
Abstract
Conveyor belt deviation is a commmon and severe type of fault in belt conveyor systems, often resulting in significant economic losses and potential environment pollution. Traditional detection methods have obvious limitations in fault localization precision and analysis accuracy, unable to meet the demands of efficient and real-time fault detection in complex industrial scenarios. To address these issues, this paper proposes an improved detection algorithm based on YOLOv8, aiming to achieve efficient and accurate detection during the operation of the belt. Firstly, an Enhanced Squeeze-and-Excitation (ESE) module is incorporated into C2f to boost feature extraction for rollers and belts. Secondly, the construction of the BiFPN_DoubleAttention module in the neck network enhances bidirectional feature fusion and attention mechanism, thereby improving multi-scale object localization accuracy under complex environments. Then, a Multi-Head Self-Attention (MHSA) mechanism is introduced in the head network, better capturing positional features of small roller targets and belt areas in various environments, thus enhancing detection performance. Finally, extensive experiments are conducted on a self-built dataset, achieving an accuracy of 98.1%, mAP0.5 of 99.0%, and a detection speed of 46 frames per second (FPS). This method effectively handles variations and disturbances in the conveyor belt transportation environment, meeting real-time diagnostic needs for belt misalignment in the industry.
Similar content being viewed by others

Introduction
The conveyor belt is an essential piece of equipment in modern secure production and transport, providing continuous transit of bulk materials. It primarily consists of belts, rollers, racks, tensioning devices, transmission devices, and other auxiliary devices. The conveyor belt offers several advantages, including large conveying volume, long transport distance, stable operation, low power consumption, and easy loading and unloading. It is widely used in various industries such as coal mining, construction sites, power supply, and metallurgy. With the expansion of industrial production scale, the carrying capacity of the conveyor belt has increased, bringing substantial economic benefits to the material handling industry. As the conveyor belt accounts for 40–60% of the total cost of the conveyor, continuous improvement in its design and performance is crucial. The maximum length of the conveyor can reach several kilometers, and its running status directly affects the stability of the entire production and transportation process1.
The harsh and complicated working environment of conveyor belts often leads to deviation faults2. Conveyor belt deviation refers to the belt running process where the conveyor belt surface center line deviates from the frame center line, gradually running to one side. According to statistics, conveyor belt stoppage, production stoppage, and other accidents caused by belt deviation account for about 10–30%. The fault of conveyor belt deviation results in belt wear, material spillage, wasted resources, and environmental pollution. Severe cases can cause fires, injuries, and property damage3. Moreover, if the conveyor belt deviation problem is not well solved, it restricts the wider application of belt conveyors, impeding their development.
With the advancement of state detection technology, conveyor belt runout detection methods have evolved from contact methods to non-contact methods. The contact type is mainly divided into three: manual inspection, sensor-based, and mechanical measurement4. The manual inspection method is labor-intensive, and detection accuracy decreases over time. Sensor-based methods typically require deviation sensors5, symmetrically mounted on the frame on either side of the conveyor belt to activate travel switches. When the conveyor belt tilts, the edge pushes the deviation sensors to trigger the travel switches to send out deviation correction signals, which are fed back to the terminals to complete conveyor belt deviation correction detection. Mechanical measurement methods include installing correction rollers or emergency switches for the conveyor belt, but they only work when the conveyor belt touches the vertical rollers or emergency switches. The structure and principle of this method are simple, but it causes wear on the conveyor belt edges and poor detection accuracy.
Non-contact detection methods, which incorporate machine vision6,7,8 algorithms into conveyor belt fault prediction, obtain relevant fault information from the conveyor’s operating state and predict future fault trends9. Many high-performing methods utilize the Canny edge detection algorithm10 for traditional machine vision techniques, extracting belt edge features. Liu11 proposed an approach using edge detection and line fitting to extract the belt edge, proposing an analysis method to quickly determine if the belt has deviated from its path. Wang12divided the conveyor belt into regions of interest, extracted straight line information of the conveyor belt edges through image enhancement, wavelet transformation, Canny edge detection, and Hough transform, and conducted belt deviation detection with a reference line of a normal running conveyor belt. In recent years, In recent years, deep learning has been broadly applied to machine vision for image recognition, target detection, and classification13. More scholars are using deep learning’s target detection to solve conveyor belt runout detection in complex environments14,15.
