocks, each comprising a Fully Connected Neural Network (FCNN). These FCNNs are responsible for learning expansion factors for both forecast and backcast components. The final prediction is formed by aggregating the forecasts, and the backcast model refines inputs for subsequent blocks. These blocks are arranged into stacks, with each stack specializing in different variants of basis functions. For instance, stack A may emphasize the seasonality aspect, stack B may focus on the trend, and stack C may concentrate on exogenous factors. This arrangement ensures that the output from stack A captures seasonality, while the outputs from stacks B and C represent the trend and exogenous elements, respectively, contributing to the interpretability of the ANN.

Architecture of NBEATSX model.
Let the \(l\times T\) vector \({\varvec{y}}\) be the variable to be forecasted and the \(T\times M\) matrix \({\varvec{X}}\) be the considered exogenous variables, while \(T\) is the total number of considered time steps, and \(M\) is to total number of exogenous variables. Consider the scenario that NBEATSx will be used to forecast \(H\) time steps of \({\varvec{y}}\) at time \(L\), where \(L=T-H\). Then, the inputs for NBEATSx are \({{\varvec{y}}}^{\text{back }},{{\varvec{X}}}^{\text{back}}\), and \({{\varvec{X}}}^{fut}\), where \({{\varvec{y}}}^{\text{back}}\) is a \(I\times L\) vector composed of \(L\) lagged values of \({\varvec{y}},{{\varvec{X}}}^{\text{back}}\) is the \(T\times M\) matrix composed of \(L\) lagged values of \(J\) exogenous variables and zeros elsewhere, and \({{\varvec{X}}}^{fut}\) is the \(T\times M\) matrix composed of \(T\) values of \(K\) exogenous variables known at time \(L\) and zeros elsewhere. Incidentally, \(J+K=M,{{\varvec{X}}}^{\text{back }}+{{\varvec{X}}}^{fut}={\varvec{X}}\), and the \({\varvec{y}}\) values to be forecasted are denoted as \({{\varvec{y}}}^{\text{for}}\) while the estimated \({{\varvec{y}}}^{\text{for}}\) values are denoted as \(\widehat{{\varvec{y}}}^{{{\text{for}}}}\).
The inputs of the first block consist of \({{\varvec{y}}}^{\text{back}}\), and \({\varvec{X}}\), while the inputs of each subsequent blocks include the residual connections with backcast output of the previous block. Considering the \(b\)-th block of the \(s\)-th stack, the following transformations hold:
where, \({{\varvec{h}}}_{s,b}\in {\mathbb{R}}^{{N}_{h}}\) are learned hidden units, and \({{\varvec{\theta}}}_{s,b}^{\text{back }}\in {\mathbb{R}}^{{N}_{s}}\) and \({{\varvec{\theta}}}_{s,b}^{\text{for }}\in {\mathbb{R}}^{{N}_{s}}\) are respectively backcast and forecast expansion coefficients linearly estimated from \({{\varvec{h}}}_{s,b}\). Afterwards, the following basis expansion operation and doubly residual stacking are performed:
where, \({{\varvec{V}}}_{s,b}^{\text{back }}\in {\mathbb{R}}^{L\times {N}_{s}}\) and \({{\varvec{V}}}_{s,b}^{\text{for }}\in {\mathbb{R}}^{L\times {N}_{s}}\) are the block's basis, with the possible types of basis being trend basis, \({\varvec{T}}\), seasonal basis, \({\varvec{S}}\), identity basis, \({\varvec{I}}\), and exogenous basis, \({\varvec{X}}\). The doubly residual stacking helps with the optimization procedure and forecast precision as it prepares the inputs of the subsequent layer and allows the \(s\)-th stack to sequentially decompose the modeled signal.
\({\varvec{T}}=\left[1,\mathbf{t},\dots ,{\mathbf{t}}^{{N}_{\text{pot }}}\right]\in {\mathbb{R}}^{H\times \left({N}_{\text{pol }}+1\right)}\), where \({N}_{\text{pol}}\) is the maximum polynomial degree chosen as a hyperparameter, and \({\mathbf{t}}^{\user2{\prime }} = \left[ {0,1,2, \ldots ,H - 1} \right]/H.S = \left[ {1,{\text{cos}}\left( {2\pi \frac{{\text{t}}}{{N_{hr} }}} \right), \ldots ,{\text{cos}}\left( {2\pi \left[ {\frac{H}{2} - 1} \right]\frac{{\text{t}}}{{N_{hr} }}} \right)} \right.\), \(\left.\text{sin}\left(2\pi \frac{\text{t}}{{N}_{hr}}\right),\dots ,\text{sin}\left(2\pi \left[\frac{H}{2}-1\right]\frac{\text{t}}{{N}_{hr}}\right)\right]\in {\mathbb{R}}^{H\times (H-1)}\), where the hyperparameter \({N}_{hr}\) controls the harmonic oscillations. \({\varvec{I}}={I}_{H\times H}\), where \({I}_{H\times H}\) is the identity matrix. Finally, \({\varvec{X}}=\left[{{\varvec{X}}}_{1},\dots ,{{\varvec{X}}}_{M}\right]\in\) \({\mathbb{R}}^{H\times M}\). When using \({\varvec{X}}\), the basis expansion operation can be thought as a time-varying local regression. Finally, \(\widehat{{\varvec{y}}}^{{{\text{for}}}}\) is estimated by adding all stack predictions, \(\sum_{s = 1}^{s} \widehat{{\varvec{y}}}_{s}^{{{\text{for}}}}\), as shown in the yellow rectangle of Fig. 1.
Transformer with exogenous variable (TransformerX)
The proposed model harnesses the transformative capabilities of the Transformer architecture, a DL approach that has garnered significant acclaim in the field of natural language processing. Its widespread recognition stems from its ability to effectively handle sequential data tasks, owing to its capacity for parallel computations and efficient attention mechanisms. Departing from traditional recurrent models such as Recurrent Neural Networks (RNNs), LSTM and Gated Recurrent Units (GRUs), the Transformer architecture takes a novel approach by solely relying on attention mechanisms to capture long-range dependencies within the input data. This departure from sequential constraints enables the model to excel in sequence-to-sequence tasks, including machine translation, text summarization, and time series forecasting. By leveraging the full context of the input sequence, the Transformer model can dynamically allocate attention to the most relevant information, thereby enhancing its capability to model complex relationships and intricate patterns within the data.