Wlodarczyk-Sielicka16introduced a novel method for tape edge detection utilizing deep convolutional networks, FCN (Fully Convolutional Networks)17, DeepLab18, HED (Holistically-Nested Edge Detection)19, This method offers reliable target detection and anti-jamming capabilities, addressing the shortcomings of untimely processing in traditional mechanical anti-bias methods and the diminished accuracy of machine vision for strip edge detection. However, this approach incurs a relatively large deviation degree (DD) error. Unlu20 employed a real-time belt detection algorithm based on multi-scale feature fusion networks, which improves accuracy and real-time performance through the use of deep divisible convolution to lightweight the model and feature pyramid networks (FPNs) for information fusion from different feature layers. Still, given image segmentation’s pixel-level operation, performance tops out at 13.4 FPS. Zhang21 proposed a new deep learning-based method for tape deviation monitoring, integrating CSPDarknet and Spatial Pyramid Pooling (SPP) as the backbone extraction network of YOLOv522,23,24, boosting straight line detection and improving belt edge detection accuracy. This addresses complex background strip edge detection challenges. Sun25 developed a system for curved belt deviation assessment using an ARIMA-LSTM combined prediction model and the OC-SVM algorithm, enabling real-time detection, prediction, correction, and warning of strip abnormal deviation. Wang26 introduced a variable step size row anchor segmentation method employing the UFLD algorithm, incorporated a Convolutional Block Attention Module (CBAM) for enhanced feature extraction, and improved the convolutional and downsampling operations in the ResNet-18 Stem and residual modules to better detect conveyor belt edges.
In summary, this paper aims to accurately detect conveyor belt runout issues in complex environments and ensure safe material transport. It utilizes an improved YOLOv827,28,29 algorithm combined with a conveyor belt runout discrimination criterion to determine transport state safety. Firstly, the paper adopts the EffectiveSE mechanism based on the YOLOv8 target detection network structure, enhancing attention to target region feature information and improving detection accuracy for fuzzy and small target regions. Second, the BiFPN_DoubleAttention module is introduced for bidirectional feature fusion and weighted rectification on multiple feature scales, enabling better combination of low-level detail and high-level semantic information to improve detection accuracy and robustness. Finally, the P5/32-Large is equipped with the MHSA Multi-Head Self-Attention Mechanism, allowing better understanding of global structure and relative positional relationships for small (rollers) and larger (conveyor belt area) target objects, improving detection performance. Compared to the traditional YOLOv8 algorithm, this method performs better for roller and conveyor belt detection, enhancing model accuracy, robustness, and application performance.
Materials and methods
YOLOv8 Model Architecture
YOLOv8 is a cutting-edge SOTA model, built upon previous versions of the YOLO series, introducing significant improvements and innovations to enhance performance and flexibility, making it the best choice for tasks such as image classification, object detection, and instance segmentation. The model proposes a new backbone network, a new Anchor-Free Detection header, and a new loss function, operating efficiently on a wide range of hardware platforms. The network structure of YOLOv8 consists mainly of a backbone, a neck, and a head.
Backbone also adopts the concept of the CSP module and replaces the C3 module in Yolov5 with the C2f module, which combines C3 and ELAN30 in YOLOv731,32, adopting the gradient diversion connection, enriching the information flow of the feature extraction network while maintaining its lightness. The SPPF (Spatial Pyramid Pooling Fast) module in Yolov5 is utilized, connecting each layer in series by sequentially connecting three sizes and 3 max pools, improving the accuracy of object detection at different scales and reducing the computational workload and latency.
The neck utilizes the PAN-FPN33structure to enhance the fusion of features of differing dimensions and generate a feature pyramid. This structure comprises two parts: the feature pyramid network (FPN) and the path aggregation network (PAN). The FPN enables the bottom layer of the feature map to contain stronger image semantic information via top-down upsampling, while the PAN enables the top layer to contain image position information via bottom-up downsampling. The two parts of the features are finally fused, combining the FPN and PAN structures to realize the complementarity of shallow position information and deep semantic information, achieving feature diversity and completeness, and improving recognition performance.
The head is the predicted output part of the whole network. Unlike the coupled head of YOLOv5, YOLOv8 adopts a decoupled head design. The decoupled head uses two independent branches for target classification and prediction bounding box regression, with different loss functions for each task. Binary cross-entropy loss (BCE loss) is used for classification, while distribution focal loss (DFL)34and CioU35are used for bounding box regression. This detection structure improves accuracy and accelerates model convergence. Additionally, YOLOv8 is an anchorless detection model that directly predicts the object center, rather than predicting the distance from a known anchor frame. This reduces the number of frame predictions and accelerates the non-maximum suppression (NMS) process.
Different detection scene requirements divide YOLOv8 into five versions: YOLOv8n36,37,38, YOLOv8s39, YOLOv8m40, YOLOv8l41, and YOLOv8x42. Each version corresponds to different network depths and widths. Considering the conveyor belt runout detection model’s high precision and lightweight, this paper selects the YOLOv8n mesh, which has a small volume and high precision.
Improved methodology
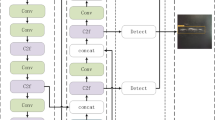
Traditional conveyor belt deflection detection methods were inaccurate, so this paper introduces a YOLOv8-based deflection detection model with improved backbone, neck, and head. The network structure of the improved algorithm is shown in Fig. 1.

The architecture of improved YOLOv8 network structure. The red boxes represent improvement points. C2f is used for concatenating different feature maps and other operations; CBS consists of Conv, BatchNorm, and SiLu activation functions for feature extraction; Spatial Pyramid Pooling Fast (SPPF) is used to increase feature diversity.
Backbone
The C2f module is a vital component of the YOLOv8 backbone network, which enhances feature representation and multi-scale information fusion through branching and connecting operations of the feature map. In this paper, we incorporate the EffectiveSE (Effective Squeeze and Extraction, ESE)43module into the C2f module, further improving the model’s feature selection and weight adjustment capabilities. This results in accurate detection of rollers and belts in complex, dynamically changing real-world environments such as mines, sandy fields, and quarries.
EffectiveSE is a convolutional neural network structure for image classification, an improved version of SENet (Squeeze-and-Excitation Networks)44. The Squeeze-Excitation (SE) channel attention module in SENet was found to inadvertently reduce computational efficiency due to the use of two fully connected (FC) layers in the SE module design. To address this, the SE module is redesigned as ESE by replacing these two FC layers with one that maintains the channel dimension, thus avoiding loss of channel information and improving performance The ESE process is defined as:
where\({{\rm X}_{div}} \in {R^{C \times W \times H}}\)is the diversified feature map calculated by \(1 \times 1\) conv in the OSA module. As a channel attentive feature descriptor, the \({A_{eSE}} \in {R^{C \times 1 \times 1}}\) is applied to the diversified feature map \({X_{div}}\) to make the diversified feature more informative. Finally, when using the residual connection, the input feature map is added to the refined feature map \({X_{refine}}\) The details of how the eSE module is plugged into the OSA module, are displayed in Fig. 2.

The overall architecture of the ESE module. \(\otimes\)indicates element-wise multiplication and \(\oplus\)denotes element-wise addition.
Neck
In the neck network structure of YOLOv8, we introduced the BiFPN_DoubleAtten module, which combines BiFPN_Concat2 and DoubleAttention. BiFPN_Concat2 enables weighted fusion of multi-layer features, effectively consolidating feature information from different scales. The DoubleAttention mechanism adjusts fused features with attention, enhancing the ability to focus on key regions. Overall, this module optimizes multi-scale feature fusion and significantly improves the capability to accurately detect multi-scale target positions in complex environments, including rollers and conveyor belts.
BiFPN45 is a target detection optimization module that is built upon the PANet structure. It is designed to reduce complexity by discarding small contributions and using a single input edge. Additionally, it assigns increasing input feature weights to differentiate the importance of features in the fusion process, thereby enhancing the multi-scale target feature fusion effect,
as shown in Fig. 3.

The network architecture of PANet and BiFPN. (a)PANet adds an additional bottom-up pathway on top of FPN; (b) BiFPN structure is based on PAN and uses the fast normalized fusion method for fusion with weights with better accuracy and efficiency trade-offs.