Overview of the transformer architecture
The Transformer model follows an encoder-decoder structure (shown in Fig. 2), where the encoder processes the input sequence and generates a continuous representation, while the decoder utilizes this representation to produce the output sequence. The distinguishing feature of the Transformer model is its self-attention mechanism, which enables the model to weigh the importance of different parts of the input sequence when computing the representation for a specific part of the sequence 52.

Transformer architecture.
Key components of the Transformer:
-
1.1.
Input embedding and positional encoding The input sequence is first transformed into high-dimensional vector representations through an embedding layer. Since the Transformer lacks inherent sequence order information, positional encodings are added to the embeddings to preserve the sequential nature of the data.
$$Embedding\left({X}_{i}\right)={X}_{i}E$$(14)
where,
\({X}_{i}:\) Represents the \({i}^{th}\) item in the input sequence.
\(E:\) The embedding matrix, typically learned during training
where,
\(pos:\) The position of the item in the sequence.
\(i:\) The dimension index of the positional encoding.
\(d:\) The dimensionality of the embeddings
-
2.2.
Multi-head self-attention The self-attention mechanism is the core component of the Transformer model. It allows the model to attend to different parts of the input sequence by computing attention weights based on the similarity between the query (current position) and key (other positions) vectors. Multiple attention heads are employed in parallel, each capturing different aspects of the input data53. When represented in matrix form, the self-attention operation in Transformers can be expressed as follows:where, \(Q\) and \(K\in {\mathbb{R}}^{{s}_{1}\times n}\) and \(V\in {\mathbb{R}}^{s\times n}\), \(Z\in {\mathbb{R}}^{s\times n}\) and \(T\) depicts the transpose mechanism.
$$Z=softmax\left(\frac{Q{K}^{T}}{\sqrt{{d}_{k}}}\right)V$$(18)
-
3.
Encoder and decoder blocks Both the encoder and decoder consist of multiple stacked layers. Each encoder layer includes a multi-head self-attention sublayer and a feedforward neural network sublayer. The decoder layers additionally have an encoder-decoder attention sublayer that attends to the output of the encoder 54.where,
-
4.
Residual connections and layer normalization To improve training stability and convergence, residual connections and layer normalization are applied within each encoder and decoder layer55.where,
$$Output=Sublayer\left(x\right)+x$$(19)$$LayerNorm\left(x\right)=\gamma \left(\frac{x-\mu }{\sigma }\right)+\beta$$(20)
\(\mu\) and \(\sigma\) are the mean and standard deviation of the features.
\(\gamma\) and \(\beta\) are learnable parameters.
-
3.5.
Feedforward neural network After the self-attention and encoder-decoder attention sublayers, a feedforward neural network is employed to further process the input representations.
$$FFN\left(x\right)=max\left(0,x{W}_{1}+{b}_{1}\right){W}_{2}+{b}_{2}$$(21)
where,
\({W}_{1}\) and \({W}_{2}\) are weight matrices and \({b}_{1}\) and \({b}_{2}\) are bias vectors.
-
4.6.
Output generation For tasks like machine translation, the decoder output is passed through a linear layer and a softmax activation function to generate the final output sequence56,57.
$$Y=DecoderOutput*W+b$$(22)
where,
\(DecoderOutput:\) The output from the final decoder block.
\(W:\) Weight matrix of the linear layer.
\(b:\) Bias vector
where,
\({z}_{i}:\) The \({i}^{th}\) element of the output vector from the linear layer.
\({e}^{{z}_{i}}:\) The exponential function applied to \({z}_{i}\)
\({\sum }_{j}{e}^{{z}_{j}}:\) The sum of the exponentials of all elements of all elements in the output vector.
The Transformer model has proven to be highly effective in various natural language processing tasks and has inspired numerous variants and adaptations for other domains, such as computer vision and time series forecasting.
Transformer with exogenous eariable
-
a.
Transformer Encoder:
-
i.
Input Embedding: The model begins by embedding the input sequences of historical prices and exogenous variables. These embeddings are then passed through the encoder layers.
-
a
Multi-Head Attention: Multi-Head Attention serves as the cornerstone of the Transformer architecture, enabling the model to assess the importance of distinct input sequence components. This mechanism encompasses three distinct linear transformations to generate query, key, and value vectors, which are subsequently partitioned into multiple heads, facilitating simultaneous attention to diverse positions within the input.
-
b
Position-wise Feed-Forward Network: Following the attention mechanism, the output undergoes processing through a position-wise feed-forward neural network, applied independently at each position. This crucial step enables the model to capture intricate patterns within the data.
-
c
Layer Normalization and Dropout: After each sub-layer, layer normalization is applied, followed by dropout for regularization, preventing overfitting during training.
-
b.
Transformer Decoder:
-
i.
Multi-Head Attention (Two Mechanisms):
-
d
First Attention Mechanism: Focuses on the exogenous variables, enabling the model to incorporate additional context from external factors such as precipitation.
-
e
Second Attention Mechanism: Focuses on the encoder context, aligning the input sequence with the target prediction and capturing the relevant historical information.
-
f
Position-wise Feed-Forward Network: Similar to the encoder, the decoder uses a position-wise feed-forward network for further processing.
-
g
Layer Normalization and Dropout: Similar to the encoder, layer normalization and dropout are applied after each sub-layer for regularization and stability.
-
c.
Output Layer:
The final layer of the model is a dense layer with linear activation. It produces the predicted output for the next time step, representing the forecasted prices based on the historical prices and exogenous variables.
Ethics approval, consent to participate and consent for publication
The manuscript does not report on or involve the use of any animal or human data and “not applicable” in this section.