The BiFPN module adopts fast normalized fusion to avoid the unstable training caused by boundless fusion in weighted feature fusion, and the significant slowdown of GPU hardware caused by Softmax-based fusion. The calculation formula is as follows:
where the ReLU activation function is added after each \({w_i}\) to ensure that \({w_i} \geqslant 0\),\(\in =0.0001\)is used to avoid numerical instability, and the value of each normalized weight also falls between 0 and 1. Finally, BiFPN integrates bidirectional cross-scale connectivity and fast normalized fusion to obtain the final weighted feature pyramid network.
The attention mechanism is a process that imitates the human visual system, enabling a neural network to focus on the most relevant parts of the input data as it is processed. In computer vision, this means the network can dynamically select which parts of an image to focus on to improve performance on a task. Double Attention Networks (DAN)46 is a neural network architecture for computer vision tasks designed to efficiently capture both global and local information in an image to improve task performance(as shown in Fig. 4). It achieves this through the introduction of two attention modules, one for global information focusing on the overall structure of the image and one for local information focusing on local details. This architecture makes full use of the different information in the image within a deep neural network and is formulated as follows:

The computational graph of the proposed double attention block.
Head
After the last C2f module in the Head part of the YOLOv8 network structure, the Multi-Head Self-Attention (MHSA)47Mechanism is added to the P5/32-large layer to enhance the model’s ability to express detailed features in complex scenes, enabling better capture of positional features for small target rollers and large target conveyor from complex and dim backgrounds.
The Multi-Head Self-Attention (MHSA) module is a stack of N single-head self-attention modules, with multi-head attention forming a central component in the Transformer encoder structure. The feature mapping sequence is normalized and passed to the multi-head attention layer, which consists of single-head self-attention. Using a cubic linear mapping, each element is weighted according to the values of other elements. The single-head attention mechanism achieves sequence weighting by combining each element into query and key vectors, which undergo matrix multiplication, scaling, masking, and SoftMax operations, and are weighted by value vectors. Figure 5 shows the structure of the MHSA Multihead Self-Attention Mechanism.

The architecture of multi-head attention mechanism.
In the multi-head attention mechanism, the input sequence is first converted into query vectors, key vectors, and value vectors. Each head can learn different query vectors, key vectors, and value vectors. Then, each head computes the similarity between each query vector and each value vector and computes the corresponding weights. These weights are used to perform a weighted sum on the value vectors to generate an output sequence for each head. Finally, these output sequences are spliced together to form the final output sequence. The multi-head attention mechanism can effectively improve model performance and enable better capture of relevant information in input sequences. The MHSA multiple-head attention output formula is:
where \({W^O},{W_i}^{Q},W_{i}^{K}\) and \(W_{i}^{V}\) is the weight matrix; Satisfy \({W^O} \in {R^{hdk \times {d_{\bmod el}}}},{W_i}^{Q} \in {R^{{d_{\bmod el}} \times {d_Q}}},W_{i}^{K} \in {R^{{d_{\bmod el}} \times {d_K}}}\), and \(W_{i}^{V} \in {R^{{d_{\bmod el}} \times {d_v}}}\) respectively; h is the number of multiple attentions; \({d_{\bmod el}}\) and \({d_v}\) are the dimensions of model and V.
Experiments
Experimental environment
All experimental environments are based on the Linux operating system, with an Intel(R) Xeon(R) CPU E5-2680 v4 CPU, an NVIDIA GeForce RTX 4090 GPU, and 32GB of RAM. The programming environment utilizes the deep learning framework PyTorch version 1.8.0, implemented in Python 3.8. During model training, the number of epochs is set to 300, the batch_size is set to 32, and the initial learning rate is set to 0.01.
Datasets and preprocessing
To validate the effectiveness of the method, experiments were conducted on a self-constructed dataset. A total of 5,800 images were collected, and categorized into three types: underground mines, sand fields, and ore yards. The coal mine data consisted of 4,241 images, with 3,493 images self-collected from several coal mines and 748 images selected from public datasets. Additionally, 1,000 images of sand fields and 559 images of ore yards were selected from public datasets. These data included various working scenarios such as empty and loaded conditions, as well as day and night settings. The data were labeled with “0” for drum labeling and “1” for conveyor belt labeling. The dataset was then divided into training, testing, and validation sets in a 7:2:1 ratio. Figure 6 illustrates a portion of the dataset.

Enumeration of datasets in different scenarios.
Evaluation index
To assess the detection performance of the model, four indicators were used to evaluate the experimental results: Precision (P), Recall (R), F1-Score, and Mean Average Precision (mAP).
In the target detection test, TP (true positive) denotes a positive sample predicted by the model to be in the positive category, FP (false positive) denotes a negative sample predicted by the model to be in the positive category, and FN (false negative) denotes a positive sample predicted by the model to be in the negative category.
Precision is the ratio of true positive predictions to the total number of samples detected, and is used to assess model accuracy. The equation for precision is:
Recall is the ratio of the number of positive samples correctly predicted by the model to the number of actual positive samples, and is used to assess the comprehensiveness of the model’s detection. The equation for recall is:
The F1 score is the weighted average of precision and recall. The equation for the F1 score is defined as follows:
The mean average precision (mAP) is one of the key performance metrics used to evaluate target detection performance. It is the average of all average precision (AP) values in the dataset and describes the area under the precision-recall (P-R) curve. A higher mAP value indicates better detection performance of the model. The equation for mAP is:
where C is the total number of classes and AP is the AP value of the ith class. In this study, two classes of target detection are used, so C = 2. The average accuracy AP is calculated.
Results and analysis
Ablation experiment
To verify the effectiveness of the above improved algorithmic modules, ablation experiments were performed with different combinations of several modules, using the original YOLOv8n as the baseline model, with Precision, F1 score and mAP0.5 as the evaluation indexes. The experimental results are shown in Table 1. Ablation experiment on each improved module, and the training process is shown in Fig. 7.

Training result of the improved YOLOv8.
The improved model’s training process showed changes in accuracy and loss over iterations. As the number of iterations increased, the model updated its weights, resulting in increasing accuracy and decreasing loss. This indicates that within a certain range of iterations, more iterations led to the model learning more feature information and achieving higher accuracy. In the early stages of iteration, the loss decreased rapidly, and accuracy increased quickly. At around 100 iterations, mAP@0.5 stabilized at approximately 0.99, and the loss function reached a relatively stable state.
Comparison with other algorithms
To verify the superiority of the algorithm proposed in this paper over currently popular conveyor bel runout detection algorithms, the algorithm of this paper is compared with several algorithms, namely Mask R-CNN, DHT, UFLD, YOLOv5, YOLOv8, and improved algorithm, under the same conditions in comparison experiments. The evaluation indices used are Precision, F1, Model size, mAP0.5 and FPS. The experimental results are shown in Table 2.
Compared to other conveyor belt detection algorithms, the improved YOLOv8 algorithm proposed in this paper demonstrates superior detection performance on our self-built conveyor belt oscillation dataset. This dataset encompasses diverse scenes, transmission states, and targets from various angles. Despite this diversity, the enhanced algorithm exhibits remarkable detection capabilities, achieving a mean Average Precision (mAP) of 99% at an IoU threshold of 0.5, with a detection speed of 46 frames per second (FPS) and a model size of 19.8 MB. Some test results are showcased in Fig. 8.

The roller and conveyor belt detection effect in different areas.
Conveyor belt offset judgment method
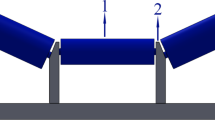
Belt conveyors operate in three states: normal, left deviation, and right deviation. This paper presents a method for detecting conveyor belt misalignment by measuring the distance between the centerline of the trapezoidal area formed by the edge lines of the idlers and the centerline of the two outer edge lines of the roller supports and the centerline of the belt edge line, as shown in Fig. 9. The steps for data acquisition can locate the position of the belt and its edge lines in surveillance video images. Considering that the relative position between the camera and the belt conveyor remains unchanged after installation, and the outer edges of the idlers on both sides of the belt conveyor will form a straight line, it is easy to pre-determine the position of the idler edge lines in the image and store them in the program as reference lines. Under normal circumstances, the two previously mentioned centerlines coincide. Considering actual operation, the belt surface usually does not run strictly in the middle and may have slight left or right deviations. Therefore, a reasonable range of misalignment is allowed, with minor misalignments not considered faults. Threshold selection depends on working conditions and detection accuracy requirements.