Study methodology
Creating forecasting models comprises five essential stages: Data Collection, Data Pre-processing, Model Compilation, Model Training, and Model Evaluation. The methodology adopted in this study is depicted through Fig. 3. The subsequent section elaborates on these phases in detail.

Procedural flowchart of the methodology.
Data collection
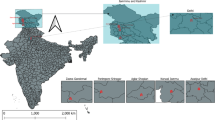
The price series data for the three major crops, commonly referred to as 'TOP crops' (Tomato, Onion, and Potato) from India, is sourced from the government's official agricultural marketing portal, 'AgMarknet' (https://agmarknet.gov.in/). This platform serves as a comprehensive hub, connecting agricultural markets, State Marketing boards/Directorates, and key National and International Organizations through an extensive information network. The price data is collected from specific markets: Tomato from the Shahdara market in Delhi, Onion from the Lasalgaon market in Maharashtra, and Potato from the Farrukhabad market in Uttar Pradesh. Additionally, weekly weather-related data such as precipitation and temperature, tailored to the markets (Shahdara, Lasalgaon and Farrukhabad) associated with the respective TOP crops, is obtained from NASA POWER (https://power.larc.nasa.gov/). NASA POWER is a repository of solar and meteorological datasets generated through NASA's research initiatives. These datasets cater to various applications, including renewable energy, building energy efficiency, and agricultural applications. Table 1 provides detailed information about the datasets considered for the present study (Fig. 4).

A map highlighting selected vegetable markets across India.
The Table 2 presents the statistical characteristics of TOP prices, while the accompanying figures (Fig. 5, 6, 7) display the actual time series plots of the datasets. The Table 2 delineates the varying price ranges among the TOP crops. Notably, the standard deviation, a straightforward measure, exposes the irregularity within the series. Analysis of skewness demonstrates that all price series exhibit positive skewness. Additionally, the kurtosis results indicate that the excess kurtosis statistic predominantly signifies leptokurtic features within the data, except for tomato price series, which display platykurtic characteristics. These findings underscore the non-normal nature of the data, a fact further affirmed by the Jarque–Bera test and Shapiro–Wilk’s test38,57.

Weekly trends of tomato prices alongside precipitation and temperature variables.

Weekly trends of onion prices alongside precipitation and temperature variables.

Weekly trends of potato prices alongside precipitation and temperature variables.
Test for stationarity
One crucial aspect of time-series analysis involves assessing data stationarity, where a series is considered stationary if it maintains a consistent mean and variance over time38,57,58. To evaluate this property, the Augmented Dickey-Fuller (ADF) was employed. The results presented in Table 3, provide conclusive evidence regarding the stationarity of the series.
Test for nonlinearity
The nonparametric Brock-Dechert-Scheinkman (BDS) test was employed to assess the nonlinearity within the data series. The results presented in Table 4 reveal that the probability values calculated within the range of 0.5 \(\sigma\) to 2.0 \(\sigma\) strongly support the presence of nonlinearity in the series, particularly for embedding dimensions 2 and 338,57,58.
However, the ML and DL models, employed to handle the agricultural time series data are assumption-free and efficient in the extraction of appropriate information from time-dependent data.
Correlation analysis
Correlation determines the association between two variables which are linearly associated. Table 5 reveals a positive correlation between tomato and potato prices with both precipitation and temperature. This suggests that when precipitation and temperature rise, the prices of tomatoes and potatoes also tend to increase, and vice versa. Conversely, onion prices demonstrate a negative correlation with precipitation, indicating that higher levels of precipitation are associated with lower onion prices. Additionally, temperature shows a positive correlation with onion prices, implying that higher temperatures are linked to higher onion prices.
Data pre-processing
Data pre-processing plays a crucial role in transforming raw data into a format conducive to effective analysis. By employing data mining techniques, Data pre-processing enhances usability and overall effectiveness, ensuring the data's quality and reliability for subsequent analyses.
Imputation techniques
In dealing with time series data, missing or uncollected data points are a common challenge, where each data point holds chronological significance. To address this, various imputation methods were considered, including Mean imputation, K-Nearest Neighbors (KNN) imputation, and Kalman smoothing imputation38.
a) Mean imputation:
Mean imputation involves replacing missing values with the mean of the available data for that variable. The formula for mean imputation is:
b) K-Nearest neighbors (KNN) imputation:
KNN imputation estimates missing values based on the values of their nearest neighbors in the dataset. The formula for KNN imputation can be represented as a weighted average of k nearest neighbors' values:
where \({w}_{i}\) represents the weight assigned to the \({i}^{th}\) neighbor, often based on inverse distance or similarity measures.
c) Kalman smoothing imputation:
Kalman smoothing imputation is a bit more complex and involves the use of Kalman filter equations. In the context of imputation, the process can be simplified as follows:
Prediction step:
Update step (Incorporating observation):
where,
\({\widehat{X}}_{t|t-1}\) is the predicted state at time \(t\) given data up to time \(t-1\)
\({P}_{t|t-1}\) is the predicted error covariance at time \(t\) given data up to time \(t-1\)
\(F\) is the state transition matrix.
\(Q\) is the process noise covariance matrix.
\({K}_{t}\) is the Kalman gain.
\(H\) is the observation matrix.
\(R\) is the measurement noise covariance matrix.
Mean imputation, a basic yet limited method, often leads to biased estimates and fails to capture intricate data relationships. KNN imputation, while more sophisticated, is highly sensitive to parameters, such as the number of neighbors and distance metrics, impacting its accuracy. In contrast, Kalman smoothing imputation, tailored for time series data, overcomes these limitations. By incorporating observed data and temporal dependencies, it provides accurate imputations, especially in the presence of missing or noisy data points. Among the considered methods, Kalman smoothing imputation emerged as the superior choice for time series datasets. Leveraging the sequential nature of the data, Kalman smoothing optimizes estimates, providing superior imputation quality even amidst missing or noisy data, making it the method of choice for enhancing time series datasets' integrity and reliability in our study. The datasets obtained after imputation are further utilized for subsequent analysis steps.
Min–max normalization
After imputation, the datasets are split into two segments: the training set and the test set, divided in a 90:10 ratio, respectively38. Following this division, the values in the datasets are normalized to a range of 0 to 1 without altering its shape using the following equation:
where \({X}_{min}\), \({X}_{max}\) and \({X}_{i}\) are the minimum, maximum and observation at time \(i\), respectively and \({X}_{i}{\prime}\) is the rescaled value.
Model building
The development of forecasting models involves two main stages: model training and hyperparameter tuning.
Model training The training set encompassing 90 percent of the data, reflecting historical information and the testing set comprises sequential data points equivalent to the number of forecasted days, derived from the remaining 10 percent of the dataset. This systematic approach ensures effective model training and evaluation57,58. Throughout the model training process, the target variable (the price series), is incorporated alongside exogenous variables such as precipitation, temperature alone, and their combined effects. This inclusion of extra information aims to enhance the models' forecasting performance. Subsequently, the model is refined by training on these datasets, considering the interplay of all variables. This methodology ensures a comprehensive analysis and robust evaluation of the forecasting models.
Hyperparameter tuning Here, a detailed overview of the hyperparameters utilized in constructing a diverse range of forecasting models. The fine-tuning process involved employing the random search approach57, although it's important to note that ARIMAX and MLR models did not require hyperparameter tuning, as they lack such parameters. Specifically, hyperparameters were optimized for ML and DL models through random search technique. The training accuracy of these models was rigorously evaluated across various randomly selected hyperparameter combinations, with the final hyperparameter configuration selected based on achieving the highest accuracy (Table 6). In our study, we proposed forecasting models for three distinct agricultural crops. For each crop, forecasting was conducted using eight different algorithms: ARIMAX, MLR, ANN, SVR, RFR, XGBoost, NBEATSX, and TransformerX. This comprehensive analysis involved the construction and comparison of total of 69 forecasting models, offering a thorough exploration of forecasting techniques.
Model evaluation
The models were evaluated on the test dataset, comprising the last 10 percent of the complete dataset. Evaluation metrics included Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), Symmetrix Mean Absolute Percentage Error (sMAPE), Mean Absolute Scaled Error (MASE) and Quantile Loss (QL).
a) Root Mean Squared Error (RMSE)
b) Mean Absolute Error (MAE)
c) Symmetric Mean Absolute Percentage Error (sMAPE)
d) Mean Absolute Scaled Error (MASE)
e) Quantile Loss (QL)
where, \(q=0.5\) and \({\rho }_{q}\) is the quantile loss function
where, \({y}_{i}\) is the true values of the variable being predicted, \(\widehat{y}\) is the predicted values of the variable and \(N\) is the number of observations in the dataset.
Experiment and results
The research conducted in this study utilized a computer system equipped with 8 GB of RAM, a 512 GB SSD, and an AMD Ryzen 7 5700U processor with Radeon Graphics clocked at 1.80 GHz. The operating system employed was Windows 11, and the source code was developed using Python 3.8 interpreter. Various packages were utilized in the development process, including Keras, TensorFlow 2.0, CUDA 10.1.0, scikit-learn 0.23.0, and pandas 1.1.2.
In the subsequent section, we present a comprehensive analysis of our forecasting models' performance for three essential agricultural commodities: Tomato, Onion, and Potato. The models were evaluated concerning two crucial exogenous variables: Precipitation and Temperature, individually and in combination. Our objective is to assess how effectively these models capture the intricate relationships between exogenous factors and crop prices. The models considered in our study include traditional methods such as ARIMAX, MLR as well as advanced ML techniques like ANN, SVR, RFR and XGBoost, and cutting-edge DL architectures—TransformerX and NBEATSX. However, the TransformerX model lacks the ability to study combined effect of exogenous variables. The models' forecasting performances were meticulously evaluated using the metrics of RMSE, MAE, sMAPE, MASE and QL.
Tomato price forecasting
When analysing the impact of precipitation, the DL models, NBEATSX and TransformerX, outperformed all others, as reported in Table 7. NBEATSX exhibited remarkable accuracy, yielding an RMSE of 256.36, MAE of 135.44, sMAPE of 36.14, MASE of 1.08 and QL of 67.72. TransformerX, not far behind, achieved an RMSE of 313.34, MAE of 170.21, sMAPE of 38.30, MASE of 1.15 and QL of 70.10. Incorporating temperature as an exogenous variable, NBEATSX again emerged as the leader with an impressive RMSE of 250.64, MAE of 131.34, sMAPE of 35.80, MASE of 1.04 and QL of 65.67, showcasing its ability to discern subtle patterns. TransformerX, with an RMSE of 328.37, MAE of 169.89, sMAPE of 39.78, MASE of 1.37 and QL of 74.94, also demonstrated competitive performance. When both precipitation and temperature were considered, NBEATSX continued its dominance with an RMSE of 250.29, MAE of 130.56, sMAPE of 35.60, MASE of 1.04 and QL of 65.28, illustrating its adaptability to multivariable scenarios. TransformerX currently lacks the capability to handle multiple input variables simultaneously. There is a pressing need to enhance its functionality to accommodate the processing of multiple variables concurrently. These outcomes emphasize the DL models' proficiency in understanding the complex interactions between precipitation, temperature and tomato prices.
Onion price forecasting
In the context of precipitation, NBEATSX showcased exceptional accuracy, yielding an RMSE of 35.68, MAE of 23.48, sMAPE of 11.40, MASE of 1.05 and QL of 11.74, while TransformerX achieved an RMSE of 42.48, MAE of 26.79, sMAPE of 12.10, MASE of 1.34 and QL of 11.39. Considering Temperature, NBEATSX stood out with an RMSE of 37.97, MAE of 22.47, sMAPE of 11.03, MASE of 1.009 and QL of 11.23. TransformerX followed closely, recording an RMSE of 40.89, MAE of 25.55, sMAPE of 11.86, MASE of 1.28 and QL of 12.77, underscoring its competence in this scenario. Even with the combined influence of precipitation and temperature, NBEATSX retained its lead, achieving an RMSE of 41.98, MAE of 22.95, sMAPE of 11.25, MASE of 1.03 and QL of 11.47. These results substantiate the DL models' robustness in handling multiple exogenous variables for onion price forecasting (shown in Table 8). DL models significantly outperformed traditional methods, highlighting their capacity to precisely forecast onion prices influenced by precipitation and temperature.