Offset judgment method.
Determination of the centerline
To determine the centerline of the edge line of the two roll holders, it is first necessary to clarify the definition of the roller bracket edge line equations. The left edge line equation of the roller holder can be expressed as:
The equation for the right edge line of the roller support is expressed as::
Here, x represents the horizontal coordinate in the image, corresponding to the pixel position; \({y_l}\) and \({y_r}\) denote the vertical coordinates of the left and right edge lines of the roller at position x, respectively. Parameters \({a_l}\) and \({a_r}\) are the slopes of the left and right roller edge lines, while \({b_l}\) and \({b_r}\)are the intercepts of the left and right roller edge lines.
The center line of the roller support region can be determined from the edge line equations. The equation of the center line is expressed as:
\({y_{roller\_center}}\)represents the vertical coordinate of the center line of the roller support area at position x, indicating the central position of the roller support region. This centerline is derived by calculating the midpoint positions of the left and right roller holder outer edge lines and fitting these endpoint positions.
Following the same approach, the centerline equation for the conveyor belt is:
In this equation, \({y_{belt\_center}}\)represents the vertical coordinate of the centerline of the edge line of the conveyor belt at position x. This vertical coordinate signifies the central position of the conveyor belt, which is derived through the calculation and fitting of the midpoint positions of the edge lines.
Calculate the deviation
In conveyor belt deviation detection, the offset is defined as the perpendicular distance between the conveyor belt centerline and the centerline of the outer edges of the two idler brackets at the same x-coordinate. To calculate this offset, follow these steps: First, for a given x-coordinate, calculate the y-coordinate values of both the conveyor belt centerline and the idler centerline at that position. Then, by comparing the difference between these two y-coordinate values, the corresponding vertical distance is obtained, which is represented by the formula:
Under normal circumstances, one can select multiple x-coordinate points to calculate the offset at different positions, and then take the average as the overall offset. The average offset can be expressed as:
where n represents the number of x-coordinate points selected, \({x_i}\)represents the i-th x position.
Conveyor belt deviation judgment:
\(\uptau\)serves as the threshold for determining the deviation of the conveyor belt.
Conclusion
This paper proposes an improved conveyor belt deviation detection algorithm based on YOLOv8, addressing the challenges faced by traditional methods in objection detection applications. In the proposed approach, firstly, to enhance precise localization capabilities across multiple scales in complex environments, an efficient ESE module is integrated. Then a BiFPN_DoubleAttention module is constructed in the neck network of YOLOv8, augmenting the feature extraction capabilities for multi-scale targets in complex environments. Thirdly, the introduction of a MHSA mechanism significantly improves detection accuracy for small target rollers. Finally, a deviation judgment method is then designed to enhance the generalization ability of our model.
Experiments demonstrate that our model has achieved higher detection accuracy than other existing models while meeting real-time requirements and reducing demand for computational and storage resources, making it easily deployable on resource-constrained devices. Future work will continue to expand the self-built dataset presented here, incorporating samples from different transportation environments to enhance industrial application potential.
Data availability
The dataset used in this article is partly collected by ourselves, and partly selected and used from the dataset publicly available on GitHub. The URL of the dataset publicly available on GitHub is https://github.com/zhangzhangzhang1618/dataset_for_belt_conveyor/tree/master. If you would like the full dataset and code, please email the corresponding author.
References
Kiriia, R., Smirnov, A., Mostovyi, B., Mishchenko, T. & Novikov, L. Ways to reduce the risk of emergencies on belt conveyors operating in mining enterprises. in IOP Conference Series: Earth and Environmental Science Vol. 1348, No. 1, 012036 (IOP Publishing, 2024).
Chu, Q. Y., Meng, G. Y. & Fan, X. Analysis of speed and belt deviation of the conveyor belt. Adv. Mater. Res.339, 444–447 (2011).
Mei, X., Miao, C., Yang, Y. & Li, X. On-line intelligent evaluation of the fatigue state of a composite conveyor belt. Therm. Sci. 25(3 Part B), 2191–2198 (2021).