Potato price forecasting
NBEATSX and TransformerX proved their performance using precipitation, achieving RMSE values of 34.0992 and 34.4187, MAE values of 21.24 and 26.77, sMAPE values of 18.89 and 19.67, MASE of 0.95 and 1.22, QL values of 10.67 and 13.38, respectively. Using temperature, NBEATSX emerged as the top performer with an RMSE of 33.7047, MAE of 20.76, sMAPE of 18.42, MASE of 0.92 and QL of 10.38, closely followed by TransformerX with an RMSE of 34.41, MAE of 27.77, sMAPE of 20.14, MASE of 1.26 and QL of 13.88. Even with the combined effect of precipitation and temperature, NBEATSX continued to excel, achieving an RMSE of 34.29, MAE of 20.73, sMAPE of 18.35, MASE of 0.92 and QL of 10.36. These outcomes reinforce the DL models' adaptability in handling diverse exogenous variables for accurate potato price forecasting. The results are reported in Table 9.
The choice of the forecasting model significantly impacts the accuracy of predictions. For instance, the NBEATSX and TransformerX models consistently outperformed other models across all scenarios (precipitation, temperature, and combined) in terms of RMSE, MAE, sMAPE, MASE and QL (from Tables 7, 8 and 9). This suggests the importance of selecting appropriate predictive models for accurate price forecasts. It's essential to consider that the values of error metrics are influenced by the scale of the data. These values indicate, on average, how much the model predictions deviate from the actual values. Both precipitation and temperature have noticeable effects on TOP price predictions. Precipitation and temperature seem to have a more substantial impact on predictions, as observed in the lower error metrics across various models. Different models respond differently to exogenous variables. For instance, the NBEATSX and TransformerX models exhibited relatively lower errors (Fig. 8), emphasizing the significance of precipitation and temperature in their predictions. On the other hand, models like ARIMAX, MLR, and ANN had higher error metrics (Fig. 8), suggesting potential challenges in capturing the complex relationships between these variables and TOP crops prices. The figures (Figs. 9, 10, 11, 12, 13, 14) depict the output of the NBEATSX and TransformerX forecasting models for the TOP crops in various markets. The graphs display model predictions in red, contrasting with the blue representation of the ground truth. Given that the test data constitutes 10 percent of the entire dataset, spanning approximately two years, the plots reveal a close alignment between actual and predicted values. This proximity underscores the robust performance of the models.

Radar plots for the comparison of performance of different models.

Forecasting performance of NBEATSX model on tomato prices.

Forecasting performance of TransformerX model on tomato prices.

Forecasting performance of NBEATSX model on onion prices.

Forecasting performance of TransformerX model on onion prices.

Forecasting performance of NBEATSX model on potato prices.

Forecasting performance of TransformerX model on potato prices.
The radar charts (Fig. 8) offer a visual representation of the performance evaluation of various models in predicting TOP prices. Each radar chart compares multiple evaluation metrics, including RMSE, MAE, sMAPE, MASE, and QL, across the different models. The radar charts identify the models that exhibit superior performance under specific conditions. Additionally, the charts highlight the potential strengths and weaknesses of each model in predicting TOP prices based on varying environmental factors. This visual representation facilitates the identification of the most suitable models for accurate price predictions under different conditions.
Discussion
Forecasting agricultural prices, especially for TOP commodities, presents a formidable challenge due to their high volatility and non-linear patterns. These crops constitute integral elements of the Indian dietary regime and play a pivotal role in its agricultural economy. Consequently, the development of reliable and effective forecasting methodologies for TOP commodities is of paramount significance. Apart from temporal fluctuations, weather data also exert influence on agricultural prices. Conventional regression models are characterized by two primary limitations: firstly, they fail to capture temporal variations and secondly, they are inadequate in capturing nonlinear dynamics. An ARIMAX model can capture temporal patterns, but modelling nonlinear patterns is beyond its capability. Statistical models, in general, are burdened by stringent assumptions that may not always be feasible to satisfy in real-world scenarios. Consequently, ML models such as ANN, SVM, RFR and XGBoost are increasingly favoured due to their data-driven nature and capacity to capture nonlinear patterns. Nonetheless, ML methods often lack inherent automatic feature extraction capabilities. Consequently, researchers frequently turn to DL models as the optimal solution to address this limitation. However, the existing DL architectures like LSTM and GRU are not capable of considering the exogenous variables. The transformer-based architecture exhibits enhanced accuracy in contrast to conventional architectures like LSTM and GRU, primarily attributed to its capacity for parallel input processing. Nonetheless, the Transformer architecture lacks suitability for handling exogenous variables. Therefore, in light of this study's objectives, TransformerX has been introduced to address this limitation, enabling the incorporation of both temporal and exogenous variables. Furthermore, the study also explored the NBEATSX architecture, renowned as an advanced DL architecture adept at accommodating both temporal patterns and exogenous variables.
The TransformerX model, utilizing the transformer architecture, incorporates a powerful attention mechanism that processes all data points concurrently, identifying long-range dependencies in the time series. This capacity to prioritize relevant data enhances its ability to discern complex patterns and external influences like precipitation and temperature. Conversely, NBEATSX, an extension of the original N-BEATS model, integrates these exogenous variables into its analysis. Its architecture, comprising stacks of fully connected layers, decomposes the time series into elements like trends and seasonality. This design enhances both interpretability and accuracy. The minimal requirement for data pre-processing and the ability to incorporate external variables render NBEATSX particularly effective in managing the dynamic and unpredictable nature of agricultural price data. Collectively, the architectural strengths of these models significantly boost their performance in forecasting agricultural prices, underscoring their importance in this field. Additionally, through radar plots (Fig. 8) and figures (Figs. 9, 10, 11, 12, 13, 14) illustrated the performance of the NBEATSX and TransformerX forecasting models for TOP crops in various markets, where the plots showed a close alignment between actual and predicted values, highlighting the models' robust performance. Conclusively, this research affirmed the potential of DL models in providing more precise agricultural price forecasts, a finding with significant practical implications for the agricultural market and farmers. By illustrating how these advanced models can be adapted to real-world contexts, the study contributed not only to academic knowledge but also provided tools for better decision-making in the field of agriculture. However, it's important to note the distinct capabilities of the NBEATSX and TransformerX models. While NBEATSX is capable of analysing multiple exogenous variables simultaneously, the TransformerX model does not inherently possess this ability. This distinction is crucial, especially considering that most DL models are primarily designed for univariate time series data. Recognizing this limitation highlights an area for future development: extending these DL models to more effectively handle multivariate time frames. Our study's success in forecasting prices of agricultural commodities under the influence of precipitation and temperature opens avenues for similar applications in financial time series datasets. In such scenarios, corresponding exogenous variables like news data, social media post and corporate reports etc. could be integrated, further expanding the utility and applicability of these DL models in diverse domains. This potential extension not only underscores the versatility of DL models but also points towards the need for continuous evolution in their design and application. Pandit et al.59, Shaikh et al.60, Abed et al.61, Mroua and Lamine62 and Hu et al.63 conducted similar studies in different domains and portrayed the efficiency of DL models on different datasets in various domains. Jaiswal et al.64 found the NARX model superior for forecasting soybean oil prices, while Alam et al.15 showed improved performance with hybrid models like ARIMAX-ANN and ARIMAX-SVM for rice yield forecasting. But none of the previous studies used DL models, that gap we have filled with the present study. In the future, the advanced architecture RESNET could potentially undergo modification to yield RESNETX for agricultural price forecasting. Furthermore, alongside temporal and exogenous variables, spatial variations may also be included.
Conclusions
In the context of economies like India, where agriculture plays a vital role, the prediction of crop prices is of significant importance, yet challenging due to its inherent nonlinear nature. Addressing this, our study introduced advanced DL architectures, namely TransformerX and NBEATSX, for more accurate forecasting. TransformerX processes input data in parallel, utilizing a self-attention mechanism, allowing for a more comprehensive analysis of complex data patterns. Concurrently, NBEATSX approaches data analysis by breaking down time series into understandable components, such as trends and seasonality, through its unique architecture of stacked fully connected neural networks. We benchmarked these models against traditional ones like ARIMAX, MLR, ANN, SVR, RFR and XGBoost, using weekly price data of Tomato, Onion and Potato from various Indian markets (2002–2023), sourced from the AgMarknet website, alongside weather variables from NASA POWER. Our findings confirmed that the proposed DL models outshine conventional models in predictive accuracy, evaluated using metrics like RMSE, MAE, sMAPE, MASE and QL. This research paves the way for future exploration, where the behaviour of financial time series and related exogenous variables, such as news data, social media posts etc. could be effectively integrated and analysed using these sophisticated DL techniques. Recognizing TransformerX's limitation in handling multiple exogenous variables underscores the need to extend DL models. This could involve modifying architectures like RESNET to accommodate exogenous variables (RESNETX) and integrating spatial variations with temporal factors for more comprehensive forecasting capabilities in future studies.
Data availability
The datasets utilized and/or analysed in the present study are accessible from the corresponding author upon reasonable request.
Code availability
The data utilized in this study will be available on reasonable request to the corresponding authors.
References
Crofils, C., Gallic, E. & Vermandel, G. The Dynamic Effects of Weather Shocks on Agricultural Production. https://egallic.fr/Recherche/WP/Crofils-et-al_2023_Weather-Peru.pdf (2023).
Gulati, A., Wardhan, H. & Sharma, P. Tomato, Onion and Potato (TOP) Value Chains. In Agricultural Value Chains in India (eds Gulati, A. et al.) 33–97 (Springer, 2022). https://doi.org/10.1007/978-981-33-4268-2_3.
Choong, K. Y., Raof, R. A. A., Sudin, S. & Ong, R. J. Time series analysis for vegetable price forecasting in E-commerce platform: A review. J. Phys. Conf. Ser. 1878, 012071–012082 (2021).
Joshi, A. M. & Patel, S. G. Stacked ensembles: Boosting model performance to new heights based on regression for forecasting future wheat commodities prices in Gujarat. Indian J. Sci. Technol. 15, 2194–2203 (2022).
Thimmegowda, M. N. et al. Weather-based statistical and neural network tools for forecasting rice yields in major growing districts of Karnataka. Agronomy 13, 704–724 (2023).
Cao, G., He, C. & Xu, W. Effect of weather on agricultural futures markets on the basis of DCCA cross-correlation coefficient analysis. Fluct. Noise Lett. 15, 1650012 (2016).
Rathod, S. et al. Modeling and forecasting of rice prices in India during the COVID-19 lockdown using machine learning approaches. Agronomy 12, 2133–2146 (2022).
Manogna, R. L. & Mishra, A. K. Forecasting spot prices of agricultural commodities in India: Application of deep-learning models. Intell. Syst. Account. Finance Manag. 28, 72–83 (2021).
Chatzopoulos, T., Pérez Domínguez, I., Zampieri, M. & Toreti, A. Climate extremes and agricultural commodity markets: A global economic analysis of regionally simulated events. Weather Clim. Extrem. 27, 100193–100207 (2020).
Letta, M., Montalbano, P. & Pierre, G. Weather shocks, traders’ expectations, and food prices. Am. J. Agric. Econ. 104, 1100–1119 (2022).
Murugesan, R., Mishra, E. & Krishnan, A. H. Deep learning based models: basic LSTM, Bi LSTM, Stacked LSTM, CNN LSTM and Conv LSTM to forecast agricultural commodities prices. Res Sq https://doi.org/10.21203/rs.3.rs-740568/v1 (2021).
Kumari, P., Goswami, V., Harshith, N. & Pundir, R. S. Recurrent neural network architecture for forecasting banana prices in Gujarat India. PLoS One 18, 0275702–0275719 (2023).