Nguyen, V., Jiao, R., Feng, D. & Hou, L. Study on running deviation mechanism and intelligent control of belt conveyor. Vibroeng. Procedia 36, 115–120 (2021).
Wang, X. J., Ding, Y. F., Liu, H. B., Chi, Y. L. & Xu, P. Study on running deviation and adjusting deviation of Belt Conveyor’s structure based on Synchronous Technology. Adv. Mater. Res. 634, 3794–3797 (2013).
Yang, J. et al. Research on conveyor belt deviation detection method based on machine vision. In Journal of Physics: Conference Series Vol. 2786(1), 012013 (IOP Publishing, 2024).
Yang, Y., Miao, C., Li, X. & Mei, X. On-line conveyor belts inspection based on machine vision. Optik, 125(19), 5803–5807 (2014).
Sun, L. & Sun, X. An intelligent detection method for conveyor belt deviation state based on machine vision. Math. Model. Eng. Probl. 11(5) (2024).
Fedorko, G. et al. Design of Evaluation Classification Algorithm for Identifying Conveyor Belt Mistracking in a Continuous Transport System’s Digital Twin[J]. Sensors 24(12), 3810 (2024).
Wang, J., Liu, Q. & Dai, M. Belt vision localization algorithm based on machine vision and belt conveyor deviation detection. in 2019 34th Youth Academic Annual Conference of Chinese Association of Automation (YAC) 269–273 (IEEE, 2019).
Liu, Y., Wang, Y., Zeng, C., Zhang, W. & Li, J. Edge detection for conveyor belt based on the deep convolutional network. In Proceedings of 2018 Chinese Intelligent Systems Conference Vol. II, 275–283 (Springer, 2019).
Xu, X., Zhao, H., Fu, X., Liu, M., Qiao, H., & Ma, Y. Real-time Belt deviation detection method based on depth edge feature and gradient constraint. Sensors 23(19), 8208 (2023).
Unlu, E., Zenou, E., Riviere, N. & Dupouy, P. E. Deep learning-based strategies for the detection and tracking of drones using several cameras. IPSJ Trans. Comput. Vis. Appl. 11, 1–13 (2019).
Gao, M., Li, S., Chen, X. & Wang, Y. A novel combined method for conveyor belt deviation discrimination under complex operational scenarios. Eng. Appl. Artif. Intell. 137, 109145 (2024).
Zhao, X., Zeng, M., Dong, Y., Rao, G., Huang, X. & Mo, X. FastBeltNet: a dual-branch light-weight network for real-time conveyor belt edge detection. J. Real-Time Image Process. 21(4), 123 (2024).
Wlodarczyk-Sielicka, M. & Polap, D. Automatic classification using machine learning for non-conventional vessels on inland waters. Sensors 19(14), 3051 (2019).
Long, J., Shelhamer, E. & Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 3431–3440 (2015).
Chen, L. C., Papandreou, G., Kokkinos, I., Murphy, K. & Yuille, A. L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Transactions on Pattern Analysis and Machine Intelligence 40(4), 834–848 (2017).
Xie, S., & Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE international conference on computer vision 1395–1403 (2015).
Zeng, C., Zheng, J. & Li, J. Real-time conveyor belt deviation detection algorithm based on multi-scale feature fusion network. Algorithms 12(10), 205 (2019).
Zhang, M. et al. A deep learning-based method for deviation status detection in intelligent conveyor belt system. J. Clean. Prod. 363, 132575 (2022).
Wang, R et al. LightR-YOLOv5: A compact rotating detector for SARS-CoV-2 antigen-detection rapid diagnostic test results. Displays 78, 102403 (2023).
Hu, H. et al. Road surface crack detection method based on improved YOLOv5 and vehicle-mounted images. Measurement 229, 114443 (2024).
Mathew, M. P. & Mahesh, T. Y. Leaf-based disease detection in bell pepper plant using YOLO v5. Signal Image Video Process. 1–7 (2022).
Sun, X., Wang, Y. & Meng, W. Evaluation system of curved conveyor belt deviation state based on the ARIMA–LSTM combined prediction model. Machines10(11), 1042 (2022).