Champika, J. A. & Mugera, A. Analysis of price behavior in Sri Lankan vegetable market. J. Agribus. Market. 10, 4–29 (2023).
Adebanjo, A. B. et al. Assessing the price relationship and weather impact on selected pairs of closely related commodities. Glob. J. Comput. Sci. Technol. C Softw. Data Eng. 21, 21–59 (2021).
Alam, W. et al. Improved ARIMAX modal based on ANN and SVM approaches for forecasting rice yield using weather variables. Indian J. Agric. Sci. 88, 1909–1913 (2018).
Yang, H. et al. The dynamic impacts of weather changes on vegetable price fluctuations in Shandong province, China: An analysis based on VAR and TVP-VAR models. Agronomy 12, 2680–2707 (2022).
Makridakis, S., Spiliotis, E. & Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS One 13, e0194889-0194915 (2018).
Avinash, G. et al. Hidden Markov guided deep learning models for forecasting highly volatile agricultural commodity prices. Soc. Sci. Res. Netw. https://doi.org/10.2139/ssrn.4594856 (2023).
Raza, A. et al. Application of non-conventional soft computing approaches for estimation of reference evapotranspiration in various climatic regions. Theor. Appl. Climatol. 139, 1459–1477 (2020).
Oktoviany, P., Knobloch, R. & Korn, R. A machine learning-based price state prediction model for agricultural commodities using external factors. Decis. Econ. Finance 44, 1063–1085 (2021).
Sun, T.-T., Wu, T., Chang, H.-L. & Tanasescu, C. Global agricultural commodity market responses to extreme weather. Econ. Res. -Ekonomska Istraživanja 36, 1–24 (2023).
Wang, Y. et al. TimeXer: Empowering Transformers for Time Series Forecasting with Exogenous Variables. arXiv preprint arXiv:2402.19072. (2024) https://doi.org/10.48550/arXiv.2402.19072.
Anggraeni, W., Andri, K. B., Sumaryanto, & Mahananto, F. The performance of ARIMAX model and vector autoregressive (VAR) model in forecasting strategic commodity price in Indonesia. Proc. Comput. Sci. 124, 189–196 (2017).
Medar, R. A., Rajpurohit, V. S. & Ambekar, A. M. Sugarcane crop yield forecasting model using supervised machine learning. Int. J. Intell. Syst. Appl. 11, 11–20 (2019).
Zhang, X. et al. Annual and non-monsoon rainfall prediction modelling using SVR-MLP: An empirical study from Odisha. IEEE Access 8, 30223–30233 (2020).
Sun, F. et al. Agricultural product price forecasting methods: A review. Agriculture 13, 1671 (2023).
Yuan, C. Z. & Ling, S. K. Long Short-Term Memory Model Based Agriculture Commodity Price Prediction Application. in Proceedings of the 2020 2nd International Conference on Information Technology and Computer Communications 43–49 (ACM, New York, NY, USA, 2020). https://doi.org/10.1145/3417473.3417481.
Cho, W., Kim, S., Na, M. & Na, I. Forecasting of Tomato yields using attention-based LSTM network and ARMA model. Electronics (Basel) 10, 1576–1590 (2021).
Olivares, K. G., Challu, C., Marcjasz, G., Weron, R. & Dubrawski, A. Neural basis expansion analysis with exogenous variables: Forecasting electricity prices with NBEATSx. Int J Forecast 39, 884–900 (2023).
Gobato Souto, H. & Moradi, A. Introducing NBEATSx to realized volatility forecasting. SSRN Electron. J. https://doi.org/10.2139/ssrn.4398498 (2023).
Panja, M. et al. An ensemble neural network approach to forecast Dengue outbreak based on climatic condition. Chaos Solitons Fractals 167, 113124 (2023).
Mohanty, M. K., Thakurta, P. K. G. & Kar, S. Agricultural commodity price prediction model: A machine learning framework. Neural Comput Appl 35, 15109–15128 (2023).
Ben Ameur, H., Boubaker, S., Ftiti, Z., Louhichi, W. & Tissaoui, K. Forecasting commodity prices: Empirical evidence using deep learning tools. Ann. Oper. Res. https://doi.org/10.1007/s10479-022-05076-6 (2023).
Tami, M. & Owda, A. Y. Efficient commodity price forecasting using long short-term memory model. IAES Int. J. Artif. Intell.. 13, 994 (2024).
Vinay, H. T., Pavithra, V., Jagadeesh, M. S., Avinash, G. & Harish Nayak, G. H. A comparative analysis of time series models for onion price forecasting: insights for agricultural economics. J. Exp. Agric. Int. 46, 146–154 (2024).
Rana, H., Farooq, M. U., Kazi, A. K., Baig, M. A. & Akhtar, M. A. Prediction of agricultural commodity prices using big data framework. Eng. Technol. Appl. Sci. Res. 14, 12652–12658 (2024).
Sari, M., Duran, S., Kutlu, H., Guloglu, B. & Atik, Z. Various optimized machine learning techniques to predict agricultural commodity prices. Neural Comput. Appl. https://doi.org/10.1007/s00521-024-09679-x (2024).
Avinash, G. et al. Hidden Markov guided Deep Learning models for forecasting highly volatile agricultural commodity prices. Appl. Soft Comput. 158, 111557 (2024).
Guo, Y. et al. Agricultural price prediction based on combined forecasting model under spatial-temporal influencing factors. Sustainability 14, 10483–10501 (2022).
Rose, N. & Dolega, L. It’s the weather: Quantifying the impact of weather on retail sales. Appl Spat Anal Policy 15, 189–214 (2022).
Vennila, S. et al. Artificial neural network techniques for predicting severity of Spodoptera litura(Fabricius) on groundnut. J Environ. Biol. 38, 449–456 (2017).
Belouz, K., Nourani, A., Zereg, S. & Bencheikh, A. Prediction of greenhouse tomato yield using artificial neural networks combined with sensitivity analysis. Sci. Hortic. 293, 110666 (2022).