Wu, L., Wang, Y., Zhang, W., Huang, S. & Li, J. X. Research on Belt Deviation Diagnosis of Belt Conveyors Based on Deep Learning (2024).
Sun, S. et al. Multi-YOLOv8: An infrared moving small object detection model based on YOLOv8 for air vehicle. Neurocomputing 588, 127685. (2024).
Wan, D. et al. YOLO-MIF: Improved YOLOv8 with Multi-Information fusion for object detection in Gray-Scale images. Adv. Eng. Inform. 62, 102709 (2024).
Xiao, B., Nguyen, M. & Yan, W. Q. Fruit ripeness identification using YOLOv8 model. Multimedia Tools Appl.83(9), 28039–28056 (2024).
Liu, S., Qi, L., Qin, H., Shi, J. & Jia, J. Path aggregation network for instance segmentation. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 8759–8768 (2018).
Chen, T. et al. Detection network for multi-size and multi-target tea bud leaves in the field of view via improved YOLOv7. Comput. Electron. Agric. 218, 108700 (2024).
Zhou, W., Cai, C., Zheng, L., Li, C. & Zeng, D. ASSD-YOLO: a small object detection method based on improved YOLOv7 for airport surface surveillance. Multimed. Tools Appl. 83(18), 55527–55548 (2024).
Lu, C., Xia, Z., Przystupa, K., Kochan, O. & Su, J. DCELANM-Net: Medical image segmentation based on dual channel efficient layer aggregation network with learner. Int. J. Imaging Syst. Technol.34(1), e22960 (2024).
Li, X. et al. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv Neural. Inf. Process. Syst. 33, 21002–21012 (2020).
Zheng, Z. et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybernet. 52(8), 8574–8586 (2021).
Chen, G. et al. YOLOv8-CML: A lightweight target detection method for Color-changing melon ripening in intelligent agriculture. Sci. Rep. 14(1), 14400 (2024).
Sun, Y. et al. SES-YOLOv8n: automatic driving object detection algorithm based on improved YOLOv8. Signal. Image Video Process. 18(5), 3983–3992 (2024).
Du, X. et al. Research on Fault Detection of BeltConveyor Drum Based on Improved YOLOv8 Network Mode (2024).
Chen, K., Du, B., Wang, Y., Wang, G., & He, J. The real-time detection method for coal gangue based on YOLOv8s-GSC. J. Real-Time Image Proc. 21(2), 37 (2024).
Bajpai, A., Tiwari, N., Yadav, A., Chaurasia, D., & Kumar, M. Enhancing underwater object detection: Leveraging YOLOv8m for improved subaquatic monitoring. SN Comput. Sci. 5(6), 1–10 (2024).
Xing, Z., Zhu, Y., Liu, R., Wang, W., & Zhang, Z. DCM-YOLOv8: An improved YOLOv8-based small target detection model for UAV images. In International Conference on Intelligent Computing, 367–379 (Springer Nature Singapore, Singapore, 2024).
Zhao, X. Y. et al. A quality grade classification method for fresh tea leavesbased on an improved YOLOv8x-SPPCSPC-CBAM model. Sci. Rep. 14(1), 4166 (2024).
Lee, Y. & Park, J. Centermask: Real-time anchor-free instance segmentation. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 13906–13915 (2020).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 7132–7141 (2018).
Tan, M., Pang, R. & Le, Q. V. Efficientdet: Scalable and efficient object detection. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 10781–10790 (2020).
Chen, Y., Kalantidis, Y., Li, J., Yan, S. & Feng, J. A^ 2-nets: Double Attention Networks 31 (Advances in Neural Information Processing Systems, 2018).
Srinivas, A. et al. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 16519–16529 (2021).
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 61701393.
Author information
Authors and Affiliations
Contributions
All the authors contributed extensively to the manuscript. Yunfeng Ni. conceived and conducted the experiments, Haixin Cheng wrote the main manuscript, and other authors made revisions and suggestions to the paper. All authors have read and agreed to the publication of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ni, Y., Cheng, H., Hou, Y. et al. Study of conveyor belt deviation detection based on improved YOLOv8 algorithm. Sci Rep 14, 26876 (2024). https://doi.org/10.1038/s41598-024-75542-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-75542-7