Panapakidis, I. P. & Dagoumas, A. S. Day-ahead electricity price forecasting via the application of artificial neural network based models. Appl. Energy 172, 132–151 (2016).
Laurindo, B. S. et al. Optimization of the number of evaluations for early blight disease in tomato accessions using artificial neural networks. Sci. Hortic. 218, 171–176 (2017).
Kishor Kumar, M. et al. Non-destructive estimation of leaf area of durian (Durio zibethinus)–An artificial neural network approach. Sci. Hortic. 219, 319–325 (2017).
Vapnik, V. & Chapelle, O. Bounds on error expectation for support vector machines. Neural Comput. 12, 2013–2036 (2000).
Zakrani, A., Najm, A. & Marzak, A. Support Vector Regression Based on Grid-Search Method for Agile Software Effort Prediction. in 2018 IEEE 5th International Congress on Information Science and Technology (CiSt) 1–6 (IEEE, 2018). https://doi.org/10.1109/CIST.2018.8596370.
Esfandiarpour-Boroujeni, I., Karimi, E., Shirani, H., Esmaeilizadeh, M. & Mosleh, Z. Yield prediction of apricot using a hybrid particle swarm optimization-imperialist competitive algorithm- support vector regression (PSO-ICA-SVR) method. Sci. Hortic. 257, 108756 (2019).
Bowden, C., Foster, T. & Parkes, B. Identifying links between monsoon variability and rice production in India through machine learning. Sci. Rep. 13, 2446 (2023).
Paul, R. K. et al. Machine learning techniques for forecasting agricultural prices: A case of brinjal in Odisha. India. PLoS One 17, e0270553-0270570 (2022).
Ribeiro, M. H. D. M. & dos Santos Coelho, L. Ensemble approach based on bagging, boosting and stacking for short-term prediction in agribusiness time series. Appl. Soft. Comput. 86, 105837 (2020).
Vaswani, A. et al. Attention Is All You Need. in 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA. 1–11 (2017).
Zeng, S., Graf, F., Hofer, C. & Kwitt, R. Topological attention for time series forecasting. Adv. Neural Inf. Process. Syst. 34, 1–21 (2021).
Ahmed, S. et al. Transformers in time-series analysis: A tutorial. Circuits Syst. Signal Process 42, 7433–7466 (2023).
Rodrawangpai, B. & Daungjaiboon, W. Improving text classification with transformers and layer normalization. Machine Learn. Appl. 10, 100403 (2022).
Wu, N., Green, B., Ben, X. & O’Banion, S. Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case. arXiv preprint arXiv:2001.08317. https://doi.org/10.48550/arXiv.2001.08317 (2020).
Nayak, G. H. H. et al. Modelling monthly rainfall of India through transformer-based deep learning architecture. Model Earth Syst. Environ. https://doi.org/10.1007/s40808-023-01944-7 (2024).
Jaiswal, R., Jha, G. K., Kumar, R. R. & Choudhary, K. Deep long short-term memory based model for agricultural price forecasting. Neural Comput. Appl. 34, 4661–4676 (2022).
Pandit, P. et al. Hybrid time series models with exogenous variable for improved yield forecasting of major Rabi crops in India. Sci. Rep. 13, 22240 (2023).
Shaikh, A. K., Nazir, A., Khan, I. & Shah, A. S. Short term energy consumption forecasting using neural basis expansion analysis for interpretable time series. Sci. Rep. 12, 22562 (2022).
Abed, M., Imteaz, M. A., Ahmed, A. N. & Huang, Y. F. Modelling monthly pan evaporation utilising random forest and deep learning algorithms. Sci. Rep. 12, 13132 (2022).
Mroua, M. & Lamine, A. Financial time series prediction under Covid-19 pandemic crisis with long short-term memory (LSTM) network. Humanit. Soc. Sci. Commun. 10, 530 (2023).
Hu, Y., Lyu, L., Wang, N., Zhou, X. & Fang, M. Application of hybrid improved temporal convolution network model in time series prediction of river water quality. Sci. Rep. 13, 11260 (2023).
Jaiswal, R., Jha, G. K., Kumar, R. R. & Lama, A. Agricultural price forecasting using NARX model for soybean oil. Curr. Sci. 125, 79–84 (2023).
Acknowledgements
The first author expresses gratitude to the Indian Council of Agricultural Research (ICAR) for providing financial assistance in the form of an ICAR-SRF fellowship. Special thanks are extended to The Graduate School, ICAR-Indian Agricultural Research Institute (ICAR-IARI), New Delhi and ICAR-Indian Agricultural Statistics Research Institute (ICAR-IASRI), New Delhi, for their support and provision of necessary facilities that facilitated the successful completion of this study.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Harish Nayak G. H., Wasi Alam, G. Avinash, Mrinmoy Ray, Rajeev Ranjan Kumar. The first draft of the manuscript was written by Harish Nayak G. H., G. Avinash, Mrinmoy Ray, Rajeev Ranjan Kumar and Wasi Alam commented on its improvement. Reviewing is done by K. N. Singh and Chandan Kumar Deb. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
See Tables
10,
11,
12,
13.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Nayak, G.H.H., Alam, M.W., Singh, K.N. et al. Exogenous variable driven deep learning models for improved price forecasting of TOP crops in India. Sci Rep 14, 17203 (2024). https://doi.org/10.1038/s41598-024-68040-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-68040-3
Keywords
This article is cited by
-
Hybrid Metaheuristic Feature Selection with Binary Puma Optimizer–Stochastic Fractal Search for Robust Potato Price Prediction
Potato Research (2026)
-
A stacked ensemble of LSTM, GRU and XGBoost with residual learning for corn futures price forecasting
Applied Intelligence (2026)
-
Time series forecasting of bed occupancy in mental health facilities in India using machine learning
Scientific Reports (2025)
-
TDLoss: A Triplet Decomposition Loss Function for Accurate and Robust Potato Price Forecasting
Potato Research (2025)
-
Exploring artificial intelligence applications in construction using a black grey white box approach for predicting project schedule performance in India
Discover Computing (2025)
